
Deep-Separation Guided Progressive Reconstruction Network for Semantic Segmentation of Remote Sensing Images

Abstract
1. Introduction
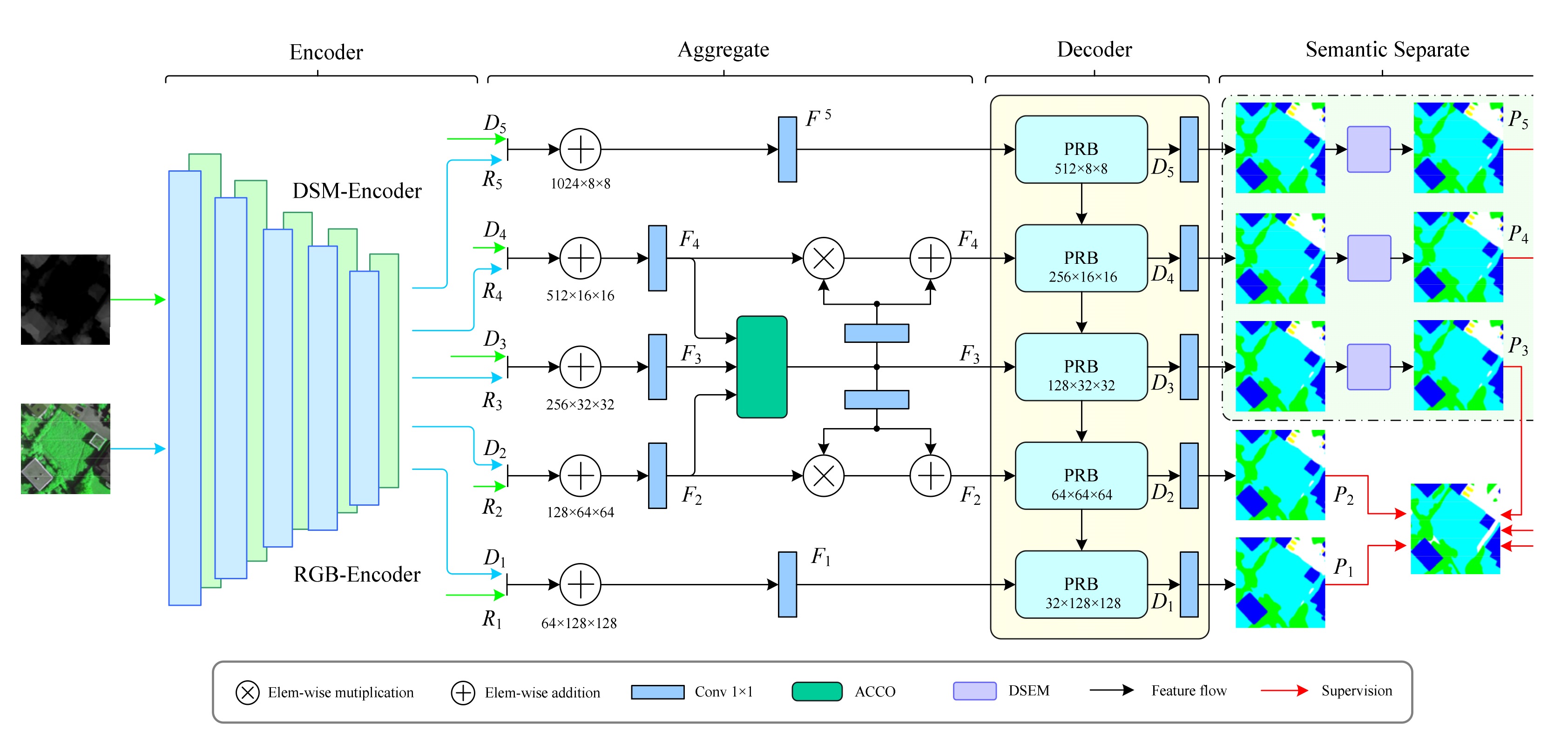
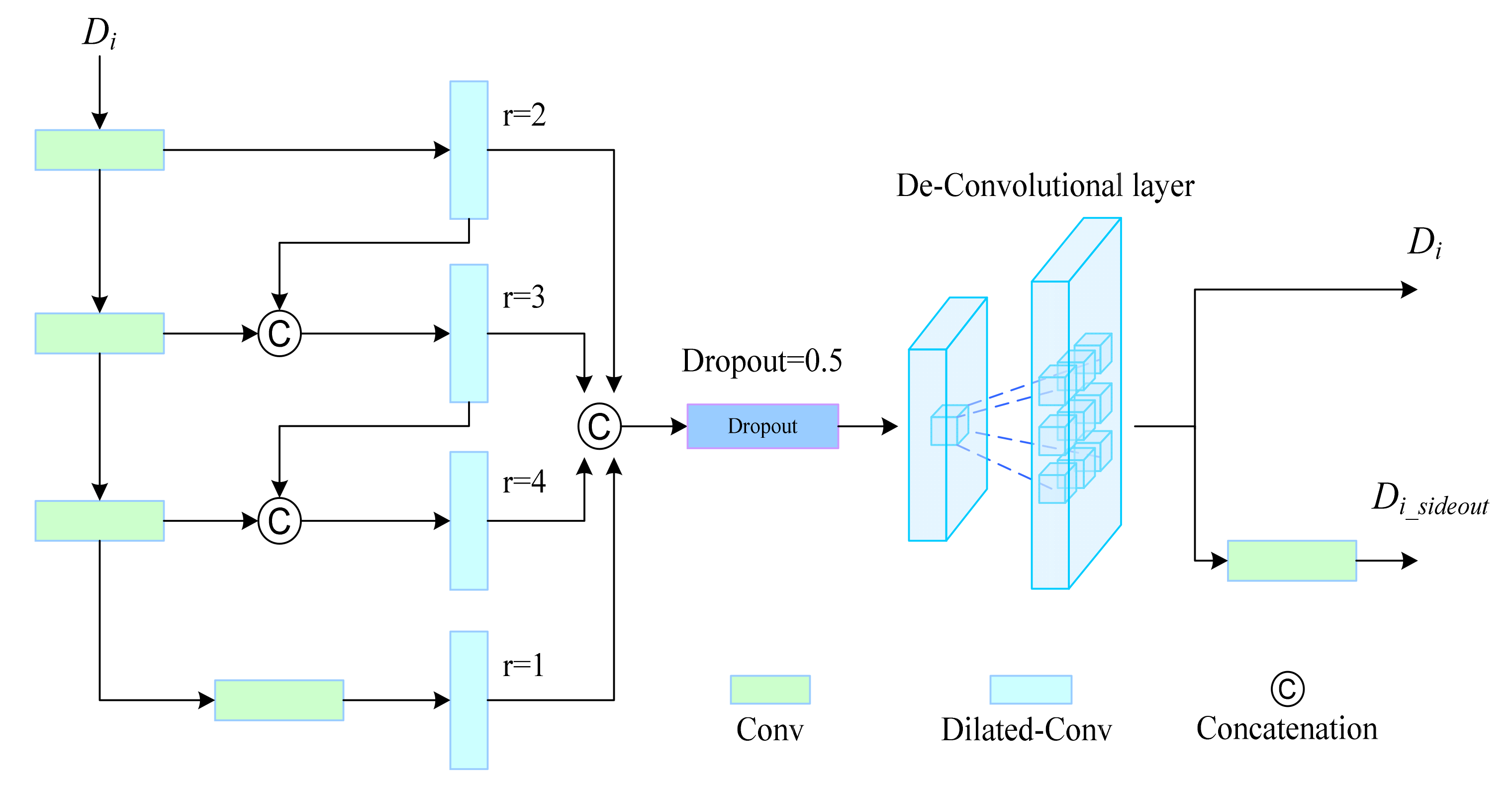
- A PRB based on ASPP [33] was embedded in the decoder to strengthen the feature reconstruction and reduce the error in this process. Five features with different resolutions were processed serially using atrous convolution layers with different ratios, and the feature resolution was expanded by deconvolution to obtain the decoding output of each block.
- The proposed DSEM processed the last three semantic features from the decoder to emphasize semantic information to use deep semantic features. Intraclass separation was minimized, while interclass separation was maximized. Meanwhile, multi-supervision was applied to DGPRNet for segmentation, improving the reconstruction ability of each module.
- Experiments on two RSI datasets showed that the proposed model outperforms 11 state-of-the-art methods, including current semantic segmentation methods.
2. Proposed DGPRNet
2.1. Encoder
2.2. PRB
2.3. DSEM
2.4. Loss Function
3. Experiments and Results
3.1. Datasets and Performance Indicators
3.2. Implementation Details
3.3. Comparison with State-of-the-Art Methods
3.3.1. Quantitative Evaluation
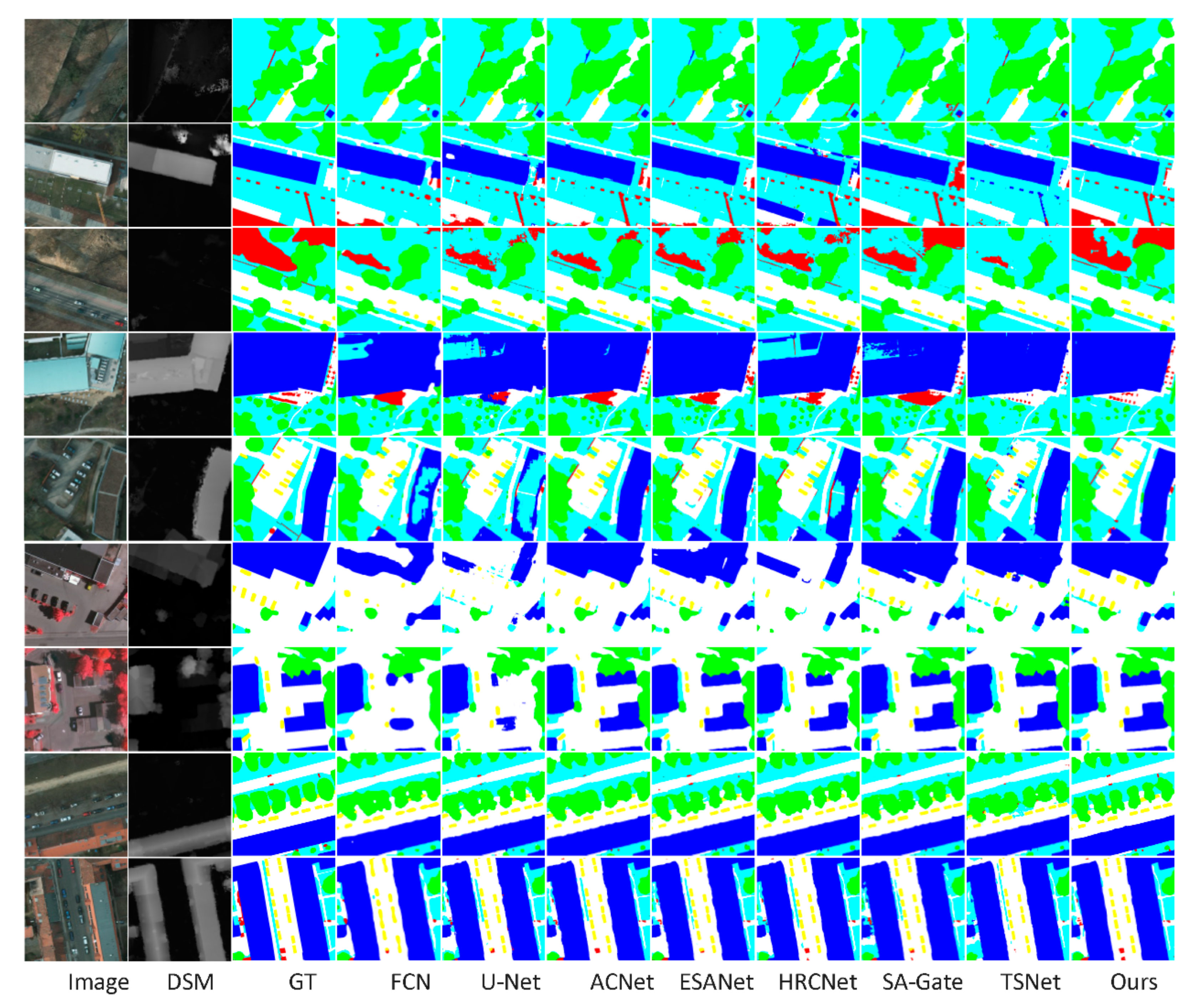
3.3.2. Qualitative Evaluation
3.4. Ablation Study
3.4.1. Effect of Modal DSM
3.4.2. Effects of Module PRB
3.4.3. Effects of Module DSEM
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neupane, B.; Horanont, T.; Aryal, J. Deep learning-based semantic segmentation of urban features in satellite images: A review and meta-analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, J.; Lei, J.; Hwang, J.-N.; Yu, L. GMNet: Graded-feature multilabel-Learning network for RGB-Thermal urban scene semantic segmentation. IEEE Trans. Image Process. 2021, 30, 7790–7802. [Google Scholar] [CrossRef]
- Chen, Z.; Li, D.; Fan, W.; Guan, H.; Wang, C.; Li, J. Self-attention in reconstruction bias U-Net for semantic segmentation of building rooftops in optical remote sensing images. Remote Sens. 2021, 13, 2524. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer meets convolution: A bilateral awareness network for semantic segmentation of very fine resolution urban scene images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Zhou, W.; Yang, E.; Lei, J.; Wan, J.; Yu, L. PGDENet: Progressive Guided Fusion and Depth Enhancement Network for RGB-D Indoor Scene Parsing. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, W.; Lei, J.; Luo, T.; Yu, L. Deep binocular fixation prediction using hierarchical multimodal fusion network. IEEE Trans. Cogn. Dev. Syst. 2021. [Google Scholar] [CrossRef]
- Wu, J.; Zhou, W.; Luo, T.; Yu, L.; Lei, J. Multiscale multilevel context and multimodal fusion for RGB-D salient object detection. Signal Process. 2021, 178, 107766. [Google Scholar] [CrossRef]
- Zhou, W.; Jin, J.; Lei, J.; Yu, L. CIMFNet: Cross-Layer Interaction and Multiscale Fusion Network for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Signal Process. 2022, 16, 666–676. [Google Scholar] [CrossRef]
- Liu, X.; Jiao, L.; Zhao, J.; Zhao, J.; Zhang, D.; Liu, F.; Tang, X. Deep multiple instance learning-based spatial–spectral classification for PAN and MS imagery. IEEE Trans. Geosci. Remote Sens. 2017, 56, 461–473. [Google Scholar] [CrossRef]
- Mou, L.; Hua, Y.; Zhu, X.X. A relation-augmented fully convolutional network for semantic segmentation in aerial scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 12416–12425. [Google Scholar]
- Zhou, W.; Dong, S.; Lei, J.; Yu, L. MTANet: Multitask-Aware Network with Hierarchical Multimodal Fusion for RGB-T Urban Scene Understanding. IEEE Trans. Intell. Veh. 2022. [Google Scholar] [CrossRef]
- Zhou, W.; Guo, Q.; Lei, J.; Yu, L.; Hwang, J.-N. IRFR-Net: Interactive recursive feature-reshaping network for detecting salient objects in RGB-D images. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Vijay, B.; Alex, K.; Roberto, C. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar]
- Jiang, J.; Zheng, L.; Luo, F.; Zhang, Z. Rednet: Residual encoder-decoder network for indoor rgb-d semantic segmentation. arXiv 2018, arXiv:1806.01054. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, X.; Lin, K.Y.; Wang, J.; Wu, W.; Qian, C.; Li, H.; Zeng, G. Bi-directional cross-modality feature propagation with separation-and-aggregation gate for RGB-D semantic segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 561–577. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-resolution context extraction network for semantic segmentation of remote sensing images. Remote Sens. 2020, 13, 71. [Google Scholar] [CrossRef]
- Zhou, W.; Yuan, J.; Lei, J.; Luo, T. TSNet: Three-stream self-attention network for RGB-D indoor semantic segmentation. IEEE Intell. Syst. 2020, 36, 73–78. [Google Scholar] [CrossRef]
- Seichter, D.; Köhler, M.; Lewandowski, B.; Wengefeld, T.; Gross, H.M. Efficient rgb-d semantic segmentation for indoor scene analysis. In Proceedings of the IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 13525–13531. [Google Scholar]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 1440–1444. [Google Scholar]
- Zhou, W.; Yu, L.; Zhou, Y.; Qiu, W.; Wu, M.; Luo, T. Local and global feature learning for blind quality evaluation of screen content and natural scene images. IEEE Trans. Image Process. 2018, 27, 2086–2095. [Google Scholar] [CrossRef]
- Zhou, W.; Yang, E.; Lei, J.; Yu, L. FRNet: Feature Reconstruction Network for RGB-D Indoor Scene Parsing. IEEE J. Sel. Top. Signal Process. 2022, 16, 677–687. [Google Scholar] [CrossRef]
- Zhou, W.; Lin, X.; Lei, J.; Yu, L.; Hwang, J.-N. MFFENet: Multiscale feature fusion and enhancement network for RGB–Thermal urban road scene parsing. IEEE Trans. Multimed. 2022, 24, 2526–2538. [Google Scholar] [CrossRef]
- Zheng, X.; Wu, X.; Huan, L.; He, W.; Zhang, H. A Gather-to-Guide Network for Remote Sensing Semantic Segmentation of RGB and Auxiliary Image. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X.; Pun, M.O. A Crossmodal Multiscale Fusion Network for Semantic Segmentation of Remote Sensing Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3463–3474. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NE, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhou, W.; Liu, C.; Lei, J.; Yu, L.; Luo, T. HFNet: Hierarchical feedback network with multilevel atrous spatial pyramid pooling for RGB-D saliency detection. Neurocomputing 2022, 490, 347–357. [Google Scholar] [CrossRef]
- Zhou, W.; Lv, Y.; Lei, J.; Yu, L. Global and Local-Contrast Guides Content-Aware Fusion for RGB-D Saliency Prediction. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 3641–3649. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Zhou, W.; Guo, Q.; Lei, J.; Yu, L.; Hwang, J.-N. ECFFNet: Effective and consistent feature fusion network for RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1224–1235. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Zeng, D.; Lin, W.; Ling, H. Adjacent context coordination network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2022. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, C.; Lei, J.; Yu, L. RLLNet: A lightweight remaking learning network for saliency redetection on RGB-D images. Sci. China Inf. Sci. 2022, 65, 160107. [Google Scholar] [CrossRef]
- Gong, T.; Zhou, W.; Qian, X.; Lei, J.; Yu, L. Global contextually guided lightweight network for RGB-thermal urban scene understanding. Eng. Appl. Artif. Intell. 2023, 117, 105510. [Google Scholar] [CrossRef]
- Zhou, W.; Wu, J.; Lei, J.; Hwang, J.-N.; Yu, L. Salient object detection in stereoscopic 3D images using a deep convolutional residual autoencoder. IEEE Trans. Multimed. 2021, 23, 3388–3399. [Google Scholar] [CrossRef]
- Zhou, W.; Zhu, Y.; Lei, J.; Wan, J.; Yu, L. CCAFNet: Crossflow and cross-scale adaptive fusion network for detecting salient objects in RGB-D images. IEEE Trans. Multimed. 2022, 24, 2192–2204. [Google Scholar] [CrossRef]
- International Society for Photogrammetry and Remote Sensing. 2D Semantic Labeling Contest-Potsdam. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx (accessed on 1 January 2020).
- International Society for Photogrammetry and Remote Sensing. 2D Semantic Labeling Contest-Vaihingen. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx (accessed on 1 January 2020).
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FCN-8S [13] | U-Net [14] | SegNet [15] | DeepLabv3+ [17] | BiseNetV2 [19] | HRCNet [20] | RedNet [16] | ACNet [23] | SA-Gate [18] | TSNet [21] | ESANet [22] | DCSwin [43] | Ours | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Imp.surf | Acc | 89.66 | 91.68 | 89.88 | 90.06 | 90.56 | 91.62 | 91.49 | 91.95 | 90.99 | 87.93 | 92.09 | 91.40 | 91.55 |
| IoU | 79.71 | 80.90 | 80.93 | 81.11 | 80.97 | 81.60 | 84.62 | 85.34 | 85.70 | 78.98 | 85.18 | 84.45 | 86.22 | |
| Building | Acc | 93.22 | 89.84 | 90.88 | 87.04 | 91.24 | 91.72 | 94.81 | 95.45 | 93.85 | 95.81 | 94.93 | 95.29 | 95.80 |
| IoU | 86.80 | 86.50 | 86.54 | 82.70 | 86.69 | 88.01 | 91.07 | 91.82 | 91.72 | 91.47 | 91.16 | 91.30 | 92.78 | |
| Low veg. | Acc | 75.83 | 77.97 | 78.66 | 76.65 | 74.68 | 79.24 | 78.67 | 78.64 | 84.95 | 71.62 | 75.72 | 79.02 | 81.27 |
| IoU | 64.33 | 65.91 | 64.07 | 64.44 | 63.66 | 67.38 | 66.59 | 66.87 | 68.68 | 57.03 | 65.48 | 66.26 | 68.62 | |
| Tree | Acc | 89.22 | 91.30 | 88.96 | 88.60 | 91.66 | 90.55 | 91.41 | 91.20 | 89.06 | 94.26 | 92.35 | 89.85 | 91.22 |
| IoU | 75.58 | 77.86 | 75.96 | 76.64 | 76.54 | 78.58 | 78.27 | 78.55 | 79.15 | 81.26 | 77.65 | 77.54 | 79.34 | |
| Car | Acc | 45.12 | 75.80 | 43.93 | 42.51 | 63.75 | 70.69 | 59.77 | 83.12 | 84.27 | 67.63 | 75.92 | 81.51 | 92.30 |
| IoU | 40.16 | 71.22 | 43.16 | 43.10 | 61.80 | 68.73 | 56.06 | 76.81 | 78.07 | 66.86 | 70.11 | 73.47 | 84.84 | |
| mAcc | 78.61 | 79.75 | 78.46 | 76.97 | 82.38 | 84.76 | 83.23 | 88.07 | 88.62 | 83.54 | 86.20 | 87.41 | 90.43 | |
| mIoU | 69.32 | 71.34 | 70.13 | 69.49 | 73.93 | 76.86 | 75.32 | 79.88 | 80.67 | 75.12 | 77.92 | 78.60 | 82.36 | |
| FCN-8S [13] | U-Net [14] | SegNet [15] | DeepLabv3+ [17] | BiseNetV2 [19] | HRCNet [20] | RedNet [16] | ACNet [23] | SA-Gate [18] | TSNet [21] | ESANet [22] | DCSwin [43] | Ours | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Imp.surf | Acc | 89.47 | 90.03 | 90.18 | 91.57 | 90.12 | 90.03 | 92.19 | 91.32 | 85.84 | 85.22 | 91.38 | 91.66 | 92.76 |
| IoU | 79.77 | 80.27 | 80.46 | 82.49 | 80.58 | 81.68 | 82.83 | 82.74 | 80.64 | 76.85 | 82.92 | 82.28 | 83.33 | |
| Building | Acc | 90.69 | 88.71 | 90.21 | 91.78 | 88.88 | 90.87 | 93.61 | 93.83 | 93.65 | 91.85 | 93.69 | 92.92 | 93.94 |
| IoU | 83.60 | 82.92 | 84.18 | 87.59 | 83.70 | 85.75 | 90.13 | 90.06 | 88.51 | 86.65 | 89.82 | 89.12 | 91.26 | |
| Low veg. | Acc | 85.13 | 85.82 | 85.88 | 87.36 | 87.68 | 88.17 | 87.00 | 86.16 | 86.46 | 88.52 | 87.10 | 87.31 | 87.12 |
| IoU | 71.12 | 71.60 | 71.63 | 73.63 | 71.55 | 73.18 | 73.22 | 73.53 | 72.71 | 67.98 | 73.16 | 74.48 | 74.46 | |
| Tree | Acc | 82.86 | 84.06 | 82.49 | 85.45 | 81.11 | 82.02 | 83.00 | 86.03 | 85.70 | 78.75 | 82.48 | 84.46 | 85.84 |
| IoU | 71.23 | 72.05 | 70.68 | 73.32 | 71.55 | 71.32 | 71.77 | 72.87 | 72.89 | 67.49 | 70.81 | 73.23 | 73.80 | |
| Car | Acc | 91.02 | 93.89 | 93.15 | 93.89 | 93.14 | 93.94 | 93.36 | 93.79 | 92.18 | 78.22 | 93.08 | 96.31 | 96.03 |
| IoU | 81.53 | 90.24 | 89.72 | 90.04 | 89.17 | 89.82 | 90.08 | 90.43 | 89.39 | 76.85 | 88.53 | 90.12 | 92.46 | |
| Clutter | Acc | 49.05 | 50.30 | 51.76 | 53.80 | 50.66 | 56.72 | 56.74 | 54.51 | 62.70 | 37.49 | 55.68 | 56.01 | 58.48 |
| IoU | 36.49 | 36.26 | 37.21 | 43.54 | 36.35 | 40.03 | 43.51 | 41.65 | 40.59 | 30.85 | 43.38 | 43.37 | 47.02 | |
| mAcc | 78.61 | 82.13 | 82.28 | 83.97 | 81.93 | 83.63 | 84.32 | 84.27 | 84.42 | 76.68 | 83.90 | 84.61 | 85.69 | |
| mIoU | 69.32 | 72.22 | 72.31 | 75.10 | 71.86 | 73.63 | 75.26 | 75.21 | 74.12 | 67.78 | 74.77 | 75.43 | 77.05 | |
| Flops (GMac) | Params (M) | |
|---|---|---|
| FCN8s | 74.55 | 134.29 |
| UNet | 55.93 | 26.36 |
| SegNet | 18.3 | 53.56 |
| DeepLabv3+ | 32.45 | 59.33 |
| BiseNet | 3.23 | 3.63 |
| HRCNet | 30.28 | 62.71 |
| RedNet | 21.17 | 81.95 |
| ACNet | 26.41 | 116.6 |
| SA-Gate | 41.23 | 110.85 |
| TSNet | 34.27 | 41.8 |
| ESANet | 10.15 | 45.42 |
| DCSwin | 34.4 | 118.39 |
| Ours | 55.39 | 142.82 |
| Vaihingen | Potsdam | |||
|---|---|---|---|---|
| mAcc | mIoU | mAcc | mIoU | |
| Baseline | 84.49 | 76.66 | 83.72 | 74.79 |
| W/o DSM | 89.67 | 81.07 | 84.89 | 75.88 |
| W/o PRB | 88.50 | 80.73 | 84.54 | 74.82 |
| W/o DSEM | 87.14 | 78.84 | 80.81 | 69.85 |
| Ours | 90.43 | 82.36 | 85.69 | 77.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Zhou, W.; Qian, X.; Yu, L. Deep-Separation Guided Progressive Reconstruction Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 5510. https://doi.org/10.3390/rs14215510
Ma J, Zhou W, Qian X, Yu L. Deep-Separation Guided Progressive Reconstruction Network for Semantic Segmentation of Remote Sensing Images. Remote Sensing. 2022; 14(21):5510. https://doi.org/10.3390/rs14215510
Chicago/Turabian StyleMa, Jiabao, Wujie Zhou, Xiaohong Qian, and Lu Yu. 2022. "Deep-Separation Guided Progressive Reconstruction Network for Semantic Segmentation of Remote Sensing Images" Remote Sensing 14, no. 21: 5510. https://doi.org/10.3390/rs14215510
APA StyleMa, J., Zhou, W., Qian, X., & Yu, L. (2022). Deep-Separation Guided Progressive Reconstruction Network for Semantic Segmentation of Remote Sensing Images. Remote Sensing, 14(21), 5510. https://doi.org/10.3390/rs14215510