
Deep Learning for Archaeological Object Detection on LiDAR: New Evaluation Measures and Insights

 ,
,  ,
,
Abstract
1. Introduction
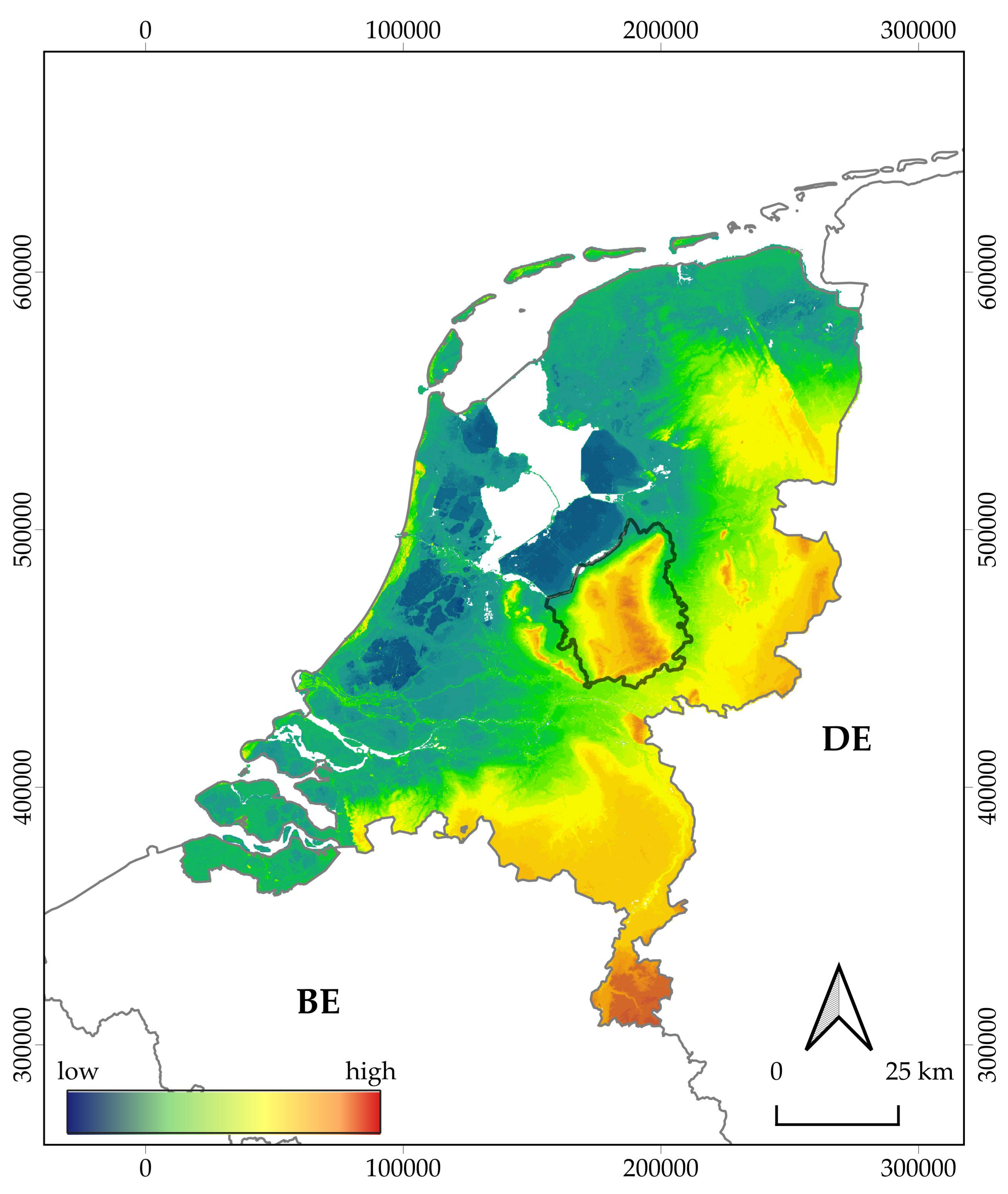
2. Research Area and Archaeological Classes
3. Related Work: The GIS-Based Measure
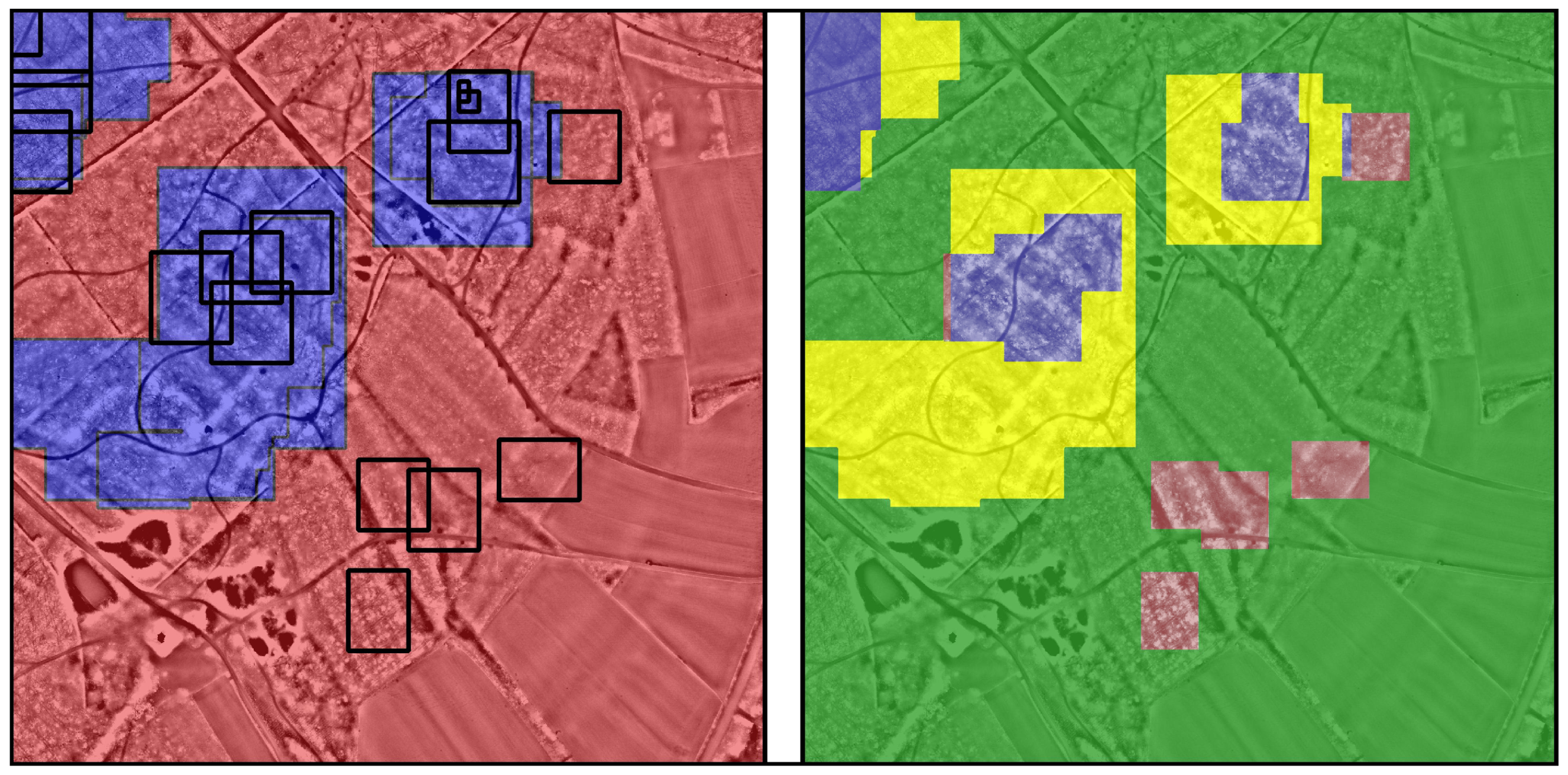
4. Automatic Evaluation Measures
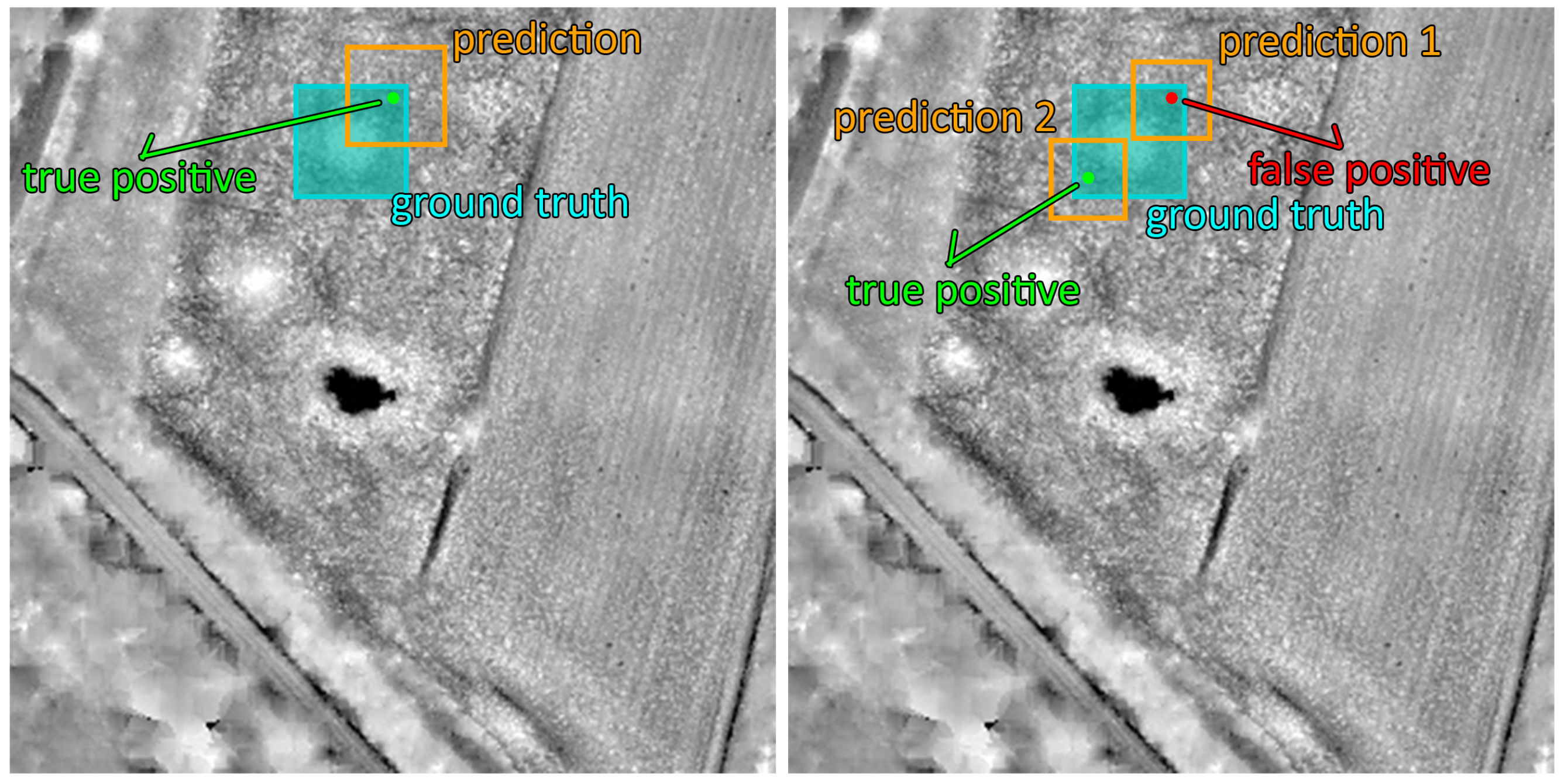
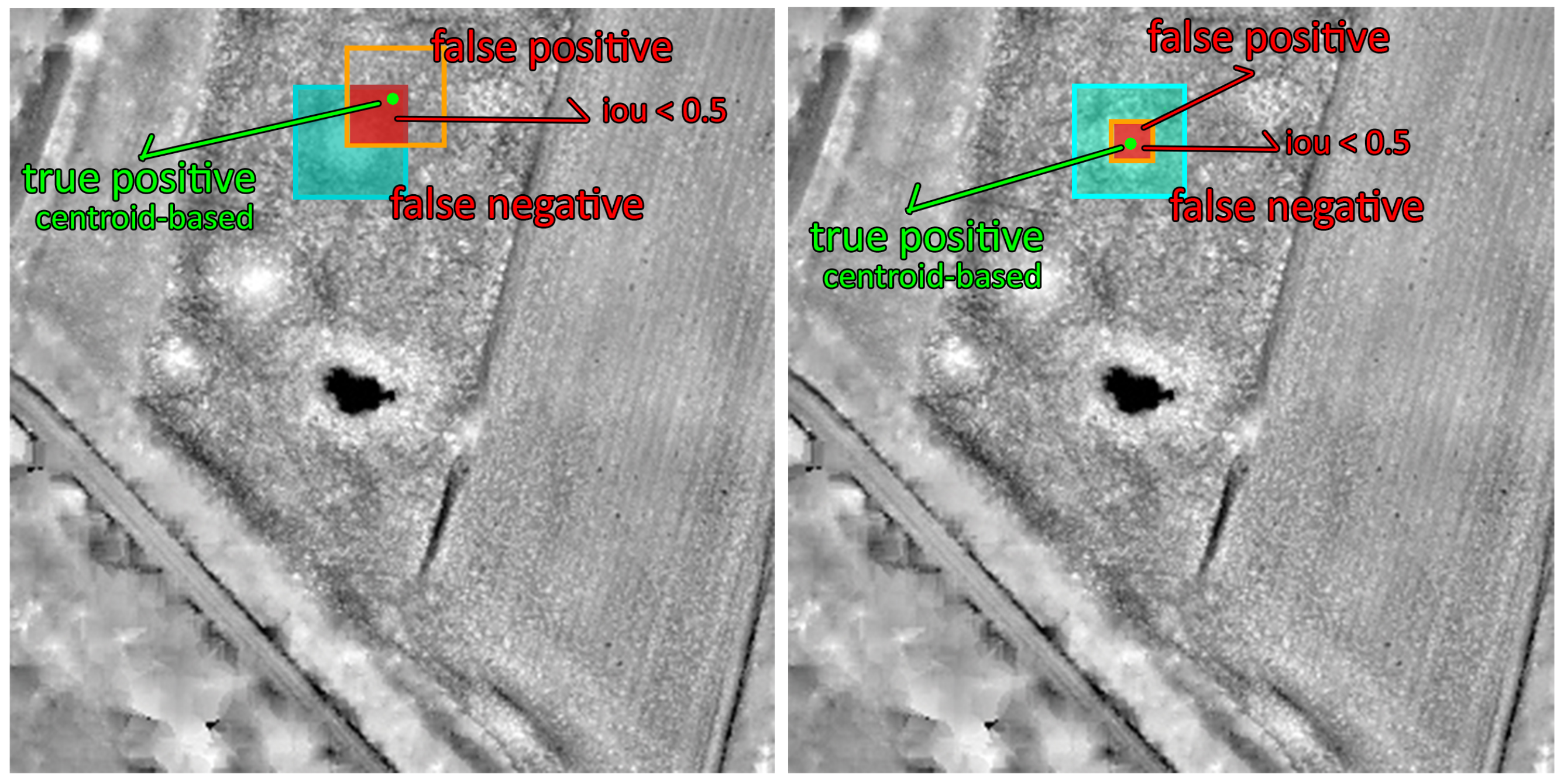
4.1. Centroid-Based Measure
| Algorithm 1: Centroid-based measure |
 |
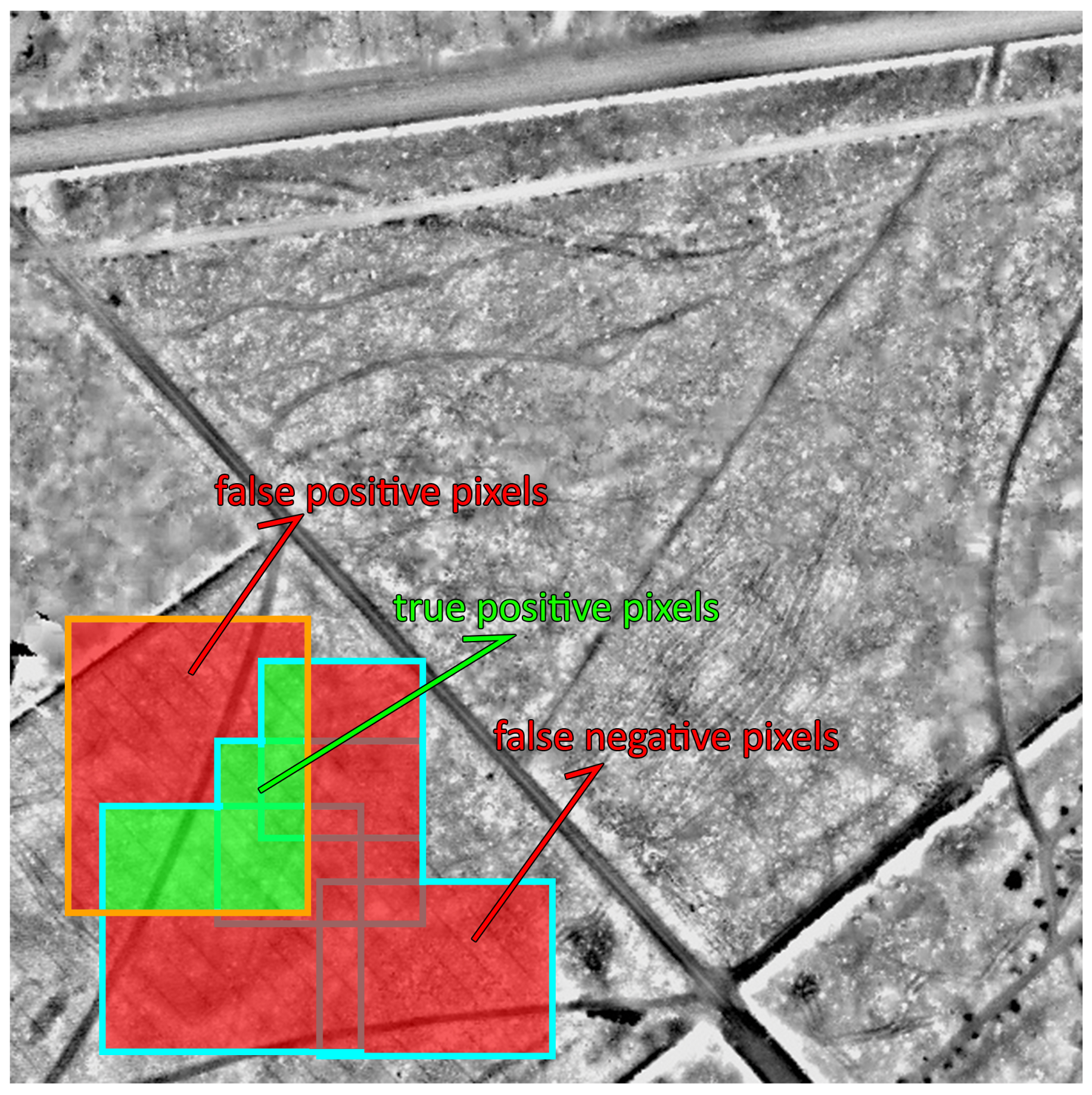
4.2. Pixel-Based Measure
| Algorithm 2: Pixel-based measure |
 |
5. Experimental Setup
5.1. Datasets
5.1.1. Training and Validation Datasets
5.1.2. Test Dataset
5.2. Experimental Methodology
5.2.1. Faster R-CNN
5.2.2. Faster R-CNN Implementations
- C4: uses the original approach of the Faster R-CNN paper, with ResNet conv4 backbone and conv5 head [39];
- FPN (Feature Pyramid Network): adds a layer that can extract multi-scale feature maps, thereby taking advantage of different receptive fields [45];
- DC5 (Dilated-C5): introduces dilations in Resnet conv5 backbone, i.e., a dedicated convolutional layer with the ability to change its sampling grid in order to enlarge its receptive field [46].
5.2.3. Hardware Setup
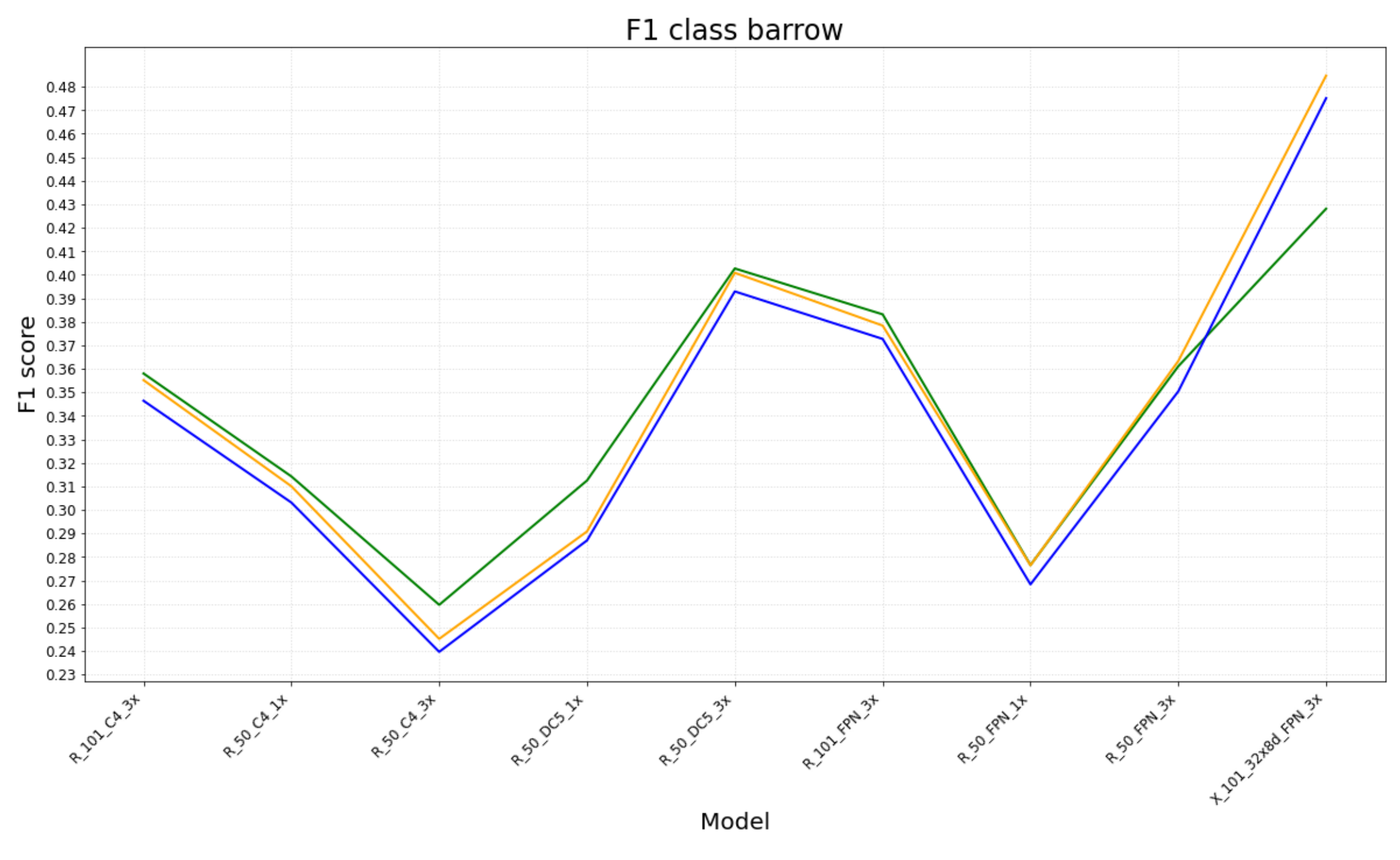
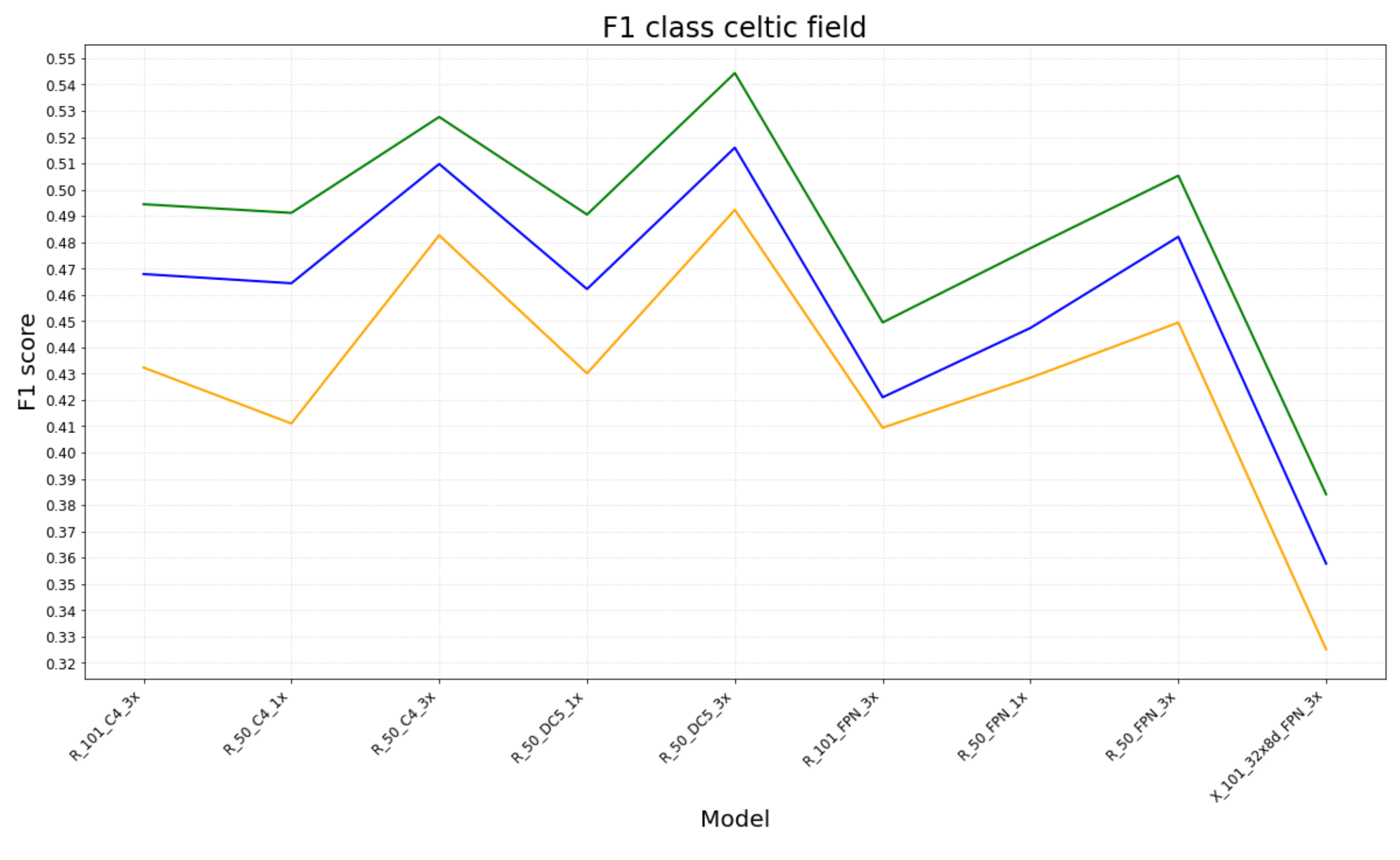
6. Results
6.1. Experimental Results
- i
- Each trained model was evaluated on the test dataset;
- ii
- iii
- The number of TP, FP and TN for each class (barrow and Celtic field) were obtained from each evaluation measure;
- iv
- Based on these values, F1-scores (for each class and a mean) were computed per model, for each evaluation measure.
7. Discussion
Archaeological Implications
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Orengo, H.A.; Conesa, F.C.; Garcia-Molsosa, A.; Lobo, A.; Green, A.S.; Madella, M.; Petrie, C.A. Automated detection of archaeological mounds using machine-learning classification of multisensor and multitemporal satellite data. Proc. Natl. Acad. Sci. USA 2020, 117, 18240–18250. [Google Scholar] [CrossRef] [PubMed]
- Bundzel, M.; Jaščur, M.; Kováč, M.; Lieskovský, T.; Sinčák, P.; Tkáčik, T. Semantic Segmentation of Airborne LiDAR Data in Maya Archaeology. Remote Sens. 2020, 12, 3865. [Google Scholar] [CrossRef]
- Somrak, M.; Džeroski, S.; Kokalj, Z. Learning to Classify Structures in ALS-Derived Visualizations of Ancient Maya Settlements with CNN. Remote Sens. 2020, 12, 2215. [Google Scholar] [CrossRef]
- Soroush, M.; Mehrtash, A.; Khazraee, E.; Ur, J.A. Deep Learning in Archaeological Remote Sensing: Automated Qanat Detection in the Kurdistan Region of Iraq. Remote Sens. 2020, 12, 500. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Salberg, A.B.; Pilø, L.H. Semi automatic mapping of charcoal kilns from airborne laser scanning data using deep learning. In CAA 2016: Oceans of Data. Proceedings of the 44th Conference on Computer Applications and Quantitative Methods in Archaeology; Matsumoto, M., Uleberg, E., Eds.; Archaeopress: Oxford, UK, 2018; pp. 219–231. [Google Scholar]
- Verschoof-van der Vaart, W.B.; Lambers, K.; Kowalczyk, W.; Bourgeois, Q.P. Combining Deep Learning and Location-Based Ranking for Large-Scale Archaeological Prospection of LiDAR Data from The Netherlands. ISPRS Int. J. Geo Inf. 2020, 9, 293. [Google Scholar] [CrossRef]
- Zingman, I.; Saupe, D.; Penatti, O.A.B.; Lambers, K. Detection of fragmented rectangular enclosures in very-high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4580–4593. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lambers, K.; Verschoof-van der Vaart, W.B.; Bourgeois, Q.P.J. Integrating Remote Sensing, Machine Learning, and Citizen Science in Dutch Archaeological Prospection. Remote Sens. 2019, 11, 794. [Google Scholar] [CrossRef]
- Verschoof-van der Vaart, W.B. Learning to Look at LiDAR. Combining CNN-Based Object Detection And GIS for Archaeological Prospection in Remotely-Sensed Data. Ph.D. Thesis, Leiden University, Leiden, The Netherlands, 2022. Available online: https://hdl.handle.net/1887/3256824 (accessed on 27 March 2022).
- Fiorucci, M.; Khoroshiltseva, M.; Pontil, M.; Traviglia, A.; Del Bue, A.; James, S. Machine Learning for Cultural Heritage: A Survey. Pattern Recognit. Lett. 2020, 133, 102–108. [Google Scholar] [CrossRef]
- Randrianarivo, H.; Le Saux, B.; Ferecatu, M. Urban structure detection with deformable part-based models. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium—IGARSS, Melbourne, VIC, Australia, 21–26 July 2013; pp. 200–203. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Xia, G.; Bai, X.; Yang, W.; Yang, M.Y.; Belongie, S.J.; Luo, J.; Datcu, M.; Pelillo, M.; et al. Object Detection in Aerial Images: A Large-Scale Benchmark and Challenges. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Rezatofighi, S.H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.D.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Gillings, M.; Hacigüzeller, P.; Lock, G. Archaeology and spatial analysis. In Archaeological Spatial Analysis: A Methodological Guide; Gillings, M., Hacigüzeller, P., Lock, G., Eds.; Routledge: New York, NY, USA, 2020; Chapter 1; pp. 1–16. [Google Scholar]
- Yoo, D.; Kweon, I.S. Learning Loss for Active Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Berendsen, H.J.A. De Vorming van het Land. Inleiding in de Geologie en de Geomorfologie, 4th ed.; Koninklijke Van Gorcum: Assen, The Netherlands, 2004. [Google Scholar]
- Verschoof-van der Vaart, W.B.; Lambers, K. Learning to look at LiDAR: The use of R-CNN in the automated detection of archaeological objects in LiDAR data from the Netherlands. J. Comput. Appl. Archaeol. 2019, 2, 31–40. [Google Scholar] [CrossRef]
- Kenzler, H.; Lambers, K. Challenges and Perspectives of Woodland Archaeology Across Europe. In CAA2014: 21st Century Archaeology, Concepts, Methods and Tools. Proceedings of the 42nd Annual Conference on Computer Applications and Quantitative Methods in Archaeology; Giligny, F., Djindjian, F., Costa, L., Moscati, P., Robert, S., Eds.; Archaeopress: Oxford, UK, 2015; pp. 73–80. [Google Scholar]
- Nationaal Georegister. Publieke Dienstverlening Op de Kaart (PDOK). 2021. Available online: https://www.pdok.nl/ (accessed on 27 March 2022).
- Arnoldussen, S. The Fields that Outlived the Celts: The Use-histories of Later Prehistoric Field Systems (Celtic Fields or Raatakkers) in the Netherlands. Proc. Prehist. Soc. 2018, 84, 303–327. [Google Scholar] [CrossRef]
- Bourgeois, Q.P.J. Monuments on the Horizon. The Formation of the Barrow Landscape throughout the 3rd and 2nd Millennium BC; Sidestone Press: Leiden, The Netherlands, 2013. [Google Scholar]
- Verschoof-van der Vaart, W.B.; Lambers, K. Applying automated object detection in archaeological practice: A case study from the southern Netherlands. Archaeol. Prospect. 2021, 29, 15–31. [Google Scholar] [CrossRef]
- Bourgeois, Q.P.J.; Fontijn, D.R. The Tempo of Bronze Age Barrow Use: Modeling the Ebb and Flow in Monumental Funerary Landscapes. Radiocarbon 2015, 57, 47–64. [Google Scholar] [CrossRef][Green Version]
- Davis, D.S. Theoretical Repositioning of Automated Remote Sensing Archaeology: Shifting from Features to Ephemeral Landscapes. J. Comput. Appl. Archaeol. 2021, 4, 94–109. [Google Scholar] [CrossRef]
- Traviglia, A.; Torsello, A. Landscape Pattern Detection in Archaeological Remote Sensing. Geosciences 2017, 7, 128. [Google Scholar] [CrossRef]
- Hesse, R. LiDAR-derived Local Relief Models—A new tool for archaeological prospection. Archaeol. Prospect. 2010, 17, 67–72. [Google Scholar] [CrossRef]
- Opitz, R.; Cowley, D. Interpreting Archaeological Topography. Airborne Laser Scanning, 3D Data and Ground Observation; Oxbow Books: Oxford, UK; Oakville, ON, Canada, 2013. [Google Scholar]
- QGIS Development Team. QGIS Geographic Information System. 2017. Available online: http://qgis.org (accessed on 27 March 2022).
- Kokalj, Ž.; Hesse, R. Airborne Laser Scanning Raster Data Visualization: A Guide to Good Practice; Založba ZRC: Ljubljana, Slovenia, 2017. [Google Scholar]
- van der Zon, N. Kwaliteitsdocument AHN-2; Technical Report; Rijkswaterstaat: Amersfoort, The Netherlands, 2013. [Google Scholar]
- Tzutalin. LabelImg. Git Code. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 27 March 2022).
- Rijksdienst voor het Cultureel Erfgoed. ArchIS and AMK. 2021. Available online: https://www.cultureelerfgoed.nl/onderwerpen/bronnen-en-kaarten/overzicht (accessed on 27 March 2022).
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 27 March 2022).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2016, arXiv:1611.05431. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kermit, M.; Reksten, J.H.; Trier, Ø.D. Towards a national infrastructure for semi-automatic mapping of cultural heritage in Norway. In Oceans of Data. Proceedings of the 44th Conference on Computer Applications and Quantitative Methods in Archaeology; Matsumoto, M., Uleberg, E., Eds.; Archaeopress: Oxford, UK, 2018; pp. 159–172. [Google Scholar]
- Bonhage, A.; Raab, A.; Eltaher, M.; Raab, T.; Breuß, M.; Schneider, A. A modified Mask region-based convolutional neural network approach for the automated detection of archaeological sites on high-resolution light detection and ranging-derived digital elevation models in the North German Lowland. Archaeol. Prospect. 2021, 28, 177–186. [Google Scholar] [CrossRef]
- El-Hajj, H. Interferometric SAR and Machine Learning: Using Open Source Data to Detect Archaeological Looting and Destruction. J. Comput. Appl. Archaeol. 2021, 4, 47–62. [Google Scholar] [CrossRef]
- Olivier, M.; Verschoof-van der Vaart, W.B. Implementing Advanced Deep Learning Approaches for Archaeological Object Detection in Remotely-Sensed Data: The Results of Cross-Domain Collaboration. J. Comput. Appl. Archaeol. 2021, 4, 274–289. [Google Scholar]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active Learning Methods for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Cowley, D.; Waldeland, A.U. Using deep neural networks on airborne laser scanning data: Results from a case study of semi-automatic mapping of archaeological topography on Arran, Scotland. Archaeol. Prospect. 2019, 26, 165–175. [Google Scholar] [CrossRef]
- Bickler, S.H. Machine Learning Arrives in Archaeology. Adv. Archaeol. Pract. 2021, 9, 186–191. [Google Scholar] [CrossRef]
- Cowley, D.; Banaszek, Ł; Geddes, G.; Gannon, A.; Middleton, M.; Millican, K. Making LiGHT Work of Large Area Survey? Developing Approaches to Rapid Archaeological Mapping and the Creation of Systematic National-scaled Heritage Data. J. Comput. Appl. Archaeol. 2020, 3, 109–121. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters AHN2 LiDAR Data | |
|---|---|
| purpose | water management |
| time of data acquisition | April 2010 |
| equipment | RIEGL LMS-Q680i Full-Waveform |
| scan angle (whole FOV) | 45° |
| flying height above ground | 600 m |
| speed of aircraft (TAS) | 36 m/s |
| laser pulse rate | 100,000 Hz |
| scan rate | 66 Hz |
| strip adjustment | yes |
| filtering | yes |
| interpolation method | moving planes |
| point-density (pt per sq m) | 6–10 |
| DTM-resolution | 0.5 m |
| Dataset | Subtiles | Barrows | Celtic Fields | Objects |
|---|---|---|---|---|
| training | 993 | 1213 | 1318 | 2531 |
| validation | 88 | 127 | 64 | 191 |
| test | 825 | 130 | 997 | 1127 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fiorucci, M.; Verschoof-van der Vaart, W.B.; Soleni, P.; Le Saux, B.; Traviglia, A. Deep Learning for Archaeological Object Detection on LiDAR: New Evaluation Measures and Insights. Remote Sens. 2022, 14, 1694. https://doi.org/10.3390/rs14071694
Fiorucci M, Verschoof-van der Vaart WB, Soleni P, Le Saux B, Traviglia A. Deep Learning for Archaeological Object Detection on LiDAR: New Evaluation Measures and Insights. Remote Sensing. 2022; 14(7):1694. https://doi.org/10.3390/rs14071694
Chicago/Turabian StyleFiorucci, Marco, Wouter B. Verschoof-van der Vaart, Paolo Soleni, Bertrand Le Saux, and Arianna Traviglia. 2022. "Deep Learning for Archaeological Object Detection on LiDAR: New Evaluation Measures and Insights" Remote Sensing 14, no. 7: 1694. https://doi.org/10.3390/rs14071694
APA StyleFiorucci, M., Verschoof-van der Vaart, W. B., Soleni, P., Le Saux, B., & Traviglia, A. (2022). Deep Learning for Archaeological Object Detection on LiDAR: New Evaluation Measures and Insights. Remote Sensing, 14(7), 1694. https://doi.org/10.3390/rs14071694