1. Introduction
Road cracks can occur on the pavement due to vehicle overloading, weathering, sun exposure, and waterlogged roads. Road cracks are one of the most common diseases on pavement, which can endanger the health and sustainable use of highways. Cracks are a sign of road damage. Cracks have “accelerated growth” properties. When cracks appear on the pavement without timely treatment, cracks will become longer and wider with the advance of time. They also cause increased maintenance cost and difficulty [
1]. Accurate crack detection is the key to determine the crack grade of channel and repair the subsequent work. The traditional crack detection method is manual survey, which is not safe; it is also time-consuming and laborious. At present, it is a common engineering practice to install cameras on vehicles for image acquisition. Extracting road cracks from the collected images and calculating the size of the cracks can help the road department solve road damage conditions, so as to formulate relevant repair strategies [
2].
In recent years, in order to solve the problem of pavement crack detection, people have conducted a lot of research on pavement crack detection methods. Currently, the mainstream methods based on image processing can be divided into the following three categories: (1) The first is the method based on threshold segmentation. In Reference [
3], an unsupervised crack detection method based on a gray histogram and the Ostu threshold method is proposed, and good results were obtained at a low signal-to-noise ratio. In Reference [
4], the crack extraction under the condition of a high signal-to-noise ratio was realized by changing the probability weighted factor of the gray histogram in the Ostu threshold method. (2) The second is the method based on edge detection. References [
5,
6] studied the sharp changes in the intensity of crack edges, detected the double edges of cracks to generate image gray crack profiles, and further separated the crack regions. In Reference [
7], a crack detection system was designed by using morphological filtering and Canny edge detection. Reference [
8] combined the Otsu threshold method with the Canny edge detection algorithm, and multi-resolution crack segmentation was realized through an adaptive analysis of global and local edge features. (3) The third is an algorithm based on salience. Such methods emphasize the difference between the crack and the background in the apparent senses, highlight the crack area, and inhibit the non-crack area, so as to achieve the purpose of separating the crack and the background. Reference [
9] demonstrated the effectiveness of detecting significant regions in the Berkeley database. However, the method based on image processing cannot obtain continuous cracks, nor can it eliminate the influence of background noise.
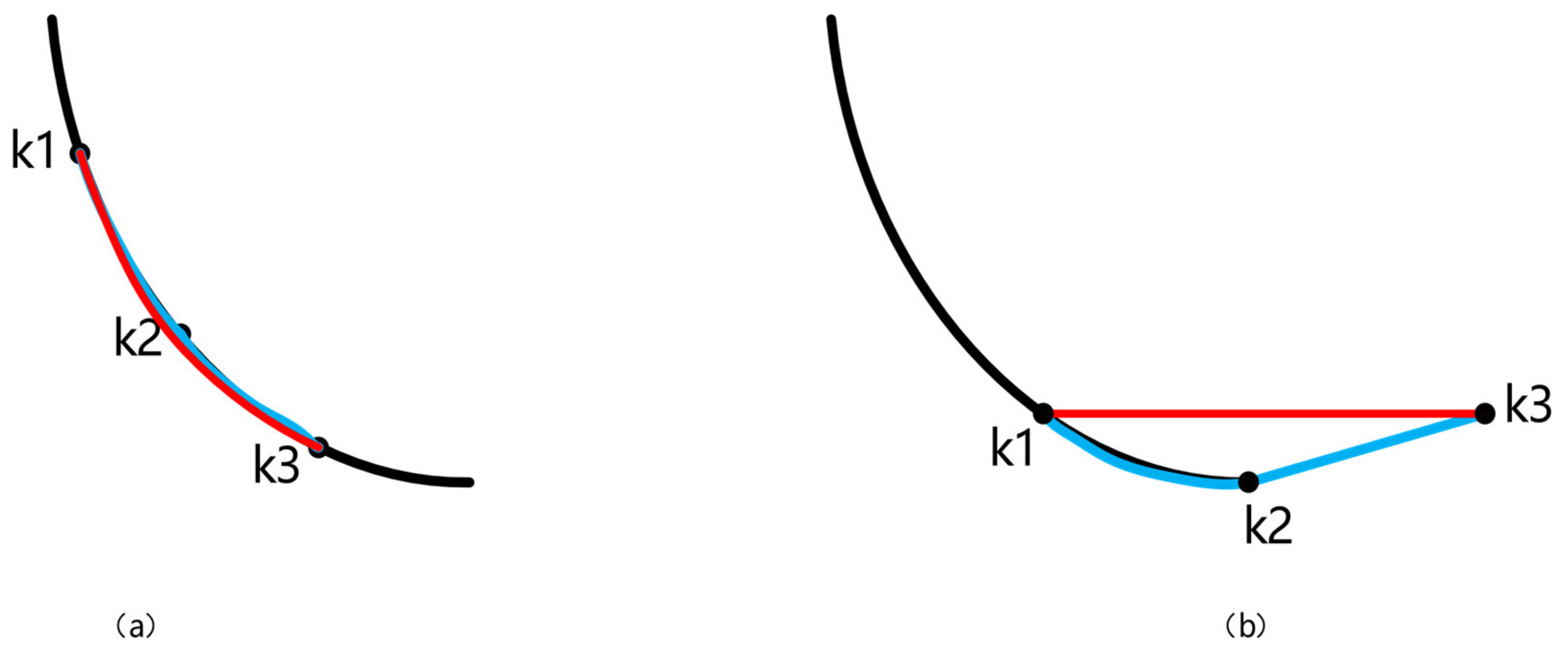
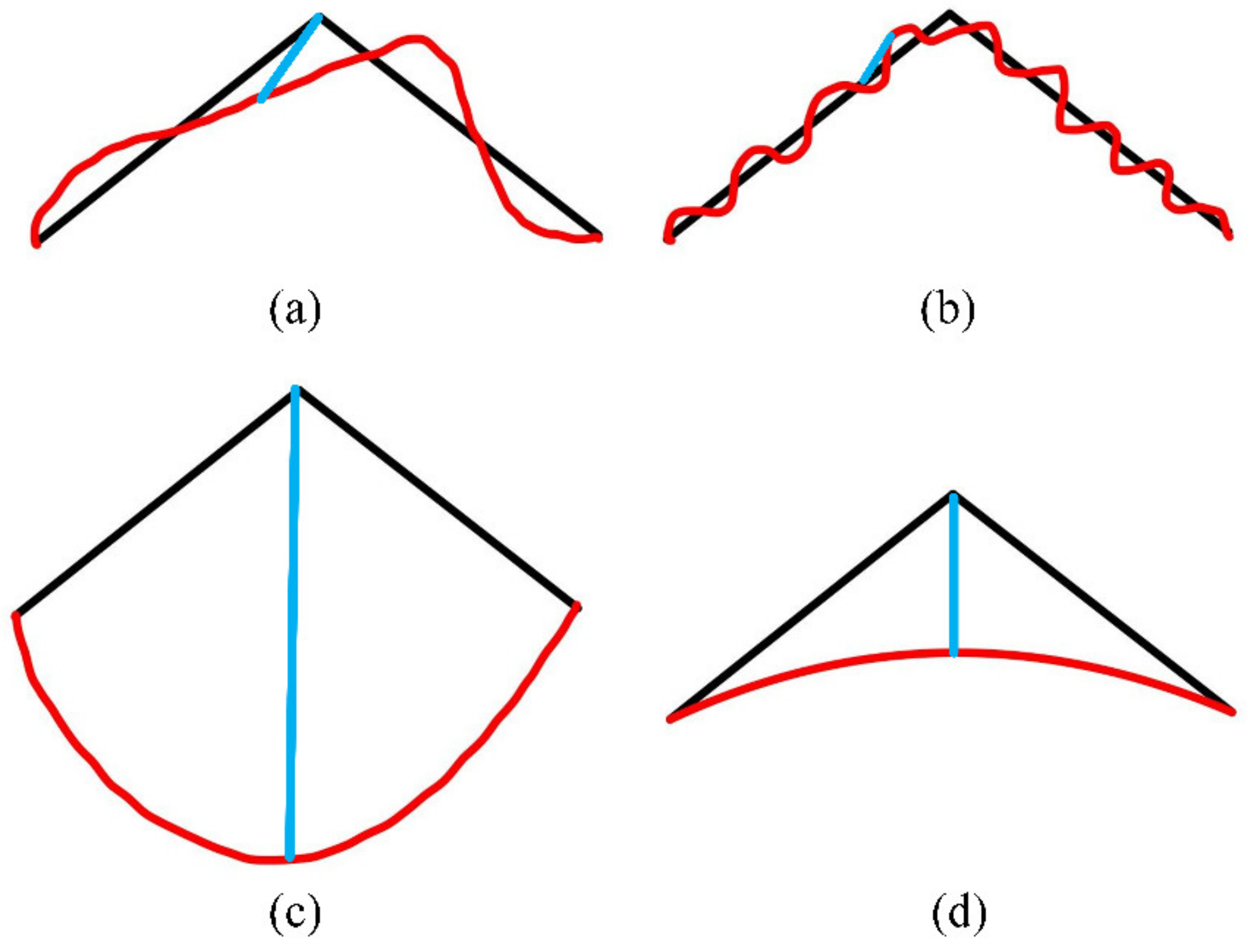
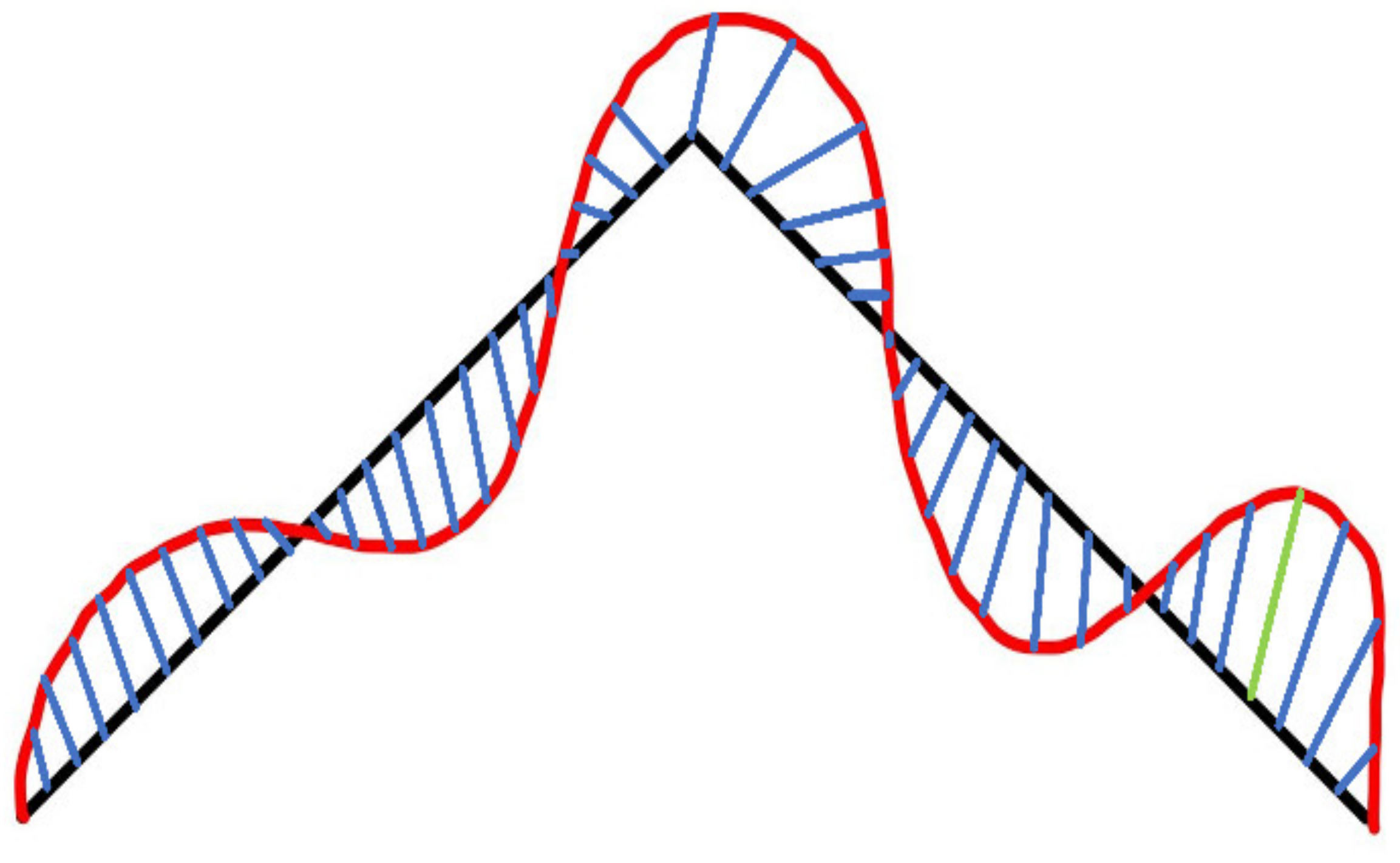
In addition, in the field of crack detection, there is also a shortest-path method, which holds that the gray intensity of cracks is small, and the shortest path curve between the two ends of cracks is taken as input. This method was first proposed by Kass et al. [
10]. In recent years, the research on crack detection based on the shortest-path algorithm has also made rich achievements. In the literature [
11], the FMM algorithm introduced key points and was used for the first time to judge whether the algorithm should be stopped according to the triangular relationship. References [
12,
13] improved the above algorithm by selecting the endpoints on a small scale and the minimum path on a global scale, while detecting the width of cracks. Free-form anisotropy was introduced in Reference [
14], and more accurate cracks were extracted by considering the pixel intensity and morphological characteristics. In Reference [
15], an MPS algorithm was combined with the global gray threshold to produce clearer endpoint selection and greatly reduce the calculation time of the shortest path. Reference [
16] selected candidate points by dividing cells to optimize the path search strategy and improve the efficiency and accuracy of the algorithm. In the work, cracks were extracted from 2D optical images and 3D depth images via automatic voting combined with seed sampling and attractive field. Reference [
17] emphasized an effective quantification of hidden damage in composite structures by using ultrasonic guided wave (GW)-propagation-based structural health monitoring (SHM) and an artificial neural network (ANN)-based active infrared thermography (IRT) analysis. Although the crack detection algorithm based on the shortest path can extract continuous cracks, it is very dependent on the significant difference between cracks and background and requires a starting point to start the algorithm.
With the continuous increase of image data, the method based on deep learning has become an important branch of road crack detection [
18]. According to the processing results, the model can be divided into two categories: (1) The first is the rough positioning model, which is mainly based on the YOLO [
19] network; you can select cracks in the image box and judge their categories. Reference [
20] designed a crack-tracking system based on PCGAN and the YOLO-MF network, which achieved 98.43% accuracy. Reference [
21] improved the CSP layer in the backbone of YOLOv5 and introduced the pyramid divided-attention mechanism into the model for the first time. Reference [
22] described a YOLOv3 model with a four-scale detection layer (FDL) that was used to detect B-scan and C-scan GPR images, and F1 Score and mAP on GPR datasets were increased by 8.7% and 5.3%, respectively. (2) The second is the accurate positioning model. Such models can pinpoint the location of cracks in the image. Through the adaptive modification of the artificial neural network, random forest, SVM, convolutional neural network and other models [
23,
24,
25,
26,
27,
28,
29,
30,
31], scholars have provided a relatively good solution for crack detection. However, the rough positioning model is not accurate, and the processing time of accurate positioning is long [
31].
The continuous improvement and application expansion of YOLO series algorithms also provide a reference for road crack detection. For example, in Reference [
32], the improved YOLOv5-Banana model was used to identify banana fruit clusters. Reference [
33] adopted YOLOv7 to improve the detection accuracy of Camellia oleifera fruits under the conditions of front lighting, backlighting, and partial occlusion. Reference [
34] combined the U-net neural network algorithm and an improved image thinning algorithm to propose a method for dam crack identification and width calculation, which does not rely on a large number of training samples and avoids setting too many artificial thresholds, and it has significant practicability and stability. Reference [
35] proposed a new crack backbone refinement algorithm and width measurement scheme for reservoir dams which simplified the redundant data in crack images and improved the efficiency of crack-shape estimation. Reference [
36] proposed an LWMG-YOLOv5 model with ghost convolution, which improved the chip profile detection speed by 3.62% and chip yield by 1.7% and significantly reduced the production cost loss by 1.83%.
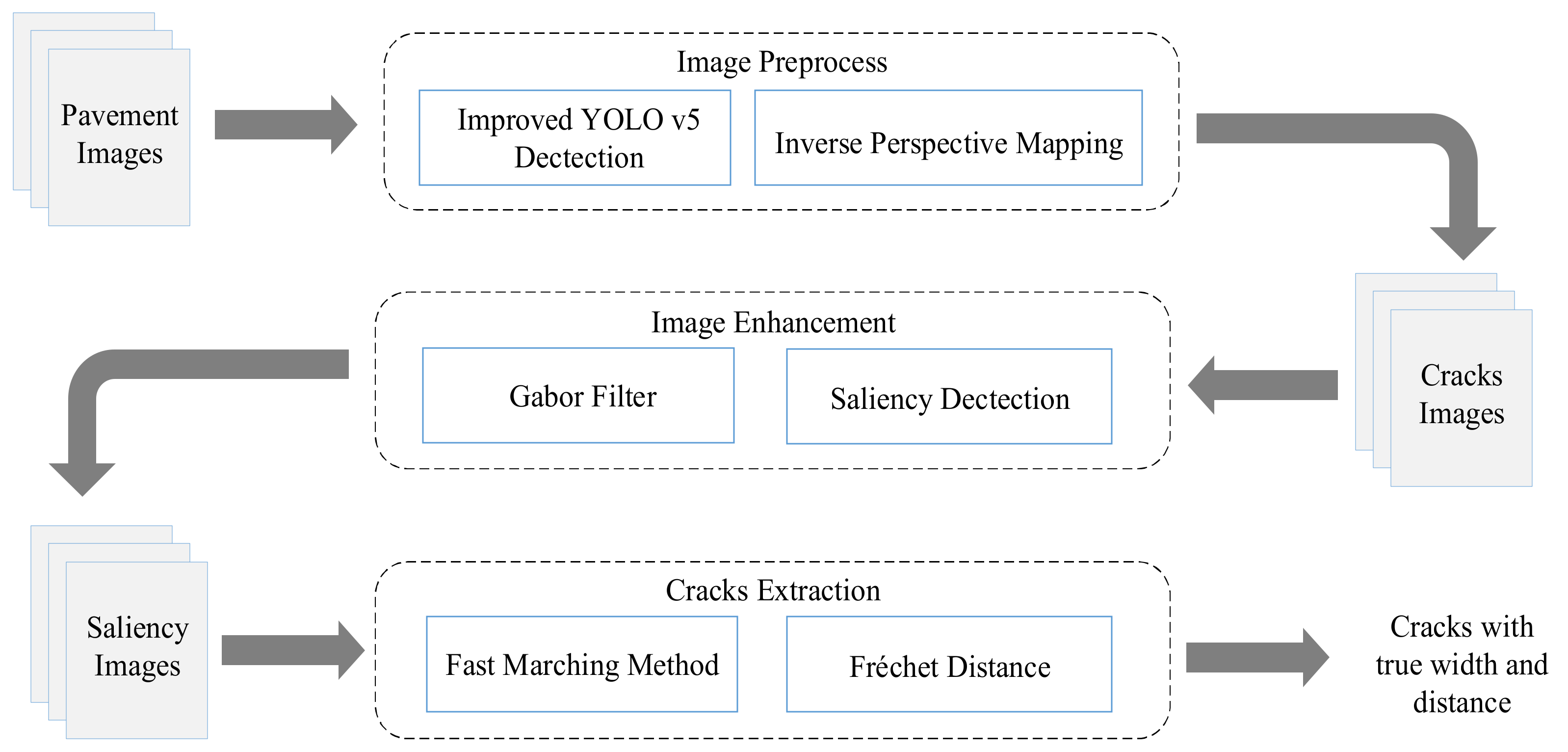
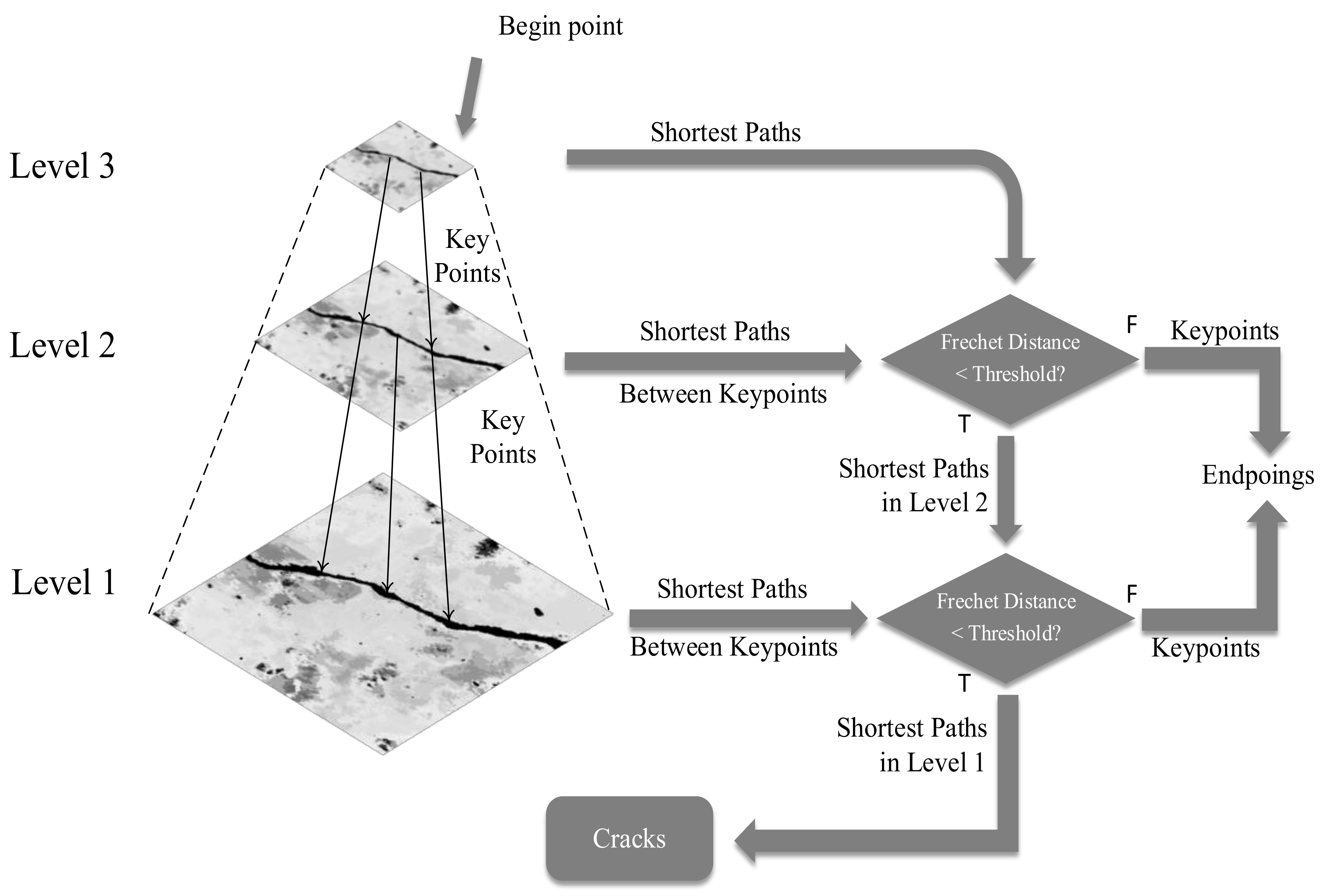
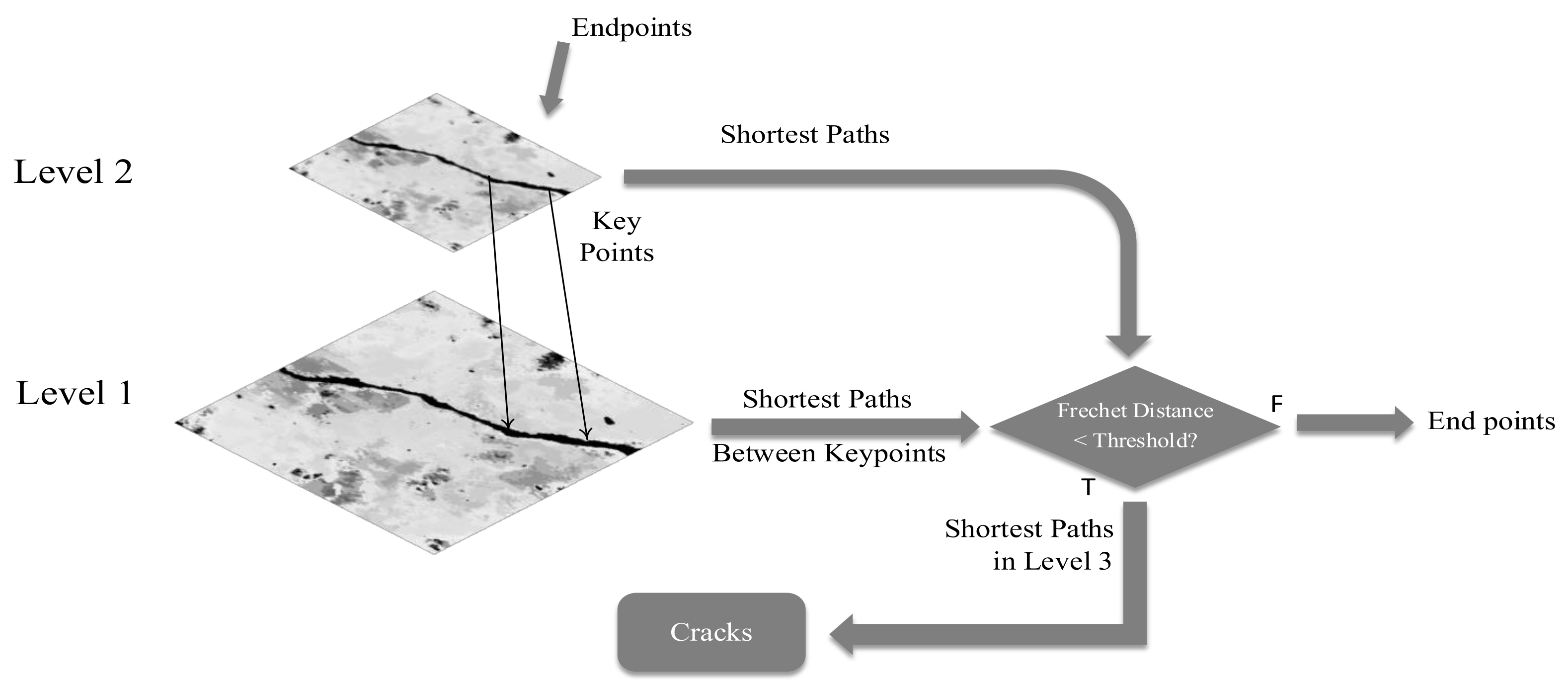
It can be found from these studies that the current crack detection methods have their own advantages and disadvantages. If the advantages of the above methods can be integrated, a fast, efficient, accurate, and robust crack extraction method can be realized. In this study, the image-processing method, the shortest-path method, and the machine-learning method were combined to make full use of the statistical significance of cracks and realize the object-based robust crack detection. First, the lightweight model of improved YOLOv5 was extended, and a large number of crack images were used for training. The improved YOLOv5 detection network was obtained, which could realize the positioning and selection of ROI in the crack region. Then, combined with the camera imaging model and the internal and external parameters of the camera, the ROI of the crack region was transformed into the reverse perspective, and the corresponding relationship between the pixel distance and the actual distance was established. The significance of each pixel at the crack point was then calculated using Bayesian probability formula and linearly stretched to increase the contrast between the crack and the background. Finally, the triangle relationship improved by Fréchet distance was used to judge whether the crack extraction was complete, and the difficult problem of spatial similarity measurement in the fast-moving method was solved. The method that was designed in this study can complete data acquisition by using very simple equipment, without the need of expensive infrared laser equipment, and the data postprocessing process is simple; the method has strong applicability and is a low-cost remote-sensing method. In this study, multiple methods were combined based on the principle of complementarity to achieve accurate crack detection under complex lighting, interference, and texture conditions. The structure diagram of the whole remote sensing process is shown in
Figure 1.
The main contributions of this paper are summarized as follows:
- (a)
A method for improved YOLOv5 and image enhancement based on crack saliency was proposed. Based on Bayesian probability, it calculates the significance of each pixel judged as a crack.
- (b)
Fréchet distance was introduced to improve the triangle relationship to determine whether the extracted key points are the fracture endpoint and whether the fast-moving method should be terminated.
- (c)
We developed a complete remote-sensing process that calculates the length and width of cracks by inverting oblique images collected by mobile phones.
3. Results
3.1. Dataset
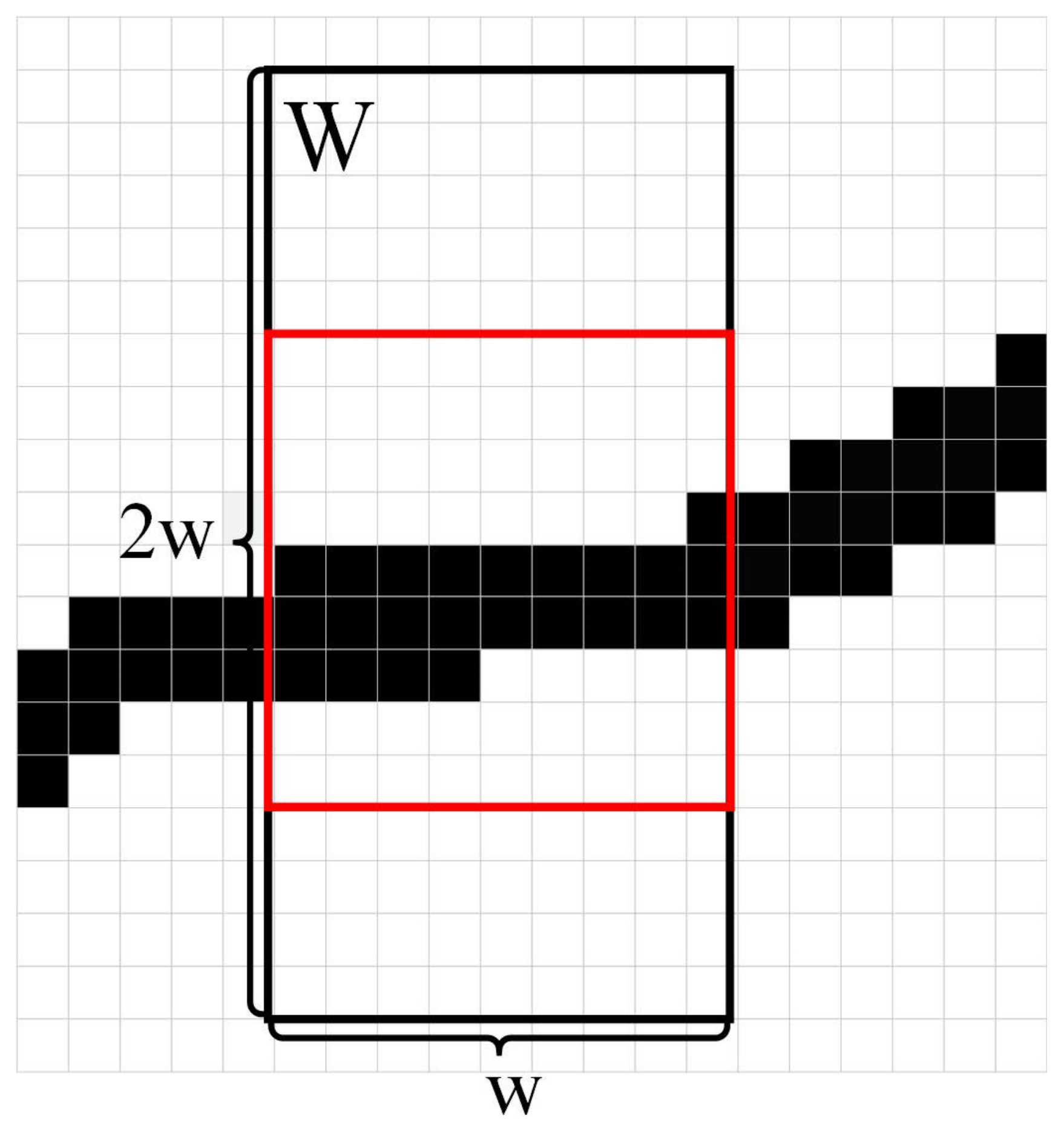
The dataset for this paper is divided into two parts, the public dataset and the self-collected dataset, respectively. The public dataset is mainly used for training and testing YOLOv5 networks. The self-collected dataset is the road image collection conducted by the author’s team around Huanshan North Road and Fengyuan Road in Wuhan University. The training dataset that was used for training and improved the YOLOv5 network is Road Damage Detection-2020 (RDD-2020), which contains 26,620 images collected from three countries: India, Japan, and the Czech Republic. There are four common damage types: longitudinal crack (D00), transverse crack (D10), crack (D20), and pothole (D40). In this study, the original training set was divided into a training set and a test set in a ratio of about 9:1. The improved YOLOv5 code proposed in this paper was run under the deep-learning framework of Python3.8, Pytorch1.8, and cuda11.0, and the model was trained and tested on the NVIDIA 3080 Ti graphics card with 12 GB video memory. Random gradient descent (SGD) optimization was adopted in this study. The initial learning rate was set as 0.01, the momentum coefficient was set as 0.937, the weight attenuation was set as 0.0005, and the learning rate adjustment strategy of cosine annealing was used. The total number of training epochs was set as 300. The batch size was set to 40–80 depending on the model size. The training data were enhanced by mosaic and then input to the network. The input image size was 640 × 640 during training and 640 × 640 during the test.
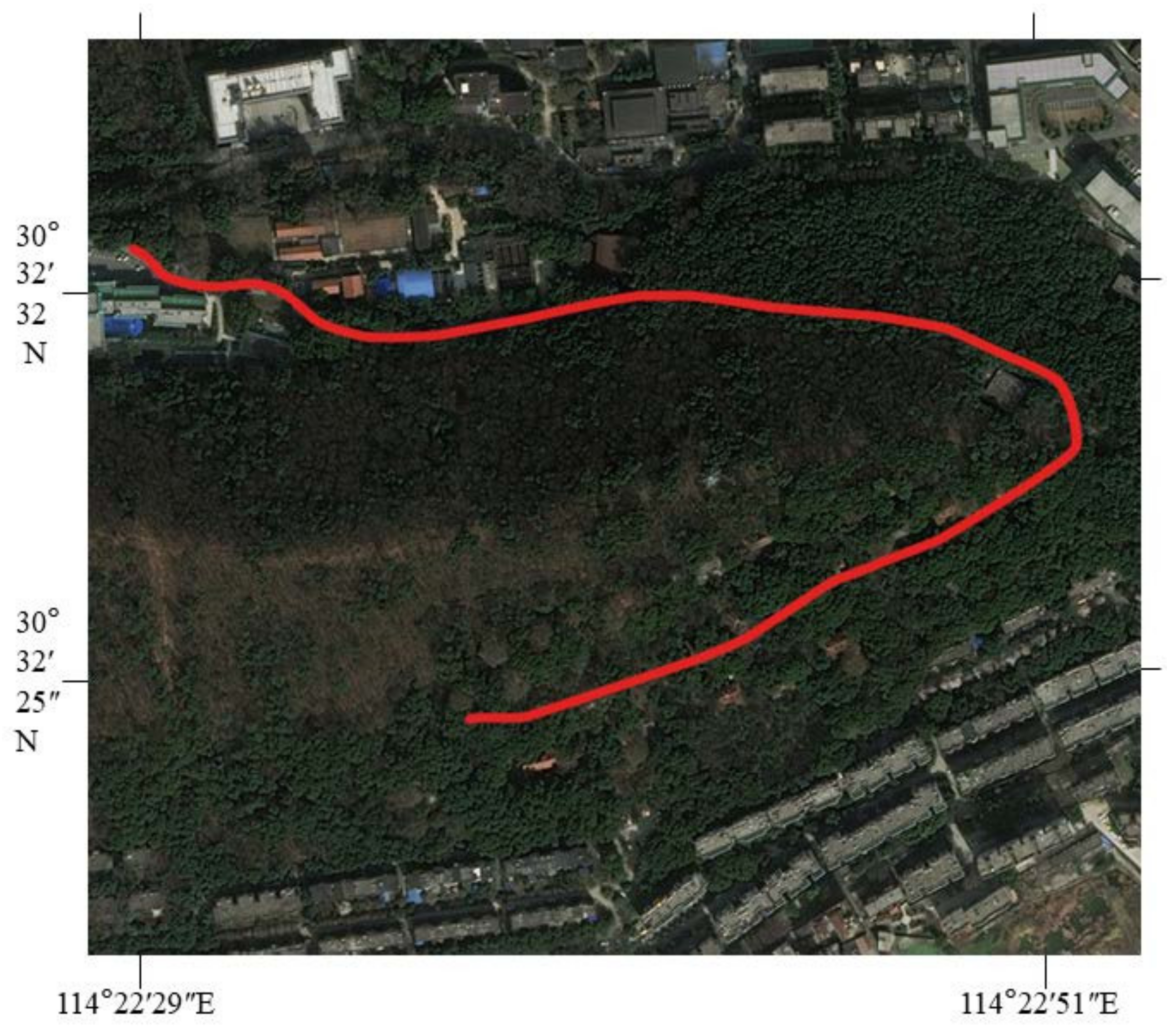
In order to evaluate the effect of the method proposed in this paper, a family car equipped with a HUAWEI P30 mobile phone was used to collect road-image data on Huanshan North Road and Fengyuan Road of Wuhan University, Wuchang District, Wuhan City, Hubei Province. The route is shown in
Figure 19. The whole experiment covered about 20 km of road mileage, and then we extracted images frame by frame. A total of 14,520 images of road surface condition were collected, with a resolution of 720 × 1280. The types of cracks in the image include longitudinal cracks, transverse cracks, and cracks. There are various scenes in the image, including a variety of straight roads and detours. The road condition is complex; there are interferences such as oil and foreign bodies on the road surface, uneven illumination of the image, cracks in crosswalks, and so on. These complex conditions may affect the accuracy of crack extraction. This paper firstly takes a typical crack as an example to give the data-processing results of each stage and the final fracture extraction results; it then gives the results of the algorithm extraction of different types of cracks and crack extraction results under complex background conditions; and, finally, it carries out the accuracy evaluation and error analysis.
3.2. Evaluation Index
To evaluate the accuracy of the road-sign detection algorithm in this article, the total number of road signs, as extracted by the algorithm, is compared with the manually counted number of road signs, and the accuracy and recall rates are calculated using the following equation:
In the formula, true positive (TP) represents the number of pixels detected by the algorithm as cracks, but not as cracks in the actual ground values. False positive (FP) represents the number of pixels detected by the algorithm as cracks, but not as cracks in the ground truth. False negative (FN) represents the number of pixels detected by the algorithm as non-crack, but in the ground truth, they are cracks.
Therefore, precision and recall are used to quantify the number of correct detections that actually belong to cracks, and these predictions are composed of all detection results in the dataset. provides a single score that balances the issues of accuracy and recalls in a single number. If crack detection meets high accuracy, recall, and values simultaneously, then it is indeed a good method.
Due to the complexity of road surface images, manually marked ground-truth values may produce deviations. Therefore, when measuring the coincidence between the detected crack curve and the ground-truth crack curve, we allow a certain tolerance. More specifically, if the detected crack pixel is no more than 1 pixel from the real crack curve on the ground, it is still considered the correct detected pixel.
3.3. Typical Situation
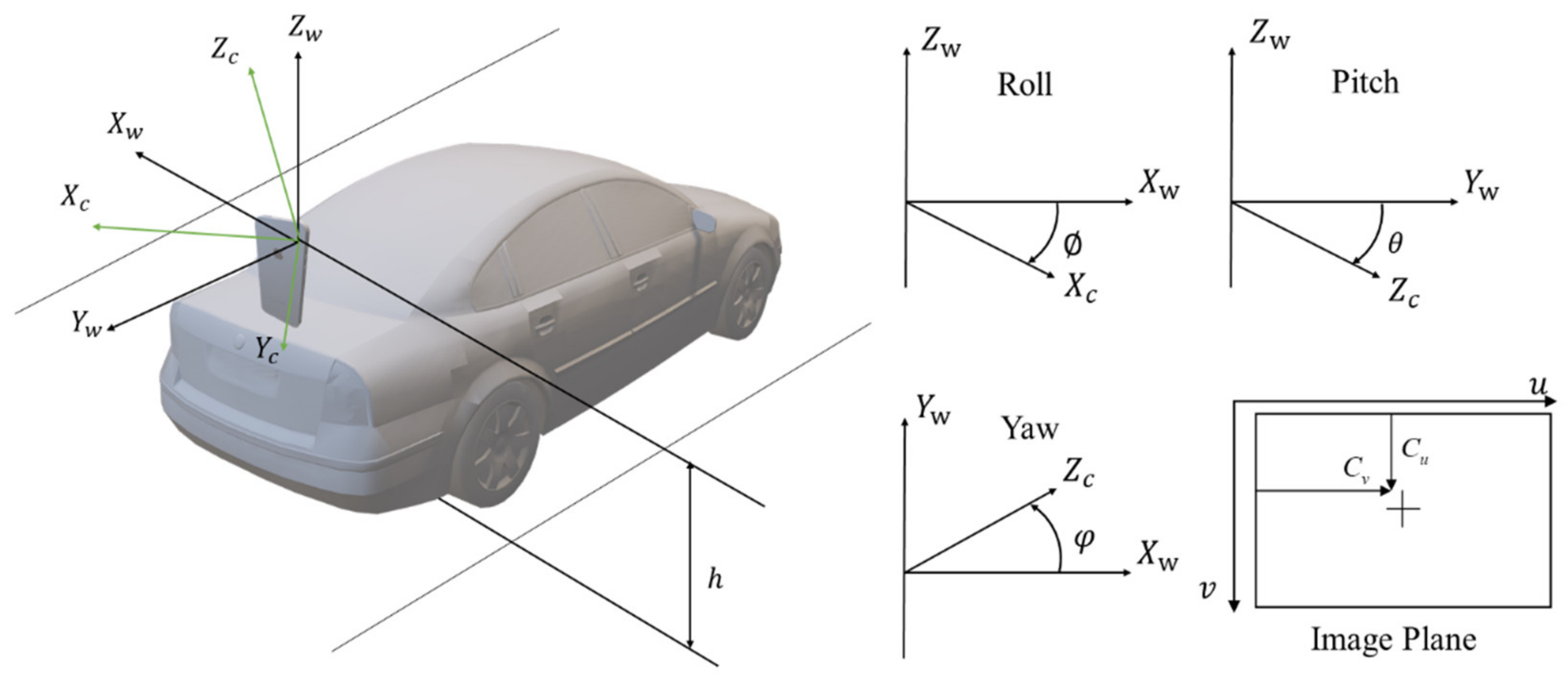
This section uses a typical road image as an example to illustrate the data-processing results of each stage of crack extraction. In order to facilitate the subsequent inverse perspective transformation, it is necessary to perform Zhang Youzheng calibration before processing.
Figure 20 shows some of the checkerboard images used during the calibration.
In order to obtain the height of the camera relative to the ground and the Euler angle of the camera, it is necessary to calibrate the checkerboard placed flat on the ground. The image set used is shown in
Figure 21.
After calibration, the rotation matrix of the camera can be obtained as follows:
The translation matrix of the camera is as follows:
According to the rotation matrix and translation matrix of the camera, the height of the camera is
, the camera’s
, the camera’s
, and the camera’s
, which can be substituted into the IPM change matrix to obtain the following:
The inverse of this change is as follows:
Using these two matrices, an inverse perspective transformation can be performed on the image.
Figure 22a is an image of a certain frame selected in the video. It can be seen that there are not only cracks in the original image but also the interference of pedestrians and various backgrounds. To focus on the cracks, we used the trained YOLOv5 network to perform rough positioning of the ROI on
Figure 22a, and the positioning result is shown in
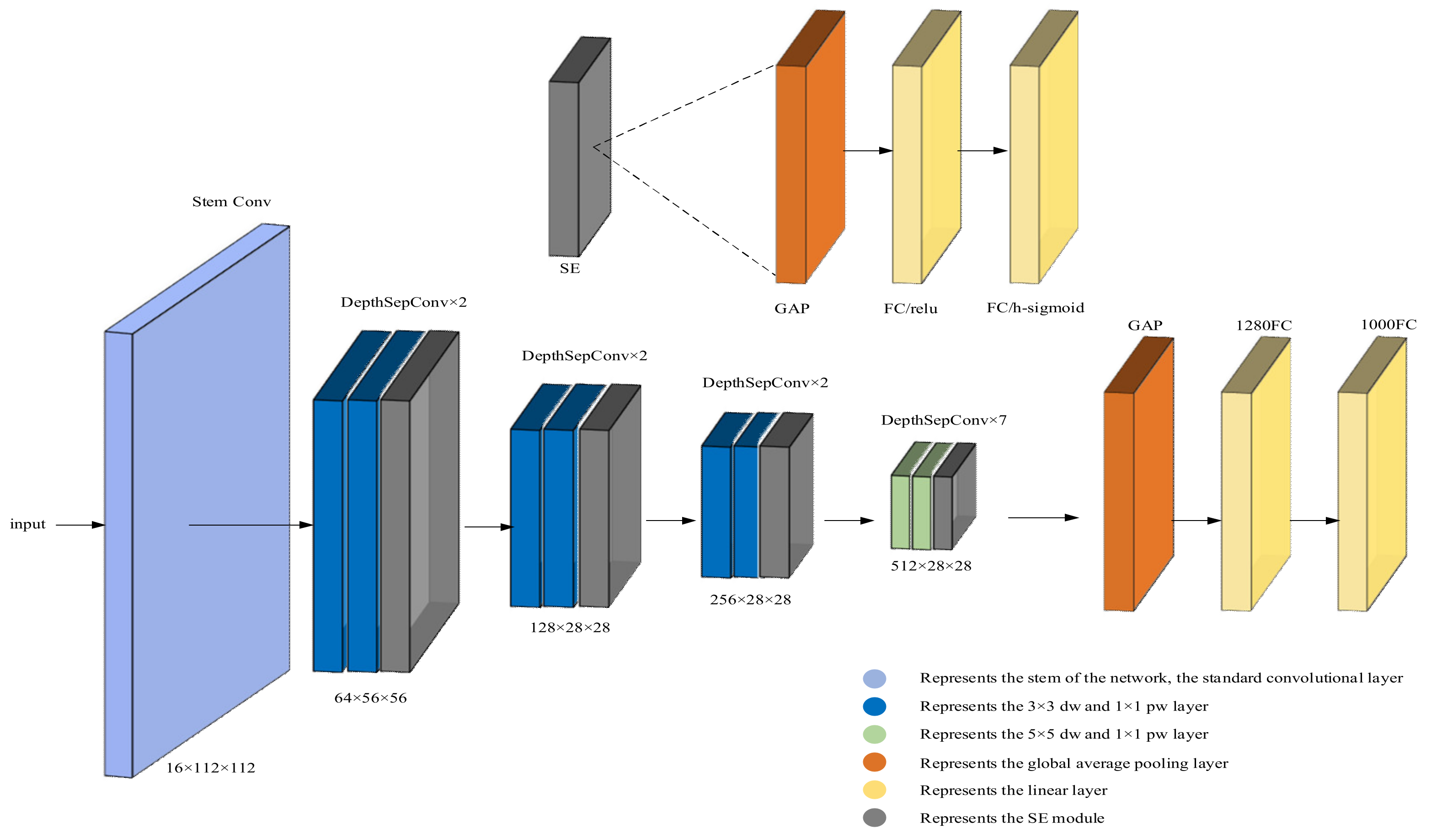
Figure 22b. The results of the proposed method, PP-LCNet-YOLOv5, in this article are shown in
Figure 22c. Compared to the original YOLOv5, the coarse localization method used in this article improved positioning accuracy and completeness. The DepthSepConv-1 module added in PP-LCNet-YOLOv5 improved the feature extraction performance of the network. The mAP of YOLOv5 is 78.9%. However, the mAP of PP-LCNet-YOLOv5 is 84.5%. Afterward, inverse perspective transformation, saliency enhancement, and crack extraction were performed on the area, and the result is shown in
Figure 23.
It can be seen that after the significance enhancement, the cracks are now very obvious and can be distinguished from the background, but there are still external noises, background points inside the cracks, and discontinuous cracks, as indicated by the red box in
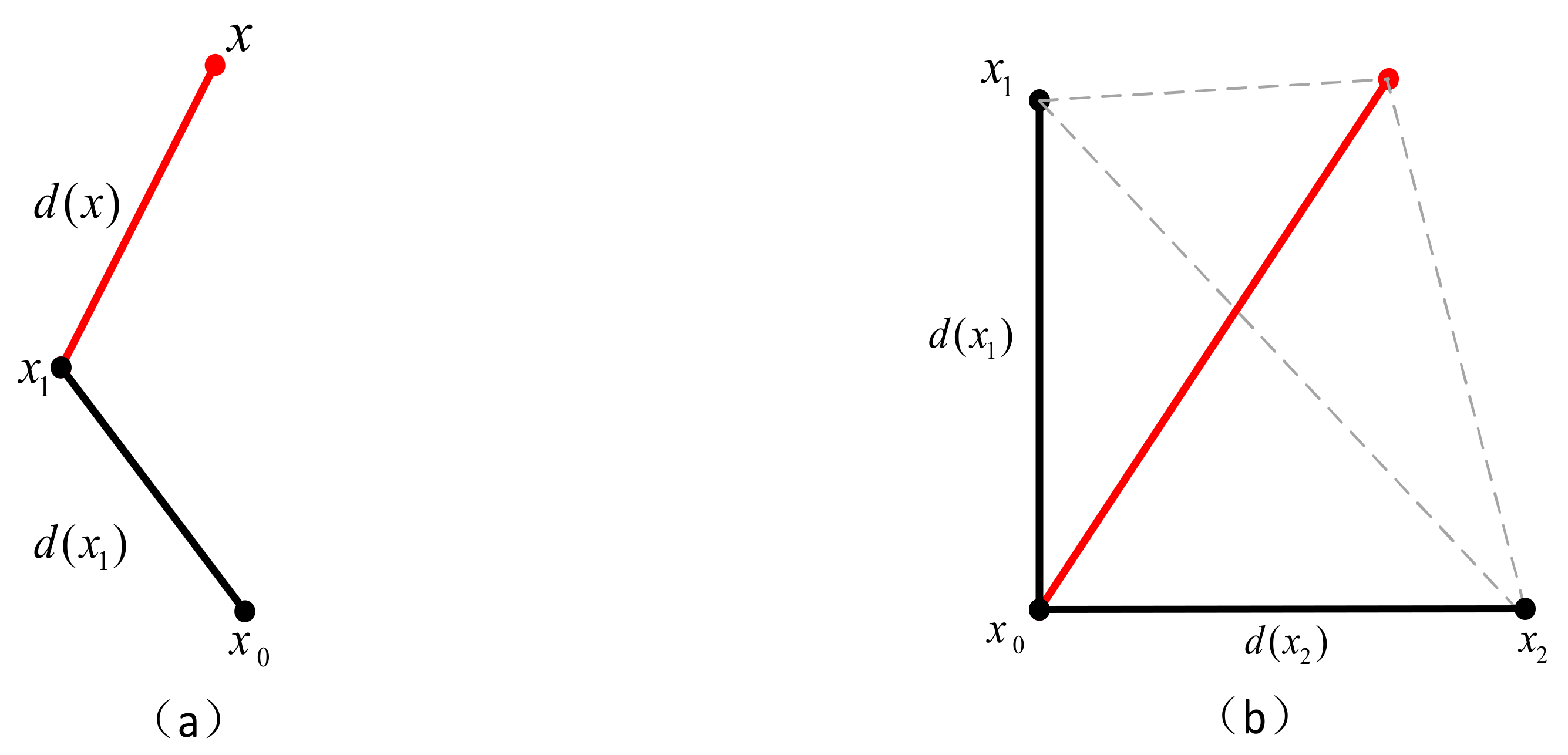
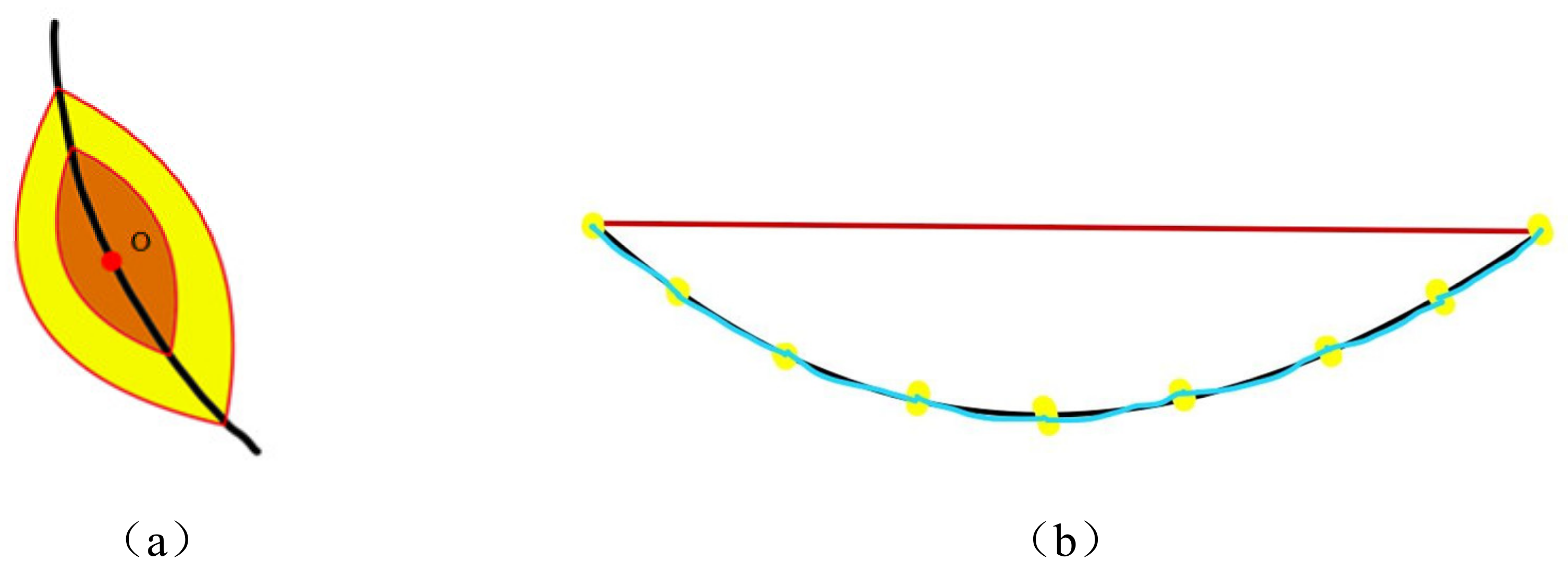
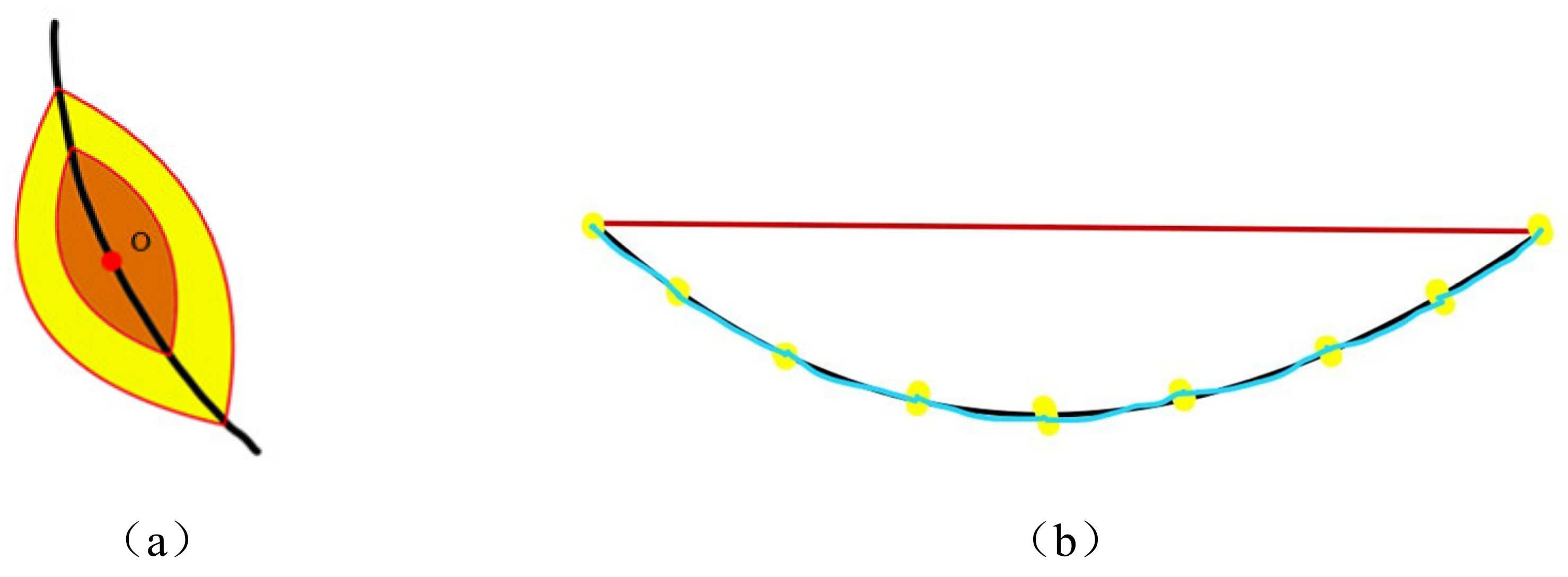
Figure 23. It is shown that the next step is to use the fast-marching method to further extract the fractures. To be able to start the fast-marching method, one needs to select a point as the starting point of the algorithm. We started the fast-marching method with the most significant point at the 5 pixels inside the IPM box as the starting point. In the process of searching for key points, we used the triangle relationship improved by the Fréchet distance as the criterion for the termination of the fast-marching method; the extracted cracks are shown in
Figure 24.
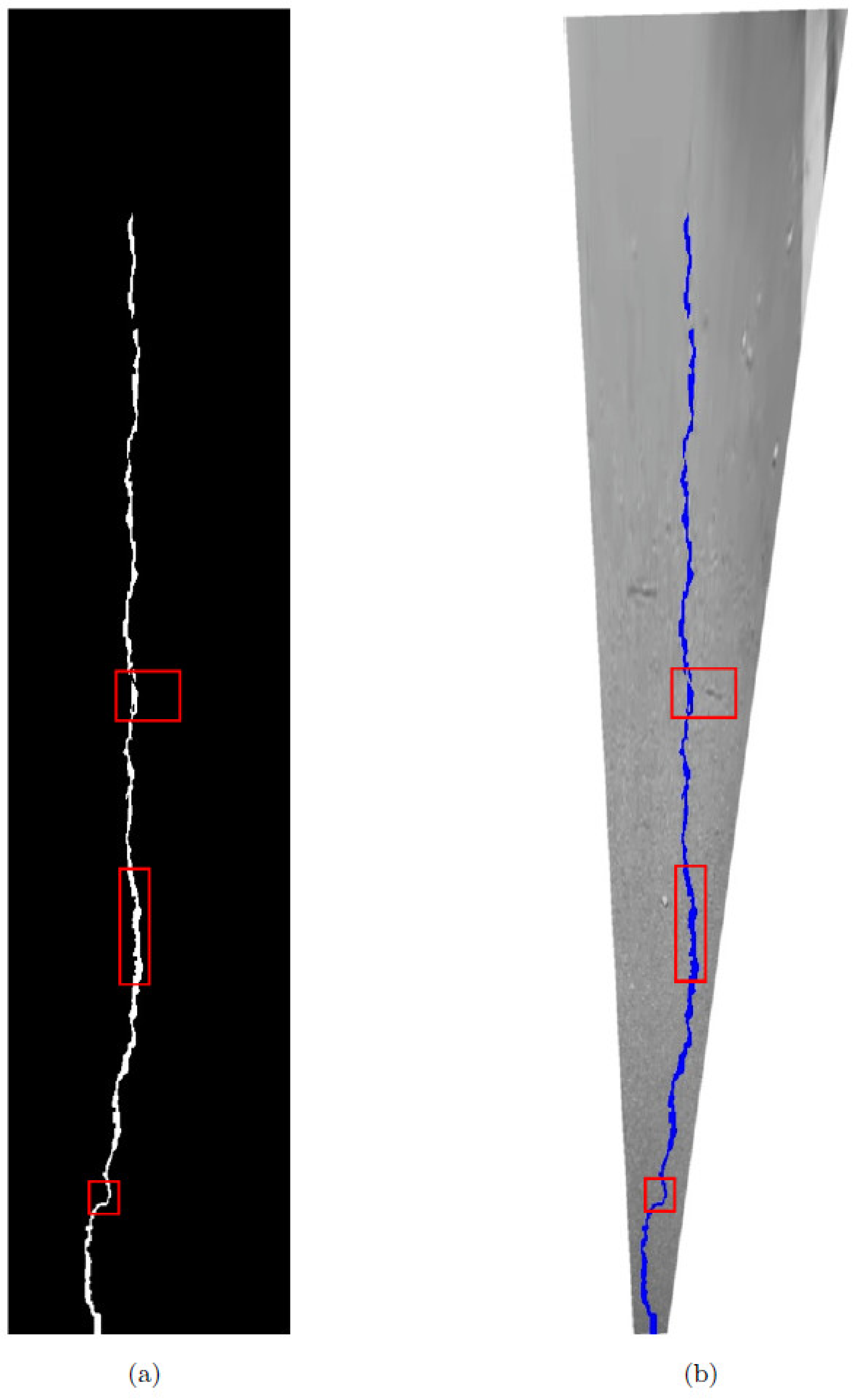
From the blue frame in
Figure 24, we can see that the extracted cracks have eliminated the interference of external noise, the inside of the cracks is also very continuous, and the two intermittent cracks on the salient image are now connected into one. Generally speaking, the crack extraction is more accurate, and the misjudgment rate is lower. The above effect could be achieved because the joint processing method of saliency image and Fréchet distance was adopted in this study.
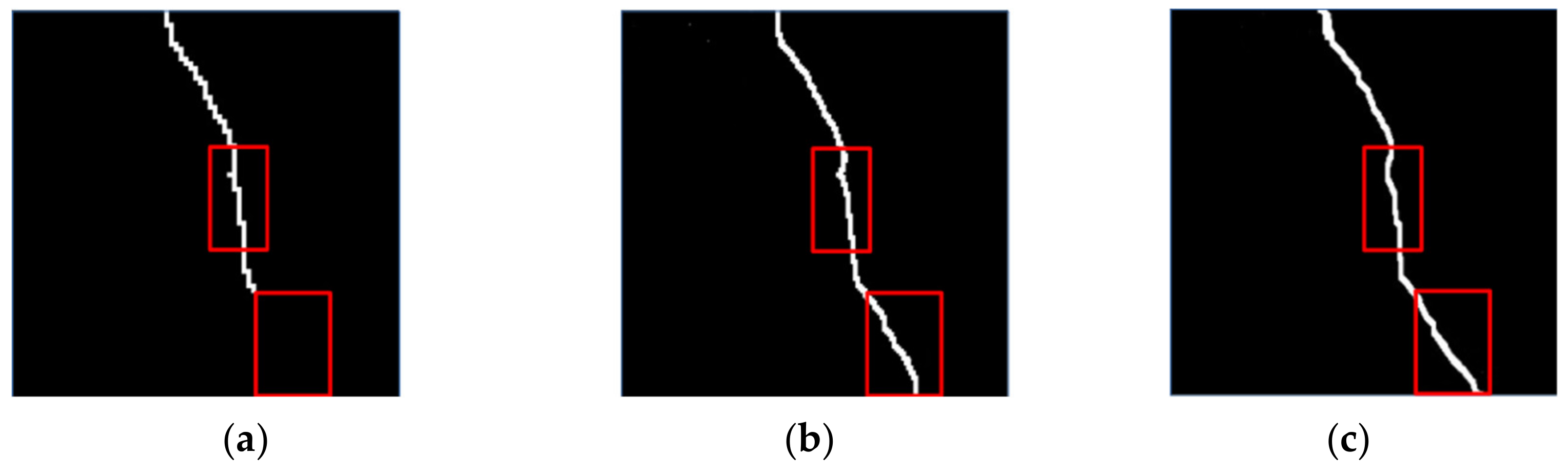
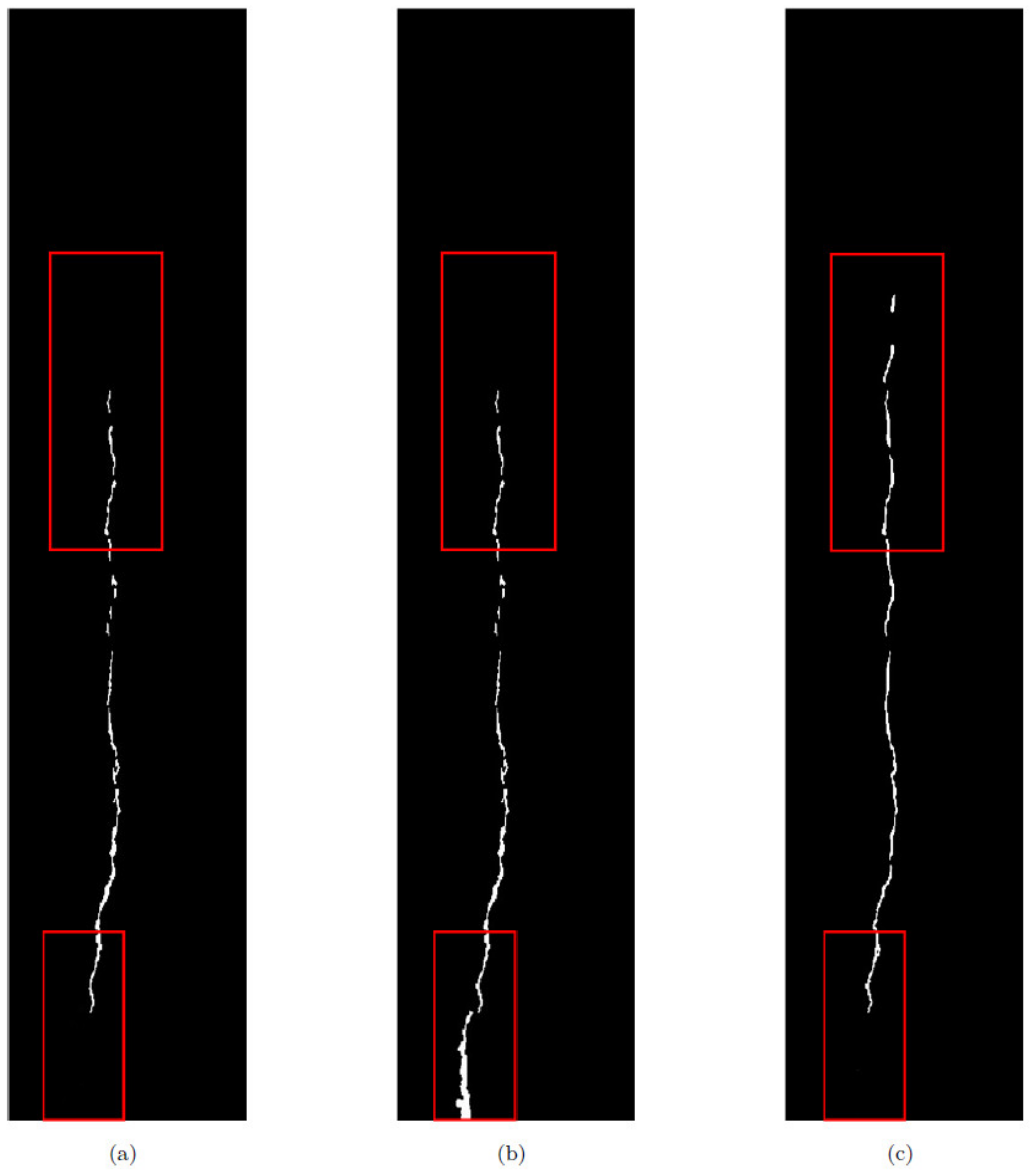
Figure 25 shows the most original results, using only saliency image results and results using only the F-distance.
It can be seen from
Figure 25 that using the F-distance criterion can increase the accuracy of crack judgment and reduce the misjudgment caused by the Euclidean distance criterion, as shown in the red box at the bottom of
Figure 25a,b. The use of saliency enhancement can make the inconspicuous cracks obvious, which helps to extract them and separate them from the background, as shown in the upper red box in
Figure 25a,b. Combining the F-distance criterion and the significance enhancement, the advantages of the two can be combined to extract the cracks with the best effect. According to the statistics, the length of the crack on the image is 2484 pixels. When an inverse perspective transformation is performed, sampling is performed every 2 mm, meaning that the actual distance represented by each pixel is 2 mm, so the actual length of the crack is 4.968 m, which is very close to the crack length we measured on the spot, i.e., 4.98 m, thus showing that the method in this paper is accurate.
3.4. Overall Results
To verify the performance of the method in this paper, taking the three common shapes of cracks—longitudinal cracks (a), transverse cracks (b), and cracks (c)—as examples, the results of inverse perspective transformation and saliency calculation are shown, as well as the effect of crack extraction, the effect superimposed on the original image and the shape attribute of the crack.
For the crack shown in
Figure 26a, its extension direction is perpendicular to the direction of travel of the car; it is called a transverse crack. Using the algorithm in this paper, the cracks in the graph can be accurately extracted. This image was collected on a road close to flat ground, and it is at the beginning of data collection, so the inverse perspective transformation has high accuracy. According to our algorithm, the crack length calculated is 3.942 m, and the actual crack length is 4.015 m. The error is 0.072 m.
For the crack shown in
Figure 27b, its extension direction is the same as the direction of travel of the car, and it is called a longitudinal crack. Accurate and complete cracks can still be extracted using the algorithm in this paper. This image was collected on an uphill road. During the uphill process, the mobile phone fixed on the car may be slightly disturbed, which will affect the result of the inverse perspective transformation to a certain extent, which is reflected in the incomplete lane in the inverse perspective image. Perpendicular to the bottom of the photo.
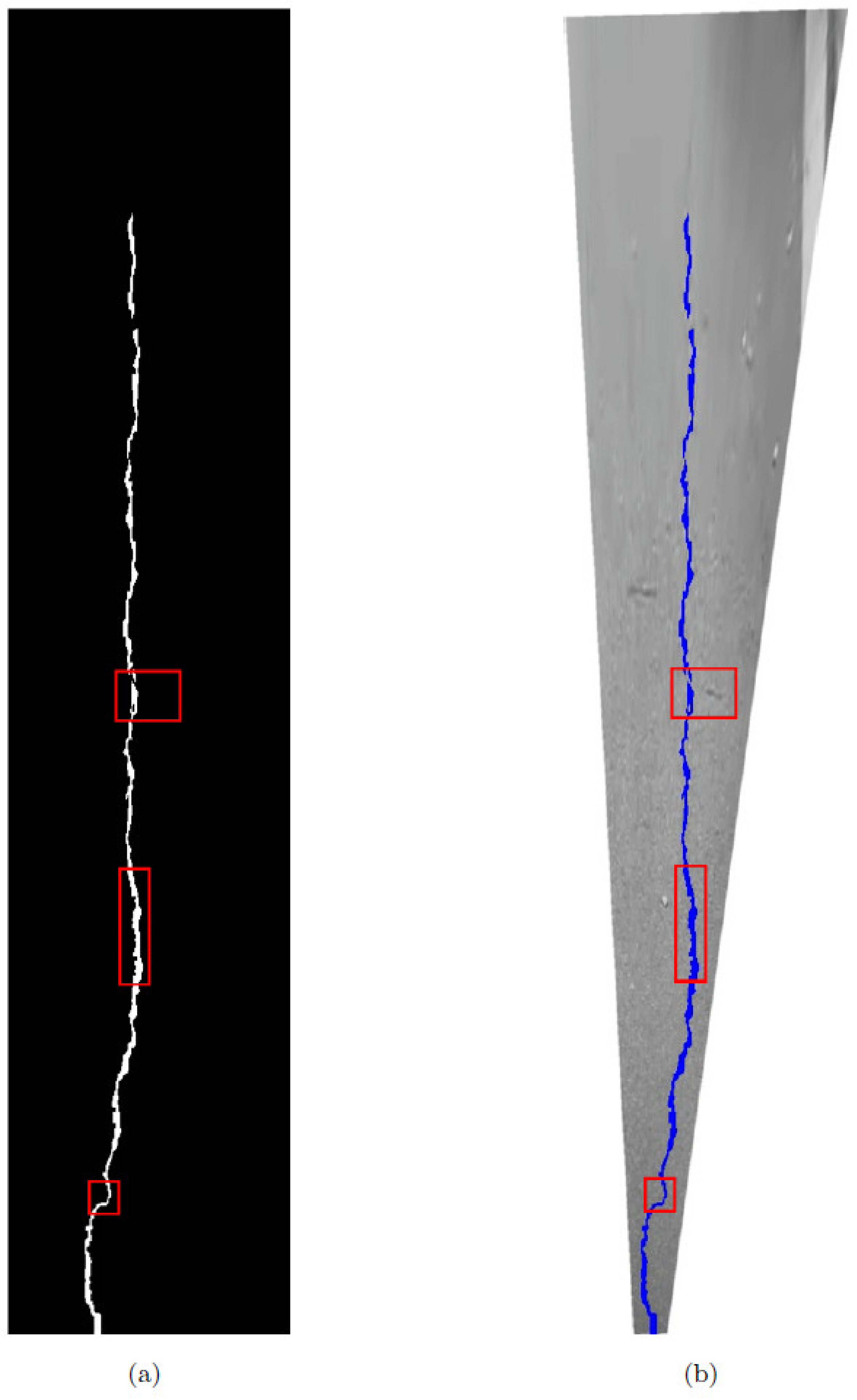
Figure 28 is the result of processing longitudinal cracks by the algorithm proposed in this paper. It can be seen that the algorithm in this paper can extract complete and continuous longitudinal cracks. The fracture length calculated according to the algorithm in this paper is 6.326 m, the actual length of the fracture is 6.201 m, and the error is 0.125 m.
Figure 28 shows the results of each stage of crack extraction in
Figure 26a. It can be seen that the cracks in the original image are not obvious. After the significance enhancement, the cracks and the background were clearly distinguished, but not continuous enough. After being processed by the FMM algorithm, continuous and complete fractures were extracted. As shown in
Figure 28c, the crack has no fixed extension direction and has a turtle-shell-like pattern. This type of crack has the greatest impact on the road and is prone to evolve into potholes, posing a significant safety hazard to drivers. Due to its irregular shape, extracting it is challenging. The result of using the method proposed in this paper to extract the crack is shown in
Figure 29. As it is difficult to accurately measure the total length of the turtle-shell-like crack, only the crack in the blue box in
Figure 30d was measured. The crack length calculated by our algorithm was 1.675 m, while the actual length of the crack was 1.613 m, resulting in an error of 0.062 m.
After statistical calculation, the average error in calculating the length of cracks is 0.127 m, and the average length of cracks is 4.68 m. The relative error in calculating the length of the method proposed in this article is 3%, which is an acceptable range of error. The same evaluation method was used for Reference [
42], with a relative accuracy of 5.3%. This indicates that the algorithm proposed in this article is a very accurate remote-sensing method.
3.5. Complex Conditions
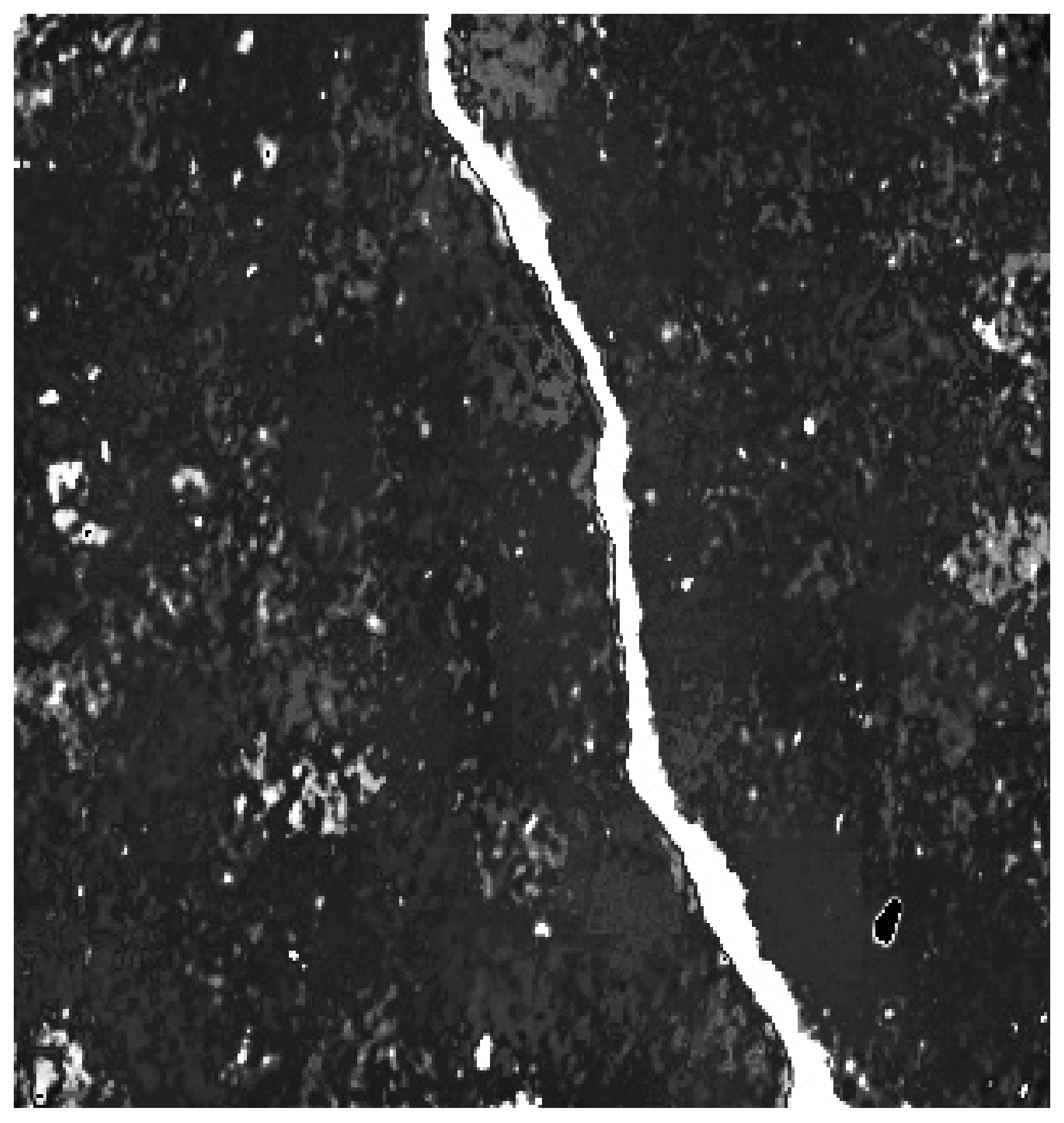
The method proposed in this paper was also tested on road images with complex backgrounds. These images were relatively blurry and were affected by factors such as shadows, noise, and non-uniform lighting. For each scenario, we enhanced the saliency image and then used the fast-marching method to extract the cracks. The extraction results are shown below.
As road images are collected from asphalt pavement, they inevitably mix with many lane markings, as shown in
Figure 30. The lane markings are pure white, and their edges have a sudden change in grayscale value where they meet the road surface. Edge-based crack detection algorithms can easily mistake these edges for crack edges. However, the method presented in this paper detects cracks using saliency enhancement, which is not affected by lane markings.
About half of the road surface image shown in
Figure 30 is covered by shadows. Compared to the area with sufficient lighting, the gray value of the background in the shadow area is approximate to the gray value of the cracks. If cracks are extracted directly, this may lead to inaccurate extraction results. First, using saliency enhancement can enhance the contrast between the cracks and the background. By extracting cracks on the saliency image, better results can be extracted.
3.6. Accuracy Evaluation and Error Analysis
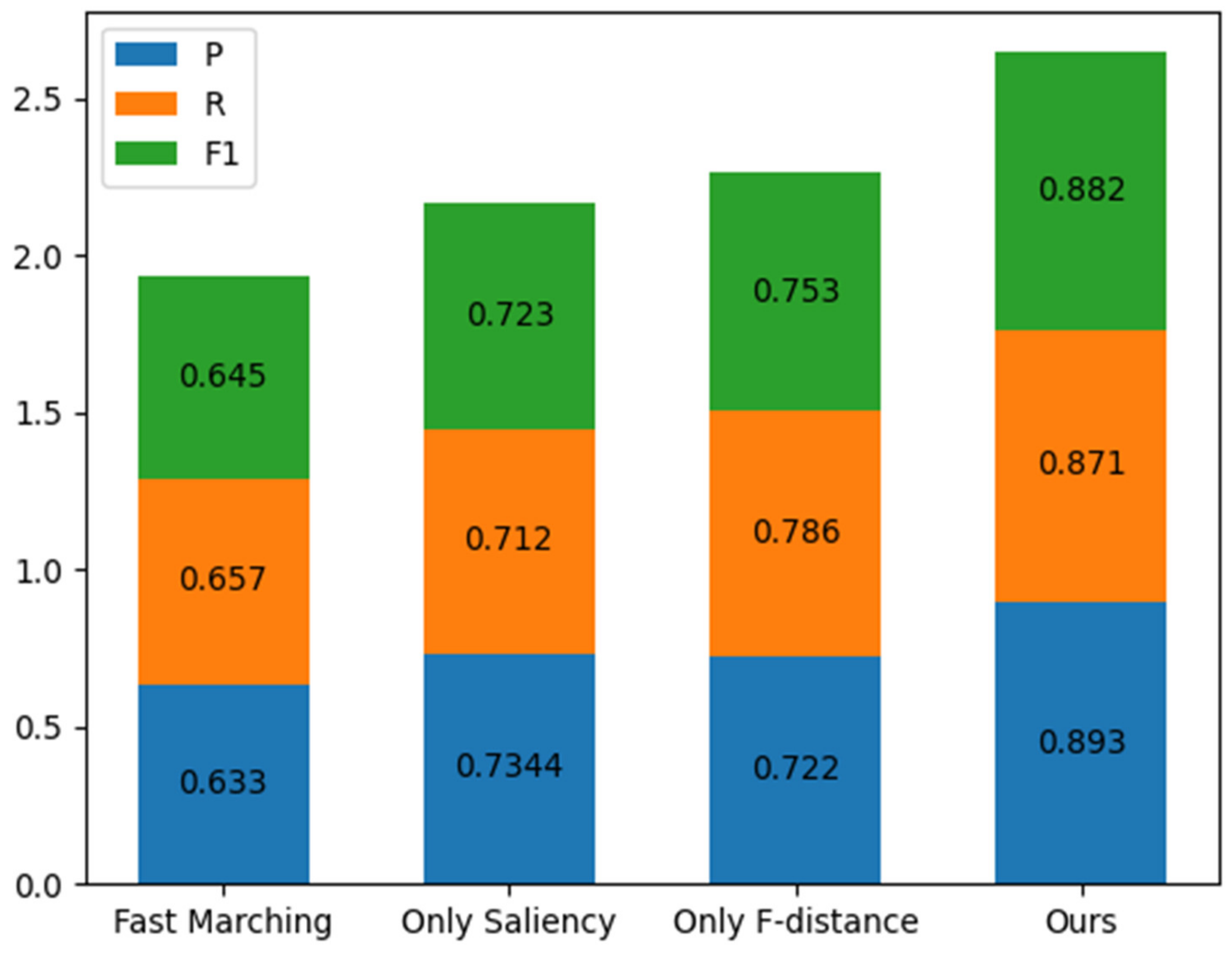
This study selected the fast-marching method, only using saliency, and only using F-distance to compare the accuracy, recall, and F1 measure evaluation indicators of the proposed method. The comparison results are shown in the
Table 1 and the
Figure 31, indicating that this article has certain advantages in all three indicators.
Although the method presented in this paper can extract most of the cracks, there are still cases where foreign objects on the ground are recognized as cracks by the improved YOLOv5 network. As shown in
Figure 32, it may detect foreign objects on the ground, such as manhole covers, as cracks (
Figure 32a), and it may mistake leaves as horizontal or vertical cracks (
Figure 32a–c). The algorithm proposed in this paper cannot exclude such foreign objects on the ground that are highly similar to cracks in both shape and texture. It is recommended to further remove false positives based on more detailed terrain recognition.
4. Conclusions
Lane cracks are one of the biggest threats to road conditions. The automatic detection of lane cracks can not only assist in evaluating road quality but also be used to develop the best crack repair plan, thereby maintaining road smoothness and ensuring driving safety. Although cracks can be extracted from road images due to their lower pixel grayscale intensity than the background grayscale intensity, extracting continuous and complete cracks from complex-texture, high-noise, and uneven-lighting lane images remains a challenge. Although the significance enhancement method can distinguish cracks from the background, the extracted cracks are discontinuous and cannot exclude the influence of noise. Although the fast-marching method can extract continuous cracks, it has the problem of “taking shortcuts” and is prone to extracting incorrect cracks under complex lighting conditions. This study innovatively used a saliency enhancement method to enhance the image, introducing Fréchet distance to solve the problems of the fast-marching method, and created a complete remote-sensing process that can collect crack images and calculate crack attributes, using low-cost equipment. This study first used the improved YOLOv5 network to roughly locate the crack ROI in the collected image, then performed an inverse perspective transformation on the crack ROI to generate a top view image, and then enhanced the saliency of the image to generate a saliency image. Finally, the fast-marching method that introduced the Fréchet distance was used to extract the crack. Due to the fact that the corresponding relationship between pixel distance and actual distance was determined during inverse perspective transformation, the actual distance of cracks can be obtained by counting the number of pixels of cracks in the image. This can help us determine the actual width and length of cracks and evaluate the damage situation of the road surface.
This study used a household car equipped with a fixed-posture mobile phone to collect road image data on Huanshan North Road and Fengyuan Road in Wuchang District, Wuhan City, Hubei Province. The experimental data cover about 20 km of road mileage, and a total of 14,520 road surface image data were collected. The cracks have complex shapes, including longitudinal cracks, transverse cracks, and cracking cracks. The road conditions where the cracks are located are diverse, with various complex conditions such as uneven lighting and noise from sidewalks and asphalt roads. A large number of experiments on real road images have shown that the algorithm proposed in this paper can achieve crack extraction with an accuracy of 89.3%, a recall rate of 87.1%, and an F1 value of 88.2% and can calculate the length and width of cracks. The algorithm proposed in this article is expected to be applied to road departments in various provinces and cities, assisting in evaluating road quality and specifying the optimal crack repair plan. Although the method proposed in this article can solve most of the problems of pavement crack detection, further in-depth research is still needed regarding the following two aspects. Firstly, for the discontinuity problem in some crack results, further continuity processing is needed to identify the cracks as complete target objects with independent features. Secondly, YOLOv7 is used to locate the location of cracks. When training the network, it is necessary to pay attention to the balance of positive and negative samples and try to increase the proportion of crack images in the overall sample as much as possible, so that the training network can more effectively locate cracks.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}