1. Introduction
The overall grape production in the United States has reached 6.05 million tons in 2021, in which approximately 5.78 million tons (~96%) were from wine grape production in California and Washington [
1]. To maintain the premium quality of wine, vineyards need to be elaborately managed so that the quantity and quality of the grapes can be well balanced for maximum vineyard profitability. Such vineyard management can be difficult because the number of berry bunches should be closely monitored by laborers throughout the entire growing season to avoid a high volume of bunches overburdening the plant and thus the berry composition may not be optimal [
2]. Presenting this information can help the growers to timely prune and thin the grape clusters during the growing season. This presents significant challenges for wine grape growers and managers due to the agricultural workforce shrinking and cost increasing. Potentially, this issue might be mitigated by leveraging the superiority of state-of-the-art computer vision technologies and data-driven artificial intelligence (AI) techniques [
3].
Object detection is one of the fundamental tasks in computer vision, which is used for detecting instances of one or more classes of objects in digital images. Several common challenges, that prevent a target object from being successfully detected, include but are not limited to variable outdoor light conditions, scale changes in the objects, small objects, and partially occluded objects. In recent years, numerous deep learning-driven object detectors have been developed for various real-world tasks, such as fully connected networks (FCNs), convolutional neural networks (CNNs), and Vision Transformer. Among these, CNN-based object detectors have demonstrated promising results [
4,
5]. Generally, CNN-based object detectors can be divided into two types, including one-stage detectors and two-stage detectors. The one-stage detector uses a single network to predict the bounding boxes and calculates the class probabilities of the boxes. Two-stage detector first proposes a set of regions of interest (i.e., region proposal) where the potential bounding box candidates can be infinite, then a classifier processes the region candidates only. Taking a few examples, one-stage detectors include Single Shot Multibox Detector (SSD) [
6], RetinaNet [
7], Fully Convolutional One-Stage (FCOS) [
8], DEtection TRansformer (DETR) [
9], EfficientDet [
10], You Only Look Once (YOLO) family [
11,
12,
13,
14], while two-stage detectors include region-based CNN (R-CNN) [
15], Fast/Faster R-CNN [
16,
17], Spatial Pyramid Pooling Networks (SPPNet) [
18], Feature Pyramid Network (FPN) [
19], and CenterNet2 [
20].
As agriculture is being digitalized, both one-stage and two-stage object detectors have been widely applied to various orchard and vineyard scenarios, such as fruit detection and localization, with promising results achieved. Some of the major reasons, which made object detection challenging in agricultural environments, include severe occlusions from non-target objects (e.g., leaves, branches, trellis-wires, and densely clustered fruits) to target objects (e.g., fruit) [
21]. Thus, in some cases, the two-stage detectors were preferred by the researchers due to their greater accuracy and robustness. Tu et al. [
22] developed an improved model based on multi-scale Faster R-CNN (MS-FRCNN) that used both RGB (i.e., red, green, and blue) and depth images to detect passion fruit. Results indicated that the precision of the proposed MS-FRCNN was improved from 0.85 to 0.93 (by ~10%) compared to generic Faster R-CNN. Gao et al. [
21] proposed a Faster R-CNN-based multi-class apple detection model for dense fruit-wall trees. It could detect apples under different canopy conditions, including non-occluded, leaf-occluded, branch/trellis-wire occluded, and fruit-occluded apple fruits, with an average detection accuracy of 0.879 across the four occlusion conditions. Additionally, the model processed each image in 241 ms on average. Although two-stage detectors have shown robustness and promising detection results in agricultural applications, there is still one major concern, the high requirement of computational resources (leading to slow inference speed), to further implement them in the field. Therefore, it has become more popular nowadays to utilize one-stage detectors in identifying objects in orchards and vineyards, particularly using YOLO family models with their feature of real-time detection.
Huang et al. [
23] proposed an improved YOLOv3 model for detecting immature apples in orchards, using Cross Stage Partial (CSP)-Darknet53 as the backbone network of the model to improve the detection accuracy. Results showed that the F1-Score and mean Average Precision (mAP) were 0.65 and 0.68, respectively, for those severely occluded fruits. Furthermore, Chen et al. [
24] also improved the YOLOv3 model for cherry tomato detection, which adopted a dual-path network [
25] to extract features. The model established four feature layers at different scales for multi-scale detection, achieving an overall detection accuracy of 94.3%, recall of 94.1%, F1-Score of 94.2%, and inference speed of 58 ms per image. Lu et al. [
26] introduced a convolutional block attention module (CBAM) [
27] and embedded a larger-scale feature map to the original YOLOv4 to enhance the detection performance on canopy apples in different growth stages. In general, object detectors tend to have false detections when occlusion occurs, no matter using a one-stage or two-stage detector. YOLO family detectors, like many other widely adopted detectors, could also have information loss affected by canopy occlusions. During the past two years, Vision Transformer has demonstrated outstanding performances in numerous computer vision tasks [
28] and, therefore, is worth being further investigated to be employed together with YOLO models in addressing the challenges.
A typical Vision Transformer architecture is based on a self-attention mechanism that can learn the relationships between components of a sequence [
28,
29]. Among all types, Swin-transformer is a novel backbone network of hierarchical Vision Transformer, using a multi-head self-attention mechanism that can focus on a sequence of image patches to encode global, local, and contextual cues with certain flexibilities [
30]. Swin-transformer has already shown its compelling records in various computer vision tasks, including region-level object detection [
31], pixel-level semantic segmentation [
32], and image-level classification [
33]. Particularly, it exhibited strong robustness to severe occlusions from foreground objects, random patch locations, and non-salient background regions. However, using Swin-transformer alone in object detection requires large computing resources as the encoding–decoding structure of the Swin-transformer is different from the conventional CNNs. For example, each encoder of Swin-transformer contains two sublayers. The first sublayer is a multi-head attention layer, and the second sublayer is a fully connected layer, where the residual connections are used between the two sublayers. It can explore the potential of feature representation through a self-attention mechanism [
34,
35]. Previous studies on public datasets (e.g., COCO [
36]) have demonstrated that Swin-transformer outperformed other models on severely occluded objects [
37]. Recently, Swin-transformer has also been applied in the agricultural field. For example, Wang et al. [
38] proposed “SwinGD” for grape bunch detection using Swin-transformer and Detection Transformer (DETR) models. Results showed that SwinGD achieved 94% of mAP, which was more accurate and robust in overexposed, darkened, and occluded field conditions. Zheng et al. [
39] researched a method for the recognition of strawberry appearance quality based on Swin-transformer and Multilayer Perceptron (MLP), or “Swin-MLP”, in which Swin-transformer was used to extract strawberry features and MLP was used to identify strawberry according to the imported features. Wang et al. [
40] improved the backbone of Swin-transformer and then applied it to identify cucumber leaf diseases using an augmented dataset. The improved model had a strong ability to recognize the diseases with a 99.0% accuracy.
Although many models for fruit detection have been studied in orchards and vineyards [
26,
41,
42,
43,
44,
45,
46,
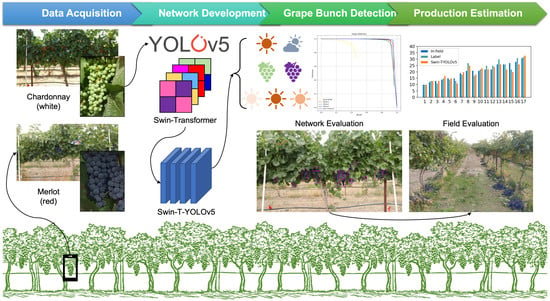
47], the critical challenges in grape detection in the field environment (e.g., multi-variety, multi-stage of growth, multi-condition of light source) have not yet been fully studied using a combined model of YOLOv5 and Swin-transformer. In this research, to achieve better accuracy and efficiency of grape bunch detection under dense foliage and occlusion conditions in vineyards, we architecturally combined the state-of-the-art, one-stage detector of YOLOv5 and Swin-transformer (i.e., Swin-Transformer-YOLOv5 or Swin-T-YOLOv5), so that the proposed new network structure had the potential to inherently preserve the advantages from both models. The overarching goal of this research was to detect wine grape bunches accurately and efficiently under a complex vineyard environment using the developed Swin-T-YOLOv5. The specific research objectives were to:
Effectively detect the in-field wine grape bunches by proposing a novel combined network architecture of Swin-T-YOLOv5 using YOLOv5 and Swin-transformer;
Compare the performance of the developed Swin-T-YOLOv5 with other widely used object detectors, including Faster R-CNN, generic YOLOv3, YOLOv4, and YOLOv5, and investigate the results under different scenarios, including different wine grape varieties (i.e., white variety of Chardonnay and red variety of Merlot), weather conditions (i.e., sunny and cloudy), berry maturities or growth stages (i.e., immature and mature), and sunlight directions/intensities (i.e., morning, noon, and afternoon) in vineyards.
4. Discussion
Compared to other fruits, such as apple, citrus, pear, and kiwifruit, grape bunches in the vineyards have more complex structural shapes and silhouette characteristics to be accurately detected using machine vision systems. Accurate and fast identification of overlapped grape bunches in dense foliage canopies under natural lighting environments remains to be a key challenge in vineyards. Therefore, this research proposed the combination of architectures from a conventional CNN YOLOv5 model and a Swin-transformer model that can inherit the advantages of both models to preserve global and local features when detecting grape bunches (
Figure 4). The newly integrated detector (i.e., Swin-T-YOLOv5) worked as expected in overcoming the drawbacks of CNNs in capturing the global features (
Figure 5).
Our proposed Swin-T-YOLOv5 was tested on two different wine grape varieties, two different weather/sky conditions, two different berry maturity stages, and three different sunlight directions/intensities for its detection performance (
Table 1). A comprehensive evaluation was made by comparing Swin-T-YOLOv5 against various commonly used detectors (
Table 4). Results verified that our proposed Swin-T-YOLOv5 outperformed all other tested models under any listed environmental conditions with achieved 90.3–97.2% mAPs. The best and worst results were obtained under cloudy weather and berry immature conditions, respectively, with a 6.9% in difference.
Specifically, Swin-T-YOLOv5 performed the best under cloudy weather conditions with the highest mAP of 97.2%, which was 1.8% higher than in sunny weather conditions (
Table 5), although the difference was inconsiderable. While testing the models at different berry maturity stages, Swin-T-YOLOv5 performed much better when the berries were mature with 95.9% of mAP than immature berries (with 5.6% lower mAP;
Table 6). It has been verified that crop early thinning can provide more berry quality benefits than late thinning in vineyards [
51]. Therefore, early (immature stage) grape bunch detection is more meaningful than late (mature stage) detection in our study. However, early detection is challenging because the berries tended to be smaller in size and lighter in color during the early growth stage and thus more difficult to be detected. Moreover, Swin-T-YOLOv5 achieved better mAP at noon (94.5%) than the other two timings in the day (
Table 7), while the afternoon sunlight condition more negatively affected the model with a lower mAP of 92.0% than in the morning. Apparently, the effectiveness of the berry maturities and light directions can be the major reasons for impacting the performances of the models, while weather conditions almost did not change the detection results. The improvements from the original YOLOv5 to the proposed Swin-T-YOLOv5 varied based on the conditions (0.5–6.1%), however, the maximum increment happened when comparing them at noon (
Table 7). Overall, it was confirmed that the Swin-T-YOLOv5 achieved the best results in terms of mAP (up to 97.2%) and F1-score (up to 0.9) among all compared models in this research for wine grape bunch detections in vineyards. Its inference speed was the second best (13.2 ms per image) only after YOLOv5′s (11.8 ms per image) under any test conditions.
To further assess the model performance, we compared the predicted number of grape bunches by Swin-T-YOLOv5 with both manual labeling and in-field manual counting. The R
2 and RMSE between Swin-T-YOLOv5 and in-field counting had the similar trends of the ones between Swin-T-YOLOv5 and manual labeling in general, potentially because some of those heavily occluded grape bunches were not taken into consideration for labeling during the annotation process. However, the values changed vastly for the two different grape varieties under various conditions. It was clear that Swin-T-YOLOv5 did not perform well on the Merlot variety when the weather condition was sunny. While for Chardonnay, the model performed well under either condition (
Figure 6). Similarly, the performance of Swin-T-YOLOv5 was poor on the Merlot variety when the berries were immature. For Chardonnay, Swin-T-YOLOv5 achieved better results under either condition (
Figure 7). In addition, Swin-T-YOLOv5 underperformed on the Merlot variety when the sunlight condition was in the afternoon. Comparatively, it worked better on Merlot at noon. For Chardonnay, the predictions were more accurate (
Figure 8). This was possibly because the Merlot variety had a more complex combination of grape bunches when the berries were immature with either white or white–red mixed color (
Figure 1e), which may cause more detection errors under more challenging test conditions, such as when imaging against the direction of the light. In general, detecting grape bunches of the Merlot variety was more challenging than the Chardonnay variety under any test conditions in this research.
We found that our proposed Swin-T-YOLOv5 could enhance the accuracy of grape bunch detection when the grape bunches were slightly/moderately occluded or clustered, attributed to the Swin-transformer module that was added to the generic YOLOv5. For example, slight/moderate canopy occlusions and overlap of grape clusters can cause detection errors in terms of detected number of bounding boxes, i.e., underestimations in
Figure 9a,b, overestimation in
Figure 9c, and bounding box misplace in
Figure 9d, comparing the results from YOLOv5 and Swin-T-YOLOv5. Swin-transformer module assisted in detecting the objects in line with common sense under such conditions. Clearly, introducing the self-attention mechanism in the backbone network should be a right direction.
Although Swin-T-YOLOv5 outperformed all other tested models in detecting grape bunches under various external or internal variations, detection failures (i.e., TNs and FPs) happened more frequently in several scenarios as illustrated in
Figure 10. For example, severe occlusion (mainly by leaves) caused detection failure, which was the major reason for having TNs and FPs in this research as marked out using the red bounding boxes, particularly when the visible part of grape bunches were small (
Figure 10e,f) or having the similar color compared to the background (
Figure 10a–c). In addition, clustered grape bunches can cause detection failures, where two grape bunches were detected as one (
Figure 10d).
5. Conclusions
This research proposed an optimal and real-time wine grape bunch detection model in natural vineyards by architecturally integrating YOLOv5 and Swin-transformer detectors, called Swin-T-YOLOv5. The research was carried out on two different grape varieties, Chardonnay (white color of berry skin when mature) and Merlot (red color of berry skin when mature), throughout the growing season from 4 July 2019 to 30 September 2019 under various testing conditions, including two different weather/sky conditions (i.e., sunny and cloudy), two different berry maturity stages (i.e., immature and mature), and three different sunlight directions/intensities (i.e., morning, noon, and afternoon). Further assessment was made by comparing the proposed Swin-T-YOLOv5 with other commonly used detectors, including Faster R-CNN, YOLOv3, YOLOv4, and YOLOv5. Based on the obtained results, the following conclusions can be drawn:
Validation results verified the advancement of proposed Swin-T-YOLOv5 with the best precision of 98%, recall of 95%, mAP of 97%, and F1-score of 0.96;
Swin-T-YOLOv5 outperformed all other studied models under all test conditions in this research:
Two weather conditions: During sunny days, Swin-T-YOLOv5 achieved 95% of mAP and 0.86 of F1-score, which were up to 11% and 0.22 higher than others. During cloudy days, it achieved 97% of mAP and 0.89 of F1-score, which were up to 18% and 0.17 higher;
Two berry maturity stages: With immature berries, Swin-T-YOLOv5 achieved 90% of mAP and 0.82 of F1-score, which were up to 7% and 0.22 higher than others. With mature berries, it achieved 96% of mAP and 0.87 of F1-score, which were up to 10% and 0.11 higher;
Three sunlight directions/intensities: In the morning, Swin-T-YOLOv5 achieved 92% of mAP and 0.83 of F1-score, which were up to 17% and 0.18 higher than others. At noon, it achieved 95% of mAP and 0.86 of F1-score, which were up to 8% and 0.19 higher; In the afternoon, it achieved 92% of mAP and 0.85 of F1-score, which were up to 15% and 0.15 higher;
Swin-T-YOLOv5 performed differently on Chardonnay and Merlot varieties when comparing the predictions against the ground truth data (i.e., manual labeling and in-field manual counting). For the Chardonnay variety, Swin-T-YOLOv5 provided desired predictions under almost all test conditions, with up to 0.91 of R2 and 2.4 of RMSE. For the Merlot variety, Swin-T-YOLOv5 performed better under several test conditions (e.g., 0.70 of R2 and 3.3 of RMSE for mature berries), while underperformed when detecting immature berries (0.08 of R2 and 9.0 of RMSE).
A novel grape bunch detector, Swin-T-YOLOv5, proposed in this study has been verified for its superiority in terms of detection accuracy and inference speed. It is expected that this integrated detection model can be deployed and implemented on portable devices, such as smartphones, to assist wine grape growers for real-time precision vineyard canopy management. Our next steps include (1) designing and developing a front-end user interface (e.g., mobile application) and a back-end program to run the trained Swin-T-YOLOv5 model and (2) establishing a digital dataset repository on GitHub to further enlarge the image dataset specifically for grape canopies.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}