
Azimuth-Sensitive Object Detection of High-Resolution SAR Images in Complex Scenes by Using a Spatial Orientation Attention Enhancement Network


Abstract
:
1. Introduction
2. Methodology
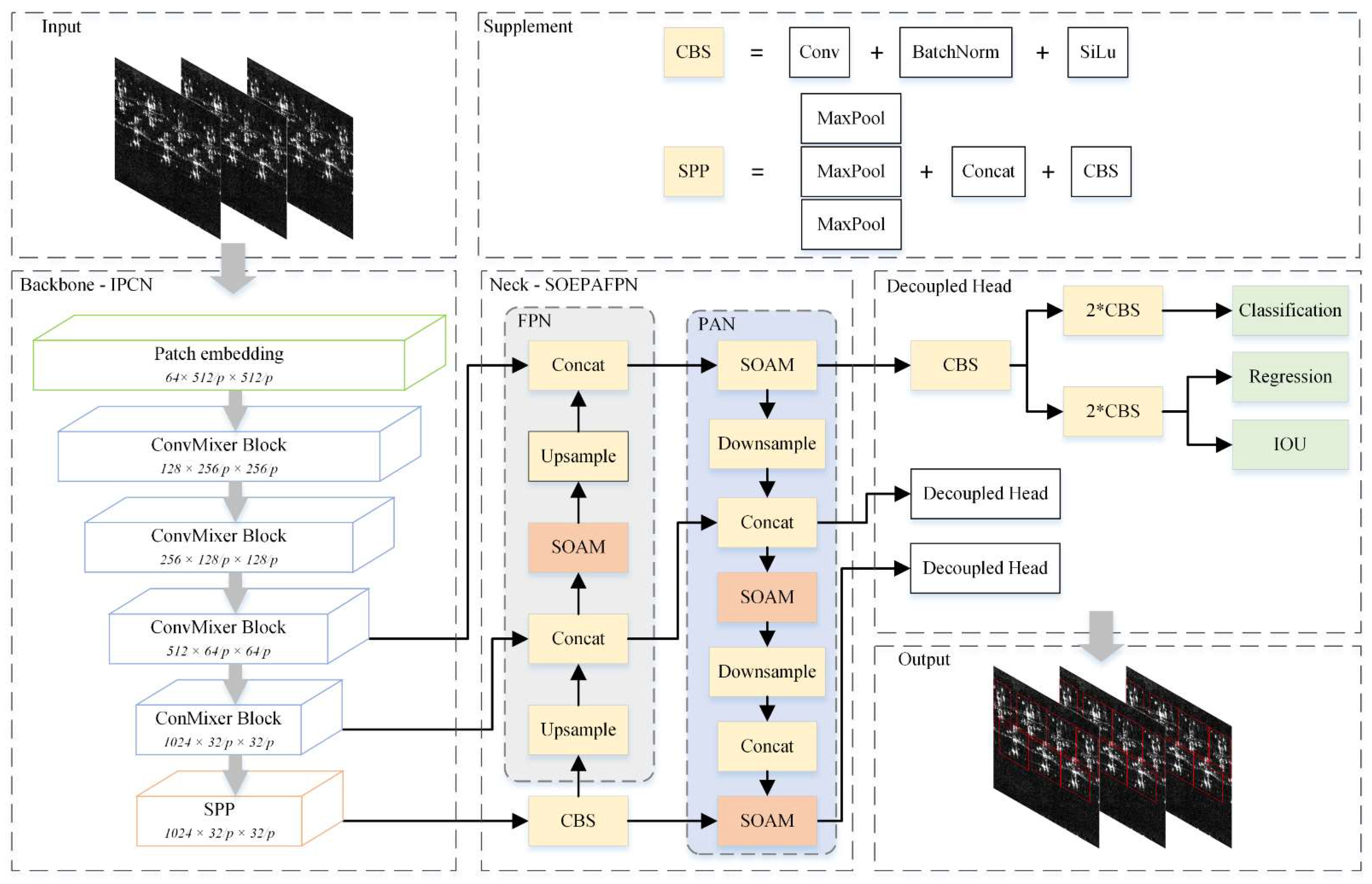
2.1. Overall Architecture
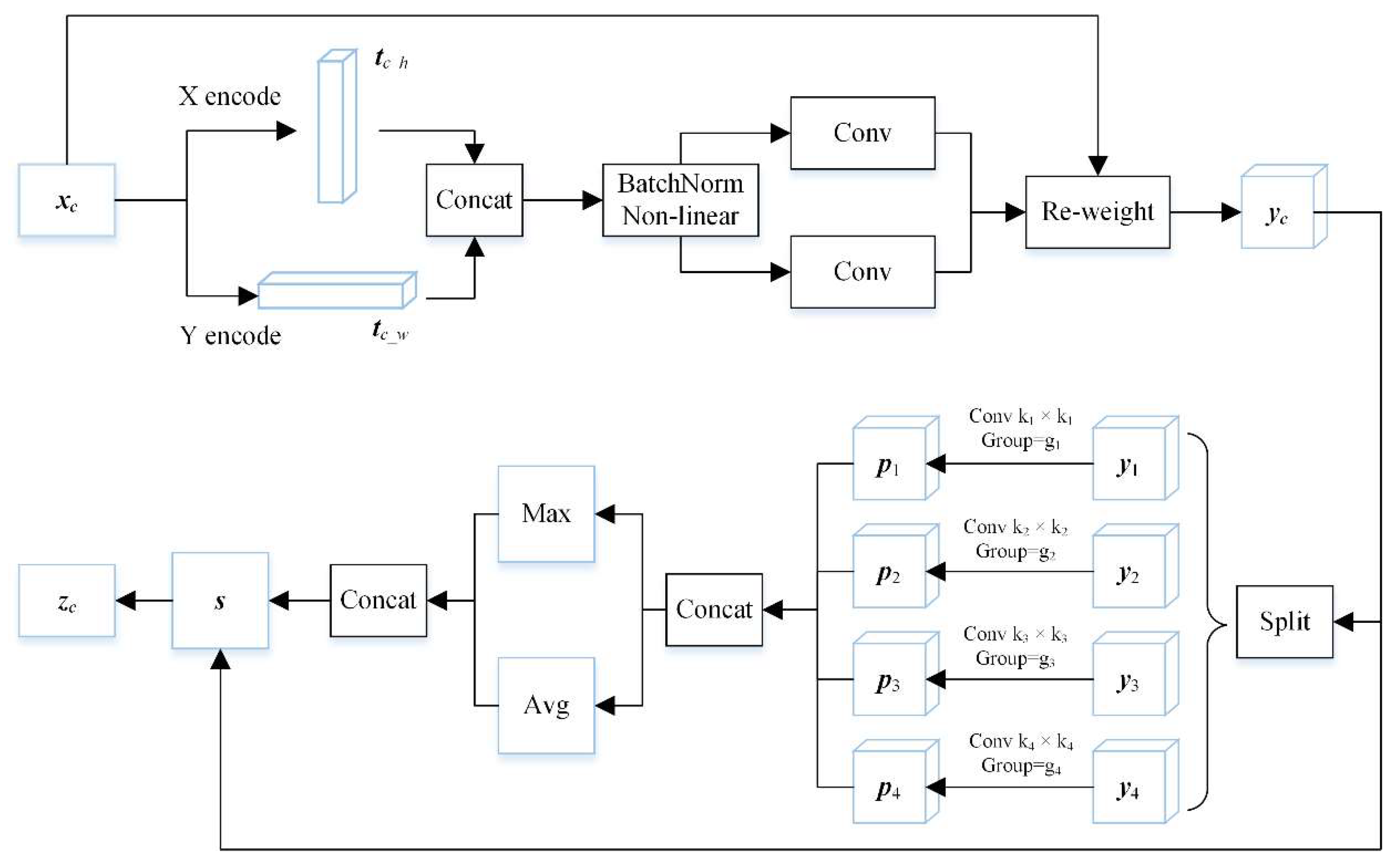
2.2. Spatial-Orientation-Enhanced PAFPN (SOEPAFPN) with Spatial Orientation Attention Modules (SOAM)
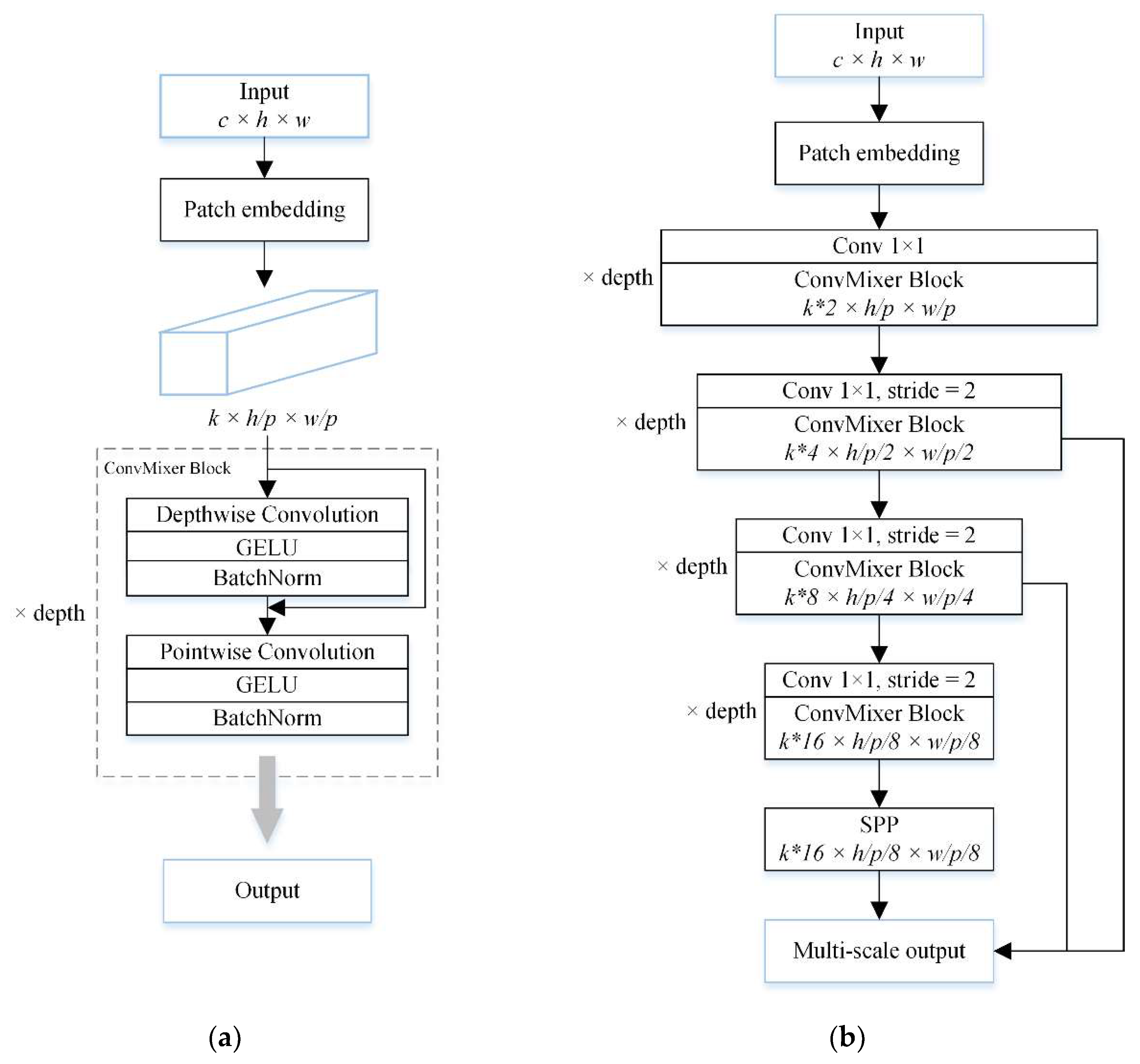
2.3. Inverted Pyramid ConvMixer Net (IPCN)
3. Experiments
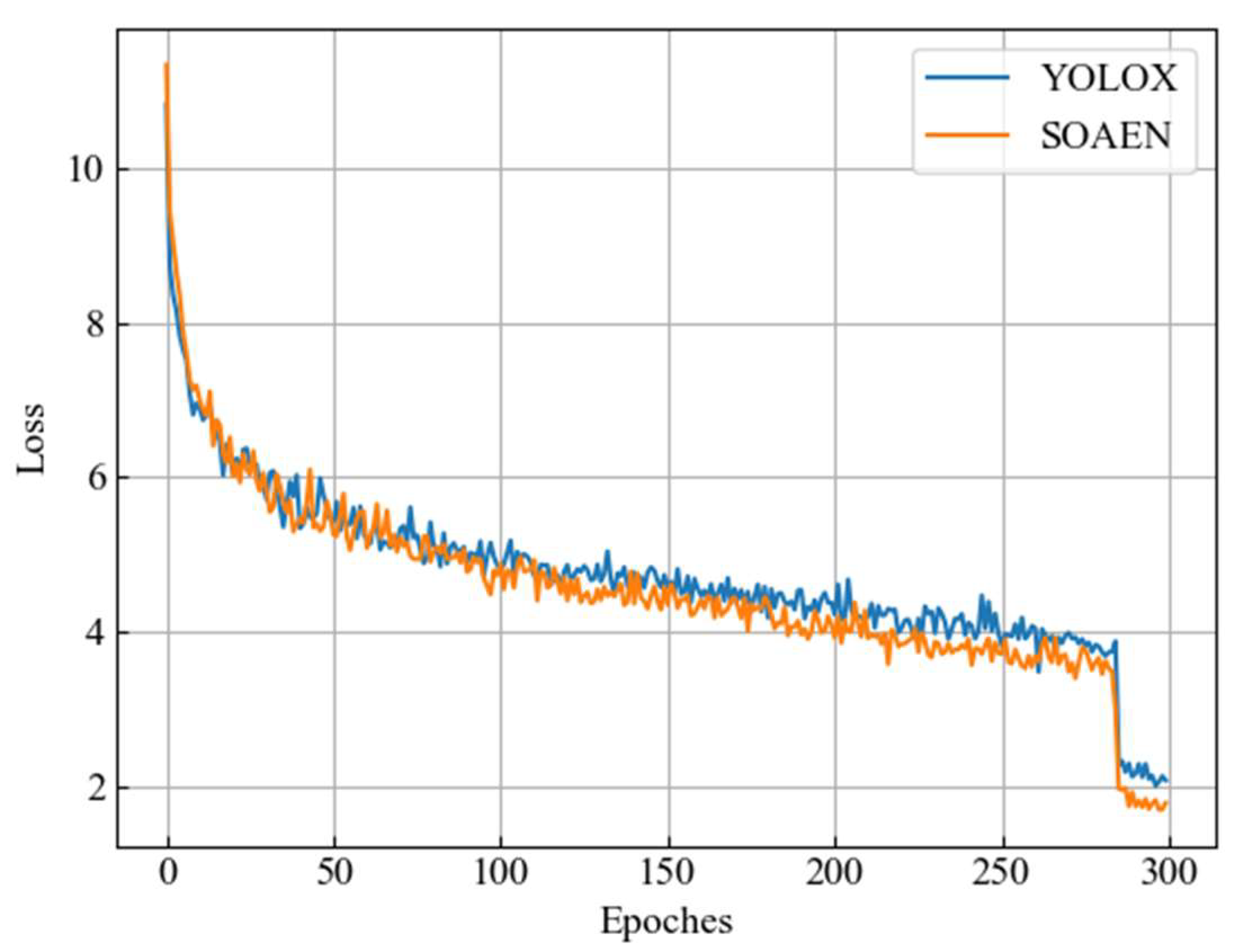
3.1. Dataset and Experiment Details
3.2. Evaluation Index
3.3. Ablation Experiments
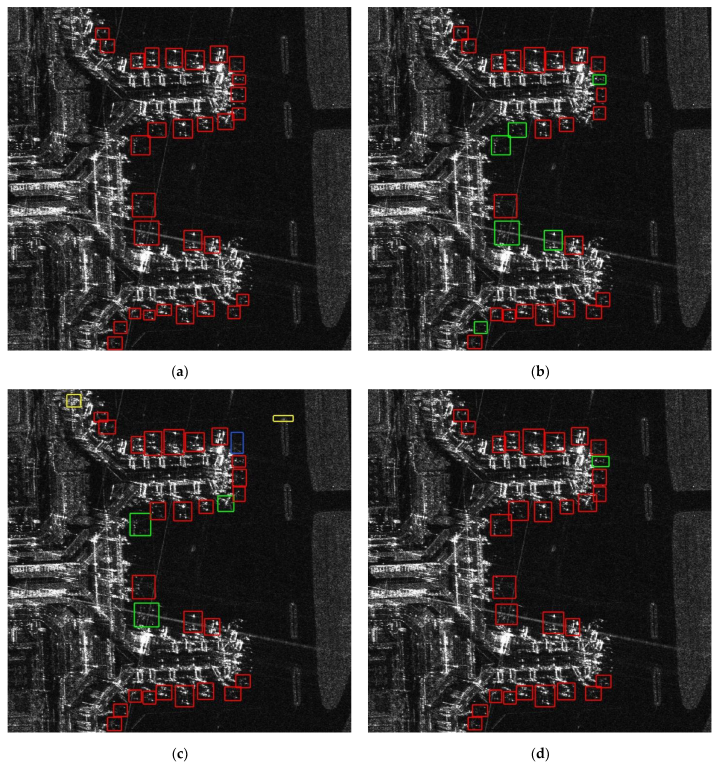
3.4. Experimental Results and Analysis in Real Scenes
3.4.1. Analysis of Hongqiao Airport
3.4.2. Analysis of Capital Airport
3.5. Performance of Different SAR Object Detection Algorithms
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ding, B.; Wen, G.; Huang, X.; Ma, C.; Yang, X. Target recognition in SAR images by exploiting the azimuth sensitivity. Remote Sens. Lett. 2017, 8, 821–830. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, B.; Wang, C. Backscattering feature analysis and recognition of civilian aircraft in TerraSAR-X images. IEEE Geosci. Remote Sens. Lett. 2014, 12, 796–800. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, X.; Liu, G.; Zhang, C.; Atkinson, P.M.; Tan, X.; Jian, X.; Zhou, X.; Li, Y. Two-phase object-based deep learning for multi-temporal SAR image change detection. Remote Sens. 2020, 12, 548. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; He, C.; Hu, C.; Pei, H.; Jiao, L. A deep neural network based on an attention mechanism for SAR ship detection in multiscale and complex scenarios. IEEE Access 2019, 7, 104848–104863. [Google Scholar] [CrossRef]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Kang, M.; Leng, X.; Lin, Z.; Ji, K. A modified faster R-CNN based on CFAR algorithm for SAR ship detection. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 19–21 May 2017; pp. 1–4. [Google Scholar]
- Tang, G.; Zhuge, Y.; Claramunt, C.; Men, S. N-Yolo: A SAR ship detection using noise-classifying and complete-target extraction. Remote Sens. 2021, 13, 871. [Google Scholar] [CrossRef]
- Wang, J.; Lin, Y.; Guo, J.; Zhuang, L. SSS-YOLO: Towards more accurate detection for small ships in SAR image. Remote Sens. Lett. 2021, 12, 93–102. [Google Scholar] [CrossRef]
- Wang, Z.; Du, L.; Mao, J.; Liu, B.; Yang, D. SAR target detection based on SSD with data augmentation and transfer learning. IEEE Geosci. Remote Sens. Lett. 2018, 16, 150–154. [Google Scholar] [CrossRef]
- Chang, Y.-L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.-Y.; Lee, W.-H. Ship Detection Based on YOLOv2 for SAR Imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Hou, B.; Ren, B.; Ren, Z.; Wang, S.; Jiao, L. A deep detection network based on interaction of instance segmentation and object detection for SAR images. Remote Sens. 2021, 13, 2582. [Google Scholar] [CrossRef]
- Wang, S.; Gao, X.; Sun, H.; Zheng, X.; Sun, X. An aircraft detection method based on convolutional neural networks in high-resolution SAR images. J. Radars 2017, 6, 195–203. [Google Scholar]
- Guo, Q.; Wang, H.; Kang, L.; Li, Z.; Xu, F. Aircraft target detection from spaceborne SAR image. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1168–1171. [Google Scholar]
- Diao, W.; Dou, F.; Fu, K.; Sun, X. Aircraft detection in SAR images using saliency based location regression network. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 23–27 July 2018; pp. 2334–2337. [Google Scholar]
- Zhang, L.; Li, C.; Zhao, L.; Xiong, B.; Quan, S.; Kuang, G. A cascaded three-look network for aircraft detection in SAR images. Remote Sens. Lett. 2020, 11, 57–65. [Google Scholar] [CrossRef]
- He, C.; Tu, M.; Xiong, D.; Tu, F.; Liao, M. Adaptive component selection-based discriminative model for object detection in high-resolution SAR imagery. ISPRS Int. J. Geo-Inf. 2018, 7, 72. [Google Scholar] [CrossRef] [Green Version]
- Guo, Q.; Wang, H.; Xu, F. Scattering Enhanced Attention Pyramid Network for Aircraft Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7570–7587. [Google Scholar] [CrossRef]
- Li, M.; Wen, G.; Huang, X.; Li, K.; Lin, S. A Lightweight Detection Model for SAR Aircraft in a Complex Environment. Remote Sens. 2021, 13, 5020. [Google Scholar] [CrossRef]
- Luo, R.; Chen, L.; Xing, J.; Yuan, Z.; Tan, S.; Cai, X.; Wang, J. A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network. Remote Sens. 2021, 13, 2940. [Google Scholar] [CrossRef]
- Luo, R.; Xing, J.; Chen, L.; Pan, Z.; Cai, X.; Li, Z.; Wang, J.; Ford, A. Glassboxing Deep Learning to Enhance Aircraft Detection from SAR Imagery. Remote Sens. 2021, 13, 3650. [Google Scholar] [CrossRef]
- Wang, J.; Xiao, H.; Chen, L.; Xing, J.; Pan, Z.; Luo, R.; Cai, X. Integrating Weighted Feature Fusion and the Spatial Attention Module with Convolutional Neural Networks for Automatic Aircraft Detection from SAR Images. Remote Sens. 2021, 13, 910. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Li, C.; Kuang, G. Pyramid attention dilated network for aircraft detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 662–666. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Liu, Z.; Hu, D.; Kuang, G.; Liu, L. Attentional Feature Refinement and Alignment Network for Aircraft Detection in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Trockman, A.; Kolter, J.Z. Patches Are All You Need? arXiv 2022, arXiv:2201.09792. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Everingham, M.; Zisserman, A.; Williams, C.K.; Van Gool, L.; Allan, M.; Bishop, C.M.; Chapelle, O.; Dalal, N.; Deselaers, T.; Dorkó, G. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. 2008. Available online: http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html (accessed on 1 March 2022).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Meaning |
|---|---|
| AP * | IoU = 0.5:0.05:0.95 |
| AP50 | IoU = 0.5 |
| AP75 | IoU = 0.75 |
| FLOPs | Floating point operations |
| ID | Backbone | Neck | Metrics | |||||
|---|---|---|---|---|---|---|---|---|
| CSPDarknet | IPCN | PAFPN | SOEPAFPN | AP (%) | AP50 (%) | AP75 (%) | FLOPs (G) | |
| Experiment 1 | ✓ | ✓ | 59.06 | 89.12 | 68.49 | 99.40 | ||
| Experiment 2 | ✓ | ✓ | 59.47 | 89.39 | 68.61 | 79.02 | ||
| Experiment 3 | ✓ | ✓ | 59.90 | 89.60 | 68.98 | 99.44 | ||
| Experiment 4 | ✓ | ✓ | 60.86 | 90.28 | 69.84 | 79.06 | ||
| Models | Regions | NGT | NDT | NDF | DR (%) | FAR (%) | |
|---|---|---|---|---|---|---|---|
| SOAEN | Capital Airport | 81 | 73 | 14 | 90.12 | 16.09 | |
| Hongqiao Airport | 78 | 72 | 9 | 92.31 | 11.11 | ||
| Mean | 91.22 | 13.60 | |||||
| YOLOX | Capital Airport | 81 | 70 | 18 | 86.42 | 20.45 | |
| Hongqiao Airport | 78 | 69 | 12 | 88.46 | 14.81 | ||
| Mean | 87.44 | 17.63 | |||||
| YOLOV5 | Capital Airport | 81 | 68 | 15 | 83.95 | 18.07 | |
| Hongqiao Airport | 78 | 69 | 10 | 88.46 | 12.66 | ||
| Mean | 86.21 | 15.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, J.; Wang, C.; Zhang, B.; Xu, C.; Wen, X. Azimuth-Sensitive Object Detection of High-Resolution SAR Images in Complex Scenes by Using a Spatial Orientation Attention Enhancement Network. Remote Sens. 2022, 14, 2198. https://doi.org/10.3390/rs14092198
Ge J, Wang C, Zhang B, Xu C, Wen X. Azimuth-Sensitive Object Detection of High-Resolution SAR Images in Complex Scenes by Using a Spatial Orientation Attention Enhancement Network. Remote Sensing. 2022; 14(9):2198. https://doi.org/10.3390/rs14092198
Chicago/Turabian StyleGe, Ji, Chao Wang, Bo Zhang, Changgui Xu, and Xiaoyang Wen. 2022. "Azimuth-Sensitive Object Detection of High-Resolution SAR Images in Complex Scenes by Using a Spatial Orientation Attention Enhancement Network" Remote Sensing 14, no. 9: 2198. https://doi.org/10.3390/rs14092198
APA StyleGe, J., Wang, C., Zhang, B., Xu, C., & Wen, X. (2022). Azimuth-Sensitive Object Detection of High-Resolution SAR Images in Complex Scenes by Using a Spatial Orientation Attention Enhancement Network. Remote Sensing, 14(9), 2198. https://doi.org/10.3390/rs14092198