
Deep Learning for Vegetation Health Forecasting: A Case Study in Kenya



Abstract
:1. Introduction
- To test LSTM based models, used in other hydrological contexts, for predicting vegetation health;
- To explore the models and demonstrate they learn physically realistic patterns.
2. Materials and Methods
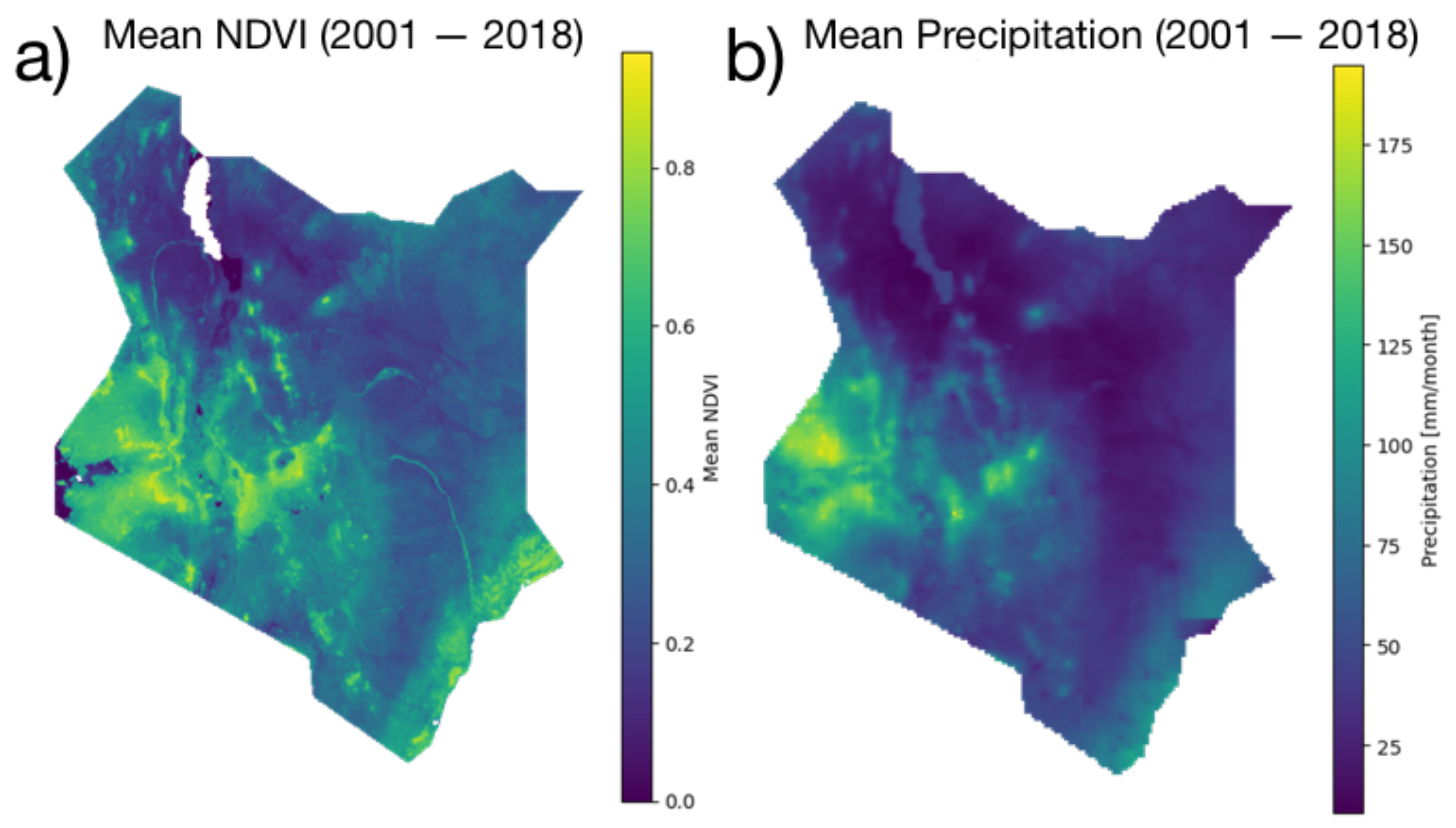
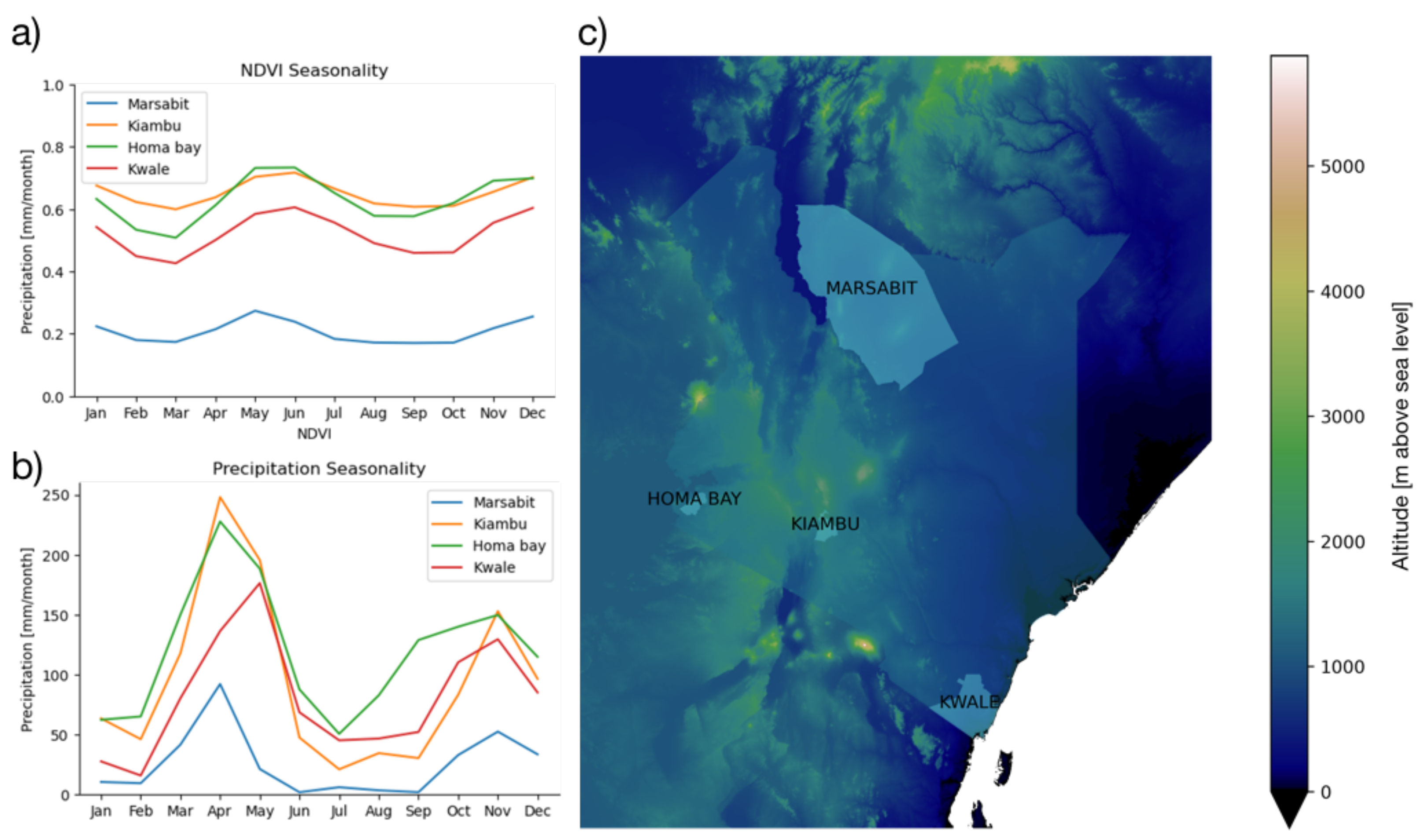
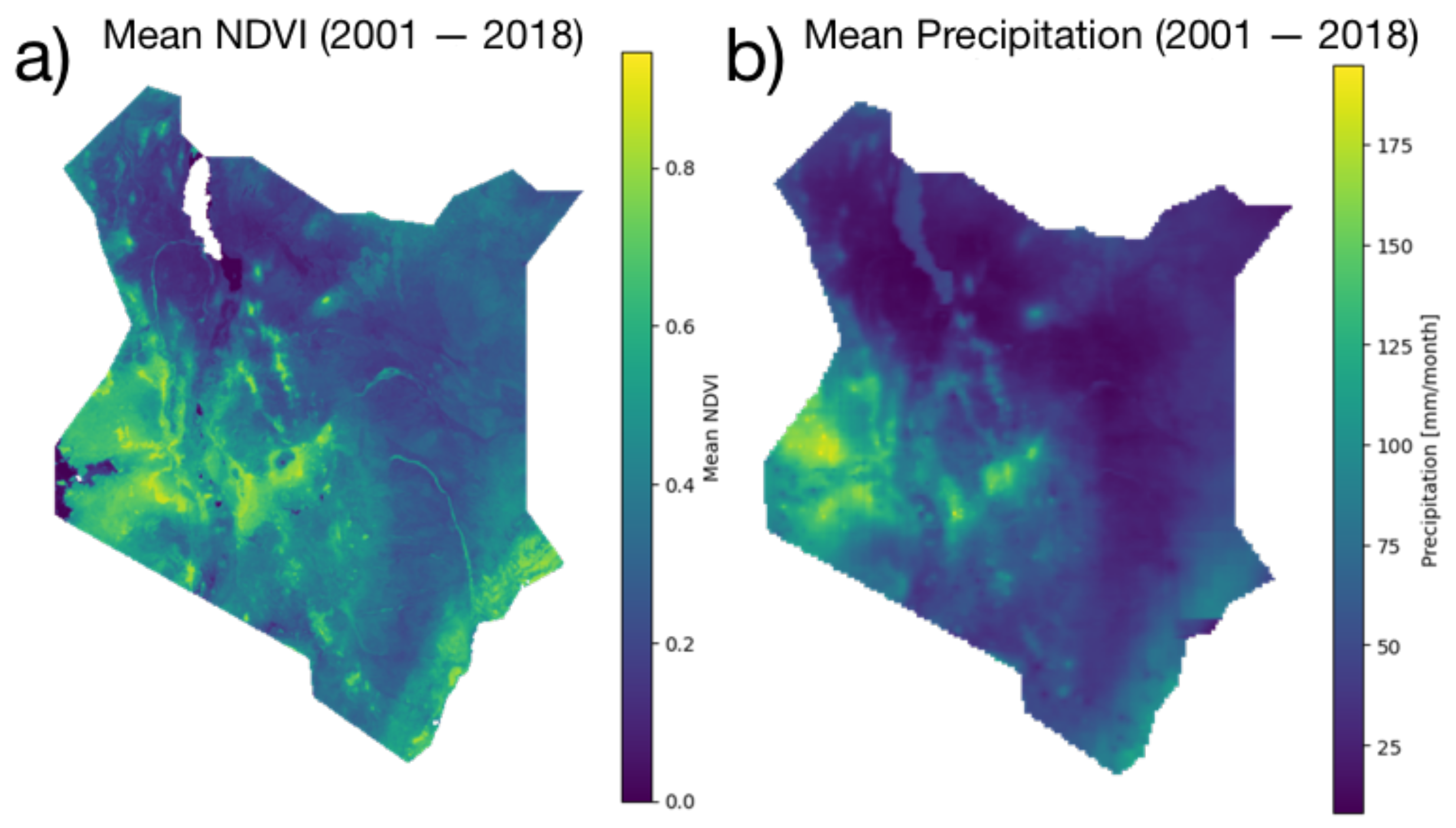
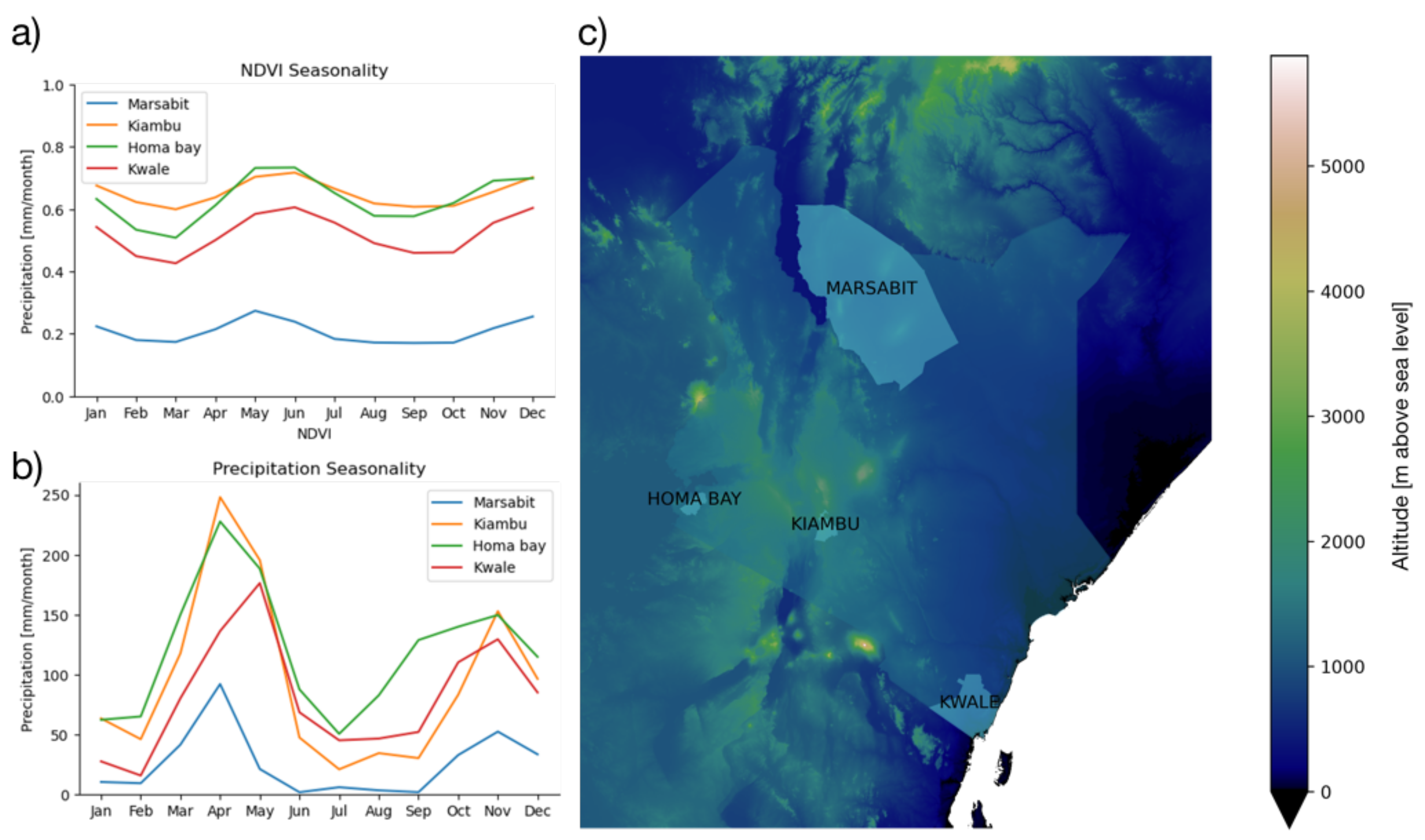
2.1. Study Area
2.2. Data
2.2.1. Target Variable: Vegetation Condition Index
2.2.2. Input Variables
2.2.3. ERA5 Reanalysis
2.2.4. CHIRPS Precipitation
2.2.5. NASA SRTM
2.3. Models
2.4. Experimental Setup
2.5. Interpreting the Models
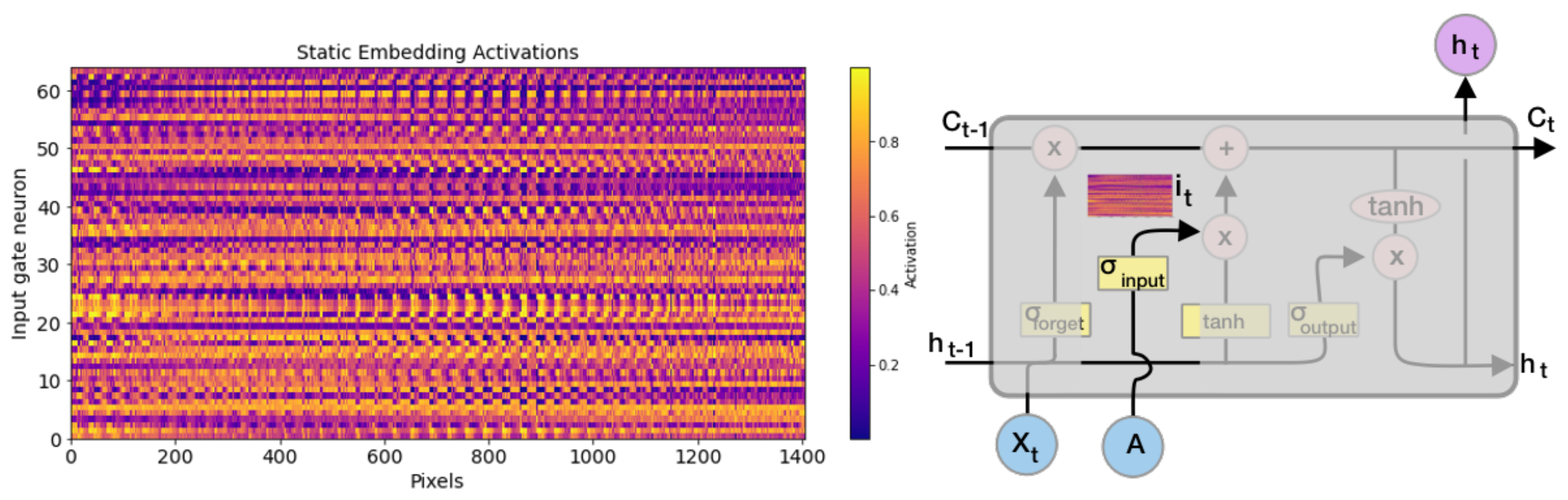
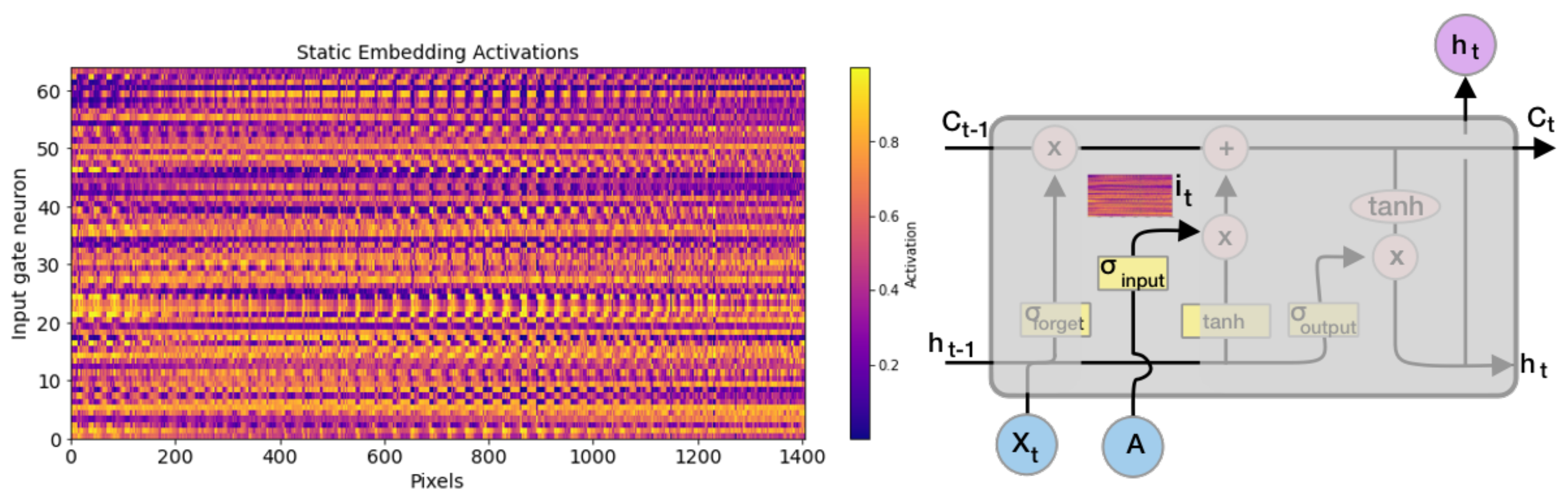
2.5.1. Clustering Analysis of the Static Embedding Layer
2.5.2. Determining Feature Importance
- A baseline output to compare our predictions to;
- Our model prediction we want to explain;
- The values for the features that we want to assign importance to.
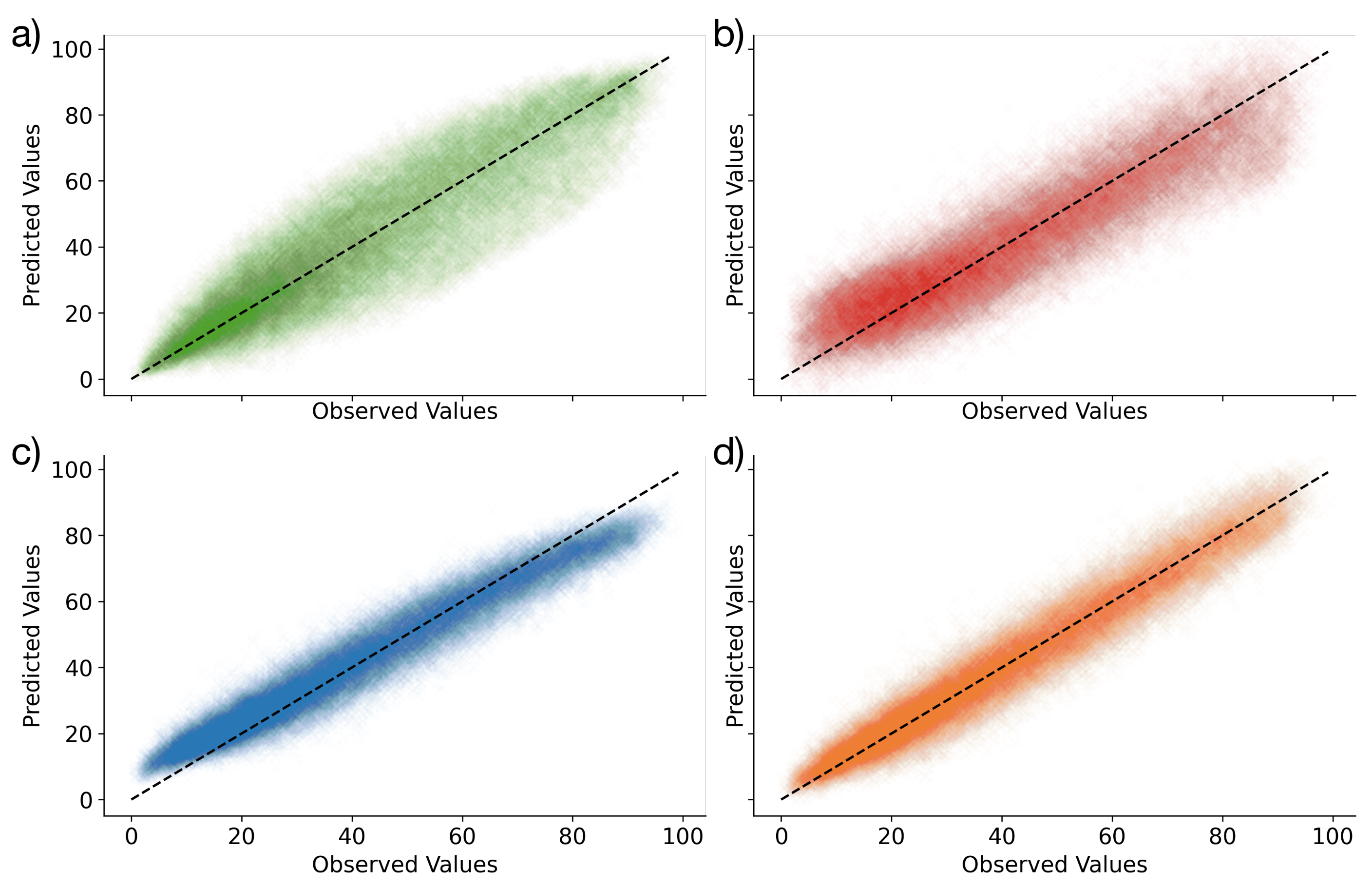
3. Results
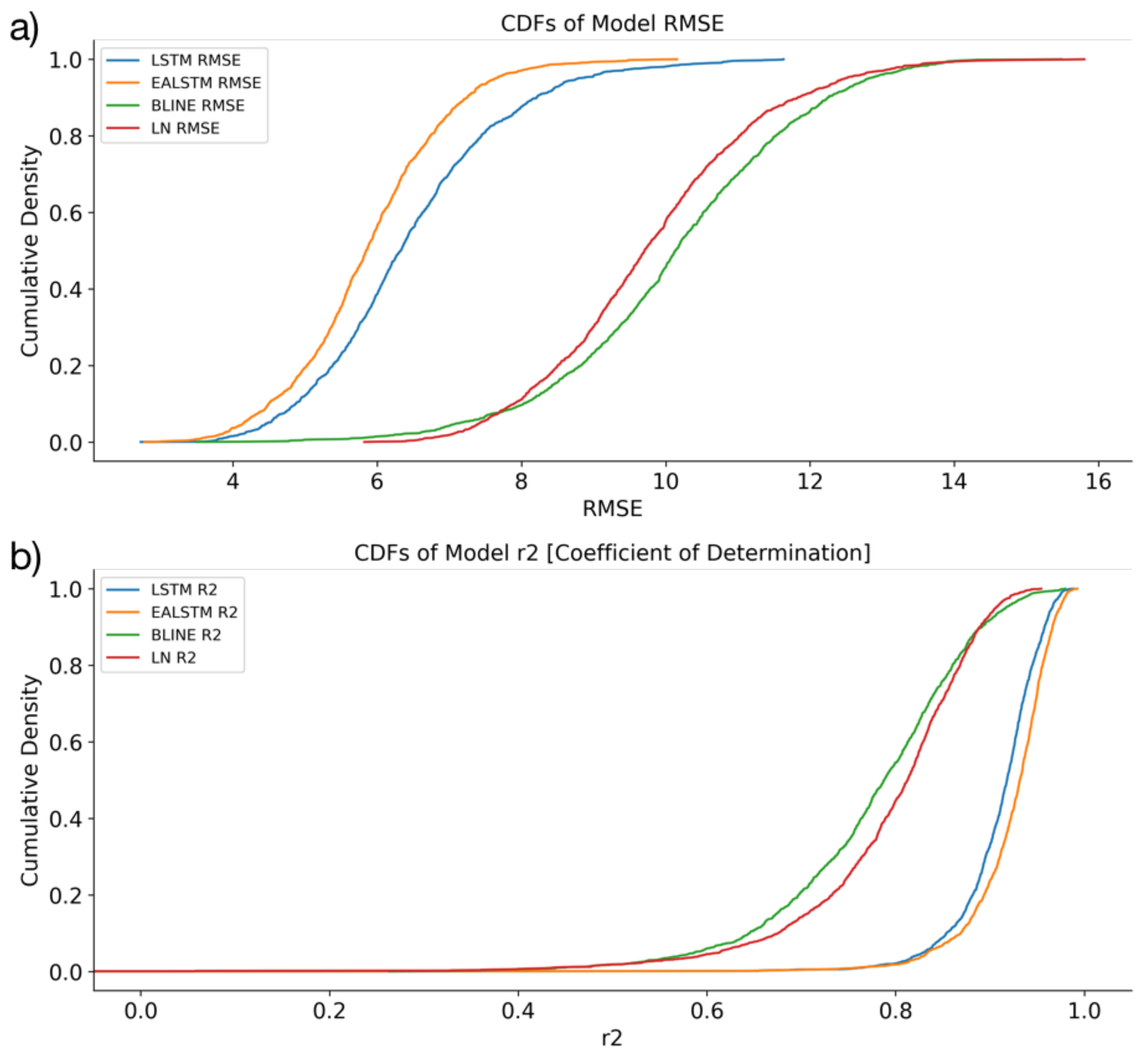
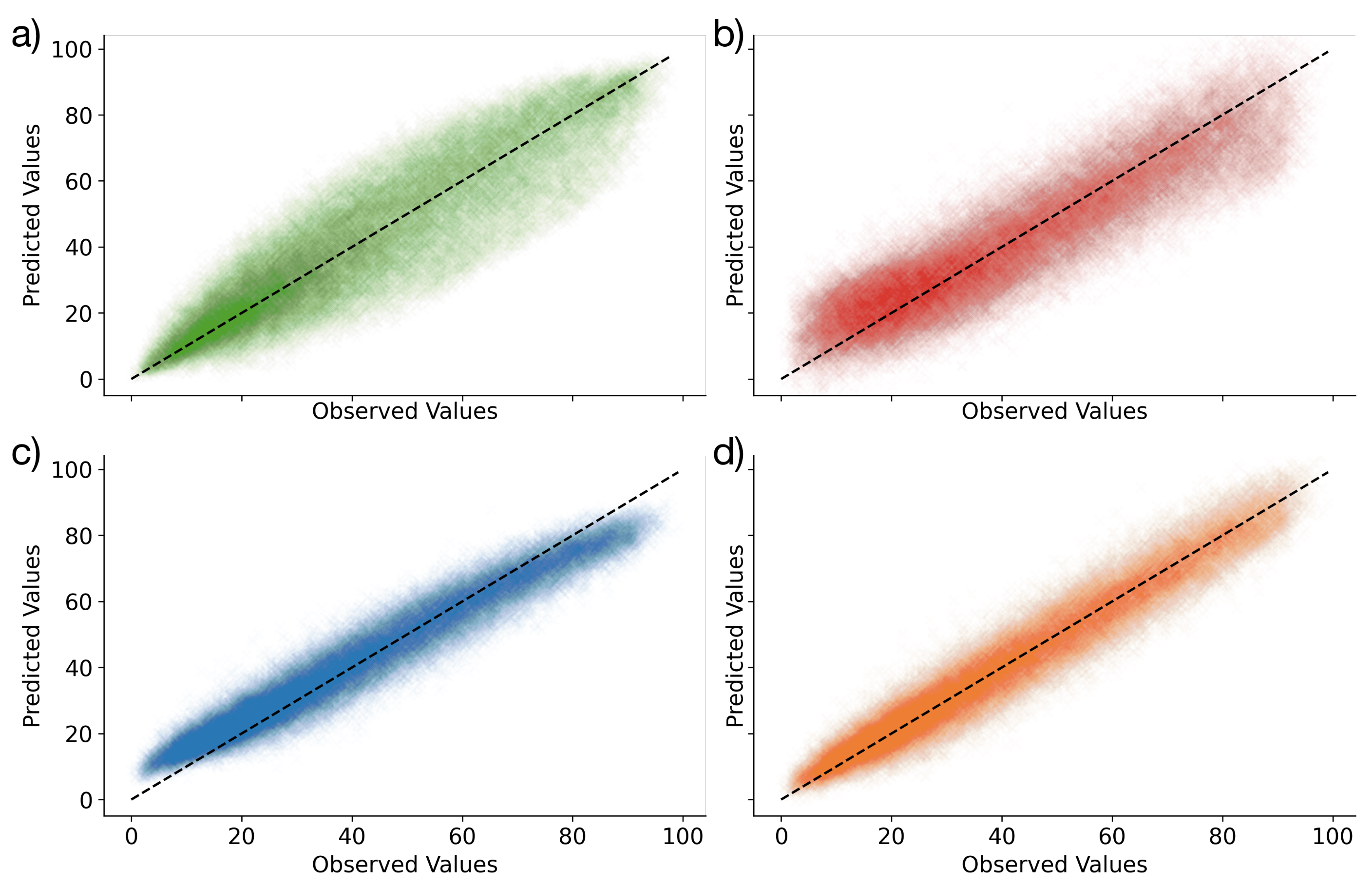
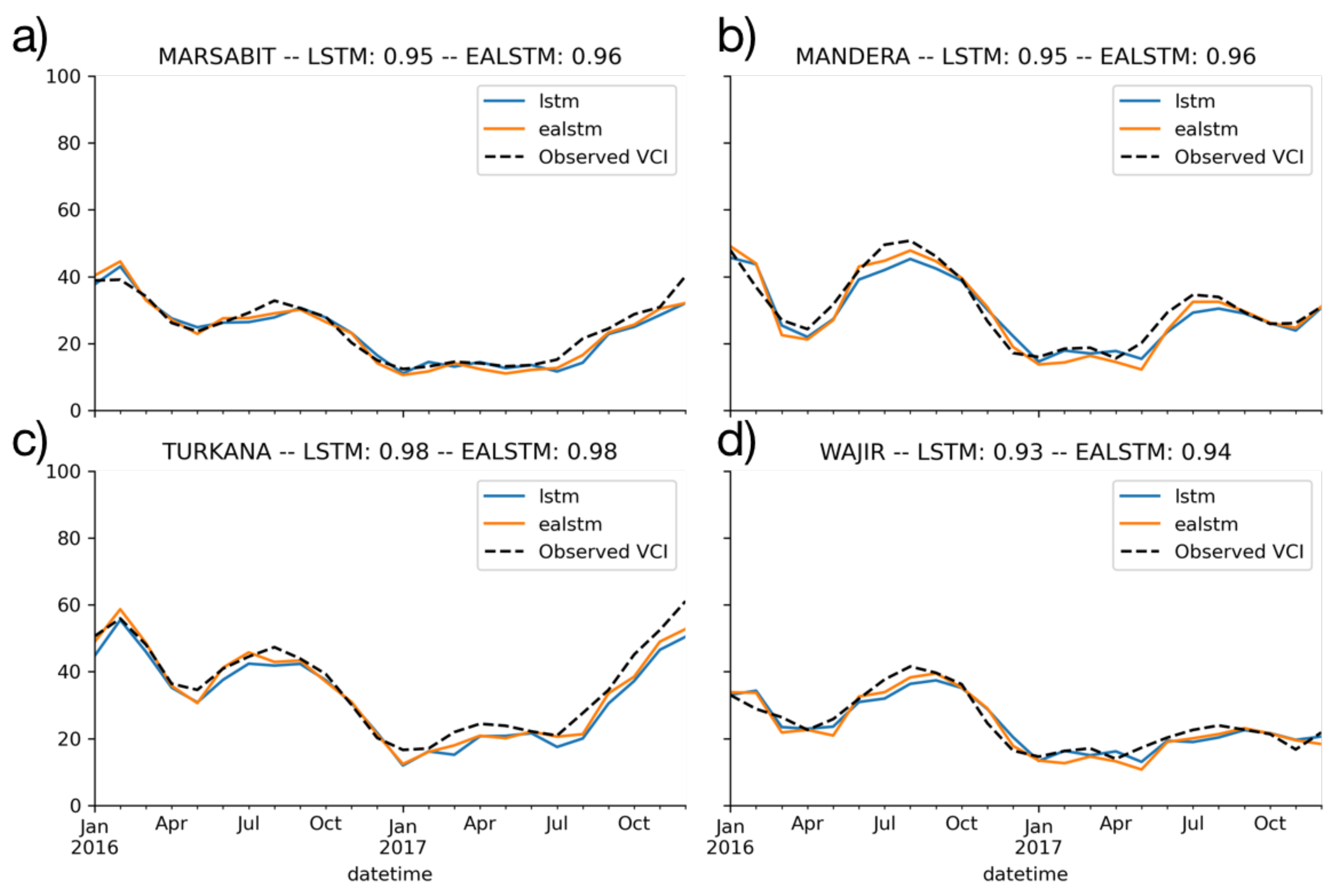
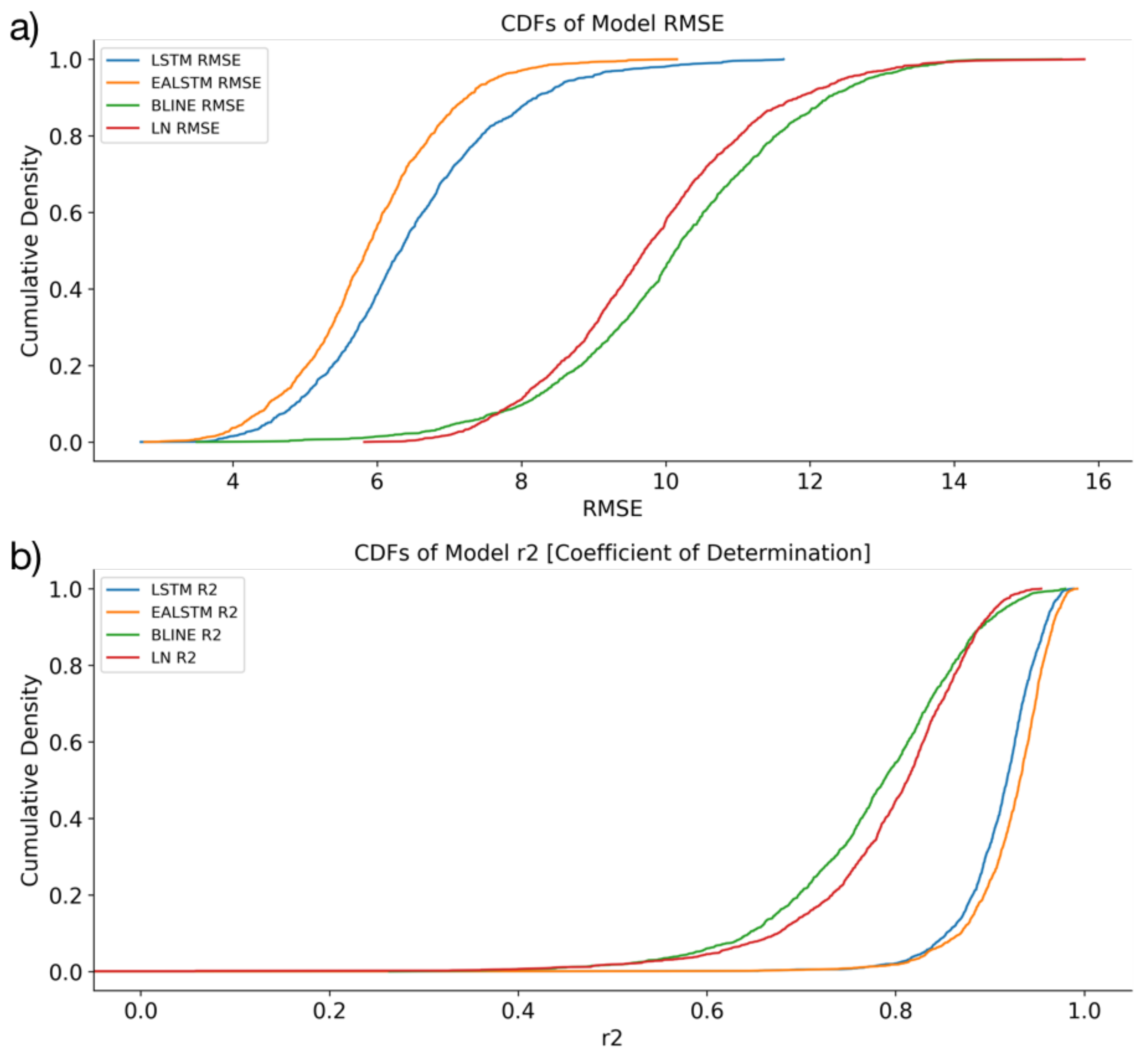
3.1. Model Performances
- The LSTM and EA LSTM performances are extremely similar;
- Both the EA LSTM and LSTM significantly outperform the persistence baseline;
- The simple feed-forward neural network performs very similarly to the persistence baseline;
- All models predict the temporally smoother VCI3M better than VCI1M.
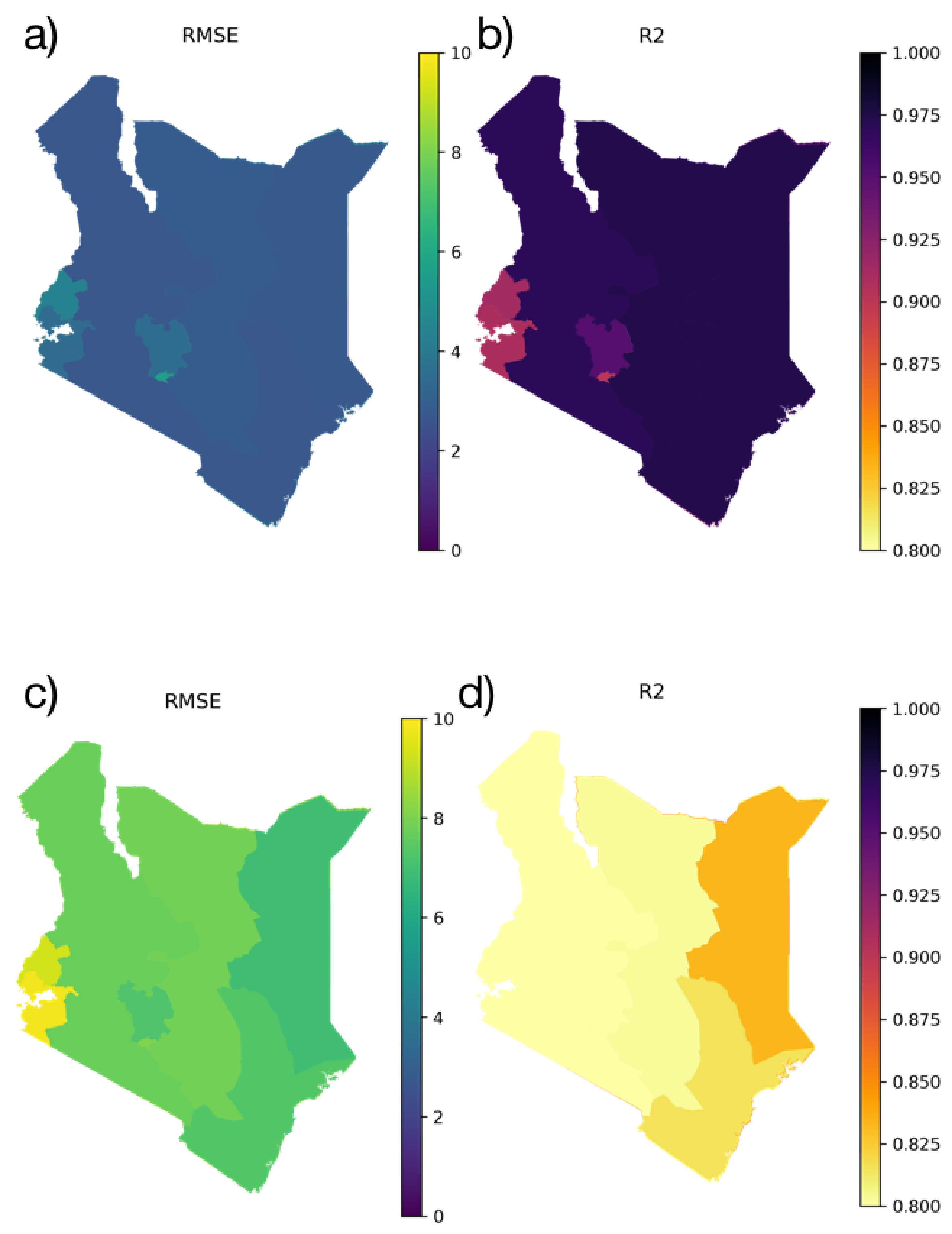
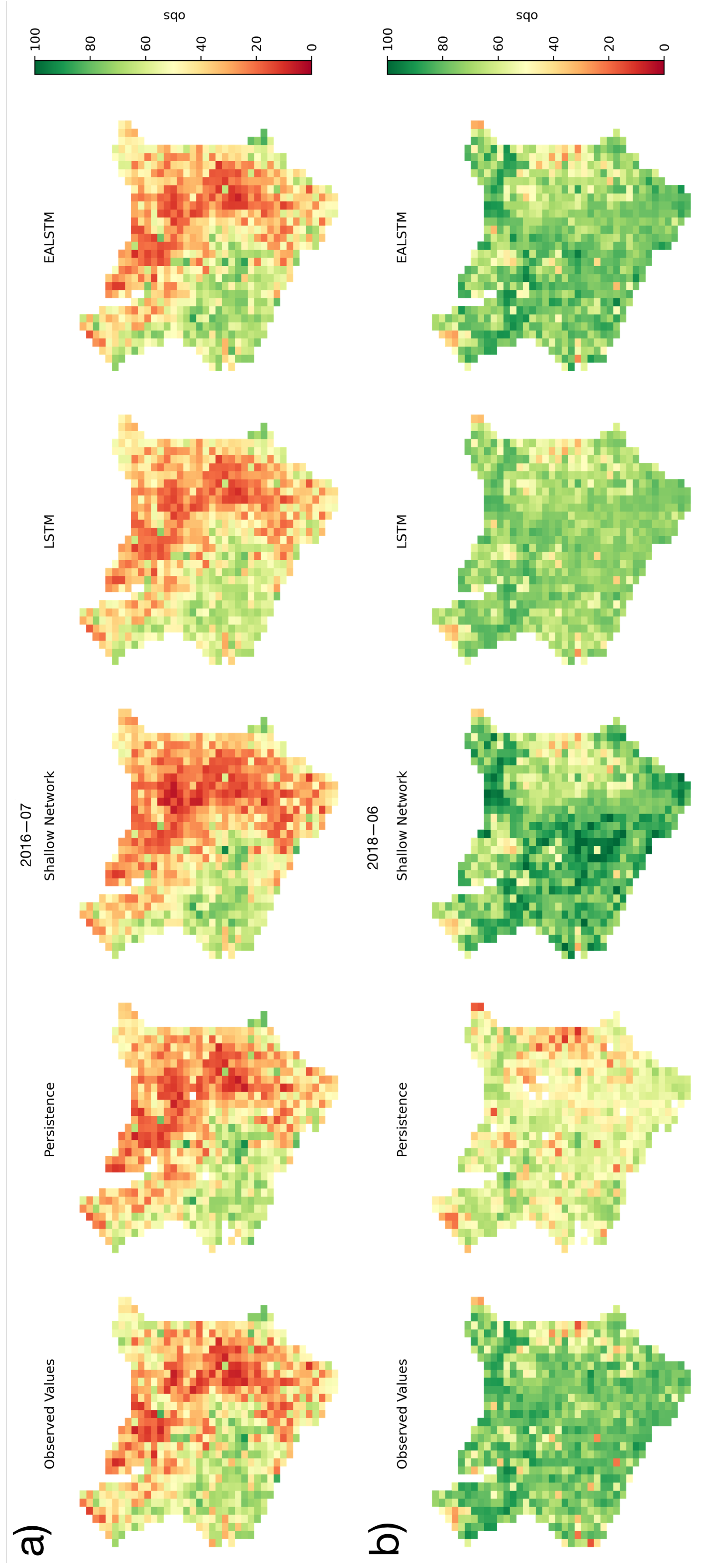
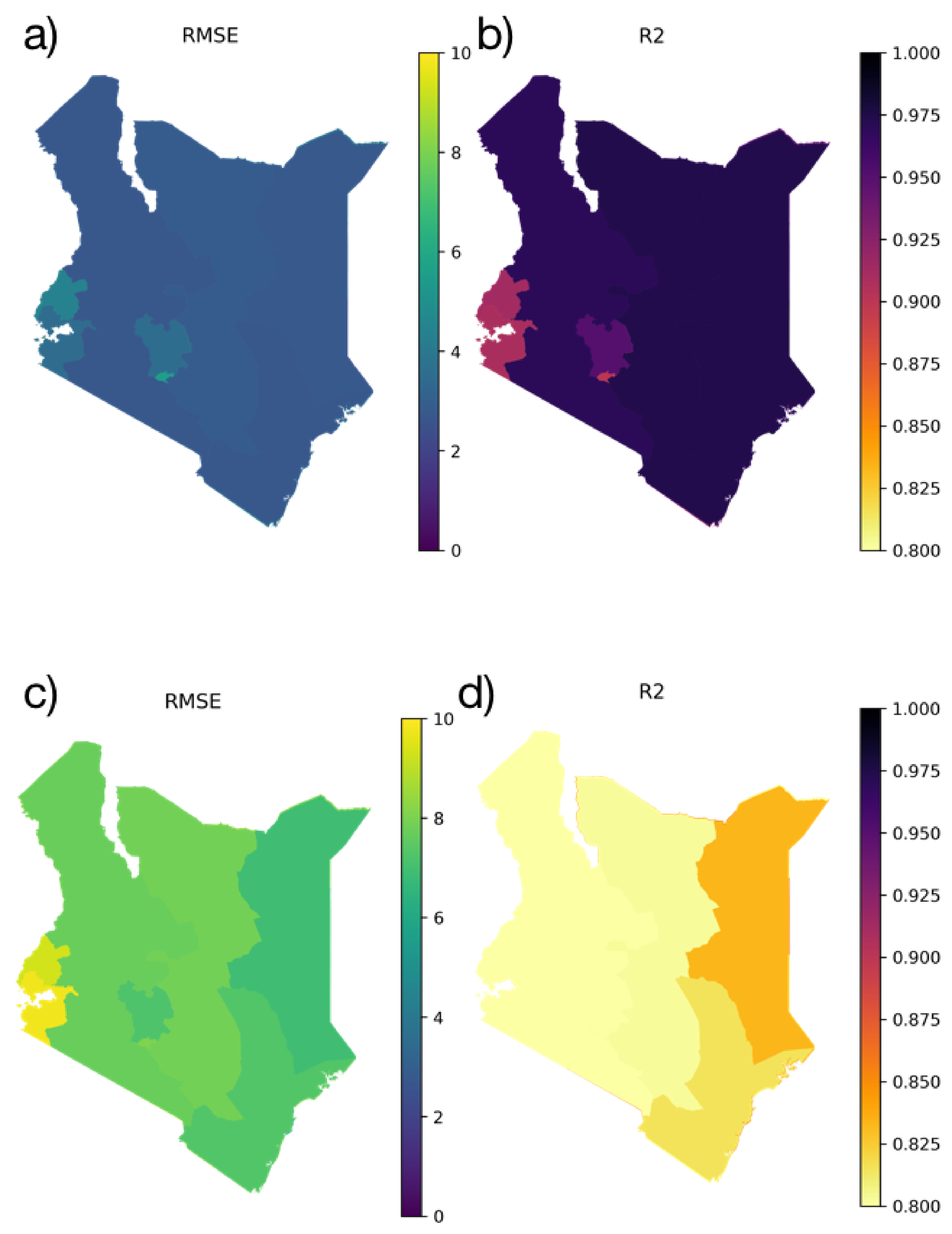
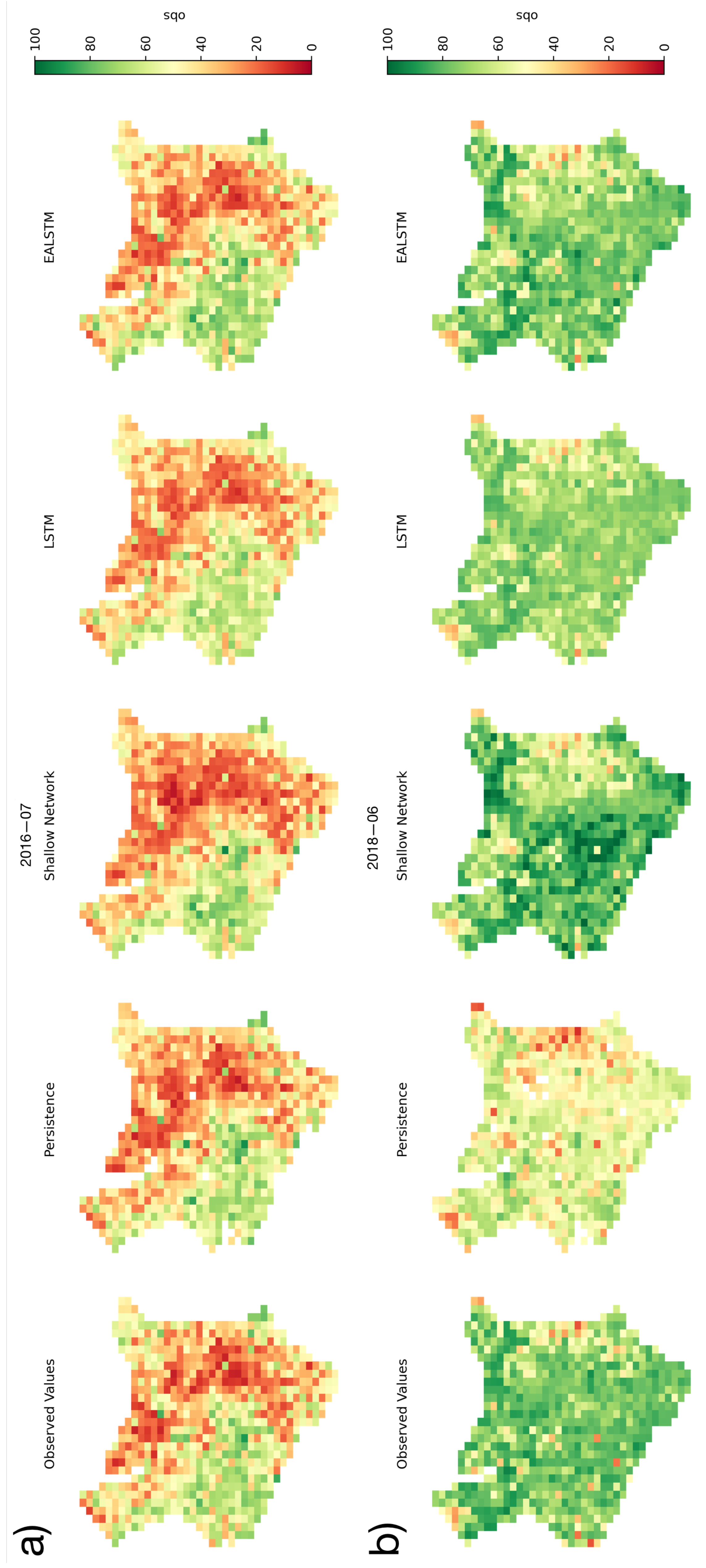
3.1.1. Spatial Distribution of Model Results
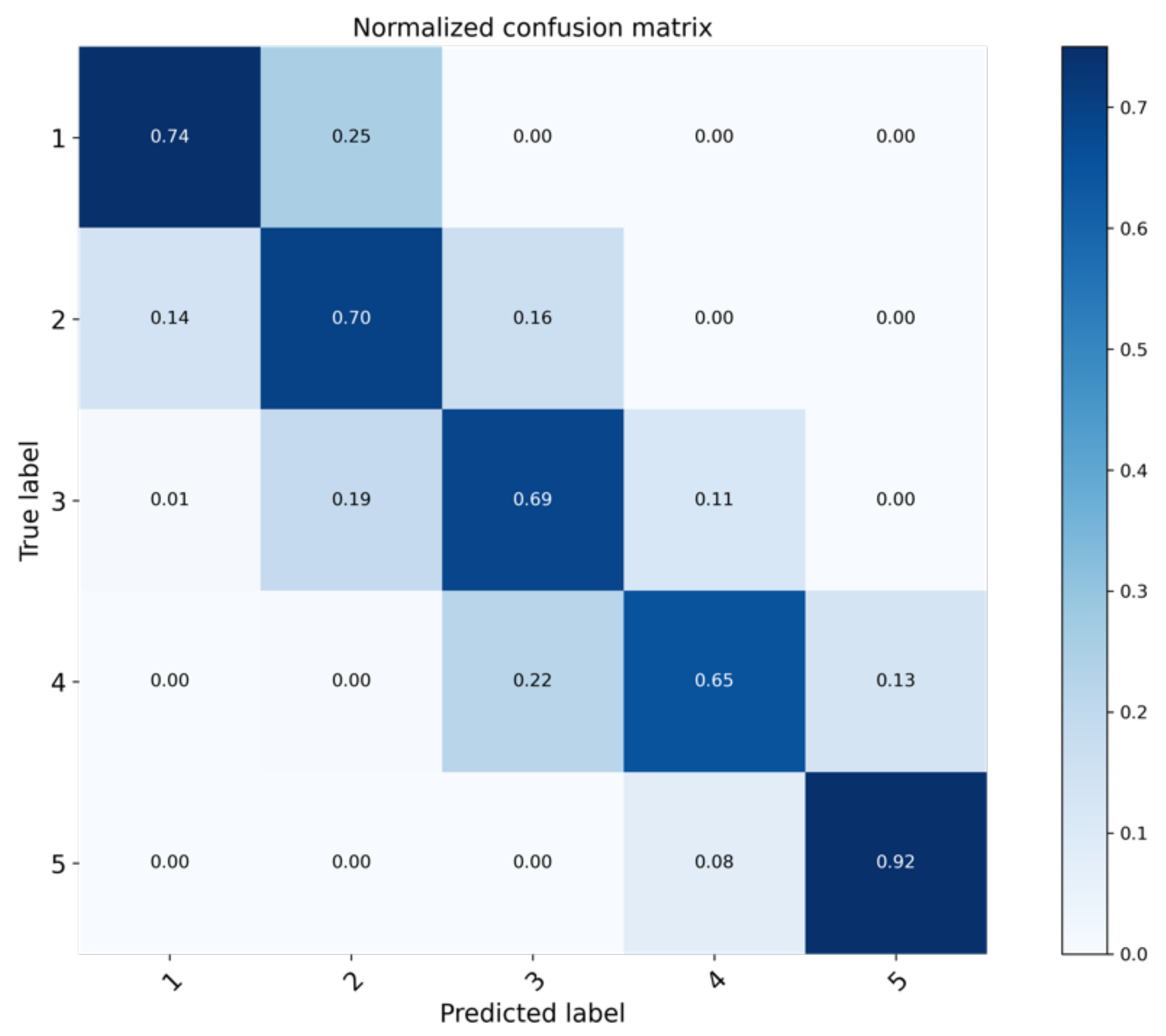
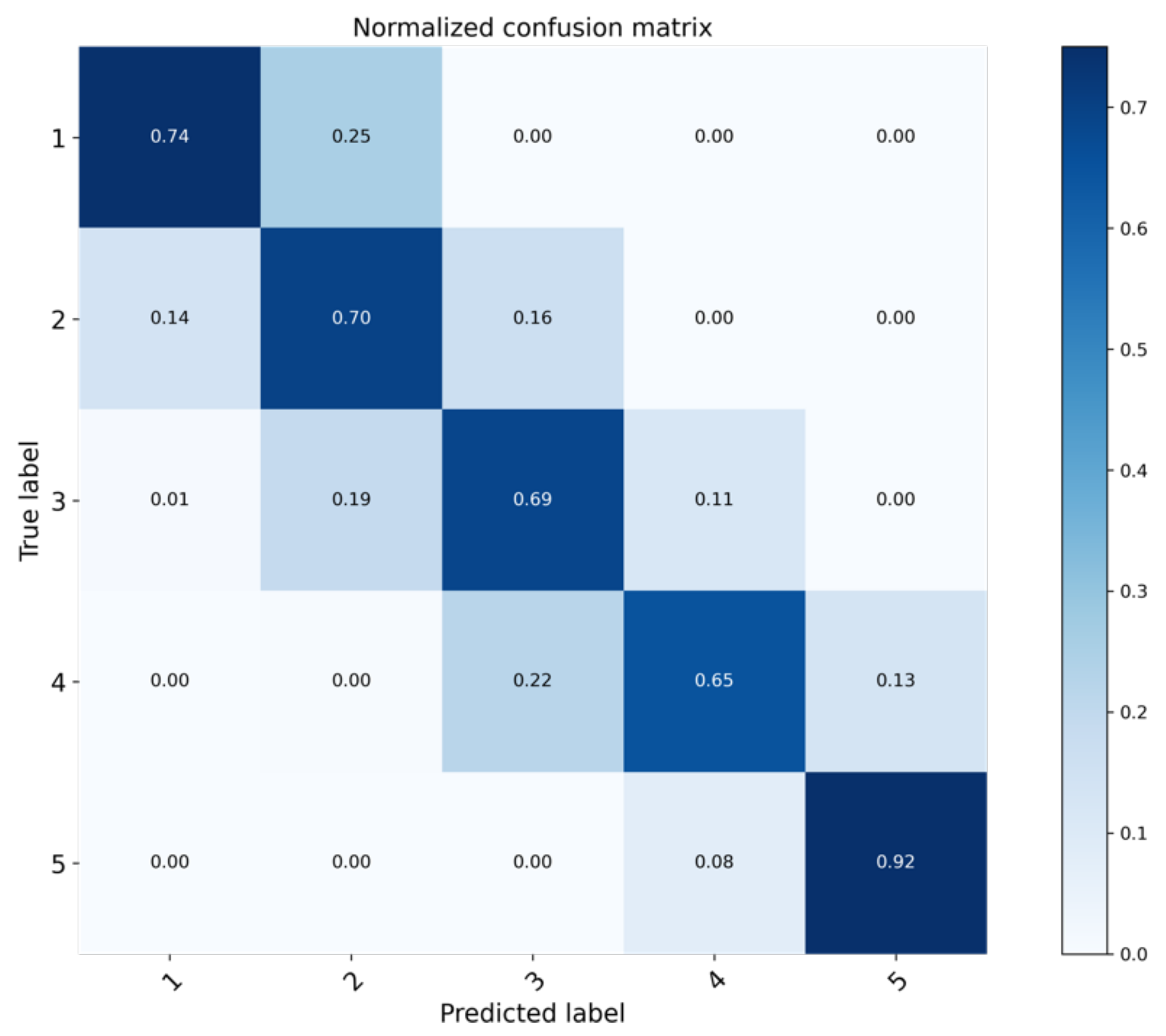
3.1.2. Performance on Drought Classes
3.1.3. Comparison with State of the Art

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| District | Adede et al. [31] | Persistence | LSTM | EA LSTM |
|---|---|---|---|---|
| Mandera | 0.94 | 0.66 | 0.95 | 0.96 |
| Marsabit | 0.94 | 0.74 | 0.95 | 0.96 |
| Turkana | 0.91 | 0.74 | 0.98 | 0.98 |
| Wajir | 0.96 | 0.84 | 0.93 | 0.94 |
3.2. Interpreting the Static Embedding
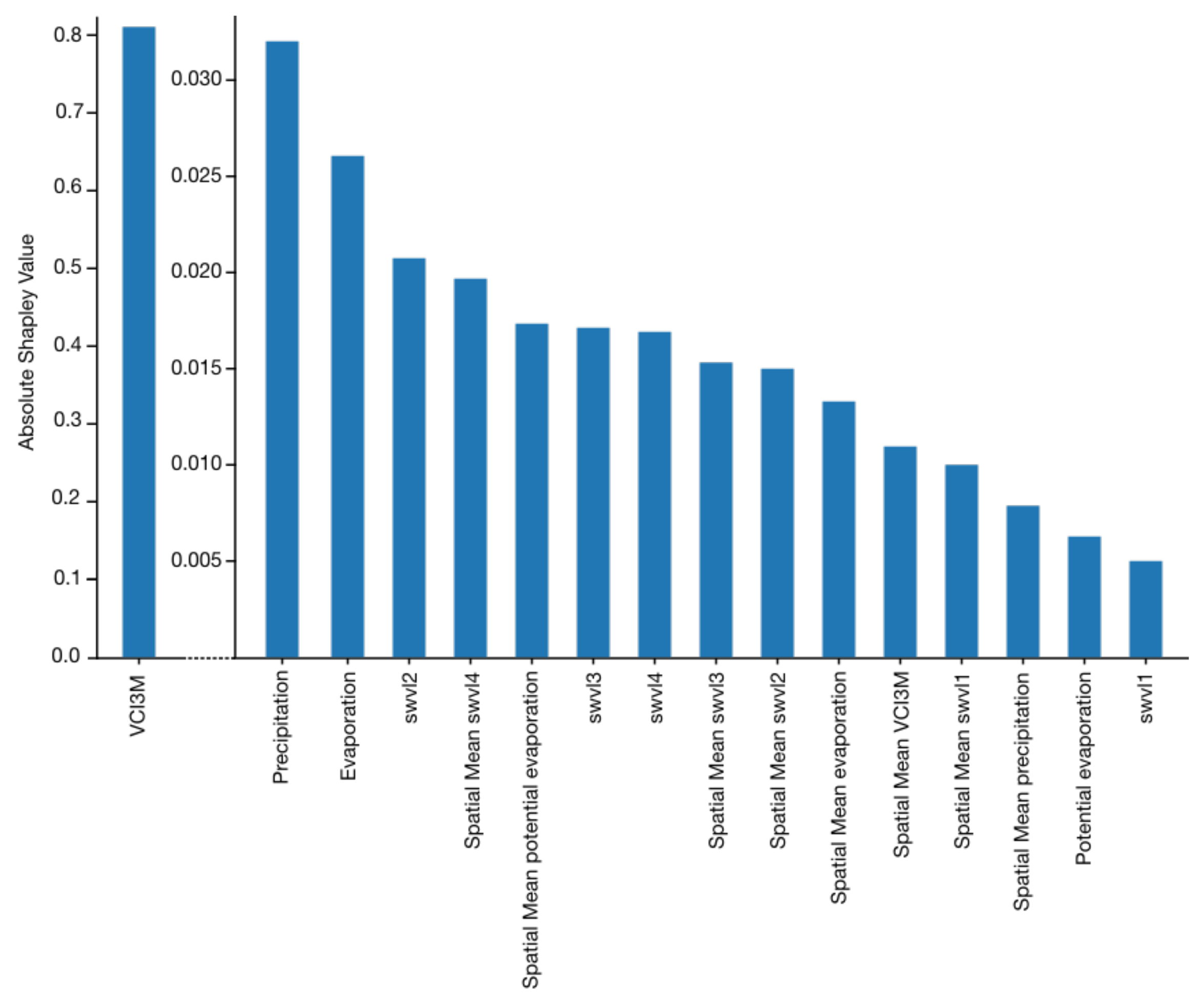
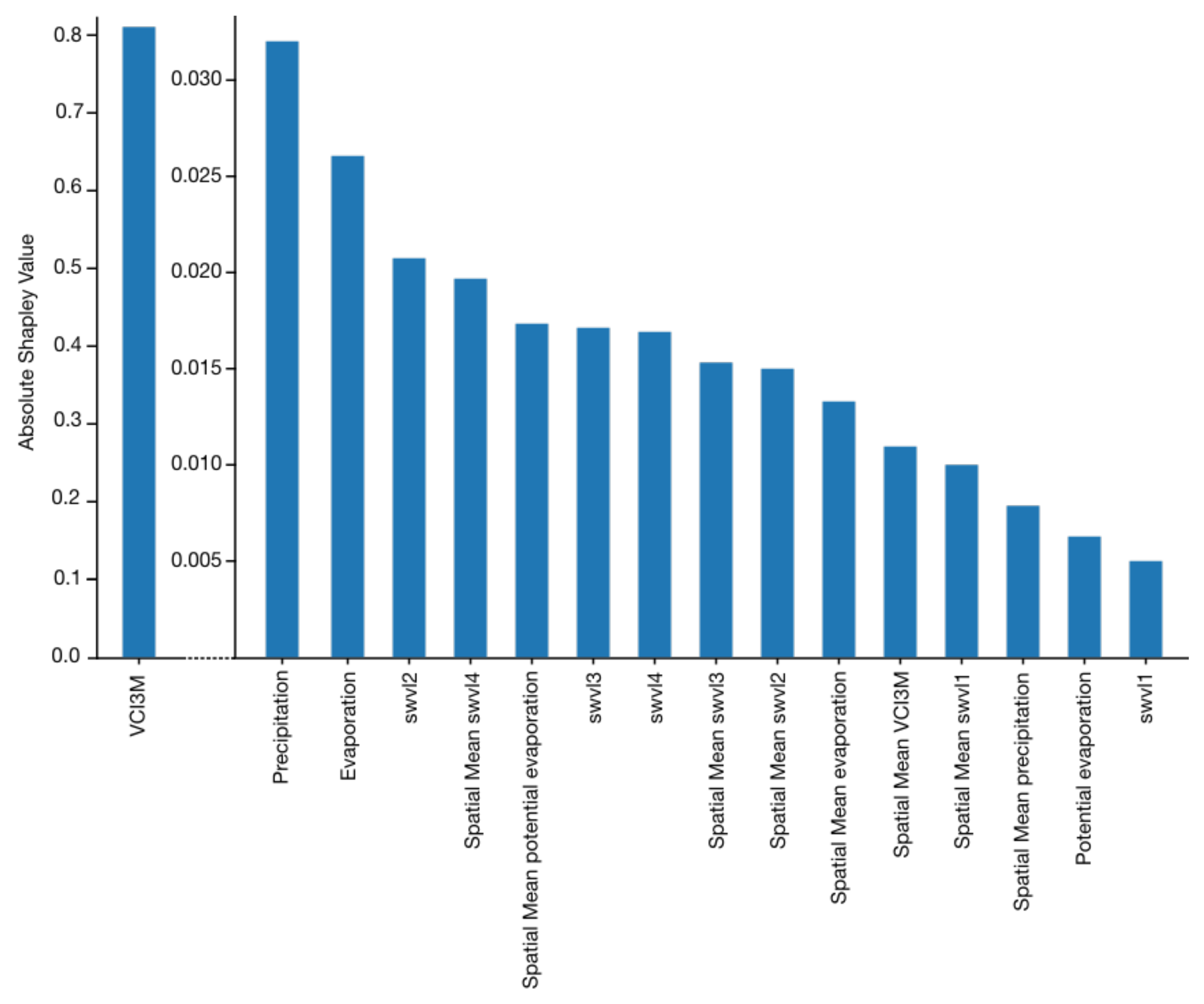
3.3. Measuring the Contribution of Dynamic Features
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VCI | Vegetation Condition Index |
| NDVI | Normalised Difference Vegetation Index |
| LSTM | Long Short Term Memory Network |
| EA LSTM | Entity Aware LSTM |
| NDMA | The National Drought Management Authority of Kenya |
| ERA5 | European Centre for Medium range Weather Forecasting (ECMWF) |
| Re-Analysis Dataset | |
| precip | Precipitation |
| e | Evaporation |
| pev | Potential Evaporation |
| swvl{1, …, 4} | Soil Water Volume Level 1 (0 cm–7 cm), 2 (7 cm–29 cm), 3 (29 cm–100 cm), |
| 4 (100 cm–289 cm) | |
| RMSE | Root Mean Squared Error |
References
- Wilhite, D.A.; Svoboda, M.D.; Hayes, M.J. Understanding the complex impacts of drought: A key to enhancing drought mitigation and preparedness. Water Resour. Manag. 2007, 21, 763–774. [Google Scholar] [CrossRef] [Green Version]
- Van Loon, A.F. Hydrological drought explained. Wiley Interdiscip. Rev. Water 2015, 2, 359–392. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M.; Beguería, S.; López-Moreno, J.I. A multiscalar drought index sensitive to global warming: The standardized precipitation evapotranspiration index. J. Clim. 2010, 23, 1696–1718. [Google Scholar] [CrossRef] [Green Version]
- Spinoni, J.; Naumann, G.; Vogt, J.V.; Barbosa, P. The biggest drought events in Europe from 1950 to 2012. J. Hydrol. Reg. Stud. 2015, 3, 509–524. [Google Scholar] [CrossRef]
- Nicholson, S.E. A detailed look at the recent drought situation in the Greater Horn of Africa. J. Arid Environ. 2014, 103, 71–79. [Google Scholar] [CrossRef]
- Swain, D.L.; Tsiang, M.; Haugen, M.; Singh, D.; Charland, A.; Rajaratnam, B.; Diffenbaugh, N.S. The extraordinary California drought of 2013/2014: Character, context, and the role of climate change. Bull. Am. Meteorol. Soc. 2014, 95, S3. [Google Scholar]
- Baudoin, M.A.; Vogel, C.; Nortje, K.; Naik, M. Living with drought in South Africa: Lessons learnt from the recent El Niño drought period. Int. J. Disaster Risk Reduct. 2017, 23, 128–137. [Google Scholar] [CrossRef]
- Muller, M. Cape Town’s drought: Don’t blame climate change. Nature 2018, 559, 174–176. [Google Scholar] [CrossRef] [Green Version]
- Zeng, N.; Yoon, J.H.; Marengo, J.A.; Subramaniam, A.; Nobre, C.A.; Mariotti, A.; Neelin, J.D. Causes and impacts of the 2005 Amazon drought. Environ. Res. Lett. 2008, 3, 014002. [Google Scholar] [CrossRef]
- García-Herrera, R.; Díaz, J.; Trigo, R.M.; Luterbacher, J.; Fischer, E.M. A review of the European summer heat wave of 2003. Crit. Rev. Environ. Sci. Technol. 2010, 40, 267–306. [Google Scholar] [CrossRef]
- Arias, P.; Bellouin, N.; Coppola, E.; Jones, R.; Krinner, G.; Marotzke, J.; Naik, V.; Palmer, M.; Plattner, G.K.; Rogelj, J.; et al. Climate Change 2021: The Physical Science Basis. Contribution of Working Group14 I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Technical Summary; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Rembold, F.; Meroni, M.; Urbano, F.; Csak, G.; Kerdiles, H.; Perez-Hoyos, A.; Lemoine, G.; Leo, O.; Negre, T. ASAP: A new global early warning system to detect anomaly hot spots of agricultural production for food security analysis. Agric. Syst. 2019, 168, 247–257. [Google Scholar] [CrossRef] [PubMed]
- Svoboda, M.D.; Fuchs, B.A. Handbook of Drought Indicators and Indices; World Meteorological Organization: Geneva, Switzerland, 2016. [Google Scholar]
- Sheffield, J.; Wood, E.F.; Chaney, N.; Guan, K.; Sadri, S.; Yuan, X.; Olang, L.; Amani, A.; Ali, A.; Demuth, S.; et al. A drought monitoring and forecasting system for sub-Sahara African water resources and food security. Bull. Am. Meteorol. Soc. 2014, 95, 861–882. [Google Scholar] [CrossRef]
- Klisch, A.; Atzberger, C. Operational drought monitoring in Kenya using MODIS NDVI time series. Remote Sens. 2016, 8, 267. [Google Scholar] [CrossRef] [Green Version]
- Brisson, N.; Gary, C.; Justes, E.; Roche, R.; Mary, B.; Ripoche, D.; Zimmer, D.; Sierra, J.; Bertuzzi, P.; Burger, P.; et al. An overview of the crop model STICS. Eur. J. Agron. 2003, 18, 309–332. [Google Scholar] [CrossRef]
- Van Diepen, C.v.; Wolf, J.; Van Keulen, H.; Rappoldt, C. WOFOST: A simulation model of crop production. Soil Use Manag. 1989, 5, 16–24. [Google Scholar] [CrossRef]
- Wilby, R.; Abrahart, R.; Dawson, C. Detection of conceptual model rainfall—Runoff processes inside an artificial neural network. Hydrol. Sci. J. 2003, 48, 163–181. [Google Scholar] [CrossRef] [Green Version]
- Dawson, C.W.; Wilby, R. An artificial neural network approach to rainfall-runoff modelling. Hydrol. Sci. J. 1998, 43, 47–66. [Google Scholar] [CrossRef]
- Shen, C. A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists. Water Resour. Res. 2018, 54, 8558–8593. [Google Scholar] [CrossRef]
- Nearing, G.; Kratzert, F.; Sampson, A.K.; Pelissier, C.S.; Klotz, D.; Frame, J.; Prieto, C.; Gupta, H. What Role Does Hydrological Science Play in the Age of Machine Learning? Water Resour. Res. 2021, 57, e2020WR028091. [Google Scholar] [CrossRef]
- Nay, J.; Burchfield, E.; Gilligan, J. A machine-learning approach to forecasting remotely sensed vegetation health. Int. J. Remote Sens. 2018, 39, 1800–1816. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Shalev, G.; Klambauer, G.; Hochreiter, S.; Nearing, G. Towards learning universal, regional, and local hydrological behaviors via machine learning applied to large-sample datasets. Hydrol. Earth Syst. Sci. 2019, 23, 5089–5110. [Google Scholar] [CrossRef] [Green Version]
- Gauch, M.; Kratzert, F.; Klotz, D.; Nearing, G.; Lin, J.; Hochreiter, S. Rainfall–runoff prediction at multiple timescales with a single Long Short-Term Memory network. Hydrol. Earth Syst. Sci. 2021, 25, 2045–2062. [Google Scholar] [CrossRef]
- Lees, T.; Buechel, M.; Anderson, B.; Slater, L.; Reece, S.; Coxon, G.; Dadson, S.J. Benchmarking data-driven rainfall–runoff models in Great Britain: A comparison of long short-term memory (LSTM)-based models with four lumped conceptual models. Hydrol. Earth Syst. Sci. 2021, 25, 5517–5534. [Google Scholar] [CrossRef]
- Klotz, D.; Kratzert, F.; Gauch, M.; Sampson, A.K.; Klambauer, G.; Hochreiter, S.; Nearing, G. Uncertainty Estimation with Deep Learning for Rainfall-Runoff Modelling. arXiv 2020, arXiv:2012.14295. [Google Scholar]
- FAO. Kenya at a Glance. Available online: https://www.fao.org/kenya/fao-in-kenya/kenya-at-a-glance/en/ (accessed on 12 December 2021).
- Nicholson, S.E. Climate and climatic variability of rainfall over eastern Africa. Rev. Geophys. 2017, 55, 590–635. [Google Scholar] [CrossRef] [Green Version]
- Network, F. Kenya Food Security: In Brief. 2013. Available online: https://fews.net/sites/default/files/documents/reports/Kenya_Food%20Security_In_Brief_2013_final_0.pdf (accessed on 12 December 2021).
- Kogan, F.N. Application of vegetation index and brightness temperature for drought detection. Adv. Space Res. 1995, 15, 91–100. [Google Scholar] [CrossRef]
- Adede, C.; Oboko, R.; Wagacha, P.W.; Atzberger, C. A mixed model approach to vegetation condition prediction using artificial neural networks (ANN): Case of Kenya’s operational drought monitoring. Remote Sens. 2019, 11, 1099. [Google Scholar] [CrossRef] [Green Version]
- Funk, C.; Peterson, P.; Landsfeld, M.; Pedreros, D.; Verdin, J.; Shukla, S.; Husak, G.; Rowland, J.; Harrison, L.; Hoell, A.; et al. The climate hazards infrared precipitation with stations—A new environmental record for monitoring extremes. Sci. Data 2015, 2, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Farr, T.G.; Rosen, P.A.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Kobrick, M.; Paller, M.; Rodriguez, E.; Roth, L.; et al. The shuttle radar topography mission. Rev. Geophys. 2007, 45, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Albergel, C.; Dutra, E.; Munier, S.; Calvet, J.C.; Munoz-Sabater, J.; de Rosnay, P.; Balsamo, G. ERA-5 and ERA-Interim driven ISBA land surface model simulations: Which one performs better? Hydrol. Earth Syst. Sci. 2018, 22, 3515–3532. [Google Scholar] [CrossRef] [Green Version]
- Agutu, N.; Ndehedehe, C.; Awange, J.; Kirimi, F.; Mwaniki, M. Understanding uncertainty of model-reanalysis soil moisture within Greater Horn of Africa (1982–2014). J. Hydrol. 2021, 603, 127169. [Google Scholar] [CrossRef]
- Tall, M.; Albergel, C.; Bonan, B.; Zheng, Y.; Guichard, F.; Dramé, M.S.; Gaye, A.T.; Sintondji, L.O.; Hountondji, F.C.; Nikiema, P.M.; et al. Towards a long-term reanalysis of land surface variables over Western Africa: LDAS-Monde applied over Burkina Faso from 2001 to 2018. Remote Sens. 2019, 11, 735. [Google Scholar] [CrossRef] [Green Version]
- Funk, C.; Hoell, A.; Shukla, S.; Blade, I.; Liebmann, B.; Roberts, J.B.; Robertson, F.R.; Husak, G. Predicting East African spring droughts using Pacific and Indian Ocean sea surface temperature indices. Hydrol. Earth Syst. Sci. 2014, 18, 4965–4978. [Google Scholar] [CrossRef] [Green Version]
- Funk, C.; Harrison, L.; Shukla, S.; Pomposi, C.; Galu, G.; Korecha, D.; Husak, G.; Magadzire, T.; Davenport, F.; Hillbruner, C.; et al. Examining the role of unusually warm Indo-Pacific sea-surface temperatures in recent African droughts. Q. J. R. Meteorol. Soc. 2018, 144, 360–383. [Google Scholar] [CrossRef] [Green Version]
- Uhe, P.; Philip, S.; Kew, S.; Shah, K.; Kimutai, J.; Mwangi, E.; van Oldenborgh, G.J.; Singh, R.; Arrighi, J.; Jjemba, E.; et al. Attributing drivers of the 2016 Kenyan drought. Int. J. Climatol. 2018, 38, e554–e568. [Google Scholar] [CrossRef] [Green Version]
- Gauch, M.; Lin, J. A Data Scientist’s Guide to Streamflow Prediction. arXiv 2020, arXiv:2006.12975. [Google Scholar]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef] [Green Version]
- Kratzert, F.; Klotz, D.; Herrnegger, M.; Sampson, A.K.; Hochreiter, S.; Nearing, G.S. Toward Improved Predictions in Ungauged Basins: Exploiting the Power of Machine Learning. Water Resour. Res. 2019, 55, 11344–11354. [Google Scholar] [CrossRef] [Green Version]
- Kratzert, F.; Herrnegger, M.; Klotz, D.; Hochreiter, S.; Klambauer, G. NeuralHydrology—Interpreting LSTMs in Hydrology. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Samek, W., Montavon, G., Vedaldi, A., Hansen, L.K., Müller, K.R., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 347–362. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S. Untersuchungen zu Dynamischen Neuronalen Netzen. Ph.D. Thesis, Technische Universität München, München, Germany, 1991. [Google Scholar]
- Fang, K.; Shen, C.; Kifer, D.; Yang, X. Prolongation of SMAP to Spatiotemporally Seamless Coverage of Continental U.S. Using a Deep Learning Neural Network. Geophys. Res. Lett. 2017, 44, 11030–11039. [Google Scholar] [CrossRef] [Green Version]
- Olah, C. Understanding LSTM Networks—Colah’s Blog. 2016. Available online: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 12 December 2021).
- Girshick, R. Fast r-cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Shapley, L.S. Stochastic games. Proc. Natl. Acad. Sci. USA 1953, 39, 1095–1100. [Google Scholar] [CrossRef] [PubMed]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3145–3153. [Google Scholar]
- OCHA Flash Update #6: Floods in Kenya: 7 June 2018—Kenya. Available online: https://reliefweb.int/report/kenya/ocha-flash-update-6-floods-kenya-7-june-2018 (accessed on 12 December 2021).
- Meroni, M.; Fasbender, D.; Rembold, F.; Atzberger, C.; Klisch, A. Near real-time vegetation anomaly detection with MODIS NDVI: Timeliness vs. accuracy and effect of anomaly computation options. Remote Sens. Environ. 2019, 221, 508–521. [Google Scholar] [CrossRef] [PubMed]
- Kenduiywo, B.K.; Carter, M.R.; Ghosh, A.; Hijmans, R.J. Evaluating the quality of remote sensing products for agricultural index insurance. PLoS ONE 2021, 16, e0258215. [Google Scholar] [CrossRef]
- NDMA. Drought Early Warning Bulletin for April 2017. 2017. Available online: https://www.ndma.go.ke/index.php/resource-center/national-drought-bulletin/send/39-drought-updates/4569-national-drought-early-warning-bulletin-october-2017 (accessed on 13 December 2021).
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A 2021, 379, 20200209. [Google Scholar] [CrossRef]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]


| Raw Spatial Resolution (Prior to Resmapling) | Feature | Model Usage | Source |
|---|---|---|---|
| Precipitation | X_dynamic | CHIRPS [32] | 5 km |
| Potential Evaporation (pev) | X_dynamic | ERA5 [33] | 30 km |
| Evaporation (e) | X_dynamic | ERA5 [33] | 30 km |
| Soil Moisture (4 Levels) (swvl {1, …, 4} | X_dynamic | ERA5 [33] | 30 km |
| Altitude | X_static | NASA SRTM [34] | 0.03 km |
| Month of Year | X_dynamic | — | — |
| Vegetation Condition Index (VCI {1, …, 3}) | X_dynamic, y | MODIS Reflectances processed according to [15] | 1 km |
| Error Metric | Persistence (BLINE) | Neural Network (LN) | LSTM | EA LSTM | |
|---|---|---|---|---|---|
| VCI3M | RMSE | 10.20 | 9.81 | 6.46 | 5.88 |
| R | 0.86 | 0.88 | 0.95 | 0.95 | |
| VCI1M | RMSE | 18.84 | 25.68 | 13.23 | 13.23 |
| R | 0.66 | 0.14 | 0.83 | 0.82 |
| VCI3M Limits | Description | Value |
|---|---|---|
| Extreme Vegetation Deficit | 1 | |
| Severe Vegetation Deficit | 2 | |
| Moderate Vegetation Deficit | 3 | |
| Normal Vegetation Conditions | 4 | |
| Above normal Vegetation Condition | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lees, T.; Tseng, G.; Atzberger, C.; Reece, S.; Dadson, S. Deep Learning for Vegetation Health Forecasting: A Case Study in Kenya. Remote Sens. 2022, 14, 698. https://doi.org/10.3390/rs14030698
Lees T, Tseng G, Atzberger C, Reece S, Dadson S. Deep Learning for Vegetation Health Forecasting: A Case Study in Kenya. Remote Sensing. 2022; 14(3):698. https://doi.org/10.3390/rs14030698
Chicago/Turabian StyleLees, Thomas, Gabriel Tseng, Clement Atzberger, Steven Reece, and Simon Dadson. 2022. "Deep Learning for Vegetation Health Forecasting: A Case Study in Kenya" Remote Sensing 14, no. 3: 698. https://doi.org/10.3390/rs14030698
APA StyleLees, T., Tseng, G., Atzberger, C., Reece, S., & Dadson, S. (2022). Deep Learning for Vegetation Health Forecasting: A Case Study in Kenya. Remote Sensing, 14(3), 698. https://doi.org/10.3390/rs14030698