
Kernel Ridge Regression Hybrid Method for Wheat Yield Prediction with Satellite-Derived Predictors

 ,
,  ,
, 
 ,
,  and
and 
Abstract
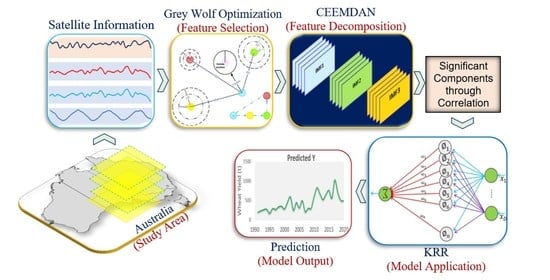
:
1. Introduction
2. Materials and Methods
2.1. Theoretical Frameworks
2.1.1. Kernel Ridge Regression (KRR)
2.1.2. Complete Ensemble Empirical Mode Decomposition with Adaptive Noise
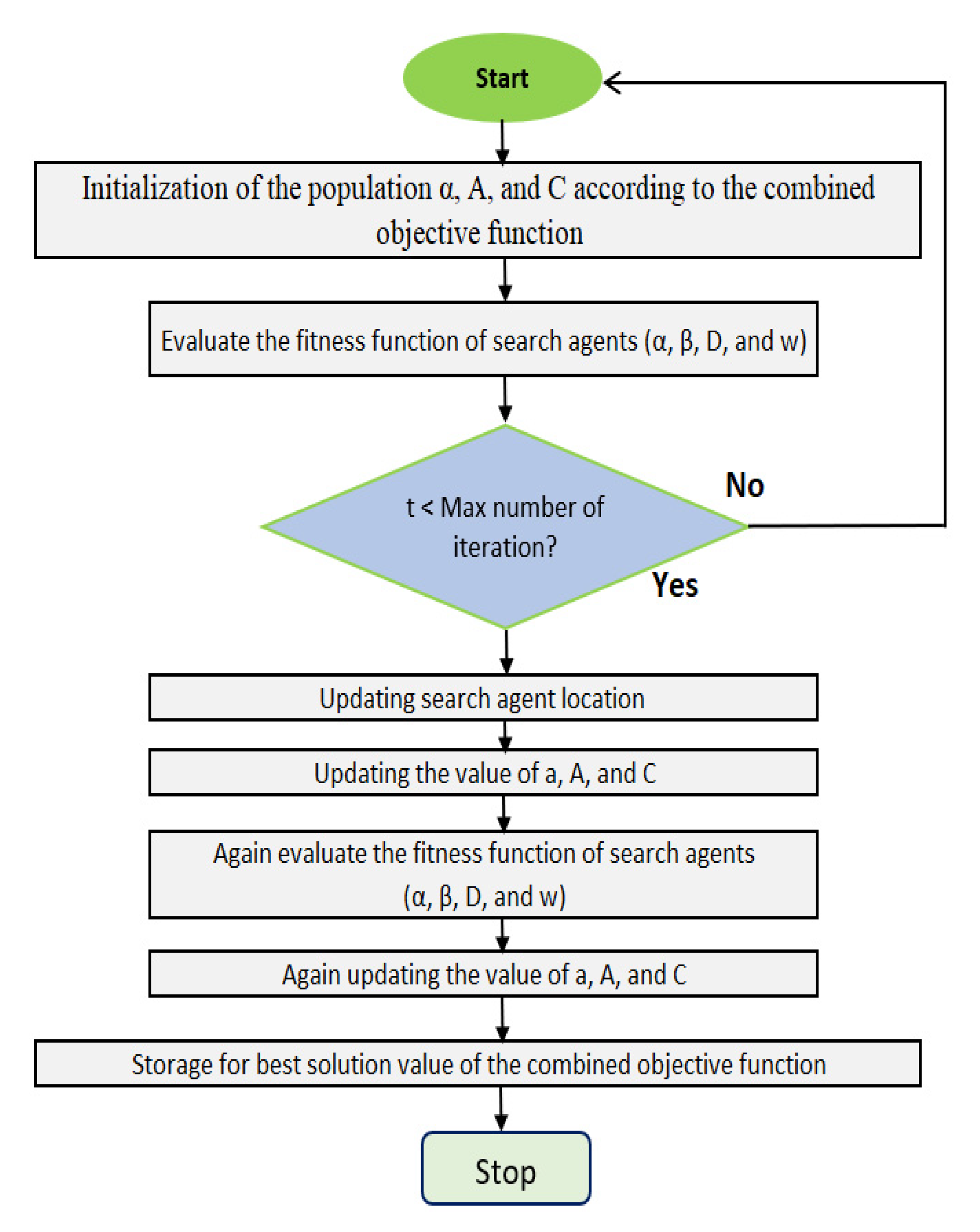
2.1.3. Grey Wolf Optimizer (GWO)
2.1.4. Particle Swarm Optimiser (PSO)
2.1.5. Atom Search Optimiser (ASO)
2.1.6. Ant Colony Optimiser (ASO)
2.1.7. Comparing Predictive Models
3. Study Area and Data
3.1. Study Area and Wheat Yield Data
3.2. Predictor Variables
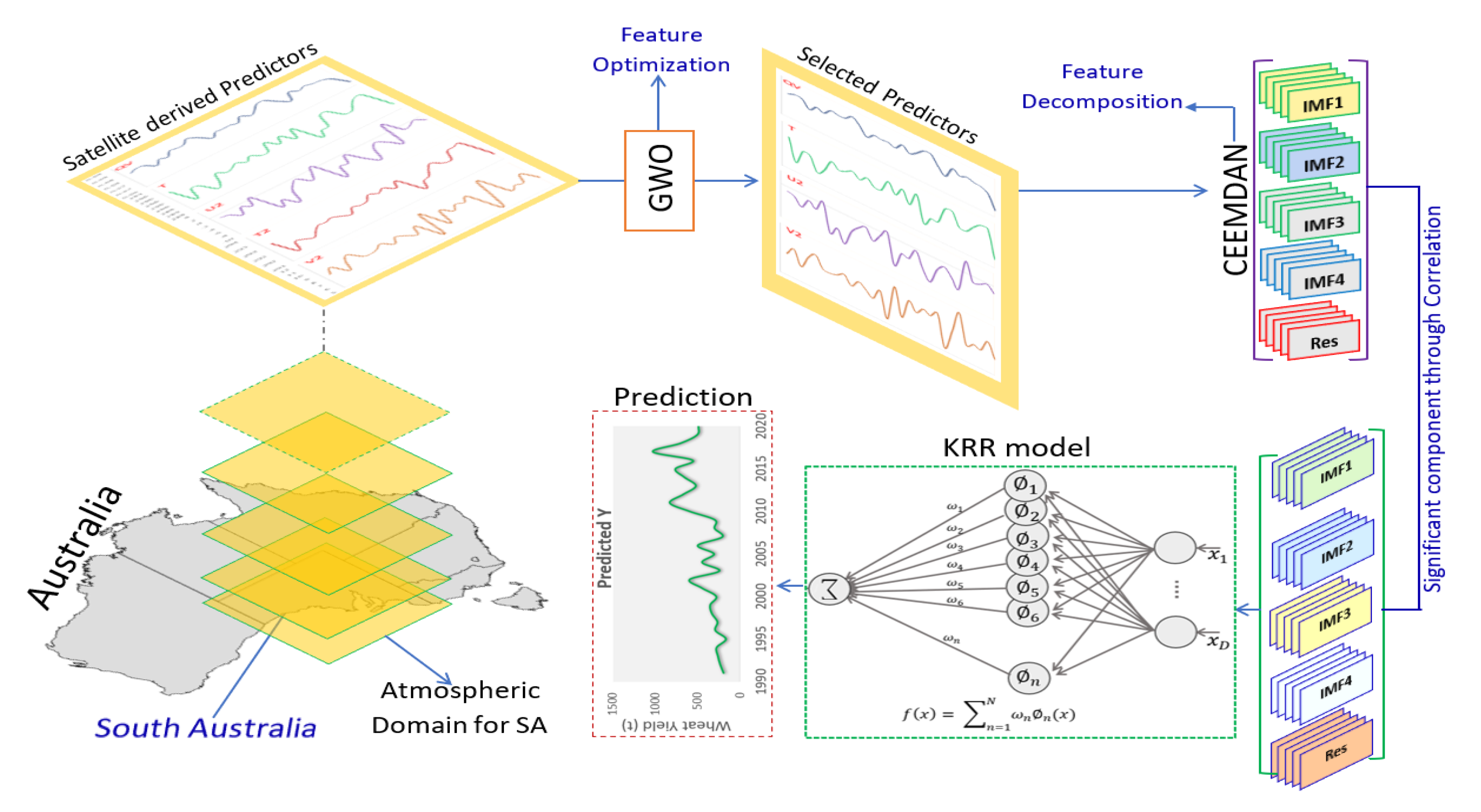
3.3. Development of GWO-CEEMDAN-KRR Model
3.4. Predictive Model Evaluation
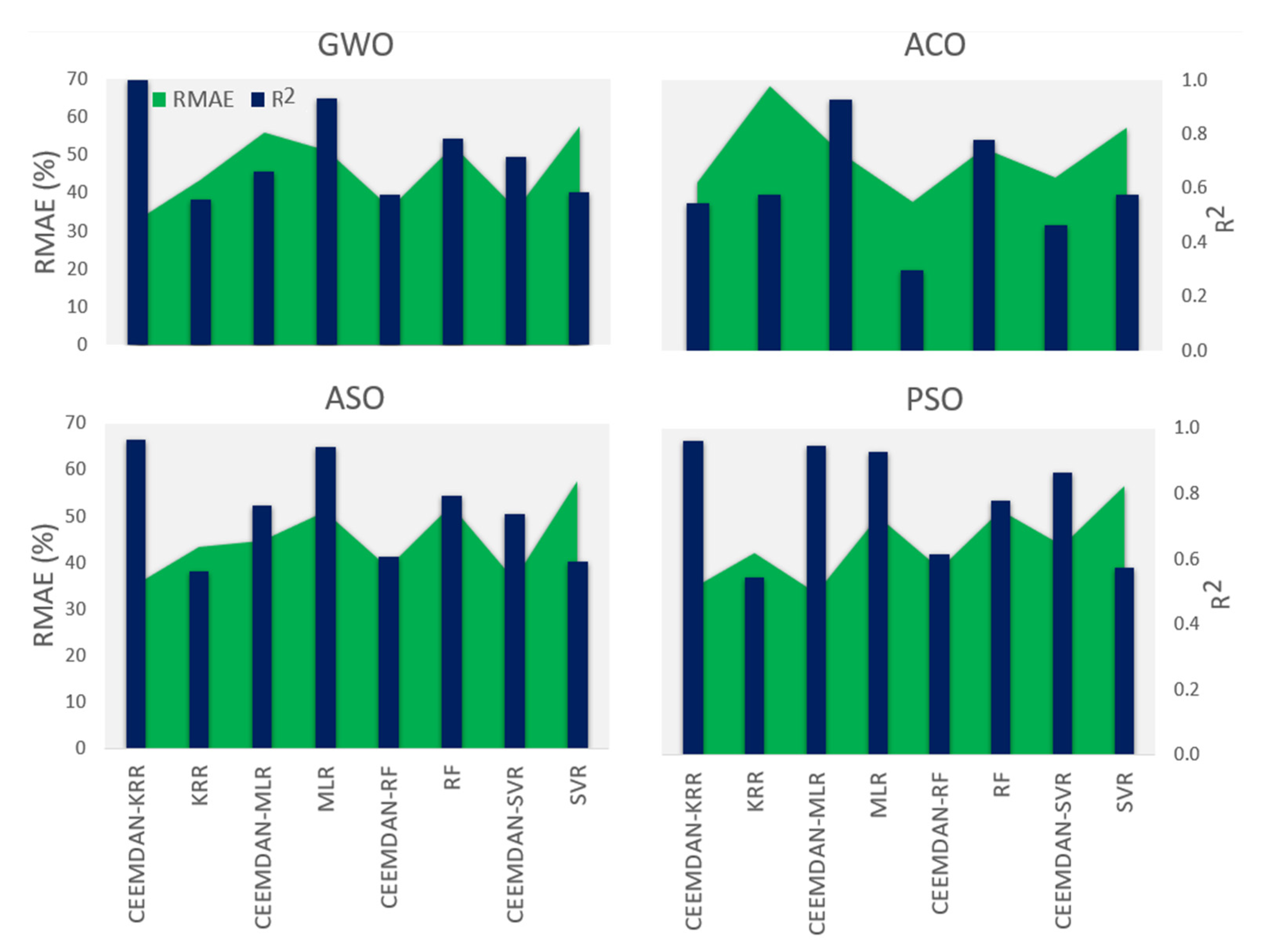
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pathak, H.; Aggarwal, P.K.; Singh, S. Climate Change Impact, Adaptation and Mitigation in Agriculture: Methodology for Assessment and Applications; Indian Agricultural Research Institute: New Delhi, India, 2012; Volume 302. [Google Scholar]
- Rosenberg, N.J. Adaptation of agriculture to climate change. Clim. Chang. 1992, 21, 385–405. [Google Scholar] [CrossRef]
- Rickards, L.; Howden, S.M. Transformational adaptation: Agriculture and climate change. Crop Pasture Sci. 2012, 63, 240–250. [Google Scholar] [CrossRef]
- Leng, G.; Hall, J.W. Predicting spatial and temporal variability in crop yields: An inter-comparison of machine learning, regression and process-based models. Environ. Res. Lett. 2020, 15, 044027. [Google Scholar] [CrossRef]
- Iizumi, T.; Ramankutty, N. How do weather and climate influence cropping area and intensity? Glob. Food Secur. 2015, 4, 46–50. [Google Scholar] [CrossRef] [Green Version]
- Ruane, A.C.; Major, D.C.; Winston, H.Y.; Alam, M.; Hussain, S.G.; Khan, A.S.; Hassan, A.; Al Hossain, B.M.T.; Goldberg, R.; Horton, R.M. Multi-factor impact analysis of agricultural production in Bangladesh with climate change. Glob. Environ. Chang. 2013, 23, 338–350. [Google Scholar] [CrossRef] [Green Version]
- Challinor, A.J.; Watson, J.; Lobell, D.B.; Howden, S.; Smith, D.; Chhetri, N. A meta-analysis of crop yield under climate change and adaptation. Nat. Clim. Chang. 2014, 4, 287–291. [Google Scholar] [CrossRef]
- Olesen, J.E.; Bindi, M. Consequences of climate change for European agricultural productivity, land use and policy. Eur. J. Agron. 2002, 16, 239–262. [Google Scholar] [CrossRef]
- Thornton, P.K.; Jones, P.G.; Alagarswamy, G.; Andresen, J. Spatial variation of crop yield response to climate change in East Africa. Glob. Environ. Chang. 2009, 19, 54–65. [Google Scholar] [CrossRef]
- Alexandrov, V.; Hoogenboom, G. The impact of climate variability and change on crop yield in Bulgaria. Agric. For. Meteorol. 2000, 104, 315–327. [Google Scholar] [CrossRef]
- Romeijn, H.; Faggian, R.; Diogo, V.; Sposito, V. Evaluation of deterministic and complex analytical hierarchy process methods for agricultural land suitability analysis in a changing climate. ISPRS Int. J. Geo-Inf. 2016, 5, 99. [Google Scholar] [CrossRef] [Green Version]
- Aschonitis, V.; Mastrocicco, M.; Colombani, N.; Salemi, E.; Kazakis, N.; Voudouris, K.; Castaldelli, G. Assessment of the intrinsic vulnerability of agricultural land to water and nitrogen losses via deterministic approach and regression analysis. Water Air Soil Pollut. 2012, 223, 1605–1614. [Google Scholar] [CrossRef]
- Meenken, E.; Wheeler, D.; Brown, H.; Teixeira, E.; Espig, M.; Bryant, J.; Triggs, C. Framework for uncertainty evaluation and estimation in deterministic agricultural models. Nutr. Manag. Farmed Landsc. Occas. Rep. 2020, 33, 1–11. [Google Scholar]
- Kingsley, J.; Afu, S.M.; Isong, I.A.; Chapman, P.A.; Kebonye, N.M.; Ayito, E.O. Estimation of soil organic carbon distribution by geostatistical and deterministic interpolation methods: A case study of the southeastern soils of nigeria. Environ. Eng. Manag. J. EEMJ 2021, 20, 1077–1085. [Google Scholar] [CrossRef]
- Holman, I.; Tascone, D.; Hess, T. A comparison of stochastic and deterministic downscaling methods for modelling potential groundwater recharge under climate change in East Anglia, UK: Implications for groundwater resource management. Hydrogeol. J. 2009, 17, 1629–1641. [Google Scholar] [CrossRef]
- Sharma, E.; Deo, R.C.; Prasad, R.; Parisi, A.V. A hybrid air quality early-warning framework: An hourly forecasting model with online sequential extreme learning machines and empirical mode decomposition algorithms. Sci. Total Environ. 2020, 709, 135934. [Google Scholar] [CrossRef]
- Sharma, E.; Deo, R.C.; Prasad, R.; Parisi, A.V.; Raj, N. Deep Air Quality Forecasts: Suspended Particulate Matter Modeling With Convolutional Neural and Long Short-Term Memory Networks. IEEE Access 2020, 8, 209503–209516. [Google Scholar] [CrossRef]
- Kouadio, L.; Deo, R.C.; Byrareddy, V.; Adamowski, J.F.; Mushtaq, S.; Nguyen, V.P. Artificial intelligence approach for the prediction of Robusta coffee yield using soil fertility properties. Comput. Electron. Agric. 2018, 155, 324–338. [Google Scholar] [CrossRef]
- Ren, J.; Chen, Z.; Zhou, Q.; Tang, H. Regional yield estimation for winter wheat with MODIS-NDVI data in Shandong, China. Int. J. Appl. Earth Obs. Geoinf. 2008, 10, 403–413. [Google Scholar] [CrossRef]
- Franch, B.; Vermote, E.; Becker-Reshef, I.; Claverie, M.; Huang, J.; Zhang, J.; Justice, C.; Sobrino, J.A. Improving the timeliness of winter wheat production forecast in the United States of America, Ukraine and China using MODIS data and NCAR Growing Degree Day information. Remote Sens. Environ. 2015, 161, 131–148. [Google Scholar] [CrossRef]
- Han, J.; Zhang, Z.; Cao, J.; Luo, Y.; Zhang, L.; Li, Z.; Zhang, J. Prediction of winter wheat yield based on multi-source data and machine learning in China. Remote Sens. 2020, 12, 236. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zhang, Z.; Feng, L.; Du, Q.; Runge, T. Combining multi-source data and machine learning approaches to predict winter wheat yield in the conterminous United States. Remote Sens. 2020, 12, 1232. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Huang, J.; Feng, Q.; Yin, D. Winter wheat yield prediction at county level and uncertainty analysis in main wheat-producing regions of China with deep learning approaches. Remote Sens. 2020, 12, 1744. [Google Scholar] [CrossRef]
- Haider, S.A.; Naqvi, S.R.; Akram, T.; Umar, G.A.; Shahzad, A.; Sial, M.R.; Khaliq, S.; Kamran, M. LSTM neural network based forecasting model for wheat production in Pakistan. Agronomy 2019, 9, 72. [Google Scholar] [CrossRef] [Green Version]
- Kolotii, A.; Kussul, N.; Shelestov, A.; Skakun, S.; Yailymov, B.; Basarab, R.; Lavreniuk, M.; Oliinyk, T.; Ostapenko, V. Comparison of biophysical and satellite predictors for wheat yield forecasting in ukraine. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-7/W3, 39–44. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Landau, S.; Mitchell, R.; Barnett, V.; Colls, J.; Craigon, J.; Payne, R. A parsimonious, multiple-regression model of wheat yield response to environment. Agric. For. Meteorol. 2000, 101, 151–166. [Google Scholar] [CrossRef]
- Kumar, S.; Attri, S.; Singh, K. Comparison of Lasso and stepwise regression technique for wheat yield prediction. J. Agrometeorol. 2019, 21, 188–192. [Google Scholar] [CrossRef]
- Kogan, F.; Kussul, N.N.; Adamenko, T.I.; Skakun, S.V.; Kravchenko, A.N.; Krivobok, A.A.; Shelestov, A.Y.; Kolotii, A.V.; Kussul, O.M.; Lavrenyuk, A.N. Winter wheat yield forecasting: A comparative analysis of results of regression and biophysical models. J. Autom. Inf. Sci. 2013, 45, 68–81. [Google Scholar] [CrossRef]
- Kamir, E.; Waldner, F.; Hochman, Z. Estimating wheat yields in Australia using climate records, satellite image time series and machine learning methods. ISPRS J. Photogramm. Remote Sens. 2020, 160, 124–135. [Google Scholar] [CrossRef]
- Bali, N.; Singla, A. Deep Learning Based Wheat Crop Yield Prediction Model in Punjab Region of North India. Appl. Artif. Intell. 2021, 1–25. [Google Scholar] [CrossRef]
- Liaghat, S.; Balasundram, S.K. A review: The role of remote sensing in precision agriculture. Am. J. Agric. Biol. Sci. 2010, 5, 50–55. [Google Scholar] [CrossRef] [Green Version]
- Ozdogan, M.; Yang, Y.; Allez, G.; Cervantes, C. Remote sensing of irrigated agriculture: Opportunities and challenges. Remote Sens. 2010, 2, 2274–2304. [Google Scholar] [CrossRef] [Green Version]
- Nelson, R.; Kokic, P.; Crimp, S.; Meinke, H.; Howden, S. The vulnerability of Australian rural communities to climate variability and change: Part I—Conceptualising and measuring vulnerability. Environ. Sci. Policy 2010, 13, 8–17. [Google Scholar] [CrossRef]
- Luo, Q.; Bellotti, W.; Williams, M.; Wang, E. Adaptation to climate change of wheat growing in South Australia: Analysis of management and breeding strategies. Agric. Ecosyst. Environ. 2009, 129, 261–267. [Google Scholar] [CrossRef] [Green Version]
- Luo, Q.; Bellotti, W.; Williams, M.; Bryan, B. Potential impact of climate change on wheat yield in South Australia. Agric. For. Meteorol. 2005, 132, 273–285. [Google Scholar] [CrossRef]
- Tikhamarine, Y.; Malik, A.; Kumar, A.; Souag-Gamane, D.; Kisi, O. Estimation of monthly reference evapotranspiration using novel hybrid machine learning approaches. Hydrol. Sci. J. 2019, 64, 1824–1842. [Google Scholar] [CrossRef]
- Gundoshmian, T.M.; Ardabili, S.; Mosavi, A.; Várkonyi-Kóczy, A.R. Prediction of combine harvester performance using hybrid machine learning modeling and response surface methodology. In Proceedings of the 18th International Conference on Global Research and Education, Inter-Academia 2019, Budapest, Hungary, 4–7 September 2019; pp. 345–360. [Google Scholar]
- Shin, J.-Y.; Kim, K.R.; Ha, J.-C. Seasonal forecasting of daily mean air temperatures using a coupled global climate model and machine learning algorithm for field-scale agricultural management. Agric. For. Meteorol. 2020, 281, 107858. [Google Scholar] [CrossRef]
- Kabir, M.M.; Shahjahan, M.; Murase, K. A new hybrid ant colony optimization algorithm for feature selection. Expert Syst. Appl. 2012, 39, 3747–3763. [Google Scholar] [CrossRef]
- Too, J.; Abdullah, A.R. Chaotic atom search optimization for feature selection. Arab. J. Sci. Eng. 2020, 45, 6063–6079. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. A new feature selection method to improve the document clustering using particle swarm optimization algorithm. J. Comput. Sci. 2018, 25, 456–466. [Google Scholar] [CrossRef]
- Wang, Y.; Yuan, Z.; Liu, H.; Xing, Z.; Ji, Y.; Li, H.; Fu, Q.; Mo, C. A new scheme for probabilistic forecasting with an ensemble model based on CEEMDAN and AM-MCMC and its application in precipitation forecasting. Expert Syst. Appl. 2022, 187, 115872. [Google Scholar] [CrossRef]
- Ghali, U.M.; Usman, A.; Degm, M.A.A.; Alsharksi, A.N.; Naibi, A.M.; Abba, S. Applications of artificial intelligence-based models and multi-linear regression for the prediction of thyroid stimulating hormone level in the human body. Int. J. Adv. Sci. Technol. 2020, 29, 3690–3699. [Google Scholar]
- Ali, M.; Prasad, R.; Xiang, Y.; Yaseen, Z.M. Complete ensemble empirical mode decomposition hybridized with random forest and kernel ridge regression model for monthly rainfall forecasts. J. Hydrol. 2020, 584, 124647. [Google Scholar] [CrossRef]
- Kisi, O.; Parmar, K.S. Application of least square support vector machine and multivariate adaptive regression spline models in long term prediction of river water pollution. J. Hydrol. 2016, 534, 104–112. [Google Scholar] [CrossRef]
- Zhao, P.; Xia, J.; Dai, Y.; He, J. Wind speed prediction using support vector regression. In Proceedings of the 2010 5th IEEE Conference on Industrial Electronics and Applications, Auckland, New Zealand, 15–17 June 2015; pp. 882–886. [Google Scholar]
- Naik, J.; Satapathy, P.; Dash, P. Short-term wind speed and wind power prediction using hybrid empirical mode decomposition and kernel ridge regression. Appl. Soft Comput. 2018, 70, 1167–1188. [Google Scholar] [CrossRef]
- Li, T.; Zhou, Y.; Li, X.; Wu, J.; He, T. Forecasting daily crude oil prices using improved CEEMDAN and ridge regression-based predictors. Energies 2019, 12, 3603. [Google Scholar] [CrossRef] [Green Version]
- Santhosh, M.; Venkaiah, C.; Kumar, D.V. Ensemble empirical mode decomposition based adaptive wavelet neural network method for wind speed prediction. Energy Convers. Manag. 2018, 168, 482–493. [Google Scholar] [CrossRef]
- Liang, T.; Xie, G.; Fan, S.; Meng, Z. A Combined Model Based on CEEMDAN, Permutation Entropy, Gated Recurrent Unit Network, and an Improved Bat Algorithm for Wind Speed Forecasting. IEEE Access 2020, 8, 165612–165630. [Google Scholar] [CrossRef]
- Jin, T.; Li, Q.; Mohamed, M.A. A novel adaptive EEMD method for switchgear partial discharge signal denoising. IEEE Access 2019, 7, 58139–58147. [Google Scholar] [CrossRef]
- Zhang, W.; Qu, Z.; Zhang, K.; Mao, W.; Ma, Y.; Fan, X. A combined model based on CEEMDAN and modified flower pollination algorithm for wind speed forecasting. Energy Convers. Manag. 2017, 136, 439–451. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar]
- Ahmed, M.; Deo, R.C.; Raj, N.; Ghahramani, A.; Feng, Q.; Yin, Z.; Yang, L. Deep Learning Forecasts of Soil Moisture: Convolutional Neural Network and Gated Recurrent Unit Models Coupled with Satellite-Derived MODIS, Observations and Synoptic-Scale Climate Index Data. Remote Sens. 2021, 13, 554. [Google Scholar] [CrossRef]
- Al-Tashi, Q.; Kadir, S.J.A.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Binary optimization using hybrid grey wolf optimization for feature selection. IEEE Access 2019, 7, 39496–39508. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN′95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995. [Google Scholar]
- Roy, D.K.; Lal, A.; Sarker, K.K.; Saha, K.K.; Datta, B. Optimization algorithms as training approaches for prediction of reference evapotranspiration using adaptive neuro fuzzy inference system. Agric. Water Manag. 2021, 255, 107003. [Google Scholar] [CrossRef]
- Sun, L.; Song, X.; Chen, T. An improved convergence particle swarm optimization algorithm with random sampling of control parameters. J. Control. Sci. Eng. 2019, 2019, 7478498. [Google Scholar] [CrossRef]
- Zhao, W.; Wang, L.; Zhang, Z. Atom search optimization and its application to solve a hydrogeologic parameter estimation problem. Knowl. Based Syst. 2019, 163, 283–304. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Dorigo, M.; Di Caro, G. Ant colony optimization: A new meta-heuristic. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Washington, DC, USA, 6–9 July 1999; pp. 1470–1477. [Google Scholar]
- Ahmed, M.; Deo, R.; Feng, Q.; Ghahramani, A.; Raj, N.; Yin, Z.; Yang, L. Hybrid deep learning method for a week-ahead evapotranspiration forecasting. Stoch. Environ. Res. Risk Assess. 2022, 36, 831–849. [Google Scholar] [CrossRef]
- Sweetlin, J.D.; Nehemiah, H.K.; Kannan, A. Feature selection using ant colony optimization with tandem-run recruitment to diagnose bronchitis from CT scan images. Comput. Methods Programs Biomed. 2017, 145, 115–125. [Google Scholar] [CrossRef]
- Abba, S.; Hadi, S.J.; Abdullahi, J. River water modelling prediction using multi-linear regression, artificial neural network, and adaptive neuro-fuzzy inference system techniques. Procedia Comput. Sci. 2017, 120, 75–82. [Google Scholar] [CrossRef]
- Yang, P.; Xia, J.; Zhang, Y.; Hong, S. Temporal and spatial variations of precipitation in Northwest China during 1960–2013. Atmos. Res. 2017, 183, 283–295. [Google Scholar] [CrossRef]
- Belayneh, A.; Adamowski, J. Standard precipitation index drought forecasting using neural networks, wavelet neural networks, and support vector regression. Appl. Comput. Intell. Soft Comput. 2012, 2012, 6. [Google Scholar] [CrossRef]
- Deo, R.C.; Wen, X.; Qi, F. A wavelet-coupled support vector machine model for forecasting global incident solar radiation using limited meteorological dataset. Appl. Energy 2016, 168, 568–593. [Google Scholar] [CrossRef]
- Dhiman, H.S.; Deb, D.; Guerrero, J.M. Hybrid machine intelligent SVR variants for wind forecasting and ramp events. Renew. Sustain. Energy Rev. 2019, 108, 369–379. [Google Scholar] [CrossRef]
- Dodangeh, E.; Panahi, M.; Rezaie, F.; Lee, S.; Bui, D.T.; Lee, C.-W.; Pradhan, B. Novel hybrid intelligence models for flood-susceptibility prediction: Meta optimization of the GMDH and SVR models with the genetic algorithm and harmony search. J. Hydrol. 2020, 590, 125423. [Google Scholar] [CrossRef]
- Baydaroğlu, Ö.; Koçak, K. SVR-based prediction of evaporation combined with chaotic approach. J. Hydrol. 2014, 508, 356–363. [Google Scholar] [CrossRef]
- Khosla, E.; Dharavath, R.; Priya, R. Crop yield prediction using aggregated rainfall-based modular artificial neural networks and support vector regression. Environ. Dev. Sustain. 2020, 22, 5687–5708. [Google Scholar] [CrossRef]
- Jaikla, R.; Auephanwiriyakul, S.; Jintrawet, A. Rice yield prediction using a support vector regression method. In Proceedings of the 2008 5th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Chiang Rai, Thailand, 14–17 May 2008; pp. 29–32. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Jui, S.J.J.; Ahmed, A.A.M.; Bose, A.; Raj, N.; Sharma, E.; Soar, J.; Chowdhury, M.W.I. Spatiotemporal Hybrid Random Forest Model for Tea Yield Prediction Using Satellite-Derived Variables. Remote Sens. 2022, 14, 805. [Google Scholar] [CrossRef]
- Prasad, N.; Patel, N.; Danodia, A. Crop yield prediction in cotton for regional level using random forest approach. Spat. Inf. Res. 2021, 29, 195–206. [Google Scholar] [CrossRef]
- Zhao, Y.; Potgieter, A.B.; Zhang, M.; Wu, B.; Hammer, G.L. Predicting wheat yield at the field scale by combining high-resolution Sentinel-2 satellite imagery and crop modelling. Remote Sens. 2020, 12, 1024. [Google Scholar] [CrossRef] [Green Version]
- ABS. Agricultural Commodities, Australia, 2019–2020 Financial Year. 2020. Available online: https://www.abs.gov.au/statistics/industry/agriculture/agricultural-commodities-australia/latest-release (accessed on 25 December 2021).
- AWE. Australian Government Department of Agriculture, Water and the Environment. National Overview—DAWE. 2021. Available online: https://www.awe.gov.au/abares/research-topics/agricultural-outlook/australian-crop-report/overview (accessed on 25 December 2021).
- Wang, B.; Chen, C.; Li Liu, D.; Asseng, S.; Yu, Q.; Yang, X. Effects of climate trends and variability on wheat yield variability in eastern Australia. Clim. Res. 2015, 64, 173–186. [Google Scholar] [CrossRef]
- Lehtonen, R.; Pahkinen, E. Practical Methods for Design and Analysis of Complex Surveys; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- ABARES. Department of Agriculture, Water and the Environment-ABARES. 2022. Available online: https://www.awe.gov.au/abares (accessed on 25 December 2021).
- Doraiswamy, P.C.; Moulin, S.; Cook, P.W.; Stern, A. Crop yield assessment from remote sensing. Photogramm. Eng. Remote Sens. 2003, 69, 665–674. [Google Scholar] [CrossRef]
- Ahmed, A.A.M.; Ahmed, M.H.; Saha, S.K.; Ahmed, O.; Sutradhar, A. Optimization Algorithms as Training Approach with Deep Learning Methods to Develop an Ultraviolet Index Forecasting Model. 2021. Available online: https://www.researchgate.net/publication/354741827_Optimization_Algorithms_As_Training_Approach_With_Deep_Learning_Methods_To_Develop_An_Ultraviolet_Index_Forecasting_Model (accessed on 20 December 2021).
- Teng, W.; de Jeu, R.; Doraiswamy, P.; Kempler, S.; Mladenova, I.; Shannon, H. Improving world agricultural supply and demand estimates by integrating NASA remote sensing soil moisture data into USDA world agricultural outlook board decision making environment. In Proceedings of the American Society of Photogrammetry and Remote Sensing 2010 Annual Conference, San Diego, CA, USA, 26–30 April 2010. [Google Scholar]
- Sohrabinia, M.; Khorshiddoust, A.M. Application of satellite data and GIS in studying air pollutants in Tehran. Habitat Int. 2007, 31, 268–275. [Google Scholar] [CrossRef]
- Guan, K.; Berry, J.A.; Zhang, Y.; Joiner, J.; Guanter, L.; Badgley, G.; Lobell, D.B. Improving the monitoring of crop productivity using spaceborne solar-induced fluorescence. Glob. Chang. Biol. 2016, 22, 716–726. [Google Scholar] [CrossRef] [PubMed]
- Kramer, O. Scikit-learn. In Machine Learning for Evolution Strategies; Springer: Berlin/Heidelberg, Germany, 2016; pp. 45–53. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Barrett, P.; Hunter, J.; Miller, J.T.; Hsu, J.-C.; Greenfield, P. matplotlib--A Portable Python Plotting Package. In Proceedings of the Astronomical Data Analysis Software and Systems XIV, Pasadena, CA, USA, 24–27 October 2004; p. 91. [Google Scholar]
- Waskom, M.; Botvinnik, O.; Ostblom, J.; Gelbart, M.; Lukauskas, S.; Hobson, P.; Gemperline, D.C.; Augspurger, T.; Halchenko, Y.; Cole, J.B. Mwaskom/Seaborn: v0.10.1 (April 2020). Zenodo. 2020. Available online: https://ui.adsabs.harvard.edu/abs/2020zndo...3767070W%2F/abstract (accessed on 25 December 2021).
- Krause, P.; Boyle, D.; Bäse, F. Comparison of different efficiency criteria for hydrological model assessment. Adv. Geosci. 2005, 5, 89–97. [Google Scholar] [CrossRef] [Green Version]
- Gandomi, A.H.; Yun, G.J.; Alavi, A.H. An evolutionary approach for modeling of shear strength of RC deep beams. Mater. Struct. 2013, 46, 2109–2119. [Google Scholar] [CrossRef]
- Samui, P.; Dixon, B. Application of support vector machine and relevance vector machine to determine evaporative losses in reservoirs. Hydrol. Processes 2012, 26, 1361–1369. [Google Scholar] [CrossRef]
- Deo, R.C.; Samui, P.; Kim, D. Estimation of monthly evaporative loss using relevance vector machine, extreme learning machine and multivariate adaptive regression spline models. Stoch. Environ. Res. Risk Assess. 2015, 30, 1769–1784. [Google Scholar] [CrossRef]
- Baez-Gonzalez, A.D.; Kiniry, J.R.; Maas, S.J.; Tiscareno, M.L.; Macias, C.J.; Mendoza, J.L.; Richardson, C.W.; Salinas, G.J.; Manjarrez, J.R. Large-area maize yield forecasting using leaf area index based yield model. Agron. J. 2005, 97, 418–425. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Tian, L.; Liang, S.; Ma, H.; Becker-Reshef, I.; Huang, Y.; Su, W.; Zhang, X.; Zhu, D.; Wu, W. Improving winter wheat yield estimation by assimilation of the leaf area index from Landsat TM and MODIS data into the WOFOST model. Agric. For. Meteorol. 2015, 204, 106–121. [Google Scholar] [CrossRef] [Green Version]
- Sagan, V.; Maimaitijiang, M.; Bhadra, S.; Maimaitiyiming, M.; Brown, D.R.; Sidike, P.; Fritschi, F.B. Field-scale crop yield prediction using multi-temporal WorldView-3 and PlanetScope satellite data and deep learning. ISPRS J. Photogramm. Remote Sens. 2021, 174, 265–281. [Google Scholar] [CrossRef]
- Shetty, S.A.; Padmashree, T.; Sagar, B.; Cauvery, N. Performance analysis on machine learning algorithms with deep learning model for crop yield prediction. In Data Intelligence and Cognitive Informatics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 739–750. [Google Scholar]
- Son, N.; Chen, C.; Chen, C.; Minh, V.; Trung, N. A comparative analysis of multitemporal MODIS EVI and NDVI data for large-scale rice yield estimation. Agric. For. Meteorol. 2014, 197, 52–64. [Google Scholar] [CrossRef]
- Satir, O.; Berberoglu, S. Crop yield prediction under soil salinity using satellite derived vegetation indices. Field Crops Res. 2016, 192, 134–143. [Google Scholar] [CrossRef]
- Schwalbert, R.A.; Amado, T.; Corassa, G.; Pott, L.P.; Prasad, P.V.; Ciampitti, I.A. Satellite-based soybean yield forecast: Integrating machine learning and weather data for improving crop yield prediction in southern Brazil. Agric. For. Meteorol. 2020, 284, 107886. [Google Scholar] [CrossRef]
- Zhang, Y.; Chipanshi, A.; Daneshfar, B.; Koiter, L.; Champagne, C.; Davidson, A.; Reichert, G.; Bédard, F. Effect of using crop specific masks on earth observation based crop yield forecasting across Canada. Remote Sens. Appl. Soc. Environ. 2019, 13, 121–137. [Google Scholar] [CrossRef]
- Shao, Y.; Campbell, J.B.; Taff, G.N.; Zheng, B. An analysis of cropland mask choice and ancillary data for annual corn yield forecasting using MODIS data. Int. J. Appl. Earth Obs. Geoinf. 2015, 38, 78–87. [Google Scholar] [CrossRef]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop yield prediction with deep convolutional neural networks. Comput. Electron. Agric. 2019, 163, 104859. [Google Scholar] [CrossRef]
- Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
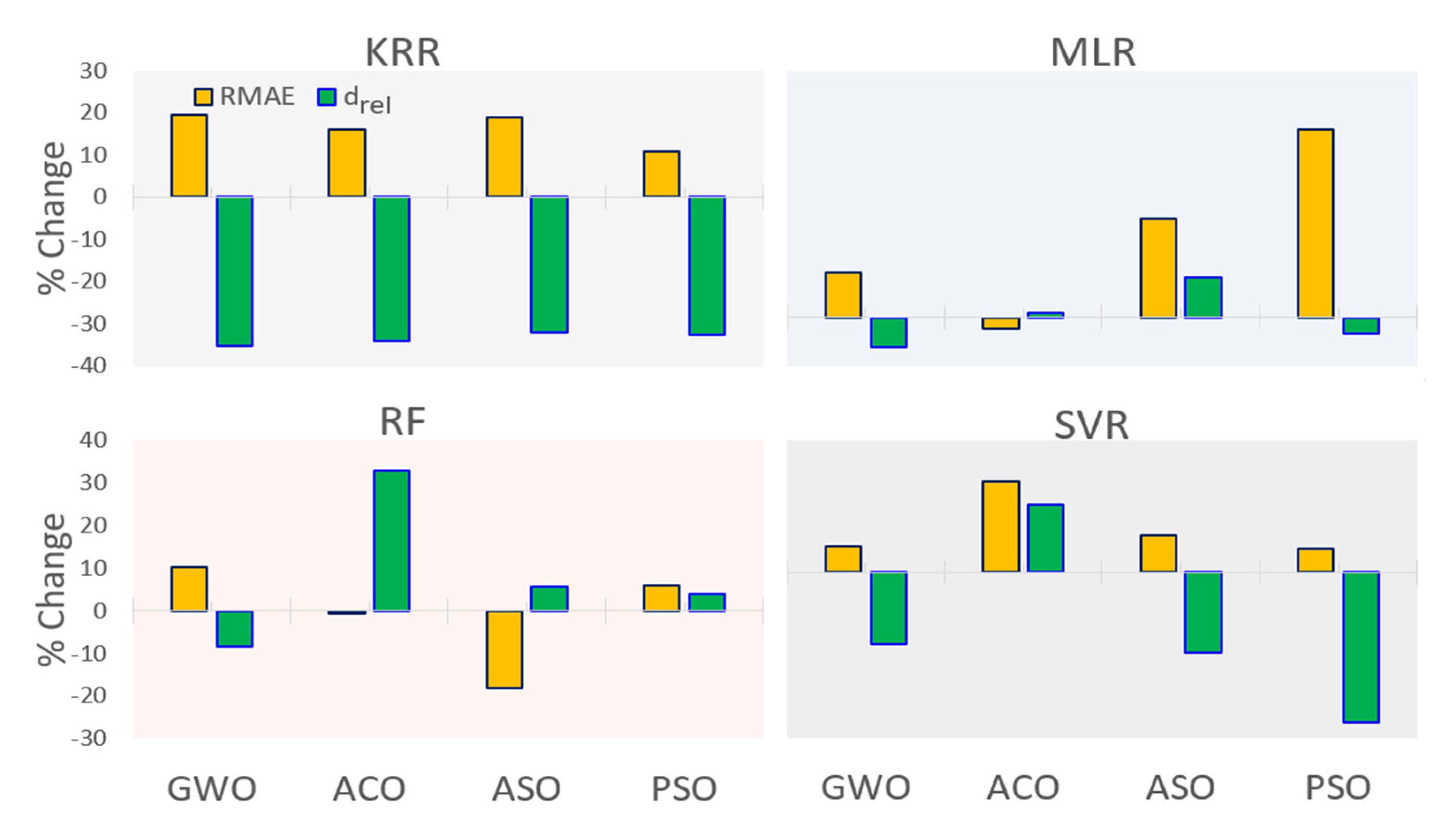
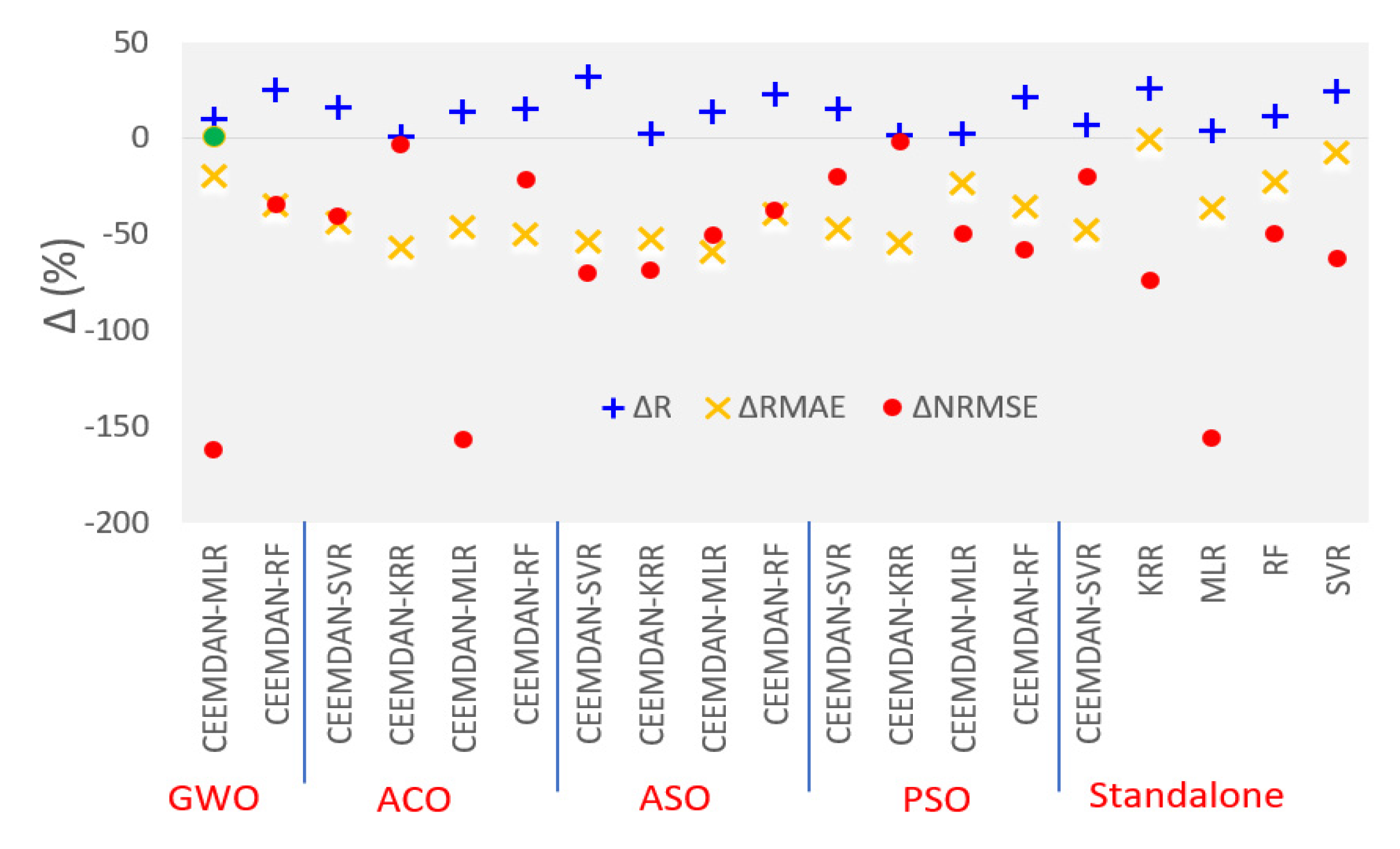
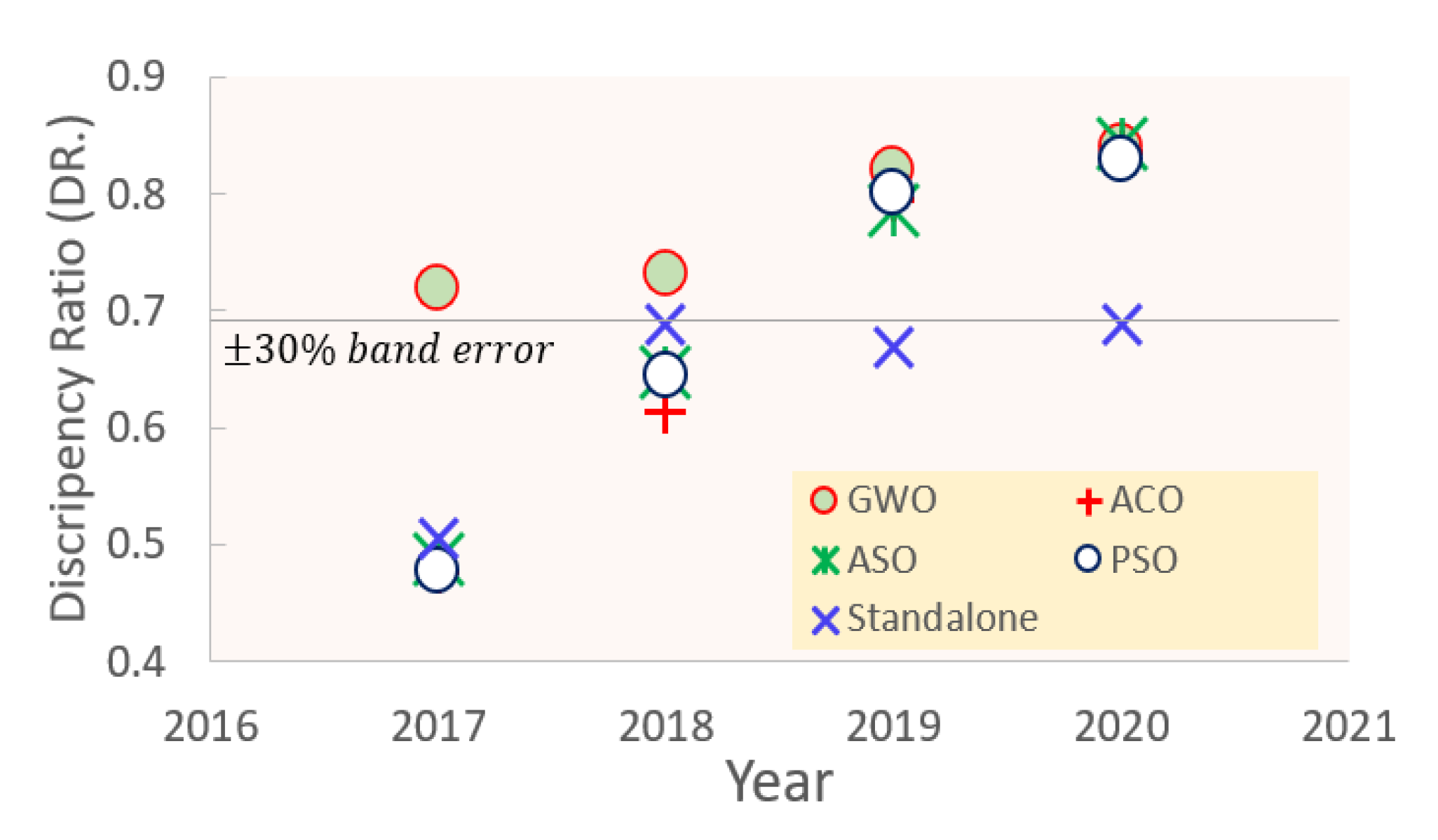
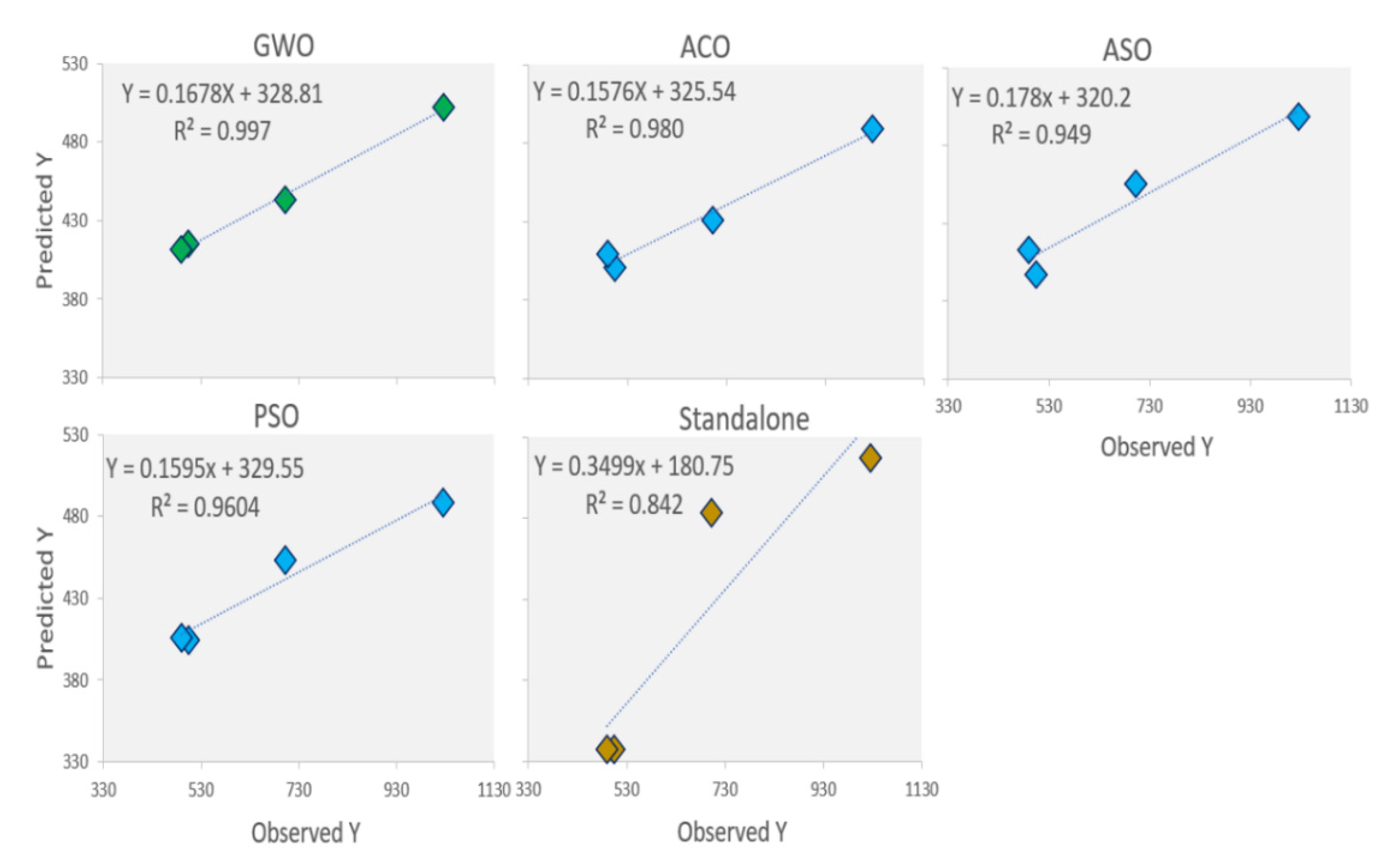
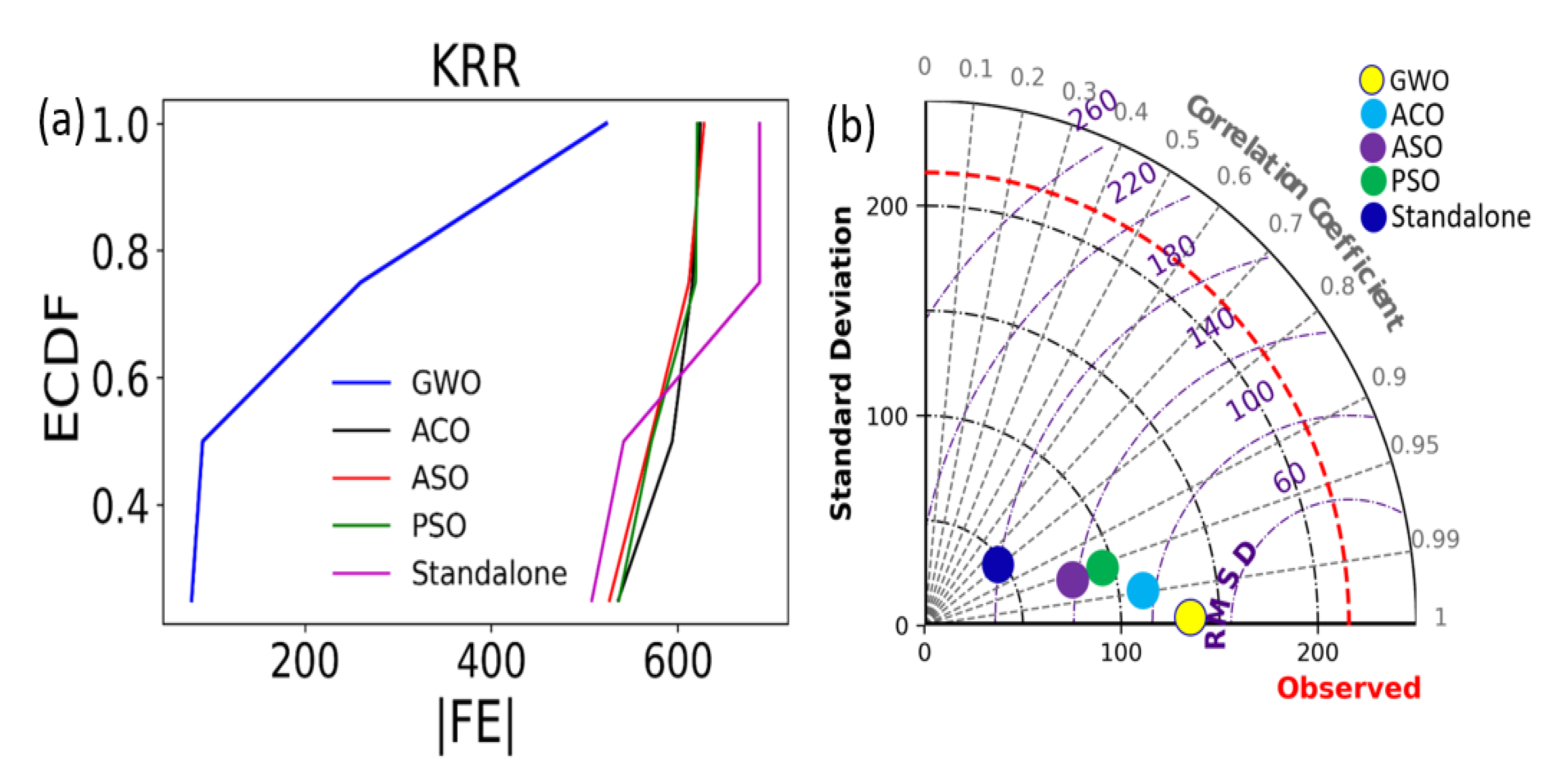

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
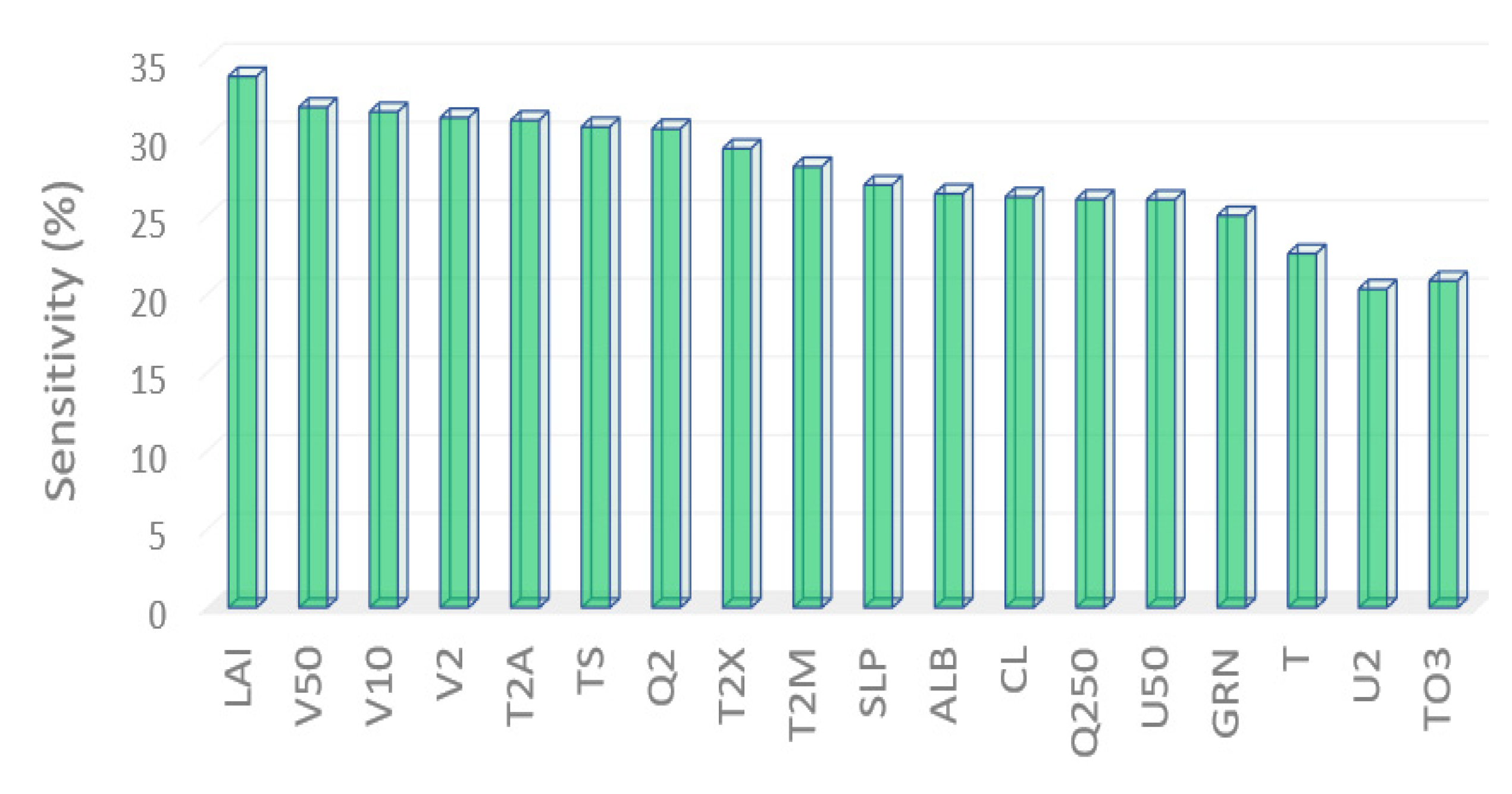
| Information of Satellite Derived Variables | Results of Feature Selection | |||||
|---|---|---|---|---|---|---|
| Notation | Description | Units | GWO | ACO | ASO | PSO |
| Q | Specific humidity @1000 hPa | kg/kg | × | √ | √ | √ |
| TA | Air temperature monthly @1000 hPa | K | √ | √ | √ | × |
| Q10 | 10-m specific humidity | kg/kg | × | √ | √ | √ |
| TO3 | Total column ozone | Dobsons | √ | × | × | √ |
| T2X | 2-m air temperature-daily max | K | √ | × | √ | √ |
| T2A | 2-m air temperature-daily mean | K | √ | √ | √ | √ |
| T2M | 2-m air temperature-daily min | K | √ | × | √ | √ |
| LE | Total latent energy flux | W/m−2 | × | × | × | × |
| PR | Total precipitation | Kg/m2 | × | √ | √ | × |
| TA | Surface air temperature monthly | K | × | √ | × | √ |
| GRN | Greenness fraction | - | √ | × | √ | × |
| SW | Surface soil wetness | - | × | √ | × | √ |
| LAI | Leaf area index | - | √ | × | × | √ |
| ALB | Surface albedo | - | √ | × | × | √ |
| CL | Total cloud area fraction | - | √ | × | √ | × |
| SSF | Surface incoming shortwave flux | W/m−2 | × | × | × | × |
| Q250 | Specific humidity at 250 hPa | kg/kg | √ | × | √ | × |
| Q500 | Specific humidity at 500 hPa | kg/kg | × | × | √ | √ |
| Q850 | Specific humidity at 850 hPa | kg/kg | × | √ | √ | √ |
| Q10 | 10-m specific humidity | kg/kg | × | × | √ | √ |
| Q2 | 2-m specific humidity | kg/kg | √ | × | √ | × |
| SLP | Sea level pressure | hPa | √ | √ | √ | × |
| T10 | Temperature at 10 m above surface | K | × | × | √ | × |
| T2 | 2-m air temperature | K | × | √ | √ | √ |
| TS | Surface skin temperature | K | √ | √ | × | × |
| U10 | 10-m eastward wind | m/s | × | √ | √ | × |
| U2 | 2-m eastward wind | m/s | √ | × | √ | × |
| U50 | Eastward wind at 50-m | m/s | √ | × | √ | √ |
| V10 | 10-m northward wind | m/s | √ | √ | √ | √ |
| V2 | 2-m northward wind | m/s | √ | √ | √ | √ |
| V50 | Northward wind at 50-m | m/s | √ | √ | √ | × |
| A | Area | Ha | × | × | √ | × |
| Total Number of Selected Features | 18 | 15 | 24 | 17 | ||
| Characteristics | Optimal Value |
|---|---|
| Grey Wolf Optimization (GWO) | |
| Number of wolves | 10 |
| Maximum number of iterates | 100 |
| Curve | Convergence |
| Ant Colony Optimization (ACO) | |
| Number of ants | 10 |
| Maximum number of iterations | 100 |
| Coefficient control tau | 1 |
| Coefficient control eta | 2 |
| Initial tau | 1 |
| Initial beta | 1 |
| Pheromone | 0.2 |
| Coefficient | 0.5 |
| Atom Search Optimization (ASO) | |
| Number of particles | 10 |
| Maximum number of iterations | 100 |
| Depth weight | 50 |
| Multiplier weight | 0.2 |
| Particle Swarm Optimization (PSO) | |
| Number of particles | 10 |
| Maximum number of iterations | 150 |
| Cognitive factor | 2 |
| Social factor | 2 |
| Maximum velocity | 6 |
| Maximum bound on inertia weight | 0.9 |
| Minimum bound on inertia weight | 0.4 |
| Predictive Model | R | NRMSE |
|---|---|---|
| GWO–Objective Feature Selection Method | ||
| CEEMDAN-KRR | 0.998 | 0.437 |
| CEEMDAN-MLR | 0.896 | 1.144 |
| CEEMDAN-RF | 0.751 | 0.589 |
| CEEMDAN-SVR | 0.840 | 0.614 |
| ACO–benchmark method | ||
| CEEMDAN-KRR | 0.990 | 0.452 |
| CEEMDAN-MLR | 0.860 | 1.122 |
| CEEMDAN-RF | 0.847 | 0.531 |
| CEEMDAN-SVR | 0.681 | 0.743 |
| ASO–benchmark method | ||
| CEEMDAN-KRR | 0.974 | 0.738 |
| CEEMDAN-MLR | 0.866 | 0.659 |
| CEEMDAN-RF | 0.768 | 0.601 |
| CEEMDAN-SVR | 0.849 | 0.523 |
| PSO–benchmark method | ||
| CEEMDAN-KRR | 0.980 | 0.475 |
| CEEMDAN-MLR | 0.973 | 0.655 |
| CEEMDAN-RF | 0.784 | 0.689 |
| CEEMDAN-SVR | 0.929 | 0.525 |
| Standalone | ||
| KRR | 0.738 | 0.761 |
| MLR | 0.963 | 2.992 |
| RF | 0.882 | 0.653 |
| SVR | 0.758 | 0.710 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, A.A.M.; Sharma, E.; Jui, S.J.J.; Deo, R.C.; Nguyen-Huy, T.; Ali, M. Kernel Ridge Regression Hybrid Method for Wheat Yield Prediction with Satellite-Derived Predictors. Remote Sens. 2022, 14, 1136. https://doi.org/10.3390/rs14051136
Ahmed AAM, Sharma E, Jui SJJ, Deo RC, Nguyen-Huy T, Ali M. Kernel Ridge Regression Hybrid Method for Wheat Yield Prediction with Satellite-Derived Predictors. Remote Sensing. 2022; 14(5):1136. https://doi.org/10.3390/rs14051136
Chicago/Turabian StyleAhmed, A. A. Masrur, Ekta Sharma, S. Janifer Jabin Jui, Ravinesh C. Deo, Thong Nguyen-Huy, and Mumtaz Ali. 2022. "Kernel Ridge Regression Hybrid Method for Wheat Yield Prediction with Satellite-Derived Predictors" Remote Sensing 14, no. 5: 1136. https://doi.org/10.3390/rs14051136
APA StyleAhmed, A. A. M., Sharma, E., Jui, S. J. J., Deo, R. C., Nguyen-Huy, T., & Ali, M. (2022). Kernel Ridge Regression Hybrid Method for Wheat Yield Prediction with Satellite-Derived Predictors. Remote Sensing, 14(5), 1136. https://doi.org/10.3390/rs14051136