1. Introduction
Remote sensing images (RSIs) are broadly employed in different aspects, for instance, obtaining geographic data, obtaining earth resource information, hazard prediction and analysis, urban investigation, yield estimation and others [
1]. However, in these applications, RSIs with high spatial, spectral or time resolution are usually required [
2,
3,
4]. The spatial and spectral resolutions of RSIs constrain each other limited by sensor technology, i.e., panchromatic (PAN) images are with high spatial and low spectral resolutions, multispectral (MS) images are with low spatial and multispectral resolutions (LRMS) and hyperspectral (HS) images are with low spatial and high spectral resolutions [
1,
5]. The PAN images and MS or HS images need to be fused to produce high spatial resolution MS (HRMS) images or high spatial resolution HS (HRHS) images. This technique is also called panchromatic sharpening (pansharpening). Pansharpening for MS and PAN images is studied. Pansharpening methods can be approximately comprised of traditional approaches and deep learning (DL) methods [
1,
2,
5]. Traditional approaches comprise the component substitution (CS) approach, multiresolution analysis (MRA) method and variational optimization (VO) technique [
2,
5].
CS methods first transform the MS images to other coordinate systems, and extract the spatial detail information. Then, the spatial detail information is substituted for the PAN image. Eventually, the substituted image is projected to the original coordinate system by inverse transformation to generate the HRMS image. Various CS methods have been developed, mainly including intensity-hue-saturation (IHS) [
6], adaptive IHS (AIHS) [
7], generalized IHS (GIHS) [
8], Gram-Schmidt (GS) [
9], GS adaptive (GSA) [
1], Brovey [
5] and partial replacement adaptive component substitution (PRACS) [
10]. CS methods are simple and easy to implement, which greatly improve the spatial resolution of MS images. CS methods have the disadvantage of severe spectrum distortion and oversharpening.
MRA methods first decompose MS images and PAN images into images of different scales. Then, the corresponding scale images are fused by a fusion technique. Finally, an HRMS image is generated by an inverse transformation. The decomposition methods used generally include the discrete wavelet transform (DWT) [
11,
12], fusion for MS and PAN images employing the Induction scaling approach (Indusion) [
13], generalized Laplacian pyramid (GLP) transform [
14], modulation transfer function-GLP (MTF_GLP) transform [
15], à trous wavelet transform (ATWT) [
16], and other spectral and wavelet decomposition techniques [
17,
18,
19]. MRA methods retain more spectral information and lessen the spectrum distortion. However, the spatial information is not rich and the resolution is lower.
The key to the VO method is to establish an energy function and optimization method [
20,
21,
22,
23]. Bayesian-based methods [
24,
25] and sparse representation-based methods [
26,
27,
28,
29] can also be classified into this category. Although the VO method can reduce spectral distortion, the optimization calculation is more complicated.
With the rapid development of DL, various types of convolutional neural networks (CNN)-based models are increasingly used in pansharpening and closely related tasks [
30,
31,
32] of RSIs. Giuseppe et al. [
33] proposed a CNN-based pansharpening method (PNN). PNN consists of only three layers and uses the nonlinear mapping of the CNN to reconstruct the LRMS image generating the HRMS image. The advantage of the PNN is that it has few layers and is easy to implement, but it also has the disadvantage of overfitting and limited expression ability. Wei et al. [
34] put forward a deep residual network-based pansharpening technique (DRPNN). The DRPNN employs residual blocks to improve the fusion ability and reduce overfitting. Yang et al. [
35] put forward a PanNet method based on residual modules and trained it in the frequency domain. To retain more spectrum information, add the upsampled MS image to the residual information. The model is trained in the frequency field to retain more spatial structure information, and the generalization ability of the network is better. Scarpa et al. [
36] proposed a target-adaptive pansharpening means based on a CNN (TA-PNN). TA-PNN proposes a target-adaptive usage mode to deal with problems of data mismatch, multisensor data, and insufficient data. Liu et al. [
37] designed a PsGan technique, which contains a generator and discriminator. The generator is a two-stream fusion structure that generates an HRMS image with MS and PAN images as inputs. The discriminator is composed of a full CNN to discriminate between the reference image and the produced HRMS image. Ma et al. [
38] proposed a generative adversarial network-based model for pansharpening (Pan-Gan). Pan-Gan employs a spectral discriminator to discriminate the spectral information between the fused HRMS image and LRMS image. The spatial discriminator is employed to discriminate the spatial structure information between the HRMS and PAN images. Zhao et al. [
39] designed an FGF-GAN method. The FGF-GAN generator uses a fast guided filter to retain details and a spatial attention module for fusion. FGF-GAN reduces network parameters and training time. Deng et al. [
40] designed a CS/MRA model-based detail injection network (FusionNet). The injected details are acquired through the deep CNN based on residual learning, and then the upsampled MS image is added to the output of the detail extraction network. For FusionNet, the difference between the MS and PAN images (i.e., the duplicated PAN image of N channels, N is the channels of the MS image) is taken as the input. The multispectral information is introduced into the detail extraction network to lessen the spectral distortion. Wu et al. [
41] designed a residual module-based distributed fusion network (RDFNet). RDFNet extracts multilevel features of MS images and PAN images, respectively. Then the corresponding level features and the fusion result of the previous step are fused to obtain the HRMS image. Although the network uses multilevel MS and PAN features as much as possible, it is affected by the depth of the network and cannot obtain more details and spectral information. Obviously, although various networks are used for pansharpening of RSIs and have acquired good results, there is rising space in terms of model complexity, implementation time, generalization ability, spectrum fidelity, retention of spatial details and so on.
In this article, we propose a novel three-stage detail injection network for pansharpening of RSIs by preserving spectral information to reduce spectral distortion and preserving details to strengthen spatial resolution. The main contributions of the work are as follows.
A dual-branch multiscale feature extraction block is established to extract four-scale details of PAN images and the difference between duplicated PAN and MS images. The details are retained, and the MS image is introduced to preserve the spectrum information.
Cascade cross-scale fusion (CCSF) employs fine-scale fusion information as prior knowledge for the coarse-scale fusion based on residual learning. CCSF combines the fine-scale and coarse-scale fusion, which compensates for the loss of information and retains details.
A multiscale high-frequency detail compensation mechanism and a multiscale skip connection block are designed to reconstruct the fused details, which strengthen spatial details and reduce parameters.
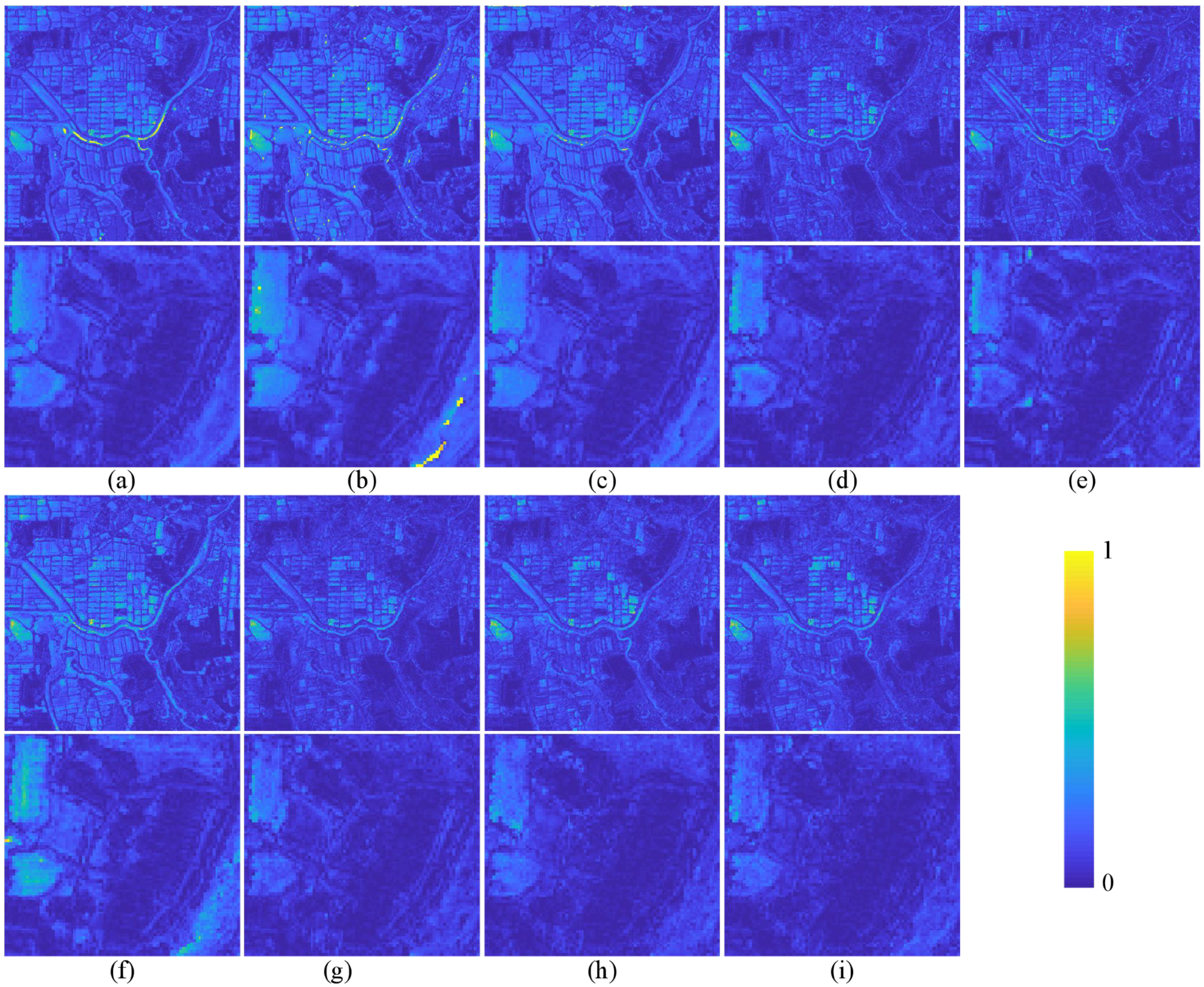
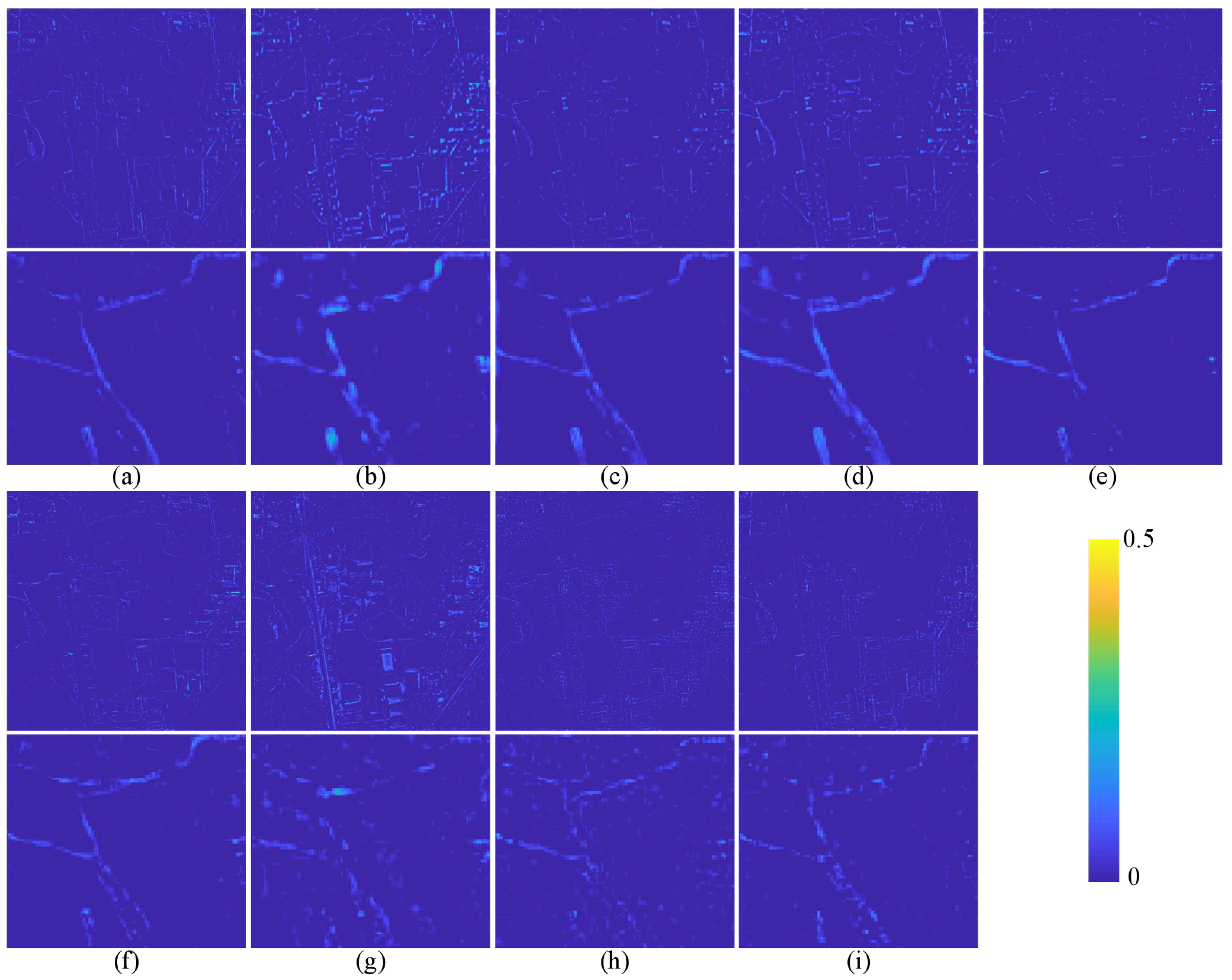
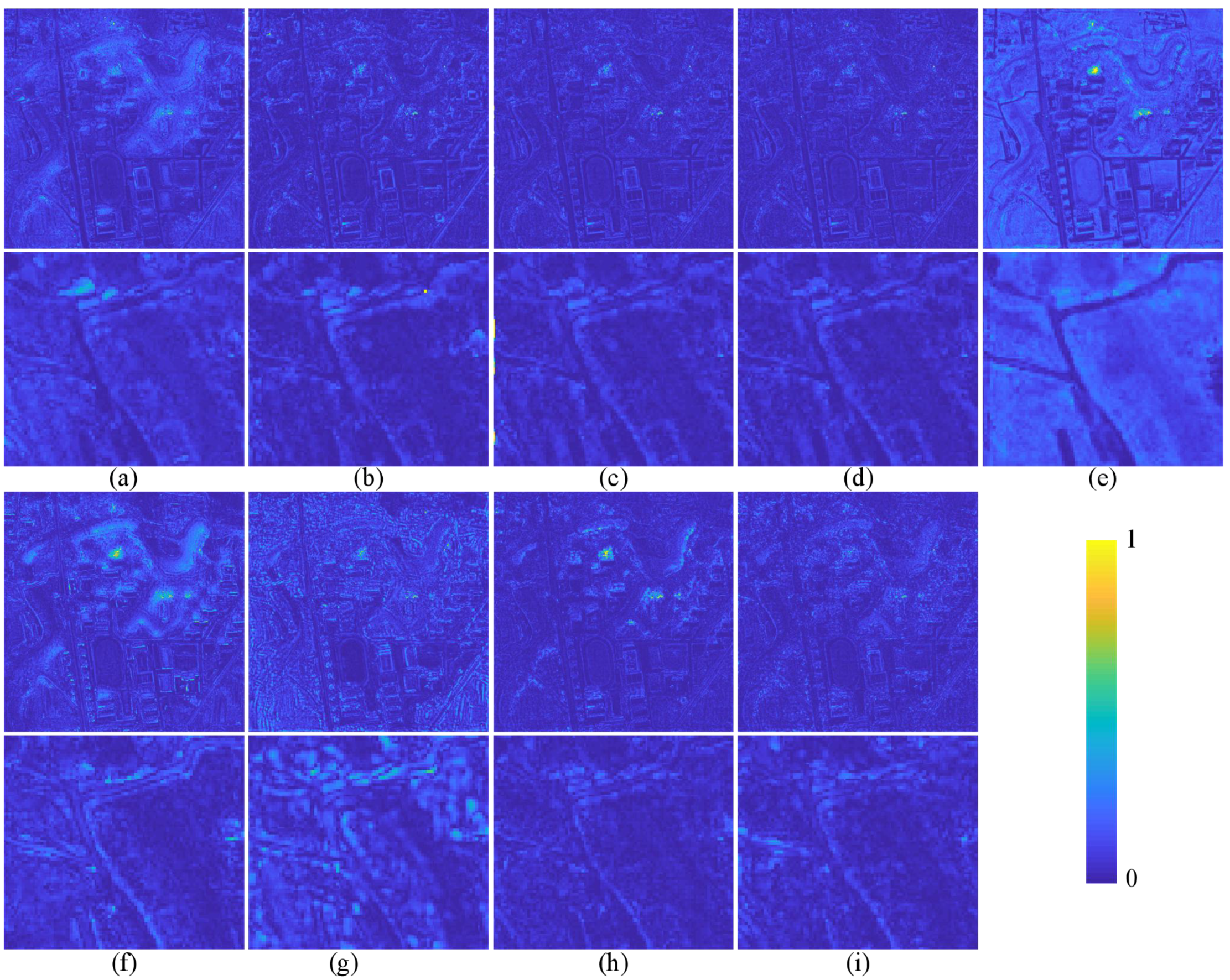
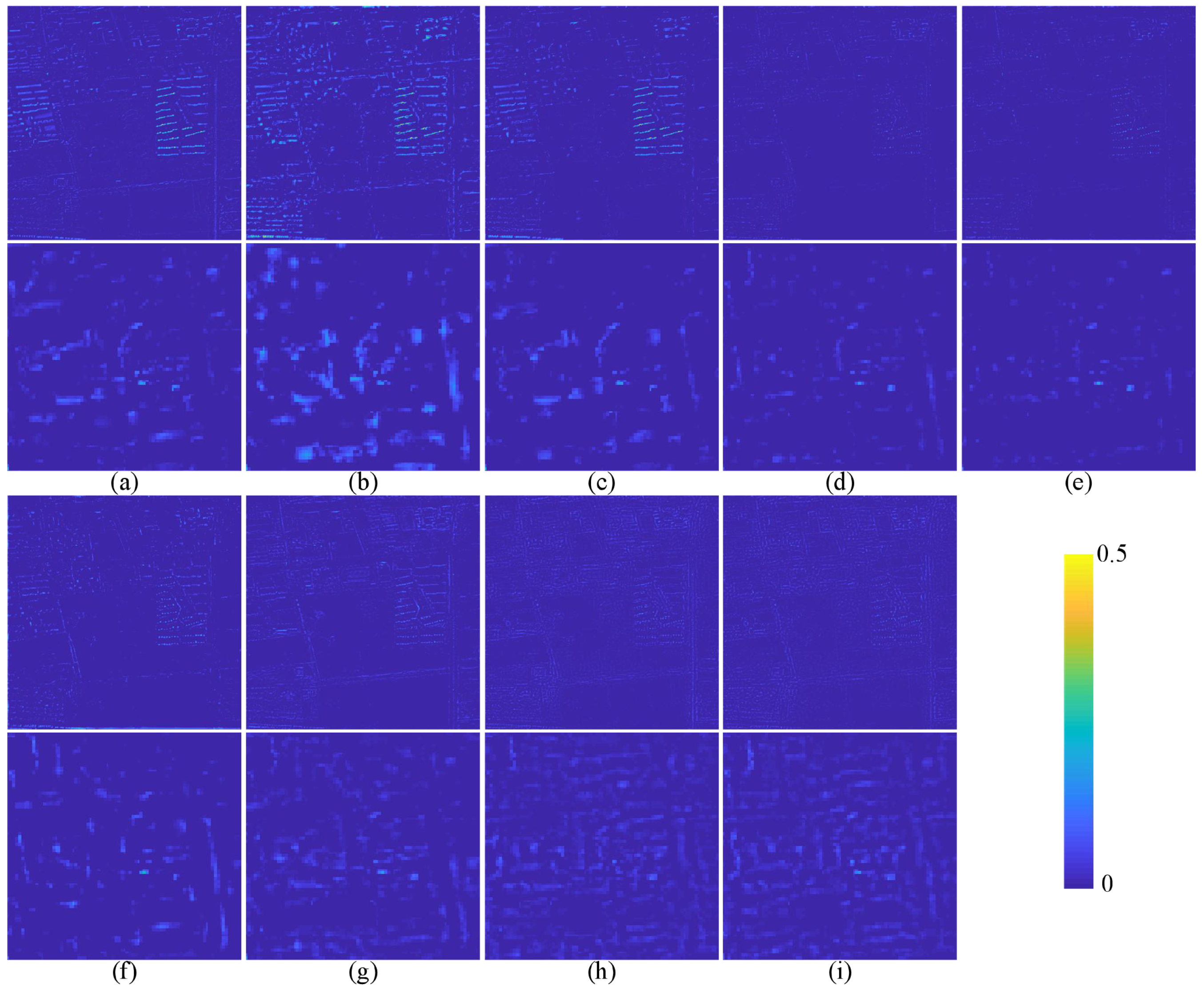
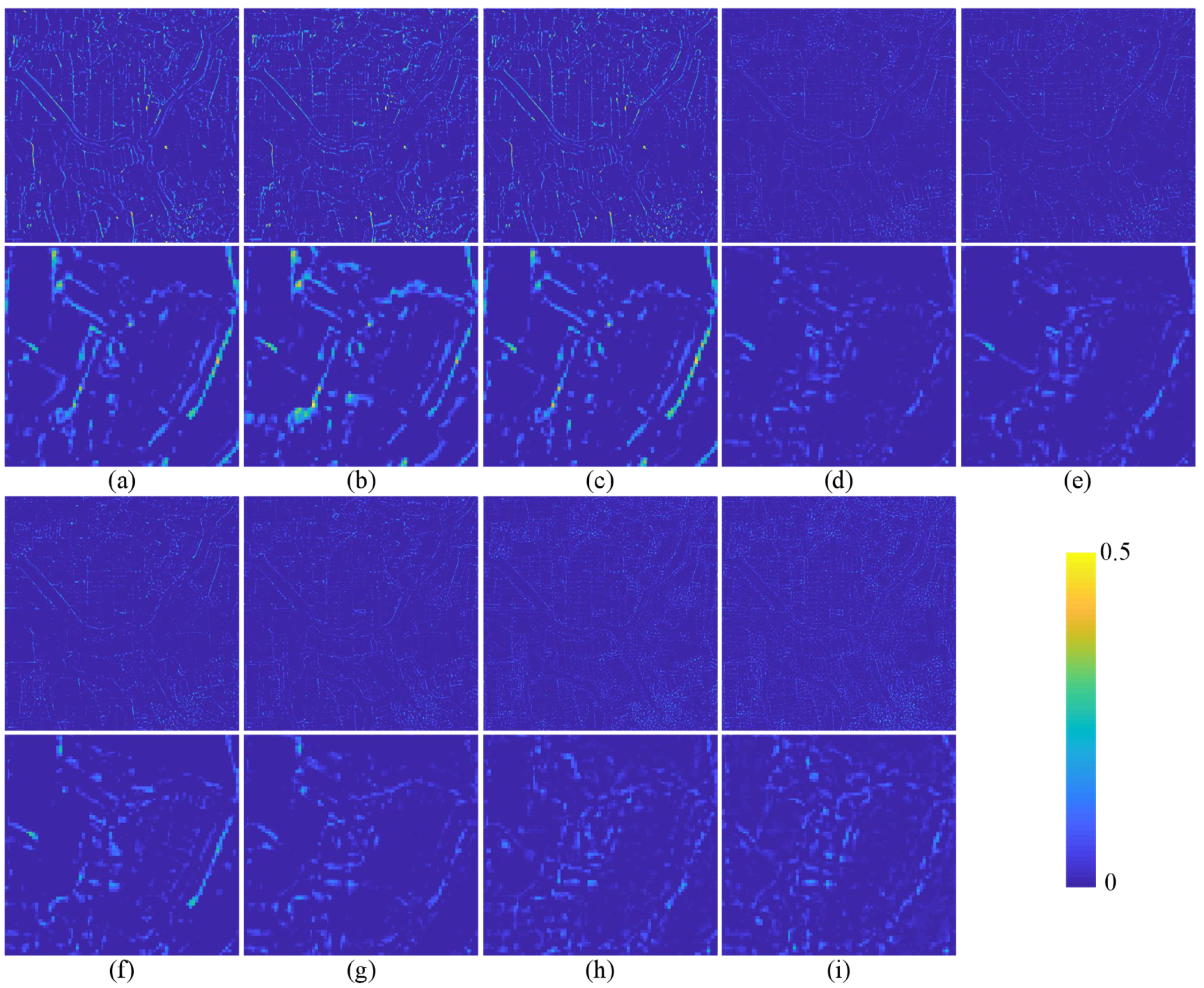
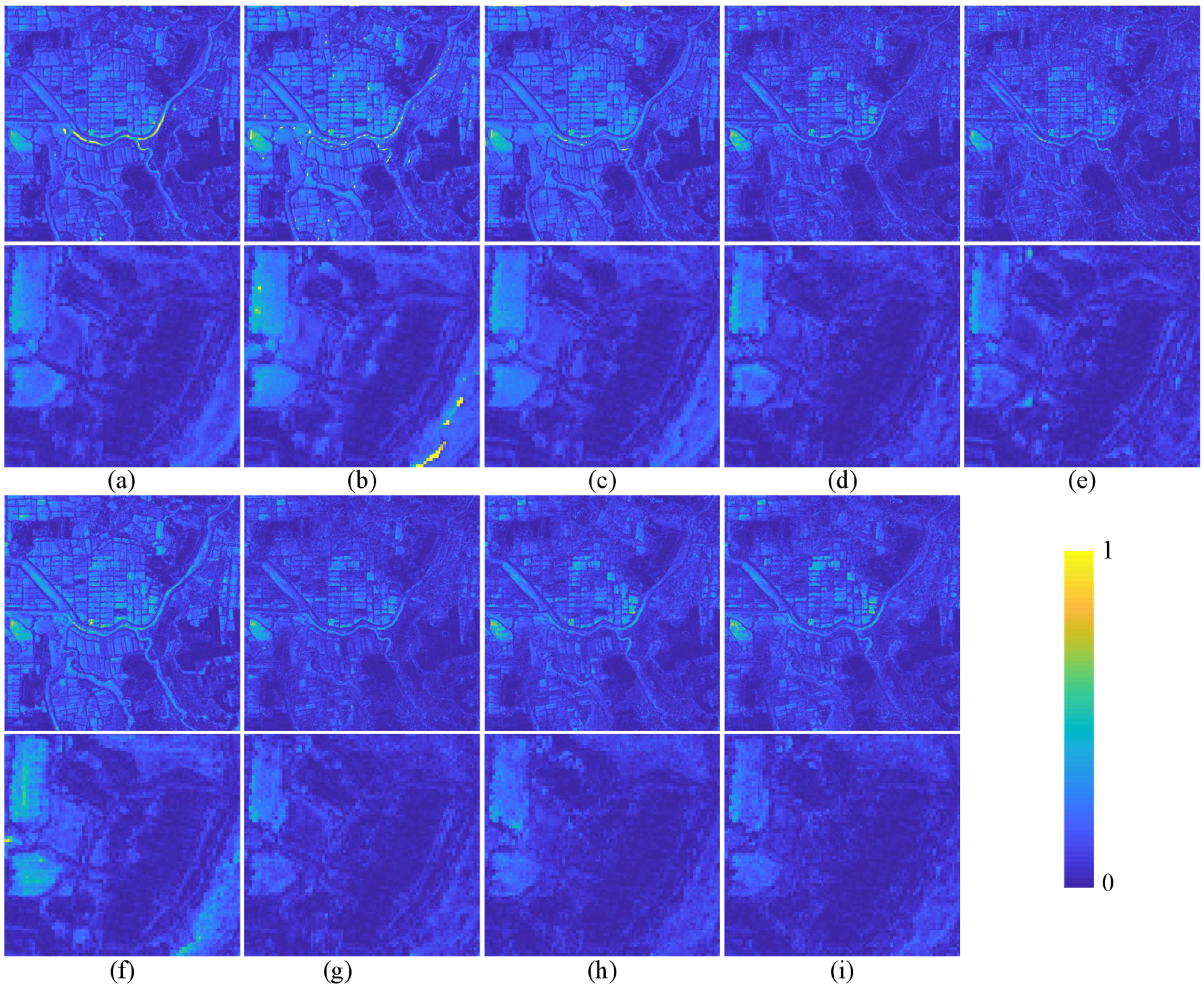
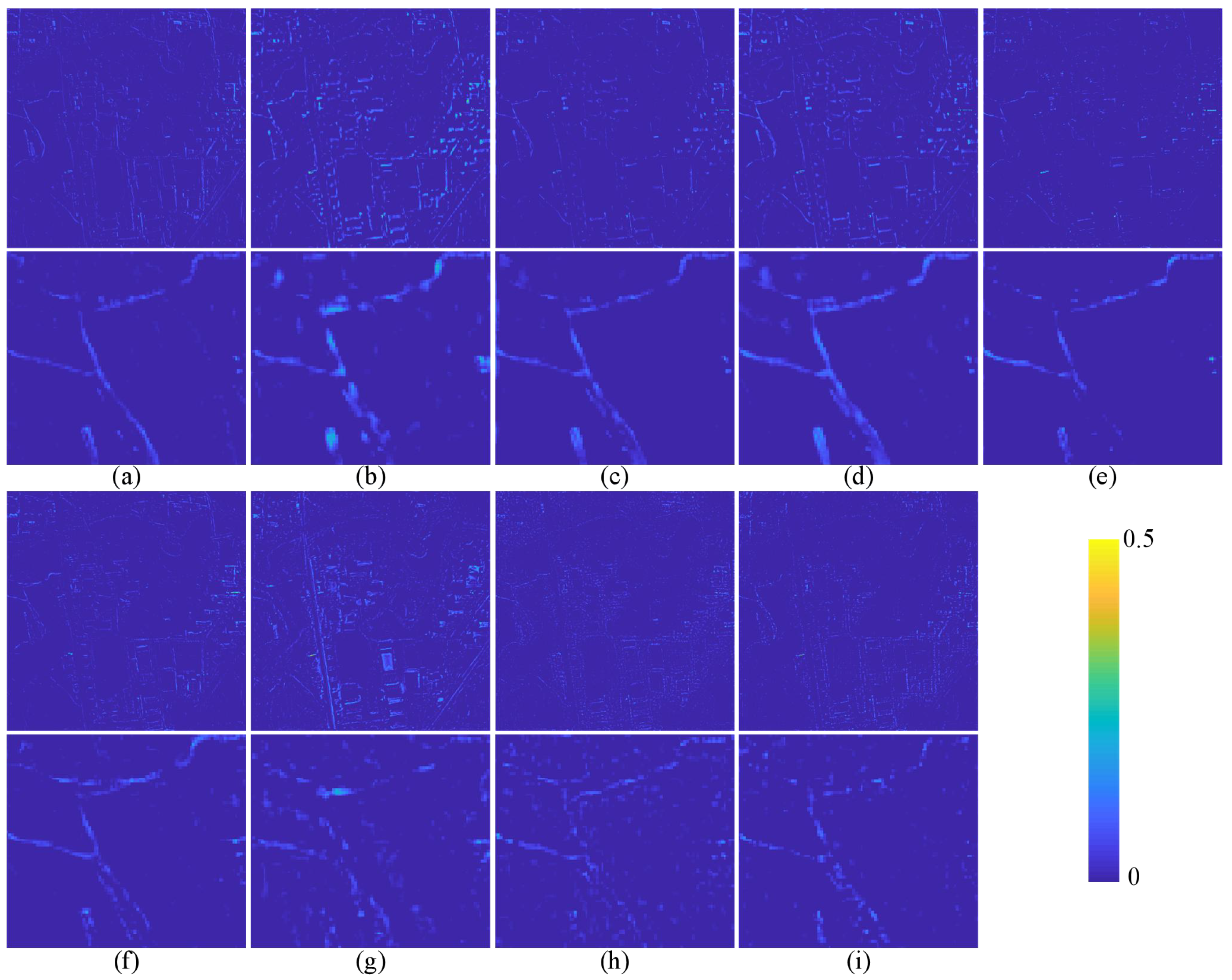
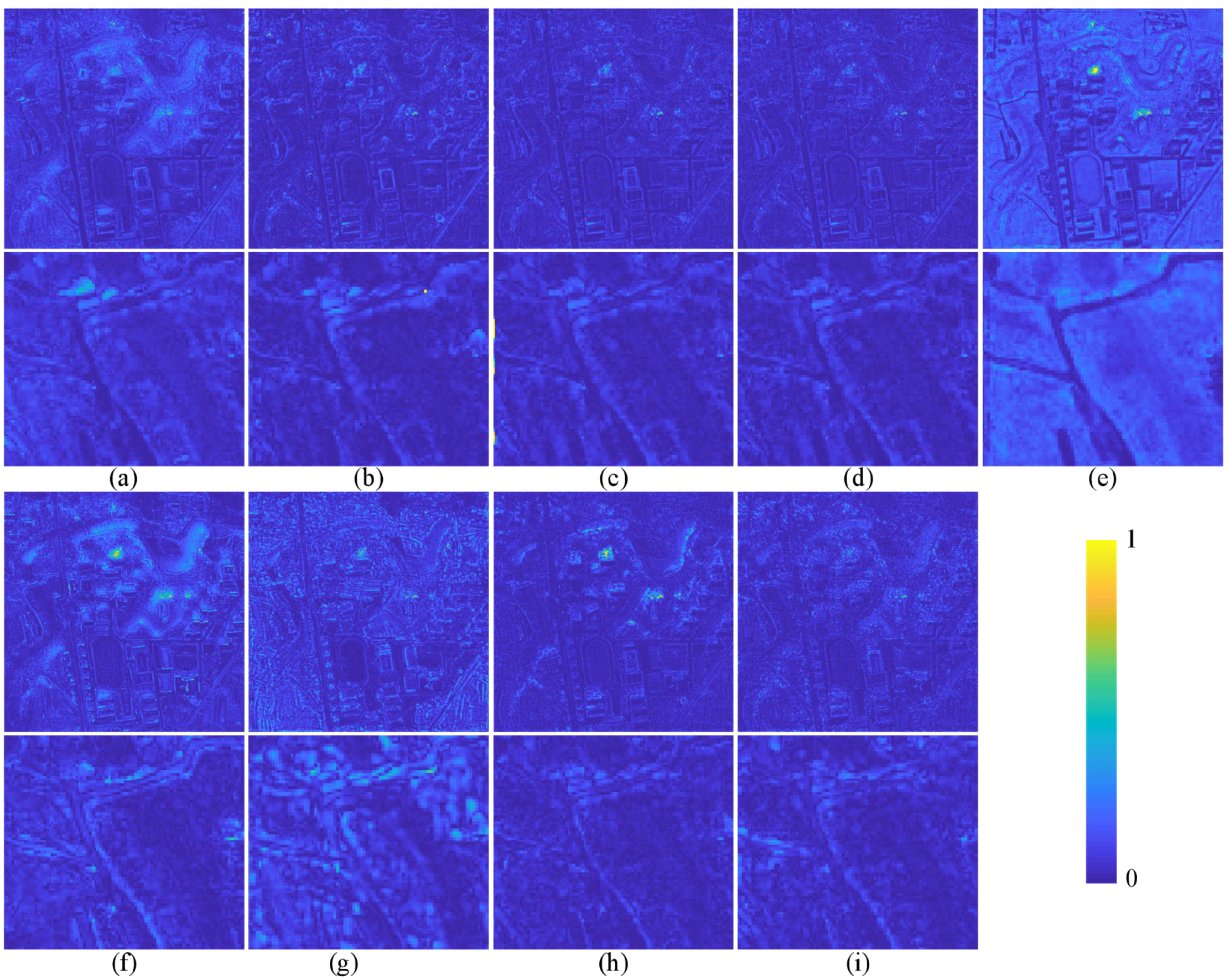
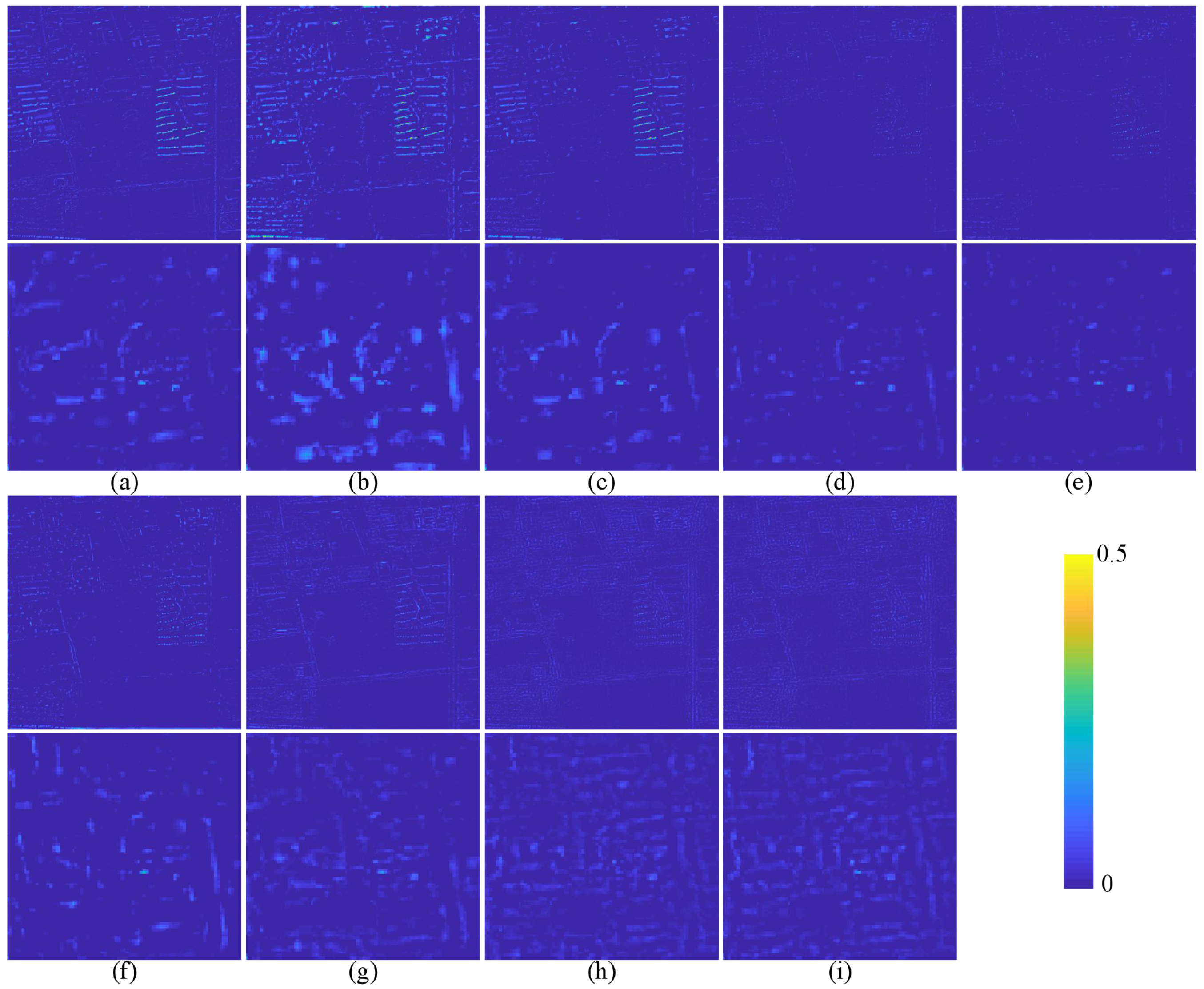
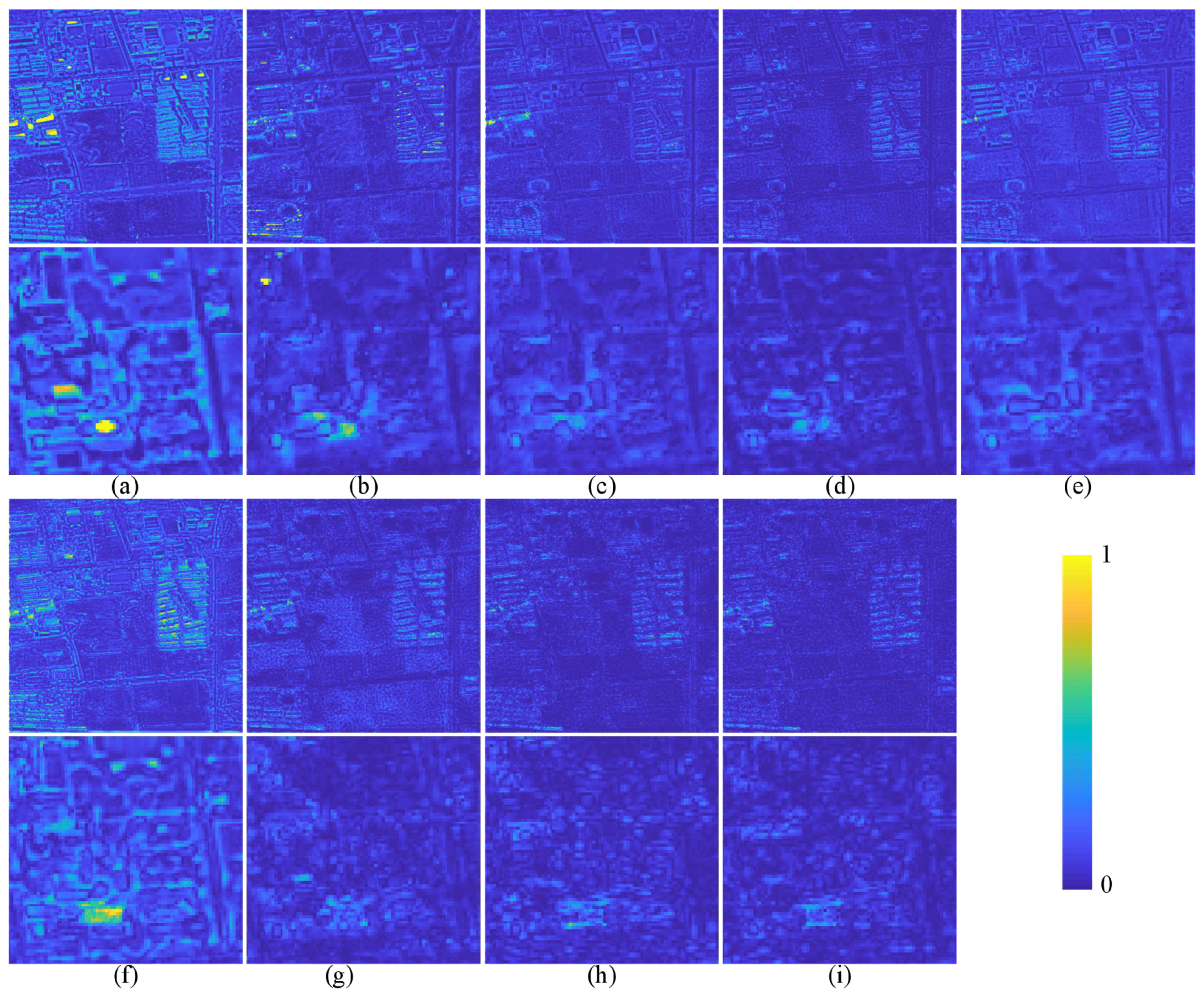
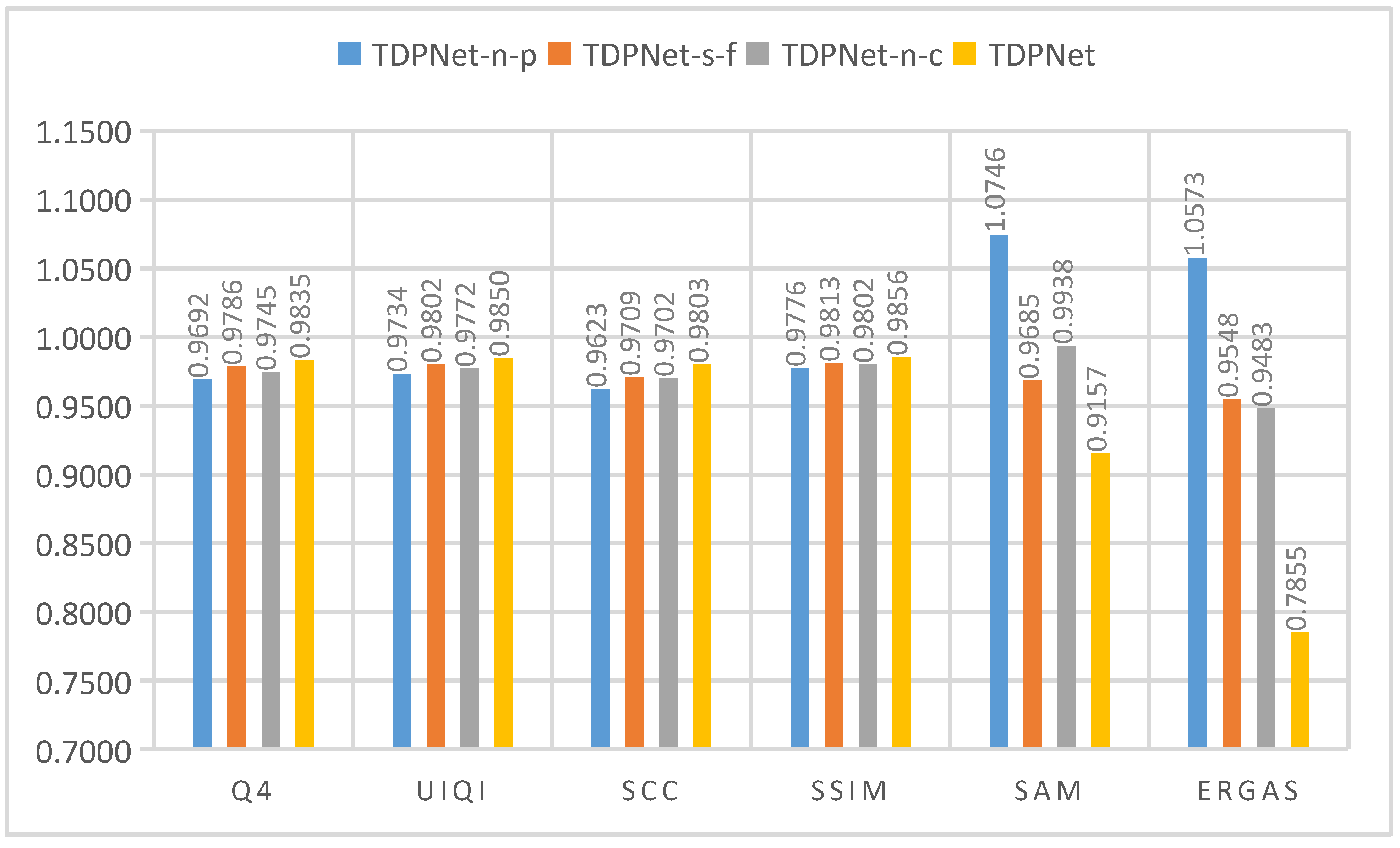
The quantitative evaluation and subjective evaluation of three satellite data sets are implemented at reduced and full resolutions.
Section 2 represents the data sets, evaluation indicators, implementation settings and proposed method at full length.
Section 3 introduces comparative experiments on three data sets.
Section 4 discusses the experimental results.
Section 5 draws conclusions.
2. Materials and Methods
2.1. Data Sets
To prove the performance of the designed pansharpening approach, three data sets are used for evaluation. The specific information of these data sets is as follows.
Gaofen-1 (GF-1) data set: These data are collected from Guangdong and Yunnan, China. The MS images have 4 bands. The resolutions of the PAN and MS images are 2 m and 8 m, respectively, and the radiometric resolution is 10 bits. The reduced resolution data are produced by Wald’s protocol [
42], and the training samples, validation data and testing data are randomly selected. The number of data pairs in the data set is 21,560, 6160 and 3080, respectively. The number of full resolution testing data is 147.
QuickBird data set: These data are collected from Chengdu, Beijing, Shenyang and Zhengzhou, China. The MS images have 4 bands. The resolutions of the PAN and MS images are 0.6 m and 2.4 m, respectively, and the radiometric resolution is 11 bits. The number of training samples, validation data and testing data pairs is 20,440, 5840 and 2920, respectively. The number of full resolution testing data is 158.
Gaofen-2 (GF-2) data set: These data are collected from Beijing and Shenyang, China. The MS images have 4 bands. The resolutions of the PAN and MS images are 1 m and 4 m, respectively, and the radiometric resolution is 10 bits. The number of training samples, validation data and testing data pairs is 21,000, 6000 and 3000, respectively. The number of full resolution testing data is 286.
The sizes of the LMS (the reduced resolution form of the MS image), MS and (the reduced resolution form of the PAN image) images of the training data are 16 × 16 × 4, 64 × 64 × 4 and 64 × 64 × 1, respectively. The sizes of the MS and PAN images of the testing data at full resolution are 100 × 100 × 4 and 400 × 400 × 1, respectively.
2.2. Evaluation Indicators
The evaluation of pansharpening performance is performed at reduced and full resolutions. Subjective visual evaluation and objective evaluation are implemented on the experimental results. The objective evaluation indicators used in the reduced resolution experiment include the universal image quality index (UIQI) [
43] extended to 4-band (Q4) [
44], spectral angle mapping (SAM) [
44], structural similarity (SSIM) [
45], spatial correlation coefficient (SCC) [
44] and erreur relative global adimensionnelle de Synthése (ERGAS) [
44].
UIQI [
43] assesses image quality from three sides: correlation, luminance and contrast. The representation of
UIQI is Equation (
1).
where
g and
f indicate the ground truth (GT) and pansharpened images, respectively.
means the covariance between
g and
f images.
and
are the means and variance of
g.
and
are the means and variance of
f. The optimal value for
UIQI is 1, and the pansharpening result is optimum.
The expression for
Q4 [
44] is Equation (
2).
where
and
indicate the 4-band GT and pansharpened images, respectively.
is the covariance between
and
.
and
are the means and variance of
.
and
are the means and variance of
.
SAM [
44] is an error indicator, which represents the angle difference of spectral vector between the GT and pansharpened images. The expression of
SAM is Equation (
3).
where
and
are the spectrum vector of the GT and pansharpened images.
SAM expresses the spectral distortion. When
SAM = 0, the pansharpening performance is the best.
SSIM [
45] represents the proximity of structural information between the GT and pansharpened images.
SSIM is shown as Equation (
4).
where
and
are constants. When
SSIM = 1, the pansharpening result is the best.
SCC [
44] represents the correlation of spatial details between the GT and pansharpened images. Spatial details are acquired through the high-pass filter. When
SCC = 1, the pansharpened and GT images are most relevant.
ERGAS [
44] is an error indicator, which shows the global effect of the pansharpened image. The representation of
ERGAS is Equation (
5).
where
and
indicate the spatial resolution of PAN and MS images, respectively.
N is the number of bands.
expresses the root mean square error of the
bth band between the GT image and pansharpened image.
indicates the mean of the
bth band. The smaller the
ERGAS, the better the pansharpening result. The optimum value for
ERGAS is 0.
The objective evaluation indicators used in the full resolution experiment include the quality with no-reference (QNR),
and
[
46].
denotes the spectrum distortion, the representation is Equation (
6).
where
and
are the
b-band and
c-band low spatial resolution MS images,
and
are the
b-band and
c-band pansharpened images, and
s is a positive integer to amplify the difference.
denotes the spatial distortion, the expression is Equation (
7).
where
p and
mean the PAN image and degraded version of PAN image, and
t is a positive integer to amplify the difference.
The representation for
QNR [
46] is shown as Equation (
8).
where
and
are constants. When
and
,
QNR is the largest and the pansharpening effect is the best. The optimum value for
QNR is 1, and the ideal values for
and
are 0.
2.3. Implementation Settings
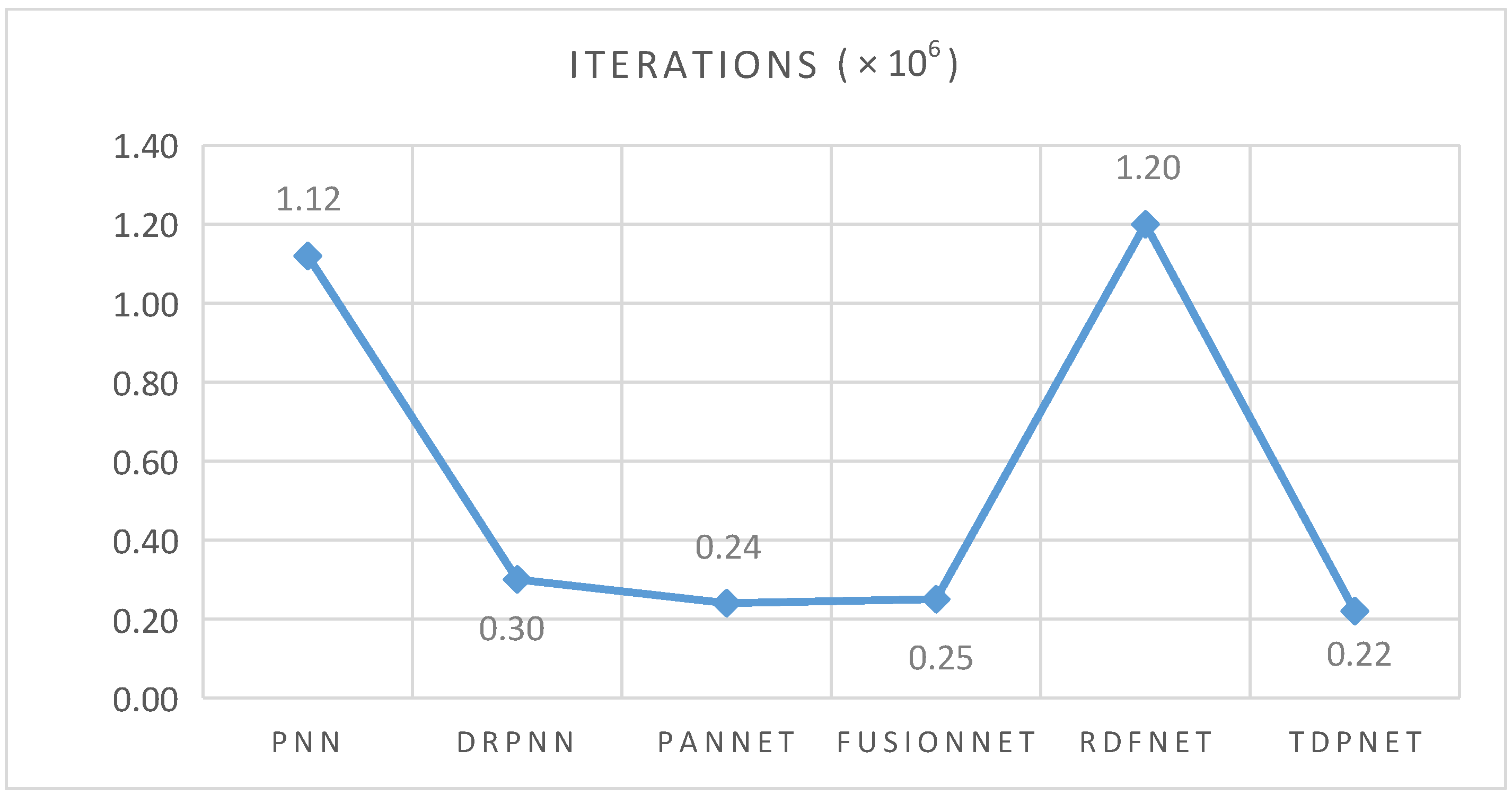
The implementation of the pansharpening network is the TensorFlow framework and a workstation containing an NVIDIA Tesla V100 PCIE GPU with 16 GB RAM and Intel Xeon CPU. The batch size is 32, and the number of iterations is
. We employ the Adam optimizer [
47] to optimize the pansharpening model, with the learning rate
,
,
and
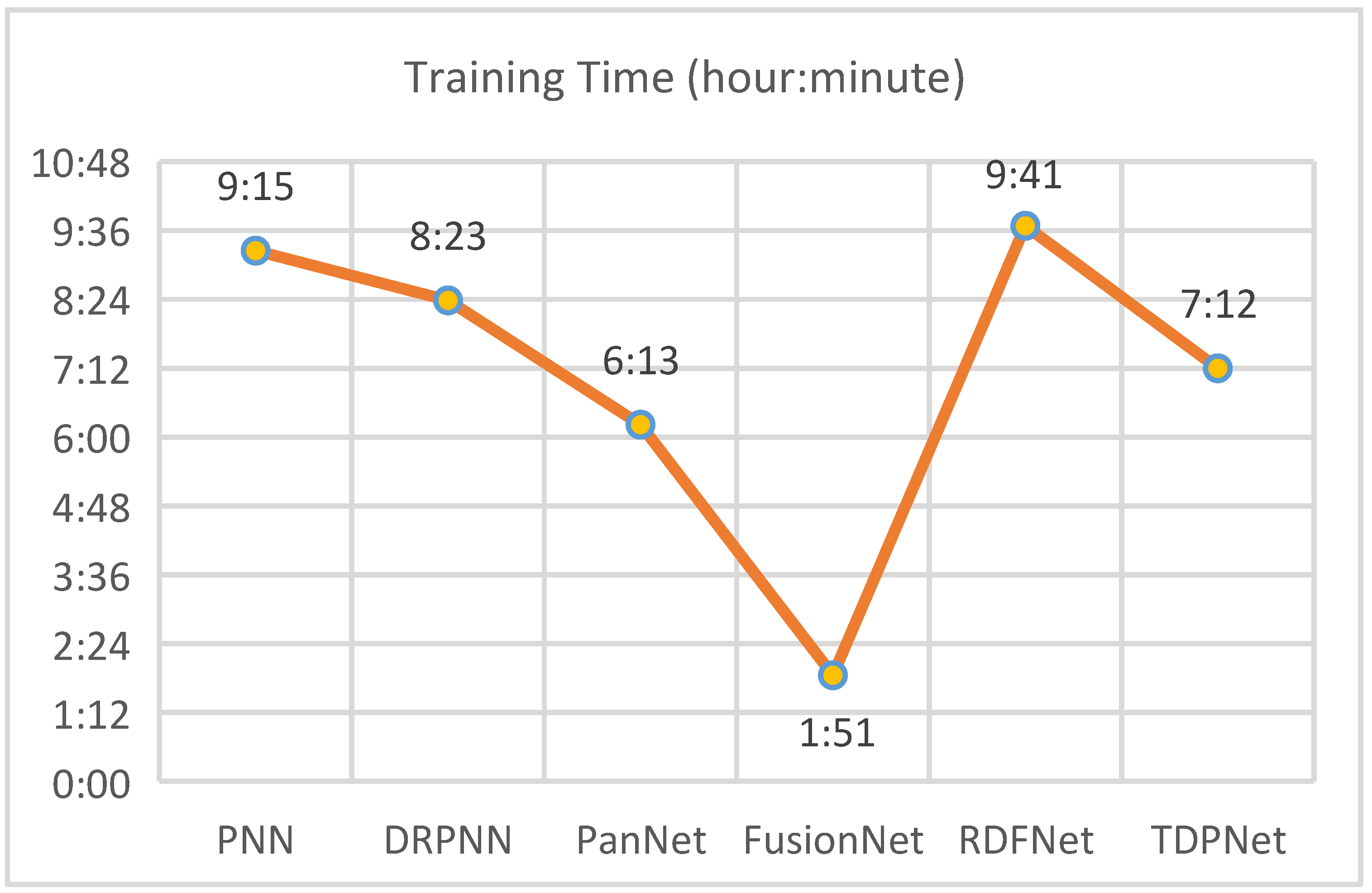
. The channels of input and output of the network can be set according to the image channels used. The number of output channels of the network is 4 since the bands of MS and PAN are 4 and 1. To compare the pansharpening effect fairly, the CNN-based experiments are completed on the GPU, and the CS/MRA-based experiments are conducted in MATLAB on the CPU.
2.4. Network Structure
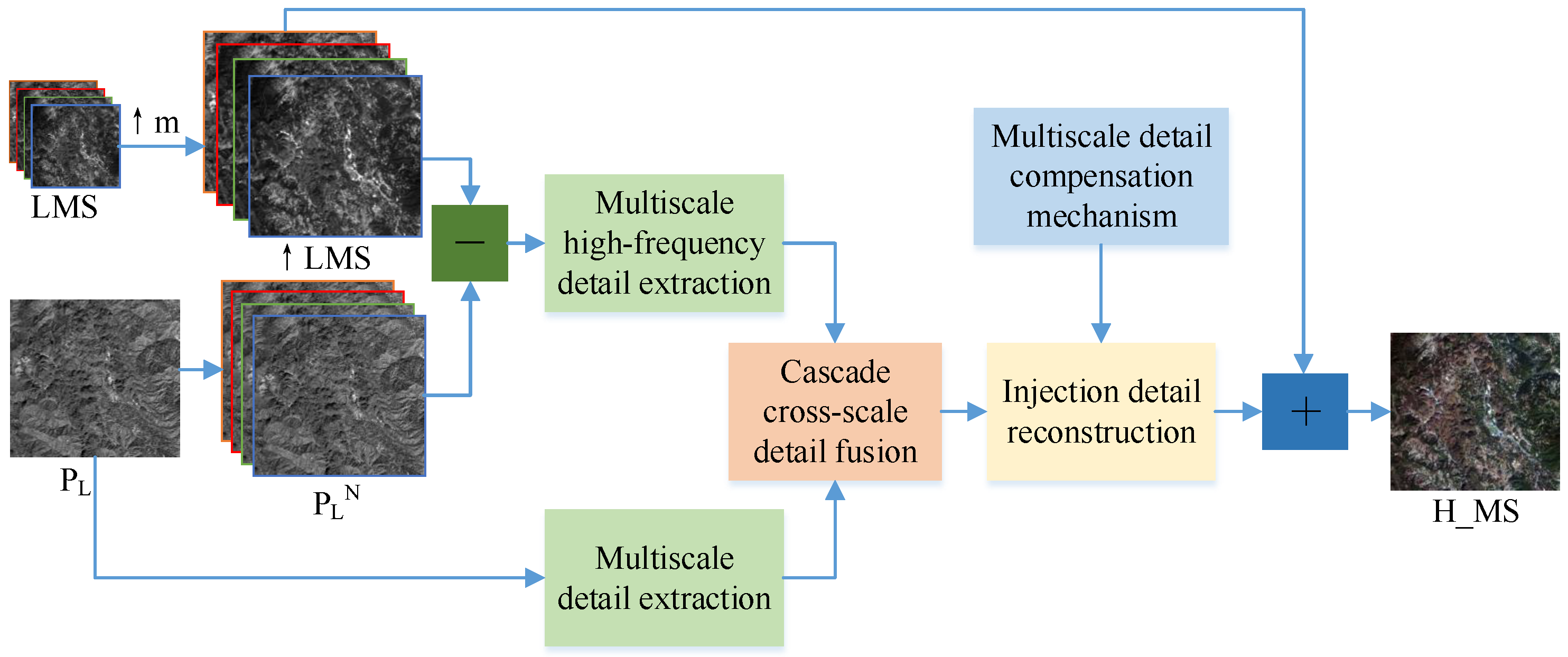
We propose a novel three-stage detail injection pansharpening network (TDPNet) for RSIs.
Figure 1 represents the structure of TDPNet. Because of the lack of reference images, TDPNet is trained on the reduced resolution image. We employ the reduced resolution images LMS and
of the MS and PAN images. The ↑LMS image is an upsampled LMS image, the same size as
. MS represents the reference image, and H_MS indicates the generated pansharpening result. Here,
m is the ratio of the resolution of the MS and PAN images. TDPNet includes three stages: a dual-branch multiscale detail extraction stage, cascade cross-scale detail fusion stage, and reconstruction stage of injecting details. The dual-branch multiscale detail extraction stage extracts multiscale details from the PAN image and ↑LMS image generating details of four scales. The first stage consists of two branches. One branch extracts multiscale details from the PAN image. The other branch extracts multiscale features from the difference image between the
image (the
image is duplicated N channels, where N is the channels of the LMS image.) and ↑LMS image. The second is a cascade cross-scale detail fusion stage. Cascade cross-scale fusion is achieved by combining fine-scale and coarse-scale fusion based on residual learning and prior information of four scales. Cascade cross-scale fusion employs the fine-scale fusion information as prior knowledge for the coarse-scale fusion to compensate for the loss of information caused by downsampling and retain details. The third is a reconstruction stage of injecting details. In this stage, the key information generated in the second stage is reconstructed. To compensate for the loss of information, we design a multiscale detail compensation mechanism. In addition, the fusion results generated in the cascade cross-scale fusion stage are used as the prior knowledge to reconstruct details (i.e., a multiscale skip connection block). This can strengthen spatial details and reduce parameters. Finally, the pansharpening result is produced by adding the reconstructed details to the ↑LMS image.
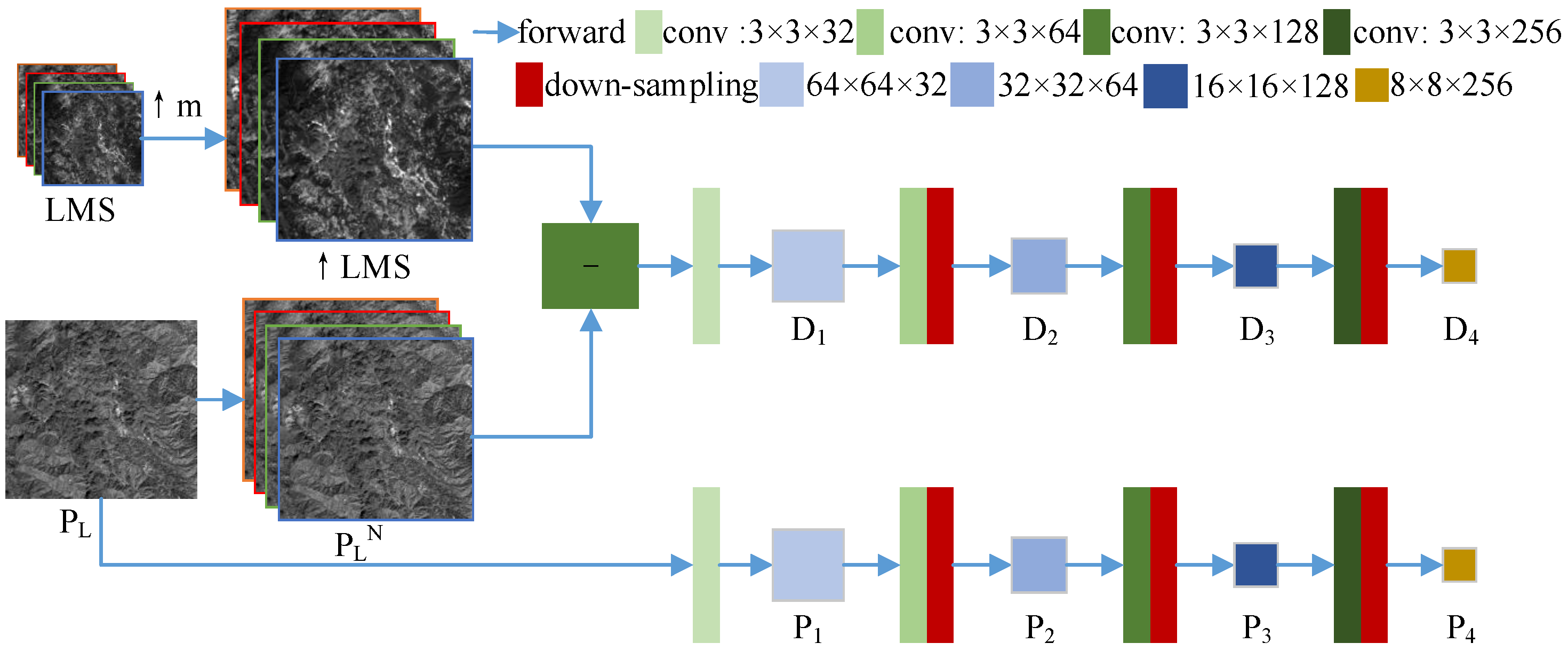
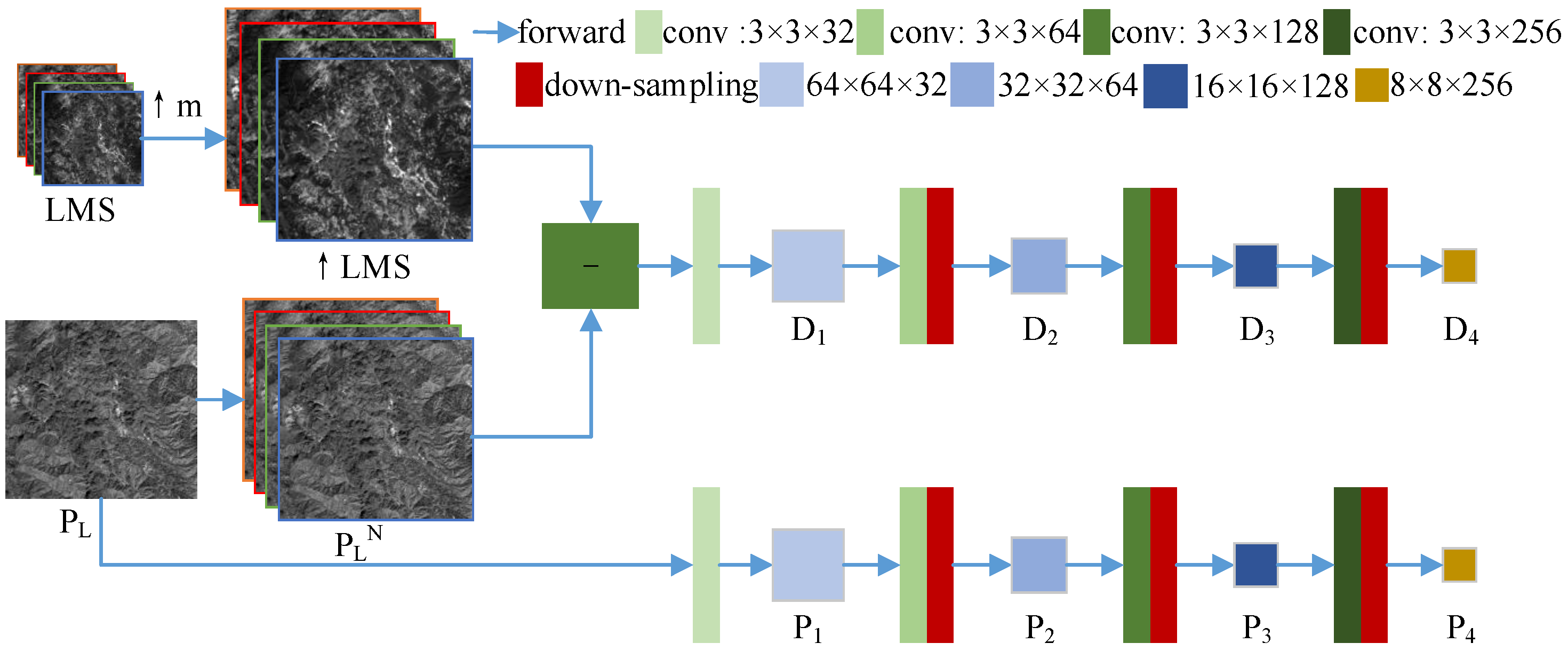
2.4.1. Dual-Branch Multiscale Detail Extraction Stage
FusionNet [
40] introduces the details of the difference between MS and PAN images, which has better performance than directly obtaining the details from the PAN image. Inspired by this approach, we propose a dual-branch multiscale detail extraction network. The composition of the network is shown in
Figure 2. The proposed network is trained using the reduced resolution
image and LMS image. One branch takes the difference between the ↑LMS and
images as the input to obtain the high-frequency details of four scales. The introduction of MS details reduces the spectrum distortion and details distortion caused by the lack of relevant spectrum information in the PAN image. The details extracted by this branch are named composite high-frequency details (CHFDs). The other branch is to acquire the details of four scales of the
image. In
Figure 2,
–
represent the extracted CHFDs of four scales.
–
represent the extracted PAN details of the four scales.
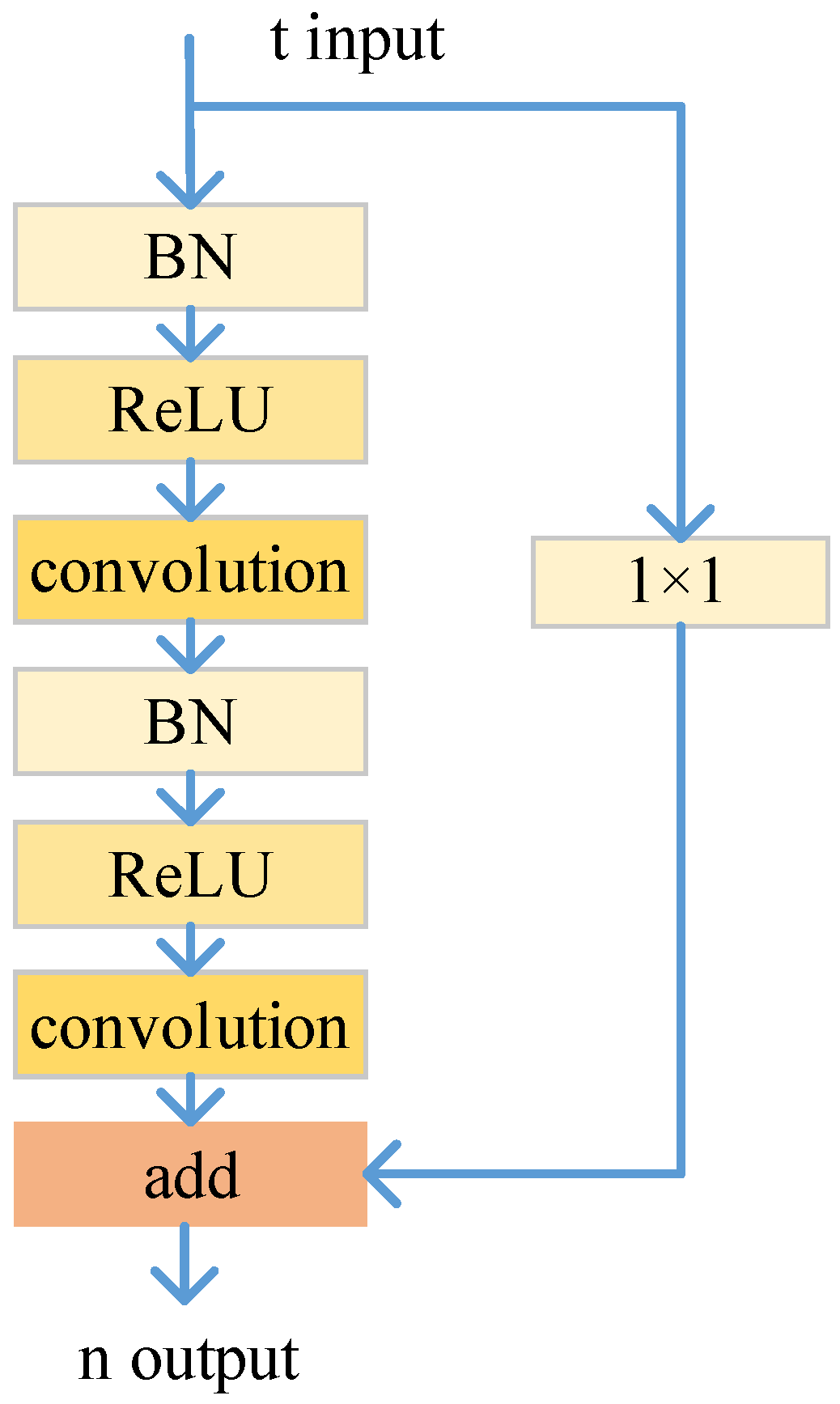
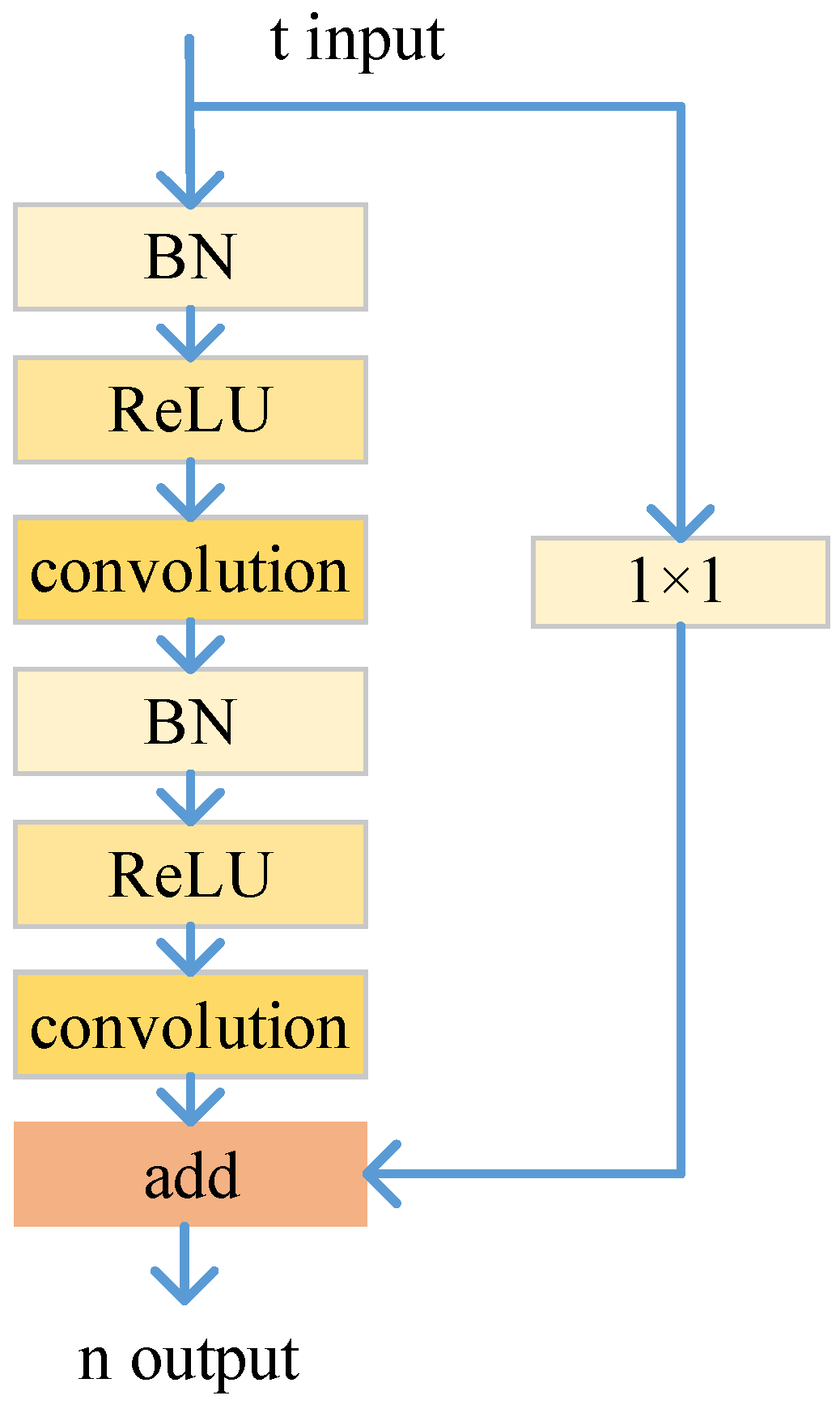
The conv module in
Figure 2 adopts a residual learning block [
48], and
Figure 3 shows the structure.
t represents the dimension of the input, and
n represents the dimension of the output. In
Figure 2, the sizes of the convolution kernels of the four conv modules are 3 × 3 × 32, 3 × 3 × 64, 3 × 3 × 128 and 3 × 3 × 256. The downsampling adopts the maximum pooling operation, and the sizes of the convolution kernels are 2 × 2 × 64, 2 × 2 × 128 and 2 × 2 × 256. The sizes of the
and
images are
of those of the
and
images. The expressions for extracting the CHFDs are Equations (
9)–(
12).
where
(
) shows the CHFDs of the
jth scale,
and
are the reduced resolution images of the MS and PAN images, ↑
is an upsampled
image, and
↑
presents the difference between MS and PAN images.
represents the function of the direct connection part of the residual module. ∗ is a convolution operation.
(
) represents the parameter of the direct connection part, and the convolution kernel size is 1 × 1, and the numbers are 32, 64, 128 and 256, respectively.
expresses the residual part function of the residual module,
(
) represents the parameter of the residual part, the convolution kernel size is 3 × 3, and the numbers are 32, 64, 128 and 256, respectively.
indicates the function of the maximum pooling operation.
The expressions for extracting details from the
image are Equations (
13)–(
16).
where
(
) means the PAN detail of the
jth scale.
(
) represents the parameter of the direct connection part, and the convolution kernel size is 1 × 1, and the numbers are 32, 64, 128 and 256, respectively.
(
) represents the parameter of the residual part, the convolution kernel size is 3 × 3, and the numbers are 32, 64, 128 and 256, respectively.
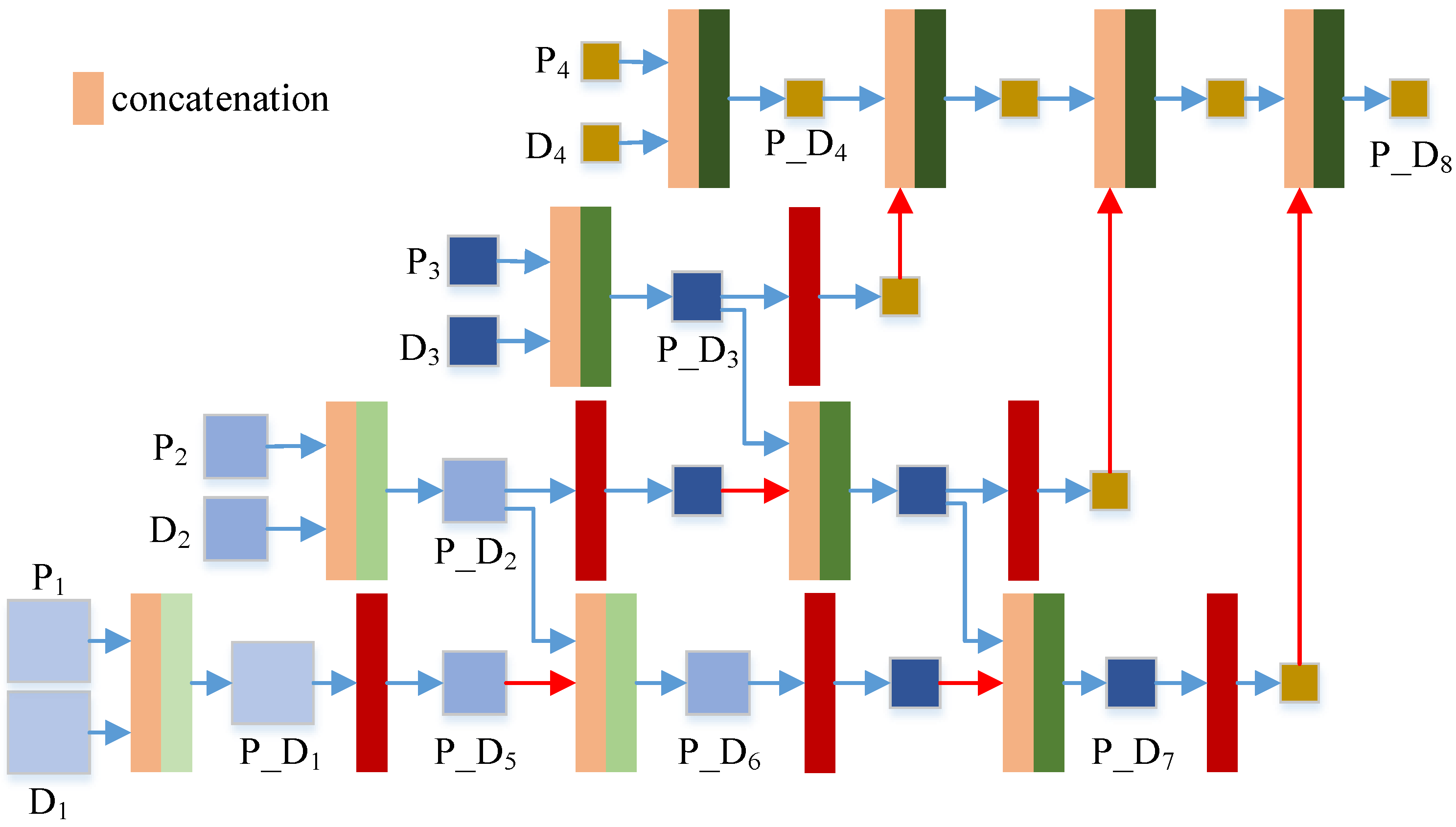
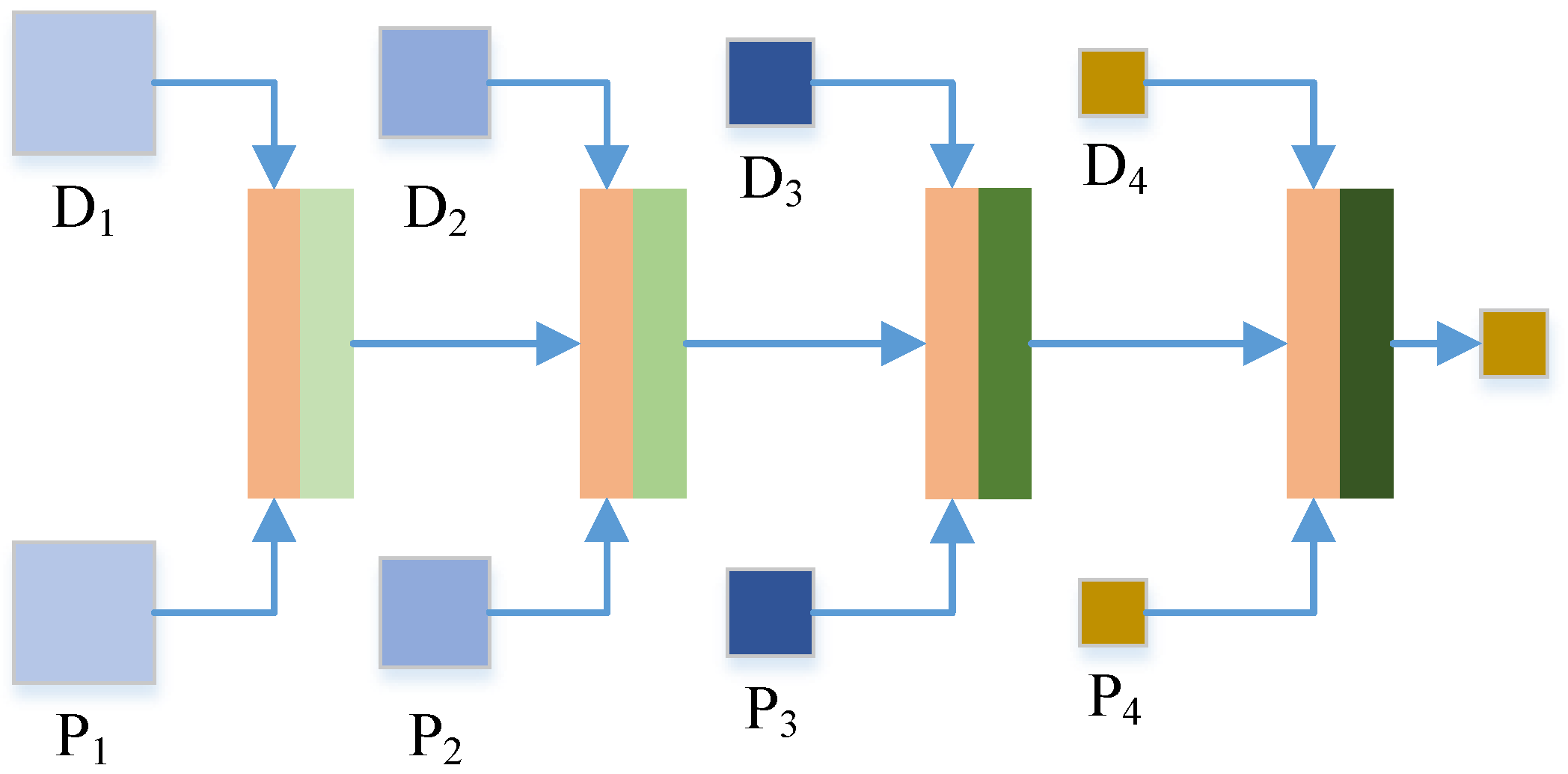
2.4.2. Cascade Cross-Scale Detail Fusion Stage
This section describes the second stage of the TDPNet method, i.e., the cascade cross-scale detail fusion stage. The structure of this stage is shown in
Figure 4. In this stage, the CHFDs and PAN details of four corresponding scales are concatenated, and then they are fused at the same scale. CCSF employs fine-scale fusion information as prior knowledge for coarse-scale fusion. CCSF is achieved by combining fine-scale and coarse-scale fusion based on residual learning and prior information of four scales. The representation of each content in
Figure 4 is the same as the representation in
Figure 2. First, the CHFDs
and the PAN details
are concatenated and then fused at the same scale to generate the prior fusion result
. Then, the fine-scale fusion result
provides the prior information for coarse-scale fusion. Cross-scale fusion (
and
) requires a scale transfer module to convert the fine-scale information into coarse-scale information. The scale transfer module used is a maxpooling operation, as shown in the red module of
Figure 4. Then
is downsampled and
is generated. The
and
are fused, and the fusion result
provides a priori information for the fusion of the next scale (i.e.,
). In this way, the CCSF of four scales is carried out by combining the fine-scale and coarse-scale fusion, and finally, the key information
is generated.
The expression of the cascade cross-scale detail fusion stage is Equation (
17).
where
shows the fused information of the cascade cross-scale detail fusion stage,
indicates the function of the cascade cross-scale detail fusion network, and
means the parameter.
2.4.3. Injection Detail Reconstruction Stage
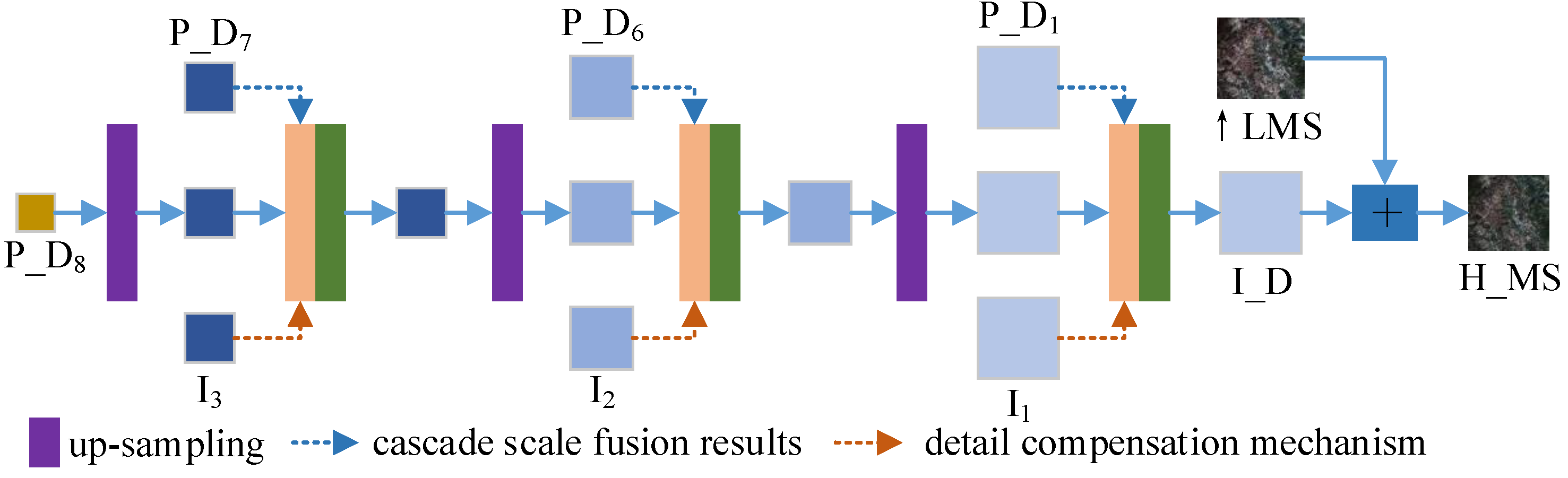
This section is the third stage of the proposed TDPNet approach generating injection detail, i.e., the reconstruction stage of injection detail. The structure is shown in
Figure 5. To compensate for the lost information, we design a multiscale high-frequency detail compensation mechanism. In addition, we take the fusion results generated in the cascade cross-scale fusion stage as a multiscale prior compensation module by multiscale skip connections. Finally, the pansharpening result is produced by adding the reconstructed injection detail to the ↑LMS image. This stage consists of three upsampling operations (i.e., deconvolution operation) and three convolutions after concatenating operations.
As shown in
Figure 5, considering that some details will be lost in the downsampling process, to enhance the injection details generated by reconstruction, the fusion results of the first scale
, the second scale
and the third scale
are introduced, forming multiscale skip connections. The multiscale skip connections not only reduce the network parameters but also compensate for the details. To further compensate for the information lost in the downsampling operations, we also design a multiscale high-frequency detail compensation mechanism, i.e.,
–
in
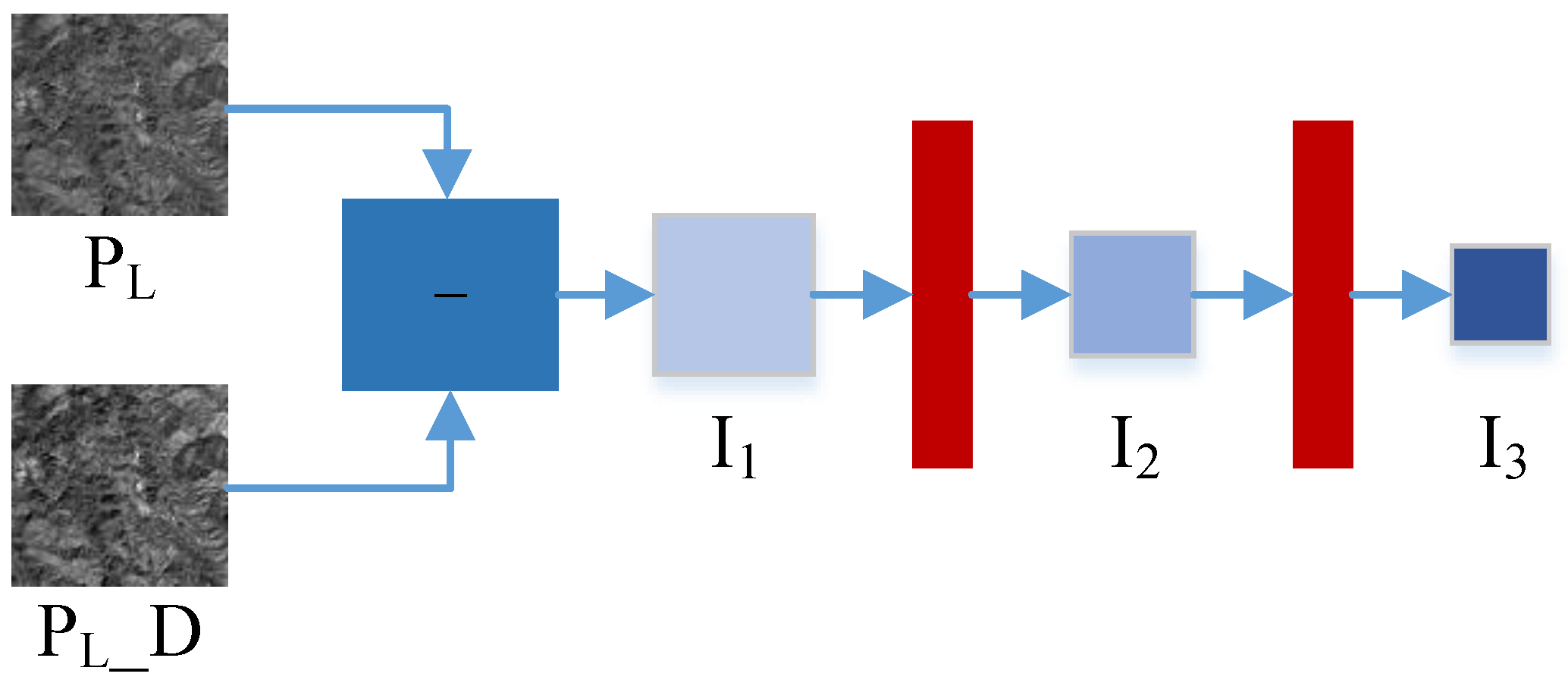
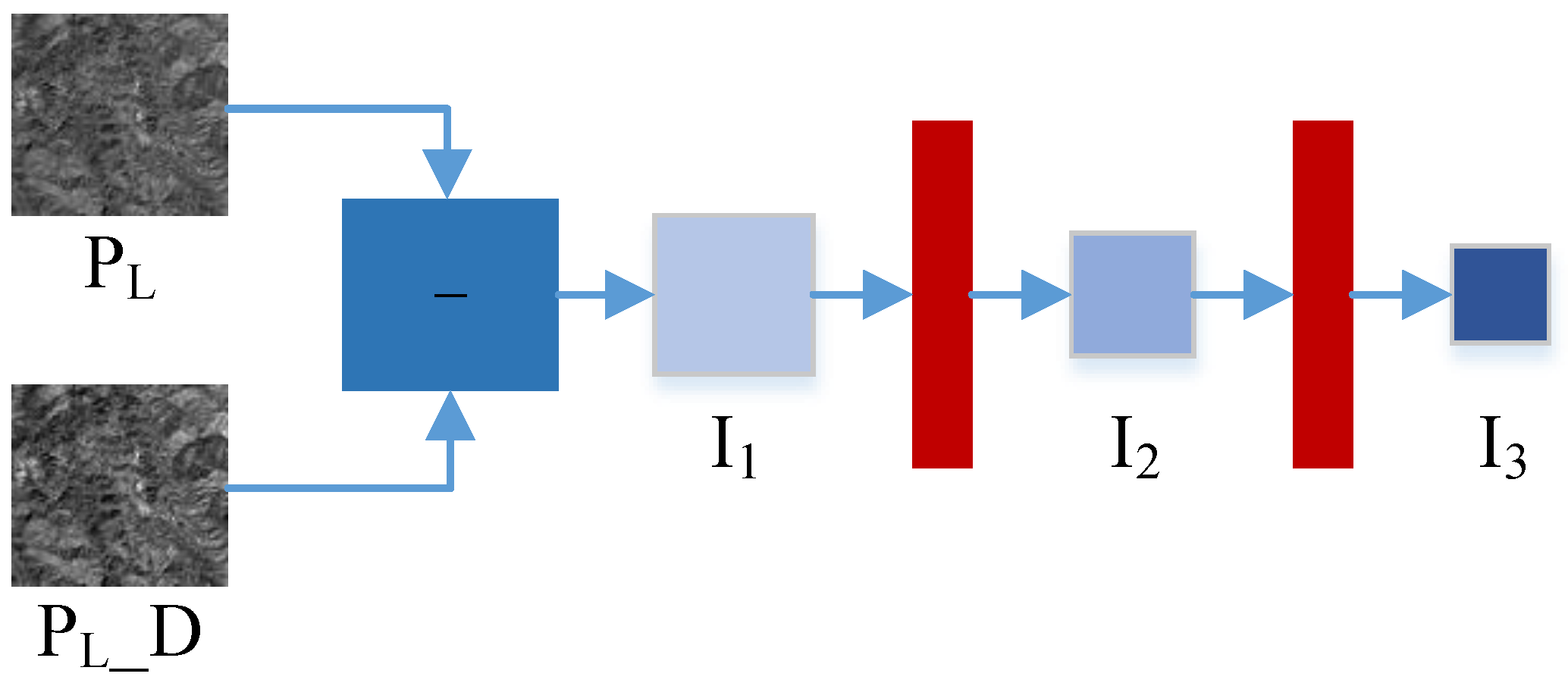
Figure 5. To match the scale of the reconstructed information, we design a scale transfer block for the compensation details.
Figure 6 describes the structure diagram of the compensation details
–
.
means the reduced form of the
image.
is obtained from the difference between
and
, and then two-scale details
and
are obtained by the downsampling operation. In this way, the detail compensation mechanism can further compensate for the information lost in the downsampling of the fusion stage and enhance the reconstruction details.
As shown in
Figure 5, the result
of CCSF undergoes a deconvolution operation, and convolution is performed after concatenating
and
, generating a finer scale image. After three such operations in turn, the final injection detail
is generated. Finally,
and ↑LMS images are added to obtain the pansharpening image.
The expression of obtaining the injection detail is Equation (
18).
where
presents the injection detail,
d is the function of the three-stage injection detail extraction network, and
indicates the parameter of the network.
The expression for pansharpening model TDPNet is Equation (
19).
where
indicates the generated pansharpening result.
The optimization objective of the pansharpening network TDPNet is the loss function, expressed as Equation (
20).
where
is the loss function,
K indicates the number of training data in each iteration, and
represents the reference image.










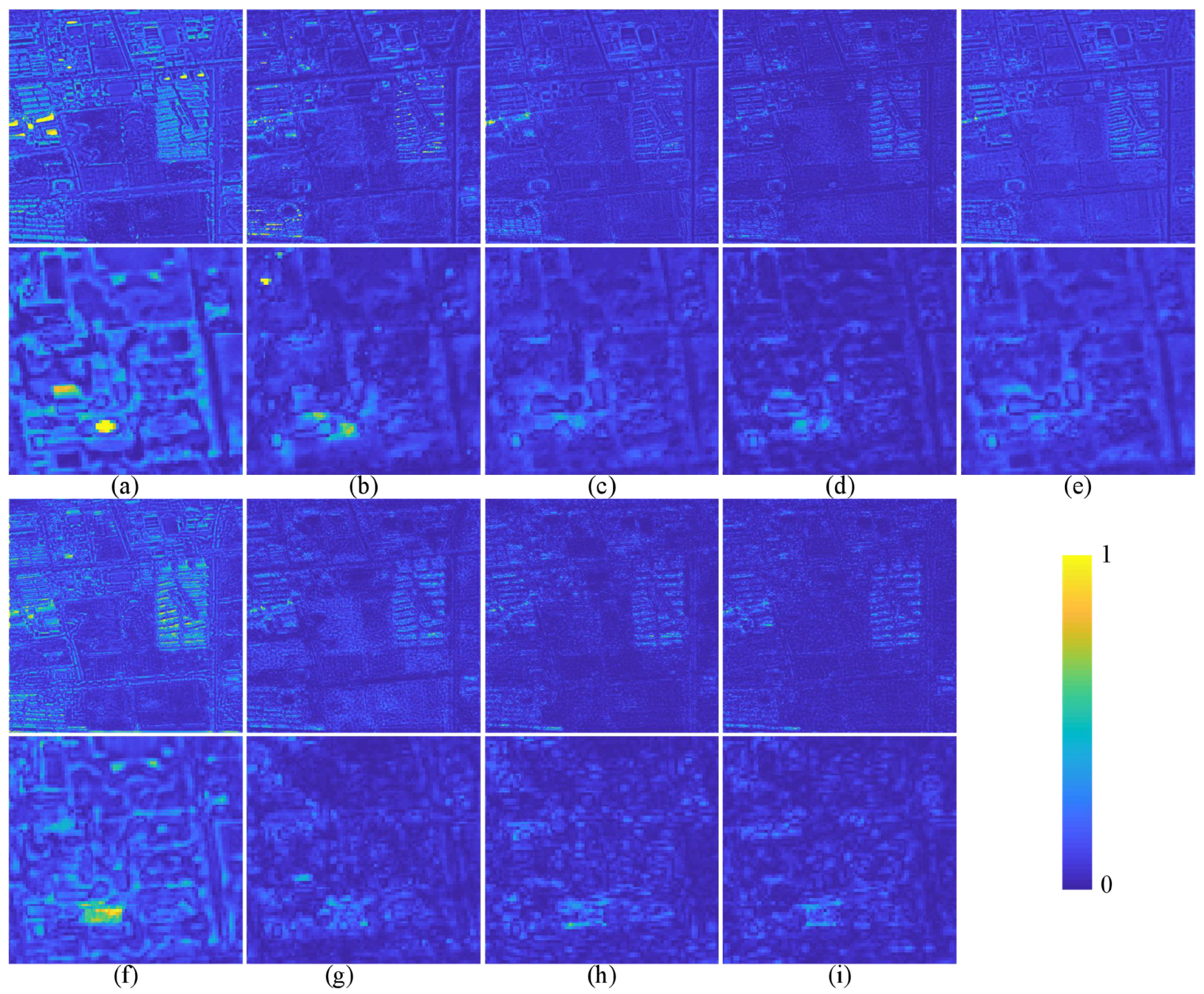

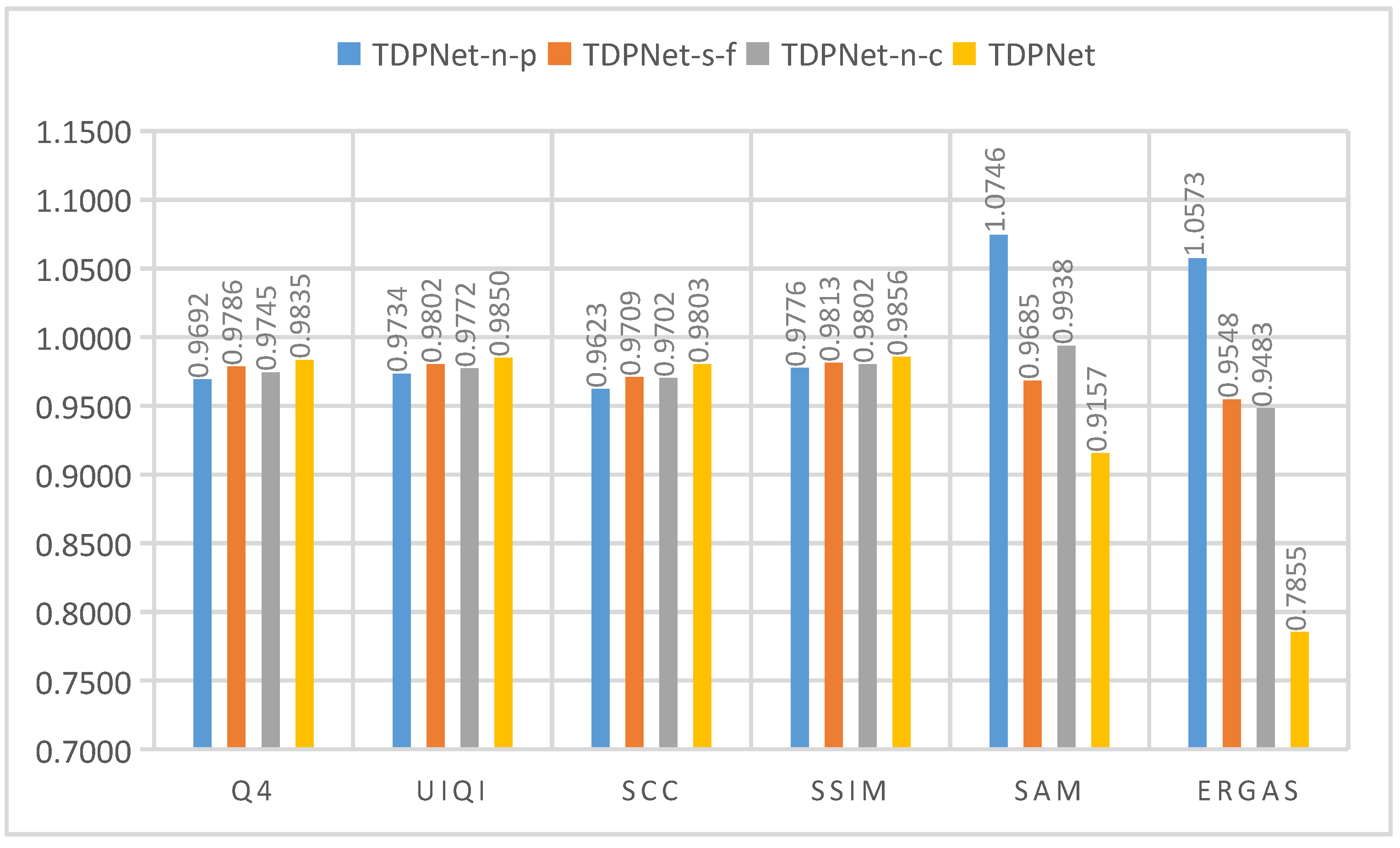
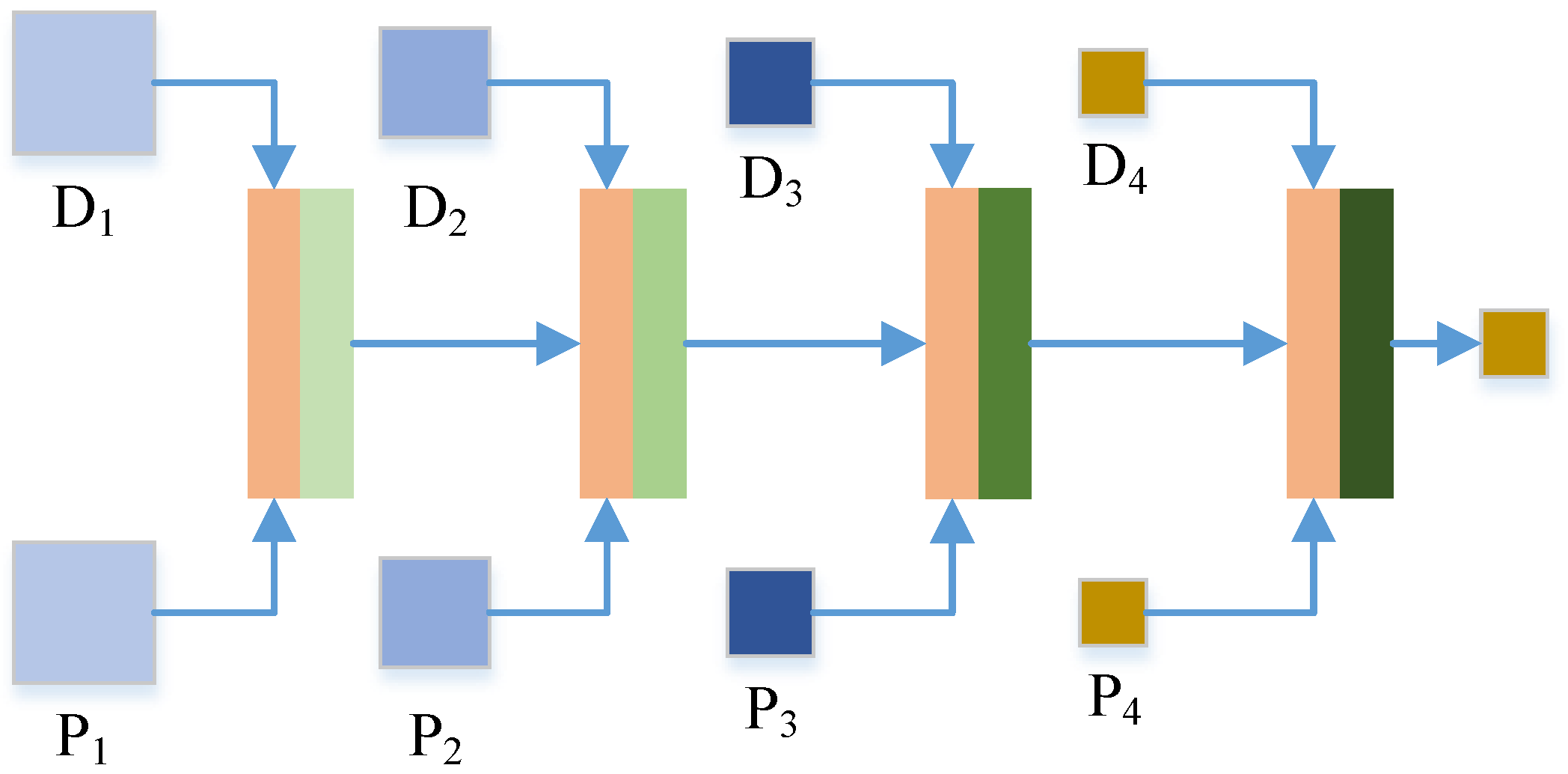

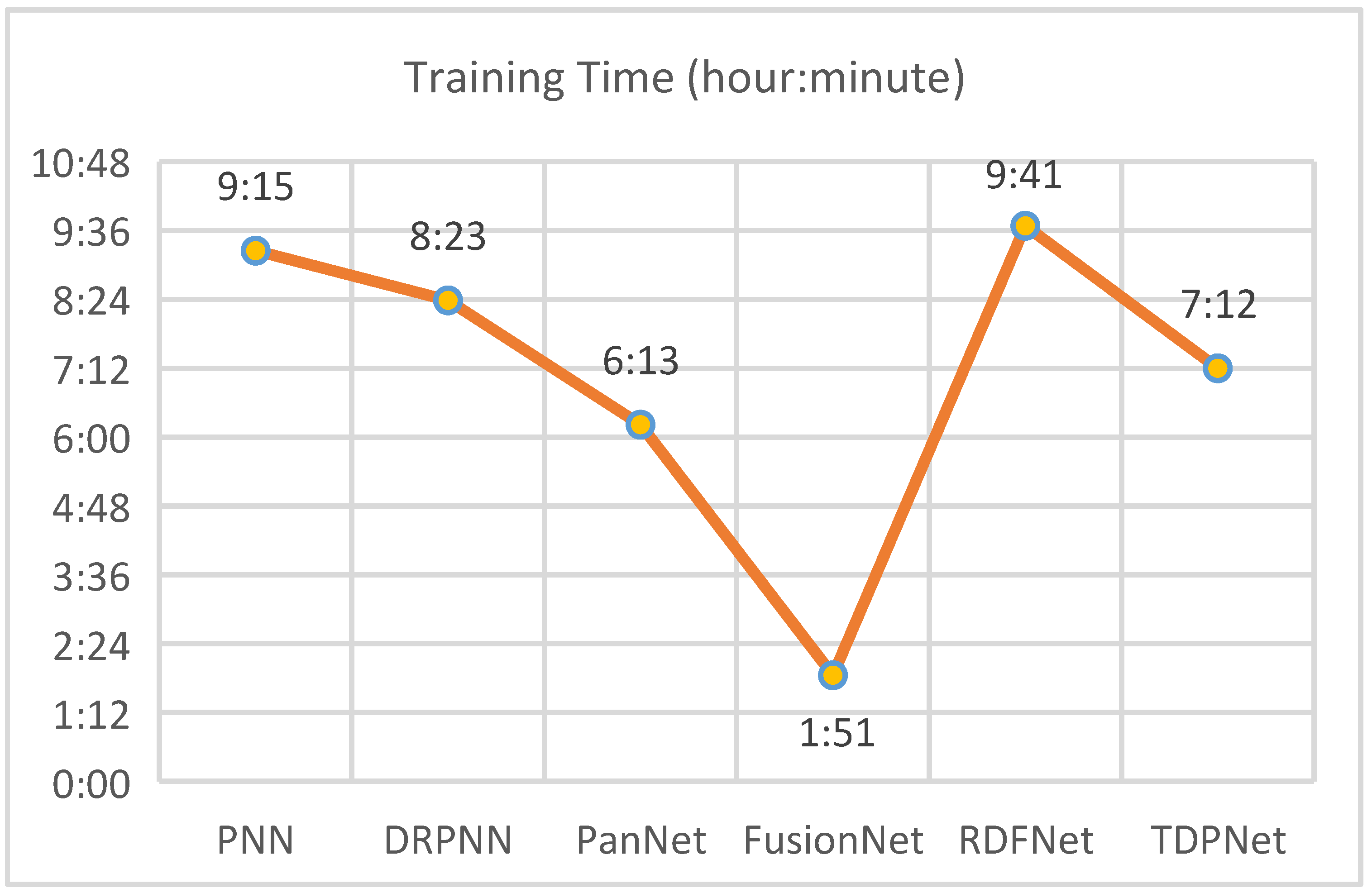

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}