1. Introduction
Synthetic aperture radar (SAR) is an active microwave detection system that can emit microwaves around the clock and generate high-resolution images using microwaves reflected by objects [
1]. SAR can perform large-area detection at night and under adverse conditions and can penetrate vegetation, soil, and lakes, overcoming the limitations of optical and infrared systems. Therefore, SAR images have high research and application value for agricultural surveying and mapping, oceanographic research, ship inspection, and military reconnaissance [
2]. However, during SAR image generation, echoes of multiple scattering points are superimposed coherently, which inevitably forms coherent speckles [
3,
4] (see
Figure 1). The existence of coherent speckles reduces the contrast of SAR images, weakens edge details, and significantly reduces the efficiency of SAR image interpretation, retrieval, and other applications, including SAR image segmentation [
5], object detection [
6], recognition, and classification [
7]. In particular, the above-mentioned situation is further exacerbated in the inshore scene, since metallic objects have similar scattering properties to shores. Therefore, coherent speckling is the primary problem to be solved for understanding and analyzing SAR images.
Based on the generation mechanism of SAR images, coherent speckle suppression methods have been developed with the advent of SAR images. Researchers first proposed an estimation domain-based method based on natural optical image processing methods, and many studies have confirmed its effectiveness [
8,
9]. However, statistical models of noise in SAR images are usually built on the premise that the area is homogeneous, and ideal performance can be achieved in homogeneous areas, while in texture-rich areas, the image structure information (edges, textures, and point objects) will be blurred or lost. In addition to the estimated domain-based methods described above, other effective speckle suppression methods exist [
10,
11,
12]. However, similar to statistical domain-based methods, they often fail to preserve sharp features such as edges and often contain blocking artifacts in denoised images.
In recent years, with the outstanding performance of deep learning in the field of computer vision, researchers have begun to explore methods for speckle suppression based on convolutional neural networks (CNN). Efficient methods have also been proposed, such as DnCNN [
13] and ID-CNN [
14]. However, existing CNN-based methods usually use the feature mapping model to remove coherent speckle by constructing mapping between the coherent speckle and clean SAR image. This feature mapping model is significantly affected by human factors, which significantly limits the generalization ability of the model. In addition, these methods are derived from general image denoising techniques and are not specialized in speckle noise, and the additional training model makes it impossible to achieve end-to-end training.
To solve these problems, this paper proposes a filtered convolution for SAR image ship detection. Inspired by dynamic convolution [
15], filtered convolution can replace classic convolutional layers with plug-and-play and suppress speckle noise while extracting features. The filtering convolutional layer is composed of two important modules: the kernel-generation module and the local weight generation module. The kernel-generation module was implemented using a dynamic convolution structure. We referred to the SENet [
16] structure and generated dynamic convolution kernels based on the global statistical properties of the input. The local weight generation module is used to generate local weights based on the local statistical features of the input such that the extracted features contain more local information. In addition, we theoretically and experimentally confirmed that the coupling of the kernel-generation module and local weight generation module can effectively suppress speckle noise during the feature extraction process. Finally, the proposed filtered convolution was applied to SAR image ship detection, and its effectiveness was verified on challenging datasets LS-SSDD-v1.0 and HRSID.
In short, the contributions of this study are as follows:
We propose a filtered convolutional layer based on a dynamic convolutional structure. It is composed of a kernel-generation module and a local weight generation module and can replace the traditional convolutional layer with plug-and-play.
We theoretically confirm that the proposed filter convolutional layer can effectively suppress speckle noise in the feature extraction process and design experiments to verify its effectiveness.
The proposed filtered convolution is applied to the ship detection task and improves the performance of the baseline method Cascade RCNN for ship detection in SAR images. The experimental results show that our method achieves outstanding performance on LS-SSDD-v1.0 and HRSID.
The remainder of this paper is organized as follows.
Section 2 summarizes the related work on ship detection, coherent speckle suppression, and dynamic convolution.
Section 3 describes material and methods, and a detailed analysis of its characteristics.
Section 4 reports the details of the experiment and results, including the datasets, ablation experiments, and the overall evaluation. Finally,
Section 5 presents the conclusions of this study.
3. Material and Methods
In this section, we describe in detail the filtered convolutional neural network (F-CNNs). The purpose was to suppress the coherent speckle noise of the SAR image during the feature extraction process and improve the performance of the ship detection model. Compared to existing speckle suppression methods, the proposed filtered convolution method has the following advantages:
Filtered convolutional layers are able to suppress speckle noise in the feature extraction process without an additional separate step.
The extracted features contain more local information, which is beneficial for SAR image ship detection.
The convolution kernel parameters were learnable and can be updated during the back propagation of the network.
3.1. Filtered Convolution Kernel Generation
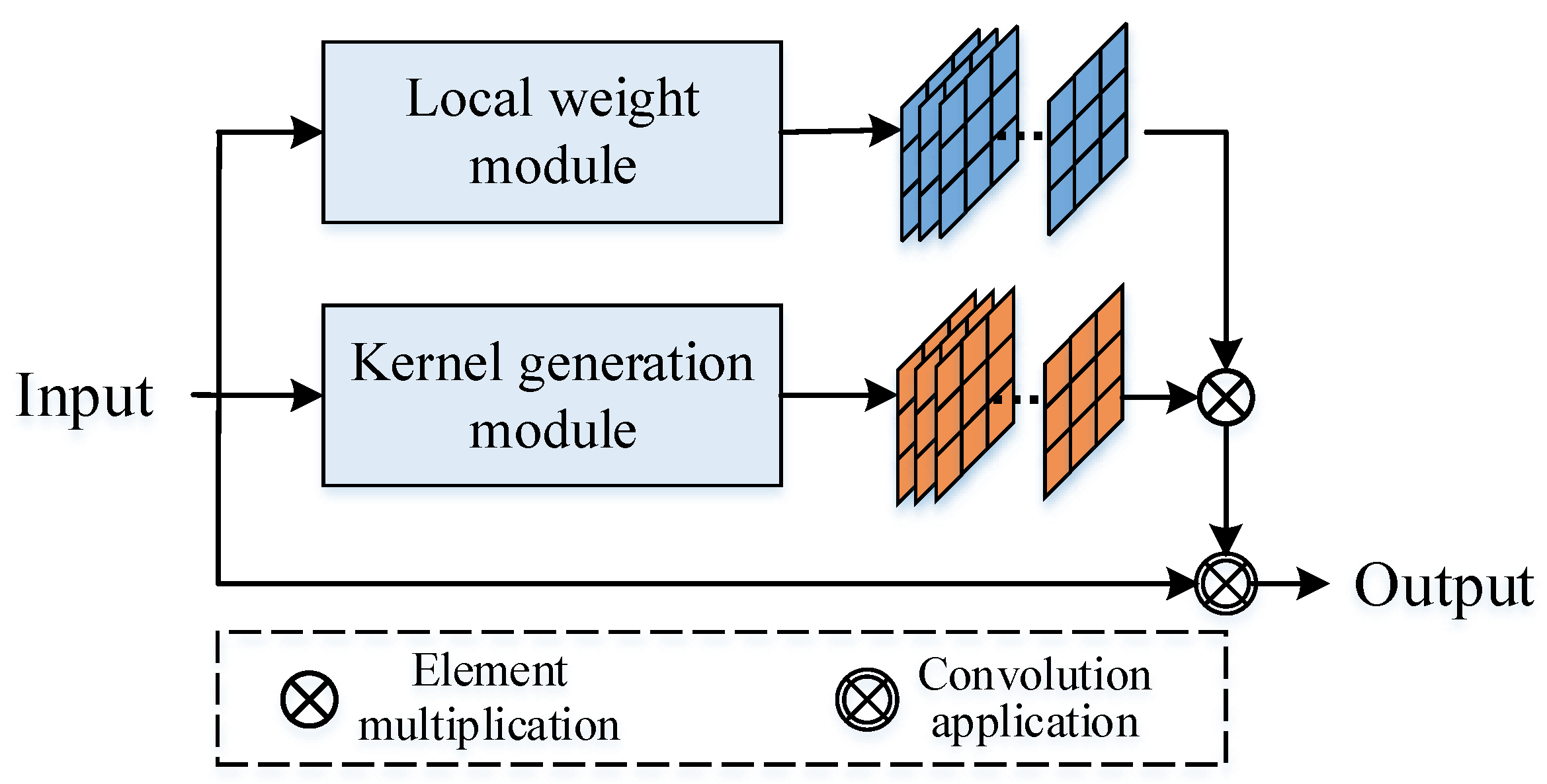
Inspired by the traditional coherent speckle noise suppression algorithm, we propose a filtered convolution based on the statistical characteristics of an input image or feature map. In filtered convolution, the convolution kernel is generated by the kernel-generation module and local weight generation module. The convolution kernel-generation branch is used to generate the dynamic convolution kernel, and the local weight generation branch makes the network pay more attention to the local area, both of which originate from the input image or feature map.
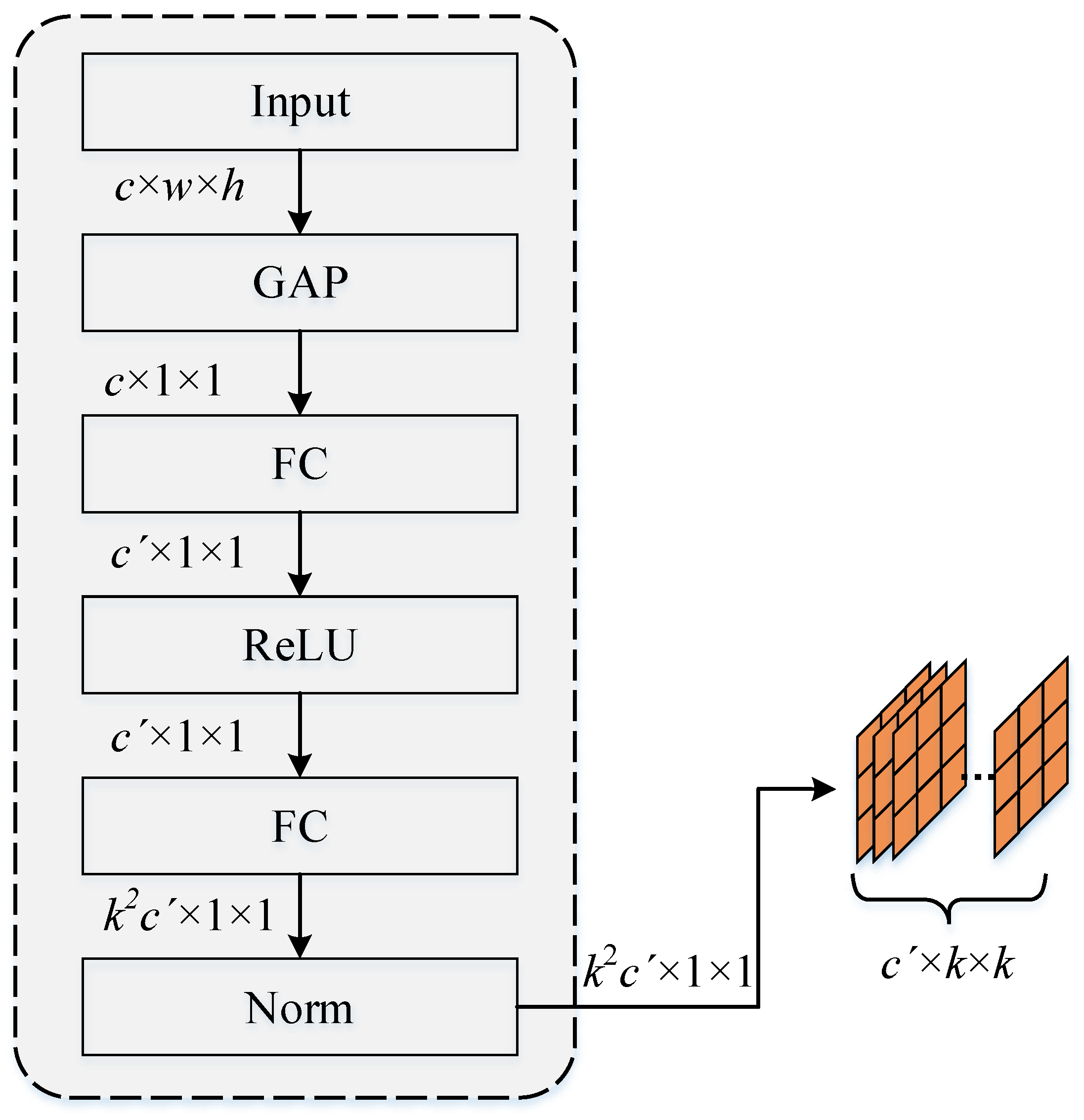
3.1.1. Kernel Generation
The kernel-generation module is primarily used to generate dynamic convolution kernels according to the global characteristics of the input, and the network structure is shown in
Figure 2. We refer to the basic structure of SENet [
16]. For the input image or feature map
(where
h,
w, and
c are the height, width, and number of channels of input
I, respectively), we first pass a global average pooling layer to obtain global features. Then, the FC layer is used to transform the number of channels, the ReLU layer is used for non-linearization, and the Norm layer is used for normalization. Finally, the elements of each channel dimension were resized as kernels with
.
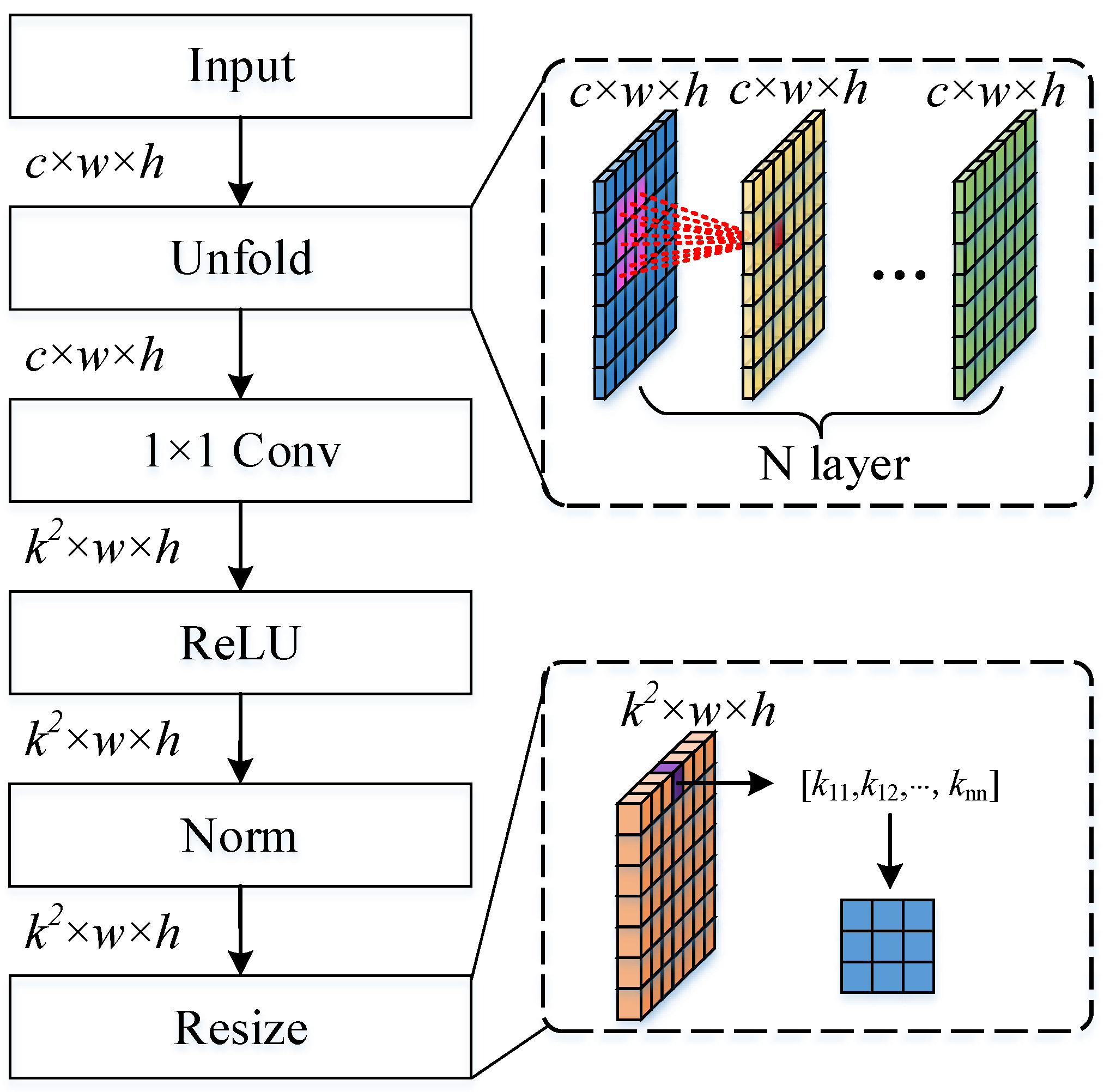
3.1.2. Local Weight Generation
The local weight generation module is mainly used to improve the network’s ability to represent local information, which is crucial for both coherent speckle suppression and ship detection tasks. For the input image or feature map
, we first obtain the local statistical properties of each element through a specific multilayer sliding window. The size of the sliding window is
with a stride of 1. Multilayer processing is used to expand the regional receptive field. Then, the
convolutional layer was used to resize the feature channel to
and normalize it. Finally, the elements at the same position in each channel were resized to
convolution kernels. The detailed structure of the local weight-generation network is shown in
Figure 3.
3.2. Filter Convolutional Layer
First, we briefly formulate a standard convolution, given an input
, the standard convolution operation at the
pixel can be written as a linear combination:
where
is the filter at the position offset between the
and
pixels and can also be denoted as an adjacent element.
denotes the input feature vector of the
pixel, and
denotes the bias vector.
Y denotes the output feature map, and
denotes the output feature vector of the
pixel.
denotes the convolution window around the
pixel. In the standard convolution, each convolution kernel is shared among all pixels in the input feature map.
In the proposed filter convolution, the convolution kernel is generated from the input image (feature map), and the detailed network structure is shown in
Figure 4. The key technology is to construct the statistical features of the convolution kernel based on the input, in which the kernel-generation module is used to obtain the global statistical features and the local weight module is used to obtain the local statistical features:
where
denotes the output feature value at the
pixel and
channel, and
denotes the input feature values in the
pixel and
channel.
is the dynamic convolution kernel, where
denotes the filter at the
pixel.
denotes the local weights, with
denoting the weights at the
channel.
3.3. Suppression of Coherent Speckle Noise
Several studies have confirmed that speckle noise can be regarded as a multiplicative noise model [
34,
35]. An input image containing coherent speckles can be expressed as:
where
I,
X, and
U denote the input image, the ideal image without noise, and coherent speckle noise, respectively. Specifically,
X and
U are independent of one another. To facilitate calculation, it was transformed into a linear model using the Taylor formula:
where
and
denote the expectations of
U and
X, respectively.
Based on the above assumptions, the proposed filtering convolutional layer can be formulated as:
where
S denotes the element output of the filtered convolutional layer, and
X and
U are the expected values of the clean image elements and noise components, respectively.
In the filter convolutional layer,
K is the multiplication of the output of the kernel-generation module and the local weight generation module and is also regarded as the multiplication of the global and local statistical features (
and
) of the input. Therefore, the convolution process can be expressed as:
The speckle noise
U in the SAR image obeys the
Gamma distribution [
36], and the expected value
is 1. The probability density function of
U can be formulated as:
where
denotes the gamma function, and
and
.
Therefore, the first term
in Equation (
6) can be rewritten as
In a clean SAR image
X, the global mean characteristic
is an extremely small value because most of the background elements are 0. The second term
in Equation (
6) is discarded.
In addition, based on the network structure of the global feature module, the elements of
can be regarded as the expectation
of the input
I. Therefore, the third term in Equation (
6) can be converted into:
To sum up the above, the proposed filtered convolution can be expressed as:
As shown in Equation (
10), the proposed filter convolution has a low correlation with speckle noise
U in the feature extraction process. Therefore, we believe that the filtered convolution can effectively suppress the influence of speckle noise on visual tasks, which confirms our idea.
3.4. Backward Propagation
The back-propagation of filtered convolutions is essentially the same as that of the standard convolutional layers. We introduce
as the
input feature map and
as the input convolution kernel and let
be the
output feature map. In the backpropagation process, the filter convolutional layer calculates the gradient of the loss function
l relative to
, similar to the previous one, and the gradient of the loss function
L relative to
is:
where ∗ denotes zero-padding convolution.
The gradient of the loss function
L with respect to
is:
where
is the transpose of
.
Compared with traditional convolutional layers, is not a network parameter, but a function of the input X. Therefore, the value of the gradient is passed to the convolutional layer, and is calculated as a part of the backpropagation algorithm.
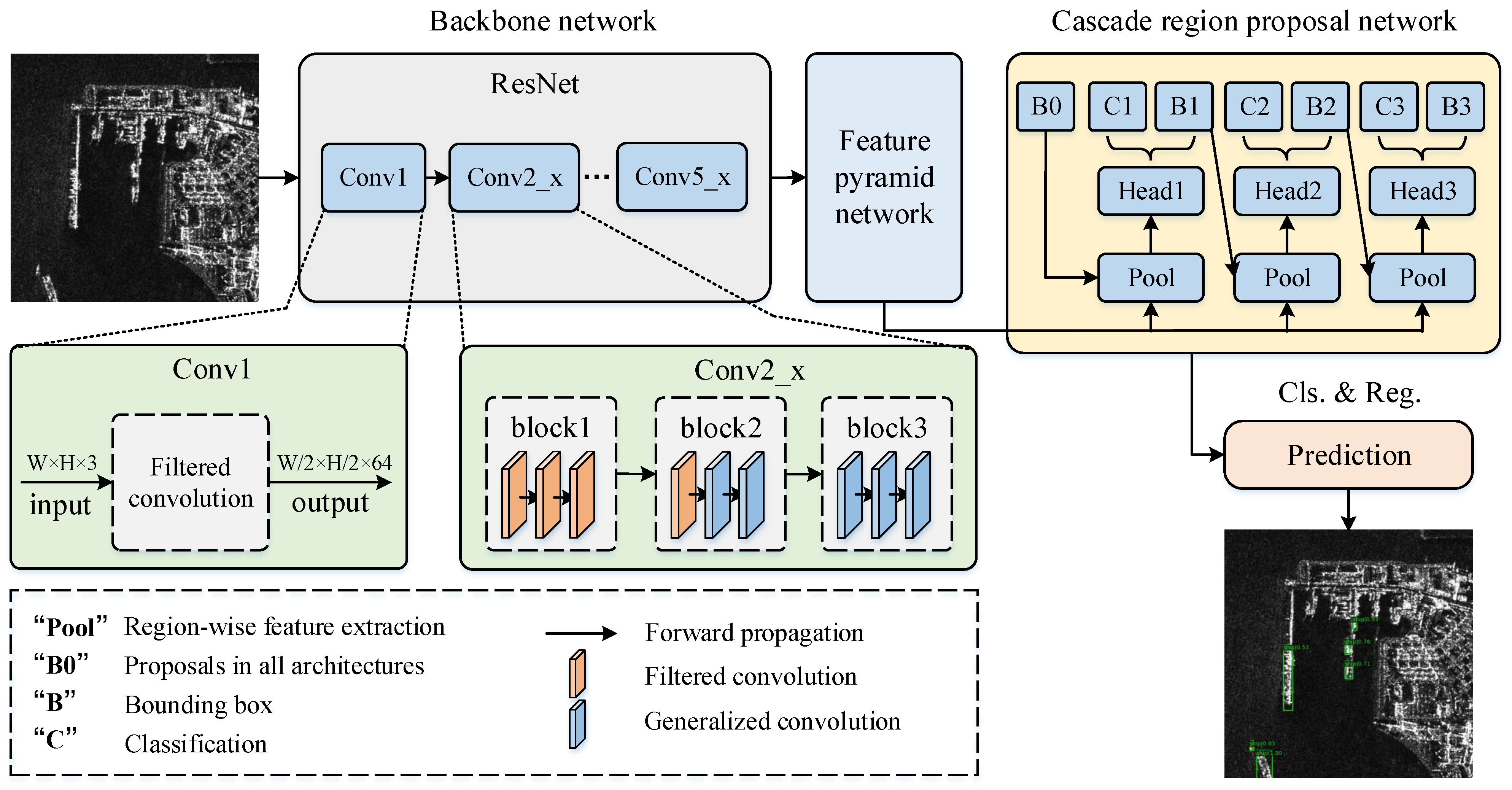
3.5. Filtered Convolution for Ship Detection
In this section, we will introduce an ship detection algorithm based on filtered convolution. The baseline method adopts the Cascade RCNN method, and the network structure is shown in
Figure 5. For the input image, the multi-scale feature map is firstly acquired through the backbone network and FPN; then, the proposal is generated through the cascaded region proposal network; and finally, the bounding box and category of the object are output through the head structure. Specifically, The proposed filtered convolution is applied in the backbone network, replacing the traditional convolutional layers in the first five convolutional layers (based on the analysis in
Section 4.6).
5. Conclusions
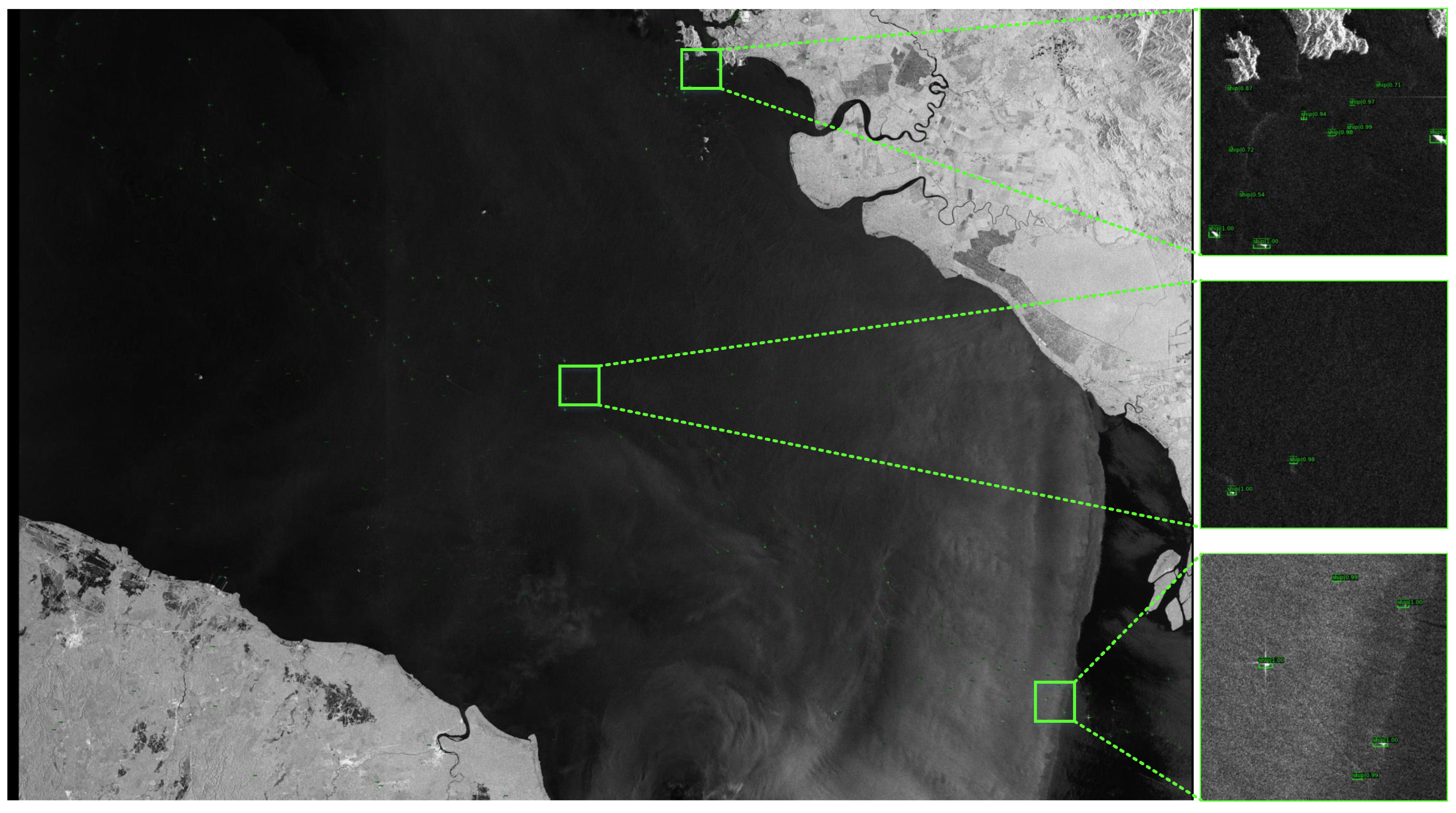
This study proposes a filtered convolution structure for ship detection in SAR images. This structure is applied in the backbone network and can replace traditional convolution, which is mainly composed of a kernel-generation module and a local weight generation module. Specifically, the kernel-generation module uses a dynamic convolution structure to generate dynamic convolution kernels based on the global statistical properties of the input. The local weight generation module is based on the local statistical characteristics of the input and is used to improve the network’s ability to represent local information. In addition, we theoretically confirmed that the coupling of these two modules can effectively suppress speckle noise in SAR images. Our method was introduced into cascade R-CNN and achieved outstanding performance. Compared with the baseline method on the LS-SSDD-v1.0 dataset, improvements of 1.9% and 2.2% were obtained on the backbone network of ResNet50 and ResNet101, respectively. Improvements of 1.2 % and 2.4 % were also obtained in the inshore scenarios. Similarly, improvements of 1.4 % and 1.8 % were obtained on the backbone network of ResNet50 and ResNet101, respectively, compared to the baseline method on the HRSID dataset. Moreover, 4.2% and 4.7% improvements were also achieved in inshore scenarios.
In this study, we improve the performance of the SAR image ship detection algorithm by constructing a filtered convolution structure. However, filtered convolution can only perform well when applied to the initial layers of the backbone, and specific results are obtained experimentally, which limits its generalization performance.
Therefore, in future research, we tend to try a more generalized structure, similar to the residual structure, which can be adapted to images of any scene. In addition, enhancing the contextual relationship between nearshore instances and the coast is also a direction worth considering.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}