


Self-Supervised Remote Sensing Image Dehazing Network Based on Zero-Shot Learning


Abstract
:1. Introduction
- (1)
- This paper presents a novel zero-shot dehazing framework embedded with hazy image priors as pre-dehazing. The proposed method generates a cycle-consistent hazy image from the input, enabling zero-shot training with a single image, eliminating laborious data collection, and improving generalizability. Importantly, the prior-based pre-dehazing contributes to an accelerated convergence rate within the zero-shot learning paradigm of the network;
- (2)
- The DCP is embedded into the proposed framework to improve the dehazing capability and convergence efficacy, while two CNN-based RefineNets are implemented to refine the outputs of the DCP module. Consequently, the proposed method can produce pleasing results, even in scenarios where the DCP fails, embracing the advantages of both prior-based and learning-based methods;
- (3)
- Comprehensive experiments were conducted to evaluate the effectiveness of the proposed method. Both the quantitative and visual results demonstrate that our method is superior to other dehazing methods in processing both uniform and non-uniform RS hazy images. Moreover, the proposed method yields a substantial enhancement over the chosen prior-based method (DCP) in this study.
2. Related Work
2.1. Traditional Dehazing Methods
2.2. Learning-Based Dehazing Methods with Training Datasets
2.3. Zero-Shot Dehazing Methods
3. Methodology
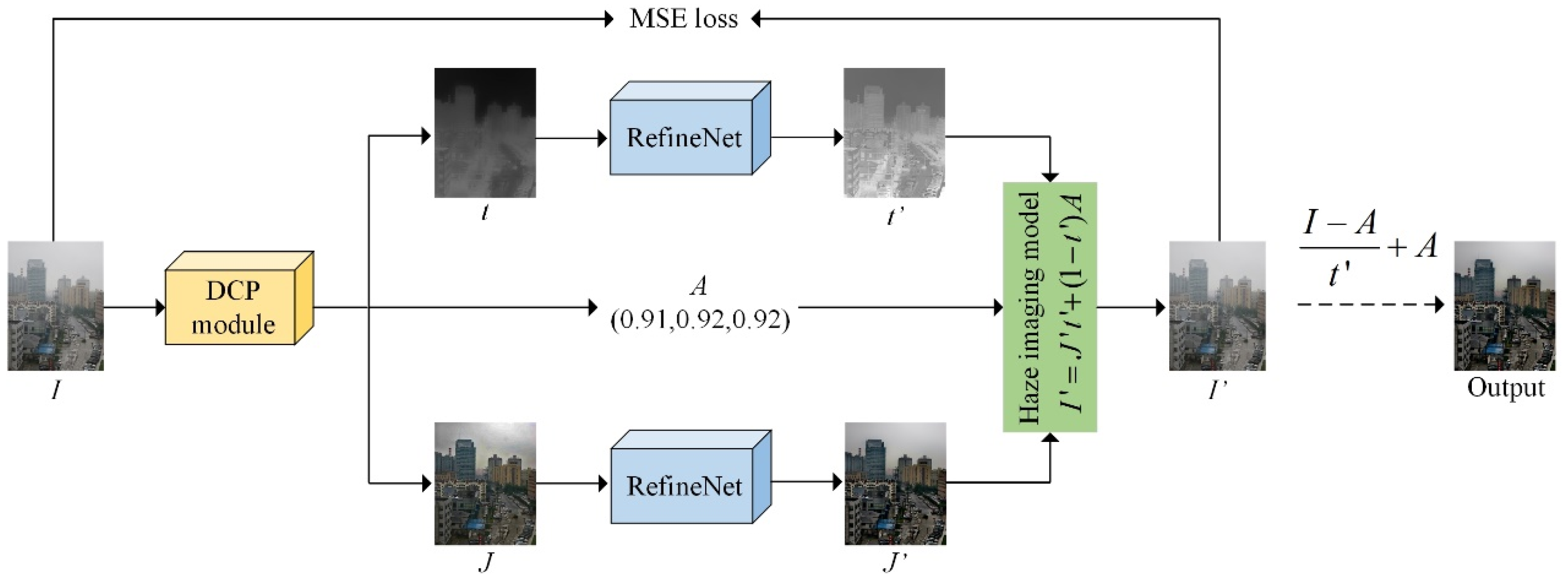
3.1. Overall Dehazing Framework
3.2. The DCP Module
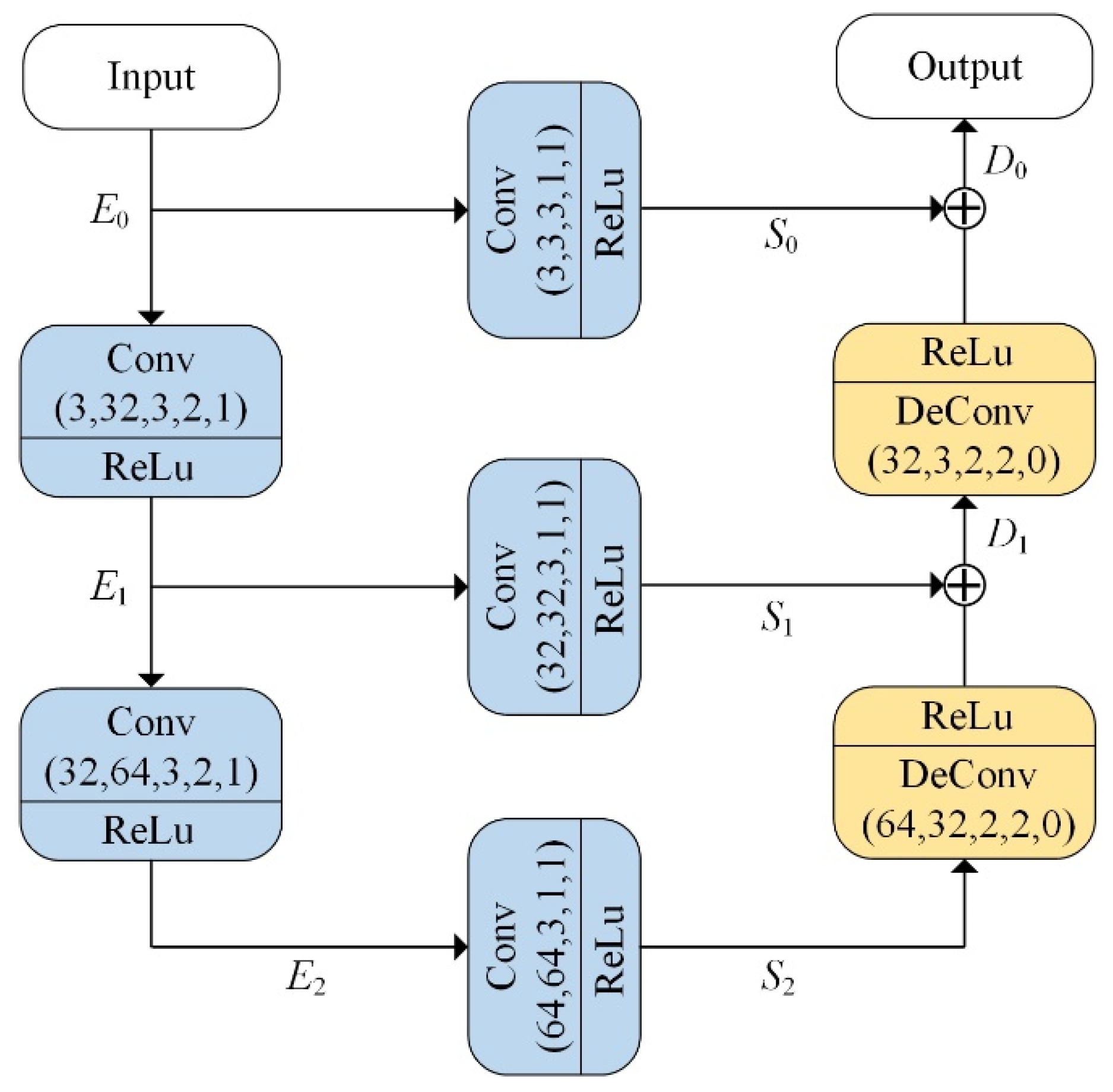
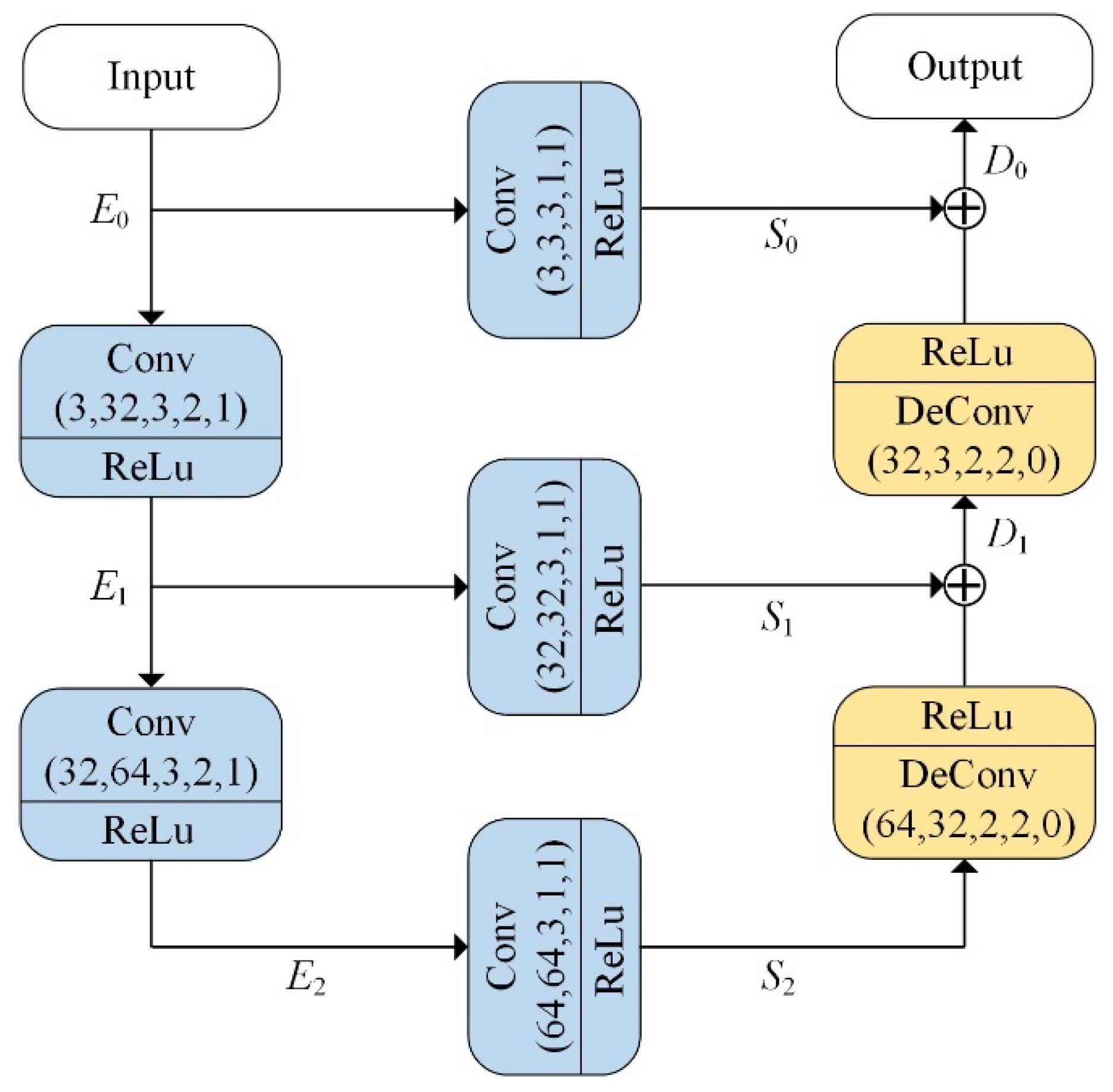
3.3. RefineNet
3.4. Loss Function Design
3.5. Functionality of Modules in the Dehazing Framework
4. Experiments and Discussions
4.1. Experimental Settings
| Algorithm 1: Zero-shot training details at each iteration, where indicates the DCP module for preliminary dehazing, and refer to the RefineNets for transmission map and initial dehazed image . | |
| Input: Initialized RefineNet , hazy image , max training iterations , balancing parameters and . | |
| Output: Dehazed image . | |
| 1: | while do |
| 2: | obtain initial dehazed image, , transmission map, , atmospheric light, , by |
| 3: | obtain refined dehazed image, , by |
| 4: | obtain refined transmission map, , by |
| 5: | obtain reconstructed hazy image, , by Equation (1), |
| 6: | obtain reconstruction loss, , by Equation (12) |
| 7: | obtain TV loss, , by Equation (13) |
| 8: | obtain DCP loss, , by Equation (14) |
| 9: | obtain minimum pixel intensity loss, , by Equation (15) |
| 10: | back propagate loss function, , by |
| 11: | |
| 12: | end while |
| 13: | obtain final dehazed output by |
4.2. Results for Real-World RS Hazy Images
4.3. Results on Synthetic Uniform RS Hazy Images
4.4. Results for Synthetic Non-Uniform RS Hazy Images
4.5. Application to a High-Level Vision Task
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.; Zhang, L. Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities. IEEE Geosci. Remote Sens. Mag. 2022, 10, 2–27. [Google Scholar] [CrossRef]
- Yang, F.; Guo, J.; Tan, H.; Wang, J. Automated extraction of urban water bodies from ZY-3 multi-spectral imagery. Water 2017, 9, 144. [Google Scholar] [CrossRef]
- Lian, R.; Zhang, Z.; Zou, C.; Huang, L. An Effective Road Centerline Extraction Method From VHR. IEEE Geosci. Remote Sens. Lett. 2022, 19, 69052025. [Google Scholar] [CrossRef]
- Yang, K.; Xia, G.-S.; Liu, Z.; Du, B.; Yang, W.; Pelillo, M.; Zhang, L. Asymmetric siamese networks for semantic change detection in aerial images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5609818. [Google Scholar] [CrossRef]
- Zhu, D.; Wang, B.; Zhang, L. Airport target detection in remote sensing images: A new method based on two-way saliency. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1096–1100. [Google Scholar]
- Liu, X.; Li, H.; Zhu, C. Joint contrast enhancement and exposure fusion for real-world image dehazing. IEEE Trans. Multimed. 2021, 24, 3934–3946. [Google Scholar] [CrossRef]
- Khan, H.; Sharif, M.; Bibi, N.; Usman, M.; Haider, S.A.; Zainab, S.; Shah, J.H.; Bashir, Y.; Muhammad, N. Localization of radiance transformation for image dehazing in wavelet domain. Neurocomputing 2020, 381, 141–151. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Single image dehazing using haze-lines. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 720–734. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Chen, W.-T.; Fang, H.-Y.; Ding, J.-J.; Kuo, S.-Y. PMHLD: Patch map-based hybrid learning DehazeNet for single image haze removal. IEEE Trans. Image Process. 2020, 29, 6773–6788. [Google Scholar] [CrossRef]
- Li, B.; Gou, Y.; Gu, S.; Liu, J.Z.; Zhou, J.T.; Peng, X. You only look yourself: Unsupervised and untrained single image dehazing neural network. Int. J. Comput. Vis. 2021, 129, 1754–1767. [Google Scholar] [CrossRef]
- Li, B.; Gou, Y.; Liu, J.Z.; Zhu, H.; Zhou, J.T.; Peng, X. Zero-shot image dehazing. IEEE Trans. Image Process. 2020, 29, 8457–8466. [Google Scholar] [CrossRef] [PubMed]
- Wei, J.; Wu, Y.; Chen, L.; Yang, K.; Lian, R. Zero-Shot Remote Sensing Image Dehazing Based on a Re-Degradation Haze Imaging Model. Remote Sens. 2022, 14, 5737. [Google Scholar] [CrossRef]
- Kar, A.; Dhara, S.K.; Sen, D.; Biswas, P.K. Zero-Shot Single Image Restoration Through Controlled Perturbation of Koschmieder’s Model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16205–16215. [Google Scholar]
- Zhao, S.; Zhang, L.; Shen, Y.; Zhou, Y. RefineDNet: A weakly supervised refinement framework for single image dehazing. IEEE Trans. Image Process. 2021, 30, 3391–3404. [Google Scholar] [CrossRef]
- Wang, W.; Yuan, X.; Wu, X.; Liu, Y. Fast image dehazing method based on linear transformation. IEEE Trans. Multimed. 2017, 19, 1142–1155. [Google Scholar] [CrossRef]
- Ni, W.; Gao, X.; Wang, Y. Single satellite image dehazing via linear intensity transformation and local property analysis. Neurocomputing 2016, 175, 25–39. [Google Scholar] [CrossRef]
- Cho, Y.; Jeong, J.; Kim, A. Model-assisted multiband fusion for single image enhancement and applications to robot vision. IEEE Robot. Autom. Lett. 2018, 3, 2822–2829. [Google Scholar]
- Han, Y.; Yin, M.; Duan, P.; Ghamisi, P. Edge-preserving filtering-based dehazing for remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8019105. [Google Scholar] [CrossRef]
- Singh, D.; Kumar, V.; Kaur, M. Single image dehazing using gradient channel prior. Appl. Intell. 2019, 49, 4276–4293. [Google Scholar] [CrossRef]
- Han, J.; Zhang, S.; Fan, N.; Ye, Z. Local patchwise minimal and maximal values prior for single optical remote sensing image dehazing. Inf. Sci. 2022, 606, 173–193. [Google Scholar] [CrossRef]
- Chen, T.; Liu, M.; Gao, T.; Cheng, P.; Mei, S.; Li, Y. A Fusion-Based Defogging Algorithm. Remote Sens. 2022, 14, 425. [Google Scholar] [CrossRef]
- Dharejo, F.A.; Zhou, Y.; Deeba, F.; Jatoi, M.A.; Du, Y.; Wang, X. A remote-sensing image enhancement algorithm based on patch-wise dark channel prior and histogram equalisation with colour correction. IET Image Process. 2021, 15, 47–56. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, X. Single Remote Sensing Image Dehazing Using a Dual-Step Cascaded Residual Dense Network. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3852–3856. [Google Scholar]
- Shi, Z.; Shao, S.; Zhou, Z. A saliency guided remote sensing image dehazing network model. IET Image Process. 2022, 16, 2483–2494. [Google Scholar] [CrossRef]
- Jiang, B.; Chen, G.; Wang, J.; Ma, H.; Wang, L.; Wang, Y.; Chen, X. Deep Dehazing Network for Remote Sensing Image with Non-Uniform Haze. Remote Sens. 2021, 13, 4443. [Google Scholar] [CrossRef]
- Engin, D.; Genç, A.; Ekenel, H.K. Cycle-dehaze: Enhanced cyclegan for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 825–833. [Google Scholar]
- Zheng, Y.; Su, J.; Zhang, S.; Tao, M.; Wang, L. Dehaze-AGGAN: Unpaired Remote Sensing Image Dehazing Using Enhanced Attention-Guide Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5630413. [Google Scholar] [CrossRef]
- Chen, X.; Huang, Y. Memory-Oriented Unpaired Learning for Single Remote Sensing Image Dehazing. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3511705. [Google Scholar] [CrossRef]
- Li, L.; Dong, Y.; Ren, W.; Pan, J.; Gao, C.; Sang, N.; Yang, M.H. Semi-supervised image dehazing. IEEE Trans. Image Process. 2019, 29, 2766–2779. [Google Scholar] [CrossRef]
- Bie, Y.; Yang, S.; Huang, Y. Single Remote Sensing Image Dehazing using Gaussian and Physics-Guided Process. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3512405. [Google Scholar] [CrossRef]
- Li, Y.; Chen, H.; Miao, Q.; Ge, D.; Liang, S.; Ma, Z.; Zhao, B. Image Hazing and Dehazing: From the Viewpoint of Two-Way Image Translation With a Weakly Supervised Framework. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Gandelsman, Y.; Shocher, A.; Irani, M. “double-dip”: Unsupervised image decomposition via coupled deep-image-priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11026–11035. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9446–9454. [Google Scholar]
- Singh, D.; Kumar, V. A comprehensive review of computational dehazing techniques. Arch. Comput. Methods Eng. 2019, 26, 1395–1413. [Google Scholar] [CrossRef]
- Zhang, K.; Ma, S.; Zheng, R.; Zhang, L. UAV Remote Sensing Image Dehazing Based on Double-Scale Transmission Optimization Strategy. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6516305. [Google Scholar] [CrossRef]
- Huang, B.; Zhi, L.; Yang, C.; Sun, F.; Song, Y. Single satellite optical imagery dehazing using SAR image prior based on conditional generative adversarial networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1806–1813. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Li, Z.; Zheng, X.; Bhanu, B.; Long, S.; Zhang, Q.; Huang, Z. Fast region-adaptive defogging and enhancement for outdoor images containing sky. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8267–8274. [Google Scholar]
- Li, H.; Li, J.; Zhao, D.; Xu, L. DehazeFlow: Multi-scale Conditional Flow Network for Single Image Dehazing. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event China, 20–24 October 2021; pp. 2577–2585. [Google Scholar]
- Chen, T.; Fu, J.; Jiang, W.; Gao, C.; Liu, S. SRKTDN: Applying super resolution method to dehazing task. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 487–496. [Google Scholar]
- Fu, M.; Liu, H.; Yu, Y.; Chen, J.; Wang, K. DW-GAN: A discrete wavelet transform GAN for nonhomogeneous dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 203–212. [Google Scholar]
- Li, J.; Li, Y.; Zhuo, L.; Kuang, L.; Yu, T. USID-Net: Unsupervised Single Image Dehazing Network via Disentangled Representations. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Method | Short Explanation |
|---|---|---|
| Traditional | DCP [8] | Dark channel prior |
| CEEF [6] | Joint contrast enhancement and exposure fusion | |
| FADE [41] | Fast region-adaptive defogging and enhancement | |
| Learning-based | DehazeFlow [42] | Multi-scale conditional flow dehazing network |
| SRKTDN [43] | Dehazing network with super-resolution method and knowledge transfer method | |
| DWGAN [44] | Discrete wavelet-transform GAN | |
| RefineDNet [17] | Weakly supervised refinement dehazing framework | |
| USIDNet [45] | Unsupervised single-image dehazing network via disentangled representations | |
| Zero-shot | ZID [14] | Zero-shot dehazing |
| DDIP [35] | Coupled deep image prior | |
| YOLY [13] | You only look yourself | |
| ZIR [16] | Zero-shot single-image restoration | |
| Ours | Our proposed dehazing method |
| Category | Methods | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| Traditional | DCP | 19.62 | 0.77 | 0.154 |
| CEEF | 20.26 | 0.75 | 0.163 | |
| FADE | 18.24 | 0.73 | 0.193 | |
| Learning-based | DehazeFlow | 19.41 | 0.78 | 0.151 |
| SRKTDN | 18.26 | 0.74 | 0.186 | |
| DWGAN | 18.89 | 0.77 | 0.163 | |
| RefineD-Net | 18.73 | 0.74 | 0.184 | |
| USIDNet | 18.44 | 0.74 | 0.191 | |
| Zero-shot | ZID | 18.16 | 0.74 | 0.189 |
| DDIP | 19.93 | 0.77 | 0.148 | |
| YOLY | 18.45 | 0.75 | 0.185 | |
| ZIR | 22.04 | 0.86 | 0.1 | |
| Ours | 21.66 | 0.88 | 0.098 |
| Category | Density | Thin | Moderate | Thick | Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Traditional | DCP | 17.07 | 0.82 | 0.123 | 16.93 | 0.81 | 0.130 | 15.81 | 0.76 | 0.159 | 16.61 | 0.80 | 0.137 |
| CEEF | 15.20 | 0.75 | 0.154 | 15.27 | 0.74 | 0.164 | 15.00 | 0.74 | 0.175 | 15.16 | 0.74 | 0.164 | |
| FADE | 15.97 | 0.76 | 0.149 | 14.92 | 0.72 | 0.179 | 14.28 | 0.72 | 0.185 | 15.05 | 0.73 | 0.171 | |
| Learning-based | DehazeFlow | 14.09 | 0.77 | 0.136 | 14.44 | 0.79 | 0.132 | 12.73 | 0.68 | 0.216 | 13.75 | 0.75 | 0.162 |
| SRKTDN | 14.36 | 0.77 | 0.191 | 14.20 | 0.80 | 0.178 | 13.42 | 0.73 | 0.233 | 14.00 | 0.77 | 0.201 | |
| DWGAN | 16.73 | 0.84 | 0.116 | 18.26 | 0.86 | 0.106 | 17.34 | 0.82 | 0.138 | 17.44 | 0.84 | 0.120 | |
| RefineDNet | 16.68 | 0.83 | 0.091 | 17.00 | 0.84 | 0.092 | 16.98 | 0.82 | 0.109 | 16.89 | 0.83 | 0.097 | |
| USIDNet | 18.99 | 0.78 | 0.170 | 18.51 | 0.76 | 0.185 | 17.39 | 0.73 | 0.207 | 18.30 | 0.76 | 0.187 | |
| Zero-shot | ZID | 11.32 | 0.57 | 0.218 | 12.02 | 0.60 | 0.202 | 12.20 | 0.61 | 0.212 | 11.85 | 0.59 | 0.211 |
| DDIP | 15.56 | 0.79 | 0.108 | 16.41 | 0.81 | 0.099 | 15.91 | 0.79 | 0.122 | 15.96 | 0.80 | 0.110 | |
| YOLY | 18.14 | 0.84 | 0.088 | 17.66 | 0.84 | 0.091 | 15.96 | 0.78 | 0.138 | 17.25 | 0.82 | 0.104 | |
| ZIR | 14.79 | 0.80 | 0.118 | 15.31 | 0.83 | 0.113 | 13.64 | 0.74 | 0.179 | 14.58 | 0.79 | 0.137 | |
| Ours | 17.54 | 0.84 | 0.084 | 17.91 | 0.86 | 0.086 | 16.85 | 0.81 | 0.120 | 17.43 | 0.84 | 0.098 | |
| Input | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|
| Hazy | 0.367 | 0.379 | 0.373 | 0.229 |
| Clear | 0.949 | 0.931 | 0.940 | 0.887 |
| Category | Method | Precision | Recall | F1-Score | IoU |
|---|---|---|---|---|---|
| Traditional | DCP | 0.854 | 0.853 | 0.854 | 0.745 |
| CEEF | 0.810 | 0.802 | 0.806 | 0.675 | |
| FADE | 0.646 | 0.665 | 0.655 | 0.487 | |
| Learning-based | DehazeFlow | 0.652 | 0.652 | 0.652 | 0.484 |
| SRKTDN | 0.860 | 0.862 | 0.861 | 0.756 | |
| DWGAN | 0.847 | 0.852 | 0.850 | 0.738 | |
| RefineDNet | 0.789 | 0.801 | 0.795 | 0.659 | |
| USIDNet | 0.732 | 0.750 | 0.741 | 0.589 | |
| Zero-shot | ZID | 0.614 | 0.636 | 0.625 | 0.455 |
| DDIP | 0.790 | 0.793 | 0.791 | 0.655 | |
| YOLY | 0.711 | 0.720 | 0.715 | 0.557 | |
| ZIR | 0.819 | 0.823 | 0.821 | 0.697 | |
| Ours | 0.863 | 0.862 | 0.862 | 0.758 |
| Method | ZID [14] | DDIP [35] | YOLY [13] | ZIR [16] | Ours |
|---|---|---|---|---|---|
| Params size (MB) | 39.49 | 1.64 | 38.14 | 0.51 | 0.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, J.; Cao, Y.; Yang, K.; Chen, L.; Wu, Y. Self-Supervised Remote Sensing Image Dehazing Network Based on Zero-Shot Learning. Remote Sens. 2023, 15, 2732. https://doi.org/10.3390/rs15112732
Wei J, Cao Y, Yang K, Chen L, Wu Y. Self-Supervised Remote Sensing Image Dehazing Network Based on Zero-Shot Learning. Remote Sensing. 2023; 15(11):2732. https://doi.org/10.3390/rs15112732
Chicago/Turabian StyleWei, Jianchong, Yan Cao, Kunping Yang, Liang Chen, and Yi Wu. 2023. "Self-Supervised Remote Sensing Image Dehazing Network Based on Zero-Shot Learning" Remote Sensing 15, no. 11: 2732. https://doi.org/10.3390/rs15112732
APA StyleWei, J., Cao, Y., Yang, K., Chen, L., & Wu, Y. (2023). Self-Supervised Remote Sensing Image Dehazing Network Based on Zero-Shot Learning. Remote Sensing, 15(11), 2732. https://doi.org/10.3390/rs15112732