1. Introduction
Synthetic Aperture Radar (SAR) provides sample information of the ground surface in all weather and time circumstances. Recently, SAR-ATR has attracted more and more attention with the fast development of space technology and deep learning. Thanks to its ability to process a large amount of data, a lot of deep learning methods have been used in SAR-ATR problems [
1]. As an effective way of obtaining information of the ground surface, SAR-ATR has been widely applied in GIS system research, military reconnaissance, environmental monitoring, geological exploration, and so on.
However, as the quality of SAR images becomes better and better, the cost of acquiring images does not decrease accordingly, making it hard to obtain enough images. In addition, due to the sampling strategy of SAR, it is hard to ensure that the sampled regions and targets are uniformly distributed. So, there is always an unbalanced problem in different classes of samples. This brings a huge challenge to SAR-ATR tasks. In optical image processing, there is an effective way to handle this, which is called Few-Shot Learning (FSL) [
2]. FSL is a branch of machine learning which is specialized in learning with limited supervised information. The lack of real samples accelerates its booming. Up to now, the existing few-shot learning algorithms either try to connect to extra large-scale datasets with strong correlations [
3] or use specific measurements to represent the mapping relationships between samples [
4]. Yet, this kind of dataset may not always exist, and average measurements are just too simple to represent the complicated mapping relationships explicitly enough, thus making few-shot learning a tough subject to explore.
To improve the performance of few-shot learning algorithms, a lot of work has been conducted [
5].
Table 1 shows a summarization of these methods. First, from the image itself, some have tried to teach a classifier under the supervision of different azimuths, sizes, or areas of shadow, etc. [
6,
7,
8,
9,
10]. However, due to the different observation angles, there could be parts covered with shadows, which results in black zones in an image. This increases the intra-class difference, making it even harder to extract invariant features. Another attempt is to enlarge the previous datasets using data augmentation [
11,
12,
13]. Either learning a set of geometric transformations [
14,
15] or generating samples from other highly correlated datasets could alleviate the shortage of data to a great extent. Still, this kind of method can only work for some specific datasets, and different datasets usually follow different augmentation strategies.
In terms of model improvements, there exist several other methods. First of all, metric learning [
16,
17,
18] maps an image into a lower-dimensional space with more distinguishability, where intra-class samples become closer while inter-class samples become further away from each other. Considering the limitation of the capacity of a model, some try to introduce external memory to store the mapping relationships between samples [
19,
20]. We can simply perform a weighted average on the contents extracted from the memory to represent a novel one. However, this external memory often has a limited capacity. So, we have to give up some existing values when it is out of memory. What is more, fine-tuning methods provide a way to fine-tune pre-trained parameters with the supervision of the current dataset. Again, overfitting is more likely in auxiliary datasets, causing a lack of generalization ability in new categories. To better learn the task-generic information among datasets, meta-learning is also an excellent way to refine a better group of initialization parameters [
21,
22]. This method could avoid falling into a local minimum to a great extent. Still, a precision sacrifice for speed and huge computation cost due to extensive use of second derivative calculation is the main drawback.
To minimize the complexity of the learning procedure and to reduce the number of additional images included, a metric learning algorithm named Prototypical Network (PN) was proposed by Snell in 2017 [
23]. While taking a four-layer CNN as the backbone [
24], PN learns a metric space in which classification can be performed by simply computing their Euclidean distances to the class prototypes. PN gives better performance while adopting a simpler inductive inference within this limited-data regime. However, CNN does not possess spatial invariance, making Euclidean distance a bit less meaningful [
25]. Moreover, the mapping space is not bound to be separable, leading to lower performance on the current dataset [
26].
To solve all these above problems, we propose an improved Prototypical Network based on a spatial transformer here. Taking a four-layer CNN as the backbone, a spatial transformer module is then included to perform an affine transformation on the extracted features. Spatial alignment is achieved during the modification of loss backpropagation. To summarize our efforts as follows:
An extra Spatial Transformer Network (STN) is employed as a module to achieve spatial alignment on features derived from a CNN-based feature extractor, since CNN cannot extract features with invariance [
27]. STN makes this learning process more explicit.
We have conducted several experiments on the location, structure, and transformation type of STN and found out that a feature-wise alignment is better than a pixel-wise one. In addition, rotation outperforms all the other affine transformations.
We have also conducted several experiments on loss function and found out that a simple Cross-Entropy loss fits the best.
3. Materials and Methods
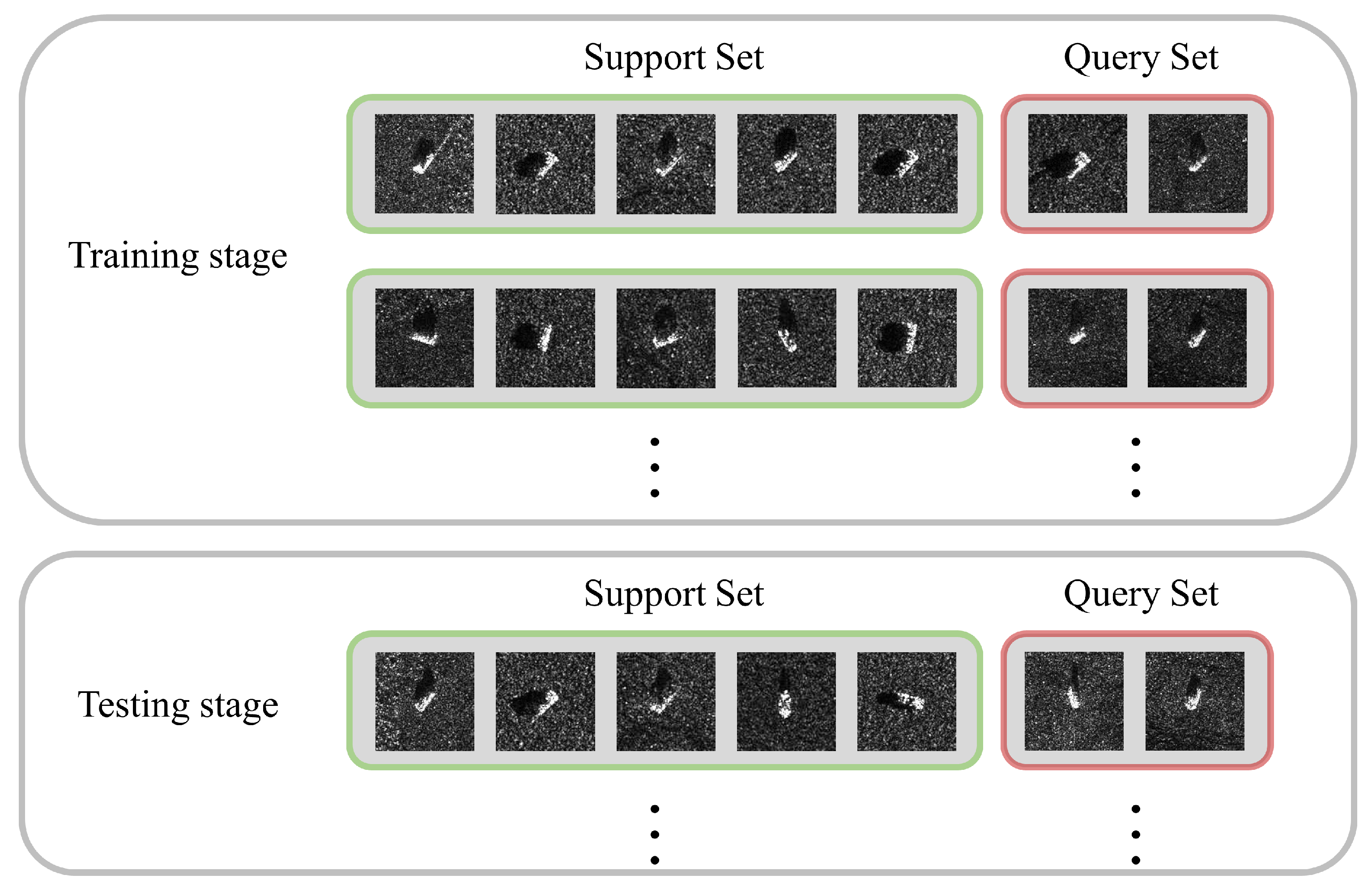
Few-shot classification tries to generalize to novel classes, given only a few samples of each class. Among all those mainstream methods, metric-based methods give excellent performance with independence on extra large-scale datasets [
5]. Prototypical Network is one of the well-performed baselines by computing distances to the prototype embeddings of each class. Therefore, how to map the inputs into an appropriate embedding space becomes a crucial but challenging problem here.
The Prototypical Network maps inputs into a metric space using a four-layer CNN as the feature extractor. Taking the mean of a class’s embeddings as the class prototype, classification is then performed for a query embedding by simply categorizing it into the nearest class via the Euclidean distance. However, CNN can only keep the translation invariance of a local small range, not to mention the global invariance of scale or rotation. When it comes to inputs with multi-azimuth and multi-depression-angle, CNN usually cannot work well in obtaining features with good spatial invariance [
27]. In addition, a support set is not bound to be representative in every training episode [
26], thus making the Euclidean distance meaningless to some extent. Therefore, instead of letting the network learn invariant features automatically, our goal is to make this procedure more explicit and ensure that features of the same class are aligned when query set classification is conducted.
We solved this problem by proposing a novel Spatial-Transformer-based Prototypical Network, denoted as ST-PN.
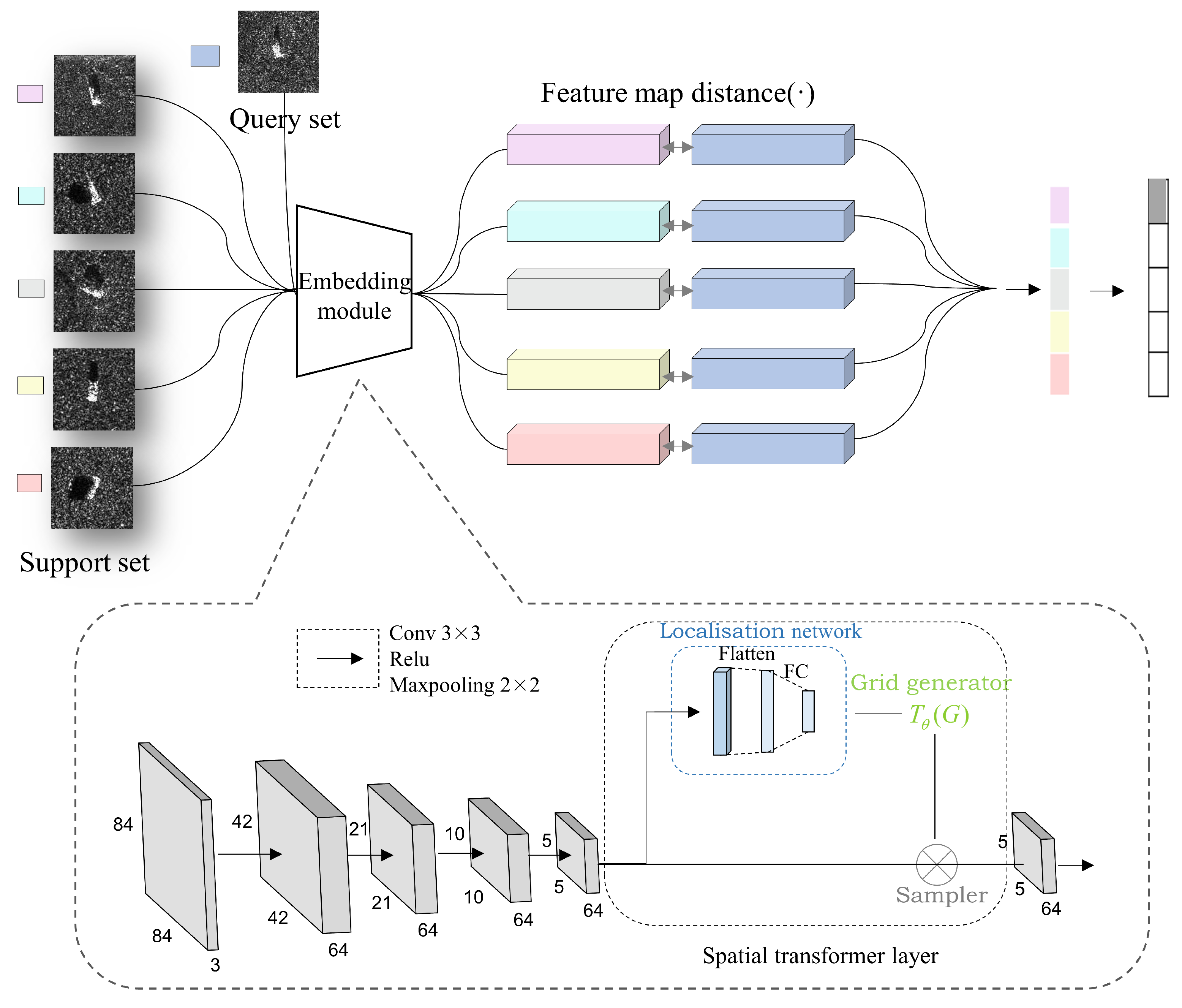
Figure 2 shows the overall architecture of our proposed ST-PN. An input image is embedded by the embedding module, which consists of a four-layer CNN and a spatial transformer module. Then, we use Euclidean distance to represent the similarity between one another and categorize it into the nearest class. A spatial transformer module is designed to achieve spatial alignment so that Euclidean distance makes more sense with better characteristics of invariance [
27]. Moreover, Table 4 shows that a feature-wise alignment fits better than a pixel-wise one. Furthermore, more latent information is to be explored as the layer goes deeper. We employ a rotation transformation here to align samples from different azimuths. All these parts work together to give better performances on SAR image classification.
3.1. Spatial Transformer Module
A spatial transformer module tries to achieve spatial alignment to features extracted by CNN. These features either contain semantic information of higher-level or local detailed information of lower level. Prototypical Network takes mean of the class’ embeddings as prototypes, which contains azimuth information. That makes Euclidean distance meaningless due to the azimuth divergence. To better classify feature representations, spatial alignment is needed to alleviate this discrepancy.
A detailed structure of the embedding module is shown in the lower part of
Figure 2. Feature embeddings are generated via 4 convolutional layers, each followed by a ReLU activation function and a max-pooling layer. After that, a spatial transformer module is included to implement the spatial alignment, which is formed by a localization network, a grid generator, and a sampler [
27].
The localization network takes feature maps as input and outputs , parameters to be applied to transform input feature maps. There are usually convolutional or fully connected layers in a localization network which ends with a regression layer for . In detail, a 3 × 3 convolutional layer followed by a max-pooling layer and a ReLU function, appended with a fully connected layer is employed to regress the transformation parameters in localization network. While a convolutional layer attempts for semantic information of higher-level, a fully connected layer introduces more non-linearity to fit the complex mapping relationships between features and parameters. The input feature size must be the same as the output. Hence, to perform the feature mapping, the grid generator generates a corresponding sampling grid according to the input feature map. Then, a sampling operation is conducted to fill up the output feature map for each channel, mostly through bilinear interpolation. For when mapped into the output feature maps, the corresponding coordinates of pixels are not usually integers. Then, the surrounding pixels are needed when calculating their values.
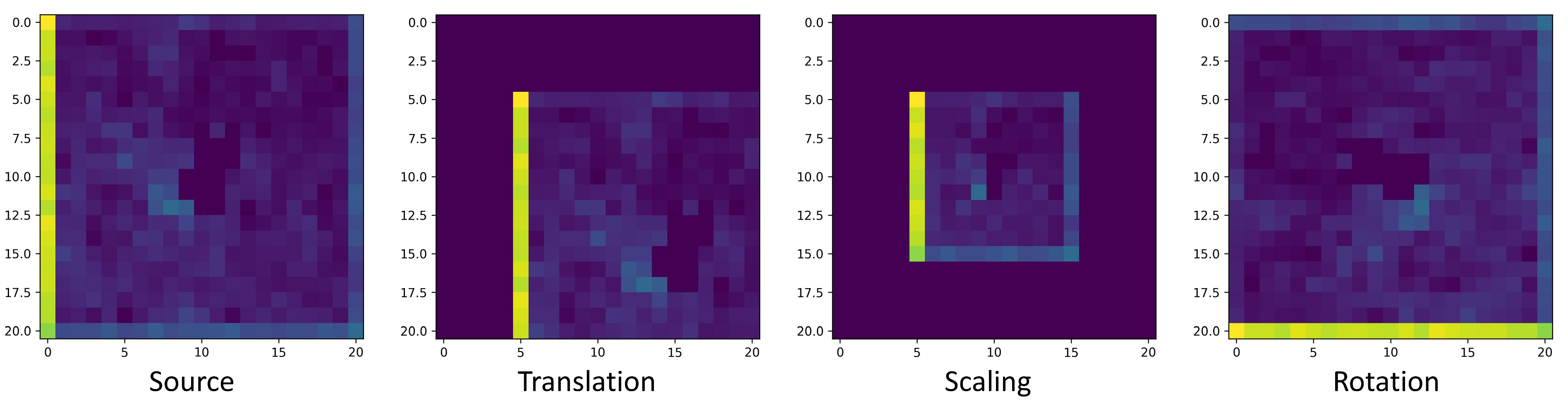
A simple affine transformation is used here in order to not bring in too many parameters and is also enough to represent most transformations of the 2D SAR images.
Figure 3 shows some of the transformations.
Usually a point-wise affine transformation can be described as:
where
denotes a source coordinate of the input, while
denotes the corresponding target coordinate of the output. For example,
for translation is denoted as
, and
is for rotation.
3.2. CNN as Backbone
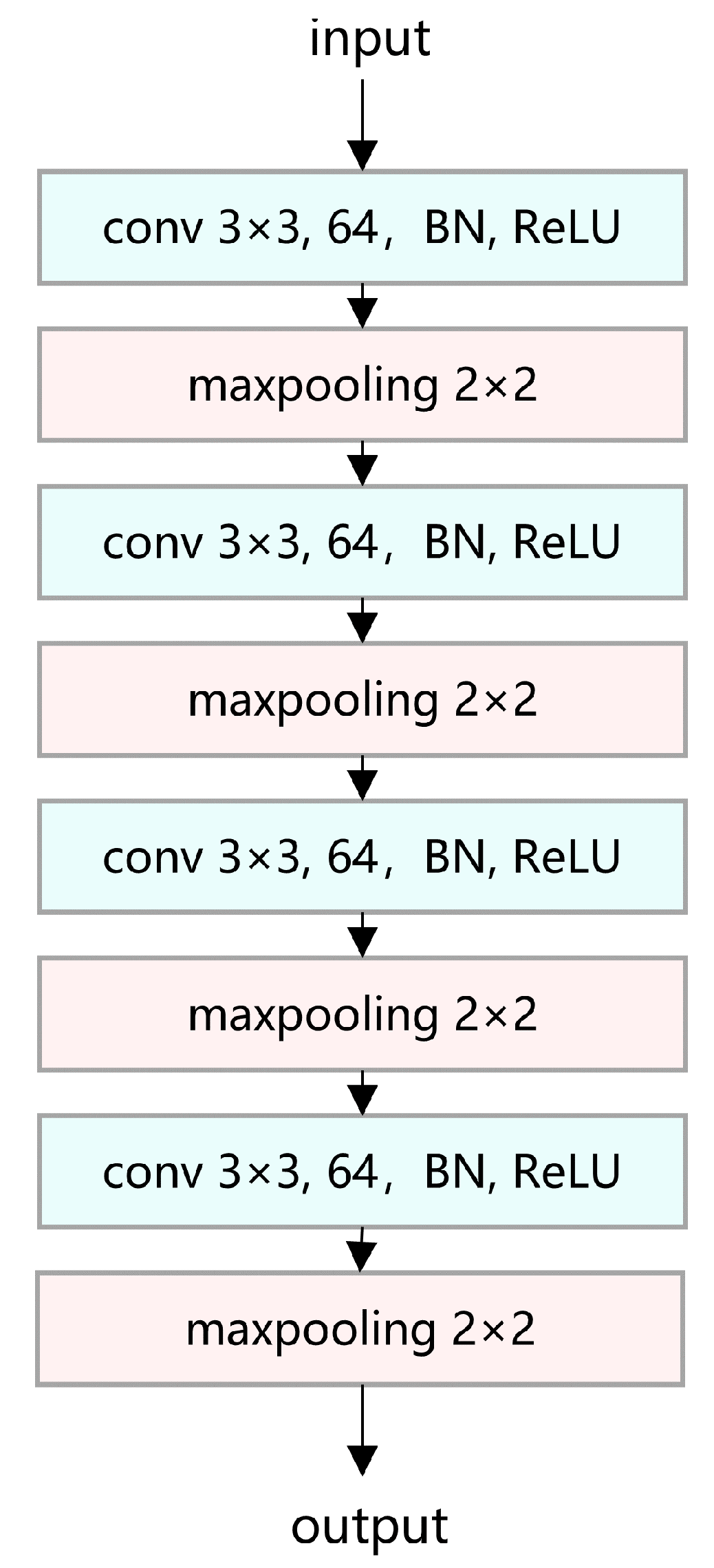
Extracting features from the input images could be an essential part of image processing. The whole backbone architecture is shown in
Figure 4. There are four convolutional layers in this structure, each followed by a ReLU activation, a batch normalization, and a max-pooling layer. It maps the input images into a lower and more organized metric space. Here, we use a typical setting of 3 × 3 kernel of a convolutional layer to extract global features. Then, a max-pooling layer with a kernel of 2 × 2 is included to decrease the dimensions of features as well as maintain its information.
3.3. Prediction and Loss
Here, the SAR image classification can be described as an N-way K-shot problem as mentioned above. Let
S be the support set where
.
denotes the
ith class of unseen classes. There are K labeled samples in each of the N classes in the support set, which is defined as
.
stands for the corresponding class label of
. Let the mapping function of the backbone be
, then the prototype for each class in the support set can be represented as:
The whole network is trained from scratch. Both the support set and query set are embedded via the same embedding module. Then, a Euclidean distance is calculated to measure the similarity between the query set and class prototypes. In detail, given feature vector
q of an unlabeled image and
as the prototype of the
ith class, the similarity can be calculated as:
Then, a softmax function is adopted to measure it probability of belonging to the
ith class:
Prediction of
q depends on the maximum probability over N classes, which is denoted as:
An overall loss function of the proposed network is CrossEntropy loss, which is widely used in image classification problems.
5. Discussion
Because of the insufficiency of SAR images, few-shot learning is introduced to tackle tasks like image classification, change detection, etc. From previous works, metric learning with Prototypical Network usually leads to the best performance among all others, so we started with it here. Some of the most notable features for targets in SAR images are luminance, shape, and azimuth information, etc. Geometric features usually cause the biggest variance for targets of the same class. However, what we want is more similarity among intra-class embeddings. In addition, CNN can only maintain translation invariance in a small range instead of being invariant to all other spatial transformations. Therefore, to alleviate this discrepancy, a spatial transformation is of great necessity, which is already applied in many other studies. Here, we take a spatial transformer into consideration.
As it shown in the location experiments above, STM performed the best when placed after the last convolutional layer. In addition, the further behind it positions, the better it performs. For locations after inputs and the first convolutional layer, it performs even worse than without STM, which demonstrates that a pixel-wise alignment is not suitable for this situation. In typical SAR images, even the same target shows different shapes and shadows due to different illuminations, angles, etc. In contrast to locations at the front, experiments of the last three locations show slight improvements, indicating that a feature-wise alignment works at least. More latent information can be obtained in deeper layers compared with the first few, and it has a more direct impact on updating parameters with less amount, making it a lot easier for calculation.
There are usually convolutional layers and full-connected layers in STM. In our study, one convolutional layer together with one full-connected layer is the best-performing structure. For comparison, one single fully connected layer is not complex enough to handle the whole bunch of parameters, leading to the worst performance among all others. In addition, either an extra cascading fully connected or convolutional layer is overly complex to regress a few parameters. So far, it has improved accuracy by 3.586% in 5-way 5-shot experiments and 3.387% in 5-way 1-shot experiments, which is relatively considerable and validates the effectiveness of our algorithm.
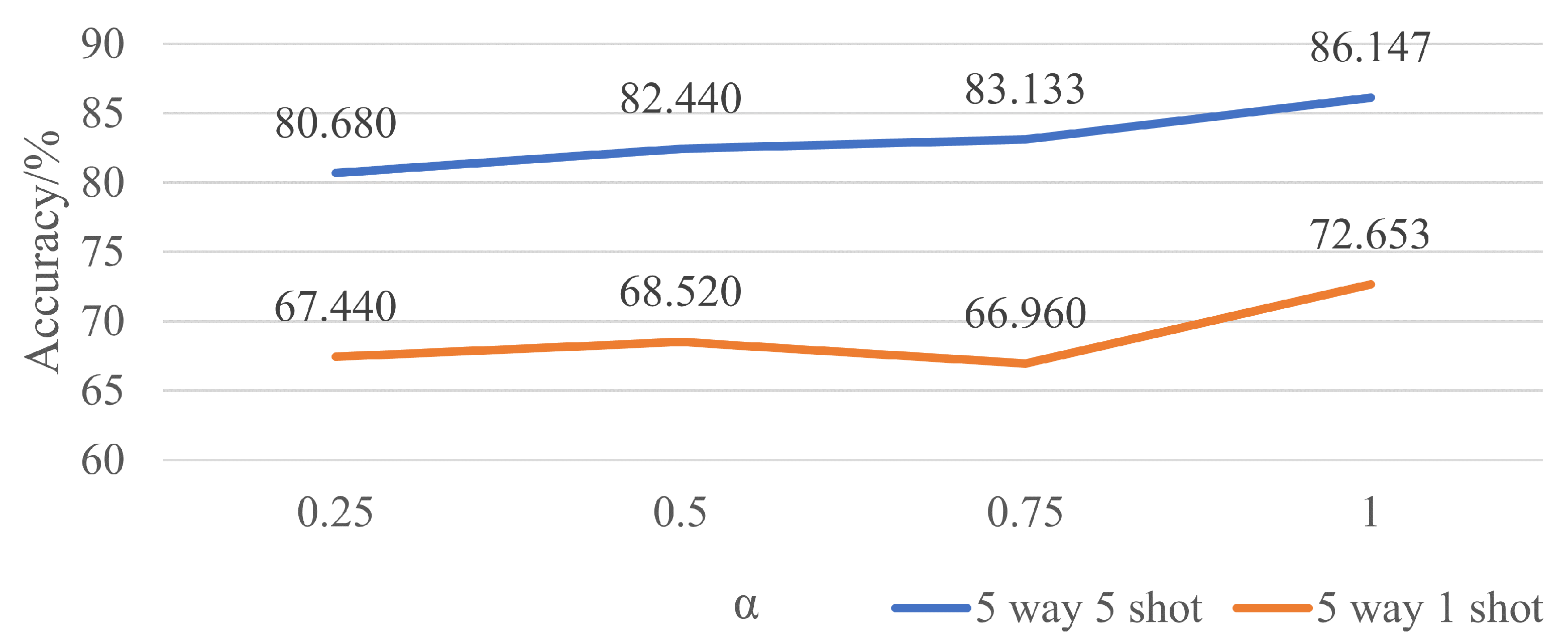
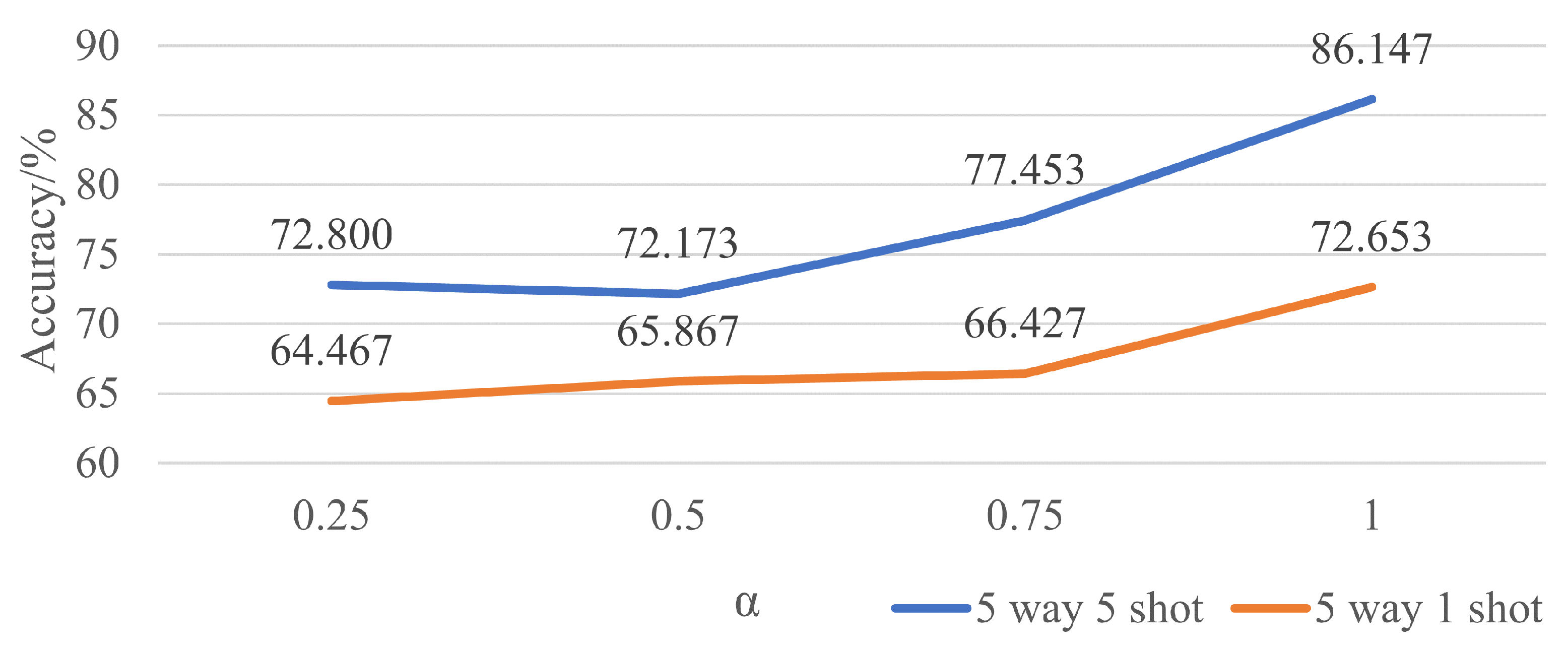
Furthermore, as we restrict the geometric transformations to rotations, there are further improvements in accuracy. That makes sense because all these images included are taken under the same circumstances with only a difference in azimuth. Each has the target right in the middle. Thus, translation does not work when it comes to accuracy. Shearing and scaling also cut no ice since they will narrow the gap between different classes as well as magnify that of the same class to some extent.
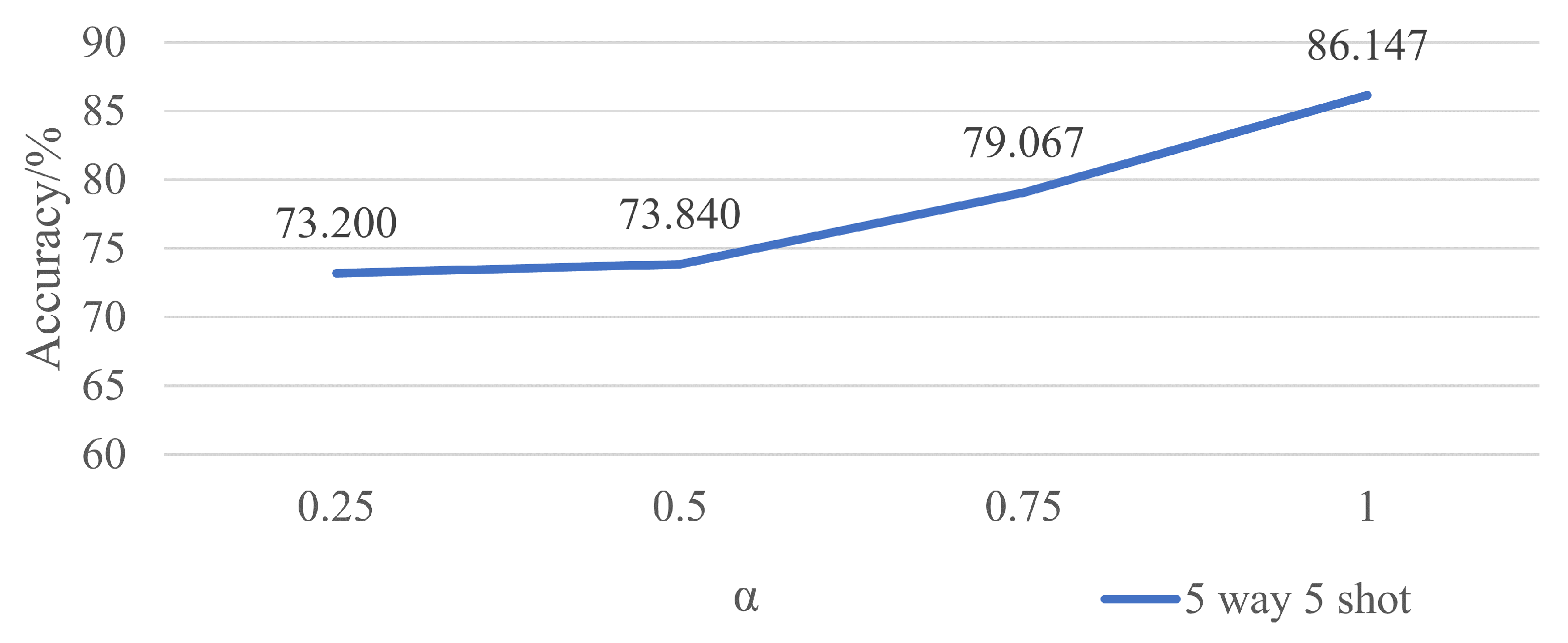
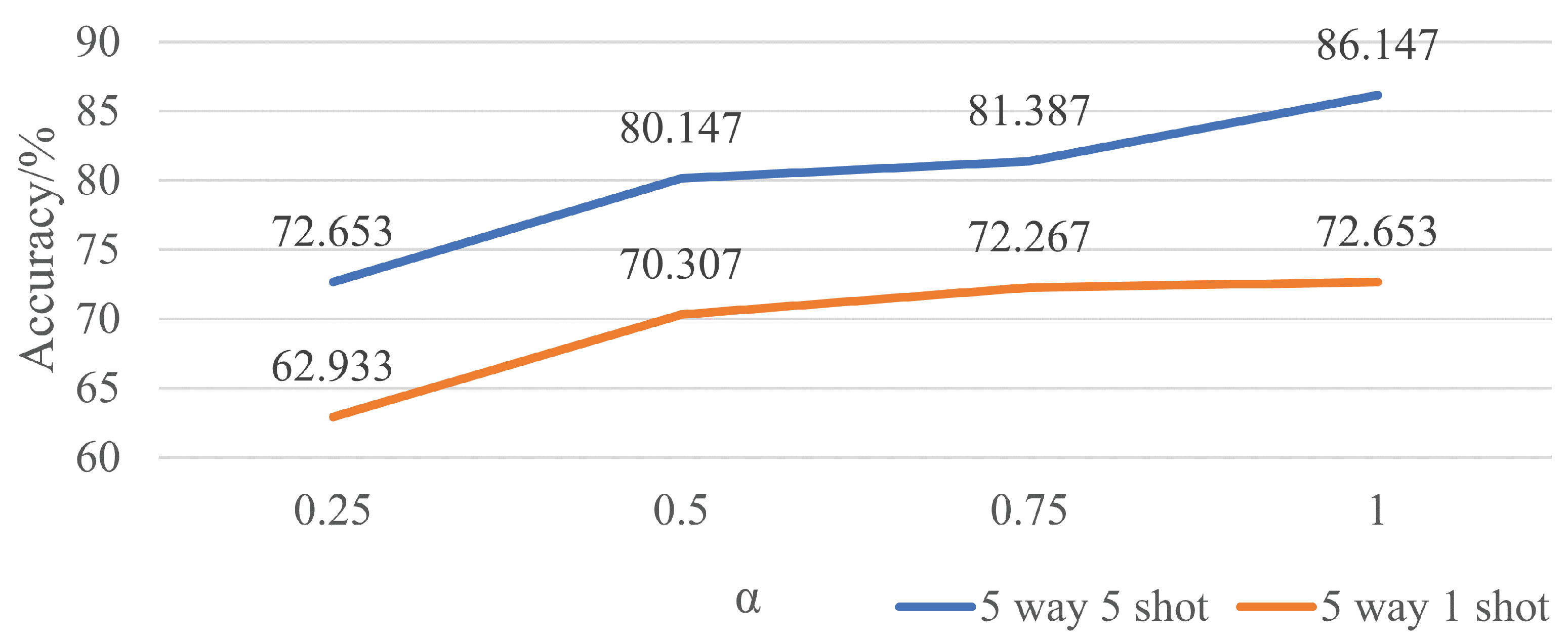
As the ablation study reveals that cos fits better than , there is an improvement of 3.960% in 5-way 5-shot experiments and 9.386% in 5-way 1-shot experiments, respectively, which is literally a big step forward. What may cause this situation is that cos is a periodic function against , and multiple s can result in the same cos, which may confuse the machine to fit the best parameters. That is why although there is a slight improvement when is applied in five-way five-shot experiments, there is a great loss in five-way one-shot experiments. Until now, a rotation transformation with cos as the regression parameter stands out with 86.147% for 5-way 5-shot experiments and 72.653% for 5-way 1-shot experiments.
Another ablation study shows that a single cross-entropy loss is the best loss function of all. Either with extra loss from an additional softmax layer or from clustering of support set or the whole set, the larger the proportion of original cross-entropy loss is, the better accuracy it will achieve. So it did with an extra contrastive loss. All four attempts try to restrict the distribution of the data to a better-organized one. However, they all work the opposite, which demonstrates that a single cross-entropy loss is already complex enough to fit the current dataset.
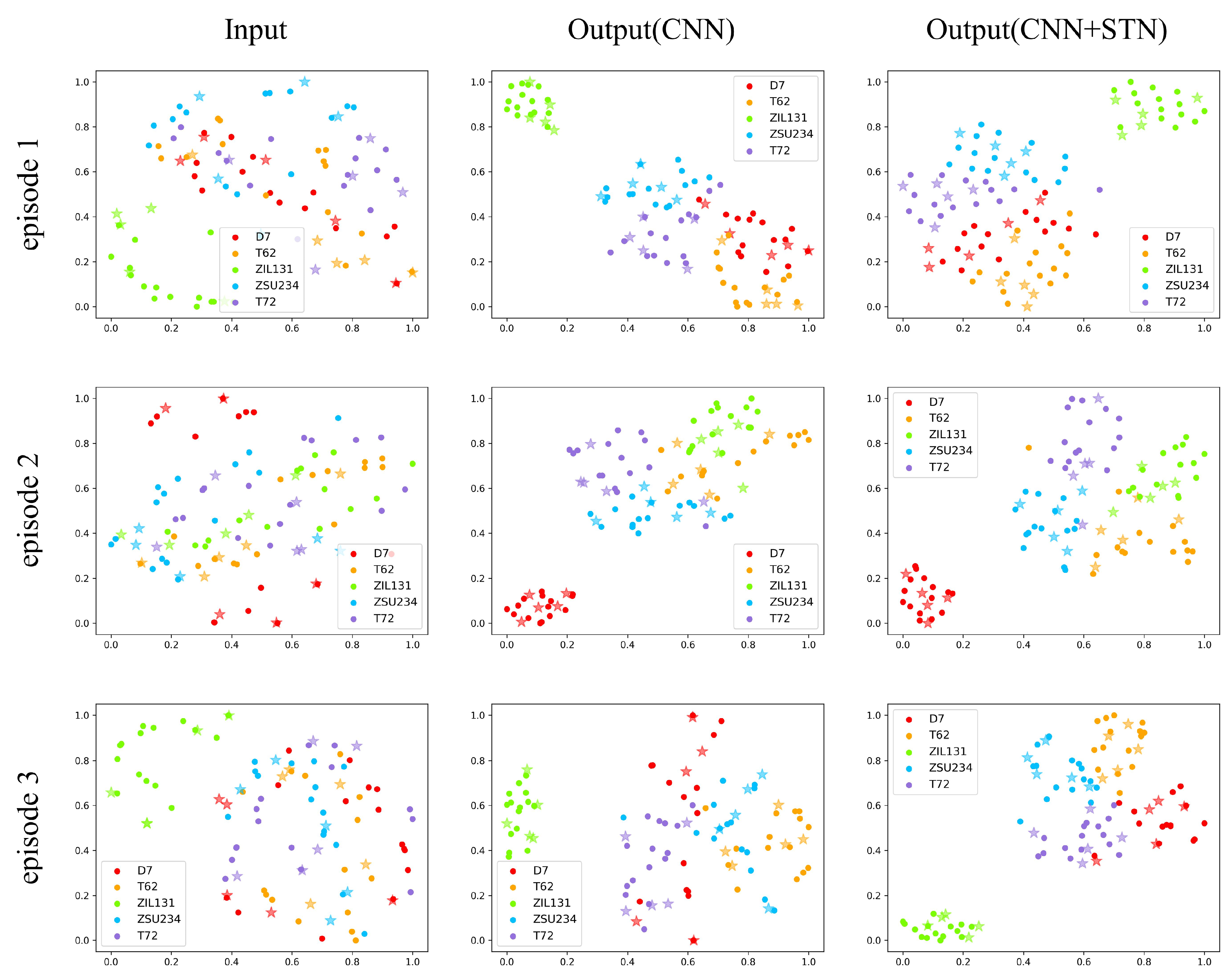
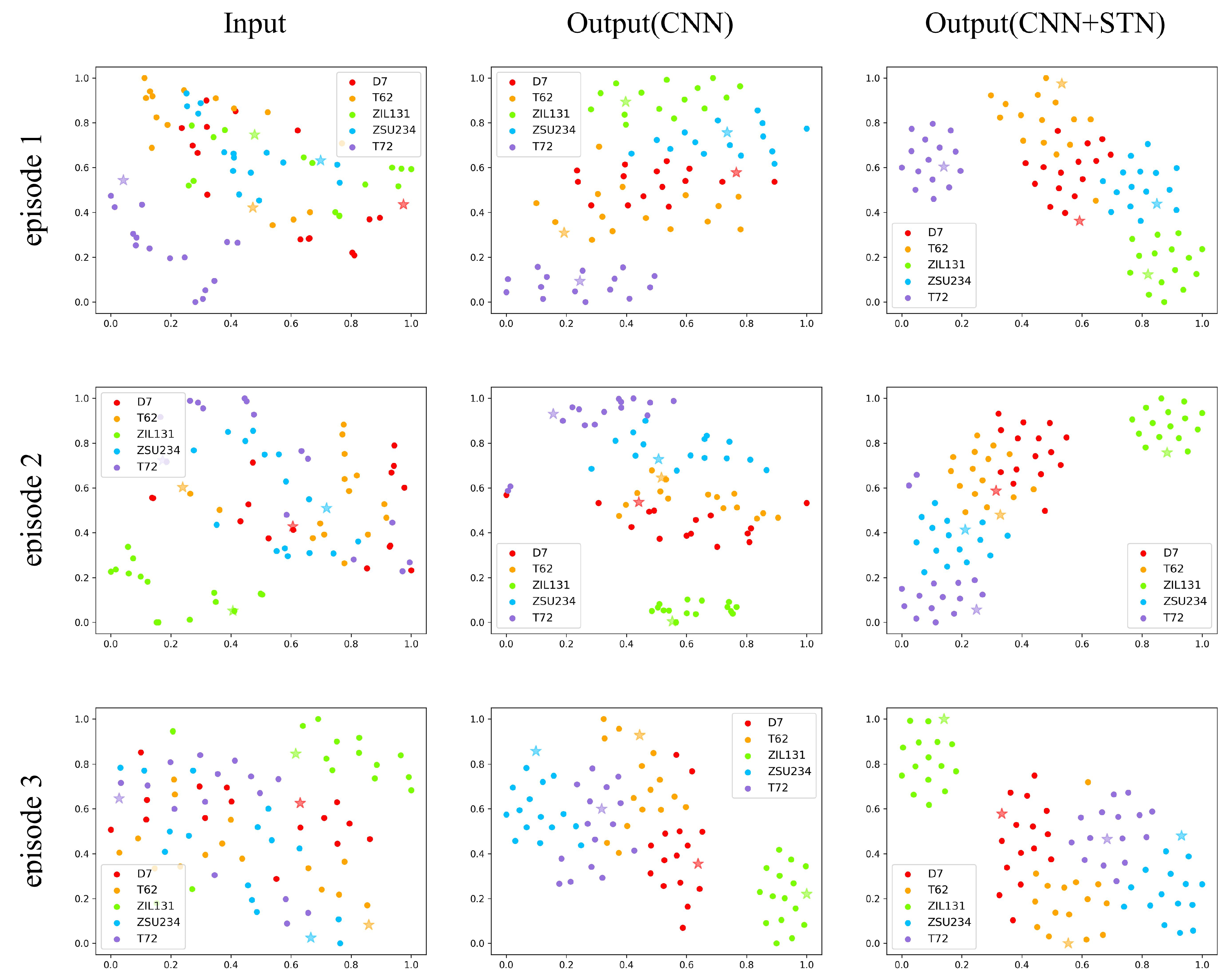
The visualization results of the three episodes show a random distribution at the beginning due to a vast difference in values of pixels, which is also consistent with the previous location experiments. After being extracted by a four-layer CNN, there is a better-organized situation allowing features of the same class to be closer to each other while separating features of variant classes. Still, it is relatively scattered out there. With a final spatial transformer module cascaded, a more centralized distribution exists, which is more obvious in five-way one-shot visualizations. That is because when rotation is conducted on these targets, the distance between features of the same class becomes even smaller. Clearly, it is another proof of the effectiveness of our algorithm.
While we have obtained an encouraging result, there are still some more things to do. Since we only experimented with four kinds of extra loss functions and simply added them together with weight to form an overall loss function, we recommend that there is another combination of loss functions. In addition, as we set the weight of two parts of loss to be added as 1, an accurate weight needs to be experimented with. What is more, as STM is cascaded after the last convolutional layer of each backbone, we believe that the relationship between the support set and query set is needed to be taken into consideration when regressing the transformation parameter , which leads to future experiments.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}