

YOLO-RS: A More Accurate and Faster Object Detection Method for Remote Sensing Images

Abstract
:
1. Introduction
2. Related Work
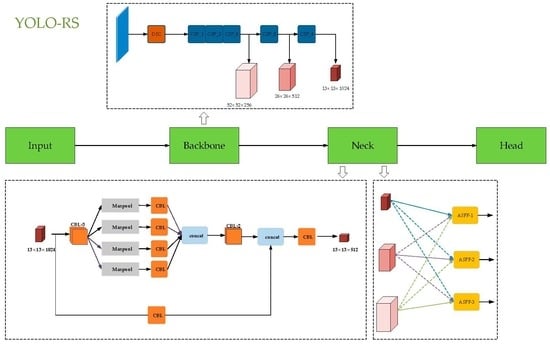
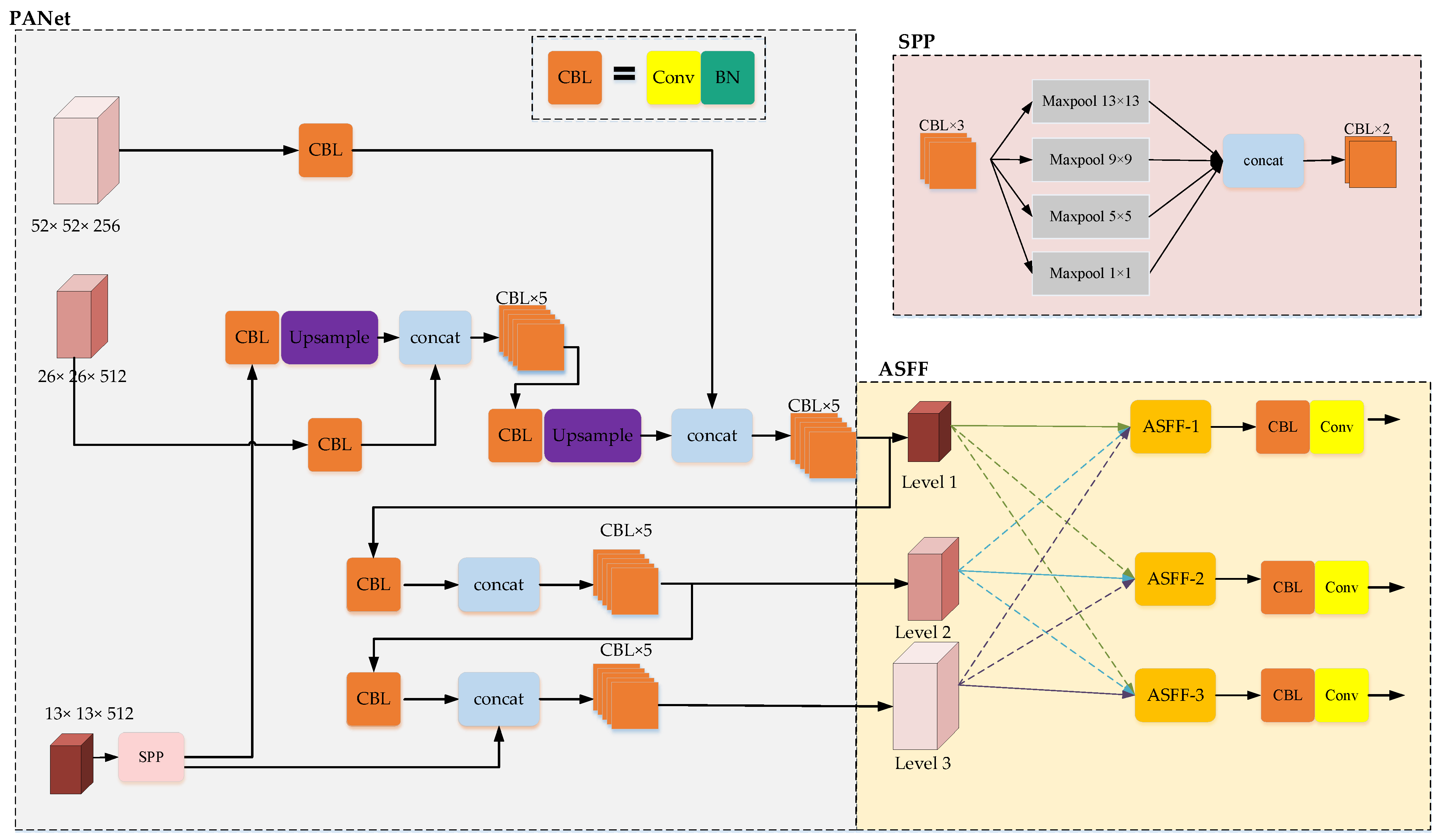
3. Materials and Methods
3.1. ASFF
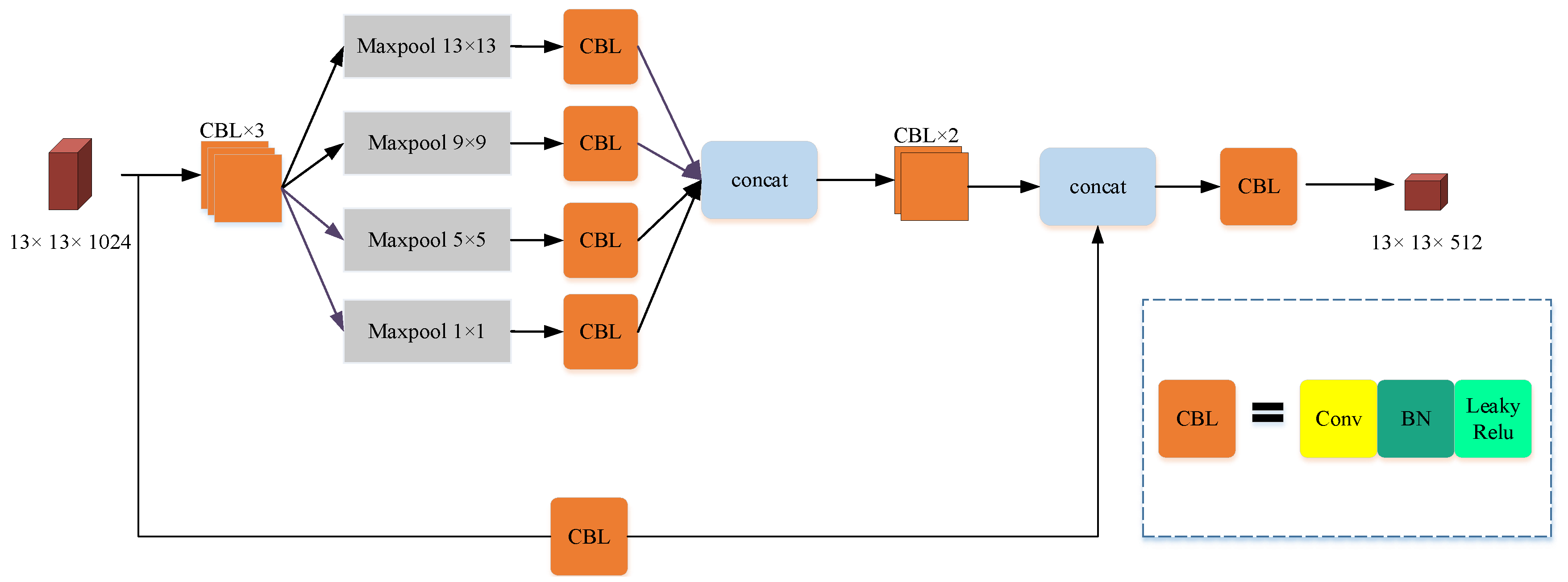
3.2. OSPP
3.2.1. Residual Connection
3.2.2. 1 × 1 Convolution
3.3. Lightnet
3.4. EIOU
4. Results
4.1. Experimental Environment
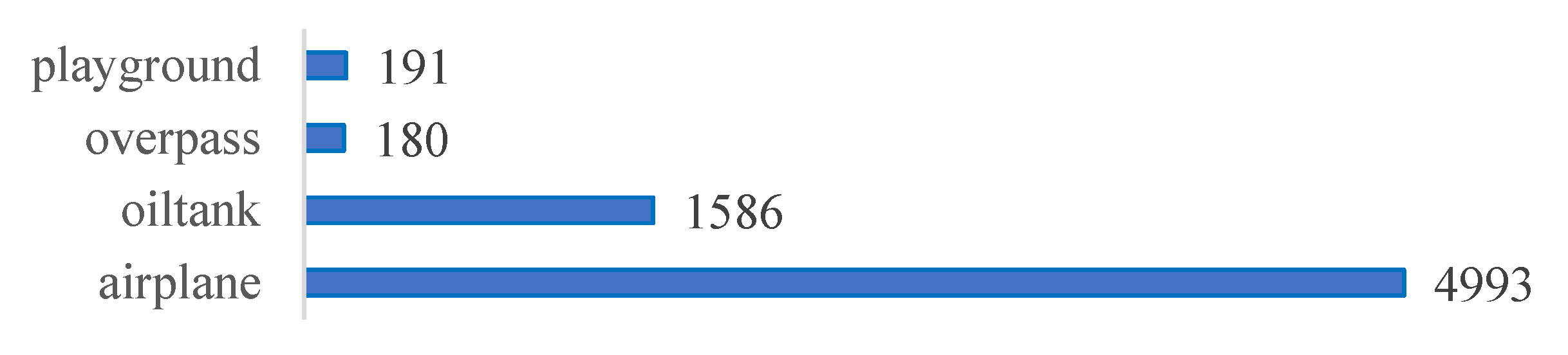
4.2. Dataset Description
4.2.1. TGRS-HRRSD
4.2.2. RSOD
4.3. Training Details
4.4. Evaluation Metrics
4.4.1. Detection Accuracy
4.4.2. Detection Speed
4.5. Ablation Study
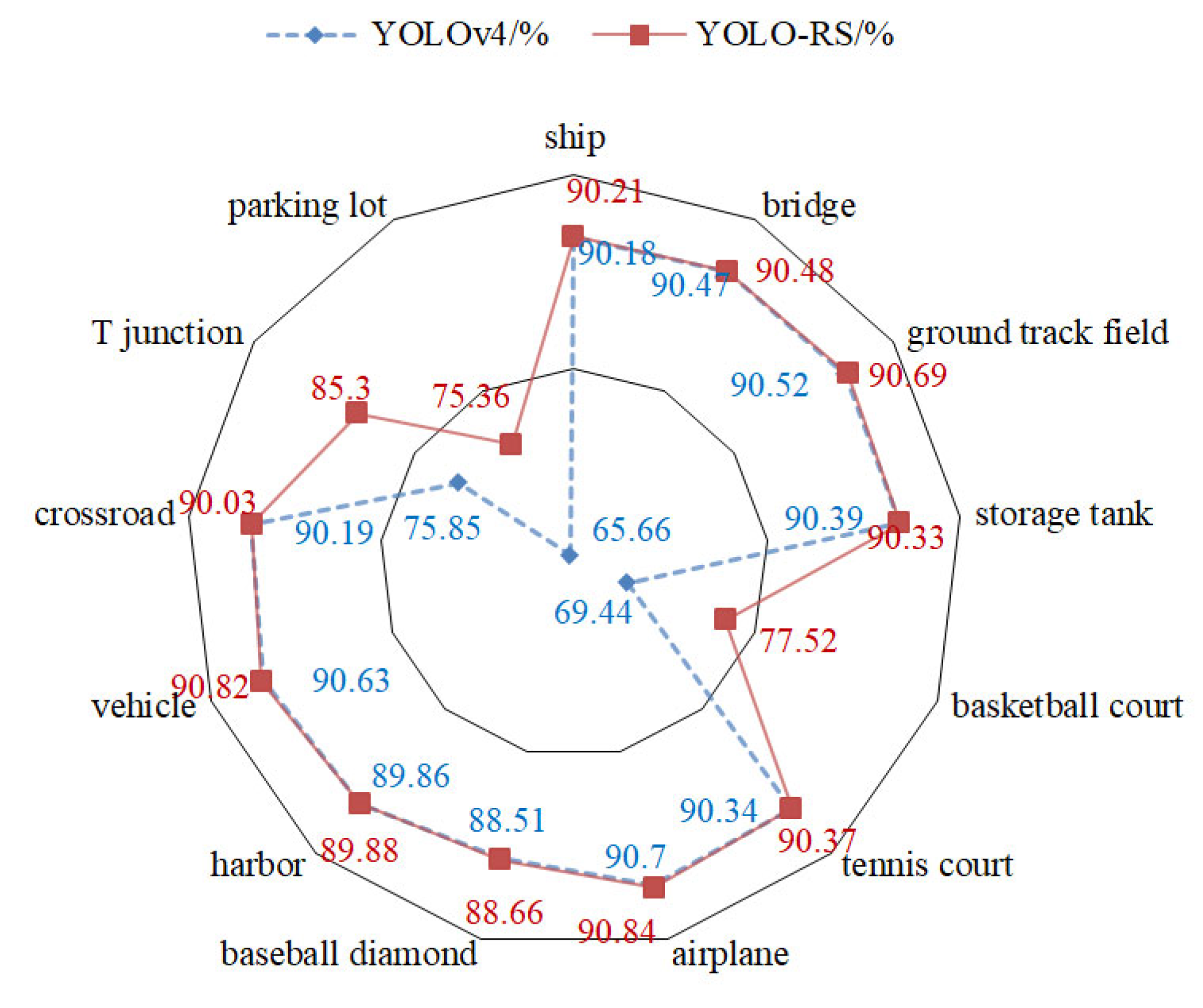
4.6. Single Class Precision Presentation
4.7. Presentation Comparison
4.8. Methodology Comparison Experiment
5. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Gagliardi, V.; Tosti, F.; Ciampoli, L.B.; Battagliere, M.L.; D’amato, L.; Alani, A.M.; Benedetto, A. Satellite Remote Sensing and Non-Destructive Testing Methods for Transport Infrastructure Monitoring: Advances, Challenges and Perspectives. Remote Sens. 2023, 15, 418. [Google Scholar] [CrossRef]
- Gong, J.; Liu, C.; Huang, X. Advances in urban information extraction from high-resolution remote sensing imagery. Sci. China Earth Sci. 2020, 63, 463–475. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Conrad, C. Crop type classification using a combination of optical and radar remote sensing data: A review. Int. J. Remote Sens. 2019, 40, 6553–6595. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Roy, D.; Filatova, T.; Kerle, N. Agent-based modelling of post-disaster recovery with remote sensing data. Int. J. Disaster Risk Reduct. 2021, 60, 102285. [Google Scholar] [CrossRef]
- Huang, W.; Huang, Y.; Wang, H.; Li, W.; Zhang, L. Local Binary Patterns and Superpixel-Based Multiple Kernels for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4550–4563. [Google Scholar] [CrossRef]
- Huang, H.; Xu, K.; Shi, G. Joint Multiscale and Multifeature for High-Resolution Remote Sensing Image Scene Classification. Chin. J. Electron. 2020, 48, 1824–1833. [Google Scholar]
- Zhu, F.; Chen, X.; Chen, S.; Zheng, W.; Ye, W. Relative Margin Induced Support Vector Ordinal Regression. Expert Syst. Appl. 2023, 231, 120766. [Google Scholar] [CrossRef]
- Zhu, F.; Gao, J.; Yang, J.; Ye, N. Neighborhood Linear Discriminant Analysis. Pattern Recognit. 2022, 123, 108422. [Google Scholar] [CrossRef]
- Zhu, F.; Zhang, W.; Chen, X.; Gao, X.; Ye, N. Large Margin Distribution Multi-Class Supervised Novelty Detection. Expert Syst. Appl. 2023, 224, 119937. [Google Scholar] [CrossRef]
- Nie, T.; Han, X.; He, B.; Zhang, L. Ship Detection in Panchromatic Optical Remote Sensing Images Based on Visual Saliency and Multi-Dimensional Feature Description. Remote Sens. 2020, 12, 152. [Google Scholar] [CrossRef] [Green Version]
- Sha, M.; Li, Y.; Li, A. Improved Faster R-CNN for Aircraft Object Detection in Remote Sensing Images. Nat. Remote Sens. Bull. 2022, 26, 1624–1635. [Google Scholar] [CrossRef]
- Yang, D.; Mao, Y. Remote Sensing Landslide Target Detection Method Based on Improved Faster R-CNN. J. Appl. Remote Sens. 2022, 16, 044521. [Google Scholar]
- Wen, G.Q.; Cao, P.; Wang, H.N.; Yang, L.; Zhang, L. MS-SSD: Multi-Scale Single Shot Detector for Ship Detection in Remote Sensing Images. Appl. Intell. 2023, 53, 1586–1604. [Google Scholar] [CrossRef]
- Qu, Z.F.; Zhu, F.Z.; Qi, C.X. Remote Sensing Image Target Detection: Improvement of the YOLOv3 Model with Auxiliary Networks. Remote Sens. 2021, 13, 3908. [Google Scholar] [CrossRef]
- Shen, L.; Tao, H.; Ni, Y.; Wang, Y.; Stojanovic, V. Improved YOLOv3 Model with Feature Map Cropping for Multi-Scale Road Object Detection. Meas. Sci. Technol. 2023, 34, 045406. [Google Scholar] [CrossRef]
- Tutsoy, O.; Tanrikulu, M.Y. Priority and Age-Specific Vaccination Algorithm for Pandemic Diseases: A Comprehensive Parametric Prediction Model. BMC Med. Inform. Decis. Mak. 2022, 22, 4. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhao, S.; Xu, T.; Wu, X.J.; Hoi, S.C.H. Adaptive Feature Fusion for Visual Object Tracking. Pattern Recognit. 2021, 111, 107679. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Khan, Z.Y.; Niu, Z. CNN with Depthwise Separable Convolutions and Combined Kernels for Rating Prediction. Expert Syst. Appl. 2021, 170, 114528. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE International Conference on Computer Visionand Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhang, Y.F.; Ren, W.Q.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Xiao, Z.; Liu, Q.; Tang, G.; Zhai, X. Elliptic Fourier Transformation-Based Histograms of Oriented Gradients for Rotationally Invariant Object Detection in Remote-Sensing Images. Int. J. Remote Sens. 2015, 36, 618–644. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.P.; Xiao, Z.F.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| Operating System | ubuntu 18.04 |
| GPU | GeForce RTX 3090 |
| Deep Learning Framework | TensorFlow-gpu 2.4.0 |
| CUDA | 11.0 |
| Cudnn | 8.0.5.39 |
| Programming Language | Python 3.7 |
| id | PANet | ASFF | Darknet53 | Lightnet | SPP | OSPP | EIoU | mAP (%) | FPS (f/s) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | √ | √ | √ | 85.58 | 38.16 | ||||
| 2 | √ | √ | √ | √ | 85.79 | 38.16 | |||
| 3 | √ | √ | √ | √ | √ | 87.81 | 33.75 | ||
| 4 | √ | √ | √ | √ | √ | 86.58 | 41.78 | ||
| 5 | √ | √ | √ | √ | 85.93 | 39.26 | |||
| 6 | √ | √ | √ | √ | √ | 88.39 | 35.64 | ||
| 7 | √ | √ | √ | √ | √ | 87.73 | 43.45 |
| id | PANet | ASFF | Darknet53 | Lightnet | SPP | OSPP | EIoU | mAP (%) | FPS (f/s) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | √ | √ | √ | 91.15 | 38.38 | ||||
| 2 | √ | √ | √ | √ | 91.34 | 38.38 | |||
| 3 | √ | √ | √ | √ | √ | 93.47 | 33.84 | ||
| 4 | √ | √ | √ | √ | √ | 92.14 | 42.02 | ||
| 5 | √ | √ | √ | √ | 91.90 | 39.95 | |||
| 6 | √ | √ | √ | √ | √ | 93.95 | 35.41 | ||
| 7 | √ | √ | √ | √ | √ | 92.81 | 43.68 |
| Methodology | TGRS-HRRSD | RSOD | ||
|---|---|---|---|---|
| mAP (%) | FPS (f/s) | mAP (%) | FPS (f/s) | |
| Faster R-CNN | 81.43 | 11.67 | 80.39 | 11.83 |
| SSD | 72.98 | 26.89 | 78.28 | 26.73 |
| YOLOv3 | 75.06 | 32.53 | 82.47 | 31.97 |
| YOLOv4 | 85.58 | 38.16 | 91.15 | 38.38 |
| YOLOv5 | 84.86 | 49.50 | 90.91 | 50.23 |
| YOLO-RS (ours) | 87.73 | 43.45 | 92.81 | 43.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, T.; Han, W.; Xu, S. YOLO-RS: A More Accurate and Faster Object Detection Method for Remote Sensing Images. Remote Sens. 2023, 15, 3863. https://doi.org/10.3390/rs15153863
Xie T, Han W, Xu S. YOLO-RS: A More Accurate and Faster Object Detection Method for Remote Sensing Images. Remote Sensing. 2023; 15(15):3863. https://doi.org/10.3390/rs15153863
Chicago/Turabian StyleXie, Tianyi, Wen Han, and Sheng Xu. 2023. "YOLO-RS: A More Accurate and Faster Object Detection Method for Remote Sensing Images" Remote Sensing 15, no. 15: 3863. https://doi.org/10.3390/rs15153863
APA StyleXie, T., Han, W., & Xu, S. (2023). YOLO-RS: A More Accurate and Faster Object Detection Method for Remote Sensing Images. Remote Sensing, 15(15), 3863. https://doi.org/10.3390/rs15153863