1. Introduction
The lack of accurate, high-spatial-resolution crop yield data constrains research, policy, and business development. Accurate yield data are needed for crop insurance [
1,
2], farm advisory services, understanding how productivity responds to environmental change [
3], forecasting commodity prices [
4], and assessing opportunities for increasing production [
5]. In the absence of reliable data reported by producers or government agencies, crop yield can be estimated with remotely sensed data [
6,
7].
Remote-sensing-based yield prediction models are typically constructed with field observations of crop yield and corresponding reflectance data from satellite-based sensors. There has been ample research comparing modeling methods [
7,
8,
9,
10,
11], but not much attention has been given to the effect of the field data collection method and sample size on model quality. This is important to consider because measuring crop yield in the field is generally expensive, and the costs may differ considerably between methods. Modern agricultural harvesting machinery can monitor the mass flow of crops in real time [
12,
13]; however, this technology is not available in many areas. A relatively straightforward method is to ask farmers what their yield was or what it will be. This may be the only available approach after crops have been harvested or when it is still too early to harvest, and it has been used to understand longer-term annual variability in crop yields [
2]. Such approaches may provide accurate yield estimates under certain conditions, especially if all produce is weighed and sold to a single source. In developing countries, this is often not the case, and farmer estimates are likely to be inaccurate [
14]; using such data may lead to poor predictive models [
15]. An additional problem is a potential bias in farmers’ estimates if they perceive that their responses may influence subsequent taxation or benefit allocations [
15,
16].
As an alternative to farmer reports, crop yield can be estimated based on a variety of field sampling techniques. The crop cut method is often considered the best sampling method to estimate crop yield [
17]. In this method, one or a few small areas within a field are harvested and weighed. However, crop cuts can lead to yield overestimation because areas within the field with poor crop stands are more likely to be under-sampled [
18]. This may be addressed by randomly selecting (multiple) crop cut locations within a field. Alternatively, point transect methods can be used to sample a fixed number of plants and to estimate plant density at random or systematic intervals, thus allowing for an estimation of crop yield with generally lower costs of data collection [
19,
20].
As there are different field estimation methods available, selecting the best method requires balancing the costs (time, money) and benefits (accuracy in estimating crop yield). While it is generally better to have data from more fields and larger samples within fields, it is not clear whether it would be preferable to make noisy observations of many fields or highly accurate (and more expensive) observations of fewer fields. Given a fixed level of available resources (time or money), models built with a larger data set of lower-quality data could outperform models built with a small quantity of high-quality data. Understanding these tradeoffs may provide important practical guidance for optimizing training data collection efforts.
To address this question, we evaluated the effect of field estimation methods on crop yield prediction, using a dataset for 196 maize fields in Ethiopia for which yield was estimated with seven different sampling methods. Maize is the dominant food crop in much of East Africa, and estimating maize yield for satellite data is an active area of research [
21]. We used linear regression and Random Forest models to estimate crop yield in response to vegetation indices derived from Sentinel-2 reflectance data. Model accuracy is typically evaluated with cross-validation and the implicit assumption that the field observations are without error. In our study, we evaluated the models’ internal accuracy with standard cross-validation and their external accuracy by evaluating them with the true yield data obtained by harvesting entire fields.
2. Materials and Methods
2.1. Field Data Collection
Maize yield data were collected in 2019 in three woredas (districts) in Ethiopia’s Amhara Region: Dera, Fenote Selam, and Merawi. In each woreda, the survey team coordinated with extension services to identify maize farmers willing to harvest their fields in collaboration with the survey team. Samples were taken from 7–29 November 2019, coinciding with the maize harvest season in these areas. Prior to field data collection, farmers were asked to estimate the size and maize production of their fields. One group of enumerators walked field boundaries with GPS receivers. Another group took yield measurements using the sampling protocols described below and used GPS receivers to locate the subplots used in the crop cuts. All field boundaries and crop cut locations were visually checked by plotting them on high-resolution satellite images for the same season, and minor errors were corrected where necessary. The resulting dataset contained information on 227 fields. We discarded the data for 3 fields because of inconsistent coordinates, and 28 fields were so small that they did not contain a single 20 m pixel from Sentinel-2. The resulting 196 fields consisted of 52 fields in Dera, 67 in Fenote Selam, and 77 in Merawi. Field sizes ranged from 0.06 to 0.29 ha (median = 0.13 ha; mean = 0.14 ha) or between 4 and 30 pixels (median = 14, mean = 15.16).
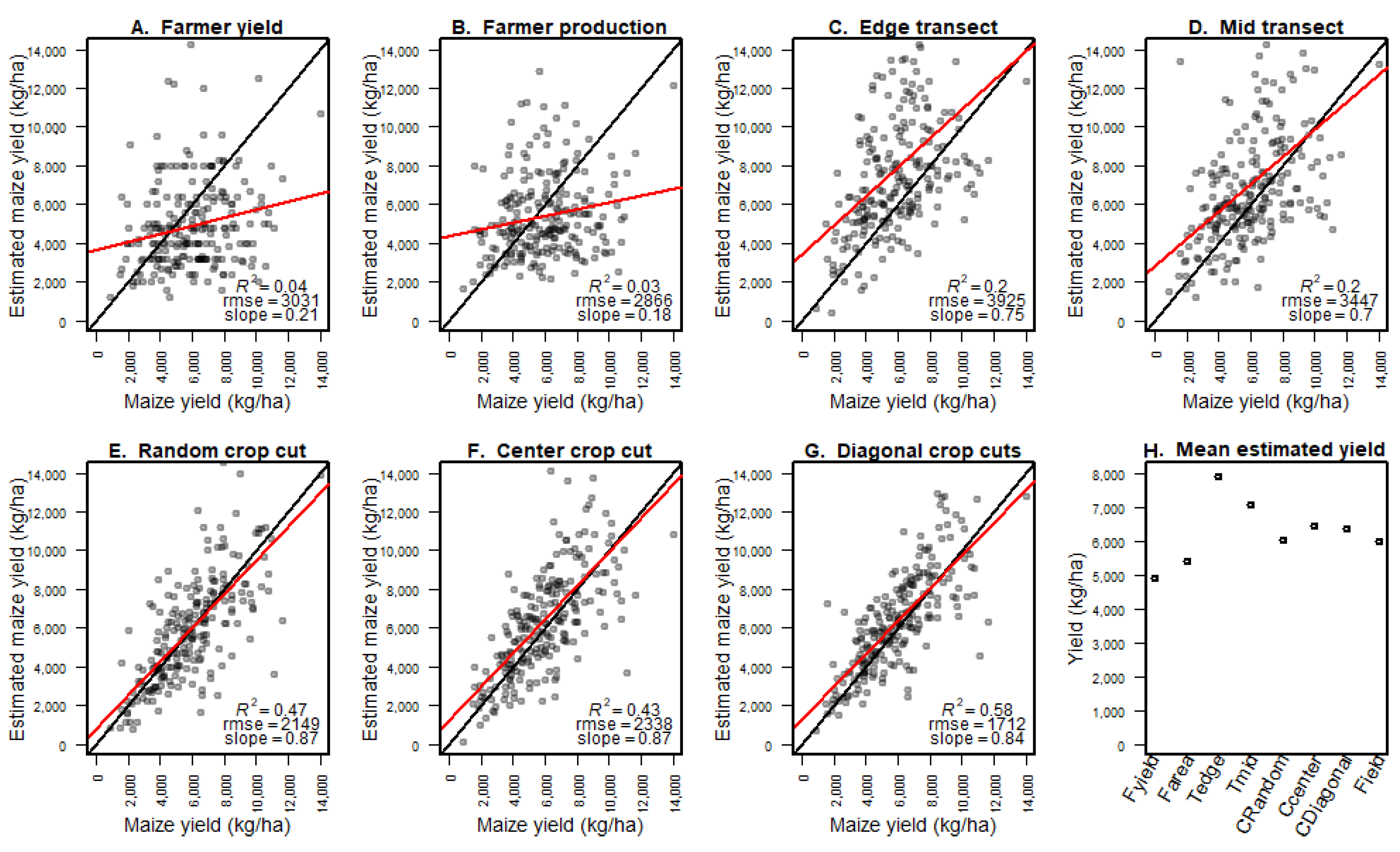
Seven sampling methods were used to estimate maize grain yield (kg/ha) for each field (
Table 1). For methods that involved harvesting a sample, cobs were left after weighing where the plant was located to avoid counting errors when one sampling method overlapped with another. After these sampling methods were completed, the entire field was harvested. Subsamples of the grain were taken for each field to determine moisture content. This was used to standardize all the yield data to 12.5% moisture.
2.2. Satellite Data
We used Sentinel-2 surface reflectance (SR) data for the growing season (July–November 2019). Collectively, the European Space Agency (ESA) twin satellites, Sentinel-2A and Sentinel-2B, referred to as Sentinel-2, have 13 spectral bands from visible to shortwave infrared at 10–20 m resolution and a five-day revisit period. Sentinel-2 SR has been processed with an atmospheric correction applied to top-of-atmosphere (TOA) Level-1C orthoimage products. In addition, we used a cloud mask to remove cloudy pixels. We used Google Earth Engine to download data for all pixels in each field using a 5 m negative buffer to ensure that pixels were entirely within fields and to account for some imprecision in field boundaries.
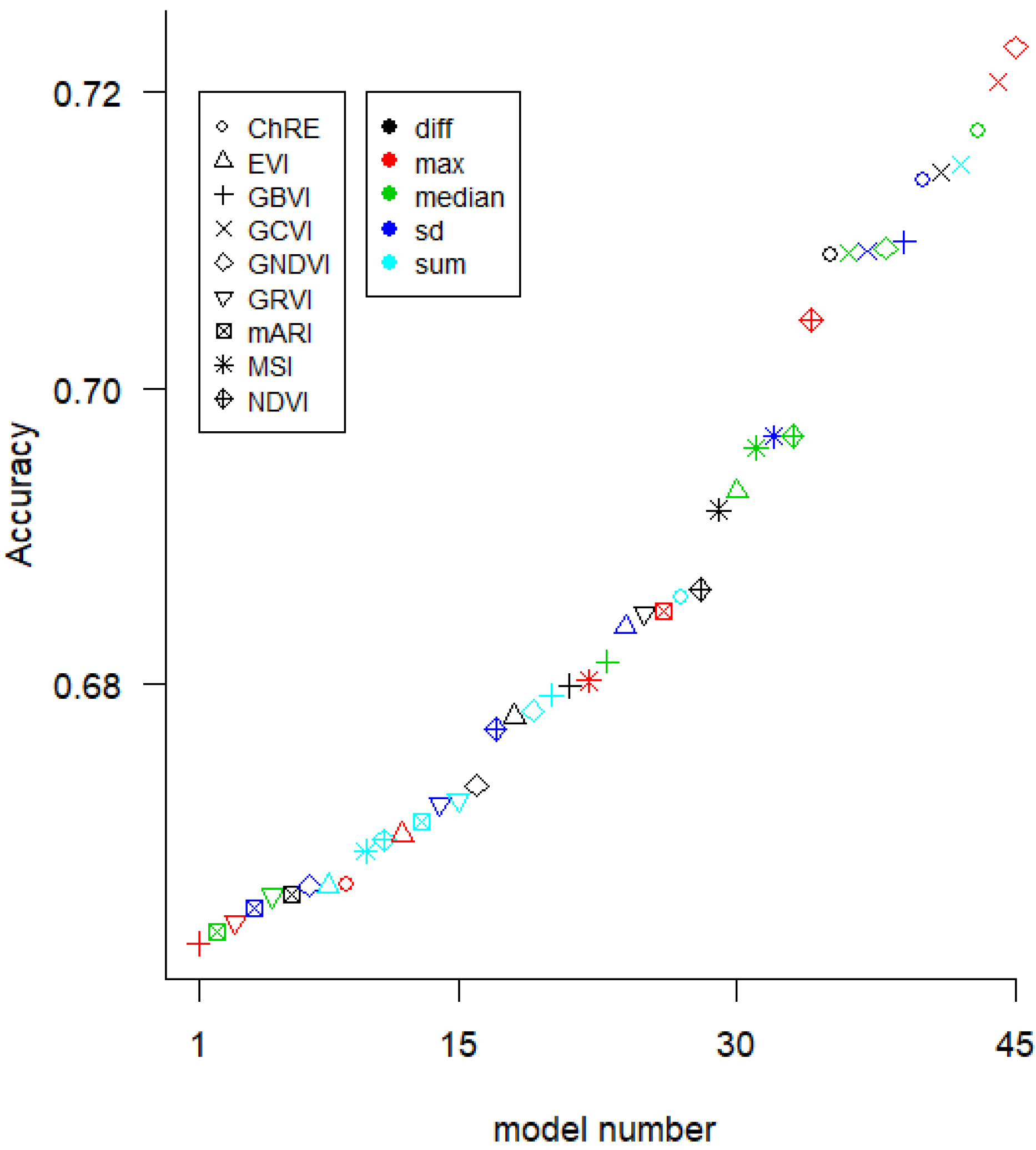
Reflectance data used for yield prediction are commonly transformed into vegetation indices (VIs) for the growing season [
11,
22]. VIs used for this purpose include NDVI [
23,
24,
25], red-edge VIs [
24,
26,
27,
28,
29], and GCVI [
9,
30]. We computed and used nine different indices (
Table 2).
2.3. Growing Season Aggregates
We used composites of VIs for the growing season. We determined the timing of the growing season based on the green-up and senescence of each field or when NDVI values exceeded a threshold of 0.2, using the R package “phenex” [
31]. We removed very low or high values (outliers) that were missed by the cloud filter, and we estimated missing values with interpolation and smoothed the VIs with the filterVI method from R package “luna” [
32]. We then computed the median VI for all pixels of each field for each date to make the statistic less sensitive to outliers (in space or in time). We temporally aggregated the VI values for the growing season, for each field, with the following functions: sum, median, maximum, difference (max–min), and standard deviation. The seasonal sum or cumulative VI is a commonly used metric, as the accumulation of biomass, and hence crop yield, is assumed to be proportional to the cumulative greenness (NDVI) [
22].
2.4. Modeling Methods and Evaluation
We used three modeling methods for the yield prediction models. First, we created 360 univariate ordinary least-squares (OLS) linear models (which we refer to as “LR-1”), one for each yield measurement, VI, and aggregation method (8 yield measurement methods × 9 VIs × 5 aggregation methods). Second, we created a Random Forest (RF) model using the 15 VI-(aggregation method) variables that performed best in the univariate linear models. Third, we made OLS regression models with two predictor variables (referred to as linear regression-2 “LR-2” in the text) for all 990 pairs of the 45 VI variables (9 VIs × 5 aggregation methods).
Models were evaluated with five-fold cross-validation. We assessed model fit with the proportion of explained variance (
) as the square of the Pearson correlation coefficient between observed and predicted values. We computed model accuracy (A) (Equation (
1)) as one minus the root-mean-squared error (RMSE) standardized by the mean yield.
where
y is crop yield for observation (field)
i, field sampling method
f, modeling method
m, and number of observations
n.
is the mean observed crop yield and
the predicted crop yield. Subscript
e indicates the data used for the evaluation and can have these values: internal (INT), external (EXT), and extrapolation (TRA); see below. Thus,
refers to the predicted yield of field
i using sampling method
f and modeling method
m and
observed crop yield for a given evaluation method
e.
refers either to
,
, or
.
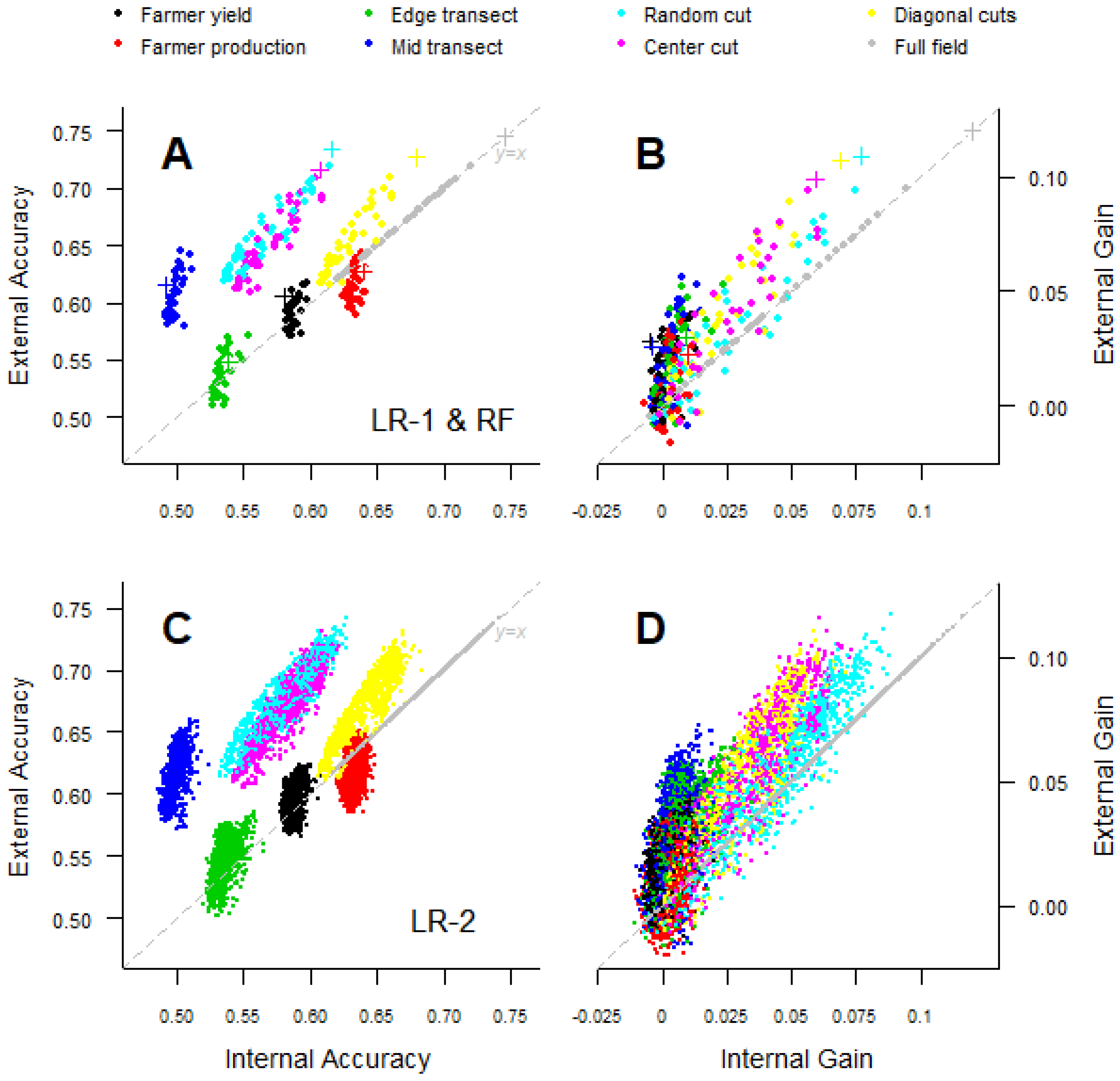
(internal accuracy) is the standard RMSE. A weakness of this standard measure is that the observed data may be biased, and a high could reflect that the model reproduces this bias. (external accuracy) evaluates the model with the “true yield”, as measured from the harvest of the entire field. This measure allows us to distinguish between a model that fits bad data well (high , but low ) from a model that predicts well (high and likely a high as well). Furthermore, we evaluated the ability of models to extrapolate to other areas by using evaluation data from the regions other than the data used to fit the model (). To calculate , we used the fields from two woredas as the training data for the model and evaluated the model accuracy when predicting on the remaining woreda, for example using samples from the Dera and Fenote Selam woredas to predict the yield in Merawi.
We also computed a NULL model
N (Equation (
2)), which expresses the accuracy of using the mean value of all observations (either internal, external, or extrapolation) to predict the yield.
We used the NULL model to compute the model gain
G (Equation (
3)), which is the model accuracy
A minus the accuracy of the NULL model
NAs such, gives the change in model accuracy compared to using the mean value, gives the change in model accuracy compared to the mean true yield, and gives the improvement to the models’ ability to extrapolate across regions compared to the mean true yield in the regions predicted.
2.5. Sample Size and Model Quality
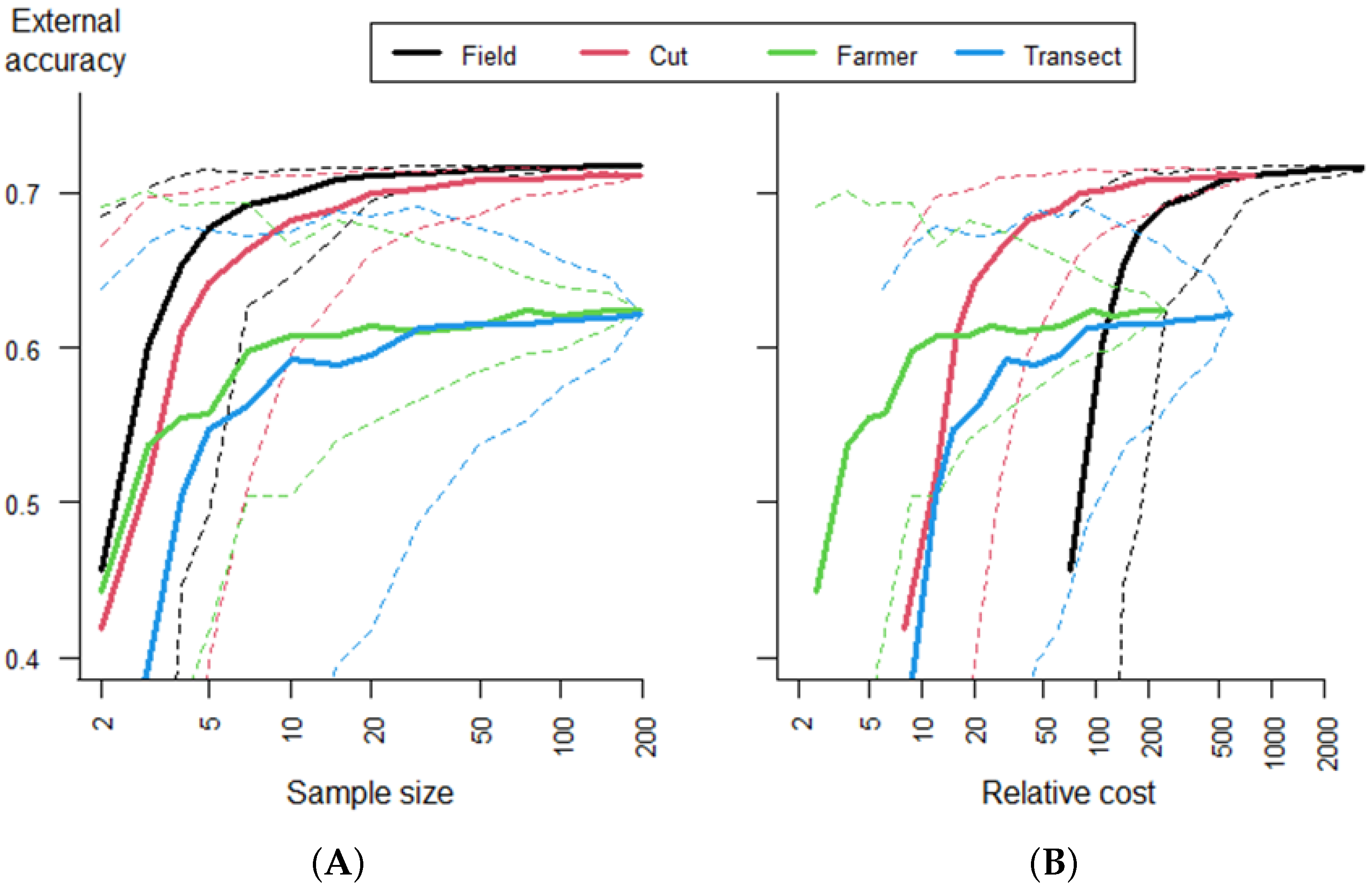
We estimated the cost per sample for each field method based on the time expense in the field for each method (
Table 1). We assessed the tradeoff between the sample size (cost) and model accuracy using Monte Carlo simulation. For each field method, we drew 200 samples from the entire data set for each of the following sample sizes: 2, 3, 4, 5, 7, 10, 15, 20, 30, 50, 75, 100, 150, and 196, where each sample is one field. For each draw, all regression models were fit and evaluated. In the results, the “group” of each method was used in addition to the 8 methods. Groups include field (full field), cut (random cut, center cut, and three cuts), farmer (farmer yield and farmer production), and transect (mid- and edge transect).
4. Discussion
We compared models predicting maize yield from satellite reflectance data and field data from eight different yield measurement methods. We found that crop cut data accurately predicted full-field harvest data and that the models that used crop cut data were as accurate as those based on the full-field harvest data. We also found that crop cuts are highly cost-effective relative to other field methods to estimate crop yield. While farmer estimates were cheaper to obtain, they were only competitive with crop cuts at very small expenditures (<20 farmer estimates) and low accuracy. Our findings clearly indicated that for research under similar conditions, crop cuts should be used to build models to predict yield. The type of crop cut protocol used did not have a strong effect on model quality when using remote sensing to predict yield, but a single random location crop cut performed best. It was possible to obtain good results, on average, with relatively small sample sizes in the order of 30 crop cuts, but larger sample sizes improved the average accuracy and reduced the variability.
The transect methods performed poorly, and given that their costs are similar to crop cuts, there seems to be no good reason for using them, especially as it may be difficult to obtain an accurate plant density estimate with the transect methods. The advantage of the remote-sensing-based models relative to the NULL model (model gain) was relatively small even though we had a wide range of yield values. However, the gain was higher for crop cut methods, indicating that remote sensing is not a solution for fixing poor field data, but rather that it can further increase the value of good field data.
While taking multiple crop cuts per field gave a better direct estimate of yield, it did not lead to better remote sensing models than when using a single crop cut. This is unsurprising because the slope of the regression line between the crop cut yield estimate and the true yield was closer to one for the single crop cut data than for three crop cuts. Thus, while the better goodness of fit scores (R
and RMSE) showed that the three crop cuts data were less noisy, the random location single-crop cut data were less biased—perhaps because the three cuts were taken along a diagonal. The ideal number of cuts and the size of the cuts should depend on in-field variability, and the results may also depend on the size of the cuts. The 16 m
crop cut size has been used in other research [
16,
33]; however, smaller areas have also been used and the size can affect data quality. Given the high fixed cost of traveling to a field and obtaining permission to take a sample, we would recommend taking multiple cuts of at least 16 m
. Future work could evaluate the use of historical or in-season satellite data to estimate within-field variability to guide the amount and location of crop cuts.
The quality of farmer yield estimates may vary considerably by crop, region, and method employed. Our farmer estimates were elicited just prior to harvesting, rather than post-harvest, which is more commonly the case in survey data. Post-harvest estimates can be more accurate [
34], as farmers will have observed and perhaps measured the amount harvested, for example through sales transactions. Farmers’ estimates of field size may be inaccurate, in particular due to rounding of the size of smaller fields [
34]. However, we did not find a clear difference in crop yield estimates when using farmer estimates of both production and field size or only using farmer-estimated production combined with the researcher-determined field size. We found that farmers tended to underestimate yield, which is consistent with other studies (e.g., [
14]). However, the most important shortcoming was that the relationship between the farmer estimate and the actual yield was very weak. Farmer yield estimates are commonly used in survey-based research, and our results suggest that a critical evaluation of their quality is important. Farmer estimates have been used to reconstruct time series of yield to support remote-sensing-based modeling for crop insurance [
2,
35]. It has been shown that with longer recall times, farmers tend to overestimate production and underestimate or forget the effect of marginally productive plots [
36]. This suggests that farmer estimates may be more valid in a relative sense (bad and good years) than for absolute numbers.
The accuracy of our models was comparable with other studies of maize yield in East Africa [
9,
10,
30]. However, our models are not directly comparable to studies that use additional predictor variables such as household size [
34] and climatic variables [
3,
11]. We found that external accuracy was generally higher than internal accuracy, meaning that for most methods, the models predicted the full-field yield better than they predicted the estimated yield data on which the model was based. External accuracy being higher than internal accuracy was due to the noise (measurement error) in the sample-based field data used to evaluate the models, which led to an overestimation of the error. This implies that remote-sensing-based models may generally perform somewhat better than the reported (internal) cross-validation-based estimates suggest.
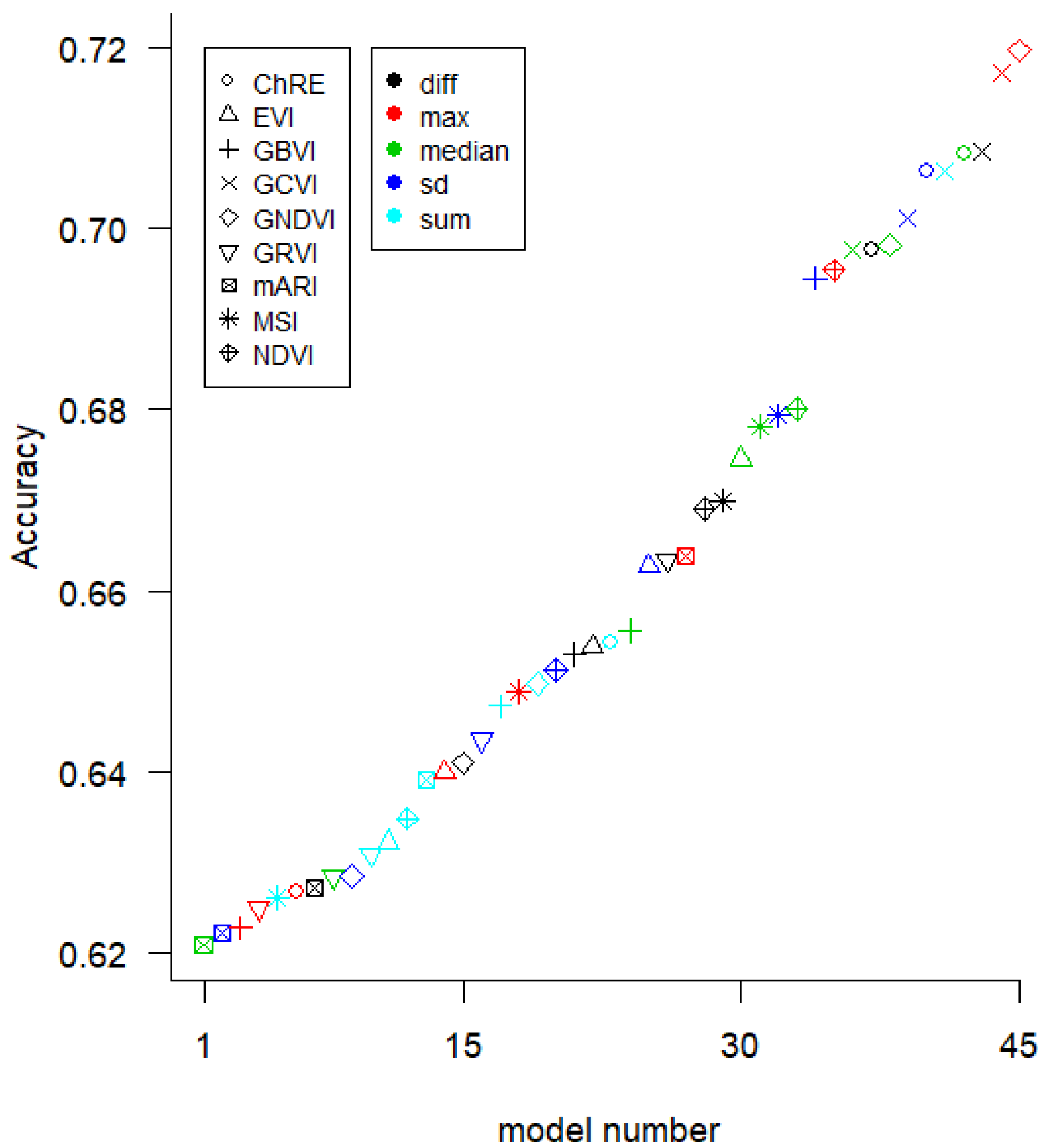
There was not a substantial difference in accuracy between the LR-1, LR-2, and RF modeling methods. However, the VI selected was important for accuracy. It has been reported that GCVI and Red edge VIs are useful in yield prediction for nitrogen-limited systems [
9,
24]. These VIs worked well with our data, though GNDVI performed best, in addition to GCVI and indices that used the Red edge, as reported by others [
37]. The cumulative NDVI, which has been often used to predict yield, was one of the least accurate methods in our study. Many studies use the VI from a single date or a few dates [
10] as the dependent variables in linear models of yield, due to the lack of available cloud-free imagery. More clarity is needed on what temporal aggregations to use and on the stability and generalizability of models based on a single date.
Model gain increased when using the remote sensing models to extrapolate, showing that the models had some degree of generality, making them useful for predicting in other (nearby) regions. Previous work indicated that the yield–VI relationship is very site-specific [
38], and it is also dependent on the crop growth stage. We found that the differences between field methods were less pronounced for extrapolation between regions. Further study is needed to determine the generalizability of yield estimates from remote-sensing-based models across regions.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}