
SFRE-Net: Scattering Feature Relation Enhancement Network for Aircraft Detection in SAR Images


Abstract
:1. Introduction
- The proposed SFRE-Net comprehensively considers the distribution of aircraft target scattering points and background clutter points and models the relationship between feature points, and the performance on the Gaofen-3 dataset is better than the state-of-the-art detection algorithms.
- In order to improve the integrity detection of aircraft targets, a cascade transformer block (TRsB) structure is adopted to capture the correlation between scattering feature points, effectively alleviating the phenomenon of aircraft’s discrete detection.
- In order to alleviate the semantic conflict caused by common feature pyramid structures in different scale information fusion, a feature-adaptive fusion pyramid structure (FAFP) is proposed. This design enables the network to independently select useful semantic information and improve the multi-scale expression ability of the network.
- In order to suppress the clutter interference in the background, a context attention-enhancement module (CAEM) is designed to improve the receptive field and enhance the attention of the target scattering points, which can realize the accurate positioning of aircraft targets in complex backgrounds.
2. Related Work
2.1. Deep-Learning-Based Object-Detection Methods
2.2. Feature Pyramid Structure in Object-Detection Methods
2.3. SAR Aircraft-Detection Methods with Deep Learning
3. Materials and Methods
3.1. Overview of SFRE-Net
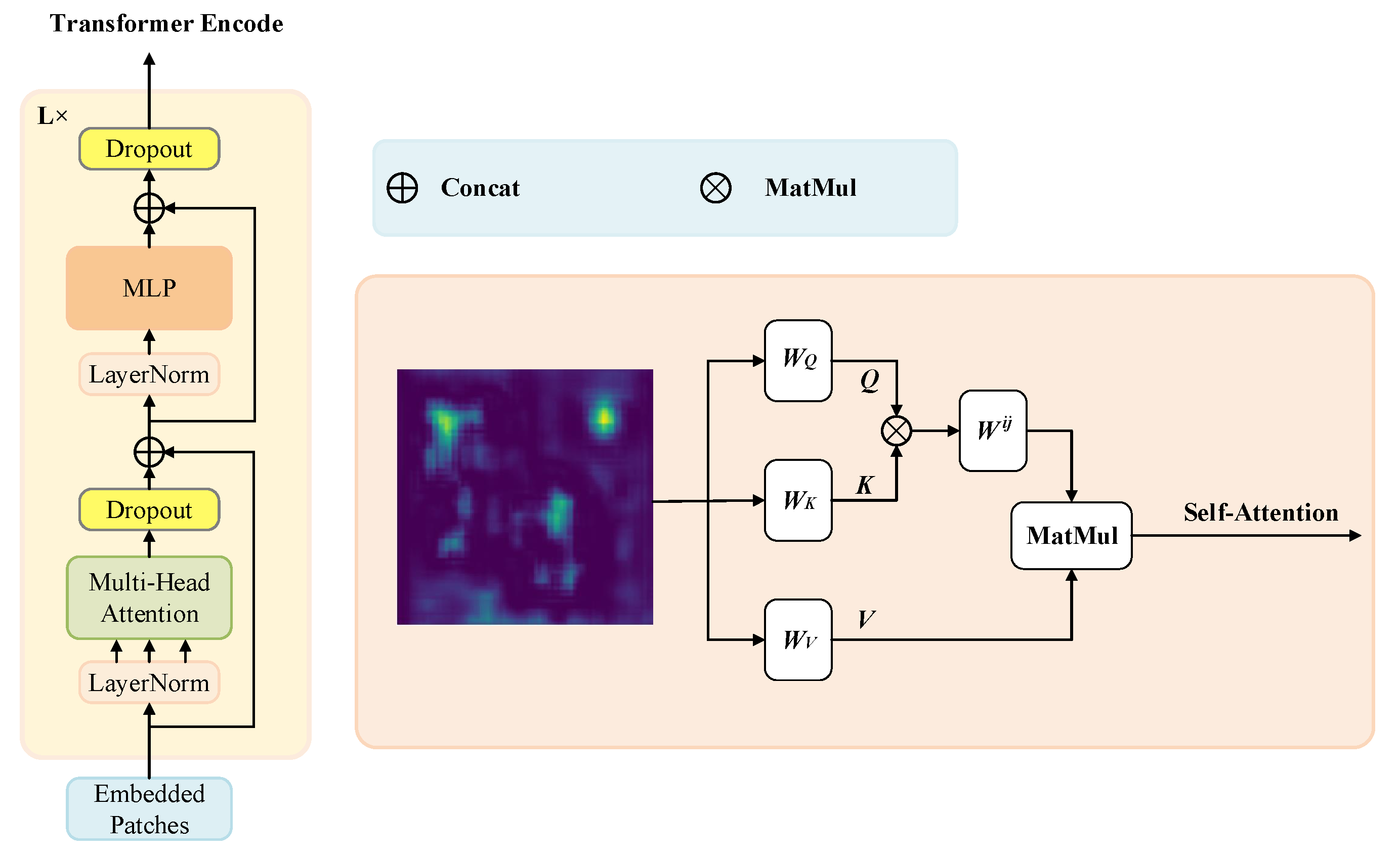
3.2. Transformer Block (TRsB)
3.3. Feature-Adaptive Fusion Pyramid (FAFP)
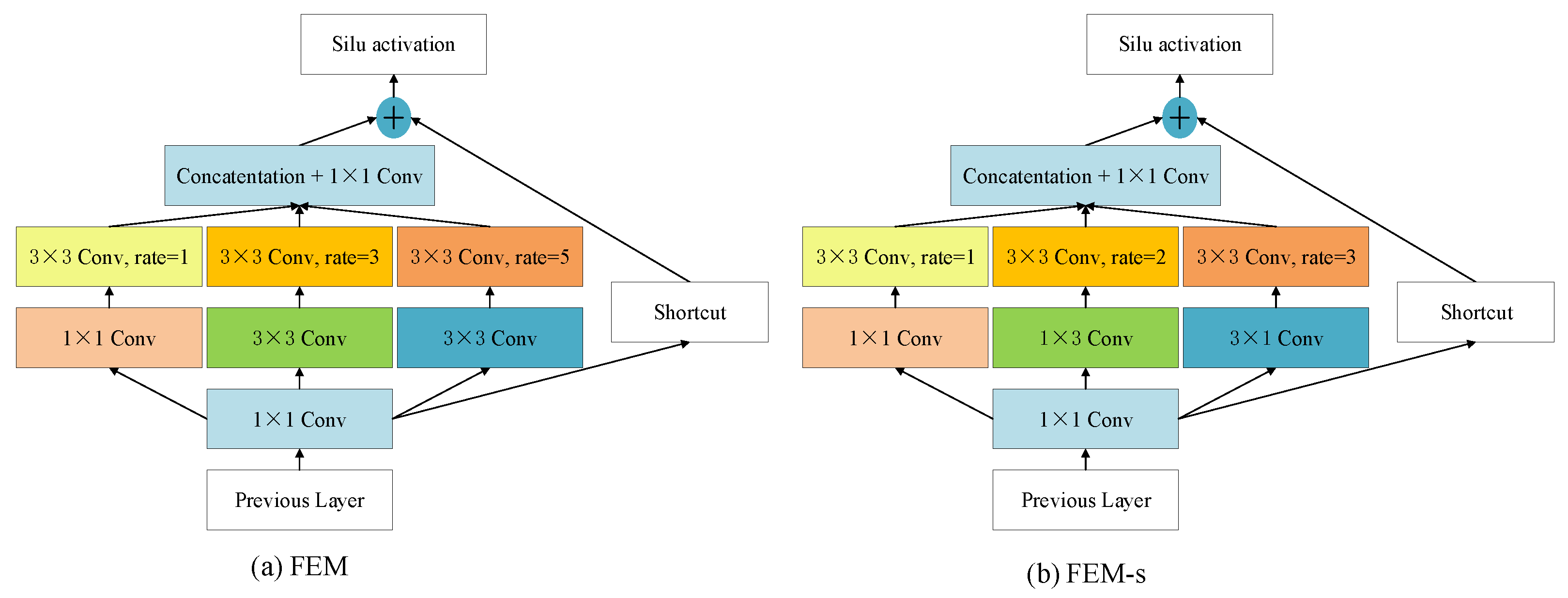
3.4. Context Attention-Enhancement Module (CAEM)
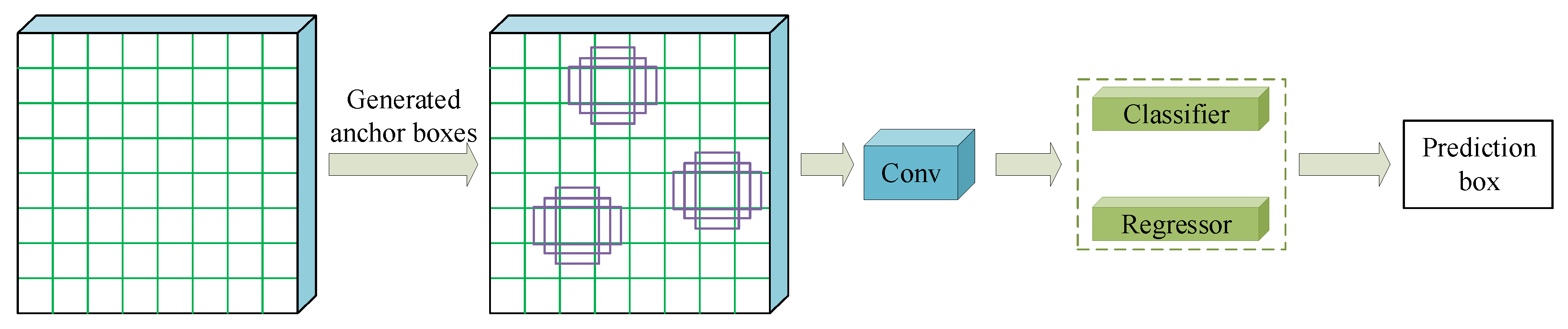
3.5. Prediction and Loss Function
4. Experimental Results
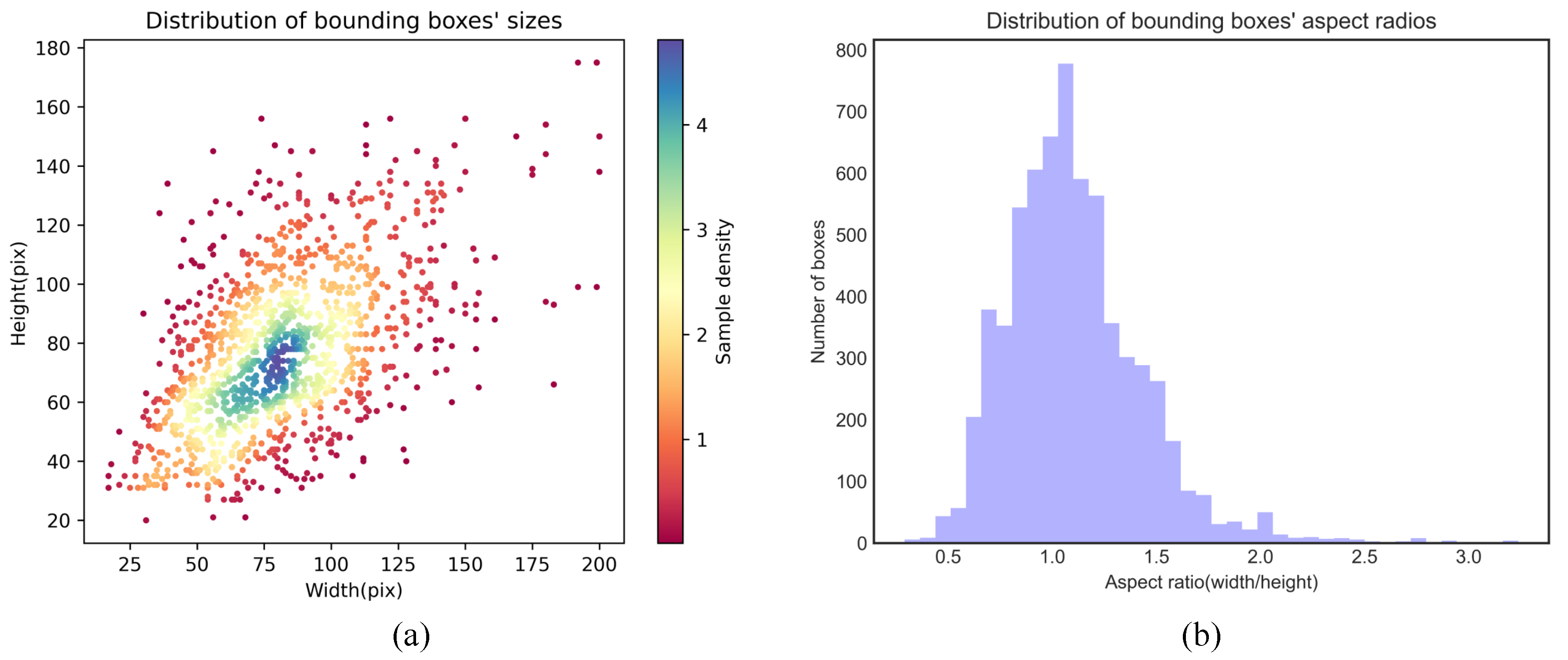
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Setup
4.4. Comparison of Results with the State of the Art
4.5. Ablation Studies
5. Discussion
- (1)
- Location of TRsB: Due to the complexity of multi-scale feature fusion, the placement of the transformer block (TRsB) is also worth exploring. Table 5 shows the contribution of TRsB at different locations, where the other components of SFRE-Net remain unchanged, only changing the location of TRsB. means that TRsB is placed between and , as shown in Figure 2. We can see that in the multi-scale feature fusion, the effect of placing TRsB behind the layer with deep depth and large feature map size is better. The feature map output from layer has a large size and richer feature information, which is helpful for TRsB to capture the correlation between feature points.
- (2)
- Types of attention modules in CAEM: The attention mechanism can make the model focus on the region of interest in the image. For SAR aircraft detection, using attention mechanisms is helpful to distinguish between target and background. In order to explore the effects of different attention mechanisms in SAR aircraft detection, we compared several typical attention modules in CAEM, as shown in Table 6, where the other components of SFRE-Net remain unchanged, only changing the types of attention modules in CAEM. Squeeze-and-excitation (SE) [54] pays attention to the importance of channels in the feature map, but ignores the information in spatial direction. Bottleneck attention module (BAM) [55] and convolutional block attention module (CBAM) [56] consider both channel and spatial information, but the local convolution is still used for attention calculation in the specific implementation process. Since aircraft targets in SAR images appear as bright discrete points, using the local convolution to calculate the attention easily introduces too much background information, which is not conducive to the accurate positioning of aircraft scattering points. Coordinate attention (CA) [51] decouples the spatial information into two independent feature maps through two 1D global average pooling operations, one with horizontal information and the other with vertical information. The two sub-attention maps obtained have long-distance dependence information in a specific direction. Finally, the two sub-attention maps are multiplied to obtain a global attention map. The coordinate attention mechanism avoids the shortage of local convolution. Each feature point in the output feature map takes advantage of the long distance information in the horizontal and vertical directions, which is helpful to associate with other scattering points and distinguishes between background clutter and aircraft scattering points.
- (3)
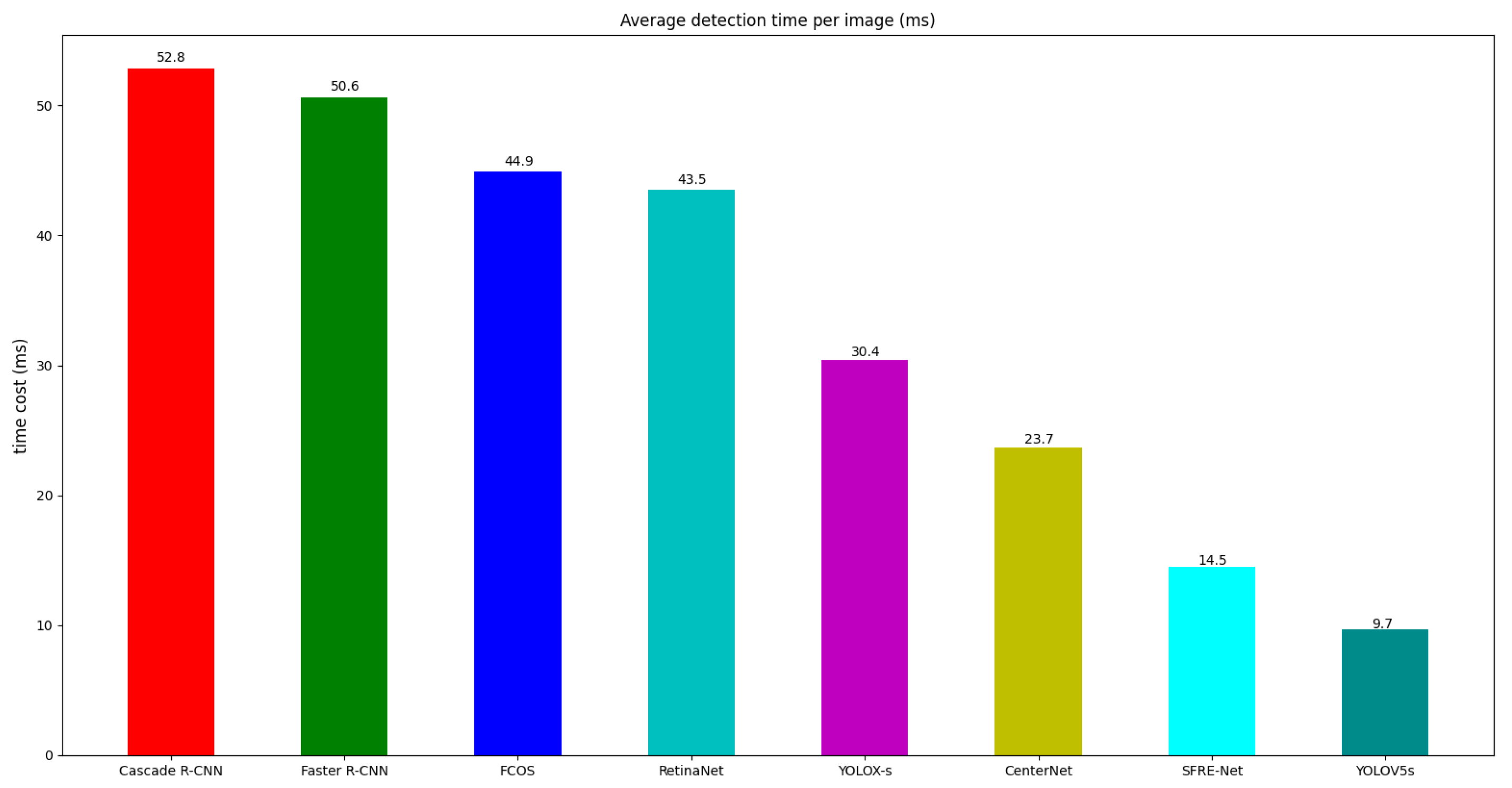
- Overall effects of SFRE-Net: The detection speed of the object-detection algorithm attracts more and more attention from scholars. In order to comprehensively analyze our method, we made statistics on the average inference time of different algorithms on the test set, as shown in Figure 11. SFRE-Net has the highest detection accuracy, and the detection speed is also at the top level.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, L.; Zhang, H.; Wang, C.; Zhang, B.; Liu, M. Crop classification based on temporal information using sentinel-1 SAR time-series data. Remote. Sens. 2019, 11, 53. [Google Scholar] [CrossRef] [Green Version]
- Zeng, K.; Wang, Y. A deep convolutional neural network for oil spill detection from spaceborne SAR images. Remote Sens. 2020, 12, 1015. [Google Scholar] [CrossRef] [Green Version]
- Luti, T.; De Fioravante, P.; Marinosci, I.; Strollo, A.; Riitano, N.; Falanga, V.; Mariani, L.; Congedo, L.; Munafò, M. Land Consumption Monitoring with SAR Data and Multispectral Indices. Remote Sens. 2021, 13, 1586. [Google Scholar] [CrossRef]
- Shu, Y.; Li, W.; Yang, M.; Cheng, P.; Han, S. Patch-based change detection method for SAR images with label updating strategy. Remote Sens. 2021, 13, 1236. [Google Scholar] [CrossRef]
- Cui, Z.; Wang, X.; Liu, N.; Cao, Z.; Yang, J. Ship detection in large-scale SAR images via spatial shuffle-group enhance attention. IEEE Trans. Geosci. Remote Sens. 2021, 59, 379–391. [Google Scholar] [CrossRef]
- Eshqi Molan, Y.; Lu, Z. Modeling InSAR phase and SAR intensity changes induced by soil moisture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4967–4975. [Google Scholar] [CrossRef]
- Gao, G.; Liu, L.; Zhao, L.; Shi, G.; Kuang, G. An adaptive and fast CFAR algorithm based on automatic censoring for target detection in high-resolution SAR images. IEEE Trans. Geosci. Remote Sens. 2008, 47, 1685–1697. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention receptive pyramid network for ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Zhu, X.X.; Montazeri, S.; Ali, M.; Hua, Y.; Wang, Y.; Mou, L.; Shi, Y.; Xu, F.; Bamler, R. Deep learning meets SAR: Concepts, models, pitfalls, and perspectives. IEEE Geosci. Remote Sens. Mag. 2021, 9, 143–172. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Liu, Z.; Hu, D.; Kuang, G.; Liu, L. Attentional feature refinement and alignment network for aircraft detection in SAR imagery. arXiv 2022, arXiv:2201.07124. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Scattering enhanced attention pyramid network for aircraft detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7570–7587. [Google Scholar] [CrossRef]
- Luo, R.; Chen, L.; Xing, J.; Yuan, Z.; Tan, S.; Cai, X.; Wang, J. A fast aircraft detection method for SAR images based on efficient bidirectional path aggregated attention network. Remote Sens. 2021, 13, 2940. [Google Scholar] [CrossRef]
- Kang, Y.; Wang, Z.; Fu, J.; Sun, X.; Fu, K. SFR-Net: Scattering feature relation network for aircraft detection in complex SAR images. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Steenson, B.O. Detection performance of a mean-level threshold. IEEE Trans. Aerosp. Electron. Syst. 1968, 4, 529–534. [Google Scholar] [CrossRef]
- Finn, H. Adaptive detection mode with threshold control as a function of spatially sampled clutter-level estimates. Rca Rev. 1968, 29, 414–465. [Google Scholar]
- Smith, M.E.; Varshney, P.K. VI-CFAR: A novel CFAR algorithm based on data variability. In Proceedings of the 1997 IEEE National Radar Conference, Syracuse, NY, USA, 13–15 May 1997; pp. 263–268. [Google Scholar]
- Ai, J.; Yang, X.; Song, J.; Dong, Z.; Jia, L.; Zhou, F. An adaptively truncated clutter-statistics-based two-parameter CFAR detector in SAR imagery. IEEE J. Ocean. Eng. 2017, 43, 267–279. [Google Scholar] [CrossRef]
- Olson, C.F.; Huttenlocher, D.P. Automatic target recognition by matching oriented edge pixels. IEEE Trans. Image Process. 1997, 6, 103–113. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaplan, L.M. Improved SAR target detection via extended fractal features. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 436–451. [Google Scholar] [CrossRef]
- Sandirasegaram, N.M. Spot SAR ATR Using Wavelet Features and Neural Network Classifier; Technical Report; Defence Research and Development Canada Ottawa: Ottawa, ON, Canada, 2005. [Google Scholar]
- Jao, J.K.; Lee, C.; Ayasli, S. Coherent spatial filtering for SAR detection of stationary targets. IEEE Trans. Aerosp. Electron. Syst. 1999, 35, 614–626. [Google Scholar]
- Zhou, G.; Chen, W.; Gui, Q.; Li, X.; Wang, L. Split depth-wise separable graph-convolution network for road extraction in complex environments from high-resolution remote-sensing Images. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.W.; et al. Artificial intelligence: A powerful paradigm for scientific research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef]
- Diao, W.; Dou, F.; Fu, K.; Sun, X. Aircraft detection in sar images using saliency based location regression network. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, IEEE, Valencia, Spain, 22–27 July 2018; pp. 2334–2337. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, C.; Tu, M.; Xiong, D.; Tu, F.; Liao, M. A component-based multi-layer parallel network for airplane detection in SAR imagery. Remote Sens. 2018, 10, 1016. [Google Scholar] [CrossRef] [Green Version]
- An, Q.; Pan, Z.; Liu, L.; You, H. DRBox-v2: An improved detector with rotatable boxes for target detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8333–8349. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Li, C.; Kuang, G. Pyramid attention dilated network for aircraft detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 662–666. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In European Conference on Computer Vision; Springer: New York, NY, USA, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- YOLOV5. Available online: https://github.com/ultralytics/yolov5 (accessed on 12 October 2021).
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9627–9636. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer: New York, NY, USA, 2020; pp. 213–229. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhang, L.; Li, C.; Zhao, L.; Xiong, B.; Quan, S.; Kuang, G. A cascaded three-look network for aircraft detection in SAR images. Remote Sens. Lett. 2020, 11, 57–65. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Aircraft detection in high-resolution SAR images using scattering feature information. In Proceedings of the 2019 6th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), IEEE, Xiamen, China, 26–29 November 2019; pp. 1–5. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- 2021 Gaofen Challenge on Automated High-Resolution Earth Observation Image Interpretation. Available online: http://gaofen-challenge.com (accessed on 1 October 2021).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper Parameters | Value |
|---|---|
| Optimizer | Adam |
| Learning rate | 0.001 |
| Momentum | 0.937 |
| Decay | 0.0005 |
| Warmup | 3 |
| Batch size | 32 |
| Epochs | 200 |
| Method | Precision | Recall | F1 |
|---|---|---|---|
| faster R-CNN [33] | 0.875 | 0.929 | 0.901 |
| Cascade R-CNN [34] | 0.926 | 0.911 | 0.918 |
| FCOS [42] | 0.865 | 0.891 | 0.878 |
| RetinaNet [36] | 0.923 | 0.881 | 0.902 |
| CenterNet [41] | 0.934 | 0.922 | 0.928 |
| YOLOX-s [53] | 0.928 | 0.912 | 0.920 |
| YOLOV5s [39] | 0.940 | 0.914 | 0.927 |
| SFRE-Net (ours) | 0.944 | 0.945 | 0.944 |
| Method | Precision | Recall | F1 |
|---|---|---|---|
| FPN [29] | 0.931 | 0.916 | 0.923 |
| PANet [30] | 0.940 | 0.914 | 0.927 |
| BiFPN [45] | 0.936 | 0.920 | 0.928 |
| FAFP (Ours) | 0.940 | 0.921 | 0.930 |
| FEM/FEM-s | TRsB | CAEM | Precision | Recall | F1 |
|---|---|---|---|---|---|
| ✕ | ✕ | ✕ | 0.940 | 0.921 | 0.930 |
| ✓ | ✕ | ✕ | 0.940 | 0.926 | 0.933 |
| ✓ | ✓ | ✕ | 0.941 | 0.939 | 0.940 |
| ✓ | ✓ | ✓ | 0.944 | 0.945 | 0.944 |
| Position | Precision | Recall | F1 |
|---|---|---|---|
| 0.940 | 0.941 | 0.940 | |
| 0.942 | 0.942 | 0.942 | |
| 0.944 | 0.945 | 0.944 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, P.; Xu, H.; Tian, T.; Gao, P.; Tian, J. SFRE-Net: Scattering Feature Relation Enhancement Network for Aircraft Detection in SAR Images. Remote Sens. 2022, 14, 2076. https://doi.org/10.3390/rs14092076
Zhang P, Xu H, Tian T, Gao P, Tian J. SFRE-Net: Scattering Feature Relation Enhancement Network for Aircraft Detection in SAR Images. Remote Sensing. 2022; 14(9):2076. https://doi.org/10.3390/rs14092076
Chicago/Turabian StyleZhang, Peng, Hao Xu, Tian Tian, Peng Gao, and Jinwen Tian. 2022. "SFRE-Net: Scattering Feature Relation Enhancement Network for Aircraft Detection in SAR Images" Remote Sensing 14, no. 9: 2076. https://doi.org/10.3390/rs14092076
APA StyleZhang, P., Xu, H., Tian, T., Gao, P., & Tian, J. (2022). SFRE-Net: Scattering Feature Relation Enhancement Network for Aircraft Detection in SAR Images. Remote Sensing, 14(9), 2076. https://doi.org/10.3390/rs14092076