
Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data in an Agricultural Watershed


Abstract
1. Introduction
2. Literature Review
2.1. Use of Remote Sensing in Agriculture
2.2. Classification Methods
2.3. Land Use & Land Cover Classes (LULC)
2.4. Post Classification Correction (PCC)
2.5. Classification Accuracy Assessment
3. Materials and Methods
3.1. Study Area
3.2. Remote Sensing Data and Processing
3.3. Ancillary Data
3.4. Mask Generation
3.5. LULC Classification and Post-Classification Correction
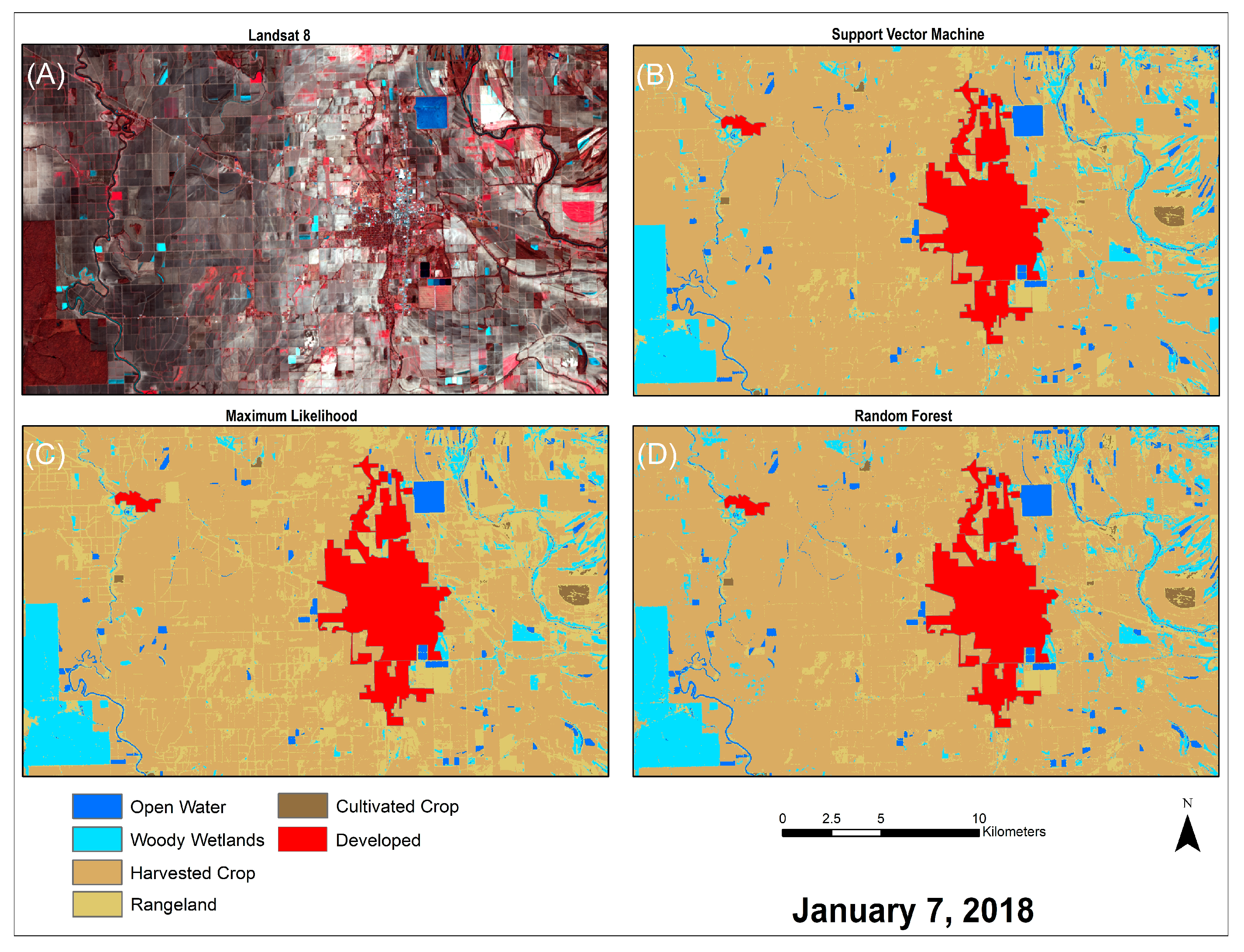
4. Results
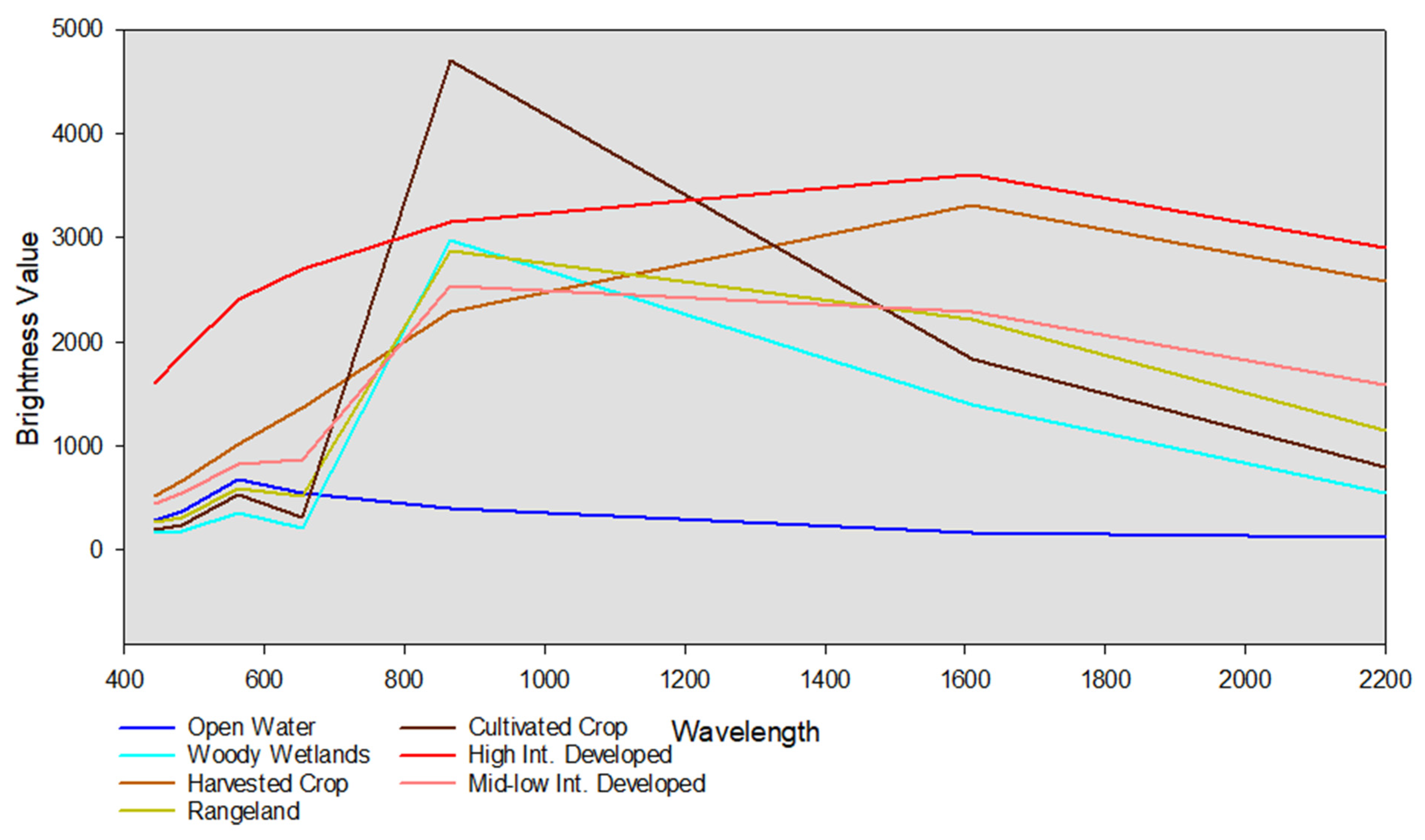
4.1. Growing Season
4.1.1. Classification of the Growing Season Imagery before Post-Classification Correction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | High Int. Dev | Mid-Low Int. Dev | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| Open Water | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 1 | 0 |
| Woody Wetlands | 0 | 55 | 0 | 0 | 0 | 0 | 0 | 55 | 1 | 0 |
| Harvested Crop | 0 | 0 | 90 | 0 | 0 | 0 | 0 | 90 | 1 | 0 |
| Rangeland | 0 | 19 | 1 | 37 | 74 | 0 | 1 | 132 | 0.28 | 0 |
| Cultivated Crop | 0 | 12 | 0 | 1 | 111 | 0 | 0 | 124 | 0.895 | 0 |
| High Int. Developed | 2 | 0 | 3 | 1 | 0 | 3 | 1 | 10 | 0.3 | 0 |
| Mid-Low Int. Developed | 0 | 4 | 29 | 29 | 20 | 0 | 4 | 86 | 0.047 | 0 |
| Total | 12 | 90 | 123 | 68 | 205 | 3 | 6 | 507 | 0 | 0 |
| Producer’s Accuracy | 0.83 | 0.61 | 0.73 | 0.54 | 0.54 | 1 | 0.667 | 0 | 0.611 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.515 |
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | High Int. Dev | Mid-Low Int. Dev | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| Open Water | 10 | 0 | 0 | 0 | 0 | 4 | 0 | 14 | 0.71 | 0 |
| Woody Wetlands | 0 | 13 | 0 | 5 | 2 | 0 | 0 | 20 | 0.65 | 0 |
| Harvested Crop | 0 | 0 | 22 | 0 | 0 | 0 | 3 | 25 | 0.88 | 0 |
| Rangeland | 0 | 0 | 0 | 10 | 1 | 0 | 4 | 15 | 0.67 | 0 |
| Cultivated Crop | 0 | 0 | 0 | 10 | 23 | 0 | 4 | 37 | 0.62 | 0 |
| High Int. Developed | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 6 | 1 | 0 |
| Mid-Low Int. Developed | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Total | 10 | 13 | 22 | 25 | 26 | 10 | 11 | 117 | 0 | 0 |
| Producer’s Accuracy | 1 | 1 | 1 | 0.4 | 0.88 | 0.6 | 0 | 0 | 0.72 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.66 |
4.1.2. Classification of the Growing Season Imagery after Post-Classification Correction
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | High Int. Dev | Mid-Low Int. Dev | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| Open Water | 9 | 0 | 0 | 1 | 0 | 0 | 0 | 10 | 0.9 | 0 |
| Woody Wetlands | 1 | 63 | 0 | 2 | 1 | 0 | 0 | 67 | 0.94 | 0 |
| Harvested Crop | 0 | 0 | 100 | 1 | 0 | 0 | 1 | 102 | 0.98 | 0 |
| Rangeland | 0 | 27 | 3 | 26 | 48 | 0 | 1 | 105 | 0.248 | 0 |
| Cultivated Crop | 0 | 5 | 0 | 3 | 136 | 0 | 0 | 144 | 0.94 | 0 |
| High Int. Developed | 2 | 0 | 2 | 0 | 0 | 5 | 1 | 10 | 0.5 | 0 |
| Mid-Low Int. Developed | 0 | 3 | 21 | 23 | 17 | 0 | 9 | 73 | 0.12 | 0 |
| Total | 12 | 98 | 126 | 56 | 202 | 5 | 12 | 511 | 0 | 0 |
| Producer’s Accuracy | 0.75 | 0.64 | 0.79 | 0.46 | 0.67 | 1 | 0.75 | 0 | 0.68 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.595 |
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|
| Open Water | 8 | 1 | 1 | 0 | 0 | 10 | 0.8 | 0 |
| Woody Wetlands | 0 | 56 | 0 | 0 | 0 | 56 | 1 | 0 |
| Harvested Crop | 0 | 0 | 106 | 1 | 0 | 107 | 0.99 | 0 |
| Rangeland | 0 | 27 | 9 | 88 | 79 | 203 | 0.434 | 0 |
| Cultivated Crop | 0 | 4 | 0 | 2 | 119 | 125 | 0.952 | 0 |
| Total | 8 | 88 | 116 | 91 | 198 | 501 | 0 | 0 |
| Producer’s Accuracy | 1 | 0.636 | 0.913 | 0.967 | 0.60 | 0 | 0.753 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.674 |
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|
| Open Water | 9 | 0 | 0 | 0 | 0 | 9 | 1 | 0 |
| Woody Wetlands | 1 | 13 | 0 | 3 | 0 | 17 | 0.76 | 0 |
| Harvested Crop | 0 | 0 | 24 | 4 | 0 | 28 | 0.86 | 0 |
| Rangeland | 0 | 0 | 0 | 11 | 1 | 12 | 0.92 | 0 |
| Cultivated Crop | 0 | 0 | 0 | 15 | 27 | 42 | 0.64 | 0 |
| Total | 10 | 13 | 24 | 33 | 28 | 108 | 0 | 0 |
| Producer’s Accuracy | 0.9 | 1 | 1 | 0.33 | 0.96 | 0 | 0.78 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.72 |
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|
| Open Water | 10 | 0 | 0 | 0 | 0 | 10 | 1 | 0 |
| Woody Wetlands | 0 | 64 | 0 | 0 | 4 | 68 | 0.94 | 0 |
| Harvested Crop | 1 | 0 | 114 | 5 | 1 | 121 | 0.94 | 0 |
| Rangeland | 0 | 24 | 3 | 78 | 33 | 138 | 0.565 | 0 |
| Cultivated Crop | 0 | 5 | 1 | 2 | 158 | 166 | 0.95 | 0 |
| Total | 11 | 93 | 118 | 85 | 196 | 503 | 0 | 0 |
| Producer’s Accuracy | 0.909 | 0.688 | 0.966 | 0.917 | 0.806 | 0 | 0.84 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.789 |
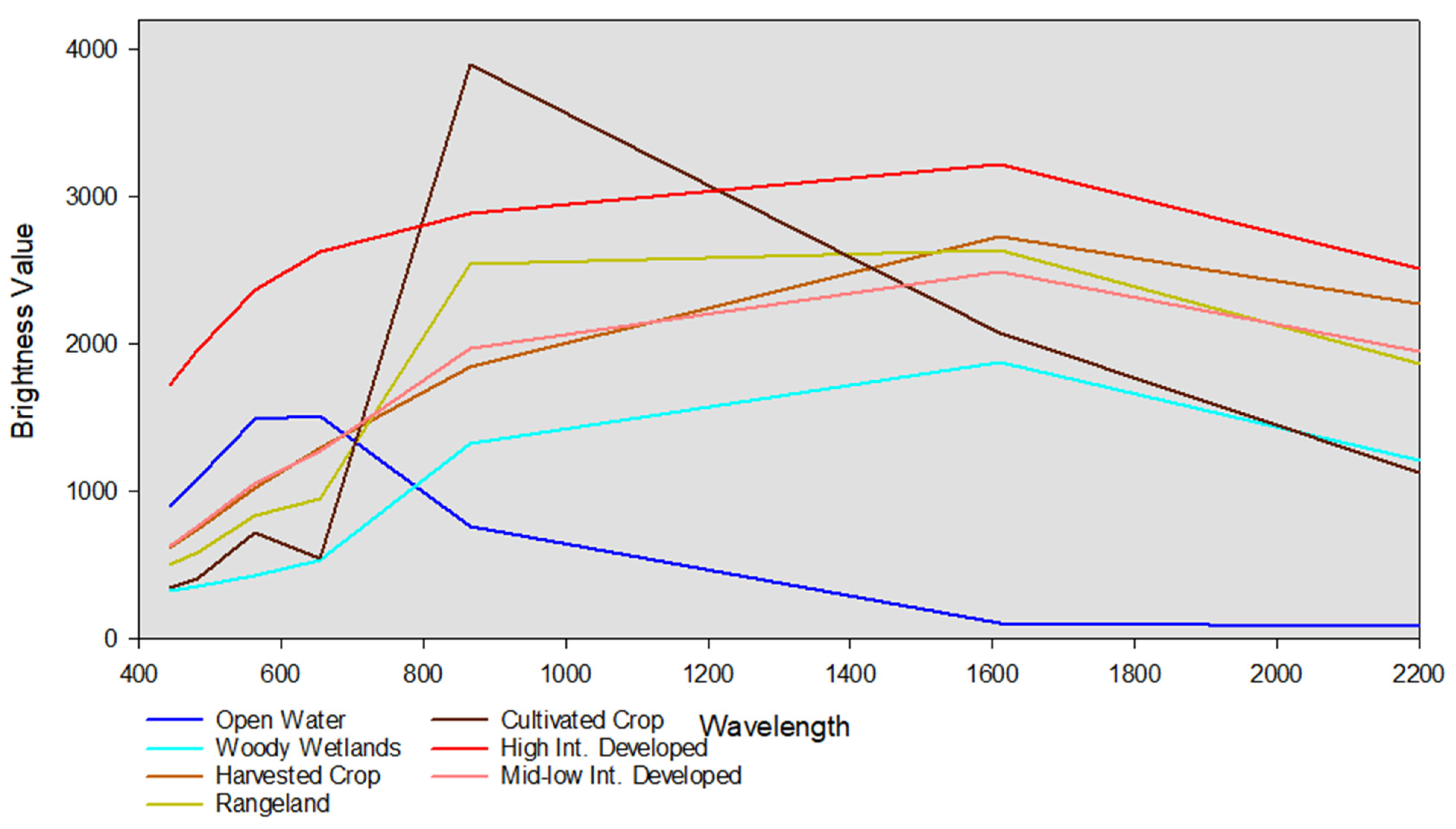
4.2. Post-Harvest
4.2.1. Classification of the Post-Harvest Imagery before Post-Classification Correction
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | High Int. Dev | Mid-Low Int. Dev | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| Open Water | 11 | 0 | 0 | 1 | 0 | 0 | 0 | 12 | 0.92 | 0 |
| Woody Wetlands | 0 | 73 | 0 | 1 | 0 | 0 | 0 | 74 | 0.986 | 0 |
| Harvested Crop | 0 | 1 | 222 | 1 | 0 | 0 | 0 | 224 | 0.99 | 0 |
| Rangeland | 0 | 7 | 9 | 74 | 2 | 0 | 2 | 94 | 0.787 | 0 |
| Cultivated Crop | 0 | 0 | 0 | 2 | 8 | 0 | 0 | 10 | 0.8 | 0 |
| High Int. Developed | 7 | 4 | 2 | 2 | 0 | 0 | 0 | 15 | 0 | 0 |
| Mid-Low Int. Developed | 0 | 8 | 49 | 20 | 0 | 0 | 4 | 81 | 0.049 | 0 |
| Total | 18 | 93 | 282 | 101 | 10 | 0 | 6 | 510 | 0 | 0 |
| Producer’s Accuracy | 0.61 | 0.785 | 0.787 | 0.73 | 0.8 | 0 | 0.667 | 0 | 0.768 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.665 |
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | High Int. Dev | Mid-Low Int. Dev | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| Open Water | 14 | 0 | 2 | 0 | 0 | 0 | 0 | 16 | 0.875 | 0 |
| Woody Wetlands | 0 | 76 | 3 | 7 | 0 | 0 | 1 | 87 | 0.874 | 0 |
| Harvested Crop | 0 | 4 | 225 | 11 | 0 | 0 | 0 | 240 | 0.94 | 0 |
| Rangeland | 0 | 8 | 1 | 34 | 4 | 0 | 2 | 49 | 0.69 | 0 |
| Cultivated Crop | 0 | 0 | 0 | 1 | 9 | 0 | 0 | 10 | 0.9 | 0 |
| High Int. Developed | 2 | 1 | 2 | 1 | 0 | 2 | 2 | 10 | 0.2 | 0 |
| Mid-Low Int. Developed | 0 | 10 | 55 | 23 | 0 | 0 | 8 | 96 | 0.083 | 0 |
| Total | 16 | 99 | 288 | 77 | 13 | 2 | 13 | 508 | 0 | 0 |
| Producer’s Accuracy | 0.875 | 0.767 | 0.78 | 0.44 | 0.69 | 1 | 0.62 | 0 | 0.72 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.59 |
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | High Int. Dev | Mid-Low Int. Dev | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
| Open Water | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 15 | 1 | 0 |
| Woody Wetlands | 0 | 78 | 0 | 3 | 0 | 0 | 0 | 81 | 0.96 | 0 |
| Harvested Crop | 0 | 2 | 228 | 0 | 0 | 0 | 0 | 230 | 0.99 | 0 |
| Rangeland | 0 | 8 | 0 | 50 | 2 | 0 | 5 | 65 | 0.769 | 0 |
| Cultivated Crop | 0 | 0 | 0 | 3 | 7 | 0 | 0 | 10 | 0.7 | 0 |
| High Int. Developed | 5 | 2 | 1 | 0 | 0 | 2 | 0 | 10 | 0.2 | 0 |
| Mid-Low Int. Developed | 0 | 12 | 56 | 27 | 0 | 0 | 3 | 98 | 0.03 | 0 |
| Total | 20 | 102 | 285 | 83 | 9 | 2 | 8 | 509 | 0 | 0 |
| Producer’s Accuracy | 0.75 | 0.76 | 0.8 | 0.6 | 0.778 | 1 | 0.375 | 0 | 0.75 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.64 |
4.2.2. Classification of the Post-Harvest Imagery after Post-Classification Correction
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|
| Open Water | 17 | 1 | 0 | 0 | 0 | 18 | 0.94 | 0 |
| Woody Wetlands | 0 | 77 | 0 | 1 | 0 | 78 | 0.98 | 0 |
| Harvested Crop | 2 | 4 | 251 | 3 | 0 | 260 | 0.96 | 0 |
| Rangeland | 0 | 13 | 31 | 97 | 2 | 143 | 0.67 | 0 |
| Cultivated Crop | 0 | 0 | 0 | 0 | 10 | 10 | 1 | 0 |
| Total | 19 | 95 | 282 | 101 | 12 | 509 | 0 | 0 |
| Producer’s Accuracy | 0.89 | 0.81 | 0.89 | 0.96 | 0.83 | 0 | 0.888 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.82 |
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|
| Open Water | 17 | 1 | 1 | 1 | 0 | 20 | 0.85 | 0 |
| Woody Wetlands | 0 | 81 | 2 | 10 | 0 | 93 | 0.87 | 0 |
| Harvested Crop | 1 | 12 | 281 | 26 | 0 | 320 | 0.87 | 0 |
| Rangeland | 0 | 5 | 14 | 45 | 0 | 64 | 0.70 | 0 |
| Cultivated Crop | 0 | 2 | 0 | 3 | 5 | 10 | 0.5 | 0 |
| Total | 18 | 101 | 298 | 85 | 5 | 507 | 0 | 0 |
| Producer’s Accuracy | 0.94 | 0.80 | 0.94 | 0.53 | 1 | 0 | 0.846 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.72 |
| LULC Class | Open Water | Woody Wetlands | Harvested Crop | Rangeland | Cultivated Crop | Total | User’s Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|
| Open Water | 19 | 0 | 0 | 0 | 0 | 19 | 1 | 0 |
| Woody Wetlands | 0 | 80 | 0 | 3 | 0 | 83 | 0.96 | 0 |
| Harvested Crop | 3 | 11 | 292 | 12 | 0 | 318 | 0.91 | 0 |
| Rangeland | 0 | 2 | 0 | 75 | 1 | 78 | 0.96 | 0 |
| Cultivated Crop | 0 | 0 | 0 | 1 | 9 | 10 | 0.9 | 0 |
| Total | 22 | 93 | 292 | 91 | 10 | 508 | 0 | 0 |
| Producer’s Accuracy | 0.86 | 0.86 | 1 | 0.82 | 0.9 | 0 | 0.935 | 0 |
| Kappa | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.88 |
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Otukei, J.R.; Blaschke, T. Land Cover Change Assessment Using Decision Trees, Support Vector Machines and Maximum Likelihood Classification Algorithms. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 27–31. [Google Scholar] [CrossRef]
- Foody, G.M. Status of Land Cover Classification Accuracy Assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Thakkar, A.K.; Desai, V.R.; Patel, A.; Potdar, M.B. Post-Classification Corrections in Improving the Classification of Land Use/Land Cover of Arid Region Using RS and GIS: The Case of Arjuni Watershed, Gujarat, India. Egypt. J. Remote Sens. Space Sci. 2017, 20, 79–89. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A Survey of Image Classification Methods and Techniques for Improving Classification Performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Stefanov, W.L.; Ramsey, M.S.; Christensen, P.R. Monitoring Urban Land Cover Change: An Expert System Approach to Land Cover Classification of Semiarid to Arid Urban Centers. Remote Sens. Environ. 2001, 77, 173–185. [Google Scholar] [CrossRef]
- Xiuwan, C. Using Remote Sensing and GIS to Analyse Land Cover Change and Its Impacts on Regional Sustainable Development. Int. J. Remote Sens. 2002, 23, 107–124. [Google Scholar] [CrossRef]
- Currit, N. Development of a Remotely Sensed, Historical Land-Cover Change Database for Rural Chihuahua, Mexico. Int. J. Appl. Earth Obs. Geoinf. 2005, 7, 232–247. [Google Scholar] [CrossRef]
- Yuan, F.; Sawaya, K.E.; Loeffelholz, B.C.; Bauer, M.E. Land Cover Classification and Change Analysis of the Twin Cities (Minnesota) Metropolitan Area by Multitemporal Landsat Remote Sensing. Remote Sens. Environ. 2005, 98, 317–328. [Google Scholar] [CrossRef]
- Qian, Y.; Zhang, K.; Qiu, F. Spatial Contextual Noise Removal for Post Classification Smoothing of Remotely Sensed Images. Proc. ACM Symp. Appl. Comput. 2005, 1, 524–528. [Google Scholar] [CrossRef]
- Judex, M.; Thamm, H.; Menz, G. Improving Land-Cover Classification with a Knowledge- Based Approach and Ancillary Data. In Proceedings of the 2nd Workshop of the EARSeL SIG on Land Use and Land Cover, Bonn, Germany, 28–30 September 2006; pp. 184–191. [Google Scholar]
- Manandhar, R.; Odehi, I.O.A.; Ancevt, T. Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data Using Post-Classification Enhancement. Remote Sens. 2009, 1, 330–344. [Google Scholar] [CrossRef]
- McIver, D.K.; Friedl, M.A. Using Prior Probabilities in Decision-Tree Classification of Remotely Sensed Data. Remote Sens. Environ. 2002, 81, 253–261. [Google Scholar] [CrossRef]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective; Pearson Education, Inc.: Glenview, IL, USA, 2015. [Google Scholar]
- Mesev, V. The Use of Census Data in Urban Image Classification. Photogramm. Eng. Remote Sens. 1998, 64, 431–438. [Google Scholar]
- Tucker, C.J.; Holben, B.N.; Elgin, J.H.; McMurtrey, J.E. Remote Sensing of Total Dry-Matter Accumulation in Winter Wheat. Remote Sens. 1980, 11, 171–189. [Google Scholar]
- Moran, M.S.; Clarke, T.R.; Inoue, Y.; Vidal, A. Estimating Crop Water Deficit Using the Relation between Surface-Air Temperature and Spectral Vegetation Index. Remote Sens. Environ. 1994, 49, 246–263. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L. Large-Area Crop Mapping Using Time-Series MODIS 250 m NDVI Data: An Assessment for the U.S. Central Great Plains. Remote Sens. Environ. 2008, 112, 1096–1116. [Google Scholar] [CrossRef]
- Bolton, D.K.; Friedl, M.A. Forecasting Crop Yield Using Remotely Sensed Vegetation Indices and Crop Phenology Metrics. Agric. For. Meteorol. 2013, 173, 74–84. [Google Scholar] [CrossRef]
- Mulla, D.J. Twenty Five Years of Remote Sensing in Precision Agriculture: Key Advances and Remaining Knowledge Gaps. Biosyst. Eng. 2013, 114, 358–371. [Google Scholar] [CrossRef]
- Pinter, P.J.; Hatfield, J.L.; Schepers, J.S.; Barnes, E.M.; Moran, M.S.; Daughtry, C.S.T.; Upchurch, D.R. Remote Sensing for Crop Management; American Society for Photogrammetry and Remote Sensing: Baton Rouge, LA, USA, 2003; Volume 69. [Google Scholar]
- Cheng, Y.B.; Ustin, S.L.; Riaño, D.; Vanderbilt, V.C. Water Content Estimation from Hyperspectral Images and MODIS Indexes in Southeastern Arizona. Remote Sens. Environ. 2008, 112, 363–374. [Google Scholar] [CrossRef]
- Ben-Dor, E.; Chabrillat, S.; Demattê, J.A.M. Characterization of Soil Properties Using Reflectance Spectroscopy. In Fundamentals, Sensor Systems, Spectral Libraries, and Data Mining for Vegetation, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2018; pp. 187–247. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Lewis, P. Geostatistical Classification for Remote Sensing: An Introduction. Comput. Geosci. 2000, 26, 361–371. [Google Scholar] [CrossRef]
- Aplin, P.; Atkinson, P.M.; Curran, P.J. Fine Spatial Resolution Simulated Satellite Sensor Imagery for Land Cover Mapping in the United Kingdom. Remote Sens. Environ. 1999, 68, 206–216. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of Hyperspectral Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar]
- Gualtieri, J.A.; Cromp, R.F. Support Vector Machine for Hypserspectral Remote Sensing Classification. Adv. Comput. Assist. Recognit. 1998, 3584, 221–232. [Google Scholar]
- Gualtieri, J.A.; Chettri, S.R.; Cromp, R.F.; Johnson, L.F. Support Vector Machine Classifiers as Applied to AVIRIS Data. In Proceedings of the Eighth JPL Airborne Earth Science Workshop, Pasadena, CA, USA, 10–11 February 1999. [Google Scholar]
- Premalatha, M.; Lakshmi, C.V. SVM Trade-off between Maximize the Margin and Minimize the Variables Used for Regression. Int. J. Pure Appl. Math. 2013, 87, 741–750. [Google Scholar] [CrossRef]
- Gualtieri, J.A.; Cromp, R. SVM for Hyperspectral Remote Sensing Classification. Proc. SPIE 1998, 3584, 221–232. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Anderson, J.R.; Hardy, E.E.; Roach, J.T.; Witmer, R.E. Land Use and Land Cover Classification System for Use with Remote Sensor Data; U.S. Government Printing Office: Washington, DC, USA, 1976.
- Homer, C.; Fry, J. The National Land Cover Database. US Geol. Surv. Fact Sheet 2012, 3020, 1–4. [Google Scholar]
- Homer, C.; Dewitz, J.; Yang, L.; Jin, S.; Danielson, P.; Xian, G.; Coulston, J.; Herold, N.; Wickham, J.; Megown, K. Completion of the 2011 National Land Cover Database for the Conterminous United States—Representing a Decade of Land Cover Change Information. Photogramm. Eng. Remote Sens. 2015, 81, 345–354. [Google Scholar]
- Canters, F. Evaluating the Uncertainty of Area Estimates Derived from Fuzzy Land-Cover Classification. Photogramm. Eng. Remote Sens. 1997, 63, 403–414. [Google Scholar]
- Stehman, S.V. Selecting and Interpreting Measures of Thematic Classification Accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Smits, P.C.; Dellepiane, S.G.; Schowengerdt, R.A. Quality Assessment of Image Classification Algorithms for Land-Cover Mapping: A Review and a Proposal for a Cost-Based Approach. Int. J. Remote Sens. 1999, 20, 1461–1486. [Google Scholar] [CrossRef]
- Rosenfield, G.H.; Fitzpatrick-Lins, K. A Coefficient of Agreement as a Measure of Thematic Classification Accuracy. Photogramm. Eng. Remote Sens. 1986, 52, 223–227. [Google Scholar]
- Fitzgerald, R.W.; Lees, B.G. Assessing the Classification Accuracy of Multisource Remote Sensing Data. Remote Sens. Environ. 1994, 47, 362–368. [Google Scholar] [CrossRef]
- Fung, T.; Ledrew, E. The Determination of Optimal Threshold Levels for Change Detection Using Various Accuracy Indices. Photogramm. Eng. Remote Sens. 1988, 54, 1449–1454. [Google Scholar]
- Ma, Z.; Redmond, R.L. Tau Coefficients for Accuracy Assessment of Classification of Remote Sensing Data. Photogramm. Eng. Remote Sens. 1994, 61, 435–439. [Google Scholar]
- Stehman, S.V. Comparing Thematic Maps Based on Map Value. Int. J. Remote Sens. 1999, 20, 2347–2366. [Google Scholar] [CrossRef]
- Stehman, S.V.; Czaplewski, R.L. Design and Analysis for Thematic Map Accuracy Assessment: Fundamental Principles. Remote Sens. Environ. 1998, 64, 331–344. [Google Scholar] [CrossRef]
- Saucier, R.T. Quaternary Geology of the Lower Mississippi Valley; Arkansas Archeological Survey: Fayetteville, AR, USA, 1994; Volume I. [Google Scholar]
- Risal, A.; Parajuli, P.B.; Dash, P.; Ouyang, Y.; Linhoss, A. Sensitivity of Hydrology and Water Quality to Variation in Land Use and Land Cover Data. Agric. Water Manag. 2020, 241, 106366. [Google Scholar] [CrossRef]
- Snipes, C.E.; Evans, L.P.; Poston, D.H.; Nichols, S.P. Agricultural Practices of the Mississippi Delta; ACS Publications: Washington, DC, USA, 2004; pp. 43–60. [Google Scholar] [CrossRef]
- National Agricultural Statistics Service. Field Crops Usual Planting and Harvesting Dates. In Agriculural Handbook; NASS: Burr Ridge, IL, USA, 2010; pp. 1–51. [Google Scholar]
- USDA. Data Gateway; USDA: Washington, DC, USA, 2018.
- Pal, M.; Mather, P.M. Support Vector Machines for Classification in Remote Sensing. Int. J. Remote Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Herold, M.; Roberts, D.A.; Gardner, M.E.; Dennison, P.E. Spectrometry for Urban Area Remote Sensing—Development and Analysis of a Spectral Library from 350 to 2400 Nm. Remote Sens. Environ. 2004, 91, 304–319. [Google Scholar] [CrossRef]
- South, S.; Qi, J.; Lusch, D.P. Optimal Classification Methods for Mapping Agricultural Tillage Practices. Remote Sens. Environ. 2004, 91, 90–97. [Google Scholar] [CrossRef]









| USDA: 2010 | Usual Planting Dates | Usual Harvesting Dates | ||||
|---|---|---|---|---|---|---|
| Crops | Begin | Most Active | End | Begin | Most Active | End |
| Barley | n/a | n/a | n/a | n/a | n/a | n/a |
| Corn | 17 Mar | 24 March–27 April | 4 May | 11 August | 23 August–23 September | 7 October |
| Cotton | 20 April | 27 April–19 May | 29 May | 15 September | 27 September–29 October | 12 November |
| Potatoes, Sweet | 4 May | 7 June–23 June | 7 July | 20 August | 2 September–28 October | 7 November |
| Hay, other | n/a | n/a | n/a | 10 April | n/a | 26 September |
| Oats | n/a | n/a | n/a | n/a | n/a | n/a |
| Peanuts | 25 April | 6 May–31 May | 15 June | 20 September | 29 September–31 October | 10 November |
| Rice | 6 April | 18 April–16 May | 24 May | 29 August | 5 September–6 October | 20 October |
| Rye | n/a | n/a | n/a | n/a | n/a | n/a |
| Sorghum | 8 April | 14 April–21 May | 3 June | 19 August | 29 August–27 September | 2 October |
| Soybeans | 19 April | 26 April–31 May | 17 June | 10 September | 13 September–31 October | 9 November |
| Sugarbeets | n/a | n/a | n/a | n/a | n/a | n/a |
| Tobacco | n/a | n/a | n/a | n/a | n/a | n/a |
| Wheat (Winter) | 24 September | 10 October–18 November | 30 November | 28 May | 2 June–21 June | 1 July |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dash, P.; Sanders, S.L.; Parajuli, P.; Ouyang, Y. Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data in an Agricultural Watershed. Remote Sens. 2023, 15, 4020. https://doi.org/10.3390/rs15164020
Dash P, Sanders SL, Parajuli P, Ouyang Y. Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data in an Agricultural Watershed. Remote Sensing. 2023; 15(16):4020. https://doi.org/10.3390/rs15164020
Chicago/Turabian StyleDash, Padmanava, Scott L. Sanders, Prem Parajuli, and Ying Ouyang. 2023. "Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data in an Agricultural Watershed" Remote Sensing 15, no. 16: 4020. https://doi.org/10.3390/rs15164020
APA StyleDash, P., Sanders, S. L., Parajuli, P., & Ouyang, Y. (2023). Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data in an Agricultural Watershed. Remote Sensing, 15(16), 4020. https://doi.org/10.3390/rs15164020