1. Introduction
China is one of the countries with the highest earthquake losses in the world. More than 50% of the total cities and 70% of the great and middle cities in China are located within areas with more than VII degree of earthquake intensity [
1] and are threatened by moderate and massive earthquakes. China has experienced many devastating earthquakes with heavy losses. For example, the 12 May 2008 Wenchuan Ms8.0 earthquake in Sichuan Province, with an epicentral intensity of degree XI, led to more than 440,000 square kilometers of affected area, and more than 15 million rooms collapsed [
2]. On 14 April 2010, the Yushu Ms7.1 earthquake in Qinghai Province caused more than 80% of the buildings in Jiegu Town to be destroyed [
3]. According to China Earthquake Administration (CEA), 80,900 houses collapsed and 129,100 were severely damaged as a result of the 2014 Ludian Ms6.5 earthquake in Yunnan Province [
4]. In 2021, the Yangbi Ms6.4 earthquake in Dali Prefecture, Yunnan Province caused damage to many rural houses [
5].
After an earthquake, there is an urgent need to quickly and accurately acquire information on the damaged houses or buildings for emergency rescue and damage assessment purposes [
6]. However, this has remained a challenging problem in disaster’s emergency management. Generally, field investigation cannot meet the above requirements because it consumes a lot of manpower and material resources with poor efficiency. In addition, it is difficult to carry out field investigations to obtain detailed information on extreme earthquake areas shortly after a strong earthquake, which often not only destroys houses or buildings but also severely interrupts ground transportation and communication with accompanying geological disasters, such as landslide, mudslide, and barrier lake. As remote sensing technology is rapid, macroscopic, and dynamic, it has gradually become one of the most effective means for disaster information acquisition, emergency responses, and disaster assessment. Due to the advantages of low-altitude flexible deployment, UAV remote sensing has increasingly become more important than satellite remote sensing for automated building damage assessment owing to its higher resolution and the lessened impact from clouds [
7].
A lot of progress has been made in the detection of damaged houses from damaged roofs to damage degree classification via UAV remote sensing. The representative methods include modified Chinese Restaurant Franchise (CRF)-based unsupervised classification, object-oriented classification, and the deep-learning-based method. In addition, there are some methods that integrate features of the 3D point cloud of Lidar. Li S. et al. proposed a modified Chinese Restaurant Franchise (CRF) unsupervised classification model, which used color and shape features to segment the “roof holes” of slightly damaged rural houses [
8]. Its accuracy was 98.62%, showing an improvement of 2.29% and 2.24%, respectively, compared with unsupervised K-means classification and ISODATA. Moreover, Li S. et al. divided the damaged houses into four tiers: basically intact, slightly damaged, partially collapsed, and completely collapsed, based on the elevation information of point cloud data and the spectral and morphological characteristics of UAV orthophotos acquired after the earthquake [
9]. Çömert et al. used the object-oriented classification method to extract damaged houses through two UVA images from before and after the simulated earthquake [
10]. Mainly based on the spectral, texture, and morphological features of the damaged houses, these methods have their own advantages, but their construction is time consuming, and it is difficult to simultaneously balance their accuracy and efficiency. In recent years, deep learning has benefited from the availability of large datasets and recent advances in architectures, algorithms, and computational hardware [
11]. At present, this progress is widely used in some typical applications, such as machine translation, face recognition, autonomous driving, etc. The combination of remote sensing and deep learning is emerging as a fundamentally new approach that could detect damaged houses. Vetrivel et al. used Multiple Kernel Learning (MKL), integrating the features from AlexNet (a Convolutional Neural Network (CNN)) and 3D point cloud features for the detection of damaged houses [
12]. The average accuracy when only using CNN features is about 91%; via the integration of 3D point cloud features, a 3% improvement can be attained.
Object detection plays an important role in the interpretation of remote sensing images [
13], such as intelligent monitoring, urban planning, precision agriculture, and disaster loss assessment. The current mainstream object detection algorithms are mainly based on deep learning models, which can be divided into region-based algorithms and regression-based algorithms. The former, such as the R-CNN family, in which the region proposals are first generated and then classified, demonstrates a high accuracy but slow speed. The latter is based on the end-to-end concept. For efficient object detection, the representative algorithm is YOLO (You Only Look Once), proposed by Redmon et al. [
14,
15,
16]. YOLOv1 can carry out region proposal, classify proposed boxes, refine the bounding boxes, eliminate duplicate detections, and rescore the boxes being connected together [
14]. Therefore, YOLOv1 greatly improves the speed of object detection compared with R-CNN. YOLOv2 [
15] uses DarkNet-19 [
17] as a Backbone to extract the features, which can increase the resolution of the input image, delete the fully connected layer, and learn better boxes for object detection by K-means and multi-scale training. Pi Y. et al. applied YOLOv2 to detect the roof damage from UAV and helicopter images [
18]. It was found that the detection ability is insufficient for small scale targets. Therefore, to improve this, YOLOv3 [
16] adopts Darknet-53 as the Backbone for the deeper feature extraction and multi-scale prediction. In order to establish a damaged-houses detection model for earthquake emergency response, Ma H and Liu Y et al. [
19] used YOLOv3 and made some improvements by replacing the Darknet53 with ShuffleNet v2 [
20], which is a lightweight CNN. This method greatly reduced the number of network parameters, and by using the Generalized Intersection over Union (GIoU) loss function as the bounding box loss function, the speed and accuracy of the detection were significantly improved. Their tests showed that the improved YOLO has the potential to detect damaged houses [
18,
19]. For the new generation networks, the improvements in data enhancement and network architecture are commonly used. Based on YOLOv1, YOLOv2, and YOLOv3, YOLOv4 [
21] was constructed by Bochkovskiy A. through optimizing the data enhancement algorithm, the Backbone, the Neck, etc., to improve the detection accuracy while simultaneously ensuring the detection speed. Jocher G. et al. proposed the latest YOLOv5 [
22] via a series of improvements, such as utilizing the Pytorch deep learning framework, mixed precision and distributed training, optimization for the trunk network, etc. The training time was reduced and the detection accuracy was improved. In addition, the experiment showed that the fastest detection speed for natural images can reach 0.007 s per frame, and the model can realize real-time detection for natural images. Lema D.G et al. found that YOLOv5 could achieve the highest accuracy compared with YOLOv2, SSD, and Azure Custom Vision for the detection of livestock activity scenes [
23]. Moreover, some studies have also transferred YOLOv5 to remote sensing images and have demonstrated the adaptability of YOLOv5 in different scenarios. YOLOv5 mainly includes four models, named YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x [
22]. YOLOv5s has the smallest depth and width for the network. To reduce the misdetection rate for occluded and densely arrayed ships in aerial images, Zhang H. et al. improved YOLOv5s by using the Complete Intersection over Union (CIoU) loss function and Distance Intersection over Union_Non-Maximum Suppression (DIoU_NMS) algorithm to replace the GIoU loss function and NMS algorithm, respectively [
24]. To solve the problem of the high density and overlap of wheat spikes, Zhao J. et al. improved YOLOv5 by adding a microscale detection layer to detect small-sized wheat spikes in UAV images [
25]. These two applications successfully transferred YOLOv5 to aerial and UAV images.
To meet the post-earthquake emergency response requirements, in our study we attempt to transfer YOLOv5 to the detection of damaged houses using UAV images. Regarding the complex background to damaged houses in earthquake-stricken areas due to the influence of the undamaged houses, the stacking of building materials and occlusion by trees, as well as the inconsistent resolution of UAV images, YOLOv5s, which has the smallest volume in YOLOv5, was selected to improve the model due to the strong demand for time efficiency. Based on this, YOLOv5s-ViT-BiFPN was established. To verify our model’s feasibility, we used it to detect the damaged houses in areas that were seriously stricken by the Yangbi Ms6.4 earthquake in Yunnan Province using UAV orthophotos.
2. Materials and Methods
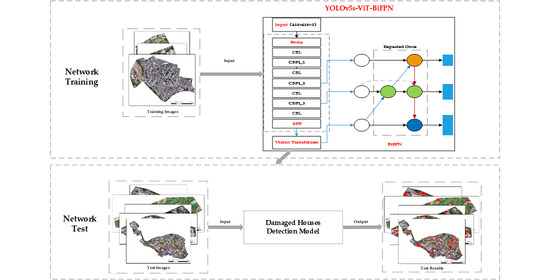
This study constructed an improved YOLOv5, named YOLOv5s-ViT-BiFPN, to detect houses damaged by the earthquake. Its main steps include: (1) standard block clipping and annotation for the UAV orthophotos; (2) constructing YOLOv5s-ViT-BiFPN; (3) model training and validation; (4) using the well-trained YOLOv5s-ViT-BiFPN to detect the damaged houses for each standard image block with a size of 416 pixels; and (5) recovering the geographical coordinate information for the detection results. The flow is shown in
Figure 1.
The construction and the improvements for YOLOv5s-ViT-BiFPN are introduced in the following parts.
2.1. Study Area and Data
At 21:48:34 on 21 May 2021, the Ms6.4 earthquake occurred in Yangbi County, Dali Prefecture, Yunnan Province, in China. The epicenter was located at (25.67° N, 99.87° E) and the focal depth was 8 km. The earthquake, which had a maximum epicentral intensity of VIII and covered an area of about 170 km
2, mainly affected the three towns of Cangshanxi, Yangjiang, and Taiping in Yangbi County. As several small earthquakes occurred before this earthquake, the local people became alert about the earthquakes, so there were few casualties. However, the houses in these rural areas were built with low seismic capacity due to economic reasons and weak awareness of seismic prevention [
26,
27,
28], so the earthquake caused a number of houses to become severely damaged or collapse in the VII–VIII intensity zone. According to the statistics from the local government, the damaged houses involved nine towns of Yangbi County, so 232 rooms collapsed and 13,930 suffered medium and slight damage [
5].
Cangshanxi Town of Dali Prefecture was the most seriously stricken area of the seismic intensity VIII zone, involving eight villages of Beiyinpo, Jinniu, Xiajie, Baiyang, Cunwei, Baimu, Hetaoyuan, and Longjing. We used this as our study area, as shown in
Figure 2. Their locations were labeled by red dots and letters from a to h. The categories for the house structures in the study areas were soil/beam, soil/wood, stone/wood, brick/wood, brick/concrete, and frame structure. A total of 80% of the houses were the first three structures, which have poor anti-seismicity [
26]. The damaged houses in this study were mostly the soil/beam, soil/wood, and stone/wood structures. The main types of damage for houses in the area were roof cracks, partial roof collapse, and total roof collapse. This was verified by field investigation, as shown in
Figure 3.
The UAV data for above eight villages were acquired and processed to eight ortho images by the Shanghai Ocean University and the Aerospace Information Research Institute, Chinese Academy of Sciences (AIR/CAS). The post-seismic UAV images were acquired by DJI Phantom 4 on 23–25 May 2021, and the flying heights were between 50 and 200 m. All of the images we used were taken from repeated paths of UAV flight, as shown in
Figure 4. The spatial resolution of the orthophotos is between 0.01 and 0.06 m. The data were divided into two parts for individual training and testing for our proposed model.
In order to prepare the training samples for YOLOv5, 400 image samples (including 860 damaged houses) were selected from the images (a–c) shown in
Figure 4. Each sample image contained at least one damaged house. The default size of the input image for YOLOv5 is 640 × 640 pixels. However, considering its training efficiency and the comparison with YOLOv3, for which the default size of input image is 416 × 416 pixels, we adopted the smaller input size, as used for YOLOv3. The three training UAV images were separately clipped into sub-images of 416 × 416 pixels. The sub-images that contained the damaged houses were manually and randomly selected as the samples. Each damaged house was annotated with a vertical bounding box by LabelImg (a free annotation tool).
Figure 5 shows examples of damaged houses annotated by the LabelImg, which can save the annotations as XML files. The annotation files contain the corresponding information of the coordinates and classes of each ground truth bounding box for the images. In order to verify the detection accuracy by YOLOv5 and to test its robustness performance, images (d–h) were taken as the transferability scenes for this model.
2.2. Improvement of YOLOv5s
YOLOv5 is the latest YOLO object detection model. The improvements in the optimization of trunk network and the use of the latest Pytorch framework can reduce the training time and improve the detection speed [
22]. Its network architecture consists of four modules, including input, Backbone, Neck, and Head [
24,
29], as shown in
Figure 6. We depicted the network structure of YOLOv5 by referencing [
22].
For the input images for YOLOv5, to improve the generalization performance of the model, generally, data enhancement is used as the essential procedure. The common methods, such as image rotation, image reversal, and color space transformation, are broadly used. Additionally, mosaic data enhancement is used in most cases to reduce the generalization errors [
22]. This combines four images into one image in a certain proportion to increase the background complexity, reducing the amount of computation and improving the robustness and detection speed. Examples are shown in
Figure 7.
The Backbone module for YOLOv5 is used to extract the features of the damaged house from the input image [
25]. It is based on the Focus structure [
22], Cross Stage Partial Network (CSPNet), and Spatial Pyramid Pooling (SPP). Conv refers to the convolutional operation for feature processing. CBL, as shown in
Figure 6, consists of a convolutional (Conv) layer, batch normalization (BN) layer, and activation layer using a Leaky ReLU. Concat is used to combine features. CSP is short for CSPNet.
The Focus structure is shown in
Figure 8. The Focus can reduce the parameters of the model and memory space of GPU for themodel’s execution and speed up the model. The first step in its construction is to slice the input image, and the second is to merge the results into Concat operation. After these two processes, the number of channels for the merged image is increased by four times compared to those of the former images without information loss. The final step is to implement the convolution operation to expand the number of channels of the feature map. We depicted the structure of Focus as in reference [
22].
The structure of CSPNet is shown in
Figure 6. CSPNet includes two types of structures; the difference is the repeated numbers of ResUnit. CSP2 has deeper layers that can extract deeper features [
30]. The input feature layer is divided into two parts by splitting the channels equally. One part is transformed into a cross-stage hierarchical structure and then concatenated with the other to the next convolutional layer. This structure not only reduces the computations of the model but also achieves a richer combination of features and improves the speed and accuracy of the detection.
The SPP module can increase the receptive field. A large receptive field can perceive the target information and separate the most important context features from the input feature layer [
31].
The Neck module’s main function is to generate the feature pyramid, so that the model can identify targets at different scales. YOLOv5 uses Path Aggregation Network (PANet) [
32], which makes it easier to transfer low-level features to high-level features using the bottom-up path on the basis of the Feature Pyramid Network (FPN).
The function of the Head module is the same as YOLOv3 and YOLOv4, which can predict the class probabilities and the bounding boxes of the targets on three scales (13 × 13, 26 × 26, 52 × 52).
YOLOv5s has the smallest network depth and width, the shortest training time, and the fastest detection speed compared with YOLOv5m, YOLOv5l, and YOLOv5x. For this reason, we utilized it to construct the damaged houses detection model.
However, the original YOLOv5s cannot fully meet the testing requirements due to the complexity of the background of damaged houses in UAV orthophotos, such as the influence of undamaged houses, stacked construction materials and other objects, the shading of trees, and the scale of the damaged houses, which are inconsistent in the different images due to the changes in flying height. Therefore, we proposed an improved model, YOLOv5s-ViT-BiFPN, based on YOLOv5s network architecture, for the detection of damaged houses. Firstly, Vision Transformer was introduced to modify the backbone network to integrate information from global features and focus on the target characteristics. Secondly, the feature fusion network was further optimized, and the original feature extraction network PANet of YOLOv5s was replaced by BiFPN to enhance the ability to fuse multi-scale information due to the different scales of damaged houses.
2.2.1. Improvements for Backbone
As the current CNN struggled to extract features from global features, the use of Multi-Head Attention, Transformer, allows the model to jointly integrate to the information from the whole inputs at different positions [
33]. For a standard Transformer, the input is one-dimensional data. The Vision Transformer attempted to transfer the Transformer into image-processing domains and verified that a pure Transformer can perform well in image classification tasks [
34]. Regarding the complexity of remote sensing images, we utilized a hybrid form by adding a Transformer to the CNN. Thus, the model could maintain the feature-extraction ability of CNN for deep features and the ability to extract the global features of Transformer at the same time.
Vision Transformer consists of Patch Embedding and Transformer Encoder. Firstly, Path Embedding was used to make the input’s dimension fit in the Transformer Encoder. Secondly, due to the loss of the descending dimension, the position embedding operation was added to restore the position information. Finally, the vector sequence was provided to a Transformer Encoder. The original Transformer encoder consists of multi-head attention and Multilayer Perception (MLP) layers. To allow the model to focus more on the target features and increase the number of parameters as little as possible by the Vision Transformer structure, we replaced the MLP layer with two fully connected (FC) layers and chose four heads for multi-head attention.
In this study, a Vision Transformer was introduced into the Backbone by adding the last layer of the Backbone feature extraction module. Furthermore, 416 × 416 × 3 (height × width × channel) refers to the size of the input image, with three channels. After the feature extraction by Backbone, the original image was transformed into the feature map with the size of 13 × 13 × 512 (height × width × channel). Therefore, the input size for Vision Transformer was 13 × 13 × 512 (height × width × channel). Through Patch Embedding, the dimensions for the feature map were 169 × 512 (length × channel). Positional Embedding uses a simple additive operation by a learnable vector. The input and output vectors for Transformer Encoder had the same dimension, as shown in
Figure 9. We depicted the structure of our modified Vision Transformer by referencing [
34].
The YOLOv5s-ViT was constructed by integrating the relationship between pixels in different locations in the feature map to enhance the key information.
2.2.2. Improvements for Neck
Generally, it is hard to maintain the exact same initial resolution for UAV images due to the changes in flying height. For this study, the resolution of the UAV images we obtained was between 0.01 and 0.06 m. Therefore, for damaged houses with multiple scales, we improved the Neck module in order to improve the detection accuracy.
Although PANet in YOLOv5 achieved good results for multi-scale fusion through up-sampling and down-sampling [
21], its volume of computations was large. However, the Bi-Directional Feature Pyramid Network (BiFPN) could allow for an easy and fast multi-scale feature fusion. It adopted the cross-scale connection to remove the nodes which contribute less to feature fusion in PANet and added the additional connections between input and output nodes for the same level [
35]. We used BiFPN to improve the Neck module for this study, and one-layer structure BiFPN was utilized to improve the training efficiency of the model, as shown in
Figure 10.
Using the above improvements for this study, based on Vision Transformer and BiFPN, the YOLOv5s-ViT-BiFPN was established to detect damaged houses in UVA orthophotos. Its structure is shown in
Figure 11.
2.3. Experimental Configuration
For training the YOLOv5s-ViT-BiFPN, the hardware configuration includes Intel Core i7-8700@3.7GHz six-core processor, 32 GB memory, and NVIDIA GeForce RTX 2080Ti graphics card. The software environment is Windows 10 Professional 64-bit operating system. Pytorch framework was the tool used to build the damaged houses’ detection model, using Python3.6.13 as the programming language, CUDA11.1 as the GPU computing platform, and the GPU acceleration library by CUDN10.0 deep learning.
The model was trained using an initial learning rate of 0.01, Batch Size 2. Adam’s optimization method was used, with a maximum number of iterations of 200.
2.4. Evaluation Metrics
In order to evaluate the performance of the detection model, Precision (P), Recall (R), Average Precision (AP), and F1 score [
19] are usually used for the quantitative analysis. The detection speed of the model was evaluated by Frames Per Second (FPS). P, R, and F1 were assessed by Equations (1)–(3), respectively.
where TP refers to the number of correctly detected targets, FP refers to the number of non-targets incorrectly detected as a target, and FN refers to the number of undetected targets. If an object’s predicted bounding box does not completely match the ground truth, it does not mean that the detection is wrong. A common solution is the Intersection over Union (IoU). IoU is the ratio of the bounding box, predicted by the detection and the ground truth bounding box. If the IoU value is greater than the defined threshold, then the detect is correct (TP); otherwise, it is wrong (FP).
The recall Precision–Recall Curve (PRC) is a curve with the recall rate as the abscissa and the accuracy as the ordinate. The area under PRC is called the average precision (AP), which can be assessed by Formula (4).
FPS refers to the number of frames that can process a specified size image per second. It is used to measure the running speed of the object detection model. The higher the FPS, the faster the model runs and the better the real-time performance.
5. Conclusions
Regarding the complex background for damaged houses as well as the inconsistent resolution of UAV images, we employed the latest YOLO model, named YOLOv5, and optimized its network architecture for the Backbone and Neck modules to improve the model in view of the demand of high accuracy and strong timeliness and proposed an improved model, YOLOv5s-ViT-BiFPN. We added the Vision Transformer structure to the Backbone of the YOLOv5s. On this basis, the BiFPN structure with was used to construct the YOLOv5s-ViT-BiFPN in order to effectively aggregate multi-scale features. For these improvements, the model has an optimized structure, which can fuse the features better and simultaneously consider the characteristics of multi-scale features. In order to verify its feasibility, we used it to detect the damaged houses for areas that were seriously stricken by the Yangbi Ms6.4 earthquake in Yunnan Province by UAV orthophotos. The results show that the precision, recall rate, F1, and AP increased by 4.04%, 4.81%, 4.43%, and 1.77%, respectively. Compared with the YOLOv5s, the training time decreased by about 15 min, and, in the five test areas mentioned in
Section 2.1, the average accuracy was 91.23% and the total detection time was about 4 min, which can verify the model’s transferability to different scenes.
Therefore, the findings from this study demonstrated that the YOLOv5s-ViT-BiFPN model can automatically detect damaged houses in UAV images with a good performance in terms of accuracy and timeliness, as well as being robust and transferable. Although the images in the test areas do not cover every hard-hit area, which probably causes some errors in the number of damaged houses, this model can improve the accuracy and efficiency based on UAVs’ remote sensing and meet the emergency response requirements after an earthquake.
However, due to the different types and scales of remote sensing data, with multiple platforms and sensors, used after earthquakes, the data are quite different. Further studies on this model should aim to validate its adaptability to multi-data sources and multi-resolution damaged houses in rural and urban areas, in order to test its transferability to large areas with great differences in resolution and the type of houses or buildings.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}