1. Introduction
With the development and progress of sensor technology, applications of remote sensing (RS) images in scientific research and human activities have become increasingly extensive [
1,
2]. For example, air pollution prediction [
3], the automated detection of intra-urban surface water [
4], the prediction of nitrogen accumulation in wheat [
5], vegetation detection, land use detection [
6], and other field applications have been carried out. Some research areas and applications require RS images with a high temporal and spatial resolution. Unfortunately, due to technology and other limitations, no single satellite sensor can currently provide global coverage with a high spatial resolution and high temporal resolution at the same time [
7,
8]. The increasing availability of RS data makes it possible to merge multi-sensor data [
9]. Therefore, many spatiotemporal fusion algorithms have been proposed to alleviate this issue. The term ’spatiotemporal fusion algorithm’ refers to the algorithmic fusion of at least two data sources with similar spectral ranges to generate data with more information than the original data sources [
10,
11]. These spatiotemporal fusion algorithms have been proven to be cost effective and useful [
7].
Spatiotemporal data fusion techniques have developed rapidly in recent years, and the existing spatiotemporal data fusion methods can be broadly classified into several categories according to the types of algorithms used. The weighting function-based approach predicts the pixels in a high-resolution image by combining information from all input images using some manual weighting functions. The spatiotemporal adaptive reflection fusion model (STARFM) [
12] is the first proposed and most widely used weighting function-based model. STARFM divides pixels in low-resolution images into two categories, the first of which is pixels containing only one land cover type. Then, it is assumed that the change in reflectance is the same in the low-resolution images and the high-resolution images. In this case, the pixel changes of the low-resolution images can be added directly to the pixels of the high-resolution images to obtain the prediction result. In the other category, when a pixel consists of a mixture of different land cover types, the prediction result is obtained by a function that assigns a higher weight to the purer coarse pixels based on the information of the adjacent fine pixels [
13]. Obviously, STARFM does not apply to heterogeneous regions, and an enhanced spatiotemporal adaptive reflection fusion model [
14] improves the accuracy of prediction in heterogeneous regions by introducing a conversion factor based on STARFM that measures the rate of change in reflection for each category instead of the fixed constant rate of change in reflection [
15]. The main differences between weighting function-based methods are the design of the relationship between high-resolution images and low-resolution images and the rules used to determine the weights [
16].
In addition, there are many methods based on decomposition. Unmixing-based models use linear spectral mixing theory to decompose pixels in low-resolution images and predict pixels in high-resolution images. The multisensor multiresolution technique [
17] proposed by Zhukov et al. is perhaps the first decomposition-based model for spatiotemporal fusion. The spatial and temporal data fusion approach improves the performance by separating the end element reflectance of the input and predicted dates in a sliding window to estimate the reflectance change, then applying the estimated change to a high-resolution image of the reference date to obtain the prediction [
18]. The modified spatial and temporal data fusion approach [
19] uses adaptive windows to further improve the performance on top of STDFA. Both types of models mentioned above are based on a single algorithm, but there are also spatiotemporal models based on multiple algorithms that combine the advantages of multiple algorithms. For instance, the flexible spatiotemporal data fusion method (FSDAF) combines the ideas of separation-based and weighting function-based methods and spatial interpolation [
13]. FSDAF can obtain good predictions for landscapes with heterogeneity and abrupt land cover changes occurring between input images and predictions. Sub-pixel class fraction change information [
20], as proposed by Li et al., can identify the image reflectance changes from different sources and improve the prediction accuracy. These traditional methods have achieved good results in some applications [
21], such as surface temperature detection [
22,
23] and leaf area index detection [
24]. However, these algorithms empirically make certain assumptions, which makes it difficult to take all cases into account, and in addition some algorithms are sensitive to data quality, making it difficult to obtain a more stable performance.
Recently, learning-based methods have developed more rapidly. Instead of obtaining predictions based on certain assumptions, they learn to extract some abstract features from the acquired historical data and then use these features to reconstruct the generated prediction images. Learning-based methods are mainly divided into dictionary-based learning methods and machine-based learning methods. Dictionary-based methods establish correspondence between high-resolution images and low-resolution images based on structural similarity to capture the main features in the prediction, including changes in land cover types. The sparse representation-based spatiotemporal reflectance fusion model [
25] was probably the first to introduce dictionary pair learning techniques from natural image super-resolution to spatiotemporal data fusion. The hierarchical spatiotemporal adaptive fusion model [
26] and compressed sensing for spatiotemporal fusion [
27] further improve the prediction quality. However, the dictionary-based pair approach uses sparse coding, which has the advantage of being able to predict changes in land cover and changes in phenology along with a high computational complexity; therefore, this reduces its applicability [
16].
With the development of deep neural network (DNN) and graphics processing unit (GPU) parallel computing [
28], convolutional neural network (CNN) -based methods have come to be widely used in speech recognition [
29] and computer vision tasks [
30] due to their powerful expressive power. Several researchers have tried to apply CNN to spatiotemporal fusion, and spatiotemporal fusion using deep convolutional neural networks has demonstrated the effectiveness of the use of super-resolution techniques in the field of spatiotemporal fusion [
31]. The two-stream convolutional neural network for spatiotemporal image fusion [
32] performs fusion at the pixel level and can preserve rich texture details. The deep convolutional spatiotemporal fusion network (DCSTFN) [
16] uses CNN to extract the main frame and background information from high-resolution images and high-frequency components from low-resolution images [
33], and the two extracted features are fused and reconstructed to obtain the prediction results. A convolutional neural network with multiscale and attention mechanisms (AMNet) [
34] improved accuracy using a spatial attention mechanism. To further improve the generalization ability and prediction accuracy of the model, Tan proposed an enhanced deep convolutional spatiotemporal fusion network (EDCSFTN) [
35], where the relationship between the input and output was obtained entirely by network learning, further improving its accuracy.
However, the existing algorithms still have limitations. First, RS images contain rich feature information, and the feature extraction capability may be limited when using only the convolutional layer of a single sensing field of view. Second, some methods do not fully utilize inter-channel information or spatial information. Solving these outstanding problems may enable us to effectively improve the accuracy of reconstructed images. In this paper, a multiscale method combining channel and spatial attention mechanisms for spatiotemporal fusion is proposed to try to alleviate these two problems. The main contributions of our work are summarized as follows:
- (1)
A multiscale feature extraction (MFE) module for spatiotemporal fusion, which combines the feature depth extraction features of different perception fields to enhance the feature extraction ability of the network, is proposed.
- (2)
A spatial channel attention mechanism (SCA), which can focus on the relationship between channels and the relationship between spaces at the same time, is proposed.
- (3)
A new compound loss function is proposed; this considers the proportion of loss and mean square error (MSE) in different training periods to better optimize the network.
The rest of this article is organized as follows.
Section 2 introduces related research work.
Section 3 elaborates on the proposed network structure.
Section 4 gives the experimental details and analysis and describes the experimental results.
Section 5 is a summary of this article.
2. Related Work
In recent years, DNN-based spatiotemporal fusion algorithms have received increasing attention. DCSTFN uses CNN for feature extraction and fusion at the pixel level based on the linearity assumption, while EDCSFTN discards the linearity assumption based on DCSTFN and fuses at the feature level to improve performance and robustness. AMNet uses multiple networks to collaboratively generate fused images. These methods simply stack CNNs in the feature extraction part, which may limit the performance of the model. Deeper networks can learn richer feature information and correlation mappings, while deep residual learning for image recognition (ResNet) [
36] makes it easier to train deep networks. Aggregated residual transformations for deep neural networks (ResNext) [
37] redesigned the residual block of ResNet, which uses a homogeneous multi-branch architecture to obtain a better performance while maintaining the model complexity. Inception-ResNet and the impact of residual connections on learning (Inception) [
38] and deep learning with depthwise separable convolutions (Xception) [
39] extended the width of the network and significantly reduced the computational effort of the model while ensuring its performance.
The attention mechanism has recently been widely used in various computer vision tasks, which can be interpreted as a method of biasing the allocation of available resources to the most informative part of the input signal [
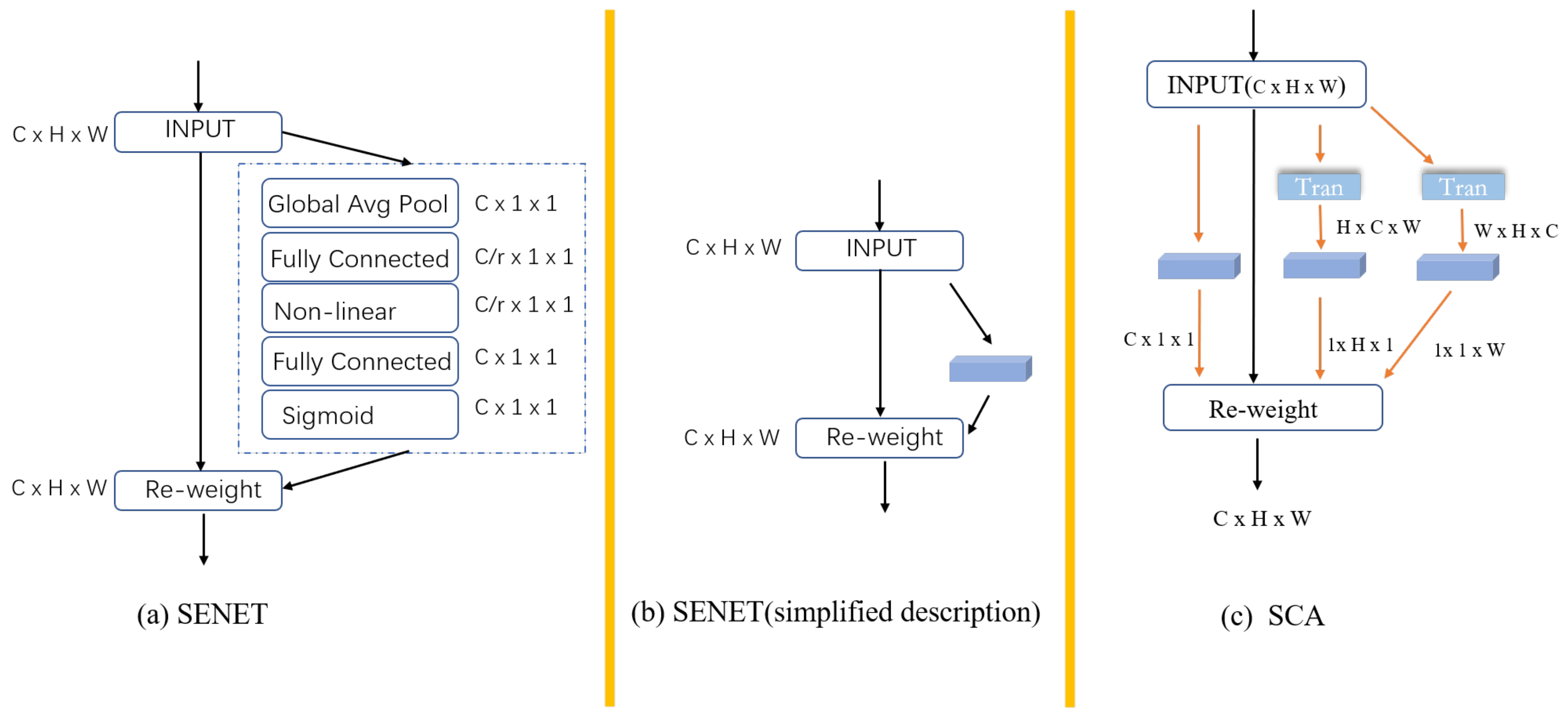
40]. Among these, the squeeze-and-excitation network (SENET) [
40] can learn the relationship between channels, has achieved remarkable results in image classification, and has been widely used. SENET first uses the squeeze operation for global information embedding and then uses the excitation operation for learning inter-channel relationships. Subsequently, BAM [
41] and CBAM [
42] tried to introduce the position information between the features by using a larger sized data core, but the convolution could only obtain a partial perception field of view, while its capture of spatial information was limited. The non-local method [
43] has become a more popular spatial attention method recently because it can capture global spatial information, but its huge overhead makes its application range limited.
4. Experiments
4.1. Datasets
A classic scene in spatiotemporal data fusion is the fusion of Landsat and MODIS images. Landsat images have a spatial resolution of 30 m and a return visit time of 16 days [
50]. MODIS can cover most of the Earth every day, but it obtains data with a spatial resolution of only 250 to 1000 m [
50]. In this experiment, the LEVEL-2 product of Landsat 8 OLI (which has undergone preliminary radiation calibration and atmospheric correction) and the 8-day composite data MOD09A1 of MODIS are used, and the four bands of blue, green, red, and near-infrared (NIR) are used for fusion. To verify the generality of the proposed model, we selected areas in Shandong and Guangdong for experiments. Guangdong is in a coastal area, and its humid climate makes the surface of the region covered by clouds most of the time, so there are few data available for reference use after screening. The climate of Shandong is relatively drier than that of Guangdong and more cloud-free or less cloudy images are available, meaning that the dataset of Shandong is of higher quality and the heterogeneity is lower compared with that of Guangdong. For the study area in Shandong, the coordinates in the Landsat Global Reference System (WRS) are represented as
and the area corresponding to
in the MODIS Sinusoidal Tile Grid. For the study area in Guangdong, the coordinates in the WRS are represented as
and the area corresponding to
in the MODIS Sinusoidal Tile Grid. The image selection period is from 1 January 2013 to 31 December 2017. The Landsat 8 image requires a cloud coverage rate of less than
, and each scene is cropped to a size of
(to avoid the part at the edge with no data). Considering that there are more eligible MODIS data, we choose the one closest to the date of Landsat image acquisition. The corresponding MODIS image is reprojected with a spatial resolution of 480 m and then cropped to the same area as the Landsat image with an image size of
. The cropped Landsat image and the corresponding MODIS image are a data pair. Finally, the Landsat and MODIS data pairs are grouped, with each group containing two Landsat and two MODIS images. Fourteen groups are chosen for each area, and the groups are then randomly divided into a training set and a test set. The training set is 10 sets of data, and the test set is 4 sets of data (the Landsat image data can be downloaded at
https://earthexplorer.usgs.gov/; the MODIS image data can be downloaded at
https://ladsweb.modaps.eosdis.nasa.gov/search/order/4/MOD09A1--61/2013-01-01..2017-12-31/DB/).
4.2. Experiment Settings
We use the following spatiotemporal fusion methods as references, including STARFM based on the weighted function algorithm, FSDAF based on hybrid, DCSTFN, AMNet, and EDCSTFN.
For quantitative evaluation, the following indicators are used to measure the results: spectral angle mapper (SAM) [
51], relative dimensionless integrated global error (ERGAS) [
52], correlation coefficient (CC), and MS-SSIM. Among these, the closer the SAM and ERGAS indexes are to 0, the closer the fusion image is to the real image. The closer the CC and MS-SSIM indicators are to 1, the closer the fusion image is to the real image.
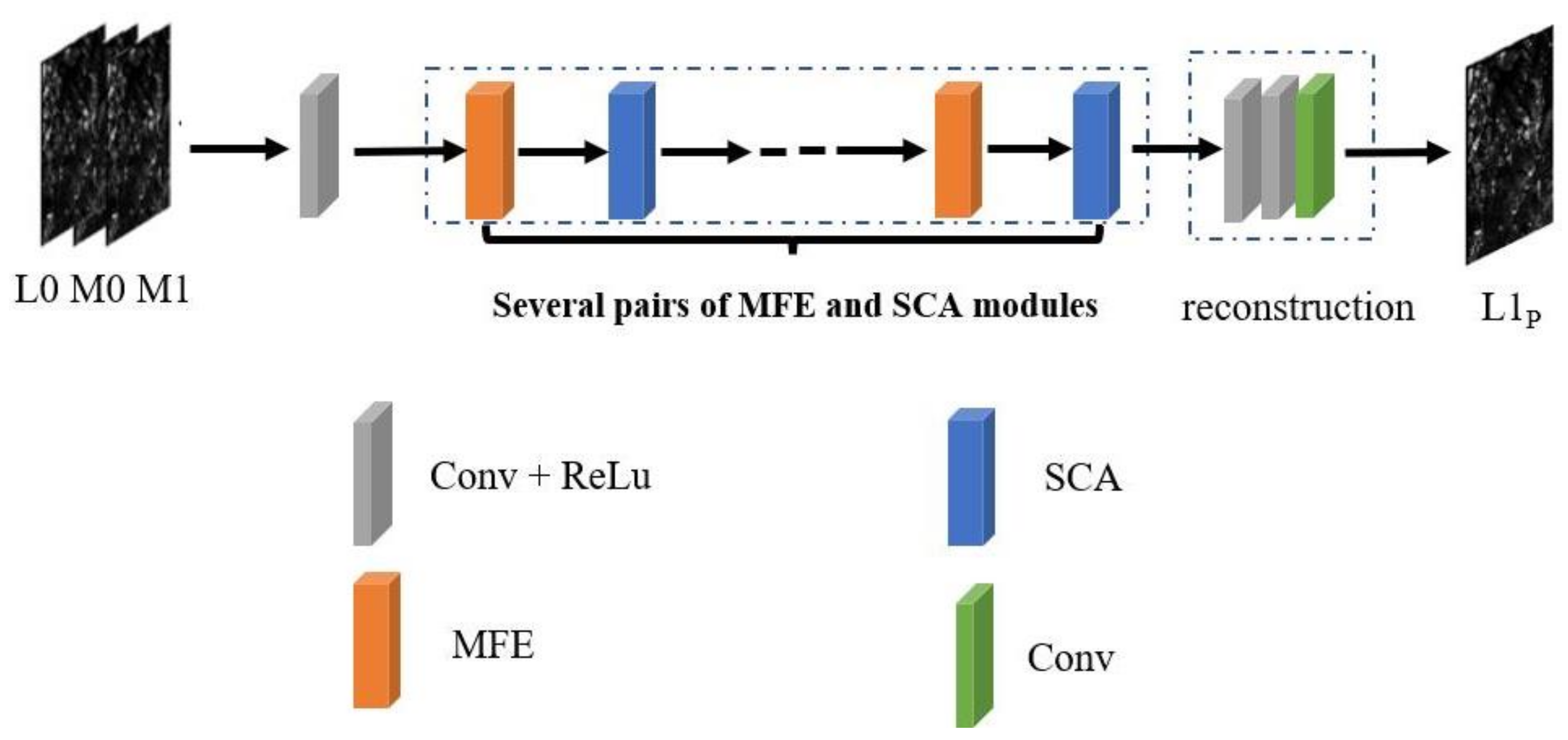
Input settings: M0 and M1 are upsampled to the same resolution as the Landsat image using a bilinear interpolation method, and then with in the channel dimension Concat as an input.
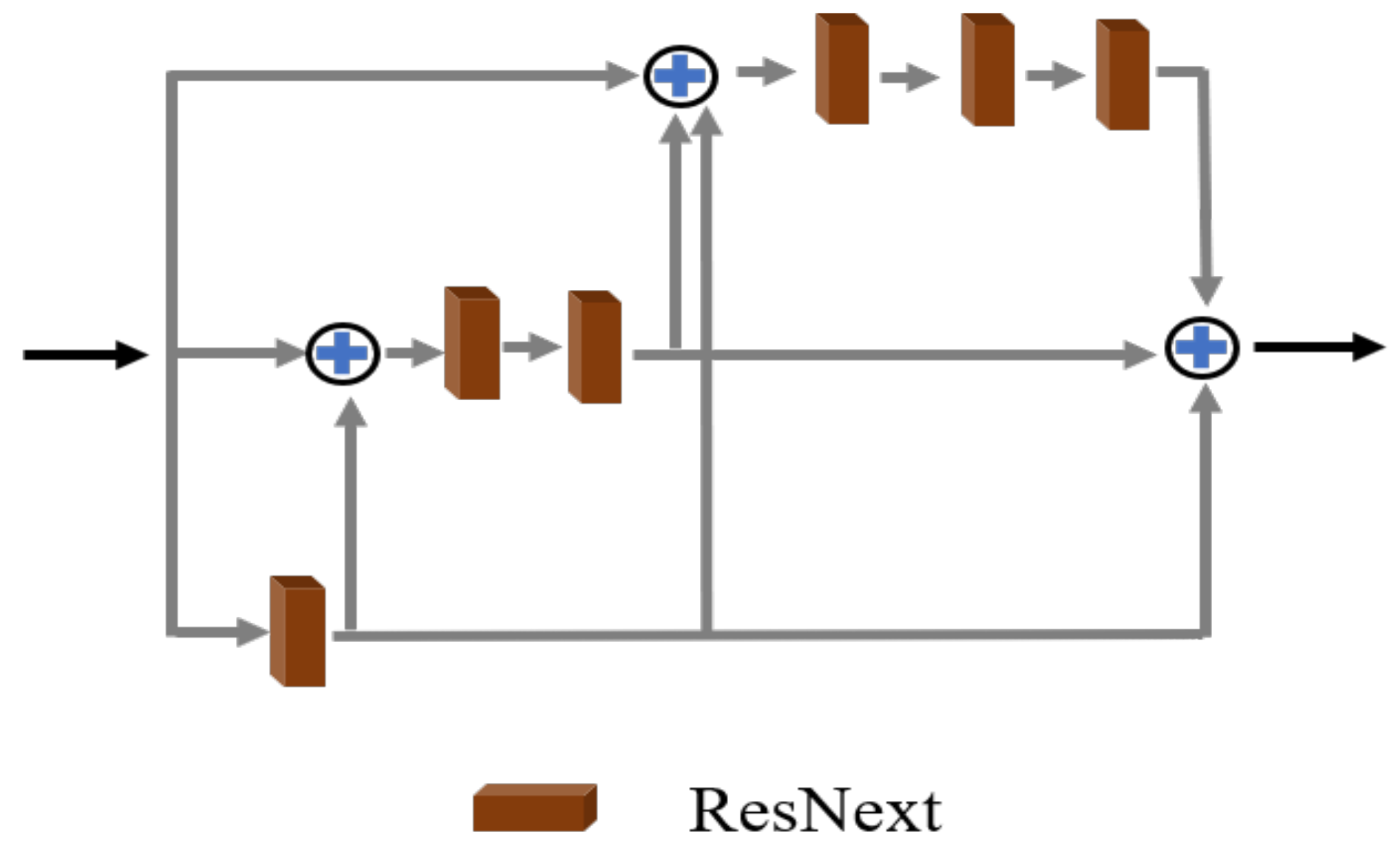
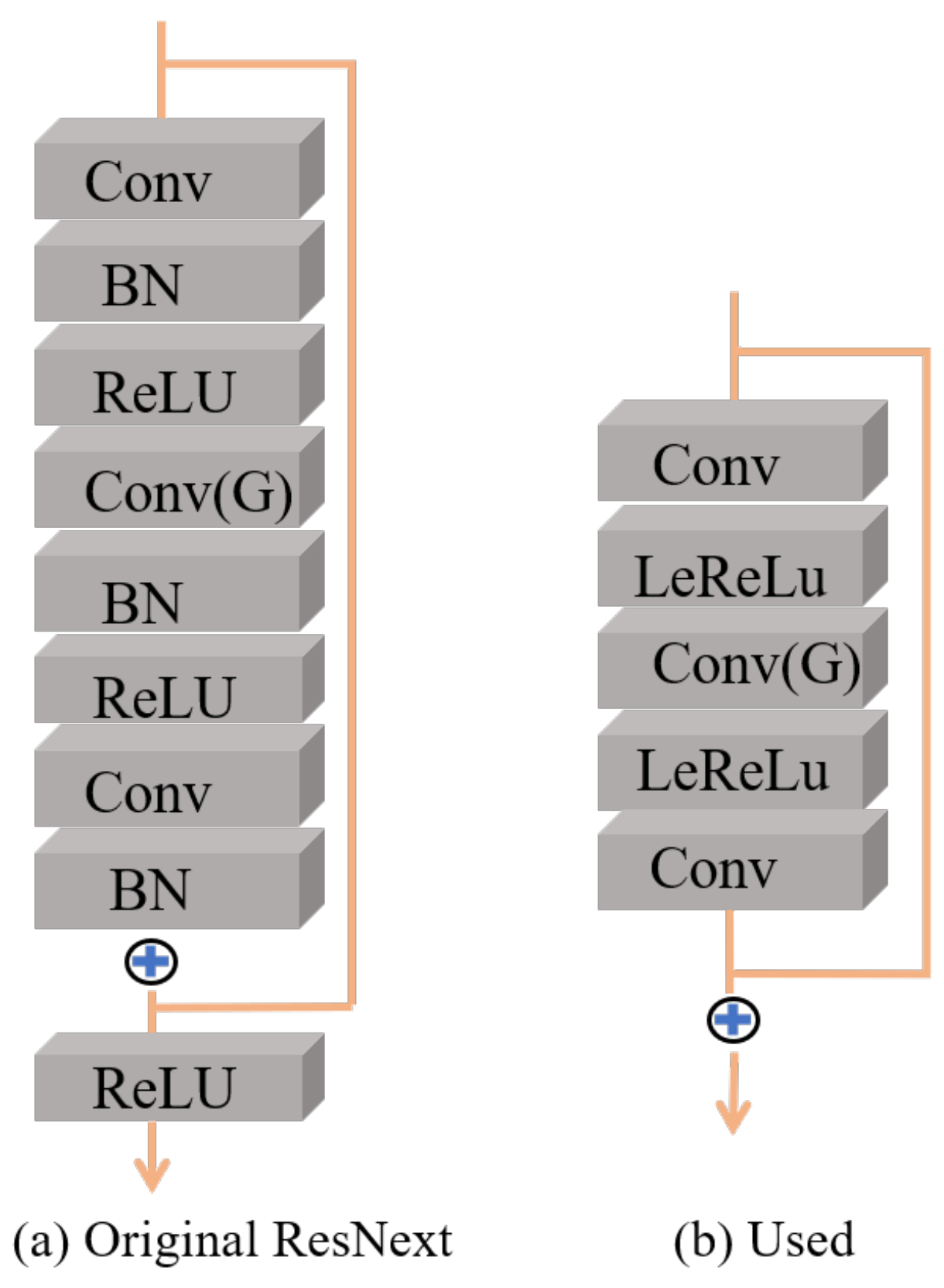
Network settings: The size of the convolution kernel in the “Conv + ReLu” module is 3, the step size is 1, and the output channel is 24. Three pairs of MFE and SCA are used. In the MFE module, all ResNext networks use the same settings. The three convolution operations of the ResNext network are as follows: cov (24, 30, 1), cov (30, 30, 3, g = 10), and cov (30, 24, 1). The parameters in brackets represent the input channel, output channel, and convolution core size in turn. G is the number of group convolutions. In the SCA module, the squeeze multiplier of SENET is set to 4 in the target inter-channel relationship branch. The squeeze multiplier of SENET in both the target inter-row relationship and target inter-column relationship branches is set to 32. The reconstruction module uses three-layer convolution; the convolution core size is 3; and the channels are set to 24, 12, and 4, respectively.
Training and testing settings: Inputting the entire image into the network for processing requires a large memory, which is unnecessary and not economical. It is economical and feasible to divide MODIS and Landsat images into small patch input networks in combination with hardware conditions. The patch size during training is set to 30, and the sliding step size is set to 25. The patch size during prediction is set to 30, and the sliding step size is set to 30. The initial learning rate is set to , and a total of 70 epochs are trained. To optimize the network training parameters, we choose the Adam optimized stochastic gradient descent method. The experiment is implemented using PyTorch, and all experiments are performed with the same two GeForce RTX 2080Ti GPUs.
4.3. Results and Discussion
4.3.1. Quantitative Evaluation Comparison
The average value of each evaluation index of the fusion results is calculated separately and used as a representative of the method performance. The evaluation results of the Shandong dataset are shown in
Table 1, and the evaluation results of the Guangdong dataset are shown in
Table 2.
From
Table 1 and
Table 2, it is easy to find that the fusion results of FSDAF are better than those of STARFM, which may be due to the better performance results of FSDAF for heterogeneous regions. DCSTFN has a larger improvement than FSDAF, which may benefit from the stronger representation capability of CNN. The relationship between the input and output in AMNet and EDCSTFN models is completely learned by the network, rather than based on some assumptions; thus, there is a more significant improvement in the fusion results compared to DCSTFN. AMNet performs better than EDCSTFN in the Shandong dataset, but AMNet slightly outperforms EDCSTFN in the Guangdong region, probably due to the contrast caused by the complexity of the topography in the Guangdong dataset. The proposed method uses the MFE and SCA modules to effectively analyze the complex spatial information of the images and capture inter-channel information, which plays a positive role in the fusion results; therefore, it performs better in objective metrics.
4.3.2. Visual Comparison
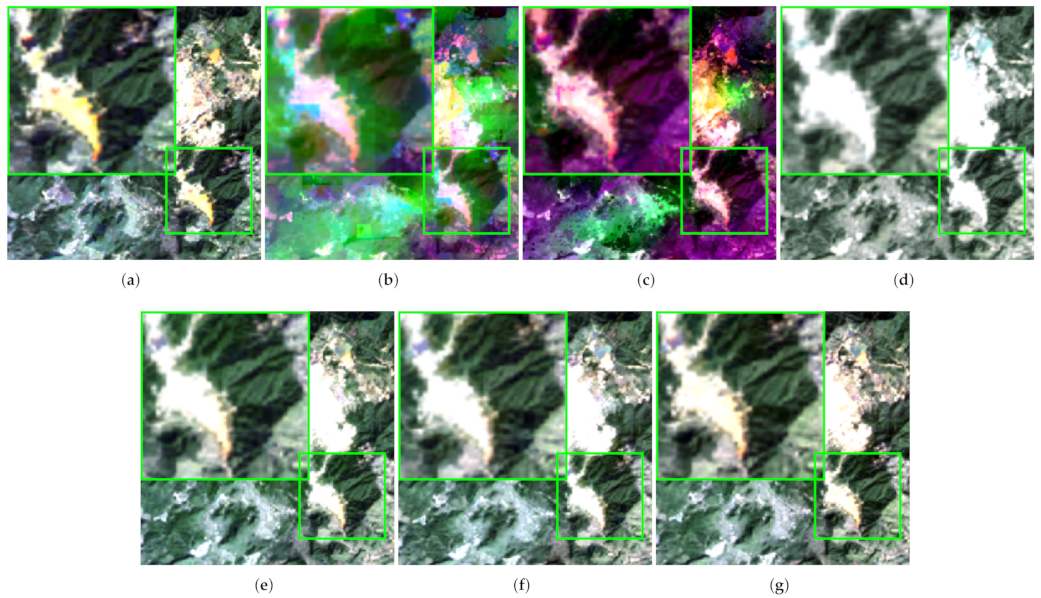
In order to visualize the performance comparison of each algorithm, we intercepted the same area of
in the fusion results of different algorithms under the same test case and magnified the area of
twice to compare the details. To verify the performance and robustness of the method, we selected areas with different land cover types on different data sets; the selected areas had rich color information and texture information. For the Shandong dataset, we selected a building area with rich spectral information; for the Guangdong dataset, we selected a mountainous area with rich spectral information. For the Shandong region,
Figure 5 shows a sample with time 20160310 as the reference data and time 20160326 as the target data, and the fusion results were compared as shown in
Figure 6. For the Guangdong region,
Figure 7 shows a sample with time 20141015 as the reference data and time 20150119 as the target data, and the fusion results are compared as shown in
Figure 8.
From the zoomed area in the upper left corner of the fusion results in
Figure 6, it can be clearly seen that STARFM and FSDAF are richer in their color performance but poorer in texture details, and there are large differences with the real image. In particular, STARFM has obvious mosaic patches. DCSTFN, AMNet, and EDCSTFN are better at retaining texture information, but they all exhibit a “lighter” color representation. Our proposed method not only retains texture details better but also is closer to the real image in terms of spectral information.
It is easy to see from the enlarged area in the upper left corner of the fusion results of each experiment in
Figure 8: STARFM and FSADF are equally bad in terms of texture information retention, and STARFM can barely see the texture information. In DCSTFN, AMNet, and EDCSTFN, the texture information is well preserved and the mountain contours can be seen, but DCSTFN has almost no spectral information, and AMNet and EDCSTFN retain only a very small amount of information in the lower right corner. Our proposed model outperforms other algorithms in terms of both spectral information retention and texture detail retention.
In summary, the fusion results of our proposed method are closer to those of the real image, both in terms of texture detail information and spectral information.
4.3.3. Computational Efficiency Comparison
We compared the DNN-based models in the benchmark experiments in two dimensions, model parameters and floating points of operations (FLOPs); the results are shown in
Table 3. Parameters represent the number of parameters that the model needs to learn. In FLOPs(G), G represents
, and FLOPs is used to measure the computational complexity of the model. From
Table 3, we can find that our proposed model is much lower than the other methods in terms of the number of parameters and FLOPs, where the number of parameters is only half that of EDCSTFN and the difference between FLOPs and DCSTFN is more than 10 times. It can be considered that our proposed model is more advantageous in terms of its computational complexity.
4.3.4. Comparison of Residual Graphs
To further verify the effectiveness of the proposed method, the residual image experiment is set up by selecting regions in the visual comparison experiment. The residual image is the real image subtracted from the fused image pixel by pixel, and the average value of each band is taken. Theoretically, the closer the fused image is to the real image, the less content appears on the residual image. The results of the comparison of residual image for the Shandong and Guangdong datasets are shown in
Figure 9 and
Figure 10, respectively. As can be seen in
Figure 9, the residual map of the proposed method has less texture. In
Figure 10, the residual maps of the last three DNN-based methods are similar, and a closer look shows that the residual maps of our proposed method are generally smoother, meaning that the proposed method has the best fusion effect. In general, the DNN-based methods generally outperform the traditional algorithms.
4.3.5. Ablation Experiments
We performed ablation experiments on the Guangdong data set to demonstrate the effectiveness of the proposed module. To verify the effect of each module, we first designed the basic network structure as a comparison. The basic network uses SENET instead of the proposed SCA module, and the loss function is
+
.
represents the compound loss function we proposed. +BN means adding the BN layer to the network, +SCA means replacing SENET with the proposed SCA module, and +
means replacing the loss function in the base network with the proposed loss function. the results are shown in
Table 4.
From the comparison of experiment 1 and experiment 2, it can be found that the BN layer is not suitable for spatiotemporal fusion tasks because it destroys the internal connection of the image. The comparison of experiment 1 and experiment 3 can verify that the SCA module can acquire certain spatial information while learning the relationship between channels, thereby improving the performance. The comparison between experiment 3 and experiment 4 can verify that the proposed composite loss function can more effectively optimize the network and improve its performance.
4.3.6. Sensitivity of the Method to the Amount of Training Data
To explore the sensitivity of the proposed method to the training data, we compared the performance of AMNet, EDCSTFN, and the proposed method with 3, 5, and 8 sets of training data, respectively, on the Shandong dataset. The comparison results are shown in
Table 5,
Table 6 and
Table 7.
From
Table 1 and
Table 5,
Table 6 and
Table 7, it can be seen that in the case of different training groups, the performance of DNN-based methods has different degrees of impact, and the proposed method has considerable competitiveness. The corresponding data for each algorithm in
Table 5 and
Table 6 show that the performance obtained using five sets of training data is better than that obtained using three sets of training data, where the proposed method has the largest increase, probably because three sets of training data are too few for the method, which limits its performance. The corresponding data for AMNet in
Table 6 and
Table 7 have large fluctuations, while EDCSTFN and the proposed method show only small changes. From
Table 1 and
Table 7, it can be found that the performance of each algorithm fluctuates less.
4.4. Discussion
The experimental data of the Shandong and Guangdong regions shows that our proposed model has a better prediction accuracy and better visual effects than other methods. The regional geologies of Shandong and Guangdong are quite different, and the proposed model still maintains a good performance, which shows that it has better robustness. These superiorities may be due to the fact that the multiscale mechanism can extract more complex features and the attention mechanism focuses on both the relationships between channels and the spatial relationships. In the proposed method, the relationship between the fusion result and the input is obtained entirely by the network learning, without relying on specific assumptions. The proposed method can effectively capture spectral information and texture features.
Despite these improvements in our approach, there are still some areas where our work could be improved. The quality of the dataset is not high enough. For example, in areas such as Guangdong, dates in the majority of the year have cloud coverage, and it is difficult to collect enough high-quality data. In addition, there is limited ability to capture changes in scenarios where the land cover changes drastically in a short period of time. In the future, we will consider the better preprocessing of the data, such as cloud processing, and at the same time will work to collect higher-quality data and investigate methods to better capture changes.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}