
Assessing the Impact of the Loss Function and Encoder Architecture for Fire Aerial Images Segmentation Using Deeplabv3+

 ,
, 
 and
and 
Abstract
:
1. Introduction
- -
- An in-depth analysis of the impact of different loss function, with different encoder architectures over different types of aerial images is performed. Firefront_Gestosa and FLAME are two dataset of aerial images covering different scenarios. The first set contains very limited fire pixels, less than 1% over the final dataset. The second set contains a higher ratio of fire pixels in comparison to the first one, but it includes some different images of the same view. Usually, the aerial datasets draw segmentation results very low in comparison with the attended performance presented in this paper.
- -
- Deeplabv3+ parameter fine tuning to train a model in order to efficiently segment aerial images with limited flame area. Moreover, choosing the adequate encoder architecture combined with a proper loss function will reduce the false negatives (FN) and boost the intersection over union (IoU) and BF score.
- -
- A private labeled set of aerial fire pictures named Firefront_Gestosa dataset has been used in the experiments. The labeling task of such aerial profiles is challenging since the part of smoke sometimes fully cover the flame part. A wrong labeled data while induce a misleading trained classifier. The firefighters are more interested in localizing the exact GPS positions of flames to promptly start intervention to limit the propagation. With huge smoke clouds, it is unbearable to visibly localize the flame positions from soil or air.
2. Related Work
3. Materials and Methods
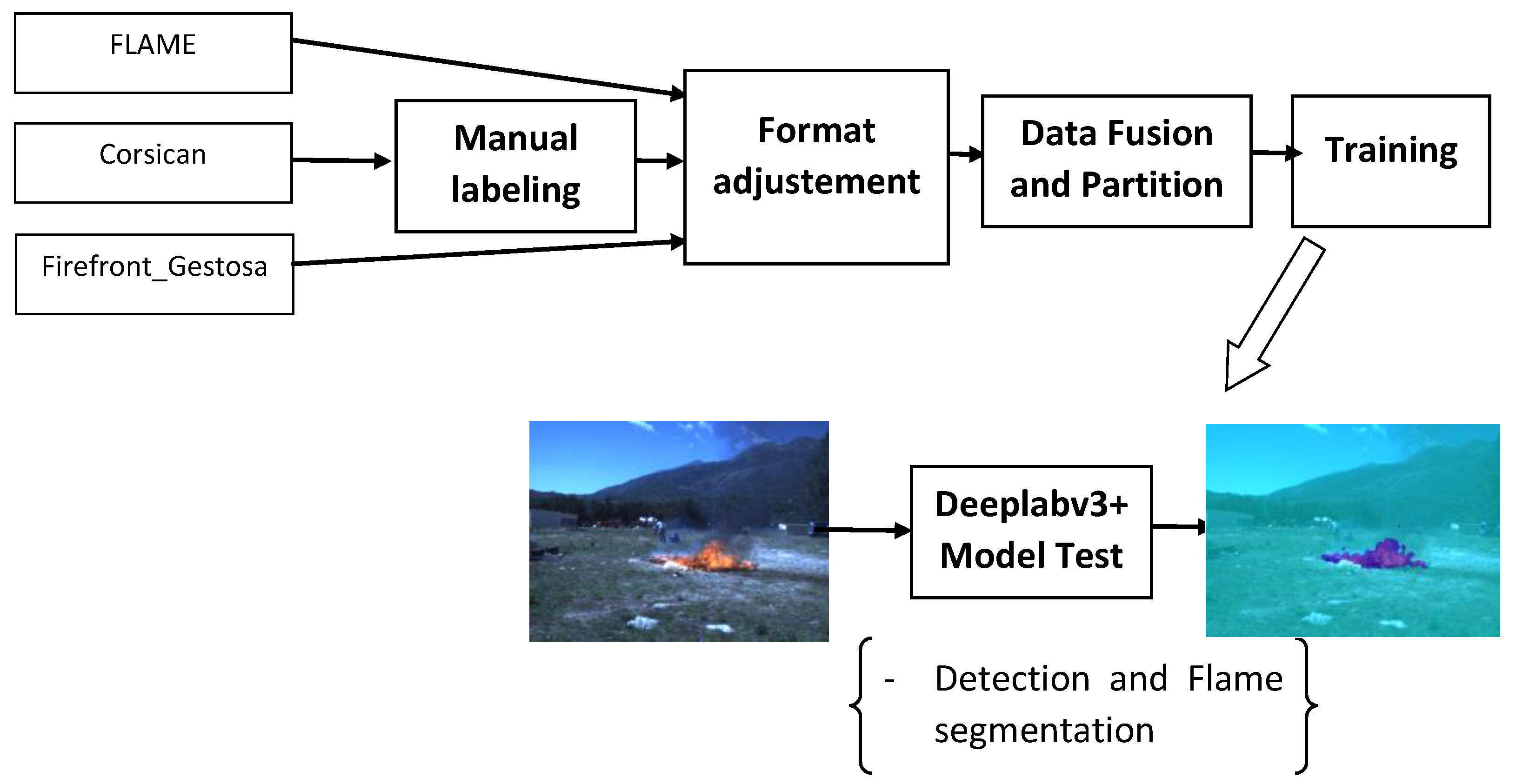
3.1. Dataset
3.1.1. Description
3.1.2. Data Annotation Technique
3.1.3. The Final Dataset
3.2. Segmentation Approach
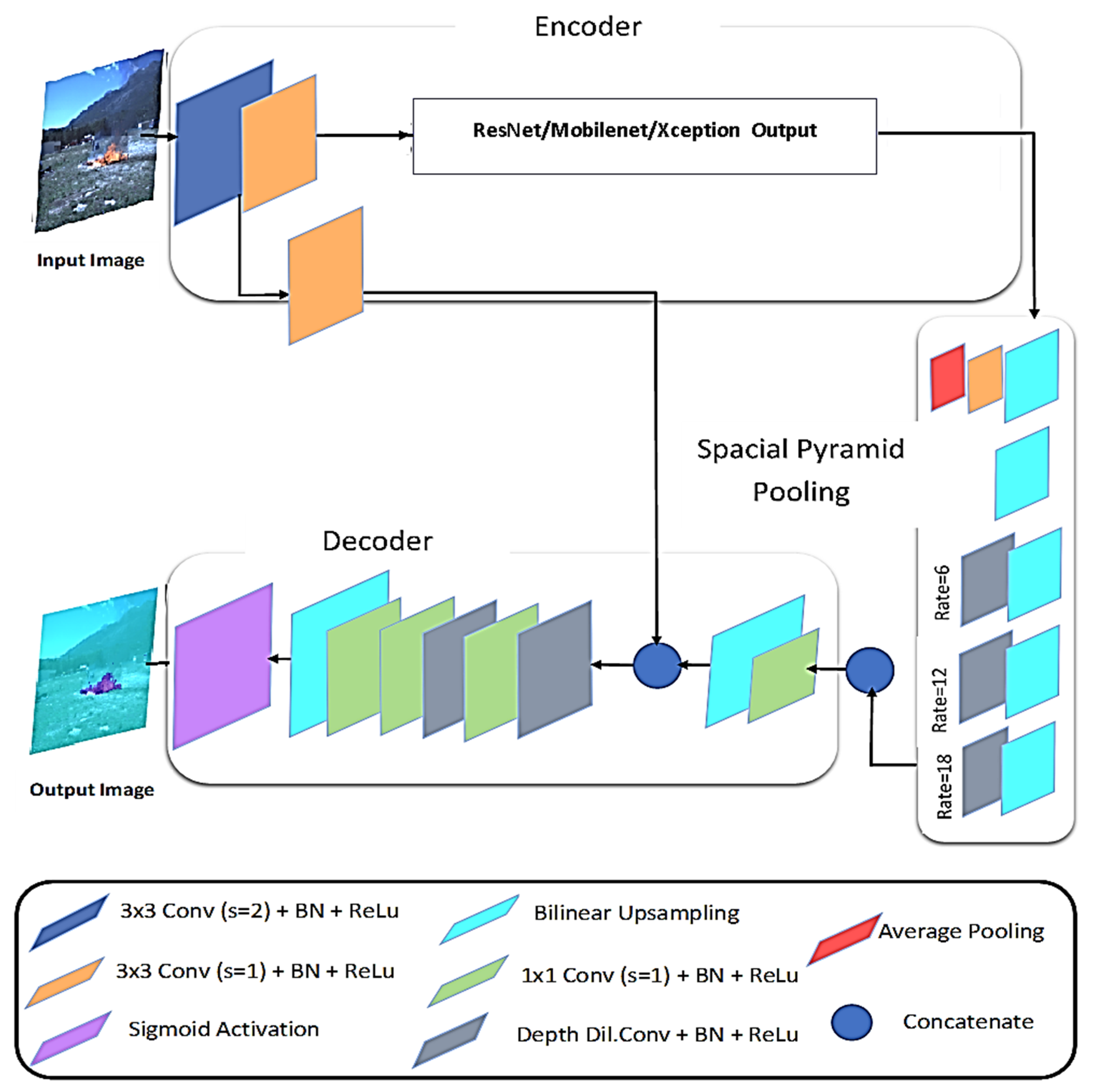
3.2.1. DeeplabV3+
3.2.2. Loss Function
- The Cross-entropy loss: It is the default function with the deeplabv3+ model. It is formulated as follows [47]:where N corresponds to the number of classes in the dataset.
- Generalized dice loss: The mathematical formulation alleviates the class imbalance problem. The function is given as follows [44]:
- Tversky loss: The loss function is defined as follows [45]:
- Focal loss: It is a variant of the original cross-entropy loss that performs class weighting by down-weighting the contribution of every class with a corresponding modulating factor. The following equation gives the mathematical formulation: [46]
3.2.3. Assessment Metric
- Global accuracy is a more general metric that gives insight into the percentage of correctly classified pixels without considering the classes. This metric is completely misleading in the case of highly unbalanced datasets.
- Mean accuracy gives an idea about the portion of correctly classified pixels considering all the classes. Mathematically defined as:where TPs is the number of true positives, the number of positive pixels correctly classified.
- Mean IoU or Jaccard similarity measure, computed as the average IoU measure of all data classes calculated for all the images and averaged. In other words, it is a statistical measure of precision that penalizes FPs. IoU (or Jaccard) metric is mathematically defined as:
- Weighted IoU is a measure that considers the minority classes in unbalanced datasets. Hence, the overall score is more realistic. This metric is defined as the mean IoU of each class in the data, weighted by the number of pixels in that class.
- Mean BF Score, the boundary F1 contour matching score, mathematically defined by the following formula:
4. Experiments
4.1. Experimental Setup
4.2. Implementation and Results
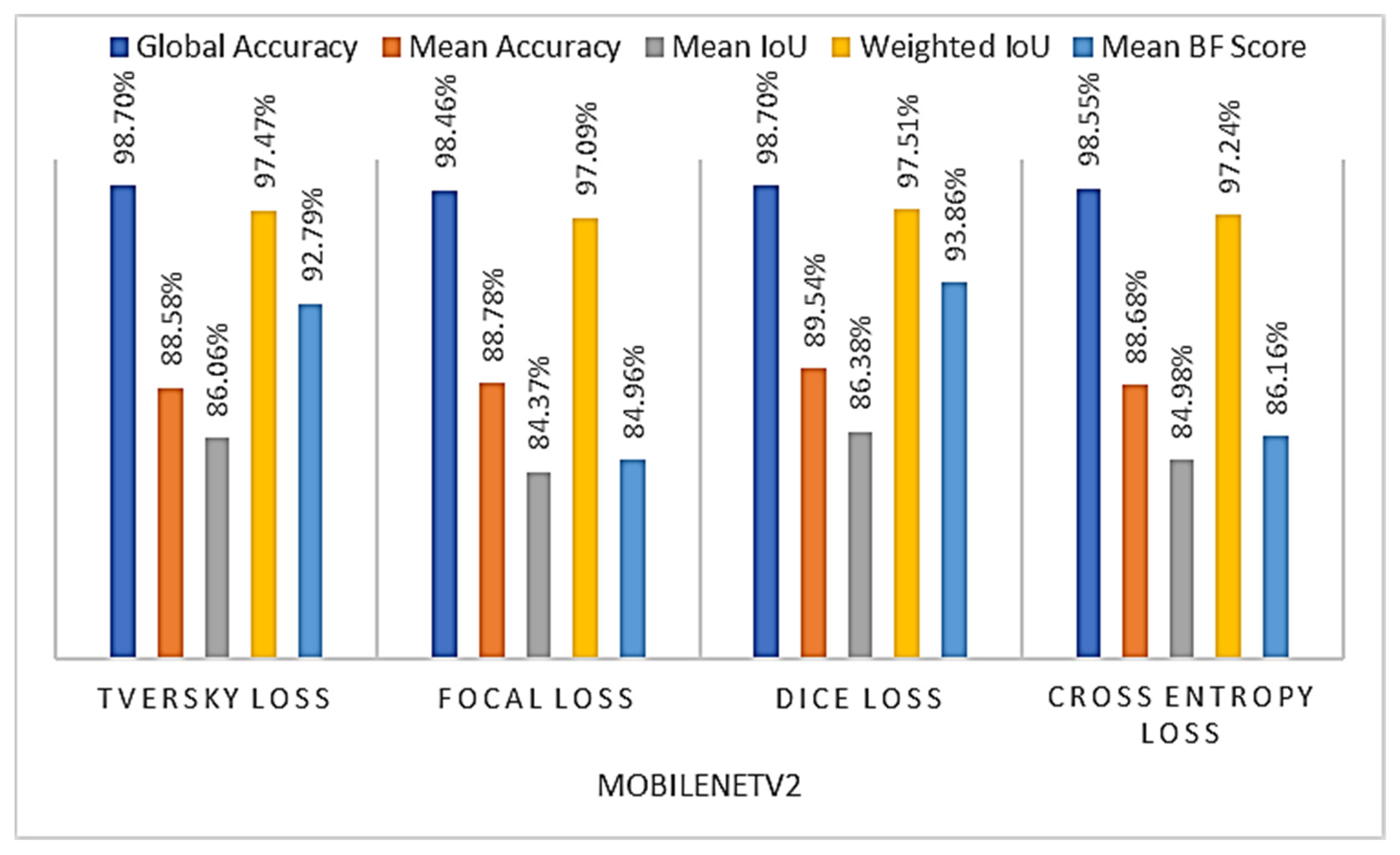
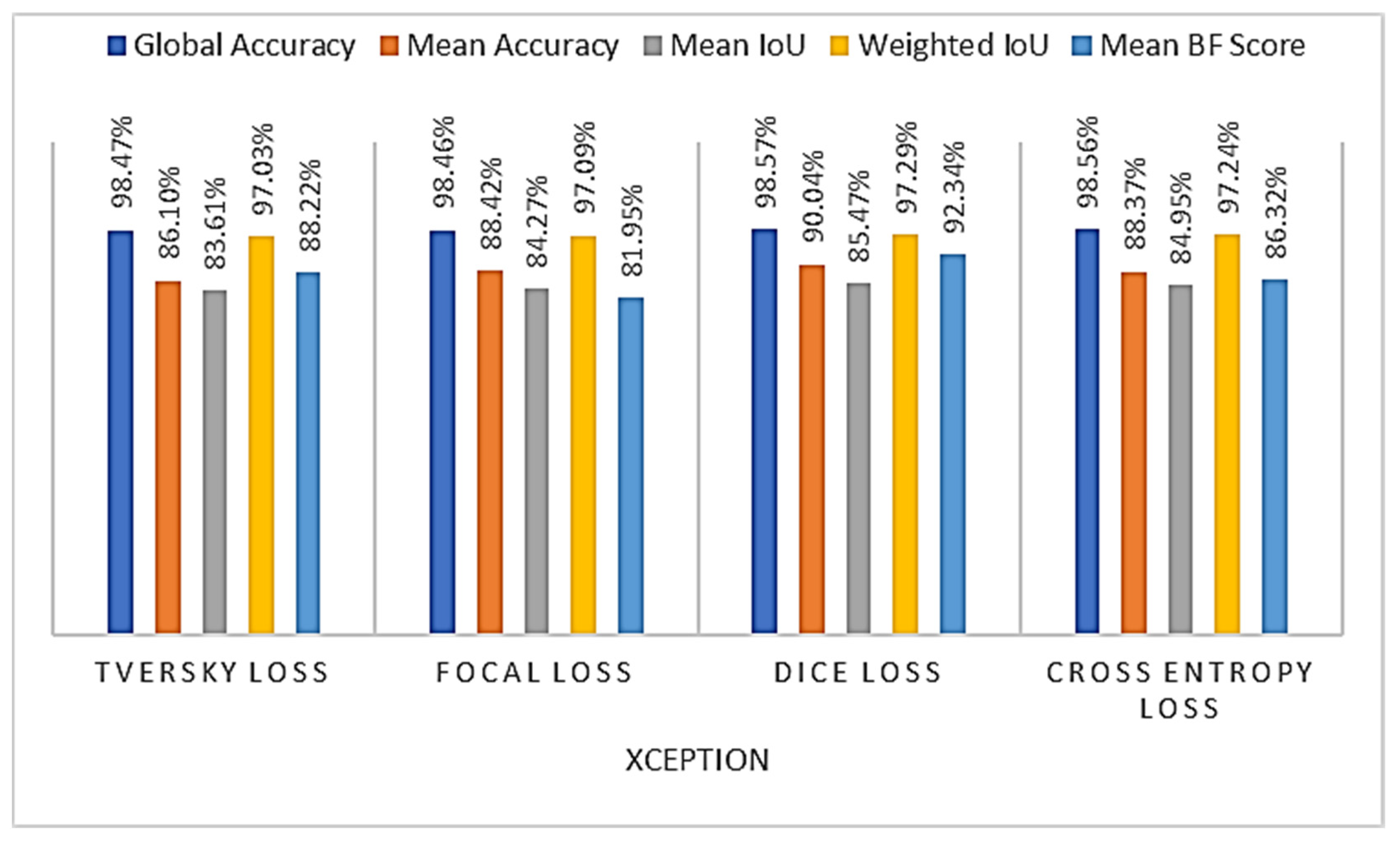
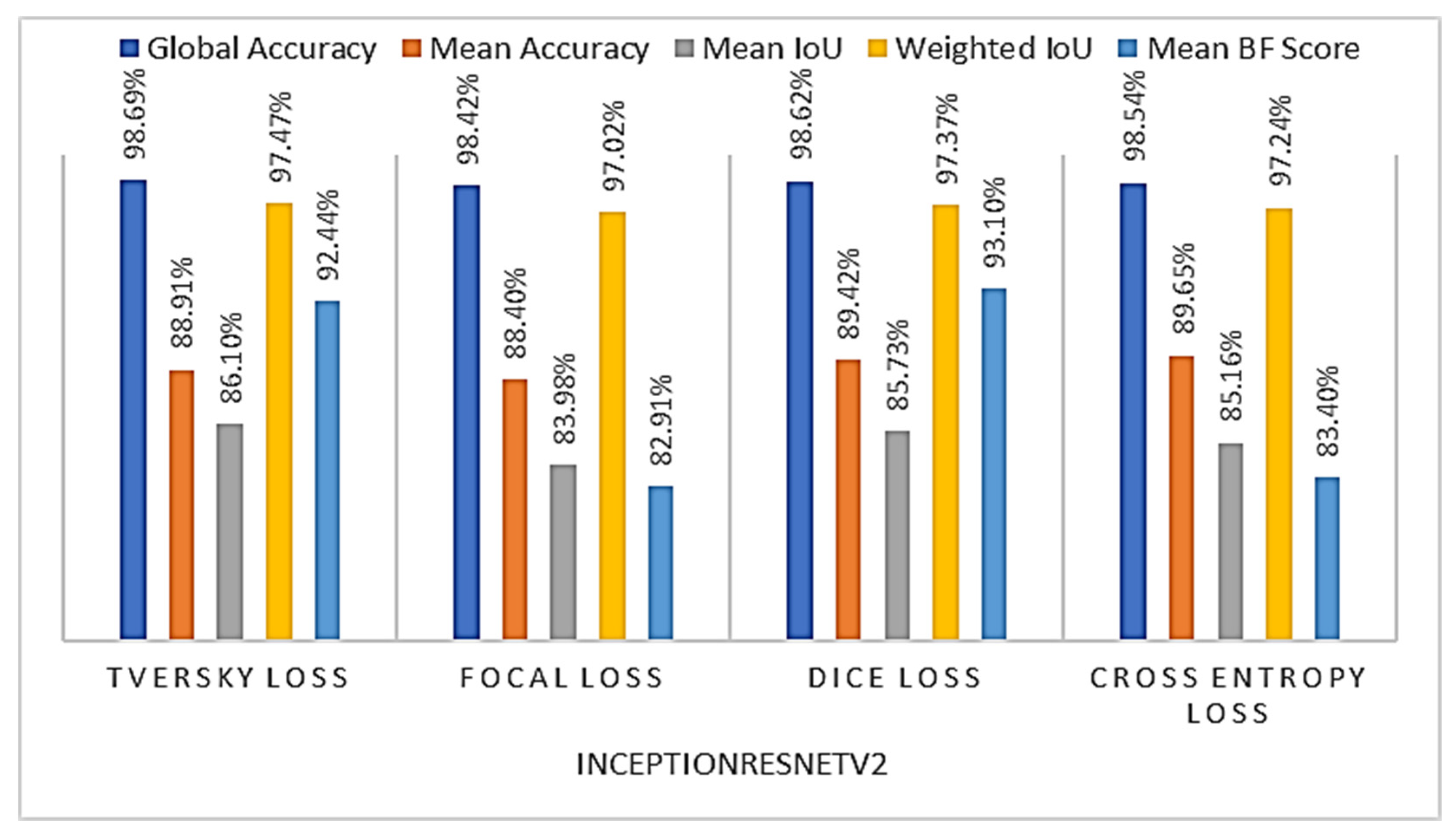
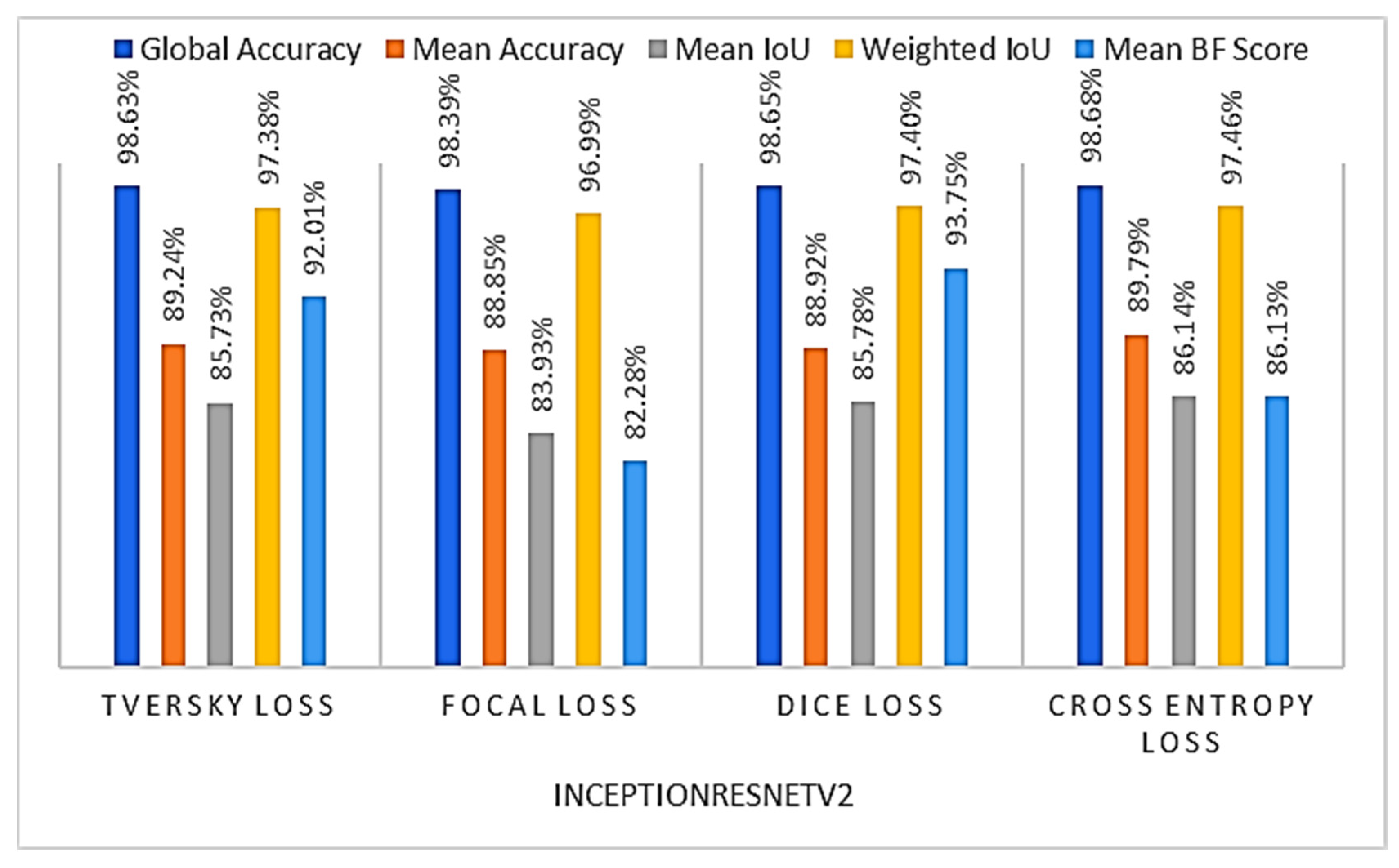
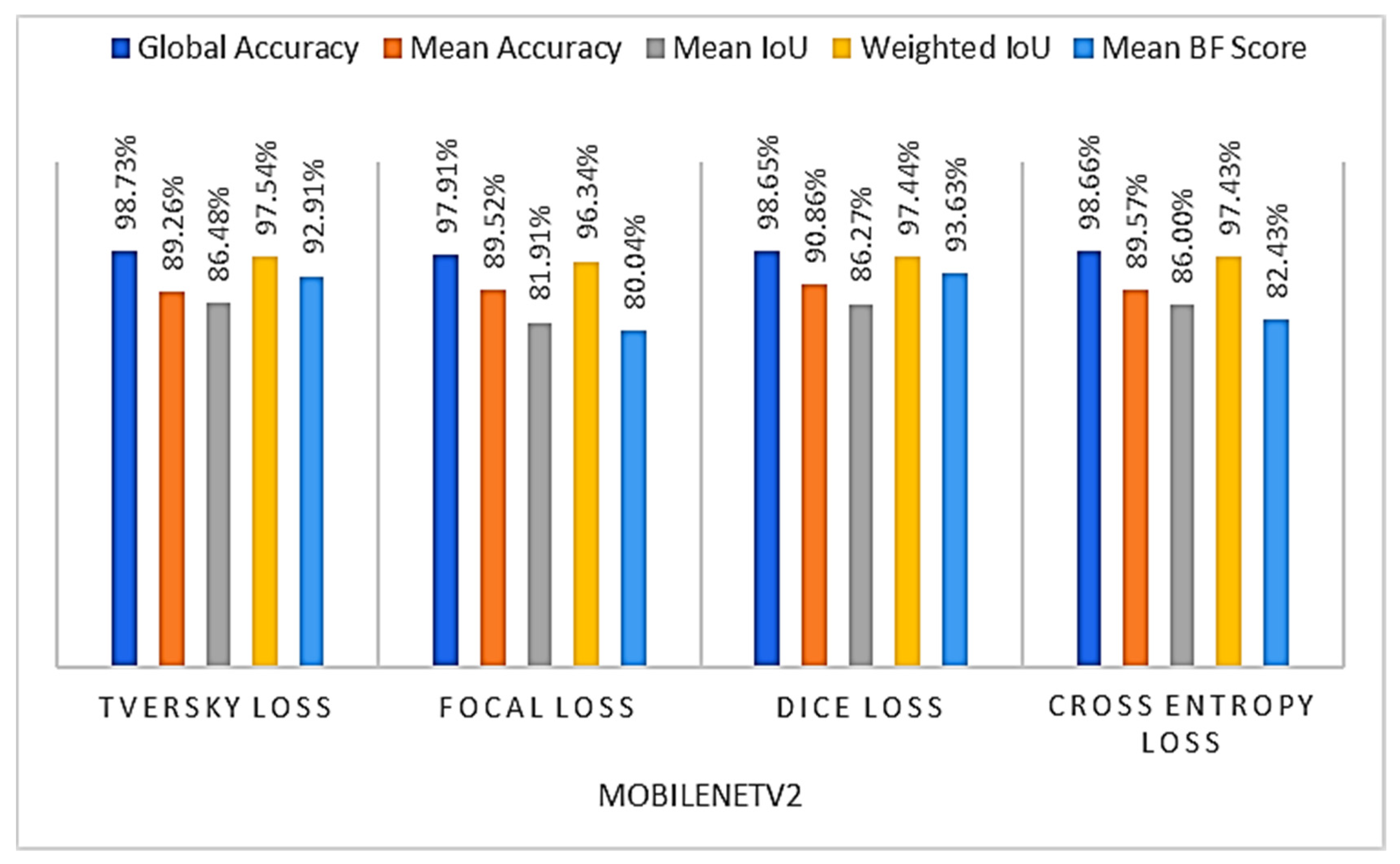
4.2.1. Loss Function Choice
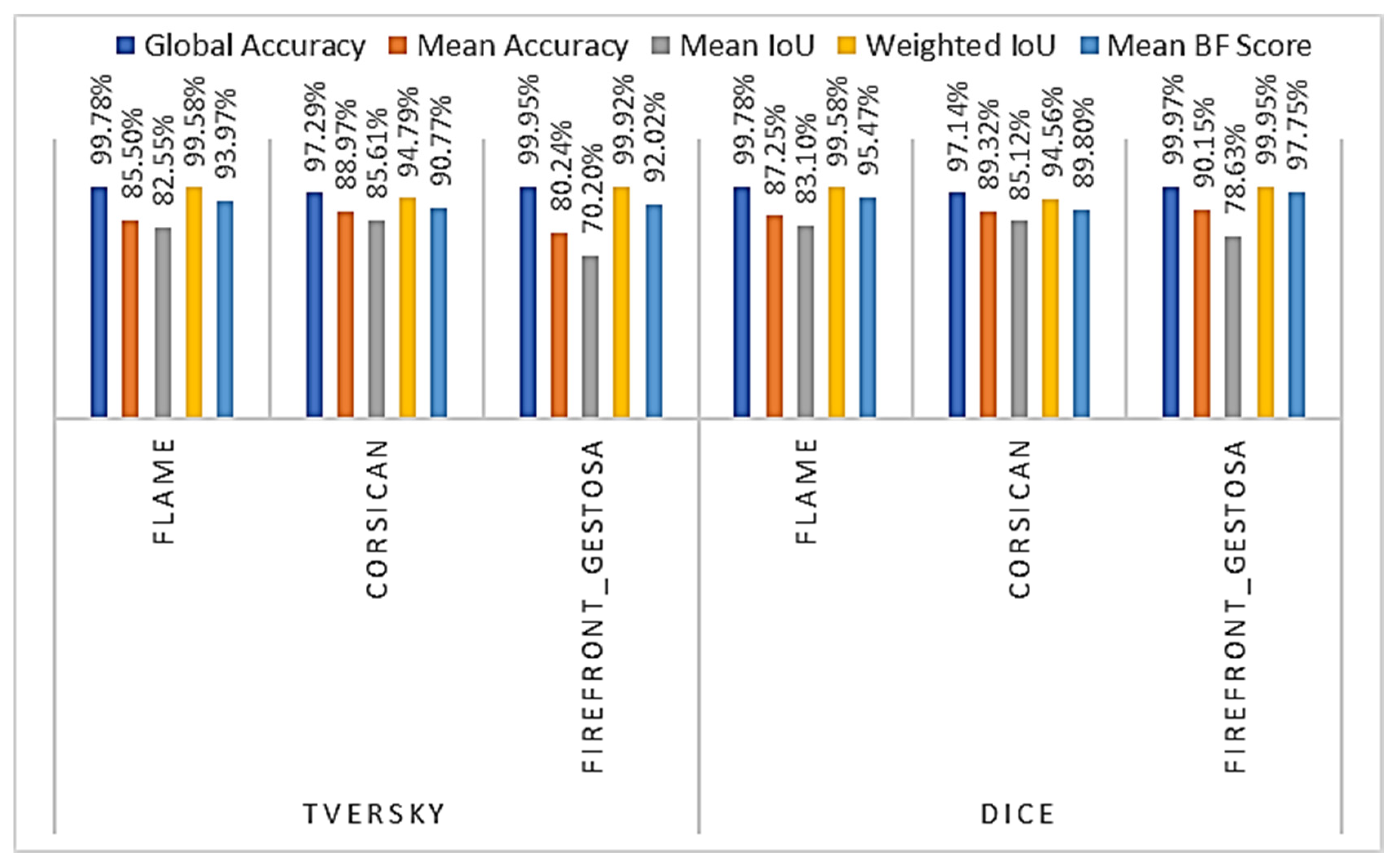
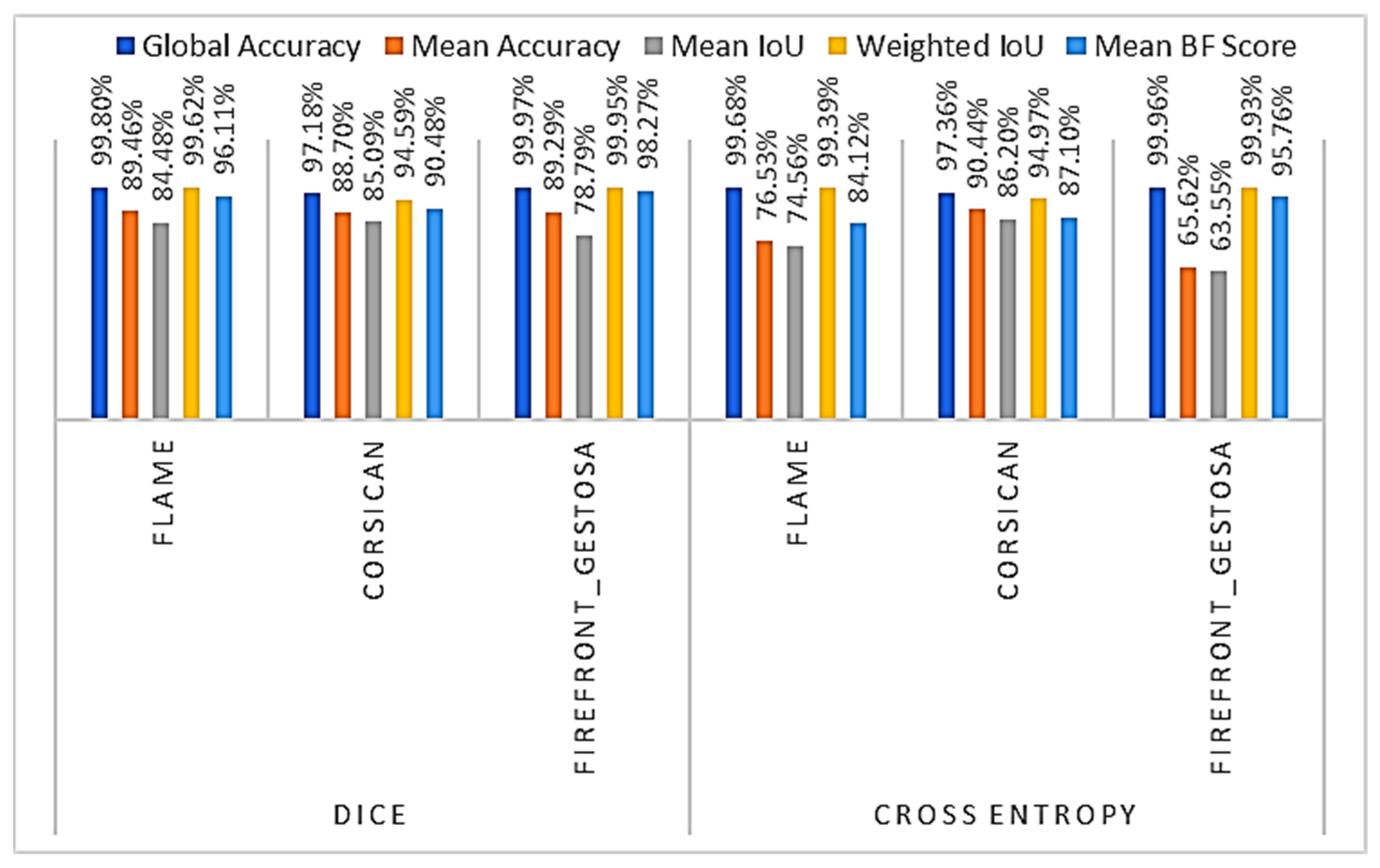
4.2.2. Model’s Comparison
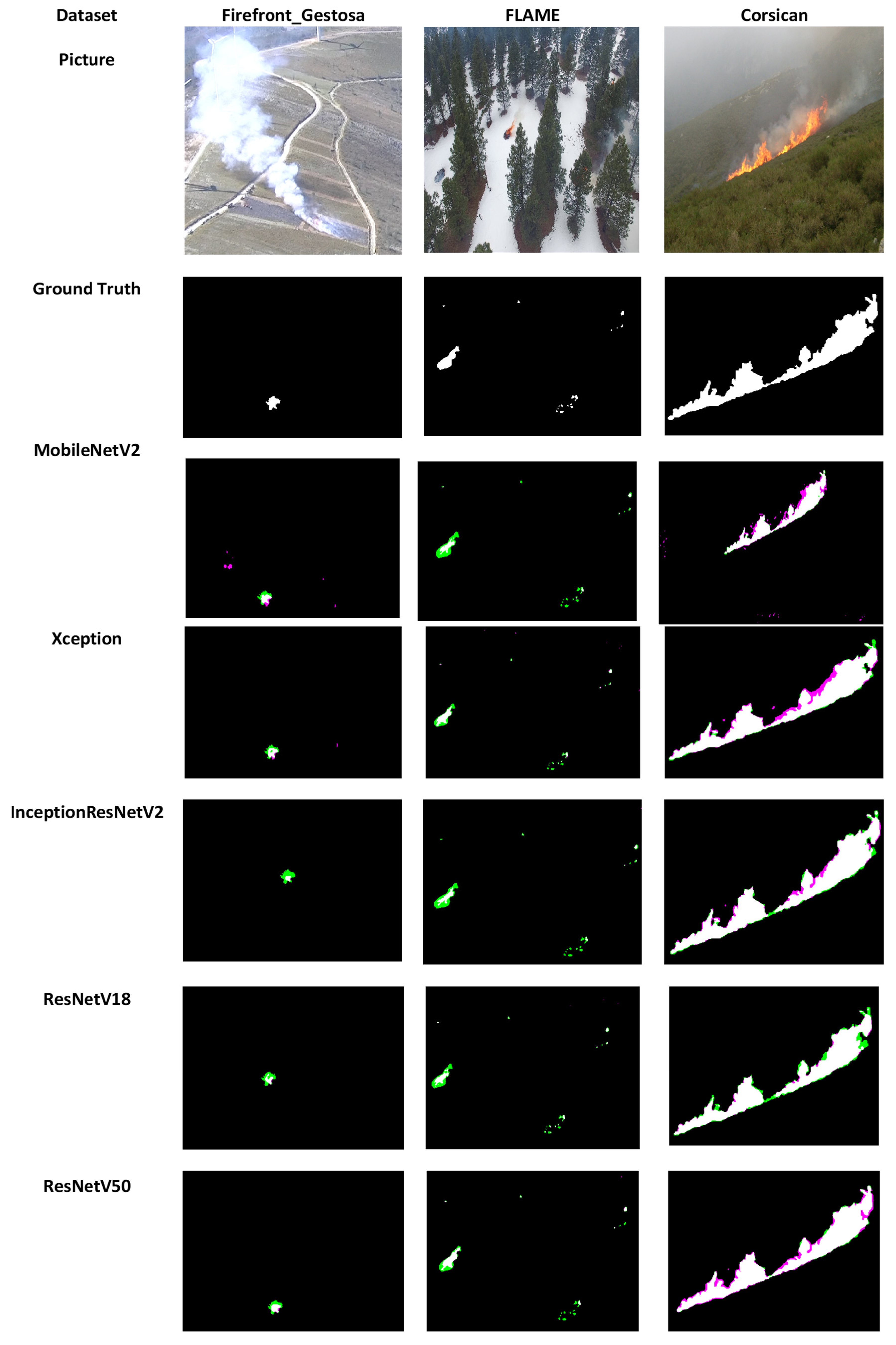
4.2.3. Test Samples
4.3. State-of-the-Art Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Global Forest Watch. Available online: https://www.globalforestwatch.org/ (accessed on 7 February 2022).
- Libonati, R.; Geirinhas, J.L.; Silva, P.S.; Russo, A.; Rodrigues, J.A.; Belém, L.B.; Nogueira, J.; Roque, F.O.; DaCamara, C.C.; Nunes, A.M. Assessing the role of compound drought and heatwave events on unprecedented 2020 wildfires in the Pantanal. Environ. Res. Lett. 2022, 17, 015005. [Google Scholar] [CrossRef]
- Mansoor, S.; Farooq, I.; Kachroo, M.M.; Mahmoud, A.E.D.; Fawzy, M.; Popescu, S.M.; Alyemeni, M.; Sonne, C.; Rinklebe, J.; Ahmad, P. Elevation in wildfire frequencies with respect to the climate change. J. Environ. Manag. 2022, 301, 113769. [Google Scholar] [CrossRef] [PubMed]
- Rego, F.C.; Silva, J.S. Wildfires and landscape dynamics in Portugal: A regional assessment and global implications. In Forest Landscapes and Global Change; Springer: Berlin/Heidelberg, Germany, 2014; pp. 51–73. [Google Scholar]
- Oliveira, S.; Gonçalves, A.; Zêzere, J.L. Reassessing wildfire susceptibility and hazard for mainland Portugal. Sci. Total Environ. 2021, 762, 143121. [Google Scholar] [CrossRef] [PubMed]
- Ferreira-Leite, F.; Ganho, N.; Bento-Gonçalves, A.; Botelho, F. Iberian atmospheric dynamics and large forest fires in mainland Portugal. Agric. For. Meteorol. 2017, 247, 551–559. [Google Scholar] [CrossRef]
- Costa, L.; Thonicke, K.; Poulter, B.; Badeck, F.-W. Sensitivity of Portuguese forest fires to climatic, human, and landscape variables: Subnational differences between fire drivers in extreme fire years and decadal averages. Reg. Environ. Chang. 2011, 11, 543–551. [Google Scholar] [CrossRef]
- Yuan, C.; Liu, Z.; Zhang, Y. Vision-based forest fire detection in aerial images for firefighting using UAVs. In Proceedings of the 2016 International Conference on Unmanned Aircraft Systems (ICUAS), Arlington, VA, USA, 7–10 June 2016; pp. 1200–1205. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Toulouse, T.; Rossi, L.; Campana, A.; Celik, T.; Akhloufi, M.A. Computer vision for wildfire research: An evolving image dataset for processing and analysis. Fire Saf. J. 2017, 92, 188–194. [Google Scholar] [CrossRef] [Green Version]
- Shamsoshoara, A.; Afghah, F.; Razi, A.; Zheng, L.; Fulé, P.Z.; Blasch, E. Aerial Imagery Pile burn detection using Deep Learning: The FLAME dataset. Comput. Netw. 2021, 193, 108001. [Google Scholar] [CrossRef]
- Blalack, T.; Ellis, D.; Long, M.; Brown, C.; Kemp, R.; Khan, M. Low-Power Distributed Sensor Network for Wildfire Detection. In Proceedings of the 2019 SoutheastCon, Huntsville, AL, USA, 11–14 April 2019; pp. 1–3. [Google Scholar]
- Brito, T.; Pereira, A.I.; Lima, J.; Valente, A. Wireless sensor network for ignitions detection: An IoT approach. Electronics 2020, 9, 893. [Google Scholar] [CrossRef]
- Veraverbeke, S.; Dennison, P.; Gitas, I.; Hulley, G.; Kalashnikova, O.; Katagis, T.; Kuai, L.; Meng, R.; Roberts, D.; Stavros, N. Hyperspectral remote sensing of fire: State-of-the-art and future perspectives. Remote Sens. Environ. 2018, 216, 105–121. [Google Scholar] [CrossRef]
- Dennison, P.E.; Roberts, D.A.; Kammer, L. Wildfire detection for retrieving fire temperature from hyperspectral data. J. Sci. Eng. Res. 2017, 4, 126–133. [Google Scholar]
- Toan, N.T.; Cong, P.T.; Hung, N.Q.V.; Jo, J. A deep learning approach for early wildfire detection from hyperspectral satellite images. In Proceedings of the 2019 7th International Conference on Robot Intelligence Technology and Applications (RiTA), Daejeon, Korea, 1–3 November 2019; pp. 38–45. [Google Scholar]
- Liu, C.; Xing, C.; Hu, Q.; Wang, S.; Zhao, S.; Gao, M. Stereoscopic hyperspectral remote sensing of the atmospheric environment: Innovation and prospects. Earth-Sci. Rev. 2022, 226, 103958. [Google Scholar] [CrossRef]
- Mei, S.; Geng, Y.; Hou, J.; Du, Q. Learning hyperspectral images from RGB images via a coarse-to-fine CNN. Sci. China Inf. Sci. 2022, 65, 1–14. [Google Scholar] [CrossRef]
- Yuan, C.; Zhang, Y.; Liu, Z. A survey on technologies for automatic forest fire monitoring, detection, and fighting using unmanned aerial vehicles and remote sensing techniques. Can. J. For. Res. 2015, 45, 783–792. [Google Scholar] [CrossRef]
- Sudhakar, S.; Vijayakumar, V.; Kumar, C.S.; Priya, V.; Ravi, L.; Subramaniyaswamy, V. Unmanned Aerial Vehicle (UAV) based Forest Fire Detection and monitoring for reducing false alarms in forest-fires. Comput. Commun. 2020, 149, 1–16. [Google Scholar] [CrossRef]
- Badiger, V.; Bhalerao, S.; Mankar, A.; Nimbalkar, A. Wireless Sensor Network-Assisted Forest Fire Detection and Control Firefighting Robot. SAMRIDDHI J. Phys. Sci. Eng. Technol. 2020, 12, 50–57. [Google Scholar]
- Vani, K. Deep learning based forest fire classification and detection in satellite images. In Proceedings of the 2019 11th International Conference on Advanced Computing (ICoAC), Chennai, India, 18–20 December 2019; pp. 61–65. [Google Scholar]
- Toulouse, T.; Rossi, L.; Akhloufi, M.; Celik, T.; Maldague, X. Benchmarking of wildland fire colour segmentation algorithms. IET Image Process. 2015, 9, 1064–1072. [Google Scholar] [CrossRef] [Green Version]
- Toptaş, B.; Hanbay, D. A new artificial bee colony algorithm-based color space for fire/flame detection. Soft Comput. 2019. [Google Scholar] [CrossRef]
- Toulouse, T.; Rossi, L.; Akhloufi, M.A.; Pieri, A.; Maldague, X. A multimodal 3D framework for fire characteristics estimation. Meas. Sci. Technol. 2018, 29, 025404. [Google Scholar] [CrossRef]
- Cheng, S.; Ma, J.; Zhang, S. Smoke detection and trend prediction method based on Deeplabv3+ and generative adversarial network. J. Electron. Imaging 2019, 28, 033006. [Google Scholar] [CrossRef]
- Frizzi, S.; Kaabi, R.; Bouchouicha, M.; Ginoux, J.; Moreau, E.; Fnaiech, F. Convolutional neural network for video fire and smoke detection. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 877–882. [Google Scholar]
- Jia, Y.; Yuan, J.; Wang, J.; Fang, J.; Zhang, Q.; Zhang, Y. A Saliency-Based Method for Early Smoke Detection in Video Sequences. Fire Technol. 2016, 52, 1271–1292. [Google Scholar] [CrossRef]
- Nemalidinne, S.M.; Gupta, D. Nonsubsampled contourlet domain visible and infrared image fusion framework for fire detection using pulse coupled neural network and spatial fuzzy clustering. Fire Saf. J. 2018, 101, 84–101. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, L.; Xia, X.; Huang, Q.; Li, X. A Gated Recurrent Network With Dual Classification Assistance for Smoke Semantic Segmentation. IEEE Trans. Image Process. 2021, 30, 4409–4422. [Google Scholar] [CrossRef] [PubMed]
- Mahmoud, M.A.I.; Ren, H. Forest fire detection and identification using image processing and SVM. J. Inf. Process. Syst. 2019, 15, 159–168. [Google Scholar]
- Yuan, C.; Liu, Z.; Zhang, Y. UAV-based forest fire detection and tracking using image processing techniques. In Proceedings of the 2015 International Conference on Unmanned Aircraft Systems (ICUAS), Denver, CO, USA, 9–12 June 2015; pp. 639–643. [Google Scholar]
- Guede-Fernández, F.; Martins, L.; Almeida, R.V.d.; Gamboa, H.; Vieira, P. A deep learning based object identification system for forest fire detection. Fire 2021, 4, 75. [Google Scholar] [CrossRef]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency detection and deep learning-based wildfire identification in UAV imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, K.; Choi, H.-S.; Kang, M. Squeezed fire binary segmentation model using convolutional neural network for outdoor images on embedded device. Mach. Vis. Appl. 2021, 32, 120. [Google Scholar] [CrossRef]
- Mlích, J.; Koplík, K.; Hradiš, M.; Zemčík, P. Fire Segmentation in Still Images. In Proceedings of the Advanced Concepts for Intelligent Vision Systems, Auckland, New Zealand, 10–14 February 2020; pp. 27–37. [Google Scholar]
- Available online: http://firefront.pt/ (accessed on 7 February 2022).
- Thomas, S.W. Efficient inverse color map computation. In Graphics Gems II; Elsevier: Amsterdam, The Netherlands, 1991; pp. 116–125. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2017; pp. 240–248. [Google Scholar]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Quebec City, QC, Canada, 10 September 2017; pp. 379–387. [Google Scholar]
- Yin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Ma, Y.-D.; Liu, Q.; Qian, Z.-B. Automated image segmentation using improved PCNN model based on cross-entropy. In Proceedings of the 2004 International Symposium on Intelligent Multimedia, Video and Speech Processing, Hong Kong, China, 20–22 October 2004; pp. 743–746. [Google Scholar]
- Akhloufi, M.A.; Tokime, R.B.; Elassady, H. Wildland fires detection and segmentation using deep learning. In Proceedings of the Pattern Recognition and Tracking xxix, Orlando, FL, USA, 18–19 April 2018; p. 106490B. [Google Scholar]
- Choi, H.-S.; Jeon, M.; Song, K.; Kang, M. Semantic Fire Segmentation Model Based on Convolutional Neural Network for Outdoor Image. Fire Technol. 2021, 57, 3005–3019. [Google Scholar] [CrossRef]
- Niknejad, M.; Bernardino, A. Attention on Classification for Fire Segmentation. arXiv 2021, arXiv:2111.03129. [Google Scholar]
- Dzigal, D.; Akagic, A.; Buza, E.; Brdjanin, A.; Dardagan, N. Forest Fire Detection based on Color Spaces Combination. In Proceedings of the 2019 11th International Conference on Electrical and Electronics Engineering (ELECO), Bursa, Turkey, 28–30 November 2019; pp. 595–599. [Google Scholar]
- Niknejad, M.; Bernardino, A. Weakly-supervised fire segmentation by visualizing intermediate CNN layers. arXiv 2021, arXiv:2111.08401. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video | Pixel Resolution | Number of Frames Second (Frame Rate) | Durations in Seconds | Number of Bits per Pixel | Video Format |
|---|---|---|---|---|---|
| PIC_081.MP4 | 1920 × 1080 | 50 | 182.88 | 24 | RGB24 |
| PIC_082.MP4 | 1920 × 1080 | 50 | 163.68 | 24 | RGB24 |
| PIC_083.MP4 | 1920 × 1080 | 50 | 178.56 | 24 | RGB24 |
| PIC_085.MP4 | 1920 × 1080 | 50 | 66.24 | 24 | RGB24 |
| PIC_086.MP4 | 1920 × 1080 | 50 | 191.04 | 24 | RGB24 |
| Gestosa2019.MP4 | 1280 × 270 | 29.97 | 218.18 | 24 | RGB24 |
| Preprocessing Algorithm | |
|---|---|
| Initialization | For the Mask of Every Picture |
| Image normalization |
xsize and ysize correspond to the number of row and columns of the ground truth picture.
ncol corresponds to the Number of columns of the used gray map. The function round is used to round the results to the next integer number. |
| Storing format switch: number colors adjustment |
map is a matrix defining the gray colormap used. map is an 256 × 3 containing floating-point values of color intensities in the range [0, 1]. Reduce the number of colors and translation to indexed image using Inverse colormap computation algorithm [38], input is rgb_mask and output is ind_mask. |
| Final step: Switch to binary image |
is the luminance threshold, the adopted value is 0.5.
|
| Dataset | Corsican Dataset | FLAME | Firefront_Gestosa | Total |
|---|---|---|---|---|
| Fire pictures | 1775 | 2003 | 238 | 4016 |
| Dataset | Corsican Dataset | FLAME | Firefront_Gestosa |
|---|---|---|---|
| Fire pixels count | 2.95 × 108 | 9.71 × 107 | 1.77 × 105 |
| Background pixels count | 1.72 × 109 | 1.66 × 1010 | 6.58 × 108 |
| Contribution in final dataset in terms of percentage (%) | 24.74 | 75.22 | <1 |
| Model | Global Accuracy | Mean Accuracy | Mean IoU | Weighted IoU | Mean BF Score |
|---|---|---|---|---|---|
| Model_1 | 98.70% | 89.54% | 86.38% | 97.51% | 93.86% |
| Model_2 | 98.57% | 90.04% | 85.47% | 97.29% | 92.34% |
| Model_3 | 98.62% | 89.42% | 85.73% | 97.37% | 93.10% |
| Model_4 | 98.65% | 88.92% | 85.78% | 97.40% | 93.75% |
| Model_5 | 98.65% | 90.86% | 86.27% | 97.44% | 93.63% |
| Model | Average Training Time per Network (Hour:Minute:Second) | Average Detection Time per Image (Second) | ||
|---|---|---|---|---|
| FLAME | Corsican | Firefont_Gestosa | ||
| Model_1 | 00:55:10 | 1.0181 | 0.6178 | 0.8745 |
| Model_2 | 00:47:21 | 1.2033 | 0.68 | 1.0016 |
| Model_3 | 01:29:20 | 7.0613 | 2.4511 | 4.9538 |
| Model_4 | 00:47:59 | 0.9122 | 0.8375 | 0.7407 |
| Model_5 | 01:05:34 | 1.1677 | 0.6459 | 1.0029 |
| Model | Dataset | Global Accuracy | Mean Accuracy | Mean IoU | Weighted IoU | Mean BF Score |
|---|---|---|---|---|---|---|
| Model_1 | FLAME | 99.80% | 87.81% | 84.32% | 99.62% | 95.66% |
| Corsican | 97.30% | 89.46% | 85.76% | 94.83% | 91.21% | |
| Firefront_Gestosa | 99.98% | 89.01% | 80.13% | 99.96% | 98.39% | |
| Model_5 | FLAME | 99.79% | 92.02% | 84.74% | 99.61% | 96.43% |
| Corsican | 97.18% | 90.49% | 85.60% | 94.69% | 89.81% | |
| Firefront_Gestosa | 99.97% | 92.61% | 79.09% | 99.95% | 98.60% |
| Algorithm Reference | Approach | Dataset | Global Accuracy | Mean Accuracy (Recall) | Mean IoU | Weighted IoU | Mean BF Score (F1 Score) |
|---|---|---|---|---|---|---|---|
| [11] | UNET | FLAME | 99% | 83.88% | 78.17% | ___ | 87.75% |
| Proposed approach | Deeplabv3+ with ResNet-50 backbone and Dice loss function | 99.79% | 92.02% | 84.74% | 99.61% | 96.43% | |
| [49] | Custom CNN residual network | Corsican | 97.46% | 95.17% | 90.02% | ___ | 94.70% |
| [48] | Deep–Fire U-Net | 94.39% | 88.78% | 82.32% | ___ | 89.48% | |
| [36] | Deeplab | 96.92% | 90.42% | 86.96% | ___ | 92.69% | |
| [51] | Color segmentation with fuzzy criteria | 92.74% | 75.10% | 72.53% | ___ | 80.04% | |
| [24] | bee colony algorithm-based color space segmentation | ___ | ___ | 76% | ___ | ___ | |
| [50] | Custom CNN architecture | 98.02% | ___ | ___ | 92.53% | ___ | |
| [52] | Weakly supervised CNN | ___ | ___ | 72.86% | ___ | ___ | |
| Proposed approach | Deeplabv3+ with ResNet-50 backbone and Dice loss function | 97.18% | 90.49% | 85.60% | 94.69% | 89.81% | |
| Proposed approach | Deeplabv3+ with ResNet-50 backbone and Dice loss function | Firefront_Gestosa | 99.97% | 92.61% | 79.09% | 99.95% | 98.60% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harkat, H.; Nascimento, J.M.P.; Bernardino, A.; Thariq Ahmed, H.F. Assessing the Impact of the Loss Function and Encoder Architecture for Fire Aerial Images Segmentation Using Deeplabv3+. Remote Sens. 2022, 14, 2023. https://doi.org/10.3390/rs14092023
Harkat H, Nascimento JMP, Bernardino A, Thariq Ahmed HF. Assessing the Impact of the Loss Function and Encoder Architecture for Fire Aerial Images Segmentation Using Deeplabv3+. Remote Sensing. 2022; 14(9):2023. https://doi.org/10.3390/rs14092023
Chicago/Turabian StyleHarkat, Houda, José M. P. Nascimento, Alexandre Bernardino, and Hasmath Farhana Thariq Ahmed. 2022. "Assessing the Impact of the Loss Function and Encoder Architecture for Fire Aerial Images Segmentation Using Deeplabv3+" Remote Sensing 14, no. 9: 2023. https://doi.org/10.3390/rs14092023
APA StyleHarkat, H., Nascimento, J. M. P., Bernardino, A., & Thariq Ahmed, H. F. (2022). Assessing the Impact of the Loss Function and Encoder Architecture for Fire Aerial Images Segmentation Using Deeplabv3+. Remote Sensing, 14(9), 2023. https://doi.org/10.3390/rs14092023