


Imitation Learning through Image Augmentation Using Enhanced Swin Transformer Model in Remote Sensing


Abstract
:
1. Introduction
- Swin Transformer is a computer vision model that extracts local and global features of an image with cyclic shift and window-based self-attention. However, we find that applying Swin Transformer is a possibility for an imitation learning algorithm because it can be utilized to augment datasets. This is the first method using the Swin Transformer model for imitation learning by data augmentation.
- Traditional Swin Transformer does not support any functions of augmentation, but we revise the traditional Swin Transformer as an augmentation approach. We modify its inner structure to shuffle the features of dynamic objects and generate a new combination of the features of objects. It is possible to train with data that did not previously exist by augmenting existing data.
- The proposed method involves modifying the architecture of the Swin Transformer model by adding Preprocessor and Action model to augment images and train the model to predict actions as imitation learning.
2. Related Work
2.1. Imitation Learning
2.2. Data Augmentation
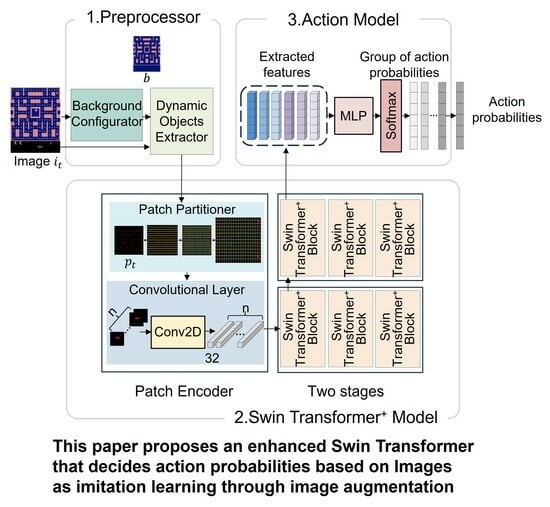
3. Swin Transformer+ Model for Imitation Learning
3.1. Overview
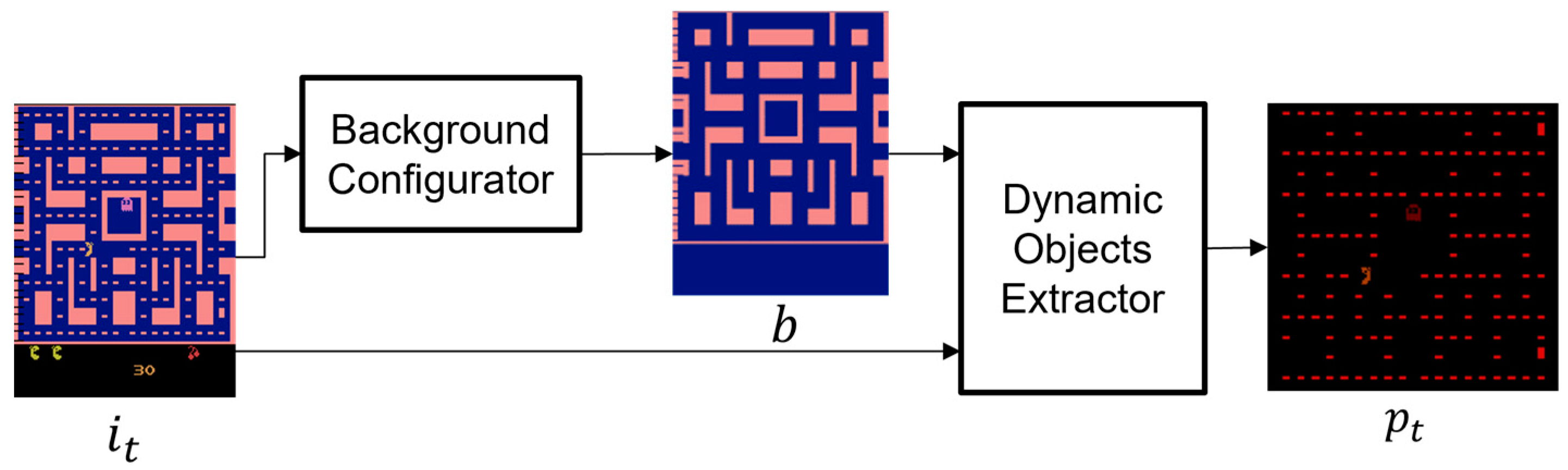
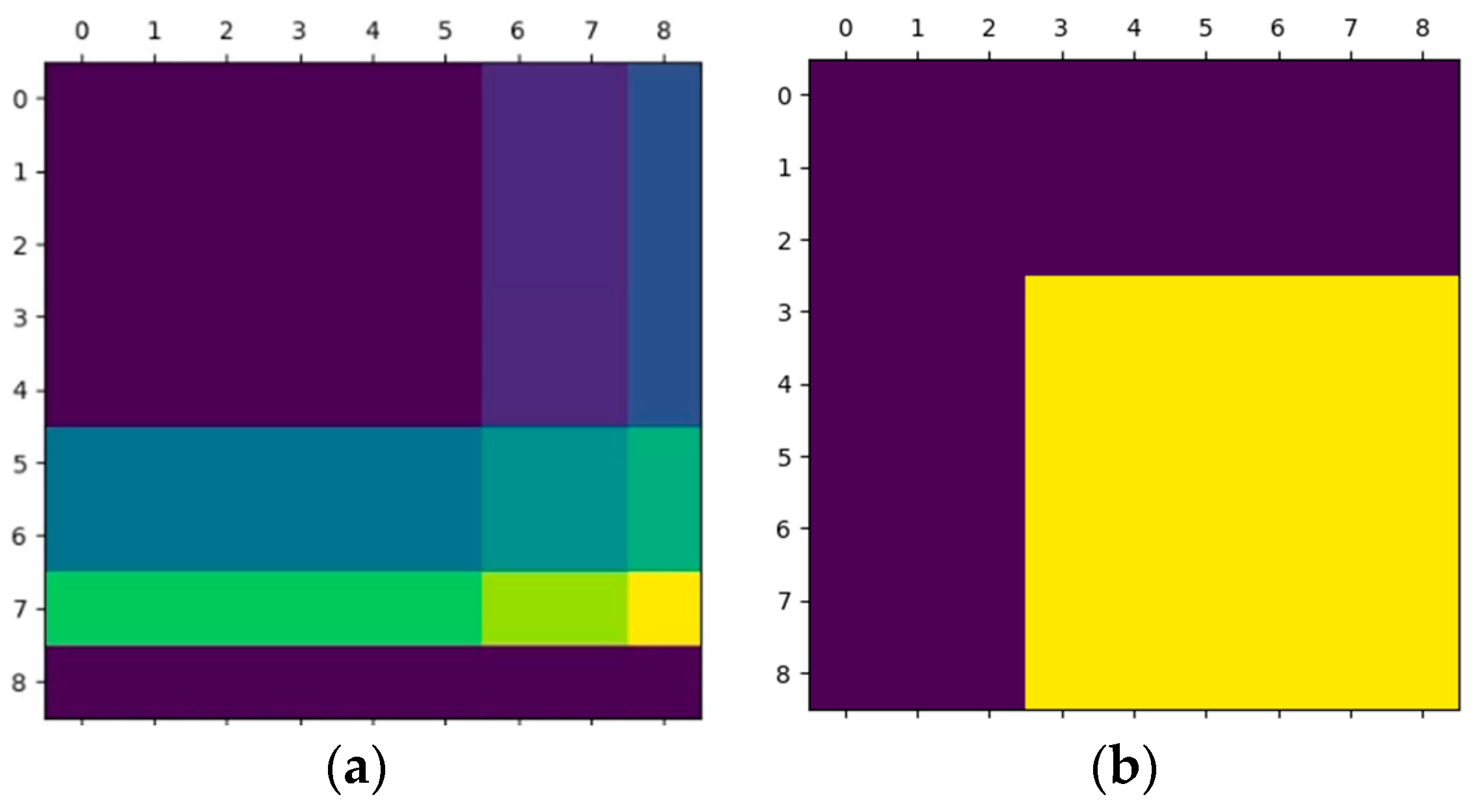
3.2. Preprocessor
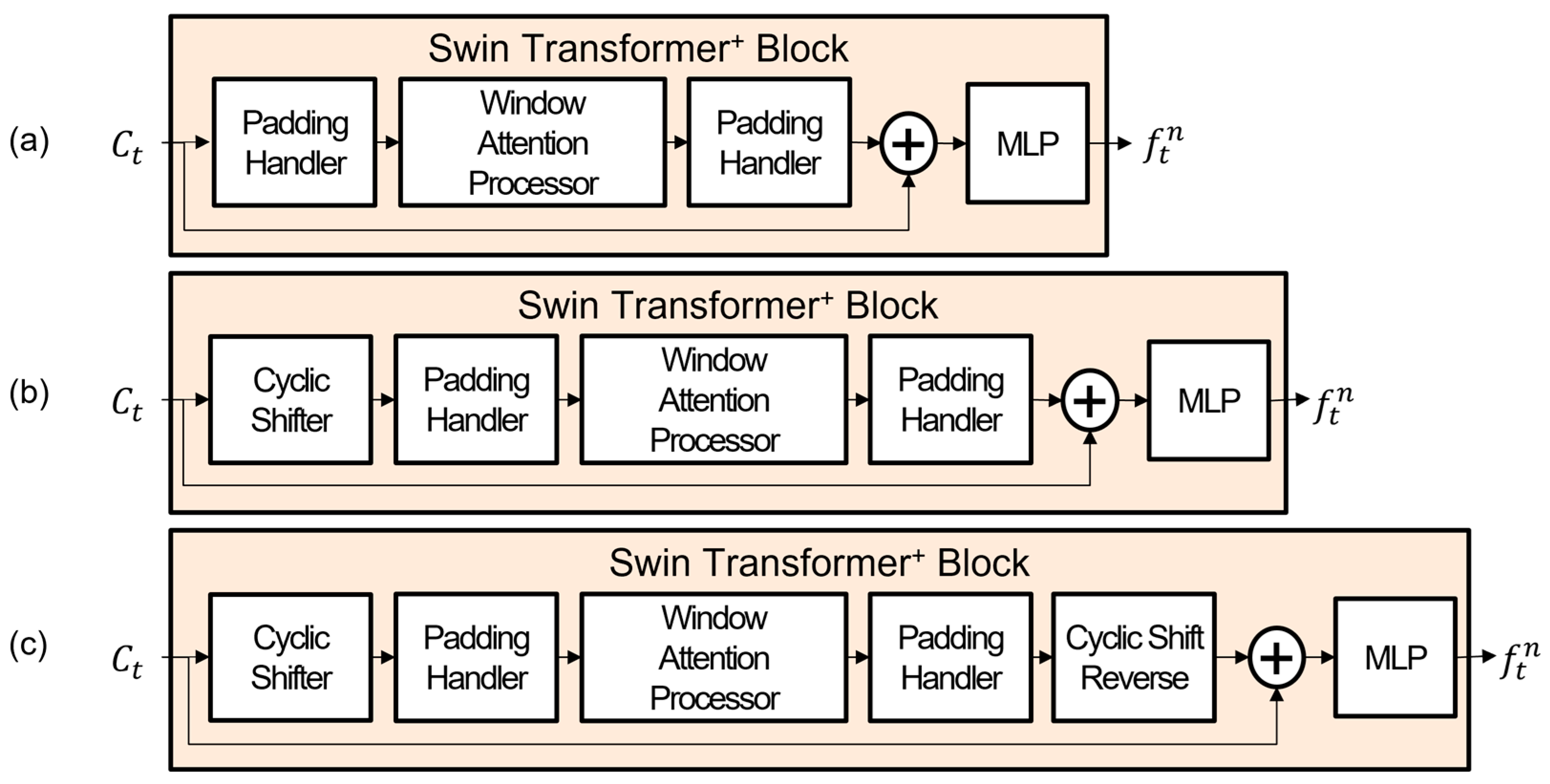
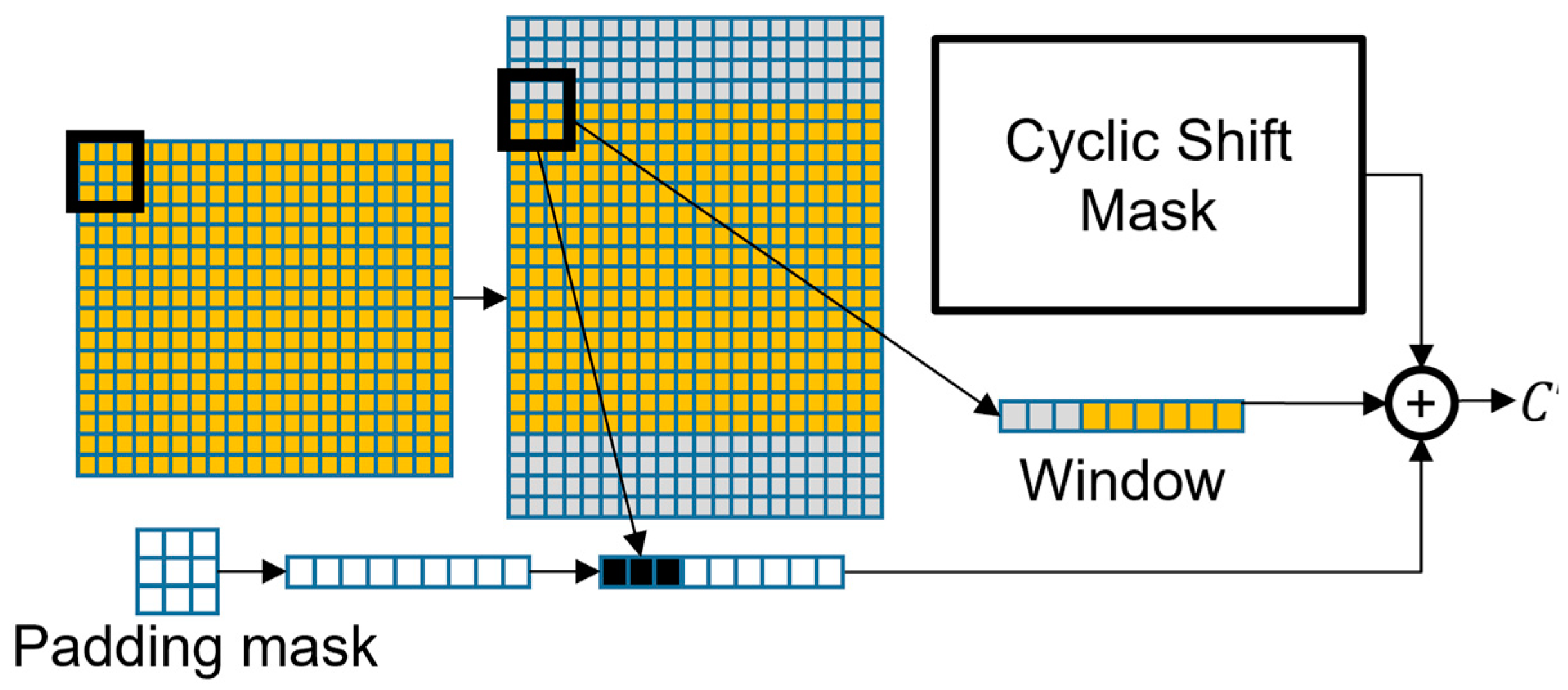
3.3. Swin Transformer+ Model
3.4. Action Model
4. Experiment
4.1. Datasets
4.2. Experimental Environments
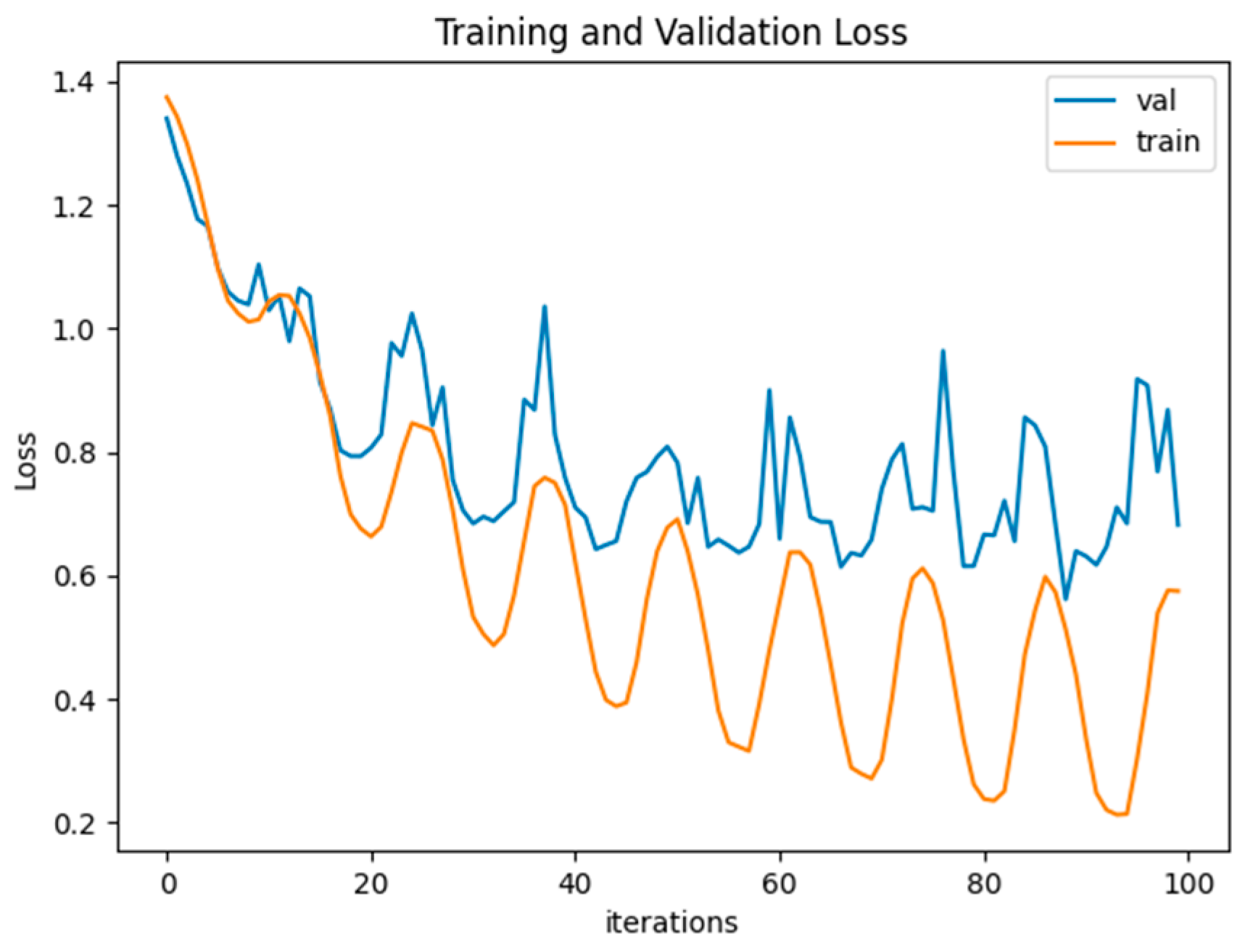
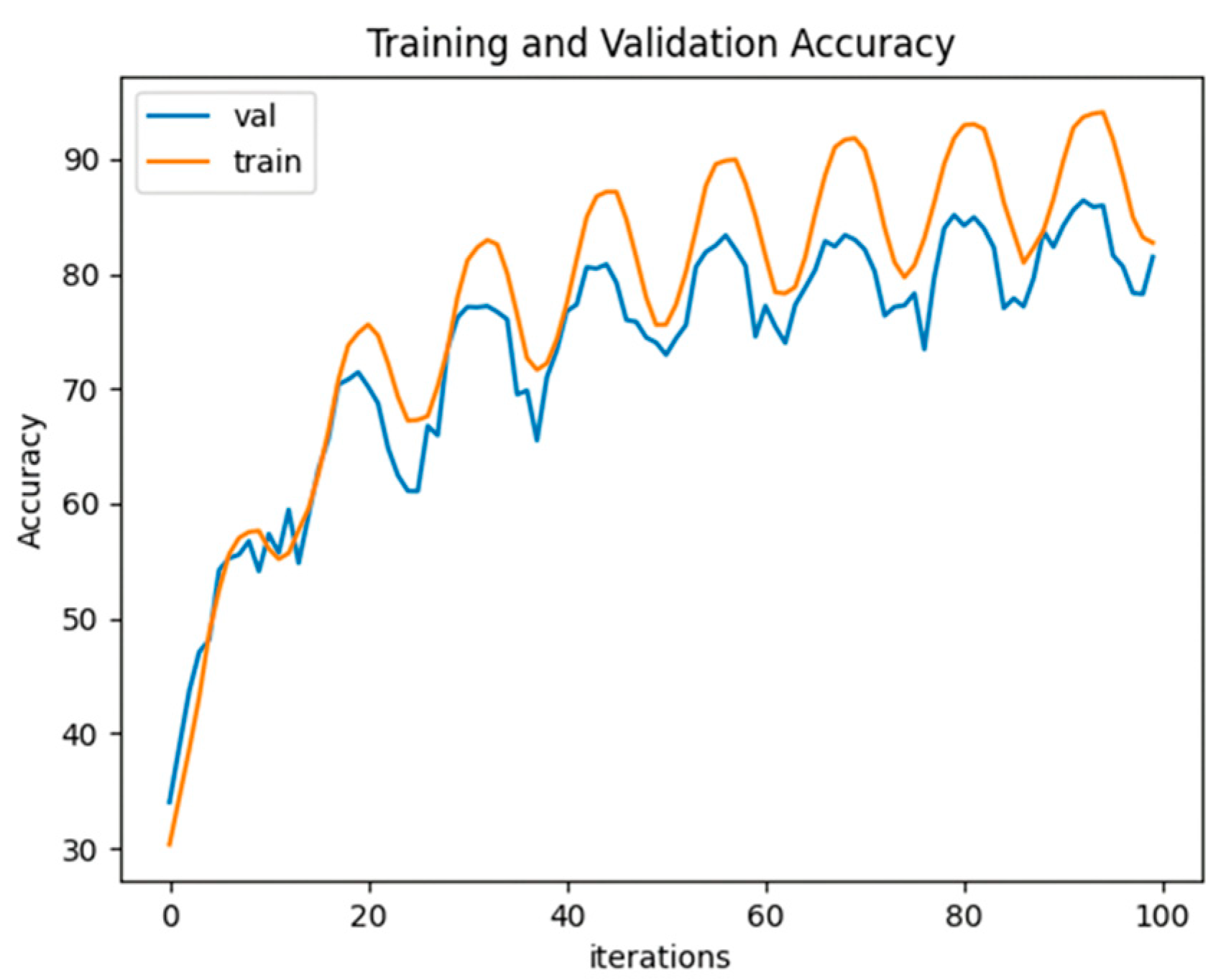
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jiang, Z.; Li, S.; Sung, Y. Enhanced Evaluation Method of Musical Instrument Digital Interface Data based on Random Masking and Seq2Seq Model. Mathematics 2022, 10, 2747. [Google Scholar] [CrossRef]
- Song, W.; Li, D.; Sun, S.; Zhang, L.; Yu, X.; Choi, R.; Sung, Y. 2D&3DHNet for 3D Object Classification in LiDAR Point Cloud. Remote Sens. 2022, 14, 3146. [Google Scholar] [CrossRef]
- Yoon, H.; Li, S.; Sung, Y. Style Transformation Method of Stage Background Images by Emotion Words of Lyrics. Mathematics 2021, 9, 1831. [Google Scholar] [CrossRef]
- Balakrishna, A.; Thananjeyan, B.; Lee, J.; Li, F.; Zahed, A.; Gonzalez, J.E.; Goldberg, K. On-policy robot imitation learning from a converging supervisor. In Proceedings of the 3rd Conference on Robot Learning (CoRL), Virtual, 16–18 November 2020; pp. 24–41. [Google Scholar]
- Jang, E.; Irpan, A.; Khansari, M.; Kappler, D.; Ebert, F.; Lynch, C.; Levine, S.; Finn, C. BC-Z: Zero-shot task generalization with robotic imitation learning. In Proceedings of the 5th Conference on Robot Learning (CoRL), Auckland, New Zealand, 14–18 December 2022; pp. 991–1002. [Google Scholar]
- Codevilla, F.; Müller, M.; López, A.; Koltun, V.; Dosovitskiy, A. End-to-end driving via conditional imitation learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 4693–4700. [Google Scholar]
- Kebria, P.M.; Khosravi, A.; Salaken, S.M.; Nahavandi, S. Deep Imitation Learning for Autonomous Vehicles based on Convolutional Neural Networks. IEEE/CAA J. Autom. Sin. 2020, 7, 82–95. [Google Scholar] [CrossRef]
- Zhifei, S.; Meng Joo, E. A Survey of Inverse Reinforcement Learning Techniques. Int. J. Intell. Comput. Cybern. 2012, 5, 293–311. [Google Scholar] [CrossRef]
- Torabi, F.; Warnell, G.; Stone, P. Behavioral Cloning from Observation. arXiv 2018, arXiv:1805.01954. [Google Scholar]
- Ross, S.; Bagnell, D. Efficient reductions for imitation learning. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS), Sardinia, Italy, 13–15 May 2010; pp. 661–668. [Google Scholar]
- Taylor, L.; Nitschke, G. Improving deep learning with generic data augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bengaluru, India, 18–21 November 2018; pp. 1542–1547. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13001–13008. [Google Scholar]
- Nanni, L.; Paci, M.; Brahnam, S.; Lumini, A. Feature Transforms for Image Data Augmentation. Neural Comput. Appl. 2022, 34, 22345–22356. [Google Scholar] [CrossRef]
- Gong, C.; Ren, T.; Ye, M.; Liu, Q. Maxup: Lightweight adversarial training with data augmentation improves neural network training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 2474–2483. [Google Scholar]
- Zheng, X.; Chalasani, T.; Ghosal, K.; Lutz, S.; Smolic, A. STaDA: Style Transfer as Data Augmentation. arXiv 2019, arXiv:1909.01056. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 28th Advances in Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 8–13 December 2014; pp. 1–9. [Google Scholar]
- Huang, S.W.; Lin, C.T.; Chen, S.P.; Wu, Y.Y.; Hsu, P.H.; Lai, S.H. AugGAN: Cross domain adaptation with GAN-based data augmentation. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 718–731. [Google Scholar]
- Dornaika, F.; Sun, D.; Hammoudi, K.; Charafeddine, J.; Cabani, A.; Zhang, C. Object-centric Contour-aware Data Augmentation Using Superpixels of Varying Granularity. Pattern Recognit. 2023, 139, 109481–109493. [Google Scholar] [CrossRef]
- Knyazev, B.; Cătălina Cangea, H.; Aaron Courville, G.W.T.; Belilovsky, E. Generative compositional augmentations for scene graph prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 15827–15837. [Google Scholar]
- Yin, Z.; Gao, Y.; Chen, Q. Structural generalization of visual imitation learning with position-invariant regularization. In Proceedings of the 11th International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023; pp. 1–14. [Google Scholar]
- Zhang, L.; Wen, T.; Min, J.; Wang, J.; Han, D.; Shi, J. Learning object placement by inpainting for compositional data augmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Virtual, 23–28 August 2020; pp. 566–581. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 21st IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Sasaki, F.; Yamashina, R. Behavioral cloning from noisy demonstrations. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021; pp. 1–14. [Google Scholar]
- Codevilla, F.; Santana, E.; López, A.M.; Gaidon, A. Exploring the limitations of behavior cloning for autonomous driving. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9329–9338. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Yu, T.; Finn, C.; Xie, A.; Dasari, S.; Zhang, T.; Abbeel, P.; Levine, S. One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning. arXiv 2018, arXiv:1802.01557. [Google Scholar]
- Bronstein, E.; Palatucci, M.; Notz, D.; White, B.; Kuefler, A.; Lu, Y.; Paul, S.; Nikdel, P.; Mougin, P.; Chen, H.; et al. Hierarchical model-based imitation learning for planning in autonomous driving. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 8652–8659. [Google Scholar]
- Chen, L.; Lu, K.; Rajeswaran, A.; Lee, K.; Grover, A.; Laskin, M.; Abbeel, P.; Srinivas, A.; Mordatch, I. Decision transformer: Reinforcement learning via sequence modeling. In Proceedings of the 2021 Advances in Neural Information Processing Systems (NIPS), Virtual, 6–14 December 2021; pp. 15084–15097. [Google Scholar]
- Laskey, M.; Lee, J.; Fox, R.; Dragan, A.; Goldberg, K. DART: Noise injection for robust imitation learning. In Proceedings of the 1st Annual Conference on Robot Learning (CoRL), Mountain View, CA, USA, 13–15 November 2017; pp. 143–156. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.; Graves, A.; Riedmiller, M.; Fidjeland, A.; Ostrovski, G. Human–level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Kelly, M.; Sidrane, C.; Driggs-Campbell, K.; Kochenderfer, M.J. HG-DAgger: Interactive imitation learning with human experts. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8077–8083. [Google Scholar]
- Ross, S.; Gordon, G.; Bagnell, D. A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar]
- Yan, C.; Qin, J.; Liu, Q.; Ma, Q.; Kang, Y. Mapless Navigation with Safety-enhanced Imitation Learning. IEEE Trans. Ind. Electron. 2022, 70, 7073–7081. [Google Scholar] [CrossRef]
- Galashov, A.; Merel, J.S.; Heess, N. Data augmentation for efficient learning from parametric experts. In Proceedings of the 39th Advances in Neural Information Processing Systems (NIPS), New Orleans, LA, USA, 28 November–9 December 2022; pp. 31484–31496. [Google Scholar]
- Zhu, Y.; Joshi, A.; Stone, P.; Zhu, Y. VIOLA: Imitation Learning for Vision-Based Manipulation with Object Proposal Priors. arXiv 2022, arXiv:2210.11339. [Google Scholar]
- Antotsiou, D.; Ciliberto, C.; Kim, T.K. Adversarial imitation learning with trajectorial augmentation and correction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 4724–4730. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. In Proceedings of the 30th Advances in Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 1–9. [Google Scholar]
- Pfrommer, D.; Zhang, T.; Tu, S.; Matni, N. TaSIL: Taylor series imitation learning. In Proceedings of the 36th Advances in Neural Information Processing Systems (NeurlPS), New Orleans, LA, USA, 28 November–9 December 2022; pp. 20162–20174. [Google Scholar]
- GitHub—Microsoft/Swin-Transformer: This Is an Official Implementation for “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows”. Available online: https://github.com/microsoft/Swin-Transformer (accessed on 29 December 2022).
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the 32nd Advances in Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 2–8 December 2018; pp. 8778–8788. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Kurin, V.; Nowozin, S.; Hofmann, K.; Beyer, L.; Leibe, B. The Atari Grand Challenge Dataset. arXiv 2017, arXiv:1705.10998. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research | Deep Learning Architecture | Augmentation Method | Spatial Relation |
|---|---|---|---|
| DART [29] | DQN | Noise Generator | × |
| HG-Dagger [31] | - | Data Aggregation | × |
| CAT and DAugGI [36] | GAIL | Adversarial Method | × |
| TaSIL [38] | - | Taylor Series | × |
| Decision Transformer [28] | GPT | - | × |
| The Proposed Method | Swin Transformer | Cyclic Shift | √ |
| Actions | Up | Right | Left | Down |
|---|---|---|---|---|
| Total Number | 1875 | 2283 | 2687 | 2371 |
| Hyper Parameter | Value |
|---|---|
| Image size | (252, 234) |
| Patch size | (18, 13) |
| Input channels | 3 |
| Classes | 4 |
| 1st Stage Embedding dimension | 32 |
| 2nd Stage Embedding dimension | 128 |
| Swin Transformer+ Block number | [3, 3] |
| Multi-Head number | [4, 4] |
| Window size | 3 |
| Dropout rate | 0.5 |
| Epochs | 100 |
| Learning rate | 0.0003 |
| Batch size | 16 |
| Model | Accuracy (%) | Best Eval. Score | Avg. Eval. Score |
|---|---|---|---|
| The Proposed Method | 86.4% | 1700 | 286 |
| Preprocessor + Swin Transformer model + Action model | 98% | 780 | 60 |
| Preprocessor + Vision Transformer model + Action model | 95.1% | 500 | 227 |
| Preprocessor + Decision Transformer model + Action model | 23.6% | 680 | 251 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, Y.; Sung, Y. Imitation Learning through Image Augmentation Using Enhanced Swin Transformer Model in Remote Sensing. Remote Sens. 2023, 15, 4147. https://doi.org/10.3390/rs15174147
Park Y, Sung Y. Imitation Learning through Image Augmentation Using Enhanced Swin Transformer Model in Remote Sensing. Remote Sensing. 2023; 15(17):4147. https://doi.org/10.3390/rs15174147
Chicago/Turabian StylePark, Yoojin, and Yunsick Sung. 2023. "Imitation Learning through Image Augmentation Using Enhanced Swin Transformer Model in Remote Sensing" Remote Sensing 15, no. 17: 4147. https://doi.org/10.3390/rs15174147
APA StylePark, Y., & Sung, Y. (2023). Imitation Learning through Image Augmentation Using Enhanced Swin Transformer Model in Remote Sensing. Remote Sensing, 15(17), 4147. https://doi.org/10.3390/rs15174147