

A Region-Based Feature Fusion Network for VHR Image Change Detection

 , ,
, ,  , , , and
, , , and
Abstract
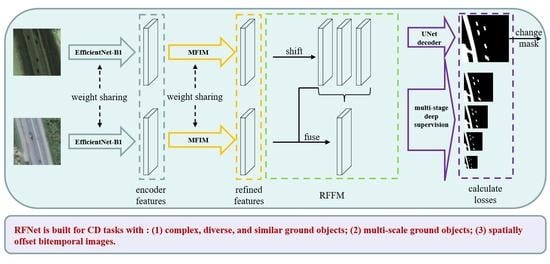
1. Introduction
- In the encoding stage, we design MFIM to strengthen the interaction of multi-stage features, so as to better extract features of complex objects and reduce the sensitivity of the network to different scale objects.
- We design RSIM, which takes the neighborhood as the base unit to measure the distance of bitemporal features. The similarity is formulated by introducing prior knowledge to reduce the impact of the spatial offset in bitemporal images.
- Based on RSIM, this paper designs an RFFM to generate changing information by fusing channel-wise enhanced bitemporal features. The RFFM strengthens the learning of change features with few parameters and calculation costs.
- Based on the idea of deep supervision, the region similarities are introduced to auxiliary tasks to help the network directly optimize deep features and get more discriminative features.
2. Methodology
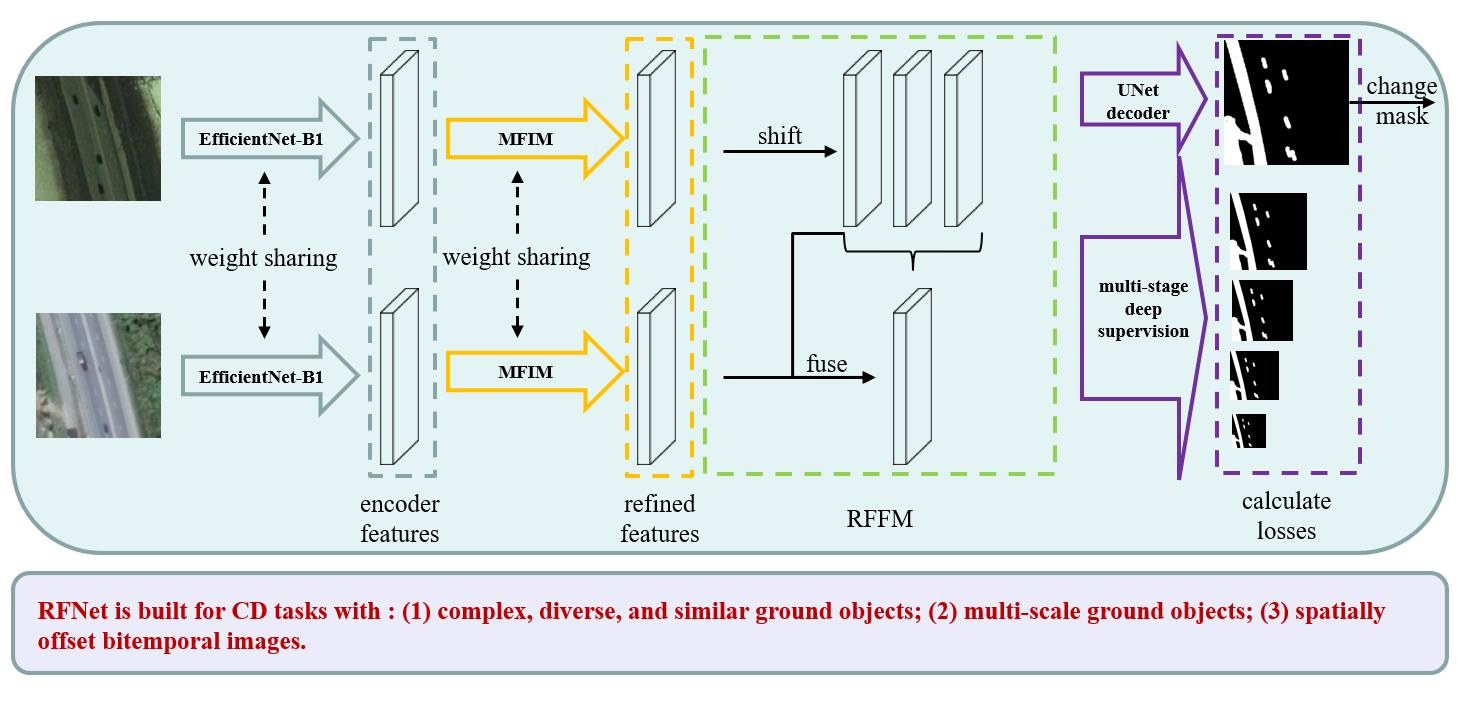
2.1. Overall Structure
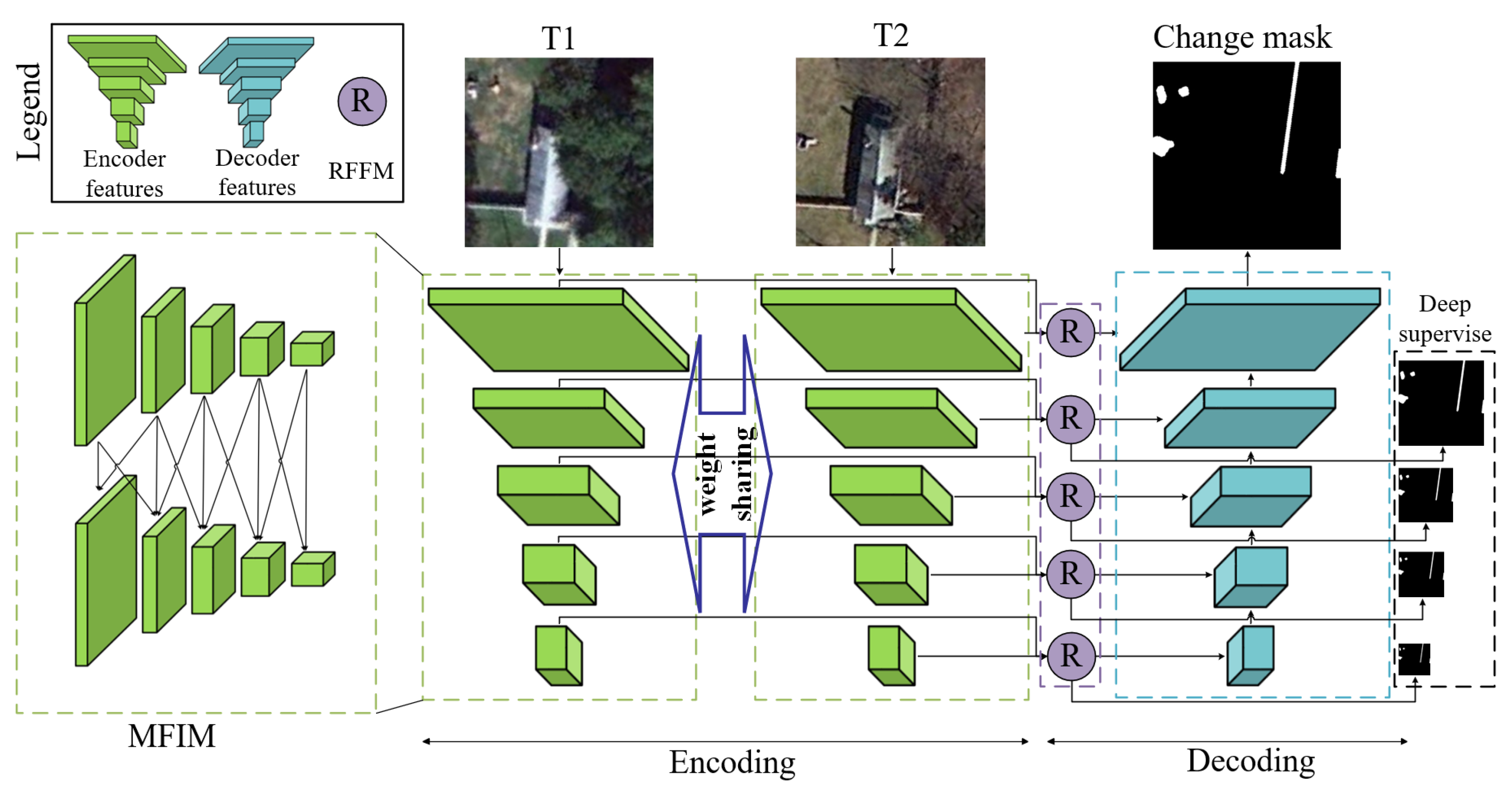
2.2. Multi-Stage Feature Interaction Module
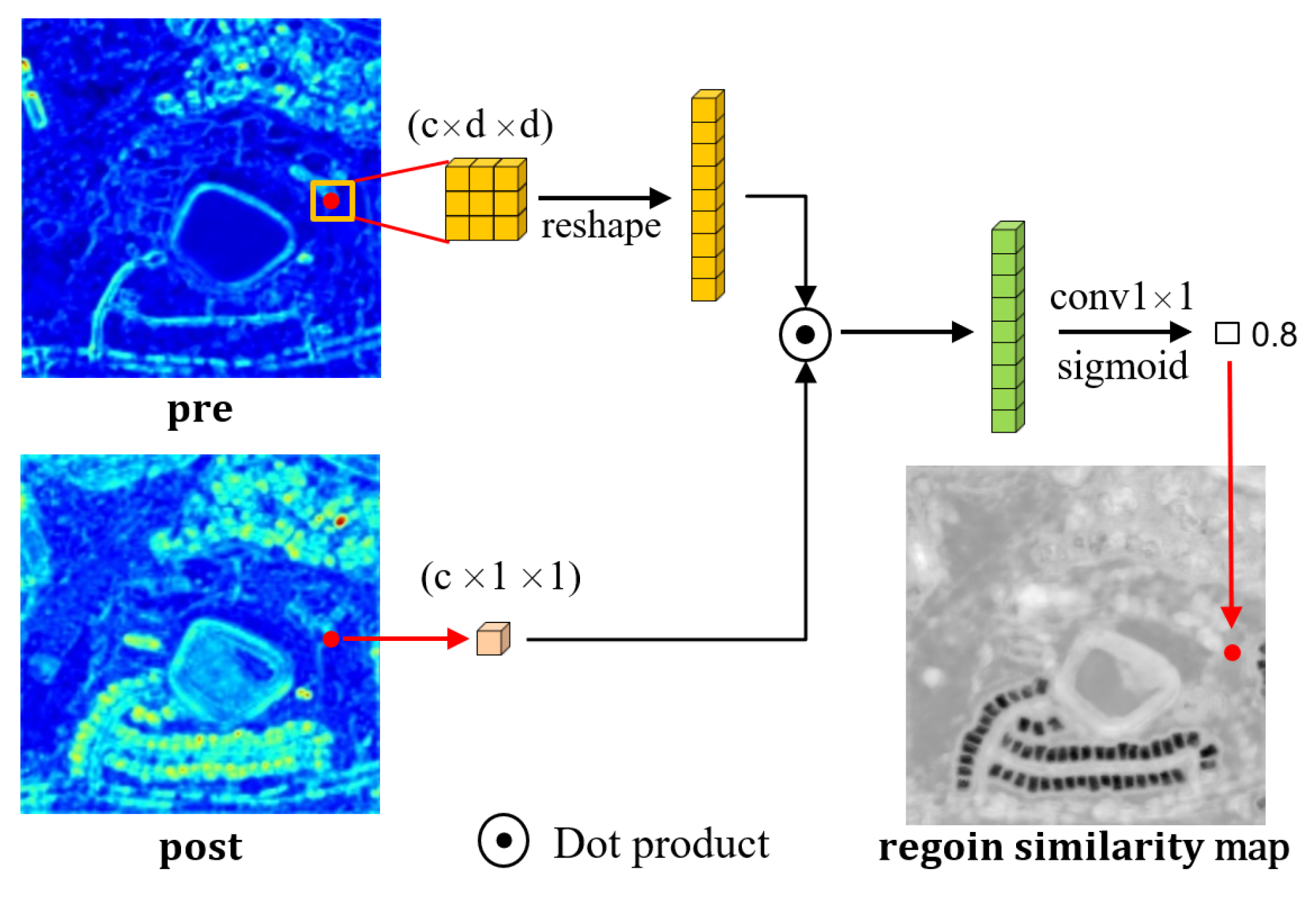
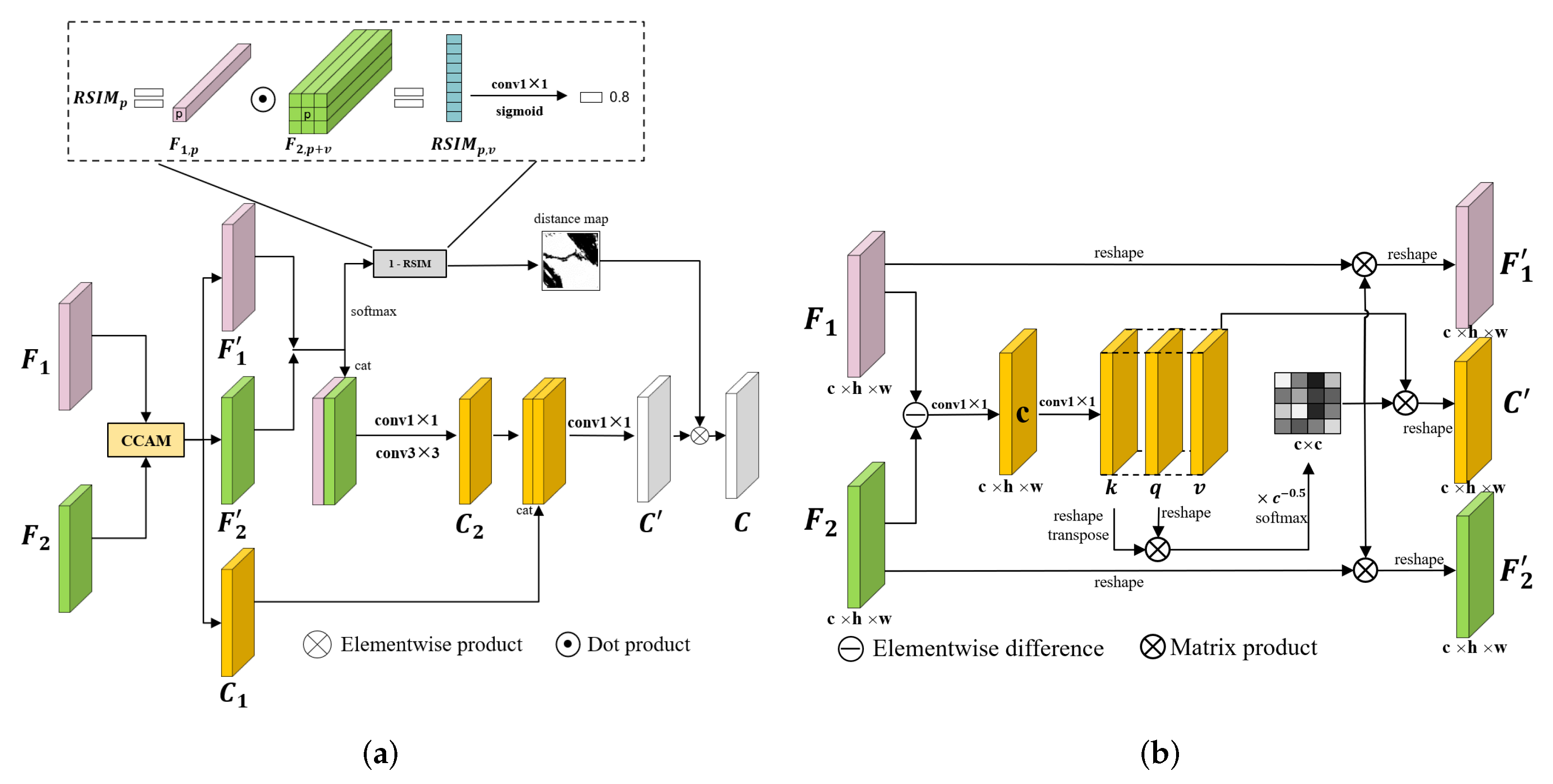
2.3. Region Similarity
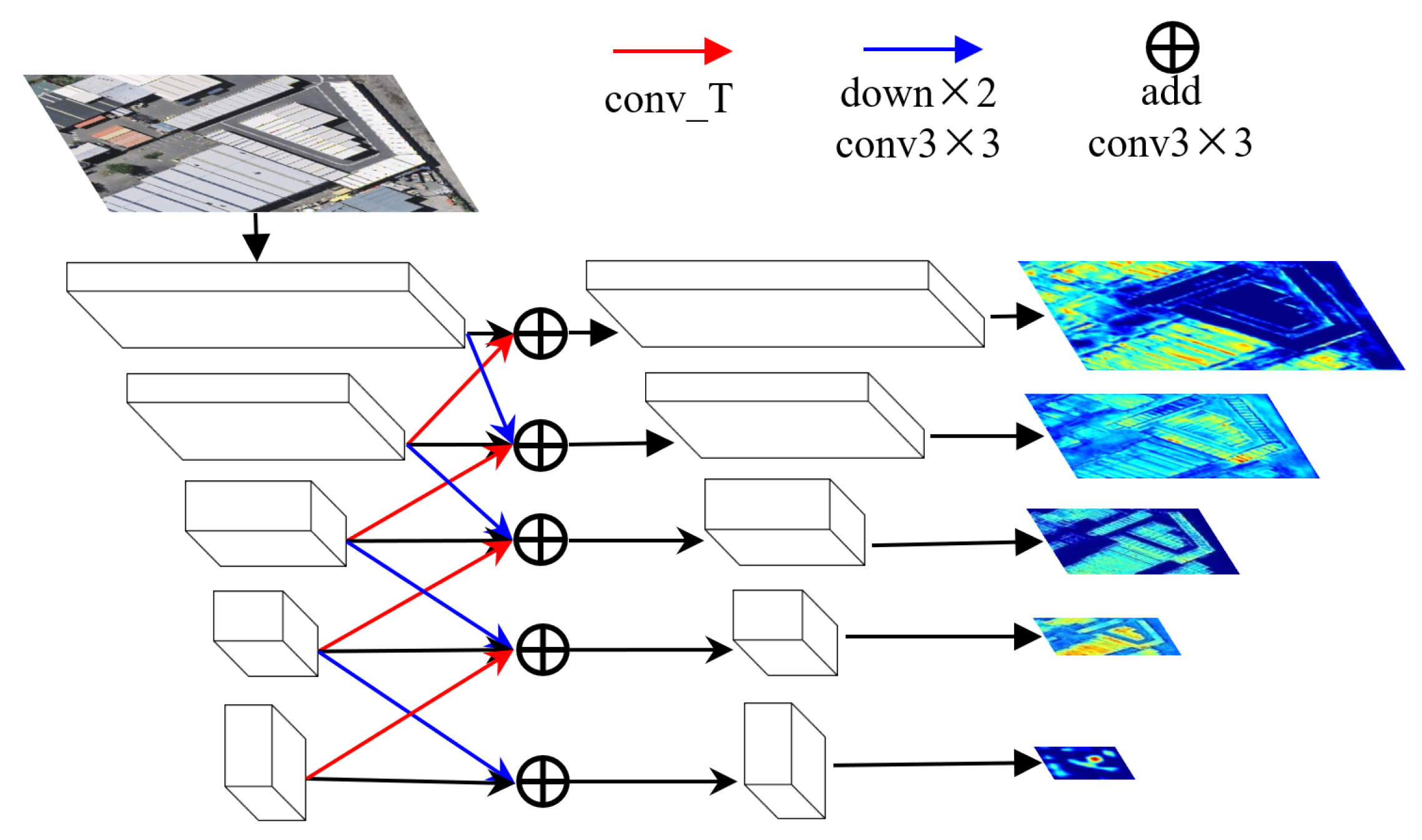
2.4. Region-Based Feature Fusion Module
2.5. Deep Supervise-Based Loss Function
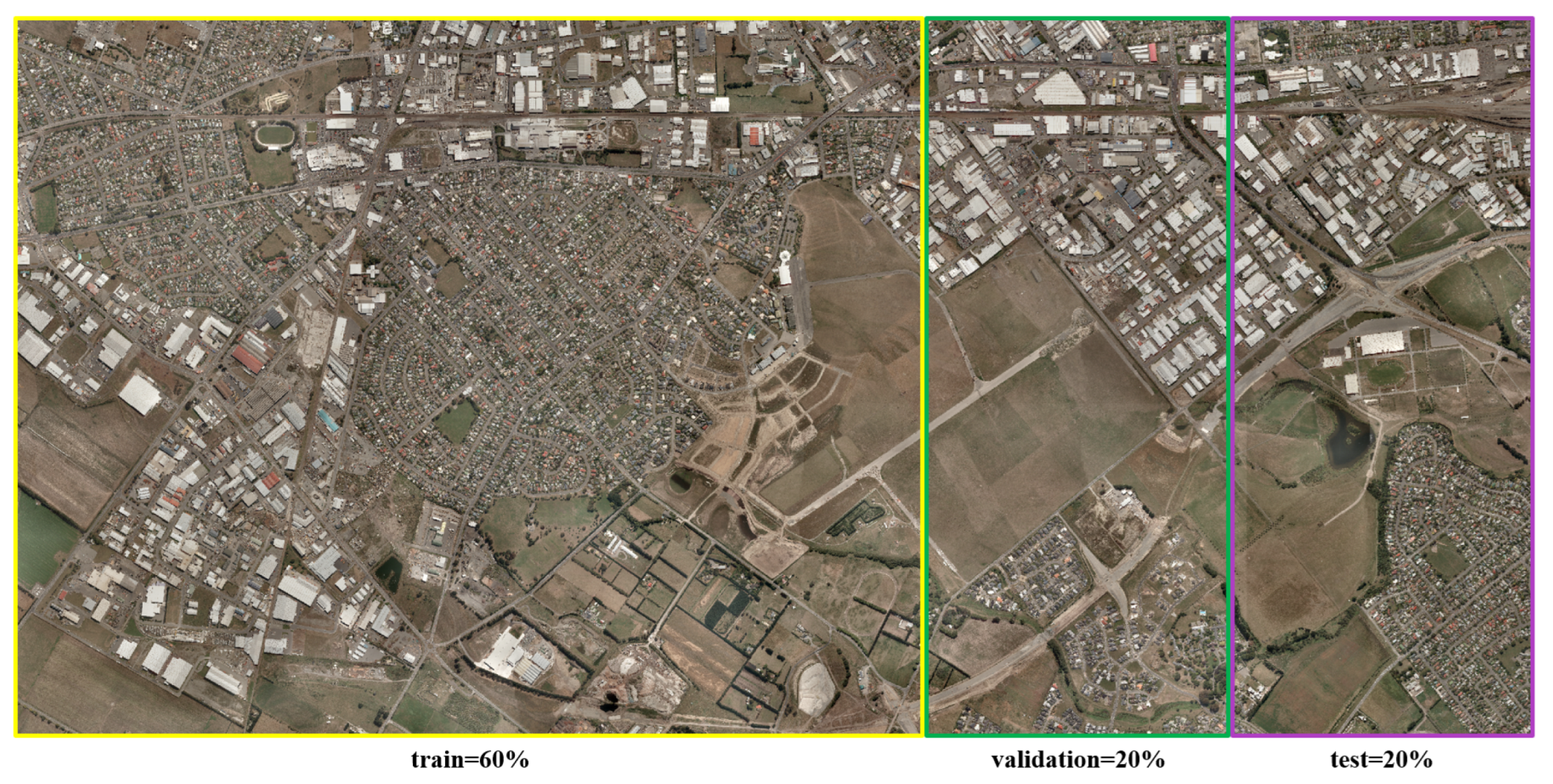
3. Datasets
3.1. SECOND dataset
3.2. WHU Dataset
4. Experiments and Results
4.1. Benchmark Methods
- FC-EF [51]: A fully convolution early fusion CD network that inputs channel-wise stacked bitemporal images and outputs change masks. The network generates change masks in an encode–decode manner.
- FC-Siam-Conc [51]: A fully convolutional siamese-concatenation CD network. This is a Siamese network that separates the encoding layers of FC-EF into dual streams with weight sharing. Bitemporal images are fed into the dual streams and generate bitemporal features. The bitemporal features are directly sent to the decoder and fused with concatenation.
- FC-Siam-Diff [51]: A fully convolutional Siamese-difference network for CD tasks. Different from FC-Siam-Conc, it decodes the difference of dual encoder features to gain the change mask.
- CDNet [39]: CDNet is a UNet-like CD network, which inputs concatenated bitemporal images. All the convolution layers are designed with kernel size = 7.
- UNet++_MSOF [11]: The network first concatenates bitemporal images to multi-spectral data and inputs it to a modified UNet++ network. Features from different semantic stages of UNet++ are fused to get the final change maps.
- IFN [59]: IFN is a fully convolutional Siamese CD network that introduces deep supervision into CD tasks. The network uses spatial-wise and channel-wise attention modules to fuse multi-level deep features. To help better optimize the network and enhance network performance, a deep supervision strategy is introduced in the intermediate features.
- SNUNet_CD [60]: A CD network built with dense connections. The network is made up of a dual UNet encoder and a UNet++ decoder. The channel-wise attention mechanism is introduced in deep supervision and an ensemble channel-wise attention module is proposed to refine representative features of different semantic levels for the final classification.
- BiT [69]: The network introduces a vision transformer into CD tasks. Bitemporal images are embedded into tokens and are fed to the transformer module to generate context information in the compact token-based space-time.
4.2. Training Details
4.3. Ablation Study
4.3.1. Comparison of MFIM
4.3.2. Comparison of RFFM
4.3.3. Comparison of Deep Supervision
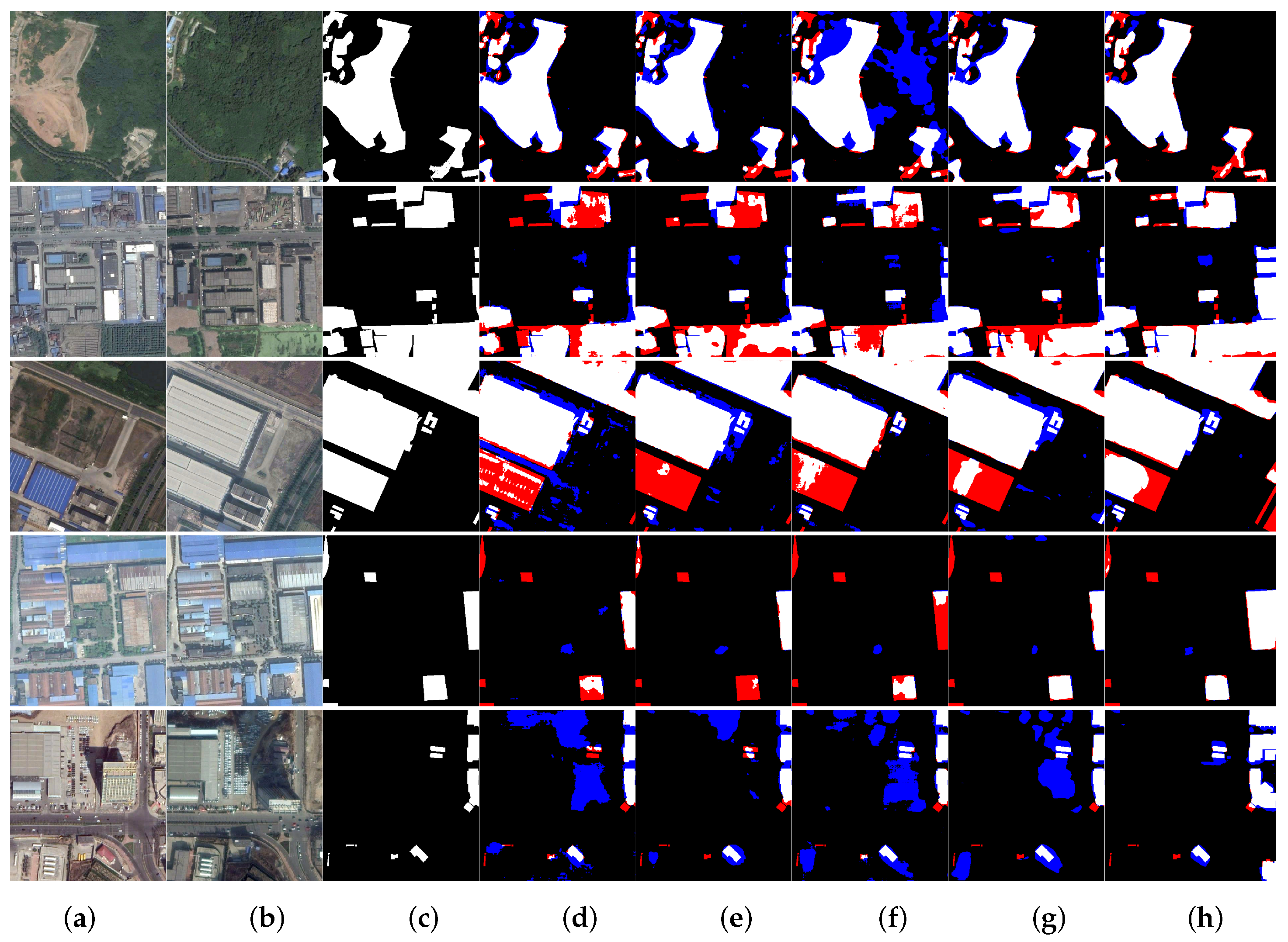
4.4. Comparisons on SECOND
4.5. Comparison on WHU
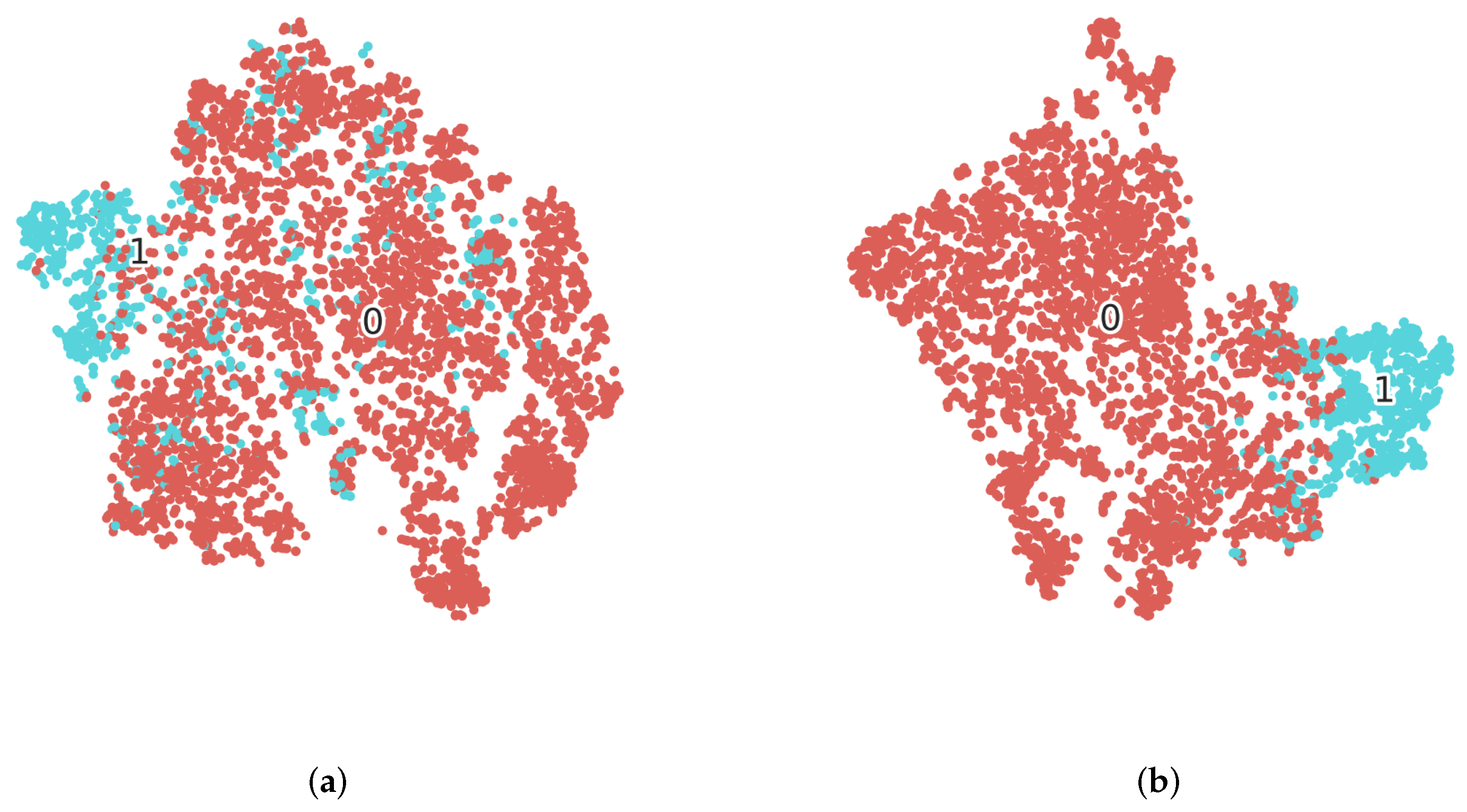
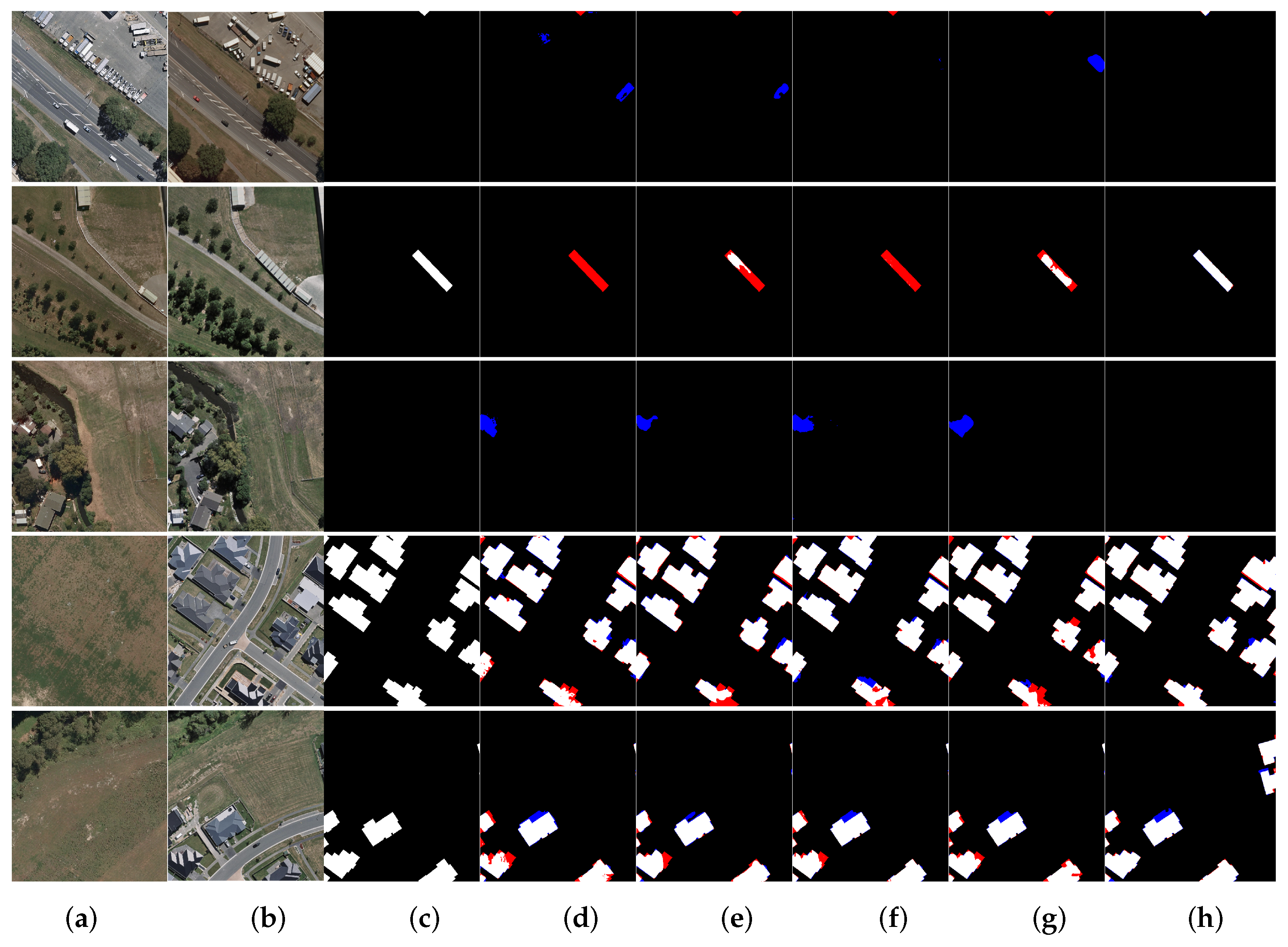
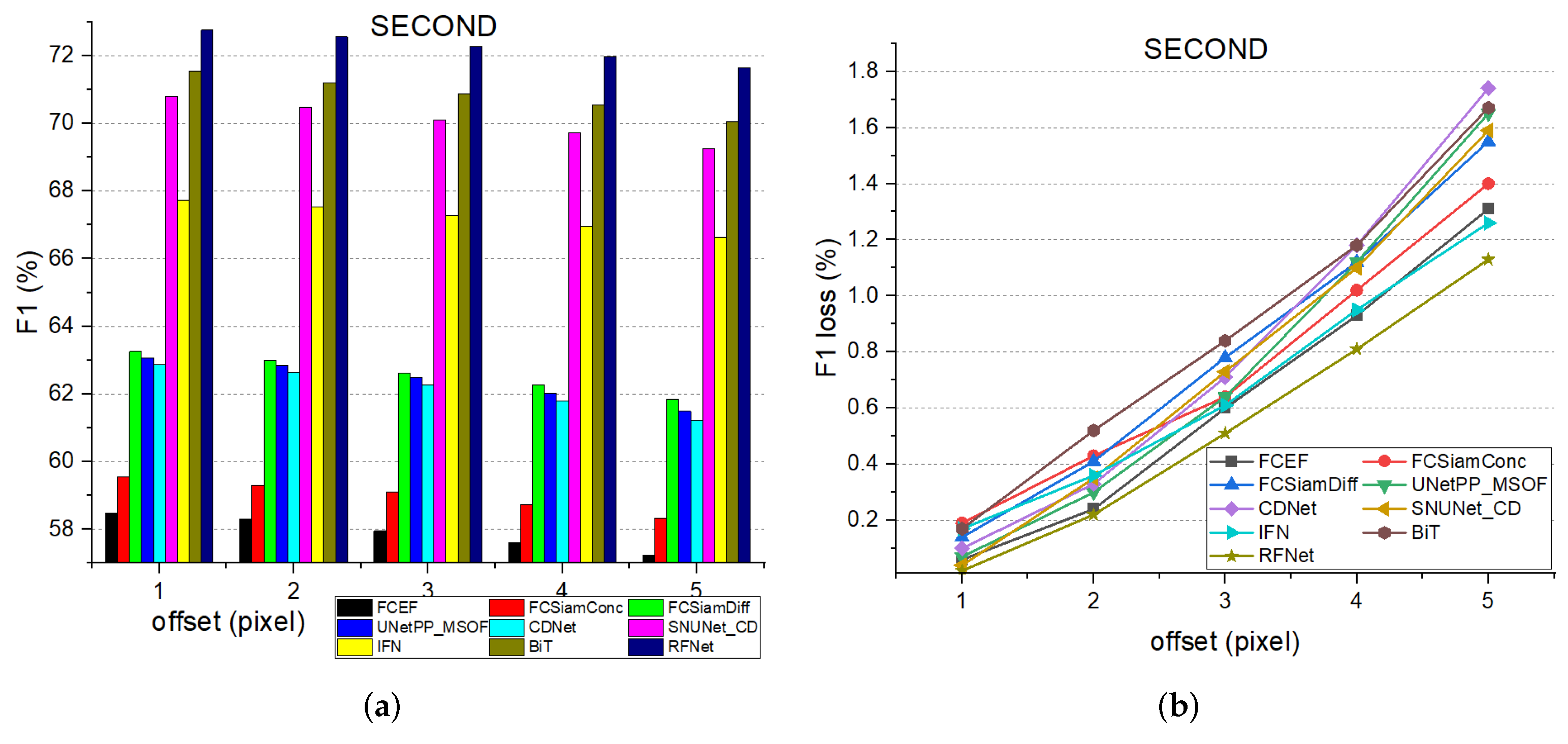
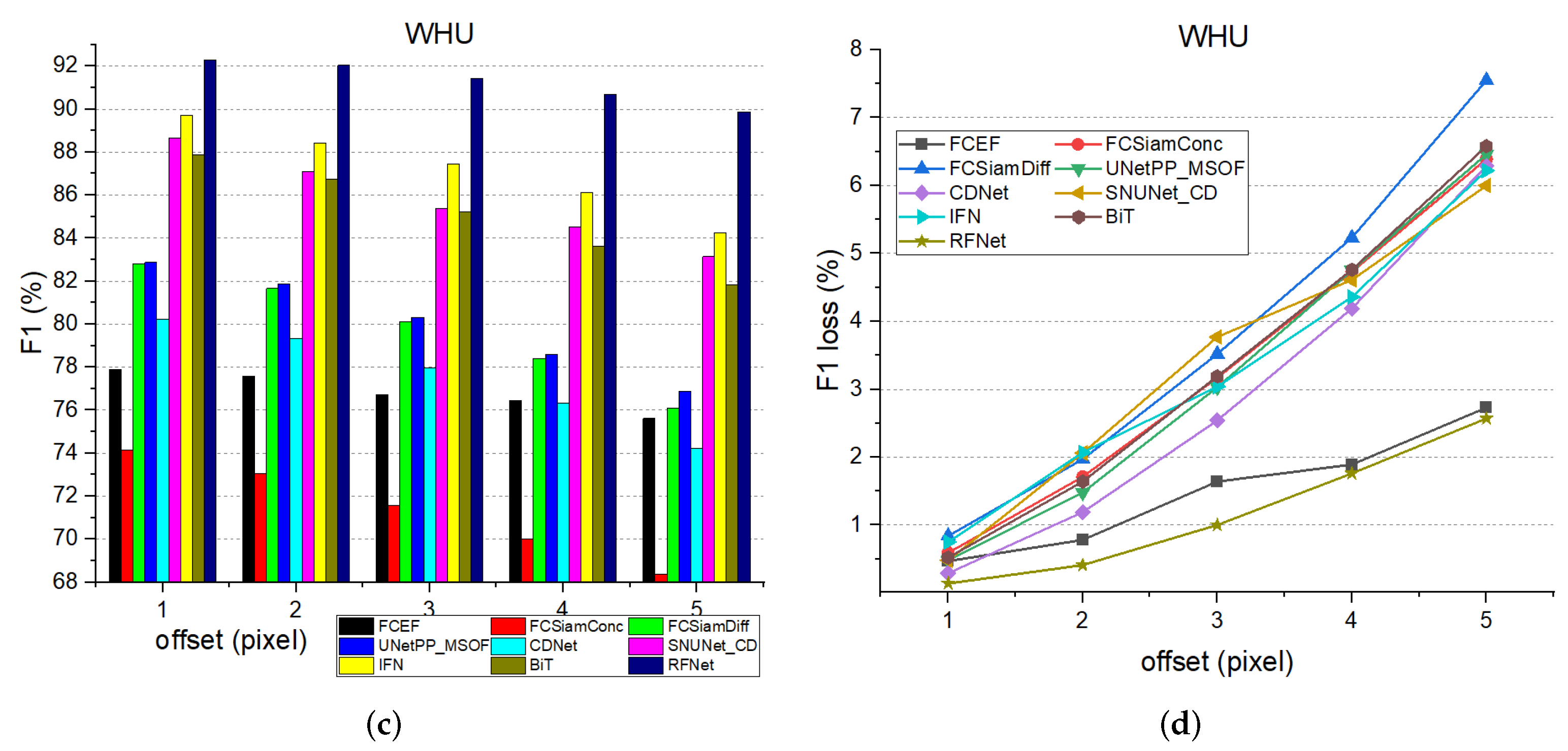
4.6. Robustness Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Quarmby, N.; Cushnie, J. Monitoring urban land cover changes at the urban fringe from SPOT HRV imagery in south-east England. Int. J. Remote Sens. 1989, 10, 953–963. [Google Scholar] [CrossRef]
- Howarth, P.J.; Wickware, G.M. Procedures for change detection using Landsat digital data. Int. J. Remote Sens. 1981, 2, 277–291. [Google Scholar] [CrossRef]
- Richards, J. Thematic mapping from multitemporal image data using the principal components transformation. Remote Sens. Environ. 1984, 16, 35–46. [Google Scholar] [CrossRef]
- Jin, S.; Sader, S.A. Comparison of time series tasseled cap wetness and the normalized difference moisture index in detecting forest disturbances. Remote Sens. Environ. 2005, 94, 364–372. [Google Scholar] [CrossRef]
- Xing, J.; Sieber, R.; Caelli, T. A scale-invariant change detection method for land use/cover change research. ISPRS J. Photogramm. Remote Sens. 2018, 141, 252–264. [Google Scholar] [CrossRef]
- Zerrouki, N.; Harrou, F.; Sun, Y.; Hocini, L. A machine learning-based approach for land cover change detection using remote sensing and radiometric measurements. IEEE Sens. J. 2019, 19, 5843–5850. [Google Scholar] [CrossRef]
- Ma, W.; Wu, Y.; Gong, M.; Xiong, Y.; Yang, H.; Hu, T. Change detection in SAR images based on matrix factorisation and a Bayes classifier. Int. J. Remote Sens. 2019, 40, 1066–1091. [Google Scholar] [CrossRef]
- Fisher, P. The pixel: A snare and a delusion. Int. J. Remote Sens. 1997, 18, 679–685. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Addink, E.A.; Van Coillie, F.M.; De Jong, S.M. Introduction to the GEOBIA 2010 special issue: From pixels to geographic objects in remote sensing image analysis. Int. J. Appl. Earth Obs. Geoinf. 2012, 15, 1–6. [Google Scholar] [CrossRef]
- Lefebvre, A.; Corpetti, T.; Hubert-Moy, L. Object-oriented approach and texture analysis for change detection in very high resolution images. In Proceedings of the IGARSS 2008-2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; Volume 4. [Google Scholar]
- De Chant, T.; Kelly, M. Individual object change detection for monitoring the impact of a forest pathogen on a hardwood forest. Photogramm. Eng. Remote Sens. 2009, 75, 1005–1013. [Google Scholar] [CrossRef]
- Dingle Robertson, L.; King, D.J. Comparison of pixel-and object-based classification in land cover change mapping. Int. J. Remote Sens. 2011, 32, 1505–1529. [Google Scholar] [CrossRef]
- El Amin, A.M.; Liu, Q.; Wang, Y. Zoom out CNNs features for optical remote sensing change detection. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 812–817. [Google Scholar]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Hou, X.; Bai, Y.; Li, Y.; Shang, C.; Shen, Q. High-resolution triplet network with dynamic multiscale feature for change detection on satellite images. ISPRS J. Photogramm. Remote Sens. 2021, 177, 103–115. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical Remote Sensing Image Change Detection Based on Attention Mechanism and Image Difference. IEEE Trans. Geosci. Remote. Sens. 2020, 59, 7296–7307. [Google Scholar] [CrossRef]
- Shafique, A.; Cao, G.; Khan, Z.; Asad, M.; Aslam, M. Deep learning-based change detection in remote sensing images: A review. Remote Sens. 2022, 14, 871. [Google Scholar] [CrossRef]
- Zhang, Y.; Fu, L.; Li, Y.; Zhang, Y. HDFNet: Hierarchical Dynamic Fusion Network for Change Detection in Optical Aerial Images. Remote Sens. 2021, 13, 1440. [Google Scholar] [CrossRef]
- Cheng, H.; Wu, H.; Zheng, J.; Qi, K.; Liu, W. A hierarchical self-attention augmented Laplacian pyramid expanding network for change detection in high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2021, 182, 52–66. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, Z.; Peng, D.; Benediktsson, J.A.; Liu, B.; Zou, L.; Li, J.; Plaza, A. Remotely sensed big data: Evolution in model development for information extraction [point of view]. Proc. IEEE 2019, 107, 2294–2301. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Lei, T.; Zhang, Y.; Lv, Z.; Li, S.; Liu, S.; Nandi, A.K. Landslide inventory mapping from bitemporal images using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 982–986. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 9 December 2017).
- Dabre, R.; Chu, C.; Kunchukuttan, A. A survey of multilingual neural machine translation. ACM Comput. Surv. (CSUR) 2020, 53, 1–38. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/hash/14bfa6bb14875e45bba028a21ed38046-Abstract.html (accessed on 9 December 2017). [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision; Springer: Glasgow, UK, 2020; pp. 213–229. [Google Scholar]
- Brooks, T.; Mildenhall, B.; Xue, T.; Chen, J.; Sharlet, D.; Barron, J.T. Unprocessing images for learned raw denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11036–11045. [Google Scholar]
- Chen, C.; Xiong, Z.; Tian, X.; Wu, F. Deep boosting for image denoising. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–18. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Gao, Y.; Gao, F.; Dong, J.; Wang, S. Change detection from synthetic aperture radar images based on channel weighting-based deep cascade network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4517–4529. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Stent, S.; Ros, G.; Arroyo, R.; Gherardi, R. Street-view change detection with deconvolutional networks. Auton. Robot. 2018, 42, 1301–1322. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, X.; Chen, G.; Dai, F.; Gong, Y.; Zhu, K. Change detection based on Faster R-CNN for high-resolution remote sensing images. Remote Sens. Lett. 2018, 9, 923–932. [Google Scholar] [CrossRef]
- Han, P.; Ma, C.; Li, Q.; Leng, P.; Bu, S.; Li, K. Aerial image change detection using dual regions of interest networks. Neurocomputing 2019, 349, 190–201. [Google Scholar] [CrossRef]
- Pomente, A.; Picchiani, M.; Del Frate, F. Sentinel-2 change detection based on deep features. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 6859–6862. [Google Scholar]
- Geng, J.; Wang, H.; Fan, J.; Ma, X. Change detection of SAR images based on supervised contractive autoencoders and fuzzy clustering. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–3. [Google Scholar]
- Chen, H.; Wu, C.; Du, B.; Zhang, L. Deep Siamese multi-scale convolutional network for change detection in multi-temporal VHR images. In Proceedings of the 2019 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; pp. 1–4. [Google Scholar]
- Gao, F.; Liu, X.; Dong, J.; Zhong, G.; Jian, M. Change detection in SAR images based on deep semi-NMF and SVD networks. Remote Sens. 2017, 9, 435. [Google Scholar] [CrossRef]
- Lv, N.; Chen, C.; Qiu, T.; Sangaiah, A.K. Deep learning and superpixel feature extraction based on contractive autoencoder for change detection in SAR images. IEEE Trans. Ind. Informatics 2018, 14, 5530–5538. [Google Scholar] [CrossRef]
- Cui, F.; Jiang, J. Shuffle-CDNet: A Lightweight Network for Change Detection of Bitemporal Remote-Sensing Images. Remote Sens. 2022, 14, 3548. [Google Scholar] [CrossRef]
- Ye, Y.; Zhou, L.; Zhu, B.; Yang, C.; Sun, M.; Fan, J.; Fu, Z. Feature Decomposition-Optimization-Reorganization Network for Building Change Detection in Remote Sensing Images. Remote Sens. 2022, 14, 722. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Granada, Spain, 2018; pp. 3–11. [Google Scholar]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. PGA-SiamNet: Pyramid feature-based attention-guided Siamese network for remote sensing orthoimagery building change detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Haozhe, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional siamese networks for change detection of high resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 14, 1194–1206. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Liu, T.; Gong, M.; Lu, D.; Zhang, Q.; Zheng, H.; Jiang, F.; Zhang, M. Building Change Detection for VHR Remote Sensing Images via Local–Global Pyramid Network and Cross-Task Transfer Learning Strategy. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–17. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P. Looking for change? Roll the Dice and demand Attention. Remote Sens. 2021, 13, 3707. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected Siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- You, Y.; Cao, J.; Zhou, W. A survey of change detection methods based on remote sensing images for multi-source and multi-objective scenarios. Remote Sens. 2020, 12, 2460. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Jin, J.; Qian, M.; Zhang, Y. SUACDNet: Attentional change detection network based on siamese U-shaped structure. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102597. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Munich, Germany, 2015; pp. 234–241. [Google Scholar]
- Yang, K.; Xia, G.S.; Liu, Z.; Du, B.; Yang, W.; Pelillo, M. Asymmetric siamese networks for semantic change detection. arXiv 2020, arXiv:2010.05687. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2019; pp. 6105–6114. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2015; pp. 448–456. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://openreview.net/pdf?id=BJJsrmfCZ (accessed on 9 December 2017).
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Efficient Transformer based Method for Remote Sensing Image Change Detection. arXiv 2021, arXiv:2103.00208. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9. Available online: https://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf?fbcl (accessed on 9 December 2017).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SECOND | WHU | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Introduce | Precision (%) | Recall (%) | IoU (%) | F1 (%) | Precision (%) | Recall (%) | IoU (%) | F1 (%) | Params |
| MFIM | (Mb) | ||||||||
| no | 67.94 | 72.37 | 53.95 (±0.28) | 70.09 (±0.24) | 92.85 | 86.78 | 81.35 (±0.44) | 89.71 (±0.25) | 32.5 |
| yes | 72.54 | 70.37 | 55.57 (±0.31) | 71.44 (±0.27) | 95.54 | 88.41 | 84.11 (±0.27) | 91.37 (±0.11) | 39.3 |
| SECOND | WHU | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Introduce | Precision (%) | Recall (%) | IoU (%) | F1 (%) | Precision (%) | Recall (%) | IoU (%) | F1 (%) | Params |
| RFFM | (Mb) | ||||||||
| no | 67.94 | 72.37 | 53.95 (±0.28) | 70.09 (±0.24) | 92.85 | 86.78 | 81.35 (±0.44) | 89.71 (±0.25) | 32.5 |
| yes | 72.9 | 69.71 | 55.36 (±0.19) | 71.27 (±0.17) | 95.06 | 87.74 | 83.51 (±0.35) | 91.25 (±0.19) | 32.7 |
| SECOND | WHU | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Use Deep | Precision (%) | Recall (%) | IoU (%) | F1 (%) | Precision (%) | Recall (%) | IoU (%) | F1 (%) | Params |
| Supervise | (Mb) | ||||||||
| no | 72.9 | 69.71 | 55.36 (±0.19) | 71.27 (±0.17) | 95.06 | 87.74 | 83.51 (±0.35) | 91.25 (±0.19) | 32.7 |
| yes | 71.67 | 71.54 | 55.77 (±0.3) | 71.6 (±0.25) | 94.7 | 89.46 | 85.19 (±0.51) | 92 (±0.32) | 32.7 |
| Precision (%) | Recall (%) | IoU (%) | F1 (%) | Params (Mb) | |
|---|---|---|---|---|---|
| FC-EF [51] | 59.53 | 57.6 | 38.46 | 58.55 | 5.15 |
| FC-Sima-conc [51] | 61.21 | 58.33 | 42.59 | 59.74 | 5.9 |
| FC-Sima-diff [51] | 63.68 | 63.128 | 46.418 | 63.48 | 5.15 |
| CDNet [39] | 57.41 | 69.73 | 45.95 | 62.97 | 7.75 |
| UNet++_MSOF [11] | 68.74 | 58.39 | 46.14 | 63.14 | 35 |
| IFN [59] | 73.09 | 63.4 | 51.4 | 67.9 | 137 |
| SNUNet_CD [60] | 72.37 | 69.35 | 54.84 | 70.83 | 46 |
| BiT [69] | 71.12 | 72.33 | 55.91 | 71.72 | 45.8 |
| RFNet (ours) | 74.15 | 71.46 | 57.21 | 72.78 | 39.4 |
| Precision (%) | Recall (%) | IoU (%) | F1 (%) | Params (Mb) | |
|---|---|---|---|---|---|
| FC-EF [51] | 78.58 | 78.13 | 64.41 | 78.35 | 5.15 |
| FC-Sima-conc [51] | 76.19 | 73.35 | 59.68 | 74.75 | 5.9 |
| FC-Sima-diff [51] | 84.03 | 83.24 | 70.63 | 83.63 | 5.15 |
| CDNet [39] | 82.86 | 78.3 | 67.39 | 80.52 | 7.75 |
| UNet++_MSOF [11] | 86.7 | 80.25 | 71.45 | 83.35 | 35 |
| IFN [59] | 94.81 | 86.5 | 82.59 | 90.47 | 137 |
| SNUNet_CD [60] | 90.07 | 88.23 | 80.4 | 89.14 | 46 |
| BiT [69] | 85.31 | 91.06 | 78.72 | 88.09 | 45.8 |
| RFNet (ours) | 95.72 | 89.46 | 86.02 | 92.49 | 39.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Li, C.; Zhang, B.; Chen, Z.; Yang, X.; Lu, K.; Zhuang, L. A Region-Based Feature Fusion Network for VHR Image Change Detection. Remote Sens. 2022, 14, 5577. https://doi.org/10.3390/rs14215577
Chen P, Li C, Zhang B, Chen Z, Yang X, Lu K, Zhuang L. A Region-Based Feature Fusion Network for VHR Image Change Detection. Remote Sensing. 2022; 14(21):5577. https://doi.org/10.3390/rs14215577
Chicago/Turabian StyleChen, Pan, Cong Li, Bing Zhang, Zhengchao Chen, Xuan Yang, Kaixuan Lu, and Lina Zhuang. 2022. "A Region-Based Feature Fusion Network for VHR Image Change Detection" Remote Sensing 14, no. 21: 5577. https://doi.org/10.3390/rs14215577
APA StyleChen, P., Li, C., Zhang, B., Chen, Z., Yang, X., Lu, K., & Zhuang, L. (2022). A Region-Based Feature Fusion Network for VHR Image Change Detection. Remote Sensing, 14(21), 5577. https://doi.org/10.3390/rs14215577