
BES-Net: Boundary Enhancing Semantic Context Network for High-Resolution Image Semantic Segmentation


Abstract
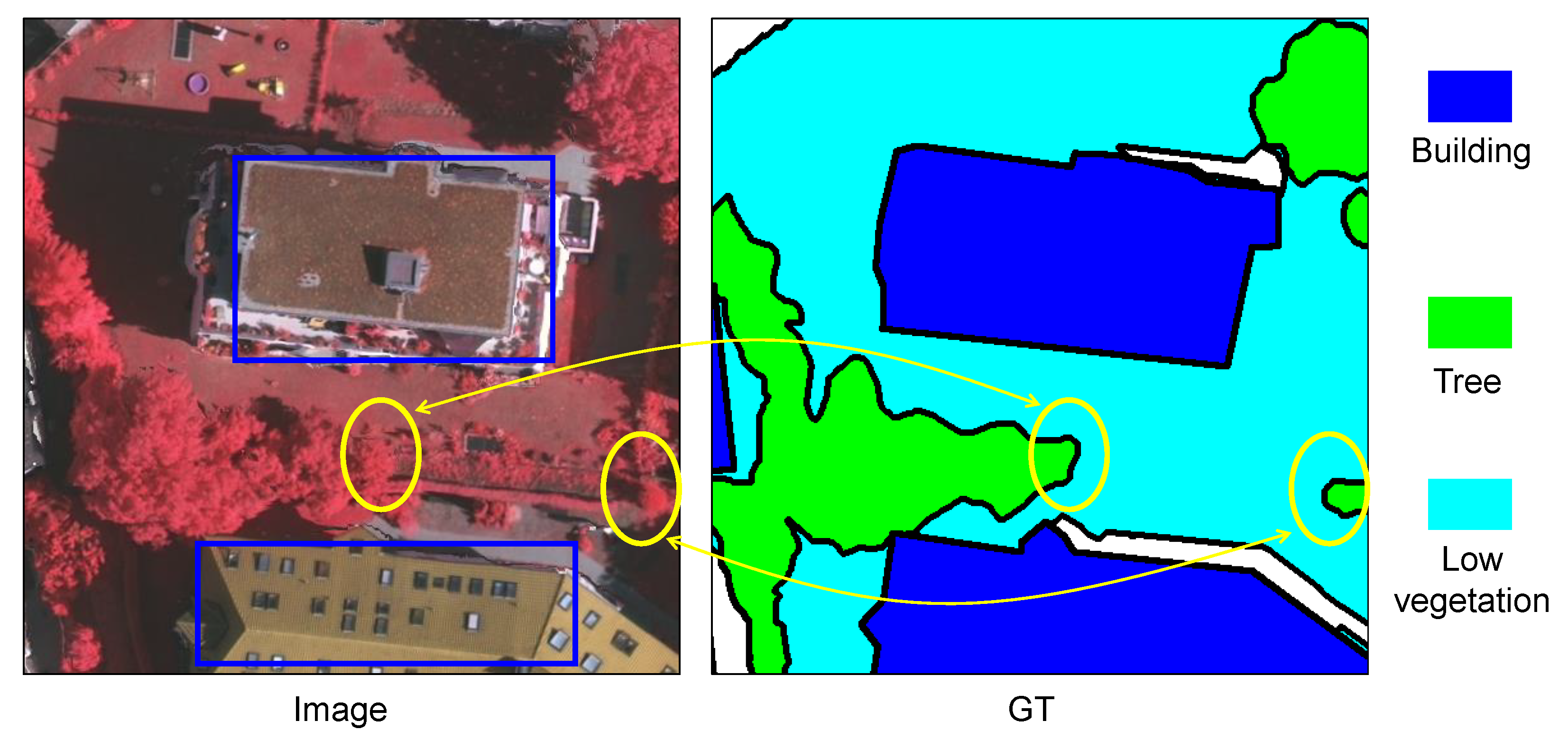
:1. Introduction
- We present a simple yet effective semantic segmentation framework, BES-Net, for HR remote sensing images semantic segmentation.
- We explicitly, not implicitly, adopt the well-extracted boundary to enhance the semantic context for semantic segmentation. Accordingly, three modules are designed to enhance the semantic consistency in the complex HR remote sensing images.
- Experimental results on two HR remote sensing images semantic segmentation datasets demonstrate the effectiveness of our proposed approach compared with state-of-the-art methods.
2. Related Work
2.1. Multi-Scale Feature Learning for Semantic Segmentation
2.2. Boundary Improved Semantic Segmentation
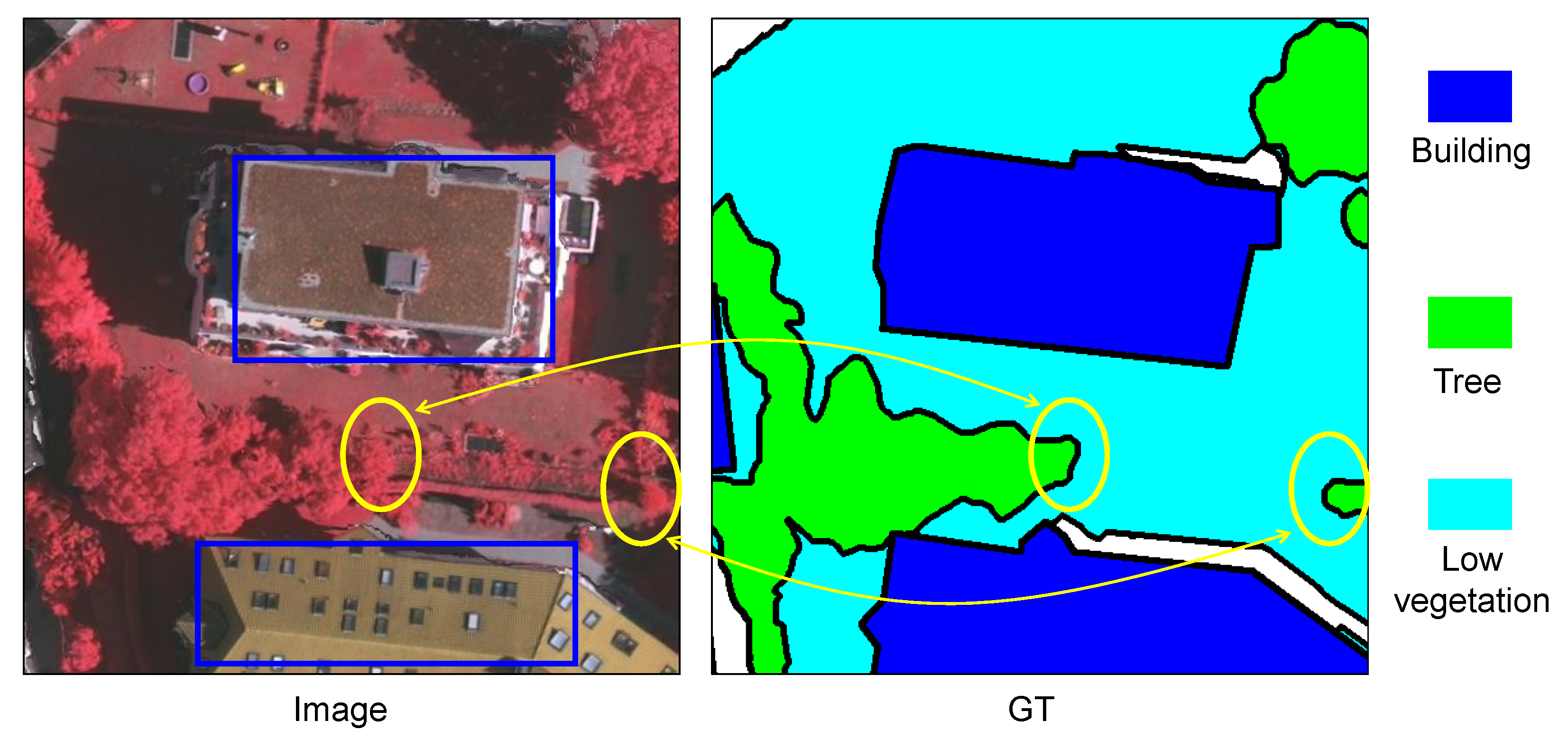
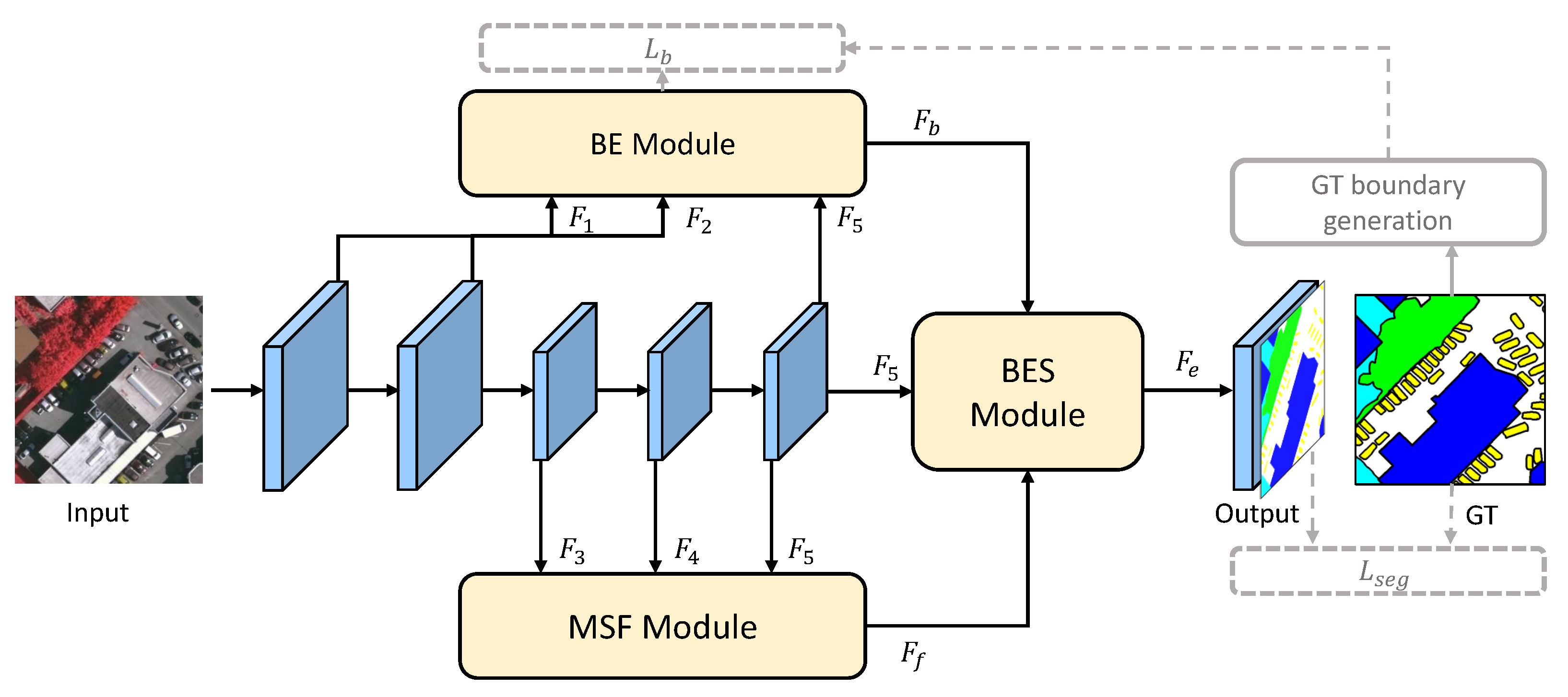
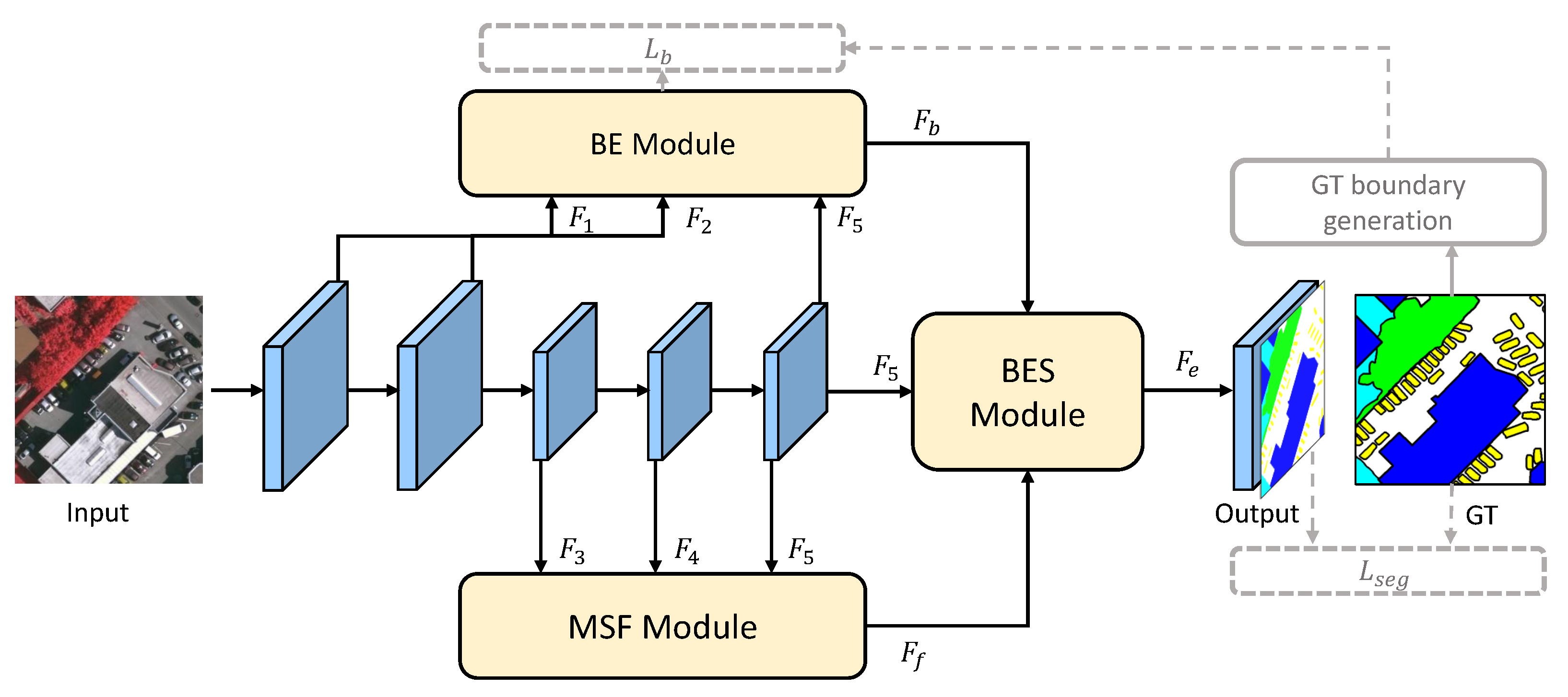
3. Methodology
3.1. The Framework of BES-Net
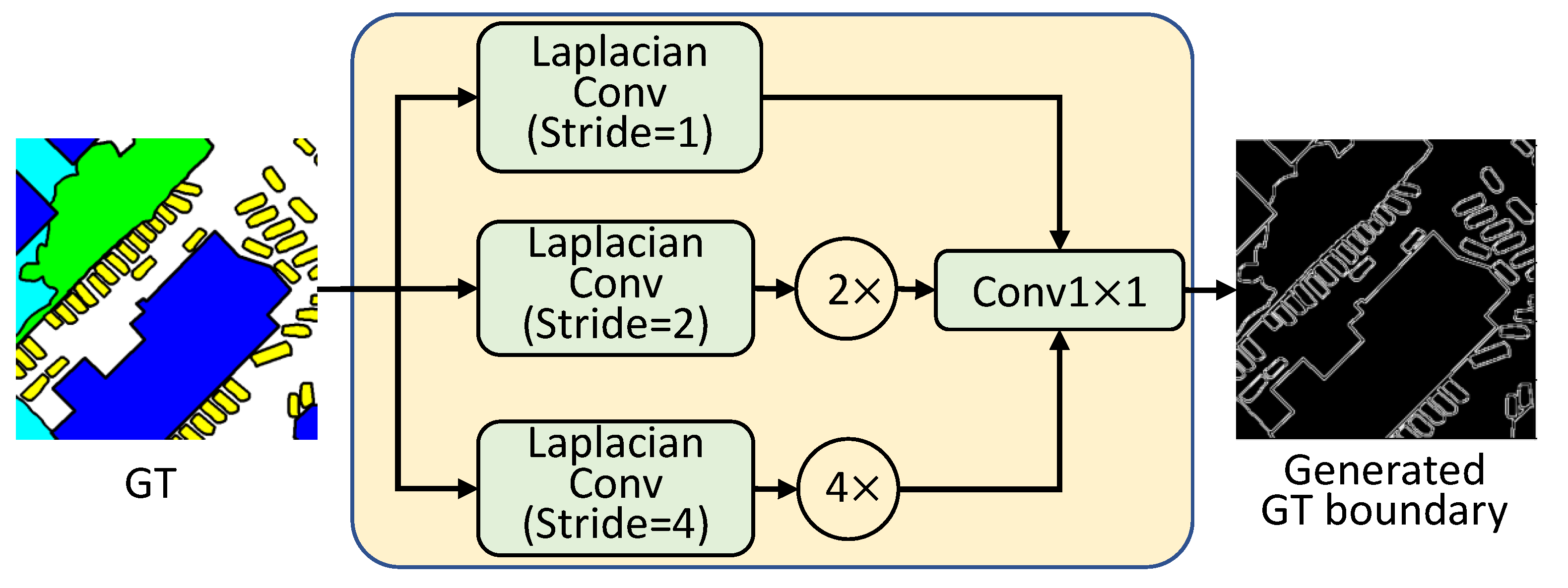
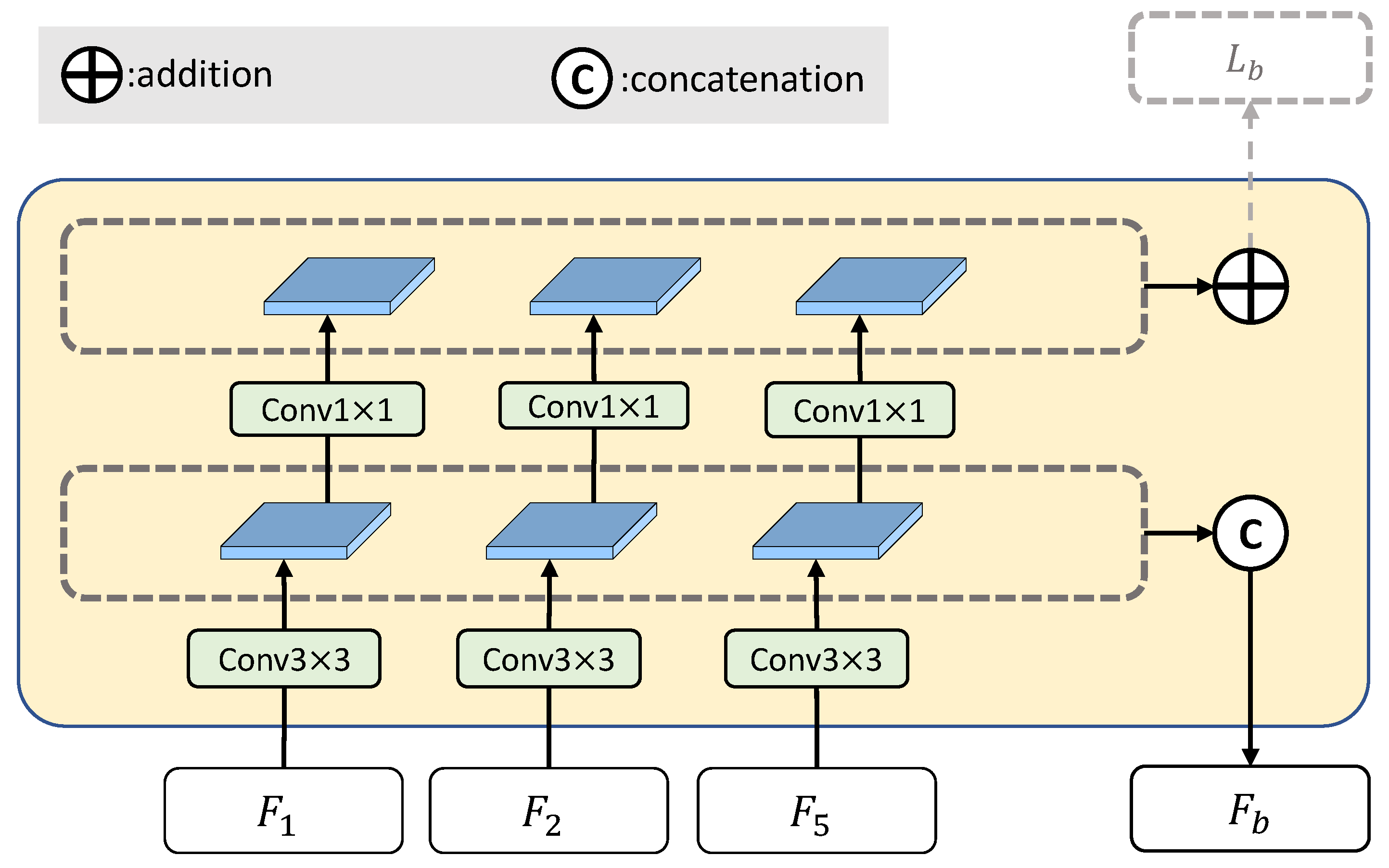
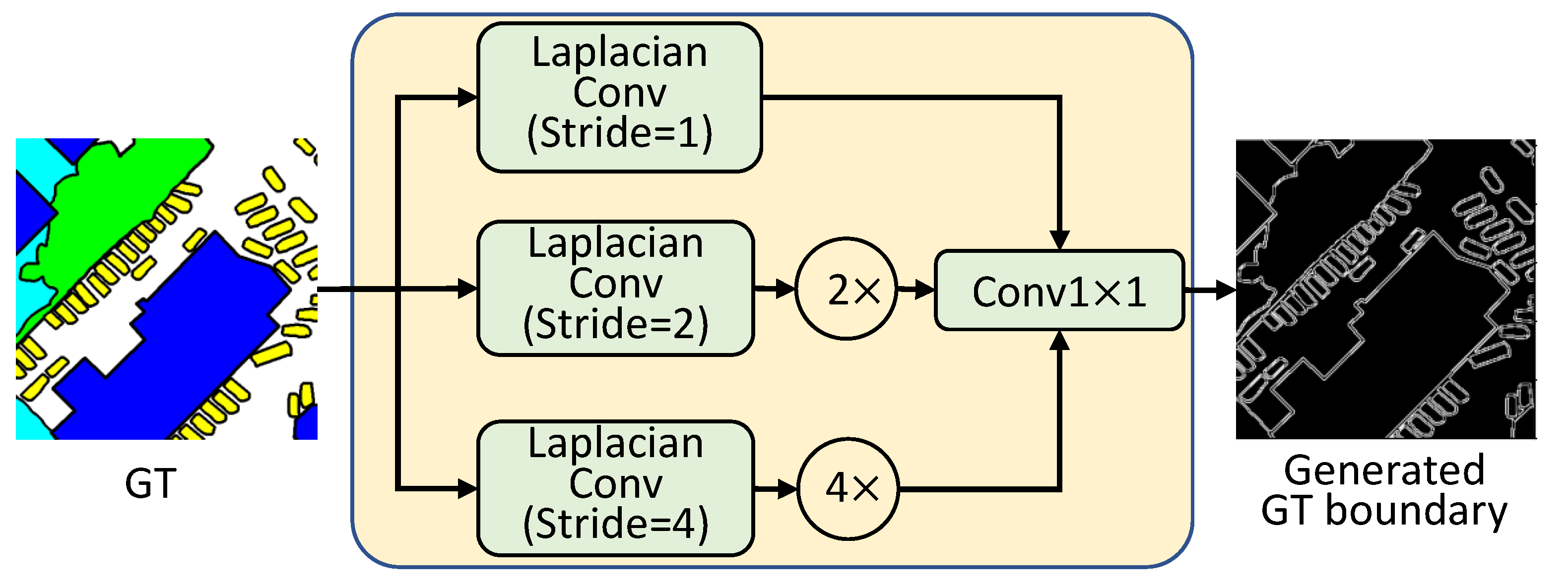
3.2. Boundary Extraction Module
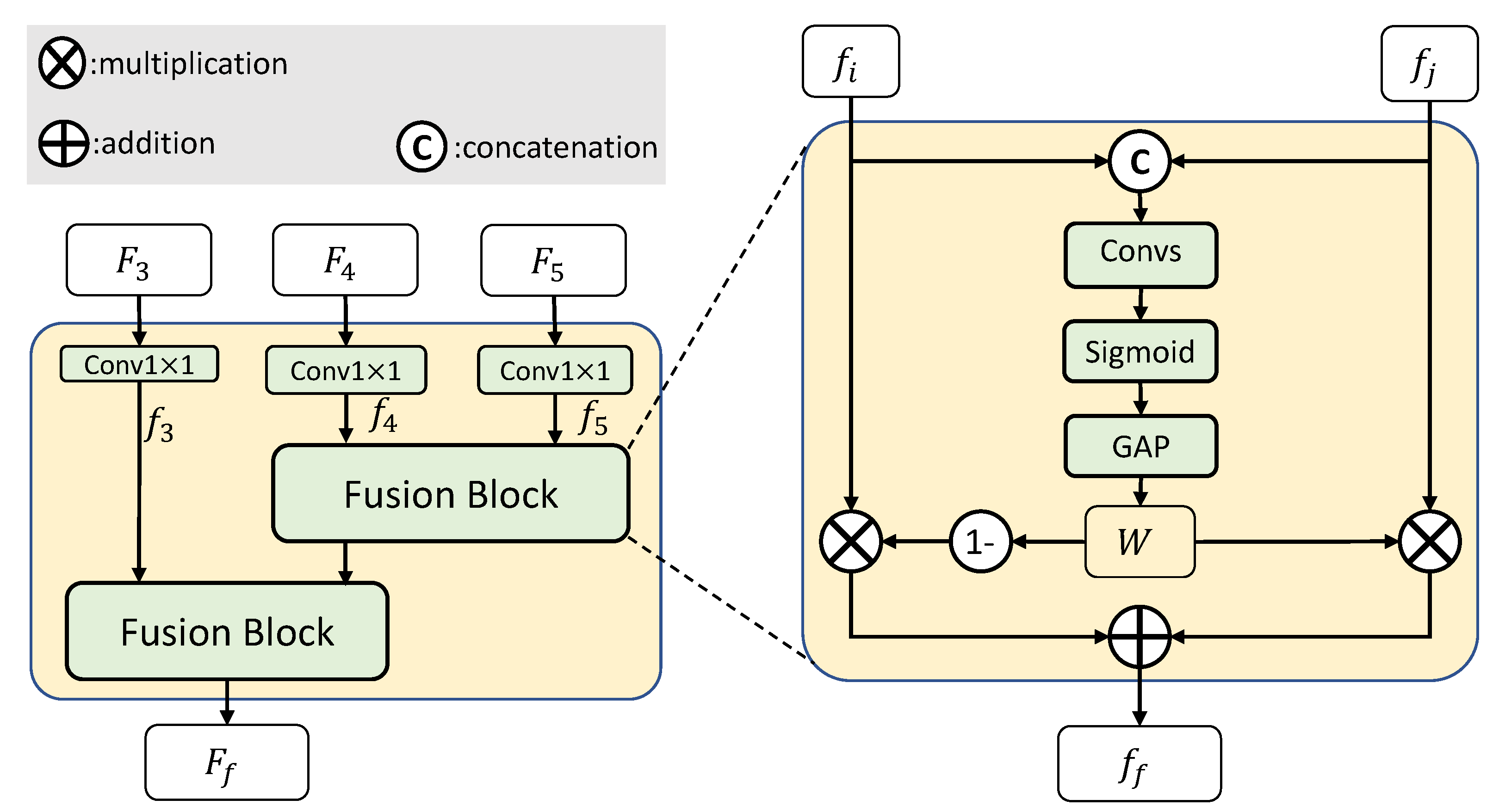
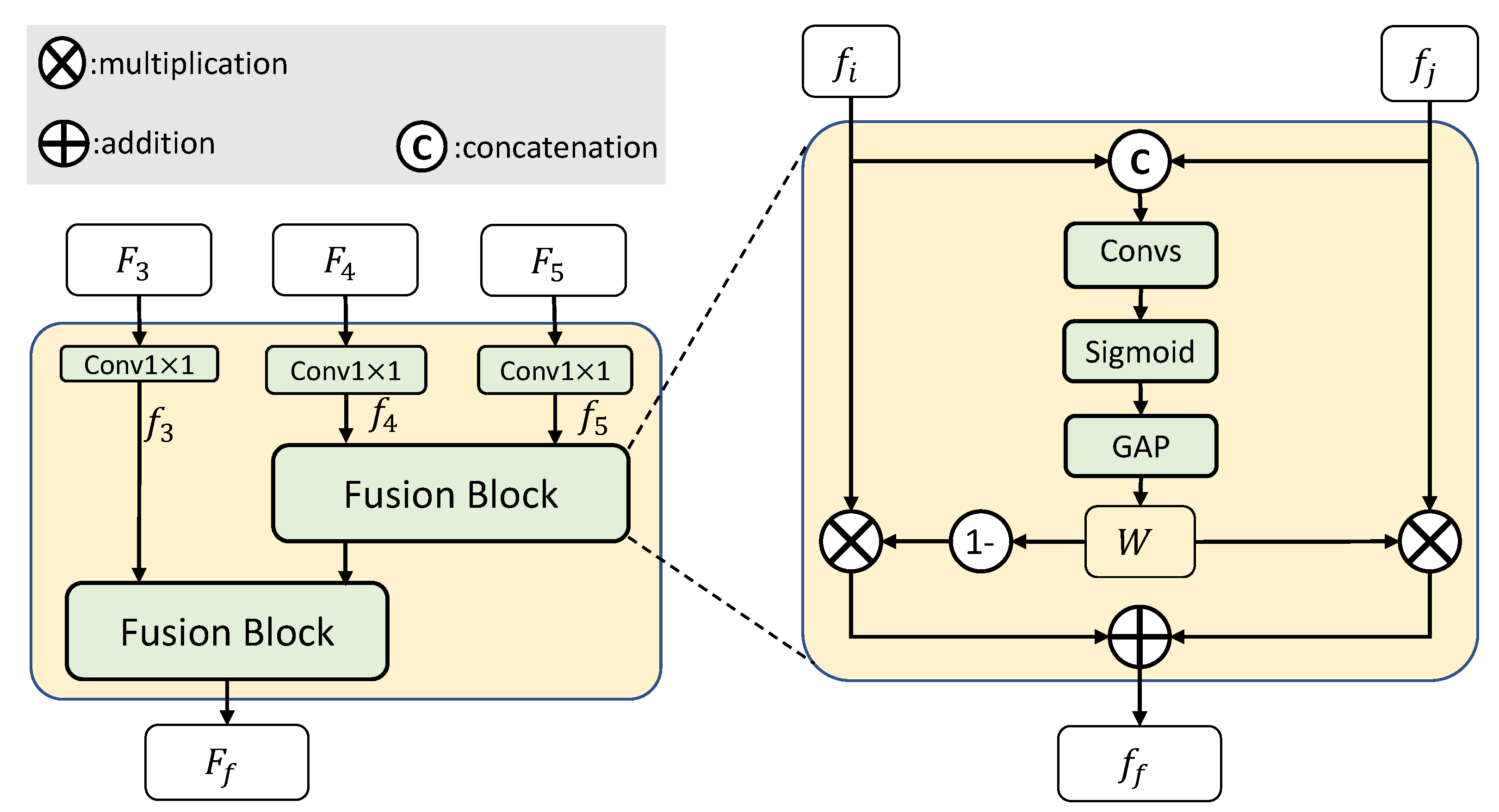
3.3. Multi-Scale Semantic Context Fusion Module
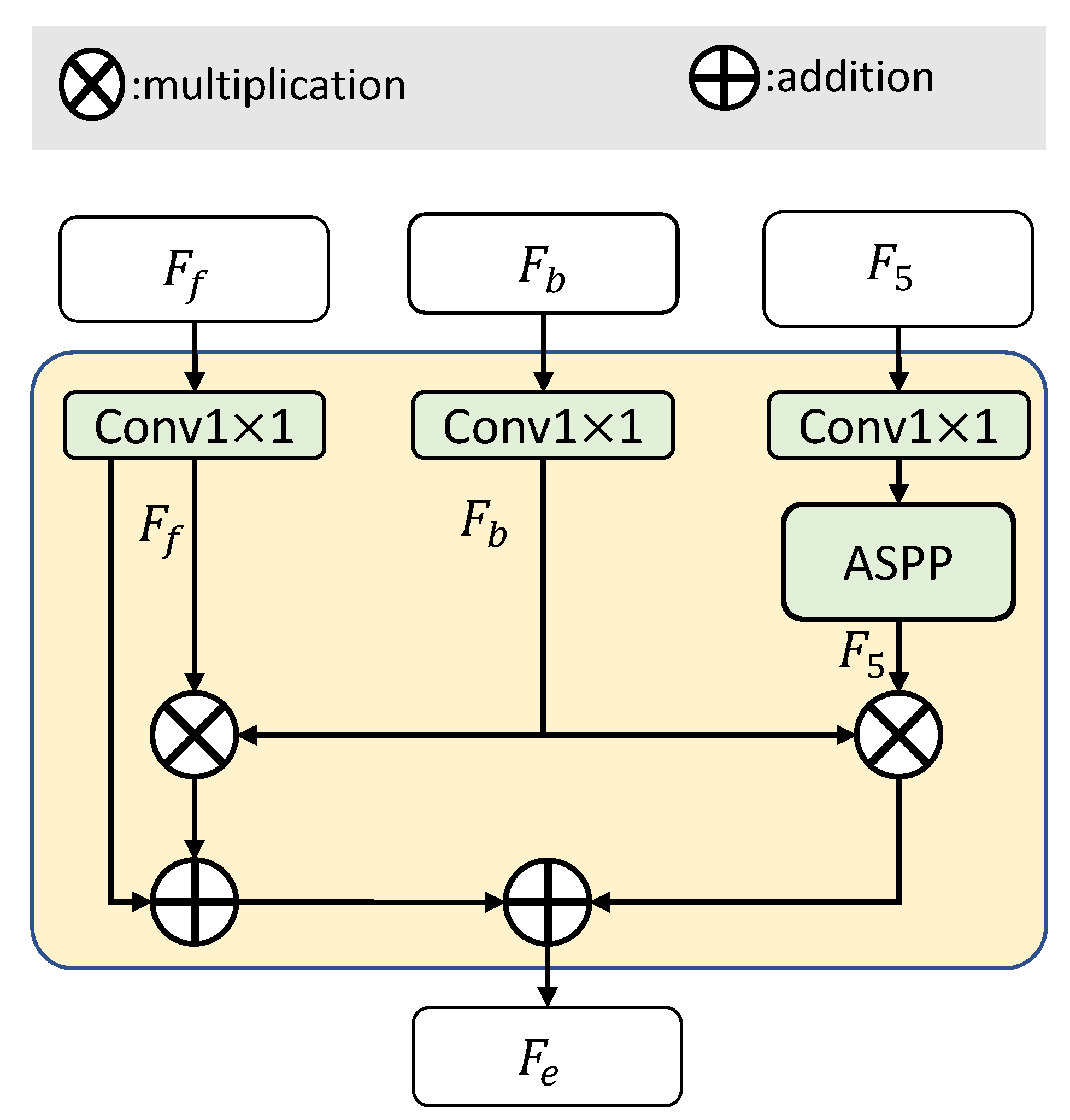
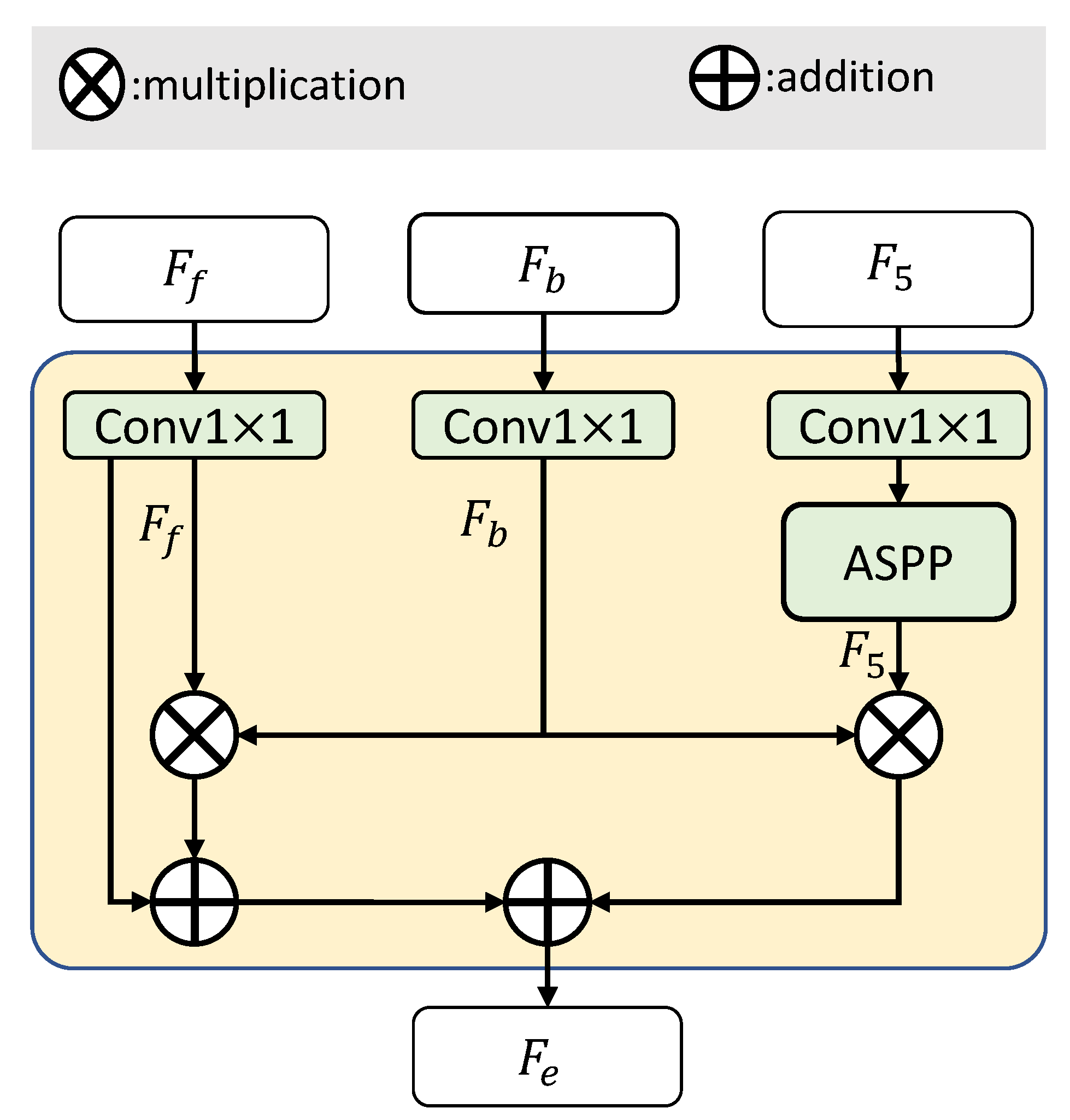
3.4. Boundary Enhancing Semantic Context Module
3.5. Loss Function
4. Experiments and Results
4.1. Experimental Settings
4.1.1. Datasets and Settings
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
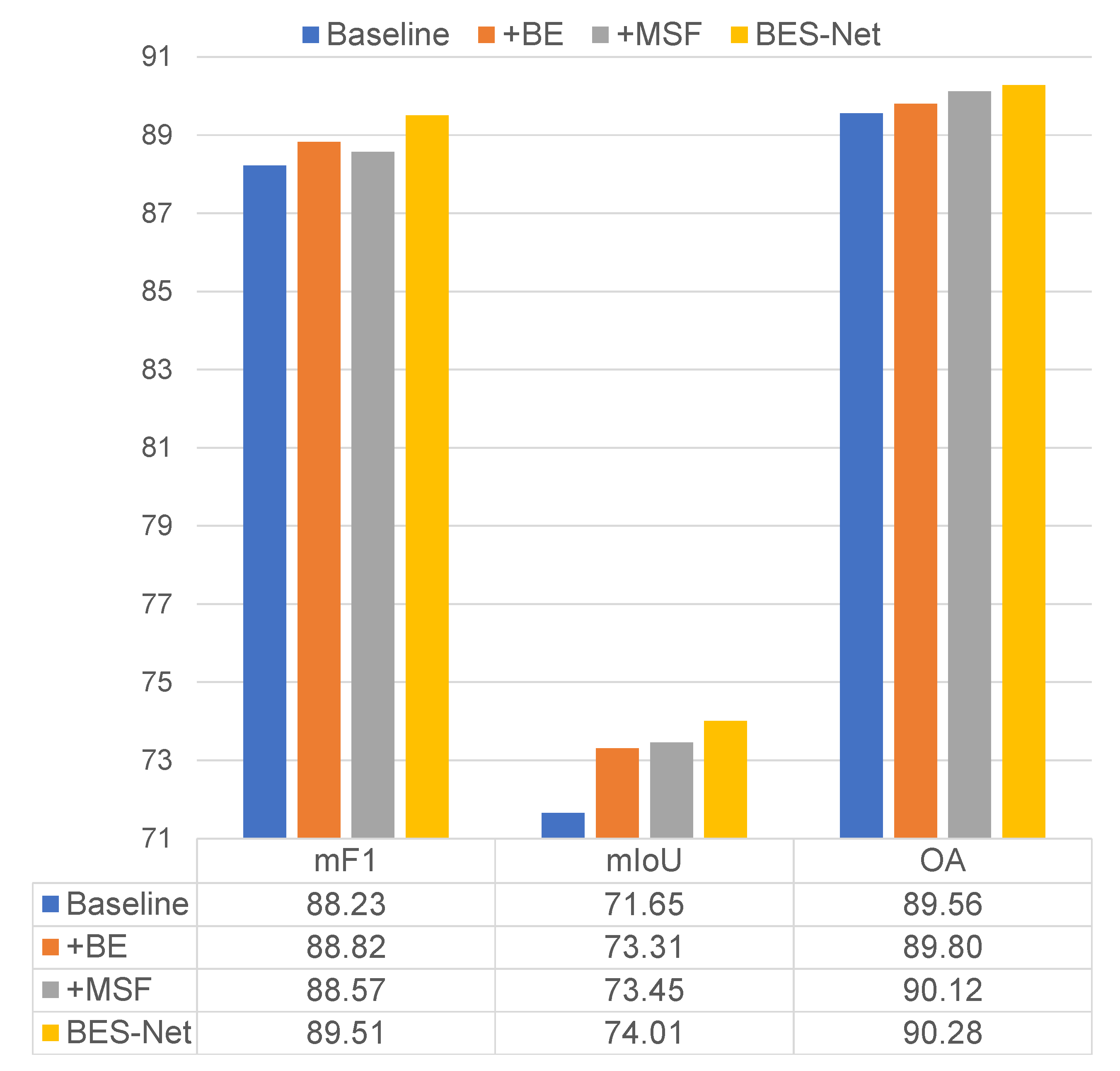
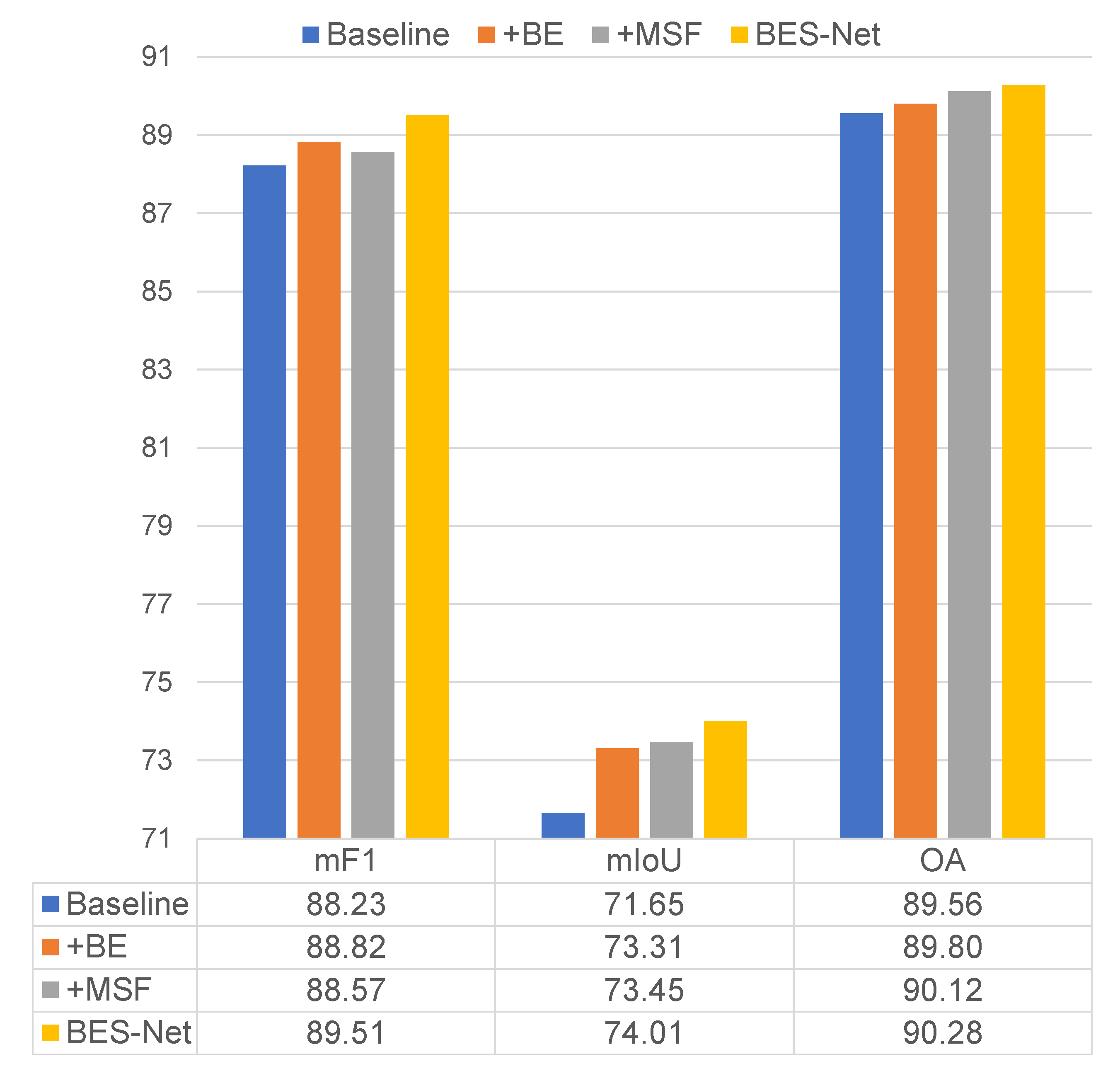
4.2. Ablation Experiments
- Compared to the baseline, using only the BE module (+BE) improved the mF1, mIoU, and OA by 0.59%, 1.66%, and 0.24%, respectively.
- Compared to the baseline, using only the MSF module (+MSF) improved the mF1, mIoU, and OA by 0.34%, 1.80%, and 0.56%, respectively.
- When combining the BE and MSF modules using the BES module (our BES-Net), the mF1, mIoU, and OA were improved by 1.28%, 2.36%, and 0.72%, respectively, compared to the baseline.
- Compared to +BE and +MSF methods, our BES-Net performed much better. This demonstrates the effectiveness of explicitly adopting boundary information to enhance the semantic context.
- The ablation experiments demonstrated the effectiveness of our proposed three modules, BE, MSF, and BES, for HR remote sensing images semantic segmentation.
4.2.1. Boundary Extraction
4.2.2. Multi-Scale Semantic Context Fusion
4.2.3. Boundary Enhancing Semantic Context
- When the highest-level backbone semantic feature is enhanced by the boundary feature , corresponding to index ⑧, it achieves better performance compared to the baseline.
- When enhances the fused multi-scale semantic features , corresponding to index ⑨, it slightly outperforms method ⑧.
- Finally, simultaneously enhancing and , corresponding to index ⑩, achieves the best performance.
- The experimental results demonstrate the effectiveness of our BES-Net in explicitly adopting boundary information to enhance the semantic context.
4.2.4. Backbone
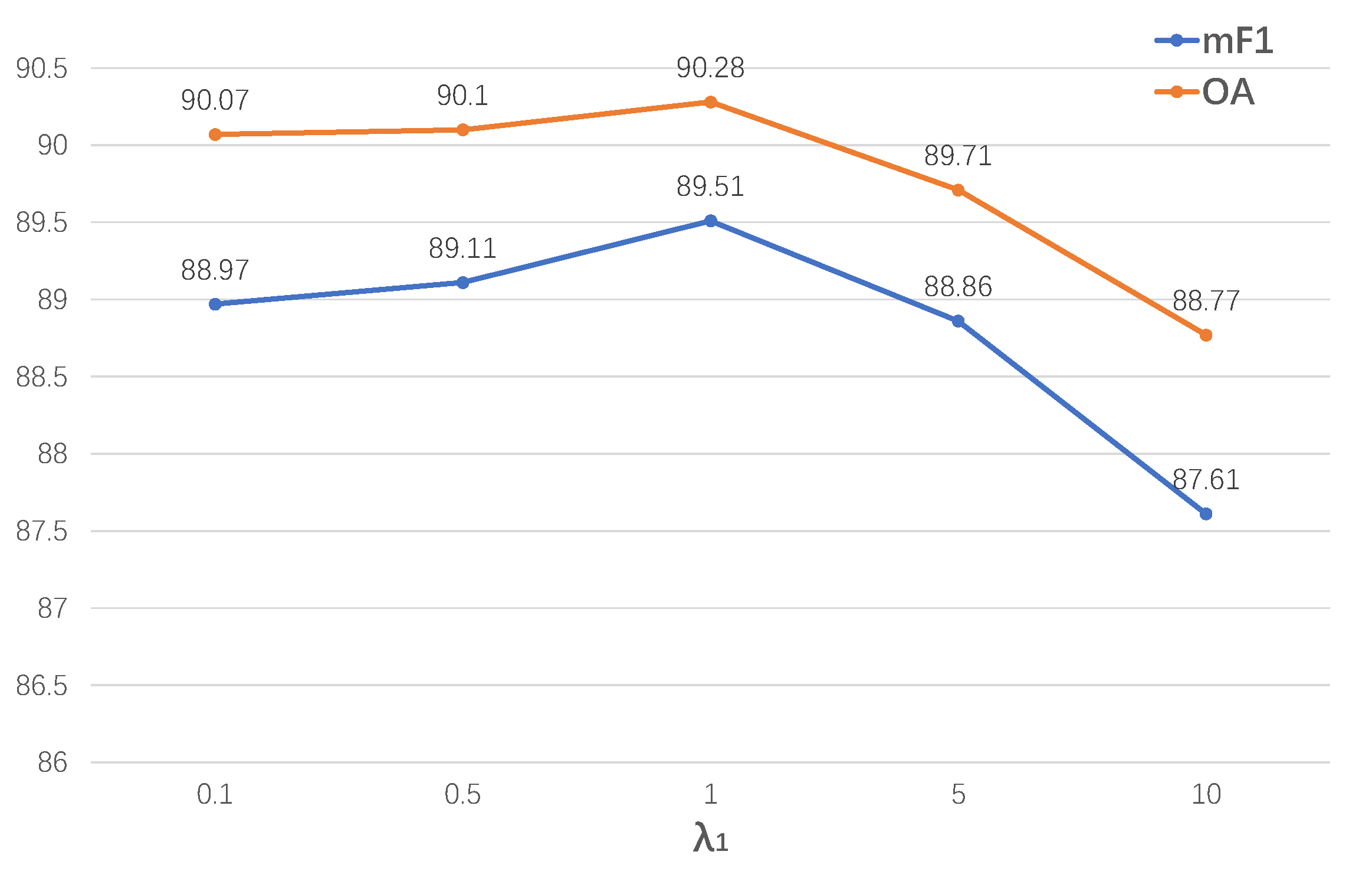
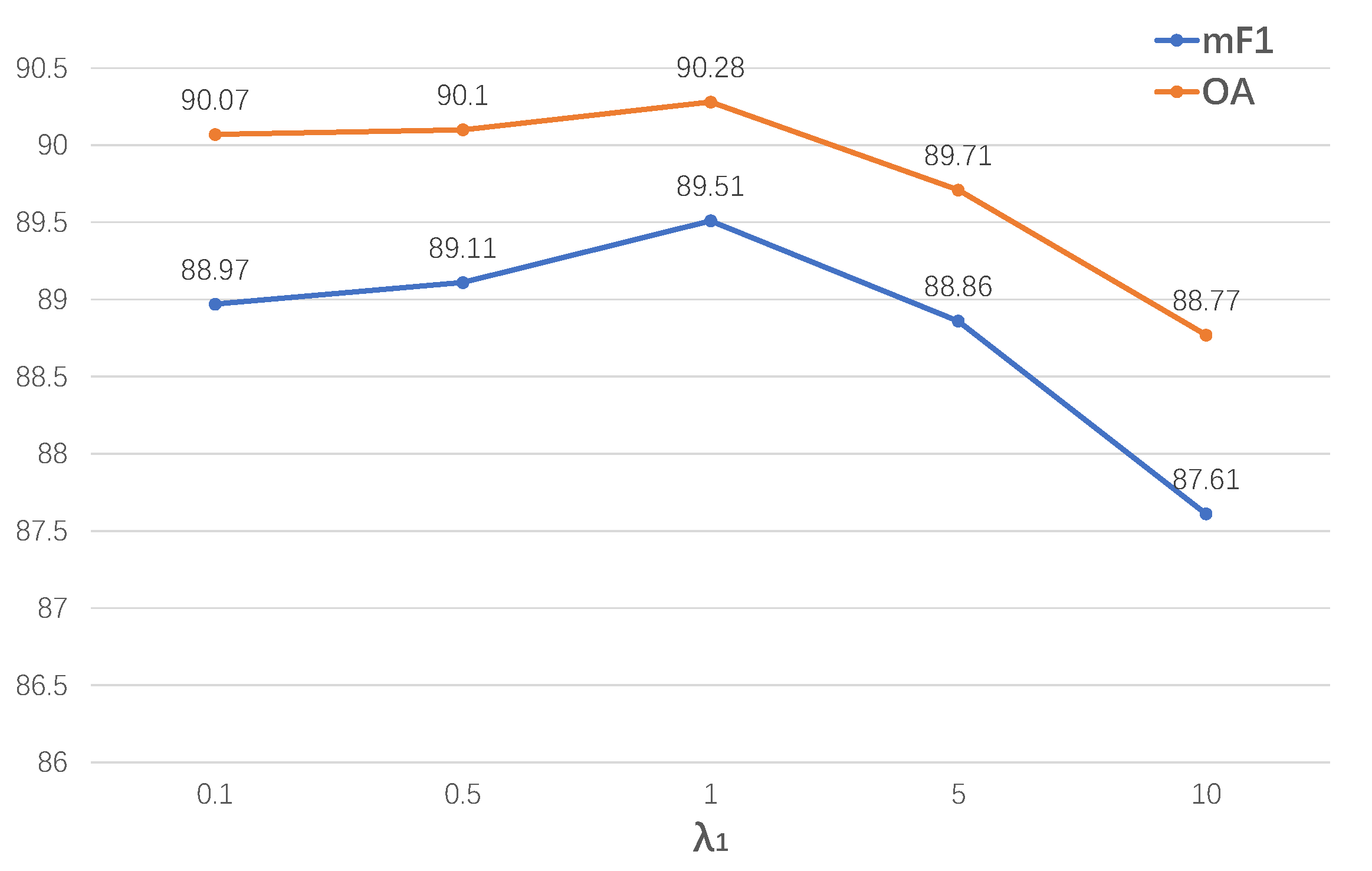
4.2.5. The Hyperparameters in the Loss Function
4.3. Comparison to the State of the Art
- Our proposed BES-Net method can achieve comparable performance to the current state-of-the-art results obtained by BASNet [19], except on car segmentation, and it outperforms all the other comparison methods. However, BASNet has more parameters due to the additional discriminator network.
- Regarding the lightweight models, compared to ABCNet [27] our BES-Net method with the ResNset18 backbone can achieve a slightly better performance on all metrics.
- All the results demonstrate the effectiveness of our proposed BES-Net method for enhancing the semantic context using boundary information to improve the intra-class semantic consistency.
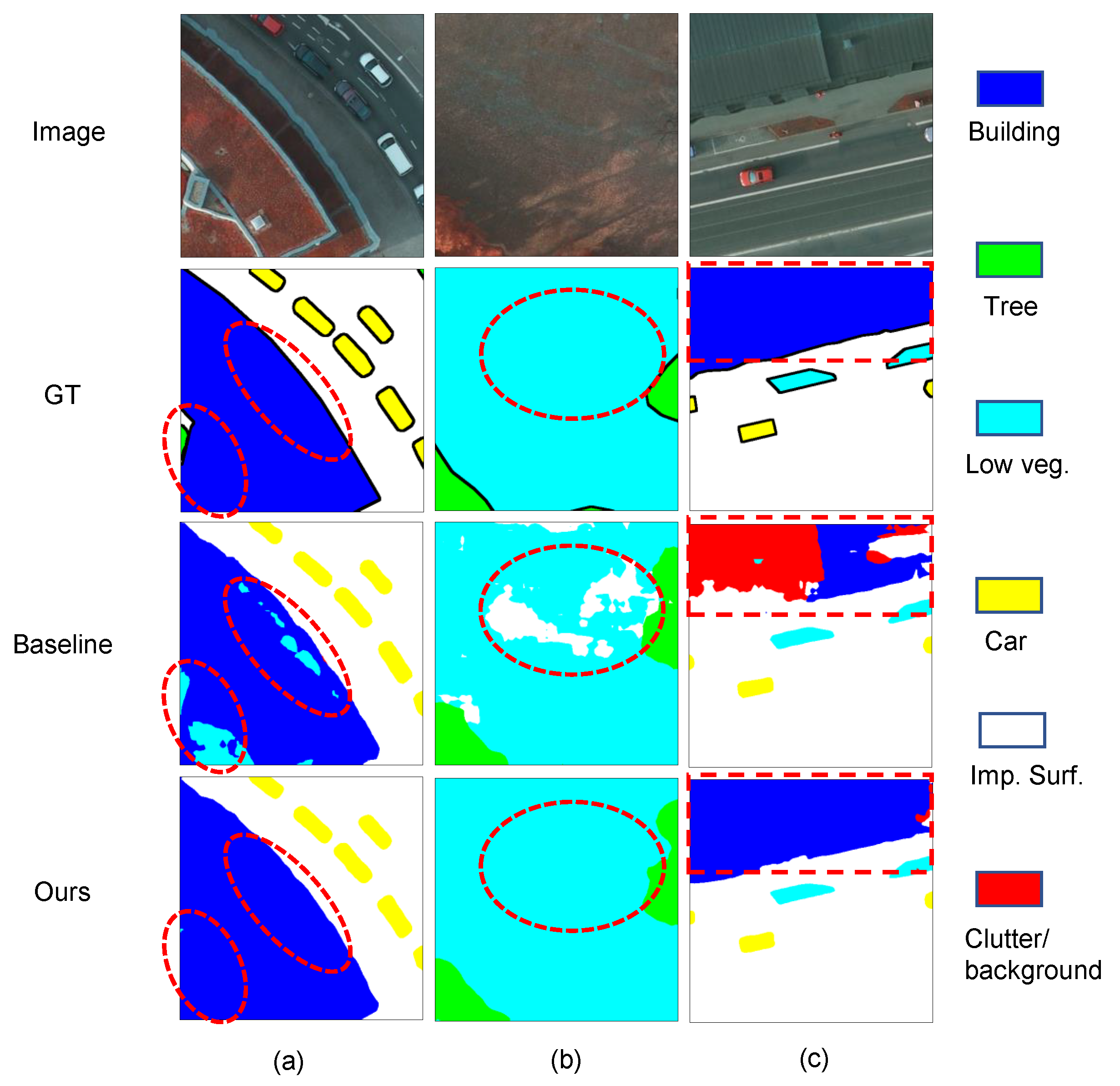
4.4. Qualitative Analysis
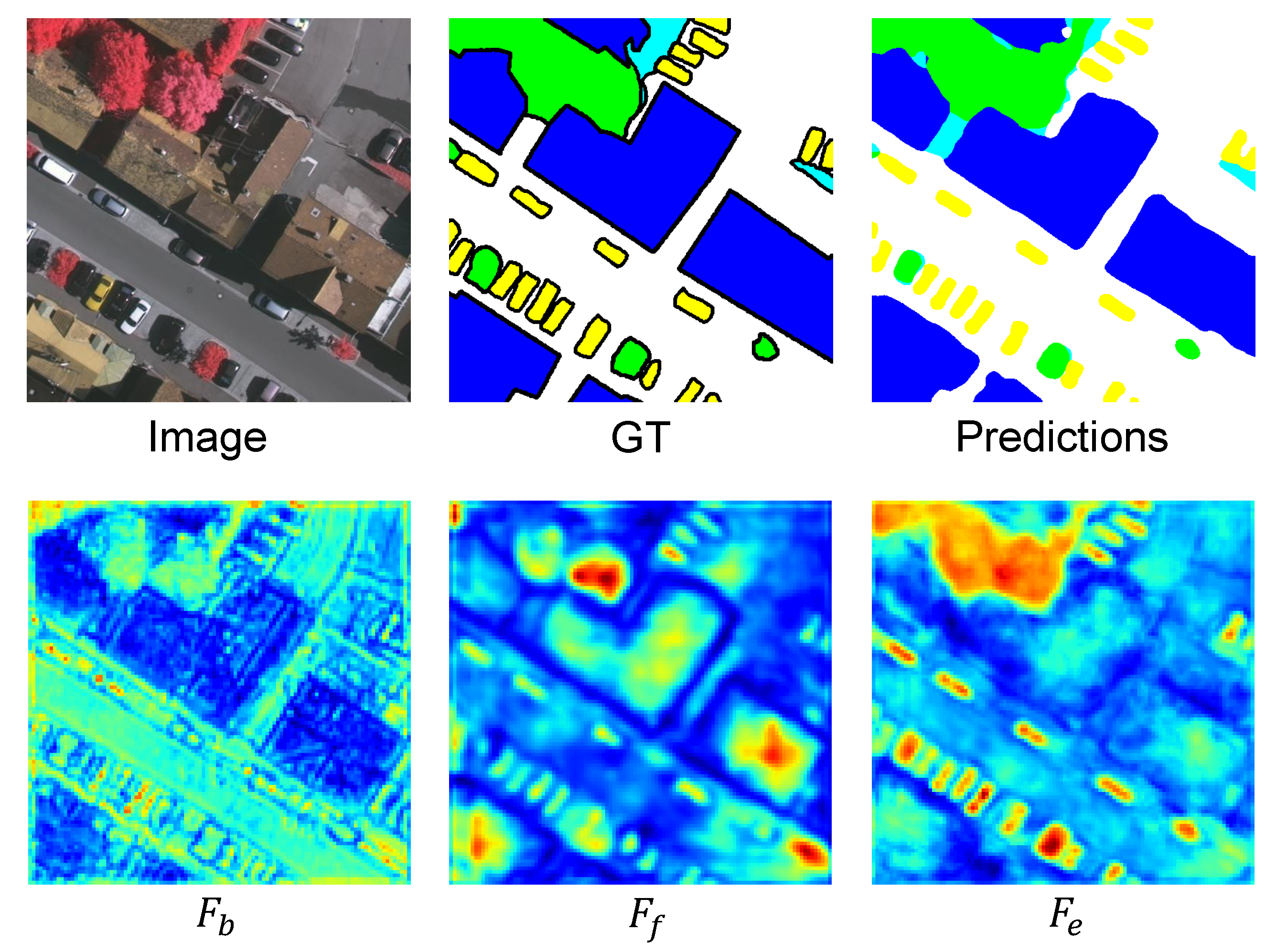
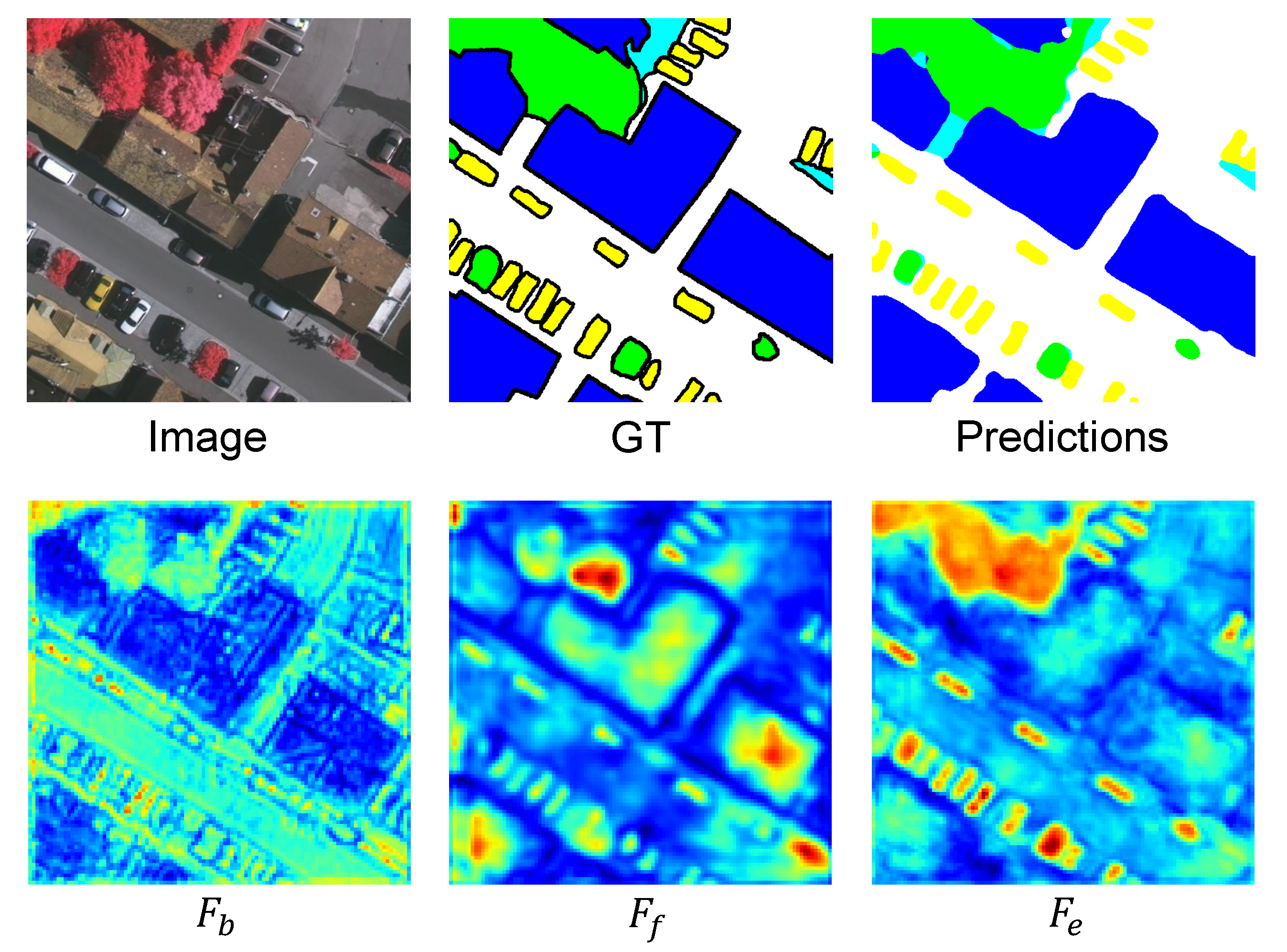
- Some pixels are easily misclassified by the baseline method. (1) in Figure 10a and Figure 11a, some regions of the building with a red roof are misclassified as low vegetation. (2) In Figure 11b, some regions of low vegetation with complex textures are misclassified as impervious surfaces. (3) In Figure 11c, some regions of the building with a gray roof are misclassified as clutter/background. The baseline method could not process those pixels belonging to one object in a holistic fashion, while our BES-Net method considering the semantic boundary had the global concept of an entire semantic object to improve the segmentation performance.
- As shown in Figure 10b, our BES-Net can separate two adjacent cars while the baseline may link them. This is because our BES-Net with boundary enhancement can generate clear boundaries and regular shapes.
- The object boundaries generated by our BES-Net are remarkably more complete than those from baseline, especially for regular objects such as buildings, as shown in Figure 10c and Figure 11c. BES-Net can draw out the complete shape of the building with a clear boundary, while the baseline yields an incomplete building due to interruptions caused by different textures.
- All these results demonstrate that our BES-Net is more robust to adjacent object confusion and can effectively capture fine-structured objects with both boundary and semantic information at an entire semantic object level.
4.5. Computational Complexity
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, S.; Cheng, J.; Liang, L.; Bai, H.; Dang, W. Light-Weight Semantic Segmentation Network for UAV Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8287–8296. [Google Scholar] [CrossRef]
- Tong, X.Y.; Xia, G.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Cheng, J.; Ji, Y.; Liu, H. Segmentation-Based PolSAR Image Classification Using Visual Features: RHLBP and Color Features. Remote Sens. 2015, 7, 6079–6106. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Hallman, S.; Ramanan, D.; Fowlkes, C.C. Layered Object Models for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1731–1743. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7151–7160. [Google Scholar]
- Liu, Y.; Xie, Y.; Yang, J.; Zuo, X.; Zhou, B. Target Classification and Recognition for High-Resolution Remote Sensing Images: Using the Parallel Cross-Model Neural Cognitive Computing Algorithm. IEEE Geosci. Remote Sens. Mag. 2020, 8, 50–62. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Xia, R.; Lyu, X.; Gao, H.; Tong, Y. Hybridizing Cross-Level Contextual and Attentive Representations for Remote Sensing Imagery Semantic Segmentation. Remote Sens. 2021, 13, 2986. [Google Scholar] [CrossRef]
- Zheng, X.; Huan, L.; Xia, G.; Gong, J. Parsing very high resolution urban scene images by learning deep ConvNets with edge-aware loss. ISPRS J. Photogramm. Remote Sens. 2020, 170, 15–28. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Zhang, L.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving semantic segmentation via decoupled body and edge supervision. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 435–452. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5229–5238. [Google Scholar]
- Ma, H.; Yang, H.; Huang, D. Boundary Guided Context Aggregation for Semantic Segmentation. arXiv 2021, arXiv:2110.14587. [Google Scholar]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. BAS4Net: Boundary-Aware Semi-Supervised Semantic Segmentation Network for Very High Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking BiSeNet For Real-time Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9716–9725. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Bai, H.; Cheng, J.; Huang, X.; Liu, S.; Deng, C. HCANet: A Hierarchical Context Aggregation Network for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Yang, X.S.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Bertasius, G.; Shi, J.; Torresani, L. Semantic segmentation with boundary neural fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3602–3610. [Google Scholar]
- Ke, T.W.; Hwang, J.J.; Liu, Z.; Yu, S.X. Adaptive affinity fields for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 587–602. [Google Scholar]
- Bertasius, G.; Torresani, L.; Yu, S.X.; Shi, J. Convolutional random walk networks for semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 858–866. [Google Scholar]
- Ding, H.; Jiang, X.; Liu, A.Q.; Thalmann, N.M.; Wang, G. Boundary-aware feature propagation for scene segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6819–6829. [Google Scholar]
- Zhang, C.; Jiang, W.; Zhao, Q. Semantic Segmentation of Aerial Imagery via Split-Attention Networks with Disentangled Nonlocal and Edge Supervision. Remote Sens. 2021, 13, 1176. [Google Scholar] [CrossRef]
- Han, H.Y.; Chen, Y.C.; Hsiao, P.Y.; Fu, L.C. Using Channel-Wise Attention for Deep CNN Based Real-Time Semantic Segmentation With Class-Aware Edge Information. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1041–1051. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Li, X.; Zhao, H.; Han, L.; Tong, Y.; Tan, S.; Yang, K. Gated fully fusion for semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11418–11425. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Chen, G.; Zhang, X.; Wang, Q.; Dai, F.; Gong, Y.; Zhu, K. Symmetrical dense-shortcut deep fully convolutional networks for semantic segmentation of very-high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1633–1644. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Liu, Q.; Kampffmeyer, M.; Jenssen, R.; Salberg, A.B. Dense dilated convolutions’ merging network for land cover classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6309–6320. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Hu, P.; Perazzi, F.; Heilbron, F.C.; Wang, O.; Lin, Z.L.; Saenko, K.; Sclaroff, S. Real-Time Semantic Segmentation with Fast Attention. IEEE Robot. Autom. Lett. 2021, 6, 263–270. [Google Scholar] [CrossRef]
- Li, R.; Su, J.; Duan, C.; Zheng, S. Multistage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Orsic, M.; Segvic, S. Efficient semantic segmentation with pyramidal fusion. Pattern Recognit. 2021, 110, 107611. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Inputs | mF1 | mIoU | OA | ||||
|---|---|---|---|---|---|---|---|---|
| ine ① | ✓ | ✓ | - | - | ✓ | 88.82 | 73.31 | 89.80 |
| ② | ✓ | ✓ | - | ✓ | ✓ | 88.85 | 71.56 | 89.73 |
| ③ | ✓ | ✓ | ✓ | ✓ | ✓ | 88.59 | 71.90 | 89.80 |
| Index | Fusion Orders | mF1 | mIoU | OA |
|---|---|---|---|---|
| ④ | 88.57 | 73.45 | 90.12 | |
| ⑤ | 88.53 | 72.95 | 89.95 | |
| ⑥ | 88.35 | 72.31 | 90.09 | |
| ⑦ | Cat(④,⑤,⑥) | 88.89 | 72.66 | 89.97 |
| Index | Inputs | mF1 | mIoU | OA | ||
|---|---|---|---|---|---|---|
| Baseline | - | - | - | 88.23 | 71.65 | 89.56 |
| ⑧ | ✓ | - | ✓ | 89.01 | 72.97 | 90.18 |
| ⑨ | ✓ | ✓ | - | 89.47 | 73.61 | 90.17 |
| ⑩ | ✓ | ✓ | ✓ | 89.51 | 74.01 | 90.28 |
| Backbone | Vaihingen | Potsdam | ||||
|---|---|---|---|---|---|---|
| mF1 | mIoU | OA | mF1 | mIoU | OA | |
| ine ReNet18 | 88.86 | 73.00 | 89.92 | 92.05 | 78.21 | 90.52 |
| ResNet50 | 89.51 | 74.01 | 90.28 | 92.09 | 77.98 | 90.64 |
| ResNet101 | 89.68 | 75.04 | 90.57 | 92.26 | 77.91 | 90.71 |
| Method | Backbone | Per-Class F1-Score | mF1 | OA | |||||
|---|---|---|---|---|---|---|---|---|---|
| Impervious Surfaces | Building | Low Vegetation | Tree | Car | |||||
| Vaihingen | DeepLabV3+ [11] | ResNet101 | 92.4 | 95.2 | 84.3 | 89.5 | 86.5 | 89.6 | 90.6 |
| PSPNet [10] | ResNet101 | 92.8 | 95.5 | 84.5 | 89.9 | 88.6 | 90.3 | 90.9 | |
| IPSPNet [39] | ResNet101 | 89.6 | 91.5 | 82.0 | 88.3 | 68.4 | 84.0 | 87.8 | |
| CVEO [40] | SDFCN139 | 90.5 | 92.4 | 81.7 | 88.5 | 79.4 | 86.5 | 88.3 | |
| LWN [1] | ResNet101 | 91.0 | 94.9 | 79.2 | 88.6 | 88.4 | 87.6 | 88.9 | |
| DANet [41] | ResNet101 | 91.6 | 95.0 | 83.3 | 88.9 | 87.2 | 89.2 | 90.4 | |
| DDCM-Net [42] | ResNet50 | 92.7 | 95.3 | 83.3 | 89.4 | 88.3 | 89.8 | 90.4 | |
| CASIA2 [43] | ResNet101 | 93.2 | 96.0 | 84.7 | 89.9 | 86.7 | 90.1 | 91.1 | |
| HCANet [24] | ResNet101 | 92.5 | 95.0 | 84.2 | 89.4 | 84.0 | 89.0 | 90.3 | |
| BASNet [19] | ResNet101 | 93.3 | 95.8 | 85.0 | 90.1 | 90.1 | 90.9 | 91.3 | |
| ABCNet [27] | ResNet18 | 92.7 | 95.2 | 84.5 | 89.7 | 85.3 | 89.5 | 90.7 | |
| BES-Net (ours) | ResNet18 | 92.8 | 95.5 | 84.8 | 90.0 | 85.8 | 89.8 | 90.9 | |
| BES-Net (ours) | ResNet50 | 93.0 | 96.0 | 85.4 | 90.0 | 88.3 | 90.6 | 91.2 | |
| BES-Net (ours) | ResNet101 | 93.4 | 95.9 | 85.2 | 90.3 | 87.8 | 90.5 | 91.4 | |
| Potsdam | DeepLabV3+ [11] | ResNet101 | 93.0 | 95.9 | 87.6 | 88.2 | 96.0 | 92.1 | 90.9 |
| PSPNet [10] | ResNet101 | 93.4 | 97.0 | 87.8 | 88.5 | 95.4 | 92.4 | 91.1 | |
| CVEO [40] | SDFCN139 | 91.2 | 94.5 | 86.4 | 87.4 | 95.4 | 91.0 | 89.0 | |
| DDCM-Net [42] | ResNet50 | 92.9 | 96.9 | 87.7 | 89.4 | 94.9 | 92.4 | 90.8 | |
| CCNet [44] | ResNet101 | 93.6 | 96.8 | 86.9 | 88.6 | 96.2 | 92.4 | 91.5 | |
| HCANet [24] | ResNet101 | 93.1 | 96.6 | 87.0 | 88.5 | 96.1 | 92.3 | 90.8 | |
| ABCNet [27] | ResNet18 | 93.5 | 96.9 | 87.9 | 89.1 | 95.8 | 92.6 | 91.3 | |
| BES-Net (ours) | ResNet18 | 93.8 | 97.0 | 88.1 | 88.9 | 96.4 | 92.9 | 91.5 | |
| BES-Net (ours) | ResNet50 | 93.9 | 97.3 | 87.9 | 88.5 | 96.5 | 92.8 | 91.4 | |
| BES-Net (ours) | ResNet101 | 93.7 | 97.2 | 87.9 | 88.9 | 96.3 | 92.8 | 91.3 | |
| Model | Backbone | Params (M) | FLOPs (G) | mF1 | OA |
|---|---|---|---|---|---|
| PSPNet [10] | ResNet18 | 24.0 | 12.6 | 79.0 | 87.7 |
| DANet [41] | ResNet18 | 12.7 | 9.9 | 79.6 | 88.2 |
| FANet [45] | ResNet18 | 21.7 | 13.8 | 85.4 | 88.9 |
| MAResU-Net [46] | ResNet18 | 25.4 | 16.2 | 87.7 | 90.1 |
| SwiftNet [47] | ResNet18 | 18.8 | 34.2 | 88.3 | 90.2 |
| ABCNet [27] | ResNet18 | 14.1 | 18.7 | 89.5 | 90.7 |
| BES-Net(ours) | ResNet18 | 13.6 | 15.8 | 89.8 | 90.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, F.; Liu, H.; Zeng, Z.; Zhou, X.; Tan, X. BES-Net: Boundary Enhancing Semantic Context Network for High-Resolution Image Semantic Segmentation. Remote Sens. 2022, 14, 1638. https://doi.org/10.3390/rs14071638
Chen F, Liu H, Zeng Z, Zhou X, Tan X. BES-Net: Boundary Enhancing Semantic Context Network for High-Resolution Image Semantic Segmentation. Remote Sensing. 2022; 14(7):1638. https://doi.org/10.3390/rs14071638
Chicago/Turabian StyleChen, Fenglei, Haijun Liu, Zhihong Zeng, Xichuan Zhou, and Xiaoheng Tan. 2022. "BES-Net: Boundary Enhancing Semantic Context Network for High-Resolution Image Semantic Segmentation" Remote Sensing 14, no. 7: 1638. https://doi.org/10.3390/rs14071638
APA StyleChen, F., Liu, H., Zeng, Z., Zhou, X., & Tan, X. (2022). BES-Net: Boundary Enhancing Semantic Context Network for High-Resolution Image Semantic Segmentation. Remote Sensing, 14(7), 1638. https://doi.org/10.3390/rs14071638