


DCFusion: Dual-Headed Fusion Strategy and Contextual Information Awareness for Infrared and Visible Remote Sensing Image



Abstract
1. Introduction
- (1)
- We propose the DCFusion can preserve more significant information by a suitable dual-headed fusion strategy and reconstruction method.
- (2)
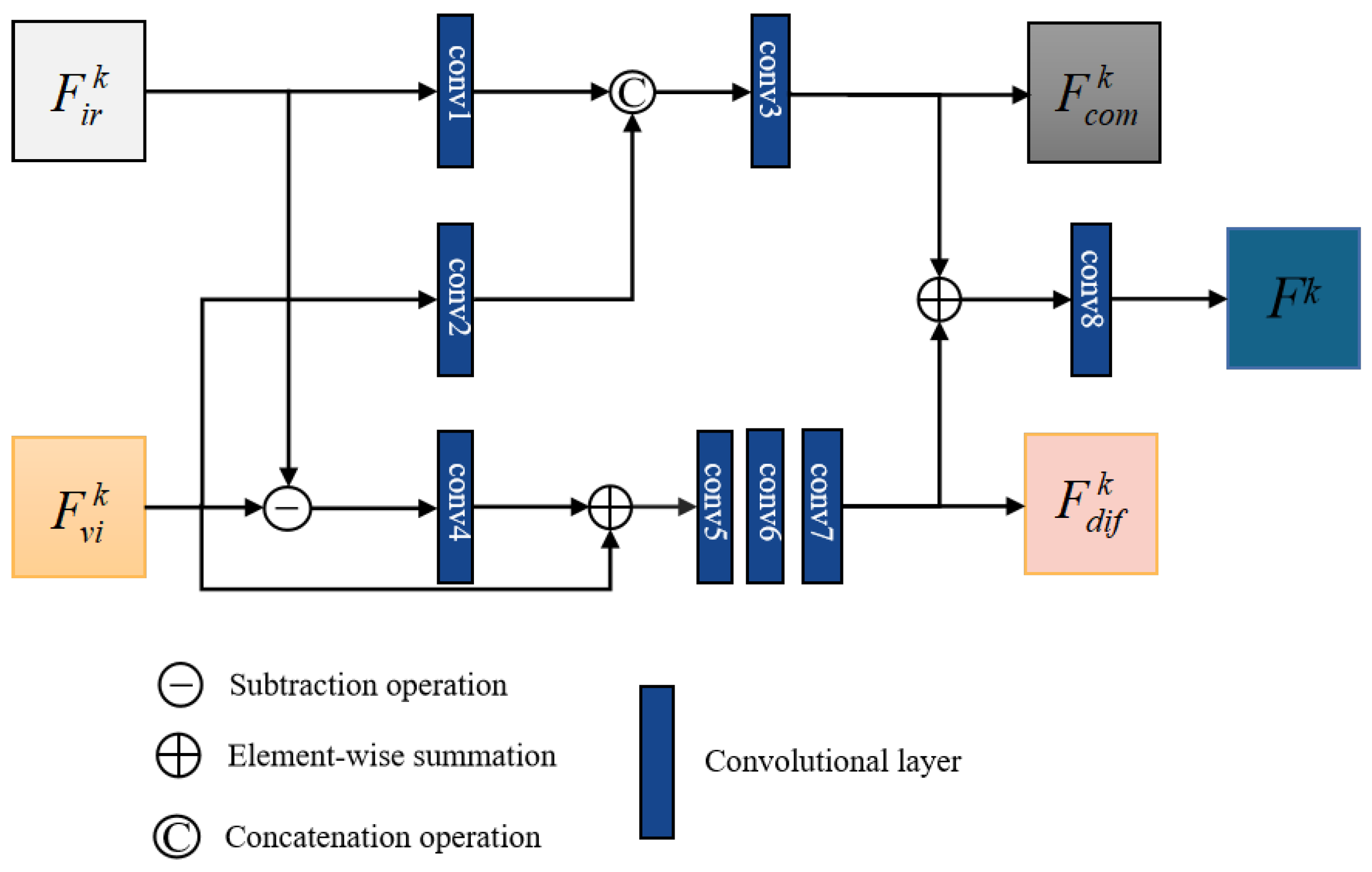
- The dual-headed fusion strategy (DHFS) is designed to integrate different modal features. In addition to preserving common information, the fusion strategy also allows for the effective integration of complementary information for source images by differential information compensation.
- (3)
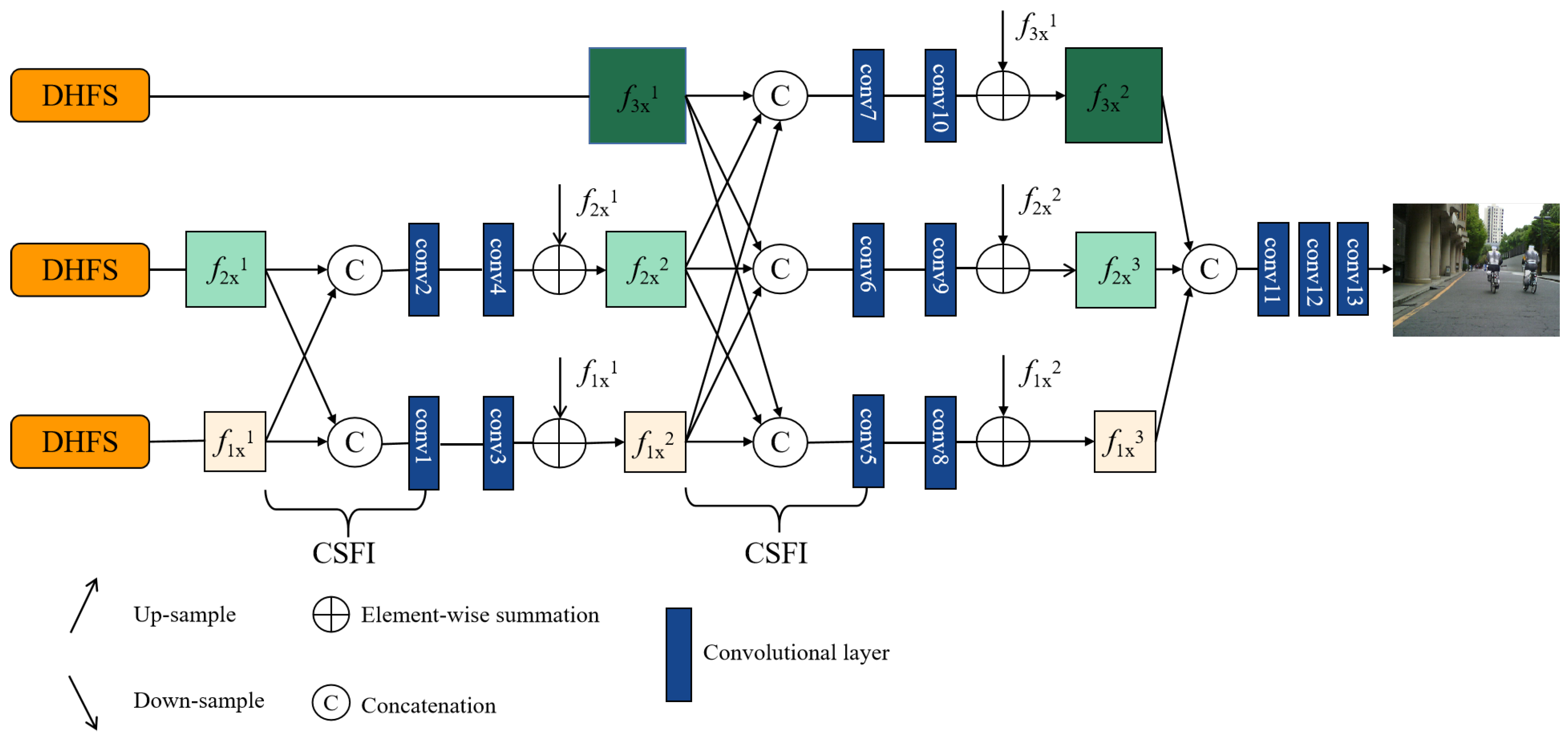
- We propose a contextual information awareness module (CIAM) to merge different scale features and generate result. The module achieve more competitive reconstruction performance by exchanging information for different scale feature.
2. Related Works
2.1. Traditional Image Fusion Algorithms
2.2. AE-Based Image Fusion Algorithms
2.3. CNN-Based Image Fusion Algorithms
2.4. GAN-Based Image Fusion Algorithms
3. Methodology
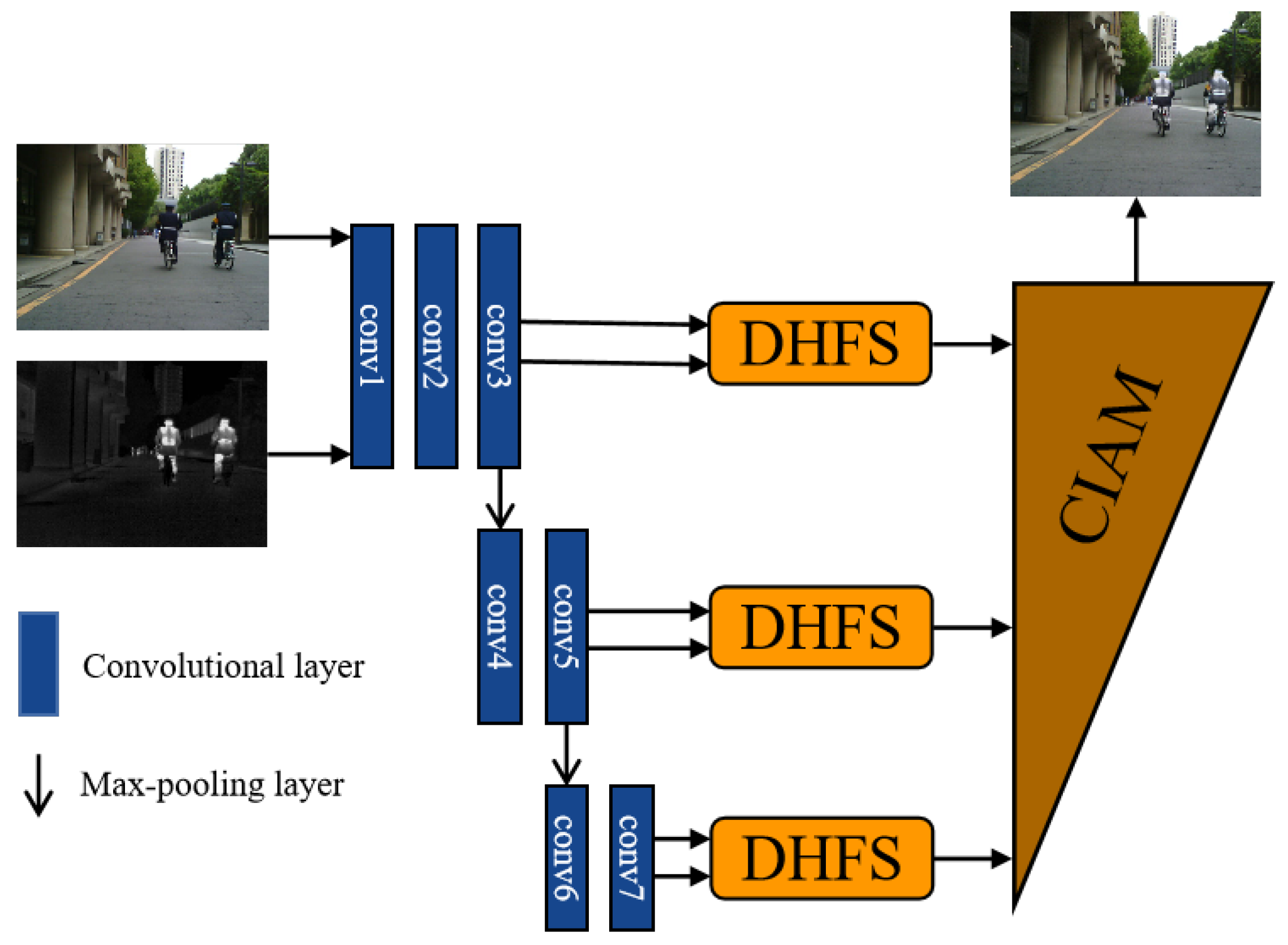
3.1. Network Architecture
3.1.1. Encoder Module
3.1.2. Fusion Strategy
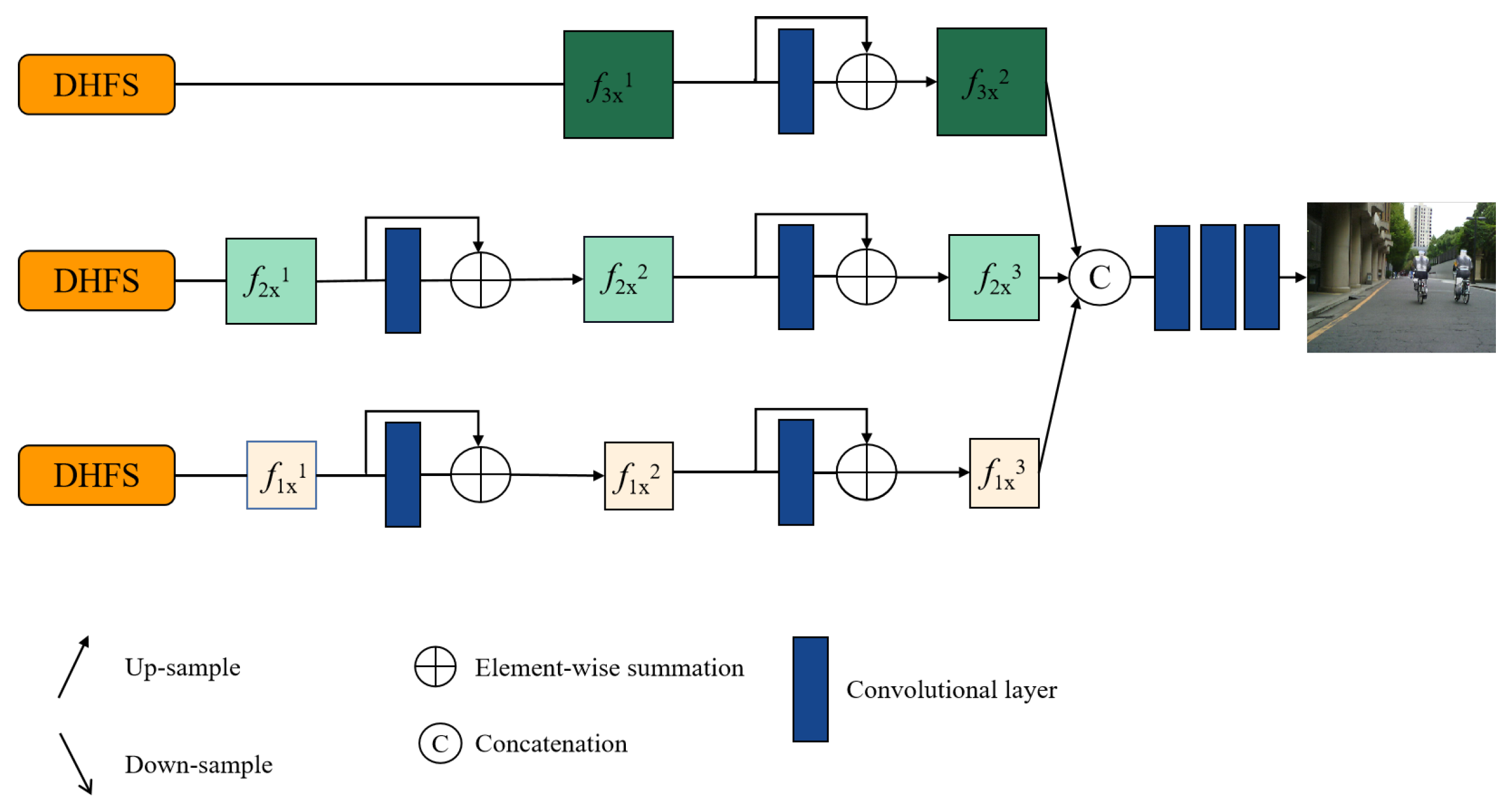
3.1.3. Decoder Module
3.2. Loss Function
4. Experiments
4.1. Experimental Details
4.2. Comparative Experiment
4.2.1. Qualitative Analysis
4.2.2. Quantitative Analysis
4.3. Generalization Experiment
4.4. Ablation Experiment
4.4.1. Ablation Study for the DHFS
4.4.2. Ablation Study for the CSFI
4.4.3. Ablation Study for the CIAM
4.5. Efficiency Comparison Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Cao, Y.; Guan, D.; Huang, W.; Yang, J.; Cao, Y.; Qiao, Y. Pedestrian detection with unsupervised multispectral feature learning using deep neural networks. Inf. Fusion 2019, 46, 206–217. [Google Scholar] [CrossRef]
- Li, C.; Zhu, C.; Huang, Y.; Tang, J.; Wang, L. Cross-modal ranking with soft consistency and noisy labels for robust RGB-T tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 808–823. [Google Scholar]
- Lu, Y.; Wu, Y.; Liu, B.; Zhang, T.; Li, B.; Chu, Q.; Yu, N. Cross-modality person re-identification with shared-specific feature transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13379–13389. [Google Scholar]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5108–5115. [Google Scholar]
- Zhou, Z.; Wang, B.; Li, S.; Dong, M. Perceptual fusion of infrared and visible images through a hybrid multi-scale decomposition with Gaussian and bilateral filters. Inf. Fusion 2016, 30, 15–26. [Google Scholar] [CrossRef]
- Li, H.; Qi, X.; Xie, W. Fast infrared and visible image fusion with structural decomposition. Knowl.-Based Syst. 2020, 204, 106182. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Y. Infrared and visible image fusion via gradientlet filter. Comput. Vis. Image Underst. 2020, 197, 103016. [Google Scholar] [CrossRef]
- Liu, F.; Chen, L.; Lu, L.; Ahmad, A.; Jeon, G.; Yang, X. Medical image fusion method by using Laplacian pyramid and convolutional sparse representation. Concurr. Comput. Pract. Exp. 2020, 32, e5632. [Google Scholar] [CrossRef]
- Liu, F.; Chen, L.; Lu, L.; Jeon, G.; Yang, X. Infrared and visible image fusion via rolling guidance filter and convolutional sparse representation. J. Intell. Fuzzy Syst. 2021, 40, 10603–10616. [Google Scholar] [CrossRef]
- Gao, C.; Liu, F.; Yan, H. Infrared and visible image fusion using dual-tree complex wavelet transform and convolutional sparse representation. J. Intell. Fuzzy Syst. 2020, 39, 4617–4629. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. MDLatLRR: A novel decomposition method for infrared and visible image fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Bai, X.; Zhou, F.; Xue, B. Fusion of infrared and visual images through region extraction by using multi scale center-surround top-hat transform. Opt. Express 2011, 19, 8444–8457. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Liu, Y.; Jin, J.; Wang, Q.; Shen, Y.; Dong, X. Region level based multi-focus image fusion using quaternion wavelet and normalized cut. Signal Process. 2014, 97, 9–30. [Google Scholar] [CrossRef]
- Liu, X.; Mei, W.; Du, H. Structure tensor and nonsubsampled shearlet transform based algorithm for CT and MRI image fusion. Neurocomputing 2017, 235, 131–139. [Google Scholar] [CrossRef]
- Zhang, Q.; Maldague, X. An adaptive fusion approach for infrared and visible images based on NSCT and compressed sensing. Infrared Phys. Technol. 2016, 74, 11–20. [Google Scholar] [CrossRef]
- Cvejic, N.; Bull, D.; Canagarajah, N. Region-based multimodal image fusion using ICA bases. IEEE Sens. J. 2007, 7, 743–751. [Google Scholar] [CrossRef]
- Fu, Z.; Wang, X.; Xu, J.; Zhou, N.; Zhao, Y. Infrared and visible images fusion based on RPCA and NSCT. Infrared Phys. Technol. 2016, 77, 114–123. [Google Scholar] [CrossRef]
- Mou, J.; Gao, W.; Song, Z. Image fusion based on non-negative matrix factorization and infrared feature extraction. In Proceedings of the 2013 6th International Congress on Image and Signal Processing (CISP), Hangzhou, China, 16–18 December 2013; Volume 2, pp. 1046–1050. [Google Scholar]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12797–12804. [Google Scholar]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An infrared and visible image fusion network based on salient target detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Li, J.; Huo, H.; Li, C.; Wang, R.; Feng, Q. AttentionFGAN: Infrared and visible image fusion using attention-based generative adversarial networks. IEEE Trans. Multimed. 2020, 23, 1383–1396. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2020, 70, 1–14. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inf. Fusion 2022, 83, 79–92. [Google Scholar] [CrossRef]
- Toet, A. TNO Image fusion dataset. Figshare Dataset 2014. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, J. SDNet: A versatile squeeze-and-decomposition network for real-time image fusion. Int. J. Comput. Vis. 2021, 129, 2761–2785. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Size | Stride | Channel (Input) | Channel (Output) | Activation | |
|---|---|---|---|---|---|
| conv1 | 1 | 1 | 1 | 16 | ReLU |
| conv2 | 3 | 1 | 16 | 8 | ReLU |
| conv3 | 3 | 1 | 8 | 64 | ReLU |
| conv4 | 3 | 1 | 64 | 32 | ReLU |
| conv5 | 3 | 1 | 32 | 112 | ReLU |
| conv6 | 3 | 1 | 112 | 56 | ReLU |
| conv7 | 3 | 1 | 56 | 160 | ReLU |
| Size | Stride | Channel (Input) | Channel (Output) | Activation | |
|---|---|---|---|---|---|
| conv1-conv2 | 3 | 1 | ReLU | ||
| conv3 | 3 | 1 | ReLU | ||
| conv4-conv7 | 3 | 1 | ReLU | ||
| conv8 | 1 | 1 | 64 | ReLU |
| Size | Stride | Channel (Input) | Channel (Output) | Activation | |
|---|---|---|---|---|---|
| conv1-conv2 | 3 | 1 | 128 | 64 | - |
| conv3-conv4 | 3 | 1 | 64 | 64 | - |
| conv5-conv7 | 3 | 1 | 192 | 64 | - |
| conv8-conv10 | 3 | 1 | 64 | 64 | - |
| conv11 | 3 | 1 | 192 | 64 | - |
| conv12 | 3 | 1 | 64 | 32 | - |
| conv13 | 3 | 1 | 32 | 1 | - |
| MI | SD | VIF | EN | ||
|---|---|---|---|---|---|
| MDLatLRR | 2.5017 | 7.4546 | 0.7529 | 0.5319 | 6.0099 |
| FusionGAN | 1.8569 | 5.9602 | 0.4999 | 0.1396 | 5.4404 |
| GANMcC | 2.5211 | 8.3479 | 0.6567 | 0.2975 | 6.1232 |
| IFCNN | 2.8397 | 7.9868 | 0.8530 | 0.6015 | 6.4379 |
| RFN-Nest | 2.4728 | 7.0526 | 0.6514 | 0.2660 | 5.6984 |
| SDNet | 1.6601 | 5.7893 | 0.4338 | 0.3707 | 5.2535 |
| PIAFusion | 4.5837 | 8.3451 | 0.9476 | 0.6597 | 6.5710 |
| Ours | 4.7319 | 8.3783 | 0.9749 | 0.6624 | 6.6164 |
| MI | SD | VIF | EN | ||
|---|---|---|---|---|---|
| MDLatLRR | 2.2154 | 8.8255 | 0.7115 | 0.4791 | 6.5917 |
| FusionGAN | 2.3543 | 8.4866 | 0.6560 | 0.2202 | 6.5932 |
| GANMcC | 2.5211 | 8.3479 | 0.6567 | 0.2975 | 6.7322 |
| IFCNN | 2.5156 | 9.1559 | 0.8026 | 0.5381 | 6.9264 |
| RFN-Nest | 2.1575 | 9.1453 | 0.7661 | 0.3352 | 6.9585 |
| SDNet | 2.1048 | 8.7633 | 0.7027 | 0.4627 | 6.6938 |
| PIAFusion | 3.5409 | 9.3599 | 0.9015 | 0.5937 | 7.0528 |
| Ours | 2.8913 | 9.4613 | 0.8509 | 0.5794 | 7.1252 |
| MI | SD | VIF | EN | ||
|---|---|---|---|---|---|
| add | 3.6191 | 8.3286 | 0.8640 | 0.6285 | 6.4944 |
| max | 3.9265 | 8.3660 | 0.9561 | 0.6720 | 6.6289 |
| RFN | 4.5917 | 8.3671 | 0.9421 | 0.6567 | 6.5379 |
| DHFS | 4.7319 | 8.3783 | 0.9749 | 0.6624 | 6.6164 |
| MI | SD | VIF | EN | ||
|---|---|---|---|---|---|
| No-CSFI | 4.6376 | 8.3574 | 0.9547 | 0.6444 | 6.6065 |
| DCFusion | 4.7319 | 8.3783 | 0.9749 | 0.6624 | 6.6164 |
| MI | SD | VIF | EN | ||
|---|---|---|---|---|---|
| RFN-Decoder | 4.6560 | 8.3488 | 0.9663 | 0.6851 | 6.5884 |
| CIAM | 4.7319 | 8.3783 | 0.9749 | 0.6624 | 6.6164 |
| Method | Time |
|---|---|
| MDLatLRR | 123.4549 |
| FusionGAN | 0.0681 |
| GANMcC | 0.1333 |
| IFCNN | 0.0160 |
| RFN-Nest | 0.1924 |
| SDNet | 0.0154 |
| PIAFusion | 0.0895 |
| Ours | 0.1546 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, Q.; Chehri, A.; Jeon, G.; Zhang, L.; Yang, X. DCFusion: Dual-Headed Fusion Strategy and Contextual Information Awareness for Infrared and Visible Remote Sensing Image. Remote Sens. 2023, 15, 144. https://doi.org/10.3390/rs15010144
Pu Q, Chehri A, Jeon G, Zhang L, Yang X. DCFusion: Dual-Headed Fusion Strategy and Contextual Information Awareness for Infrared and Visible Remote Sensing Image. Remote Sensing. 2023; 15(1):144. https://doi.org/10.3390/rs15010144
Chicago/Turabian StylePu, Qin, Abdellah Chehri, Gwanggil Jeon, Lei Zhang, and Xiaomin Yang. 2023. "DCFusion: Dual-Headed Fusion Strategy and Contextual Information Awareness for Infrared and Visible Remote Sensing Image" Remote Sensing 15, no. 1: 144. https://doi.org/10.3390/rs15010144
APA StylePu, Q., Chehri, A., Jeon, G., Zhang, L., & Yang, X. (2023). DCFusion: Dual-Headed Fusion Strategy and Contextual Information Awareness for Infrared and Visible Remote Sensing Image. Remote Sensing, 15(1), 144. https://doi.org/10.3390/rs15010144