1. Introduction
Several types of ground objects are distributed in wetlands, making their classification challenging [
1]. Understanding the distribution of ground objects in wetlands can help prevent alien species from encroaching on the living environment of local species that may otherwise cause an imbalance in the ecological environment. A good survey of the distribution of ground objects in wetland areas can provide technical support for wetland protection. In recent years, a large number of studies have focused on the classification of wetlands. In 2008, Touzi et al. [
2] proposed the Touzi decomposition method for extracting polarization information from synthetic aperture radar (SAR) images and applied the extracted polarimetric features to classify wetland areas which provided a new method of wetland classification. However, this decomposition method still has space to advance. Chen et al. [
3] investigated the influence of different polarimetric parameters and an object-based approach on the classification results for various land use or land cover types in coastal wetlands in Yancheng using quad-polarimetric ALOS PALSAR data. The results showed that utilizing polarimetric parameters such as Shannon entropy can notably improve the classification results. It also demonstrated that different polarimetric parameters and object-based methods could notably improve the classification accuracy of coastal wetland land cover using QP data. It shows that these polarimetric parameters are helpful for wetland classification. Yang et al. [
4] fused GF-1 wide format optical image and RadarSat-2 SAR image, then used a support vector machine (SVM) method for supervised classification. The results indicated that the accuracy of the fused image was higher than that of the single. Moreover, using the SVM method of optical and SAR image fusion could obtain more ground feature information and thus improve performance. He et al. [
5] proposed an efficient generative adversarial network: ShuffleGAN, which uses Jilin-1 satellite data to classify wetlands. ShuffleGAN is composed of two neural networks (i.e., generator and discriminator), which behave as adversaries in the training phase, and ShuffleNet units were added in both generator and discriminator with a speed-accuracy tradeoff. Compared with the existing generative adversarial network (GAN) algorithm, the final overall accuracy of ShuffleGAN is higher by 2% and is effective for analyzing land cover.
Apart from the above research, the following works are worth mentioning. Liu et al. [
6] used C-band sentinel-1 and L-band ALOS-2 PALSAR data to determine the distribution of coastal wetlands in the Yellow River Delta. Using three classical machine learning algorithms, namely naive Bayes (NB), random forest (RF), and multilayer perceptron (MLP), they proposed an algorithm based on SAR coherence, backscatter intensity, and optical image classification. The OA was 98.3%. This method is superior to a single data source, indicating that using more satellite data can improve the classification accuracy of machine learning algorithms. Gao et al. [
7] combined hyperspectral and multispectral images based on a CNN method and designed a spatial-spectral vision transformer (SSVIT) to extract sequence relations from the combined images. This is also a case of using multiple satellite data to classify wetland ground objects. In 2021, Gao [
8] et al. proposed a depthwise feature interaction network to classify the multispectral images of the Yellow River Delta region. A depthwise cross-attention module was designed to extract self-correlation and cross-correlation from multisource feature pairs. Thus, meaningful complementary information is emphasized for classification. Chen et al. [
9] used an object-oriented method to classify polarimetric synthetic aperture radar (PolSAR) images of coastal wetlands based on the scattering characteristics of polarization decomposition and finally achieved an overall accuracy of 87.29%. However, this method was ineffective for separating reed from Spartina alterniflora and could be improved for more detailed classification. Delancey et al. [
10] applied a deep CNN and a shallow CNN to classify large-area wetlands and compared the effectiveness of the two CNNs. The experimental results indicated that a deep CNN could extract more informative features of ground objects and be useful for complex land use classification. However, the depth neural network is not suitable for all wetland classification occasions, and it also needs to consider satellite spatial resolution, data type, surface features, and other factors to determine the depth of the network. Banks et al. [
11] classified wetlands using an RF algorithm using images combined with SAR and digital elevation model (DEM) data with different resolutions. The results indicated that PolSAR data are reliable for wetland classification. From investigation, deep learning methods have a wide application in wetland classification areas.
A PolSAR transmits and receives electromagnetic waves through different polarization modes and multiple channels, forming a complete polarization basis. Thus, the polarization scattering matrix and scattering features can be obtained. A PolSAR is used for active remote sensing and observing targets by actively transmitting electromagnetic waves to target surfaces; the PolSAR then receives scattered information reflected from targets. Moreover, it can capture all-day and all-weather high-resolution images. By using PolSAR images from the GF-3 satellite, several polarization features of targets can be acquired through polarization decomposition. The back-scattered information of different ground objects is different. We incorporated this principle to classify PolSAR images through convolutional neural networks (CNNs) in this study.
In addition, CNNs are highly popular in areas of computer vision and are used in domains such as region of interest (ROI) [
12,
13,
14,
15], synthetic aperture sonar (SAS) image classification [
16,
17,
18,
19], visual quality assessment [
20], mammogram classification [
21], brain tumor classification [
22], and PolSAR image classification [
23,
24,
25,
26,
27] et al. Especially in the field of PolSAR, in recent years, many new CNN frameworks were proposed by researchers. These CNNs are superior to the existing methods either in accuracy or efficiency. For example, Wang et al. [
23] proposed a method named vision transformer (ViT) for PolSAR classification. The ViT can extract features from the global range of images based on a self-attention block which is suitable for PolSAR image classification at different resolutions. Dong et al. [
24] firstly explored the application of neural architecture search (NAS) in the PolSAR area and proposed a PolSAR-tailored differentiable architecture search (DARTS) method to adapt NAS to the PolSAR classification. The architecture parameters can be optimized with high efficiency by a stochastic gradient descent (SGD) method rather than randomly setting. Dong et al. [
25] introduced the state-of-the-art method in natural language processing, i.e., transformer into PolSAR image classification for the first time to tackle the problem of the bottleneck that may be induced by their inductive biases. This is a meaningful work that provided new thoughts in this underexploited field. Nie et al. [
26] proposed a deep reinforcement learning (RL)-based PolSAR image classification framework. Xie et al. [
27] proposed a novel fully convolutional network (FCN) model by adopting a complex-valued domain stacked-dilated convolution (CV-SDFCN). The proposed method adopts the FCN model combined with polarimetric characteristics for PolSAR image classification.
Conventionally, the physical scattering features [
28] and texture information [
29] of SAR are broadly adopted. Some SAR classifications at the pixel level are enough in low and medium spatial resolution. However, for target recognition and classification, reflecting the texture features of targets at the pixel level is not sufficient. Deep CNNs can effectively extract not only polarimetric features but also spatial features from PolSAR images which can comprehensively classify ground object [
30]. A few traditional classification methods, such as the gray-level co-occurrence matrix [
31] and four component decomposition [
32], can be used to classify PolSAR images; however, these methods could not extract all information from the data. With the development of computer hardware, several excellent neural networks have been proposed such as SVM, random forest (RF) [
33], deep belief network (DBN) [
34], stack autoencoder (SAE) [
35], and deep CNN [
36,
37]. Thus, the efficiency and accuracy of data recognition and classification tasks have been improved considerably. With the help of deep learning, the terrain surface classification using PolSAR images is a direction of SAR. Several studies have applied these algorithms to the applications such as classification [
38], segmentation [
39], and object detection [
40] of SAR images [
41,
42,
43,
44] and achieved desirable results.
Early research on neural networks primarily focused on the classification of SAR images using the SAE algorithm and its variants [
45,
46,
47,
48]. Instead of simply applying an SAE, Geng et al. [
45] proposed a deep convolution autoencoder (DCAE) to extract features automatically. The first layer of the DECA is the manually designed convolution layer, wherein the filter is predefined. The second layer performs scale transformation and integrates relevant neighborhood pixels to reduce speckles. After the two layers, a trained SAE model was used to extract more abstract features. In high-resolution unipolar TerraSAR-X images. Based on the classification of SAR using DCAE, Geng et al. [
46] proposed a deep supervised contraction neural network (DSCNN) with a histogram of a directional gradient descriptor. In addition, a supervised penalty was designed to capture the information between features and tags, and a contraction constraint was incorporated to enhance local invariance. Compared with other methods, DSCNN can be used to classify images with higher accuracy. Zhang et al. [
47] applied a sparse SAE to PolSAR image classification by considering local spatial information. Hou et al. [
48] proposed a method that involved combining superpixels for PolSAR image classification. Multiple layers of an SAE are trained pixel by pixel. Superpixels are formed with a pseudocolor image based on Pauli decomposition. In the last step of k-Nearest neighbor superpixel clustering, the output of the SAE is used as a feature.
In addition to using the SAE algorithm, some scholars also have realized the classification of PolSAR images using CNNs [
49,
50,
51,
52]. Zhao et al. [
49] proposed a discriminant DBN for SAR image classification. It extracts discriminant features in an unsupervised manner by combining ensemble learning with the DBN. In addition, most of the current deep learning methods use the features of polarization information and spatial information of PolSAR images. Gao et al. [
50] proposed a two-branch CNN to achieve the feature classification of two kinds of holes. This method involves two types of feature extraction: the extraction of polarization features from a six-channel real matrix and the extraction of spatial features through Pauli decomposition. Next, two parallel and fully connected layers combine the extracted features and input them into a softmax layer for classification. Wang et al. [
51] proposed a CNN named full convolution network that integrates sparse and low-rank subspace representation for PolSAR images. Qin et al. [
52] applied an enhanced adaptive restricted Boltzmann machine for PolSAR image classification.
The polarization coherency matrix (
T) contains complete information regarding the polarization scattering of the targets. Since the back-scattering coefficients of different targets are different, studies have used three diagonal elements and correlation coefficients of non-diagonal elements of the
T matrix to classify PolSAR images with high accuracy [
53,
54,
55,
56]. Instead of using the information in the
T matrix for classification, a polarization covariance matrix also be used. For example, Zhou et al. [
53] first extracted a six-channels covariance matrix and then inputted it into a trainable CNN for PolSAR image classification. Xie et al. [
55] used a stacked sparse auto-encoder for multi-layer PolSAR feature extraction. In addition, the input data is represented as a nine-dimensional real vector extracted from the covariance matrix. After polarimetric decomposition, surface scattering, double-bounce scattering, and volume scattering could be acquired [
56]. A few studies have implemented these three components in CNNs with overall accuracy (OA) of as high as 95.85% [
57]. A few studies have also combined the information in the
T matrix and polarization power parameters to classify PolSAR images with different weights. OA was higher by adjusting the weights [
58]. Chen et al. [
54] improved the performance of a CNN by combining the target scattering mechanism and polarization feature mining. A recent work by He et al. [
59] combined the features extracted using nonlinear manifold embedding; next, they applied FCN to input PolSAR images. The final classification was performed using the SVM integration method. In [
60], the authors emphasized the computational efficiency of deep learning methods and proposed a lightweight 3D CNN. They demonstrated that the classification accuracy of the proposed method was higher than that of other CNN methods. The number of learning parameters was notably reduced, and high computational efficiency was achieved.
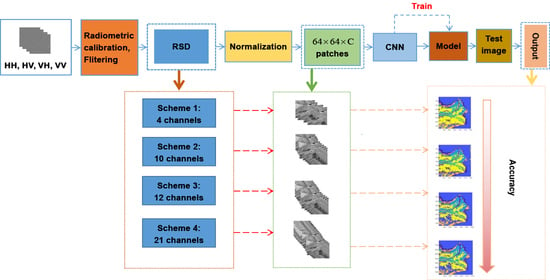
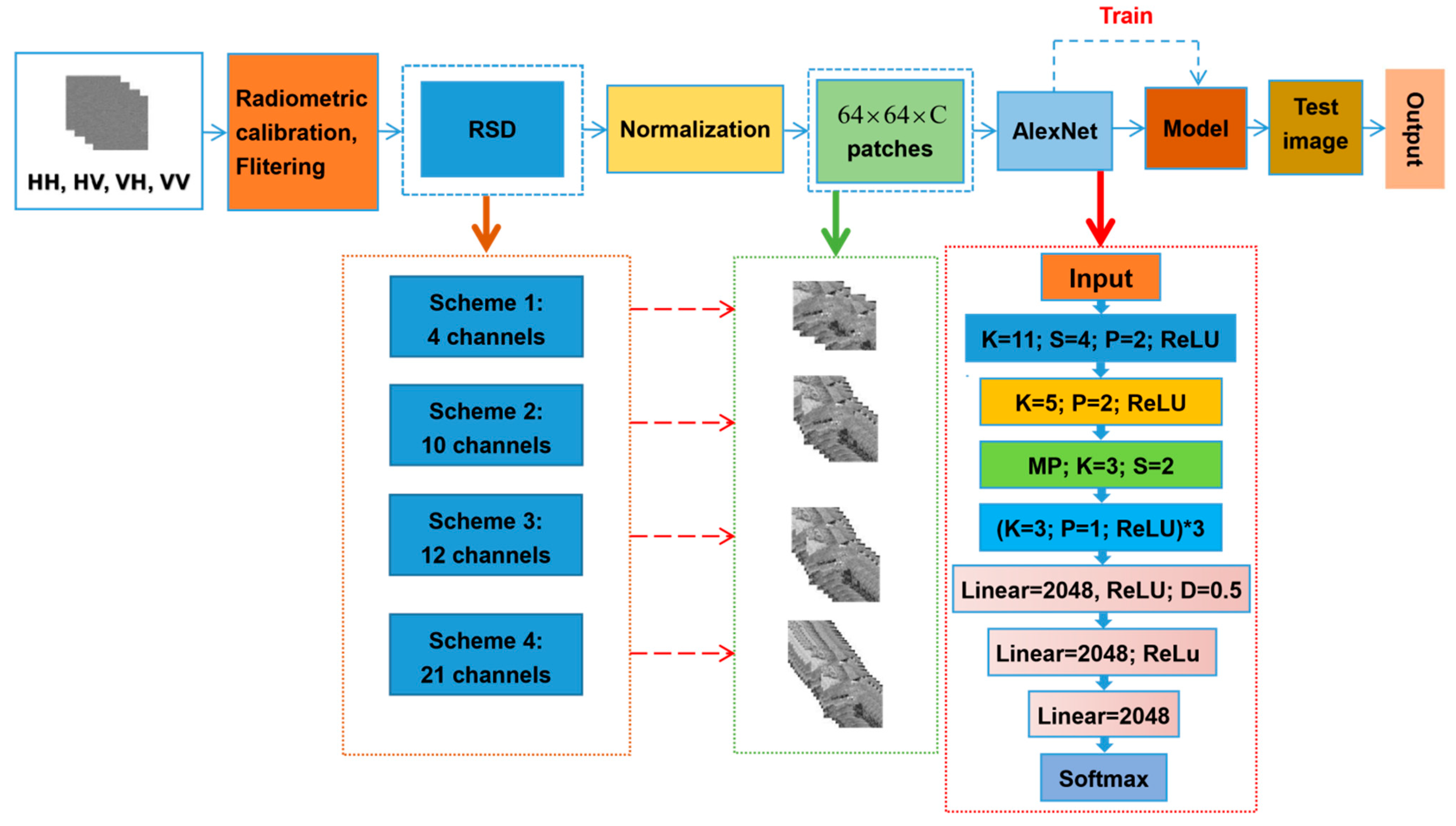
Through the literature survey, we discovered that ground objects could be classified using polarization features decomposed from PolSAR images. However, few studies have focused on polarization scattering features decomposed using excellent polarization decomposition algorithms. Reflection symmetry decomposition (RSD) [
61] is an effective algorithm and can be used to obtain polarization scattering characteristics. This study investigated if higher classification accuracy can be acquired when more informative polarimetric features were input CNNs. To this end, this paper proposes four schemes to explore the combination of polarization scattering features for QP image classification based on polarization scattering characteristics obtained through RSD and
T matrix. The remainder of this paper is as follows: the first section serves as an introduction to the current research progress of using polarization scattering information and describes the innovations in current; the second section discusses the research area and data preprocessing; the third section discusses the experimental method and the experimental process; the fourth section presents an analysis of the experimental results and accuracy; finally, we discussed the strengths and limitations of the experiment.
The main goals of this study were, therefore, (1) to provide a method for wetlands classification based on polarimetric features; (2) to examine the power of classical CNNs for the classification of back-scattering similar wetland classes; (3) to investigate the generalization capacity of existing CNNs for the classification of different satellite imagery; (4) to explore polarimetric features which are helpful for wetland classification and provide comparisons with different polarimetric features combinations; (5) to compare the performance and efficiency of the most well-known deep CNNs. Thus, this study contributes to the CNN classification tools for complex land cover mapping using QP data based on polarimetric features.
5. Discussion
To verify that the polarization features classified by employing CNNs were informative, we designed noise test experiments by adding one, two, and three channels of Gaussian random noise to each scheme. The results on AlexNet indicated that after adding one channel of Gaussian random noise, the OAs of schemes from schemes 1 to 4 were 81.36%, 85.47%, 94.93%, and 95.71%, respectively, and the kappa coefficients were 78.25%, 83.05%, 94.08%, and 95%, respectively. The OAs and kappa coefficients were lower than those obtained using the original schemes. Similarly, upon adding two channels of Gaussian random noise, the OAs using the four schemes were 81.2%, 90.44%, 94.9%, and 93.76%, respectively, and kappa coefficients were 78.07%, 88.85%, 93.22%, and 92.72%, respectively. Upon adding three channels of Gaussian random noise, the OAs of the four schemes were 85.09%, 91.87%, 93.89%, and 94.5%, respectively, and the kappa coefficients were 82.6%, 90.52%, 92.87%, and 93.58%, respectively. When we added noise on VGG16, the OAs and kappa coefficient also decreased to varying degrees. The OAs and kappa coefficients obtained upon adding the noise were worse than the original schemes, meaning that AlexNet and VGG16 had a good anti-noise performance. Higher accuracy can be acquired when adopting more informative polarimetric features to classify QP images. Furthermore, the results of RSD were slightly better than the T matrix.
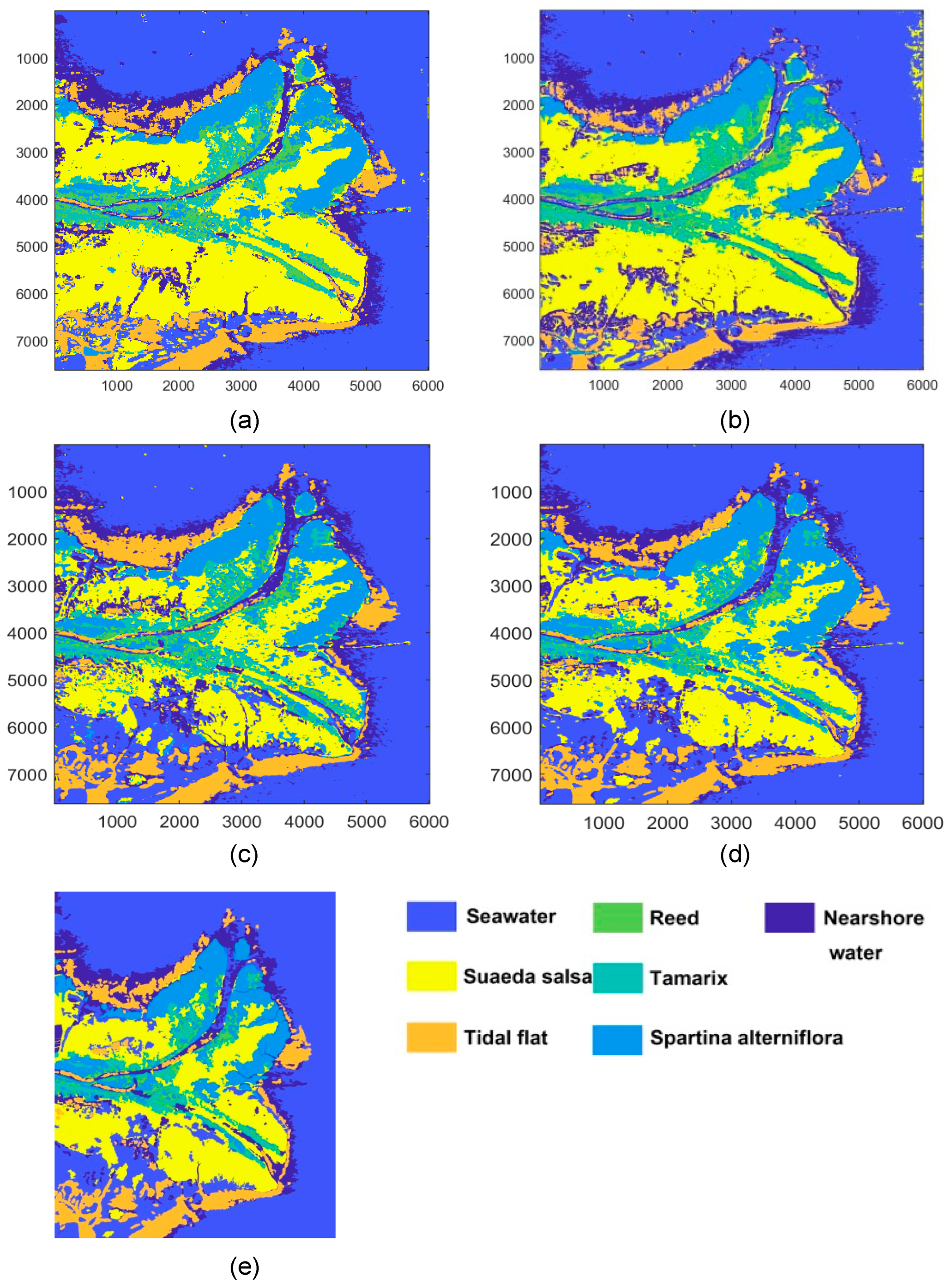
According to the results obtained using different schemes, the scheme with 21 polarimetric features had the highest OA because of more scattering of polarization information. The back-scattering coefficient is a crucial factor affecting the classification of targets. A CNN can distinguish targets easily when the back-scattering coefficients of specific targets differ from those of other ground objects. For example, the back-scattering coefficients of seawater and vegetation are considerably different; thus, the boundary between them is apparent. Distinguishing seawater from nearshore water is challenging because of their similar back-scattering coefficients.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}