4.3.1. Experimental Results on the VisDrone Dataset
We evaluated our model using the VisDrone dataset and compared our model with other models to validate its effectiveness. As shown in
Table 2, our CGMDet achieved the highest mAP0.5 and mAP. Compared with baseline YOLOv7 [
18], mAP0.5 and mAP are increased by 1.9% and 1.2%, respectively. At the same time, CGMDet achieved the second-highest result on mAP0.75 and
, where it was only 0.1% lower than CDMNet’s
. Compared with YOLOv7, our CGMDet increases by 1.3%
and 1.2%
. Although the value of
is 0.4% lower than that of YOLOv7, on the whole, CGMDet is superior to YOLOv7 in the detection performance of multi-scale targets, which also indicates that our proposed FFM can better integrate the features of different scales and improve the model’s perception ability of features of different scales. Compared to Edge YOLO, our CGMDet is 5.7% lower on
, but our CGMDet is better than Edge YOLO on other metrics. Compared with NWD, CGMDet is 10.6% higher at mAP0.5 but 2.0% lower at
. Although our CGMDet is lower than ClusDet and DMNet on
, it is higher than them on other metrics. Our CGMDet was only 0.2% higher than CEASC on mAP0.5, but significantly higher than CEASC on mAP0.75 and mAP. At the same time, compared with CDMNet, CGMDet has slight disadvantages in mAP0.75,
, and
, but has obvious advantages in mAP0.5 and
. Compared to RetinaNet, Cascade-RCNN, Faster-RCNN, YOLOv3, YOLOX, YOLOv5l, HawkNet, and QueryDet, our CGMDet outperformed them on all metrics.
We also listed the mAP0.5 for each category to describe in more detail which categories our model has improved on. As shown in
Table 3, our model has a higher mAP0.5 than other models for each category. In addition, except for the tricycle category, which has the same result as YOLOv7, all other categories have greatly improved, especially the bus and bicycle categories, which increased by 3.3% and 3.8%, respectively.
To make it more deployable on mobile devices, we also designed a tiny version of the model and conducted experiments. The inference time was obtained by calculating the average prediction time of all images in the test set. The results in
Table 4 show that our CGMDet-tiny achieved the best results. Compared to YOLOv7-tiny, our CGMDet-tiny achieved a 4% improvement in mAP0.5, 3.6% in mAP0.75, and 3.1% in mAP. Meanwhile,
,
, and
increased by 2.8%, 4.1%, and 1%, respectively. Moreover, our model has only increased by 1.4 M parameters. Although our CGMDet-tiny is slower than other models in terms of inference time, it can still detect in real time. Moreover, judging from the results of detection performance, it is worth trading inference time for detection accuracy.
To better illustrate the advantages of our model, we provide the detection results of several images in different scenarios. As shown in
Figure 8(a1–a4) are the results of YOLOv7, and
Figure 8(b1–b4) are the detection results of our CGMDet. From the red dashed box in (a1,b1) of
Figure 8, YOLOv7 recognized that text on the ground as a car, while our model can recognize it as the background. From
Figure 8(a2,b2), our model can also distinguish between two objects with very similar features that are close together. Due to the indistinct features of small targets, it is difficult for the model to learn, and it is easy to recognize similar backgrounds as targets. However, our improved model is better able to detect small targets and can effectively distinguish the background, as shown in
Figure 8(a3,b3). In addition, we also tested the detection performance in nighttime scenes, as shown in the red dashed box in
Figure 8(a4,b4). YOLOv7 failed to detect it, while our model accurately marked it out.
As shown in
Table 5, in order to verify the effectiveness of the proposed CGAM module, we compared it with other similar modules. Compared to ELAN, our CGAM improved the mAP0.5 by 0.7% and mAP by 0.5%. Although the mAP0.75 and mAP of CGAM have a slight disadvantage compared with the CSPRepResStage, the number of parameters brought to the model by CGAM is much smaller than that of the CSRepResStage. The results show that our CGAM can effectively enhance the model’s feature extraction ability without too many parameters.
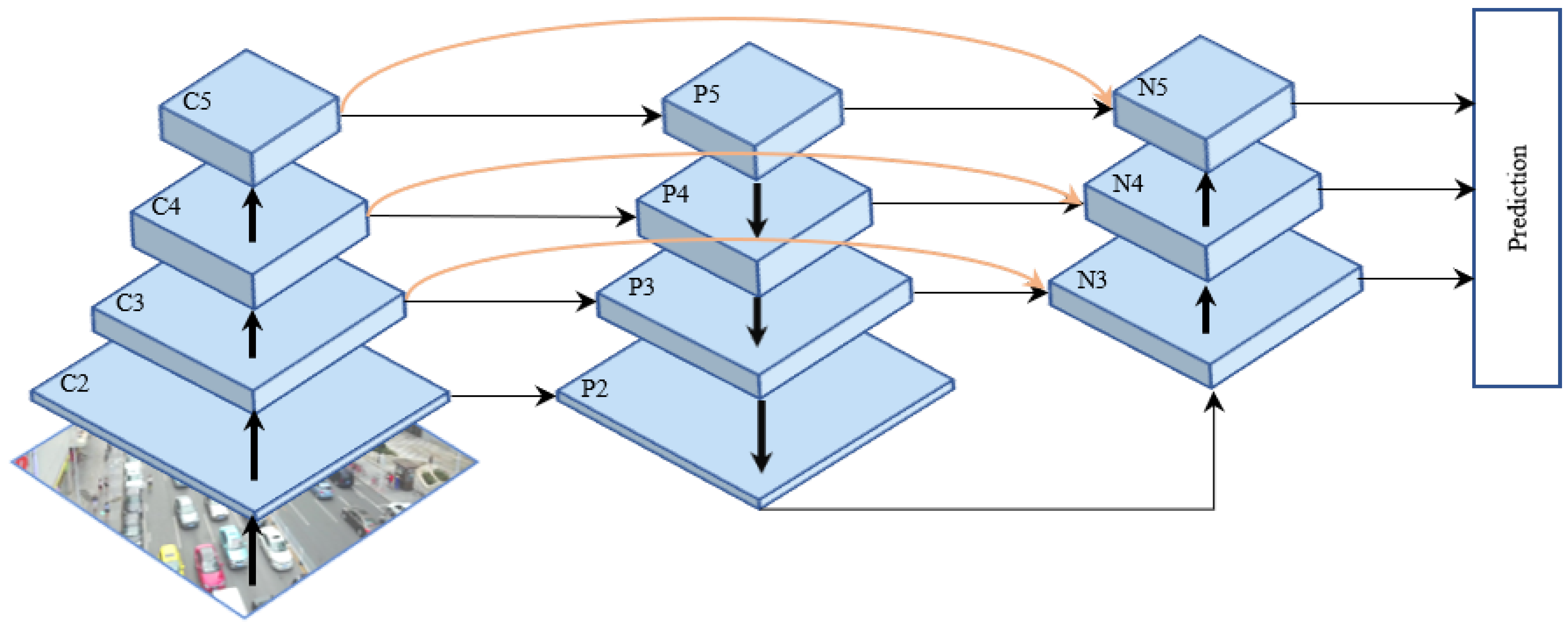
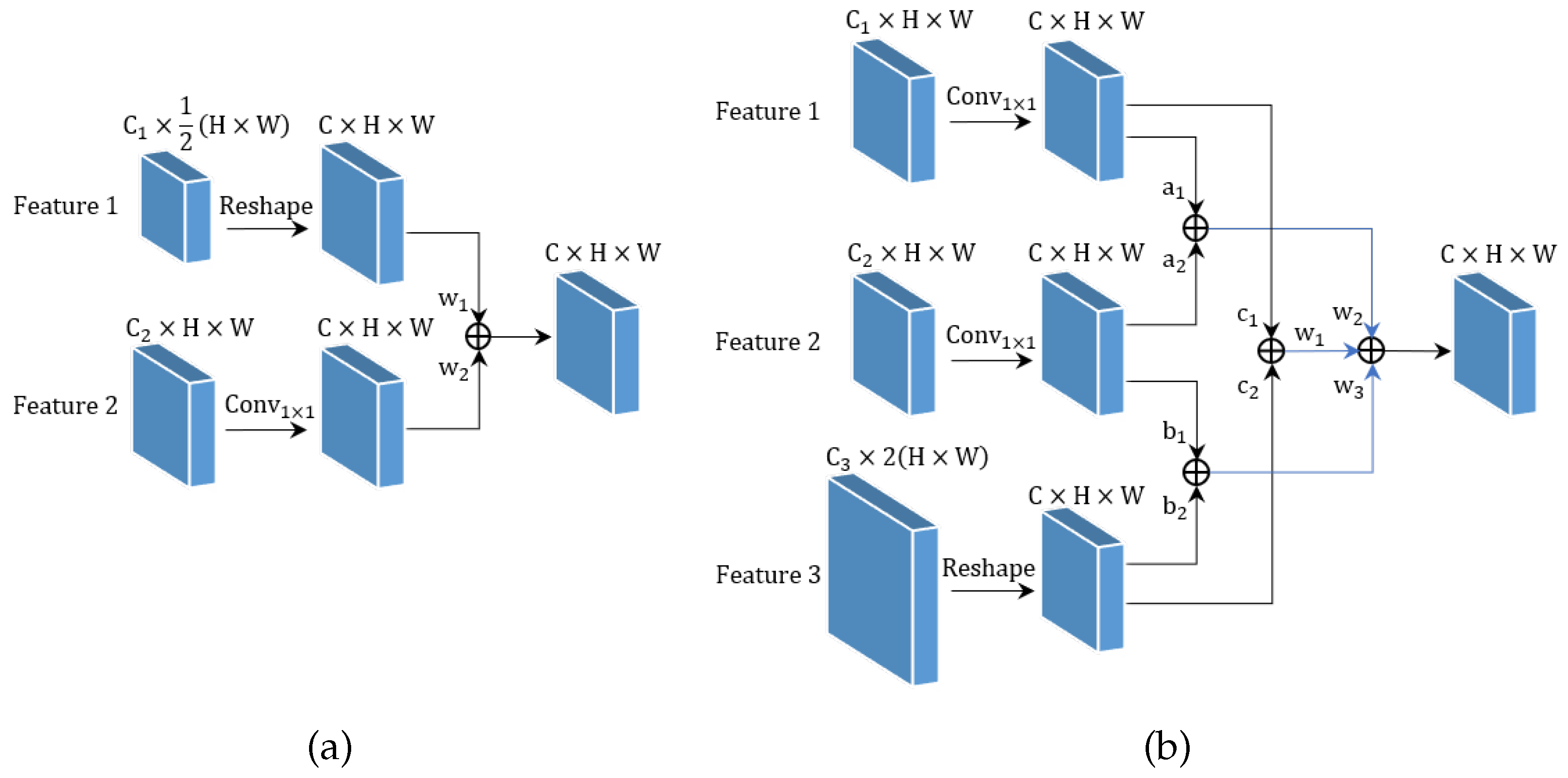
We also compared our MF-FPN with other multi-scale fusion methods. We only incorporate the last three scale features generated by the YOLOv7 backbone. As shown in
Table 6, our MF-FPN is similar to PAFPN on all metrics, but MF-FPN has fewer parameters and computations than PAFPN. Although the number of parameters and the calculation amount are the lowest among the three, the BiFPN also has a gap with the other two in performance. The results show that our MF-FPN can effectively integrate multi-scale features and enhance the model’s perception for multi-scale targets.
As shown in
Figure 9, we present the visualized results of three different multi-scale fusion methods. As shown in
Figure 9(b1), there are many false detections in the red dotted box, while the PAFPN and our MF-FPN reduce the number of false check targets. In the green dotted box, the MF-FPN accurately boxes the target, while the BiFPN and PAFPN do not fully box the target. As shown in the red and green dotted boxes in
Figure 9(b2), BiFPN missed one of the two adjacent targets, while neither PAFPN nor MF-FPN missed it, but MF-FPN’s bounding box in the green dotted box was less accurate than PAFPN’s. As shown in the green dotted boxes in
Figure 9(a3,b3), although PAFPN and BiFPN detected the truck, they generated a redundant detection box, and the detection box’s scope is not accurate. However, the MF-FPN does not generate redundant detection boxes, and the detection box can accurately enclose the target. It can also be seen from
Figure 9 that our MF-FPN can also better detect targets of different scales.
4.3.2. Experimental Results on the UAVDT Dataset
We also evaluated our model using the UAVDT dataset and compared our model with others. As shown in
Table 7, compared with YOLOv7, our model has increased mAP0.5 by 3.0%, mAP0.75 by 3.2%, and mAP by 2.3%. The detection performance of YOLOv7 on the UAVDT dataset is worse than that of YOLOv5l. Compared with YOLOv5l, the mAP0.5 is 1.2% lower, the mAP0.75 is 1.3% lower, and the mAP is 1.1% lower. However, our model outperforms YOLOv5l in terms of mAP0.5, mAP0.75, and mAP. We also listed the mAP0.5 results for each category in the table, which showed that our model improved by 2.9% over YOLOv7 in the car category, and the results for the truck and bus categories both improved by 3.4%. In addition, our model outperforms YOLOv5l by 3.3% in the truck category and is also 0.6% and 2.2% higher in the car and bus categories, respectively. At the same time, our model’s performance is also superior to YOLOv3 and YOLOX.
In
Table 7, we also included the results of the tiny version for comparison. Our CGMDet-tiny improved the results for the car, truck, and bus categories by 2.3%, 1.0%, and 0.9%, respectively, compared to YOLOv7-tiny. It also increased the mAP0.5 by 1.4% and improved the mAP0.75 and mAP by 2.2% and 1.8%, respectively. In addition, our CGMDet-tiny outperforms YOLOX-tiny in all metrics. However, compared to YOLOv5s, our CGMDet-tiny only outperforms by 0.3% in terms of mAP.
To illustrate the superiority of our CGMDet, we present detection results for several images in different scenarios. As shown in
Figure 10(a1–a3) are the results of YOLOv7, and
Figure 10(b1–b3) are the results of our proposed model. From
Figure 10(a1,b1), our model performs significantly better than YOLOv7 in terms of detecting small targets. From
Figure 10(a2,b2), even under low light conditions at night, our model has a significant improvement over the baseline. In addition, as shown in
Figure 10(a3,b3), YOLOv7 detected the left tree as a car, and the bus as a truck, and did not detect the objects that were truncated at the bottom of the image or slightly occluded on the right side of the image. In contrast, our model correctly recognized the tree as the background, accurately identified the object categories, and accurately detected the objects at the bottom and right of the image.
4.3.3. Ablation Experiments
We used the VisDrone dataset to conduct ablation experiments for our model to verify the effectiveness of our improved methods. For fairness, all experimental settings have the same parameters and are conducted in the same environment. As shown in
Table 8, we use YOLOv7 as the baseline and achieved a 49% mAP. Furthermore, the results show that each improvement can enhance the detection ability of the model to some extent.
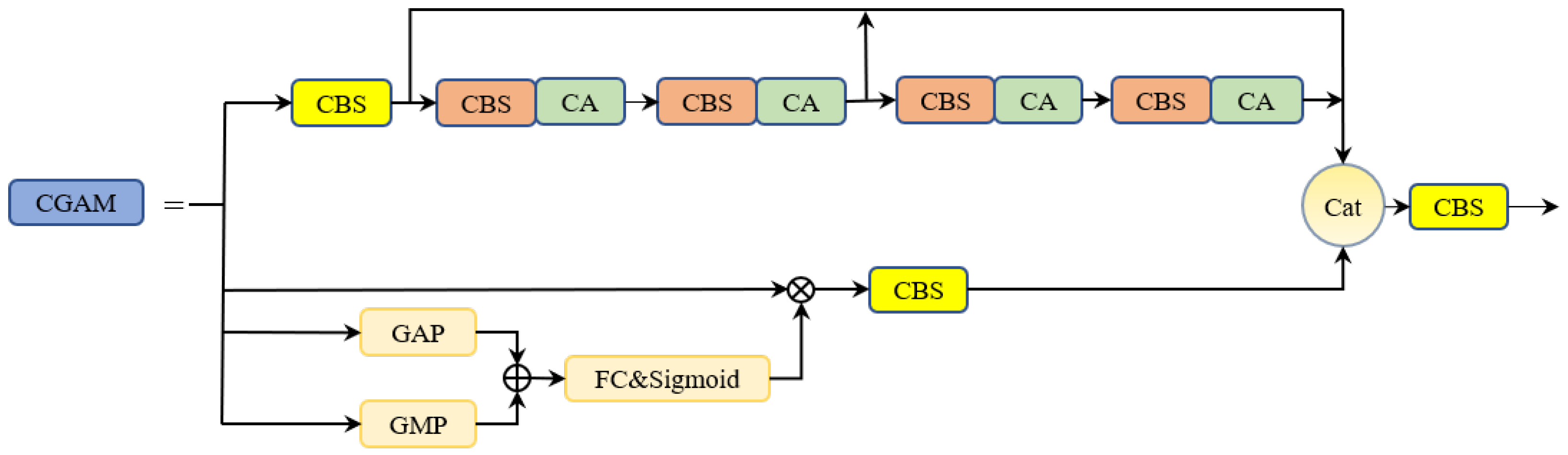
CGAM: To reflect the effectiveness of the CGAM, we replaced the ELAN [
37] module in the YOLOv7 backbone with our CGAM module. Compared with YOLOv7, using CGAM increased the mAP0.5 by 0.7%. This is because our CGAM can simultaneously extract local, coordinate, and global information, making the extracted feature map richer in contextual information, and thereby improving the ability of the backbone network to extract features;
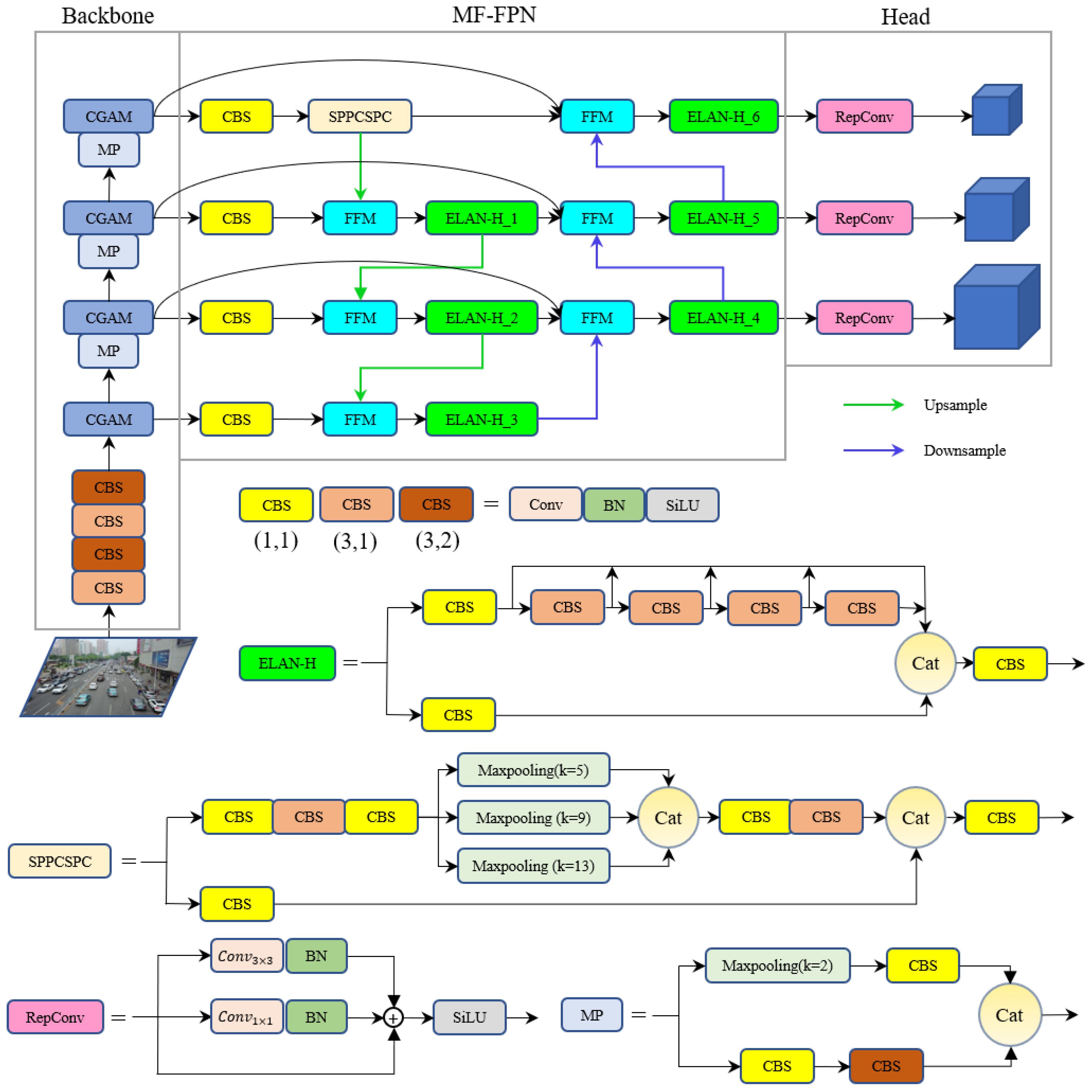
MF-FPN: To demonstrate the effectiveness of MF-FPN, we replaced the neck part of YOLOv7 with the proposed MF-FPN. Compared with YOLOv7, the improved model with MF-FPN increased mAP0.5 by 1%, and the parameters of the model also decreased by 2.2M. This shows that the MF-FPN can fully integrate multi-scale features with fewer parameters. This also proves that our FFM can fully integrate features of different scales and obtain multi-scale feature maps with stronger representation ability;
Focal-EIOU Loss: To reflect the effectiveness of Focal-EIOU Loss, we replaced the CIOU loss in YOLOv7 with Focal-EIOU Loss. Compared with CIOU Loss, Focal-EIOU Loss can more accurately regress the bounding box and allow high-quality anchor boxes to make more contributions during training, thereby improving detection performance. Compared with YOLOv7, the model’s mAP0.5 increased by 0.5%;
Proposed Method: When CGAM, MF-FPN, and Focal-EIOU loss were all incorporated into YOLOv7, our model was obtained. Compared with YOLOv7, the precision increased by 0.5%, the recall increased by 2.1%, the mAP0.5 increased by 1.9%, and the parameter size of our model was reduced by 0.7M compared to the baseline. The results show that our improvement methods are very effective, and each improvement can enhance the performance of the model;
We plotted the change process of mAP0.5 and mAP during training, as shown in
Figure 11. It is evident from the figure that compared with YOLOv7, each of our improvement points significantly improved the model’s performance. The model we proposed by integrating all the improvement points undergoes an especially significant improvement compared to YOLOv7.
In addition, we also listed the changes in the convolutional parameter sizes of each ELAN-H module in the neck part of the model. As shown in
Table 1, ELAN-H_3 and ELAN-H_4 are two additional modules that we added to our model.
To better demonstrate the effectiveness of CGMDet, we used Grad-CAM [
54] to visualize the model’s execution results in the form of heatmaps. As shown in
Figure 12, the first row of the image shows that, compared with YOLOv7, our model reduces the focus on similar objects around small targets and can more accurately detect small targets. The second row shows that our model alleviates the interference of background factors. The third row shows the heat map results generated by our model in low-light nighttime scenes, where we can observe that, even under low-light conditions, our model can accurately focus on the target while reducing the attention to the background.
We briefly tested the effects of
,
, and
in Formula (23) on the model’s performance. As shown in
Table 9, when
,
, and
, mAP0.75 and mAP obtained the highest result, but mAP0.5 is 0.7% lower than the best result. When
,
, and
, the mAP is also the highest, but the mAP0.5 and mAP0.75 are not very good. When
,
, and
, the mAP0.5 is the highest, and the mAP0.75 and mAP are only 0.2% lower than the highest result. It can be seen from the results that, when
,
, and
, the mAP0.5, mAP0.75, and mAP can achieve good balance, so we choose them as the final values.
In addition, we explored the effects of different learning rates on the performance of our model. As shown in
Table 10, the model performance gradually improves when the learning rate increases from 0.005 to 0.010. When it is higher than 0.010, the model’s overall performance declines slightly. When the learning rate is 0.011, mAP reaches the highest, but mAP0.5 and mAP0.75 are lower than when the learning rate is 0.010. Similarly, when the learning rate is 0.012, mAP0.75 reaches the highest, but mAP0.5 and mAP are relatively low. Therefore, we chose 0.010 as our final learning rate.
4.3.4. Extended Experiments
To verify the generalization ability of our model, we conducted experiments on the generic dataset VOC2012 [
55]. We use
VOC2012 train for training and
VOC2012 val for validation. The training set contains 5717 images, and the validation set contains 5823 images. The value of mAP0.5 for each category is shown in
Table 11. Our model is superior to the baseline model in some categories. However, some categories are worse than the baseline model. For further analysis, we list the detection results of different scales on the VOC2012 dataset in
Table 12. Our model improves by 1.8% on
and 0.3% on
but decreases by 3.3% on
. This shows that our model is more suitable for detecting small and medium targets.
From the results of the extended experiment, our model’s performance on the VOC2012 dataset is not very good, which indicates that our model is more suitable for UAV images. However, it also shows that the generalization ability of our model needs to be stronger. The result of our analysis is that after adding the P2 layer to the model for feature fusion, the feature proportion of small and medium targets increases, resulting in the model paying more attention to small and medium targets while ignoring large targets. Therefore, our model is more suitable for detecting UAV images with more small- and medium-sized targets.






 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}