1. Introduction
Point cloud registration is widely used in 3D reconstruction [
1], object pose estimation [
2], simultaneous localization and mapping, [
3] and other fields [
4,
5,
6]. The feature-based point cloud registration pipelines commonly start from keypoint detection [
7,
8,
9], feature point description [
10,
11,
12], followed by robust alignment by outlier rejection [
13,
14,
15]. Although feature point detection and 3D local features have developed rapidly, there are still many outliers in the initial correspondences generated by the feature-based matching, especially when the overlap of the two point clouds is very small. In this paper, we mainly design an outlier rejection network, which is a critical step in the robust point cloud registration pipeline, to alleviate the above issue.
Recently, 3D outlier rejection tasks based on deep learning, such as 3DRegNet [
13] and DGR [
14], formulated the outlier rejection as a classification problem of inlier/outlier. These networks embed deep features of input correspondences and utilize the resulting features to predict the probability that each correspondence is an inlier to remove the outlier. For feature embedding, they solely rely on general descriptors such as pointwise multilayer perceptron (MLP) and sparse convolution to capture contextual feature information of each correspondence. They all ignore the important spatial consistency properties that the inlier should follow in geometric properties in the 3D domain. Instead, PointDSC [
15] considers the length of spatial consistency in the feature embedding of each correspondence. The PointDSC combines the length consistency and the spatial feature similarity to capture contextual features about each input correspondence. However, the above networks still cannot focus on essential channels contextual for each correspondence. In addition, they also lack crucial spatial information that would complement the channel features and effectively highlight areas of important spatial feature information extracted along the channel axis. Therefore, each correspondence has poor contextual feature representation in the above networks. In particular, ignoring the channel-spatial global context information would enormously limit the ability of the network to distinguish each correspondence, especially when the point clouds of pairs are less overlapping. As a result, these networks retain more outliers and, thus, reduce the point cloud alignment accuracy. Observing
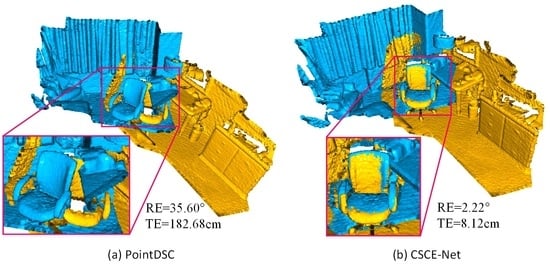
Figure 1a, we find that the outlier rejection network PointDSC retains many outliers due to inadequate extraction of contextual features, which results in huge point cloud alignment errors and consequent registration failures.
In this paper, we propose a practical channel-spatial contextual (CSC) block to solve the above issues. CSC block can capture each correspondence’s channel-spatial global context information by computing complementary channel and spatial attention. We also import the spatial consistency and the channel-spatial attention into the nonlocal network to compute the feature similarity for each pair of correspondences in spatial dimension based on the channel and spatial feature fusion. Therefore, the CSC block can separately calculate the channel-spatial features of each correspondence and the correlation between the correspondences, which enables the network to extract sufficient contextual information and process each correspondence distinguishably. Furthermore, we propose an advanced Seed Selection mechanism that more accurately calculates each correspondence’s initial confidence to select the seeds with well-distributed and highly confident, which contributes to the construction of a more reliable consensus set for each seed. Integrating the newly proposed CSC block and advanced Seed Selection mechanism with the Second Order Spatial Compatibility (SC
) measure [
16] and Spectral Matching (SM) [
17], we propose a novel outlier rejection network Channel-Spatial Contextual Enhancement Network (CSCE-Net). Specifically, CSCE-Net introduces a CSC block to capture rich global context information and enhance the presentation capability of important channel-spatial map information. In addition, CSCE-Net designs an advanced seeding mechanism to select high-confidence correspondences for the SC
measure and SM to improve the inlier/outlier discrimination. In addition, we iteratively used CSCE-Net twice, with the inlier probability obtained from the previous network serving as an additional input to the following network to improve the performance of the final network. Observing
Figure 1b, it is not difficult to see that our CSCE-Net is able to retain more inliers in two low-overlap scenes, dramatically reducing alignment errors when performing positional estimation compared to
Figure 1a. The quantitative and visual results provide excellent evidence of the effectiveness of our CSCE-Net in seeking reliable correspondence during point cloud registration.
The main contributions of this work are in three aspects:
We propose a CSC block in which the CSA layer and Nonlocal CSA layer are backbones to capture sufficient contextual information and enhance the representative ability of inliers and important channels and spatial.
We construct an advanced seed selection mechanism to more accurately calculate seeds with high confidence and well-distributed and facilitate the construction of more reliable consensus sets for each seed.
Our CSCE-Net outperforms state-of-the-art methods for outlier rejection and pose estimation tasks on two challenging public datasets by combining different 3D local descriptors and better balancing the number of parameters in the network.
The rest of this article is structured as follows: We describe the related literature in
Section 2. In
Section 3, we introduce the structure information of CSCE-Net, CSC block, and Seed Selection in detail. We exhibit the experimental details and comparative results in
Section 4. In the end, we give the relevant conclusions in
Section 5.
2. Related Works
In feature-based point cloud registration, firstly, a putative correspondence set has been built by some 3D local features, such as fast point feature histograms (FPFH) [
18] and fully convolutional geometric features (FCGF) [
10]. Secondly, it is necessary to remove outliers, as the putative correspondence set usually has a large number of incorrect matches. In this section, we briefly introduce some traditional and learning-based outlier rejection methods in
Section 2.1 and
Section 2.2, respectively.
2.1. Traditional Outlier Rejection
Random Sample Consensus (RANSAC) [
19] is still the more popular method of outlier rejection. It iteratively uses the smallest subset obtained by random sampling and employs a least-squares fitting that is not robust to outliers in the model fitting step. Many of its various variants [
20,
21,
22] have introduced new sampling strategies and local optimizations to speed up estimation or improve robustness. LO-RANSAC [
20] makes the parametric model calculated for the outlier-free sample consistent with all interior points by applying local optimization to the solution estimated for the random sample. Since most existing registration methods require a set of assumed correspondences obtained by extracting invariant descriptors, SDRSAC [
21] presents a new stochastic algorithm for robust point cloud alignment without correspondences. GESAC [
22] improves on classical RANSAC by generating a larger subset in the sampling phase and introducing a shape-annealing robust estimate in the model fitting step. However, their main drawback, as with RANSAC, continues to be slow convergence and low accuracy in the case of a relatively large outlier ratio. More recently, Graph-cut RANSAC [
23] runs a graph-cutting algorithm in a local optimization step to perform efficient outlier separation. Magsac [
24] introduces a
-consensus to construct a without inlier-outlier threshold method for RANSAC. As a result, they can improve the efficiency of outliers rejection further.
In addition, spectral matching (SM) [
17] is a famous traditional algorithm that relies heavily on 3D spatial consistency to find inlier correspondences. It uses length consistency to construct a compatibility graph and then finds the main clusters of the graph to obtain an inlier set through eigenanalysis. However, as explained in [
25], it cannot effectively deal with high outlier ratios, in which case the main internal clusters become less obvious. Moreover, FGR [
26] achieves a fast global alignment algorithm for locally overlapping 3D surfaces by manipulating the candidate matches on the covered surface. TEASER [
27] reformulates the registration problem using a truncated least squares (TLS) cost and solving the 3D rotation transformation through a general graph-theoretic framework. FGR and TEASER can tolerate outliers using robust loss functions (e.g., GemanMcClure). Quatro [
28] utilizes a global alignment method based on degenerate robust decoupling to solve the problem of a large number of anomalous correspondences. Most traditional outlier rejection methods have been summarized in [
25,
29,
30,
31,
32].
Although widely used in computer vision, traditional outlier rejection methods still suffer from some fundamental drawbacks. For example, as the ratio of outliers in the initial matching set increases dramatically, the above-mentioned traditional algorithms struggle to balance accuracy and efficiency. Hence comes the emergence of deep learning-based outlier rejection.
2.2. Learning-Based Outlier Rejection
In learning-based approaches, some feature learning methods [
8,
9,
10,
12] have used convolutional neural networks (CNN) to acquire more reliable keypoints and descriptors. Although these methods have better results than manual methods [
18], they do not solve the problem of having a large number of outliers in the initial correspondence set. Therefore, learning-based outlier removal methods are proposed as a post-processing step to solving this problem.
A learning-based outlier rejection approach is introduced for the first time in the 2D image matching area, [
33,
34,
35,
36,
37,
38] where outlier rejection is represented as an inlier/outlier classification problem. CN-Net [
33] is the first method to use an end-to-end learning-based approach to label each correspondence as an inlier or outlier value. Meanwhile, the fundamental matrix for recovering the camera pose of two matched images is estimated using a weighted eight-point algorithm. NM-Net [
34] redefines neighbors to find reliable correspondence. OANet [
35] introduces an order-aware filtering block to cluster correspondences crucial global context. MS2DG-Net [
36] uses sparse semantic similarity instead of Euclidean distance to generate dynamic contextual features.
Recent attempts [
13,
14,
15,
39,
40] have also introduced deep learning networks to perform 3D correspondence pruning. The 3DRegNet [
13] redefines the CN-Net [
33] into a 3D form and devises a regression module to solve the rigid transformation. DGR [
14] recommends the use of a learning-based feature called the full convolutional geometric feature (FCGF) [
10] to perform the alignment and employs a 6D convolutional network to predict the likelihood of each correspondence. DetarNet [
39] introduces a decoupled solution for translation and rotation, resulting in better performance for both. Using Hough voting in 6D transformed parameter space, DHVR [
40] describes a robust and efficient framework for paired registration of realistic 3D scans. However, when performing feature embedding of correspondences and pruning, these networks ignore the important property of spatial consistency that 3D point clouds should follow in the 3D domain. In contrast, the recent PointDSC [
15] has developed a non-local module and neural spectrum matching based on the length spatial consistency to accelerate model generation.
However, these networks still do not capture enough contextual information for network learning because their feature embedding networks ignore each correspondence’s channel and spatial features, thus, limiting the feature representation capability. In this paper, our CSCE-Net uses complementary spatial channel attention combined with length spatial consistency to adequately extract the contextual features of each correspondence to improve the performance of outlier rejection and hence the accuracy of the final alignment.
3. Method
In this section, we first introduce the problem formulation in
Section 3.1. Then, the network framework is introduced in
Section 3.2. Finally, we describe the proposed CSC block and the Seed Selection in
Section 3.3 and
Section 3.4, respectively.
3.1. Problem Formulation
In this work, we are given two sets of keypoints ∈ and ∈ from a pair of partially overlapping 3D point clouds and each keypoint comes with an associated local descriptor. After that, the putative correspondence set of the network inputs are generated by performing a nearest neighbor search using local descriptors. Each correspondence ∈ is denoted as = (,) ∈, where ∈, ∈ are the space coordinates of a pair of 3D keypoints. Our final goal is to find an outlier/inlier label value for , i.e., = 0 or 1, respectively, and then utilize these inliers between two point sets to recover an optimal 3D rigid transformation , .
Specifically, we first embed the correspondence of two point sets into the high-dimensional feature. Next, we employ these features to find the high-confidence correspondences as seeds. The corresponding consensus set (i.e.,
) of each seed is obtained by the SC
measure. Then we compute the 3D rigid transformation {
} for each seed set by the least-squares fitting [
41]:
where
is the weight of inlier probability calculated from the NSM module. Equation (
1) is solved by SVD [
41].
Further, we find the optimal 3D rigid transformation {
,
} by the number of corresponding relations for each {
} satisfying a given threshold:
where
denotes the inlier threshold and [·] is the Iverson bracket. Finally, the outlier/inlier label
∈
is obtained by
=
. We then recompute the final 3D rotation transformation {
,
} by the least squares using all the retained inliers.
Loss Function. Following previous work in PointDSC [
15], we optimize the neural network utilizing a hybrid loss function (i.e., a node-wise loss and an edge-wise loss) as follows:
where
is a hyper-parameter that balances the two losses.
denotes the node-wise loss that is used to supervise each correspondence individually. We employ binary cross-entropy loss as node-wise supervision to learn the initial confidence:
where
is the initial confidence of the prediction, and
represents the ground-truth outlier/inlier labels constructed by
where
and
are the ground truth rotation and translation matrices, and
is the inlier threshold.
is the edge-wise loss, which is applied to supervise the pairwise relationship between correspondences as a complement to node-wise supervision.
where
is the relevance value estimated based on feature similarity and
=[
and
are inliers] is the ground-truth relevance value, which is defined as:
where
and
are the
-normalized eigenvectors, and
is a parameter of feature difference sensitivity.
3.2. Network Framework
The framework of our CSCE-Net is shown in
Figure 2. The CSCE-Net consists of four main parts: our proposed CSC block, the presented seed selection, the Second Order Spatial Compatibility Measure, and Spectral Matching. Our CSCE-Net starts with
initial correspondences as input and maps the features from 6 to 128 dimensions using a shared perceptron. Next, it adequately extracts the global context information for each correspondence by utilizing 6 CSC blocks. Then, the seed selection mechanism exploits the high-dimensional features obtained from the CSC blocks to calculate the initial confidence of each correspondence and selects these high-confidence and well-distributed correspondences as seeds (
) using the Non-Maximum Suppression method. Seeds selected for rich contextual information are more likely to be represented as inliers, which contributes to the construction of a more reliable consensus set. In addition, to better distinguish between insertions and outliers, we inserted a second-order spatial compatibility (SC
) measure proposed by SC
-PCR [
16], which constructs a new global measure of similarity between two correspondences by counting the number of correspondences that are compatible with both correspondences simultaneously. The role of the SC
measure is to construct a consensus set for each seed. Finally, CSCE-Net adopts the spectral matching [
16,
17] to compute the weight vector
of inlier probabilities and the 3D rigid transform {
} for each consensus set by least-squares fitting.
3.3. CSC Block
The CSC block mainly utilizes perceptrons and complementary channel-spatial attention to selectively aggregate information in the channel and spatial dimensions, capture the complex global context of feature maps, and obtain feature maps with solid and expressive capabilities. As shown in
Figure 2, the newly proposed CSC block consists of four key parts, i.e., the two identical Context Norm layers, the CSA layer, and the Nonlocal CSA layer. The Context Norm layer contains a Context Normalization layer to get the global context, a Batch Normalization layer with ReLU activation function to speed up network training, and a Multi-Layer Perceptrons layer containing 128 neurons for network learning. We use the Context Norm layer to handle disordered and irregular correspondences.
As shown in
Figure 3, the CSA layer reinforces the channel-spatial features by serially concatenating the 2D maps produced by the Channel attention (CA) module and the Spatial attention (SA) module, respectively. The lack of channel-spatial features in feature embeddings greatly limits the ability of the network to reject outliers. Therefore, we construct a novel channel-spatial attention layer to improve the representation ability and emphasize significant characteristics along these two main dimensions: channel and spatial. For aggregating spatial information, the average pooling method is generally used at present [
42]. Moreover, Woo et al. [
43] believe that max-pooling infers more delicate channel-level and spatial-level attention, combining average pooling and max pooling to retain more feature information. However, max-pooling only preserves important local feature cues. Thus, we apply the global standard deviation pooling operation to channel and spatial attention, which can take global and local feature cues into account, enhance feature representation capabilities, and strengthen the correlation between features of each correspondence. Specifically, to obtain more robust feature maps, we concatenate the 2D attention map
and
, which are output by CA module and SA module, respectively. Our experiments (see
Section 4.4) conclude that the optimal connection method of the CA and SA module is sequential connection. Therefore, the CSA layer is summarized as follows:
where ⊙ represents element-wise multiplication and
is the final refinement output of the CSA layer.
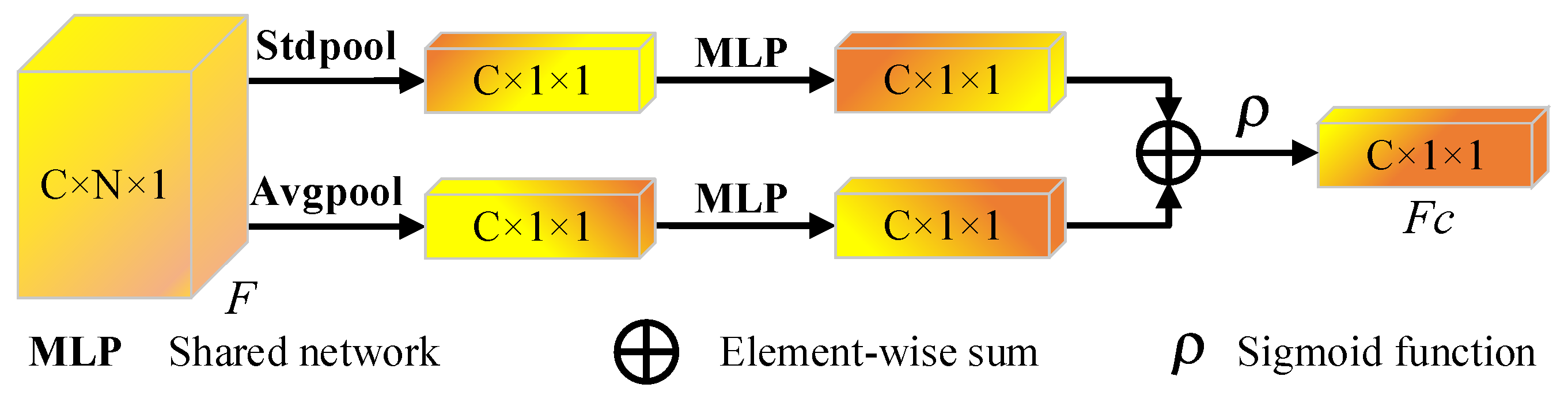
CA module: The channel attention module is shown in
Figure 4. We first aggregate the spatial information of feature maps by using the standard deviation pooling and average pooling operation to generate two distinct spatial context descriptors:
and
, which represent std-pooled features and average-pooled features, respectively. Then, the above two features are forwarded to the shared network to generate our channel attention map
, where C is the number of channels. The shared network consists of a multilayer perceptron (MLP) with a hidden layer. The activation size of the hidden layer is set as
, where
is the reduction ratio. After applying the shared network to both descriptors, we use element-wise summation to combine the output feature vectors. The channel attention is calculated as follows:
where
represents the sigmoid function. MLP stands for the shared network.
SA module: As shown in
Figure 5, we first generate two 2D maps
and
by using two pooling operations to aggregate the channel information of one feature map. Each feature represents the std-pooled and average-pooled features of the entire channel. Then we concatenate the above two features together. After that, we apply a standard convolutional layer to generate a 2D spatial attention map. Finally, the sigmoid function is used to normalize the attention map. The spatial attention is calculated as follows:
where
denotes a convolution operation with a filter size of
and
represents the sigmoid function.
The nonlocal CSA layer is used to update features inspired by PointDSC [
15], which mainly introduces a spatial consistency to complement the feature similarity of the nonlocal network [
44]. To enhance the channel spatial features, we present the CSA layer to supplement the features of each correspondence after spatial topology and feature similarity computation. Therefore, the nonlocal CSA layer can not only obtain the spatial consistency and feature similarity information of each correspondence but also enhance the representation ability of the channel-spatial.
3.4. Seed Selection
Finding a dominant inlier cluster is difficult in the next SM layer, which cannot clearly distinguish both inlier and outlier. In this instance, utilizing the output of SM via weighted least-squares fitting [
41] to transformation estimation may result in a suboptimal solution, since many outliers are still not explicitly eliminated. Therefore, we propose a new seed selection mechanism applied to apply spectral matching locally. In PointDSC [
15], the seed selection mechanism is designed by two identical shared perceptrons and ReLu activation functions to compute the initial confidence for each correspondence. However, the random and straightforward structure ignores the global context encoding before calculating the confidence for each correspondence. That causes seed selection to find a suboptimal confidence distribution. Therefore, our new seed selection incorporates two contextual normalizations (shown in
Figure 6) that encode each correspondence’s contextual feature maps by means and variances. The new seed selection mechanism can accurately calculate the context of each correspondence before calculating the confidence so that the confidence distribution is optimal. Therefore, it finds well-distributed and more reliable correspondences as seeds and looks for consistent correspondences around them in the feature space. After then, the new seed selection makes each subset have a higher inlier ratio than the set of input correspondences, which contributes SC
to construct a more reliable consensus set for each seed.
As shown in
Figure 6, we use an MLP to select seeds by calculating the initial confidence for each correspondence, which uses the features learned by the CSC block. Then we utilize Non-Maximum Suppression [
45] on these confidences to find well-distributed seeds. These selected seeds will be formed into multiple corresponding consensus sets by SC
measure and input into SM.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}