

A High-Performance Automated Large-Area Land Cover Mapping Framework


Abstract
1. Introduction
2. Materials and Methods
2.1. Experimental Data
2.1.1. Landsat8
2.1.2. GDEM
2.1.3. GLC Products
2.2. Framework Design
2.2.1. Stage 1: Automatic Sample Generation
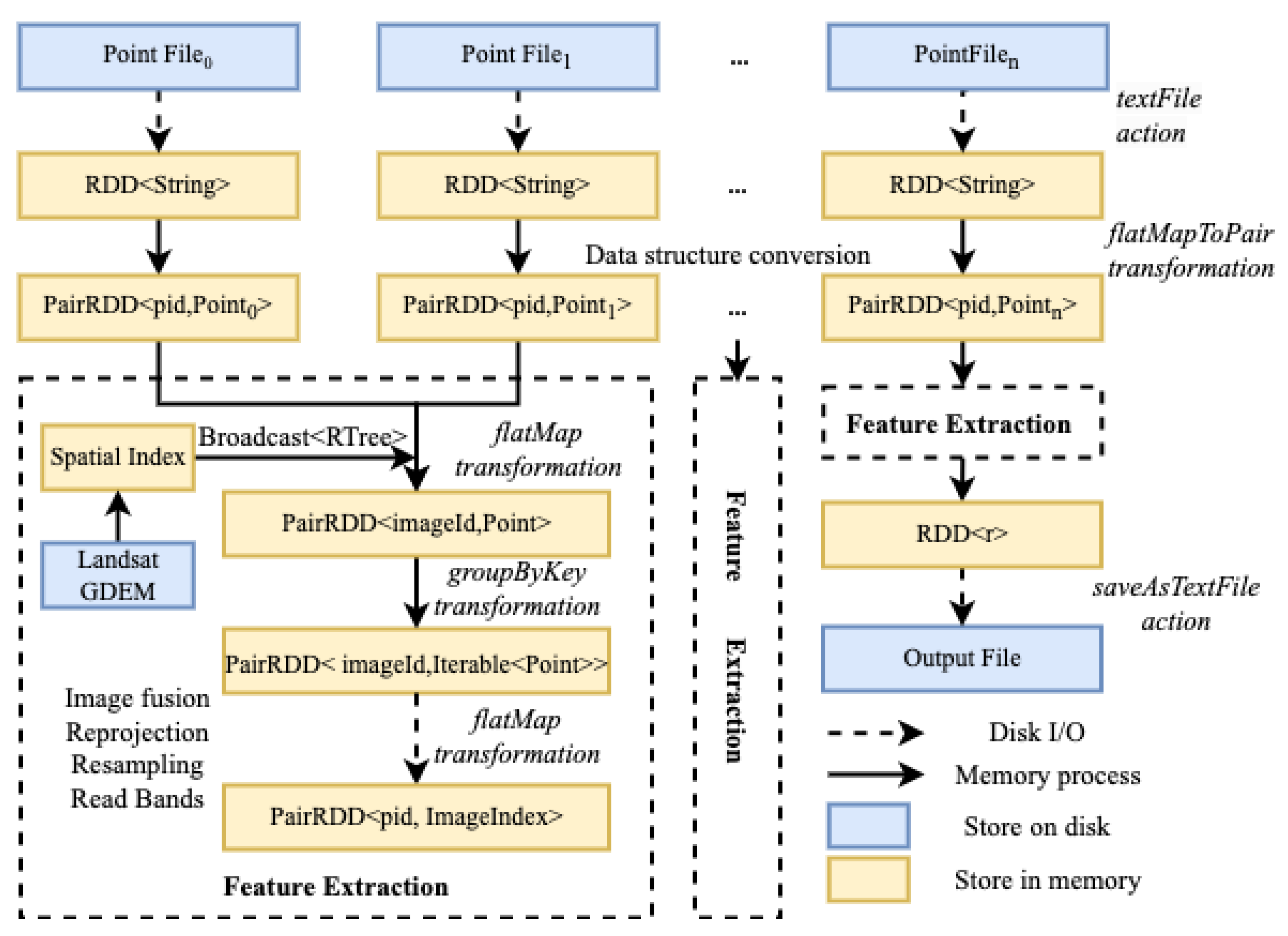
2.2.2. Stage 2: Parallel Matching of Samples and Images
- Read all the center point data to be matched into memory; use the longitude and latitude of the point to form a unique identifier pid; read its spatial and attribute information to form a spatial point object; and compose a tuple <pid, Point>;
- Read the Landsat image metadata information; use the boundary coordinates to construct a spatial index STRtree; and use the broadcast variable in Spark to transmit it to each node. The broadcast variable will save a copy on each node, thus saving the network transmission cost for multiple calls;
- Distribute the computing tasks. To address the issue of data skew resulting from unequal allocation of images to different computing nodes during task distribution, a custom partitioning strategy was developed, and the groupByKey operator was used to allocate data evenly across all computing nodes as much as possible;
- For each image, parallel operations are performed using GDAL. Then, the image is subjected to image fusion, reprojection, and resampling, and the row and column numbers of the sample point’s longitude and latitude on the remote sensing image are calculated. If a sample is covered by clouds for most of the year or its quality is poor, it is discarded. The feature indicators are calculated for samples that meet the quality criteria, and both the data, along with their corresponding match results, are outputted.
2.2.3. Stage 3: Regional Adaptive Classification Model
2.2.4. Stage 4: Parallel Mosaicking of Large-Area Classification Results
- Set the spatial extent, resolution, number of bands, and other parameters for different application scenarios. Then, create blank map sheets. For example, a latitude and longitude range of 10° × 10° corresponds to a grid of geographic extent of approximately 1100 km in length and width. If the sub-image resolution is set to 100 m, and each sub-image size is 256 × 256 pixels, then there are approximately 44 × 44 sub-images in this spatial range. The metadata information of the sub-images is stored in binary format, including spatial location and description, and files are created based on whether they already exist;
- Read the image information, and use the flatMap operator to match the spatial position of the sub-image with the metadata of the remote sensing image to establish a spatial correspondence. In this step, the key-value pairs of SubId and remote sensing images are obtained;
- Use the unique identification code pertaining to the SubId of the sub-image as the key to call the groupByKey operator to obtain the complete set of remote sensing images corresponding to each sub-image; the task is then distributed. Each task unit performs the sub-image filling task;
- In each task computing unit, perform coordinate transformation and row/column calculation for the image classification result, and fill in the corresponding pixel points for the sub-image. If no additional settings are made, the result from the latest remote sensing image corresponding to the sub-image is selected for writing.
2.3. HALF Workflow
2.4. Experimental Environment
3. Results
3.1. Model Performance Testing
3.2. Automatically Generated Samples
3.3. Performance of Sample and Image Matching
3.4. Performance of Large-Area Classification Result Mosaicking
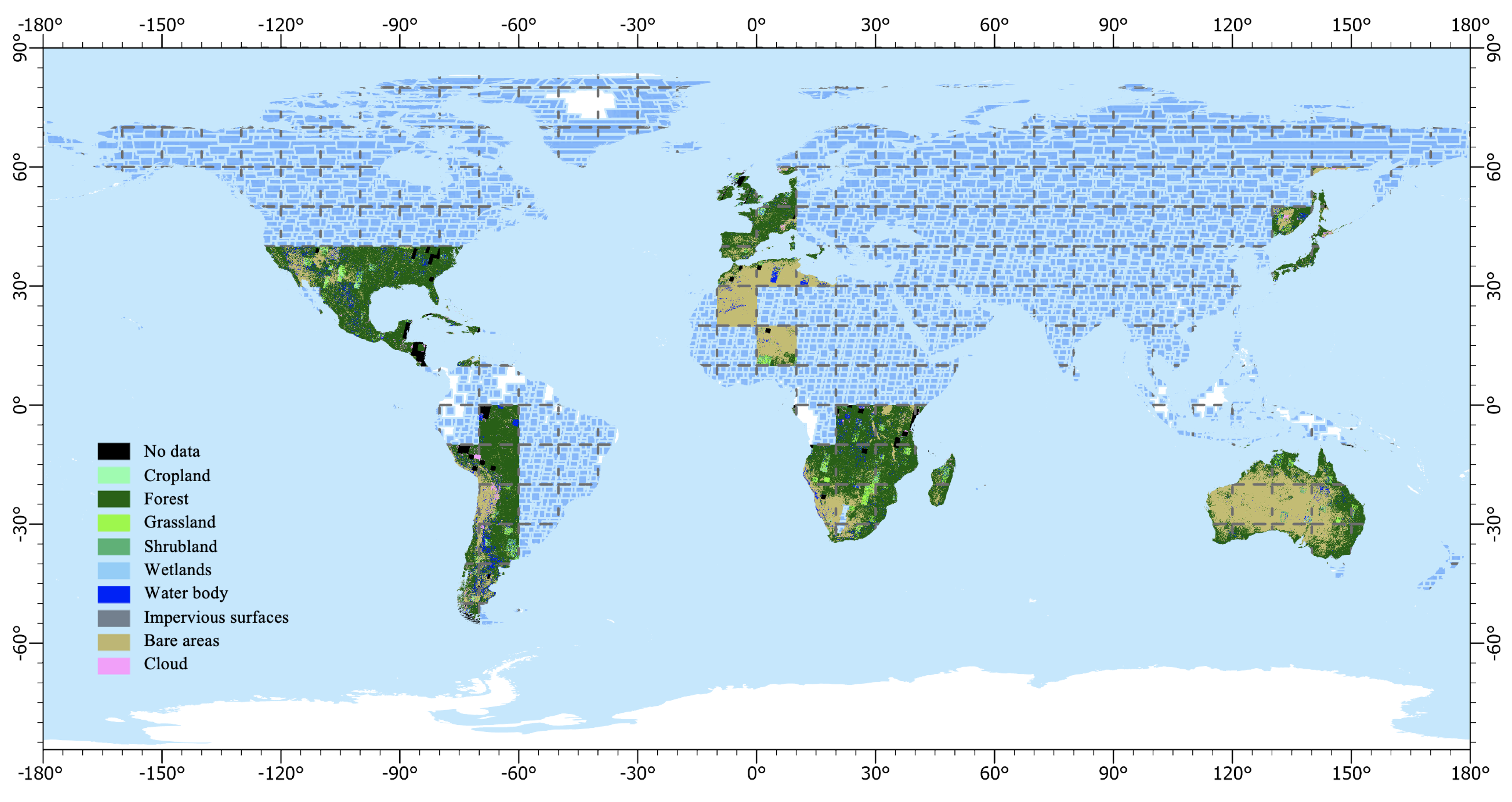
3.5. Result of Mapping
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sterling, S.M.; Ducharne, A.; Polcher, J. The impact of global land-cover change on the terrestrial water cycle. Nat. Clim. Chang. 2013, 3, 385–390. [Google Scholar] [CrossRef]
- Feddema, J.J.; Oleson, K.W.; Bonan, G.B.; Mearns, L.O.; Buja, L.E.; Meehl, G.A.; Washington, W.M. The Importance of Land-Cover Change in Simulating Future Climates. Science 2005, 310, 1674–1678. [Google Scholar] [CrossRef]
- Ban, Y.; Gong, P.; Giri, C. Global land cover mapping using Earth observation satellite data: Recent progresses and challenges. ISPRS J. Photogramm. Remote Sens. 2015, 103, 1–6. [Google Scholar] [CrossRef]
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Yu, L.; Du, Z.; Dong, R.; Zheng, J.; Tu, Y.; Chen, X.; Hao, P.; Zhong, B.; Peng, D.; Zhao, J.; et al. FROM-GLC Plus: Toward near real-time and multi-resolution land cover mapping. Giscience Remote Sens. 2022, 59, 1026–1047. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Gray, J.M.; Abercrombie, S.P.; Friedl, M.A. Hierarchical mapping of annual global land cover 2001 to present: The MODIS Collection 6 Land Cover product. Remote Sens. Environ. 2019, 222, 183–194. [Google Scholar] [CrossRef]
- Buchhorn, M.; Lesiv, M.; Tsendbazar, N.E.; Herold, M.; Bertels, L.; Smets, B. Copernicus Global Land Cover Layers—Collection 2. Remote Sens. 2020, 12, 1044. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- ESA WorldCover 10 m 2020 v100. Available online: https://zenodo.org/record/7254221 (accessed on 7 June 2023).
- Li, X.; Gong, P. An “exclusion-inclusion” framework for extracting human settlements in rapidly developing regions of China from Landsat images. Remote Sens. Environ. 2016, 186, 286–296. [Google Scholar] [CrossRef]
- Zhang, H.K.; Roy, D.P. Using the 500m MODIS land cover product to derive a consistent continental scale 30m Landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Radoux, J.; Lamarche, C.; Bogaert, E.V.; Bontemps, S.; Brockmann, C.; Defourny, P. Automated Training Sample Extraction for Global Land Cover Mapping. Remote Sens. 2014, 6, 3965–3987. [Google Scholar] [CrossRef]
- Yu, L.; Wang, J.; Li, X.; Li, C.; Zhao, Y.; Gong, P. A multi-resolution global land cover dataset through multisource data aggregation. Sci. China Earth Sci. 2014, 57, 2317–2329. [Google Scholar] [CrossRef]
- Wessels, K.J.; Van den Bergh, F.; Roy, D.P.; Salmon, B.P.; Steenkamp, K.C.; MacAlister, B.; Swanepoel, D.; Jewitt, D. Rapid Land Cover Map Updates Using Change Detection and Robust Random Forest Classifiers. Remote Sens. 2016, 8, 888. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Xie, S.; Gao, Y. Fine Land-Cover Mapping in China Using Landsat Datacube and an Operational SPECLib-Based Approach. Remote Sens. 2019, 11, 1056. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Chen, X.; Gao, Y.; Xie, S.; Mi, J. GLC_FCS30: Global land-cover product with fine classification system at 30m using time-series Landsat imagery. Earth Syst. Sci. Data 2021, 13, 2753–2776. [Google Scholar] [CrossRef]
- Venter, Z.S.; Barton, D.N.; Chakraborty, T.; Simensen, T.; Singh, G. Global 10 m Land Use Land Cover Datasets: A Comparison of Dynamic World, World Cover and Esri Land Cover. Remote Sens. 2022, 14, 4101. [Google Scholar] [CrossRef]
- Shirani, K.; Solhi, S.; Pasandi, M. Automatic Landform Recognition, Extraction, and Classification using Kernel Pattern Modeling. J. Geovis. Spat. Anal. 2023, 7, 2. [Google Scholar] [CrossRef]
- Gong, P.; Yu, L.; Li, C.; Wang, J.; Liang, L.; Li, X.; Ji, L.; Bai, Y.; Cheng, Y.; Zhu, Z. A new research paradigm for global land cover mapping. Ann. GIS 2016, 22, 87–102. [Google Scholar] [CrossRef]
- Camargo, A.; Schultz, R.R.; Wang, Y.; Fevig, R.A.; He, Q. GPU-CPU implementation for super-resolution mosaicking of Unmanned Aircraft System (UAS) surveillance video. In Proceedings of the 2010 IEEE Southwest Symposium on Image Analysis & Interpretation (SSIAI), Chicago, IL, USA, 23–25 May 2010; pp. 25–28. [Google Scholar] [CrossRef]
- Ma, Y.; Song, J.; Zhang, Z. In-Memory Distributed Mosaicking for Large-Scale Remote Sensing Applications with Geo-Gridded Data Staging on Alluxio. Remote Sens. 2022, 14, 5987. [Google Scholar] [CrossRef]
- Zhang, J.; Ke, T.; Sun, M. Parallel processing of mass aerial digital images base on cluster computer—The application of parallel computing in aerial digital photogrammetry. Comput. Eng. Appl. 2008, 44, 12–15. [Google Scholar] [CrossRef]
- Chen, C.; Tan, Y.; Li, H.; Gu, H. A Fast and Automatic Parallel Algorithm of Remote Sensing Image Mosaic. Microelectron. Comput. 2011, 28, 59–62. [Google Scholar]
- Ma, Y.; Wang, L.; Zomaya, A.Y.; Chen, D.; Ranjan, R. Task-Tree Based Large-Scale Mosaicking for Massive Remote Sensed Imageries with Dynamic DAG Scheduling. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 2126–2137. [Google Scholar] [CrossRef]
- Jing, W.; Huo, S.; Miao, Q.; Chen, X. A Model of Parallel Mosaicking for Massive Remote Sensing Images Based on Spark. IEEE Access 2017, 5, 18229–18237. [Google Scholar] [CrossRef]
- Rabenseifner, R.; Hager, G.; Jost, G. Hybrid MPI/OpenMP Parallel Programming on Clusters of Multi-Core SMP Nodes. In Proceedings of the 2009 17th Euromicro International Conference on Parallel, Distributed and Network-based Processing, Washington, DC, USA, 18–20 February 2009; pp. 427–436. [Google Scholar] [CrossRef]
- Apache Hadoop. Available online: https://hadoop.apache.org (accessed on 20 April 2023).
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 95. [Google Scholar]
- Garland, M.; Le Grand, S.; Nickolls, J.; Anderson, J.; Hardwick, J.; Morton, S.; Phillips, E.; Zhang, Y.; Volkov, V. Parallel Computing Experiences with CUDA. IEEE Micro 2008, 28, 13–27. [Google Scholar] [CrossRef]
- Eldawy, A.; Mokbel, M. SpatialHadoop: A MapReduce framework for spatial data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, ICDE 2015. IEEE Computer Society, Proceedings—International Conference on Data Engineering, Seoul, Korea, 13–16 April 2015; pp. 1352–1363. [Google Scholar] [CrossRef]
- Aji, A.; Wang, F.; Vo, H.; Lee, R.; Liu, Q.; Zhang, X.; Saltz, J. Hadoop GIS: A High Performance Spatial Data Warehousing System over Mapreduce. Proc. VLDB Endow. 2013, 6, 1009–1020. [Google Scholar] [CrossRef]
- Shaikh, S.A.; Mariam, K.; Kitagawa, H.; Kim, K. GeoFlink: A Framework for the Real-time Processing of Spatial Streams. arXiv 2004, arXiv:2004.03352. [Google Scholar]
- Kopp, S.; Becker, P.; Doshi, A.; Wright, D.J.; Zhang, K.; Xu, H. Achieving the Full Vision of Earth Observation Data Cubes. Data 2019, 4, 94. [Google Scholar] [CrossRef]
- Nüst, D.; Konkol, M.; Pebesma, E.; Kray, C.; Schutzeichel, M.; Przibytzin, H.; Lorenz, J. Opening the publication process with executable research compendia. D-Lib Mag. 2017, 23, 451. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, M.; Huang, Q.; Yue, P. A Container-Based Service Publishing Method for Heterogeneous Geo-processing Operators. J. Geomat. 2021, 46, 174–177. [Google Scholar] [CrossRef]
- Huffman, J.; Forsberg, A.; Loomis, A.; Head, J.; Dickson, J.; Fassett, C. Integrating advanced visualization technology into the planetary Geoscience workflow. Planet. Space Sci. 2011, 59, 1273–1279. [Google Scholar] [CrossRef]
- Yue, P.; Zhang, M.; Tan, Z. A geoprocessing workflow system for environmental monitoring and integrated modelling. Environ. Model. Softw. 2015, 69, 128–140. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, H.; Xiao, L.; Jing, Q.; You, L.; Ding, Y.; Hu, M.; Devlin, A.T. Versioned geoscientific workflow for the collaborative geo-simulation of human-nature interactions—A case study of global change and human activities. Int. J. Digit. Earth 2021, 14, 510–539. [Google Scholar] [CrossRef]
- Gesch, D.; Oimoen, M.; Danielson, J.; Meyer, D. Validation of the aster global digital elevation model version 3 over the conterminous united states. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B4, 143–148. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Foody, G.M.; Arora, M.K. An evaluation of some factors affecting the accuracy of classification by an artificial neural network. Int. J. Remote Sens. 1997, 18, 799–810. [Google Scholar] [CrossRef]
- Du, P.; Lin, C.; Chen, Y.; Wang, X.; Zhang, W.; Guo, S. Training Sample Transfer Learning from Multi-temporal Remote Sensing Images for Dynamic and Intelligent Land Cover Classification. J. Tongji Univ. (Nat. Sci. Ed.) 2022, 50, 955–966. [Google Scholar] [CrossRef]
- Huang, Y.; Liao, S. Automatic collection for land cover classification based on multisource datasets. J. Remote Sens. 2017, 21, 757–766. [Google Scholar] [CrossRef]
- Liu, K.; Yang, X.; Zhang, T. Automatic Selection of Clasified Samples with the Help of Previous Land Cover Data. J. -Geo-Inf. Sci. 2012, 14, 507–513. [Google Scholar] [CrossRef]
- Tianjun, W.; Jiancheng, L.; Liegang, X.; Haiping, Y.; Zhanfeng, S.; Xiaodong, H. An Automatic Sample Collection Method for Object-oriented Classification of Remotely Sensed Imageries Based on Transfer Learning. Acta Geod. Cartogr. Sin. 2014, 43, 908. [Google Scholar] [CrossRef]
- Anderson, J.R. A Land Use and Land Cover Classification System for Use with Remote Sensor Data; US Government Printing Office: Washington, DC, USA, 1976; Volume 964.
- Gregorio, A.D.; Jansen, L.J.M. Land Cover Classification System (LCCS): Classification Concepts and User Manual; FAO: Geneva, Switzerland, 2000; ISBN 92-5-104216-0. [Google Scholar]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote. Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef]
- Chaaban, F.; Khattabi, J.E.; Darwishe, H. Accuracy Assessment of ESA WorldCover 2020 and ESRI 2020 Land Cover Maps for a Region in Syria. J. Geovisualization Spat. Anal. 2022, 6, 31. [Google Scholar] [CrossRef]
- Apache Airflow. Available online: https://airflow.apache.org (accessed on 20 April 2023).
- Amstutz, P.; Mikheev, M.; Crusoe, M.R.; Tijanić, N.; Lampa, S. Existing Workflow Systems. Available online: https://s.apache.org/existing-workflow-systems. (accessed on 18 April 2023).
- Leipzig, J. A review of bioinformatic pipeline frameworks. Briefings Bioinform. 2017, 18, 530–536. [Google Scholar] [CrossRef] [PubMed]
- Schultes, E.; Wittenburg, P. FAIR Principles and Digital Objects: Accelerating Convergence on a Data Infrastructure; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 3–16. [Google Scholar]
- Common Workflow Language. Available online: http://www.commonwl.org (accessed on 20 April 2023).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| USGS [46] | FAO [47] | FROM_GLC | GlobalLand30 | GLC_FCS |
|---|---|---|---|---|
| 1972 | 1996 | 2013 | 2014 | 2021 |
| Forest | Cultivated and Managed Terrestrial Areas | Forest | Forest | Forest |
| Agricultural | Natural and Semi-Natural Terrestrial Vegetation | Crop | Cultivated land | Cropland |
| Cultivated Aquatic or Regularly Flooded Areas | Shrub | Shrubland | Shrubland | |
| Range | Natural and Semi-Natural Aquatic or Regularly Flooded Vegetation | Grass | Grassland | Grassland |
| Wetlands | Wetland | Wetland | Wetlands | |
| Urban or Built-Up | Artificial Surfaces and Associated Areas | Impervious | Artificial Surfaces | Impervious Surfaces |
| Barren | Bare Areas | Bareland | Bareland and Tundra | Bare Areas |
| Water | Artificial Waterbodies, Snow and Ice | Water | Water Bodies | Water Body |
| Perennial Snow and Ice | Natural Waterbodies, Snow and Ice | Snow/Ice | Permanent Snow/Ice | Permanent Ice and Snow |
| Tundra | Tundra | |||
| Cloud |
| Images | Description | Base Images | Models |
|---|---|---|---|
| landuse-py | Used to run models written in Python | python:3.8.3 | Sample Generation Classifier Training Image Classification Prediction |
| gdal-spark | Used to run models written in Java Spark | osgeo/gdal:ubuntu-full-3.6.3 | Sample–Image Matching Image Mosaicking |
| pg12-citus-postgis | Used to storage metadata and spatial queries | postgres:12.14-alpine3.17 | Building Spatial Index Spatial Querying |
| end-point | Used to launch the back-end project and provide network services | java:openjdk-8 | Back-end Project |
| Feature | Data Source | Characteristic |
|---|---|---|
| Spatial Characteristics | Landsat | Longitude and Latitude |
| Temporal Characteristics | Image Acquisition Time | |
| Spectral Characteristics | Band1, Band2…Band7 | |
| RS Index | NDVI, NDWI, EVI, NBR | |
| Topographic Feature | DEM | DEM, Slope, Aspect |
| Land Cover Type | GLC | First-Level Type |
| Stages | Time Cost(s) | GDAL | HALF |
|---|---|---|---|
| 1 | Build spatial index | 0.7 | 0.7 |
| 2 | Read data and create spatial relationships | 4.2 | 2.6 |
| 3 | Distribute tasks | / | 4.9 |
| 4 | Compute feature values | 174.1 | 24.6 |
| 5 | Total | 179.2 | 32.8 |
| Region | Spatial Extent | Number of Images | Number of Samples | Mosaic Time (s) | Match Time (s) |
|---|---|---|---|---|---|
| Region 1 | (50°S–40°S, 70°W–60°W) | 43 | 9,276,097 | 361 | 166.12 |
| Region 2 | (40°S–30°S, 70°W–60°W) | 64 | 7,557,768 | 481 | 204.07 |
| Region 3 | (40°S–30°S, 140°E–150°E) | 59 | 6,770,182 | 468 | 31.20 |
| Region 4 | (30°S–20°S, 20°E–30°E) | 64 | 3,663,073 | 413 | 99.72 |
| Region 5 | (30°S–20°S, 140°E–150°E) | 64 | 5,716,990 | 408 | 233.32 |
| Region 6 | (30°S–20°S, 130°E–140°E) | 63 | 6,657,017 | 417 | 109.19 |
| Region 7 | (20°S–10°S, 110°E–120°E) | 7 | 6,698,112 | 16 | 175.16 |
| Region 8 | (20°S–10°S, 20°E–30°E) | 63 | 1,675,984 | 401 | 182.95 |
| Region 9 | (20°S–10°S, 30°E–40°E) | 55 | 4,159,308 | 324 | 80.81 |
| Region 10 | (−10°S–0°N, 40°E–50°E) | 13 | 11,522,471 | 72 | 169.84 |
| Region 11 | (30°N–40°N, 80°W–70°W) | 31 | 16,008,303 | 222 | 143.02 |
| Region 12 | (0°N–10°N, 30°E–40°E) | 62 | 1,022,583 | 359 | 119.86 |
| Region 13 | (10°N–20°N, 80°W–70°W) | 35 | 9,698,301 | 250 | 134.51 |
| Region 14 | (20°N–30°N, 90°W–80°W) | 39 | 12,549,213 | 253 | 146.13 |
| Region 15 | (20°N–30°N, 80°W–70°W) | 34 | 11,688,087 | 224 | 153.62 |
| Region 16 | (30°N–40°N, 90°W–80°W) | 63 | 12,793,479 | 439 | 259.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Fu, Z.; Zhu, Y.; Wang, B.; Sun, K.; Zhang, F. A High-Performance Automated Large-Area Land Cover Mapping Framework. Remote Sens. 2023, 15, 3143. https://doi.org/10.3390/rs15123143
Zhang J, Fu Z, Zhu Y, Wang B, Sun K, Zhang F. A High-Performance Automated Large-Area Land Cover Mapping Framework. Remote Sensing. 2023; 15(12):3143. https://doi.org/10.3390/rs15123143
Chicago/Turabian StyleZhang, Jiarui, Zhiyi Fu, Yilin Zhu, Bin Wang, Keran Sun, and Feng Zhang. 2023. "A High-Performance Automated Large-Area Land Cover Mapping Framework" Remote Sensing 15, no. 12: 3143. https://doi.org/10.3390/rs15123143
APA StyleZhang, J., Fu, Z., Zhu, Y., Wang, B., Sun, K., & Zhang, F. (2023). A High-Performance Automated Large-Area Land Cover Mapping Framework. Remote Sensing, 15(12), 3143. https://doi.org/10.3390/rs15123143