
Dual-Branch Attention-Assisted CNN for Hyperspectral Image Classification



Abstract
1. Introduction
- To fully utilize the spatial-spectral features of HSI, we propose a new dual-branch network for classification. It can extract enough different information, where the spectral attention branch extracts more effective spectral features from HSI and connects with the features extracted by the spatial–spectral branch, to achieve higher classification accuracy.
- Considering the limited training samples, the spatial–spectral branch is designed to extract shallow spatial–spectral features using 3D convolution, and then to use the PSA module to learn richer multi-scale spatial information, while adaptively assigning attention weights to the spectral channels.
- We designed the spectral attention branch, which uses 2-D CNN to map the original features into the spectral interaction space to obtain a spectral weight matrix, so as to obtain more discriminative spectral information.
2. Materials and Methods
2.1. Related Work
2.1.1. Basics of CNNs for HSI Classification
2.1.2. Squeeze-and-Excitation (SE) Block
2.2. Proposed Method
2.2.1. Spatial–Spectral Branch
- (1)
- Spatial–spectral feature extraction module
- (2)
- PSA module.
2.2.2. Spectral Attention Branch
3. Results
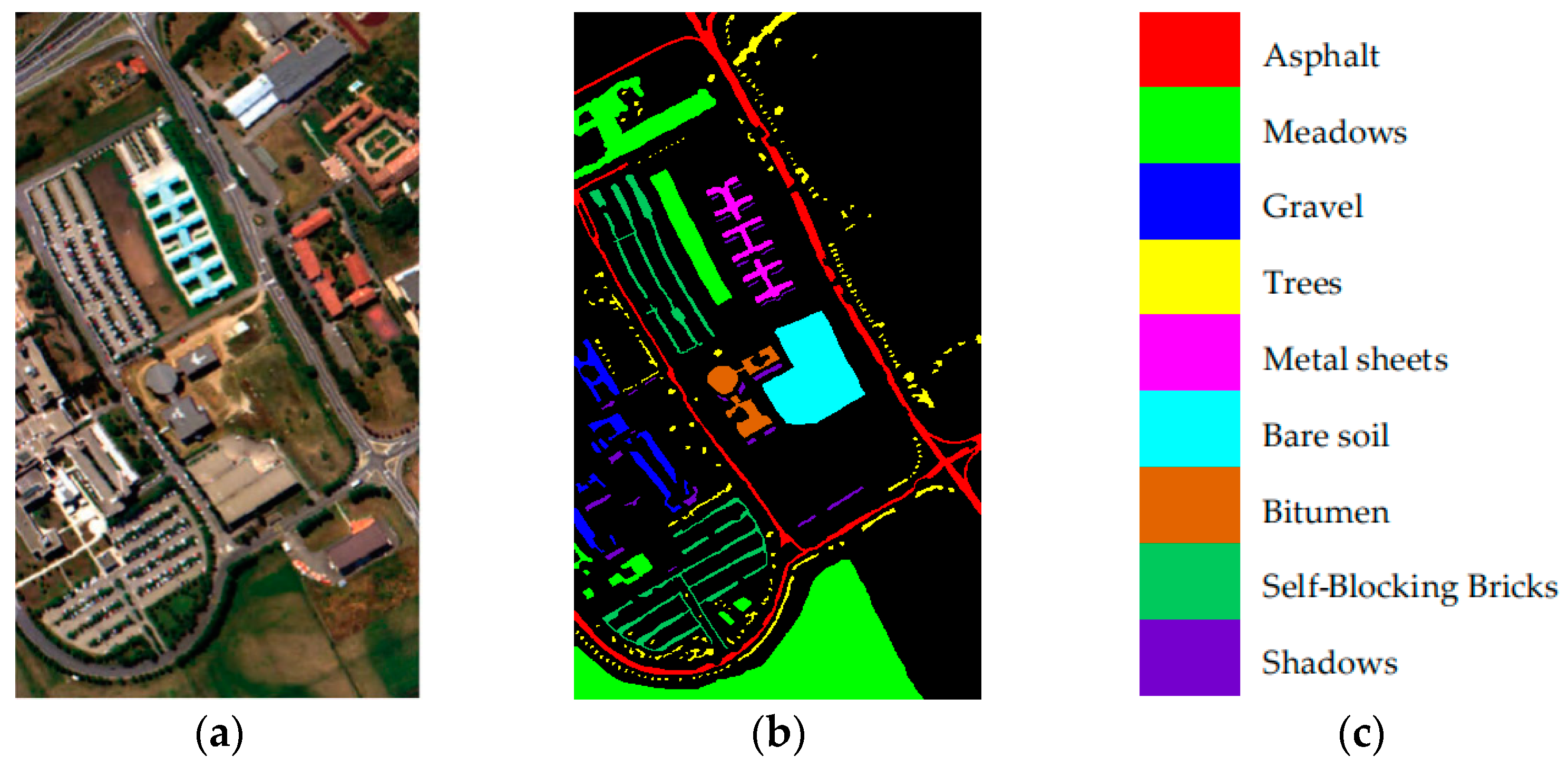
3.1. Data Description
3.2. Experimental Setting
3.3. Classification Performance
3.4. Parameter Analysis
3.5. Ablation Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| HSI | Hyperspectral Image |
| PSA | Pyramid Squeeze-And-Excitation Attention |
| KNN | K-Nearest Neighbor |
| SVM | Support Vector Machines |
| SAE | Stacked Auto Encoder |
| DBN | Deep Belief Networks |
| RNN | Recurrent Neural Networks |
| NLP | Natural Language Processing |
| SE | Squeeze-and-Excitation |
| GAP | Global Average Pooling |
| FC | Fully Connected |
| SAC | Squeeze And Concat |
| IP | Indian Pines |
| PU | Pavia University |
| SV | Salinas Valley |
| OA | Overall Accuracy |
| AA | Average Accuracy |
| Kappa | Kappa Coefficient |
References
- Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection. Remote Sens. 2021, 13, 847. [Google Scholar] [CrossRef]
- Huang, W.; Li, G.; Jin, B.; Chen, Q.; Yin, J.; Huang, L. Scenario Context-Aware-Based Bidirectional Feature Pyramid Network for Remote Sensing Target Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Sabbah, S.; Rusch, P.; Eichmann, J.; Gerhard, J.-H.; Harig, R. Remote Sensing of Gases by Hyperspectral Imaging: Results of Field Measurements. In Proceedings of the Electro-Optical Remote Sensing, Photonic Technologies, and Applications VI, Edinburgh, UK, 24–27 September 2012; Kamerman, G.W., Steinvall, O., Lewis, K.L., Hollins, R.C., Merlet, T.J., Gruneisen, M.T., Dusek, M., Rarity, J.G., Bishop, G.J., Gonglewski, J., Eds.; SPIE: Bellingham, WA, USA, 2012; Volume 8542, p. 854227. [Google Scholar]
- Gevaert, C.M.; Suomalainen, J.; Tang, J.; Kooistra, L. Generation of Spectral–Temporal Response Surfaces by Combining Multispectral Satellite and Hyperspectral UAV Imagery for Precision Agriculture Applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3140–3146. [Google Scholar] [CrossRef]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral Imaging for Military and Security Applications: Combining Myriad Processing and Sensing Techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Ardouin, J.-P.; Levesque, J.; Rea, T.A. A Demonstration of Hyperspectral Image Exploitation for Military Applications. In Proceedings of the 2007 10th International Conference on Information Fusion, Quebec, QC, Canada, 9–12 July 2007; pp. 1–8. [Google Scholar]
- Fan, J.; Zhou, N.; Peng, J.; Gao, L. Hierarchical Learning of Tree Classifiers for Large-Scale Plant Species Identification. IEEE Trans. Image Process. 2015, 24, 4172–4184. [Google Scholar] [PubMed]
- Hsieh, T.-H.; Kiang, J.-F. Comparison of CNN Algorithms on Hyperspectral Image Classification in Agricultural Lands. Sensors 2020, 20, 1734. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Dong, Y.; Liang, T.; Zhang, Y.; Du, B. Spectral–Spatial Weighted Kernel Manifold Embedded Distribution Alignment for Remote Sensing Image Classification. IEEE Trans. Cybern. 2021, 51, 3185–3197. [Google Scholar] [CrossRef]
- Yue, J.; Fang, L.; Rahmani, H.; Ghamisi, P. Self-Supervised Learning With Adaptive Distillation for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Han, J.; Yao, X.; Guo, L. Exploring Hierarchical Convolutional Features for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6712–6722. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral Remote Sensing Data Analysis and Future Challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Awad, M.M. Cooperative Evolutionary Classification Algorithm for Hyperspectral Images. J. Appl. Remote Sens. 2020, 14, 016509. [Google Scholar] [CrossRef]
- Li, J.; Khodadadzadeh, M.; Plaza, A.; Jia, X.; Bioucas-Dias, J.M. A Discontinuity Preserving Relaxation Scheme for Spectral–Spatial Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 625–639. [Google Scholar] [CrossRef]
- Wambugu, N.; Chen, Y.; Xiao, Z.; Tan, K.; Wei, M.; Liu, X.; Li, J. Hyperspectral Image Classification on Insufficient-Sample and Feature Learning Using Deep Neural Networks: A Review. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102603. [Google Scholar] [CrossRef]
- Fabiyi, S.D.; Murray, P.; Zabalza, J.; Ren, J. Folded LDA: Extending the Linear Discriminant Analysis Algorithm for Feature Extraction and Data Reduction in Hyperspectral Remote Sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12312–12331. [Google Scholar] [CrossRef]
- Duan, Y.; Huang, H.; Tang, Y. Local Constraint-Based Sparse Manifold Hypergraph Learning for Dimensionality Reduction of Hyperspectral Image. IEEE Trans. Geosci. Remote Sens. 2021, 59, 613–628. [Google Scholar] [CrossRef]
- Luo, F.; Zhang, L.; Zhou, X.; Guo, T.; Cheng, Y.; Yin, T. Sparse-Adaptive Hypergraph Discriminant Analysis for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1082–1086. [Google Scholar] [CrossRef]
- Duan, Y.; Huang, H.; Li, Z.; Tang, Y. Local Manifold-Based Sparse Discriminant Learning for Feature Extraction of Hyperspectral Image. IEEE Trans. Cybern. 2021, 51, 4021–4034. [Google Scholar] [CrossRef]
- Ma, L.; Crawford, M.M.; Tian, J. Local Manifold Learning-Based $k$ -Nearest-Neighbor for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4099–4109. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and Spatial Classification of Hyperspectral Data Using SVMs and Morphological Profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of Hyperspectral Remote Sensing Images with Support Vector Machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Huang, W.; Huang, Y.; Wang, H.; Liu, Y.; Shim, H.J. Local Binary Patterns and Superpixel-Based Multiple Kernels for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4550–4563. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Pereira, N.S.; Plaza, J.; Plaza, A. Ghostnet for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10378–10393. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a Fast and Flexible Solution for CNN-Based Image Denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Remote Sensing|Free Full-Text|Combing Triple-Part Features of Convolutional Neural Networks for Scene Classification in Remote Sensing. Available online: https://www.mdpi.com/2072-4292/11/14/1687 (accessed on 12 July 2022).
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–Spatial Classification of Hyperspectral Data Based on Deep Belief Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Hang, R.; Li, Z.; Ghamisi, P.; Hong, D.; Xia, G.; Liu, Q. Classification of Hyperspectral and LiDAR Data Using Coupled CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4939–4950. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep Supervised Learning for Hyperspectral Data Classification through Convolutional Neural Networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Ben Hamida, A.; Benoit, A.; Lambert, P.; Ben Amar, C. 3-D Deep Learning Approach for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral-Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.J.; Pla, F. Deep Pyramidal Residual Networks for Spectral–Spatial Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 740–754. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource Remote Sensing Data Classification Based on Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 937–949. [Google Scholar] [CrossRef]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing Ag: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Haut, J.M.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Li, J. Visual Attention-Driven Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8065–8080. [Google Scholar] [CrossRef]
- Sun, H.; Zheng, X.; Lu, X.; Wu, S. Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3232–3245. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of Hyperspectral Image Based on Double-Branch Dual-Attention Mechanism Network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Hu, X.; Li, T.; Zhou, T.; Liu, Y.; Peng, Y. Contrastive Learning Based on Transformer for Hyperspectral Image Classification. Appl. Sci. 2021, 11, 8670. [Google Scholar] [CrossRef]
- Remote Sensing|Free Full-Text|Improved Transformer Net for Hyperspectral Image Classification. Available online: https://www.mdpi.com/2072-4292/13/11/2216 (accessed on 1 September 2022).
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification With Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–Spatial Feature Tokenization Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar]
- Licciardi, G.; Marpu, P.R.; Chanussot, J.; Benediktsson, J.A. Linear Versus Nonlinear PCA for the Classification of Hyperspectral Data Based on the Extended Morphological Profiles. IEEE Geosci. Remote Sens. Lett. 2012, 9, 447–451. [Google Scholar] [CrossRef]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network. In Proceedings of the Asian Conference on Computer Vision (ACCV), Macau SAR, China, 4–8 December 2022. [Google Scholar]
- Zhao, W.; Du, S. Spectral–Spatial Feature Extraction for Hyperspectral Image Classification: A Dimension Reduction and Deep Learning Approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NO. | Class | Train | Test |
|---|---|---|---|
| 1 | Alfalfa | 5 | 41 |
| 2 | Corn—notill | 143 | 1285 |
| 3 | Corn—mintill | 83 | 747 |
| 4 | Corn | 24 | 213 |
| 5 | Grass–pasture | 48 | 435 |
| 6 | Grass-tree | 73 | 657 |
| 7 | Grass–pasture–mowed | 3 | 25 |
| 8 | Hay—windrowed | 48 | 430 |
| 9 | Oats | 2 | 18 |
| 10 | Soybeans—notill | 97 | 875 |
| 11 | Soybeans—mintill | 245 | 2210 |
| 12 | Soybeans—clean | 59 | 534 |
| 13 | Wheat | 20 | 185 |
| 14 | Woods | 126 | 1139 |
| 15 | Buildings–grass–trees | 39 | 347 |
| 16 | Stone–steel–towers | 9 | 84 |
| Total | 1024 | 9225 |
| NO. | Class | Train | Test |
|---|---|---|---|
| 1 | Asphalt | 332 | 6299 |
| 2 | Meadows | 932 | 17,717 |
| 3 | Gravel | 105 | 1994 |
| 4 | Trees | 153 | 2911 |
| 5 | Metal sheets | 67 | 1278 |
| 6 | Bare soil | 251 | 4778 |
| 7 | Bitumen | 67 | 1263 |
| 8 | Self-Blocking bricks | 184 | 3498 |
| 9 | Shadows | 47 | 900 |
| Total | 2138 | 40,638 |
| NO. | Class | Train | Test |
|---|---|---|---|
| 1 | Broccoli green weeds_1 | 100 | 1909 |
| 2 | Broccoli green weeds_2 | 186 | 3540 |
| 3 | Fallow | 99 | 1877 |
| 4 | Fallow_rough_plow | 70 | 1324 |
| 5 | Fallow_smooth | 134 | 2544 |
| 6 | Stubble | 198 | 3761 |
| 7 | Celery | 179 | 3400 |
| 8 | Grapes_untrained | 564 | 10,707 |
| 9 | Soil_vinyard_develop | 310 | 5893 |
| 10 | Corn_senesced_green_weeds | 164 | 3114 |
| 11 | Lettuce_romaine_4wk | 53 | 1015 |
| 12 | Lettuce_romaine_5wk | 96 | 1831 |
| 13 | Lettuce_romaine_6wk | 46 | 870 |
| 14 | Lettuce_romaine_7wk | 54 | 1016 |
| 15 | Vinyard_untrained | 364 | 6904 |
| 16 | Vinyard_vertical_trellis | 90 | 1717 |
| Total | 2707 | 51,422 |
| Class No. | 1-D CNN | 2-D CNN | 3-D CNN | HybridSN | DBDA | SSFTT | Ours |
|---|---|---|---|---|---|---|---|
| 1 | 26.83 | 85.37 | 48.78 | 68.29 | 97.56 | 97.56 | 100 |
| 2 | 71.75 | 88.48 | 92.14 | 99.84 | 89.96 | 94.24 | 96.73 |
| 3 | 53.68 | 79.92 | 98.53 | 95.72 | 96.79 | 97.05 | 99.06 |
| 4 | 52.11 | 76.06 | 87.79 | 92.49 | 99.06 | 97.65 | 100 |
| 5 | 86.90 | 90.34 | 98.39 | 94.71 | 99.54 | 99.08 | 97.93 |
| 6 | 94.06 | 98.48 | 96.35 | 100 | 97.11 | 98.32 | 99.85 |
| 7 | 44.00 | 84.00 | 100 | 60.00 | 92.00 | 88.00 | 100 |
| 8 | 98.84 | 97.91 | 100 | 100 | 99.77 | 100 | 100 |
| 9 | 33.33 | 83.33 | 72.22 | 100 | 100 | 72.22 | 100 |
| 10 | 66.40 | 91.89 | 96.80 | 96.00 | 97.03 | 96.91 | 98.74 |
| 11 | 81.44 | 94.21 | 96.38 | 98.69 | 98.64 | 98.73 | 99.64 |
| 12 | 76.40 | 85.96 | 94.19 | 96.07 | 96.63 | 98.31 | 96.25 |
| 13 | 98.38 | 99.46 | 98.38 | 100 | 96.22 | 97.28 | 99.46 |
| 14 | 95.52 | 95.43 | 99.39 | 98.95 | 95.87 | 100 | 100 |
| 15 | 63.98 | 79.54 | 91.07 | 96.54 | 97.98 | 97.11 | 99.42 |
| 16 | 79.76 | 88.10 | 80.95 | 44.05 | 89.29 | 89.16 | 98.80 |
| OA(%) | 78.38 | 90.10 | 95.75 | 97.27 | 96.49 | 97.69 | 98.89 |
| AA(%) | 70.21 | 88.65 | 90.71 | 90.08 | 96.47 | 95.10 | 99.12 |
| Kappa × 100 | 75.17 | 89.70 | 95.18 | 96.88 | 95.39 | 97.36 | 98.74 |
| Class No. | 1-D CNN | 2-D CNN | 3-D CNN | HybridSN | DBDA | SSFTT | Ours |
|---|---|---|---|---|---|---|---|
| 1 | 94.22 | 95.22 | 87.93 | 98.84 | 97.98 | 99.13 | 99.17 |
| 2 | 97.17 | 96.65 | 99.77 | 99.98 | 98.78 | 99.60 | 99.92 |
| 3 | 82.55 | 87.66 | 96.74 | 98.99 | 98.45 | 98.40 | 96.58 |
| 4 | 93.82 | 98.97 | 98.28 | 98.97 | 96.74 | 98.21 | 99.66 |
| 5 | 100 | 99.77 | 100 | 99.37 | 100 | 100 | 100 |
| 6 | 90.79 | 92.97 | 96.40 | 100 | 98.35 | 99.98 | 100 |
| 7 | 86.70 | 88.92 | 95.09 | 99.92 | 97.47 | 100 | 100 |
| 8 | 82.91 | 79.25 | 94.37 | 96.11 | 96.31 | 98.48 | 98.83 |
| 9 | 100 | 99.89 | 99.67 | 97.11 | 100 | 96.56 | 99.78 |
| OA(%) | 93.61 | 94.15 | 96.68 | 99.27 | 98.25 | 99.27 | 99.54 |
| AA(%) | 92.02 | 93.26 | 96.47 | 98.81 | 98.23 | 98.93 | 99.33 |
| Kappa × 100 | 91.53 | 92.28 | 95.59 | 99.03 | 97.89 | 99.09 | 99.39 |
| Class No. | CNN1D | CNN2D | CNN3D | HybridSN | DBDA | SSFTT | Ours |
|---|---|---|---|---|---|---|---|
| 1 | 99.79 | 100 | 100 | 100 | 99.90 | 99.84 | 100 |
| 2 | 99.94 | 99.89 | 100 | 100 | 99.72 | 98.98 | 100 |
| 3 | 99.73 | 99.84 | 100 | 100 | 99.68 | 98.61 | 100 |
| 4 | 99.70 | 99.62 | 98.94 | 100 | 98.94 | 98.79 | 100 |
| 5 | 94.58 | 98.82 | 99.88 | 99.49 | 99.92 | 99.80 | 99.88 |
| 6 | 99.02 | 99.92 | 100 | 100 | 98.78 | 98.70 | 99.89 |
| 7 | 99.94 | 99.59 | 99.97 | 99.70 | 98.74 | 99.91 | 99.47 |
| 8 | 87.82 | 94.23 | 99.99 | 99.93 | 100 | 99.93 | 99.96 |
| 9 | 99.81 | 100 | 100 | 100 | 99.54 | 100 | 100 |
| 10 | 97.05 | 98.72 | 100 | 100 | 99.87 | 99.58 | 100 |
| 11 | 96.65 | 99.01 | 100 | 99.70 | 99.80 | 100 | 100 |
| 12 | 100 | 100 | 100 | 100 | 100 | 97.76 | 100 |
| 13 | 98.97 | 100 | 100 | 100 | 99.89 | 99.43 | 100 |
| 14 | 89.67 | 99.21 | 99.90 | 100 | 99.31 | 99.61 | 99.61 |
| 15 | 77.87 | 93.14 | 96.48 | 98.19 | 98.60 | 99.83 | 99.46 |
| 16 | 98.95 | 99.65 | 99.71 | 100 | 99.83 | 99.30 | 99.59 |
| OA(%) | 93.60 | 97.64 | 99.48 | 99.71 | 99.53 | 99.55 | 99.85 |
| AA(%) | 96.22 | 98.85 | 99.68 | 99.77 | 99.49 | 99.38 | 99.87 |
| Kappa × 100 | 92.87 | 97.99 | 99.42 | 99.67 | 99.51 | 99.50 | 99.83 |
| Methods | IP | PU | SV | |||
|---|---|---|---|---|---|---|
| Train(s) | Test(s) | Train(s) | Test(s) | Train(s) | Test(s) | |
| 1-D CNN | 39.73 | 0.36 | 141.32 | 1.26 | 187.38 | 1.64 |
| 2-D CNN | 64.77 | 0.86 | 220.86 | 2.23 | 207.11 | 1.87 |
| 3-D CNN | 126.96 | 1.36 | 325.96 | 3.70 | 296.71 | 6.52 |
| HybridSN | 80.34 | 1.58 | 75.59 | 2.50 | 94.02 | 3.21 |
| DBDA | 62.03 | 2.54 | 196.76 | 14.20 | 215.26 | 15.35 |
| SSFTT | 57.13 | 1.90 | 237.53 | 8.03 | 300.38 | 10.24 |
| Ours | 52.19 | 1.20 | 105.71 | 4.64 | 88.05 | 5.32 |
| Window Sizes | OA | Testing Time(s) | ||||
|---|---|---|---|---|---|---|
| IP | PU | SV | IP | PU | SV | |
| 9 × 9 | 98.39 | 99.19 | 99.42 | 0.66 | 3.01 | 3.76 |
| 11 × 11 | 98.52 | 99.44 | 99.78 | 0.91 | 3.79 | 5.28 |
| 13 × 13 | 98.89 | 99.54 | 99.85 | 1.20 | 4.64 | 5.32 |
| 15 × 15 | 98.89 | 99.45 | 99.92 | 1.57 | 5.64 | 7.36 |
| 17 × 17 | 98.57 | 99.47 | 99.95 | 1.68 | 6.36 | 10.47 |
| Cases | 3D Conv | PSA Module | Spectral Attention Branch | OA (%) | AA (%) | Kappa (%) |
|---|---|---|---|---|---|---|
| 1 | × | √ | √ | 96.41 | 94.66 | 95.90 |
| 2 | √ | × | √ | 95.70 | 93.42 | 95.38 |
| 3 | √ | √ | × | 97.96 | 94.42 | 95.10 |
| 4 | √ | √ | √ | 98.89 | 99.12 | 98.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Zhao, Z.; Sun, L.; Ju, M. Dual-Branch Attention-Assisted CNN for Hyperspectral Image Classification. Remote Sens. 2022, 14, 6158. https://doi.org/10.3390/rs14236158
Huang W, Zhao Z, Sun L, Ju M. Dual-Branch Attention-Assisted CNN for Hyperspectral Image Classification. Remote Sensing. 2022; 14(23):6158. https://doi.org/10.3390/rs14236158
Chicago/Turabian StyleHuang, Wei, Zhuobing Zhao, Le Sun, and Ming Ju. 2022. "Dual-Branch Attention-Assisted CNN for Hyperspectral Image Classification" Remote Sensing 14, no. 23: 6158. https://doi.org/10.3390/rs14236158
APA StyleHuang, W., Zhao, Z., Sun, L., & Ju, M. (2022). Dual-Branch Attention-Assisted CNN for Hyperspectral Image Classification. Remote Sensing, 14(23), 6158. https://doi.org/10.3390/rs14236158