

Analysis of East Asia Wind Vectors Using Space–Time Cross-Covariance Models

Abstract
1. Introduction
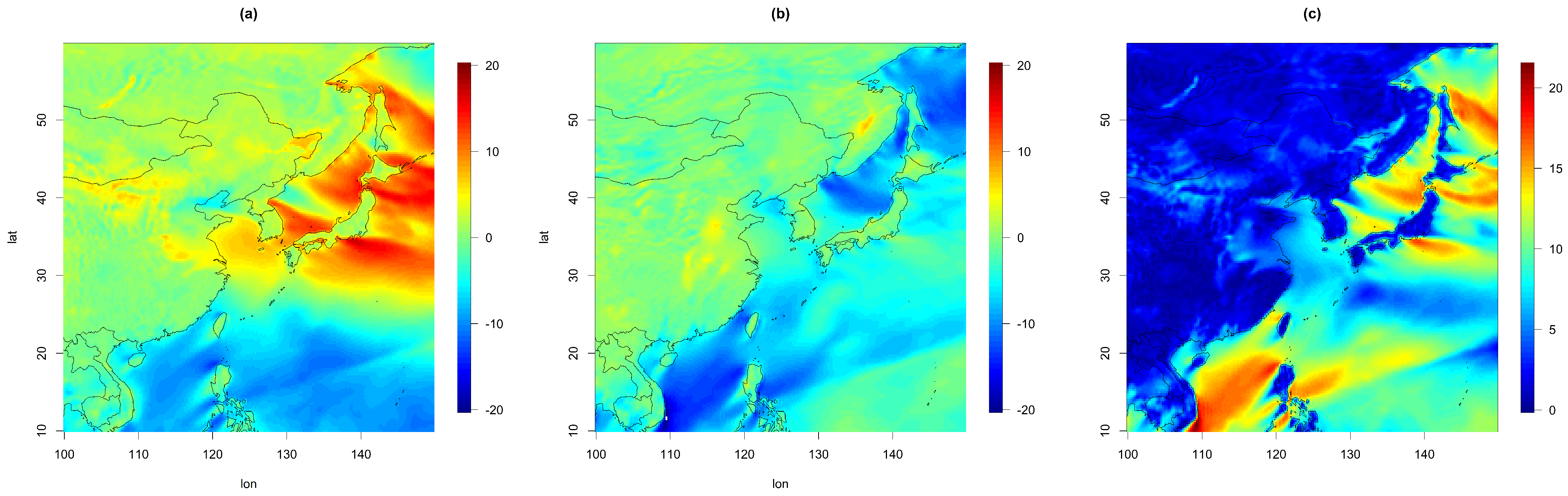
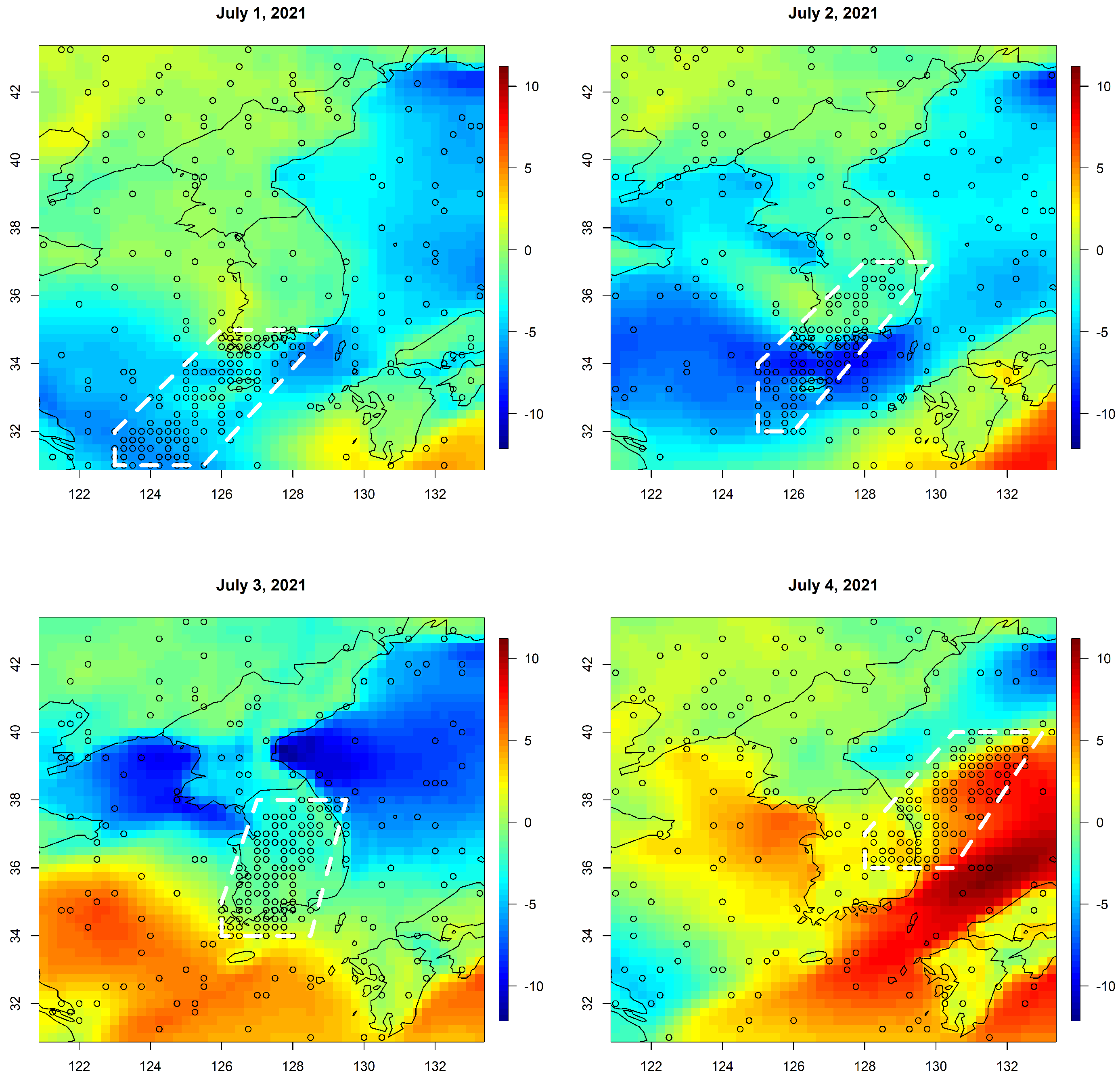
2. Data
3. Method
3.1. Model
3.2. Inference Scheme
- Step 1. We fit the TGH-AR(p) at each spatial location and each variable. Then, we obtained the residuals by filtering out the fitted values based on their estimated parameters of TGH-AR(p), i.e., . Here, we could select either the univariate TGH-AR(p) or the bivariate Tukey g-and-h vector autoregressive model of order p as in [23]. In any case, we could perform estimation independently at each site, i.e., the computation could be easily parallelized.
- Step 2. We fit the space–time cross-covariance model to the residuals and estimated the remaining parameters. Here, if the computation costs matter, we could sub-sample in each partition and use them for parameter estimation. In this study, we split the whole dataset into partitions (16 spatial pieces × 5 temporal pieces), and then sub-sampled approximately 15% and 15% of observations from each spatial and temporal piece, respectively. As a result, the number of data points was 78,400, which was still large enough for the parameter estimation. We tried different partition numbers (from to ) and subsampling proportions (from to ) and did not find notable changes in inference performance.
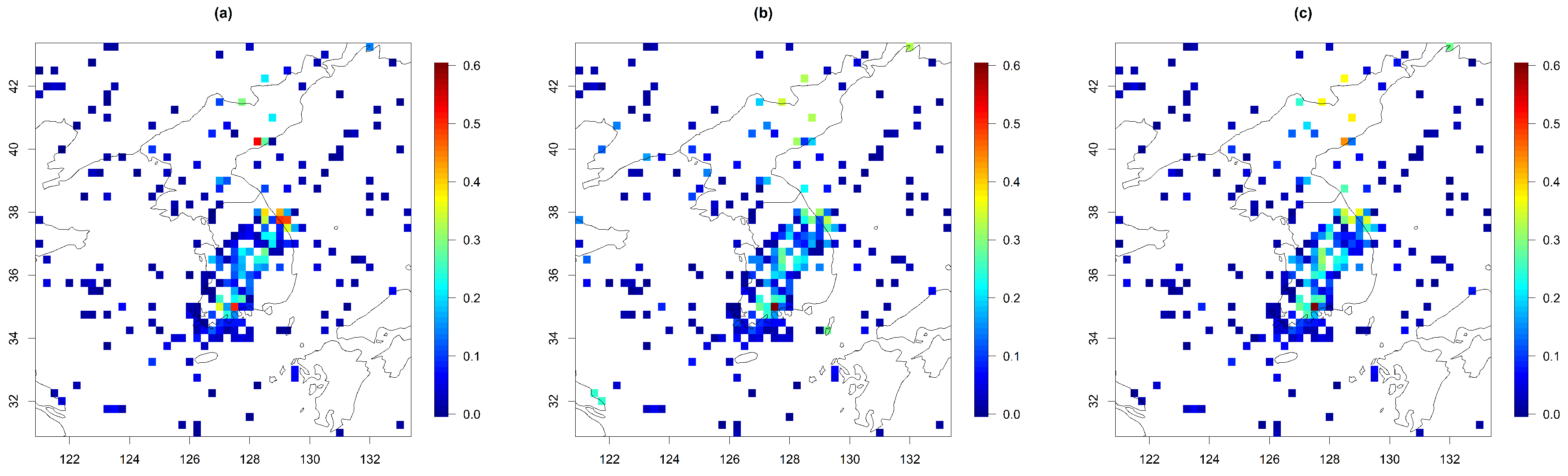
4. Results
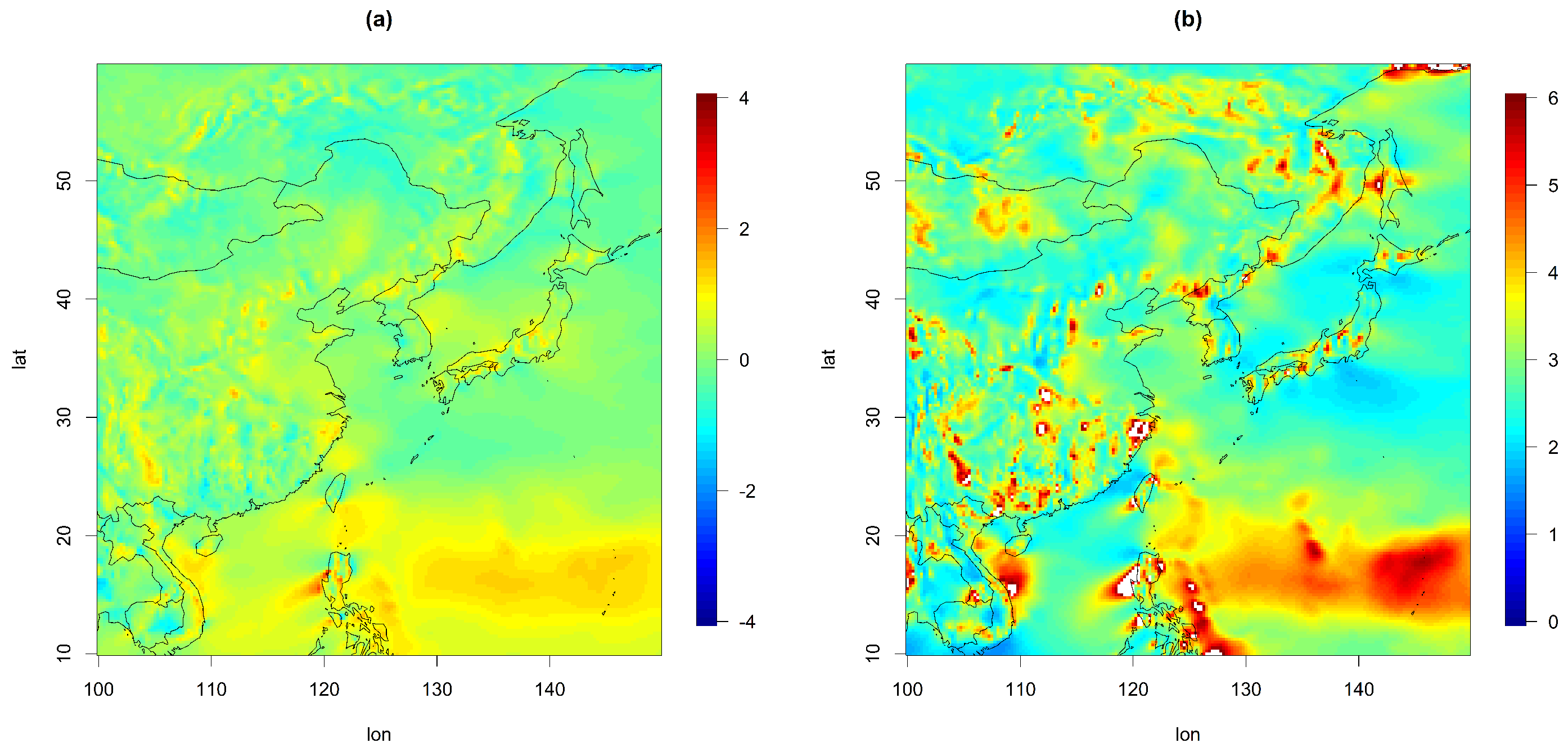
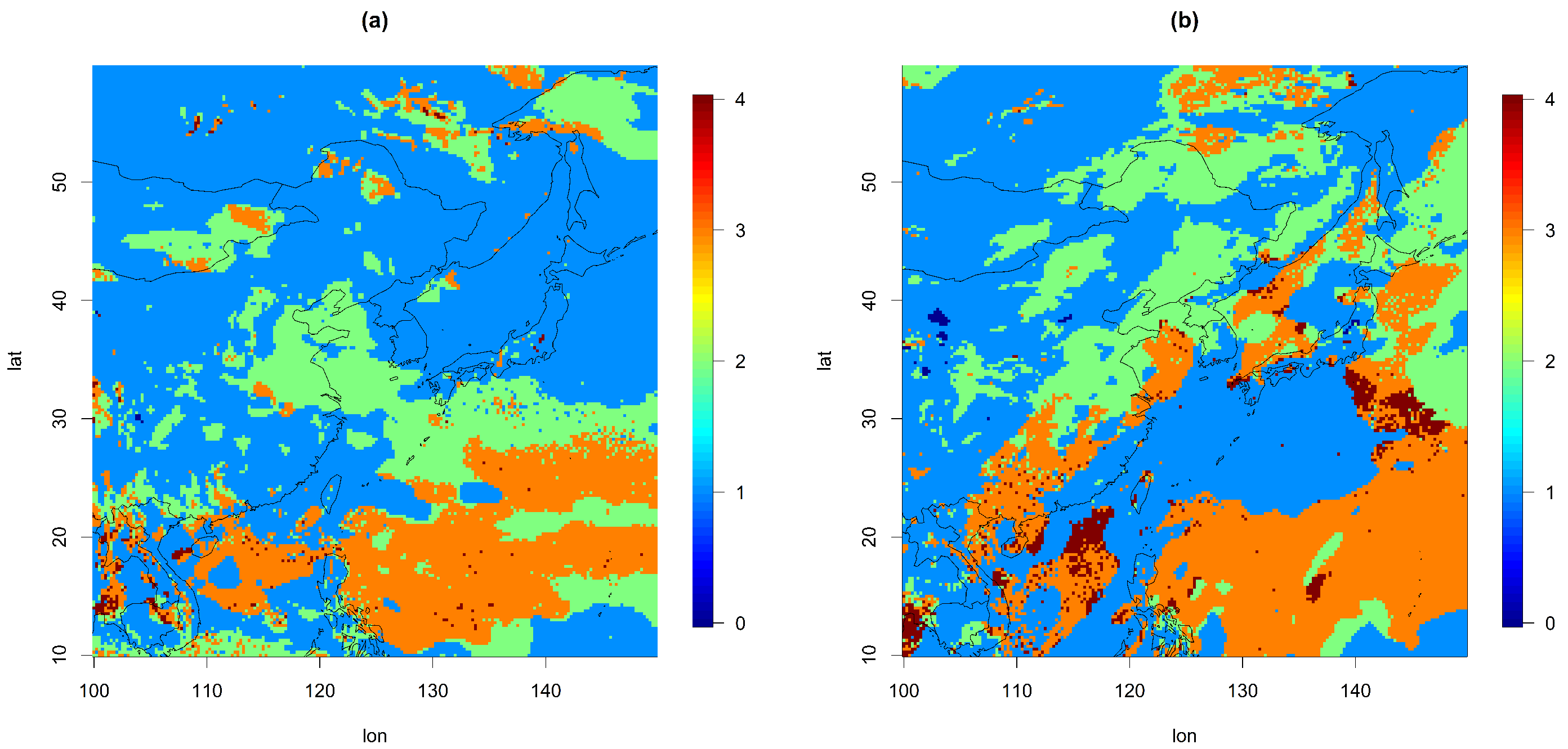
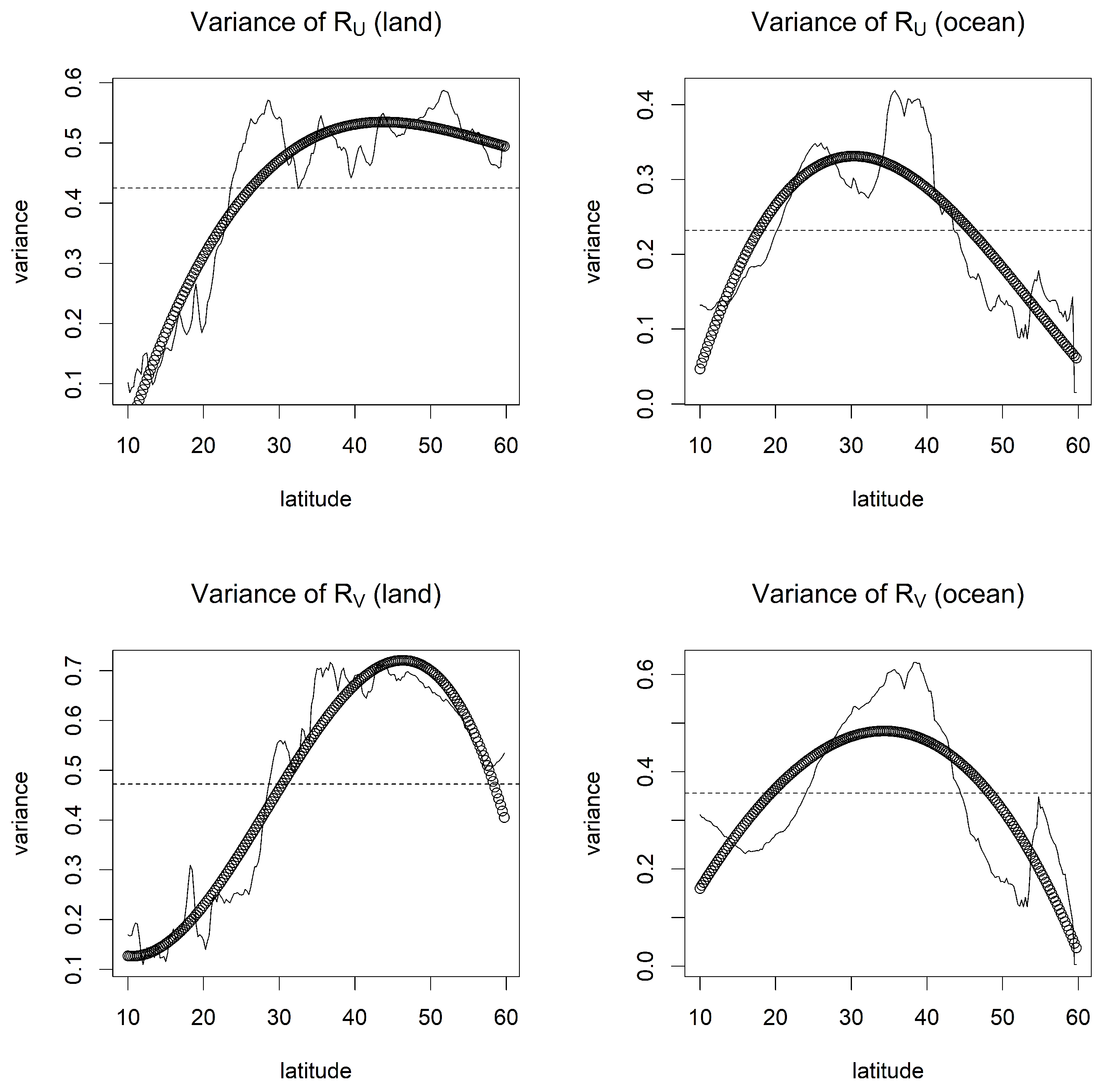
4.1. Parameter Estimation
- Model 1: A parsimonious version of the space–time Gneiting-Matérn of (1); i.e., we assumed the same spatial range r for both variables.
- Model 2: This model was the same as Model 1, but the variances and had different values over the land and the ocean.
- Model 3: This model was the same as Model 1, but the variances and had varying values depending on the latitude over the land and the ocean. Here, we fixed the variances to their estimated values from the second-order polynomial regression in Figure 5.

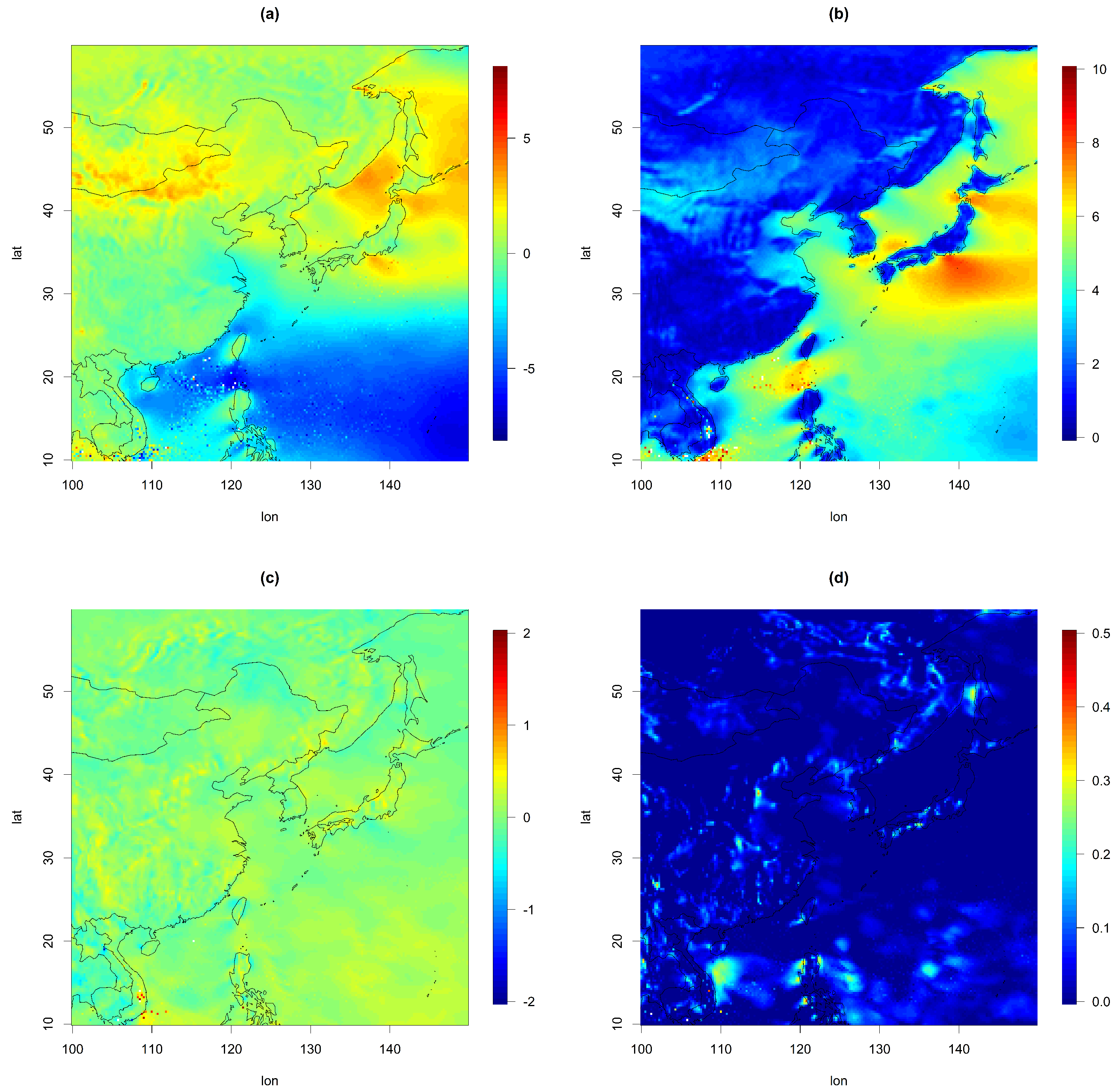
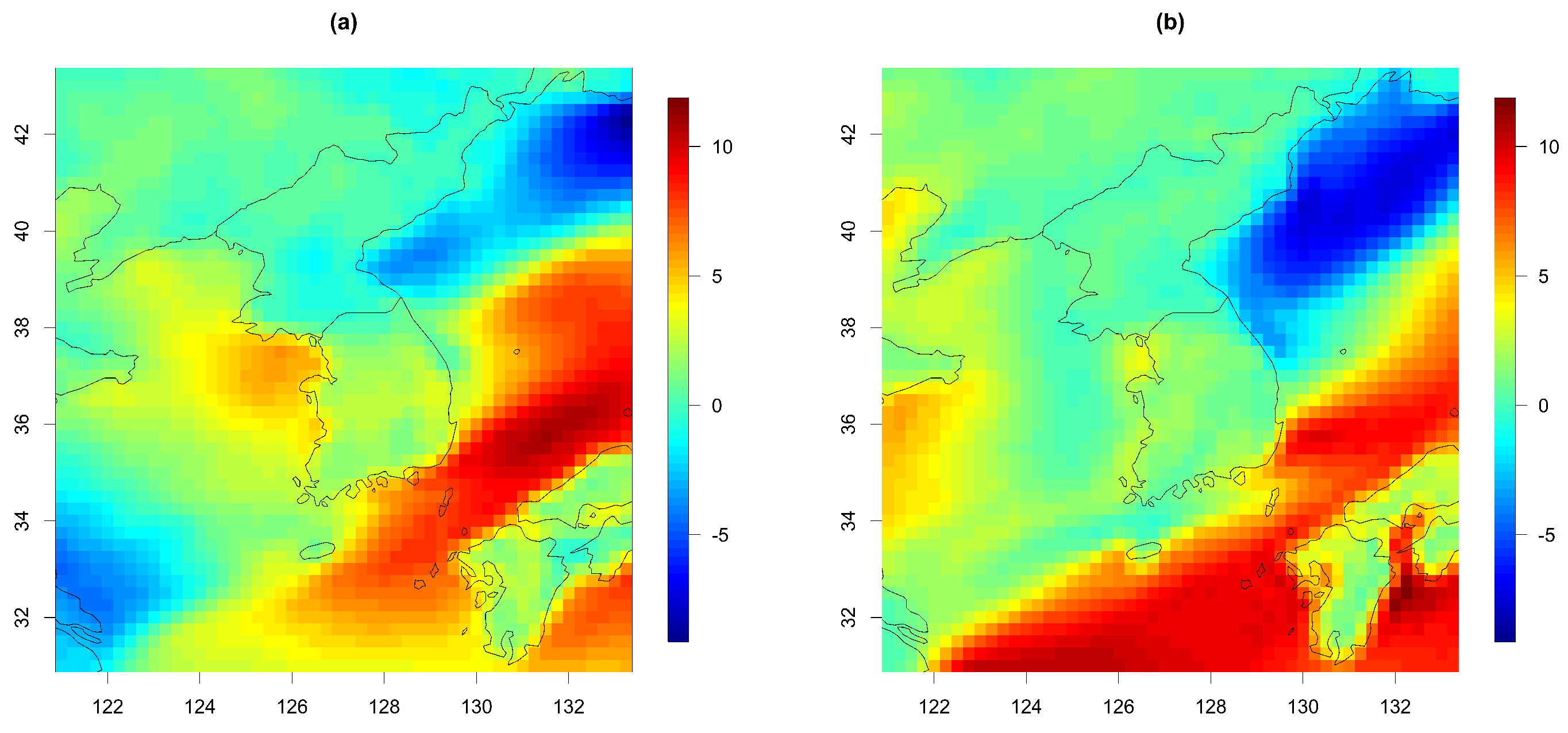
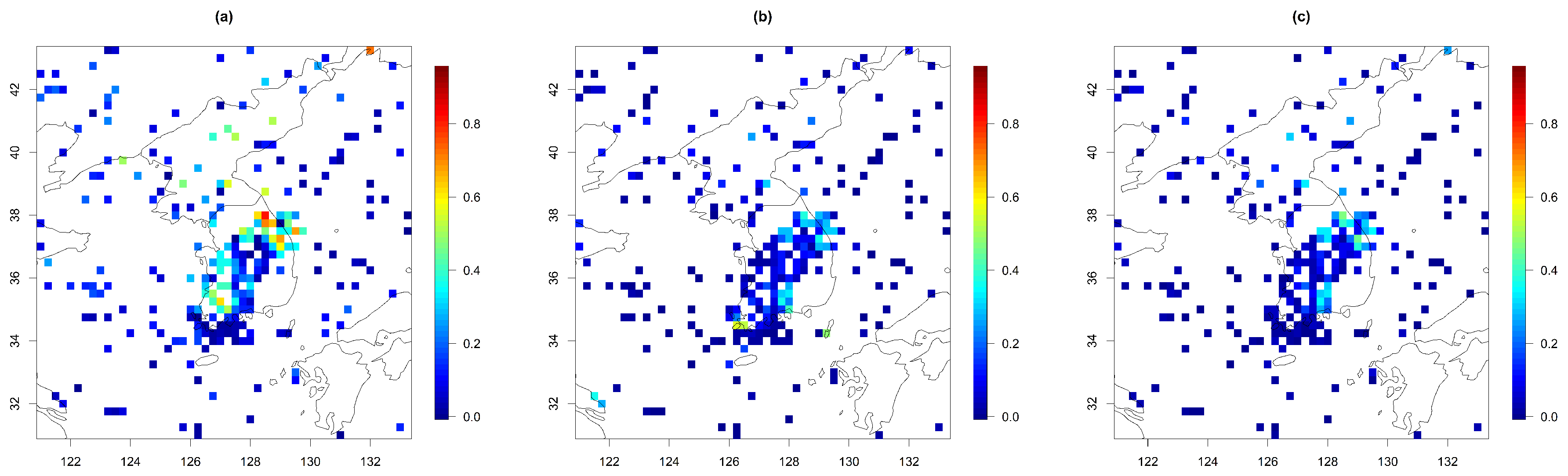
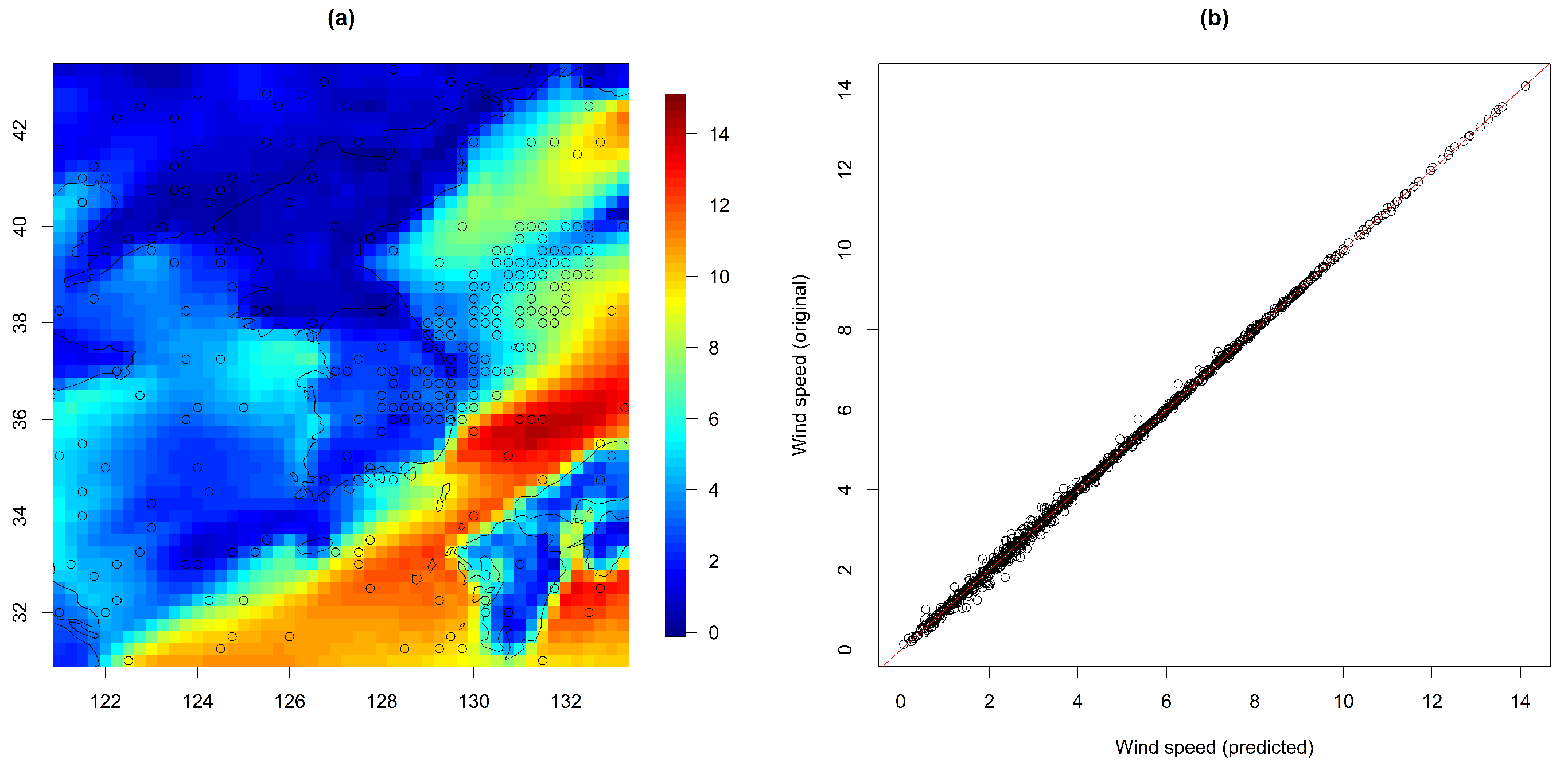
4.2. Prediction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Moomaw, W.; Yamba, F.; Kamimoto, M.; Maurice, L.; Nyboer, J.; Urama, K.; Weir, T.; Bruckner, T.; Jäger-Waldau, A.; Krey, V.; et al. Introduction. In IPCC Special Report on Renewable Energy Sources and Climate Change Mitigation; Edenhofer, O., Pichs-Madruga, R., Sokona, Y., Seyboth, K., Matschoss, P., Kadner, S., Zwickel, T., Eickemeier, P., Hansen, G., Schlömer, S., et al., Eds.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2011. [Google Scholar]
- Obama, B. The irreversible momentum of clean energy. Science 2017, 355, 126–129. [Google Scholar] [CrossRef] [PubMed]
- Barthelmie, R.; Pryor, S.C. Potential contribution of wind energy to climate change mitigation. Nat. Clim. Chang. 2014, 4, 684–688. [Google Scholar] [CrossRef]
- Koebrich, S.; Bowen, T.; Sharpe, A. 2018 Renewable Energy Data Book (No. NREL/BK-6A20-75284); National Renewable Energy Lab. (NREL): Golden, CO, USA, 2020. [Google Scholar]
- Hersbach, H.; Bell, B.; Berrisford, P.; Biavati, G.; Horányi, A.; Muñoz Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Rozum, I.; et al. ERA5 Hourly Data on Pressure Levels from 1979 to Present; Copernicus Climate Change Service (c3s) Climate Data Store (cds): Reading, UK, 2018; Volume 10. [Google Scholar]
- Jeong, J.; Castruccio, S.; Crippa, P.; Genton, M.G. Reducing Storage of Global Wind Ensembles with Stochastic Generators. Ann. Appl. Stat. 2018, 12, 490–509. [Google Scholar] [CrossRef]
- Jeong, J.; Yan, Y.; Castruccio, S.; Genton, M.G. A stochastic generator of global monthly wind energy with Tukey g-and-h autoregressive processes. Stat. Sin. 2019, 29, 1105–1126. [Google Scholar] [CrossRef]
- Tagle, F.; Castruccio, S.; Crippa, P.; Genton, M.G. A non-Gaussian spatio-temporal model for daily wind speeds based on a multi-variate skew-t distribution. J. Time Ser. Anal. 2019, 40, 312–326. [Google Scholar] [CrossRef]
- Chen, W.; Castruccio, S.; Genton, M.G.; Crippa, P. Current and future estimates of wind energy potential over Saudi Arabia. J. Geophys. Res. Atmos. 2018, 123, 6443–6459. [Google Scholar] [CrossRef]
- Tagle, F.; Genton, M.G.; Yip, A.; Mostamandi, S.; Stenchikov, G.; Castruccio, S. A high-resolution bilevel skew-t stochastic generator for assessing Saudi Arabia’s wind energy resources. Environmetrics 2020, 31, e2628. [Google Scholar]
- Giani, P.; Tagle, F.; Genton, M.G.; Castruccio, S.; Crippa, P. Closing the gap between wind energy targets and implementation for emerging countries. Appl. Energy 2020, 269, 115085. [Google Scholar] [CrossRef]
- Zhang, J.; Crippa, P.; Genton, M.G.; Castruccio, S. Sensitivity Analysis of Wind Energy Resources with Bayesian non-Gaussian and nonstationary Functional ANOVA. arXiv 2021, arXiv:2112.13136. [Google Scholar]
- Gualtieri, G. A comprehensive review on wind resource extrapolation models applied in wind energy. Renew. Sustain. Energy Rev. 2019, 102, 215–233. [Google Scholar] [CrossRef]
- Kim, S.; Lee, H.; Kim, H.; Jang, D.H.; Kim, H.J.; Hur, J.; Cho, Y.S.; Hur, K. Improvement in policy and proactive interconnection procedure for renewable energy expansion in South Korea. Renew. Sustain. Energy Rev. 2018, 98, 150–162. [Google Scholar] [CrossRef]
- Cripps, E.; Nott, D.; Dunsmuir, W.T.; Wikle, C. Space–Time Modelling of Sydney Harbour Winds. Aust. New Zealand J. Stat. 2005, 47, 3–17. [Google Scholar] [CrossRef]
- Ailliot, P.; Monbet, V.; Prevosto, M. An autoregressive model with time-varying coefficients for wind fields. Environmetrics 2006, 17, 107–117. [Google Scholar] [CrossRef]
- Ezzat, A.A.; Jun, M.; Ding, Y. Spatio-temporal short-term wind forecast: A calibrated regime-switching method. Ann. Appl. Stat. 2019, 13, 1484–1510. [Google Scholar] [CrossRef]
- Huang, H.; Castruccio, S.; Genton, M.G. Forecasting high-frequency spatio-temporal wind power with dimensionally reduced echo state networks. J. R. Stat. Soc. Ser. C Appl. Stat. 2022, 71, 449–466. [Google Scholar] [CrossRef]
- Ding, Y. Data Science for Wind Energy; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Chen, W.; Genton, M.G.; Sun, Y. Space-time covariance structures and models. Annu. Rev. Stat. Its Appl. 2021, 8, 191–215. [Google Scholar] [CrossRef]
- Fan, M.; Paul, D.; Lee, T.C.; Matsuo, T. Modeling tangential vector fields on a sphere. J. Am. Stat. Assoc. 2018, 113, 1625–1636. [Google Scholar] [CrossRef]
- Porcu, E.; Furrer, R.; Nychka, D. 30 Years of space–time covariance functions. Wiley Interdiscip. Rev. Comput. Stat. 2021, 13, e1512. [Google Scholar] [CrossRef]
- Yan, Y.; Jeong, J.; Genton, M.G. Multivariate transformed Gaussian processes. Jpn. J. Stat. Data Sci. 2020, 3, 129–152. [Google Scholar] [CrossRef]
- Wackernagel, H. Multivariate Geostatistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Tukey, J.W. Modern Techniques in Data Analysis. In Proceedings of the NSF-Sponsored Regional Research Conference, Southern Massachusetts University, North Dartmouth, MA, USA, 1977; Volume 7. [Google Scholar]
- Jones, M.C.; Pewsey, A. Sinh-arcsinh distributions. Biometrika 2009, 96, 761–780. [Google Scholar] [CrossRef]
- Yan, Y.; Genton, M.G. Non-Gaussian autoregressive processes with Tukey g-and-h transformations. Environmetrics 2019, 30, e2503. [Google Scholar] [CrossRef]
- Genton, M.G.; Kleiber, W. Cross-covariance functions for multivariate geostatistics. Stat. Sci. 2015, 30, 147–163. [Google Scholar] [CrossRef]
- Matérn, B. Spatial Variation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 36. [Google Scholar]
- Gneiting, T.; Kleiber, W.; Schlather, M. Matérn cross-covariance functions for multivariate random fields. J. Am. Stat. Assoc. 2010, 105, 1167–1177. [Google Scholar] [CrossRef]
- Bourotte, M.; Allard, D.; Porcu, E. A flexible class of non-separable cross-covariance functions for multivariate space–time data. Spat. Stat. 2016, 18, 125–146. [Google Scholar] [CrossRef]
- Kleiber, W.; Nychka, D. Nonstationary modeling for multivariate spatial processes. J. Multivar. Anal. 2012, 112, 76–91. [Google Scholar] [CrossRef]
- Jun, M. Matérn-based nonstationary cross-covariance models for global processes. J. Multivar. Anal. 2014, 128, 134–146. [Google Scholar] [CrossRef]
- Furrer, R.; Genton, M.G.; Nychka, D. Covariance Tapering for Interpolation of Large Spatial Datasets. J. Comput. Graph. Stat. 2006, 15, 502–523. [Google Scholar] [CrossRef]
- Cressie, N.; Johannesson, G. Fixed Rank Kriging for Very Large Spatial Data Sets. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2008, 70, 209–226. [Google Scholar] [CrossRef]
- Banerjee, S.; Gelfand, A.E.; Finley, A.O.; Sang, H. Gaussian Predictive Process Models for Large Spatial Data Sets. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2008, 70, 825–848. [Google Scholar] [CrossRef]
- Lindgren, F.; Rue, H.; Lindström, J. An Explicit Link Between Gaussian Fields and Gaussian Markov Random Fields: The Stochastic Partial Differential Equation Approach. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2011, 73, 423–498. [Google Scholar] [CrossRef]
- Katzfuss, M.; Guinness, J. A general framework for Vecchia approximations of Gaussian processes. Stat. Sci. 2021, 36, 124–141. [Google Scholar] [CrossRef]
- Heaton, M.J.; Datta, A.; Finley, A.O.; Furrer, R.; Guinness, J.; Guhaniyogi, R.; Gerber, F.; Gramacy, R.B.; Hammerling, D.; Katzfuss, M.; et al. A case study competition among methods for analyzing large spatial data. J. Agric. Biol. Environ. Stat. 2019, 24, 398–425. [Google Scholar] [CrossRef] [PubMed]
- Lindsay, B.G. Composite likelihood methods. Contemp. Math. 1988, 80, 221–239. [Google Scholar]
- Varin, C.; Reid, N.; Firth, D. An overview of composite likelihood methods. Stat. Sin. 2011, 21, 5–42. [Google Scholar]
- Hannachi, A.; Jolliffe, I.T.; Stephenson, D.B. Empirical orthogonal functions and related techniques in atmospheric science: A review. Int. J. Climatol. J. R. Meteorol. Soc. 2007, 27, 1119–1152. [Google Scholar] [CrossRef]
- Jeong, J.; Jun, M. A class of Matérn-like covariance functions for smooth processes on a sphere. Spat. Stat. 2015, 11, 1–18. [Google Scholar] [CrossRef]
- Peterson, E.W.; Hennessey, J.P., Jr. On the Use of Power Laws for Estimates of Wind Power Potential. J. Appl. Meteorol. 1978, 17, 390–394. [Google Scholar] [CrossRef]
- Newman, J.; Klein, P. Extrapolation of Wind Speed Data for Wind Energy Applications. In Proceedings of the Fourth Conference on Weather, Climate, and the New Energy Economy. Annual Meeting of the American Meteorological Society, Austin, TX, USA, 5–7 January 2013; Volume 7. [Google Scholar]
- Castruccio, S.; Guinness, J. An evolutionary spectrum approach to incorporate large-scale geographical descriptors on global processes. J. R. Stat. Soc. Ser. C (Appl. Stat.) 2017, 66, 329–344. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Parameters | Log-Likelihood | AIC | BIC | |
|---|---|---|---|---|
| Model 1 | 11 | 519.433 | −1016.865 | −914.900 |
| Model 2 | 13 | 650.794 | −1275.589 | −1155.084 |
| Model 3 | 9 | 525.153 | −1032.306 | −948.880 |
| a | b | r | |||||
|---|---|---|---|---|---|---|---|
| Model 1 | 0.259 | 0.930 | 0.999 | 0.999 | 131.059 | 4.685 | 0.853 |
| Model 2 | 0.065 | 1296.877 | 0.745 | 507.661 | 0.513 | 0.524 | |
| Model 3 | 0.155 | 4392.535 | <0.001 | <0.001 | 429.204 | 0.394 | 0.393 |
| Model 1 | 1.427 | 1.427 | 0.700 | 0.700 | <0.001 | ||
| Model 2 | 0.907 | 0.668 | 0.905 | 0.692 | <0.001 | <0.001 | |
| Model 3 | <0.001 | <0.001 |
| U | Model 1 | Model 2 | Model 3 | |||
|---|---|---|---|---|---|---|
| MAE (Land/Ocean) | RMSE (Land/Ocean) | MAE (Land/Ocean) | RMSE (Land/Ocean) | MAE (Land/Ocean) | RMSE (Land/Ocean) | |
| Min | 0.135 (10.174/0.103) | 0.187 (0.229/0.146) | 0.051 (0.085/0.030) | 0.089 (0.127/0.059) | 0.044 (0.066/0.026) | 0.072 (0.093/0.045) |
| 0.136 (0.189/0.109) | 0.192 (0.248/0.155) | 0.056 (0.097/0.034) | 0.104 (0.149/0.067) | 0.046 (0.078/0.028) | 0.079 (0.115,0.047) | |
| 0.139 (0.192/0.112) | 0.196 (0.253/0.158) | 0.060 (0.101/0.037) | 0.113 (0.158/0.075) | 0.047 (0.082/0.029) | 0.083 (0.122/0.051) | |
| Mean | 0.139 (0.192/0.111) | 0.196 (0.251/0.158) | 0.060 (0.104/0.037) | 0.117 (0.166/0.078) | 0.047 (0.081/0.029) | 0.084 (0.121/0.053) |
| 0.142 (0.195/0.113) | 0.200 (0.255/0.163) | 0.062 (0.109/0.039) | 0.120 (0.171/0.080) | 0.048 (0.084/0.030) | 0.086 (0.127/0.056) | |
| Max | 0.144 (0.205/0.117) | 0.207 (0.268/0.170) | 0.094 (0.158/0.059) | 0.256 (0.367/0.166) | 0.052 (0.091/0.033) | 0.095 (0.141/0.069) |
| V | Model 1 | Model 2 | Model 3 | |||
|---|---|---|---|---|---|---|
| MAE (land/Ocean) | RMSE (Land/Ocean) | MAE (Land/Ocean) | RMSE (Land/Ocean) | MAE (Land/Ocean) | RMSE (Land/Ocean) | |
| Min | 0.042 (0.073/0.022) | 0.076 (0.115/0.038) | 0.057 (0.099/0.030) | 0.104 (0.148/0.056) | 0.050 (0.084/0.026) | 0.090 (0.132/0.042) |
| 0.045 (0.078/0.025) | 0.089 (0.129/0.043) | 0.061 (0.105/0.036) | 0.110 (0.165/0.069) | 0.051 (0.090/0.030) | 0.097 (0.142/0.054) | |
| 0.046 (0.083/0.026) | 0.091 (0.140/0.049) | 0.064 (0.112/0.038) | 0.120 (0.172/0.077) | 0.054 (0.096/0.031) | 0.101 (0.150/0.058) | |
| Mean | 0.046 (0.082/0.027) | 0.094 (0.140/0.054) | 0.065 (0.113/0.038) | 0.125 (0.181/0.079) | 0.054 (0.096/0.032) | 0.103 (0.152/0.062) |
| 0.047 (0.085/0.029) | 0.096 (0.144/0.062) | 0.066 (0.119/0.040) | 0.128 (0.188/0.083) | 0.056 (0.100/0.033) | 0.106 (0.161/0.067) | |
| Max | 0.056 (0.101/0.034) | 0.133 (0.175/0.108) | 0.097 (0.165/0.059) | 0.254 (0.366/0.162) | 0.064 (0.110/0.040) | 0.131 (0.180/0.107) |
| Speed | Model 1 | Model 2 | Model 3 | |||
|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| Min | 0.102 | 0.150 | 0.054 | 0.093 | 0.049 | 0.083 |
| 0.104 | 0.157 | 0.055 | 0.099 | 0.051 | 0.090 | |
| 0.106 | 0.159 | 0.059 | 0.106 | 0.053 | 0.092 | |
| Mean | 0.107 | 0.159 | 0.059 | 0.111 | 0.053 | 0.093 |
| 0.109 | 0.162 | 0.062 | 0.114 | 0.054 | 0.096 | |
| Max | 0.115 | 0.174 | 0.076 | 0.205 | 0.062 | 0.112 |
| WPD | Model 1 | Model 2 | Model 3 | |||
|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| Min | 3.937 | 7.064 | 1.724 | 3.339 | 1.612 | 3.206 |
| 4.179 | 7.676 | 1.834 | 3.868 | 1.757 | 3.386 | |
| 4.261 | 7.885 | 1.993 | 4.276 | 1.866 | 3.749 | |
| Mean | 4.282 | 7.909 | 1.984 | 4.416 | 1.863 | 3.755 |
| 4.405 | 8.165 | 2.086 | 4.561 | 1.949 | 3.945 | |
| Max | 4.600 | 8.827 | 2.427 | 7.317 | 2.169 | 4.787 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, J.; Chang, W. Analysis of East Asia Wind Vectors Using Space–Time Cross-Covariance Models. Remote Sens. 2023, 15, 2860. https://doi.org/10.3390/rs15112860
Jeong J, Chang W. Analysis of East Asia Wind Vectors Using Space–Time Cross-Covariance Models. Remote Sensing. 2023; 15(11):2860. https://doi.org/10.3390/rs15112860
Chicago/Turabian StyleJeong, Jaehong, and Won Chang. 2023. "Analysis of East Asia Wind Vectors Using Space–Time Cross-Covariance Models" Remote Sensing 15, no. 11: 2860. https://doi.org/10.3390/rs15112860
APA StyleJeong, J., & Chang, W. (2023). Analysis of East Asia Wind Vectors Using Space–Time Cross-Covariance Models. Remote Sensing, 15(11), 2860. https://doi.org/10.3390/rs15112860