
Semantic Segmentation of Very-High-Resolution Remote Sensing Images via Deep Multi-Feature Learning


Abstract
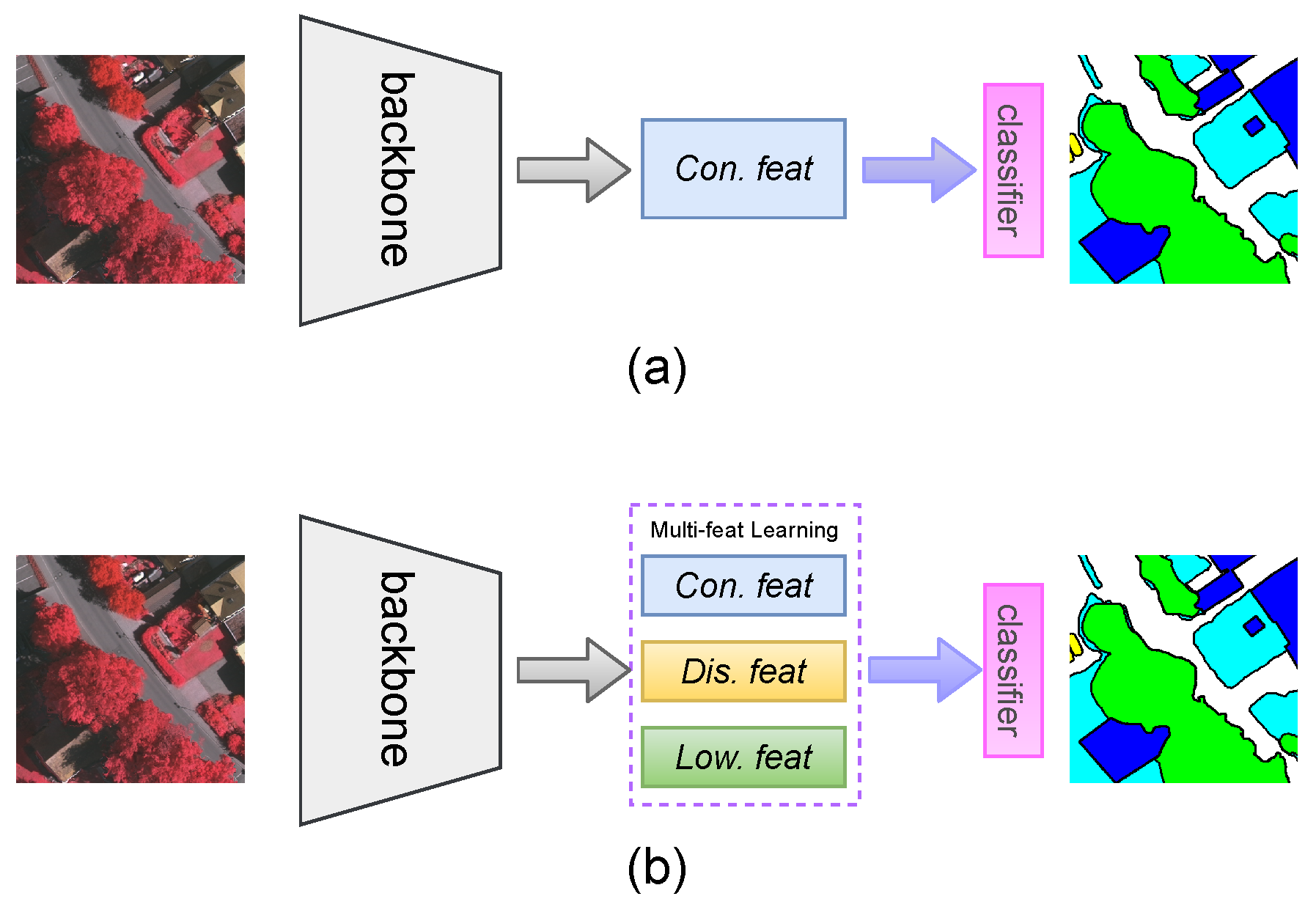
:1. Introduction
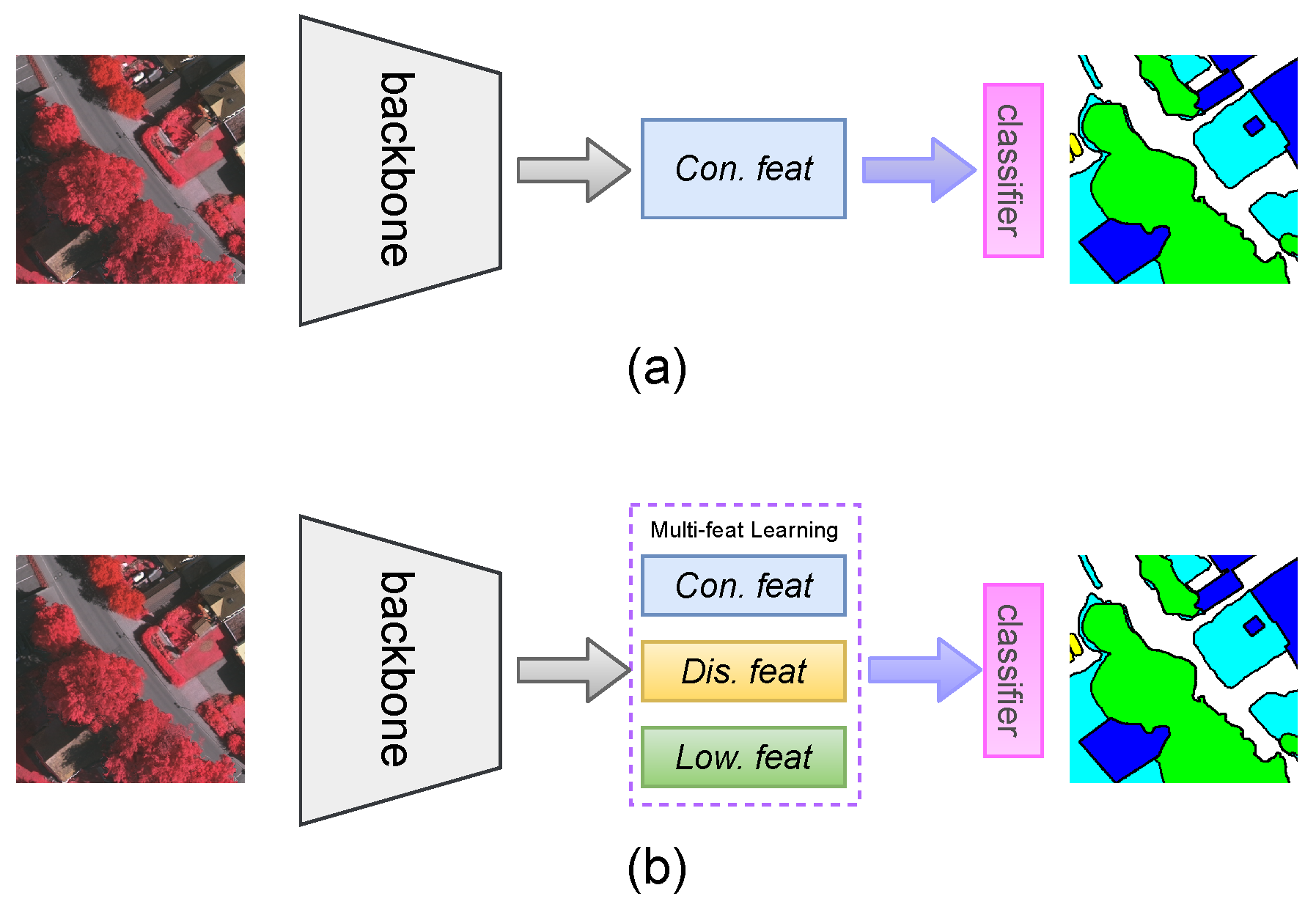
- We present a novel multi-feature learning mechanism that simultaneously learns con. feat, low. feat, and dis. feat to improve the performance of semantic segmentation.
- Based on the above mechanism, we design a novel convolutional neural network framework (MFNet) for VHR RSI segmentation. Except for the context aggregation module for capturing con. feat, there is a branch for learning low. feat at the shallow layer in the backbone network through local contrast processing, and a branch for generating dis. feat with better inter-class discriminative capability via a class-specific group-optimized strategy.
- We evaluate our proposed MFNet on two well-known VHR RSI benchmark datasets, the ISPRS Vaihingen and Potsdam datasets. Extensive experiments suggest that our proposed framework outperforms most cutting-edge models. In particular, we attain an overall accuracy score of 91.91% using only VGG16 [2] as the backbone on the Potsdam test set.
2. Related Works
3. Methodology
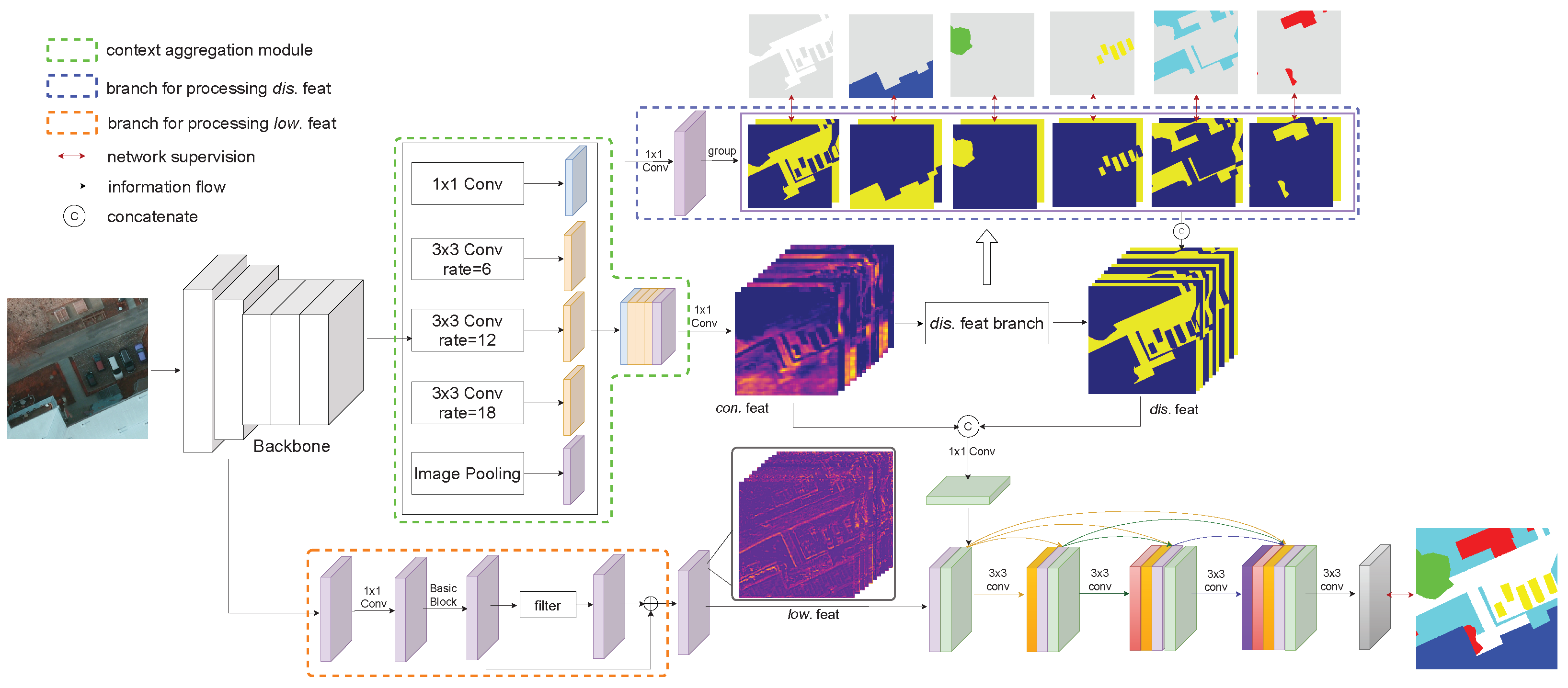
3.1. Overview
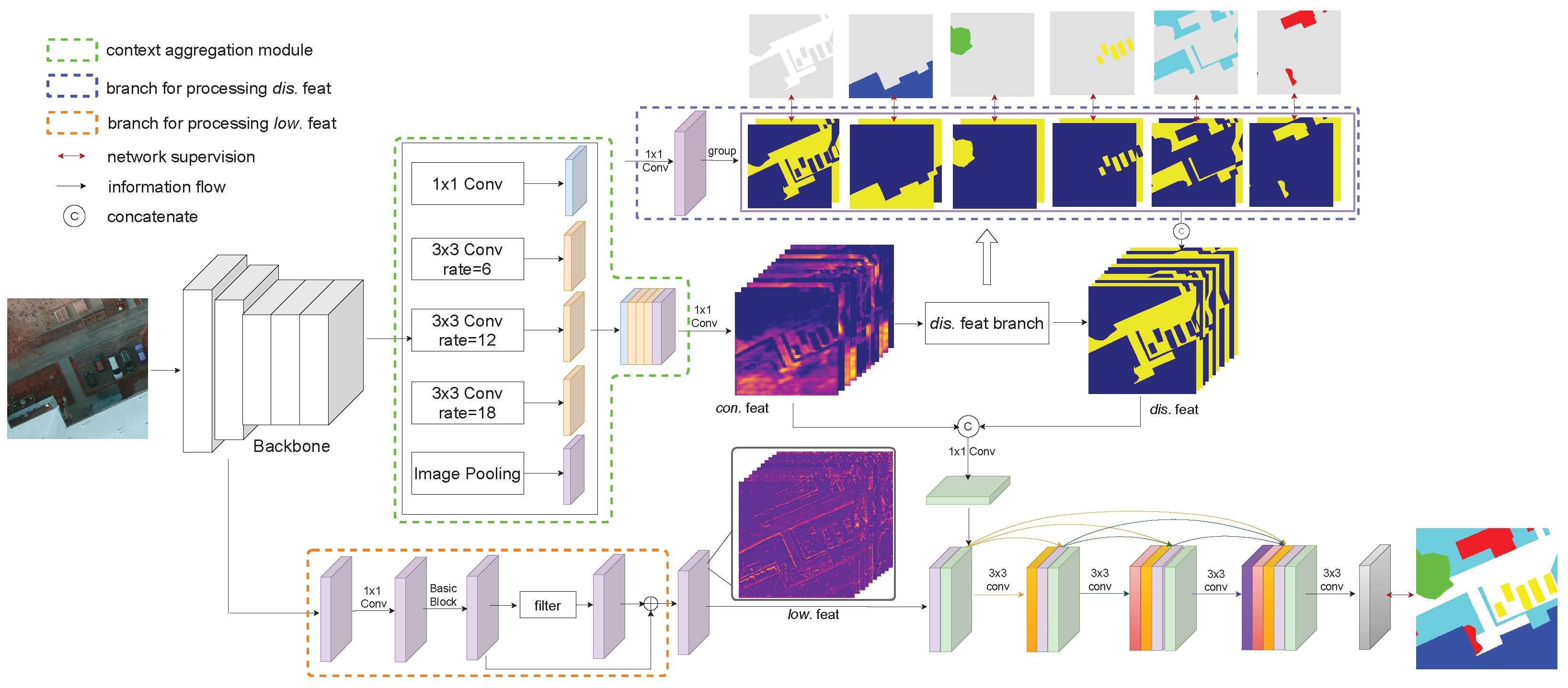
3.2. Network Architecture
3.3. Contextual Feature
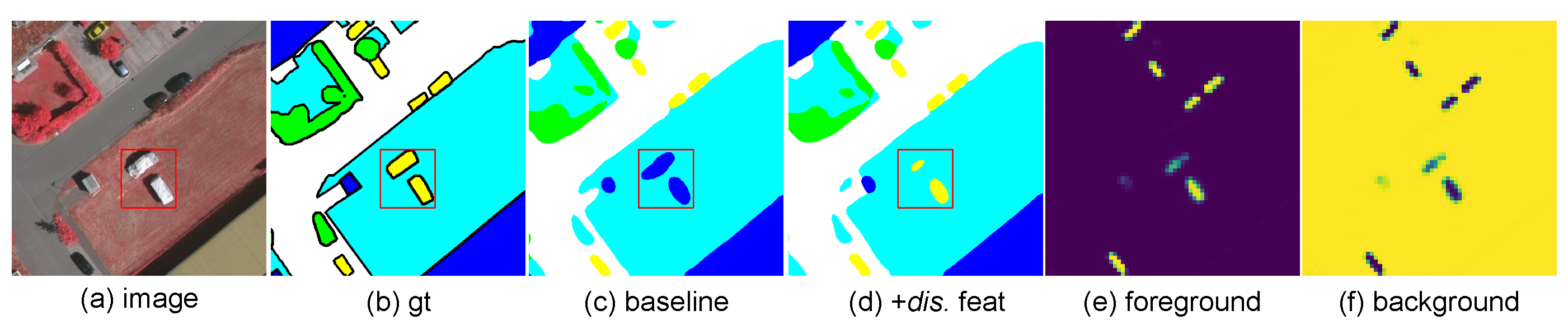
3.4. Class-Specific Discriminative Feature
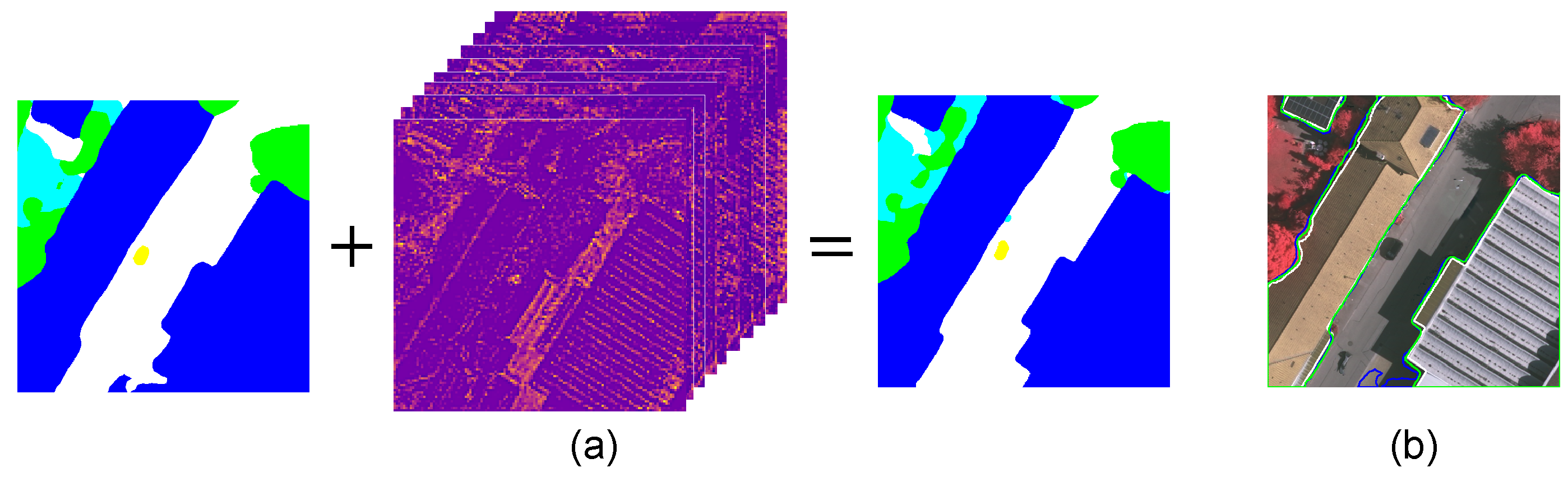
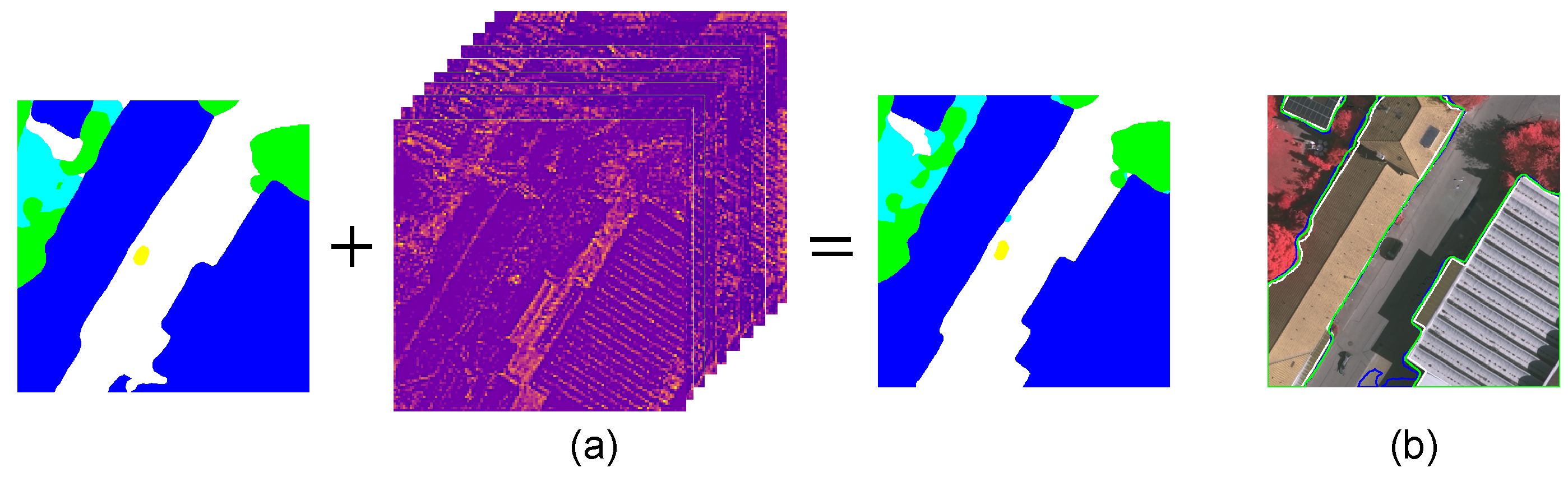
3.5. Low-Level Features
3.6. Dense Feature Aggregation
3.7. Loss
4. Description of Datasets and Design of Experiments
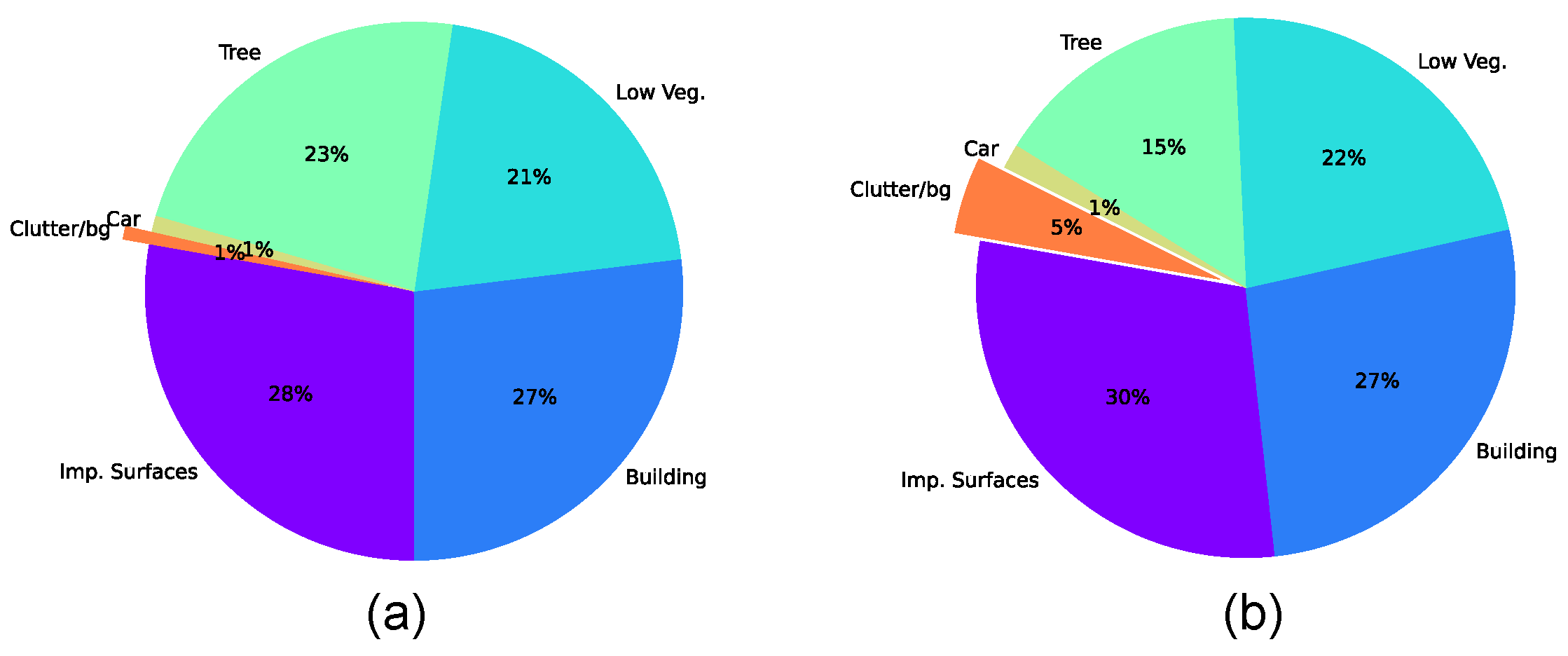
4.1. Dataset Description
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Inference Strategy
5. Experimental Results
5.1. Experiments on Vaihingen
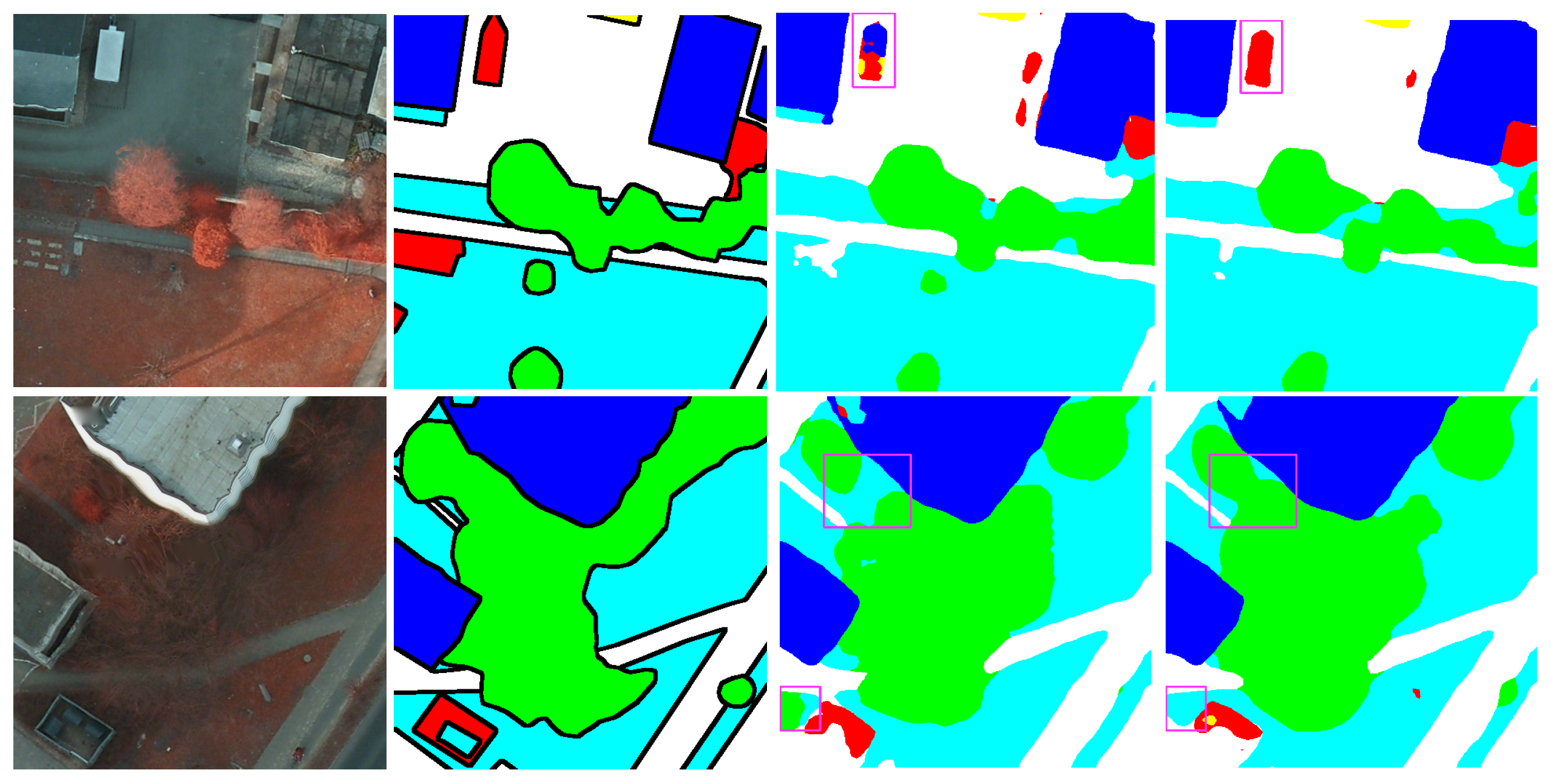
5.1.1. Ablation Study of Multi-Feature Learning
5.1.2. Ablation Study for Improvement Strategies
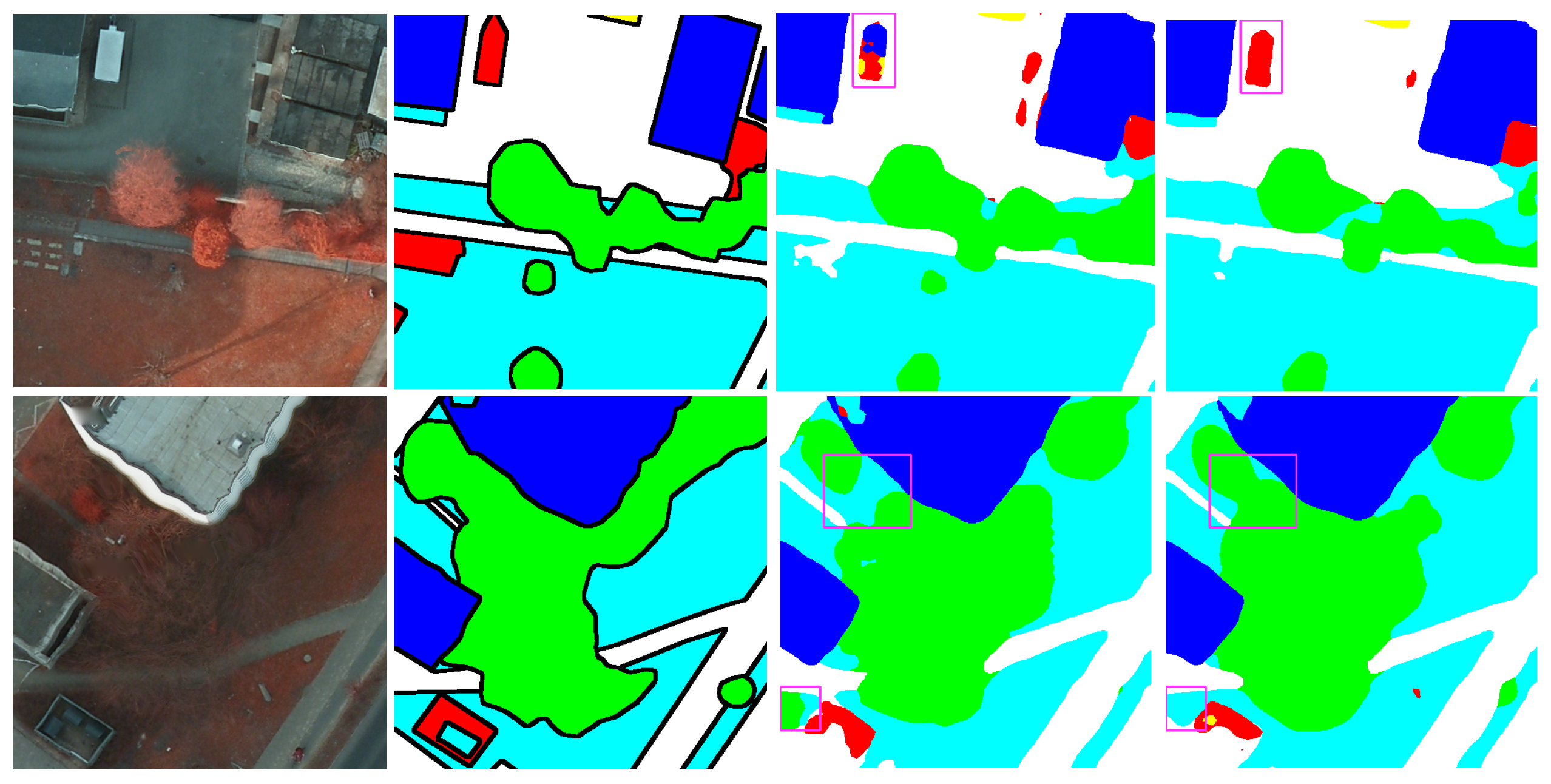
5.1.3. Results on Vaihingen Dataset
5.2. Experiments on Potsdam
5.2.1. Ablation Study of Multi-Feature Learning
5.2.2. Ablation Study for Improvement Strategies
5.2.3. Results for Potsdam Dataset
5.3. Experiments on UAVid
5.4. Computational Complexity
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, W.; Jiang, Z.; Wang, Z.; Cui, K.; Qian, X. Collaborative global-local networks for memory-efficient segmentation of ultra-high resolution images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8924–8933. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S.; Wang, Q.; Emery, W. Contextually guided very-high-resolution imagery classification with semantic segments. ISPRS J. Photogramm. Remote Sens. 2017, 132, 48–60. [Google Scholar] [CrossRef]
- Sun, W.; Wang, R. Fully convolutional networks for semantic segmentation of very high resolution remotely sensed images combined with DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Ding, L.; Zhang, J.; Bruzzone, L. Semantic segmentation of large-size VHR remote sensing images using a two-stage multiscale training architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5367–5376. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Shi, H.; Li, H.; Wu, Q.; Song, Z. Scene parsing via integrated classification model and variance-based regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5307–5316. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference On Computer Vision And Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Yue, K.; Sun, M.; Yuan, Y.; Zhou, F.; Ding, E.; Xu, F. Compact generalized non-local network. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 6511–6520. [Google Scholar]
- Li, X.; Zhang, L.; You, A.; Yang, M.; Yang, K.; Tong, Y. Global Aggregation then Local Distribution in Fully Convolutional Networks. arXiv 2019, arXiv:1909.07229. [Google Scholar]
- Luo, Z.; Mishra, A.; Achkar, A.; Eichel, J.; Li, S.; Jodoin, P. Non-local deep features for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6609–6617. [Google Scholar]
- Tu, Z.; Ma, Y.; Li, C.; Tang, J.; Luo, B. Edge-guided non-local fully convolutional network for salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 582–593. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Lin, Z.; Bidart, R.; Hu, X.; Daya, I.; Li, Z.; Zheng, W.; Li, J.; Wong, A. Squeeze-and-attention networks for semantic segmentation. In Proceedings of the IEEE/CVF Conference On Computer Vision And Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13065–13074. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K. Densely connected convolutional networks. In Proceedings of the IEEE Conference On Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Diakogiannis, F.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 905–909. [Google Scholar] [CrossRef]
- Pan, S.; Tao, Y.; Nie, C.; Chong, Y. PEGNet: Progressive edge guidance network for semantic segmentation of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 637–641. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mou, L.; Hua, Y.; Zhu, X. A relation-augmented fully convolutional network for semantic segmentation in aerial scenes. In Proceedings of the IEEE/CVF Conference On Computer Vision And Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 12416–12425. [Google Scholar]
- Li, X.; Zhao, H.; Han, L.; Tong, Y.; Tan, S.; Yang, K. Gated fully fusion for semantic segmentation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11418–11425. [Google Scholar] [CrossRef]
- Chen, X.; Han, Z.; Liu, X.; Li, Z.; Fang, T.; Huo, H.; Li, Q.; Zhu, M.; Liu, M.; Yuan, H. Semantic boundary enhancement and position attention network with long-range dependency for semantic segmentation. Appl. Soft Comput. 2021, 109, 107511. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Li, X.; Li, X.; Zhang, L.; Cheng, G.; Shi, J.; Lin, Z.; Tan, S.; Tong, Y. Improving semantic segmentation via decoupled body and edge supervision. In Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 435–452. [Google Scholar]
- Lyu, Y.; Vosselman, G.; Xia, G.; Yilmaz, A.; Yang, M. UAVid: A semantic segmentation dataset for UAV imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 108–119. Available online: http://www.sciencedirect.com/science/article/pii/S0924271620301295 (accessed on 15 December 2021). [CrossRef]
- ISPRS 2D Semantic Labeling Contest-Vaihingen. 2016. Available online: https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/ (accessed on 15 December 2021).
- ISPRS 2D Semantic Labeling Contest-Potsdam. 2016. Available online: https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-potsdam/ (accessed on 15 December 2021).
- Niu, R.; Sun, X.; Tian, Y.; Diao, W.; Chen, K.; Fu, K. Hybrid Multiple Attention Network for Semantic Segmentation in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–18. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; An kumar, A.; Alvarez, J.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]
- Volpi, M.; Tuia, D. Dense semantic labeling of subdecimeter resolution images with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 55, 881–893. [Google Scholar] [CrossRef] [Green Version]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Hua, Y.; Zhu, X. Relation matters: Relational context-aware fully convolutional network for semantic segmentation of high-resolution aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7557–7569. [Google Scholar] [CrossRef]
- Nogueira, K.; Dalla Mura, M.; Chanussot, J.; Schwartz, W.; Dos Santos, J. Dynamic multicontext segmentation of remote sensing images based on convolutional networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7503–7520. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Schindler, K.; Wegner, J.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Yue, K.; Yang, L.; Li, R.; Hu, W.; Zhang, F.; Li, W. TreeUNet: Adaptive Tree convolutional neural networks for subdecimeter aerial image segmentation. ISPRS J. Photogramm. Remote Sens. 2019, 156, 1–13. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, Y.; Li, Z.; Hong, Z.; Liu, J.; Ma, F.; Han, J.; Ding, E. Acfnet: Attentional class feature network for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6798–6807. [Google Scholar]
- Sun, Y.; Zhang, X.; Xin, Q.; Huang, J. Developing a multi-filter convolutional neural network for semantic segmentation using high-resolution aerial imagery and LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 143, 3–14. [Google Scholar] [CrossRef]
- Sun, Y.; Tian, Y.; Xu, Y. Problems of encoder-decoder frameworks for high-resolution remote sensing image segmentation: Structural stereotype and insufficient learning. Neurocomputing 2019, 330, 297–304. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Romera, E.; Alvarez, J.; Bergasa, L.; Arroyo, R. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L. A2-FPN for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. arXiv 2021, arXiv:2102.07997. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) ResNet50 | ||
|---|---|---|
| Layer Name | Output Size | 50 Layer |
| conv1 | , 64, stride 2 | |
| conv2_x | max pool, stride 2 | |
| conv3_x | ||
| conv4_x | ||
| conv5_x | ||
| avgrage pool | ||
| 1000-d fc | ||
| softmax | ||
| (b) VGG16 | ||
| Layer Name | Output Size | 16 Layer |
| , 64 | ||
| conv1 | , 64 | |
| max pool, stride 2 | ||
| , 128 | ||
| conv2_x | , 128 | |
| max pool, stride 2 | ||
| conv3_x | , 256 | |
| , 256 | ||
| , 256 | ||
| max pool, stride 2 | ||
| conv4_x | , 512 | |
| , 512 | ||
| , 512 | ||
| max pool, stride 2 | ||
| conv5_x | , 512 | |
| , 512 | ||
| , 512 | ||
| max pool, stride 2 | ||
| 4096-d fc | ||
| 4096-d fc | ||
| 1000-d fc | ||
| softmax | ||
| Category | RGB Value |
|---|---|
| Imp. Surf. | (255, 255, 255) |
| Building | (0, 0, 255) |
| Low veg. | (0, 255, 255) |
| Tree | (0, 255, 0) |
| Car | (255, 255, 0) |
| Clutter/background | (255, 0, 0) |
| Backbone | Model | Imp. Surf. | Building | Low Veg. | Tree | Car | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|---|---|---|---|---|
| VGG16 | FCN | 90.61 | 93.82 | 82.08 | 89.03 | 72.43 | 85.59 | 75.56 | 88.96 |
| +low. | 91.55 | 94.25 | 83.37 | 89.44 | 84.39 | 88.60 | 79.78 | 89.78 | |
| +dis. | 91.12 | 84.11 | 81.89 | 88.83 | 76.65 | 86.52 | 76.79 | 89.13 | |
| +con. | 90.97 | 94.10 | 82.65 | 89.15 | 74.68 | 86.31 | 76.55 | 89.28 | |
| +low.+dis. | 91.84 | 94.59 | 82.92 | 89.42 | 86.47 | 89.05 | 80.50 | 89.90 | |
| +con.+low. | 92.03 | 94.67 | 83.41 | 89.56 | 85.40 | 89.01 | 80.45 | 90.09 | |
| +con.+dis. | 91.71 | 94.61 | 82.70 | 89.29 | 78.17 | 87.30 | 77.96 | 89.70 | |
| +con.+dis.+low. | 92.31 | 95.06 | 83.45 | 89.74 | 85.59 | 89.23 | 80.82 | 90.36 | |
| Res50 | FCN | 92.06 | 95.27 | 83.74 | 89.61 | 84.96 | 89.13 | 80.66 | 90.36 |
| +low. | 92.21 | 95.21 | 83.69 | 89.68 | 87.30 | 89.62 | 81.42 | 90.40 | |
| +dis. | 92.45 | 95.41 | 83.85 | 89.56 | 86.82 | 89.62 | 81.44 | 90.51 | |
| +con. | 92.23 | 95.51 | 83.92 | 89.77 | 84.94 | 89.27 | 80.91 | 90.54 | |
| +low.+dis. | 92.70 | 95.68 | 83.53 | 89.54 | 87.86 | 89.86 | 81.85 | 90.64 | |
| +con.+low. | 92.33 | 95.58 | 83.92 | 89.89 | 86.18 | 89.58 | 81.39 | 90.62 | |
| +con.+dis. | 92.84 | 95.70 | 84.04 | 89.67 | 87.50 | 89.95 | 81.99 | 90.77 | |
| +con.+dis.+low. | 92.93 | 95.77 | 84.08 | 89.80 | 88.49 | 90.21 | 82.41 | 90.89 |
| Backbone | Method | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|
| VGG16 | FCN (baseline) | 85.59 | 75.56 | 88.96 |
| +ASPP [6] | 86.31 | 76.55 | 89.28 | |
| +PPM [5] | 85.43 | 75.44 | 89.14 | |
| +SA [16] | 85.77 | 75.77 | 88.96 | |
| +CGNL [17] | 85.82 | 75.92 | 89.20 | |
| +CC [13] | 87.77 | 75.82 | 89.10 | |
| Res50 | FCN (baseline) | 89.13 | 80.66 | 90.36 |
| +ASPP [6] | 89.27 | 80.91 | 90.54 | |
| +PPM [5] | 89.27 | 80.91 | 90.53 | |
| +SA [16] | 89.03 | 80.52 | 90.26 | |
| +CGNL [17] | 88.88 | 80.31 | 90.36 | |
| +CC [13] | 89.10 | 80.61 | 90.23 |
| Backbone | Model | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|
| VGG16 | cat | 88.78 | 80.11 | 90.23 |
| dense | 89.23 | 80.82 | 90.36 | |
| Res50 | con | 90.04 | 82.13 | 90.80 |
| dense | 90.21 | 82.41 | 90.89 |
| Backbone | DA | MG | MS | Imp. Surf. | Building | Low Veg. | Tree | Car | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG16 | 92.31 | 95.06 | 83.45 | 89.74 | 85.59 | 89.23 | 80.82 | 90.36 | |||
| ✓ | 92.36 | 95.42 | 84.01 | 89.88 | 84.60 | 89.25 | 80.88 | 90.61 | |||
| ✓ | - | - | - | - | - | - | - | - | - | ||
| ✓ | - | ✓ | 92.78 | 95.57 | 85.08 | 90.52 | 84.38 | 89.67 | 81.55 | 91.11 | |
| Res50 | 92.93 | 95.77 | 84.08 | 89.80 | 88.49 | 90.21 | 82.41 | 90.89 | |||
| ✓ | 93.03 | 96.01 | 84.58 | 90.08 | 87.71 | 90.28 | 82.53 | 91.13 | |||
| ✓ | ✓ | 93.23 | 96.19 | 85.12 | 90.03 | 87.85 | 90.48 | 82.86 | 91.32 | ||
| ✓ | ✓ | ✓ | 93.43 | 96.35 | 85.85 | 90.50 | 88.31 | 90.88 | 83.50 | 91.67 |
| Method | Backbone | Imp. Surf. | Building | Low Veg. | Tree | Car | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|---|---|---|---|---|
| FCN [15] | VGG16 | 88.67 | 92.83 | 76.32 | 86.67 | 74.21 | 83.74 | 72.69 | 86.51 |
| UZ_1 [37] | - | 89.20 | 92.50 | 81.60 | 86.90 | 57.30 | 81.50 | - | 87.30 |
| RoteEqNet [38] | - | 89.50 | 94.80 | 77.50 | 86.50 | 72.60 | 84.18 | - | 87.50 |
| S-RA-FCN [39] | VGG16 | 91.47 | 94.97 | 80.63 | 88.57 | 87.05 | 88.54 | 79.76 | 89.23 |
| UFMG_4 [40] | - | 91.10 | 94.50 | 82.90 | 88.80 | 81.30 | 87.72 | - | 89.40 |
| V-FuseNet [41] | - | 92.00 | 94.4 | 84.50 | 89.90 | 86.30 | 89.42 | - | 90.00 |
| DLR_9 [42] | - | 92.40 | 95.20 | 83.90 | 89.90 | 81.20 | 88.52 | - | 90.30 |
| TreeUNet [43] | - | 92.50 | 94.90 | 83.60 | 89.60 | 85.90 | 89.30 | - | 90.40 |
| DANet [12] | ResNet101 | 91.63 | 95.02 | 83.25 | 88.87 | 87.16 | 89.19 | 81.32 | 90.44 |
| DeepLabv3+ [6] | ResNet101 | 92.38 | 95.17 | 84.29 | 89.52 | 86.47 | 89.57 | 81.47 | 90.56 |
| PSPNet [5] | ResNet101 | 92.79 | 95.46 | 84.51 | 89.94 | 88.61 | 90.26 | 82.58 | 90.85 |
| ACFNet [44] | ResNet101 | 92.93 | 95.27 | 84.46 | 90.05 | 88.64 | 90.27 | 82.68 | 90.90 |
| BKHN11 | ResNet101 | 92.90 | 96.00 | 84.60 | 89.90 | 88.60 | 90.40 | - | 91.00 |
| CASIA2 [7] | ResNet101 | 93.20 | 96.00 | 84.70 | 89.90 | 86.70 | 90.10 | - | 91.10 |
| CCNet [13] | ResNet101 | 93.29 | 95.53 | 85.06 | 90.34 | 88.70 | 90.58 | 82.76 | 91.11 |
| MFNet (Ours) | VGG16 | 92.78 | 95.57 | 85.08 | 90.52 | 84.38 | 89.67 | 81.55 | 91.11 |
| MFNet (Ours) | ResNet50 | 93.43 | 96.35 | 85.85 | 90.50 | 88.31 | 90.88 | 83.50 | 91.67 |
| Backbone | Model | Imp. Surf. | Building | Low Veg. | Tree | Car | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|---|---|---|---|---|
| VGG16 | FCN | 92.47 | 96.10 | 86.41 | 87.93 | 94.79 | 91.52 | 84.59 | 90.06 |
| +low. | 92.72 | 96.37 | 86.88 | 88.09 | 96.17 | 92.05 | 85.52 | 90.35 | |
| +dis. | 92.70 | 96.45 | 86.97 | 88.56 | 94.56 | 91.85 | 85.12 | 90.52 | |
| +con. | 93.13 | 96.75 | 87.29 | 88.40 | 95.27 | 92.17 | 85.69 | 90.88 | |
| +low.+dis. | 93.06 | 96.62 | 87.23 | 88.26 | 96.02 | 92.24 | 85.83 | 90.71 | |
| +con.+low. | 93.39 | 96.99 | 87.26 | 88.69 | 96.16 | 92.50 | 86.29 | 91.02 | |
| +con.+dis. | 93.49 | 97.15 | 87.53 | 88.31 | 95.57 | 92.41 | 86.12 | 91.14 | |
| +con.+dis.+low. | 93.55 | 97.12 | 87.49 | 88.53 | 96.17 | 92.57 | 86.42 | 91.25 | |
| Res50 | FCN | 93.55 | 97.08 | 87.16 | 88.45 | 96.31 | 92.51 | 86.33 | 91.04 |
| +low. | 93.50 | 96.92 | 87.46 | 88.95 | 96.19 | 92.60 | 86.46 | 91.16 | |
| +dis. | 93.56 | 97.17 | 87.50 | 88.93 | 96.39 | 92.71 | 86.65 | 91.20 | |
| +con. | 93.71 | 97.15 | 87.75 | 88.98 | 96.25 | 92.77 | 86.74 | 91.38 | |
| +low.+dis. | 93.63 | 97.17 | 87.58 | 88.55 | 96.41 | 92.67 | 86.59 | 91.22 | |
| +con.+low. | 93.59 | 97.09 | 88.02 | 89.28 | 96.14 | 92.82 | 86.82 | 91.49 | |
| +con.+dis. | 93.83 | 97.33 | 87.72 | 88.92 | 96.74 | 92.91 | 87.01 | 91.47 | |
| +con.+dis.+low. | 93.92 | 97.40 | 87.83 | 88.99 | 96.69 | 92.96 | 87.10 | 91.61 |
| Backbone | Method | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|
| VGG16 | FCN(baseline) | 91.52 | 84.59 | 90.06 |
| +ASPP [6] | 92.17 | 85.69 | 90.88 | |
| +PPM [5] | 92.04 | 85.47 | 90.80 | |
| +SA [16] | 92.12 | 85.59 | 90.95 | |
| +CGNL [17] | 92.17 | 85.70 | 90.85 | |
| +CC [13] | 91.88 | 85.19 | 90.67 | |
| Res50 | FCN(baseline) | 92.51 | 86.33 | 91.04 |
| +ASPP [6] | 92.77 | 86.74 | 91.38 | |
| +PPM [5] | 92.66 | 86.57 | 91.24 | |
| +SA [16] | 92.49 | 86.29 | 91.25 | |
| +CGNL [17] | 92.54 | 86.35 | 91.29 | |
| +CC [13] | 92.66 | 86.55 | 91.30 |
| Backbone | Model | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|
| VGG16 | cat | 92.55 | 86.39 | 91.14 |
| dense | 92.57 | 86.42 | 91.25 | |
| Res50 | cat | 92.90 | 87.01 | 91.46 |
| dense | 92.96 | 87.10 | 91.61 |
| Backbone | DA | MG | MS | Imp. Surf. | Building | Low Veg. | Tree | Car | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG16 | 93.55 | 97.12 | 87.49 | 88.53 | 96.17 | 92.57 | 86.42 | 91.25 | |||
| ✓ | 93.82 | 97.33 | 87.93 | 88.83 | 96.21 | 92.82 | 86.84 | 91.56 | |||
| - | - | - | - | - | - | - | - | - | - | - | |
| ✓ | - | ✓ | 94.09 | 97.43 | 88.49 | 89.29 | 96.40 | 93.14 | 87.38 | 91.91 | |
| Res50 | 93.92 | 97.40 | 87.83 | 88.99 | 96.69 | 92.96 | 87.10 | 91.61 | |||
| ✓ | 94.02 | 97.22 | 87.99 | 89.08 | 96.34 | 92.93 | 87.02 | 91.68 | |||
| ✓ | ✓ | 94.27 | 97.41 | 88.05 | 89.06 | 96.57 | 93.07 | 87.28 | 91.82 | ||
| ✓ | ✓ | ✓ | 94.25 | 97.52 | 88.42 | 89.43 | 96.62 | 93.25 | 87.57 | 91.96 |
| Method | Backbone | Imp. Surf. | Building | Low Veg. | Tree | Car | mF1(%) | mIoU(%) | OA(%) |
|---|---|---|---|---|---|---|---|---|---|
| FCN [15] | VGG16 | 88.61 | 93.29 | 83.29 | 79.83 | 93.02 | 87.61 | 78.34 | 85.59 |
| UZ_1 [37] | - | 89.30 | 95.40 | 81.80 | 80.50 | 86.50 | 86.70 | - | 85.80 |
| UFMG_4 [40] | - | 90.80 | 95.60 | 84.40 | 84.30 | 92.40 | 89.50 | - | 87.90 |
| S-RA-FCN [39] | VGG16 | 91.33 | 94.70 | 86.81 | 83.47 | 94.52 | 90.17 | 82.38 | 88.59 |
| V-FuseNet [41] | - | 92.70 | 96.30 | 87.30 | 88.50 | 95.40 | 92.04 | - | 90.60 |
| TSMTA [11] | ResNet101 | 92.91 | 97.13 | 87.03 | 87.26 | 95.16 | 91.90 | - | 90.64 |
| Multi-filter CNN [45] | VGG16 | 90.94 | 96.80 | 76.32 | 73.37 | 88.55 | 85.23 | - | 90.65 |
| TreeUNet [43] | - | 93.10 | 97.30 | 86.60 | 87.10 | 95.80 | 91.98 | - | 90.70 |
| DeepLabv3+ [6] | ResNet101 | 92.95 | 95.88 | 87.62 | 88.15 | 96.02 | 92.12 | 84.32 | 90.88 |
| CASIA3 [7] | ResNet101 | 93.40 | 96.80 | 87.60 | 88.30 | 96.10 | 92.44 | - | 91.00 |
| PSPNet [5] | ResNet101 | 93.36 | 96.97 | 87.75 | 88.50 | 95.42 | 92.40 | 84.88 | 91.08 |
| BKHN3 | ResNet101 | 93.30 | 97.20 | 88.00 | 88.50 | 96.00 | 92.60 | - | 91.10 |
| AMA_1 | - | 93.40 | 96.80 | 87.70 | 88.80 | 96.00 | 92.54 | - | 91.20 |
| CCNet [13] | ResNet101 | 93.58 | 96.77 | 86.87 | 88.59 | 96.24 | 92.41 | 85.65 | 91.47 |
| HUSTW4 [46] | - | 93.60 | 97.60 | 88.50 | 88.80 | 94.60 | 92.62 | - | 91.60 |
| SWJ_2 | ResNet101 | 94.40 | 97.40 | 87.80 | 87.60 | 94.70 | 92.38 | - | 91.70 |
| MFNet(Ours) | VGG16 | 94.09 | 97.43 | 88.49 | 89.29 | 96.40 | 93.14 | 87.38 | 91.91 |
| MFNet(Ours) | ResNet50 | 94.25 | 97.52 | 88.42 | 89.43 | 96.62 | 93.25 | 87.57 | 91.96 |
| Methods | Class IoU(%) | mIoU (%) | OA(%) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Clutter | Building | Road | Tree | Low Veg. | Mov. Car | Sta. Car | Human | |||
| Dilation Net [30] | 45.40 | 80.70 | 65.10 | 73.80 | 45.50 | 53.60 | 24.50 | 0.00 | 48.60 | - |
| FCN-8s [15] | 63.91 | 84.72 | 76.51 | 78.32 | 61.88 | 65.87 | 45.54 | 22.26 | 62.38 | 84.55 |
| SegNet [47] | 65.62 | 85.89 | 79.23 | 78.78 | 63.73 | 68.94 | 52.10 | 19.29 | 64.20 | 85.54 |
| U-Net [48] | 61.80 | 82.94 | 75.15 | 77.27 | 62.03 | 59.59 | 29.98 | 18.62 | 58.42 | 83.43 |
| MSD [32] | 57.00 | 79.80 | 74.00 | 74.50 | 55.90 | 62.90 | 32.10 | 19.70 | 57.00 | - |
| ERFNet [49] | 64.50 | 85.58 | 77.34 | 77.87 | 62.21 | 60.64 | 46.13 | 0.00 | 59.28 | 84.69 |
| BiSeNetV2 [50] | 61.18 | 81.62 | 77.11 | 75.97 | 61.30 | 66.36 | 38.51 | 15.40 | 59.68 | 83.10 |
| ABCNet [51] | 67.44 | 86.43 | 81.24 | 79.92 | 63.10 | 69.84 | 48.42 | 13.91 | 63.79 | 86.25 |
| DANet [12] | 64.85 | 85.88 | 77.94 | 78.29 | 61.47 | 59.64 | 47.44 | 9.14 | 60.58 | 84.99 |
| MANet [52] | 64.46 | 85.37 | 77.81 | 76.98 | 60.33 | 67.18 | 53.61 | 14.89 | 62.58 | 84.48 |
| BANet [53] | 66.66 | 85.38 | 80.71 | 78.87 | 62.09 | 69.32 | 52.83 | 21.03 | 64.61 | 85.73 |
| A2-FPN [54] | 67.37 | 87.20 | 80.16 | 80.11 | 63.73 | 70.14 | 53.33 | 23.43 | 65.68 | 86.35 |
| PSPNet [5] | 68.89 | 87.96 | 82.20 | 81.07 | 65.69 | 70.30 | 56.31 | 24.67 | 67.13 | 87.28 |
| DeepLabV3 [4] | 69.70 | 88.50 | 82.10 | 80.23 | 65.76 | 71.75 | 61.43 | 21.37 | 67.60 | 87.27 |
| DeepLabV3+ [6] | 68.86 | 87.62 | 82.22 | 79.76 | 65.88 | 69.86 | 55.39 | 26.07 | 66.96 | 86.94 |
| MFNet(VGG16) | 68.62 | 87.64 | 81.97 | 81.43 | 66.84 | 72.60 | 55.16 | 23.13 | 67.17 | 87.33 |
| MFNet(ResNet50) | 69.66 | 88.63 | 82.51 | 81.31 | 66.42 | 73.21 | 60.59 | 27.44 | 68.72 | 87.63 |
| Model | Backbone | Params (M) | Macs (G) | FPS |
|---|---|---|---|---|
| FCN [15] | VGG16 | 15.90 | 38.62 | 69.63 |
| DeepLab V3 [4] | ResNet50 | 42.12 | 85.44 | 16.47 |
| DeepLab V3+ [6] | ResNet50 | 42.83 | 94.41 | 16.27 |
| PSPNet [5] | ResNet50 | 68.06 | 128.66 | 20.09 |
| Non-local [16] | ResNet50 | 54.75 | 110.96 | 23.29 |
| CCNet [13] | ResNet50 | 35.76 | 74.14 | 22.83 |
| CGNL [17] | ResNet50 | 36.26 | 75.09 | 19.45 |
| DANet [12] | ResNet50 | 49.92 | 101.56 | 19.34 |
| MFNet | VGG16 | 18.86 | 51.37 | 46.01 |
| MFNet | ResNet50 | 49.88 | 133.73 | 13.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, Y.; Cheng, J.; Bai, H.; Liu, H.; He, C. Semantic Segmentation of Very-High-Resolution Remote Sensing Images via Deep Multi-Feature Learning. Remote Sens. 2022, 14, 533. https://doi.org/10.3390/rs14030533
Su Y, Cheng J, Bai H, Liu H, He C. Semantic Segmentation of Very-High-Resolution Remote Sensing Images via Deep Multi-Feature Learning. Remote Sensing. 2022; 14(3):533. https://doi.org/10.3390/rs14030533
Chicago/Turabian StyleSu, Yanzhou, Jian Cheng, Haiwei Bai, Haijun Liu, and Changtao He. 2022. "Semantic Segmentation of Very-High-Resolution Remote Sensing Images via Deep Multi-Feature Learning" Remote Sensing 14, no. 3: 533. https://doi.org/10.3390/rs14030533
APA StyleSu, Y., Cheng, J., Bai, H., Liu, H., & He, C. (2022). Semantic Segmentation of Very-High-Resolution Remote Sensing Images via Deep Multi-Feature Learning. Remote Sensing, 14(3), 533. https://doi.org/10.3390/rs14030533