

FARMSAR: Fixing AgRicultural Mislabels Using Sentinel-1 Time Series and AutoencodeRs

Abstract
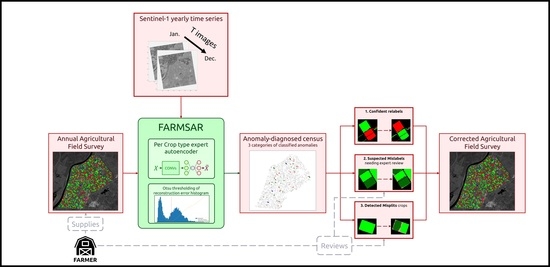
1. Introduction
- supervised anomaly detection, where a model is trained to detect anomalies that are labeled as such. Such an approach is prevalent in medical applications for novelty detection [19]. However, having a labeled anomaly dataset is rare, and such a training paradigm is not robust against unexpected anomalies.
- semi-supervised anomaly detection [20,21]: labels of anomalies and normal instances are still present but in a significant imbalance. In this context, deep autoencoders [22] are used. They are unsupervised deep learning models trained with a reconstruction task. In a semi-supervised context, they are trained only on normal observations. Then, deviating instances are used to fit a reconstruction performance threshold above which anomalies can be separated from the norm. However, despite requiring a much lower amount of anomalies than supervised anomaly detection, there is still a need for such labels. If there is no anomalous label on hand, one must use unsupervised anomaly detection.
- unsupervised anomaly detection [23]: methodologies of this kind train deep autoencoders in the same way, but without knowledge of which data point is normal and which is an anomaly. The distinction between the two classes is entirely made from data and is much harder to find. However, it is much more robust to new unseen kinds of anomalies.
- we use deep convolutional autoencoders to model, without supervision, the expected temporal signature of crops in Sentinel-1 multitemporal images.
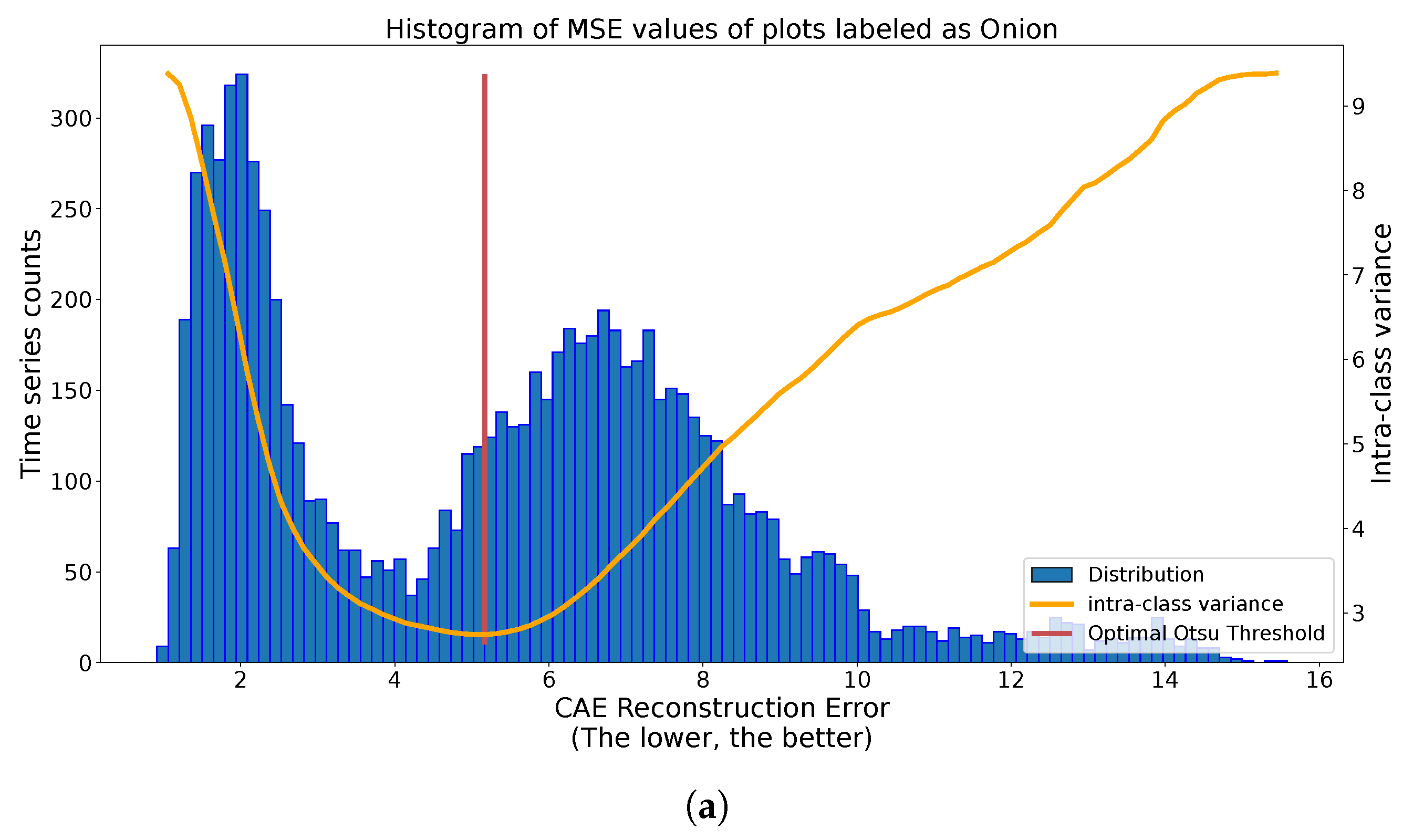
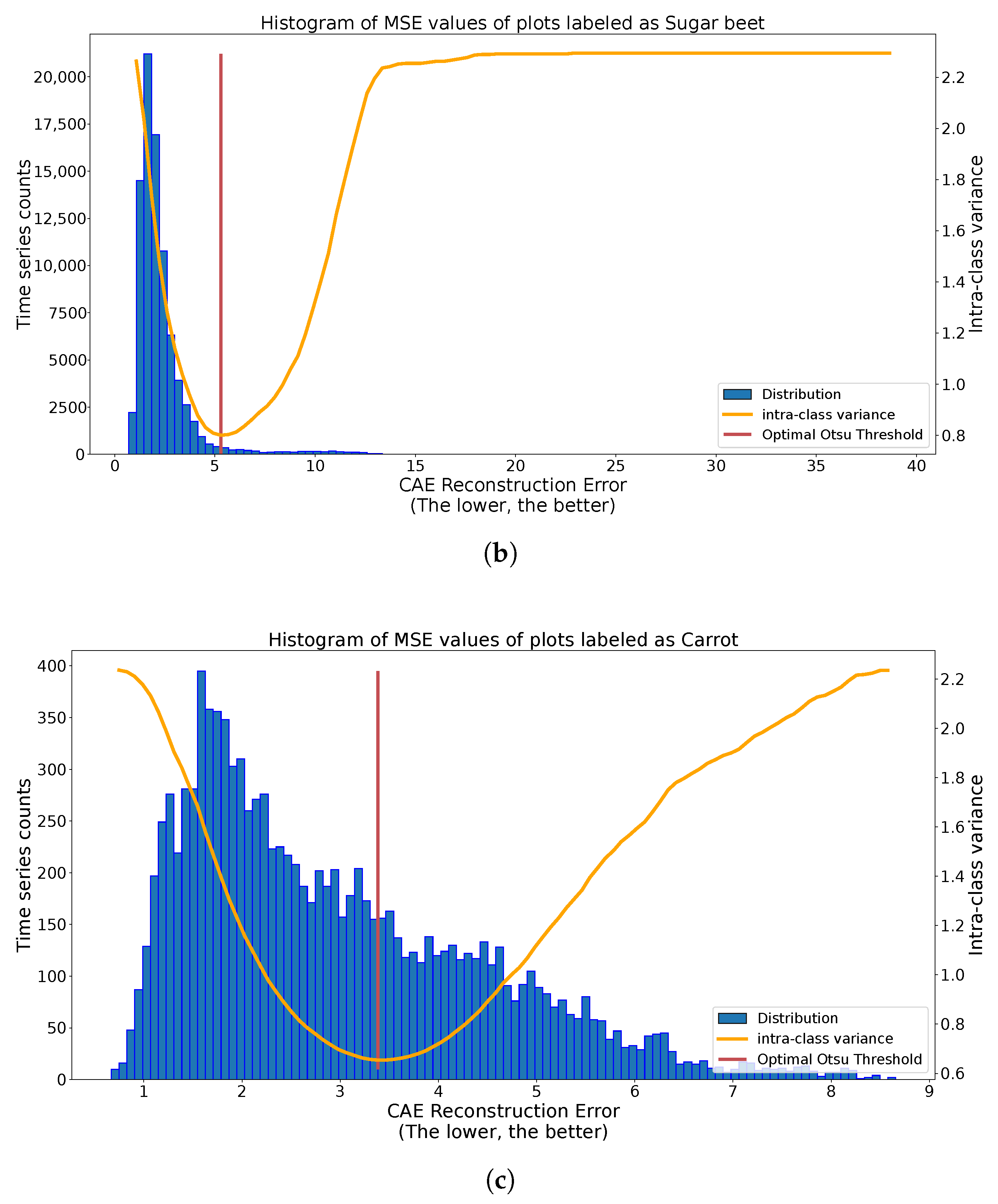
- we leverage the reconstruction performance of autoencoders as a class belongingness measure and present an automatic binary thresholding strategy for confidence relabeling using Otsu thresholding [31].
- we combine time series-level and parcel-level analysis to better extract and correct anomalies.
2. The Stakes in Agricultural Ground Truths
2.1. The Value of Ground Truths
2.2. The Difficulties of Building Agricultural Datasets
2.3. The Impacts of Errors in Ground Truth Data
2.4. Ontology of Studied Crop Type Errors
- Each parcel is atomic, because they are not supposed to be dividable into smaller parcels.
- The atomicity of parcels is assured by the homogeneity of the crop type: every part of the parcel contains the same plant. We can then assign to the field this crop type as a class.
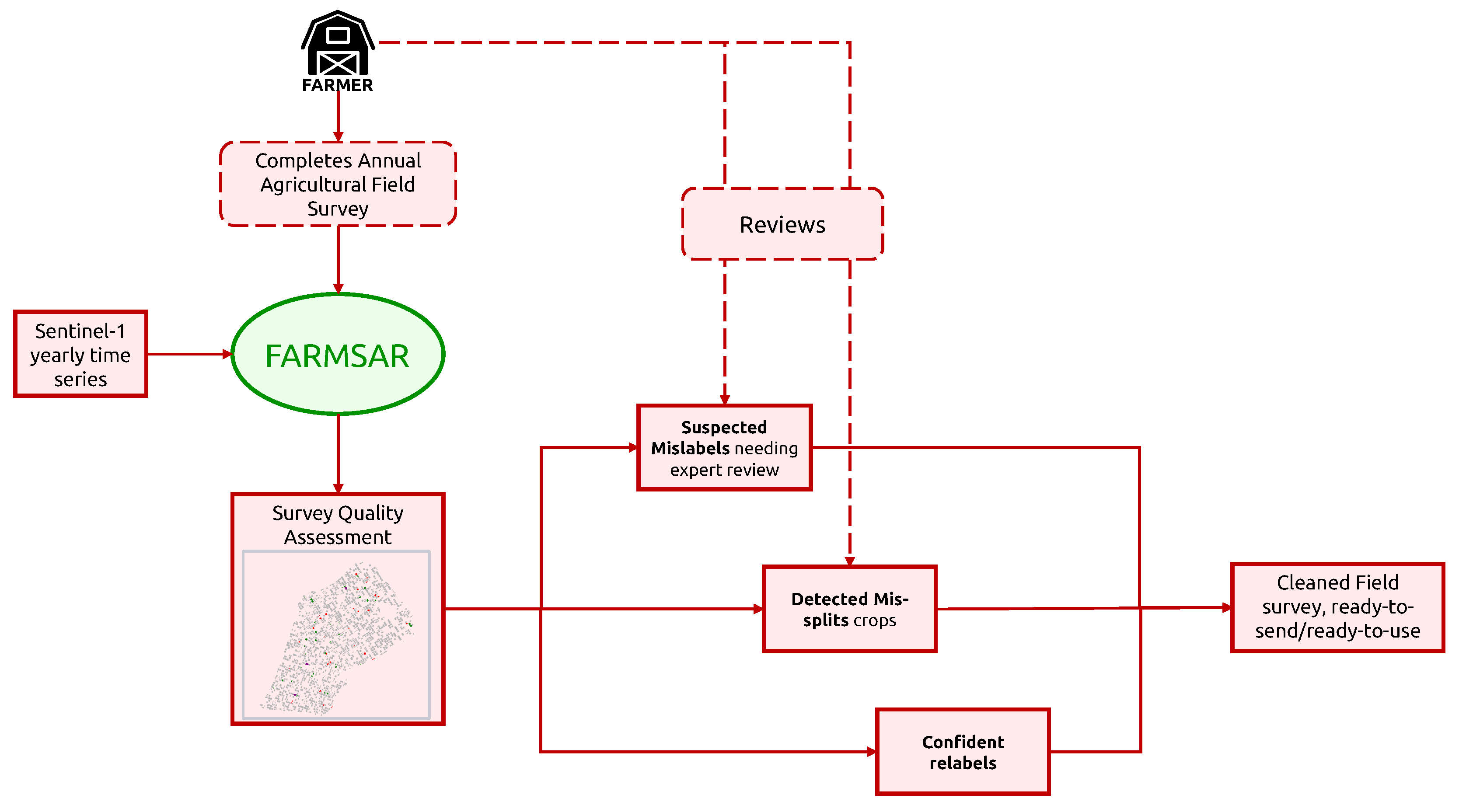
3. The FARMSAR Methodology
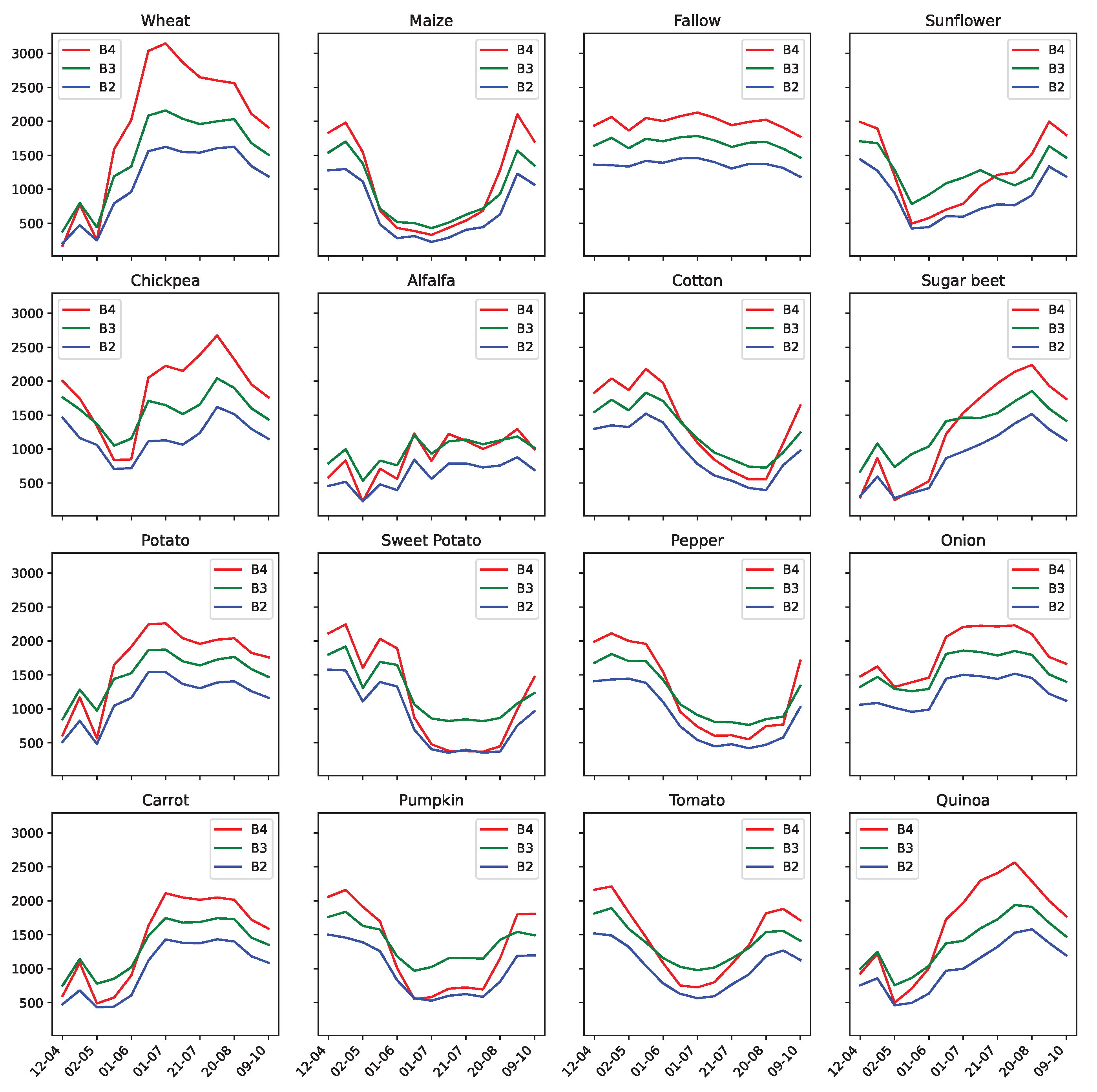
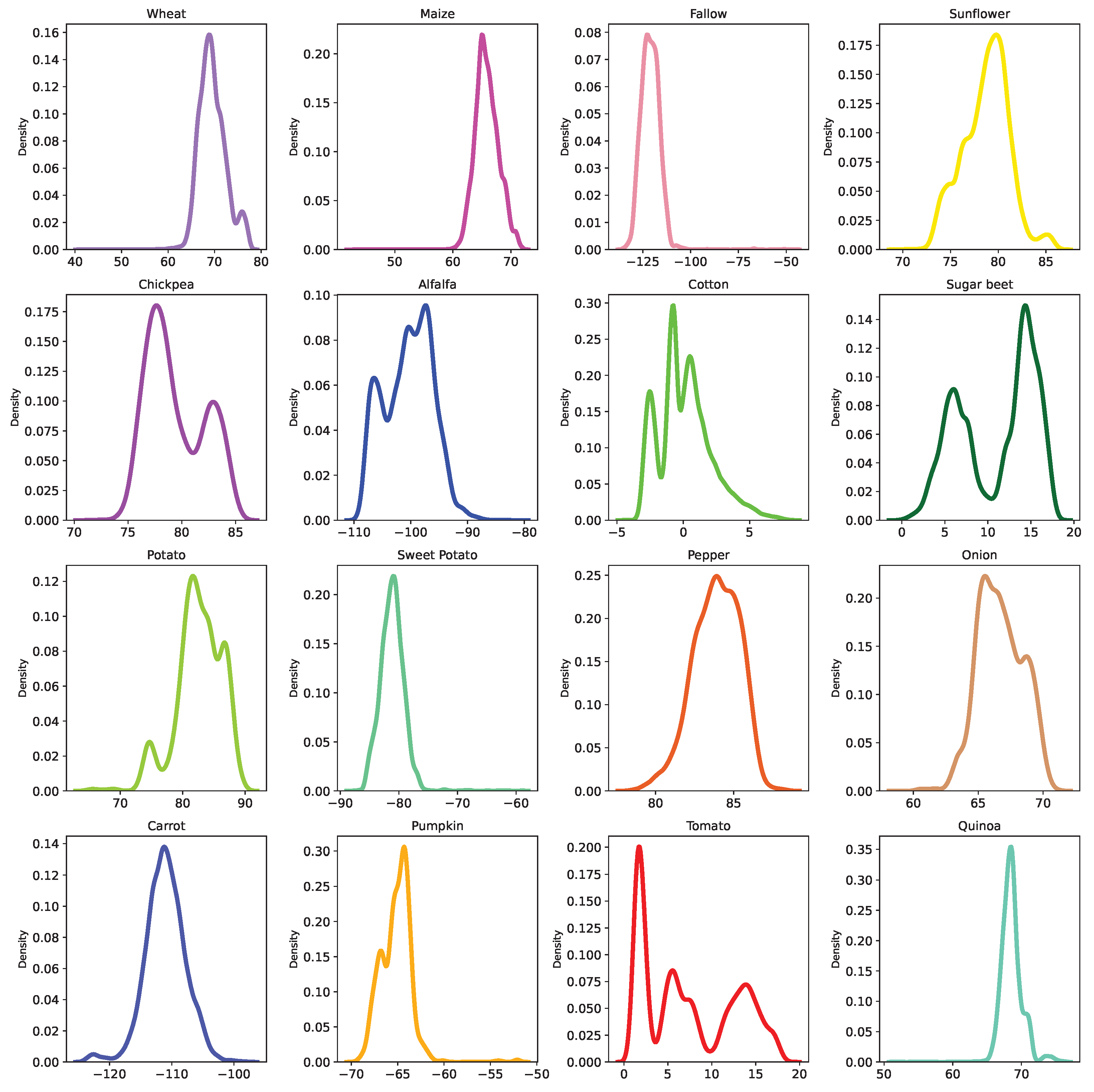
3.1. SAR Temporal Modeling of Crops, a Study Case of Sector BXII, Sevilla
- A first group, representing 50% of the crops (field-wise), is used for quantitative validation of the methodology. In this group, we filter out any suspicious crop, with a process that we detail in the following sections, only to keep crops with high confidence in the veracity of their labels. We then perform repeated random introduction of label errors ten separate times for accurate statistical and numerical evaluation of the proposed methodology. The reader may also find details of this process in the validation section.
- A second group, representing the other 50% of the crops, illustrates the methodology workflow and is corrected. We extract what FARMSAR classifies as mis-split and mislabeled crops and evaluate the appointed corrections qualitatively using Sentinel-2 imagery.
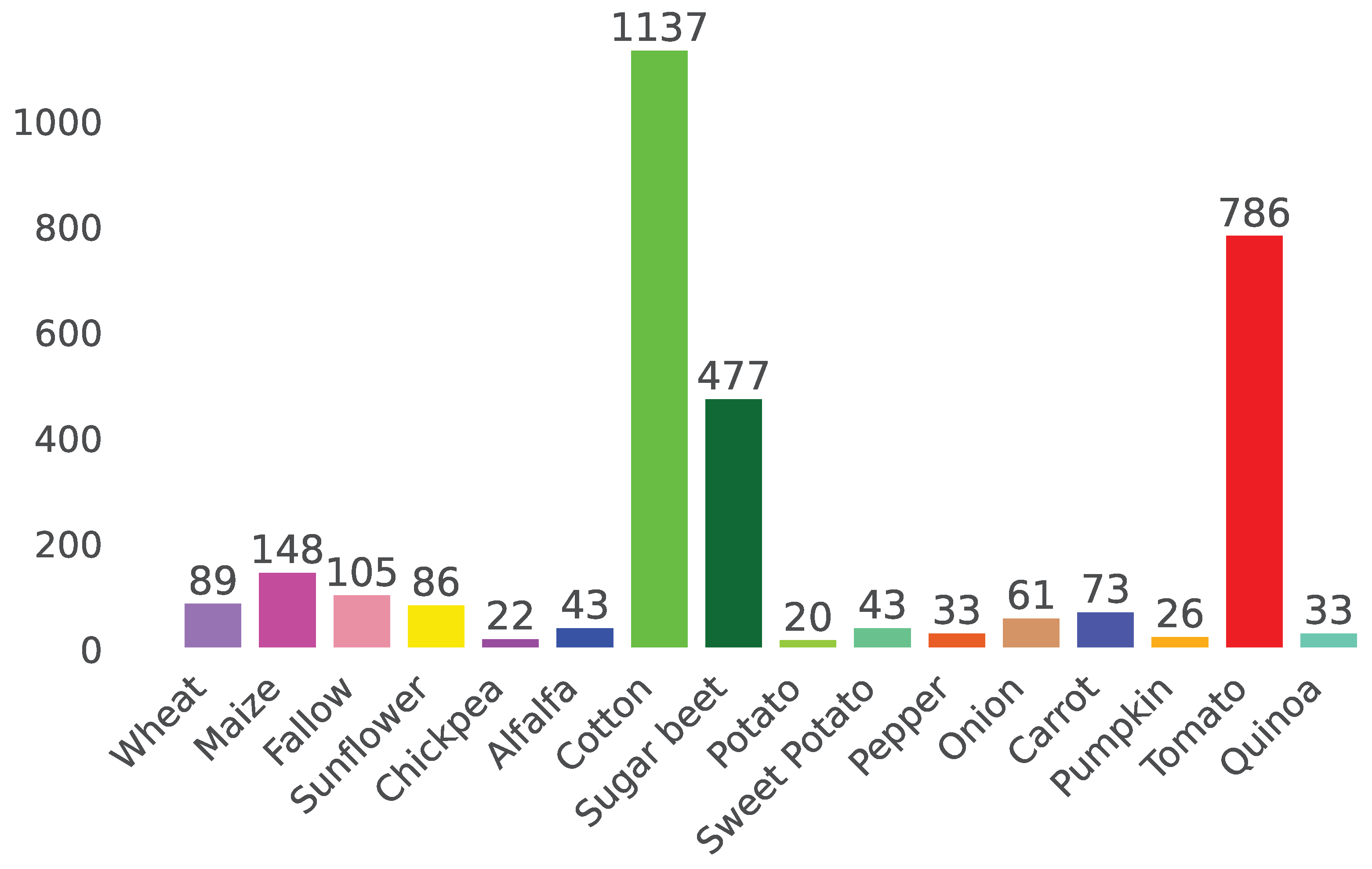
3.2. Convolutional Autoencoder for SAR Time Series
- The convolutional encoder uses convolutions to extract temporal features from the input time series that are then transformed by a stack of fully-connected layers (FC Layers), with Exponential Linear Unit (ELU) activation functions [40], and projected onto an embedding space of low dimension.
- The decoder consists of a stack of fully-connected layers, combined with ELU activation functions, tasked with reconstructing the original time series, from the embedding space representation, through a mean square error loss function computed between the input time series and the output of the decoder.
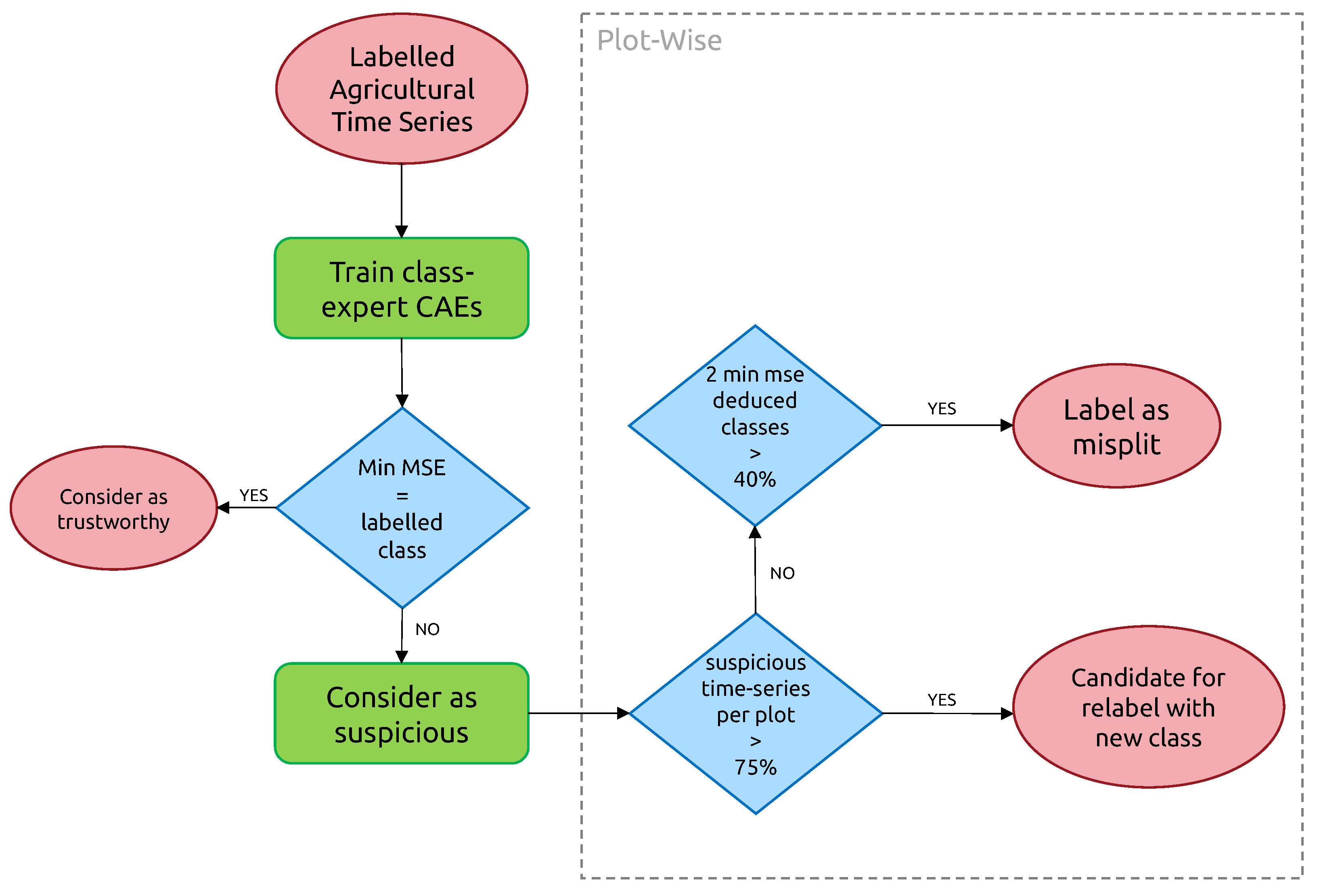
3.3. Detection of Mis-Split and Mislabeled Crops
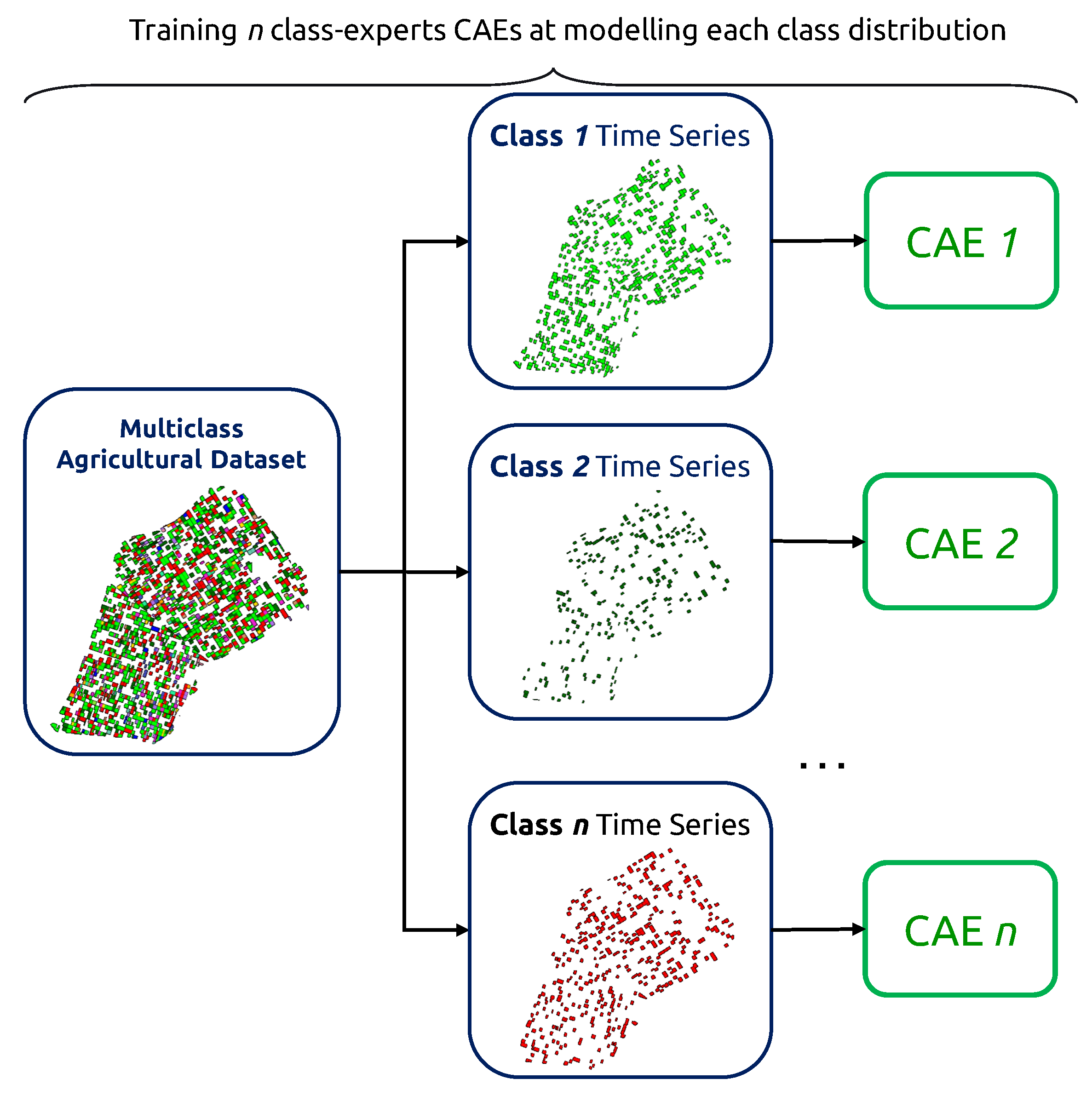
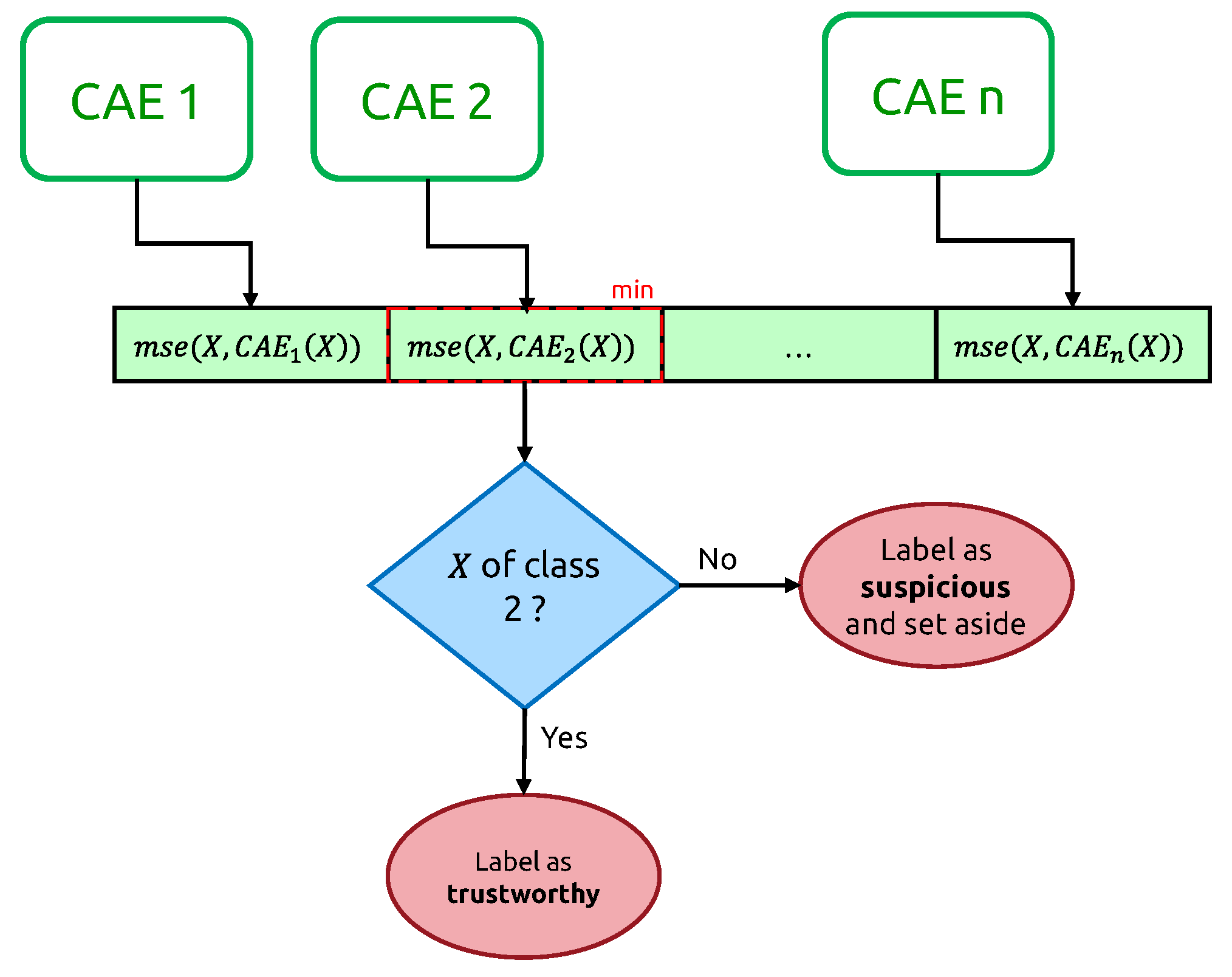
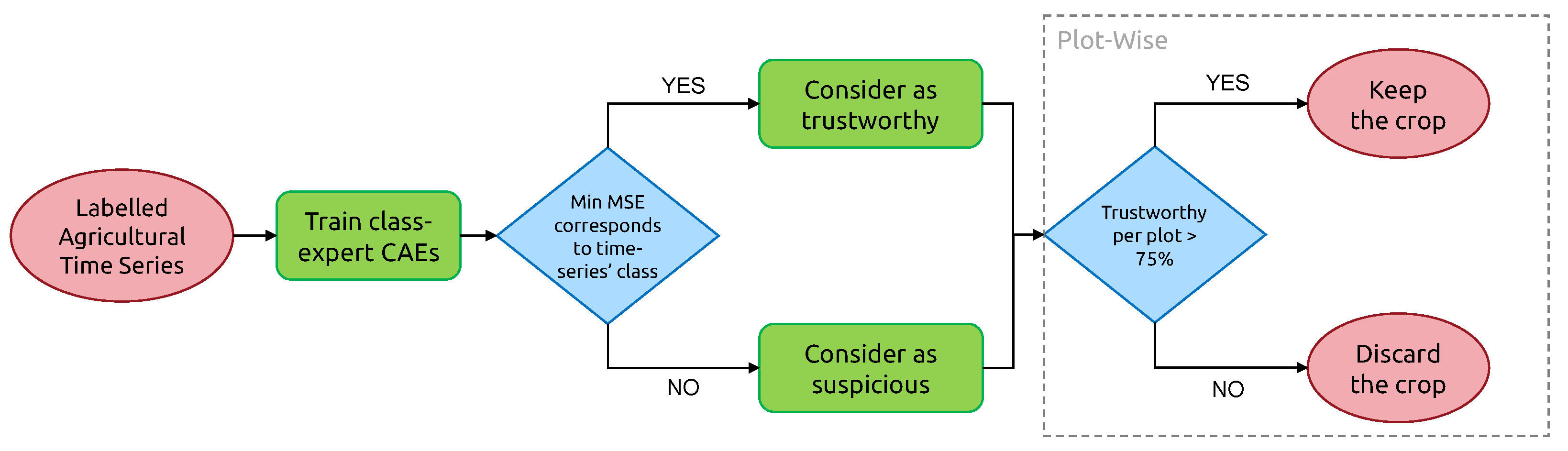
3.3.1. Iterative Training of Class-Expert CAEs
| Algorithm 1 Iterative training of CAE, with removal of suspicious elements |
|
3.3.2. Plot-Level Classification of Time Series Anomalies
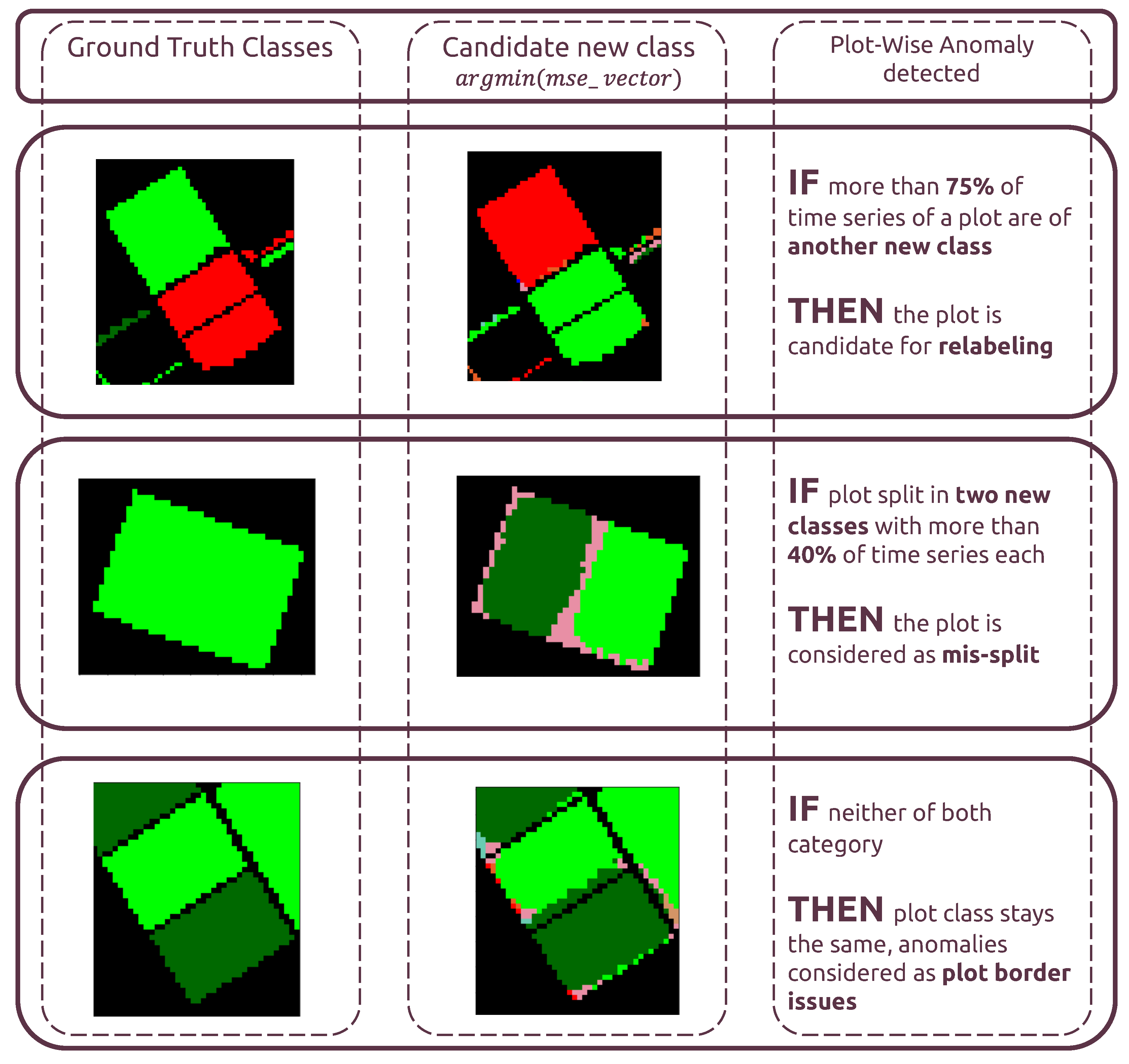
- “Candidate for relabeling”: we consider a plot as a candidate for relabeling when more than 75% of the pixel-wise time series within the field are of the same new class. We empirically chose the value of 75% as “edge cases“ can represent up to 20% of the time series-level mislabels within a field. Allowing a margin of error of approximately 5%, we thus reach the threshold of 75%.
- “Mis-split plot”: we consider a plot as “mis-split” if two different classes are present with the crops boundaries, according to each time series’ candidate new class, with each representing at least 40% of the plot size. The 40% criteria is also empirically found, as a field composed of at least two candidates classes, each representing 40% of its inner time series, will have 80% categorized as candidates classes, leaving up to 20% of the rest to potential edge cases.
- “Edge Cases”: we consider any other time series-level anomaly as edge cases. We believe they arise for multiple reasons, including differences in resolution between the labels and the satellite imagery, the preprocessing of Sentinel-1 data, which included boxcar despeckling, or approximate incorrect geolocation of labels/SAR data.
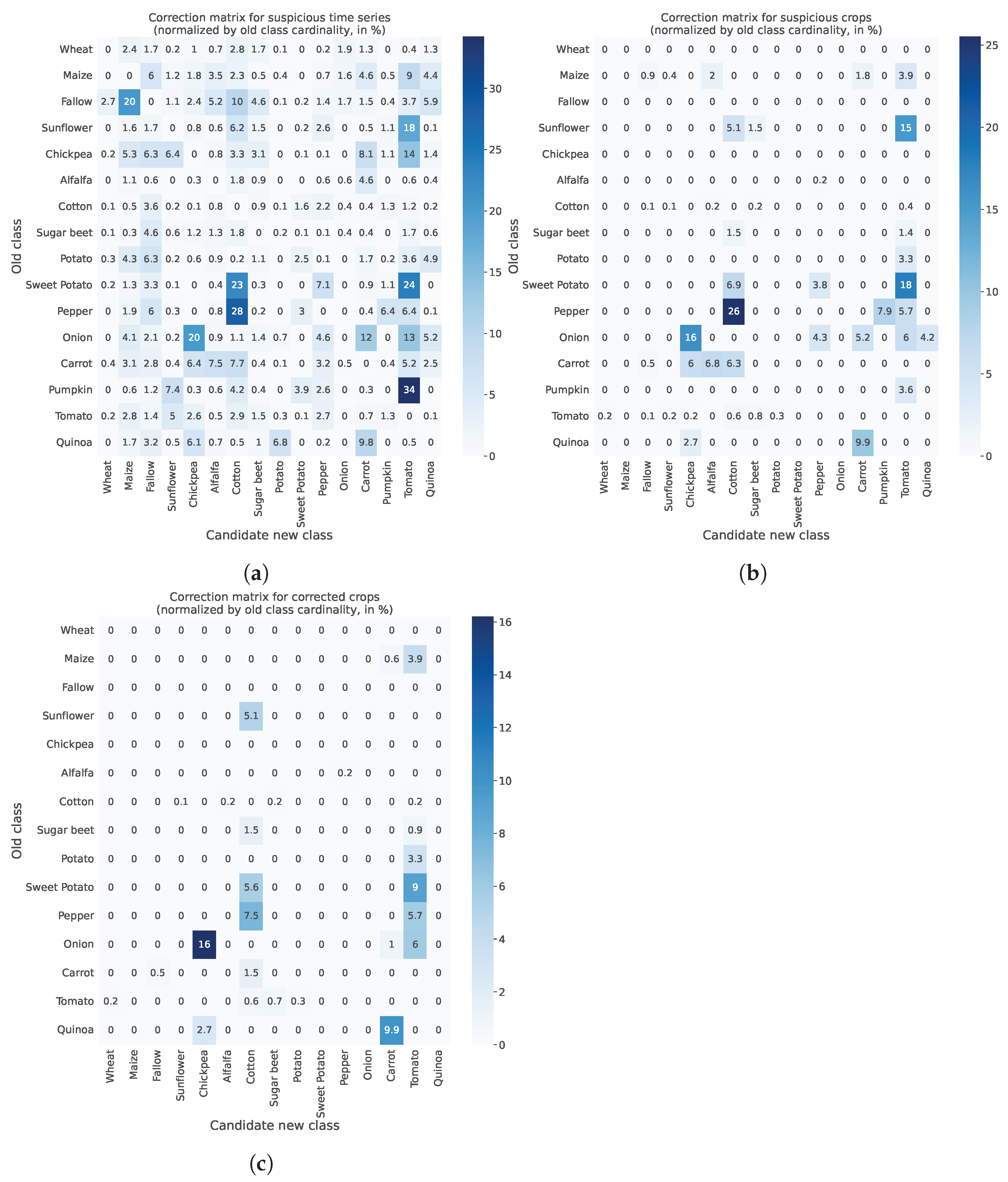
3.4. Correction of Mislabeled Crops
- The prior class of a given time series is not correct (i.e., class outlier detection). We model this using .
- A given time series belongs to the new candidate class (i.e., class belongingness detection). We model this using .
- Check that the parcel is among the least well reconstructed of its ground truth class, i.e., .
- Check that the parcel is among the best reconstructed of its new class,i.e., .
4. Numerical Validation of the Methodology
4.1. Quantitative Validation Scheme: A Controlled Disturbed Environment
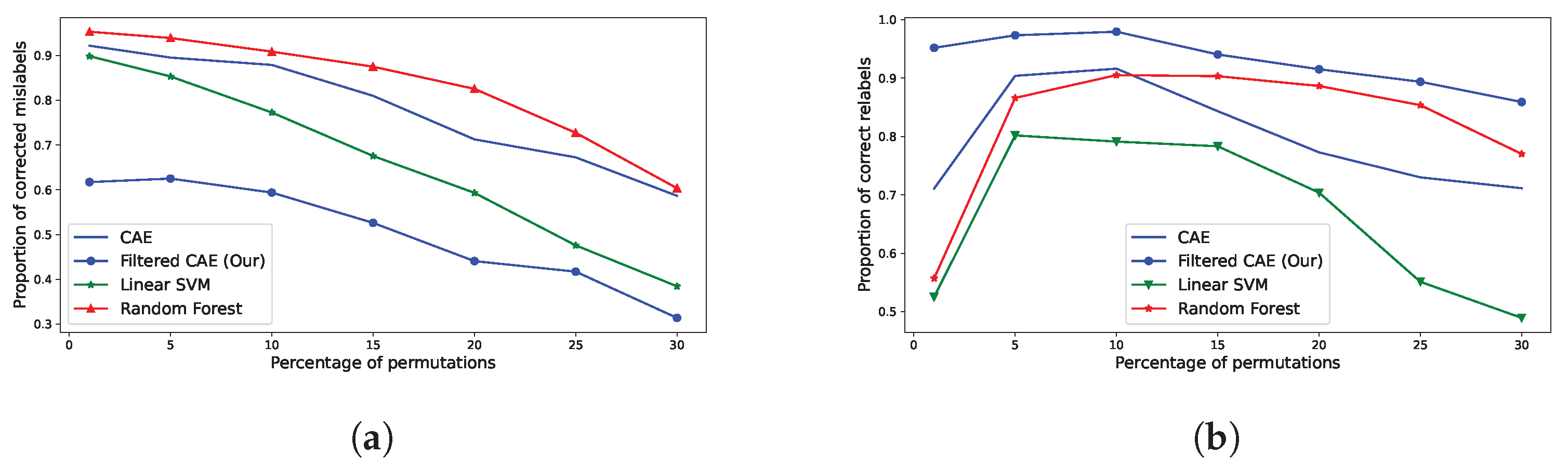
4.2. Correction Performance, a Comparison with Supervised and Unsupervised Methods
- How many mislabels are correctly relabeled?This metric offers a measure of how many mislabels we expect to miss, given the chosen method. It provides an approximate of how many mistakes may be remaining in the cleaned crop type survey (without taking into account mistakes that may be added by the correcting algorithms themselves).
- Out of every relabels, how many are correct?Given a set of corrections, this metric provides an estimate of how many are erroneous. In other words, it is similar to estimating how many mistakes are introduced by the correcting algorithm.
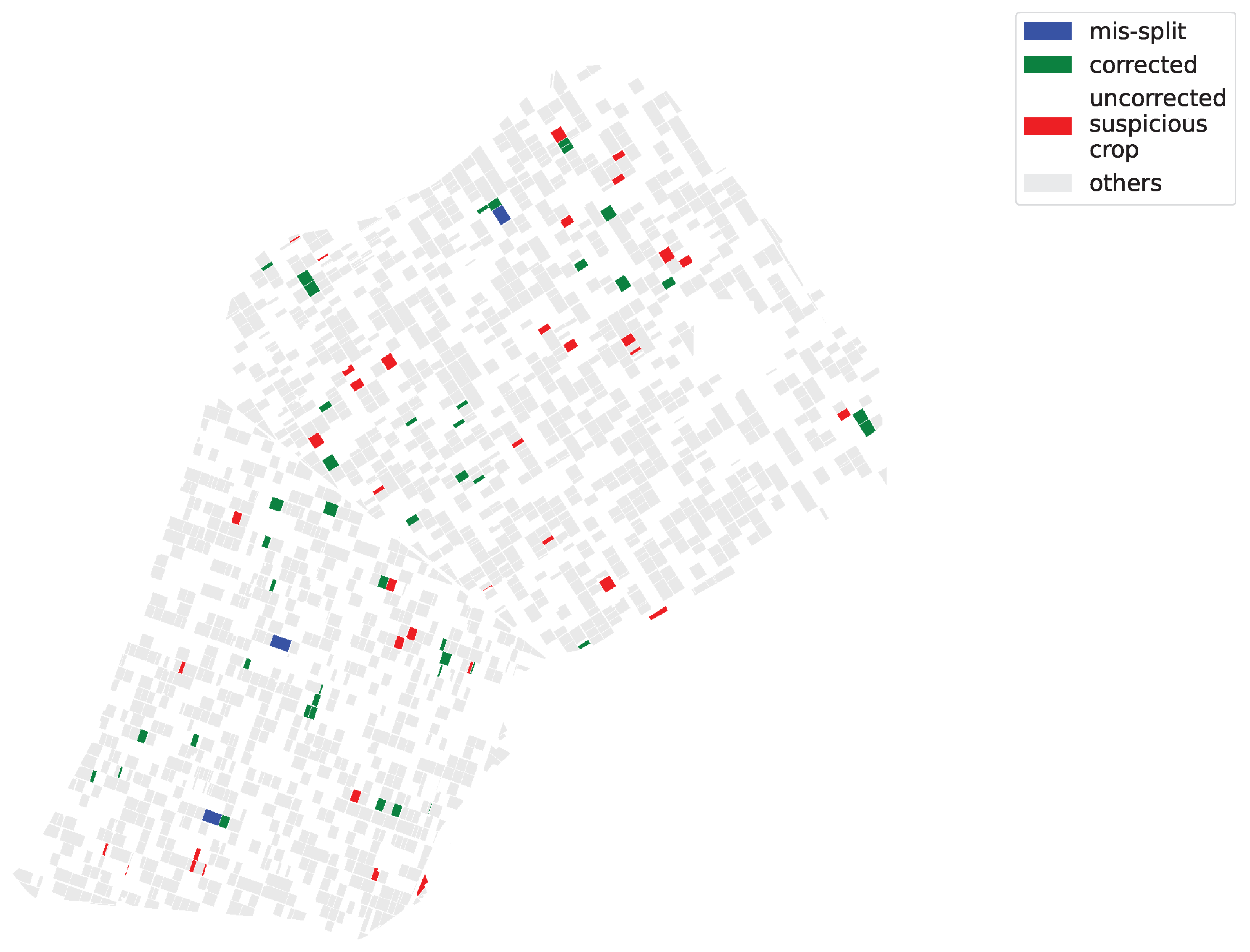
5. Results, and Their Qualitative Validation
5.1. Results
- FARMSAR discovers 3 mis-split crops;
- our method classifies 81 crops as suspicious mislabels (around 5% out of the approx. 1600 crops of this half of the dataset). FARMSAR relabels 44 crops confidently, and 37 crops are to be inspected for potential erroneous labels.
5.2. Qualitative Validation: Sentinel-2 Imagery over the First Group of Crops
5.2.1. Validation of Relabels
5.2.2. Validation of Mis-Splits
Mis-Split Field n°1
Mis-Split Field n°2
Mis-Split Field n°3
- the two classes that are potentially seen in the mis-split crop are “cotton” and “pumpkin”.
- the separation is not as clear as the last two mis-split crops.
6. Discussion
- On a farmer’s side, FARMSAR provides a fast and reliable methodology to double-check the agricultural census of grown crops, leading to less risk-taking at the time of declaration.
- On the local administration side, FARMSAR provides a tool to monitor the quality of the delivered census. FARMSAR could facilitate the detection and extraction of anomalies in declarations.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

References
- Kurosu, T.; Fujita, M.; Chiba, K. Monitoring of rice crop growth from space using the ERS-1 C-band SAR. IEEE Trans. Geosci. Remote Sens. 1995, 33, 1092–1096. [Google Scholar] [CrossRef]
- Le Toan, T.; Ribbes, F.; Wang, L.F.; Floury, N.; Ding, K.H.; Kong, J.A.; Fujita, M.; Kurosu, T. Rice crop mapping and monitoring using ERS-1 data based on experiment and modeling results. IEEE Trans. Geosci. Remote Sens. 1997, 35, 41–56. [Google Scholar] [CrossRef]
- Bhogapurapu, N.; Dey, S.; Bhattacharya, A.; Mandal, D.; Lopez-Sanchez, J.M.; McNairn, H.; López-Martínez, C.; Rao, Y. Dual-polarimetric descriptors from Sentinel-1 GRD SAR data for crop growth assessment. ISPRS J. Photogramm. Remote Sens. 2021, 178, 20–35. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Mack, B.; Conrad, C. Crop Type Classification Using Fusion of Sentinel-1 and Sentinel-2 Data: Assessing the Impact of Feature Selection, Optical Data Availability, and Parcel Sizes on the Accuracies. Remote Sens. 2020, 12, 2779. [Google Scholar] [CrossRef]
- Mestre-Quereda, A.; Lopez-Sanchez, J.M.; Vicente-Guijalba, F.; Jacob, A.W.; Engdahl, M.E. Time-Series of Sentinel-1 Interferometric Coherence and Backscatter for Crop-Type Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4070–4084. [Google Scholar] [CrossRef]
- McNairn, H.; Champagne, C.; Shang, J.; Holmstrom, D.; Reichert, G. Integration of optical and Synthetic Aperture Radar (SAR) imagery for delivering operational annual crop inventories. ISPRS J. Photogramm. Remote Sens. 2009, 64, 434–449. [Google Scholar] [CrossRef]
- Jiao, X.; Kovacs, J.M.; Shang, J.; McNairn, H.; Walters, D.; Ma, B.; Geng, X. Object-oriented crop mapping and monitoring using multi-temporal polarimetric RADARSAT-2 data. ISPRS J. Photogramm. Remote Sens. 2014, 96, 38–46. [Google Scholar] [CrossRef]
- Hoekman, D.H.; Vissers, M.A.M.; Tran, T.N. Unsupervised Full-Polarimetric SAR Data Segmentation as a Tool for Classification of Agricultural Areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 402–411. [Google Scholar] [CrossRef]
- Di Martino, T.; Guinvarc’h, R.; Thirion-Lefevre, L.; Koeniguer, E.C. Beets or Cotton? Blind Extraction of Fine Agricultural Classes Using a Convolutional Autoencoder Applied to Temporal SAR Signatures. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Dey, S.; Bhattacharya, A.; Ratha, D.; Mandal, D.; McNairn, H.; Lopez-Sanchez, J.M.; Rao, Y. Novel clustering schemes for full and compact polarimetric SAR data: An application for rice phenology characterization. ISPRS J. Photogramm. Remote Sens. 2020, 169, 135–151. [Google Scholar] [CrossRef]
- Adrian, J.; Sagan, V.; Maimaitijiang, M. Sentinel SAR-optical fusion for crop type mapping using deep learning and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 175, 215–235. [Google Scholar] [CrossRef]
- Ndikumana, E.; Ho Tong Minh, D.; Baghdadi, N.; Courault, D.; Hossard, L. Deep Recurrent Neural Network for Agricultural Classification using multitemporal SAR Sentinel-1 for Camargue, France. Remote Sens. 2018, 10, 1217. [Google Scholar] [CrossRef]
- Tiedeman, K.; Chamberlin, J.; Kosmowski, F.; Ayalew, H.; Sida, T.; Hijmans, R.J. Field Data Collection Methods Strongly Affect Satellite-Based Crop Yield Estimation. Remote Sens. 2022, 14, 1995. [Google Scholar] [CrossRef]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Marais Sicre, C.; Dedieu, G. Effect of Training Class Label Noise on Classification Performances for Land Cover Mapping with Satellite Image Time Series. Remote Sens. 2017, 9, 173. [Google Scholar] [CrossRef]
- Abay, K. Measurement Errors in Agricultural Data and their Implications on Marginal Returns to Modern Agricultural Inputs. Agric. Econ. 2020, 51, 323–341. [Google Scholar] [CrossRef]
- Zhong, J.X.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph Convolutional Label Noise Cleaner: Train a Plug-And-Play Action Classifier for Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Aggarwal, C.C. An Introduction to Outlier Analysis. In Outlier Analysis; Springer International Publishing: Cham, Switzerland, 2017; pp. 1–34. [Google Scholar] [CrossRef]
- Enderlein, G.; Hawkins, D.M. Identification of Outliers. Biom. J. 1987, 29, 198. [Google Scholar] [CrossRef]
- Chalapathy, R.; Borzeshi, E.Z.; Piccardi, M. An Investigation of Recurrent Neural Architectures for Drug Name Recognition. arXiv 2016, arXiv:1609.07585. [Google Scholar] [CrossRef]
- Wulsin, D.; Blanco, J.A.; Mani, R.; Litt, B. Semi-Supervised Anomaly Detection for EEG Waveforms Using Deep Belief Nets. In Proceedings of the 2010 Ninth International Conference on Machine Learning and Applications, Washington, DC, USA, 12–14 December 2010; pp. 436–441. [Google Scholar]
- Song, H.; Jiang, Z.; Men, A.; Yang, B. A Hybrid Semi-Supervised Anomaly Detection Model for High-Dimensional Data. Comput. Intell. Neurosci. 2017, 2017, 1–9. [Google Scholar] [CrossRef]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.V.D. Memorizing Normality to Detect Anomaly: Memory-Augmented Deep Autoencoder for Unsupervised Anomaly Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Aytekin, C.; Ni, X.; Cricri, F.; Aksu, E. Clustering and Unsupervised Anomaly Detection with l2 Normalized Deep Auto-Encoder Representations. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, N.; Li, B.; Xu, Q.; Wang, Y. Automatic Ship Detection in Optical Remote Sensing Images Based on Anomaly Detection and SPP-PCANet. Remote Sens. 2019, 11, 47. [Google Scholar] [CrossRef]
- Meroni, M.; Fasbender, D.; Rembold, F.; Atzberger, C.; Klisch, A. Near real-time vegetation anomaly detection with MODIS NDVI: Timeliness vs. accuracy and effect of anomaly computation options. Remote Sens. Environ. 2019, 221, 508–521. [Google Scholar] [CrossRef]
- León-López, K.M.; Mouret, F.; Arguello, H.; Tourneret, J.Y. Anomaly Detection and Classification in Multispectral Time Series Based on Hidden Markov Models. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Santos, L.A.; Ferreira, K.R.; Camara, G.; Picoli, M.C.; Simoes, R.E. Quality control and class noise reduction of satellite image time series. ISPRS J. Photogramm. Remote Sens. 2021, 177, 75–88. [Google Scholar] [CrossRef]
- Wang, C.; Shi, J.; Zhou, Y.; Li, L.; Yang, X.; Zhang, T.; Wei, S.; Zhang, X.; Tao, C. Label Noise Modeling and Correction via Loss Curve Fitting for SAR ATR. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–10. [Google Scholar] [CrossRef]
- Avolio, C.; Tricomi, A.; Zavagli, M.; De Vendictis, L.; Volpe, F.; Costantini, M. Automatic Detection of Anomalous Time Trends from Satellite Image Series to Support Agricultural Monitoring. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 6524–6527. [Google Scholar] [CrossRef]
- Crnojević, V.; Lugonja, P.; Brkljač, B.N.; Brunet, B. Classification of small agricultural fields using combined Landsat-8 and RapidEye imagery: Case study of northern Serbia. J. Appl. Remote Sens. 2014, 8, 083512. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Angus, D.; Kernal, D.; William, E.; Takatoshi, I.; Joseph, S.; Shadid, Y. World Development Report 2008: Agriculture for Development; The World Bank: Washington, DC, USA, 2007. [Google Scholar] [CrossRef]
- Song, X.P.; Potapov, P.V.; Krylov, A.; King, L.; Di Bella, C.M.; Hudson, A.; Khan, A.; Adusei, B.; Stehman, S.V.; Hansen, M.C. National-scale soybean mapping and area estimation in the United States using medium resolution satellite imagery and field survey. Remote Sens. Environ. 2017, 190, 383–395. [Google Scholar] [CrossRef]
- D’Andrimont, R.; Verhegghen, A.; Lemoine, G.; Kempeneers, P.; Meroni, M.; van der Velde, M. From parcel to continental scale – A first European crop type map based on Sentinel-1 and LUCAS Copernicus in-situ observations. Remote Sens. Environ. 2021, 266, 112708. [Google Scholar] [CrossRef]
- Beegle, K.; Carletto, C.; Himelein, K. Reliability of recall in agricultural data. J. Dev. Econ. 2012, 98, 34–41. [Google Scholar] [CrossRef]
- Wollburg, P.; Tiberti, M.; Zezza, A. Recall length and measurement error in agricultural surveys. Food Policy 2021, 100, 102003. [Google Scholar] [CrossRef]
- Kilic, T.; Moylan, H.; Ilukor, J.; Mtengula, C.; Pangapanga-Phiri, I. Root for the tubers: Extended-harvest crop production and productivity measurement in surveys. Food Policy 2021, 102, 102033. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef]
- Lozano, D.; Arranja, C.; Rijo, M.; Mateos, L. Canal Control Alternatives in the Irrigation Distriction ’Sector BXII, Del Bajo Guadalquivir’, Spain. In Proceedings of the Fourth International Conference on Irrigation and Drainage, Sacramento, CA, USA, 3–6 October 2007; pp. 667–679. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Di Martino, T.; Koeniguer, E.C.; Thirion-Lefevre, L.; Guinvarc’h, R. Modelling of agricultural SAR Time Series using Convolutional Autoencoder for the extraction of harvesting practices of rice fields. In Proceedings of the EUSAR 2022; 14th European Conference on Synthetic Aperture Radar, Leipzig, Germany, 25–27 July 2022; pp. 1–6. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentinel-1 Acquisitions Metadata | |
|---|---|
| Acquisition Mode | Interferometric Wide |
| Polarisation | VV + VH |
| Relative Orbit Number | 74 |
| Wavelength | C-Band |
| Orbit Pass | Ascending |
| Near Incidence Angle | approx. 31.47° |
| Far Incidence Angle | approx. 32.82° |
| Acquisition Dates | 3 Jan. to 29 Dec. 2017 |
| Location | 36°59′00.0″ N 6°06′00.0″ W |
| Operation Layer | Number of Filters | Size of Each Filter | Stride Value | Padding Value | Ouput Vector Size | |
|---|---|---|---|---|---|---|
| Input time series | - | - | - | - | ||
| Convolution Layer | 1D Convolution | 64 | 7 | 1 | 1 | |
| ELU | - | - | - | - | ||
| Pooling Layer | Max Pooling 1D | - | 2 | 2 | - | |
| Convolution Layer | 1D Convolution | 128 | 5 | 1 | 0 | |
| ELU | - | - | - | - | ||
| Pooling Layer | Max Pooling 1D | - | 2 | 2 | - | |
| Convolution Layer | 1D Convolution | 256 | 3 | 1 | 0 | |
| ELU | - | - | - | - | ||
| Pooling Layer | Max Pooling 1D | - | 2 | 2 | - | |
| Flatten Layer | Flatten | - | - | - | - | 1280 |
| FC Layer | Fully Connected | - | - | - | - | 128 |
| ELU | - | - | - | - | 128 | |
| FC Layer | Fully Connected | - | - | - | - | 64 |
| ELU | - | - | - | - | 64 | |
| FC Layer | Fully Connected | - | - | - | - | 32 |
| ELU | - | - | - | - | 32 | |
| Embedding Layer | Fully Connected | - | - | - | - | 1 |
| ELU | - | - | - | - | 1 | |
| FC Layer | Fully Connected | - | - | - | - | 32 |
| ELU | - | - | - | - | 32 | |
| FC Layer | Fully Connected | - | - | - | - | 64 |
| ELU | - | - | - | - | 64 | |
| FC Layer | Fully Connected | - | - | - | - | 128 |
| ELU | - | - | - | - | 128 | |
| Output Layer | Fully Connected | - | - | - | - | 122 |
| Reshape | - | - | - | - | ||
| Method | Parameterization |
|---|---|
| CAE | ADAM optimizer |
| Learning Rate = 1 × 10 | |
| Batch Size = 128 | |
| Epochs = 20 |
| Mislabels’ Proportion | Amount of Corrected Mislabels | Amount of Correct Relabels | ||||||
|---|---|---|---|---|---|---|---|---|
| F-CAE 1 | CAE | SVM | RF | F-CAE 1 | CAE | SVM | RF | |
| 1 | 0.62 | 0.92 | 0.90 | 0.95 | 0.95 | 0.71 | 0.52 | 0.56 |
| 5 | 0.62 | 0.90 | 0.85 | 0.94 | 0.97 | 0.90 | 0.80 | 0.86 |
| 10 | 0.59 | 0.88 | 0.77 | 0.90 | 0.98 | 0.92 | 0.79 | 0.91 |
| 15 | 0.53 | 0.81 | 0.67 | 0.87 | 0.94 | 0.84 | 0.78 | 0.90 |
| 20 | 0.44 | 0.71 | 0.59 | 0.83 | 0.92 | 0.77 | 0.70 | 0.89 |
| 25 | 0.42 | 0.67 | 0.48 | 0.73 | 0.89 | 0.73 | 0.55 | 0.85 |
| 30 | 0.31 | 0.59 | 0.38 | 0.60 | 0.86 | 0.71 | 0.49 | 0.77 |
| Class | S2 Date (DD/MM/YYYY) | True ... | Mislabeled as ... | Relabeled as ... |
|---|---|---|---|---|
| Alfalfa | 12/04 |  |  |  |
| 11/07 |  |  |  | |
| Carrot | 22/05 |  |  |  |
| 21/07 |  |  |  | |
| Chickpea | 12/04 |  | ∅ |  |
| 01/06 |  | ∅ |  | |
| Cotton | 01/06 |  |  |  |
| 20/08 |  |  |  | |
| Fallow | 12/04 |  | ∅ |  |
| 21/06 |  | ∅ |  | |
| Maize | 12/04 |  |  | ∅ |
| 21/06 |  |  | ∅ | |
| Onion | 12/04 |  |  | ∅ |
| 21/06 |  |  | ∅ | |
| Pepper | 12/04 |  |  |  |
| 20/08 |  |  |  | |
| Potato | 12/04 |  |  |  |
| 20/08 |  |  |  | |
| Quinoa | 12/04 |  |  | ∅ |
| 21/06 |  |  | ∅ | |
| Sugar Beet | 22/05 |  |  |  |
| 20/08 |  |  |  | |
| Sunflower | 12/04 |  |  | ∅ |
| 01/06 |  |  | ∅ | |
| Sweet Potato | 21/06 |  |  | ∅ |
| 30/08 |  |  | ∅ | |
| Tomato | 12/04 |  |  |  |
| 21/06 |  |  |  | |
| Wheat | 22/05 |  | ∅ |  |
| 01/06 |  | ∅ |  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Martino, T.; Guinvarc’h, R.; Thirion-Lefevre, L.; Colin, E. FARMSAR: Fixing AgRicultural Mislabels Using Sentinel-1 Time Series and AutoencodeRs. Remote Sens. 2023, 15, 35. https://doi.org/10.3390/rs15010035
Di Martino T, Guinvarc’h R, Thirion-Lefevre L, Colin E. FARMSAR: Fixing AgRicultural Mislabels Using Sentinel-1 Time Series and AutoencodeRs. Remote Sensing. 2023; 15(1):35. https://doi.org/10.3390/rs15010035
Chicago/Turabian StyleDi Martino, Thomas, Régis Guinvarc’h, Laetitia Thirion-Lefevre, and Elise Colin. 2023. "FARMSAR: Fixing AgRicultural Mislabels Using Sentinel-1 Time Series and AutoencodeRs" Remote Sensing 15, no. 1: 35. https://doi.org/10.3390/rs15010035
APA StyleDi Martino, T., Guinvarc’h, R., Thirion-Lefevre, L., & Colin, E. (2023). FARMSAR: Fixing AgRicultural Mislabels Using Sentinel-1 Time Series and AutoencodeRs. Remote Sensing, 15(1), 35. https://doi.org/10.3390/rs15010035