5.1. Experimental Environment Introduction
In the experimental part of this paper, we have chosen the UAV view small target detection datasets VisDrone2019-DET and UAVDT as the experimental datasets. Where the VisDrone2019-DET dataset was used as the main test dataset for the experiments, the UAVDT dataset was used to further test the robustness and applicability of the model. All the images in these two datasets are from the aerial view of UAVs, which are typical UAV view small target detection datasets. Among them, VisDrone2019-DET is a dataset collected and published by the AISKYEYE team [
34], which ensures the rigour of the dataset. The UAVDT dataset is a dataset proposed by Dawei Du et al. [
35]. at ICCV2018. Both datasets contain images taken with different models of UAV equipment in different scenarios, weather and lighting conditions, respectively, and are highly representative.
The VisDrone2019-DET dataset is a dataset mainly used for image classification and object detection experiments, consisting of 10,209 images divided into four subsets as shown in
Table 2. The training subset is used to train the algorithm and contains 6471 images. The validation subset is used to verify the performance of the algorithm during the training process and contains 548 images. The test-challenge subset is used for competition and contains 1580 images. The test-dev subset is the default test set for public evaluation and contains 1610 images. The VisDrone2019-DET dataset contains 10 categories, including motor, bus, awning-tricycle, tricycle, truck, van, car, bicycle, person and pedestrian.
Dividing the dataset is one of the most important steps in the training of a network model. Firstly, dividing the dataset avoids the problem of over-fitting the model to the training data, which can lead to degradation in generalisation performance. Secondly, dividing the dataset helps us to evaluate the performance of the model more accurately. Finally, partitioning the dataset also ensures the independence of the training, validation and testing datasets, which is important for evaluating the performance of the model and avoiding data leakage problems. We will use the following three subsets in the next experiments: the training set, the validation set and the test-dev set. The train set is used to train the model, the validation set is used to evaluate the performance of the model during training and to perform hyperparameter tuning, and the test-dev set is used to finally evaluate the performance of the model.
The UAVDT dataset is specifically designed for vehicle detection tasks from an unmanned aerial vehicle (UAV) perspective. It contains images taken by UAVs at different heights and angles on urban roads, along with corresponding annotation information such as vehicle position, bounding box and category in each frame. Vehicle categories in the dataset include private cars, buses and trucks. The dataset has features such as different perspectives, rich vehicle categories, large data volume and high annotation accuracy.
The UAVDT dataset contains a total of 40,735 images, including 15 scenes and over 20,000 vehicle instances. The dataset is divided into three subsets as shown in
Table 3. The training subset is used to train the algorithm and contains 31,515 images; the validation subset is used to verify the performance of the algorithm during training and contains 2396 images; and the test subset is used to evaluate the generalization ability of the overall model and contains 6824 images.
This experimental project is based on the PyTorch open source framework and uses the GPU to train and test the YOLOv5 algorithm. The data is accelerated by GPU computing through the CUDA and CUDNN environments, which speeds up the training process. The batch size of training samples is set to 16. The input image size is
. The specific configuration of the training and testing environments is shown in
Table 4.
5.2. Evaluation Indicators
The most commonly used metrics in object detection algorithms include Precision (P), Recall (R), F1 Score, Average Precision (AP), and mean Average Precision (mAP). Here are brief introductions to their calculation:
The
Precision (P), which represents the proportion of true positive predictions among all samples predicted as positive. Its formula is shown in this equation:
where
TP represents the number of true positive samples that are predicted as positive, and
FP represents the number of false positive samples that are predicted as positive but are actually negative.
The
Recall (R) is used to determine how many true positive samples are successfully detected among all actual positive samples. Its formula is shown in this equation:
where
TP represents the number of true positive samples that are predicted as positive, and
FN represents the number of false negative samples that are predicted as negative but are actually positive.
The
F1 score is the weighted harmonic mean of precision and recall, and is used to balance the trade-off between precision and recall. The formula for calculating the
F1 score is shown in equation:
Mean Average Precision (
mAP) is an important evaluation metric for object detection that is usually involved in research that involves detecting multiple classes. For each class, the model calculates its corresponding average precision, and the
mAP is obtained by summing the average precision of all classes in the dataset and dividing it by the number of classes. The formula for calculating
mAP is shown in this equation:
where
Average Precision(c) represents the average precision of a class
c, and
N(classes) represents the total number of classes in the dataset.
5.3. Experimental Results
Through experiments, we can obtain the specific performance comparison between the original YOLOv5s model and the optimized YOLOv5s-pp model on the VisDrone2019-DET dataset, as shown in
Table 5. It can be seen that the overall performance of the YOLOv5s-pp model is better than that of the original YOLOv5s model.
The validation results of the YOLOv5s model on the val subset are shown in
Table 6.
The validation results of the YOLOv5s-pp model on the val subset are shown in
Table 7.
The overall performance of the trained YOLOv5s and YOLOv5s-pp models on the VisDrone2019-DET dataset test-dev subset is shown in
Table 8.
The validation results of the YOLOv5s model on the test-dev subset are shown in
Table 9.
The validation results of the YOLOv5s-pp model on the test-dev subset are shown in
Table 10.
From
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10, it can be observed that the performance of the YOLOv5s-pp model on the VisDrone2019-DET dataset is superior to the original YOLOv5s model for both the val and test subsets. The overall optimization and generalization ability of the YOLOv5s-pp model is better.
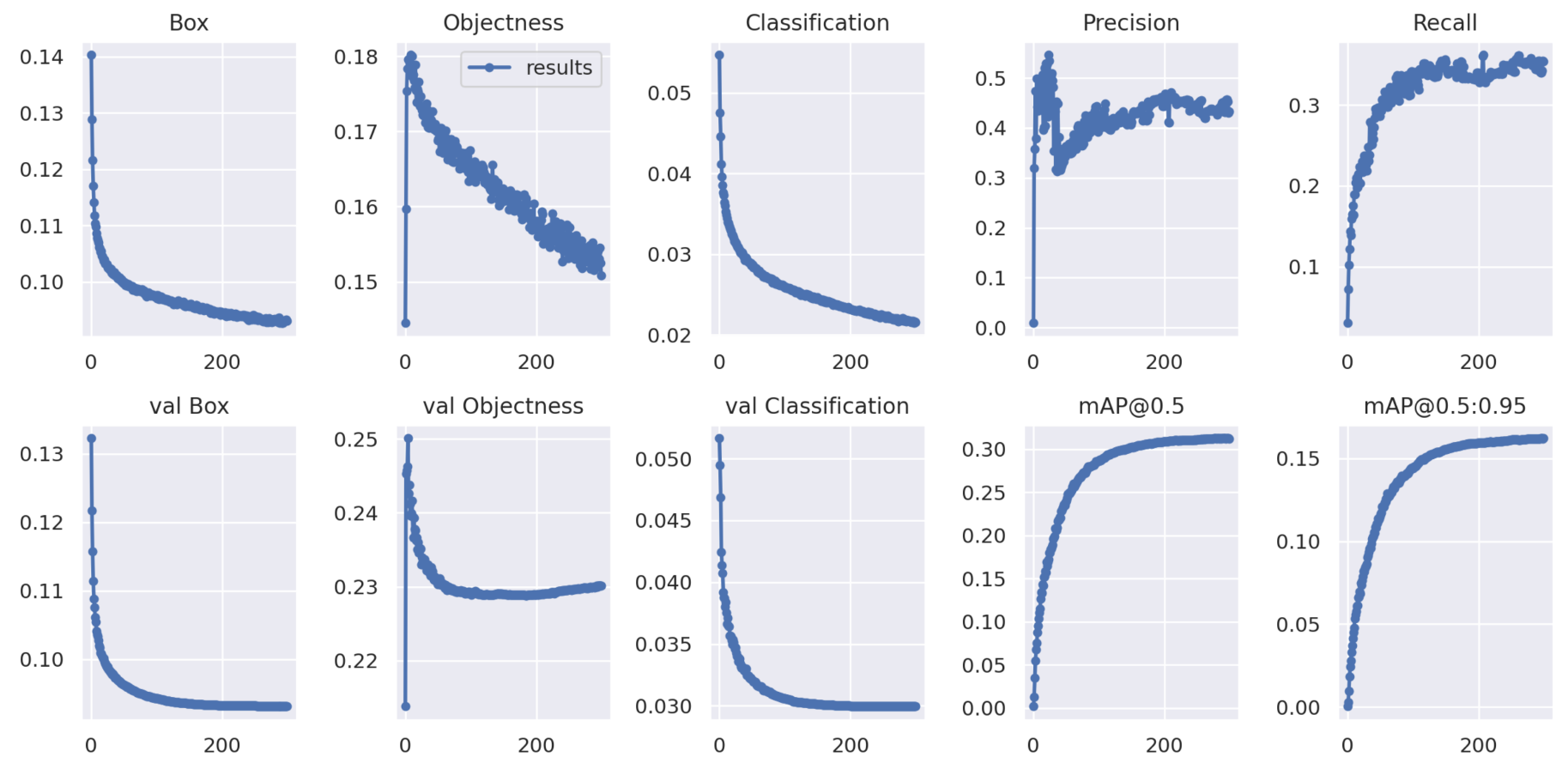
The performance parameter results of YOLOv5s trained on the VisDrone2019-DET dataset are shown in
Figure 10.
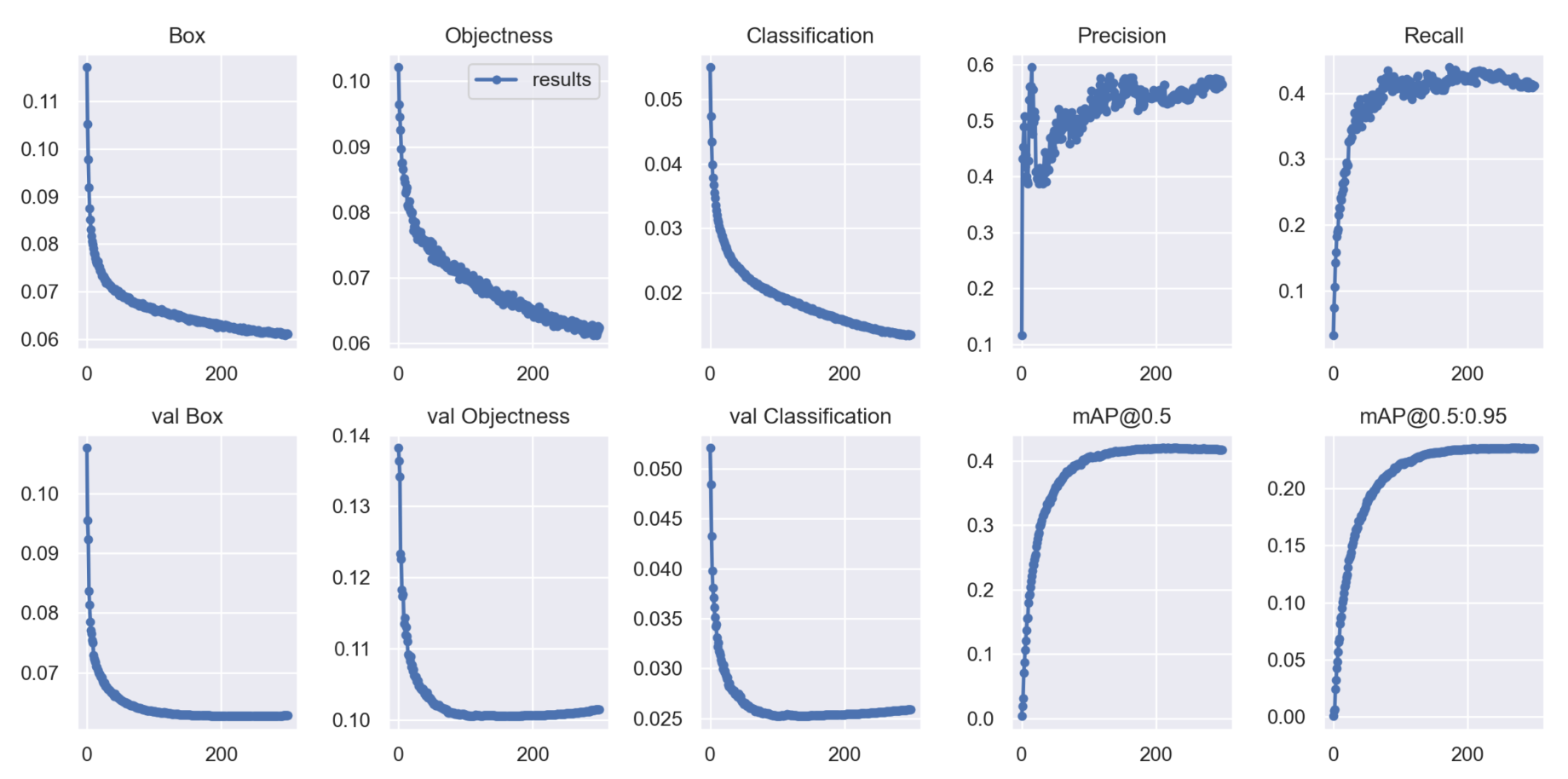
The performance parameter results of YOLOv5s-pp trained on the VisDrone2019-DET dataset are shown in
Figure 11.
From the experimental results shown in
Figure 10 and
Figure 11, we can observe the improvement curves of the overall optimization performance of the model before and after the improvements. The figures not only display performance curves such as Precision, Recall and mAP, but also demonstrate the loss curves of model parameter optimization. Among them, the Box curve is the loss of bounding box using GIOU Loss in YOLOv5s. The smaller the value, the more accurate the selected target is. The Objectness curve is the mean loss inferred as the target, and the smaller the value, the more accurate the target detection is. The Classification curve is the mean loss inferred as classification, and the smaller the value, the more accurate the target classification is. From the before-and-after optimization result figures, it can be seen that the optimized YOLOv5s-pp model has better overall loss and detection performance.
Through experiments, we evaluated the effects of the CA attention mechanism, Meta-ACON activation function, SPD Conv module, and small object detection head on the YOLOv5s-pp network model. Specifically, we refer to the YOLOv5s-pp model with the CA attention mechanism removed as the YOLOv5s-A model; the YOLOv5s-pp model with the Meta-ACON activation function removed as the YOLOv5s-B model; the YOLOv5s-pp model with the SPD Conv module removed as the YOLOv5s-C model; and the YOLOv5s-pp model with the small object detection head modified as the YOLOv5s-D model.
We trained each of the above models on the VisDrone2019-DET dataset and tested them on the validation subset. The comparison results of the test data are shown in
Table 11.
After training, each model was tested on the test-dev subset, and the comparison results of the test data are shown in
Table 12.
Through
Table 11 and
Table 12, we can see that when any of the CA attention mechanism, Meta-ACON activation function, SPD Conv module, or any module in the small object detection head is removed from the YOLOv5s-pp model, it will have a negative impact on the overall performance of the model. It is worth noting that the change in the small object detection head has a greater impact on the recognition performance of the entire model, while the impact of the other modules on the model is relatively small. However, overall, the recognition performance of these modified models is better than that of the YOLOv5s model.
In order to further verify the advantages of the YOLOv5s-pp algorithm, we compared it with other object detection models and conducted tests on the test set and validation set of the VisDrone2019-DET dataset. The model training information is shown in
Table 13, and the model performance comparison results are shown in
Table 14 and
Table 15.
The algorithms used for performance comparison in
Table 14 and
Table 15 are all based on the VisDrone2019-DET dataset, where the FocSDet, ClusDet, HRDNet, YOLOv5sm+, AF-O-YOLOv5, QueryDet, and RRNet algorithms are cited from the training results of other researchers, and since the research results are not explicitly listed in the results of some researchers’ papers, we do not fill in the corresponding F1 scores and Rs in
Table 14 and
Table 15.The rest of the YOLOv5 versions and the YOLOv8 versions are trained by ourselves.
From
Table 13,
Table 14 and
Table 15, we can see that the overall performance of the YOLOv5s-pp model is superior to the four different sizes of YOLOv5 models. From
Table 15, we can see that the mAP@.5 value of the YOLOv5s-pp algorithm on the test-dev subset is 7.4% higher than that of the YOLOv5s, 4.1% higher than that of the YOLOv5m, 2.6% higher than that of the YOLOv5l and 1.3% higher than that of the YOLOv5x. From
Table 13, we can see that the YOLOv5s-pp algorithm has 10.5 M parameters, which is 3.3 M more than the YOLOv5s model, but far less than the parameters of the other three versions of YOLOv5. The main reason for the different numbers of parameters between the different versions of YOLOv5 is the difference in the depth of the network model, which to some extent reflects the width and depth of the network model. As the width and depth of the network model increases, the spatial and temporal complexity of the model also increases, which means that the GPU resources occupied during model training also increase, and the training time and forward inference time of the model will also increase to some extent. This can be reflected from the model training time and model parameters in
Table 13. From
Table 15, we can also see that the overall performance of the YOLOv5s-pp model is better than that of the YOLOv8s model. The mAP@.5 value of the YOLOv5s-pp algorithm on the test-dev subset is 0.8% higher than that of the YOLOv8s, and its overall performance is comparable to that of the YOLOv8m model, but lower than that of the YOLOv8l and YOLOv8x models. Although the mAP@.5 values of YOLOv8l and YOLOv8x models on the test-dev subset are 3.1% and 4.2% higher than that of the YOLOv5s-pp model, respectively, their parameter amounts are 4.1 and 6.5 times that of the YOLOv5s-pp model. Their network model depth and parameter amounts far exceed those of the YOLOv5s-pp model, which requires more GPU resources and time to train and infer the model.
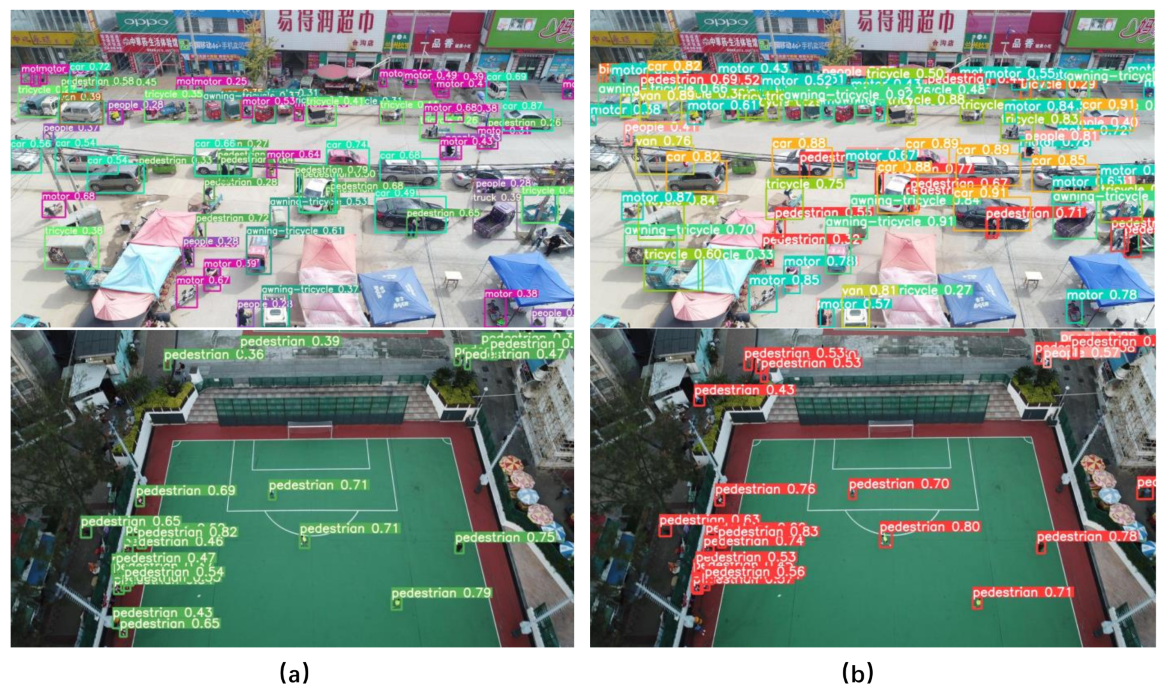
The images in
Figure 12 and
Figure 13 are selected from real scenes taken from the UAV’s perspective. To better test the model’s performance, we have selected images from both daytime and nighttime scenes, respectively. As we can see in
Figure 12, the YOLOv5s model did not recognize the two motorbikes in the lower left corner of the image in the night environment; however, the YOLOv5s-pp model detected the motorbikes successfully. As we can see in
Figure 13, in the above set of test comparisons, the YOLOv5s-pp model identified more small targets than the YOLOv5s model, and for the relatively more distant and smaller targets, the YOLOv5s model showed a large number of missed detections. Also in the upper left and right corners of the basketball court, the YOLOv5s model failed to fully detect the pedestrians in the image, while the YOLOv5s-pp model successfully detected the pedestrians in it. In contrast, the YOLOv5s-pp model is more accurate in detecting small targets in the image.
To further test the applicability of the YOLOv5s-pp model, we evaluated the model again on the UAVDT dataset. In this evaluation, we only compared the relatively lightweight YOLOv5s, YOLOv5m, YOLOv8s and YOLOv8m models, as the UAVDT dataset has a larger amount of data and does not train well on the same training environment as heavier models such as YOLOv5l, YOLOv5x, YOLOv8l and YOLOv8x. Detailed information related to the training of the models is presented in
Table 16, while
Table 17 and
Table 18 present the final performance comparison results.
Combining
Table 16,
Table 17 and
Table 18, we can see that the YOLOv5s-pp model has better overall performance than the three different-sized models of YOLOv5s, YOLOv5m and YOLOv8s. In
Table 18, it can be observed that the YOLOv5s-pp algorithm’s mAP@.5 value on the test subset is 6.5% higher than that of YOLOv5s, 4.2% higher than that of YOLOv5m and 2.1% higher than that of YOLOv8m. Compared to the YOLOv8m model, the mAP@.5 value of the YOLOv5s-pp model on the test subset is slightly lower by 0.2%. However, it should be noted that the parameter size of the YOLOv8m model is 2.5 times that of the YOLOv5s-pp model. The overall network depth and parameter size of YOLOv8m are much larger than those of YOLOv5s-pp, which will have a negative impact on the training and inference speed of the model.
The images in
Figure 14 and
Figure 15 are also selected from real scene images taken from the UAV viewpoint, and again we selected images from both daytime and nighttime scenes. From
Figure 14, we can see that in the night environment, the YOLOv5s model does not recognise the vehicle further away in the upper left corner of the picture; however, the YOLOv5s-pp model detects all the vehicles in the picture smoothly. As we can see from
Figure 15, in the above set of test comparisons, the YOLOv5s-pp model identifies more small targets on the motorway than the YOLOv5s model, and there is a significant amount of under-detection by the YOLOv5s model of vehicles that are relatively farther away and smaller in the picture. In addition, near the toll booths in the following set of images, the YOLOv5s model fails to fully detect vehicles further away in the images, while the YOLOv5s-pp model detects more targets. In contrast, the YOLOv5s-pp model has better detection performance for small targets in the pictures.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}