
Efficient Instance Segmentation Paradigm for Interpreting SAR and Optical Images

 , , and
, , and 
Abstract
:1. Introduction
- EISP is proposed for efficient instance segmentation of remote sensing images.
- Effects of Swin Transformer, CIF, and confluent loss function to the EISP are individually verified, which boost the integral network performance.
- EISP achieves the highest AP value of instance segmentation in remote sensing images compared to the other state-of-the-art methods.
2. Related Work
2.1. Semantic Segmentation
2.2. Instance Segmentation
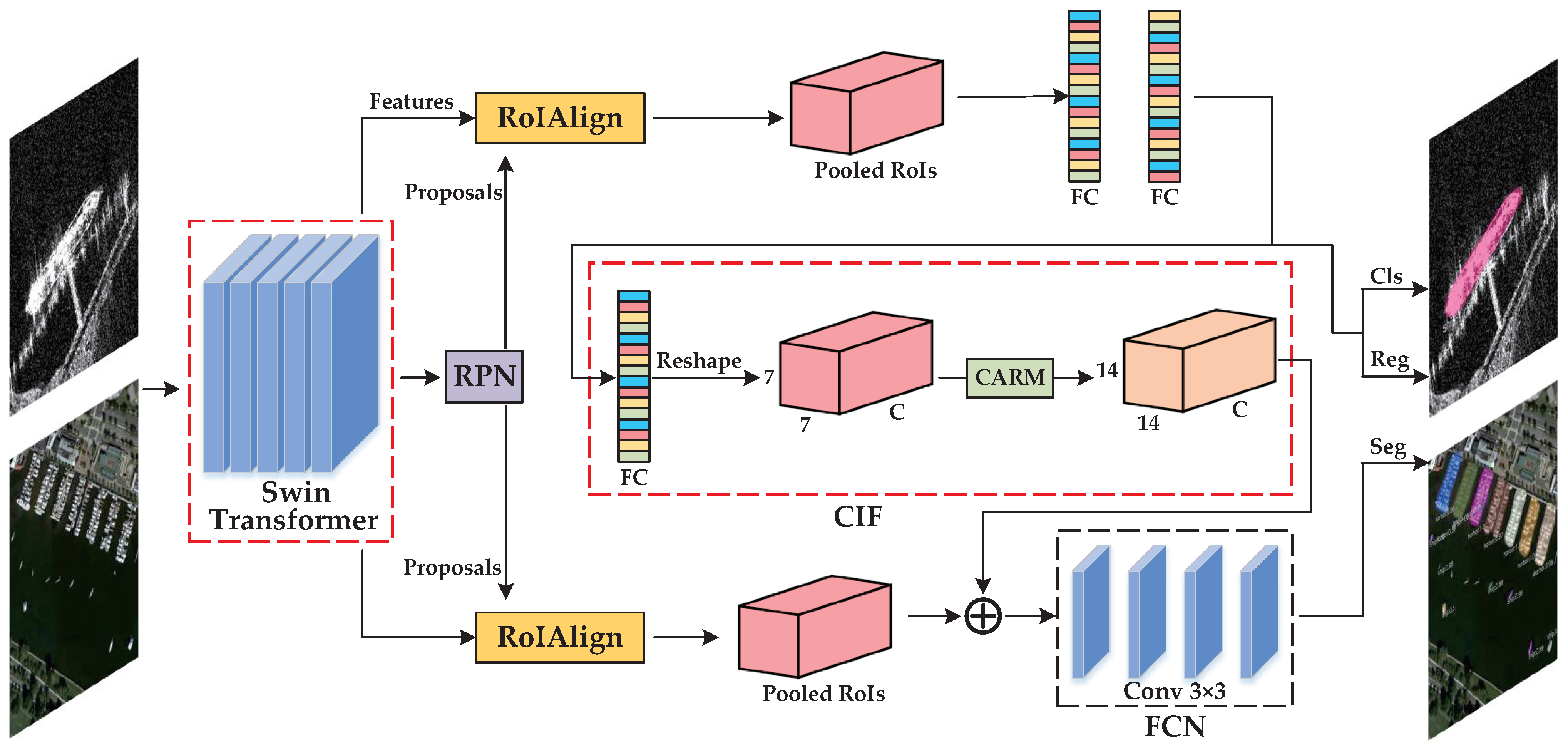
3. The Proposed Method
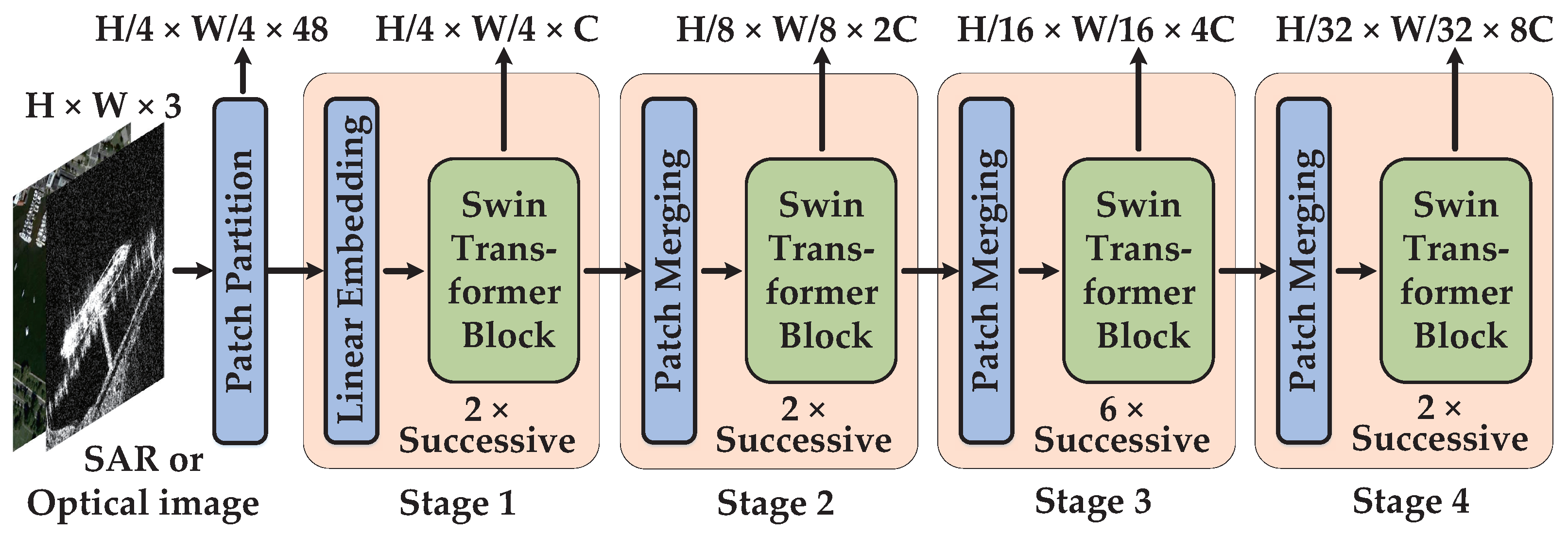
3.1. Swin Transformer
3.1.1. Swin Transformer Block
3.1.2. Hyperparameters Setting
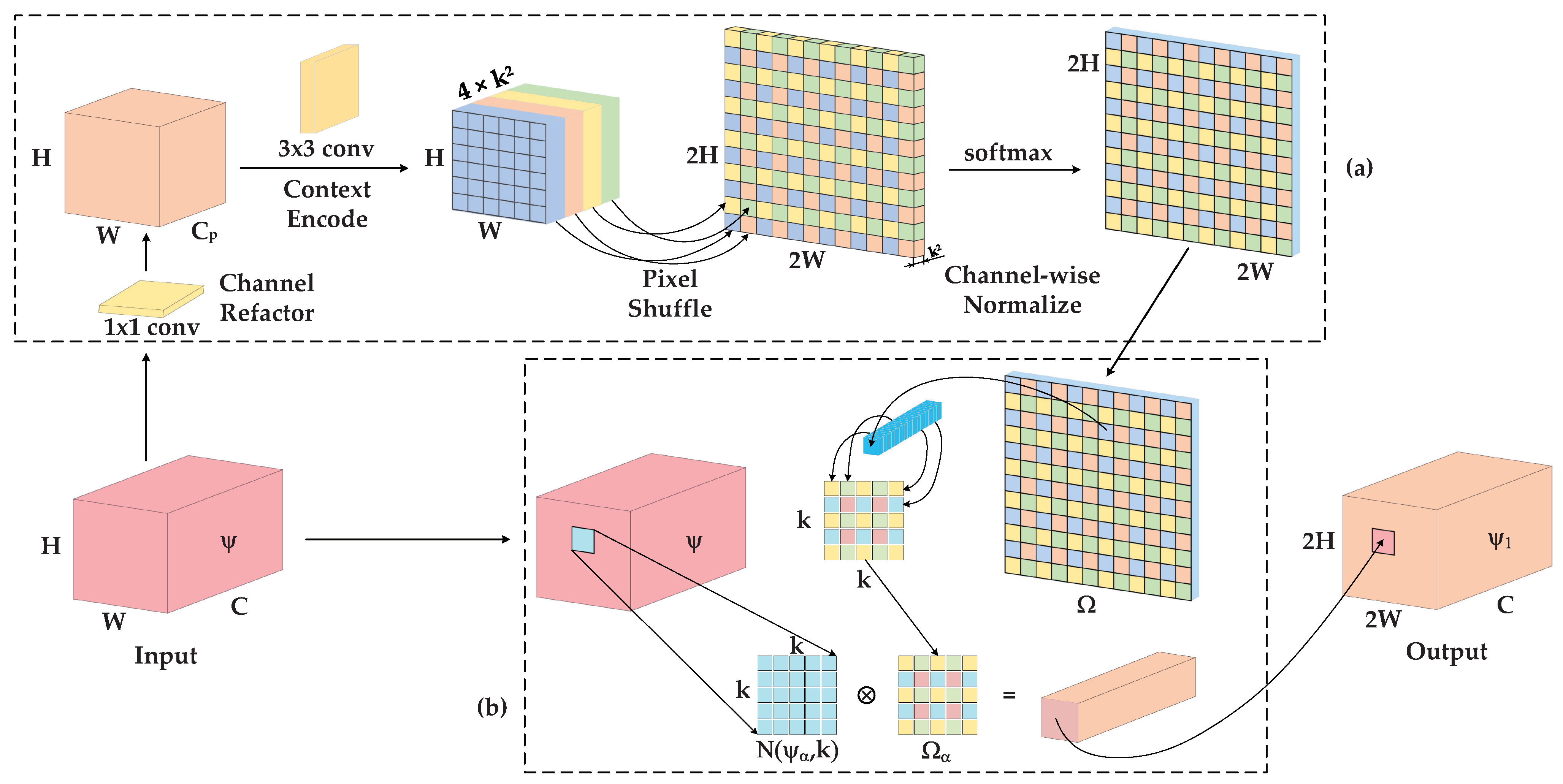
3.2. Context Information Flow
- Step 1: Content-aware Kernel Generation
- Step 2: Feature Reassemble
3.3. Confluent Loss Function
4. Experiments
4.1. Datasets
4.1.1. SAR Ship Detection Dataset
4.1.2. NWPU VHR-10 Instance Segmentation Dataset
4.2. Evaluation Metrics
4.3. FLOPs
4.4. Implementation Details
4.5. Effects of the EISP
4.6. Ablation Experiments
4.6.1. Experiments on Swin Transformer
4.6.2. Experiments on CIF
4.6.3. Experiments on Confluent Loss Function
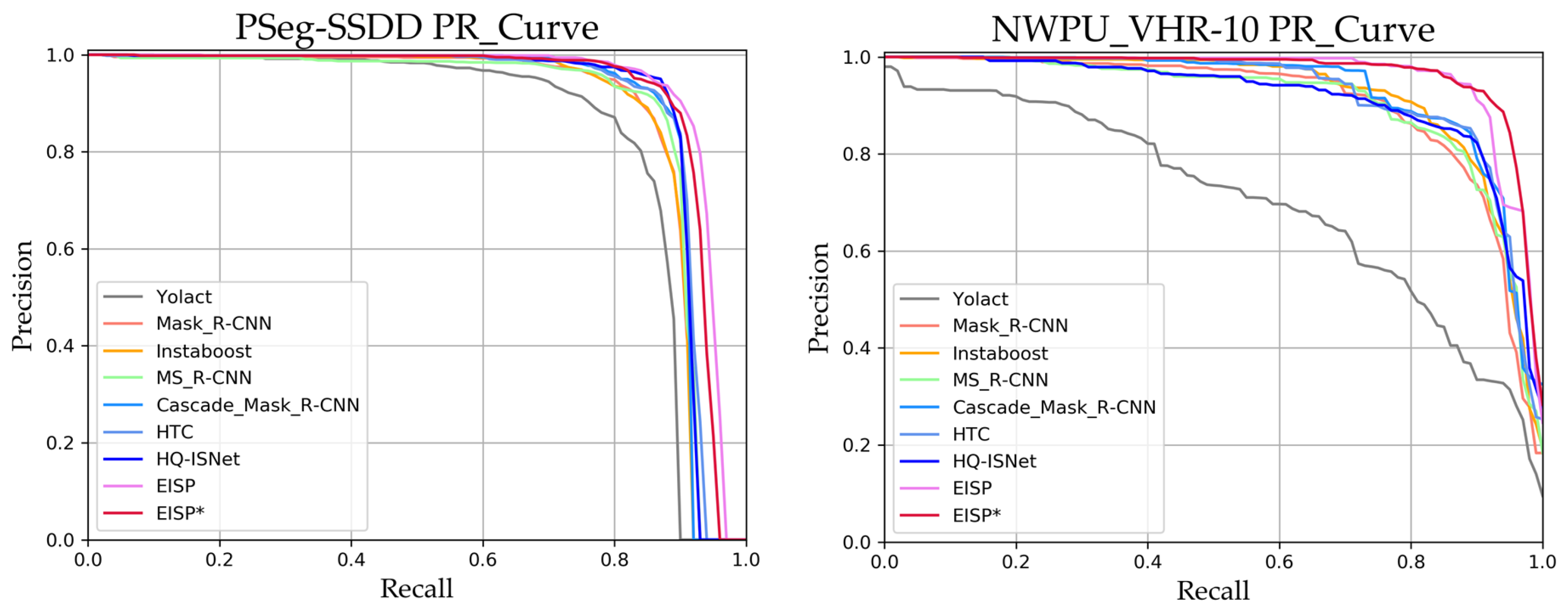
4.7. Ship Segmentation Result of PSeg-SSDD
4.8. Instance Segmentation Result of NUPU VHR-10
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zeng, X.; Wei, S.; Shi, J.; Zhang, X. A lightweight adaptive roi extraction network for precise aerial image instance segmentation. IEEE Trans. Instrum. Meas. 2021, 70, 5018617. [Google Scholar] [CrossRef]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and robust ship detection for high-resolution sar imagery based on hr-sdnet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhang, X. A polarization fusion network with geometric feature embedding for sar ship classification. Pattern Recognit. 2022, 123, 108365. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S.; Ahmad, I.; Zhan, X.; Zhou, Y.; Pan, D.; Li, J.; et al. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Song, Q.; Xu, F.; Jin, Y.-Q. Sar image representation learning with adversarial autoencoder networks. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 9498–9501. [Google Scholar]
- Liu, X.; Huang, Y.; Wang, C.; Pei, J.; Huo, W.; Zhang, Y.; Yang, J. Semi-supervised sar atr via conditional generative adversarial network with multi-discriminator. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 2361–2364. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X.; Liu, C.; Xu, X.; Zhan, X.; Wang, C.; Ahmad, I.; Zhou, Y.; Pan, D.; et al. Hog-shipclsnet: A novel deep learning network with hog feature fusion for sar ship classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5210322. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S. Hyperli-net: A hyper-light deep learning network for high-accurate and high-speed ship detection from synthetic aperture radar imagery. ISPRS J. Photogramm. Remote Sens. 2020, 167, 123–153. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. Shipdenet-20: An only 20 convolution layers and <1-mb lightweight sar ship detector. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1234–1238. [Google Scholar]
- Zhang, T.; Zhang, X.; Ke, X. Quad-fpn: A novel quad feature pyramid network for sar ship detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. Segmentation for object-based image analysis (obia): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Tuia, D.; Muñoz-Marí, J.; Camps-Valls, G. Remote sensing image segmentation by active queries. Pattern Recognit. 2012, 45, 2180–2192. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. Dota: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Waqas Zamir, S.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Shahbaz Khan, F.; Zhu, F.; Shao, L.; Xia, G.S.; Bai, X. isaid: A large-scale dataset for instance segmentation in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 28–37. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Su, H.; Wei, S.; Yan, M.; Wang, C.; Shi, J.; Zhang, X. Object detection and instance segmentation in remote sensing imagery based on precise mask r-cnn. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1454–1457. [Google Scholar]
- Su, H.; Wei, S.; Liu, S.; Liang, J.; Wang, C.; Shi, J.; Zhang, X. Hq-isnet: High-quality instance segmentation for remote sensing imagery. Remote Sens. 2020, 12, 989. [Google Scholar] [CrossRef] [Green Version]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. Hrsid: A high-resolution sar images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in vhr optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- An, Q.; Pan, Z.; Liu, L.; You, H. Drbox-v2: An improved detector with rotatable boxes for target detection in sar images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8333–8349. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S.; Wang, J.; Li, J.; Su, H.; Zhou, Y. Balance scene learning mechanism for offshore and inshore ship detection in sar images. IEEE Geosci. Remote Sens. Lett. 2020, 19, 4004905. [Google Scholar] [CrossRef]
- Bokhovkin, A.; Burnaev, E. Boundary loss for remote sensing imagery semantic segmentation. In International Symposium on Neural Networks; Springer: Cham, Switzerland, 2019; pp. 388–401. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. Scattnet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 905–909. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, S.; Ding, L.; Bruzzone, L. Multi-scale context aggregation for semantic segmentation of remote sensing images. Remote Sens. 2020, 12, 701. [Google Scholar] [CrossRef] [Green Version]
- Zeng, X.; Wei, S.; Wei, J.; Zhou, Z.; Shi, J.; Zhang, X.; Fan, F. Cpisnet: Delving into consistent proposals of instance segmentation network for high-resolution aerial images. Remote Sens. 2021, 13, 2788. [Google Scholar] [CrossRef]
- Chen, L.; Fu, Y.; You, S.; Liu, H. Efficient hybrid supervision for instance segmentation in aerial images. Remote Sens. 2021, 13, 252. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6409–6418. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Vu, T.; Kang, H.; Yoo, C.D. Scnet: Training inference sample consistency for instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 2701–2709. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. Blendmask: Top-down meets bottom-up for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8573–8581. [Google Scholar]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. Polarmask: Single shot instance segmentation with polar representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12193–12202. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H. Conditional convolutions for instance segmentation. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part I 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 282–298. [Google Scholar]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. Solo: Segmenting objects by locations. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 649–665. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. Sar ship detection dataset (ssdd): Official release and comprehensive data analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Gao, S.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P.H. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [Green Version]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10428–10436. [Google Scholar]
- Fang, H.-S.; Sun, J.; Wang, R.; Gou, M.; Li, Y.-L.; Lu, C. Instaboost: Boosting instance segmentation via probability map guided copy-pasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 682–691. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | Swin-L | CIF | Conf Loss | AP | AP50 | AP75 | APS | APM | APL | FLOPs |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSeg-SSDD | Mask R-CNN | 56.7 | 88.6 | 70.8 | 56.8 | 57.8 | 27.6 | 134.2G | |||
| Modules | 🗸 | 59.0 | 91.3 | 72.8 | 58.5 | 61.7 | 40.0 | 283.9G | |||
| 🗸 | 58.4 | 89.8 | 73.0 | 58.2 | 60.0 | 17.9 | 150.7G | ||||
| 🗸 | 58.5 | 89.8 | 72.5 | 58.0 | 61.4 | 15.6 | 134.2G | ||||
| EISP | 🗸 | 🗸 | 🗸 | 60.3 | 93.3 | 73.3 | 58.9 | 65.9 | 35.6 | 293.9G | |
| NWPU VHR-10 | Mask R-CNN | 57.9 | 90.2 | 61.0 | 41.5 | 58.6 | 53.1 | 229.1G | |||
| Modules | 🗸 | 63.1 | 94.2 | 68.9 | 47.5 | 63.0 | 72.4 | 577.8G | |||
| 🗸 | 59.4 | 92.1 | 64.1 | 42.9 | 60.3 | 62.0 | 245.5G | ||||
| 🗸 | 62.8 | 91.5 | 69.2 | 46.3 | 63.8 | 70.2 | 229.1G | ||||
| EISP | 🗸 | 🗸 | 🗸 | 68.1 | 95.8 | 74.5 | 52.7 | 68.4 | 76.9 | 594.2G |
| Dataset | Backbone | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| PSeg-SSDD | ResNet-101 | 56.7 | 88.6 | 70.8 | 56.8 | 57.8 | 27.6 |
| HRNetv2-w32 | 57.1 | 87.8 | 72.2 | 56.8 | 59.7 | 18.2 | |
| RegNetx-3.2G | 57.5 | 89.1 | 70.3 | 57.2 | 60.7 | 12.9 | |
| RegNetx-4.0G | 57.7 | 89.7 | 71.4 | 57.5 | 60.4 | 14.2 | |
| Res2Net-101 | 57.6 | 89.4 | 71.9 | 57.2 | 60.7 | 24.2 | |
| Swin-S | 57.2 | 89.7 | 68.8 | 56.4 | 60.1 | 30.2 | |
| Swin-B | 57.8 | 90.5 | 71.1 | 57.2 | 60.6 | 26.7 | |
| Swin-L | 59.0 | 91.3 | 72.8 | 58.5 | 61.7 | 40.0 | |
| NWPU VHR-10 | ResNet-101 | 57.9 | 90.2 | 61.0 | 41.5 | 58.6 | 53.1 |
| HRNetv2-w32 | 60.3 | 90.7 | 66.3 | 45.9 | 61.1 | 65.6 | |
| RegNetx-3.2G | 59.1 | 91.2 | 62.0 | 44.6 | 60.1 | 63.2 | |
| RegNetx-4.0G | 60.3 | 91.8 | 67.4 | 45.8 | 60.9 | 65.4 | |
| Res2Net-101 | 60.9 | 93.3 | 68.1 | 44.6 | 61.9 | 65.9 | |
| Swin-S | 62.3 | 92.9 | 69.3 | 46.7 | 62.3 | 71.9 | |
| Swin-B | 62.7 | 92.6 | 69.6 | 47.5 | 63.2 | 63.9 | |
| Swin-L | 63.1 | 94.2 | 68.9 | 47.5 | 63.0 | 72.4 |
| Dataset | No. of Channels | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| PSeg-SSDD | 32 | 57.5 | 89.4 | 71.8 | 57.1 | 60.1 | 18.0 |
| 64 | 58.4 | 89.8 | 73.0 | 58.2 | 60.0 | 17.9 | |
| 128 | 57.9 | 89.8 | 70.9 | 57.4 | 60.8 | 16.6 | |
| 256 | 57.7 | 90.4 | 70.6 | 57.6 | 60.2 | 12.4 | |
| NWPU VHR-10 | 32 | 59.3 | 92.4 | 66.3 | 42.3 | 60.0 | 66.1 |
| 64 | 59.4 | 92.1 | 64.1 | 42.9 | 60.3 | 62.0 | |
| 128 | 59.0 | 91.6 | 64.5 | 41.5 | 59.5 | 66.7 | |
| 256 | 58.5 | 91.4 | 64.1 | 42.3 | 59.3 | 59.7 |
| Dataset | AP | AP50 | AP75 | APS | APM | APL | |
|---|---|---|---|---|---|---|---|
| PSeg-SSDD | 0 | 58.4 | 90.0 | 72.3 | 58.0 | 61.4 | 13.5 |
| 0.3 | 58.5 | 89.8 | 72.5 | 58.0 | 61.4 | 15.6 | |
| 0.9 | 57.4 | 89.4 | 72.0 | 57.0 | 60.3 | 14.8 | |
| 1.5 | 57.1 | 89.2 | 71.2 | 56.8 | 59.5 | 7.6 | |
| 2.1 | 56.2 | 87.6 | 71.1 | 55.7 | 59.2 | 8.5 | |
| 2.7 | 55.6 | 88.0 | 69.3 | 55.5 | 58.0 | 7.2 | |
| NWPU VHR-10 | 0 | 61.9 | 91.3 | 68.1 | 47.1 | 62.8 | 68.6 |
| 0.3 | 62.8 | 91.5 | 69.2 | 46.3 | 63.8 | 70.2 | |
| 0.9 | 60.9 | 90.8 | 67.9 | 45.8 | 62.2 | 68.1 | |
| 1.5 | 59.3 | 88.1 | 66.3 | 44.8 | 59.8 | 71.7 | |
| 2.1 | 58.4 | 87.9 | 64.2 | 42.1 | 59.2 | 65.7 | |
| 2.7 | 54.7 | 82.4 | 62.0 | 41.6 | 55.5 | 62.2 |
| Dataset | Model | AP | AP50 | AP75 | APS | APM | APL | FLOPs |
|---|---|---|---|---|---|---|---|---|
| PSeg-SSDD | Yolact [40] | 44.5 | 84.7 | 40.4 | 43.2 | 51.6 | 37.2 | 67.14G |
| Mask R-CNN [35] | 56.7 | 88.6 | 70.8 | 56.8 | 57.8 | 27.6 | 134.2G | |
| Instaboost [54] | 57.7 | 88.4 | 71.6 | 57.6 | 59.4 | 19.9 | 134.2G | |
| MS R-CNN [36] | 57.9 | 88.7 | 73.1 | 57.6 | 59.6 | 16.4 | 134.2G | |
| CM R-CNN [37] | 58.2 | 89.5 | 71.8 | 57.6 | 61.0 | 21.9 | 265.0G | |
| HTC [38] | 58.5 | 90.1 | 72.9 | 58.0 | 60.6 | 33.1 | 279.0G | |
| HQ-ISNet [17] | 59.4 | 90.0 | 73.3 | 58.7 | 61.9 | 36.2 | 279.6G | |
| EISP | 60.3 | 93.3 | 73.3 | 58.9 | 65.9 | 35.6 | 300.4G | |
| EISP* | 60.9 | 92.0 | 75.1 | 60.2 | 63.9 | 47.3 | 300.4G |
| Dataset | Model | AP | AP50 | AP75 | APS | APM | APL | FLOPs |
|---|---|---|---|---|---|---|---|---|
| NWPU VHR-10 | Yolact [40] | 38.6 | 70.4 | 38.5 | 24.3 | 39.9 | 46.2 | 164.8G |
| Mask R-CNN [35] | 57.9 | 90.2 | 61.0 | 41.5 | 58.6 | 53.1 | 229.1G | |
| Instaboost [54] | 58.7 | 91.9 | 65.9 | 42.8 | 59.1 | 65.6 | 229.1G | |
| MS R-CNN [36] | 59.4 | 90.4 | 66.4 | 40.2 | 59.9 | 63.9 | 229.1G | |
| CM R-CNN [37] | 60.7 | 92.8 | 66.6 | 47.9 | 61.4 | 62.1 | 360.2G | |
| HTC [38] | 61.9 | 92.4 | 67.7 | 49.0 | 62.1 | 64.1 | 390.0G | |
| HQ-ISNet [17] | 62.7 | 91.2 | 69.7 | 54.6 | 63.5 | 64.3 | 391.4G | |
| EISP | 68.1 | 95.8 | 74.5 | 52.7 | 68.4 | 76.9 | 594.2G | |
| EISP* | 69.1 | 96.3 | 76.1 | 55.6 | 69.3 | 78.2 | 594.2G |
| Model | AI | BD | GTF | VC | SH | TC | HB | ST | BC | BR |
|---|---|---|---|---|---|---|---|---|---|---|
| Yolact | 5.1 | 77.0 | 67.6 | 33.0 | 47.5 | 24.9 | 31.6 | 55.5 | 36.7 | 6.9 |
| Mask R-CNN | 27.1 | 81.1 | 85.8 | 51.8 | 53.3 | 58.6 | 55.2 | 71.5 | 67.1 | 27.3 |
| Instaboost | 26.5 | 81.6 | 83.8 | 52.4 | 55.9 | 61.0 | 60.0 | 71.7 | 65.2 | 28.8 |
| MS R-CNN | 27.0 | 79.7 | 87.5 | 52.0 | 51.6 | 60.9 | 60.2 | 70.0 | 74.3 | 30.6 |
| CM R-CNN | 28.0 | 83.5 | 87.6 | 53.6 | 56.9 | 65.3 | 59.6 | 71.5 | 74.2 | 26.6 |
| HTC | 28.1 | 83.6 | 88.8 | 54.8 | 55.0 | 67.1 | 61.6 | 73.5 | 77.3 | 28.8 |
| HQ-ISNet | 38.7 | 85.8 | 87.9 | 57.8 | 59.2 | 72.2 | 60.2 | 75.1 | 69.2 | 20.9 |
| EISP | 46.6 | 86.5 | 92.0 | 59.3 | 58.6 | 73.0 | 65.3 | 76.3 | 80.3 | 42.9 |
| EISP* | 47.0 | 86.6 | 93.0 | 62.9 | 60.1 | 73.4 | 66.4 | 75.4 | 80.4 | 45.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, F.; Zeng, X.; Wei, S.; Zhang, H.; Tang, D.; Shi, J.; Zhang, X. Efficient Instance Segmentation Paradigm for Interpreting SAR and Optical Images. Remote Sens. 2022, 14, 531. https://doi.org/10.3390/rs14030531
Fan F, Zeng X, Wei S, Zhang H, Tang D, Shi J, Zhang X. Efficient Instance Segmentation Paradigm for Interpreting SAR and Optical Images. Remote Sensing. 2022; 14(3):531. https://doi.org/10.3390/rs14030531
Chicago/Turabian StyleFan, Fan, Xiangfeng Zeng, Shunjun Wei, Hao Zhang, Dianhua Tang, Jun Shi, and Xiaoling Zhang. 2022. "Efficient Instance Segmentation Paradigm for Interpreting SAR and Optical Images" Remote Sensing 14, no. 3: 531. https://doi.org/10.3390/rs14030531
APA StyleFan, F., Zeng, X., Wei, S., Zhang, H., Tang, D., Shi, J., & Zhang, X. (2022). Efficient Instance Segmentation Paradigm for Interpreting SAR and Optical Images. Remote Sensing, 14(3), 531. https://doi.org/10.3390/rs14030531