1. Introduction
Synthetic aperture radar (SAR), an essential aerospace remote sensor, is characterized by its ability to achieve all-weather observation of the ground [
1]. Based on this advantage, SAR technology has developed rapidly [
2,
3,
4], and has a wide range of applications in target detection [
5], disaster detection, military operations [
6], and resource exploration [
7].
SAR is an essential tool for maritime surveillance [
8]. As the maritime trade and transportation carrier is an important military object, it is of great significance to realize the real-time detection of ship targets in spaceborne SAR images [
9]. Due to the satellite’s limited computing and storage resources, the accuracy, detection speed, and model size of the target detection algorithm are required simultaneously [
10]. At present, the methods of ship target detection [
11] in SAR images are mainly divided into two types: traditional detection methods, and target detection methods based on deep learning [
12].
Traditional ship detection algorithms in SAR images generally detect ship targets by manually selectively extracting features such as gray level, contrast ratio, texture, geometric size, scattering characteristics, histogram of oriented gradient (HOG) [
13], and scale-invariant feature transform (SIFT) [
14]. Generally, they can achieve better detection performance in simple scenes with less interference. The constant false alarm rate (CFAR) [
15,
16,
17] detection algorithm is widely used as a contrast-based target detection algorithm for SAR ship detection. However, each pixel point in the CFAR detection algorithm is involved in the calculation of distribution parameter estimation multiple times, and the calculation of background clutter distribution is extensive. The detection speed cannot meet the demand of real-time.
In recent years, deep learning technology has developed rapidly natural image recognition. R-CNN [
18] introduced convolutional neural networks (CNN) into the field of target detection, which has brought new research ideas to target detection, and its application in SAR images has an ample exploration space. Currently, the algorithms based on convolutional neural networks mainly used in ship detection in SAR images include two-stage detection methods represented by R-CNN, Fast R-CNN [
19], and Faster R-CNN [
20]. This kind of algorithm takes a series of candidate regions as the candidate boxes of samples, and then produces secondary corrections based on the candidate regions to obtain the detection results, so that they have high detection accuracy. However, their network structures are complex, there are many parameters, and the recognition speed is slow, which cannot meet the real-time requirements of ship detection tasks. Furthermore, SSD [
21] and YOLO [
22,
23,
24] series algorithms based on single-stage regard the target detection problem as a regression analysis problem of target location and category information. They directly output the detection results through a neural network model, with high speed and accuracy, and are more suitable for ship detection tasks with near real-time detection requirements [
25].
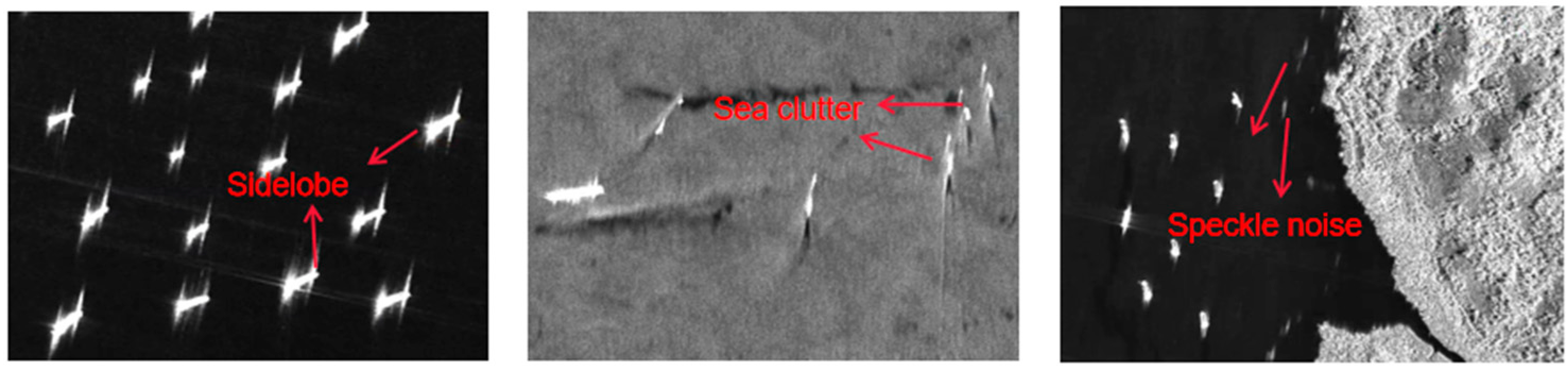
Although the above algorithms have good detection performance, applying them directly to ship detection in SAR images is difficult. In addition, there are still some challenges in the deep learning-based ship detection method in SAR images [
26,
27]: (1) Due to the unique imaging technology of SAR, there are more scattering noise and sea clutter in SAR images, and the phenomenon of side flap is also severe, which will cause the contrast between the ship and the sea to decrease. This leads to a decline in detection accuracy. Furthermore, the interference from the land, islands, and other natural factors increases the false alarm rate. (2) Ships have arbitrary directionality and multi-scale in SAR images. Various ships are of different sizes and scales, reflected in SAR images as different numbers of pixels, especially for small-scale ships. Fewer pixels are easily confused with SAR image speckle noise, and there is little information for position refinement and classification compared to large ships. Meanwhile, the orientation of ship targets in satellite images taken from the air vary greatly, and can change between 0° and 360°, which improves the detection difficulty and leads to poor detection and recognition accuracy. (3) SAR images cannot be directly input to the network for detection if the scene is enormous. It is assumed that the SAR image of the large scene is now input into the network. In this case, the ship target will be resampled to a few or even just one pixel, seriously affecting the detection accuracy.
To solve the above problems, Kang et al. [
28] added context features to the corresponding region of interest to make the background information help to eliminate false alarms. In order to better obtain the salient features in the image and suppress clutter, some studies use the attention mechanism. Du et al. [
29] introduced important information into the network, so that the detector could focus more on the target area. Zhao et al. [
30] proposed an extended attention block to enhance the feature extraction ability of the detector. Unlike the horizontal bounding box method, An et al. [
31] and Chen et al. [
32] adopt a directional bounding box, which is better for densely arranged objects. Cui et al. [
33] proposed a multiscale ship detection method based on a dense attention pyramid network (DAPN) in SAR images. Wang et al. [
34] improved the performance of detecting multiscale ships by enhancing the ability of feature extraction and the nonlinear relationship between different features. Wu et al. [
35] proposed a new ship detection network, called case segmentation assisted ship detection network (ISASDet), which uses case segmentation to promote ship detection. Shi et al. [
36] proposed an adaptive sliding window algorithm to extract the connected water region, and proposed the ship’s suspicious target region.
The above improvements are based on specific hardware and storage resources. Although these methods improve the detection performance of the model to a certain extent, it is still difficult to meet the development needs of real-time mission planning on satellites [
37]. However, the hardware resources on the satellite are limited, thus reducing the network parameters and compressing the network model on the premise of ensuring the network performance has also become a challenge in the target detection task on the satellite [
38]. Chollet et al. [
39] constructed deep separable convolution by combining the branching structure of inception, and reduced the computation of convolution operation on the premise of ensuring the model’s accuracy through the BottleNeck method. Zhang et al. [
40] proposed a high-speed SAR ship detection method based on depth separable convolutional neural network (DS-CNN) using a combination of multi-scale detection mechanism, cascade system, and anchor box mechanism.
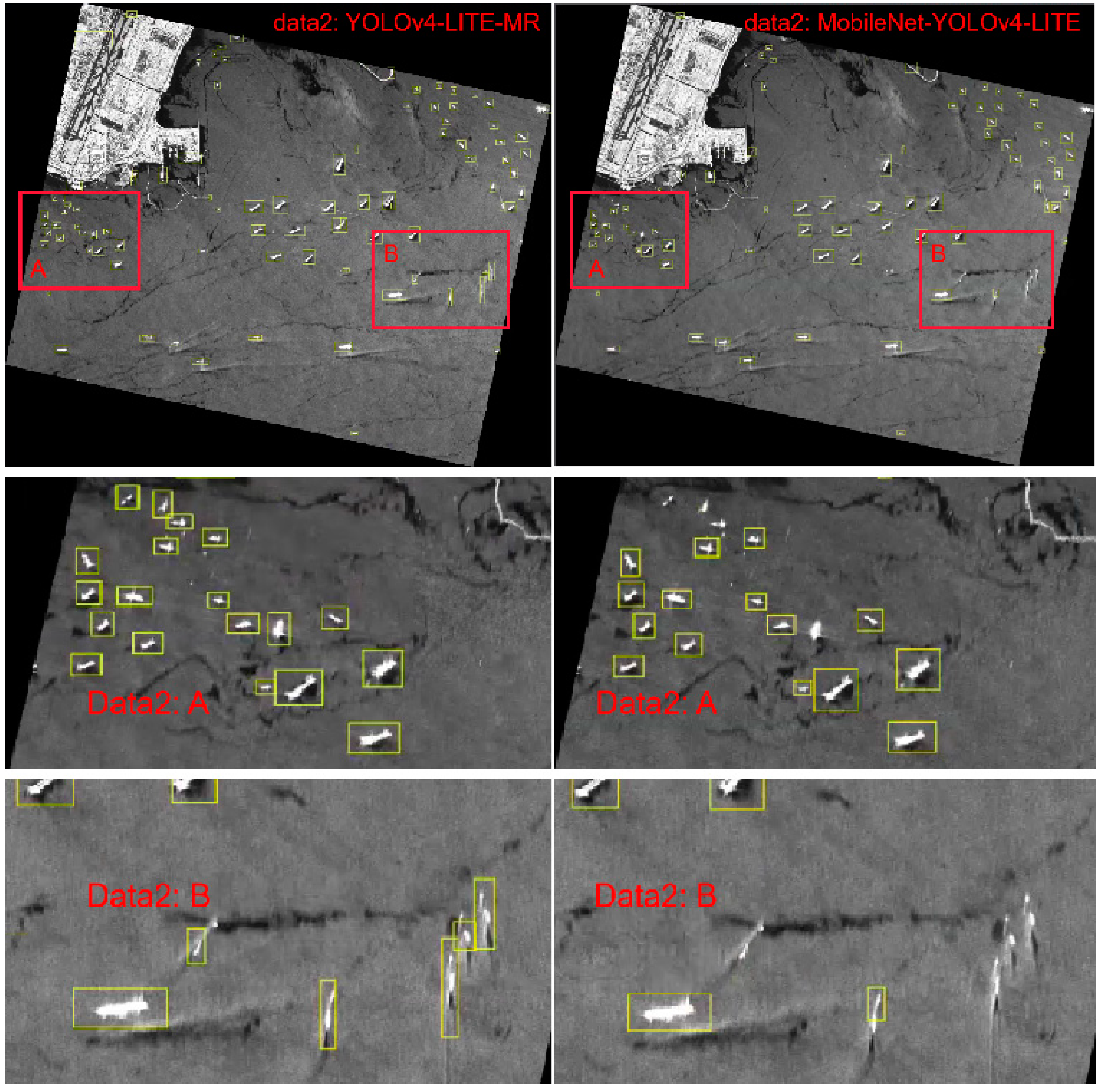
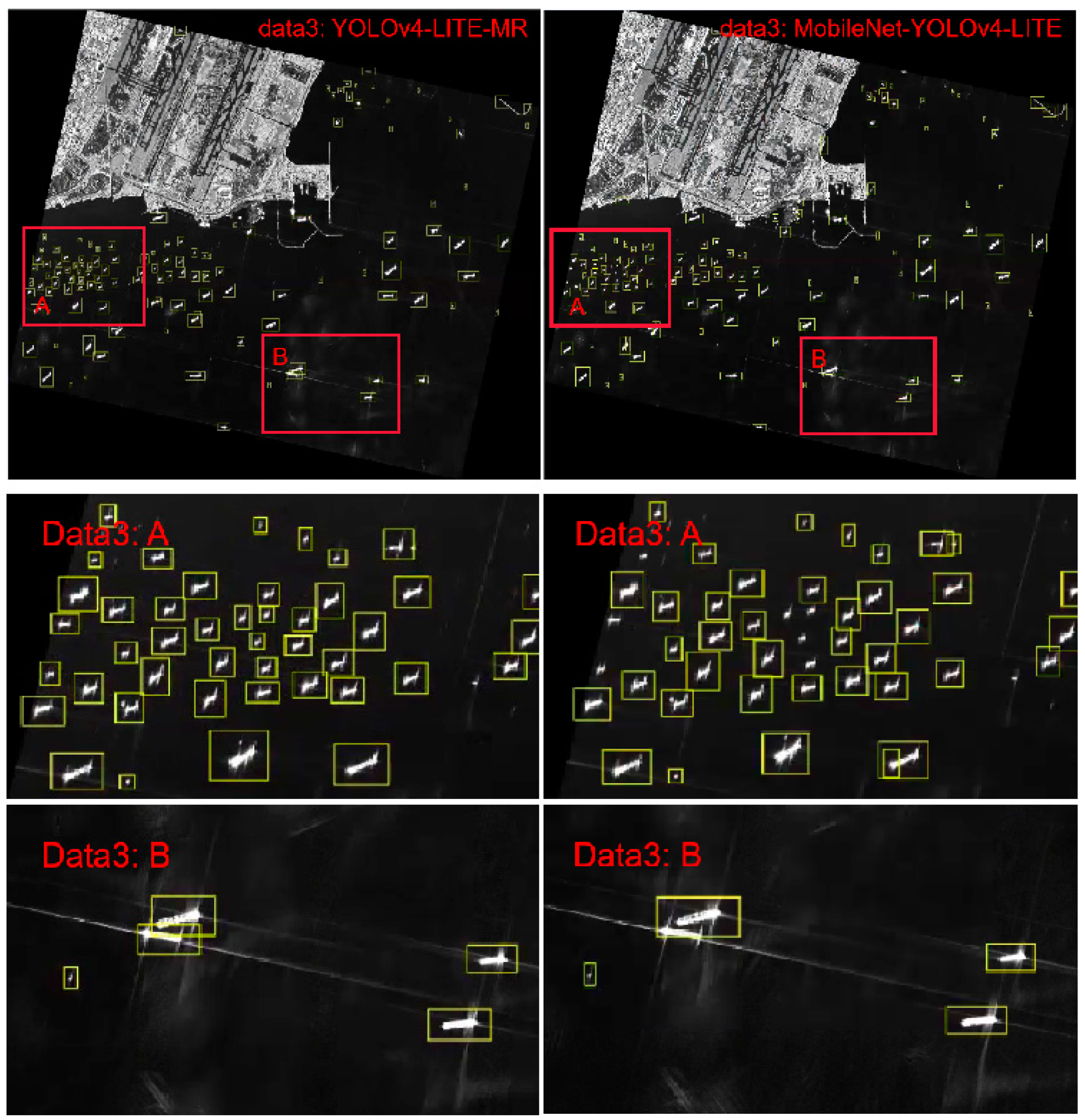
According to the above analysis, considering the sea observation, the situation of ship detection, and the resource space of the satellite system, we propose a lightweight detection method for multi-scale ships in satellite SAR images. A real-time ship detection model on satellites robust enough to multi-scale objects, complex backgrounds, and large scene SAR images under the platform of limited computing resources is implemented. Aiming at the diversity of ship target scales in ship detection in spaceborne SAR images, the input of large scene images, and the limited resources on board, the single-stage target detection method is improved, respectively. The main contributions of our work are as follows:
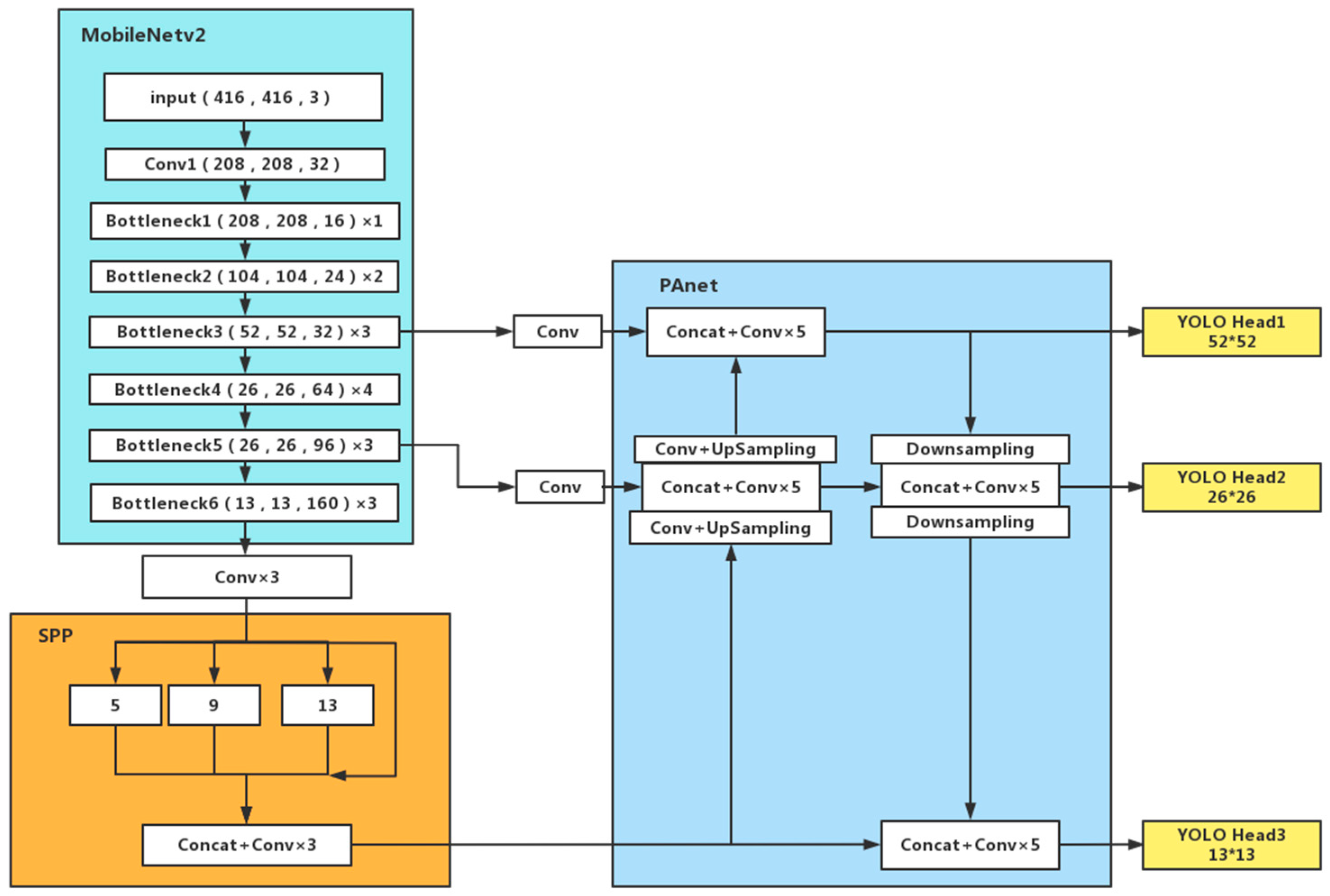
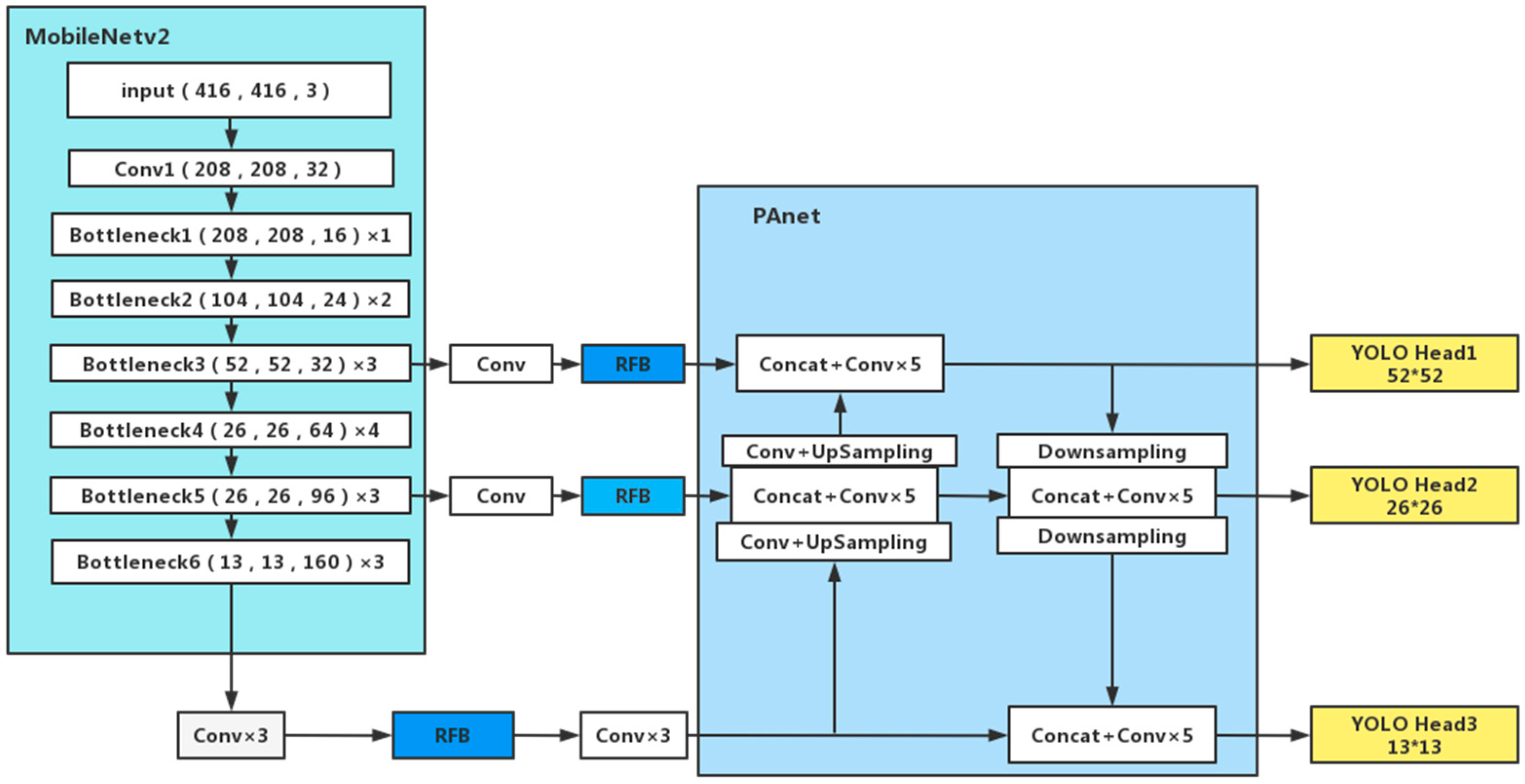
In order to make the model meet the development needs of real-time mission planning on satellites, we use the improved MobileNetv2 as the backbone feature extraction network of the YOLOv4-LITE model. In the Path Aggregation Network (PANet) structure, the depthwise separable convolution is used to replace the standard convolution, which ensures the lightness and detection speed of the network, and enables the constructed network model to meet the requirements of limited computing resources on the satellite;
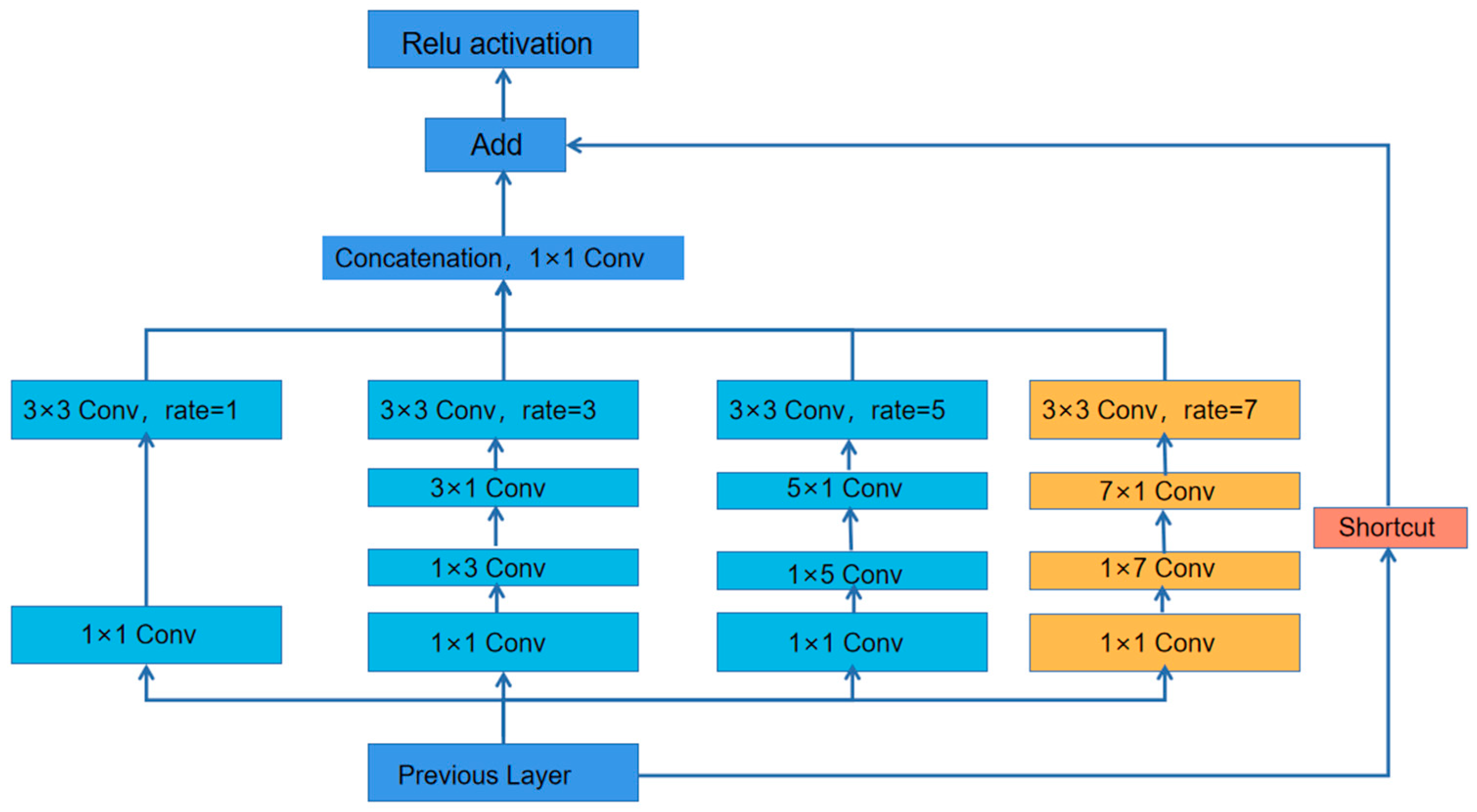
In order to solve the problem of ship target scale diversity, the RFB structure is introduced and improved to enhance the learning characteristics of the lightweight model, obtain more effective information by increasing the receptive field of the network model, and improve the accuracy of multi-scale ship detection, especially the detection accuracy of small target ships. This makes full use of fewer parameters to extract features effectively, and builds a real-time ship detection model on satellite to meet the development needs of real-time mission planning on satellite;
The K-means algorithm is used to cluster the data set, and a sliding window blocking method is designed to solve the problem of image input. At the same time, based on the sliding window blocking method, a quadratic non-maximum suppression (NMS) operation is added to the output of the network, and the
CIoU (Complete Intersection over Union)-NMS combination method is used to suppress the repeated frame selection of a ship caused by the sliding window blocking method. The organizational structure of this paper is as follows. In
Section 2, we will introduce two detection methods, respectively, and describe the detailed process of our proposed method.
Section 3 describes the sliding window blocking method and the quadratic non maximum suppression operation. The detailed experimental process is shown in
Section 4. See
Section 5 for conclusions.
3. Sliding Window Partition Method
All target detection methods based on deep learning have strict restrictions on image input, and all input images will be adjusted to fixed pixel size. The imaging scene of the SAR image is enormous, therefore the image needs to be divided into blocks to avoid the size of the ship target from being resampled to a few or even only one pixel, which affects the detection performance.
It was inspired by the idea of the CFAR algorithm to detect images through sliding window technology. A sliding window detection method is designed and used, as shown in
Figure 5. The square area with side length L is used to traverse the whole image in both horizontal and vertical directions, set an overlap of the sub-image with a length of S to avoid damage to the ship by the block, and complete the sliding window block process of the entire image.
The subgraph size is L × L, and the length of the overlapping part is S (
Figure 5). Among them, L is set at 1650 pixels. The size of S should be larger than the number of pixels along ship’s length in the image. It is set to 320 pixels, according to the ship size and image resolution. The above parameters can be changed adaptively based on the image’s resolution.
However, in practical applications, it is found that the sliding window detection method will bring a large number of false alarms, mainly due to repeated frame selection of a ship. In order to solve this problem, we added a non-maximum suppression (NMS) operation in the output part of the network to exclude the detection box where the intersection over union (
IoU) [
46] is less than the threshold, and to suppress the ships selected repeatedly.
At the same time, it is found that different
IoU strategies used in the sliding window blocking method have different inhibitory effects on the repeated frame selection of ship targets. In order to determine the best combination of the
IoU method and NMS, the experiments of
IoU,
DIoU [
47], and
CIoU [
48] methods are carried out, respectively. Finally, it is determined to add the combination of
CIoU loss and NMS to the output port of the prediction network.
CIoU is set to 0.3, eliminating the detection frames more minor than the threshold, suppressing repeated false positives, and selecting targets in multiple frames.
IoU loss function is needed in the detection frame regression in the target detection task. The prediction box is defined as
, and the actual box is
, the
IoU loss function Equation (3) as follows:
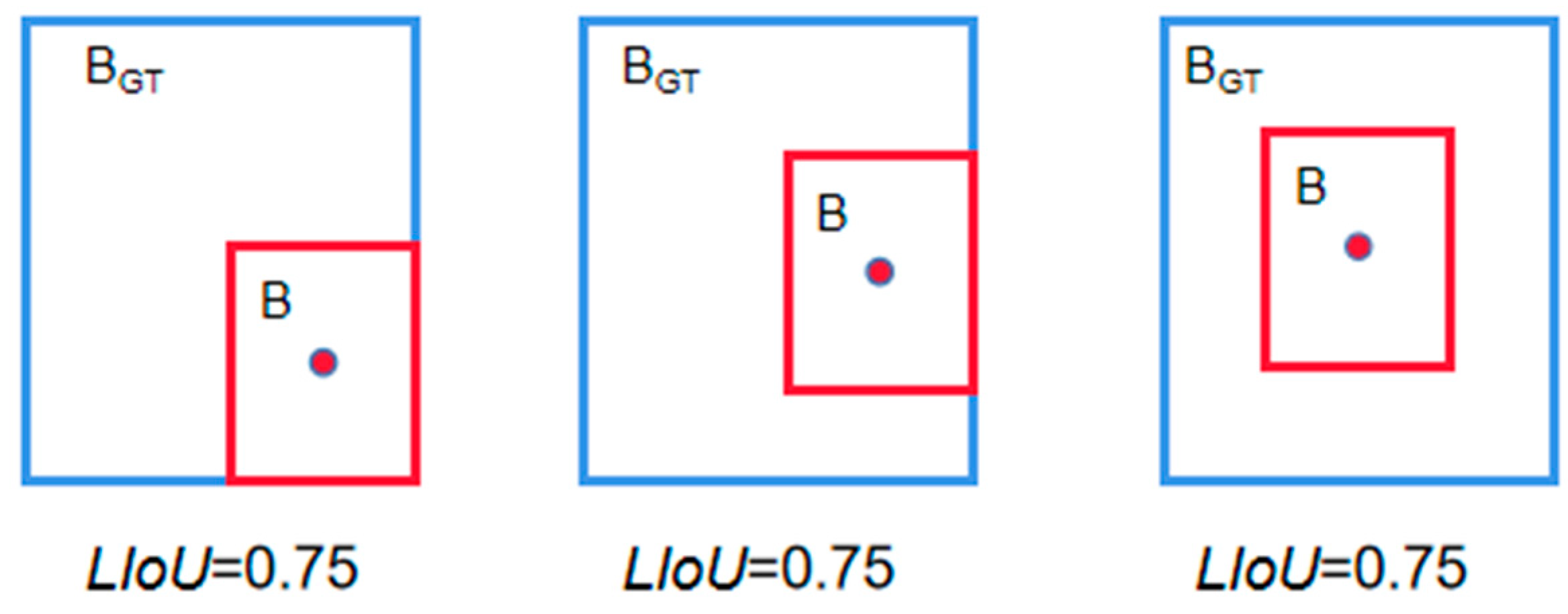
However, as shown in
Figure 6, the
IoU loss function has two problems: first, when the prediction box and the target box do not intersect,
IoU is 0. Then, the loss function is not differentiable, and the gradient direction is lost. In the
IoU loss function, it is impossible to optimize the disjoint case of two boxes. Second, when the size of the two prediction boxes are the same, the two IOUs are also equal, and the
IoU loss cannot distinguish the difference in the intersection of the two.
Compared to the
IoU loss function, the
DIoU loss function is more consistent with the mechanism of target box regression and converges faster without the risk of divergence. The
DIoU loss is defined as:
Among them,
b and
bGT are the center points of
B and
BGT, respectively.
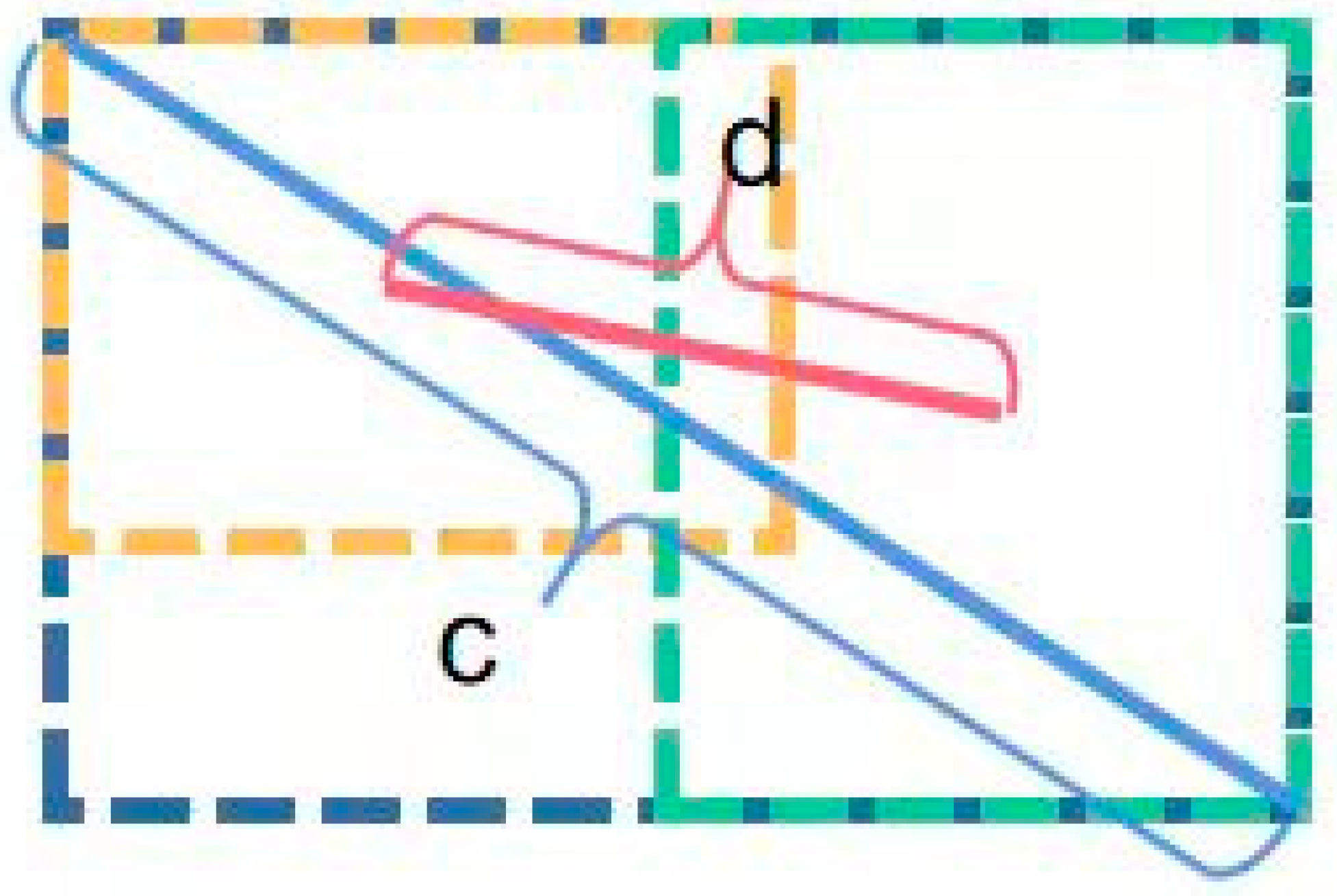
represents the Euclidean distance between the two centers; and c is the diagonal length of the minimum enclosing box that can enclose
and
, as shown in
Figure 7.
DIoU has two distinct advantages: (1) When and BGT do not intersect, it can guide the direction movement of and directly minimize the distance between and BGT, convergence speed is fast; (2) it can be applied to non-maximum suppression (NMS) to make NMS more reasonable.
However, when the center points of the two frames coincide, that is, the values of c and d remain unchanged,
DIoU cannot accurately determine the position of the anchor frame, which brings a loss of accuracy. Therefore, it is necessary to introduce the aspect ratio of the anchor frame at this time.
CIoU can effectively solve this problem and make the prediction frame more consistent with the actual frame. The calculation formula is shown in Equation (6):
where α is the weight function, and
is used to measure the consistency of the aspect ratio.
The
CIoU loss is defined as:


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}