1. Introduction
As an underwater sensor, a hydrophone can realize the real-time monitoring of various opportunistic sound sources and environmental noise in the ocean. However, estimating the distance and direction of the sound source solely based on a single hydrophone is difficult, and a single hydrophone has a low signal-to-noise ratio (SNR) and limited detection range. On the contrary, an array of hydrophones exhibits strong capabilities in estimating the direction and distance of the sound source and has a significantly higher SNR than a single hydrophone. Research on underwater acoustic arrays in terms of SNR improvement, distance, and direction estimation has become a significant topic.
Array signal processing is a technology that uses a group of sensor arrays to spatially sample signals and then uses corresponding signal processing algorithms to enhance and estimate the parameters of the received data. Compared to methods that use a single sensor to collect and process signals, array signal processing technology can achieve spatial gains by utilizing the spatial characteristics of the signal, thereby improving the accuracy of parameter estimation [
1].
DOA estimation of underwater wave propagation is a significant research subject in array signal processing and has substantial theoretical and practical implications for underwater target detection and tracking. In the field of underwater acoustic signal processing, commonly used DOA estimation methods include conventional beamforming and the Multiple Signal Classification (MUSIC) algorithm. However, these methods have limited ability to estimate the direction of adjacent signal sources and may even fail in the case of impulsive noise [
2]. Therefore, conducting research on the DOA estimation of underwater targets has significant theoretical and practical implications.
Beamforming technology, based on array technology, is the main approach for high-precision target detection. In their research, Kawachi et al. demonstrated the design and testing of an echo-PIV system that efficiently mapped the interior and fluid flow of a submerged vessel using a single divergent signal wave and delay-and-sum processing. However, the DW-DAS echo-PIV method is not useful for sensing leakage points and underwater debris at relatively short distances and over a narrow field of view [
3]. Meanwhile, Shostak et al. proposed a new method for estimating the distance to any underwater object or physical phenomenon by analyzing the curvature of the wavefront and its impact on the measuring sonar system of correlated noise. They also provided results that substantiated this method [
4]. Li et al. demonstrated a method for estimating seabed parameters that used the spatial characteristics of the ocean’s ambient noise without relying on matched-field processing [
5]. Zhou et al. reported improvements over conventional PGC methods, and the hydroacoustic sensor system has great potential in large-scale multiplexing [
6]. Li et al. investigated the effectiveness of array processing for the passive monitoring of gas seeps and proposed using beamforming methods to enhance the SNR and improve the productivity of passive acoustic systems [
7]. Verdon et al. presented a case study showcasing the use of an “L”-shaped downhole fiber-optic array for monitoring microseismic activity [
8]. Other influential work includes Schinault et al., 2019. The array, in its current state of development, is a low-cost alternative to obtain quality acoustic data from a towed array system. Their study demonstrated that this array could be used for observing whales and ship tonals at ranges up to 5 km, receiving acoustic signals from targets of interest with enhanced SNR and directional sensing capabilities. Marine mammal vocalizations have been captured by this prototype array, and whale species have been identified through visual observation [
9]. Xie et al. proposed a robust wideband beamforming algorithm based on subspace spectrum separation for addressing the issue of manifold deviations that may occur in sensor arrays. In this algorithm, a sensor array manifold calibration method based on subspace partitioning was proposed, and an improved interference–noise covariance matrix reconstruction method based on spectral separation was derived. Firstly, the space was divided into several subspaces using the Capon spatial spectrum, and the array manifold deviation was calibrated. Then, noise and interference information was accurately extracted through spectral separation, and finally, the optimal beamformer was designed based on the extracted information. Simulation results showed that this algorithm had good performance for different types and ranges of array manifold deviations. Furthermore, the wideband interference will be further considered in future work [
10]. Zou et al. developed a hybrid analytical–numerical method that combines the analytical technique with the acoustic superposition approach to predict the sound radiation of a spherical double-shell within the ocean’s acoustic environment. Green’s function was utilized to simultaneously analyze the coupled vibration of fluid–structure, near-field, and far-field sound radiation. To reduce the computational complexity, the near-field was simulated using the image source method, while the far-field was simulated using the normal mode method. This method was used to calculate the sound radiation field of a spherical double-shell with positive and negative gradient sound velocity profiles in a shallow ocean acoustic environment. However, there was no obvious interfering phenomenon in the contour of the sound pressure distribution when the spherical shell was at a certain submerging depth. This requires further study of the related mechanism [
11]. The numerical results were compared with finite element calculation results, and the efficiency was improved without compromising the calculation accuracy. A deconvolution method for conventional beamforming (CBF) was proposed in reference [
12], which showed theoretically higher array gain (AG) than CBF and provided the possibility of detecting weak signals using the SNR [
12]. However, simulation data processing showed that effective AG decreased with a decreasing SNR. The method of output signal subspace deconvolution for CBF was used to recover most of the AG loss and track the azimuth and time of weak signals. Frequency difference beamforming (FDB) provided a robust estimate of the wave propagation direction by shifting the signal processing to lower frequencies. Xie et al. proposed a deconvolution frequency difference beamforming (Dv-FDB) method to improve array performance, which produced narrower beams and lower sidelobes while maintaining robustness. Based on this, the R-L algorithm was used for deconvolution to make Dv-FDB’s spatial spectrum clearer. Simulation and experimental results showed that Dv-FDB was superior to FDB in higher resolution and lower sidelobes while maintaining robustness. Existing R-L methods are limited to arrays with offset-invariant beam patterns [
13]. Byun et al. (2020) proposed a multi-constraint method for matching field processing (MFP) to address the uncertainty of the array tilt, and the experimental results verified the robustness of MFP. In summary, beamforming-based target direction estimation algorithms for underwater acoustic arrays can improve the performance of weak signal detection and underwater noise suppression, but the computational complexity of these algorithms needs to be considered. An additional important source of mismatch is the array tilt, which has not received much attention, in spite of its significant impact, especially for a large array tilt observed in shallow environments [
14]. Other influential works in this field included Zhu et al. and Zhang et al. [
15,
16].
Another representative class of estimation algorithms is the MUSIC algorithm. MUSIC is a high-resolution DOA estimation algorithm that was first introduced by Schmidt in 1986. It is a non-parametric algorithm that does not require any prior knowledge of signal statistics, and it is widely used in many fields, including radar, sonar, and wireless communications. The main idea behind the MUSIC algorithm is to transform the received signal into the frequency-domain and estimate the DOAs of the incoming signals based on the eigenvalues and eigenvectors of the covariance matrix of the received signal. Specifically, the MUSIC algorithm first divides the entire space into two subspaces: the signal subspace and the noise subspace. The signal subspace contains the eigenvectors corresponding to the signal, while the noise subspace contains the eigenvectors corresponding to the noise. The DOAs of the incoming signals are then estimated by calculating the peaks of the spectrum of the noise subspace. Compared to other DOA estimation algorithms, such as beamforming and the Estimation Signal Parameter via Rotational Invariance Techniques (ESPRIT), MUSIC has several advantages, including a high-resolution, robustness to noise, and the ability to handle both coherent and incoherent signals. However, it also has some limitations, such as sensitivity to array geometry, the need for an accurate estimation of the noise subspace, and computational complexity. Overall, MUSIC is a powerful and widely used DOA estimation algorithm that has applications in many fields, including signal processing, wireless communications, radar, and sonar.
Yi et al. utilized passive array sonar systems to track a changing number of underwater targets, also known as acoustic emitters [
17]. However, the authors did not consider information fusion among multiple passive sonar’s systems. Huang et al. addressed the problem of DOA estimation with one-bit quantized array measurements. Otherwise, the approximation error becomes relatively large at a high SNR, which deserves further Investigation [
18]. Cheng et al. proposed a marine environment noise suppression method for multiple-input multiple-output (MIMO) applied to the DOA estimation of multiple targets. In future work, it is worth exploring further optimization of the noise suppression algorithm model to reduce the impact of pre-estimation results on the DOA estimation accuracy [
19]. As the underwater detection platform has a limited size, the traditional bulky linear array is not feasible. To address this issue, Li et al. investigated the joint processing–MUSIC (JMUSIC) algorithm for estimating the DOA in shallow sea multi-path environments using a non-uniform line array of acoustic vector sensors. It is a pity that the authors only conducted research in an ideal situation and did not take into account complex situations [
20]. Zhu et al. proposed a method for obtaining the optimal waveform estimation of source signals in a spatial scanning orientation through the estimation of the maximum posterior probability criterion and the iterative convergence process of the constraint equation. The experiment yielded excellent results in the case of single snapshots, but it is also worth paying attention to how fast the shots were [
21]. Ahmed et al. conducted a comparative study of deterministic and heuristic algorithms for viable DOA estimation for different dynamic objects in underwater environments. To achieve the precise positioning of underwater targets at a close range [
22], Ahmed et al. utilized the Cuckoo Search Algorithm (CSA) and swarm intelligence to optimize DOA estimation with a Uniform Linear Array (ULA) in various underwater scenarios [
23]. An et al. proposed a combination of a linear array composed of multiple mutually perpendicular sub-arrays, overcoming the ambiguity of a single linear array’s port and starboard orientation [
24]. Under normal circumstances, both Ahmed and An had achieved research results, but in unconventional situations, such as pulse environments, it is worth exploring the advanced nature of the algorithms.
In recent years, there has been significant development in DOA estimation algorithms based on SBL. SBL is a statistical inference technique that is used to estimate sparse signals from noisy and incomplete data. It is a type of Bayesian regularization method that aims to find the most probable solution to an inverse problem by incorporating prior knowledge and assumptions about the underlying signal. In the context of DOA estimation, SBL is used to estimate the sparse signal of the DOA parameters from the array measurements. The key idea of SBL is to formulate the DOA estimation problem as a Bayesian inference problem, where the unknown DOA parameters are modeled as random variables, and the prior distribution of the DOA parameters is assumed to be sparse. By incorporating the prior information about the sparsity of the DOA parameters, SBL can effectively suppress the noise and interference in the array measurements and accurately estimate the DOA parameters, even in the presence of a limited number of snapshots. SBL algorithms typically involve iterative optimization procedures that update the estimates of the unknown parameters based on the observed data and the prior distribution. These algorithms can be computationally intensive, but they have been shown to be effective in a wide range of DOA estimation applications, including radar, sonar, and wireless communications.
Wang et al. aimed at the problem of interactions among the hydrophone array elements of the actual sonar array, which causes estimation performance dropping of the array’s DOA, and a DOA estimation method under uncertain interactions of the array elements was proposed. However, the author did not note the relevant signals [
25]. In order to achieve the high-precision Direction-of-Arrival (DOA) estimation of array signals in complex underwater acoustic environments, the root off-grid sparse Bayesian learning (ROGSBL) algorithm was applied to an underwater acoustics field [
26]. In 2022, Haodong Bai studied the efficient DOA processing algorithm under multi-snapshots by aiming at the problem that the DOA estimation method, based on sparse Bayesian learning under single snapshots, has a low estimation accuracy and a large number of operations for increasing the number of snapshots [
27]. He et al. proposed the SS-OGSBI algorithm to solve the problem of off-grid DOA estimation under coherent sources [
28]. Guo et al. applied sparse Bayesian learning to the DOA estimation of underdetermined broadband signals with mutual arrays in unknown noise fields [
29], while Shen et al. proposed an off-grid DOA estimation method based on subspace fitting and block-SBL to address the poor performance of traditional SBL-based DOA estimation algorithms under low SNR conditions [
30]. Other influential works in this field included Yu et al., Ma et al., Zhu et al., Jimenez-Martinez M and Zhang et al. [
31,
32,
33,
34,
35].
Although researchers have provided answers to the questions raised and made significant contributions to the field of Direction-of-Arrival (DOA) estimation using beamforming in underwater acoustics, the algorithms themselves have limitations. The researchers conducted their studies under the background of Gaussian noise, and further investigation is necessary to determine the robustness of the algorithms in highly impulsive noise environments.
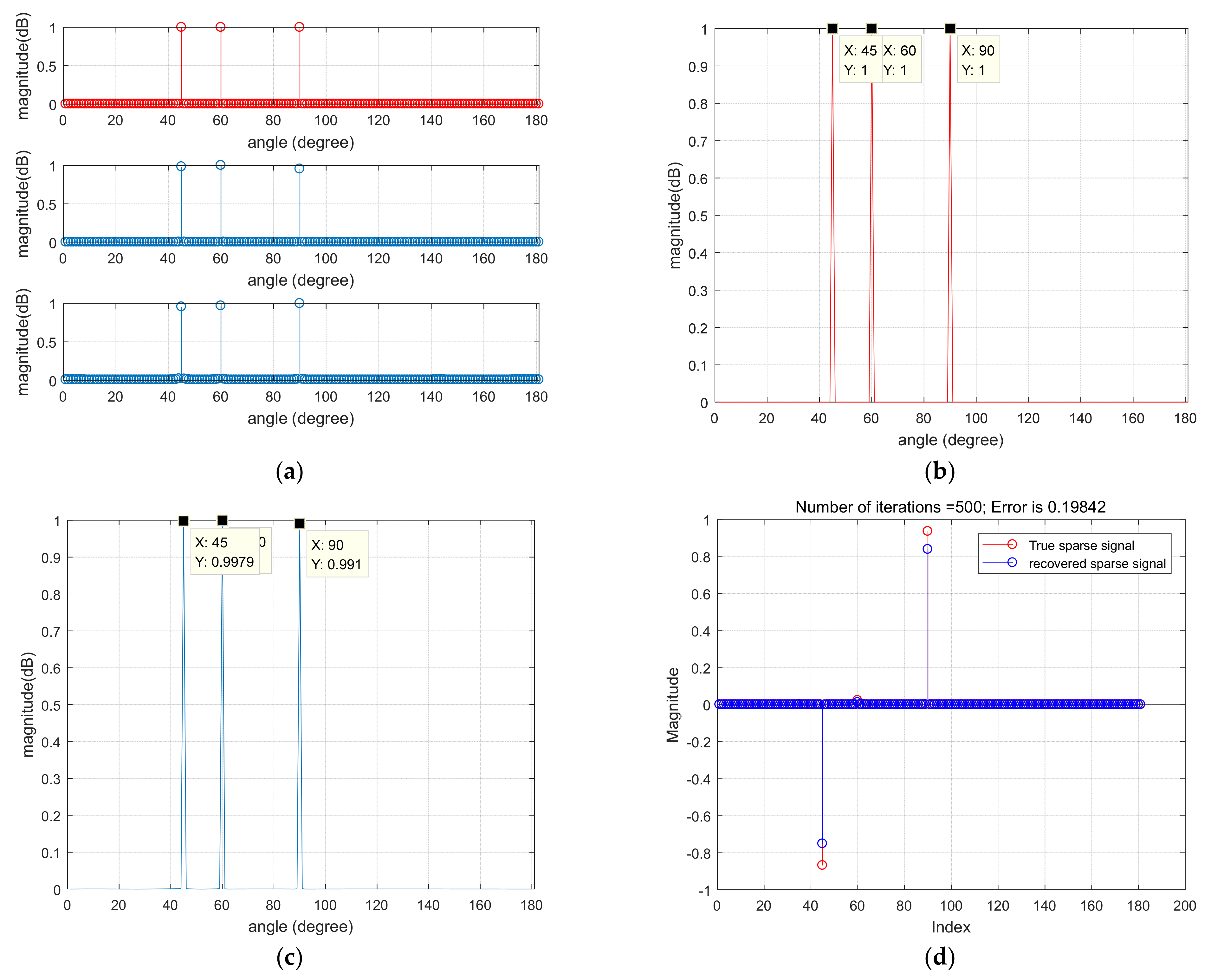
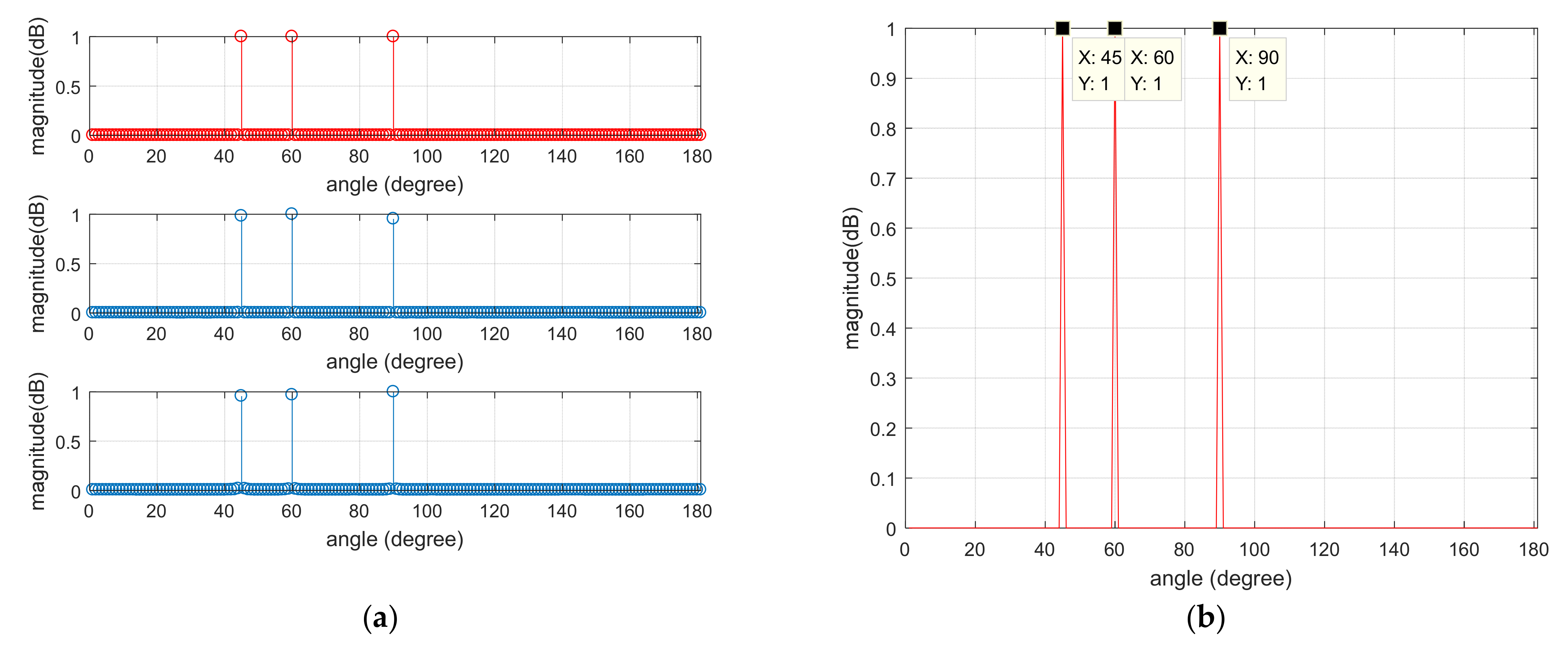
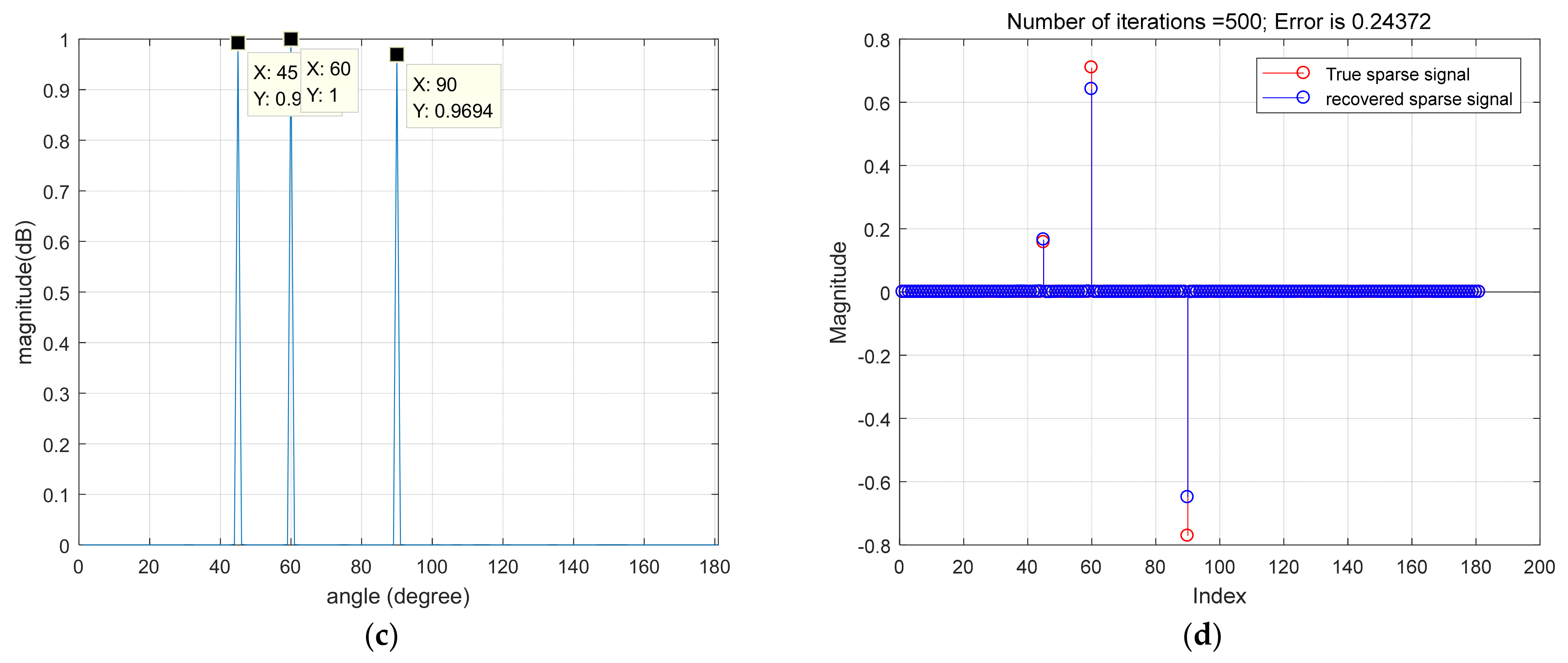
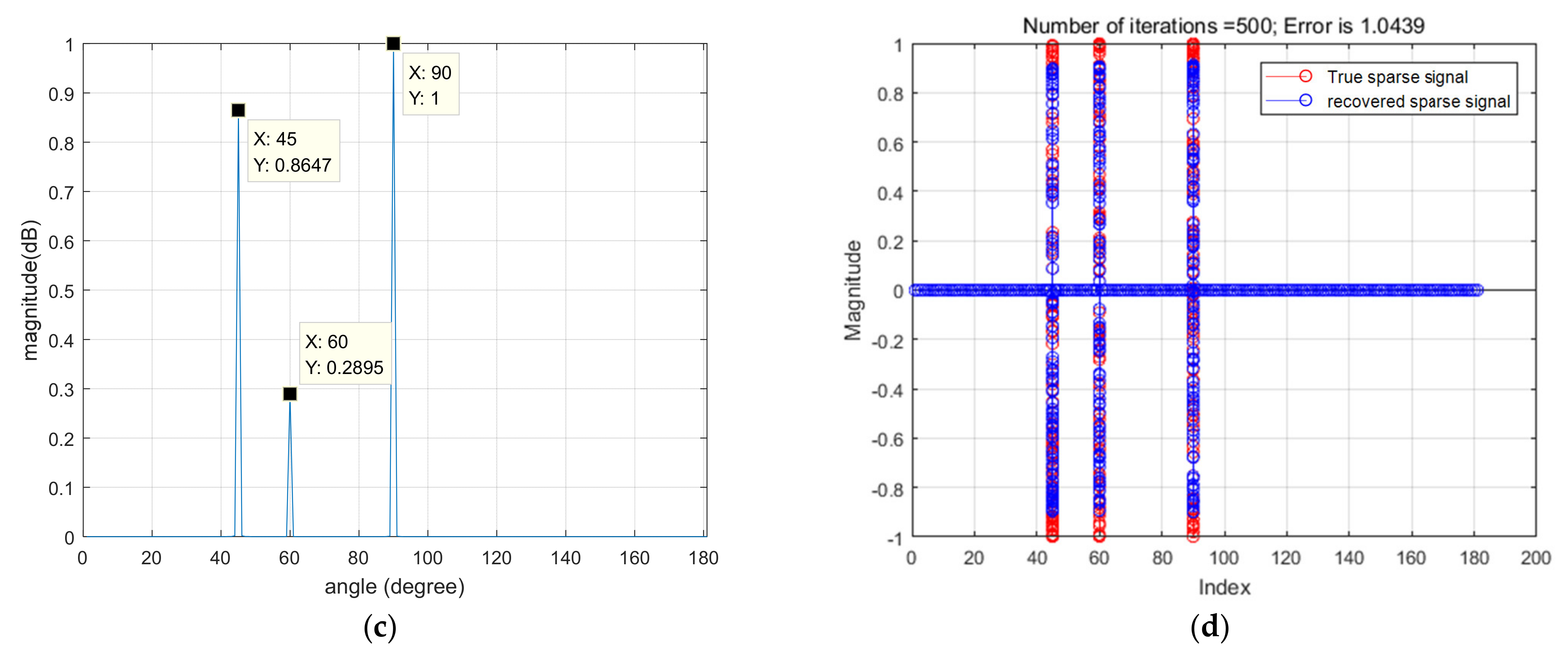
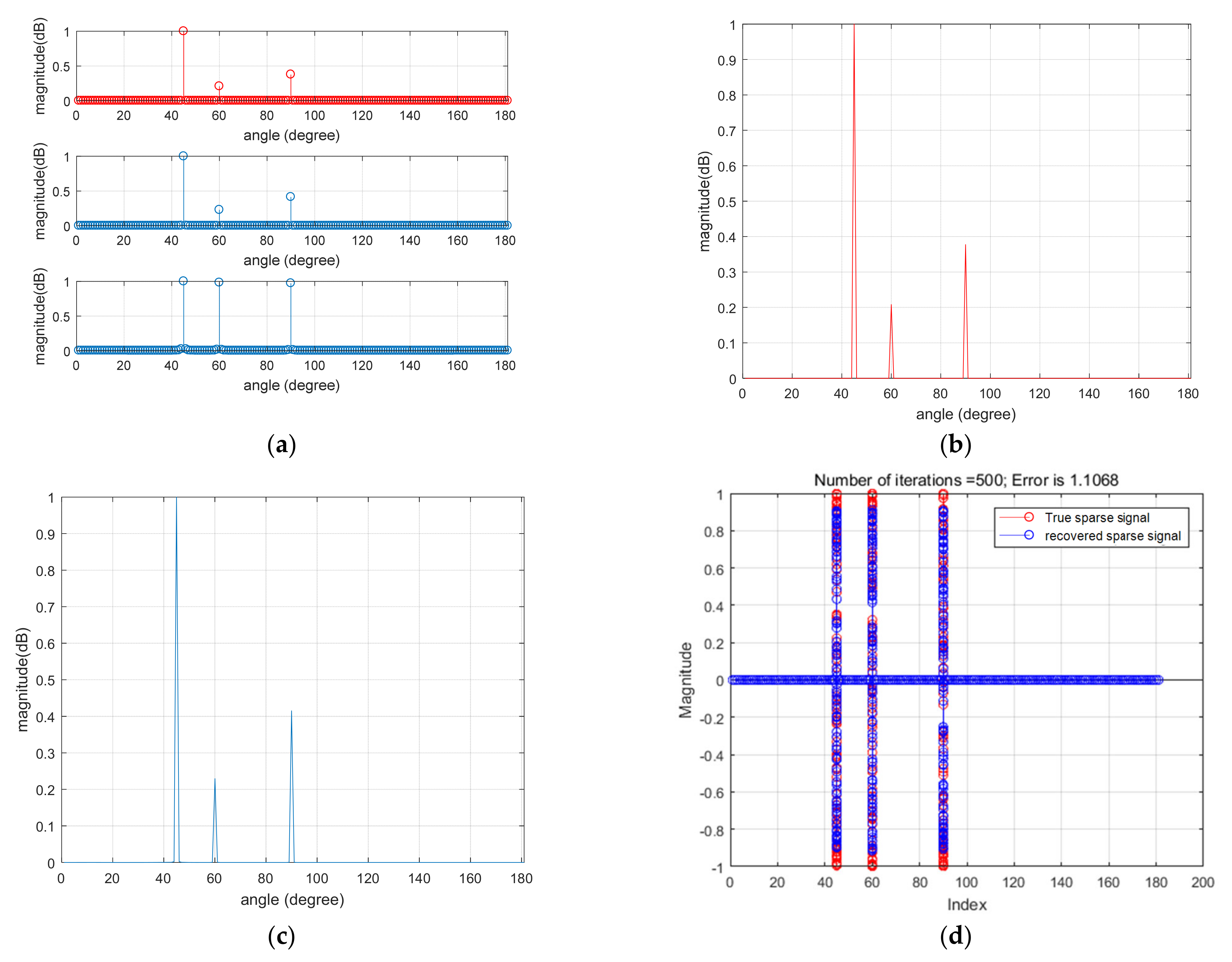
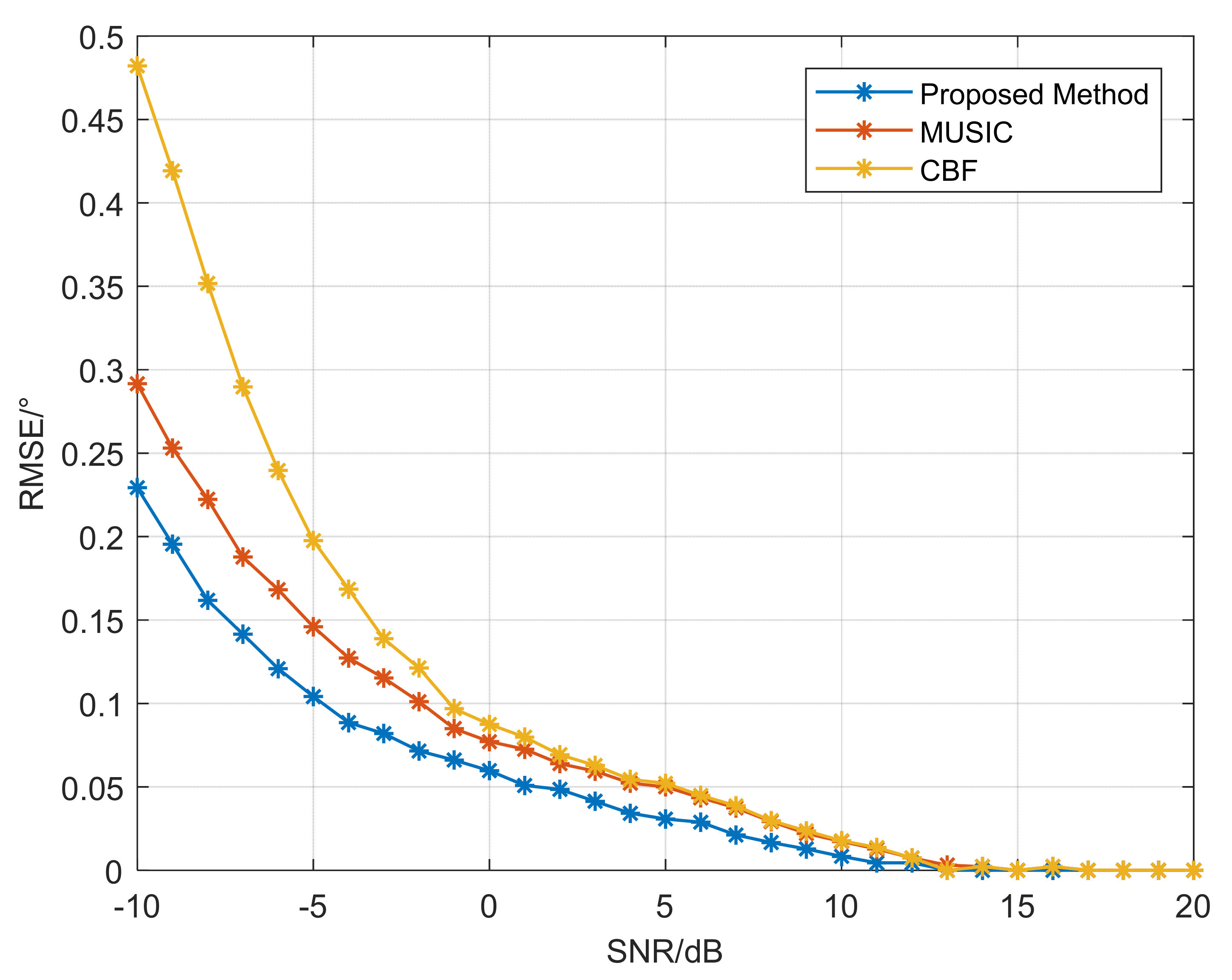
In this article, a high robustness underwater target estimation technique based on variational sparse Bayesian is put forward by studying and analyzing the sparse prior assumption characteristics of the signal. The method models the observed signal by modeling the pulse noise, completes the derivation of the conditional distribution of the observed variables and the prior distribution of the sparse signal, and then combines the approximate posterior distribution obtained by the VB method to obtain the recovered sparse signal, thereby reducing the impact of pulse noise on the estimation system. Finally, the performance of the aforementioned method was validated through simulation experiments.
2. Materials and Methods
2.1. Uniform Linear Array Signal Model
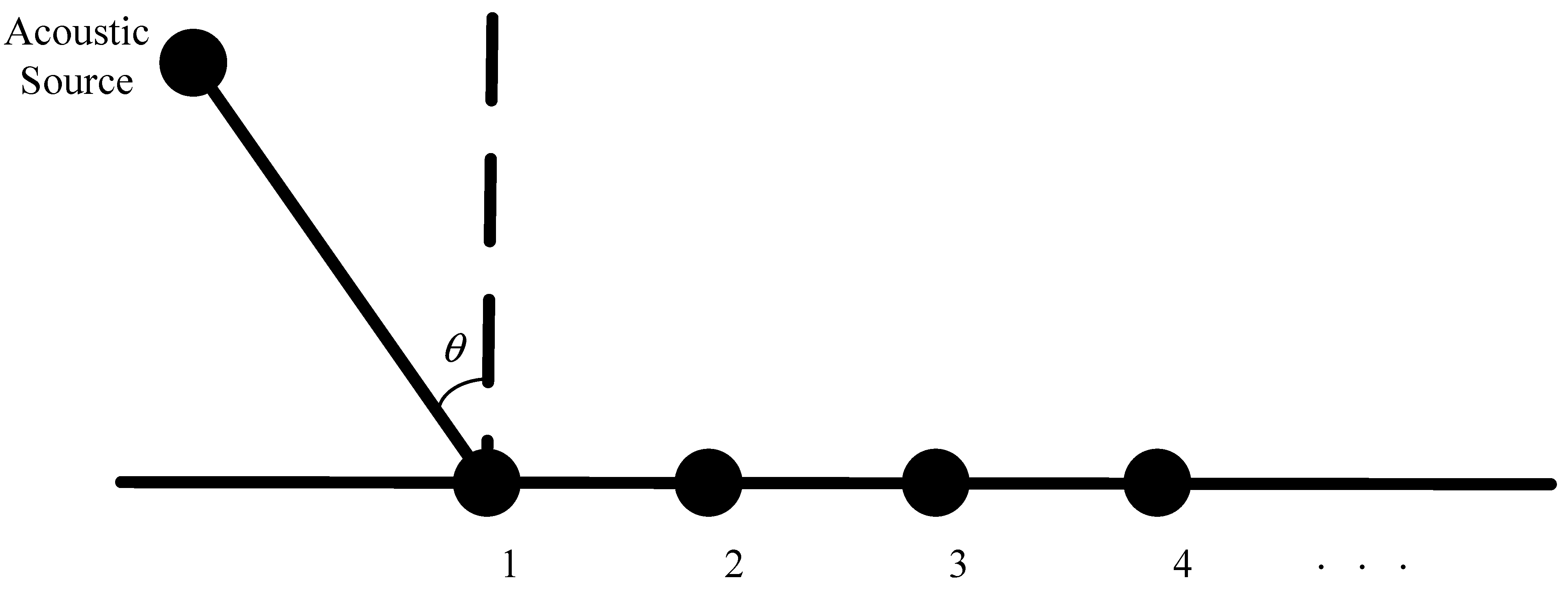
The linear array model is a fundamental mathematical framework for addressing the problem of sound source direction estimation. The model posits the existence of a linear array composed of multiple small sound sources, each of which continuously emits the same sound wave signal. These sound waves propagate through distinct paths to reach the receiving array, where the signal measured by each receiving element is expressed as a weighted sum of the signals stemming from each emitting source. More specifically, the linear array model comprises a transmit array and a receive array. Each sound-emitting source within the transmit array emits identical sound wave signals, which subsequently arrive at different receiving elements in the receive array via various propagation paths. The signal measured by each receiving element in the receive array is then computed as a weighted sum of the signals originating from the sound-emitting sources. These weighting coefficients reflect the path delay and attenuation factors experienced by the sound wave signal as it travels from the emitting source to the receiving element. Through the processing of signals within the linear array model, the direction of the sound source can be estimated. This involves calculating key parameters, such as the time delay and phase difference between individual receiving elements within the receiving array. Hence, the linear array model finds extensive applications in fields such as sound source direction estimation, sound beamforming, and signal source separation.
Consider an M-element ULA, the observation vector of the array can be defined as:
Here,
represents independent identically distributed Gaussian white noise. The array manifold matrix is denoted by
and denoted as
. The matrix
A of size
M ×
N represents the phase information of the array, where
N is the number of signal sources, and
M is the number of sensors.
The covariance matrix for the array output is defined as follows:
In this equation,
.
In practical applications, the correlation matrix is commonly used to estimate the output covariance matrix of the array. The correlation matrix is represented as follows:
In order to explain the principle of ULA more clearly, it can be explained in more detail in
Figure 1.
2.2. Pulse Noise Distribution Model—Student-t Distribution
In this section, we will present an exposition on the Student-t distribution from three perspectives: origin, definition, and frequency spectrum. Regarding the parameter settings of the noise model in the frequency spectrum section, we will adopt the parameters used in the experiment described in this article as the standard. The primary objective is to provide a more intuitive illustration of the advantages of replacing pulse noise with the Student-t distribution model.
The main objective of array signal processing is to effectively remove noise from noisy observation data, thereby enabling the accurate recovery of the original signal and extraction of desired information. In many areas of array signal processing, narrowband signal models are commonly assumed, and noise is modeled as following a Gaussian distribution due to the fact that the Gaussian distribution satisfies the central limit theorem and has finite second-order and higher-order statistics. Additionally, signal characteristics can be represented by the mean and variance at any time. However, in real-world experimental environments, many types of noise do not adhere to a Gaussian distribution model. Such noises typically exhibit instantaneous pulse characteristics and more frequent abnormal data compared to Gaussian noise. Therefore, using a Gaussian distribution model to replace the noise model is not a realistic approach. For instance, if pulse noise is present in the DOA estimation environment, the noise distribution would have a heavy tail and a distribution with a heavier tail would be required to replace the Gaussian distribution.
Pulse noise models can be classified into two categories based on their generation mechanism: real physical statistical models and theoretical analytical models. Compared to physical statistical models, theoretical analytical models have relatively fixed mathematical expressions, which makes them more convenient for theoretical analysis. In the field of DOA estimation in the pulse environment, three models have been widely used, including the mixed Gaussian distribution model, the Alpha stable distribution model, and the Student-t distribution model. This paper primarily models pulse noise using the Student-t distribution, and the fundamental concepts of the Student-t distribution will be elaborated in detail below.
Gosset was a quality control officer at a brewery in 1908 when he discovered and proposed the Student-t distribution. At that time, he needed to study the variability of beer brewing in small sample sizes. However, since the data samples that he studied were very small, he could not use a traditional normal distribution for statistical analysis. To remedy this issue, Gosset examined the distribution of the population mean given the sample mean and sample standard deviation. He discovered that if the sample came from a normal distribution, the difference between the sample mean and the population mean could be described by a new distribution, which was later named the Student-t distribution. Gosset initially dubbed this distribution the “distribution of errors” because it was used to describe the error between the sample mean and the population mean. Later, the Student-t distribution became widely used in statistics, and it was named after Gosset’s pen name, “Student.” The Student-t distribution is a probability distribution that is commonly utilized to model data with heavy tails, i.e., tail probabilities that are significantly higher than those of a normal distribution.
The model of the Student-t distribution can be defined as follows:
where
is the average of the
M-dimensional vector,
,
denotes the precision matrix, and
denotes the degree of freedom (DOF) parameter. The decay becomes slower as the DOF decreases. When the degrees of freedom decrease, the shape of the Student-
t distribution changes, with the peak of the probability density function becoming lower and the tails becoming thicker. This makes it better suited for describing pulse noise. In order to explain the student’s t-distribution more clearly, we did a simple simulation experiment and obtained the results shown in
Figure 2.
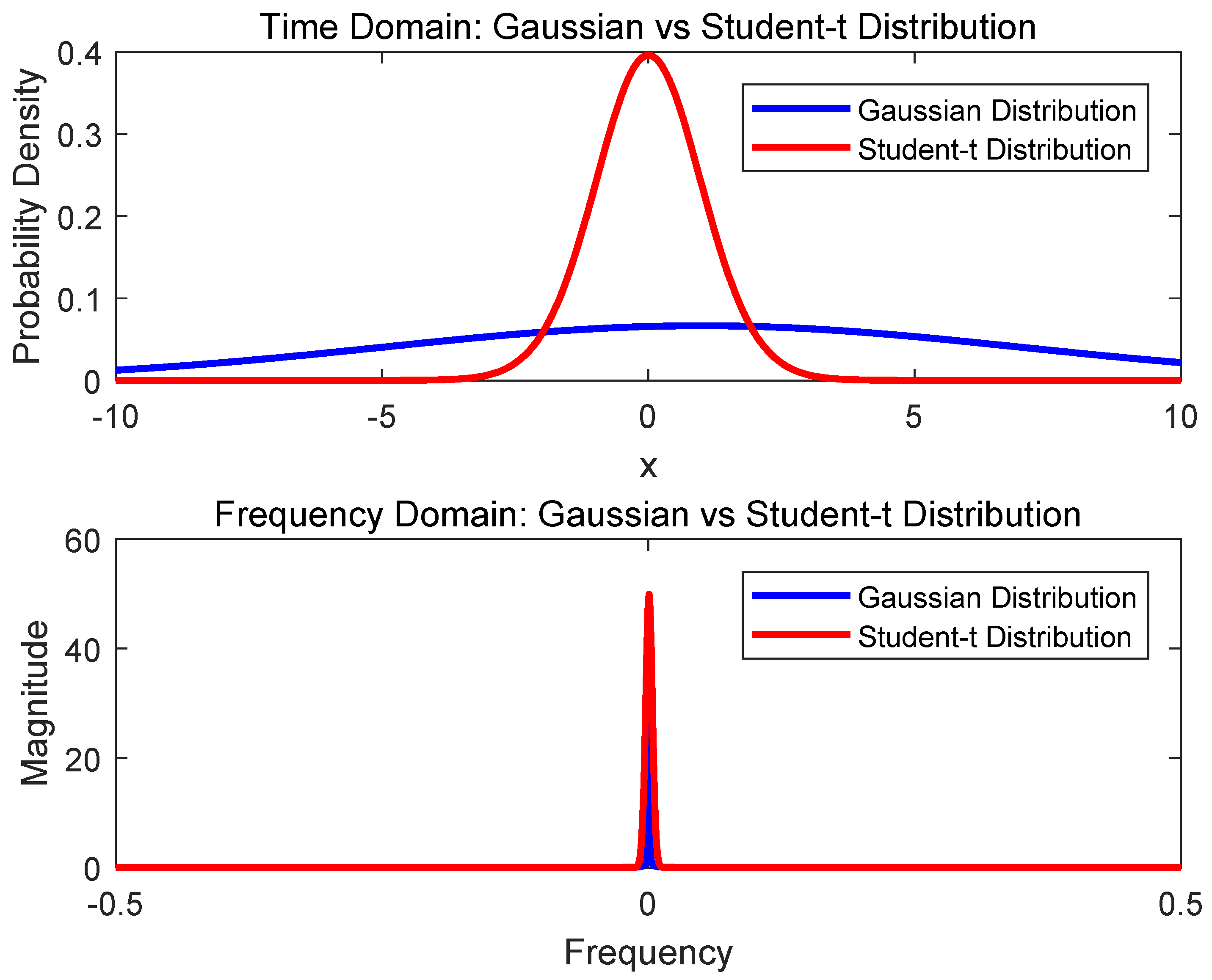
This experiment was mainly used to plot the time-domain and frequency-domain graphs of the Gaussian distribution and Student-t distribution. We first set three parameters: mean = 1, standard deviation = 6, and degrees of freedom = 30. Then, it generated an x-axis vector containing 1000 points using the “linspace” function, used to represent the continuous variable, x, in the time-domain. Next, the probability density functions of the Gaussian distribution and Student-t distribution were calculated to generate the time-domain graphs of the two distributions. The program used the “plot” function to plot the time-domain graphs of the two distributions.
The next part of the experiment was used to plot the frequency-domain graphs of the Gaussian distribution and Student-t distribution. The experiment first used the “fft” function to calculate the Fourier transform of the time-domain graph and used the “fftshift” function to center the result. Then, we used the “linspace” function to generate the continuous variable “freq” in the frequency domain and used the “plot” function to plot the frequency-domain graphs of the two distributions and added axis labels, legends, and titles.
When plotting the graphs, the program used the “hold on” function to make both graphs of the distributions plotted on the same figure. This is performed to better compare the differences between the two distributions.
In the present illustration, it can be observed that the time-domain spectrum of the Student-t distribution exhibits a shape similar to that of the Gaussian distribution. However, compared to the Gaussian distribution, under the parameters set in this experiment, the Student-t distribution is better able to model noise with local outliers, such as impulse noise. Additionally, in the frequency-domain spectrum, the frequency response of the Student-t distribution is smoother than that of the Gaussian distribution. That is, its amplitude changes more slowly with frequency, which also helps to reduce the impact of impulse noise in the high-frequency range. Therefore, in this paper, the Student-t distribution is adopted as the model for impulse noise.
2.3. Graphical Models
The interaction between entities involved in a probabilistic system is represented by a graphical model, where nodes represent random variables, and arrows depict dependencies between variables [
36]. A directed arrow from node A to node B indicates that the value of random variable B depends on the value of random variable A. Graphical models can be categorized into directed graph models and undirected graph models [
15,
36]. This paper focuses on directed graph models, also known as Bayesian network graphical models [
37].
The definition of a directed graph model is as follows:
Given the conditional probability distribution of each node in the graphical model, the formula for calculating the joint distribution over all variable sets is
[
38].
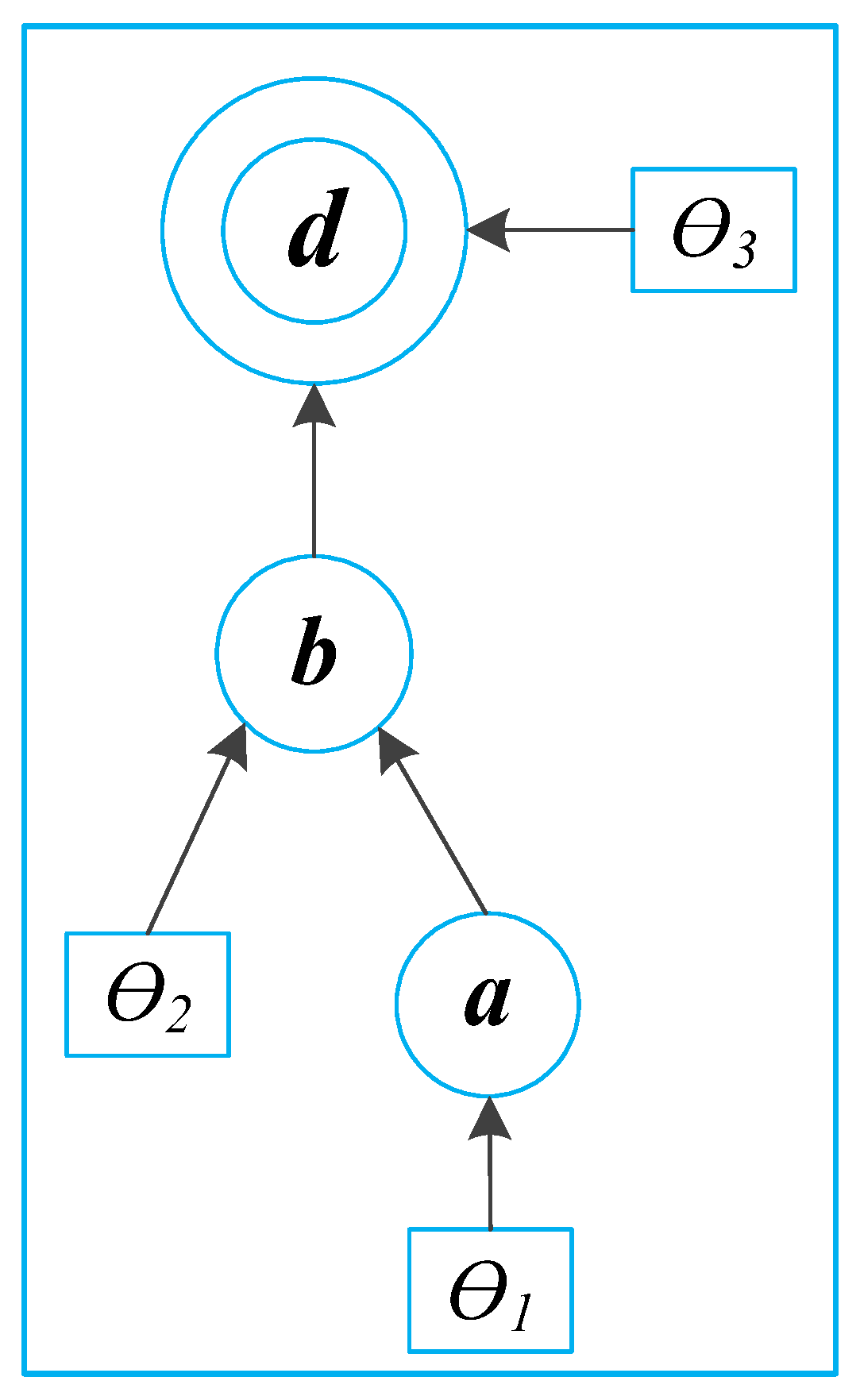
Figure 3 shows an example of a directed graph model. In this model,
a,
b, and
d represent random variables, and each node in the graphical model represents a conditional probability density. If the probability density of the node is unknown, it can be parameterized by a set of parameters. The joint distribution of the probability density is then expressed as follows:
The above expression can be simplified by considering the independence implied by the structure of the graphical model. Generally speaking, in the graphical model, each node is independent of its higher-level nodes. Therefore, expression (6) can be simplified as follows:
Another function of the graphical model is to arbitrarily distinguish random variables into those with directly observed results and those with hidden random variables without directly observed results [
39]. In addition, the graphical model can be divided into parameterized graphical models and non-parameterized graphical models. If it is a parameterized graphical model, the parameters will appear in the conditional probability distribution of some nodes; that is, the probability models of these distributions are parameterized probability models.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}