1. Introduction
The primary production sector, especially agriculture, is pivotal in driving the global economy, mitigating rural depopulation, and fostering economic development. Therefore, European sustainability strategies emphasize the importance of digital environments and advanced technologies in the agricultural sector, particularly those aimed at reducing inputs through variable applications, ensuring production efficiency, optimizing processes, and enhancing overall sustainability [
1].
Management zones (MZs) have emerged by applying specific management strategies using the right amount of input at the right time and place [
2], being a promising solution to address significant challenges in agriculture, including minimizing inputs via variable application rates, optimizing production efficiency, streamlining processes, and bolstering overall sustainability [
1]. By establishing these zones, farmers can customize their management strategies to cater to the unique requirements of each zone, factoring in the spatial variability present within their fields. As a result, this targeted approach promotes more efficient resource utilization, ultimately supporting farming operations’ long-term sustainability and profitability. However, the delimitation of MZs in crop plots remains challenging due to the multiple factors contributing to spatial and temporal variability in the field. Factors such as soil variability (texture, structure, and water content), terrain topography (slope, orientation, and altitude), climatic conditions, crop genetic variability, or biotic influences contribute to remarkable and temporal variability in the field [
3,
4]. Despite the considerable amount of literature supporting the effectiveness of these techniques [
5,
6,
7], precision agriculture techniques can present challenges and limitations for farmers for reasons such as cultural perception, access to technology, a lack of technical knowledge on the part of farmers themselves, or the high costs of implementing this type of technology [
8].
The modernization of the agricultural sector encompasses many cutting-edge technologies beyond installing sensors in the field. These technologies are transforming agriculture by improving the efficiency and precision of farming practices. Within this wide range of technologies, we can highlight the use of remote sensors such as satellites and aerial imagery, artificial intelligence (AI), and big data to analyze large amounts of data, identify patterns, and predict variables. Cloud computing services allow the storage and processing of large volumes of data, providing greater computing capacity. In addition, nanotechnology is applied to developing new and improved chemical products. Robotics is used to automate tasks. Blockchain is used to track and verify the food supply chain. The crucial role of drones equipped with cameras and sensors for crop data collection, or the Internet of Things (IoT), is to establish a wireless connection between agricultural devices and sensors [
9,
10,
11,
12,
13,
14,
15]. These technologies aim to enhance agricultural efficiency and improve sustainability [
16,
17]. This is where precision agriculture (PA) comes into play [
18], with vegetation indices [
19] being a significant contribution to agriculture since the 1970s, as they have provided an efficient and accurate way to assess vegetation health and vigor at different spatial and temporal scales [
20].
In recent decades, remote sensing [
21] has experienced significant advancements in sensor quality [
22,
23], leading to increased image resolution and enhanced dataset availability. This progress can be attributed to various satellite sources such as Landsat 8, Sentinel 2, or RapidEye, proximity remote sensing using RGB, multispectral and hyperspectral cameras, and terrestrial laser scanners (LIDAR), among many other devices. In addition, the great relevance of unmanned aerial vehicles (UAV) and other aerial platforms such as airplanes or helicopters should be highlighted. Developing new sensors, AI, big data techniques, and cloud computing platforms [
24] will propel this trend further. Cloud computing platforms, such as Google Colab, Amazon Web Services (AWS), and Google Earth Engine (GEE) [
25], offer efficient means for storing, accessing, and analyzing datasets on powerful servers [
26]. On the other hand, machine learning (ML), which is a branch of AI [
27], has demonstrated its potential for revolutionizing the agriculture sector [
28]. ML algorithms can be broadly categorized into two main types: supervised learning (SL) and unsupervised learning (UL). SL focuses on predicting dependent variable values from independent variables [
29], while UL aims to discover information, structures, or patterns in the data [
30]. However, many agricultural plots lack crop monitoring due to factors such as limited resources, connectivity issues, a shortage of experts, or a lack of time and knowledge on the part of the farmer. This often results in missing data necessary for precision agriculture, such as yield monitor data and soil and crop moisture data. ML can address the limitations of agricultural plots by employing knowledge transfer models. These models are trained in accessible areas and then applied to hard-to-reach areas, enabling the application of ML in areas with limited resources or data availability. Another way to implement ML models in this type of plot would be by accessing and analyzing historical data, which could be used as input for model training. In addition, there would be the possibility to select a representative set of nearby plots with similar characteristics to the plot(s) with access limitations, train the models with these data, and ensure that the results and models apply to the rest of the plots. Consequently, VRAs on seeding or fertilization could be performed.
The objective of this research is to implement ML models, such as random forest (RF), support vector machine (SVM), gradient tree boosting (GTB), and classification and regression trees (CART), in conjunction with satellite data and yield monitors to identify management zones in study plots. By training these models, we aim to estimate the yield of other plots for which yield data are unavailable and automatically identify their zones. In addition, ground truth data and field yield data-based maps will validate the generated zones.
2. Materials and Methods
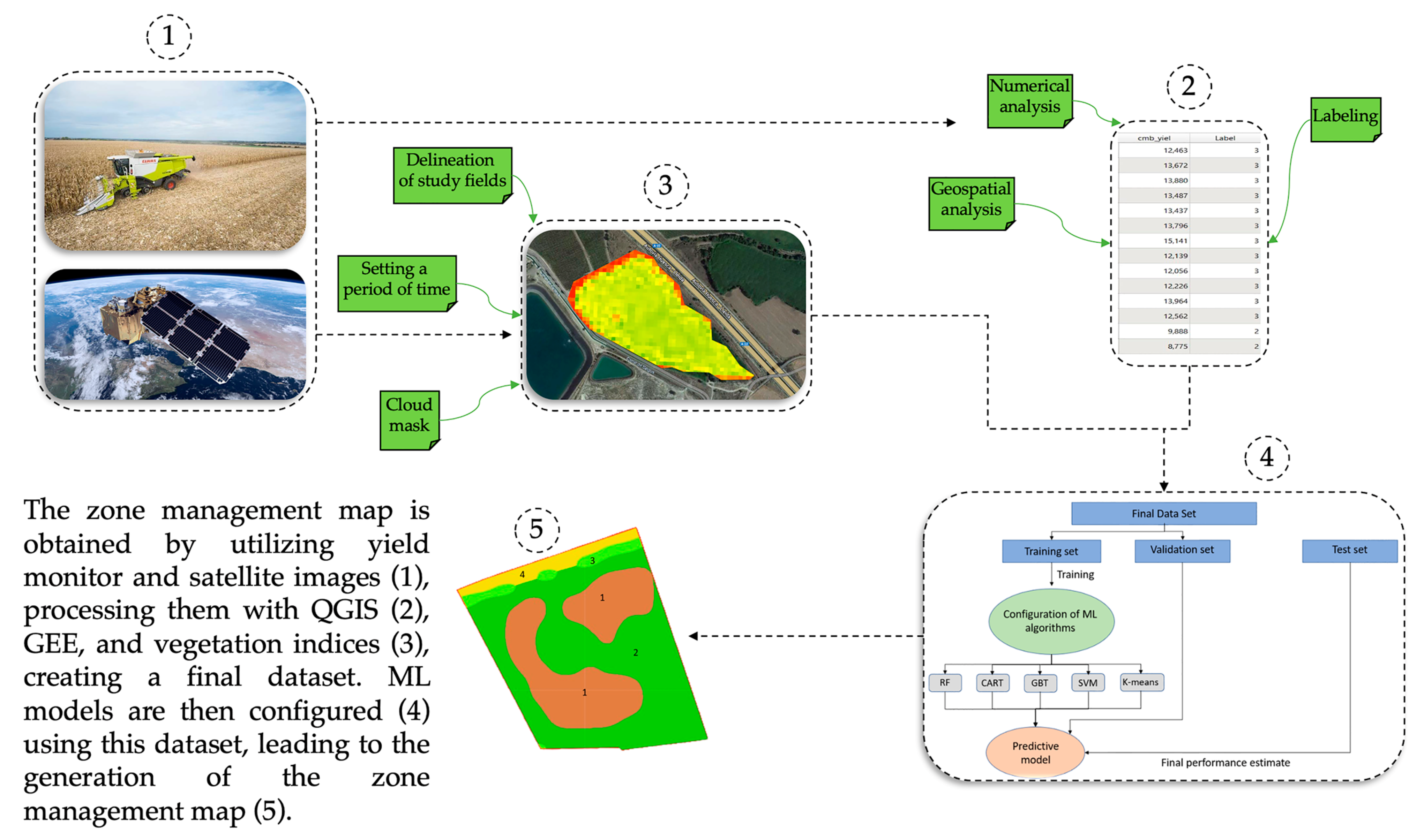
In this research, two data sources were employed to understand the spatio-temporal variability of agricultural plots and delineate management zones. Firstly, the GEE platform was utilized, providing access to a wide collection of high-resolution satellite images from different satellites. Then, using Sentinel-2 images, various vegetation indices were calculated, which provide relevant information about crops, such as the presence of stress, pests or diseases, or nutrient deficiencies, thereby evaluating the vegetative state of the crops. Additionally, yield data from multiple agricultural plots were collected using yield monitors installed in the harvesters. This allowed us to record detailed information regarding the production of the agricultural plots under study. The research flowchart, depicted in
Figure 1, encompasses five distinct steps that were executed in this study.
2.1. Experimental Sites
The study was conducted in ten commercial fields cultivated with maize (
Zea Mays L.) during the 2022 season. Fields were located in the Spanish provinces of Huesca, León, Salamanca and Zamora, as described in
Table 1.
In addition to the above table showing the location of each of the study plots,
Table 2 shows the agronomic data of these plots to facilitate the interpretation of the data obtained in the research.
Fields used as training and validation sets were planted between the 15th and 20th June 2022, and the harvesting dates were between the 4th and 28th December 2022, whereas the fields from Leon and Zamora used as a set of testing were planted on the 28th and 30th April 2022, respectively, and they were harvested on the 11th and 29th of November 2022. Yield data for each one of the fields were collected using a Claas Lexion 750 Montana combine harvester, equipped with a self-leveling system to compensate for uneven ground, an electro-mechanical guidance system, and a yield sensor to determine the quantity and quality of the harvested grain.
2.2. Analysis of Yield Data
The field-collected yield data from each plot, obtained using a yield sensor, necessitate two types of analysis. First, a numerical analysis must be performed to remove data that generate noise, such as null values, zeros, or other out-of-range values exhibiting significant variability compared to the mean. Second, a geospatial analysis is essential to examine the spatial behavior of the data and evaluate the influence of each data point on its neighboring values.
The raw performance data underwent two primary processes. The first process, numerical analysis, was conducted using an open-source geographic information system, QGIS v3.12 [
31]. The second process involved a geospatial analysis carried out on the same QGIS platform. Then, using the Smart-Map plug-in [
32], semivariograms, which provide information on the spatial variability of the data as a function of distances, and interpolations were generated using the ordinary Kriging method in conjunction with ML techniques [
33], which use information from nearby sampling points to predict values at unsampled locations. These techniques were applied to create maps of management zones from the yield data, representing the reality on the ground. The maps obtained allow the spatial variations captured to be compared with the area maps generated by GEE from yield data and satellite images. After processing the data, it is essential to designate appropriate output labels for use in ML models used for zoning. In this case, yield values were categorized into three classes, as previous studies have shown no significant improvement in results using more than three classes. Therefore, it is generally recommended to delineate between three and five types [
34,
35,
36,
37,
38]. Considering the yield data available after the elimination of outliers, it was decided to establish the following three classes. The first class consisted of yield values ranging from 1.00 to 7.99 tons per hectare (t/ha), the second class fell between 8.00 and 11.99 t/ha, and the third class was between 12.00 and 30.00 t/ha. This decision is based on the previous study of the data since it was carried out to obtain a dataset of classes with a certain degree of balance, containing several similar samples, to avoid biases in the ML models, improve generalization and robustness, and avoid overfitting problems [
39]. In addition, agronomic reasons are taken into account so that the range of the third class (12.00–30.00 t/ha) is set taking into account that the average maximum yields at plot level in the northern areas of Spain, provided by the large seed companies with distribution in Spain, are placed in values of up to 22.4 t/ha in 2020, up to 20.6 t/ha in 2019, or up to 23.6 t/ha in 2018 [
40]. Once the output labels have been designated, all maps are exported as a single shapefile, which can be imported into the GEE platform. Along with the vegetation index data obtained, this shapefile constituted the training-validation dataset for zoning. Following this approach, we can ensure that the ML models were trained on a high-quality dataset that accurately represents the different yield levels observed in the study area. This can lead to more accurate and reliable zoning results, which can ultimately help optimize agricultural management practices and improve crop yields.
2.3. Vegetation Indices
The GEE platform’s application program interface (API) [
41] was used to calculate various vegetation indices and delineate MZs. This interface can be accessed through the web browser using the GEE code editor. The code editor provides an interactive interface where JavaScript code is developed and executed. Implementation in GEE involves following a series of steps, among which are data loading and manipulation, including the loading of geospatial data from the extensive library of datasets available in GEE and their manipulation through filtering, trimming, etc., operations using the JavaScript language; the analysis and processing of the data using a wide range of functions such as the generation of vegetation indices; the creation of predictive models using ML models; or the calculation of statistics and the visualization of the results in the form of interactive maps that allow the use of legends, colors, and selection of regions. A maximum cloudiness threshold of 20% was set for image selection and a cloud mask. The QA60 cloud mask refers to a quality band that is included in MSK_CLASSI and contains both opaque clouds (band 11) and cirrus clouds (band 10), with an indicator specifying the type of cloud (cirrus or opaque clouds). This mask contains information about the pixel quality in terms of cloud presence, cloud shadows, snow, water, or band saturation, among others. The mask determination method is composed of a series of steps such as atmospheric correction, the definition of a blue reflectance threshold for opaque clouds, the calculation of the snow index, and mask refinement [
42].
The images collected from 5th July to 5th November 2022, for the training plots and from 5th June to 5th October 2022, for the test plots, covered approximately 36–38 days after sowing (DaS) and a BBCH 19 [
43] growth stage, where the crop had approximately 20% ground cover, reducing soil reflectance. The start of the period was chosen to avoid problems with crop reflectance or obtaining low and unrepresentative values of the vegetative indices. The end date corresponded to a BBCH 87 growth stage, where the crop had approximately 80% ground cover and occurred before the onset of crop senescence. We highlight that the BBCH scale is a system for uniformly coding phonologically similar growth stages of all monocotyledonous and dicotyledonous plant species. The BBCH scale is a system for the uniform coding of phenologically similar growth stages in monocotyledonous and dicotyledonous plant species. This scale uses the base structures described by Zadoks in 1974 [
44].
A total of 52 and 54 images were analyzed for the training and test plots, respectively. Ten published vegetation indices (
Table 3) were calculated to assess the vegetative state of the crops. The objective was to select the index(es) that would provide the best classification accuracy, realism, and field implementability (
Table 4).
At the GEE (Google Earth Engine) level, the most efficient approach to working with large datasets is to utilize time series that encompass the entire required period. However, handling such extensive datasets becomes challenging without applying reduction functions provided by GEE. These reduction functions offer three options: ee.Reducer.min(), ee.Reducer.median(), and ee.Reducer.max(). In this study, the reduction function that calculates the mean was implemented, as depicted in
Figure 2.
where originalImage is the original image to be resized; reproject () is the GEE function used to change the image projection; crs: originalImage.projection specifies the output projection for the resized image. In the case under study, the same projection of the original image is used; scale defines the new scale for the resized image, where newScale is the desired scale value in meters.
2.4. Machine Learning Models
In addition to offering functions for calculating spatial and spectral operations, the GEE platform provides other mathematical functions and advanced ML algorithms, both supervised and unsupervised [
55]. The dataset was partitioned into a 70–30% split for training and validation, resulting in 8670 data points for training and 3717 data points for validation. A series of steps were taken to combine the data from the different sources. Once the yield data, the satellite images corresponding to the defined period and the vegetation indices have been imported, the training and validation datasets are prepared. For this purpose, many feature collections based on the yield data are defined as zones to be used, in this case, three zones. In these zones, the filter.lt and filter.gte functions are used to split the data into 70–30%. The merge function is then used on both the training and validation data to merge the defined zones into a single variable. Next, the sampleRegions function is used, which takes as input the vegetation indices calculated for the image collection and the previously defined training variable containing the performance-based zone labels. Finally, the ML models are implemented, which take as their training dataset the training variable with the performance data and the calculated vegetation indices. The general equation to implement the indices would be as follows:
where training variable refers to the performance data file, “column zone” is the name of the column of the performance data file containing the classes that have been defined before loading the dataset into GEE, and vegetative index is the band originating from the calculation of the index to be used.
Four supervised ML algorithms, including classification and regression tree (CART), random forest (RF), gradient boosting trees (GBT), and support vector machine (SVM), were implemented. The CART algorithm is a statistical procedure that identifies mutually exclusive and exhaustive subgroups of a population based on common characteristics [
56]. During the investigation, only the parameter minLeafPopulation = 1 was considered, so that the generated nodes contained at least one point. RF is a set of decision trees that reduces overfitting and improves prediction accuracy using different subsets of data and features [
57,
58]. In the case study, 100 trees were used to perform training and subsequent classification. GBT is another ensemble method that trains trees sequentially, fitting each new tree based on the residuals of the previous trees, resulting in a weighted combination of all previous models [
59,
60]. As in RF, 100 trees are used. The rest of the parameters employed use the default values defined in the function itself. SVM, on the other hand, finds the optimal hyperplane to separate the observations into classes based on the features [
61]. In this case, the implementation of this algorithm is carried out with the default values of each of the parameters that compose it. The k-means clustering algorithm was also implemented to compare its performance with the supervised classification models based on yield values and vegetation indices. K-means is an unsupervised clustering method that groups data points into clusters based on feature similarity [
62]. It starts with a set of random centroids and performs repetitive calculations to optimize the position of the centroids.
2.5. Evaluation Metrics and Delineation of Homogeneous Management Zones
ML models must be evaluated using specific metrics to test their robustness [
63]. This research used two popular accuracy indicators, namely the overall accuracy (Equation (3)) and the Kappa coefficient (Equation (4)), to evaluate the supervised classification algorithms used in the GEE platform.
where true positives (TP) are the positive cases correctly classified as positive by the model, and false positives (FP) are the negative cases incorrectly classified as positive by the model.
where Po is the observed proportion of agreement between raters or evaluators. It is calculated by dividing the number of observed agreements by the total number of ratings performed, and Pe is the expected proportion of agreements due to chance. It is calculated by multiplying the marginal proportions of the ratings separately and summing up the results [
64].
For the authors of [
65] (pp. 111–115), overall accuracy is defined as the proportion of correct model predictions in the training dataset and is calculated by dividing the number of accurate predictions by the total number of predictions. However, overall accuracy may not always be the most useful measure since, if the classes are unbalanced, the accuracy values may be somewhat misleading. In these cases, the Kappa coefficient may be the right metric, as it measures the agreement between true labels and predictions, considering the distribution of classes [
66]. However, for the clustering algorithm used, k-means, a visual interpretation of the results was performed, taking as a reference the performance maps generated through kriging in QGIS. The calculation of these metrics requires the prior calculation of the confusion matrix, which is a fundamental tool in the evaluation of classification models. It generates a table that shows the number of instances classified correctly and incorrectly by the model. TP indicates the instances that are positive and were classified correctly; true negative (TN) indicates the instances that are negative and were classified correctly; FP indicates the instances that are negative and were incorrectly classified as positive; and false negatives (FNs) indicate the positive instances that were incorrectly classified as negative [
67].
Metrics that have been used to assess the accuracy of maps generated as ground truth using the Smart-Map plug-in are root mean square error (RMSE), defined as the difference between predicted and actual values in regression models, and the coefficient of determination (R2), which measures the variability of the data in the range 0–1, where 0 explains no variability and 1 explains all variability [
68].
Finally, after the classification of the data using ML algorithms, an isolated pixel attenuation method was used, which applies a morphological reducer to each band of the image using an octagonal kernel of radius 6 m, allowing mapping criteria such as the minimum mappable area to be met, facilitating its use in agricultural machinery and its use in the field.
4. Discussion
The findings presented in this research highlight the immense potential of integrating machine learning models with satellite data and yield monitors to effectively identify MZs in the cloud using GEE. Prior to this study, numerous researchers, such as Quebrajo et al. [
1], had employed time-consuming and manual techniques for creating management zones, which are not ideal from a precision agriculture standpoint. However, with the utilization of ML models in conjunction with satellite data and yield monitors, the process can be significantly streamlined and optimized for PA applications.
The GEE platform is one of the most efficient geospatial data analysis and processing tools. The GEE platform is a very effective geospatial data analysis and processing tool, providing access to large volumes of satellite data, including Sentinel-2 data. Unlike studies such as [
73,
74], where field data are used to perform zonal management in maize cultivation, the GEE platform allows the obtention of accurate and up-to-date data on crop vegetative status remotely without the need to take field data [
75]. This makes it possible to monitor plots that are difficult to access. An example of this would be agricultural plots located in mountainous or hard-to-reach areas due to the terrain’s topography. Plots are located in protected environments or natural reserves, where access restrictions are often imposed to protect biodiversity and ecosystems. It is also worth noting those plots of extensive crops with large surfaces, due to their size, can make it challenging to access all areas.
GEE’s cloud-based platform does not require internal storage, streamlining work and the elimination of expensive hardware and software. In addition, GEE enables the implementation of ML techniques and models. The segmentation and classification of satellite images using ML techniques, both supervised, such as RF or CART, and unsupervised, such as k-means, allow the identification of patterns in the data and the understanding of the spatial and temporal variability of the plot to perform agricultural practices in a targeted manner [
76]. Applying these techniques allows for more sustainable agricultural management by generating maps of management zones that will enable much more accurate planning of agricultural work and identify areas that require fewer inputs, leading to a reduction in production costs and a possible improvement in the quality and yield of crops.
These results indicate that machine learning algorithms, such as CART and RF, can provide accurate predictions of crop yield based on remote sensing data. Furthermore, using geospatial analysis tools, such as Smart-Map, can help identify and delineate areas of high and low yield variability, which could help optimize management practices and improve overall crop yields. These findings have important implications for precision agriculture. They can help farmers make informed decisions on input applications, irrigation management, and crop rotations, leading to more efficient resource use and increased profitability.
In comparison to previous research such as [
77,
78], where MZs were established in corn by downloading satellite images and subsequently processing them, the utilization of GEE provides the advantage of automatically generating zone maps without the need to download the images or bands. This significantly streamlines the process and eliminates the additional steps involved in data acquisition. Furthermore, when compared to other studies such as [
79,
80], which reported Kappa coefficient values ranging from 0.32 to 0.79 and 0.63 to 0.73, respectively, the ML models employed in this research demonstrated significantly higher values. Particularly, the CART and RF models exhibited superior performance, with Kappa coefficient values ranging from 0.90 to 0.99. These findings highlight the enhanced accuracy and reliability achieved through the implementation of these machine learning models in conjunction with GEE, surpassing the results obtained in earlier studies.
Although there is room for improvement in the results, particularly with respect to the availability of a more comprehensive dataset that includes a larger number of fields, it can be summarized that this research showcases the potential of integrating advanced technologies such as GEE, remote sensing, and ML models with farm management practices. By combining these techniques, valuable and timely crop information can be obtained, resulting in enhanced decision making processes and optimized resource allocation through variable rate application. The study highlights the significance of leveraging these cutting-edge technologies to improve agricultural practices and achieve more efficient and precise agricultural outcomes.
5. Conclusions
The findings of this manuscript demonstrate the effectiveness of integrating both supervised (CART, GBT, RF, and SVM) and unsupervised (k-means) ML models with GEE and Sentinel-2 imagery for vegetative crop monitoring and the automated generation of agricultural management area maps based on vegetation indices. This innovative approach offers a valuable solution that has the potential to replace specific field data collection tasks that may be challenging to conduct due to economic constraints, agricultural limitations, or accessibility issues.
Looking ahead, the future holds the promise of free access to multispectral optical satellite images with lower resolutions than those of the current standards. This anticipated advancement opens doors for the further development and refinement of agricultural applications for MZs with even greater precision. By capitalizing on these improved data sources, future research can expand the scope and accuracy of ML models in precision agriculture, enabling more informed decision making processes for farmers.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}