
Data Fusion in Earth Observation and the Role of Citizen as a Sensor: A Scoping Review of Applications, Methods and Future Trends




Abstract
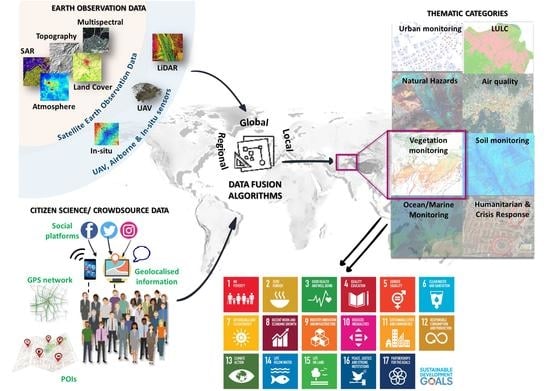
1. Introduction
2. Background
2.1. Earth Observation and Citizen Science Data Proliferation: The “Footprint” of the Digital Age
2.2. Assimilating Data from Space and Crowd
3. Methodological Framework
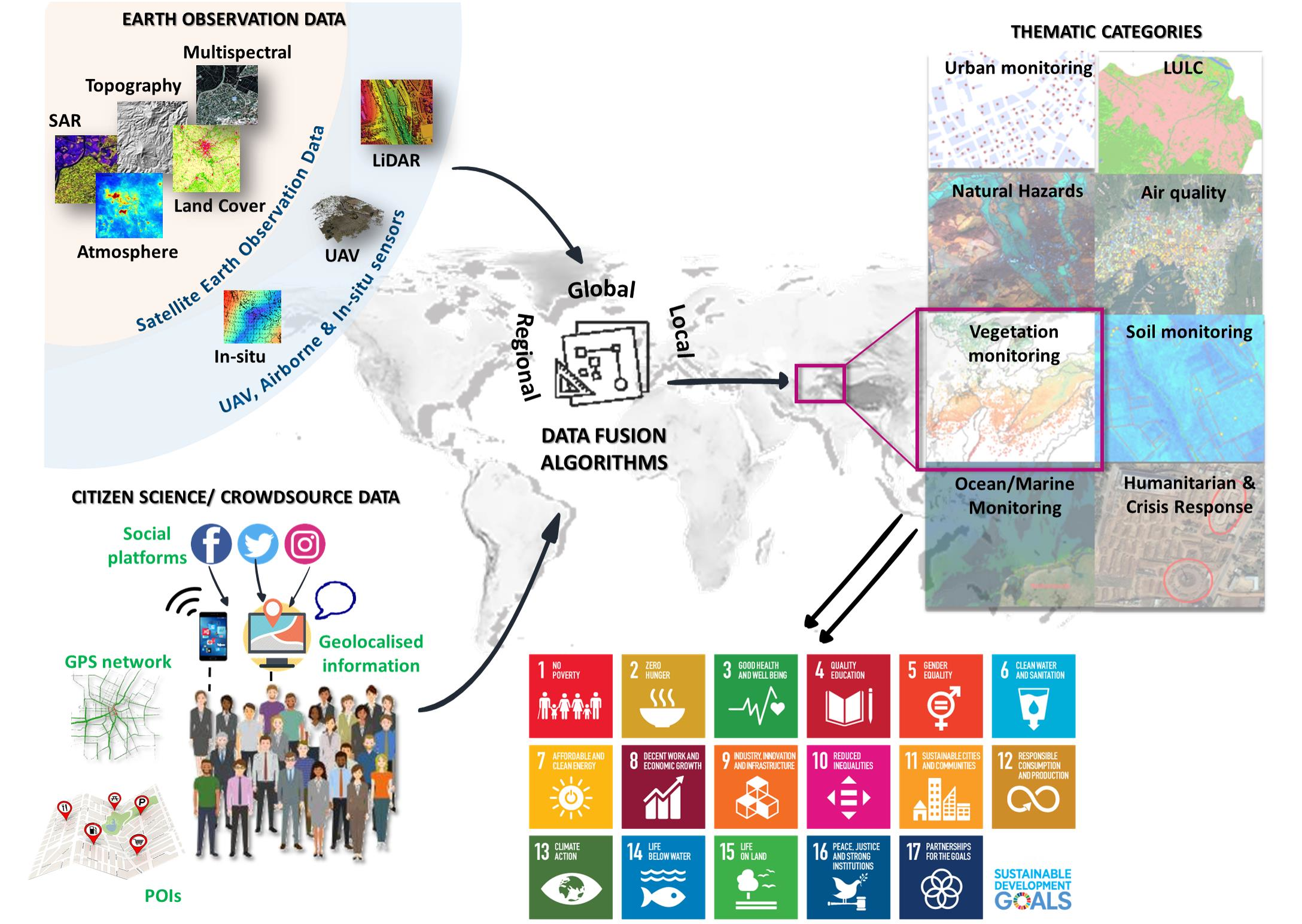
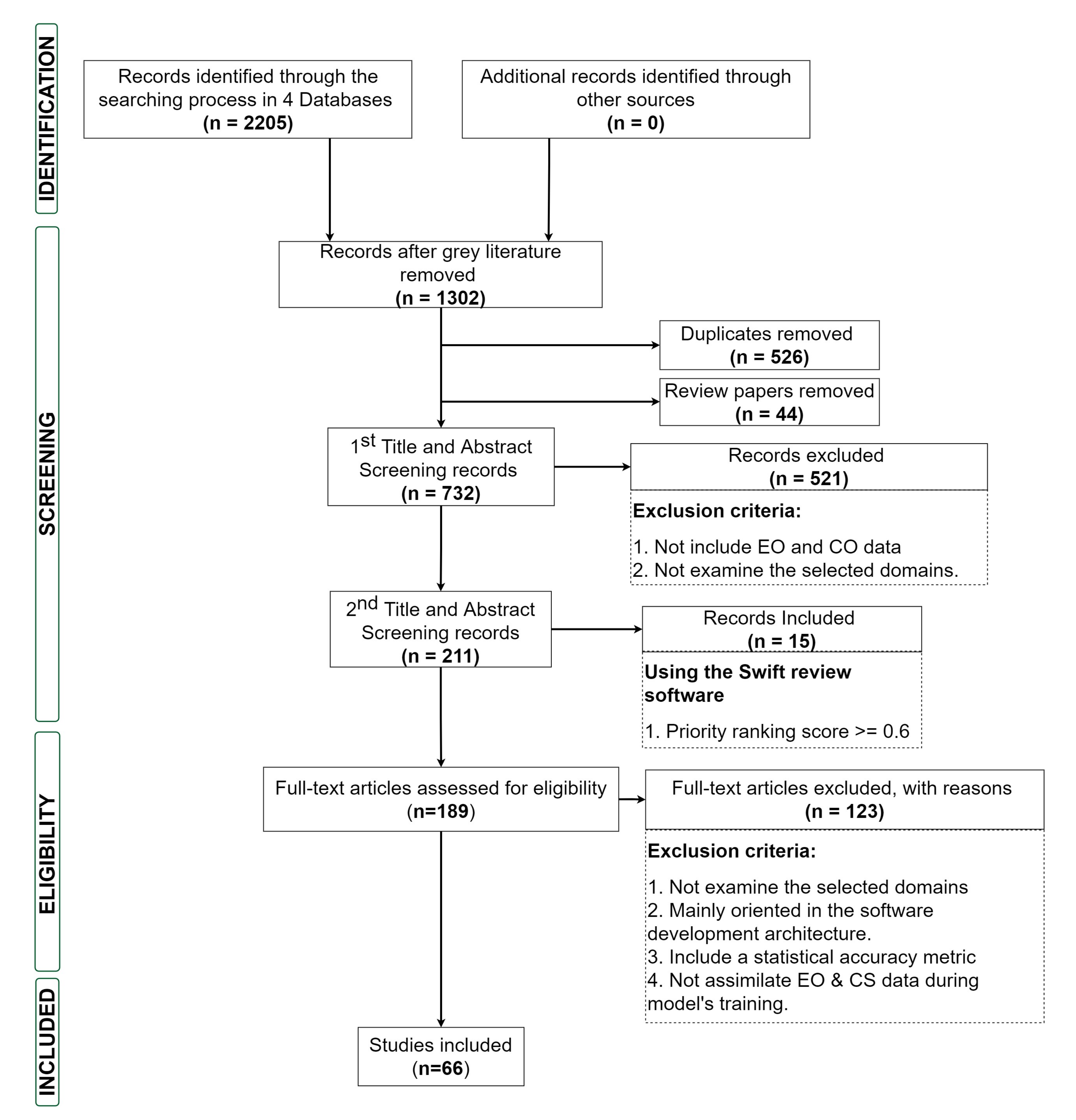
3.1. Search and Selection Strategy
3.2. Selection Criteria
- Publications must be Peer-reviewed scientific journals, written in the English language.
- Peer-reviewed articles have to be published between 2015 and 2020.
- Publications encompass data from satellite, aerial or in situ sensors with crowdsourced data.
- Studies that focused on land terrestrial applications, addressing the following research domains, among the different thematic categories presented in [20].
- (a)
- Land Use/Land Cover (LULC)
- (b)
- Natural Hazards
- (c)
- Soil moisture
- (d)
- Urban monitoring
- (e)
- Vegetation monitoring
- (f)
- Ocean/marine monitoring
- (g)
- Humanitarian and crisis response
- (h)
- Air monitoring
- Articles may validate their proposed method using a statistical accuracy metric.
- The literature review publications.
- Studies that solely use EO or CS data are excluded from the review.
- Any publication related to the investigation of extra-terrestrial environments.
- Articles that oriented their research on platforms visualising data, without applying data fusion methods among EO and CS data.
- Exclusion of studies that did not assimilate both EO and CS data during the training phase of the presented algorithm. Articles, where one of the two data types is utilized for validation purposes and therefore did not contribute to the model’s prediction, are excluded for further investigation.
3.3. Charting the Data: Transformation, Analysis and Interpretation
3.3.1. General Categories
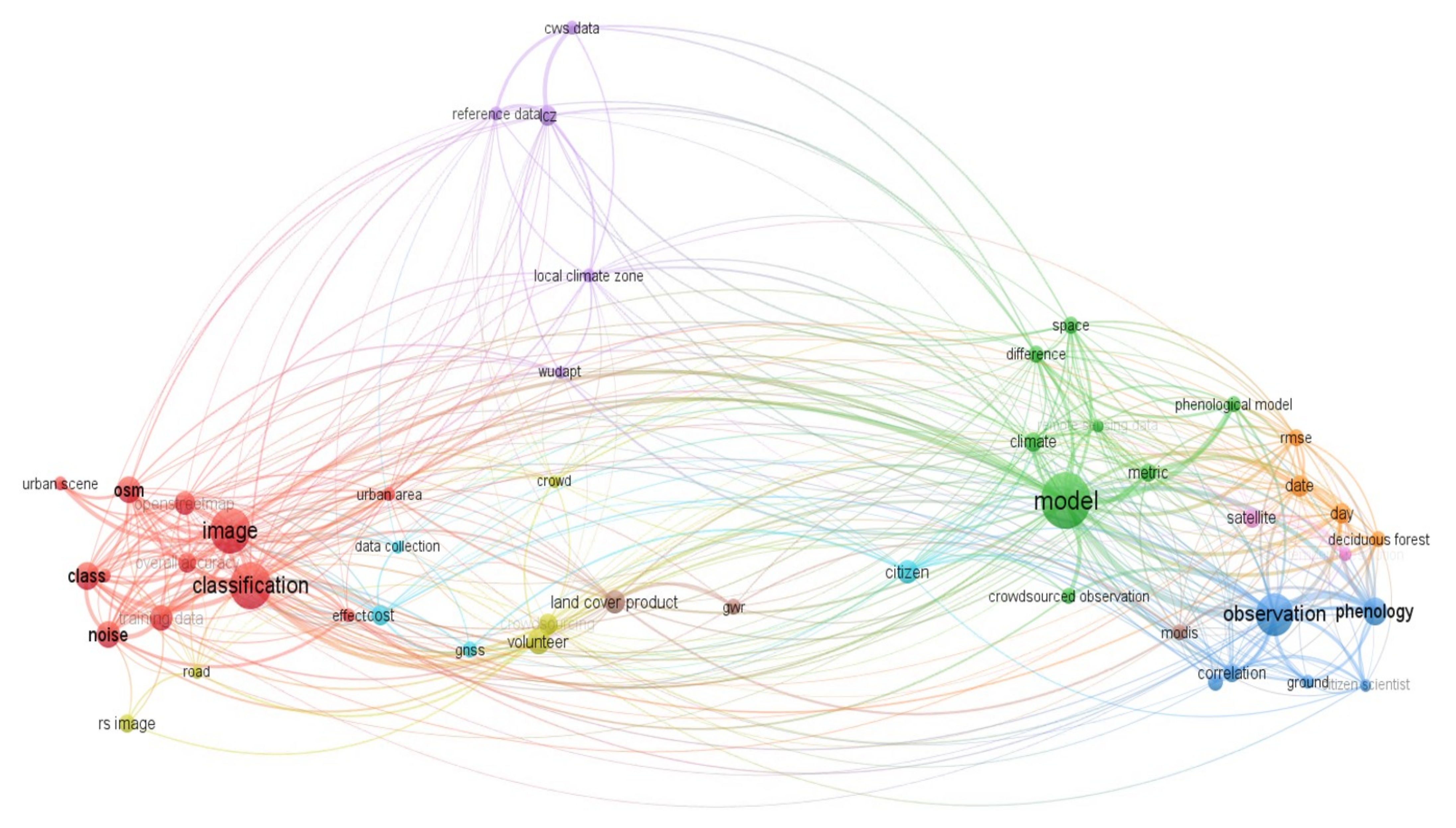
3.3.2. Applications Assimilating EO and CS Data
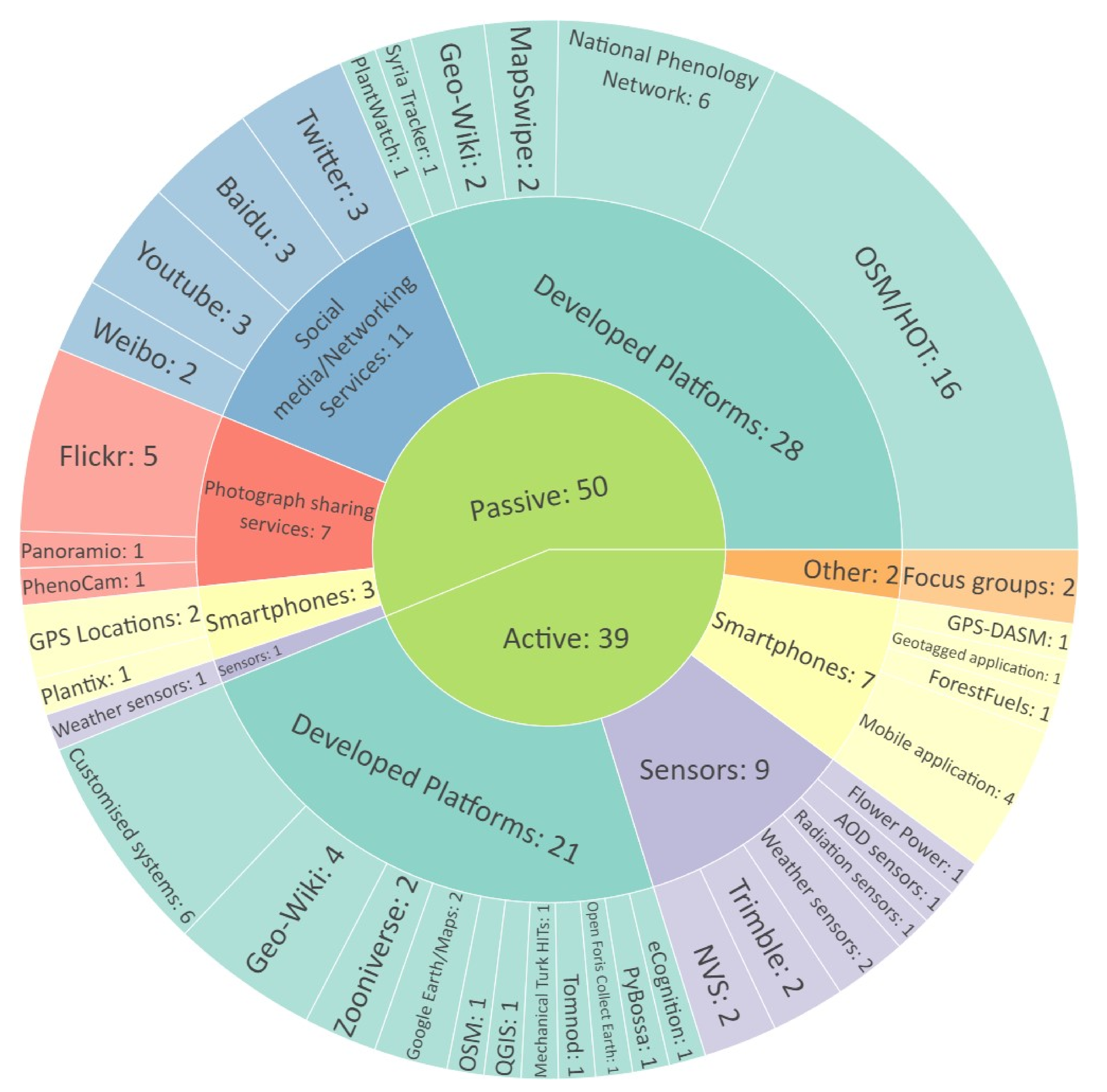
3.4. Exploitation of EO Data and Crowdsource Data Gathering Tools
- i
- Social media/networking services (SM): Including commercial platforms, developed for sharing social information content (text, sound, image, and video).
- ii
- Photograph sharing services (PH): Web services, sharing geotagged photos.
- iii
- Sensors (S): Low-cost sensors, such as magnetometers, accelerometers, etc.
- iv
- Smartphones (SP): Mobile crowd-sensing (MCS) [15] devices including their functionalities of GPS, or geotagged photos, etc.
- v
- Developed Platforms (DP): Open access crowdsourcing platforms, such as Geo-Wiki, Tomnod [57], Humanitarian Open Street Map, and customised solutions.
- vi
- Other: Referring to studies with an absence of technological equipment. An example of this case is presented in Mialhe et al. [21], where transparent plastic films were used to define the land use categories.
3.5. CS Data Uncertainties and Methods for Data Curation
3.5.1. Data Fusion Models and Evaluation Approaches
3.5.2. From Data to Information, towards Decision Making
3.6. Bias Control
4. Results
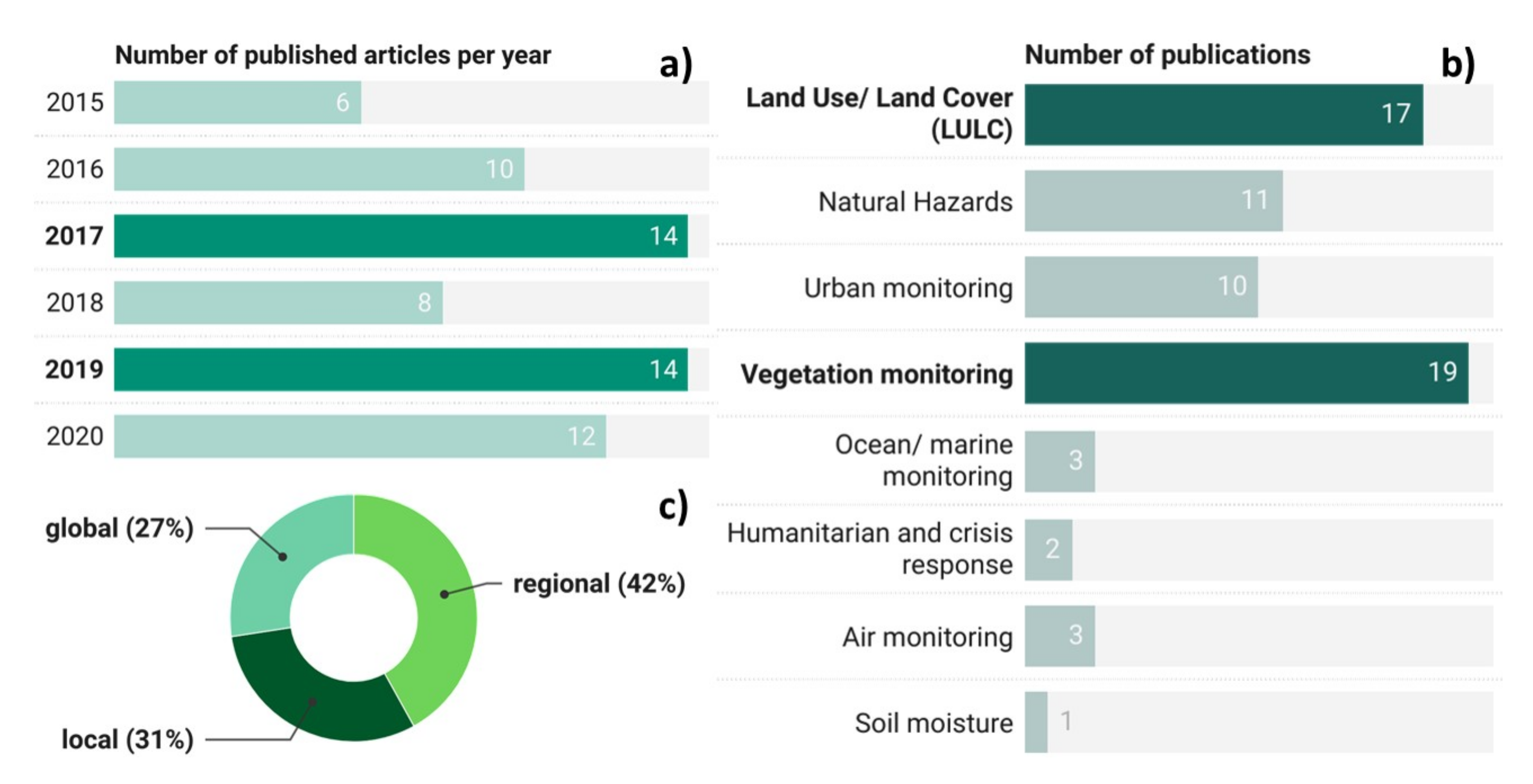
4.1. General Overview of Process and Findings
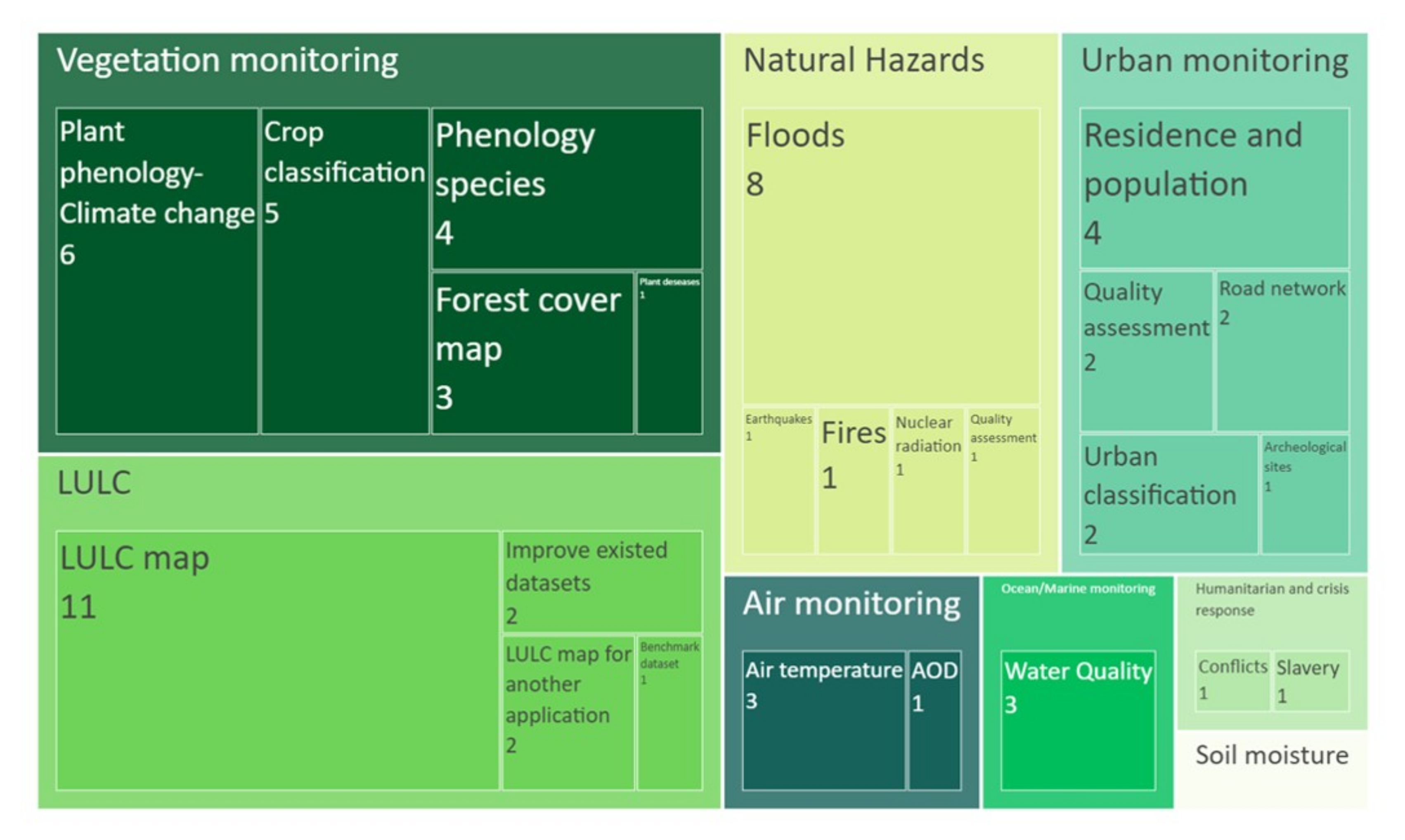
4.2. Applications Assimilating EO and CS Data
4.2.1. Vegetation Monitoring Applications
4.2.2. Land Use/Land Cover Applications
4.2.3. Natural Hazards Applications
4.2.4. Urban Monitoring Applications
4.2.5. Air Monitoring Applications
4.2.6. Ocean/Marine Monitoring Applications
4.2.7. Humanitarian and Crisis Response Applications
4.2.8. Soil Moisture Applications
4.3. Exploitation of EO Data and Crowdsource Data Gathering Tools
4.3.1. Environmental/Climatic EO Variables
4.3.2. Non-Environmental EO Variables
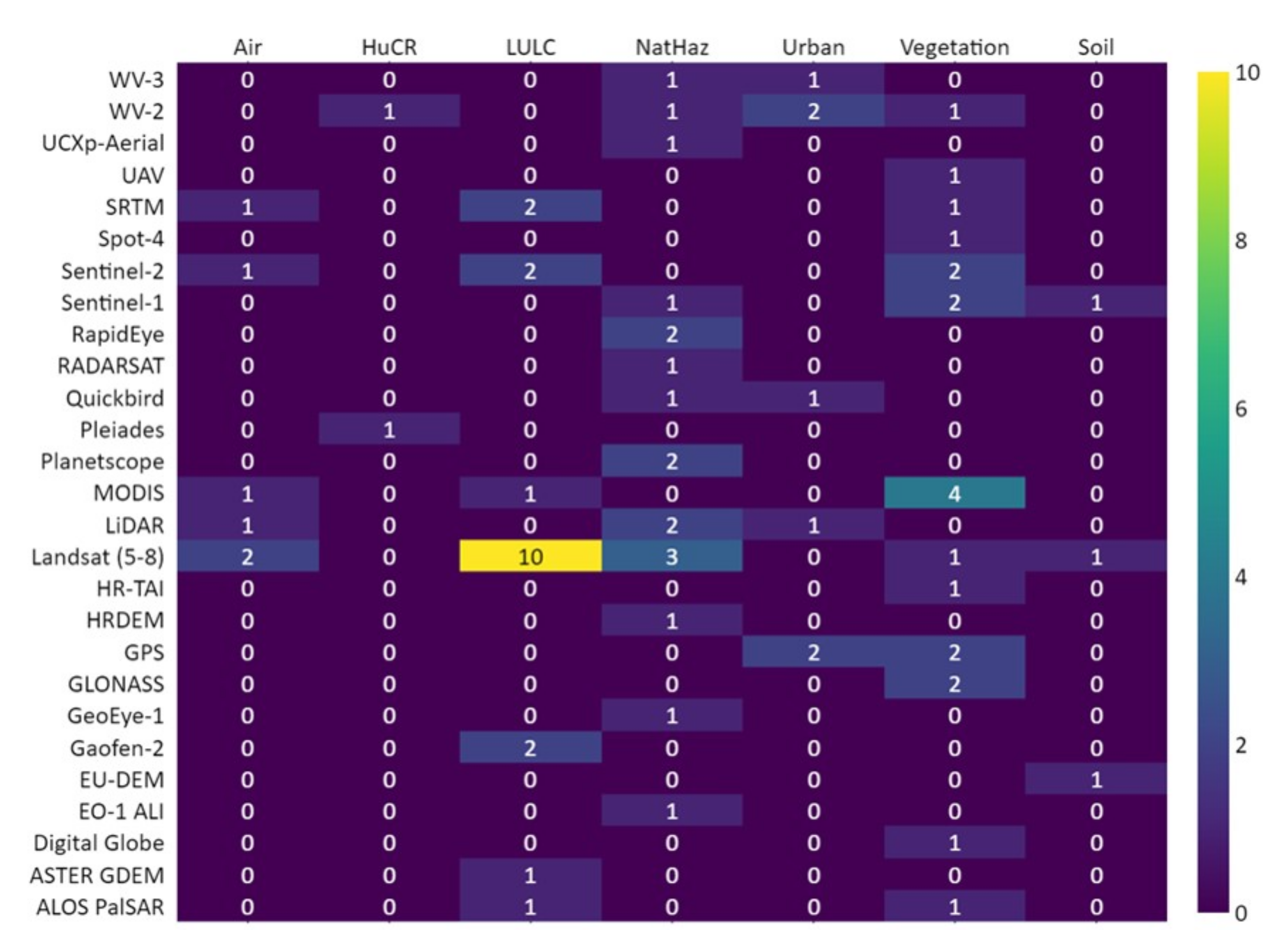
4.3.3. Satellite Data and Sensors Utilised in Data Fusion Applications
4.3.4. Web Services and Benchmark Datasets Assisting with the Data Fusion Models’ Data Needs
4.3.5. CS Platforms for EO Applications
4.3.6. Passive Crowdsourcing Tools
4.3.7. Active Participatory Sensing Tools
4.4. CS Data Uncertainties and Methods Dealing with Data Curation
4.4.1. Ex-Ante Perspectives Related to Citizens’ Engagement and Incentives
4.4.2. Ex-Post Methods Ascertain VGI Data Accuracy
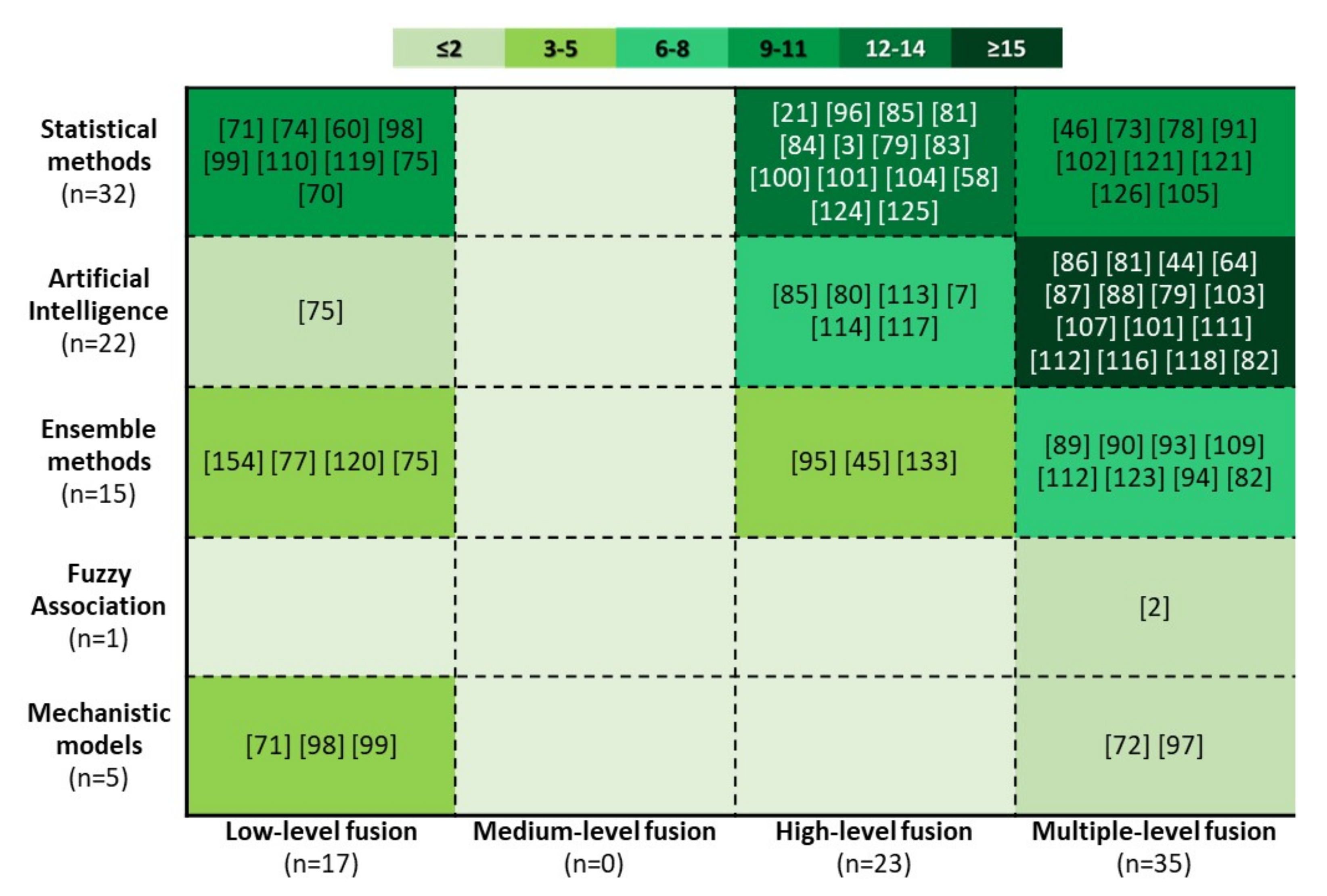
4.5. Data Fusion Models and Evaluation Approaches
4.5.1. Low-Level Data Fusion Based on Supervised Learning
4.5.2. High-Level Data Fusion Based on Supervised Learning
4.5.3. Multiple-Level Data Fusion Based on Supervised Learning
5. Discussion
5.1. General Characteristics of This Scoping Review
5.2. Datasets’ Uncertainties and Future Trends
5.2.1. Discovering the Advances of Using EO-Satellite Data in Uncommon Applications
5.2.2. Addressing the Data Scarcity
5.2.3. Data Fusion Leveraging on EO and CS Data
5.2.4. Crowdsourcing Data Curation Challenges and Future Trends
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| AFOLU | Agriculture, Forestry And Other Land Use |
| AI | Artificial Intelligence |
| AL | Active Learning |
| AlexNet | Convolutional Neural Network (CNN) Architecture, designed By Alex Krizhevsky |
| ALI | Advanced Land Imager |
| ALS | Airborne Laser Scanning |
| AOD | Aerosol Optical Depth |
| AOT | Aerosol Optical Thickness |
| API | Application Programming Interface |
| APS | Active Participatory Sensing |
| AR | Augmented Reality |
| AR6 | 6th Assessment Report |
| ARC | American Red Cross |
| ARD | Analysis-Ready Data |
| AWS | Amazon Web Service |
| BDF | Bayesian Data Fusion |
| BME | Bayesian Maximum Entropy |
| BSI | Bare Soil Index |
| BuEI | Built-Up Index |
| C/N | Carrier-To-Noise Ratio |
| CART | Classification And Regression Trees |
| CC | Climate Change |
| CCA | Canonical Correlation Analysis |
| CCF | Canonical Correlation Forests |
| CCI-LC | Climate Change Initiative Land Cover |
| CDOM | Coloured Dissolved Organic Matter |
| CEOS | Committee On Earth Observation Satellites |
| CGD | Crowdsourced Geographic Data |
| CGI | Crowdsourced Geographic Information |
| chl-a | Chlorophyll-A |
| CHM | Canopy Height Model |
| CIL | Citizen Involved Level |
| CNN | Convolutional Neural Network |
| CO | Citizen’s Observatory |
| CS | Citizen Science |
| CT | Classification Task |
| CTI | Compound Topographic Index |
| DA | Data Assimilation |
| DB | Database |
| DBSCAN | Density-Based Spatial Clustering Of Applications With Noise |
| DCT | Digitisation-Conflation Tasks |
| DEM | Digital Elevation Model |
| DF | Data Fusion |
| DMS-OLS | Defense Meteorological Satellite Program’s Operational Linescan System |
| DP | Developed Platforms |
| DSM | Digital Surface Model |
| DTM | Digital Terrain Model |
| EO | Earth Observation |
| EO4SD | Earth Observation For Sustainable Development |
| EOS | End Of Season |
| EVI | Enhanced Vegetation Index |
| EXIF | Exchangeable Image File |
| FAO | Food And Agriculture Organization |
| FCM | Fuzzy C-Means |
| FCN | Fully Connected Neural Network |
| FETA | Fast And Effective Aggregator |
| FN | False Negative |
| FP | False Positive |
| FUI | Forel-Ule Colour Index |
| FWW | Freshwater Watch |
| GAN | Generative Adversarial Networks |
| GBM | Gradient Boosting Machines |
| GCC | Green Chromatic Coordinate |
| GCOS | Global Climate Observing System |
| GEE | Google Earth Engine |
| GEO | Group On Earth Observations |
| GEOBIA | Geographic Object-Based Image Analysis |
| GF-2 | Gaofen-2 |
| GHG | Greenhouse Gas |
| GLC2000 | Global Land Cover Project |
| GLCM | Grey-Level Co-Occurrence Matrix |
| glm | Generalized Linear Models |
| GNSS | Global Navigation Positioning Systems |
| GPS | Global Positioning Systems |
| GSV | Growing Stock Volume |
| GUF | Global Urban Footprint |
| GUI | Graphical User Interface |
| GWR | Geographic-Weighted Regression |
| HF | High Data Fusion Level |
| HIT | Human Intelligence Tasks |
| HOT | OSM Team For Humanitarian Mapping Activities |
| HRSL | High-Resolution Settlement Layer |
| HV | Horizontal—Vertical Polarisation |
| IBI | Index-Based Built-Up Index |
| IIASA | International Institute For Applied Systems Analysis |
| Inc/Exc | Inclusion/Exclusion |
| InSAR | Interferometric Synthetic Aperture Radar |
| IPCC | Intergovernmental Panel on Climate Change |
| ISODATA | Iterative Self-Organizing Data Analysis Techniques |
| ISPRS | International Society for Photogrammetry And Remote Sensing |
| KDF | Kernel Density Function |
| KF | Kalman Filter |
| KIB | Kernel Interpolation with Barriers |
| kNN | K-Nearest Neighbour |
| LC | Land Cover |
| LCZ | Local Climate Zones |
| LDA | Latent Dirichlet Allocation |
| LeNet | Convolutional Neural Network (CNN) Structure Proposed By Yann Lecun |
| LF | Low Data Fusion Level |
| LST | Land Surface Temperature |
| MAD | Median Absolute Deviation |
| MAE | Mean Absolute Error |
| MaxEnt | Maximum Entropy |
| MCC | Matthews Correlation Coefficient |
| MCS | Mobile Crowd-Sensing |
| MDA | Mean Decrease in Accuracy |
| MF | Medium Data Fusion Level |
| ML | Machine Learning |
| MMS | Min–Max Scaler |
| MMU | Minimum Mapping Unit |
| MNDWI | Modified Normalised Difference Water Index |
| MNF | Minimum Noise Fraction |
| MODIS | Moderate Resolution Imaging Spectrometer |
| MRF | Markov Random Field |
| MTurk | Amazon Mechanical Turk |
| MUF | Multiple Data Fusion Level |
| NB | Naïve Bayes |
| NBAR | Nadir Bidirectional Reflectance Distribution Function-Adjusted Reflectance |
| NDBI | Normalised Difference Build-Up Index |
| NDVI | Normalised Difference Vegetation Index |
| NDWI | Normalised Difference Water Index |
| NIR | Near Infrared |
| NLP | Natural Language Processing |
| NN | Neural Networks |
| NPN | National Phenology Network |
| OBC | Object-Based Classification |
| OBIA | Object-Based Image Analysis |
| ODbL | Open Database |
| OGC | Open Geospatial Consortium |
| OLS | Ordinary Least Squares |
| OneR | One Attribute Rule |
| OOB | Out-Of-Bag |
| OSM | Openstreetmap |
| OsmAnd | Openstreetmap and the Offline Mobile Maps and Navigation |
| OSSE | Observing System Simulation Experiment |
| PART | Projective Adaptive Resonance Theory |
| PCA | Principal Component Analysis |
| PCS | Passive Crowdsourcing |
| PEAT | Progressive Environmental and Agricultural Technologies |
| PH | Photograph Sharing Services |
| Particulate Matter with Diameters of 10m | |
| Particulate Matter with Diameters of 2.5m | |
| PRISM | Parameter-Elevation Regressions on Independent Slopes Model |
| PTT | Photothermal Time |
| PWSN | Personal Weather Station Network |
| QGIS | Quantum GIS |
| RBF | Radial Basis Function |
| R-CNN | Regions with CNN Features or Region-Based CNN |
| ReLU | Rectified Linear Unit |
| ResNet | Residual Neural Network |
| RF | Random Forest |
| RGB | Red-Green-Blue |
| RIPPER | Repeated Incremental Pruning to Produce Error Reduction |
| RMSE | Root Mean Square Error |
| RoF | Rotation Forest |
| RS | Remote Sensing |
| S1 | Sentinel-1 |
| S2 | Sentinel-2 |
| SA | Simulated Annealing |
| SAR | Synthetic Aperture Radar |
| SD | Secure Digital |
| SDD | Single Shot Detection |
| SFDRR | Sendai Framework for Disaster Risk Reduction |
| SHB | Secondary Human Behaviour |
| SI-xLM | Extended Spring Indices |
| SM | Social Media-Networking Services |
| SMOTE | Synthetic Minority Oversampling Technique |
| SoEI | Soil Index |
| SOS | Start Of Season |
| SP | Smartphones |
| SPM | Suspended Particulate Material |
| SPoC | Sum-Pooled Convolutional |
| SPP | Spring Plant Phenology |
| SSD | Single-Shot-Detection |
| SSL | Signal Strength Loss |
| SSLR | Scoping Systematic Literature Review |
| StoA | State-of-the-Art |
| SVF | Sky View Factor |
| SVM | Support Vector Machine |
| TAI | True-Colour Aerial Imagery |
| TFL | Tobler’s First Law Of Geography |
| TL | Transfer Learning |
| TM | Template-Matching |
| TN | True Negative |
| TNR | Specificity |
| TP | True Positive |
| TPR | Sensitivity |
| TT | Thermal Time |
| TWI | Topographic Wetness Index |
| UAV | Unmanned Aerial Vehicle |
| UHI | Urban Heat Island |
| UN-SDG | United Nation-Sustainable Development Goals |
| USFS | United States Forest Service |
| VGG | Visual Geometry Group |
| VGI | Volunteer Geographic Information |
| VHR | Very High Resolution |
| VOC | Visual Object Classes |
| VR | Virtual Reality |
| WHO | World Health Organisation |
| WMS | Web Map Service |
| WNS | Wireless Network Stations |
| WoE | Weights-of-Evidence |
| WRF | Weather Research Forecasting Model |
| WSI | WeSenseIt |
| WUDAPT | World Urban Database and Access Portal Tools |
| WUI | Wildland-Urban Interface |
| YOLO | You-Only-Look-Once |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | EO Data | Source of CS | DF Level | Method | Validation | Evaluation Metric and Score |
|---|---|---|---|---|---|---|
| [79] | Aerial | DP/My Back Yard tool | HF | GeoBIA/S | A manually digitised reference layer and a stratified separation of the dataset was used | Overall Accuracy using Multinomial Law equation (73.5% classification result, and 76.63% CS valid decision) |
| [154] | Satellite/GNSS | Sensors/GPS receivers | LF | RF Regression/ES | Out-of-Bag error estimation leveraging on reference data of forest attributes | RMSEs: mean tree height = 14.77–20.98% Mean DBH = 15.76–22.49%; plot-based basal areas = 15.76% and 33.95%, stem volume and AGB = 27.76–40.55% and 26.21–37.92%; R = 0.7 and 0.8 |
| [77] | Satellite/GNSS | Sensors/GPS receivers | LF | RF Regression/ES | Out-of-Bag error estimation comprising of reference data with forest attributes | The combination of the GLONASS and GPS GNSS signals slightly better results than the single GPS values. |
| [60] | Satellite/MSI | DP/NPN | LF | Linear change point estimation/S | Ground-based phenological dates | RMSE, bias, MAE and Pearson’s R evaluation metrics were used, revealing a weak significance when the CS data were used (Best result: r = 0.24, MAE = 23.0, bias = −14.8, and RMSE = 28.0) |
| [73] | Satellite/MSI | DP/PlantWatch | MUF | L-Regression/S | Stratification based on the GLC2000 land cover map | Green-up date RMSE unsystematic (RMSEu) and systematic (RMSEs) were 13.6 to 15.6 days, R and p < 0.0001 |
| [85] | Satellite/LULC | DP/Geo-Wiki | HF | k-NN, Naïve Bayes, logistic regression, GWR, CART/AI + S | 10-fold cross validation | Binary classification: Apparent error rate (GWR: AER = 0.15), Sensitivity (CART: Sen = 0.844), Specificity (GWR: Spe = 0.925), pairwise McNemar’s statistically significance test (GWR: p = 0.001); % Forest cover: GWR: AER = 0.099, CART: Sen = 0.844, GWR: Spe = 0.927, GWR: p = 0.001 |
| [84] | Satellite/LULC | DP/Geo-Wiki | HF | GWR/S | Equal-area stratified random sampling | LULC OA forest recognition (89 %), specificity = 0.93, Sensitivity = 96%; Estimation of % forest cover = 0.81, RMSE = 19 |
| [83] | Satellite/LULC | DP/Geo-Wiki | HF | GWR/S | Validated with a random distribution of reference data | Apparent error % Hybrid predicted dataset = 4 (Best score for Russia), and 5 for the Sakha Republic |
| [71] | Hybrid/in situ and DEM | DP/NPN | LF | Sprint Plant Phenolog/M | Resubstitution error rate between the observed and the estimated days | RMSE and MAE of the Day of the Year (DOY) resulted in 11.48 and 6.61, respectively (Best model) |
| [3] | Satellite/LULC | DP/53,000 CS data samples were gathered on the Geo-wiki platform | HF | Convergence of evidence approach (IDW interpolation)/S | (1) Stratified dataset from 2 CS campaigns. Finalised with experts’ evaluation. (2) 1033 pixels with high disagreement randomly classified by 2 experts. | (1) Stratified dataset from 2 CS campaigns. Finalised with experts’ evaluation. (2) 1033 pixels with high disagreement randomly classified by 2 experts. |
| [78] | Hybrid/Rainfall Satellite/MSI | DP/CS campaign archived in NPN | MUF | L-Regression Spearman’s correlation, Binary-thresholding classification/S | (1) Reference data collected on the field, (2) CLaRe metrics | (1) > 0.5 between field observations and independent variables; (2) T-tests between CLaRe, native and invasive Buffelgrass depicted significant differences. (3) OA Buffelgrass classification was equal to 66–77%, with trade-offs in UA, PA accuracies |
| [46] | Satellite/MSI | Other/CS campaign | MUF | Template match binary thresholding/S | Validated with reference training samples applying hold-out dividing the dataset in train-testing | Completeness (C = 69.2 to 96.7), Thematic accuracy metrics: positive predictive value (PPV = 0.926 to 1.000), false positive (FDR = 0.037 to 0.550), false negative rate (FNR = 0.033 to 0.308), F1 = 0.545 to 0.964, Positional accuracy metrics: Diameter error for a correctly identified ITC (ed) RMSE for tree crown diameter measurement for crowdsourced observation (RMSEcd = 0.67 to 0.93) and tree crown centroid position measurement (RMSEcc = 0.28 to 1.01) |
| [86] | Aerial/MSI | DP/Amazon’s Mechanical Turk | MUF | ResNet34 CNN model/AI | Hold-out dataset separation in train, validation and test based on [193] method | OA = 0.9741, precision = 0.9351, recall = 0.9694, F1 = 0.9520 |
| [72] | Hybrid/MSI and rainfall (gridded and in situ) | DPtextbackslash NPN and PH/PhenoCam | MUF | 13 SPPs + Monte Carlo optimisation/M | in situ phenological data | Best optimised parameters were determined with 95% confidence intervals for each parameter, using the chi-squared test. AICc was used to select the best model for all the species. R = 0.7–0.8, RMSE = 5–15, and Bias = ±10 days |
| [81] | Satellite/SAR, MSI, DEM | Other/2 week CS campaign | MUF | CART/AI | Reference data set of 7500 sample points was generated and stratified based on the first stage land cover classes | Forest plantation area was estimated with high overall accuracy (85%) |
| [74] | Satellite/MSI | DP/NPN | LF | Type 2 Regression/S | - | Non-significant results, = 0.014; p = 0.052; Rule #1 = 0.19; p < 0.001 & Rule #2 = 0.29; p < 0.001. Median MODIS values improved = 0.67; p < 0.001. Lilac revealed the greatest results = 0.32–0.73; p < 0.001. = 0.23 to 0.89 across species. |
| [80] | Satellite/LC product | DP/Geo-Wiki | HF | Bayesian data fusion (BDF)/AI | Stratification keeping only those where CS data were at hand (i.e., 500) | BDF has proven a suitable method as the log-likelihood ratio () and the chi-squared () were 0.2511 and 5.991, corresponding to a p-value = 0.8820. The OA of the cropland = 98.00%. |
| [75] | Satellite/MSI | DP/NPN | LF | 6 S models 1, NN AI and RF regression ES | 10-fold cross validation with the analogy of 80/20 | RF outperformed with r = 0.69, WIA = 0.79, MAE = 12.46 days and RMSE = 17.26 days (for deciduous forest) |
| [82] | Satellite/MSI and SAR | SP/Plantix | MUF | 1D and 3D CNN/AI and RF harmonic coefficients/ES | Feature Importance via Permutation; using also governance district statistics | (A) 3-crop type classes: Accuracy: 74.2 ± 1.4%, Precision = 75.9 ± 1.7%, Recall = 74.2 ± 1.4%, F1 = 73.7 ± 1.4%; (B) crop-type map accuracy = 72% |
| Reference | EO Data | Source of CS | DF Level | Method | Validation | Evaluation Metric and Score |
|---|---|---|---|---|---|---|
| [90] | Satellite/MSI | DP/OSM | MUF | CART, RF/AI + ES | Stratified random validation using ground truth (1), Landsat-based LC maps (2) | OA and kappa coefficient of urban land can reach 88.80% and kappa-coefficient 0.74 (1), and 97.08% and 0.92 (2) |
| [44] | Satellite/MSI | MUF | SVM RBF/AI | 5-fold CV, using a manually digitized LC | OA = 93.4 and kappa coefficient = 0.913 | |
| [95] | Satellite/LC | DP/OSM | HF | Probabilistic Cluster Graphs/ES | Resubstitution using the ATKIS national Digital Landscape Model (1:250,000) | Scenario 4 with the general class-weighting factor predicted with OA = 78% and kappa: 0.67. Class-wise balanced accuracy produced more accurate results |
| [96] | Satellite/LC | DP/Geo-Wiki | HF | Logistic-GWR/S | Stratification scheme based on Zhao et al. [194] using an independent validation dataset, and 2 Geo-Wiki campaigns | Generated two-hybrid maps with the first to perform better (OA: 87.9 %). The tree-cover land class presented the best results among all classes, in both maps, PA_1: 0.95, UA_1: 0.94 and PA_2: 0.97, UA_2: 0.93 |
| [91] | Satellite/SAR and MSI | DP/OSM | MUF | ISODATA and Estimation fractional cover of LC/S | Stratification random sampling approach (50 validation points per LCC class) | The confusion matrix of the LCC classification map shows an OA = 90.2%. “Tree cover” and “cropland/grassland” reveal the greatest confusion in change classes. |
| [88] | Satellite/MSI | PH/Flickr | MUF | Naïve Bayes CS LULC, Maximum likelihood/AI | Stratified the train/testing dataset having an analogy of 70/30 | LULC (Landsat-5 TM + CS LULC map), with OA and kappa equal to 70% and 0.625, respectively. The accuracy level was mostly driven by urban areas. |
| [45] | Satellite/MSI | DP/OSM | HF | NB, DT-C.45/AI, RF/ES | (a) Random Subsampling-Hold out: 50/50 (b) SMOTE stratification method | DT C.45 gave the lowest OA values. In the LULC system, NB achieved OA = 72.0%, followed by RF in the 5 and 4-classes LULC system (OA = 81.0% and OA = 84.0%) |
| [92] | Satellite/MSI | SM/SINA WEIBO and Baidu DP/OSM | HL | Binary Thresholding, Similarity Index/S | Random Subsampling-Hold out, based on 289 visual inspected testing parcels | LU Level I classes: OA = 81.04% and kappa-coefficient = 0.78; LU Level II classes: OA = 69.89% and kappa-coefficient = 0.68% |
| [21] | Satellite/MSI | Other/Focus groups | HF | Statistical analysis/S | Resubstitution method using reference data | Confusion matrices were computed in the sense of measuring the deviation in LU-class coverage |
| [89] | Satellite/MSI | DP/OSM | MUF | RF (RoFs and DT), XG- Boost, and CNN/ES | 15 randomly defined training datasets (10 uniformly divided, 5 last extracting 500 samples for all the classes | LCZ OA = 74.94%, kappa = 0.71 (the greater score using RF method, and experts handcrafted features). The classification accuracy increased with the imbalanced dataset |
| [93] | Hybrid/MSI and DEM | DP/OSM | HF | RF Classifier/ES | Random Subsampling-Hold out randomly selecting validation points, splitted in training and testing dataset | Out-of-bag error = 4.8% and OA = 95.2%, with 95.1% of the forested areas to be correctly classified. Low user’s accuracy of 57.4% was revealed on commercial lands |
| [136] | Satellite/MSI | DP/Google Earth | MUF | RF Classifier/ES | Reference dataset by LCZ expert | OA = 0 to 0.75 (produced by several iterations) |
| [64] | Satellite/MSI | DP/OSM SM/FB and Twitter | MUF | SVM and DCNN/AI | Transfer performance learning with UC-Merced dataset and 10-fold Cross-Validation | OA is based on the mean and standard deviation of all the results. OA_train = >90% and OA_test = 86.32% and 74.13% |
| [87] | Satellite/MSI | DP/Crowd4RS | MUF | Ac-L-PBAL and SVM RBF, RF, k-NN/AI | 260 labelled samples were provided by RS experts | Three-cross-validation technique of the 3 algorithms. OA = 60.18%, 59.23% and 55% |
| [2] | Satellite/MSI | DP/OSM | HF | Fuzzy logic/FS | Stratified random sampling of 200 points per class | 5 tests were evaluated with the final one to reveal OA = 70%. Population true proportions (pi) [195], UA and PA per class also calculated. |
| [94] | Satellite/MSI | DP/OSM | MUF | RF Classifier/ES | Stratified random sampling | OA = 78% (study area A) and OA = 69% (study area B) |
| Reference | EO Data | Source of CS | DF Level | Method | Validation | Evaluation Metric and Score |
|---|---|---|---|---|---|---|
| [101] | Hybrid/Satellite and in situ | DP/VGI mappers using Google Earth | HF | Multivariate Logistic regression/S | Resubstitution DFO map | Log-Likelihood, chi-squared, and p-value tests, revealed −15,952 465.94, and 16 for the outside of the city model, and −7534, 273.41 and for the inside. |
| [110] | Aerial | Sensors | LF | Univariate L-Regression/S | Resubstitution between CS and DOE | = 0.87 |
| [109] | Aerial | DP/QGIS, Web-based eCognition | MUF | RF Classifier/ES | Hold out human-labelled training data | Estimation of feature importance of the model. Pixel-based classification seemed more noise resistant with the AUC to drop 2.02, 7.3, and 0.85% for NAR, label noise and random noise when 40% of the damage is contaminated. |
| [104] | Satellite/DEM | SM/Twitter | HF | Getis–Ord Gi*-statistic/S | Using an elevation threshold | Evaluation of statistical significance based on z-score values ± 1.64 |
| [100] | Hybrid/in situ, DEM | SM/Baidu | HF | Multivariate logistic regression/S | Resubstitution with Wuhan water authority flood risk maps | Backward stepwise significance method (Wald chi-square test = 0.001), AUC = 0.954, asymptotic significance = 0.000 |
| [98] | Satellite/DTM, LiDAR | SM/YouTube and Twitter | LF | EnKF/S | Resubstitution using the observed water depth values | Nash–Sutcliffe efficiency (NSE) > 0.90 and R > 0.97 (Best results) |
| [102] | Satellite/MSI, DEM | PH/Flickr | MUF | WoE/S | Random Subsampling-Hold out with 120 points | ROC for Flickr images was 0.6 (train) and 0.55 (test). EO was 0.88 and 0.90, and AUROC posterior = 0.95 and 0.93. Pair-wise conditional independence ratio = 6.38 |
| [103] | Satellite/MSI | DP/JORD app, SM/Twitter, YouTube, PH/Flickr, Google | MUF | V-GAN/AI | Two-fold cross-validation strategy | Matthews correlation coefficient for the binary classification = 0.805. OA = 0.913, precision = 0.883, recall = 0.862, specificity = 0.943, and F1 = 0.870 |
| [99] | in situ | Sensor, Smartphone | LF | Kalman Filter/S | Resubstitution error rate between the reference and simulated values | 4 experiments were evaluated using NSE and Bias’s indexes. However, no general conclusions can be derived. |
| [107] | Satellite/MSI, DEM | Smartphone | MUF | Mahalanobis K-NN/AI | LOOCV leveraging on the reference dataset | Canonical correlation (F = 2.77 and p < 0.001)), Wilk’s lambda = 0.007. RMSD investigated professional (P), non-professional (NP), raw data (R) and corrected by experts (C) 2 |
| [105] | Hybrid/Satellite and in situ | Smartphone | MUF | Flood-fill simulation/S | in situ reference measurements and experts’ quality control | Kappa-coefficient = 0 to 0.746 |
| Reference | EO Data | Source of CS | DF Level | Method | Validation | Evaluation Metric and Score |
|---|---|---|---|---|---|---|
| [57] | Satellite/MSI | DP/OSM | HF | Logistic regression/S | Validation by experts | OA = 89%, Sensitivity = 73%, Precision = 89%, F1-score = 0.80, and 25% volunteers contribute 80% of the classification result |
| [115] | Satellite/MSI | DP/OSM | MUF | FCN (VGG-16)/AI | Hold-out equally divided the dataset into train-test-validation | The best model “ISRPS Gold standard data” with average F1 = 0.874, Precision = 0.910, Recall = 0.841 and F1 = 0.913, 0.764, 0.923 for the building, road, and background classes. |
| [116] | Hybrid/GNSS, DEM, LC, Aerial | Smartphone | LF | RIPPER, PART, M5Rule, OneR/AI | 10-fold Cross-Validation (CV) and Visual inspection | Evaluation of CS traces using Shapiro-Wilk, skewness and kurtosis tests. RIPPER’s best results: Precision = 0.79, recall = 0.79, F1 = 0.79 |
| [113] | Satellite/MSI | DP/OSM, MapSwipe, OsmAnd | HL | LeNet, AlexNet, VggNet/AI | Random Subsampling Hold-out with MapSwipe and OsmAnd as ground-truth | Precision, Recall, F1, and AUC of combined CS data were higher with an average of 9.0%, 4.0%, and 5.7% |
| [114] | Satellite/MSI | DP/OSM; SM/Baidu | MUF | FCNN, LSTM, RNN (1)/AI; SVM, LDA (2)/AI | Random Subsampling Hold-out (4:1 train/test) | OA was increased from 74.13% to 91.44%. Building and road categories were increased by around 1% (1); OA_SVM = 72.5%, LDA = 81.6%, PM = 93.1% (2) |
| [117] | Satellite/MSI | Smartphone/GNSS | HF | U-Net, LinkNet, D-LinkNet/AI | Fusion RS with the outputs of road centerline extraction | Completeness (COM), Correctness (COR) and Quality (Q) equal to 0.761, 0.840, 0.672 |
| [118] | Satellite/LiDAR | Other/Focus Groups and DP/Zooniverse | MUF | Faster R-CNN/AI | Model division in Train, Test, Validation | Recall, Precision, F1, MaF1 evaluation metrics presented in [196] |
| [111] | Satellite/MSI | DP/Tomnod | MUF | kd-tree-based hierarchical classification/AI | Stratification based on population density classes, and reference data, created by citizens’ visual inspection | Logistic and beta regressions were applied for the precision (0.70 ± 0.11) and recall (0.84 ± 0.12) metrics, evaluating the village boundaries of (1) the examined areas, and (2) six cities of the globe. Evaluation of the Population density by the normalised correlation (NC), and the normalised absolute difference (ND). |
| [7] | Satellite/MSI | DP/OSM, MapSwipe | HF | DeepVGI model (Single Shot Detection (SSD) CNN)/AI | Hold out dataset division in train and test. Maximum training epochs was set to 60,000 | Specificity, Sensitivity, OA (ACC), Matthew’s correlation coefficient (MCC) metrics. DeepVGI model revealed similar results to MapSwipe, i.e., OA = 91–96%, MCC = 74–84%, specificity = 95–97%, and sensitivity = 81–89% |
| [112] | Hybrid/MSI and LULC | DP/OSM | MUF | Bagging CNN, V3, VGG16/ES(1); SL models 3/AI(2) | Hold-out (85//15 train/test) using a reference dataset. | Ensemble model revealed the best results in both Nigeria and Guatemala, OA_N = 94.4%, OA_G = 96.4%, and F1_N = 92.2%, F1_G = 96.3%. Transfer Learning models performed with OA_N = 93% and OA_G = 95%, Human benchmark (OA_N = 94.5%, OA_G = 96.4%). AdaBoost and logistic regression performed better. |
| Reference | EO Data | Source of CS | DF Level | Method | Validation | Evaluation Metric and Score |
|---|---|---|---|---|---|---|
| [121] | Hybrid/DEM, LULC and in situ | Sensors | MUF | Non-parametric significant tests LCZ/S | Reference weather stations | 1-way ANOVA (Kruskal-Wallis test), pairwise 2-sided Wilcoxon-Mann-Whitney and Holm-Bonferroni. Difference CS = 1.0 K and Reference = 1.8 K; Difference between the 2 datasets 0.2–2.9 K |
| [119] | Hybrid/in situ and Satellite | Sensors | LF | L-Regression/S | in situ US EPA Air Quality concentrations, and Aeronet AOD | |
| [120] | Satellite/MSI + LiDAR | Sensors | LF | RF Regression; ANOVA test for the explanatory variables/ES | Hold-out (70/30) with bootstrapping repeatedly occurred 25 times | Annual mean, daily maximum and minimum Tair can be mapped with an RMSE = C, ), C () and C (); Transferability revealed an RMSE = C difference. |
| [97] | Hybrid/LULC and in situ | S/Personal Weather Station | MUF | WRF model/M | Compared with measurements from in situ weather stations | RMSE = 0.04 K and Mean Bias = 0.06 K (p = 0.001). Weak positive correlation (r = 0.28) of the elevation with variations in model’s performance |
| Reference | EO Data | Source of CS | DF Level | Method | Validation | Evaluation Metric and Score |
|---|---|---|---|---|---|---|
| [124] | Satellite/MSI | Smartphone | HF | Multi-Linear Regression/S | - | Spearman rank coefficient; , 0.32; mean absolute difference = 21 ± 16%, 22 ± 16%), mean difference = 6 ± 26%, 6 ± 27% |
| [122] | Satellite/MSI | Smartphone | MUF | Backward step Multi-Linear-Regression/S | Field measurements | Spearman rank coefficient; Adjusted , standard error 0.274 with stream distance weighted mixed forest and urban, and riparian percentage |
| [123] | Satellite/MSI, DEM | Sensor | MUF | RF Regression/ES | out-of-bag using 10–fold cross-validation | Turbidity: OA = 65.8%, kappa = 0.32, Error good—bad evaluation 34.6% and 36.0%; Nitrate: 70.3%, 0.26, 58.8%, 14.7%; Phosphate: 71.8%, 0.39, 50.0%, 22.6% |
| Reference | EO Data | Source of CS | DF Level | Method | Validation | Evaluation Metric and Score |
|---|---|---|---|---|---|---|
| [125] | Satellite/MSI | DP/Zooniverse | HF | Averaged density of kilns/S | Random sample selection; Visual inspection by an Independent adjudicator | OA = 99.6%; Error of experts = 0.4%; of CS = 6.1% |
| [126] | Satellite/Nightlights | DP/Syria tracker | MUF | Logistic regression/S | - | Statistical significance of all models is below 5%. Best model result AIC = 127,967 |
| Reference | EO Data | Source of CS | DF Level | Method | Validation | Evaluation Metric and Score |
|---|---|---|---|---|---|---|
| [69] | Satellite/SAR, MSI, DEM | low-cost soil moisture sensorsc S | LF | multiple regression analysis (MLR), regression-kriging and cokriging/S | leave-one-out cross-validation | MLR_ = 0.19 to 0.35 and MLR_RMSE = 5.86 to 4.14; regression kriging RMSE = 1.92–4.39; cokriging RMSE = 4.61–6.16 |
References
- Rogelj, J.; Shindell, D.; Jiang, K.; Fifita, S. Mitigation Pathways Compatible with 1.5 °C in the Context of Sustainable Development; Technical Report; Intergovernmental Panel on Climate Change: Geneva, Switzerland, 2018. [Google Scholar]
- Fonte, C.C.; Lopes, P.; See, L.; Bechtel, B. Using OpenStreetMap (OSM) to enhance the classification of local climate zones in the framework of WUDAPT. Urban Clim. 2019, 28, 100456. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; Mccallum, I.; You, L.; Bun, A.; Moltchanova, E.; Duerauer, M.; Albrecht, F.; Schill, C.; Perger, C.; et al. Mapping global cropland and field size. Glob. Chang. Biol. 2015, 21, 1980–1992. [Google Scholar] [CrossRef]
- Song, Y.; Huang, B.; Cai, J.; Chen, B. Dynamic assessments of population exposure to urban greenspace using multi-source big data. Sci. Total Environ. 2018, 634, 1315–1325. [Google Scholar] [CrossRef] [PubMed]
- Huang, Q.; Cervone, G.; Zhang, G. A cloud-enabled automatic disaster analysis system of multi-sourced data streams: An example synthesizing social media, remote sensing and Wikipedia data. Comput. Environ. Urban Syst. 2017, 66, 23–37. [Google Scholar] [CrossRef]
- Masson, V.; Heldens, W.; Bocher, E.; Bonhomme, M.; Bucher, B.; Burmeister, C.; de Munck, C.; Esch, T.; Hidalgo, J.; Kanani-Sühring, F.; et al. City-descriptive input data for urban climate models: Model requirements, data sources and challenges. Urban Clim. 2020, 31, 100536. [Google Scholar] [CrossRef]
- Herfort, B.; Li, H.; Fendrich, S.; Lautenbach, S.; Zipf, A. Mapping human settlements with higher accuracy and less volunteer efforts by combining crowdsourcing and deep learning. Remote Sens. 2019, 11, 1799. [Google Scholar] [CrossRef]
- Leal Filho, W.; Echevarria Icaza, L.; Neht, A.; Klavins, M.; Morgan, E.A. Coping with the impacts of urban heat islands. A literature based study on understanding urban heat vulnerability and the need for resilience in cities in a global climate change context. J. Clean. Prod. 2018, 171, 1140–1149. [Google Scholar] [CrossRef]
- Donratanapat, N.; Samadi, S.; Vidal, J.M.; Sadeghi Tabas, S. A national scale big data analytics pipeline to assess the potential impacts of flooding on critical infrastructures and communities. Environ. Model. Softw. 2020, 133, 104828. [Google Scholar] [CrossRef]
- Duro, R.; Gasber, T.; Chen, M.M.; Sippl, S.; Auferbauer, D.; Kutschera, P.; Bojor, A.I.; Andriychenko, V.; Chuang, K.Y.S. Satellite imagery and on-site crowdsourcing for improved crisis resilience. In Proceedings of the 2019 15th International Conference on Telecommunications (ConTEL), Graz, Austria, 3–5 July 2019; pp. 1–6. [Google Scholar]
- Foody, G.M.; Ling, F.; Boyd, D.S.; Li, X.; Wardlaw, J. Earth observation and machine learning to meet Sustainable Development Goal 8.7: Mapping sites associated with slavery from space. Remote Sens. 2019, 11, 266. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- See, L.; Fritz, S.; Perger, C.; Schill, C.; McCallum, I.; Schepaschenko, D.; Duerauer, M.; Sturn, T.; Karner, M.; Kraxner, F.; et al. Harnessing the power of volunteers, the internet and Google Earth to collect and validate global spatial information using Geo-Wiki. Technol. Forecast. Soc. Chang. 2015, 98, 324–335. [Google Scholar] [CrossRef]
- Dong, J.; Metternicht, G.; Hostert, P.; Fensholt, R.; Chowdhury, R.R. Remote sensing and geospatial technologies in support of a normative land system science: Status and prospects. Curr. Opin. Environ. Sustain. 2019, 38, 44–52. [Google Scholar] [CrossRef]
- Mazumdar, S.; Wrigley, S.; Ciravegna, F. Citizen science and crowdsourcing for earth observations: An analysis of stakeholder opinions on the present and future. Remote Sens. 2017, 9, 87. [Google Scholar] [CrossRef]
- Sudmanns, M.; Tiede, D.; Lang, S.; Bergstedt, H.; Trost, G.; Augustin, H.; Baraldi, A.; Blaschke, T. Big Earth data: Disruptive changes in Earth observation data management and analysis? Int. J. Digit. Earth 2020, 13, 832–850. [Google Scholar] [CrossRef] [PubMed]
- Hsu, A.; Khoo, W.; Goyal, N.; Wainstein, M. Next-Generation Digital Ecosystem for Climate Data Mining and Knowledge Discovery: A Review of Digital Data Collection Technologies. Front. Big Data 2020, 3, 29. [Google Scholar] [CrossRef] [PubMed]
- Salcedo-Sanz, S.; Ghamisi, P.; Piles, M.; Werner, M.; Cuadra, L.; Moreno-Martínez, A.; Izquierdo-Verdiguier, E.; Mu noz-Marí, J.; Mosavi, A.; Camps-Valls, G. Machine learning information fusion in Earth observation: A comprehensive review of methods, applications and data sources. Inf. Fusion 2020, 63, 256–272. [Google Scholar] [CrossRef]
- Meng, T.; Jing, X.; Yan, Z.; Pedrycz, W. A survey on machine learning for data fusion. Inf. Fusion 2020, 57, 115–129. [Google Scholar] [CrossRef]
- Fritz, S.; Fonte, C.C.; See, L. The role of Citizen Science in Earth Observation. Remote Sens. 2017, 9, 357. [Google Scholar] [CrossRef]
- Mialhe, F.; Gunnell, Y.; Ignacio, J.A.F.; Delbart, N.; Ogania, J.L.; Henry, S. Monitoring land-use change by combining participatory land-use maps with standard remote sensing techniques: Showcase from a remote forest catchment on Mindanao, Philippines. Int. J. Appl. Earth Obs. Geoinfor. 2015, 36, 69–82. [Google Scholar] [CrossRef]
- Goodchild, M. NeoGeography and the nature of geographic expertise. J. Locat. Based Serv. 2009, 3, 82–96. [Google Scholar] [CrossRef]
- Kosmidis, E.; Syropoulou, P.; Tekes, S.; Schneider, P.; Spyromitros-Xioufis, E.; Riga, M.; Charitidis, P.; Moumtzidou, A.; Papadopoulos, S.; Vrochidis, S.; et al. HackAIR: Towards raising awareness about air quality in Europe by developing a collective online platform. ISPRS Int. J. Geo-Inf. 2018, 7, 187. [Google Scholar] [CrossRef]
- Tserstou, A. SCENT: Citizen sourced data in support of environmental monitoring. In Proceedings of the 2017 21st International Conference on Control Systems and Computer Science, Bucharest, Romania, 29–31 May 2017; pp. 612–616. [Google Scholar] [CrossRef]
- Martinelli, M.; Moroni, D. Volunteered geographic information for enhanced marine environment monitoring. Appl. Sci. 2018, 8, 1743. [Google Scholar] [CrossRef]
- Havas, C.; Resch, B.; Francalanci, C.; Pernici, B.; Scalia, G.; Fernandez-Marquez, J.L.; Van Achte, T.; Zeug, G.; Mondardini, M.R.R.; Grandoni, D.; et al. E2mC: Improving emergency management service practice through social media and crowdsourcing analysis in near real time. Sensors 2017, 17, 2766. [Google Scholar] [CrossRef] [PubMed]
- Kovács, K.Z.; Hemment, D.; Woods, M.; Velden, N.K.V.D.; Xaver, A.; Giesen, R.H.; Burton, V.J.; Garrett, N.L.; Zappa, L.; Long, D.; et al. Citizen observatory based soil moisture monitoring—The GROW example. Hung. Geogr. Bull. 2019, 2, 119–139. [Google Scholar] [CrossRef]
- Grainger, A. Citizen observatories and the new Earth observation science. Remote Sens. 2017, 9, 153. [Google Scholar] [CrossRef]
- See, L.; Mooney, P.; Foody, G.; Bastin, L.; Comber, A.; Estima, J.; Fritz, S.; Kerle, N.; Jiang, B.; Laakso, M.; et al. Crowdsourcing, citizen science or volunteered geographic information? The current state of crowdsourced geographic information. ISPRS Int. J. Geo-Inf. 2016, 5, 55. [Google Scholar] [CrossRef]
- Dell’Acqua, F.; De Vecchi, D. Potentials of active and passive geospatial crowdsourcing in complementing sentinel data and supporting copernicus service portfolio. Proc. IEEE 2017, 105, 1913–1925. [Google Scholar] [CrossRef]
- See, L.; Fritz, S.; Dias, E.; Hendriks, E.; Mijling, B.; Snik, F.; Stammes, P.; Vescovi, F.D.; Zeug, G.; Mathieu, P.P.; et al. Supporting Earth-Observation Calibration and Validation: A new generation of tools for crowdsourcing and citizen science. IEEE Geosci. Remote Sens. Mag. 2016, 4, 38–50. [Google Scholar] [CrossRef]
- Poblet, M.; García-Cuesta, E.; Casanovas, P. Crowdsourcing roles, methods and tools for data-intensive disaster management. Inf. Syst. Front. 2018, 20, 1363–1379. [Google Scholar] [CrossRef]
- Sagl, G.; Resch, B.; Blaschke, T. Contextual Sensing: Integrating Contextual Information with Human and Technical Geo-Sensor Information for Smart Cities. Sensors 2015, 15, 13. [Google Scholar] [CrossRef] [PubMed]
- Resch, B. People as sensors and collective sensing-contextual observations complementing geo-sensor network measurements. In Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2013; pp. 391–406. [Google Scholar] [CrossRef]
- Ghermandi, A.; Sinclair, M. Passive crowdsourcing of social media in environmental research: A systematic map. Glob. Environ. Chang. 2019, 55, 36–47. [Google Scholar] [CrossRef]
- Tracewski, L.; Bastin, L.; Fonte, C.C. Repurposing a deep learning network to filter and classify volunteered photographs for land cover and land use characterization. Geo-Spat. Inf. Sci. 2017, 20, 252–268. [Google Scholar] [CrossRef]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.; Anders, K.; Gloaguen, R.; et al. Multisource and multitemporal data fusion in remote sensing: A comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Prasad, S.; Pacifici, F.; Gamba, P.; Chanussot, J.; Benediktsson, J.A. Challenges and Opportunities of Multimodality and Data Fusion in Remote Sensing. Proc. IEEE 2015, 103, 1585–1601. [Google Scholar] [CrossRef]
- White, F.E. Data Fusion Lexicon; Joint Directors of Labs: Washington, DC, USA, 1991. [Google Scholar]
- Castanedo, F. A review of data fusion techniques. Sci. World J. 2013, 2013, 19. [Google Scholar] [CrossRef] [PubMed]
- Schmitt, M.; Zhu, X.X. Data Fusion and Remote Sensing: An ever-growing relationship. IEEE Geosci. Remote Sens. Mag. 2016, 4, 6–23. [Google Scholar] [CrossRef]
- Estes, L.D.; McRitchie, D.; Choi, J.; Debats, S.; Evans, T.; Guthe, W.; Luo, D.; Ragazzo, G.; Zempleni, R.; Caylor, K.K. A platform for crowdsourcing the creation of representative, accurate landcover maps. Environ. Model. Softw. 2016, 80, 41–53. [Google Scholar] [CrossRef]
- Li, J.; Benediktsson, J.A.; Zhang, B.; Yang, T.; Plaza, A. Spatial Technology and Social Media in Remote Sensing: A Survey. Proc. IEEE 2017, 105, 1855–1864. [Google Scholar] [CrossRef]
- Wan, T.; Lu, H.; Lu, Q.; Luo, N. Classification of High-Resolution Remote-Sensing Image Using OpenStreetMap Information. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2305–2309. [Google Scholar] [CrossRef]
- Johnson, B.A.; Iizuka, K. Integrating OpenStreetMap crowdsourced data and Landsat time-series imagery for rapid land use/land cover (LULC) mapping: Case study of the Laguna de Bay area of the Philippines. Appl. Geogr. 2016, 67, 140–149. [Google Scholar] [CrossRef]
- Vahidi, H.; Klinkenberg, B.; Johnson, B.A.; Moskal, L.M.; Yan, W. Mapping the individual trees in urban orchards by incorporating Volunteered Geographic Information and very high resolution optical remotely sensed data: A template matching-based approach. Remote Sens. 2018, 10, 1134. [Google Scholar] [CrossRef]
- Daudt, H.M.; Van Mossel, C.; Scott, S.J. Enhancing the scoping study methodology: A large, inter-professional team’s experience with Arksey and O’Malley’s framework. BMC Med. Res. Methodol. 2013, 13, 48. [Google Scholar] [CrossRef] [PubMed]
- Arksey, H.; O’Malley, L. Scoping studies: Towards a methodological framework. Int. J. Soc. Res. Methodol. Theory Pract. 2005, 8, 19–32. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; Brien, K.O.; Colquhoun, H.; Kastner, M.; Levac, D.; Ng, C.; Sharpe, J.P.; Wilson, K.; et al. A scoping review on the conduct and reporting of scoping reviews. BMC Med. Res. Methodol. 2016, 16, 15. [Google Scholar] [CrossRef] [PubMed]
- Munn, Z.; Peters, M.D.; Stern, C.; Tufanaru, C.; McArthur, A.; Aromataris, E. Systematic review or scoping review? Guidance for authors when choosing between a systematic or scoping review approach. BMC Med. Res. Methodol. 2018, 18, 143. [Google Scholar] [CrossRef] [PubMed]
- Peters, M.D.; Godfrey, C.M.; Khalil, H.; McInerney, P.; Parker, D.; Soares, C.B. Guidance for conducting systematic scoping reviews. Int. J. -Evid.-Based Healthc. 2015, 13, 141–146. [Google Scholar] [CrossRef] [PubMed]
- Saralioglu, E.; Gungor, O. Crowdsourcing in Remote Sensing: A review of applications and future directions. IEEE Geosci. Remote Sens. Mag. 2020, 8, 1–23. [Google Scholar] [CrossRef]
- Howard, B.E.; Phillips, J.; Miller, K.; Tandon, A.; Mav, D.; Shah, M.R.; Holmgren, S.; Pelch, K.E.; Walker, V.; Rooney, A.A.; et al. SWIFT-Review: A text-mining workbench for systematic review. Syst. Rev. 2016, 5, 87. [Google Scholar] [CrossRef] [PubMed]
- Jonnalagadda, S.; Petitti, D. A new iterative method to reduce workload in systematic review process. Int. J. Comput. Biol. Drug Des. 2013, 6, 5–17. [Google Scholar] [CrossRef] [PubMed]
- Levac, D.; Colquhoun, H.; O’Brien, K.K. Scoping studies: Advancing the methodology. Implement. Sci. 2010, 5, 69. [Google Scholar] [CrossRef] [PubMed]
- Tobler, W.; Barbara, S. Measuring Spatial Resolution. In Proceedings of the Land Resources Information Systems Conference, Beijing, China; 1987; pp. 12–16. Available online: https://www.researchgate.net/profile/Waldo-Tobler/publication/291877360_Measuring_spatial_resolution/links/595ef94ba6fdccc9b17fe8ee/Measuring-spatial-resolution.pdf (accessed on 25 January 2022).
- de Albuquerque, J.P.; Herfort, B.; Eckle, M. The tasks of the crowd: A typology of tasks in geographic information crowdsourcing and a case study in humanitarian mapping. Remote Sens. 2016, 8, 859. [Google Scholar] [CrossRef]
- Zhang, J. Multi-source remote sensing data fusion: Status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef]
- Emilien, A.V.; Thomas, C.; Thomas, H. UAV & satellite synergies for optical remote sensing applications: A literature review. Sci. Remote Sens. 2021, 3, 100019. [Google Scholar] [CrossRef]
- Xie, Y.; Wilson, A.M. Change point estimation of deciduous forest land surface phenology. Remote Sens. Environ. 2020, 240, 111698. [Google Scholar] [CrossRef]
- Jose Marıa, C.; Edward, C.; Wahlster, W. New Horizons for a Data-Driven Economy, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2005; p. 312. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Lapierre, N.; Neubauer, N.; Miguel-Cruz, A.; Rios Rincon, A.; Liu, L.; Rousseau, J. The state of knowledge on technologies and their use for fall detection: A scoping review. Int. J. Med. Inform. 2018, 111, 58–71. [Google Scholar] [CrossRef]
- Li, H.; Dou, X.; Tao, C.; Wu, Z.; Chen, J.; Peng, J.; Deng, M.; Zhao, L. Rsi-cb: A large-scale remote sensing image classification benchmark using crowdsourced data. Sensors 2020, 20, 28–32. [Google Scholar] [CrossRef] [PubMed]
- Bleiholder, J.; Naumann, F. Data Fusion. ACM Comput. Surv. 2009, 41, 1–41. [Google Scholar] [CrossRef]
- Wald, L. A conceptual approach to the fusion of earth observation data. Surv. Geophys. 2000, 21, 177–186. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; Group, T.P. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed]
- Leibrand, A.; Sadoff, N.; Maslak, T.; Thomas, A. Using Earth Observations to Help Developing Countries Improve Access to Reliable, Sustainable, and Modern Energy. Front. Environ. Sci. 2019, 7, 123. [Google Scholar] [CrossRef]
- Kibirige, D.; Dobos, E. Soil moisture estimation using citizen observatory data, microwave satellite imagery, and environmental covariates. Water 2020, 12, 2160. [Google Scholar] [CrossRef]
- Salk, C.; Sturn, T.; See, L.; Fritz, S. Local knowledge and professional background have a minimal impact on volunteer citizen science performance in a land-cover classification task. Remote Sens. 2016, 8, 774. [Google Scholar] [CrossRef]
- Mehdipoor, H.; Zurita-Milla, R.; Augustijn, E.W.; Izquierdo-Verdiguier, E. Exploring differences in spatial patterns and temporal trends of phenological models at continental scale using gridded temperature time-series. Int. J. Biometeorol. 2020, 64, 409–421. [Google Scholar] [CrossRef]
- Melaas, E.K.; Friedl, M.A.; Richardson, A.D. Multiscale modeling of spring phenology across Deciduous Forests in the Eastern United States. Glob. Chang. Biol. 2016, 22, 792–805. [Google Scholar] [CrossRef]
- Delbart, N.; Beaubien, E.; Kergoat, L.; Le Toan, T. Comparing land surface phenology with leafing and flowering observations from the PlantWatch citizen network. Remote Sens. Environ. 2015, 160, 273–280. [Google Scholar] [CrossRef]
- Elmore, A.J.; Stylinski, C.D.; Pradhan, K. Synergistic use of citizen science and remote sensing for continental-scale measurements of forest tree phenology. Remote Sens. 2016, 8, 502. [Google Scholar] [CrossRef]
- Xin, Q.; Li, J.; Li, Z.; Li, Y.; Zhou, X. Evaluations and comparisons of rule-based and machine-learning-based methods to retrieve satellite-based vegetation phenology using MODIS and USA National Phenology Network data. Int. J. Appl. Earth Obs. Geoinfor. 2020, 93, 102189. [Google Scholar] [CrossRef]
- Liu, X.; He, J.; Yao, Y.; Zhang, J.; Liang, H.; Wang, H.; Hong, Y. Classifying urban land use by integrating remote sensing and social media data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]
- Liu, J.; Hyyppä, J.; Yu, X.; Jaakkola, A.; Liang, X.; Kaartinen, H.; Kukko, A.; Zhu, L.; Wang, Y.; Hyyppä, H. Can global navigation satellite system signals reveal the ecological attributes of forests? Int. J. Appl. Earth Obs. Geoinfor. 2016, 50, 74–79. [Google Scholar] [CrossRef]
- Wallace, C.S.A.; Walker, J.J.; Skirvin, S.M.; Patrick-Birdwell, C.; Weltzin, J.F.; Raichle, H. Mapping presence and predicting phenological status of invasive buffelgrass in Southern Arizona using MODIS, climate and citizen science observation data. Remote Sens. 2016, 8, 524. [Google Scholar] [CrossRef]
- Baker, F.; Smith, C.L.; Cavan, G. A combined approach to classifying land surface cover of urban domestic gardens using citizen science data and high resolution image analysis. Remote Sens. 2018, 10, 537. [Google Scholar] [CrossRef]
- Gengler, S.; Bogaert, P. Integrating crowdsourced data with a land cover product: A Bayesian data fusion approach. Remote Sens. 2016, 8, 545. [Google Scholar] [CrossRef]
- Koskinen, J.; Leinonen, U.; Vollrath, A.; Ortmann, A.; Lindquist, E.; D’Annunzio, R.; Pekkarinen, A.; Käyhkö, N. Participatory mapping of forest plantations with Open Foris and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2019, 148, 63–74. [Google Scholar] [CrossRef]
- Wang, S.; Di Tommaso, S.; Faulkner, J.; Friedel, T.; Kennepohl, A.; Strey, R.; Lobell, D.B. Mapping crop types in southeast india with smartphone crowdsourcing and deep learning. Remote Sens. 2020, 12, 2957. [Google Scholar] [CrossRef]
- Schepaschenko, D.G.; Shvidenko, A.Z.; Lesiv, M.Y.; Ontikov, P.V.; Shchepashchenko, M.V.; Kraxner, F. Estimation of forest area and its dynamics in Russia based on synthesis of remote sensing products. Contemp. Probl. Ecol. 2015, 8, 811–817. [Google Scholar] [CrossRef]
- Schepaschenko, D.; See, L.; Lesiv, M.; McCallum, I.; Fritz, S.; Salk, C.; Moltchanova, E.; Perger, C.; Shchepashchenko, M.; Shvidenko, A.; et al. Development of a global hybrid forest mask through the synergy of remote sensing, crowdsourcing and FAO statistics. Remote Sens. Environ. 2015, 162, 208–220. [Google Scholar] [CrossRef]
- Lesiv, M.; Moltchanova, E.; Schepaschenko, D.; See, L.; Shvidenko, A.; Comber, A.; Fritz, S. Comparison of data fusion methods using crowdsourced data in creating a hybrid forest cover map. Remote Sens. 2016, 8, 261. [Google Scholar] [CrossRef]
- Wiesner-Hanks, T.; Wu, H.; Stewart, E.; DeChant, C.; Kaczmar, N.; Lipson, H.; Gore, M.A.; Nelson, R.J. Millimeter-Level Plant Disease Detection From Aerial Photographs via Deep Learning and Crowdsourced Data. Front. Plant Sci. 2019, 10, 1550. [Google Scholar] [CrossRef] [PubMed]
- Chi, M.; Sun, Z.; Qin, Y.; Shen, J.; Benediktsson, J.A. A Novel Methodology to Label Urban Remote Sensing Images Based on Location-Based Social Media Photos. Proc. IEEE 2017, 105, 1926–1936. [Google Scholar] [CrossRef]
- Sitthi, A.; Nagai, M.; Dailey, M.; Ninsawat, S. Exploring land use and land cover of geotagged social-sensing images using naive bayes classifier. Sustainability 2016, 8, 921. [Google Scholar] [CrossRef]
- Yokoya, N.; Ghamisi, P.; Xia, J.; Sukhanov, S.; Heremans, R.; Tankoyeu, I.; Bechtel, B.; Le Saux, B.; Moser, G.; Tuia, D. Open Data for Global Multimodal Land Use Classification: Outcome of the 2017 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1363–1377. [Google Scholar] [CrossRef]
- Liu, D.; Chen, N.; Zhang, X.; Wang, C.; Du, W. Annual large-scale urban land mapping based on Landsat time series in Google Earth Engine and OpenStreetMap data: A case study in the middle Yangtze River basin. ISPRS J. Photogramm. Remote Sens. 2020, 159, 337–351. [Google Scholar] [CrossRef]
- Johnson, B.A.; Iizuka, K.; Bragais, M.A.; Endo, I.; Magcale-Macandog, D.B. Employing crowdsourced geographic data and multi-temporal/multi-sensor satellite imagery to monitor land cover change: A case study in an urbanizing region of the Philippines. Comput. Environ. Urban Syst. 2017, 64, 184–193. [Google Scholar] [CrossRef]
- Hu, T.; Yang, J.; Li, X.; Gong, P. Mapping urban land use by using landsat images and open social data. Remote Sens. 2016, 8, 151. [Google Scholar] [CrossRef]
- Yang, D.; Fu, C.S.; Smith, A.C.; Yu, Q. Open land-use map: A regional land-use mapping strategy for incorporating OpenStreetMap with earth observations. Geo-Spat. Inf. Sci. 2017, 20, 269–281. [Google Scholar] [CrossRef]
- Fonte, C.C.; Patriarca, J.; Jesus, I.; Duarte, D. Automatic extraction and filtering of openstreetmap data to generate training datasets for land use land cover classification. Remote Sens. 2020, 12, 3428. [Google Scholar] [CrossRef]
- Hughes, L.H.; Streicher, S.; Chuprikova, E.; du Preez, J. A cluster graph approach to land cover classification boosting. Data 2019, 4, 10. [Google Scholar] [CrossRef]
- See, L.; Schepaschenko, D.; Lesiv, M.; McCallum, I.; Fritz, S.; Comber, A.; Perger, C.; Schill, C.; Zhao, Y.; Maus, V.; et al. Building a hybrid land cover map with crowdsourcing and geographically weighted regression. ISPRS J. Photogramm. Remote Sens. 2015, 103, 48–56. [Google Scholar] [CrossRef]
- Hammerberg, K.; Brousse, O.; Martilli, A.; Mahdavi, A. Implications of employing detailed urban canopy parameters for mesoscale climate modelling: A comparison between WUDAPT and GIS databases over Vienna, Austria. Int. J. Climatol. 2018, 38, 1241–1257. [Google Scholar] [CrossRef]
- Annis, A.; Nardi, F. Integrating VGI and 2D hydraulic models into a data assimilation framework for real time flood forecasting and mapping. Geo-Spat. Inf. Sci. 2019, 22, 223–236. [Google Scholar] [CrossRef]
- Mazzoleni, M.; Cortes Arevalo, V.J.; Wehn, U.; Alfonso, L.; Norbiato, D.; Monego, M.; Ferri, M.; Solomatine, D.P. Towards assimilation of crowdsourced observations for different levels of citizen engagement: The flood event of 2013 in the Bacchiglione catchment. Hydrol. Earth Syst. Sci. Discuss. 2018, 22, 391–416. [Google Scholar] [CrossRef]
- Zeng, Z.; Lan, J.; Hamidi, A.R.; Zou, S. Integrating Internet media into urban flooding susceptibility assessment: A case study in China. Cities 2020, 101, 102697. [Google Scholar] [CrossRef]
- Yang, D.; Yang, A.; Qiu, H.; Zhou, Y.; Herrero, H.; Fu, C.S.; Yu, Q.; Tang, J. A Citizen-Contributed GIS Approach for Evaluating the Impacts of Land Use on Hurricane-Harvey-Induced Flooding in Houston Area. Land 2019, 8, 25. [Google Scholar] [CrossRef]
- Rosser, J.F.; Leibovici, D.G.; Jackson, M.J. Rapid flood inundation mapping using social media, remote sensing and topographic data. Nat. Hazards 2017, 87, 103–120. [Google Scholar] [CrossRef]
- Ahmad, K.; Pogorelov, K.; Riegler, M.; Conci, N.; Halvorsen, P. Social media and satellites: Disaster event detection, linking and summarization. Multimed. Tools Appl. 2019, 78, 2837–2875. [Google Scholar] [CrossRef]
- Panteras, G.; Cervone, G. Enhancing the temporal resolution of satellite-based flood extent generation using crowdsourced data for disaster monitoring. Int. J. Remote Sens. 2018, 39, 1459–1474. [Google Scholar] [CrossRef]
- Olthof, I.; Svacina, N. Testing urban flood mapping approaches from satellite and in situ data collected during 2017 and 2019 events in Eastern Canada. Remote Sens. 2020, 12, 3141. [Google Scholar] [CrossRef]
- Chini, M.; Pelich, R.; Pulvirenti, L.; Pierdicca, N.; Hostache, R.; Matgen, P. Sentinel-1 InSAR coherence to detect floodwater in urban areas: Houston and hurricane harvey as a test case. Remote Sens. 2019, 11, 107. [Google Scholar] [CrossRef]
- Ferster, C.J.; Coops, N.C. Integrating volunteered smartphone data with multispectral remote sensing to estimate forest fuels. Int. J. Digit. Earth 2016, 9, 171–196. [Google Scholar] [CrossRef]
- Hardy, C.C. Wildland fire hazard and risk: Problems, definitions, and context. For. Ecol. Manag. 2005, 211, 73–82. [Google Scholar] [CrossRef]
- Frank, J.; Rebbapragada, U.; Bialas, J.; Oommen, T.; Havens, T.C. Effect of label noise on the machine-learned classification of earthquake damage. Remote Sens. 2017, 9, 803. [Google Scholar] [CrossRef]
- Hultquist, C.; Cervone, G. Citizen monitoring during hazards: Validation of Fukushima radiation measurements. GeoJournal 2018, 83, 189–206. [Google Scholar] [CrossRef]
- Gueguen, L.; Koenig, J.; Reeder, C.; Barksdale, T.; Saints, J.; Stamatiou, K.; Collins, J.; Johnston, C. Mapping Human Settlements and Population at Country Scale from VHR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 524–538. [Google Scholar] [CrossRef]
- Chew, R.F.; Amer, S.; Jones, K.; Unangst, J.; Cajka, J.; Allpress, J.; Bruhn, M. Residential scene classification for gridded population sampling in developing countries using deep convolutional neural networks on satellite imagery. Int. J. Health Geogr. 2018, 17, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Zhou, Y.; Zipf, A.; Fan, H. Deep Learning from Multiple Crowds: A Case Study of Humanitarian Mapping. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1713–1722. [Google Scholar] [CrossRef]
- Zhao, W.; Bo, Y.; Chen, J.; Tiede, D.; Thomas, B.; Emery, W.J. Exploring semantic elements for urban scene recognition: Deep integration of high-resolution imagery and OpenStreetMap (OSM). ISPRS J. Photogramm. Remote Sens. 2019, 151, 237–250. [Google Scholar] [CrossRef]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K.; Member, S. Learning Aerial Image Segmentation From Online Maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6050–6068. [Google Scholar] [CrossRef]
- Ivanovic, S.S.; Olteanu-Raimond, A.M.; Mustière, S.; Devogele, T. A filtering-based approach for improving crowdsourced GNSS traces in a data update context. ISPRS Int. J. Geo-Inf. 2019, 8, 380. [Google Scholar] [CrossRef]
- Li, Y.; Xiang, L.; Zhang, C.; Wu, H. Fusing taxi trajectories and rs images to build road map via dcnn. IEEE Access 2019, 7, 161487–161498. [Google Scholar] [CrossRef]
- Lambers, K.; Verschoof-van der Vaart, W.B.; Bourgeois, Q.P.J. Integrating remote sensing, machine learning, and citizen science in dutch archaeological prospection. Remote Sens. 2019, 11, 794. [Google Scholar] [CrossRef]
- Ford, B.; Pierce, J.R.; Wendt, E.; Long, M.; Jathar, S.; Mehaffy, J.; Tryner, J.; Quinn, C.; Van Zyl, L.; L’Orange, C.; et al. A low-cost monitor for measurement of fine particulate matter and aerosol optical depth-Part 2: Citizen-science pilot campaign in northern Colorado. Atmos. Meas. Tech. 2019, 12, 6385–6399. [Google Scholar] [CrossRef]
- Venter, Z.S.; Brousse, O.; Esau, I.; Meier, F. Hyperlocal mapping of urban air temperature using remote sensing and crowdsourced weather data. Remote Sens. Environ. 2020, 242, 111791. [Google Scholar] [CrossRef]
- Fenner, D.; Meier, F.; Bechtel, B.; Otto, M.; Scherer, D. Intra and inter ‘local climate zone’ variability of air temperature as observed by crowdsourced citizen weather stations in Berlin, Germany. Meteorol. Z. 2017, 26, 525–547. [Google Scholar] [CrossRef]
- Shupe, S.M. High resolution stream water quality assessment in the Vancouver, British Columbia region: A citizen science study. Sci. Total Environ. 2017, 603–604, 745–759. [Google Scholar] [CrossRef] [PubMed]
- Thornhill, I.; Ho, J.G.; Zhang, Y.; Li, H.; Ho, K.C.; Miguel-Chinchilla, L.; Loiselle, S.A. Prioritising local action for water quality improvement using citizen science; a study across three major metropolitan areas of China. Sci. Total Environ. 2017, 584–585, 1268–1281. [Google Scholar] [CrossRef] [PubMed]
- Garaba, S.P.; Friedrichs, A.; Voß, D.; Zielinski, O. Classifying natural waters with the forel-ule colour index system: Results, applications, correlations and crowdsourcing. Int. J. Environ. Res. Public Health 2015, 12, 16096–16109. [Google Scholar] [CrossRef]
- Boyd, D.S.; Jackson, B.; Wardlaw, J.; Foody, G.M.; Marsh, S.; Bales, K. Slavery from Space: Demonstrating the role for satellite remote sensing to inform evidence-based action related to UN SDG number 8. ISPRS J. Photogramm. Remote Sens. 2018, 142, 380–388. [Google Scholar] [CrossRef]
- Juan, A.D.; Bank, A. The Ba‘athist blackout? Selective goods provision and political violence in the Syrian civil war. J. Peace Res. 2015, 52, 91–104. [Google Scholar] [CrossRef]
- United Nations. United Nations Department of Economic and Social Affairs. Sustainable Development Knowledge Platform. Sustainable Development Goals. Available online: https://sdgs.un.org/goals/goal8 (accessed on 28 February 2022).
- Butler, B.W.; Anderson, W.R.; Catchpole, E.A. Influence of Slope on Fire Spread Rate. In Proceedings of the USDA Forest Service Proceedings, Destin, FL, USA, 26–30 March 2007; pp. 75–82. [Google Scholar]
- Beven, K.J.; Kirkby, M.J. A physically based, variable contributing area model of basin hydrology. Hydrol. Sci. Bull. 1979, 24, 43–69. [Google Scholar] [CrossRef]
- Hjerdt, K.N.; McDonnell, J.J.; Seibert, J.; Rodhe, A. A new topographic index to quantify downslope controls on local drainage. Water Resour. Res. 2004, 40, 1–6. [Google Scholar] [CrossRef]
- Kindermann, G.; Obersteiner, M.; Rametsteiner, E.; McCallum, I. Predicting the deforestation-trend under different carbon-prices. Carbon Balance Manag. 2006, 1, 15. [Google Scholar] [CrossRef] [PubMed]
- Nelson, G.C.; Valin, H.; Sands, R.D.; Havlík, P.; Ahammad, H.; Deryng, D.; Elliott, J.; Fujimori, S.; Hasegawa, T.; Heyhoe, E.; et al. Climate change effects on agriculture: Economic responses to biophysical shocks. Proc. Natl. Acad. Sci. USA 2014, 111, 3274–3279. [Google Scholar] [CrossRef] [PubMed]
- Santoro, M.; Beaudoin, A.; Beer, C.; Cartus, O.; Fransson, J.E.; Hall, R.J.; Pathe, C.; Schmullius, C.; Schepaschenko, D.; Shvidenko, A.; et al. Forest growing stock volume of the northern hemisphere: Spatially explicit estimates for 2010 derived from Envisat ASAR. Remote Sens. Environ. 2015, 168, 316–334. [Google Scholar] [CrossRef]
- Schepaschenko, D.; McCallum, I.; Shvidenko, A.; Fritz, S.; Kraxner, F.; Obersteiner, M. A new hybrid land cover dataset for Russia: A methodology for integrating statistics, remote sensing and in situ information. J. Land Use Sci. 2011, 6, 245–259. [Google Scholar] [CrossRef]
- Potapov, P.; Turubanova, S.; Hansen, M.C. Regional-scale boreal forest cover and change mapping using Landsat data composites for European Russia. Remote Sens. Environ. 2011, 115, 548–561. [Google Scholar] [CrossRef]
- Bechtel, B.; Demuzere, M.; Sismanidis, P.; Fenner, D.; Brousse, O.; Beck, C.; Van Coillie, F.; Conrad, O.; Keramitsoglou, I.; Middel, A.; et al. Quality of Crowdsourced Data on Urban Morphology—The Human Influence Experiment (HUMINEX). Urban Sci. 2017, 1, 15. [Google Scholar] [CrossRef]
- Stewart, I.D.; Oke, T.R. Local climate zones for urban temperature studies. Bull. Am. Meteorol. Soc. 2012, 93, 1879–1900. [Google Scholar] [CrossRef]
- Tsendbazar, N.E.; de Bruin, S.; Herold, M. Assessing global land cover reference datasets for different user communities. ISPRS J. Photogramm. Remote Sens. 2015, 103, 93–114. [Google Scholar] [CrossRef]
- Getmapping. Aerial Data—High Resolution Imagery. Available online: https://www.getmapping.com/products/aerial-imagery-data/aerial-data-infrared-imagery (accessed on 28 February 2022).
- Rahman, M.S.; Di, L. A systematic review on case studies of remote-sensing-based flood crop loss assessment. Agriculture 2020, 10, 131. [Google Scholar] [CrossRef]
- Heiskanen, J. Estimating aboveground tree biomass and leaf area index in a mountain birch forest using ASTER satellite data. Int. J. Remote Sens. 2006, 27, 1135–1158. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Barnes, E.M.; Clarke, T.R.; Richards, S.E.; Colaizzi, P.D.; Haberland, J.; Kostrzewski, M.; Waller, P.; Choi, C.; Riley, E.; Thompson, T.; et al. Coinddent detection of crop water stress, nitrogen status and canopy density using ground-based multispectral data. In Proceedings of the Fifth International Conference on Precision Agriculture, Bloomington, MN, USA, 16–19 July 2000. [Google Scholar]
- Buschmann, C.; Nagel, E. In vivo spectroscopy and internal optics of leaves as basis for remote sensing of vegetation. Int. J. Remote Sens. 1993, 14, 711–722. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Vi na, A.; Ciganda, V.; Rundquist, D.C.; Arkebauer, T.J. Remote estimation of canopy chlorophyll content in crops. Geophys. Res. Lett. 2005, 32, 1–4. [Google Scholar] [CrossRef]
- Meyer, G.E.; Neto, J.C. Verification of color vegetation indices for automated crop imaging applications. Comput. Electron. Agric. 2008, 63, 282–293. [Google Scholar] [CrossRef]
- Zha, Y.; Gao, J.; Ni, S. Use of normalized difference built-up index in automatically mapping urban areas from TM imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Darrel Jenerette, G.; Pauliet, S. Locally optimized separability enhancement indices for urban land cover mapping: Exploring thermal environmental consequences of rapid urbanization in Addis Ababa, Ethiopia. Remote Sens. Environ. 2016, 175, 14–31. [Google Scholar] [CrossRef]
- Xu, H. A new index for delineating built-up land features in satellite imagery. Int. J. Remote Sens. 2008, 29, 4269–4276. [Google Scholar] [CrossRef]
- Rikimaru, A.; Roy, P.S.; Miyatake, S. Tropical forest cover density mapping. Trop. Ecol. 2002, 43, 39–47. [Google Scholar]
- Gao, B.C. NDWI A Normalized Difference Water Index for Remote Sensing of Vegetation Liquid Water From Space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Leal Filho, W.; Wolf, F.; Castro-Díaz, R.; Li, C.; Ojeh, V.N.; Gutiérrez, N.; Nagy, G.J.; Savić, S.; Natenzon, C.E.; Al-Amin, A.Q.; et al. Addressing the urban heat islands effect: A cross-country assessment of the role of green infrastructure. Sustainability 2021, 13, 753. [Google Scholar] [CrossRef]
- Liu, J.; Hyyppa, J.; Yu, X.; Jaakkola, A.; Kukko, A.; Kaartinen, H.; Zhu, L.; Liang, X.; Wang, Y.; Hyyppa, H. A Novel GNSS Technique for Predicting Boreal Forest Attributes at Low Cost. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4855–4867. [Google Scholar] [CrossRef]
- Puissant, A.; Hirsch, J.; Weber, C. The utility of texture analysis to improve per-pixel classification for high to very high spatial resolution imagery. Int. J. Remote Sens. 2005, 26, 733–745. [Google Scholar] [CrossRef]
- Small, D. Flattening gamma: Radiometric terrain correction for SAR imagery. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3081–3093. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Neto, F.R.A.; Santos, C.A.S. Understanding crowdsourcing projects: A systematic review of tendencies, work flow, and quality management. Inf. Process. Manag. 2018, 54, 490–506. [Google Scholar] [CrossRef]
- Chaves, R.; Schneider, D.; Correia, A.; Borges, M.R.; Motta, C. Understanding crowd work in online crowdsourcing platforms for urban planning: Systematic review. In Proceedings of the 2019 IEEE 23rd International Conference on Computer Supported Cooperative Work in Design, CSCWD 2019, Porto, Portugal, 6–8 May 2019; pp. 273–278. [Google Scholar] [CrossRef]
- Patriarca, J.; Fonte, C.C.; Estima, J.; de Almeida, J.P.; Cardoso, A. Automatic conversion of OSM data into LULC maps: Comparing FOSS4G based approaches towards an enhanced performance. Open Geospat. Data, Softw. Stand. 2019, 4, 11. [Google Scholar] [CrossRef]
- See, L.; Fritz, S.; You, L.; Ramankutty, N.; Herrero, M.; Justice, C.; Becker-Reshef, I.; Thornton, P.; Erb, K.; Gong, P.; et al. Improved global cropland data as an essential ingredient for food security. Glob. Food Secur. 2015, 4, 37–45. [Google Scholar] [CrossRef]
- Sarı, A.; Ays, T.; Alptekine, G.I. A systematic literature review on crowdsourcing in software engineering. J. Syst. Softw. 2019, 153, 200–219. [Google Scholar] [CrossRef]
- Bubalo, M.; Zanten, B.T.V.; Verburg, P.H. Crowdsourcing geo-information on landscape perceptions and preferences: A review. Landsc. Urban Plan. 2019, 184, 101–111. [Google Scholar] [CrossRef]
- Reba, M.; Seto, K.C. A systematic review and assessment of algorithms to detect, characterize, and monitor urban land change. Remote Sens. Environ. 2020, 242, 111739. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- LeCun, Y. LeNet-5, Convolutional Neural Networks. Available online: http://yann.lecun.com/exdb/lenet/ (accessed on 28 February 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks; Curran Associates Inc.: Lake Tahoe, NV, USA, 2012; pp. 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Liu, J.; Li, T.; Xie, P.; Du, S.; Teng, F.; Yang, X. Urban big data fusion based on deep learning: An overview. Inf. Fusion 2020, 53, 123–133. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Scott, D.W. Multivariate Density Estimation and Visualization; Springer: Berlin/Heidelberg, Germany, 2012; pp. 549–569. [Google Scholar]
- Luque, A.; Carrasco, A.; Martín, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgu, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Du, P.; Samat, A.; Waske, B.; Liu, S.; Li, Z. Random Forest and Rotation Forest for fully polarized SAR image classification using polarimetric and spatial features. ISPRS J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Yang, C.; Yu, M.; Hu, F.; Jiang, Y.; Li, Y. Utilizing Cloud Computing to address big geospatial data challenges. Comput. Environ. Urban Syst. 2017, 61, 120–128. [Google Scholar] [CrossRef]
- Miao, X.; Heaton, J.S.; Zheng, S.; Charlet, D.A.; Liu, H. Applying tree-based ensemble algorithms to the classification of ecological zones using multi-temporal multi-source remote-sensing data. Int. J. Remote Sens. 2012, 33, 1823–1849. [Google Scholar] [CrossRef]
- Rainforth, T.; Wood, F. Canonical Correlation Forests. arXiv 2015, arXiv:1507.05444. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S. Deep learning approaches applied to remote sensing datasets for road extraction: A state-of-the-art review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Arsanjania, J.J.; Vaz, E. An assessment of a collaborative mapping approach for exploring land use patterns for several European metropolises. Int. J. Appl. Earth Obs. Geoinf. 2015, 35, 329–337. [Google Scholar] [CrossRef]
- Rüetschi, M.; Schaepman, M.E.; Small, D. Using multitemporal Sentinel-1 C-band backscatter to monitor phenology and classify deciduous and coniferous forests in Northern Switzerland. Remote Sens. 2018, 10, 55. [Google Scholar] [CrossRef]
- Wang, K.; Chen, J.; Kiaghadi, A.; Dawson, C. A New Algorithm for Land-Cover Classification Using PolSAR and InSAR Data and Its Application to Surface Roughness Mapping Along the Gulf Coast. IEEE Trans. Geosci. Remote Sens. 2021, 60, 4502915. [Google Scholar] [CrossRef]
- Owuor, I.; Hochmair, H.H. An Overview of Social Media Apps and their Potential Role in Geospatial Research. Int. J. -Geo-Inf. Artic. 2020, 9, 526. [Google Scholar] [CrossRef]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar] [CrossRef]
- Hagenauer, J.; Helbich, M. A geographically weighted artificial neural network. Int. J. Geogr. Inf. Sci. 2021, 36, 215–235. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Chi, C.; Wang, Y.; Li, Y.; Tong, X. Multistrategy Repeated Game-Based Mobile Crowdsourcing Incentive Mechanism for Mobile Edge Computing in Internet of Things. Wirel. Commun. Mob. Comput. 2021, 2021, 6695696. [Google Scholar] [CrossRef]
- Schuir, J.; Brinkhege, R.; Anton, E.; Oesterreich, T.; Meier, P.; Teuteberg, F. Augmenting Humans in the Loop: Towards an Augmented Reality Object Labeling Application for Crowdsourcing Communities. In Proceedings of the International Conference on Wirtschaftsinformatik, Essen, Germany, 9–11 March 2021. [Google Scholar]
- Vohland, K.; Land-Zandstra, A.; Ceccaroni, L.; Lemmens, R.; Perelló, J.; Ponti, M.; Samson, R.; Wagenknecht, K. The Science of Citizen Science: Theories, Methodologies and Platforms. In Proceedings of the CSCW ’17: Computer Supported Cooperative Work and Social Computing, Portland, OR, USA, 25 February–1 March 2017; pp. 395–400. [Google Scholar] [CrossRef]
- Van Coillie, F.M.; Gardin, S.; Anseel, F.; Duyck, W.; Verbeke, L.P.; De Wulf, R.R. Variability of operator performance in remote-sensing image interpretation: The importance of human and external factors. Int. J. Remote Sens. 2014, 35, 754–778. [Google Scholar] [CrossRef]
- Shulla, K.; Leal Filho, W.; Sommer, J.H.; Lange Salvia, A.; Borgemeister, C. Channels of collaboration for citizen science and the sustainable development goals. J. Clean. Prod. 2020, 264, 121735. [Google Scholar] [CrossRef]
- Moczek, N.; Voigt-Heucke, S.L.; Mortega, K.G.; Fabó Cartas, C.; Knobloch, J. A self-assessment of european citizen science projects on their contribution to the UN sustainable development goals (SDGs). Sustainability 2021, 13, 1774. [Google Scholar] [CrossRef]
- Bell, S.; Upchurch, P.; Snavely, N.; Bala, K. Material recognition in the wild with the Materials in Context Database. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3479–3487. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, P.; Yu, L.; Hu, L.; Li, X.; Li, C.; Zhang, H.; Zheng, Y.; Wang, J.; Zhao, Y.; et al. Towards a common validation sample set for global land-cover mapping. Int. J. Remote Sens. 2014, 35, 4795–4814. [Google Scholar] [CrossRef]
- Card, D.H. Using Known Map Category Marginal Frequencies To Improve Estimates of Thematic Map Accuracy. Photogramm. Eng. Remote Sens. 1982, 48, 431–439. [Google Scholar]
- Verschoof-van der Vaart, W.B.; Lambers, K. Learning to Look at LiDAR: The Use of R-CNN in the Automated Detection of Archaeological Objects in LiDAR Data from the Netherlands. J. Comput. Appl. Archaeol. 2019, 2, 31–40. [Google Scholar] [CrossRef]









| Question Components | Search Terms |
|---|---|
| Earth Observation | “Earth Observation”* OR Satellite* OR “Remote Sensing”* OR Aerial* OR UAV OR drones OR “in situ” |
| Crowdsourcing | Crowdsourc* OR “Citizen Science” OR “Crowd science” |
| Mapping Scale Category | Mapping Scale | Earth Observation Spatial Resolution |
|---|---|---|
| local | <1:10,000 | pixel size ≤ 5 m |
| regional | 1:10,000 to 1:250,000 | 5 m < pixel size ≤ 125 m |
| global | >1:250,000 | pixel size > 125 m |
| Relevant Publications Classified as Relevant | Relevant Publications Classified as Non-Relevant | Total Number of Publications | Sensitivity Score | |
|---|---|---|---|---|
| Relevant publications classified as Relevant | 164 | 41 | 205 | 80% |
| Name of Journal | # Publications |
|---|---|
| Remote Sensing | 14 |
| ISPRS Journal of Photogrammetry and Remote Sensing | 5 |
| Remote Sensing of Environment | 4 |
| IEEE Transactions on Geoscience and Remote Sensing | 3 |
| International Journal of Applied Earth Observation and Geoinformation | 3 |
| Scimago: Geo-Spatial Information Science | 2 |
| Scimago: Global Change Biology | 2 |
| Scimago: Global Change Biology | 2 |
| IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing | 2 |
| Science of the Total Environment | 2 |
| Other | 29 |
| LULC Dataset | Reference Year | Resolution | Source | Study IDs |
|---|---|---|---|---|
| Global Datasets | ||||
| GlobeLand30 | 2010 | 30 m | http://www.globallandcover.com/ | [83,95] |
| GlobeCover | 2009 | 300 m | http://due.esrin.esa.int/page_globcover.php | [3,83,84,96] |
| Climate Change Initiative land cover (CCI-LC) | 2010 | 500 m | http://www.esa-landcover-cci.org/ | [80,83,84,85,112] |
| Global Land Cover project (GLC2000) | 2000 | 1000 m | http://bioval.jrc.ec.europa.eu/%20products/glc2000/products.php | [3,83,84,85,96] |
| Global Land Cover by National Mapping Organisations | 2003 | 1000 m | http://www.iscgm.org/GM_glcnmo | [84,85,96] |
| MODIS land cover (MCD12Q1) | 2001–2012 | 500 m | https://lpdaac.usgs.gov/data_access%2030 | [74,75,83,84,85] |
| MODIS VCF | 2000–2010 | 250 m | http://modis-land.gsfc.nasa.gov/vcc.html | [83,84,85] |
| Landsat VCF | 2000 | 30 m | http://www.landcover.org/ | [84,85] |
| FAO forest map | 2010 | 250 m | http://www.fao.org/forestry/fra/80298/en/ | [83,85] |
| Hansen’s Tree Cover | 2000–2012 | 30 m | http://earthenginepartners.appspot.com/science?2013?global?forest/ | [83,84,85] |
| GLC-SHARE (FAO) | 2014 | 1000 m | http://www.glcn.org/databases/lc_glcshare_en.jsp | [83] |
| Sexton et al. tree canopy | 2005 | 30 m | http://landcover.org/data/landsatTreecover/ | [83] |
| forest maps from ALOS PALSAR | 2007–2010 | 100 m | http://www.eorc.jaxa.jp/ALOS/en/palsar_fnf/fnf_index.htm | [83] |
| Growing Stock Volume (GSV) Envisat | 2010 | 1000 m | ESA [133] | [83] |
| GEOCOVER | 2000 | 30 m | http://zulu.ssc.nasa.gov/mrsid// | [3] |
| Hybrid forest cover Biomass layer | 2015 | 1000 m | http://biomass.geo-wiki.org. | [84] |
| Regional/National Datasets | ||||
| Pan European CORINE Land Cover | 2018, Every 6 years | 1:100,000 | http://land.copernicus.eu/pan-european | [3,95,98,120] |
| AFRICOVER | 2002 | 1:200,000 | http://www.africover.org/ | [3] |
| Brazil PRODES forest mask | 2000–2013 | 30 m | http://terrabrasilis.dpi.inpe.br/en/download-2/ | [84,85] |
| Pan-European Forest/Non-Forest Map | 2000, 2006 | 30 m | http://glcf.umiacs.umd.edu/data/landsat/ [84,85] | |
| Land Use of Australia | 2005–2006 | 30 m | ABARES: https://www.agriculture.gov.au/abares | [84,85] |
| Congo Basin forest types map | 2007 | 300 m | http://www.observatoire-comifac.net/ | [84,85] |
| National Land Cover Database for ths US | 2006 | 30 m | https://www.mrlc.gov/data | [134] |
| Land cover of Russia | 2005 | 1000 m | Schepaschenko et. al. [134] | [134] |
| Forest mask European Russia | 2000 | 250 m | Potapov et. al. [135] | [134] |
| Index | Definition | Source | Study IDs | |
|---|---|---|---|---|
| Vegetation | NDVI | Rouse Jr. et. al. [140] | [45,46,69,78,81,89,90,91,94,114,120] | |
| EVI | Huete et. al. [130] | [60,72,75,93] | ||
| RSR | Heiskanen [141] | [107] | ||
| SR | [107] | |||
| GRVI | Tucker [142] | [79,107] | ||
| NDRE | Barnes et. al. [143] | [79,107] | ||
| GNDVI | Buschmann and Nagel [144] | [79,107] | ||
| GCVI | Gitelson et. al. [145] | [82] | ||
| ExcessGREEN | Meyer & Neto [146] | [79] | ||
| ExcessRED | Meyer & Neto [146] | [79] | ||
| ExGREENminusExRED | Meyer and Neto [146] | [79] | ||
| Urban\Bare Soil | NDBI | Zha and Gao [147] | [90,92,94] | |
| BuEI | Feyisa et. al. [148] | [90] | ||
| SoEI | Feyisa et. al. [148] | [90] | ||
| IBI | Xu [149] | [120] | ||
| BSI | Rikimaru et al. [150] | [89] | ||
| Water | NDWI | Gao [151] | [73,89,94] | |
| MNDWI | Xu [152] | [90,102,104] |
| Non-Environmental Indicators | Study IDs |
|---|---|
| Demographic data (n = 2) | |
| Population density | [7,111] |
| Other Non-environmental data (n = 2) | |
| Night Lights | [126] |
| Nuclear Radiation | [110] |
| Classification Category | Methods | Study IDs |
|---|---|---|
| Regression | Linear regression | [110,119] |
| 2 type regression (major axis regression) | [74] | |
| Change point estimation | [60,75] | |
| Amplitude threshold | [75] | |
| First, Second, Third order of derivative | [75] | |
| Relative changing rate | [75] | |
| Neural Network | [75] | |
| Random Forest | [75,77,120,154] | |
| Optimisation algorithms | Kalman Filter (KF and EnKF) | [98,99] |
| Simulated annealing | [71] | |
| Rule-based classification | Repeated Incremental Pruning to Produce Error Reduction (RIPPER) | [116] |
| Projective adaptive resonance theory (PART) | [116] | |
| M5Rules | [116] | |
| One attribute rule (OneR) | [116] | |
| Spatial interpolation | Multivariate linear regression kriging | [69] |
| Co-kriging | [69] |
| Classification Category | Methods | Study IDs |
|---|---|---|
| Spatial statistics | Spearman rank correlations tests | [124] |
| Spatial similarity indices | [92] | |
| Spatial aggregations | [125] | |
| Majority of voting classifiers | [3,21,125] | |
| Object-based image analysis (OBIA) | [79] | |
| Logistic Regression | Multivariate logistic regression | [57,100,101] |
| Geographic-Weighted Regression (GWR) | [83,84,85,96] | |
| Probabilistic | Bayesian Data Fusion (BDF) | [80] |
| Boosting probability graphical model | [95] | |
| Fuzzy Association | Fuzzy logic | [2] |
| Ensemble | Random Forest classification (RF) | [87,95] |
| Machine Learning | Nearest Neighbour(NN) | [85,87] |
| Naïve Bayes (NB) | [85] | |
| Classification and Regression Trees (CART) | [85] | |
| Support Vector Machine (SVM)-Radial Basis Function (RBF) | [87] | |
| Deep Learning | LeNet | [113] |
| AlexNet | [113] | |
| VggNet | [113] | |
| U-Net/RUNET | [117] | |
| LinkNet34/D-LinkNet34 | [117] | |
| Single-Shot-Detection (SDD) network | [7] |
| Classification Category | Methods | Study IDs |
|---|---|---|
| Spatial statistics | Spearman rank correlations tests | [124] |
| Linear regression | [73,78,122] | |
| Pairwise two-sided Wilcoxon-Mann-Whitney | [121] | |
| Hybrid classification methods | [91] | |
| Template-Matching | [46] | |
| Physical models | Weather Research Forecasting (WRF) model | [97] |
| Spring Plant Phenology (SPP) models | [72] | |
| 1D flood simulation model | [105] | |
| Logistic Regression | Logistic regression | [126] |
| Probabilistic | Weights-of-Evidence | [102] |
| Maximum Likelihood | [88] | |
| Ensemble | Random Forest | [45,81,82,90,93,94,109,112,123,136] |
| AdaBoost | [112] | |
| Rotation Forest (RoF) | [89] | |
| Canonical Correlation Forests (CCFs) | [89] | |
| Customised ensemble model (CNN, RF, GBM) | [89] | |
| Machine Learning | CART | [90] |
| C.45 DT | [45] | |
| Mahalanobis k-NN | [107] | |
| SVM-RBF | [44] | |
| kd-tree-based hierarchical clustering | [111] | |
| Deep Learning | CNNs | [112,114,115] |
| R-CNN | [118] | |
| Inception V3 | [112] | |
| VGG16 | [112] | |
| ResNet (ResNet34) | [64,86] | |
| AlexNet | [64] | |
| GoogLeNet | [64] | |
| GANs | [103] | |
| 3D UNet | [82] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karagiannopoulou, A.; Tsertou, A.; Tsimiklis, G.; Amditis, A. Data Fusion in Earth Observation and the Role of Citizen as a Sensor: A Scoping Review of Applications, Methods and Future Trends. Remote Sens. 2022, 14, 1263. https://doi.org/10.3390/rs14051263
Karagiannopoulou A, Tsertou A, Tsimiklis G, Amditis A. Data Fusion in Earth Observation and the Role of Citizen as a Sensor: A Scoping Review of Applications, Methods and Future Trends. Remote Sensing. 2022; 14(5):1263. https://doi.org/10.3390/rs14051263
Chicago/Turabian StyleKaragiannopoulou, Aikaterini, Athanasia Tsertou, Georgios Tsimiklis, and Angelos Amditis. 2022. "Data Fusion in Earth Observation and the Role of Citizen as a Sensor: A Scoping Review of Applications, Methods and Future Trends" Remote Sensing 14, no. 5: 1263. https://doi.org/10.3390/rs14051263
APA StyleKaragiannopoulou, A., Tsertou, A., Tsimiklis, G., & Amditis, A. (2022). Data Fusion in Earth Observation and the Role of Citizen as a Sensor: A Scoping Review of Applications, Methods and Future Trends. Remote Sensing, 14(5), 1263. https://doi.org/10.3390/rs14051263