The utility of images with clouds simulated using the proposed framework is tested on the two tasks directly related to clouds: cloud detection and cloud removal. In the experiments, the models are trained on the specific task from scratch on either real data or simulated data. Once trained, each variant is tested on both real and simulated datasets. This enables comparison between the two data sources to determine whether a model trained exclusively on simulated data can perform well on real data and vice versa. This can give some information about whether the simulated data are similar enough to the real data to produce models that generalise to real data. The main goal of these experiments is to preserve the training settings as much possible and compare the impact of the types of images (real versus simulated) used for training and testing, rather than push the state of the art in each task. The procedure should highlight differences with respect to both training and evaluating models for these tasks.
4.1. Cloud Detection Task
For the task of cloud detection, the lightweight fully convolutional architecture of MobileNetV2 [
20] (which achieved the highest performance on the CloudSEN12 high-quality cloud detection benchmark [
8]) is trained from scratch on Sentinel Level-2A images. The networks are optimized without any pre-training in order to match the exact optimization conditions for the explored data variants. The baseline variant (a) is optimized on the manually annotated data of real clouds sourced from the official high-quality subset of the CloudSEN12 dataset (the first released version) [
8]. The alternative variants (b–d) use the clear images from that subset and simulate the clouds using the simulation method proposed in this work. The variants involving the use of simulator data include two variants that use samples simulated without channel-specific magnitude (b) and (c) and two variants (d) and (e) where channel-specific magnitude is used. In each case, a fully synthetic approach is tested as in (b) and (d), as well as a hybrid approach that mixes 50% of real data with 50% of simulated data as in (c) and (e).
For this experiment, the network operates on the bands contained in the Sentinel-2 L2A product. The networks are trained with the standard cross entropy loss for three classes (clear, cloud, shadow), until a point where the validation loss does not decrease for 240 epochs. Each batch contains 32 clear images and 32 cloudy images, but the loss on the clear images is multiplied by a factor of 0.1 so that the cloudy images are prioritized during learning. The weights parameters are optimized using an AdamW [
21] optimizer with an initial learning rate of
, which is scaled down by a factor of
whenever the validation loss does not decrease for 128 epochs.
As a result, each network was trained for about 20,000 optimization steps until the validation loss ceased to improve. Although this process could be tuned further to optimize various learning hyperparameters and yield a lower validation loss, the motivation for the experiments conducted here is to compare the effect of the real and simulated training data for these models.
The metrics reported for the performance were selected based on the CloudSEN12 work [
8], where producer’s accuracy (PA), user’s accuracy (UA), and balanced overall accuracy (BOA) are reported. The first two metrics are more widely known in the field of object classification as recall (producer’s accuracy) and precision (user’s accuracy). Additionally, the false positive rate is reported in addition to the metrics used in CloudSEN12.
The producer’s accuracy (PA), or recall, is computed as the fraction of positives that are correctly detected. For an example of the cloud class, it corresponds to the number of correctly detected cloud pixels divided by the number of all true cloud pixels. It can be interpreted as an approximate probability of a pixel containing a cloud being assigned cloud class by the model. A high level of PA means that a large portion of the cloud present in the image is contained in the cloud mask.
User’s accuracy (UA), or precision, corresponds to the fraction of all positive detections that are correct detections. For the example of the cloud class, it is computed as the number of correctly detected cloud pixels divided by the number of all pixels detected as cloud. It can be interpreted as an approximate probability of a pixel detected as cloud containing, in fact, cloud. A high level of UA means that a large portion of the cloud mask produced in the model contains cloud pixels, with minimal leakage of non-cloudy pixels into the mask.
The balanced overall accuracy (BOA) is the average of true positive rate (producer’s accuracy or recall) and true negative rate. This is particularly helpful for non-balanced datasets, where there is a significant imbalance between positives and negatives in the ground truth. The true negative rate corresponds to the ratio of all negative instances correctly labeled as negatives.
Finally, the false positive rate (FPR) is provided as the rate of falsely rejected positive instances. For the example of cloud detection, it can be interpreted as the number of pixels incorrectly detected as cloud divided by the total number of cloud-free pixels.
Table 2 contains the metrics computed on the cloudy images of the test dataset containing the original real cloudy samples. In terms of balanced overall accuracy for the cloud class, the performance is quite comparable across variants, with the model trained on real data performing best (0.79). Yet, models (b) and (d) trained exclusively on simulated data can achieve a non-trivial performance of 0.75 and 0.78, respectively. This also demonstrates the improvement achieved with the realistic channel-specific magnitude (CSM) feature of the simulator, where higher BOA is observed for all three classes, especially for the shadow class increasing from 0.50 (without CSM, effectively no discriminative capability) to 0.72. These benefits are also observed for the hybrid approaches (c) and (e), where the BOA increases from 0.73 to 0.76 for the clear class and from 0.71 to 0.74 for the shadow class.
These observations motivate two important conclusions. First, it is possible to train cloud detection models exclusively on simulated data and achieve good performance when tested on real samples. Second, channel-specific magnitude appears to consistently lead to improved accuracy in real test data.
An important aspect of this test that should be acknowledged is that the real data labels have been produced by humans, who have inevitably instilled some bias into the ground truth. This bias is the net effect of many factors and may be difficult to determine precisely; however, it can be understood that any type of error consistently produced by humans leads to a certain bias in both real training and test data. Consequently, the models trained only on simulated data, (b) and (d), have no access to observe this type of bias, yet they are expected to reproduce it when tested on real data. Hence, they may be put at an unavoidable disadvantage. To understand this effect better, models (c) and (e) can be inspected. In terms of BOA, these models perform marginally lower for the cloud class (both scoring 0.78 compared to 0.79 achieved with (a)), meaning that the presence of simulated data in the training samples makes it more difficult to learn the biases present in the real data.
The other metrics beyond BOA provide more insight into the results. Producer’s accuracy (PA), as discussed earlier, measures the amount of coverage for each class, which can be understood as how much of the present class is actually contained in the detected region. In this case, all of the models trained on simulated data (b–e) strongly outperform the real data model (a) for the cloud class. This means that those models are more likely to contain complete sets of cloudy pixels in the cloud masks they produce, which could often be considered beneficial for the purpose of masking out the cloud-affected regions. Conversely, they consistently achieve lower user’s accuracy (UA) values, which means that the cloud masks they produce will often contain higher portions of cloud-free pixels. Models trained with simulated data are less conservative in the process of producing cloud masks, meaning that they tend to overestimate the cloud-affected region compared to models trained on real data. Depending on the application, this behavior could be considered more or less beneficial (this depends on whether precise cloud-free region masks with no presence of cloud are prioritised or not).
For the thick simulated cloud test images, as shown in
Table 3, the BOA achieved by models (b–e) is higher compared to that of the real data, which could indicate that the ground truth labels between the training and test images are more consistent. This is consistent with the fact that simulated data allow for precise ground truth extracted from the synthesis process. Another interesting observation is that the models (b) and (c) trained without channel-specific magnitude achieve the best trade-off between PA and UA, meaning that they achieve values above 0.90 for both. This means that these models can mask out most of the cloudy area and include few non-cloudy pixels in the resulting cloud mask. On the other hand, models (a), (d), and (e) consistently achieve much higher UA than PA, which means that they tend to produce masks that mostly contain cloudy pixels, but not all of the cloudy pixels in the image are contained in that mask. Finally, the issue with model (b) not being able to detect shadows is still present and appears to be minimized when channel-specific magnitude is used for the clouds, as in model (d).
For local clouds, the model trained on real data still achieves superior performance of BOA at 0.80, compared to the value of 0.77 achieved by channel-specific magnitude with only simulated data, as shown in
Table 4. However, the models (b–d) trained on simulated images achieve higher PA, meaning that they are capable of including larger portions of the cloud in the resulting cloud mask.
For the thin simulated clouds in
Table 5, the simulated data models (b–d) achieve higher accuracy than the real model (a), and their PA values are considerably higher, which again suggests that they can extract larger portions of clouds in their cloud masks.
Finally, two more subsets are tested in
Table 6 and
Table 7, which contain simulated foggy image examples and cloud-free image examples, respectively. In the case of foggy images (where the entire image is covered by cloud), only user’s accuracy is reported, which corresponds to the fraction of pixels correctly classified as cloud. In this case, all models achieve maximum performance, meaning that they assign the correct label to all examples in the test dataset.
This concludes the analysis of the cloud detection task, which demonstrates that cloud detection models can be trained exclusively on simulated cloudy data and achieve performance comparable to the models trained on real data. Furthermore, the realistic magnitude of the cloud component in each channel of multi-spectral data has been found to be beneficial for performance on real clouds when learning from simulated data.
4.2. Cloud Removal Task
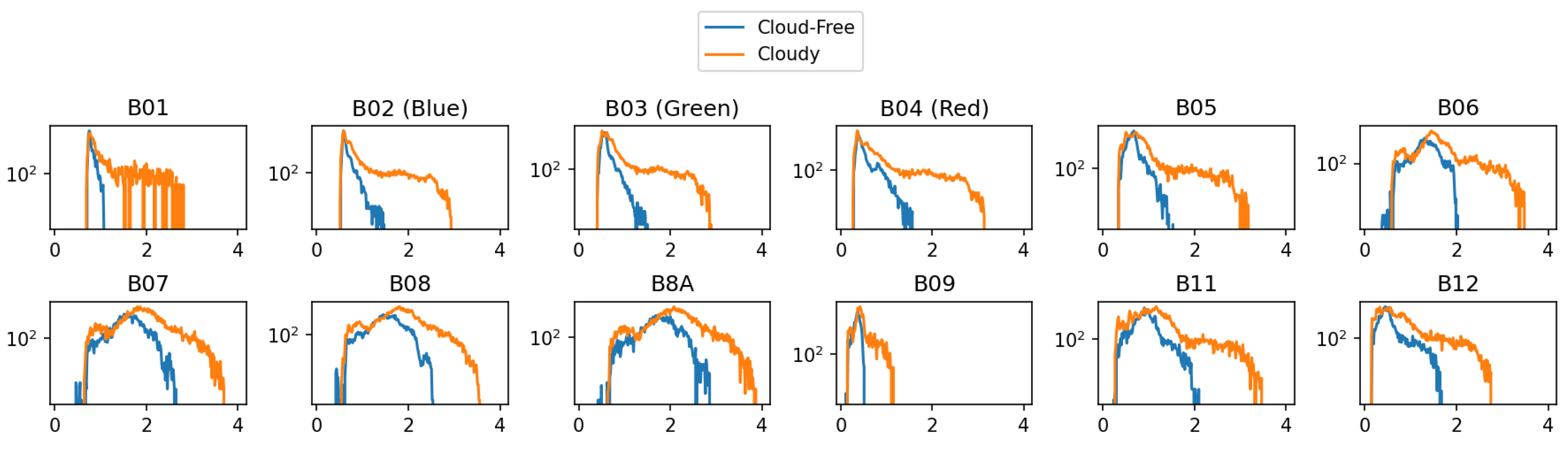
For the task of cloud removal, the dataset of SEN12MS-CR is used, containing real pairs of cloudy and non-cloudy Sentinel-2 images, along with corresponding Sentinel-1 samples. The dataset contains Sentinel-2 Level-1C product, which consists of 13 bands of multi-spectral data. Furthermore, Band 10 is excluded from the experiment, since it primarily responds to the top of atmosphere reflections of cirrus clouds [
22], which often have a different effect than in other bands, as can be observed in
Figure 19 and
Figure 20. This effect is not currently modeled by the cloud simulator and hence the exclusion. The two figures contain visualizations of individual bands from a Sentinel-2 L1C product for a cloudy and a clear sample. In both cases, all bands except for Band-10 (SWIR–Cirrus) appear to be highly correlated. In the cloudy image, the bands tend to contain a similar presence of the cloud, while in Band-10 this object appears absent. Similarly, Band-10 in the clear image appears to detect a fairly different structure than the other bands.
The baseline architecture used for the experiments on cloud removal is DSen2-CR [
6], a simple residual-based deep neural network architecture consisting primarily of convolutional operations. In each case, it is trained from scratch to a point where no improvement in validation loss occurs for 30 epochs. The networks are trained using an AdamW optimizer [
21] with a starting learning rate of
and the same decay strategy as the cloud detection model above. Each batch of data contained four clear and four cloudy images, and, similarly to the cloud detection scheme, the loss on the clear images is multiplied by a factor of 0.1. Due to the large dataset size of SEN12MS-CR, during each epoch, the loss is optimized on 1000 random samples from the training dataset, and the validation loss is computed on 500 random samples from the validation dataset.
Similar to the previous example with cloud detection, the models are tested on five different test datasets, one with real clouds and another four with simulated-only data of different cloud types. The commonly used metrics of SSIM (
Table 8) and RMSE (
Table 9) are used to evaluate the models. Furthermore, each metric is reported for the whole image (the first listed value) as well as the isolated cloud-affected region (the second listed value).
The results in
Table 8 indicate that while the model trained on the real data (a) performs best on that type of data (an SSIM of 0.623 for the whole image and 0.561 for the inpainted region), the model (d) trained exclusively on simulated data with channel-specific magnitude achieves an SSIM of 0.544/0.462. On the other hand, for any type of simulated test data, model (d) outperforms model (a). Similar to the detection task, model (b), which was trained on simulated cloudy images without channel-specific magnitude, consistently produces results of the lowest quality. In
Figure 21 and
Figure 22, it can be observed that model (b) does not really apply any visible changes to the input image, indicating that it does not recognize the cloud objects as something that should be removed. It achieves an SSIM of 0.444/0.323, compared to 0.544/0.462 in the equivalent model trained with channel-specific magnitude. This demonstrates that the channel-specific magnitude feature is crucial for cloud removal models to generalize from simulated data to real instances, indicated by the improved quality achieved with models (d) and (e).



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}