
DAFCNN: A Dual-Channel Feature Extraction and Attention Feature Fusion Convolution Neural Network for SAR Image and MS Image Fusion


Abstract
1. Introduction
2. Related Work
2.1. Residual Block Structure
2.2. Squeeze-and-Excitation Networks
2.3. Structural Similarity Index
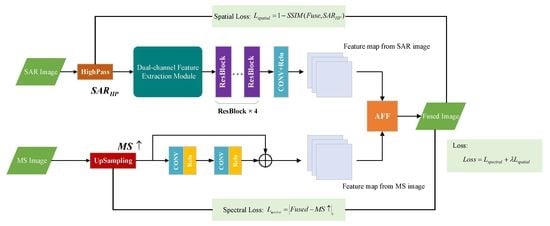
3. The Proposed Method
3.1. Spatial Feature Extraction Branch
3.2. Spectral Retention Branch
3.3. Attention Feature Fusion Module
3.4. Unsupervised Union Loss Function
4. Experiments and Results
4.1. Datasets
4.2. Experimental Setting
4.3. Comparison of Methods
- (1)
- IHS [6]: a fast intensity–hue–saturation fusion technique;
- (2)
- NSCT [27]: non-subsampled contourlet transform domain fusion method;
- (3)
- Wavelet [17]: the wavelet transform fusion method;
- (4)
- NSCT-FL [26]: a fusion method based on NSCT and fuzzy logic;
- (5)
- NSCR-PCNN [25]: a fusion method Based on NSCT and pulse-coupled neural network;
- (6)
- MSDCNN [35]: a multiscale and multidepth convolutional neural network. The MSDCNN is trained to constrain the training by using the loss function proposed in this paper.
4.4. Evaluation Indicators
4.5. Analysis of Results
4.6. Validation of the Performance of the Proposed Fusion Module
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Chen, J.; Yu, H. Wide-beam SAR autofocus based on blind resampling. Sci. China Inf. Sci. 2023, 66, 140304. [Google Scholar] [CrossRef]
- Javali, A.; Gupta, J.; Sahoo, A. A review on Synthetic Aperture Radar for Earth Remote Sensing: Challenges and Opportunities. In Proceedings of the 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 4–6 August 2021; pp. 596–601. [Google Scholar]
- Chen, J.; Zhang, J.; Jin, Y.; Yu, H.; Liang, B.; Yang, D.G. Real-time processing of spaceborne SAR data with nonlinear trajectory based on variable PRF. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5205212. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Luo, S.; Zhou, S.; Qiang, B. A novel adaptive fast IHS transform fusion method driven by regional spectral characteristics for Gaofen-2 imagery. Int. J. Remote Sens. 2020, 41, 1321–1337. [Google Scholar] [CrossRef]
- Zhu, X.; Bao, W. Investigation of remote sensing image fusion strategy applying PCA to wavelet packet analysis based on IHS transform. J. Indian Soc. Remote Sens. 2019, 47, 413–425. [Google Scholar] [CrossRef]
- Haddadpour, M.; Daneshvar, S.; Seyedarabi, H. PET and MRI image fusion based on combination of 2-D Hilbert transform and IHS method. Biomed. J. 2017, 40, 219–225. [Google Scholar] [CrossRef]
- Vivone, G.; Alparone, L.; Chanussot, J.; Dalla Mura, M.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A critical comparison among pansharpening algorithms. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2565–2586. [Google Scholar] [CrossRef]
- Shahdoosti, H.R.; Ghassemian, H. Combining the spectral PCA and spatial PCA fusion methods by an optimal filter. Inf. Fusion 2016, 27, 150–160. [Google Scholar] [CrossRef]
- Wang, Z.; Ziou, D.; Armenakis, C.; Li, D.; Li, Q. A comparative analysis of image fusion methods. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1391–1402. [Google Scholar] [CrossRef]
- Kwarteng, P.; Chavez, A. Extracting spectral contrast in Landsat Thematic Mapper image data using selective principal component analysis. Photogramm. Eng. Remote Sens. 1989, 55, 339–348. [Google Scholar]
- Choi, J.; Yu, K.; Kim, Y. A new adaptive component-substitution-based satellite image fusion by using partial replacement. IEEE Trans. Geosci. Remote Sens. 2010, 49, 295–309. [Google Scholar] [CrossRef]
- Yilmaz, V.; Serifoglu Yilmaz, C.; Güngör, O.; Shan, J. A genetic algorithm solution to the gram-schmidt image fusion. Int. J. Remote Sens. 2020, 41, 1458–1485. [Google Scholar] [CrossRef]
- Wang, Z.; Cui, Z.; Zhu, Y. Multi-modal medical image fusion by Laplacian pyramid and adaptive sparse representation. Comput. Biol. Med. 2020, 123, 103823. [Google Scholar] [CrossRef] [PubMed]
- Verma, S.K.; Kaur, M.; Kumar, R. Hybrid Image Fusion Algorithm Using Laplacian Pyramid and PCA Method. In Proceedings of the Second International Conference on Information and Communication Technology for Competitive Strategies, ICTCS ’16, Udaipur, India, 4–5 March 2016. [Google Scholar] [CrossRef]
- Vijayarajan, R.; Muttan, S. Discrete wavelet transform based principal component averaging fusion for medical images. AEU–Int. J. Electron. Commun. 2015, 69, 896–902. [Google Scholar] [CrossRef]
- Singh, R.; Khare, A. Fusion of multimodal medical images using Daubechies complex wavelet transform—A multiresolution approach. Inf. Fusion 2014, 19, 49–60. [Google Scholar] [CrossRef]
- Guo, L.; Cao, X.; Liu, L. Dual-tree biquaternion wavelet transform and its application to color image fusion. Signal Process. 2020, 171, 107513. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, J. A New Saliency-Driven Fusion Method Based on Complex Wavelet Transform for Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2433–2437. [Google Scholar] [CrossRef]
- Do, M.N.; Vetterli, M. The contourlet transform: An efficient directional multiresolution image representation. IEEE Trans. Image Process. 2005, 14, 2091–2106. [Google Scholar] [CrossRef]
- Zhang, W.; Jiao, L.; Liu, F.; Yang, S.; Liu, J. Adaptive Contourlet Fusion Clustering for SAR Image Change Detection. IEEE Trans. Image Process. 2022, 31, 2295–2308. [Google Scholar] [CrossRef]
- Arif, M.; Wang, G. Fast curvelet transform through genetic algorithm for multimodal medical image fusion. Soft Comput. 2020, 24, 1815–1836. [Google Scholar] [CrossRef]
- Devulapalli, S.; Krishnan, R. Synthesized pansharpening using curvelet transform and adaptive neuro-fuzzy inference system. J. Appl. Remote Sens. 2019, 13, 034519. [Google Scholar] [CrossRef]
- Zhu, Z.; Zheng, M.; Qi, G.; Wang, D.; Xiang, Y. A phase congruency and local Laplacian energy based multi-modality medical image fusion method in NSCT domain. IEEE Access 2019, 7, 20811–20824. [Google Scholar] [CrossRef]
- Yang, Y.; Que, Y.; Huang, S.; Lin, P. Multimodal Sensor Medical Image Fusion Based on Type-2 Fuzzy Logic in NSCT Domain. IEEE Sens. J. 2016, 16, 3735–3745. [Google Scholar] [CrossRef]
- Ganasala, P.; Kumar, V. CT and MR image fusion scheme in nonsubsampled contourlet transform domain. J. Digit. Imaging 2014, 27, 407–418. [Google Scholar] [CrossRef]
- Chu, T.; Tan, Y.; Liu, Q.; Bai, B. Novel fusion method for SAR and optical images based on non-subsampled shearlet transform. Int. J. Remote Sens. 2020, 41, 4590–4604. [Google Scholar] [CrossRef]
- Wady, S.; Bentoutou, Y.; Bengermikh, A.; Bounoua, A.; Taleb, N. A new IHS and wavelet based pansharpening algorithm for high spatial resolution satellite imagery. Adv. Space Res. 2020, 66, 1507–1521. [Google Scholar] [CrossRef]
- Luo, Y.; Liu, R.; Zhu, Y.F. Fusion of remote sensing image base on the PCA+ ATROUS wavelet transform. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 1155–1158. [Google Scholar]
- Zhao, J.; Zhou, C.; Huang, L.; Yang, X.; Xu, B.; Liang, D. Fusion of unmanned aerial vehicle panchromatic and hyperspectral images combining joint skewness-kurtosis figures and a non-subsampled contourlet transform. Sensors 2018, 18, 3467. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Malik, A.; Tanveer, M.; Suganthan, P. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A multiscale and multidepth convolutional neural network for remote sensing imagery pan-sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Ding, X.; Paisley, J. PanNet: A deep network architecture for pan-sharpening. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5449–5457. [Google Scholar]
- Yang, Y.; Tu, W.; Huang, S.; Lu, H. PCDRN: Progressive Cascade Deep Residual Network for Pansharpening. Remote Sens. 2020, 12, 676. [Google Scholar] [CrossRef]
- He, L.; Zhu, J.; Li, J.; Plaza, A.; Chanussot, J.; Yu, Z. CNN-based hyperspectral pansharpening with arbitrary resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5518821. [Google Scholar] [CrossRef]
- Saxena, N.; Balasubramanian, R. A pansharpening scheme using spectral graph wavelet transforms and convolutional neural networks. Int. J. Remote Sens. 2021, 42, 2898–2919. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Sara, U.; Akter, M.; Uddin, M.S. Image Quality Assessment through FSIM, SSIM, MSE and PSNR—A Comparative Study. J. Comput. Commun. 2019, 7, 11. [Google Scholar] [CrossRef]
- Vivone, G.; Dalla Mura, M.; Garzelli, A.; Pacifici, F. A Benchmarking Protocol for Pansharpening: Dataset, Preprocessing, and Quality Assessment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6102–6118. [Google Scholar] [CrossRef]
- Wang, W.; Zhou, Z.; Liu, H.; Xie, G. MSDRN: Pansharpening of Multispectral Images via Multi-Scale Deep Residual Network. Remote Sens. 2021, 13, 1200. [Google Scholar] [CrossRef]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolutions: Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | CC | PSNR | SAM | SSIM | QNR | ||
|---|---|---|---|---|---|---|---|
| IHS | −0.5820 | 6.3007 | 10.6878 | −0.4972 | 0.1155 | 0.0027 | 0.8821 |
| NSCT | −0.0512 | 6.9353 | 14.9826 | −0.0192 | 0.2648 | 0.0049 | 0.7315 |
| Wavelet | 0.6155 | 11.5314 | 3.1822 | 0.4338 | 0.0904 | 0.0017 | 0.9080 |
| NSCT-FL | 0.8535 | 15.6627 | 2.0313 | 0.8285 | 0.0215 | 0.0003 | 0.9782 |
| NSCT-PCNN | 0.8120 | 14.0786 | 2.3038 | 0.7873 | 0.1045 | 0.0011 | 0.8945 |
| MSDCNN | 0.9371 | 18.9213 | 2.6944 | 0.9337 | 0.0133 | 0.0004 | 0.9861 |
| DAFCNN | 0.9799 | 2.5795 | 2.4434 | 0.9679 | 0.0074 | 0.0006 | 0.9919 |
| Methods | CC | PSNR | SAM | SSIM | QNR | ||
|---|---|---|---|---|---|---|---|
| IHS | −0.0123 | 9.5775 | 8.5049 | −0.4900 | 0.0390 | 0.0091 | 0.9522 |
| NSCT | 0.5055 | 10.7658 | 9.0350 | 0.4479 | 0.0670 | 0.0218 | 0.9121 |
| Wavelet | 0.7380 | 14.3651 | 3.6564 | 0.6610 | 0.0281 | 0.0063 | 0.9658 |
| NSCT-FL | 0.8493 | 16.5720 | 2.7567 | 0.8367 | 0.0135 | 0.0030 | 0.9835 |
| NSCT-PCNN | 0.8346 | 16.2621 | 2.4721 | 0.8189 | 0.0154 | 0.0013 | 0.9833 |
| MSDCNN | 0.8577 | 15.9557 | 4.6426 | 0.8442 | 0.0089 | 0.0018 | 0.9893 |
| DAFCNN | 0.9750 | 22.3246 | 3.4506 | 0.9565 | 0.0067 | 0.0026 | 0.9908 |
| Methods | CC | PSNR | SAM | SSIM | QNR | ||
|---|---|---|---|---|---|---|---|
| IHS | 0.2909 | 8.6195 | 15.3945 | 0.0362 | 0.3730 | 0.2945 | 0.4765 |
| NSCT | 0.2607 | 8.9561 | 20.6113 | 0.1845 | 0.2380 | 0.2714 | 0.5421 |
| Wavelet | 0.7017 | 13.2078 | 4.6937 | 0.5699 | 0.1986 | 0.0431 | 0.7685 |
| NSCT-FL | 0.7061 | 19.2868 | 2.1126 | 0.6904 | 0.0296 | 0.0056 | 0.9649 |
| NSCT-PCNN | 0.6940 | 20.0053 | 2.0886 | 0.6740 | 0.0504 | 0.0046 | 0.9472 |
| MSDCNN | 0.8913 | 21.1186 | 3.0055 | 0.8466 | 0.0423 | 0.0053 | 0.9528 |
| DAFCNN | 0.9801 | 25.2072 | 2.5177 | 0.9394 | 0.0230 | 0.0053 | 0.9718 |
| Methods | CC | PSNR | SAM | SSIM | QNR | ||
|---|---|---|---|---|---|---|---|
| DAFCNN-AFF | 0.9801 | 25.2072 | 2.5177 | 0.9394 | 0.0230 | 0.0053 | 0.9718 |
| DAFCNN-ADD | 0.9645 | 24.4646 | 2.7464 | 0.9395 | 0.0401 | 0.0108 | 0.9459 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, J.; Zhou, F.; Yang, J.; Xing, M. DAFCNN: A Dual-Channel Feature Extraction and Attention Feature Fusion Convolution Neural Network for SAR Image and MS Image Fusion. Remote Sens. 2023, 15, 3091. https://doi.org/10.3390/rs15123091
Luo J, Zhou F, Yang J, Xing M. DAFCNN: A Dual-Channel Feature Extraction and Attention Feature Fusion Convolution Neural Network for SAR Image and MS Image Fusion. Remote Sensing. 2023; 15(12):3091. https://doi.org/10.3390/rs15123091
Chicago/Turabian StyleLuo, Jiahao, Fang Zhou, Jun Yang, and Mengdao Xing. 2023. "DAFCNN: A Dual-Channel Feature Extraction and Attention Feature Fusion Convolution Neural Network for SAR Image and MS Image Fusion" Remote Sensing 15, no. 12: 3091. https://doi.org/10.3390/rs15123091
APA StyleLuo, J., Zhou, F., Yang, J., & Xing, M. (2023). DAFCNN: A Dual-Channel Feature Extraction and Attention Feature Fusion Convolution Neural Network for SAR Image and MS Image Fusion. Remote Sensing, 15(12), 3091. https://doi.org/10.3390/rs15123091