1. Introduction
Object detection algorithms and drone technology have become increasingly mature and play important roles in many fields, such as traffic management, agricultural irrigation, forest patrol, and battlefield reconnaissance. These tasks can achieve higher accuracy and efficiency by using drones while also reducing casualties. However, many problems still need to be solved for object detection in remote sensing images because of the small object size and complex background in drone perspective. Moreover, the computation of algorithms is restricted by the limited computing power of edge platforms on drones, which poses challenges for their practical application.
Object detection algorithms aim to obtain the location and category of objects in images. In recent years, deep-learning-based object detection algorithms have developed rapidly. General object detection algorithms include two-stage algorithms based on candidate boxes, such as RCNN [
1], Fast RCNN [
2], Mask RCNN [
3], etc. These algorithms first generate several candidate boxes that may contain objects in the image, then classify these candidate boxes, and finally detect all objects in the image: one-stage algorithms based on regression, such as YOLO [
4,
5,
6,
7,
8,
9] series, SSD [
10] series, RetinaNet [
11], etc. These algorithms divide the image into several cells and directly predict whether each cell contains an object, as well as the category and location of the object. These methods have good detection performance on general object detection datasets such as VOC [
12] and COCO [
13] datasets. Among them, one-stage algorithms often achieve real-time detection speed and are easier to apply to edge devices. General object detection algorithms use horizontal bounding boxes (HBB) to surround objects, which are simple and intuitive in form but not accurate enough for object localization. Oriented object detection algorithms [
14,
15,
16,
17,
18,
19,
20] predict oriented bounding boxes (OBB) to surround objects, which are closer to the shape of objects and can also obtain the motion direction of objects. RoI Transformer [
18] is a two-stage object detection algorithm that achieves oriented object detection by transforming a horizontal region of interest (RoI) into a rotated RoI. However, steps such as horizontal candidate box generation, RoI alignment and oriented candidate box generation require a large amount of computation; oriented R-CNN [
19] proposes an oriented candidate box generation network (oriented RPN), which reduces the computational cost of generating oriented candidate boxes, but as a two-stage algorithm, it is still difficult to meet real-time detection; S
2ANet [
20] aligns convolutional features and arbitrary orientation objects through a feature alignment module (FAM) and then uses an oriented detection module (ODM) to achieve one-stage rotation object detection. Oriented bounding boxes require more parameters, and post-processing such as non-maximum suppression (NMS) for oriented bounding boxes is more complex than horizontal bounding boxes, which is unacceptable for embedded devices in terms of computational cost. In addition, some algorithms explore object detection algorithms that fuse infrared and visible light images. D-ViTDet [
21] and LAIIFusion [
22] use illumination perception modules to perceive the illumination difference in each region of the image, providing more suitable reference for cross-modal image fusion. UA-CMDet [
23], RISNet [
24], and ECISNet [
25] optimize the cross-modal mutual information utilization to improve the detection performance. TSFADet [
26] aligns cross-modal objects from translation, scaling, and rotation aspects through a network.
There are some datasets for object detection from a drone perspective, such as [
23,
27,
28,
29,
30,
31]. However, only a small portion of the dataset contains both infrared and visible light images. The VEDAI [
29] dataset comprises infrared and visible light dual-band images that include 1200 pairs of images and 9 different ground vehicle categories. The DroneVehicle [
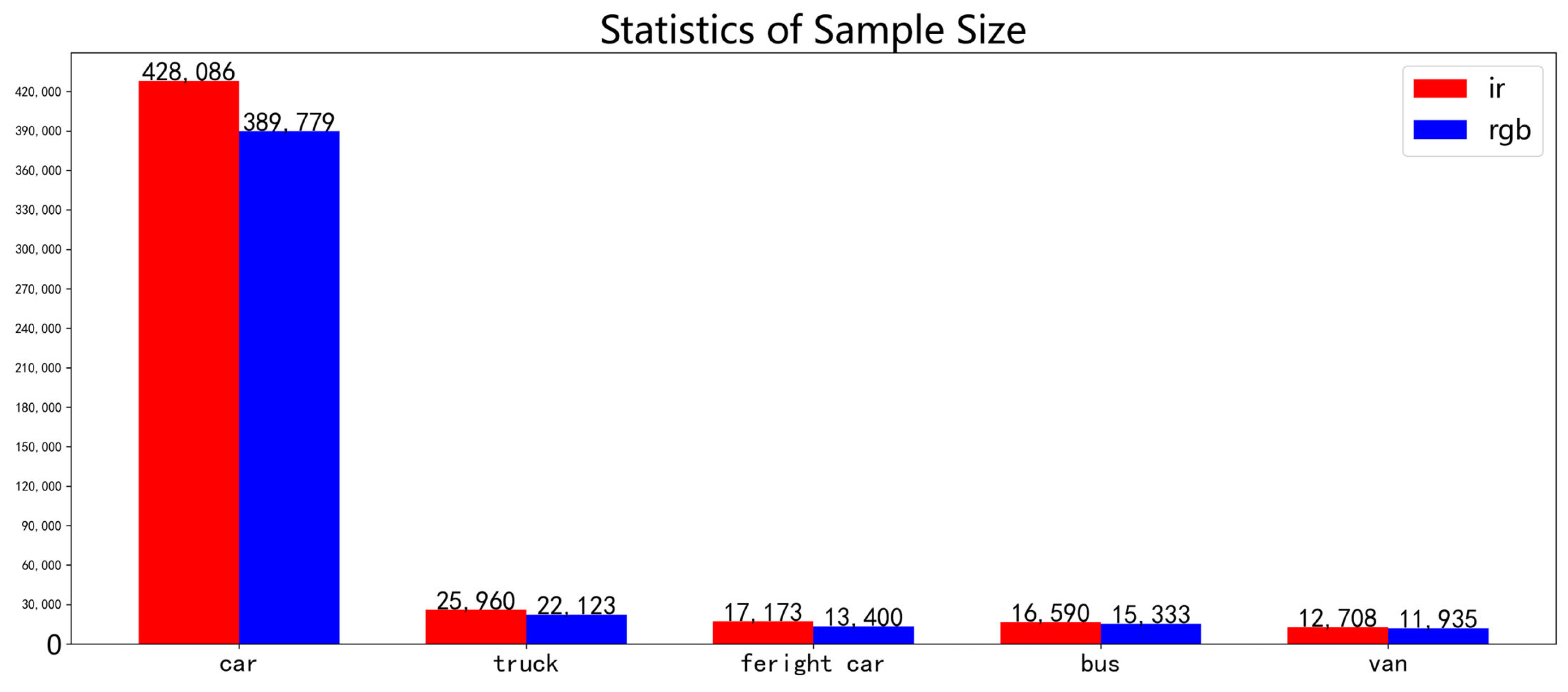
23] dataset is the first large-scale cross-modal dataset that covers all time periods under a drone perspective. It contains infrared and visible light dual-modal data that include 28,439 pairs of images and 5 different vehicle categories: car, truck, bus, van, and freight car. The objects are annotated with polygons and there are 953,087 annotations in total. The visible light images have 389,779 cars, 22,123 trucks, 15,333 buses, 11,935 vans, and 13,400 freight cars. The infrared images have 428,086 cars, 25,960 trucks, 16,590 buses, 12,708 vans, and 17,173 freight cars. The images cover scenes during day, evening, and night and show drones at different heights (80 m, 100 m, and 120 m) and angles (15°, 30°, and 45°). Each pair of images undergoes affine transformation and region cropping to ensure that most cross-modal image pairs are aligned. The DroneVehicle dataset is divided into a training set with 17,990 image pairs, a validation set with 1469 image pairs, and a test set with 8980 image pairs. All experiments are conducted in a fair comparison according to the given division method. Because oriented bounding boxes can provide additional direction information compared to horizontal bounding boxes, but they also introduce more complex post-processing operations and larger computational overheads, this paper mainly focuses on object location and algorithm speed; therefore, this paper uses horizontal bounding boxes.
Due to the large distance between the ground objects and the drone, the objects occupy a small number of pixels in the image, resulting in unsatisfactory detection performance. Moreover, since the object size span is small under the drone perspective, some methods such as feature pyramid network (FPN) [
32] are not as effective as in natural scenes with multi-scale objects. Most of the existing object detection algorithms are developed on visible light image datasets, which are greatly affected by illumination. Visible light images have richer texture information than infrared images when the illumination condition is good, but they have poor detection performance when the illumination condition is bad. As shown in
Figure 1, the objects are clearer in visible light images during daytime, but many objects are invisible in visible light images at night, while they are more obvious in infrared images. Combining different sensor information can improve the adaptability of drones to complex environments. However, due to the limited payload of drones, only some low-power embedded devices can be mounted. To achieve real-time object detection on drone images, the algorithm needs to be simple and fast.
The above-mentioned problems limit the application of object detection algorithms on drones. To enable drones to adapt to complex environments, this paper conducts research on both infrared and visible light modalities of data and improves the lightweight model YOLOv7-tiny to make it run in real time on edge devices. To address the small size span of objects in drone images and the class imbalance problem, this paper proposes a new anchor box assignment method to balance the imbalanced class samples. This method can provide more prior information that matches the size characteristics of objects under drone perspective and improve the accuracy of the network. This paper also improves the loss function to deal with the hard–easy sample imbalance problem and proposes HSM Loss to dynamically adjust the weights of hard-to-detect samples and enhance the network’s learning of hard-to-detect samples.
In summary, the main contributions of this paper are as follows:
We propose a novel anchor assignment method for drone images, AR-anchor (aspect ratio-anchor), which alleviates the sample imbalance problem, provides more effective prior information for the network, and improves the object detection performance.
We propose a hard-sample mining loss function (HSM Loss), which alleviates the hard–easy sample imbalance problem and enhances the detection ability of the network without increasing computational cost.
We demonstrate that our algorithm can be effective on both infrared and visible light modalities of data, enhancing the robustness and generalization of drone image object detection.
We present a lightweight algorithm that can be more efficiently applied in practice.
The structure of this paper is as follows:
Section 2 introduces the network structure and method in detail.
Section 3 presents our work and experimental results and compares them with related methods to verify the effectiveness of our approach. Finally,
Section 4 discusses the research content, and
Section 5 concludes the paper.
2. Materials and Methods
This section first introduces the framework and idea of deep-learning-based object detection algorithms, as well as their advantages and disadvantages, then introduces the structure and principle of the YOLOv7-tiny algorithm, and finally introduces the idea and details of our proposed anchor assignment method and improved loss function.
2.1. Overall Network Framework
Deep-learning-based object detection algorithms usually consist of three components: a backbone network for extracting image features, a neck for fusing deep semantic information and shallow detail information, and a detection head for predicting object classes and locations. The backbone network can be a network for image classification with the last classification layer removed, such as ResNet [
33], or a backbone network designed for object detection tasks such as DarkNet [
6]. These networks are often pre-trained on large-scale datasets to learn the ability to extract image features, which can significantly improve the performance for small-scale and similar-scene object detection datasets. Images are features extracted by the network to obtain feature maps. To reduce the computational complexity, the resolution of the feature maps gradually decreases in the network. Most backbone networks are designed to perform downsampling 5 times. The last layer of feature maps has a width and height of 1/32 of the original image. An object occupying 32 × 32 pixels in the image only occupies one point in the last layer of feature maps. As the network depth increases, the feature maps have stronger semantic information, but lose detail information. Therefore, object detection algorithms do not only detect objects from the last layer of feature maps but also do multi-scale detection from the last 3 layers of feature maps with different resolutions. By using the feature pyramid structure of the neck, the characteristics of different layers of the network are fully utilized to improve the adaptability of the network to multi-scale objects. The detection head realizes the classification and localization of objects. Different algorithms have different detection mechanisms. Some detection heads divide the image into several cells; each cell shares the extracted features and predicts the confidence, category, location, and width and height of the object, such as YOLOv7. Some algorithms use decoupled detection heads, which separate classification and regression tasks, such as Efficientdet [
34].
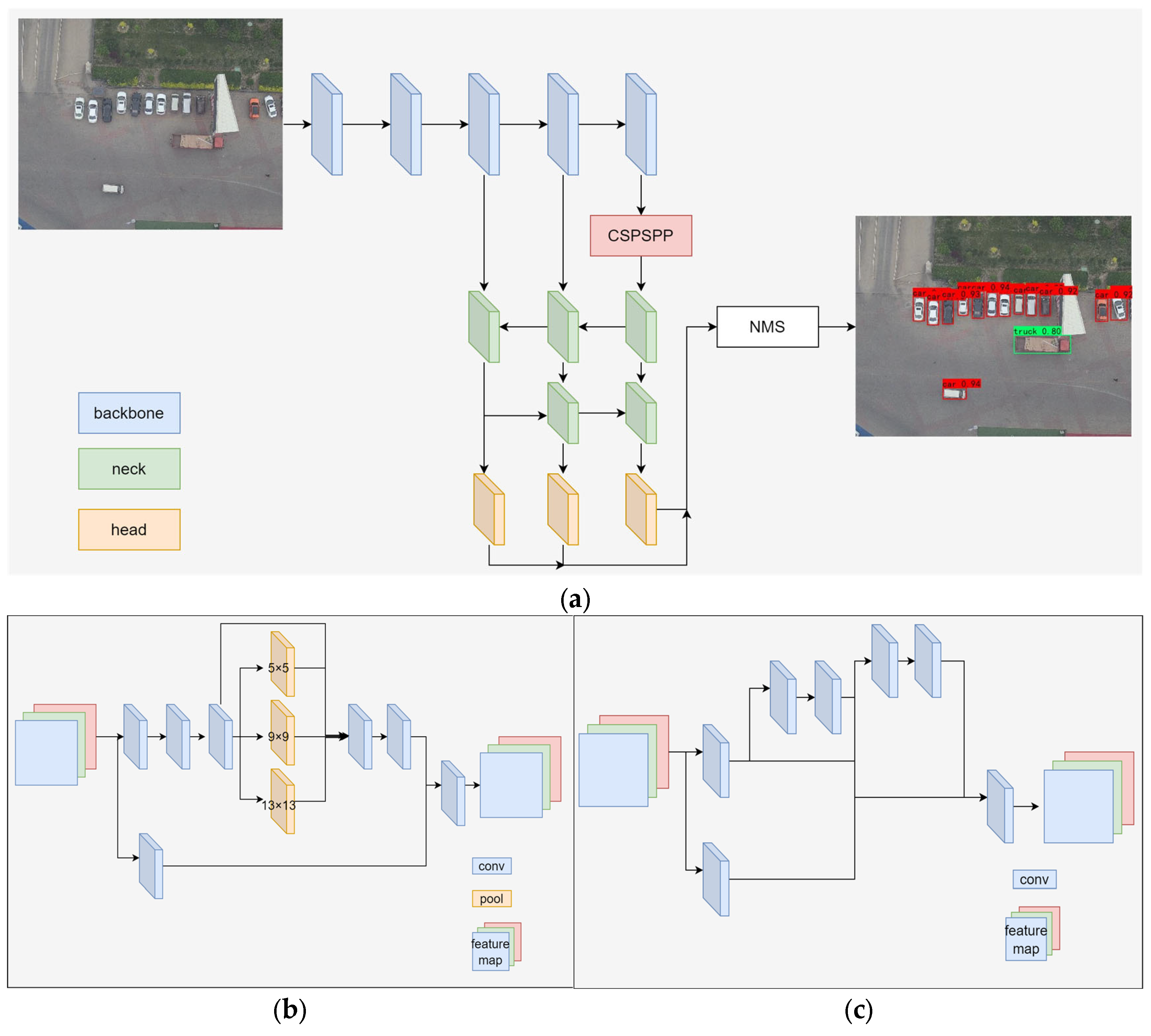
The network structure is shown in
Figure 2. Its backbone network uses a multi-branch stacked structure for feature extraction, which can extract more effective features while reducing computation. After the input image goes through the backbone network for feature extraction, the feature layers after downsampling 3, 4, and 5 times are used to predict objects; at the last feature layer of the backbone network, there is an SPP [
35] module with a CSP [
36] structure, which has max pooling layers with different sizes and can enable the network to learn more effective features from different receptive fields, allowing deep convolutional networks to extract richer semantic information; the neck part uses a PANet [
37] structure to fuse deep-feature map upsampling to shallow-feature maps to enhance the semantic information of shallow networks, while fusing shallow-feature map downsampling to deep-feature maps to supplement the detail information of deep-feature maps; a detection head with shared weights is used for final object classification and localization. Each layer uses three anchor boxes with different shapes, which are responsible for detecting objects with different shapes. Finally, non-maximum suppression is used to filter out multiple anchor boxes’ repeated predictions for the same object; the reparameterization technique is used, and there are different network branches on the same layer with different sizes of convolution kernels. During inference, convolution kernels of different branches are equivalently replaced by convolution kernels with the same size and then fused into a single branch. This improves the parallelism of computation and reduces storage and inference speed on the GPU when inferring. During training, YOLOv7-tiny uses the simOTA strategy to assign positive and negative samples. This strategy calculates the cost matrix between each ground truth box and anchor box then assigns one ground truth box to k anchor boxes. These anchor boxes are regarded as positive samples. If an anchor box is assigned multiple ground truth boxes for prediction, then this anchor box only predicts the ground truth box with the lowest cost. This strategy can greatly increase the number of positive samples.
2.2. Anchor Allocation Method Based on Aspect Ratio
The network predicts the width and height of the object by predicting the offset of the object size relative to the anchor box. Therefore, objects that are close to the size of the anchor box are easier to detect, while objects that have a large difference in size from the anchor box are easily ignored. Usually, the design of anchor boxes includes objects of various scales and shapes. Different feature layers with different receptive fields of the network are assigned different sizes of anchor boxes. Multiple anchor boxes on the same layer cover different shapes of objects according to the aspect ratio. Carefully designed anchor boxes provide effective prior information for the network and greatly improve its detection ability. However, under the drone perspective, the object size difference is not obvious. The algorithm in this paper groups the objects from the perspective of aspect ratio and assigns anchor boxes that are closer to the object shape distribution, providing more effective prior information for the network.
YOLOv7-tiny uses 9 different sizes of anchor boxes: 3 small anchor boxes on the feature layer with 3 times downsampling to detect small objects, 3 large anchor boxes on the feature layer with 5 times downsampling to detect large objects, and each layer has 3 anchor boxes with aspect ratios greater than 1, less than 1, and close to 1, respectively, to detect objects with different scales and shapes. The design method of anchor boxes is mainly based on clustering algorithms, such as K-means, on the bounding boxes to obtain the object sizes as prior information for the network. This design method can reflect the sizes of most objects in the data, but most datasets have a long-tail distribution situation where some object samples are far beyond the rest of the samples. The obtained anchor boxes mainly reflect the sizes of objects with more samples, resulting in better detection performance for categories with more samples and worse detection performance for other categories. In addition, in natural scenes, objects can be very close or far away from the camera; plus, size differences between objects exist from point objects to objects that occupy almost all the pixels of an image. Using different sizes of anchor boxes to guide different layers of the network to detect different sizes of objects is a good strategy, but when flying a drone, objects are far away from the camera, so they are mostly small objects without obvious size differences like natural scenes. At this time, what differs greatly among bounding boxes is the aspect ratio, so the original allocation method is not that effective anymore.
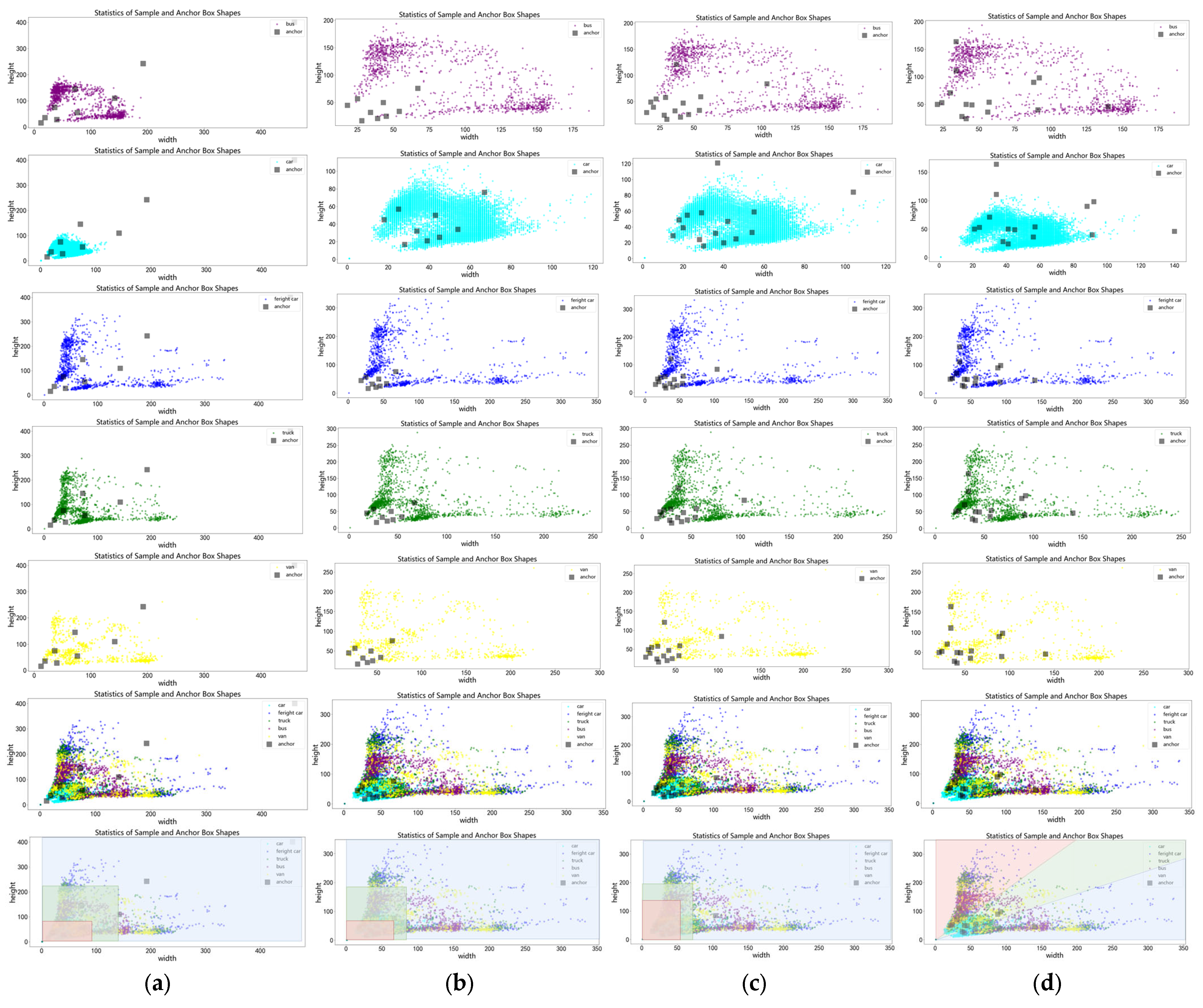
Based on the above problems, this paper proposes a new anchor box allocation method for object detection under drone perspective, abandoning the original strategy of allocating anchor boxes to different layers according to object size and using different aspect ratios of anchor boxes on different layers, making the network possess stronger detection ability for objects under drone perspective and allocating prior boxes separately for different types of objects to alleviate the impact of long-tail distribution of sample categories. Specifically, this paper first statistically analyzes the object size and anchor box size in the DroneVehicle dataset. As shown in
Figure 3, the horizontal axis represents width and the vertical axis represents height in units of pixel number. Since the objects are obtained from drone perspective, their size does not exceed 350 × 350. The default anchor boxes of YOLOv7-tiny differ greatly from object size distribution. Using the k-means algorithm to cluster on the dataset obtains 9 anchor boxes and 15 anchor boxes, which are more consistent with object size than the original default anchor boxes, but they will be affected by sample number difference among different categories. The sample categories are counted as shown in
Figure 4. Car has 428,086 samples in the infrared images and 389,779 samples in the visible light images, which are far more than other categories. Most anchor box sizes obtained directly by k-means are close to a car, so they are seriously affected by long-tail distribution of samples. Therefore, this paper’s algorithm first clusters each category’s object size using the k-means algorithm, separately obtaining 3 anchor boxes for each category. The DroneVehicle dataset has 5 categories, so it obtains a total of 15 anchor boxes. At this time, obtained anchor boxes can take into account each category’s size. Then, it explores allocation methods for the anchor boxes. From
Figure 3, it can be seen that most samples gather near the angle bisector line of the first quadrant of the coordinate system and approximate axial symmetry distribution. If it classifies objects according to the original allocation method by size as shown in
Figure 3a–c, it is equivalent to dividing objects into three parts according to the area of the rectangle formed by the coordinates with the origin point, which introduces prior information that does not match the characteristics of vehicle object size distribution under drone perspective into the network very well, so according to this paper’s method, it allocates according to the object aspect ratio, which is equivalent to using two straight lines with different slopes dividing object shape into three areas with different colors, as shown in
Figure 3d. At this time, the rule dividing objects becomes the aspect ratio, which is more suitable for object size distribution under drone perspective. Since all objects are vehicles, their own sizes have aspect ratios less than one, so when the drone direction is the same or perpendicular to the object, the bounding box shape is close to the object shape, but when the drone direction is at a 45° angle with respect to the object, the bounding box shape differs greatly from the object shape, so at this time, the bounding box aspect ratio is close to 1, so the network needs stronger semantic information for learning the difference between object and bounding box, so it puts each category’s aspect ratio close-to-one prior box on the last layer predicting network. That is to say, the green area samples in the sample distribution are allocated predicting the network with a larger receptive field and stronger semantic information deeper layer network, while because there are more samples with the same direction between the drone and vehicle than the perpendicular direction, it allocates a less-than-one aspect ratio prior box, that is, the red area samples predicting a network with less downsampling times, higher resolution, and shallower layer network.
2.3. HSM Loss (Hard-Sample Mining Loss)
Object detection from a drone’s perspective faces many challenges, mainly because objects in drone-captured images usually have small sizes, resulting in insufficient features, the contrast of visible light images is low under low illumination, and the contrast of infrared images is low when the ambient temperature and the object are close, making it difficult to distinguish between the object and the background and the motion blur of moving objects. These factors result in hard-to-detect objects that are difficult to accurately locate and identify in images, thus affecting the performance of drones in various application scenarios. For hard-sample mining, there are methods such as focal loss [
11] that adjust the weights of easy and hard samples according to confidence scores, the gradient harmonizing mechanism (GHM) [
38] that adjusts weights according to gradient contributions, online hard example mining (OHEM) [
39] that increases the number of hard samples in training samples, etc. The core of these methods is to increase the weight of hard samples during training. Based on focal loss, this paper conducts research on hard sample mining.
The loss function of object detection algorithms consists of two parts: classification and regression. YOLOv7 matches positive and negative samples based on the aspect ratio of ground truth boxes and anchor boxes, instead of using IoU as in previous versions. Classification uses cross-entropy loss.
For positive samples, the larger the prediction value, the smaller the loss; for negative samples, the larger the prediction value, the larger the loss. Focal loss is proposed to mainly solve two problems: class imbalance and easy–hard sample imbalance. Since one-stage object detection algorithms divide images into several grids, each grid has multiple anchor boxes to predict the different shapes of objects. Each prediction generates a large number of bounding boxes, among which only a small part are assigned as positive samples. The problem of class imbalance is serious.
In focal loss, parameter
is used to control the weight of different samples.
is a number between 0 and 1. For negative samples, most of them are background pixels. Since there is a large number of detection boxes that are negative samples in the network, a modulation factor
is multiplied by the cross-entropy loss to suppress the weight of negative samples and achieve the purpose of balancing positive and negative samples. For positive samples, focal loss also has the ability to dynamically adjust the network learning difficulty of samples. When
is close to 1, the sample belongs to an easy-to-detect sample, and the network reduces its weight. Smaller
values indicate positive samples that are difficult to detect, and the network increases their loss. Due to excessive suppression of a large number of negative samples by the modulation factor,
is used to adjust the weight of positive and negative samples, so that the network achieves a balance between positive and negative samples. The typical values for
and
are 0.25 and 2, respectively [
11].
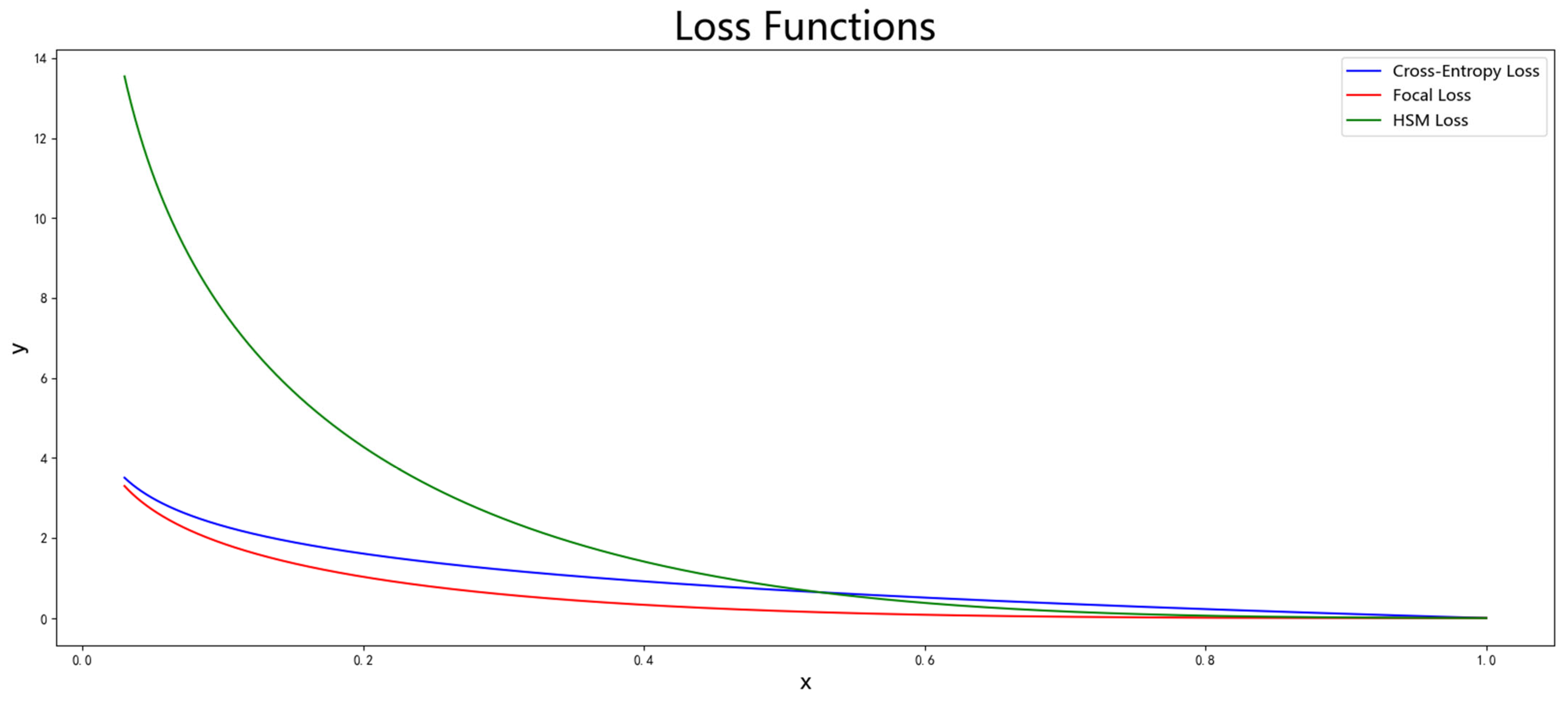
Focal loss has been proven to balance positive and negative samples and hard and easy samples in many experiments, but it performs poorly in the YOLO series, sometimes even leading to network performance degradation. This paper analyzes this problem and finds that YOLOv7-tiny itself has the ability to adjust positive and negative samples, using the simOTA strategy to assign positive and negative samples. Under this strategy, a ground truth box can match multiple anchor boxes as positive samples, and there are different modulation factors for positive and negative samples. Therefore, the imbalance of positive and negative samples in YOLOv7-tiny is not obvious, and directly introducing focal loss will cause negative samples in the network to be suppressed. The most intuitive phenomenon of this is that after introducing focal loss, the network performance does not increase but decreases, and when the confidence threshold is set low, the network will have a large amount of background predicted as objects, and negative samples are suppressed too much. At the same time, because focal loss dynamically allocates the weights of hard and easy samples by multiplying a modulation factor greater than 0 and less than 1 on the basis of cross-entropy loss, it always shows a suppressive effect on classification loss. For objects with a confidence of 0.9, the loss is only one percent of the cross-entropy loss. Although this can make the network learn more fully from hard samples, it limits the learning of easy samples. This paper improves this problem. First, this paper believes that balancing hard and easy samples should not always suppress them but also amplify them. We define hard samples as those with confidence lower than 0.5, which is consistent with the threshold used for prediction. When applying the algorithm to real images, we use 0.5 as the confidence threshold and take the objects with network prediction confidence higher than 0.5 as the prediction results. Therefore, this paper adds a modulation factor to make the weights of easy detection samples with confidence greater than 0.5 decay and the weights of hard detection samples with confidence less than 0.5 amplify; therefore, the loss of hard samples is amplified, while easy samples are suppressed. At this point, there is still a problem. For simple samples, as the confidence increases, the decay factor decreases exponentially, which will cause the network to stop learning after learning to a certain extent for easy samples. Therefore, a lower limit is set for the modulation coefficient to reduce the impact on the hard and easy sample boundaries as much as possible. A 0.1 is added to the modulation coefficient, and then, the lower limit of decay for easy samples is 10 times, and the impact on the hard and easy boundaries is relatively small; when γ = 2, the boundary is about 0.53. This bias will cause greater changes in the boundary of hard and easy samples, while a bias that is too small will cause the lower limit of the modulation coefficient decay to be too low. Therefore, 0.1 is a suitable bias. At this time, the modulation factor ranges from 0.1 to 4.1. Finally, in focal loss, after adjusting the weights of positive and negative samples by focal loss, the weight of negative samples is less than that of positive samples, which is used to reduce the weight of positive samples. This paper’s algorithm does not need this parameter to adjust the weight and removes it to obtain HSM Loss. The images of three loss functions are shown in
Figure 5. The focal loss value is always smaller than the cross-entropy loss, while the HSM Loss proposed in this paper is smaller than cross-entropy loss when the confidence is greater than 0.5 and larger than cross-entropy loss when the confidence is less than 0.5, which can better mine hard samples.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}