1. Introduction
Remote sensing imagery as a means of acquiring ground object information [
1] has found extensive applications in geological exploration [
2], marine monitoring [
3] and disaster management [
4]. In recent years, the advancement of sensor technology has facilitated the provision of a diverse range of remote sensing images. Different sensors can provide varying information for land-cover objects within the same geographic area. Hyperspectral data have been widely used in the fine classification of land-cover and land-use due to rich spectral-spatial information. However, it is always difficult to accurately classify ground objects only with hyperspectral data because of the phenomenon of the “same spectrum of foreign objects” [
5]. LiDAR data provide high-precision three-dimensional spatial information, which is complementary to hyperspectral data. For example, hyperspectral data fail to distinguish the roads and buildings because they are both concrete structures, whereas LiDAR data can effectively distinguish them due to elevation and height information. In contrast, only LiDAR data face challenges in accurately distinguishing different materials of the same height (e.g., lawn and road). Therefore, the integration of hyperspectral and LiDAR data is widely used for land-cover and land-use classification [
6,
7,
8].
In recent years, how to effectively integrate hyperspectral and LiDAR data has become a hot research topic. The current approaches can be categorized into three types: pixel-level fusion, feature-level fusion and decision-level fusion. Pixel-level fusion directly synthesizes the hyperspectral and LiDAR data at the input layer and then performs classification [
9,
10,
11]. However, pixel-level fusion generally entails a significant amount of computational overhead, and it also exhibits a general low robustness due to some disturbances, such as noise. To tackle the aforementioned challenges and optimize the synergistic information between hyperspectral and LiDAR data, feature-level fusion techniques have been extensively employed. In [
12], the classification is achieved by combining hyperspectral and LiDAR features extracted through Extended Attribute Profiles (EAPs). However, the mere concatenation or superposition of their features may result in redundant information and impede classification performance. The principal component analysis (PCA) is an effective method for reducing redundancy by mapping high-dimensional data onto an orthogonal low-dimensional space [
13]. Meanwhile, Du et al. [
14] proposed a graph fusion approach that leverages the correlation between hyperspectral and lidar data to integrate their features. Furthermore, a manifold alignment approach is proposed in [
15] to enhance the acquisition of shared features across diverse modalities and integrate them with modality specific features for classification purposes. Besides feature-level fusion, decision-level fusion is also a widely adopted approach. In [
16], it was proposed to use the support vector machine (SVM) for each feature, and then use Naive Bayes to fuse classifiers to obtain classification results. In [
17], the maximum likelihood classifier (MLC), SVM and multinomial logistic regression classifiers were used to classify the features, and weighted voting was then used to obtain the final classification results. Although both feature-level and decision-level fusion techniques are capable of integrating information from different modalities, they often heavily rely on human experience in parameter selection and feature designment. Moreover, they also face the challenge of achieving a balance between the algorithmic precision and generalizability.
With the increasing popularity of deep learning in remote sensing [
18,
19,
20,
21], a plethora of fusion algorithms have been proposed. Among them, the convolutional neural network (CNN) has proven to be effective in extracting deep features from images and is widely utilized for the joint classification of hyperspectral and LiDAR data. In [
22], a two-branch CNN is proposed to extract the spatial and spectral features of hyperspectral data, respectively, and then fuse with the features of LiDAR data for classification. The space and spectral characteristics of hyperspectral data are effectively utilized. Hang et al. [
23] tried to use the CNN to extract the features of hyperspectral and LiDAR data in the way of parameter sharing, and after the feature-level fusion, the weighted summing method was adopted at the decision level to obtain the final classification results. To better utilize the complementary information between hyperspectral and LiDAR data, many researchers have proposed some methods. For instance, Zhang et al. [
24] proposed a bidirectional autoencoder for hyperspectral and LiDAR data fusion, which utilized spectral and texture metrics to constrain the structure of the fused information, while integrating it using the Gram matrix. The resulting fusion outputs were then fed into a two-branch CNN for classification, reducing the reliance on training samples by leveraging complementary information. In [
25], a multi-branch fusion network of self-and cross-guided attention is proposed. Specifically, the LiDAR-derived attention mask guides both the HS and the LiDAR itself. Meanwhile, it is sent to the fusion module together with the spectral supplement module for classification fusion. This approach can effectively interact with complementary information from different modalities. Similarly, Fang et al. [
26] proposed a spatial-spectral enhancement module that effectively enhances the interaction between hyperspectral and LiDAR modalities by enhancing the spatial features of hyperspectral data with LiDAR features and enhancing the spectral information of LiDAR with hyperspectral features. In [
27], Wang et al. proposed a three-branch CNN backbone network that can simultaneously extract spectral, spatial and elevation information. They utilized hierarchical fusion to achieve a feature interaction and the integration of hyperspectral and LiDAR data, resulting in significant improvements in classification accuracy.
Although the above models have achieved acceptable results, most existing methods extract features of different modalities separately, and then directly integrate the complementary information. Intuitively, the complementary information highlights the distinctiveness of each modality, and the direct integration of this unique information leads to suboptimal fusion performance. Shared features across modalities can demonstrate their affinity and facilitate smoother connections between them, serving as a “bridge” to alleviate huge modality differences. Therefore, the integration of complementary and shared features across modalities is essential for their mutual enhancement. By interactively integrating these features, information from different modalities can be optimally combined. Inspired by this, our insight is the first key research question (RQ), RQ1: How can we effectively utilize the shared-complementary information of hyperspectral and LiDAR images? In addition, feature-level fusion enables the comprehensive processing of information, including edges, shapes, contours and local features, while decision-level fusion exhibits excellent error correction capabilities. Generally, the strategy of feature-level and decision-level fusion play distinct yet equally important roles in improving the performance of hyperspectral and LiDAR classification. However, the current feature-level and decision-level joint classification methods exhibit limited adaptability and flexibility. Therefore, the next key research question is raised: RQ2: How can we adaptively collaboratively integrate the strategy of feature-level and decision-level fusion?
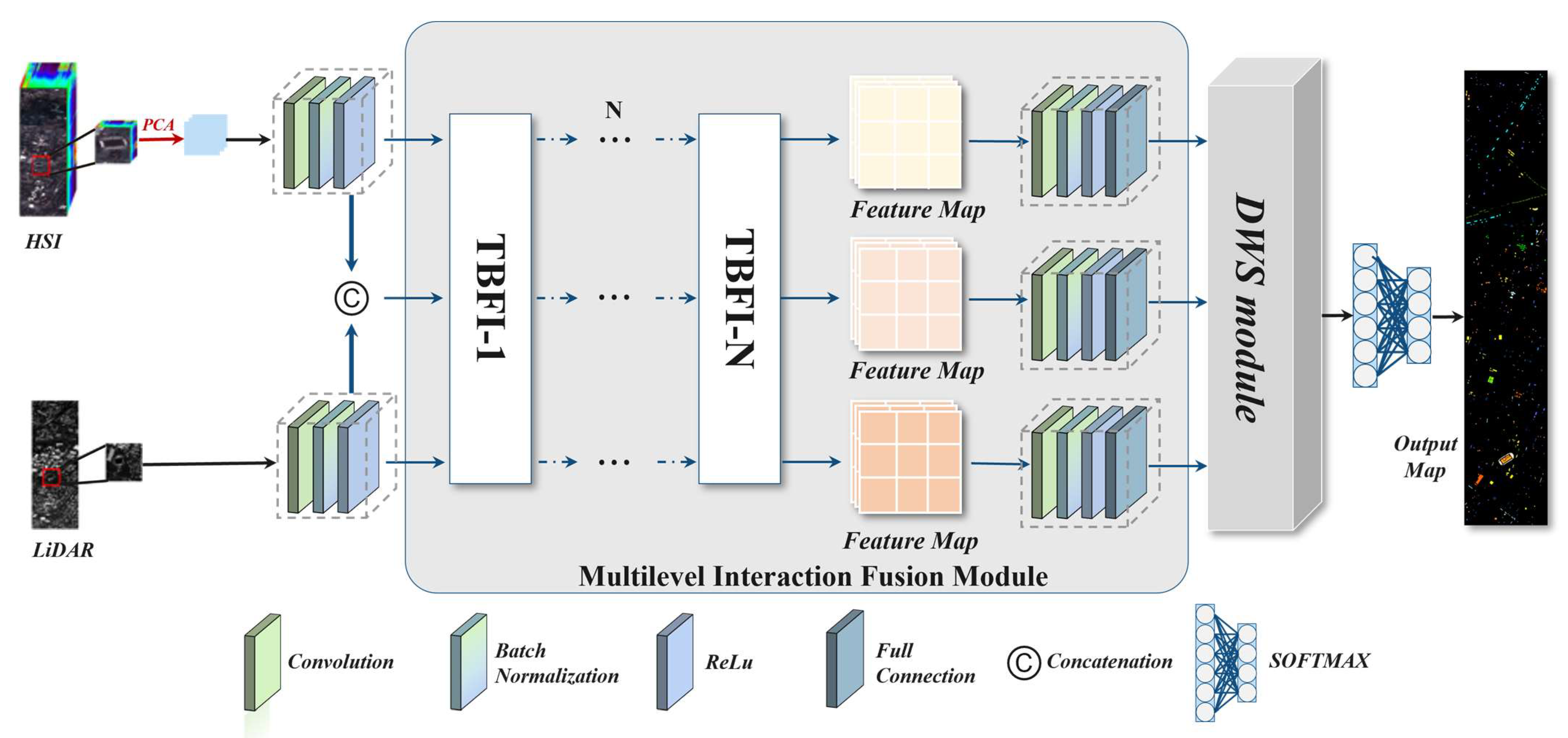
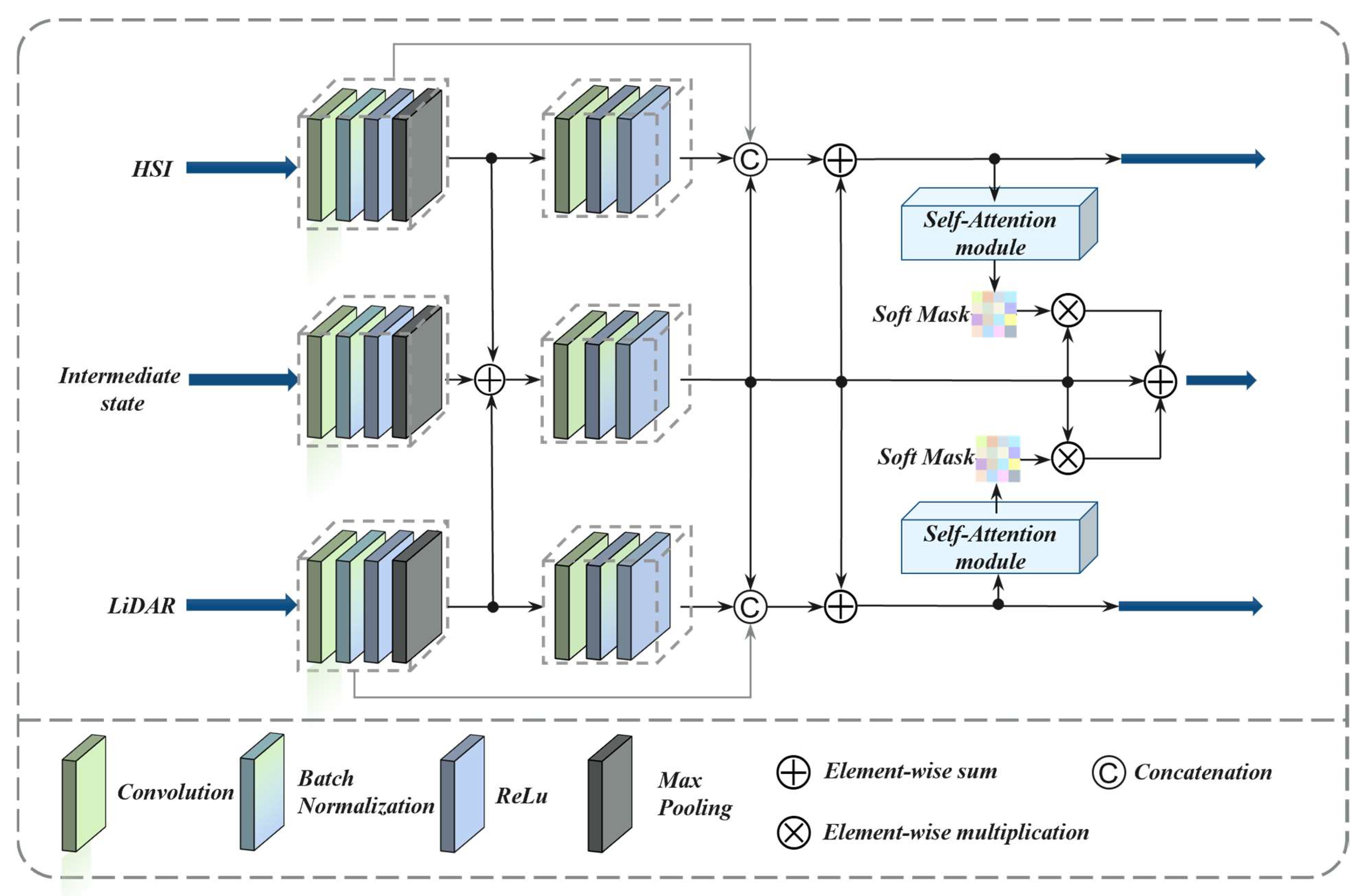
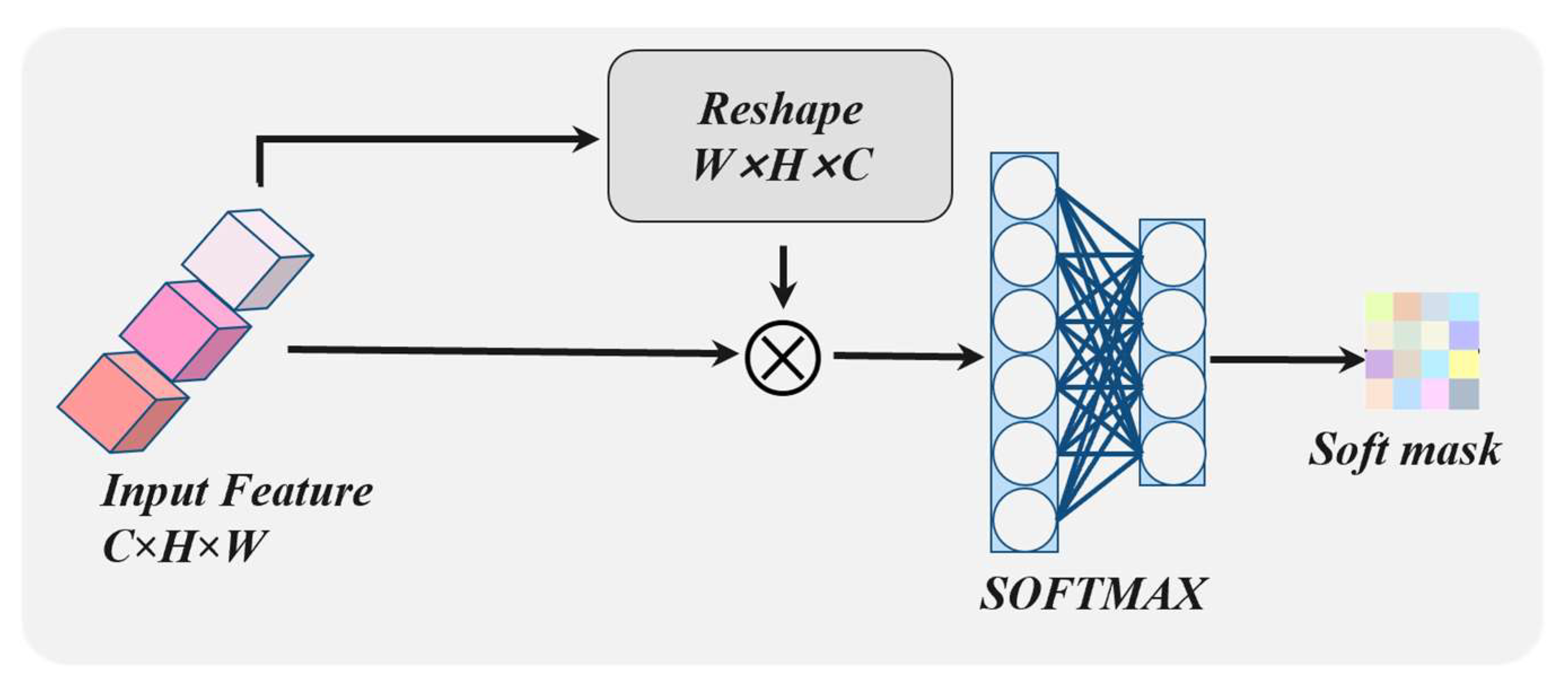
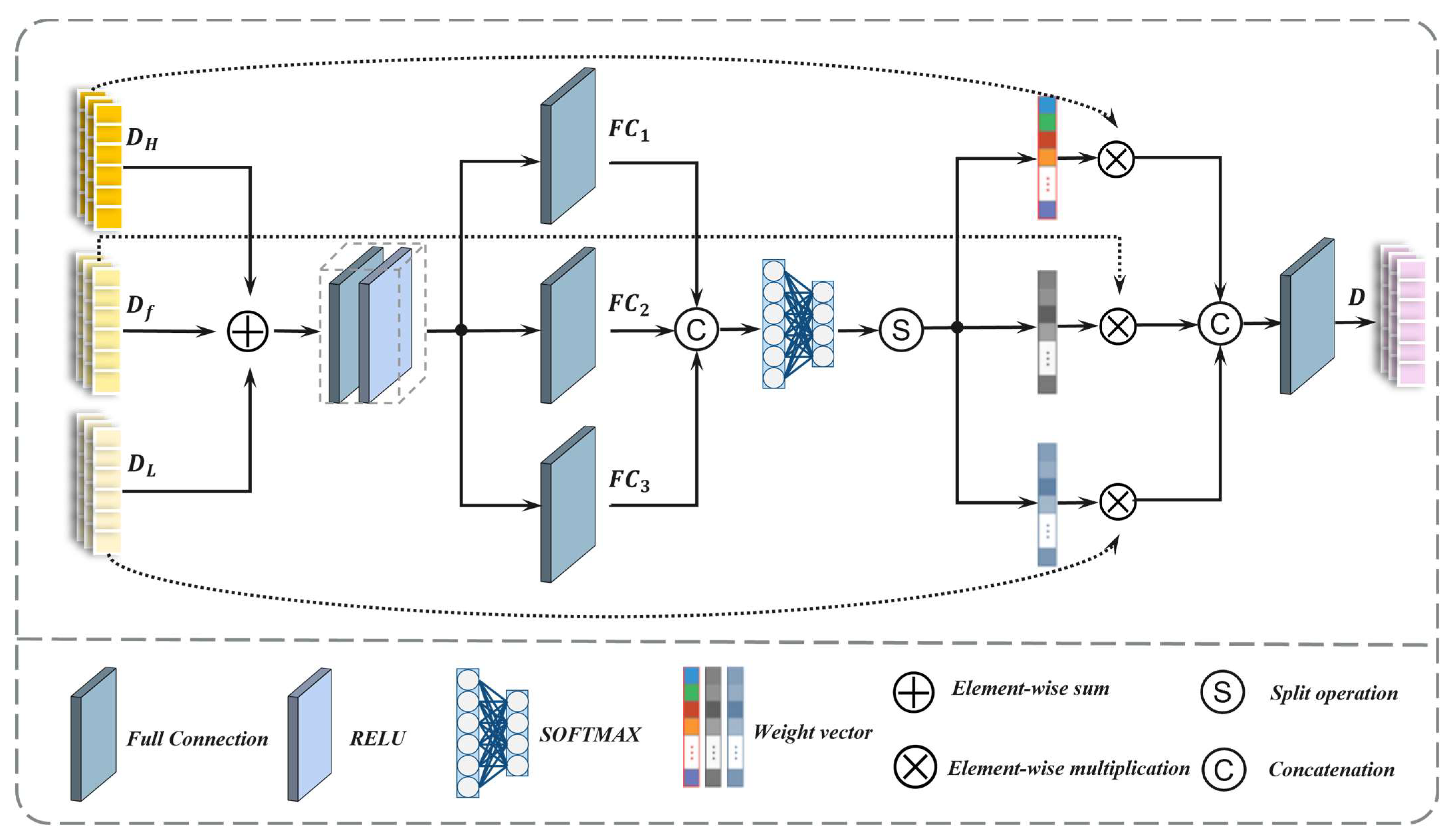
In this paper, to address the above RQ1, we propose a multilevel interactive fusion (MIF) module to integrate the shared-complementary information of HS and LiDAR data while weakening the differences between the modalities. Specifically, the MIF module is cascaded by several three-branch feature interaction (TBFI) modules, which introduces an intermediate state branch in addition to the HS and LiDAR branches, with the aim of reducing modal differences and enabling the full interaction and integration of shared and complementary information through multiple TBFI modules. To tackle the above RQ2, the dynamic weight selection (DWS) module in decision-level fusion is attentively designed, which takes the three output layers of the MIF module as the input and adaptively assigns weights to the features obtained in feature-level fusion. The main contributions of this paper are summarized as follows:
(1) A feature-decision level collaborative fusion network for hyperspectral and LiDAR classification was proposed, which collaboratively integrates the strategy of feature-level and decision-level fusion to a unified framework.
(2) In feature-level fusion, an MIF module was developed that incorporates a novel intermediate state branch to optimize the utilization of shared-complementary features between hyperspectral and lidar data while minimizing mode discrepancies. This branch facilitates the information’s interaction and integration with both the HS and Lidar branches within the TBFI module, utilizing a multi-level enhancement method to extract and transfer shared-complementary features between the two streams.
(3) In decision-level fusion, a DWS module was proposed to adaptively optimize the feature representations of the three branches by dynamically weighting their feature outputs to ensure a balanced and effective feature representation.
The rest of this article is organized as follows. The proposed framework is introduced in detail in
Section 2. In
Section 3, the experimental configuration and parameter setting, the classification results and analysis and ablation studies are given. Finally, a summary is given in
Section 4.
3. Experiment and Result
Three benchmark remote sensing (RS) datasets were utilized as opening references to assess the performance of FDCFNet. First, the experimental datasets were described. Secondly, the details of the experiments were given. After that, we compared and analyzed the classification results of FDCFNet with different comparison methods. Finally, we conducted ablation experiments to demonstrate the efficacy of various modules.
3.1. Experimental Datasets
In this paper, three common RS datasets: the Houston dataset [
31,
32], Trento dataset [
33] and MUUFL dataset [
34,
35], are selected to evaluate the performance of FDCFNet. The land-cover object classes and corresponding numbers of training and testing samples for the three datasets are presented in
Table 1,
Table 2 and
Table 3. A detailed description of these datasets follows.
(1) Houston dataset: The dataset comprises a hyperspectral image with 144 spectral bands and a wavelength range of 0.38 to 1.05 m, as well as LiDAR data, capturing the University of Houston campus at a spatial resolution of 2.5 m over an area size of 349 × 1905 pixels. The LiDAR data contains one band, while the training and testing labels encompass fifteen classes.
(2) Trento dataset: The second dataset covers a rural region situated to the south of Trento, Italy. The hyperspectral image was acquired by the AISA Eagle sensor, which features 63 spectral bands spanning from 0.42 to 0.99 m in wavelength, while the LiDAR data was collected using the Optech ALTM 3100EA sensor and consists of one spectral band. This dataset measures at a spatial resolution of 1 m with dimensions measuring at 166 × 600 pixels. The training and testing labels contain six distinct categories.
(3) MUUFL dataset: The third dataset has a size of 325 × 220 pixels and was taken at the University of Mississippi Gulf Coast campus. It contains a stream of hyperspectral imagery and LiDAR data, where the hyperspectral image has 64 spectral bands with wavelengths ranging from 0.38 to 1.05 m; LiDAR data have two spectral bands. The training and testing labels contain 11 different categories.
3.2. Experimental Configuration
To assess the performance of different methods, all experiments were conducted on a PC equipped with an Intel(R) Xeon(R) Gold 5218 CPU, operating at 2.30 GHz, an NVIDIA Quadro P5000 GPU, 32 GB of RAM and Windows 10. Our proposed programs were written in the PyCharm compiler with python3.8, and some deep learning networks were implemented using the PyTorch framework. At the same time, we use the Adam optimization algorithm [
36] to adaptively optimize these models. Set the batch size and epoch to 64 and 150, respectively, for training.
In this paper, three metrics were employed—average accuracy (AA), overall accuracy (
OA) and the kappa coefficient (kappa)—to assess the performance. The
OA represents the proportion of correctly classified pixels to total classified pixels. The AA denotes the mean classification accuracy across all categories, while the kappa measures error reduction between classification and random guessing.
Kappa can be mathematically expressed as follows:
where
where
is the number of classes,
is the number of actual samples of the
th class,
is the number of predicted samples of the
th class and n represents the aggregate quantity of samples to be classified. These performance indicators can assess the classification accuracy of the model and a higher value indicates a superior classification performance.
3.3. Classification Results and Analysis
In order to verify the validity of FDCFNet, we compare the proposed model with several state-of-the-art methods, including the support vector machine (SVM) [
37], random forest (RF) [
38], shared and specific feature learning model (S2FL) [
14], common subspace learning (CoSpace-ℓ1) [
39], Two-branch convolution neural network (two-branch CNN) [
21], Coupled CNN [
22], Multi-attentive hierarchical dense fusion net (MAHiDFNet) [
26] and Spatial–spectral cross-modal enhancement network(S2ENet) [
25]. Meanwhile, in order to ensure comparability across experiments, identical training and testing samples were used.
Table 4,
Table 5 and
Table 6 show the classification results on the three datasets, i.e., Houston, Trento and MUUFL, respectively. The visual classification maps of the three datasets are presented in
Figure 5,
Figure 6 and
Figure 7 for comparison among different methods.
Results on the Houston dataset: Our proposed method surpasses other recent influential deep learning-based methods, as demonstrated in
Table 4, including the two-branch CNN, Coupled CNN, MAHiDFNet and S2ENet on the Houston dataset. The OA was increased by 9.43%, 1.27%, 7.03% and 0.83% respectively, while the kappa was increased by 10.22%, 1.38%, 7.6% and 1.65%. Among them, the accuracy of Commercial is much higher than that of the other classification methods, which is attributed to the multilevel interaction fusion module that can better interactively integrate the spectral information of hyperspectral data and the elevation information of LiDAR data. Specifically, it combines the unique information of the two modalities and enhances the common information of the two modalities. In
Figure 5, it is evident that the proposed method yields a smoother visual effect and exhibits no classification errors or misjudgments when categorizing stressed grass, soil and water.
Results on the Trento dataset:
Table 5 shows the classification accuracy of the FDCFNet and other comparison methods on the Trento dataset; the OA of the proposed method achieves an outstanding 99.11%, in which the classification accuracy of apple trees, woods and vineyard reaches 100%. In
Figure 6, it is evident that SVM and RF exhibit more misclassification patterns than certain deep learning algorithms. It may be because the single-input model will carry out multi-mode information fusion before input, which will cause certain information loss. Additionally, the classification results of the traditional methods S2FL and CoSpace-ℓ1 are also unsatisfactory, possibly due to geometric information loss during the transformation of hyperspectral and LiDAR data into vectors. The FDCFNet exhibits a significant classification effect on large-scale objects, which can be attributed to the effective integration and interaction of complementary and shared information across different modalities facilitated by the MIF module. However, in the road classification, the effect is not satisfactory, which may be due to the phenomenon of misjudgment caused by information overlap when the common features and complementary features are fused and enhanced.
Results on the MUUFL dataset:
Table 6 presents the classification accuracy of various methods on the MUUFL dataset. The proposed method exhibits a significantly superior classification performance compared to some classical comparison methods. The OA of FDCFNet surpasses that of several recently proposed deep learning methods, including the two-branch CNN, Coupled CNN, MAHiDFNet and S2ENet by 4.23%, 3.7%, 1.07% and 6.34%, respectively. In addition, we can also see the superiority of the proposed method in
Figure 7. It can be seen that FDCFNet classifies almost all of the mixed ground surface and trees in the lower right corner of the figure correctly, and at the same time, the edges of trees and other ground objects are clear and very close to the ground truth which is attributed to the dynamic weight selection strategy, which can better balance the feature representation of hyperspectral and LiDAR data, especially in the edge processing of classification. This fully demonstrates the superiority of the proposed model in land-cover classification.
On the whole, our proposed method outperforms other state-of-the-art methods, demonstrating a superior classification performance. The exceptional results of FDCFNet can be attributed to several key factors: firstly, an intermediate branch is introduced into the model to mitigate modality discrepancies. Secondly, multiple layers of the TBFI modules are employed for deep mining and the integration of shared-complementary features from hyperspectral and LiDAR data. Finally, a DWS module is incorporated to dynamically allocate weights to the output of three branches, ensuring a more equitable representation of information across different modalities. Among the three classification result graphs, FDCFNet exhibits a superior classification performance, with clearer boundaries and closer proximity to the ground truth. This further validates the advantages of our proposed model. In summary, our model demonstrates a high competitiveness in joint hyperspectral and LiDAR data classification.








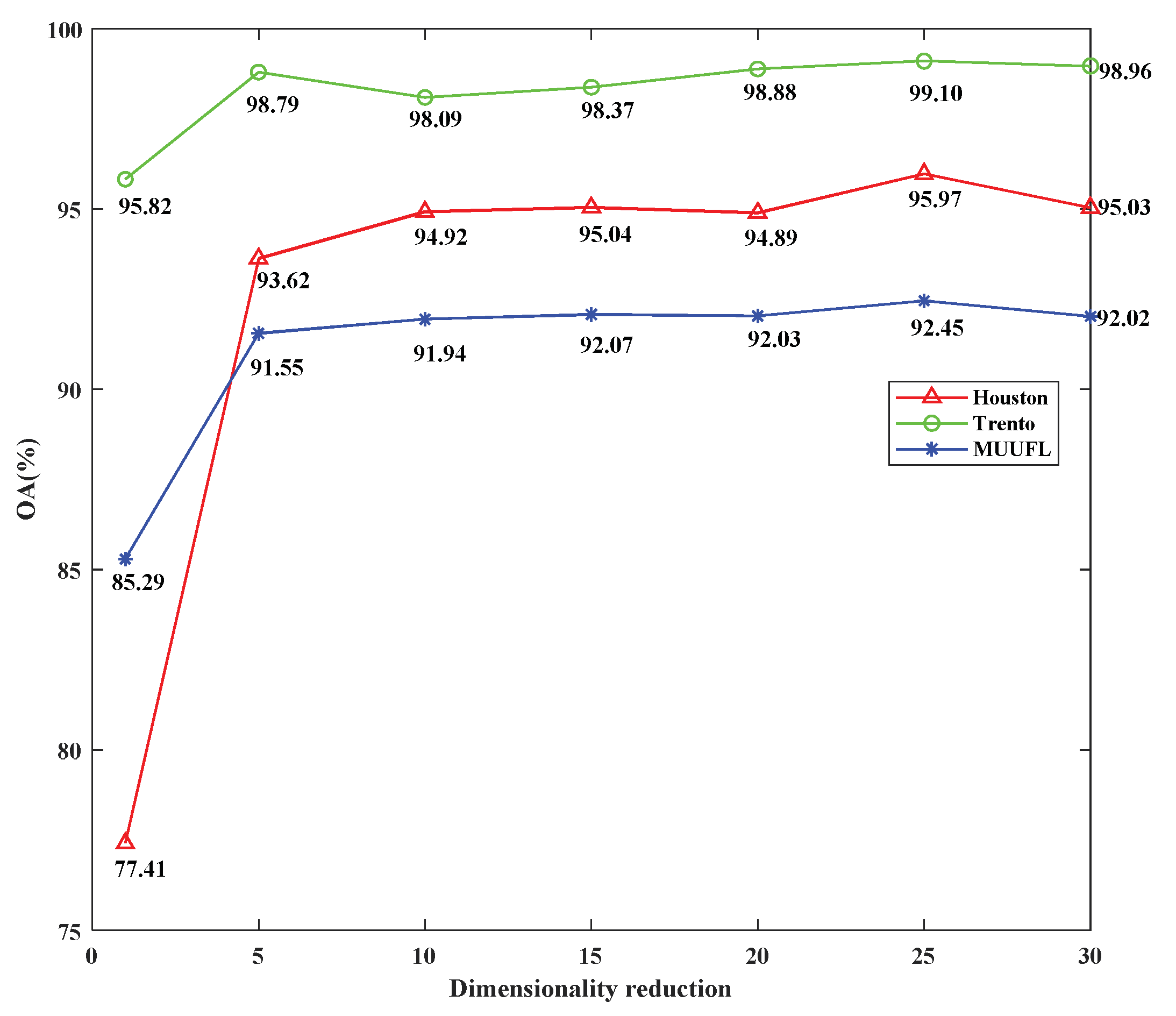
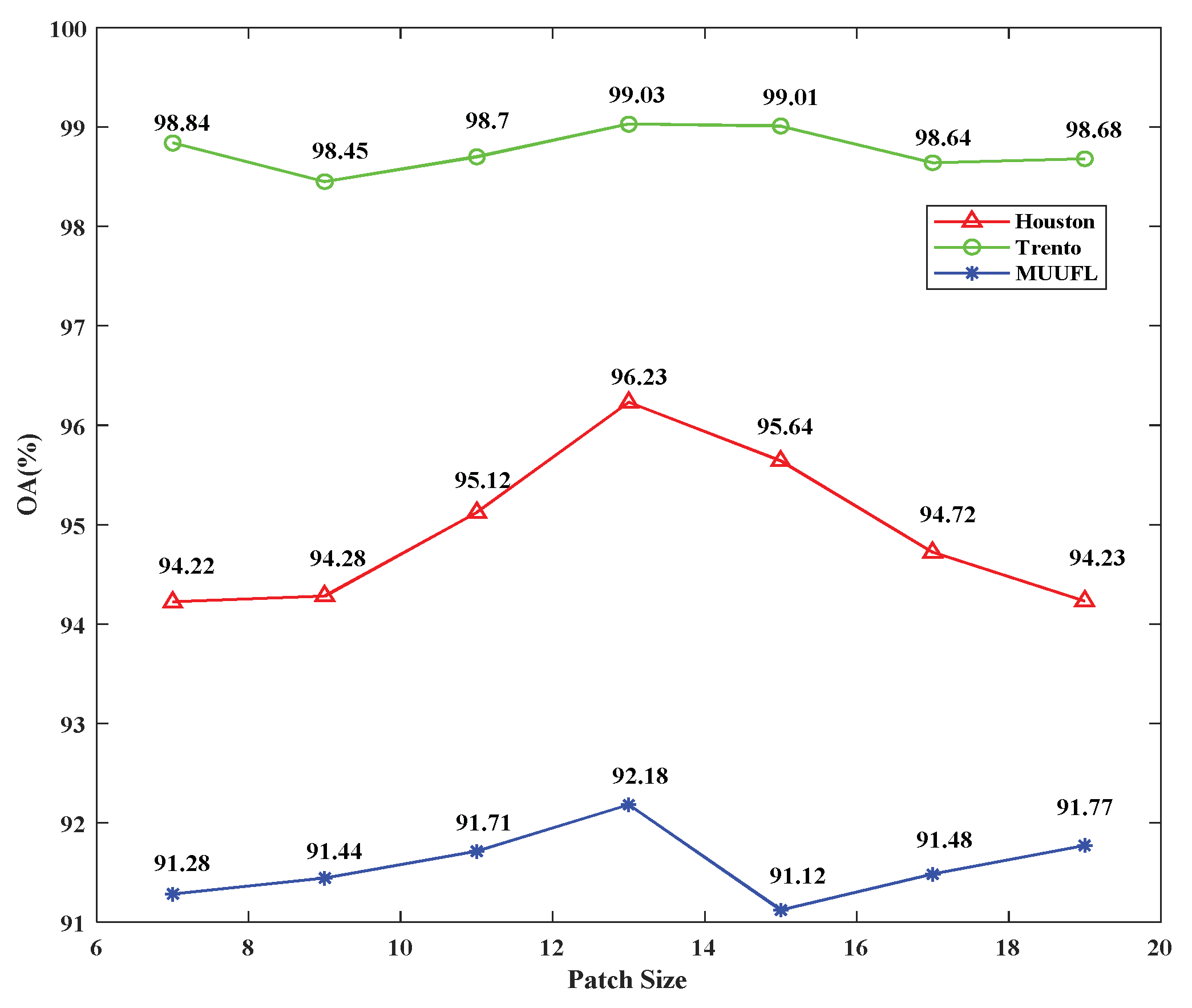

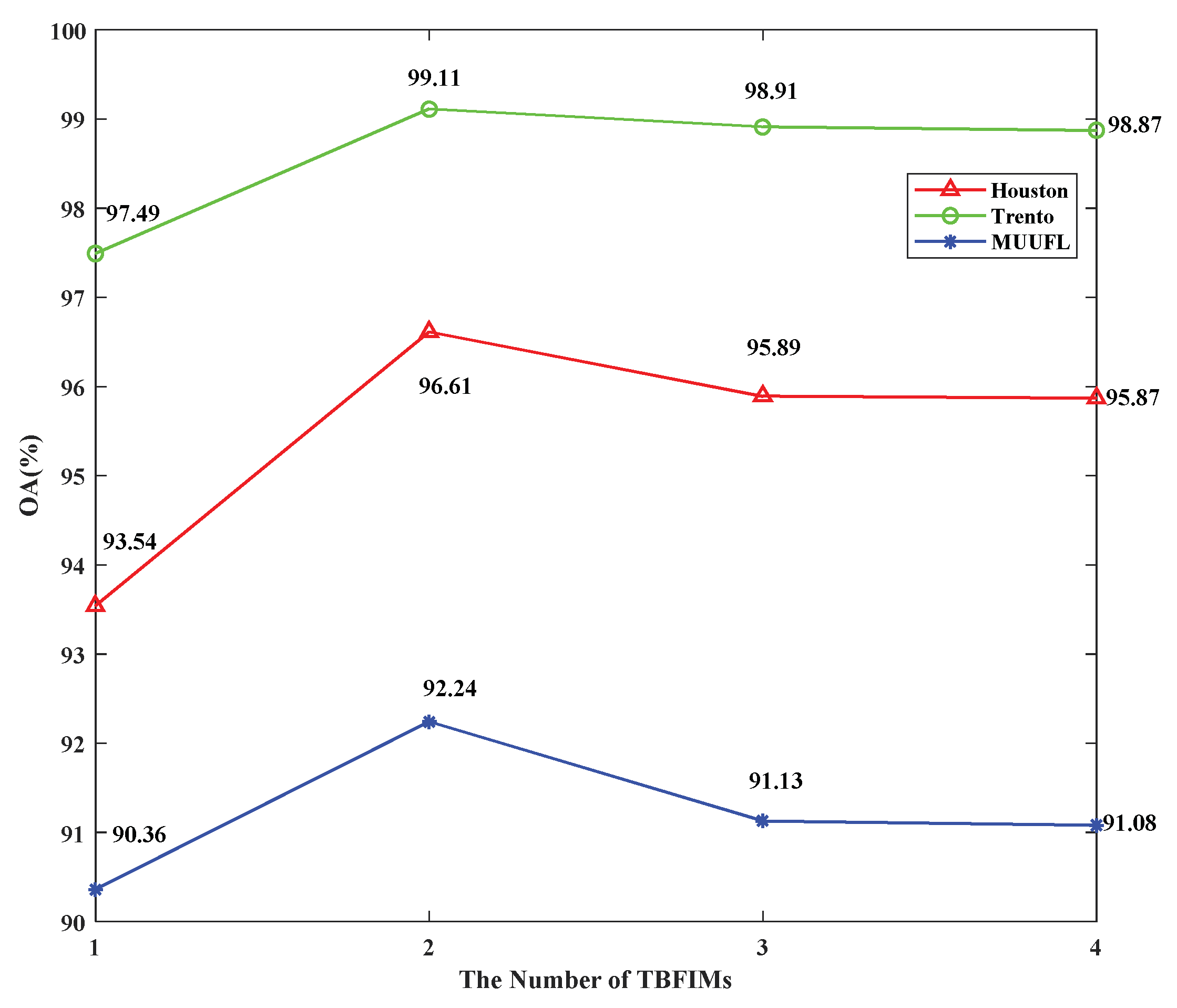
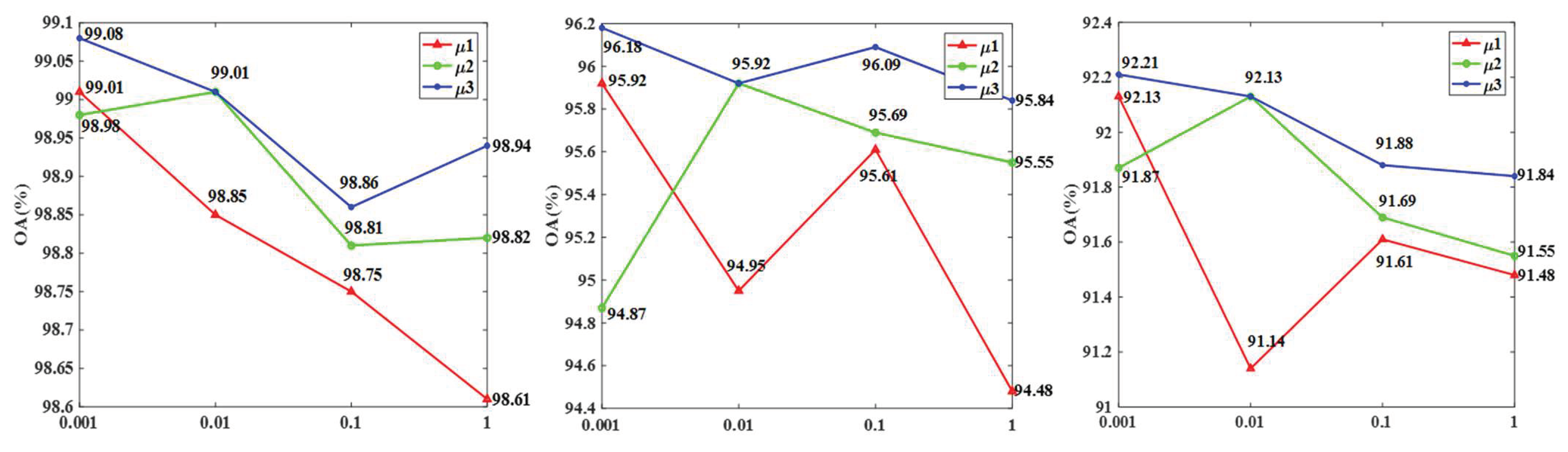

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}