1. Introduction
Due to the limited light energy and the sensitivity of remote sensing imaging sensors such as WorldView-3, QuickBird, and GaoFen-2, only multispectral (MS) images with low spatial-resolution (LR-MS) and panchromatic (PAN) gray-scaled image with high spatial-resolution (HR-PAN) can be obtained directly from optical devices. However, what is highly desirable in a wide range of applications, including change detection, classification, and object recognition, are images with rich spectral information and spatial details. The task of pansharpening is namely to obtain such high-resolution multispectral (HR-MS) images by fusing the known HR-PAN and LR-MS images, improving the spatial resolution of MS images while maintaining the high resolution in the spectral domain. Recently, pansharpening has been an active field of research, getting more and more attention in remote sensing image processing. The competition [
1] initiated by the Data Fusion Committee of the IEEE Geoscience and Remote Sensing Society in 2006, and many recently published review papers proved the rapid development trend of pansharpening. In scientific research, pansharpening has also received extensive attention in the industry of some companies, e.g., Google Earth, DigitalGlobe, etc.
Over the past few decades, a large variety of pansharpening methods have been proposed. Most of them can be divided into the following four categories: Component substitution (CS) [
2,
3,
4,
5] approaches, multi-resolution analysis (MRA) [
1,
6,
7,
8,
9,
10,
11] approaches, variational optimization (VO) [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33] approaches, and deep learning (DL) approaches [
34,
35,
36,
37,
38,
39,
40,
41,
42].
The main idea of the CS-based method can be summarized as replacing specific components of the LR-MS images with the HR-PAN image. To be more specific, the spatial component separated by a spectral transformation of the LR-MS image is first substituted with the PAN image, and then the sharpened image is transformed into the original domain through back projection. Among CS-based methods, most of them can produce results with satisfying spatial fidelity yet usually lead to severe spectral distortion. Some typical examples of methods that fall into this category are spatial details with local parameter estimation (BDSD) [
2], spatial details with a strong dependency (BDSD-PC) method [
3], and partial replacement of adaptive component substitution (PRACS) [
4].
The MRA-based methods work to inject the spatial details extracted from the HR-PAN image into the LR-MS images through a multi-resolution analysis framework. Products obtained by MRA-based techniques usually retain spectral information well, but suffer from spatial distortion. Typical instances of such a class are smoothing filter-based intensity modulation (SFIM) [
6], additive wavelet intensity ratio (AWLP) [
7], generalized Laplacian pyramid (GLP) [
1,
43], with GLP with robust regression [
44] and GLP with comprehensive regression (GLP-Reg) [
11].
VO-based methods regard pansharpening as an inverse problem that is usually ill-posed. These methods need to describe the potential relationship among HR-PAN images, LR-MS images, and unknown HR-MS images by establishing equations, which could be solved by the designed optimization algorithms. Compared with CS and MRA methods, they can achieve a better balance between spectral fidelity and spatial fidelity, but at the cost of the increased computational burden. Technologies in this category include: Bayesian methods [
14,
15,
16], variational methods [
17,
18,
19,
21,
22,
23,
24,
25,
26,
27,
28,
29], and compressed sensing technology [
30,
31,
32]. Typical instances of this class are TV [
20], LGC(CVPR19) [
12], and DGS [
13].
Recently, with the rapid development of deep learning and accessibility of high-performance computing hardware equipment, convolutional neural networks (CNNs) have shown outstanding performance in image processing fields, e.g., image resolution reconstruction [
45,
46,
47,
48,
49], image segmentation [
50,
51,
52], image fusion [
53,
54,
55,
56,
57], image classification [
58], image denoising [
59], etc. Therefore, many methods [
34,
35,
36,
37,
38,
41,
42,
58,
59,
60,
61,
62,
63,
64,
65,
66,
67,
68,
69,
70,
71,
72,
73,
74,
75] based on deep learning have also been applied to solve the pansharpening problem. Benefiting from the powerful nonlinear fitting and feature extraction capabilities of CNNs and the availability of big data, these DL-based methods could perform better than the above three methods to a certain degree, i.e., CS-, MRA-, and VO-based methods. Researchers have designed various CNNs with different structures and characteristics. Specifically, the general paradigm uses LR-MS images and HR-PAN images as input to the network. The desired HR-MS images can have output through the trained network. For example, Wei et al. [
61] proposed the concept of residual learning to make full use of the high nonlinearity of deep learning models. Moreover, Yuan et al. [
60] introduced multi-scale feature extraction into the basic convolutional neural network (CNN) architecture and proposed the multi-scale and multi-depth CNN for pansharpening. In 2018, Scarpa et al. [
72] proposed a target-adaptive usage modality to achieve good performance in the presence of a mismatch with respect to the training set and across different sensors. In [
61], the concept of residual learning was introduced by Wei et al. to form a very deep convolutional neural network to make full use of the high nonlinearity of deep learning models.
However, most of the existing CNN frameworks directly concatenate the HR-PAN image and LR-MS image together in the spectral channel dimension as the network’s input, neglecting the unique characteristics of the HR-PAN image and LR-MS images. This operation would result in the distinctive features in HR-PAN and LR-MS images that cannot be perceived and extracted effectively. Besides, there are essential differences between HR-PAN images and LR-MS images both in spatial and spectral dimensions, making the fusion procedure more difficult. In [
41], Zhang et al. designed two independent branches for HR-PAN and LR-MS images to explore their features separately and finally performed feature fusion operations on their respective deep features. In this case, BDPN will fail to fuse the feature map in shallow depth and medium depth of the network, attenuating the fusion ability.
To address the above problem, we propose an efficient full-depth feature fusion network (FDFNet) for remote sensing pansharpening. The main contributions of this paper can be summarized as follows.
- 1.
A novel FDFNet is designed to learn the continuous features for the PAN image, MS images, and the fusion images through three branches, separately. These three branches are arranged in parallel. The transfer of feature maps and information interaction among the three branches are carried out at different depths of the network, enabling the network to generate specific representations for images of various properties and the relationships between them.
- 2.
The features extracted from the MS branch and PAN branch will be injected into the fusion branch at every different depth, promoting the network to characterize better and integrate the detailed low-level features and high-level semantic features.
Extensive experiments on reduced- and full-resolution datasets captured by WorldView-3, QuickBird, and GaoFen-2 satellites prove that the proposed FDFNet with less than 100,000 parameters could exceed the other competitive methods. And the comparisons with the LR-MS and high performance DMDNet [
34] are shown in
Figure 1 for a WorldView-3 dataset.
2. Related Works
In this section, a brief review of several DL-based methods [
34,
35,
36,
37] for pansharpening will be presented.
The successful use of deep CNNs in a wide range of computer vision tasks has more recently led researchers to exploit their nonlinear fitting capabilities for image fusion problems such as pansharpening. In 2016, Masi et al. [
37] firstly attempted to apply CNNs to solve the pansharpening problem, particularly by replicating three convolution layers. The pansharpening neural network (PNN) was designed and trained on big data. Though with such a simple network structure, its performance surpasses almost all traditional methods, indicating the great potential of CNNs for pansharpening, and it motivates many researchers to carry out further research based on deep learning. In 2017, Yang et al. [
35] proposed a neural network with residual learning modules called PanNet, which are easier for retrieving training results and could reach convergence more quickly than PNN. Another important innovation of their work is that the known HR-PAN image and LR-MS image are high-pass filtered before being input into PanNet so that the network can focus more on the feature extraction of edge details of the images. Thanks to its high-frequency operation and simple network structure, PanNet has good generalization ability, making it competent for different datasets.
In 2019, a lightweight network named detail injection-based convolutional neural networks (DiCNN1) was designed by He et al. [
36], which discards the residual structure used in PanNet. It injects the LR-MS image into the HR-PAN image and then inputs it to the network that contains only three convolution layers and two ReLU activation layers. Though the number of parameters of DiCNN is small, its performance is superior to PanNet, and it also surpasses PanNet in terms of processing speed, making it more efficient in real application scenarios.
Most recently, Hu et al. [
71] proposed multi-scale dynamic convolutions that extract detailed features of PAN images at different scales to obtain effective detail features. In [
70], a simple multibranched feature extraction architecture was introduced by Lei et al. They used a gradient calculator to extract spatial structure information of panchromatic maps and designed structural and spectral compensation to fully extract and preserve the spatial structural and spectral information of images. Jin et al. [
42] proposed a Laplacian pyramid pansharpening network architecture which is designed according to the sensors’ modulation transfer functions.
In addition, Fu et al. [
34] proposed a deep multi-scale detail network (DMDNet), which adopts grouped multi-scale dilated convolutions to sharpen MS images. By grouping a common convolution kernel, the computational burden can be reduced with almost no reduction in feature extraction and characterization capabilities. In addition, the use of multi-scale dilated convolution can not only expand the receptive field of the network but also perceive spatial features on different scales. Innovative use of dilated convolution and multi-scale convolution to replace the general convolution for feature characterization make DMDNet achieve state-of-the-art performance.
The above four DL-based methods can be uniformly expressed as follows:
where
represents the process in DL-based methods with the parameters
, and
represents the concatenation of
and
.
3. Proposed Methods
In this section, we will state the motivation of our work, and then introduce the details of the proposed FDFNet.
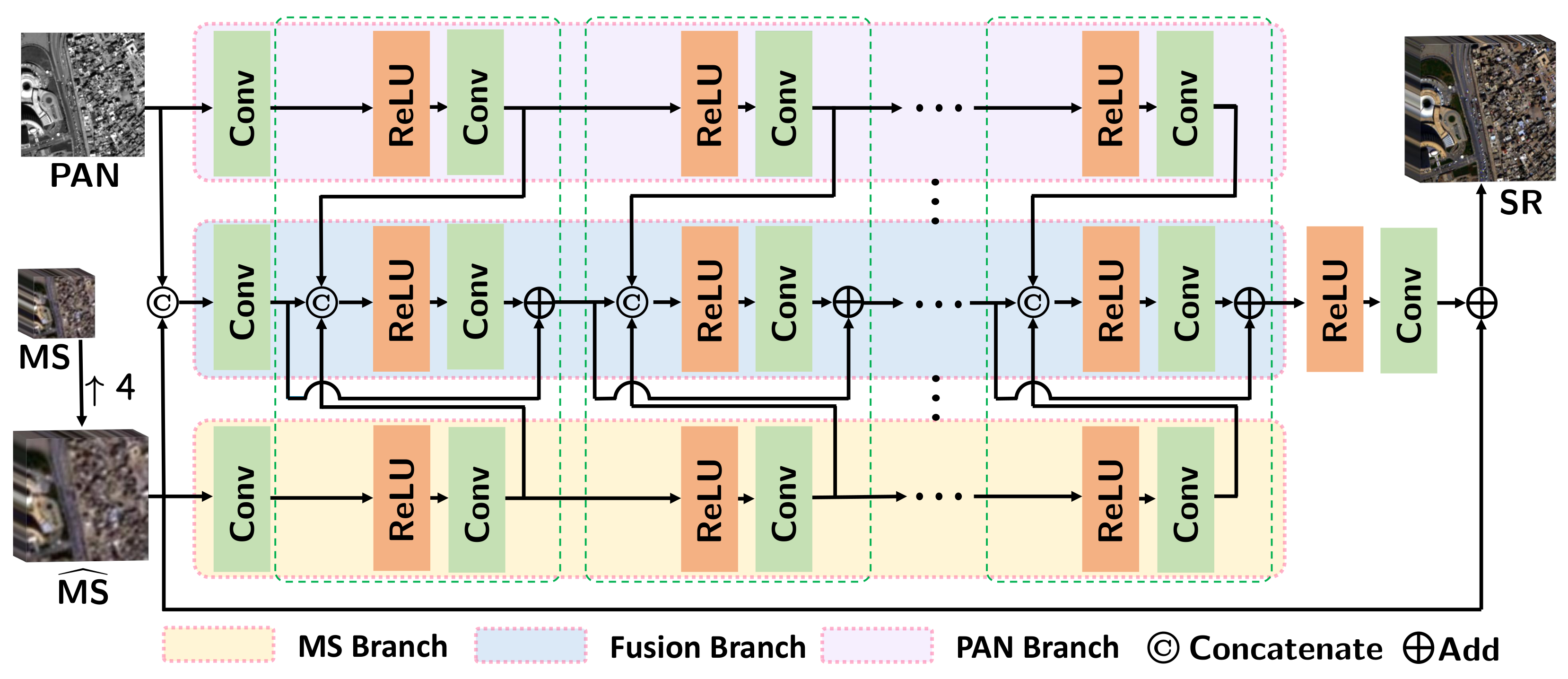
Figure 2 shows the architecture of our proposed network.
3.1. Motivation
Although the methods mentioned above provided various empirical approaches to depict the relationships between images, three main limitations have not been addressed. First, they neglected the difference between the LR-MS image and HR-PAN images in terms of the spectral and spatial information, and were just fused through concatenation or summation at first, and then the fused image directly inputted into the network, leading to the features being separately contained in the HR-PAN image and LR-MS image, which cannot be effectively extracted. Second, the existing methods only perform feature fusion at the first or last layers in the network. Thus the resulting fusion image may be inadequate for discriminative representation and integration reasonably. Third, separate feature extraction and fusion operations will make the network structure complex and computationally expensive, resulting in a cumbersome model.
In response to the above concerns, we managed to extract the rich textures and details contained in the spatial domain of the PAN image and the spectral features contained in the MS image through two independent branches to maintain the integrity of the spectral information of the multispectral image and reduce the distortion of the spatial information. In order to reduce the computational burden of feature fusion, the features obtained from the PAN branch and MS branch at the same depth are injected into the fusion branch parallel to the other two branches. While performing feature extraction, the full-depth feature fusion of the network is realized. In this way, the network can maximize the use of features at different depths and branches, that is, low-level detailed texture features and high-level semantic features to restore distortion-free fusion images.
3.2. Parallel Full-Depth Feature Fusion Network
Consider a PAN image
and a MS image
, where
b represents the number of band in the MS image. Firstly,
will be upsampled to the same size as
by a polynomial kernel with 23 coefficients [
76], and let
represent the upsampled image. Next,
and
will be concatenated together as an original fusion product
. Then,
,
, and
will be sent to three parallel convolutional layers respectively to increase the number of channels for later feature extraction.
The three feature maps,
,
, and
, obtained by the above operation will be fed into the head structure of three parallel branches. The three branches developed accordingly are called the PAN branch, MS branch, and fusion branch. Moreover, the features exacted from the PAN branch and MS branch will be injected into the fusion branch through the constructed parallel feature fusion block (PFFB). The details about PFFB can refer to
Section 3.3 and
Figure 3. In particular, there are 4 PFFBs contained in the proposed FDFNet.
The underlying detailed information and deep semantic information are fused through the distribution of PFFB in each depth of the network characteristics. We believe that such a full-depth fusion is beneficial to improving the network’s feature representation ability. After 4 PFFBs, the feature map from the fusion branch will be selected out and sent to a convolutional layer with beforehand ReLU activation to reduce its channels to the same as that of
. The output feature is denoted as
. Finally, we add
and
that transferred by a long skip to yield the final super-resolution image
. The whole process can be expressed as follows:
where
represents the FDFNet with its parameters
. For more details about FDFNet, refer to
Figure 2.
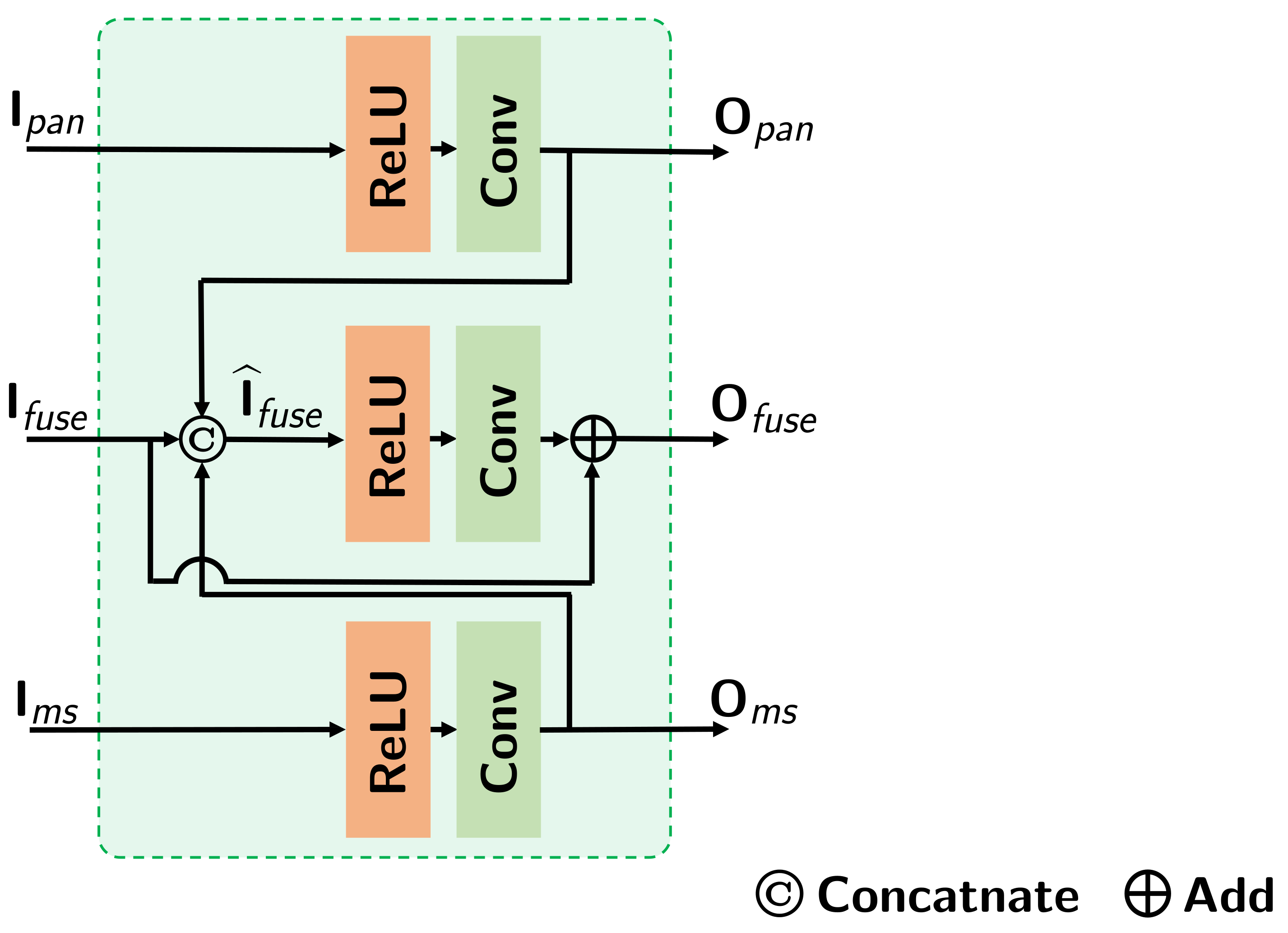
3.3. Parallel Feature Fusion Block
In order to realize the transfer and fusion of feature maps among the three branches, i.e., PAN branch, MS branch, and the fusion branch, we designed a parallel feature fusion block (PFFB). To facilitate the description, let , , and , respectively, represent the input feature of PAN branch, the MS branch, and the fusion branch, while , , and represent output feature of PAN branch, the MS branch, and the fusion branch respectively, where H and W are the size in spatial dimension, and , , and denote the channels of the feature maps.
Firstly,
and
will be subjected to feature extraction operations and get their output features
and
. After that,
,
, and
will be concatenated together as
. The process can be expressed as follows:
where
and
represents the convolutional layer in which the input channel is the same as the output channel, and
represents ReLU activation. Finally,
will be subjected to feature extraction operation and added with
by a short connection as the output feature
. The final process in PFFB can be expressed as follows:
where
represents the convolutional layer which will reduce the channels of the exacted feature to the same as
. For more details about PFFB, refer to
Figure 3.
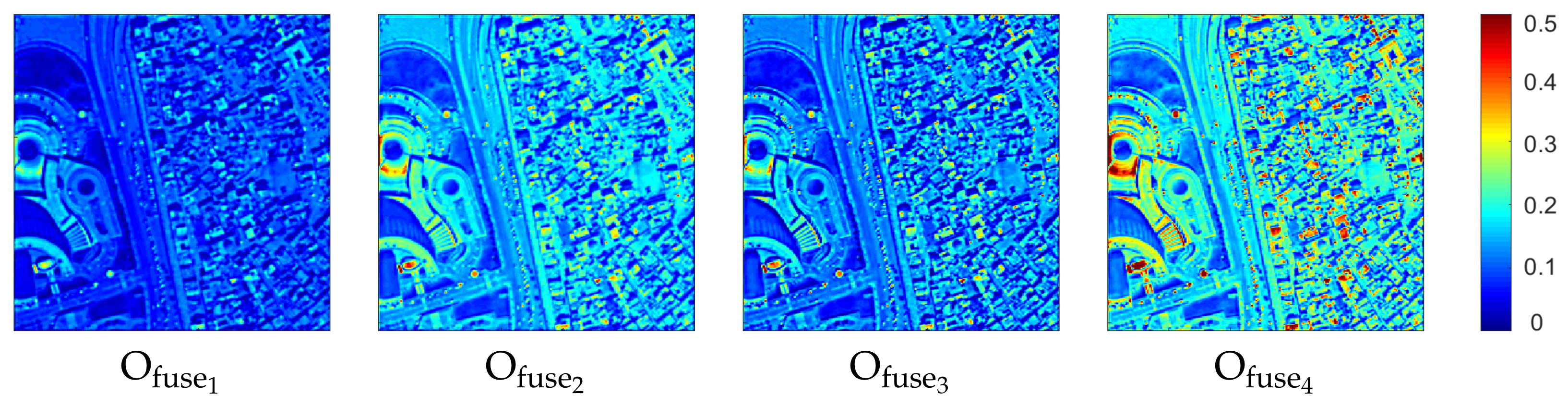
We show the output of 4 PFFBs, i.e.,
in
Figure 4. It can be seen that as the depth becomes deeper, more and more details are perceived. The contours of buildings and streets are also more clearly portrayed, ultimately in the form of high-frequency information. Compared with the previous three images, the last feature map
shows a greater difference between its maximum and minimum values. More sporadic red portions imply more chromatic aberration, sharper edge outlines, and high-frequency information, all of which are in line with our expectations.
The closer to the bottom layer, the more blurred our information and the smaller the targets that can be detected, as the
shows in
Figure 4, which is also indispensable. To get in-depth high-frequency information while retaining shallow information simultaneously, we try to skip connections between neighboring PFFB modules. By leveraging on the skip connection, the product of the previous block can be transferred to the deep layers, which retains the shallow features and enriches the deep semantics.
3.4. Loss Function
To depict the difference between SR and the ground-truth (GT) image, we adopt the mean square error (MSE) to optimize the proposed framework in the training process. The loss function can be expressed as follows:
where
N represents the number of training samples, and
is the Frobenius Norm.
4. Experiments
This section is for experimental evaluation. The proposed FDFNet is compared with some recent competitive approaches on various datasets obtained by WorldView-3 (WV3), QuickBird (QB), and GaoFen-2 (GF2) satellites. First, the preprocessing of the dataset and the training details will be described. Then, the quantitative metrics and visual results on reduced-resolution and full-resolution will be presented to illustrate the effectiveness of the full-depth feature fusion scheme. Finally, extensive ablation studies analyze how the proposed full-depth fusion scheme benefits the fusion process. Moreover, once our paper is accepted, the source code of training and testing will be open-sourced.
4.1. Dataset
To benchmark the effectiveness of FDFNet for pansharpening, we adopted a wide range of datasets, including 4-band datasets captured by QuickBird (QB) and GaoFen-2 (GF2) satellites and 8-band datasets captured by WorldView-3 (WV3). The former 4-band dataset contains four standard colors (red, green, blue, and near-infrared). Based on these, the 8-band dataset adds four new bands (coastal, yellow, red edge, and near-infrared). The spatial resolution ratio between PAN and MS is equal to 4. As the ground truth (GT) images are not available, Wald’s protocol [
77] is performed to ensure the baseline image generation. In particular, the steps for generating the training and testing data for performance assessment are as follows: (1) Downsample the original HR-PAN and LR-MS image by a downsampling factor 4 through satellite corresponding modulation transfer function (MTF) based filters; (2) take the downsampled HR-PAN image as the simulated PAN image and the downsampled LR-MS image as the simulated LR-MS image; and (3) take the original MS image as the simulated GT image. The specific information of different simulated dataset are listed as follows:
For WV3 data, we downloaded the datasets from the public website (
http://www.digitalglobe.com/samples?search=Imagery, accessed on 6 April 2021) and obtained 12,580 PAN/MS/GT image pairs (
/
/
as training/validation/testing dataset) with a size of 64 × 64 × 1, 16 × 16 × 8, and 64 × 64 × 8, respectively, the resolution of PAN and MS are 0.5 m and 2 m per pixel. For testing, we used not only the 1258 small patches mentioned above, but also the large patches of a new WorldView-3 dataset that captured Rio’s scenarios (size:
);
For QB data, we downloaded a large dataset () acquired over the city of Indianapolis and cut it into two parts. The left part () is used to simulate 20,685 training PAN/MS/GT image pairs with the size 64 × 64 × 1, 16 × 16 × 4, and 64 × 64 × 4, respectively, the resolution of PAN and MS are 0.61 m and 2.4 m per pixel, and the right part () is used to simulate 48 testing data (size: );
For GF2 data, we downloaded a large dataset (
) over the city of Beijing from the website (
http://www.rscloudmart.com/dataProduct/sample, accessed on 6 April 2021) to simulate 21,607 training PAN/MS/GT image pairs with the size 64 × 64 × 1, 16 × 16 × 4, and 64 × 64 × 4, the resolution of PAN and MS are 0.8 m and 3.2 m per pixel. Besides, a huge image acquired over the cit of Guangzhou was downloaded to simulate 81 testing data (size:
).
It is worth mentioning that our patches all come from a single acquisition and there is no network generalization problem.
4.2. Training Details and Parameters
Due to the different number of bands, we make separate training and test datasets on WV3, QB, and GF2, as described in
Section 4.1, train the network, and test separately on each dataset. All DL-based methods are fairly trained on the same dataset on NVIDIA GeForce GTX 2080Ti with 11 GB. Besides, we set 1000 epochs for the FDFNet training under the Pytorch framework, while the learning rate is set to
for the first 500 epochs and
for the last 500 epochs, which is set and adjusted empirically according to the loss curve during training.
and
are set as 16,
is set as 32, and four PFFBs are included in the network. We employed Adam [
78] as the optimizer to optimize the parameters, with batch size 32 while
and
are set as 0.9 and 0.999, respectively. The batch size has little effect on the final result. As for betta1 and 2, both are the default settings for the optimizer Adam, and we achieved satisfactory results without adjusting them. We use the source codes provided by the authors or re-implement the code with the default parameters in the corresponding papers for the compared approaches.
4.3. Comparison Methods and Quantitative Metrics
For comparison, we select 10 state-of-the-art traditional fusion mathods based on CS/MRA, including EXP [
76], GS [
5], CNMF [
79], HPM [
10], GLP-CBD [
1], GLP-Reg [
36], BDSD-PC [
3], BDSD [
2], PRACS [
4], and SFIM [
6]. Two VO-based methods are also added to the list of competitors, including DGS [
13] and LGC(CVPR19) [
12]. In addition, six recently widely-accepted proposed deep convolutional networks for pan-sharpening are used to compare the performance of the trained model, including PNN [
37], PanNet [
35], DiCNN1 [
36], LPPN [
42], BDPN [
41], and DMDNet [
34].
Quality evaluation is carried out at reduced and full resolutions. For the reduced-resolution test, the relative dimensionless global error in synthesis (ERGAS) [
80], the spectral angle mapper (SAM) [
81], the spatial correlation coefficient (SCC) [
82], and quality index for 4-band images (Q4) or 8-band images (Q8) [
83] are used to assess the quality of the results. In addition, to evaluate the performance of all involved methods on full-resolution, the
QNR,
, and
[
84,
85] indexes are applied.
4.4. Performance Comparison with Reduced-Resolution WV3 Data
We compare the performance of all the introduced benchmarks on the 1258 testing samples. For each testing example, the sizes of PAN, MS, and GT images are the same as that of the training examples, i.e., 64 × 64 for the PAN image, for the original low spatial resolution MS image, and for the GT image.
Table 1 reports the average and standard deviation metrics of all compared methods. It is clear that the proposed FDFNet outperforms other advanced methods in terms of all the assessment metrics. Specifically, the result obtained by our network exceeds the average value of DMDNet in SAM and ERGAS by almost 0.3, which is a noticeable improvement. Since SAM and ERGAS are the measures for spectral and spatial fidelity, respectively, it is easy to know that FDFNet can strike a satisfying balance between spectral and spatial information.
In addition, it can be seen that DL-based methods outperform traditional CS/MRA methods, but on the other hand, this superiority is based on large-scale training data. Therefore, we also introduce a new WorldView-3 dataset that captured Rio’s scenarios, which never fed into the networks in their training phase. The Rio dataset holds 30-cm resolution, and the size of the GT, HR-PAN, and LR-MS image is 256 × 256 × 8, 256 × 256, and 64 × 64 × 8, respectively. Then, we test all the methods on the Rio dataset, and the results are shown in
Table 2. Consistent with previous results, our method performs best on all indicators.
Moreover, we compare the testing time of all methods on the Rio dataset to prove its efficiency. The recording is reported in the last column of
Table 2. It is obvious that FDFNet takes the shortest time compared to other DL-based methods, reflecting the high efficiency of full-depth integration and parallel working.
We also display a visual comparison of our FDFNet with other state-of-the-art methods, as shown in
Figure 5. To facilitate the distinction between the quality of the results, we also show the corresponding residual map in
Figure 6, which takes the GT image as a reference. The FDFNet yields more details with less blurring, especially in areas with dense buildings. These results verify that FDFNet indeed exploits the rich texture from the source images. Compared with other methods, FDFNet performs feature fusion at all depths, which covers the detailed features of the shallow layer and the semantic features of the deep layer. It is worth noting that in this case, LPPN and DMDNet are not so far from the proposal.
4.5. Performance Comparison with Reduced-Resolution 4-Band Data
We also assess the proposed method on 4-band datasets, including QB and GF2 data. The quantitative results in terms of all indicators are reported in
Table 3 and
Table 4. As can be seen, the proposed method outperforms other competing methods with lower SAM and ERGAS and higher Q8 and SCC, which proves that the proposed framework can tackle with 4-band data effectively. We can see visual results from
Figure 7 and
Figure 8. Whether the images are recorded on sea or land, the fusion results of DFDNet are the closest to those of GT images, without noticeable artifacts or spectral distortions. This is more evident from the residual maps showed in
Figure 9 and
Figure 10, where the FDFNet produces more visually appealing results with less residual.
4.6. Performance Comparison with Full-Resolution WV3 Data
In this section, we assess the proposed framework on full-resolution data to test its performance on real data, since the various methods of pansharpening are ultimately applied in the actual scene without the reference images. Similarly to the experiments on reduced-resolution, both the quantitative and visual comparison are operated.
The results of quantitative experiments can refer to
Table 5. The proposed FDFNet has achieved optimal or suboptimal results on several indicators. It is worth noting that although some DL-based methods perform well in reduced-resolution, some indicators are even inferior to some traditional techniques in full-resolution, which also verifies the importance of network generalization. Furthermore, through the visual experiment of
Figure 11 and
Figure 12, the pros and cons of various methods can be more intuitively reflected. Obviously, the super-resolution MS image texture obtained by our method is clearer, and there are no artifacts as DMDNet and PANNet yield. This also demonstrates that FDFNet has good generalization capabilities and can deal with pansharpening problems in actual application scenarios more effectively.
4.7. Performance Comparison with Full-Resolution 4-Band Data
We also compare the proposed method on 4-band full-resolution datasets, including QB and GF2 data. The quantitative results in terms of all indicators are reported in
Table 6 and
Table 7. Furthermore, through the visual experiment of
Figure 13 and
Figure 14, the advantages and disadvantages of alternative strategies can be represented more naturally. It can be seen that our proposed FDFNet can achieve better results at the full resolution of different sensors, which also shows the effectiveness of our proposed method. But at the same time, it should be noted that traditional ones, such as BDSD have better generalization in some indicators.
4.8. Ablation Study
Ablation experiments were done to further verify the efficiency of PFFB. In this subsection, the importance of each branch, the number of PFFB modules, and the number of channels will be discussed.
4.8.1. Functions of Each Branch
In particular, we utilize the FDFNet as the baseline module. For different compositions, their abbreviations are as follows:
FDFNet-v1: The FDFNet as a baseline without the PAN branch and MS branch;
FDFNet-v2: The FDFNet as a baseline without the PAN branch;
FDFNet-v3: The FDFNet as a baseline without the MS branch.
All three variants are uniformly trained on the WV3 dataset introduced in
Section 4.1, the training details are consistent with FDFNet. Then, we perform the test on the Rio dataset. The results of the ablation experiments are shown in
Table 8. We can see that the performance of FDFNet surpassed the other three ablation variants in all indicators. Besides, both FDFNet-v2 and FDFNet-v3 performed better than the FDFNet-v1, which demonstrates that the MS branch and PAN branch can promote the fidelity of spectral and spatial features and boost the fusion outcomes for pansharpening. In addition, this also shows that it is a good choice for the MS image and PAN image to separately design branches for feature extraction and distinct representation.
4.8.2. Number of PFFB Modules
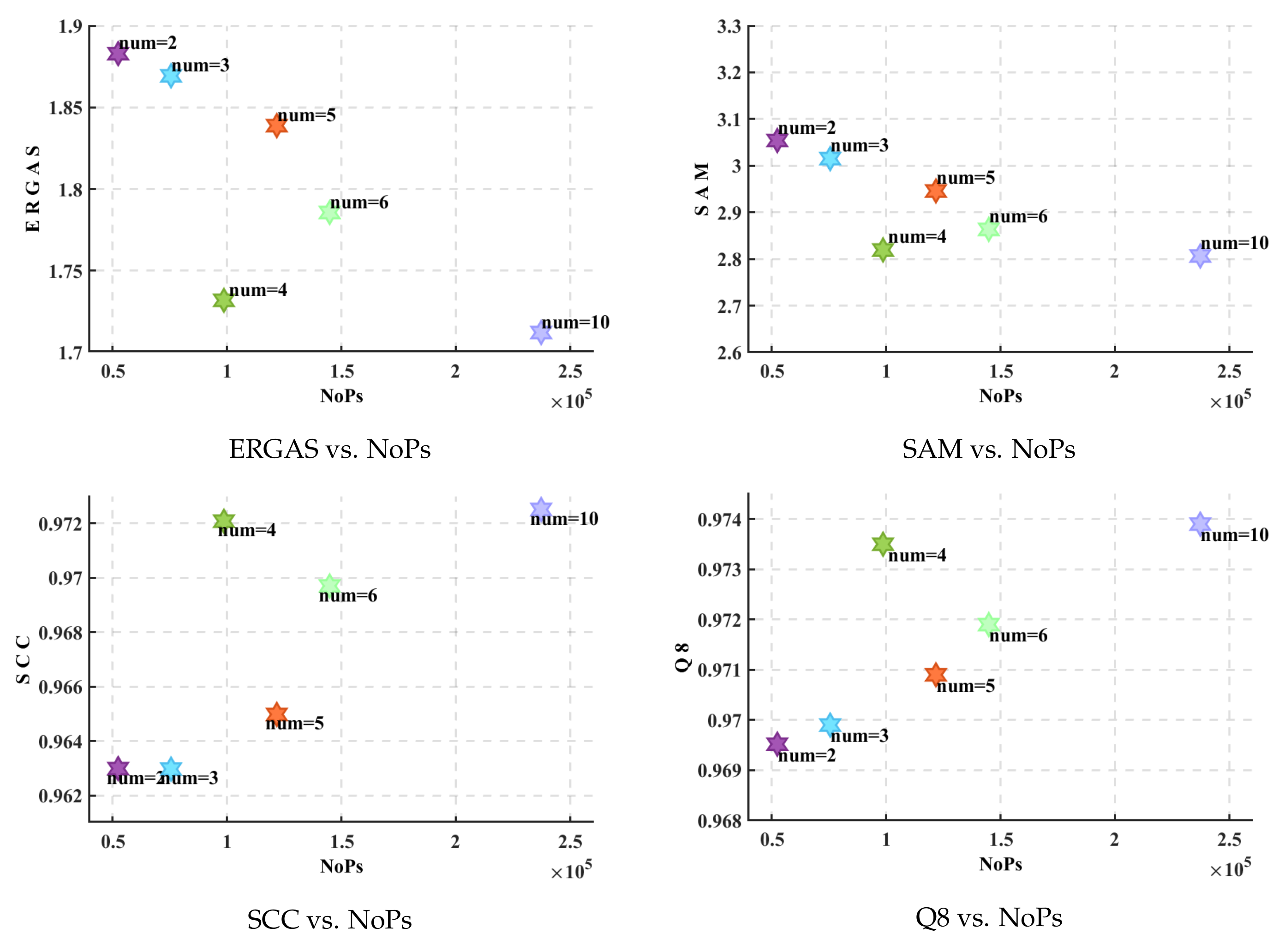
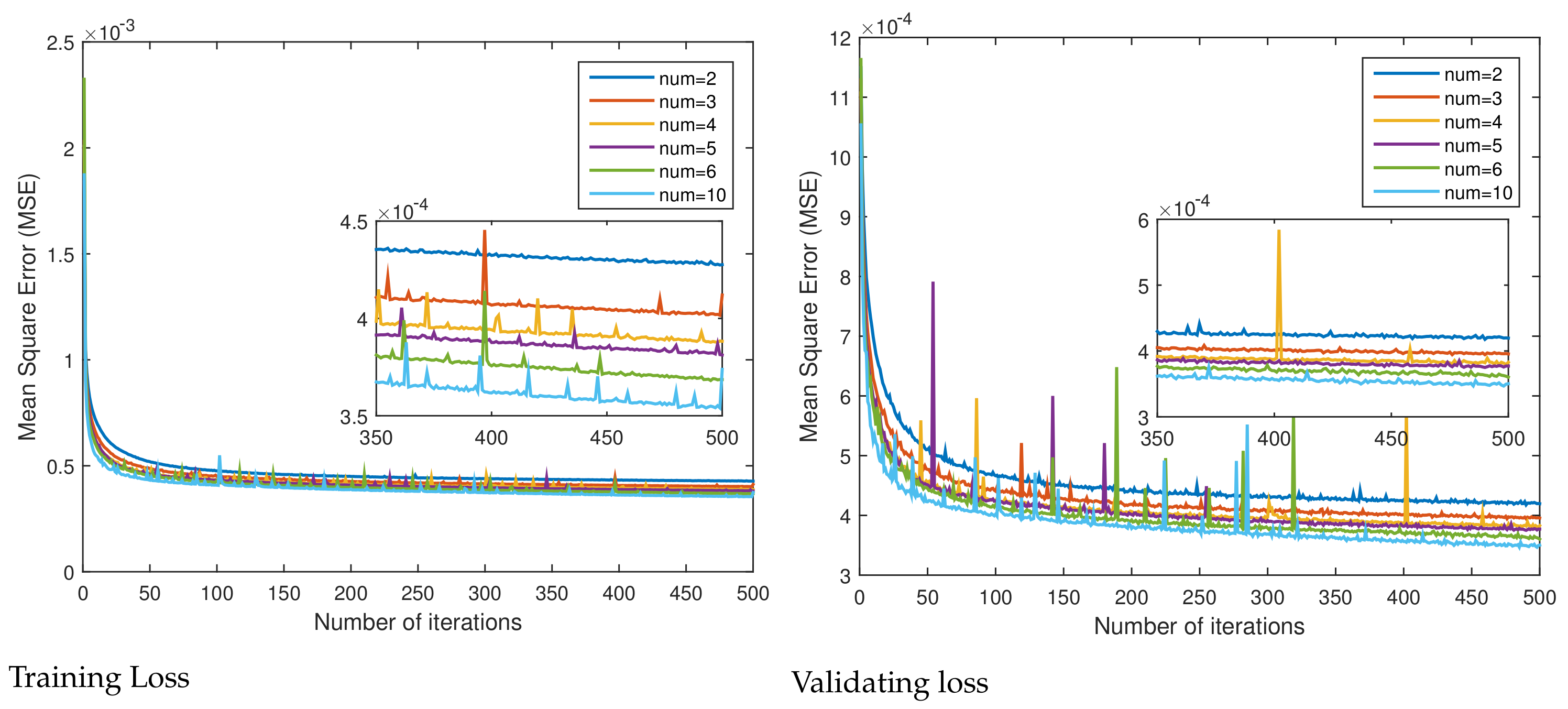
Given that the dominant point of this paper is the introduction of the PFFB, what we need to discuss first is to compare the effect of the depth of the network by testing the baseline framework containing different numbers of PFFB. In this case, we set the number of PFFB from 2 to 6 and 10, respectively. As the number of modules increases and the network deepens, the amount of training parameters also increases correspondingly.
Figure 15 and
Figure 16 present quantitative and parameter comparisons among the different numbers of the PFFB structure on the Rio dataset. The results show that a better performance can be obtained when the number of PFFB is larger. It is worth noting that, obviously, when the number of modules is within the range of 2 to 6, more PFFBs can better achieve the full-depth feature fusion of the network, but the memory burden is increased due to the corresponding increase in the number of parameters, leading to a slight decrease in the test results. However, when the number of PFFB is 10, the fusion performance of PFFB has greater advantages, so the training effect rises again. Therefore, in order to balance performance and efficiency, we chose a PFFB number of 4 as the default setting.
4.8.3. Number of Channels
We also test the effect of the number of channels on the MS and PAN branch. Based on the previous discussion on the number of PFFB, we set the number of blocks to 4 and the number of channels as 8, 16, 32, and 64, respectively, and carried out experiments on the Rio dataset. We also plotted the performance in each indicator with their parameters in
Figure 17. Obviously, with the increase in the number of channels, the number of parameters gradually increased. Thus more spectral information could be explored. It worked best when the number of channels was 64. However, considering the pressure of a large number of parameters on the memory load, in order to balance the network performance and memory load and maximize the advantages of both, we chose 16 as the default setting of the number of channels.
4.9. Parameter Numbers
The number of parameters (NoPs) of all the compared DL-based methods are presented in
Table 9. It can be seen that the amount of parameters of FDFNet has not increased much than the other compared DL-based methods, but the best results are achieved. This is because our network can perform more efficient fusion at full-depth, which leads to promising results that achieve a reasonable balance between spectral and spatial information, and also proves the efficiency of extracting features from parallel branches.



 and
and 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}