1. Introduction
The successful implementation of city digital twins requires developing digital systems that can manage, visualize, and manipulate the geospatial data and present the data in a user-friendly environment. Building information modeling (BIM) is an intelligent 3D model-based representation that manages construction projects at different stages, including planning and design, construction, operation and maintenance, and demolition [
1]. As stated in the 2nd annual BIM report of 2019, Canada is the only G7 country without a national BIM mandate [
2]. By contrast, the design community is pushing to consider BIM as standards. Currently, 3D laser scanning systems have proven their capability to capture 3D point cloud of the real world [
3,
4,
5] for BIM applications, known as scan-to-BIM.
Scanned data are imported into a 3D modelling environment to create accurate as-built models or feed the design with real-world conditions, helping in decision-making [
3,
6]. The construction industry is moving toward digital systems, whereas highly accurate 3D modelling is necessary to serve existing buildings’ operation and maintenance stage. The purpose of Scan-to-BIM of existing buildings could be for heritage documentation [
7,
8], design of a reconstruction of industrial buildings [
9], improvement of residential buildings energy efficiency [
10], smart campus implementation [
11], or operation, maintenance and monitoring of those buildings, which is defined as structural health monitoring.
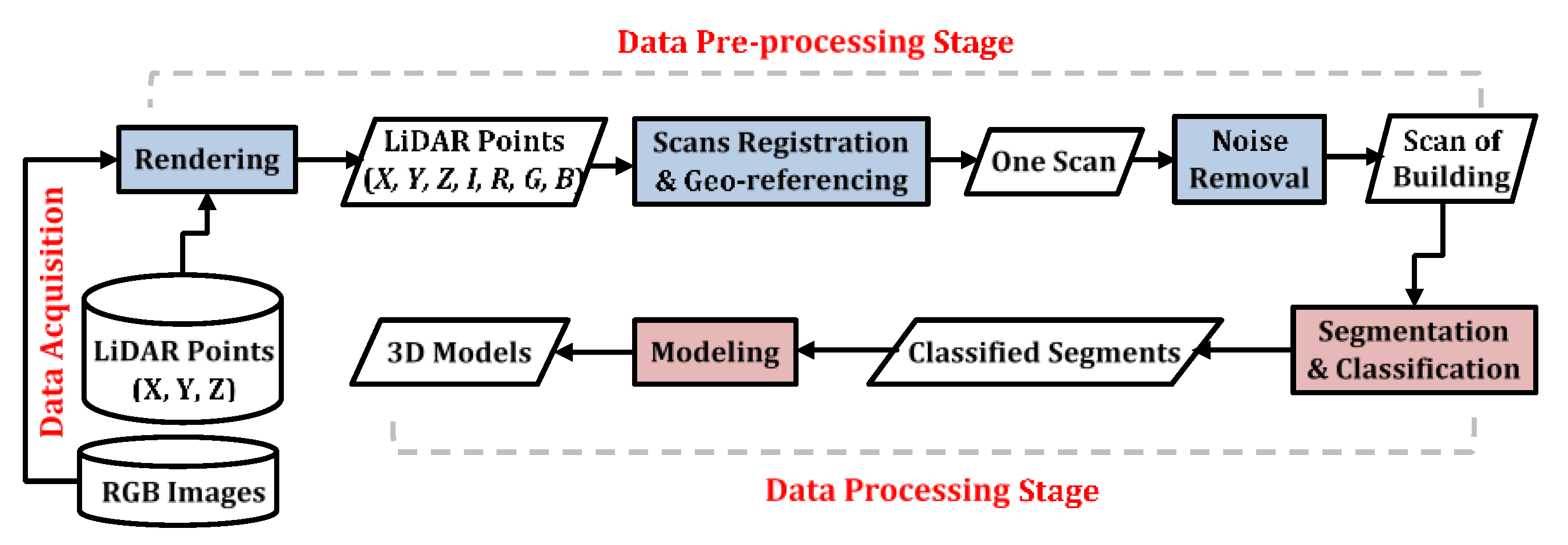
Several researchers have proposed a framework for scan-to-BIM using terrestrial laser scanning (TLS) systems [
3,
9]. The typical workflow for the scan-to-BIM can be summarized into three main stages: data acquisition stage, data pre-processing stage, and data processing stage as shown in
Figure 1. The data acquisition stage includes the determination of a specific level of details of the model required for the BIM application so that the data quality parameters (e.g., accuracy, spatial resolution and coverage) can be identified [
3,
12]. Data quality is directly associated with scanning device selection and scanning locations. The data pre-processing stage includes data registration, geo-referencing, and de-noising (i.e., noise removal). Most of the previous studies have used commercial software packages for registration, geo-referencing, or noise removal, such as Leica Cyclone [
13], Faro Scene [
7,
14], Trimble Realworks [
5] and Autodesk ReCap [
7,
9,
15]. A critical step in data pre-processing is data downsampling or downsizing [
10,
13,
14,
16]. Before processing, it is necessary to reduce the massive amount of data, and hence reduce the execution time. For instance, Wang et al. [
10] reduced the data by about half its size, while Abdelazeem et al. [
15] reduced the data by up to 95%. This was attributed to the method used in data downsampling. The data processing stage includes object recognition from point clouds and modelling those objects as BIM products. Several studies have imported the point clouds directly into commercial software packages for modelling different objects [
9]. Others have exported the point clouds after data pre-processing into BIM formats without applying any segmentation methods or object recognition steps using Autodesk Ecotect Analysis [
10,
17,
18], Trimble RealWorks [
5] or Autodesk Revit [
7,
13].
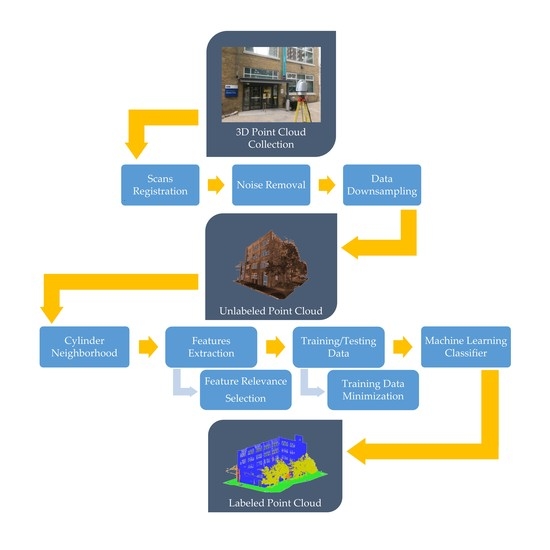
Overall, the scan-to-BIM framework relies on data acquisition, LiDAR point cloud classification, and 3D model construction. In this research, we focus on the LiDAR data classification of existing buildings, which is divided into three steps; neighborhood definition, LiDAR features extraction, and machine learning (ML) algorithms being applied to label each LiDAR point [
19,
20,
21,
22]. Generally, the classification results vary according to the implementation of the three aforementioned steps. In addition, the processing time is a crucial factor in LiDAR point cloud classification due to the vast amount of data being collected.
ML algorithms have been widely used in LiDAR data classification. They rely on a pre-trained model on a given data consisting of inputs and their corresponding outputs of the same characteristics. ML-based methods are divided into supervised and unsupervised methods. Supervised methods use attributes [
23] or feature descriptors [
24] extracted from LiDAR point cloud as inputs to ML algorithms, such as support vector machine (SVM) or random forests (RF) [
25,
26,
27]. Unsupervised methods are based on LiDAR point cloud clustering, such as k-means, DBSCAN (Density-Based Spatial Clustering of Applications with Noise) or hierarchical clustering [
28,
29,
30]. Several studies have used supervised methods, while few have been reported using unsupervised methods. Recent studies have moved to apply deep learning (DL) for point cloud classification, such as neural networks [
8,
24,
31,
32,
33]. In general, supervised ML and DL-based methods achieve accurate results. However, they require a considerable amount of pre-labeled data to be used in the training process, which is costly and time consuming.
Grilli et al. [
25] extracted different LiDAR point features based on the spherical neighborhood selection method. In addition, the Z-coordinate of points were incorporated for accuracy improvement. Then, the features were used as input for the RF classifier. They tested four heritage sites with different features configurations. The average accuracy measures reached 95.14% precision, 96.84% recall, and 95.82% F1-score in the best case studied. Teruggi et al. [
27] presented a multi-level and multi-resolution workflow for point cloud classification of historical buildings using RF classifier. They aimed to document detailed objects by applying three levels of searching radius on three levels of point resolution with an average F1-score of 95.83%.
Few studies were reported on building classification from TLS data. Chen et al. [
34] adapted the large density variation in the TLS data by presenting a building classification method using density of projected points filter. First, facade points were detected based on a polar grid, followed by applying a threshold to distinguish facades from other objects. The filtering result was then refined using an object-oriented decision tree. The roof points were finally extracted by region growing being applied on the non-facade points. Two datasets were tested in this study and revealed an average completeness and correctness of 91.00% and 97.15%, respectively. Yuan et al. [
35] used TLS data for building materials classification using ML algorithms. They evaluated different supervised learning classifiers using material reflectance, color values, and surface roughness. The highest overall accuracy of 96.65% was achieved for classifying ten building materials using the bootstrap aggregated decision trees.
Earlier in the last decade, Martinez et al. [
36] proposed an approach for building facade extraction from unstructured TLS point cloud. The main plane of the building’s façade was first extracted using the random sample consensus algorithm (RANSAC) algorithm, followed by establishing a threshold in order to automatically remove points outside the façade. The facade points were then segmented using local maxima and minima in the profile distribution function and statistical layer grouping. Each segmented layer was afterwards processed to find the façade contours. A total of 45 distances were manually measured using a total station as a reference. The mean error was 7 mm, with a standard deviation of 19 mm at an average point spacing of 10 mm. Although the high scores were revealed, the aforementioned approaches were applied on the whole point cloud available, resulting in more processing time and complex computations. Gonzalez et al. [
37] used TLS intensity data for damage recognition of historical buildings. Two-dimensional intensity images were generated from the 3D point cloud. Then, three unsupervised classifiers were applied, k-means, ISODATA, and fuzzy k-means, demonstrating average overall accuracy of 75.23%, 60.29%, and 79.85%, respectively. The aforementioned studies relied on either the intensity data [
35,
37] or the direct use of XYZ coordinates [
34,
37]. The intensity data require extensive correction and/or normalization that rely on the scan angle and distances between the TLS and scanned objects. On the other hand, geometry-based features are currently extracted from the XYZ coordinates that improve classification accuracies.
Recently, the classification process has been carried out using ML algorithms for BIM applications. In contrast, labeled data are used to train an ML model, and hence that model is used to classify the whole unlabeled dataset. Therefore, high classification accuracy methods running at acceptable processing time are required, especially with the availability of many features that could be extracted from the LiDAR point cloud. The objectives of this paper are as follows: (1) assess the relevance of LiDAR-derived features to 3D point classification, (2) optimize the training data size for LiDAR point cloud classification based on a ML algorithm, and (3) evaluate different scenarios for ML inputs based on the contribution of LiDAR-derived features of the classification process.
3. Results and Discussion
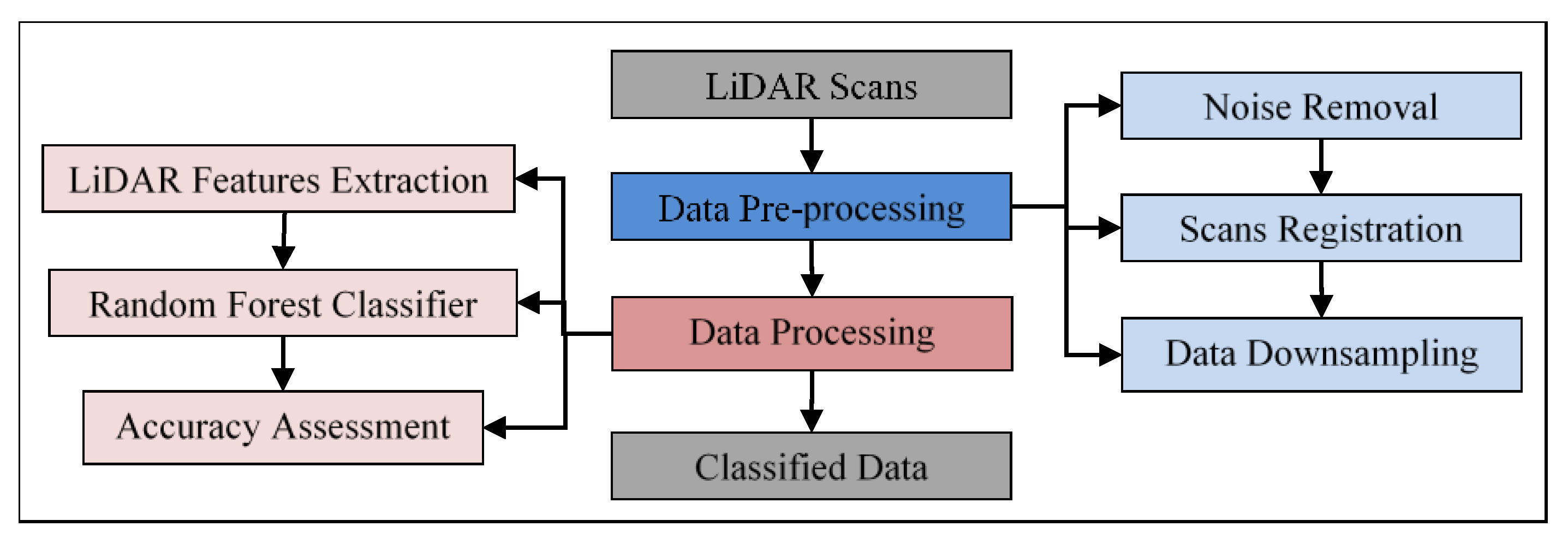
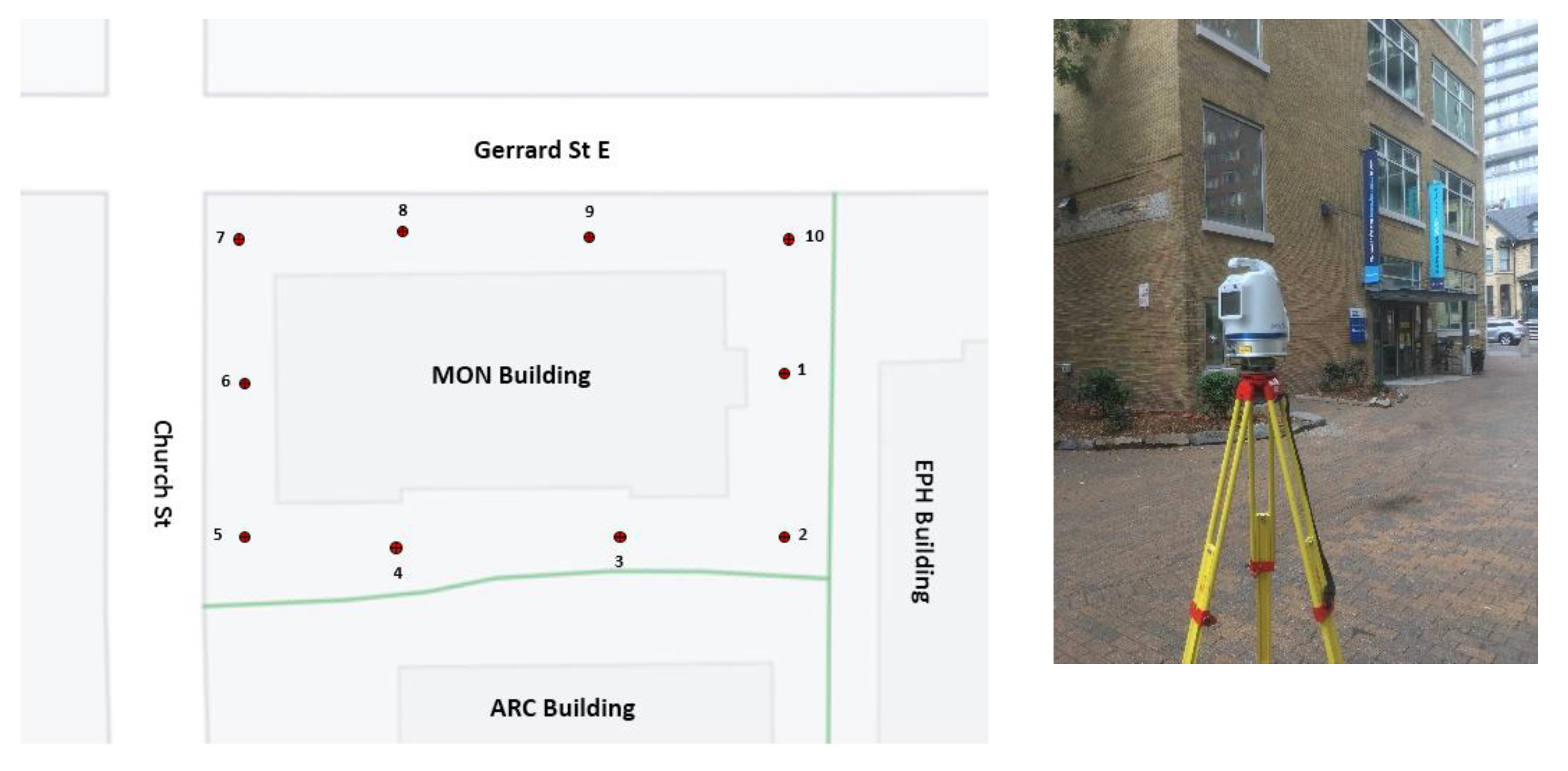
LiDAR point cloud pre-processing was employed using ATLAScan software package, developed by Teledyne Optech for processing Polaris system’s data. First, noise points were removed from each scan. Second, point cloud preregistration step was conducted. The preregistration procedures started by finding three couples of corresponding points among the scans. Then, a rough alignment between the imported scans was employed. Further, a bundle adjustment was carried out to improve the registration accuracy. The average registration error of corresponding points was 0.008 m. Finally, the 3D model for the MON building was created, and the LiDAR data in the format of XYZ were exported with more than 52 million points as shown in
Figure 4. It should be noted that the intensity as well as RGB values for each point have not been utilized in this research.
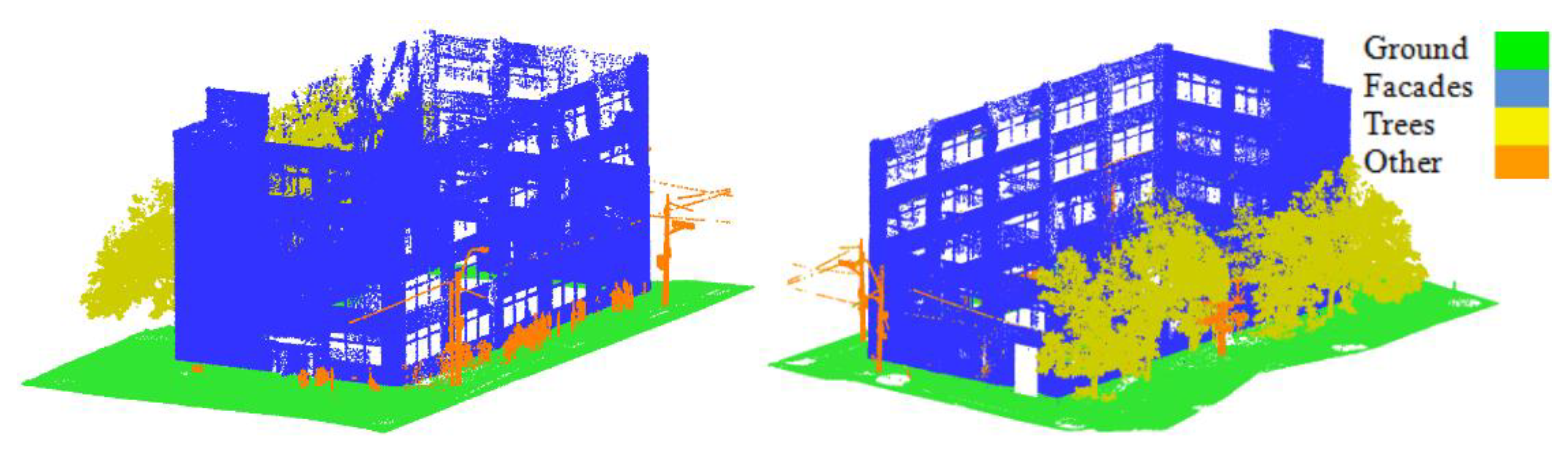
After that, the data were downsampled using the space method function embedded in the CloudCompare software with a point spacing of 2.5 cm to preserve the geometry of the building. Thus, the number of points was decreased by about 95% (about 2.6 million points). Several tests were conducted in order to conclude the suitable point spacing which achieved the desired results without losing the 3D geometry of the data. Point spacing of 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, and 3.5 cm were tested. It was found that the 2.5 cm reduced the number of points and kept the geometry of the building. This was a necessary step in LiDAR point cloud processing to reduce the execution time of either features extraction or points classification. Before proceeding with the data processing phase, the LiDAR points were manually labeled into four classes, namely ground, facades, trees, and others, as shown in
Figure 5, to be used in the training/testing process.
Table 3 provides the number of points for each class.
The data processing phase started with a neighborhood selection method. The cylindrical neighborhood was used with a radius of 0.1 m. This value was a trade-off to ensure a sufficient number of points in the neighborhood and reduce the execution time. Then, the aforementioned sixteen LiDAR geometrical features were extracted to feed the RF classifier. For each point, a 3 × 3 covariance matrix from its neighborhood was derived as shown in Equation (1). Eigenvalues and Eigenvectors were then calculated from the covariance matrix. The eight covariance features, four moment features as well as the Vert feature were extracted. Likewise, the height features were extracted based on the Z-coordinate. The RF classifier was then applied with Gini as the splitting function and hyper-parameters of number of trees equals to 50 and tree depth equals to 50. The training data were selected as randomly stratified to guarantee all classes were presented proportionally to their size in the training data, while the testing step was conducted on the whole dataset. A 10-fold cross-validation was then applied on the training data to evaluate the RF model and resulted in a mean score of 99.18%, with a standard deviation of ±0.02%.
The testing data was evaluated to address the three objectives of this research. First, the sixteen features were considered in the classification process to demonstrate the contribution of each feature. Second, the training data was reduced and the classification accuracy was recorded in order to track the minimal training data used without significant decrease in the accuracy. Third, the impact of using most contributing features to the classification process was studied. The accuracy metrics were finally calculated for the aforementioned cases. The data processing stage was implemented in the Python programing language and run on a Dell machine with Intel® Xeon® processor E5-2667 v4, 3.20 GHz and 128 GB RAM.
3.1. Relevance of LiDAR-Derived Features to 3D Point Classification
The sixteen LiDAR-derived features were used to classify the dataset. In this case, the training data were used as 50% to demonstrate the capability of each feature.
Figure 6 shows the classified point cloud, and
Table 4 shows the confusion matrix and accuracy metrics of the classification. The results revealed an overall classification accuracy of 99.49%. The accuracy metrics showed high scores for the individual classes.
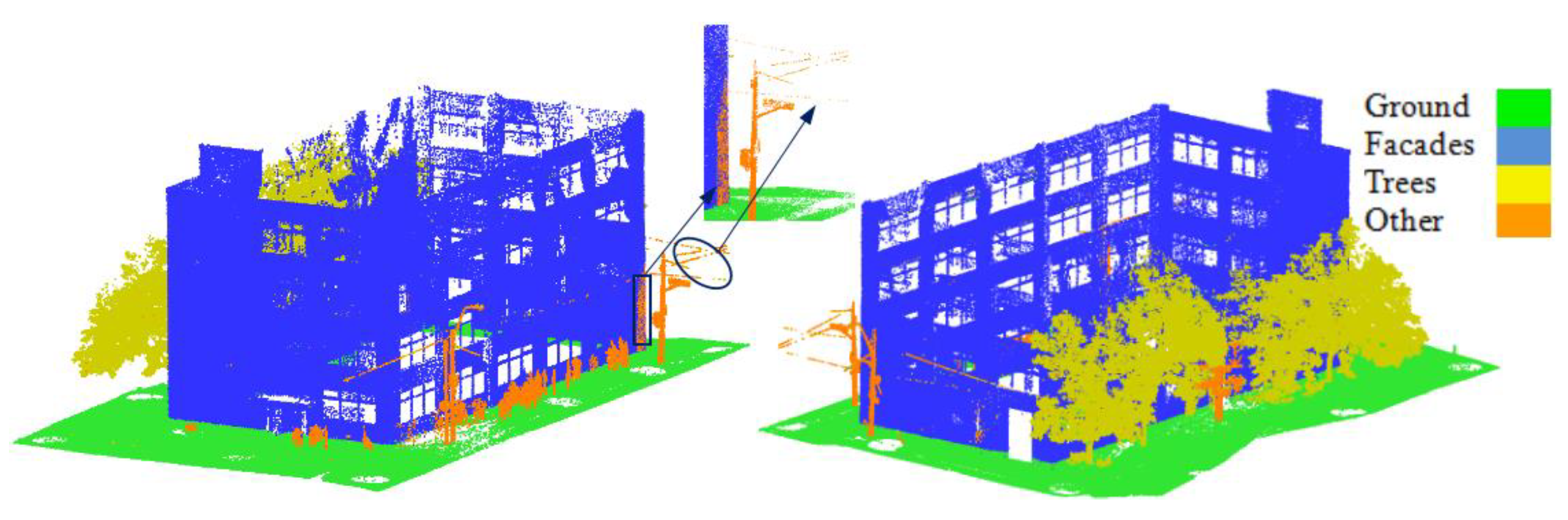
With the focus on the individual classes, ground, facades, and trees demonstrated more than 99% in all accuracy metrics. On the other hand, the others class demonstrated lower values in accuracy metrics of 90.05%, 97.38% and 93.5% in precision, recall, and F1-score, respectively. This was mainly because this class included many objects, such as streetlights, power lines, road signs, pedestrians, and a small steel structure. This could be because road signs are a planar surface similar to facades and very close to them as shown in
Figure 6 (black bounds). About 8.47% of façades points were wrongly classified as others, decreasing the precision of the class. Also, about 1.43% of the others class points were wrongly classified as trees due to the similarity of scatter behavior between and sparse point of power lines.
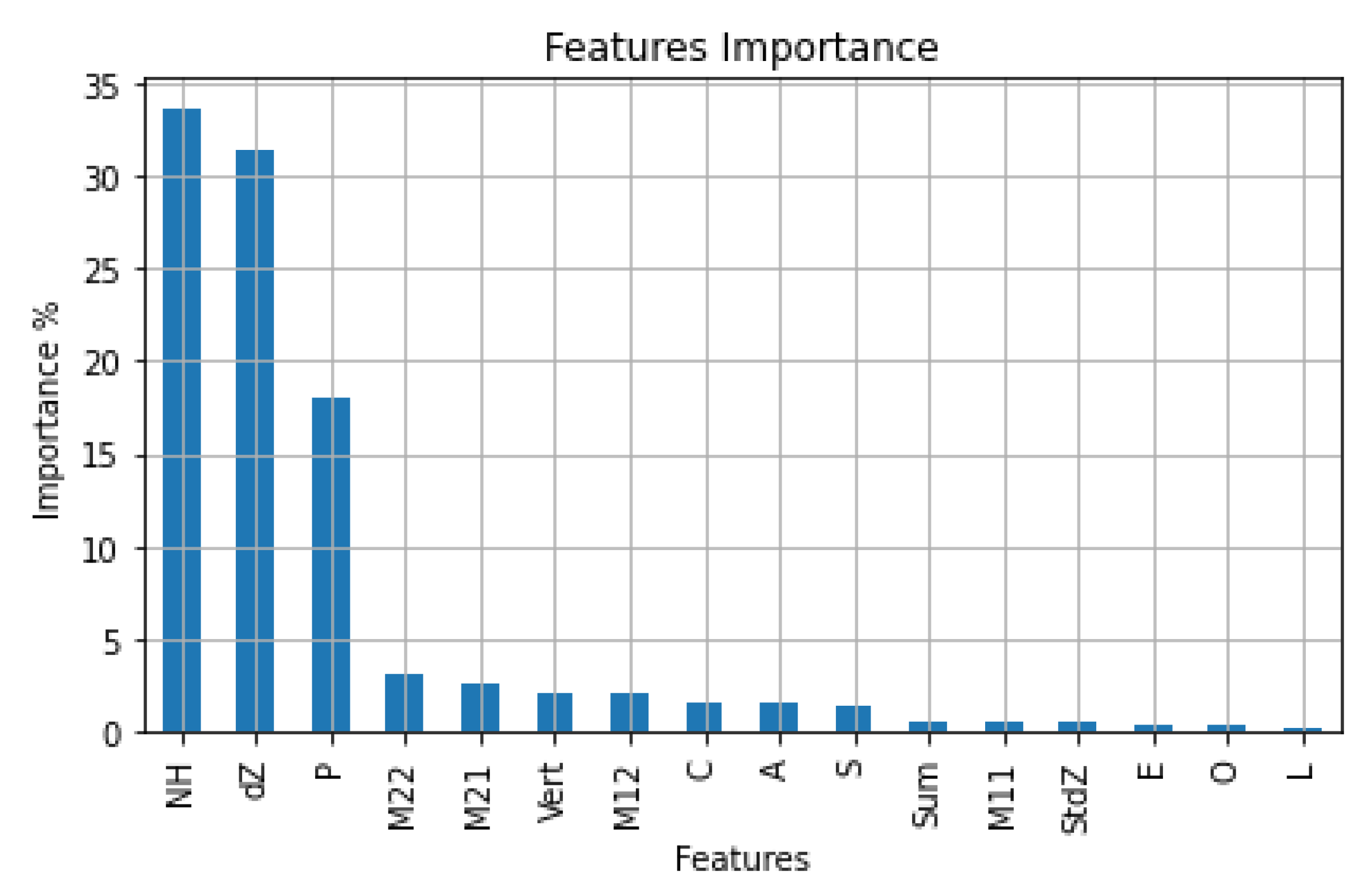
The contribution of LiDAR-derived features to the classification process was then studied. The features importance was calculated as shown in
Figure 7. The
NH feature was the most contributing feature with 33.55%, while the
dZ feature occupied the second order with 31.29%. They were followed by
Pλ feature (17.96%), then M
22,
M21, Vert, and
M12 features, with more than 2% each, while the rest demonstrated less than a 2% contribution. The first three features (i.e.,
NH,
dZ, and
Pλ, respectively) were the more significant features in the classification due to the vertically organized LiDAR point cloud of facades and tree trunks as well as facades and ground exhibited planar surfaces.
3.2. Minimal Training Data Determination
In this section, we evaluated the classification accuracy vs. different training data sizes. The purpose of that was to minimize the training data as possible, which in turn reduced the processing time, while maintaining the accuracies at a certain level. Thus, training data of 70%, 50%, 30%, 10%, and 5% were considered with testing the whole dataset. The results of the aforementioned cases are listed in
Table 5.
The results demonstrated that we can reduce the taring data along with preserving the accuracy level. Considering the overall accuracy, we can see a slight decrease from using 70% to 50% training by only 0.09% as well as from using 50% to 30% training by 0.14%, while a significant drop appeared moving to 10% and 5% training by 0.32% and 0.24%, respectively. Thus, 99% overall accuracy could be achieved with using 10% training data, with reduction of processing time reaching about 88% (70% training data) and 83% (50% training data). It should be noted that the presented time in
Table 4 is only for training and testing process. The features extraction time was about 90 min for the sixteen features. In addition, the low time (i.e., in seconds) of training and testing process was due to the high capability of the workstation used.
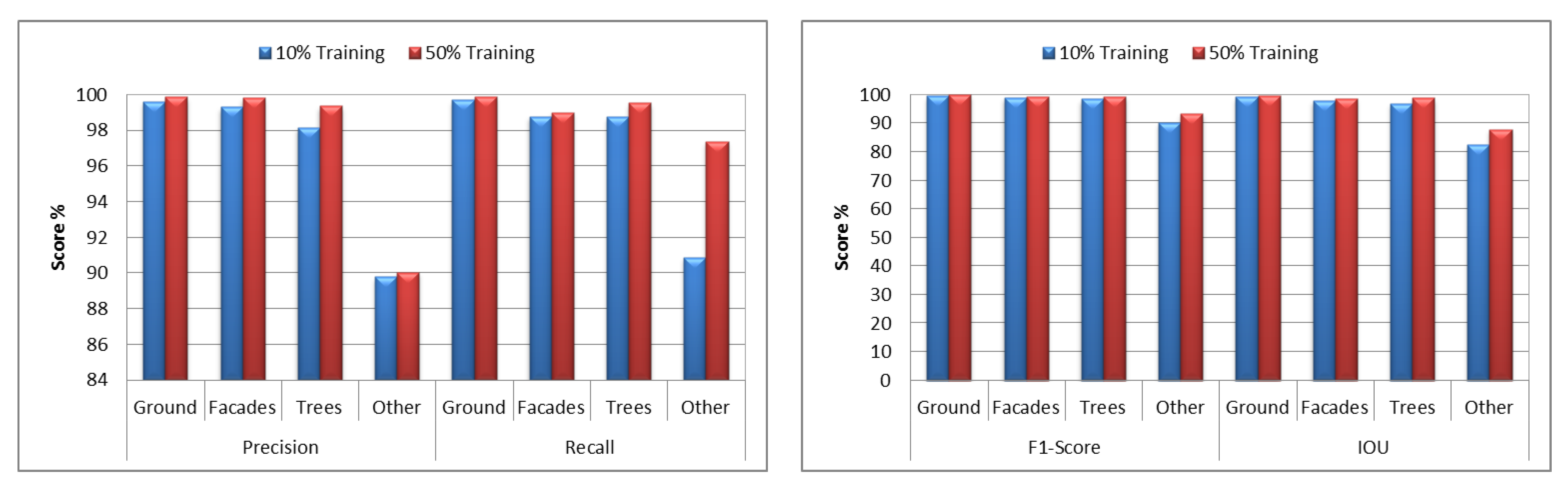
Figure 8 shows the individual classes’ accuracy measures of 10% and 50% training data. Ground, facades, and trees classes have close accuracy metrics for both training cases, while the others class from 10% training data has lower accuracy metrics than those from 50% training data. However, this is acceptable as the main classes have achieved high accuracy metrics.
3.3. The Impact of Features Reduction
Section 3.1 demonstrated the order of features that contributed to the classification process. In this section, the six most relevant features (i.e.,
NH,
dZ,
Pλ,
M22,
M21, and
Vert) as well as three features (i.e.,
NH,
dZ, and
Pλ) were studied in terms of accuracy metrics and processing time. The features extraction time for the six and three features were about 66 min and 47 min, respectively, with a decrease of extraction time by 27% and 48% compared to sixteen features extraction.
Table 6 and
Table 7 provide the accuracy metrics and processing time against different sizes of training data for testing six and three features, respectively.
Considering the most important six features, the training and classification time reduced from 45 s to 10 s, by about 78%. The use of 10% training data achieved the overall accuracy level at 99%. To preserve 99% overall accuracy using the three features with the highest importance, a 50% training set should be considered. The training and classification time were decreased by about 31% in this case.
3.4. Comparison with Previous Studies
The literature is lacking studies concerned about the minimization of training data of point cloud classification. On the other hand, many studies considered LiDAR data classification using different LiDAR-derived features, different neighborhood selection, and different classification methods [
19,
20,
21,
40,
42,
46]. Those studies demonstrated classification accuracies between 85.70% and 97.55%, while our method achieved a higher score of 99% average overall accuracy. It should be noted that we only considered four classes (ground, facades, trees, and others).
For a quantitative comparison, we applied the proposed LiDAR-derived features in previous studies on our dataset. For instance, Weinmann et al. [
20] tested twelve 3D features, including the eight covariance features, verticality, the two height features, and point density. They also tested 2D features, but we focused here on the features extracted from 3D points directly. Among different features sets, Weinmann et al. [
40] evaluated the eight covariance features only as eigenvalue-based features. Hackel et al. [
21] added four moment features and two height features defined as height below and height above the tested points, but excluded the height standard deviation (
dZ). As a result, they tested sixteen LiDAR-derived features.
Table 8 provides F1-score and overall accuracy of the aforementioned studies compared to our case. It is shown that we have achieved high scores of F1-score for all individual classes and overall accuracy. Thus, the achieved classification results have proven the usefulness of incorporating the
NH feature.
4. Conclusions
In this paper, we have classified the 3D point cloud of a campus building using LiDAR geometrical features and an RF classifier. The NH, a LiDAR-derived feature had the highest contribution percentage (more than 30%) to the classification process. The overall classification accuracy was improved by about 4.16% when the NH feature was incorporated. In addition, precision, recall and F1-score have been improved for all classes.
Supervised ML classifiers, such as the RF classifier, in most cases, achieve good results. However, they require a massive amount of annotated dataset to be used as training samples. Therefore, in this research, we tested different training data sizes against the overall accuracy and execution time. Using 10% of the whole dataset as training samples has demonstrated about 99% overall accuracy with 82% reduction of training and classification time compared to using 50% training samples.
Since the execution time is crucial in the classification process, we have tested a reduced number of features for the classification. The six and three most relevant features to the classification process were evaluated. A significant drop of features extraction time was achieved by about 27% and 48% compared to sixteen features extraction time. Also, the training and classification time was decreased by about 78% and 40%, respectively, to preserve the overall classification accuracy at 99%. Overall, this paper gives a variety of options for using training data to achieve certain accuracies with acceptable processing time.
Improvement of point cloud classification is the first step toward digital model creation that is expected to help in making informed decisions about existing buildings, such as designing of a reconstruction or extension, improvement of the building’s energy efficiency, and implementation of a smart campus or city. It also opens doors for BIM-related applications, such as the operation and maintenance, heritage documentation, and structural health monitoring. Future work will focus on incorporating the intensity and RGB values collected with the data and test their ability in improving the results of 3D point cloud classification. In addition, high-detailed building elements and building indoor environment, as well as infrastructure-related applications such as road/railways maintenance, and bridges inspection will be considered.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}