
A VHR Bi-Temporal Remote-Sensing Image Change Detection Network Based on Swin Transformer

Abstract
1. Introduction
- Registration errors and illumination variation can lead to pseudo-variation owing to pixel shifts and differences in spectral features in images with the same semantic information in different time phases.
- To increase the detection ability of the model for small target changes without introducing too many parameters and computational overhead, and to balance the local and global sensory fields, we introduce the Swin transformer in the change detection coding path and propose a VHR dual-time remote-sensing image change detection network based on the Swin transformer.
- We designed a FAF module based on a soft attention mechanism, which guides the trimming of low-level feature responses using high-level features to make the model focus more on the change region in the decoding path, reducing the impact of complex backgrounds and irrelevant changes.
- We designed a series of experiments to validate our design and further explore and discuss the model. Based on these experiments, the parameters and structure of the standard model were adjusted to introduce a lightweight version.
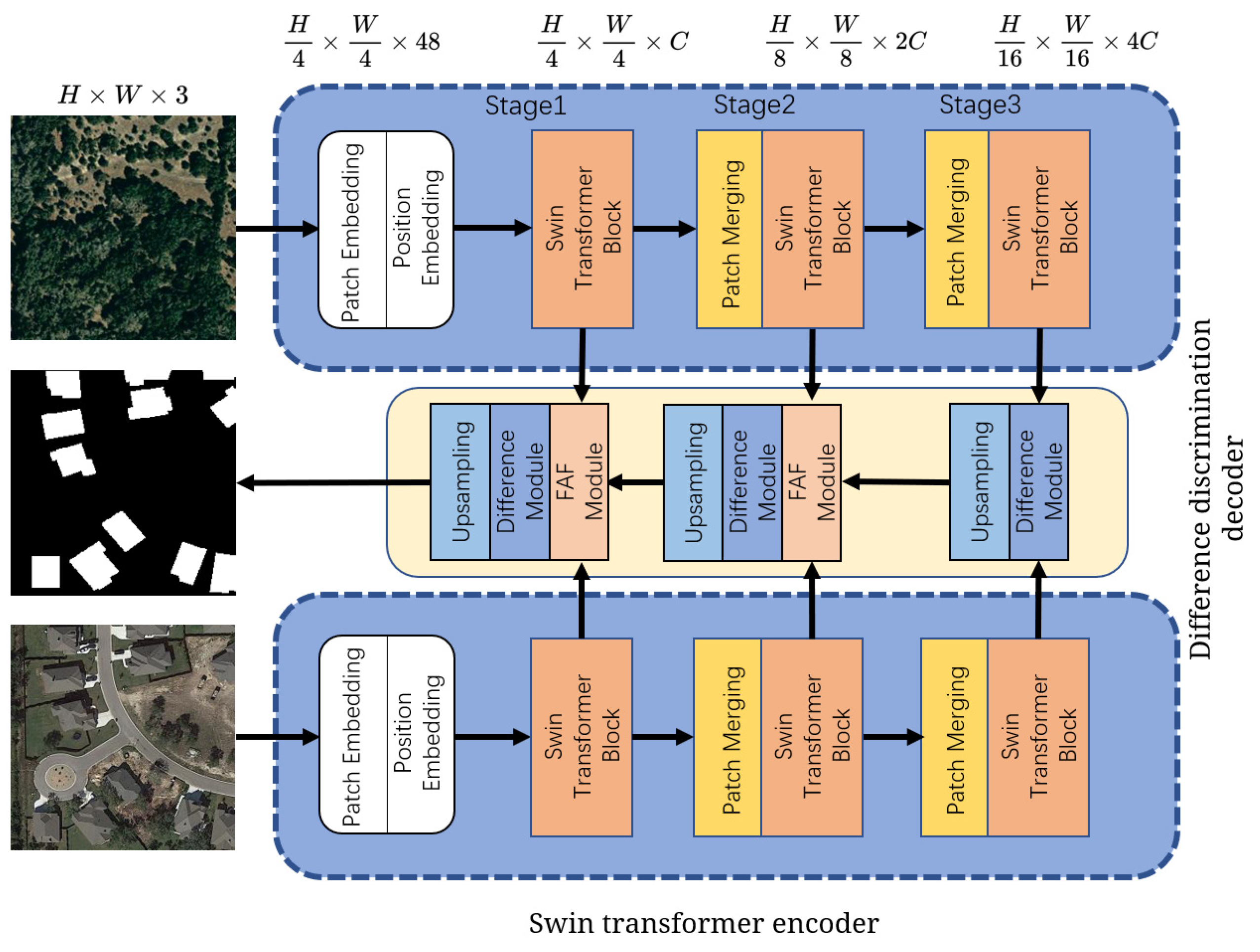
2. Methodology
2.1. Swin Transformer Encoder
2.1.1. Swin Transformer Block
2.1.2. Shifted-Window Design
2.2. Difference Discrimination Decoder
2.2.1. FAF Module
2.2.2. Difference Module
2.3. Loss Function
3. Experiments and Results
3.1. Datasets
3.1.1. LEVIR-CD
3.1.2. CCD
3.2. Evaluation Metrics
3.3. Implementation Details
3.4. Comparison with Other Methods
3.4.1. Experimental Results Obtained on the LEVIR-CD Dataset
3.4.2. Experimental Results Obtained on the CCD Dataset
4. Discussion
4.1. Ablation Studies
4.2. Parameter Analysis of Swin Transformer Encoder
4.3. Model Efficiency and Lightweight Version
4.4. Future Work Outlook
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, Y.; Lee, M.-J. Rapid Change Detection of Flood Affected Area after Collapse of the Laos Xe-Pian Xe-Namnoy Dam using Sentinel-1 GRD Data. Remote Sens. 2020, 12, 1978. [Google Scholar] [CrossRef]
- Gärtner, P.; Förster, M.; Kurban, A.; Kleinschmit, B. Object based change detection of Central Asian Tugai vegetation with very high spatial resolution satellite imagery. Int. J. Appl. Earth Obs. Geoinf. 2014, 31, 110–121. [Google Scholar] [CrossRef]
- Hulley, G.; Veraverbeke, S.; Hook, S. Thermal-based techniques for land cover change detection using a new dynamic MODIS multispectral emissivity product (MOD21). Remote Sens. Environ. 2014, 140, 755–765. [Google Scholar] [CrossRef]
- Khan, S.; He, X.; Porikli, F.; Bennamoun, M. Forest Change Detection in Incomplete Satellite Images with Deep Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5407–5423. [Google Scholar] [CrossRef]
- Jaturapitpornchai, R.; Matsuoka, M.; Kanemoto, N.; Kuzuoka, S.; Ito, R.; Nakamura, R. Newly Built Construction Detection in SAR Images Using Deep Learning. Remote Sens. 2019, 11, 1444. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, L.; Du, B. Kernel Slow Feature Analysis for Scene Change Detection. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2367–2384. [Google Scholar] [CrossRef]
- Al rawashdeh, S. Evaluation of the differencing pixel-by-pixel change detection method in mapping irrigated areas in dry zones. Int. J. Remote Sens. 2011, 32, 2173–2184. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Daudt, R.C.; Saux, B.L.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar] [CrossRef]
- Dong, R.; Pan, X.; Li, F. DenseU-Net-Based Semantic Segmentation of Small Objects in Urban Remote Sensing Images. IEEE Access 2019, 7, 65347–65356. [Google Scholar] [CrossRef]
- Li, X.; He, H.; Li, X.; Li, D.; Cheng, G.; Shi, J.; Weng, L.; Tong, Y.; Lin, Z. PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4215–4224. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J. Learning Deep Ship Detector in SAR Images from Scratch. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4021–4039. [Google Scholar] [CrossRef]
- Pang, J.; Li, C.; Shi, J.; Xu, Z.; Feng, H. Fast Tiny Object Detection in Large-Scale Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5512–5524. [Google Scholar] [CrossRef]
- Liu, J.; Xuan, W.; Gan, Y.; Zhan, Y.; Liu, J.; Du, B. An End-to-end Supervised Domain Adaptation Framework for Cross-Domain Change Detection. Pattern Recognit. 2022, 132, 108960. [Google Scholar] [CrossRef]
- Lin, M.; Yang, G.; Zhang, H. Transition Is a Process: Pair-to-Video Change Detection Networks for Very High Resolution Remote Sensing Images. IEEE Trans. Image Process. 2022, 32, 57–71. [Google Scholar] [CrossRef] [PubMed]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8007805. [Google Scholar] [CrossRef]
- Wang, H.; Cao, P.; Wang, J.; Zaïane, O. UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-Wise Perspective with Transformer. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2441–2449. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building Change Detection for Remote Sensing Images Using a Dual-Task Constrained Deep Siamese Convolutional Network Model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical Remote Sensing Image Change Detection Based on Attention Mechanism and Image Difference. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7296–7307. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, D.; Li, P.; Lv, P. Change Detection of Remote Sensing Images Based on Attention Mechanism. Comput. Intell. Neurosci. 2020, 2020, 6430627. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.-P.; Hsieh, J.-W.; Chen, P.-Y.; Hsieh, Y.-K.; Wang, B.-S. SARAS-Net: Scale and Relation Aware Siamese Network for Change Detection. arXiv 2022, arXiv:2212.01287. [Google Scholar] [CrossRef]
- Chen, P.; Hong, D.; Chen, Z.; Yang, X.; Li, B. FCCDN: Feature constraint network for VHR image change detection. ISPRS J. Photogramm. Remote Sens. 2022, 187, 101–119. [Google Scholar] [CrossRef]
- Wang, D.; Chen, X.; Guo, N.; Yi, H.; Li, Y. STCD: Efficient Siamese transformers-based change detection method for remote sensing images. Geo-Spat. Inf. Sci. 2023, 1–20. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wu, B.; Wang, S.; Yuan, X.; Wang, C.; Rudolph, C.; Yang, X. Defeating Misclassification Attacks Against Transfer Learning. IEEE Trans. Dependable Secur. Comput. 2023, 20, 886–901. [Google Scholar] [CrossRef]
- Playout, C.; Duval, R.; Boucher, M.C.; Cheriet, F. Focused Attention in Transformers for interpretable classification of retinal images. Med. Image Anal. 2022, 82, 102608. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Chen, W.; Du, X.; Yang, F.; Beyer, L.; Zhai, X.; Lin, T.-Y.; Chen, H.; Li, J.; Song, X.; Wang, Z.; et al. A Simple Single-Scale Vision Transformer for Object Detection and Instance Segmentation. In Computer Vision–ECCV 2022; Springer: Cham, Switzerland, 2022; pp. 711–727. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming Transformers for High-Resolution Image Synthesis. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12868–12878. [Google Scholar]
- Lee, K.; Chang, H.; Jiang, L.; Zhang, H.; Tu, Z.; Liu, C. ViTGAN: Training GANs with Vision Transformers. arXiv 2021, arXiv:2107.04589. [Google Scholar]
- Gao, M.; Yang, Q.F.; Ji, Q.X.; Wu, L.; Liu, J.; Huang, G.; Chang, L.; Xie, W.; Shen, B.; Wang, H.; et al. Probing the Material Loss and Optical Nonlinearity of Integrated Photonic Materials. In Proceedings of the 2021 Conference on Lasers and Electro-Optics (CLEO), San Jose, CA, USA, 9–14 May 2021; pp. 1–2. [Google Scholar]
- Liang, T.; Chu, X.; Liu, Y.; Wang, Y.; Tang, Z.; Chu, W.; Chen, J.; Ling, H. CBNetV2: A Composite Backbone Network Architecture for Object Detection. arXiv 2021, arXiv:2107.00420. [Google Scholar]
- Fang, Y.; Yang, S.; Wang, S.; Ge, Y.; Shan, Y.; Wang, X. Unleashing Vanilla Vision Transformer with Masked Image Modeling for Object Detection. arXiv 2022, arXiv:2204.02964. [Google Scholar]
- Sun, M.; Huang, X.; Sun, Z.; Wang, Q.; Yao, Y. Unsupervised Pre-training for 3D Object Detection with Transformer. In Proceedings of the Pattern Recognition and Computer Vision, Shenzhen, China, 4–7 November 2022; pp. 82–95. [Google Scholar]
- Chen, H.; Shi, Z.; Qi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]
- Wang, G.; Li, B.; Zhang, T.; Zhang, S. A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection. Remote Sens. 2022, 14, 2228. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. In Proceedings of the IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Mohammadian, A.; Ghaderi, F. SiamixFormer: A Siamese Transformer Network for Building Detection And Change Detection From Bi-Temporal Remote Sensing Images. arXiv 2022, arXiv:2208.00657. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.; Xu, D. Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images. arXiv 2022, arXiv:2201.01266. [Google Scholar]
- Xiao, X.; Guo, W.; Chen, R.; Hui, Y.; Wang, J.; Zhao, H. A Swin Transformer-Based Encoding Booster Integrated in U-Shaped Network for Building Extraction. Remote Sens. 2022, 14, 2611. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Lebedev, M.; Vizilter, Y.; Vygolov, O.; Knyaz, V.; Rubis, A. Change detection in remote sensing images using conditional adversarial networks. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-2, 565–571. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Chen, H.; Pu, F.; Yang, R.; Rui, T.; Xu, X. RDP-Net: Region Detail Preserving Network for Change Detection. arXiv 2022, arXiv:2202.09745. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Wang, J.; Ma, A.; Zhong, Y.; Zheng, Z.; Zhang, L. Cross-sensor domain adaptation for high spatial resolution urban land-cover mapping: From airborne to spaceborne imagery. Remote Sens. Environ. 2022, 277, 113058. [Google Scholar] [CrossRef]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2755–2763. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J.J.C.S. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | F1 | IoU | Precision | Recall | OA |
|---|---|---|---|---|---|
| FC-EF | 83.40 | 71.53 | 86.91 | 80.17 | 98.39 |
| FC-Siam-conc | 83.69 | 71.96 | 91.99 | 76.77 | 98.49 |
| FC-Siam-diff | 86.31 | 75.92 | 89.53 | 83.31 | 98.67 |
| DTCDSCN | 87.67 | 78.05 | 88.53 | 86.83 | 98.77 |
| STANet | 87.26 | 77.40 | 83.81 | 91.00 | 98.66 |
| IFNet | 88.13 | 78.77 | 94.02 | 82.93 | 98.87 |
| SNUNet | 88.16 | 78.83 | 89.18 | 87.17 | 98.82 |
| BIT | 89.31 | 80.68 | 89.24 | 89.37 | 98.92 |
| ChangeFormer | 90.40 | 82.48 | 92.05 | 88.80 | 99.04 |
| UVACD | 91.30 | 83.98 | 91.90 | 90.70 | 99.12 |
| RDP-Net | 88.77 | 79.81 | 88.43 | 89.11 | 98.86 |
| SARAS-Net | 90.40 | 82.49 | 91.48 | 89.35 | 98.95 |
| STCD | 89.85 | 81.58 | 92.91 | 86.99 | — |
| SFCD (ours) | 91.78 | 84.81 | 90.79 | 92.80 | 99.17 |
| Method | F1 | IoU | Precision | Recall | OA |
|---|---|---|---|---|---|
| FC-EF | 78.26 | 64.29 | 68.56 | 91.17 | 95.51 |
| FC-Siam-conc | 80.68 | 67.62 | 73.70 | 89.12 | 95.84 |
| FC-Siam-diff | 83.48 | 71.16 | 75.54 | 94.18 | 96.44 |
| DTCDSCN | 93.39 | 87.60 | 90.90 | 96.02 | 98.48 |
| UNet++ MSOF | 88.31 | 79.06 | 89.54 | 87.11 | 96.73 |
| IFN | 90.30 | 82.32 | 94.96 | 86.08 | 97.71 |
| DASNet | 91.94 | 85.09 | 91.40 | 92.50 | 98.20 |
| SNUNet | 96.33 | 92.89 | 96.27 | 96.40 | 99.14 |
| BIT | 95.70 | 91.75 | 95.59 | 95.81 | 98.99 |
| SDACD | 97.34 | 94.83 | 97.13 | 97.56 | — |
| RDP-Net | 97.21 | 94.56 | 97.19 | 97.23 | 99.34 |
| SFCD (ours) | 97.87 | 95.82 | 98.21 | 97.53 | 99.50 |
| Method | LEVIR-CD | CDD | ||||
|---|---|---|---|---|---|---|
| F1 (%) | IoU (%) | OA (%) | F1 (%) | IoU (%) | OA (%) | |
| w/o Swin, FAF | 90.13 | 82.04 | 99.02 | 95.61 | 91.59 | 98.97 |
| w/o Swin | 90.56 | 82.76 | 99.05 | 95.94 | 92.20 | 99.04 |
| w/o FAF | 91.37 | 84.09 | 99.13 | 97.48 | 95.08 | 99.40 |
| SFCD | 91.78 | 84.81 | 99.17 | 97.87 | 95.82 | 99.50 |
| Block/Stage | LEVIR-CD | CDD | ||||
|---|---|---|---|---|---|---|
| F1 (%) | IoU (%) | OA (%) | F1 (%) | IoU (%) | OA (%) | |
| (2,2) | 90.85 | 83.23 | 99.08 | 97.44 | 95.01 | 99.39 |
| (2,2,2) | 91.39 | 84.41 | 99.13 | 97.71 | 95.52 | 99.46 |
| (2,2,6) | 91.78 | 84.81 | 99.17 | 97.87 | 95.82 | 99.50 |
| (2,2,6,2) | 91.63 | 84.55 | 99.16 | 97.91 | 95.90 | 99.51 |
| Methods | Params (M) | LEVIR-CD | CCD | Test Time (ms) | ||
|---|---|---|---|---|---|---|
| F1 (%) | IoU (%) | F1 (%) | IoU (%) | |||
| DTCDSCN | 41.07 | 87.67 | 78.05 | 93.39 | 87.60 | 24.31 |
| UNet++ MSOF | 11.00 | — | — | 88.31 | 79.06 | — |
| STANet | 16.93 | 87.26 | 77.40 | — | — | 25.33 |
| IFNet | 50.17 | 88.13 | 78.77 | 90.30 | 82.32 | 30.75 |
| DASNet | 16.25 | 88.16 | 78.83 | 91.94 | 85.09 | 29.27 |
| SNUNet | 13.21 | 89.31 | 80.68 | 96.33 | 92.89 | 46.45 |
| BIT | 3.55 | 90.40 | 82.48 | 95.70 | 91.75 | 16.54 |
| ChangeFormer | 41.29 | 90.40 | 82.48 | — | — | 40.89 |
| SDACD | 50.40 | — | — | 97.34 | 94.83 | — |
| UVACD | >25.63 | 91.30 | 83.98 | — | — | — |
| RDP-Net | 1.70 | 88.77 | 79.81 | 97.21 | 94.56 | 15.66 |
| SARAS-Net | — | 90.40 | 82.49 | — | — | 92.68 |
| STCD | 9.26 | 89.85 | 81.58 | — | — | — |
| SFCD (ours) | 17.84 | 91.78 | 84.81 | 97.84 | 95.78 | 18.25 |
| SFCD-mi(ours) | 1.55 | 90.46 | 82.58 | 97.30 | 94.79 | 15.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teng, Y.; Liu, S.; Sun, W.; Yang, H.; Wang, B.; Jia, J. A VHR Bi-Temporal Remote-Sensing Image Change Detection Network Based on Swin Transformer. Remote Sens. 2023, 15, 2645. https://doi.org/10.3390/rs15102645
Teng Y, Liu S, Sun W, Yang H, Wang B, Jia J. A VHR Bi-Temporal Remote-Sensing Image Change Detection Network Based on Swin Transformer. Remote Sensing. 2023; 15(10):2645. https://doi.org/10.3390/rs15102645
Chicago/Turabian StyleTeng, Yunhe, Shuo Liu, Weichao Sun, Huan Yang, Bin Wang, and Jintong Jia. 2023. "A VHR Bi-Temporal Remote-Sensing Image Change Detection Network Based on Swin Transformer" Remote Sensing 15, no. 10: 2645. https://doi.org/10.3390/rs15102645
APA StyleTeng, Y., Liu, S., Sun, W., Yang, H., Wang, B., & Jia, J. (2023). A VHR Bi-Temporal Remote-Sensing Image Change Detection Network Based on Swin Transformer. Remote Sensing, 15(10), 2645. https://doi.org/10.3390/rs15102645