1. Introduction
Earthquake disasters have become a key social concern due to their huge destructive power and colossal threat to public lives and property. Although the prevention of such disasters is challenging, it is crucial for post-disaster reconstruction to commence as soon as possible for sufferers, for which emergency surveying and mapping are typically the first steps. The primary public property damaged caused by an earthquake is the destroyed architecture, and the information of destroyed buildings is very important for decision-makers to choose a correct reconstruction direction. In addition, the detection of collapsed buildings can provide an important reference for damage assessment after earthquake disasters, and become a crucial composition in the deployment of disaster analysis and emergency rescue [
1]. Due to the rapid development of high-resolution sensors, which have more abundant ground object texture information, the application of relevant technologies to the detection of collapsed buildings in the post-earthquake area has become the focus of research in the field of remote sensing, computer vision, etc. unmanned aerial vehicle (UAV) images have several advantages such as high resolution, low cost, and timely acquisition [
2], and they are widely used to perceive disaster areas and assist in the procedure of post-disaster rescue. Therefore, it is of great significance to investigate the usage of post-earthquake images collected by UAV and quickly identify the corresponding objects of collapsed buildings.
Over recent years, according to the employed datasets, the methods for object detection aiming at detecting collapsed buildings, in particular, can mainly be divided into two categories: multi-temporal and single-temporal methods [
3]. The core idea of the multi-temporal approach is to compare discrepancies in the images of buildings from the same area but with different time stamps, with specific image processing and analysis techniques such as direct comparison [
4,
5,
6,
7] and post-classification by comparison [
8,
9]. Direct comparison aims to construct difference images by using images from different times and then improve these difference images by decreasing the noise; post-classification, by comparison, means the images are firstly classified with various classes attributed to each pixel and these attributed images are compared. There are also other methods by virtue of the characteristics of buildings, such as shadow [
10,
11], and roof [
12] analysis and the corresponding digital elevation model (DEM) [
13]. Collapsed buildings can be found by comparing shadow length and the correlation between the roof pixels and the difference between DEMs in pre- and post-earthquake imagery. However, these methods require a reference image of a specific area and time and a target image which observes the same area at a different time, which typically yields difficulties for data acquisition and is not feasible for real-time application. In contrast, single- temporal methods, which investigate some hand-crafted features such as the salient point, edge, texture and the spectrum of collapsed buildings [
14,
15,
16,
17], are more popular in detecting collapsed buildings due to their efficiency in data acquisition. Compared with intact buildings, collapsed buildings show arbitrary deformation, such as the disappearance of regular geometric shapes, the irregular distribution of texture features and the non-existence of building shadows [
18], resulting in the limitations of handcrafted features and the weak generalization ability of the corresponding detection methods.
Recently, convolutional neural networks (CNNs) have been widely used in object detection and recognition from remote sensing imagery due to their superiority in feature extraction [
19,
20,
21]. For instance, the well-known object detection model, namely faster region-based convolutional neural network (Faster R-CNN), which was proposed in the literature [
22], gives high recall region proposals at a low cost via the region proposal network (RPN), which can significantly improve the efficiency of object detection. Compared with traditional methods, this end-to-end detection model is considered more attractive as it can reduce the complex steps of data preprocessing, manually handcrafted feature design, etc. The existing research content can be roughly divided into three categories [
23]: scene classification based on image-level labeling samples, semantic segmentation based on pixel-level labeling samples and object detection based on object-level labeling samples. Most image-based scene detection methods use artificial outlines of building boundaries, using regular domain or adaptive domain windows provided by object-oriented segmentation to analyze remote sensing images for classification and detection. As a result, the small pieces classified as collapsed buildings are generated on the images. If the collapsed buildings cover a large area, the time efficiency of this method cannot be guaranteed, which is not suitable for the rapid determination of the affected area of the disaster. Duarte et al. [
24] combined satellite images and aerial images of collapsed buildings to improve the quality and quantity of sample data, and a CNN was applied based on residual connection and cavity convolution to improve the classification efficiency by nearly 4%. Ji et al. [
25] first used ArcGIS to construct the vector boundary of buildings and solve the problem of sample imbalance on the training data between damaged and undamaged buildings by constructing the vector boundary of buildings. Then, a CNN was used to identify buildings in post-earthquake satellite images. Vetrivel et al. [
26] studied a CNN with 3D point cloud features and used a multiple kernel learning framework to improve detection precision; the destroyed buildings were determined after the disaster, obtaining a detection precision of up to 85%. Xiong et al. [
27] used the old Beichuan town as an example to generate a 3D building model based on 2D-GIS data, using it as a georeference to obtain multi-view segmented building images, and used a CNN to classify each building to obtain the damage distribution of the area with an accuracy of 89.39%. Miura et al. [
28] used a CNN to classify damaged buildings into three categories: collapsed buildings, non-collapsed buildings, and moderately damaged buildings covered with blue tarps after the disaster, based on post-disaster aerial imagery from the 2016 Kumamoto earthquake and the 1995 Kobe earthquake, with an accuracy of approximately 95% in data for both earthquakes. Pixel-based semantic segmentation requires a large number of professionals to manually mark according to the building’s boundaries when creating samples, resulting in a large workload. Rudner et al. [
29] proposed a new framework, Multi3Net, to achieve rapid and accurate building damage segmentation by fusing multiresolution, multisensory and multitemporal satellite images in a CNN. Shen [
30] proposed a new cross-directional fusion strategy to better investigate the correlation between pre- and post-disaster images. In addition, Cut Mix was used for data enhancement. This method achieved excellent results for the xBD dataset of the building damage assessment. Wu et al. [
18] proposed a Siamese neural network with an attention mechanism to focus on effective features and achieved an F1 score of 0.787 on the xBD dataset. Adriano et al. [
31] proposed a damage mapping framework based on an Attention U-Net architecture for the semantic segmentation of damaged buildings, which can achieve a considerable prediction for datasets from various scenarios. The object-level detection of post-earthquake collapsed buildings can help quickly determine the affected areas and achieve rapid disaster relief after the disaster. Ma et al. [
32] used YOLOv3 to detect collapsed buildings in post-earthquake remote sensing imagery and improved the backbone and loss function of YOLOv3. Their experiment shows that the improved method based on YOLOv3 is feasible for detecting collapsed buildings with practical application requirements.
Despite the large amount of work devoted to the detection of collapsed buildings in emergency and disaster relief, there are several outstanding difficulties which are worthy of further exploration.
Firstly, the properties of the target object, i.e., collapsed buildings, are relatively specialized. In general, collapsed buildings are distributed in a large area with ambiguous boundaries and no specific geometric shapes; this leads to considerable subjectivity when labeling datasets, which means that the same area of the collapsed building can be covered either by one large rectangular bounding box or by several smaller ones. On the other hand, the shape of collapsed buildings is arbitrary, and in the traditional CNN, the convolution kernels with regular sizes have difficulties in adapting to the variability of irregular shapes. In addition, although non-maximum suppression (NMS) manages to eliminate most of the detected overlapping bounding boxes with Faster R-CNN (for example), the detected results of large bounding boxes might contain small bounding boxes due to the fact that collapsed buildings have irregular shapes and the labeled training bounding boxes are variable. In this case, the intersection over union (IoU) between large and small bounding boxes cannot reach the corresponding threshold set by NMS, and the related overlapping detected bounding boxes can be suppressed, which can negatively influence the precision of the final detection result.
Secondly, the detected results are hard to evaluate. In the common object detection case shown in
Figure 1, the target objects to be detected corresponding to ground truth appear basically as regular shapes. As a consequence, one ground truth bounding box corresponds to only one detected bounding box; that is to say, this is a one-to-one detection mode. In this “one-to-one” mode, the IoU is the most commonly used evaluation metric for comparing similarities between the detected bounding box and ground truth bounding box. However, the main goal of object detection represented by collapsed buildings is to detect the corresponding approximate position in the image. The irregularity and uncountability of collapsed buildings make it impractical for them to be marked separately by a minimum enclosing rectangle. Thus, when targeting collapsed buildings, a "many-to-many" situation may occur in which one ground truth bounding box corresponds to one or more detected bounding boxes, and multiple ground truth bounding boxes correspond to one or more detected bounding boxes. Thus, an explicit mapping relationship between detected and ground truth bounding boxes is difficult to determine. In the "many-to-many" case, the traditional IoU-based evaluation strategy and mean average precision (mAP) are no longer applicable to some extent. The labeling strategy for collapsed buildings in a certain area is subjective regarding the scales and numbers of the ground truth bounding boxes, as shown in
Figure 2.
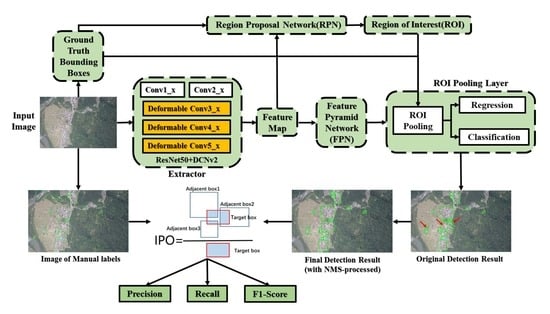
To address the problems introduced above, based on Faster R-CNN, this study addressed an efficient precision method for the detection of post-earthquake collapsed buildings. This method can be used to efficiently determine the disaster area and assist emergency and disaster relief work. The main contributions are threefold:
The Faster R-CNN model was taken as a basic framework, and deformable convolution (DCN) [
33,
34] was introduced to learn information related to the irregular geometric features of post-earthquake collapsed buildings, so as to improve the detection result.
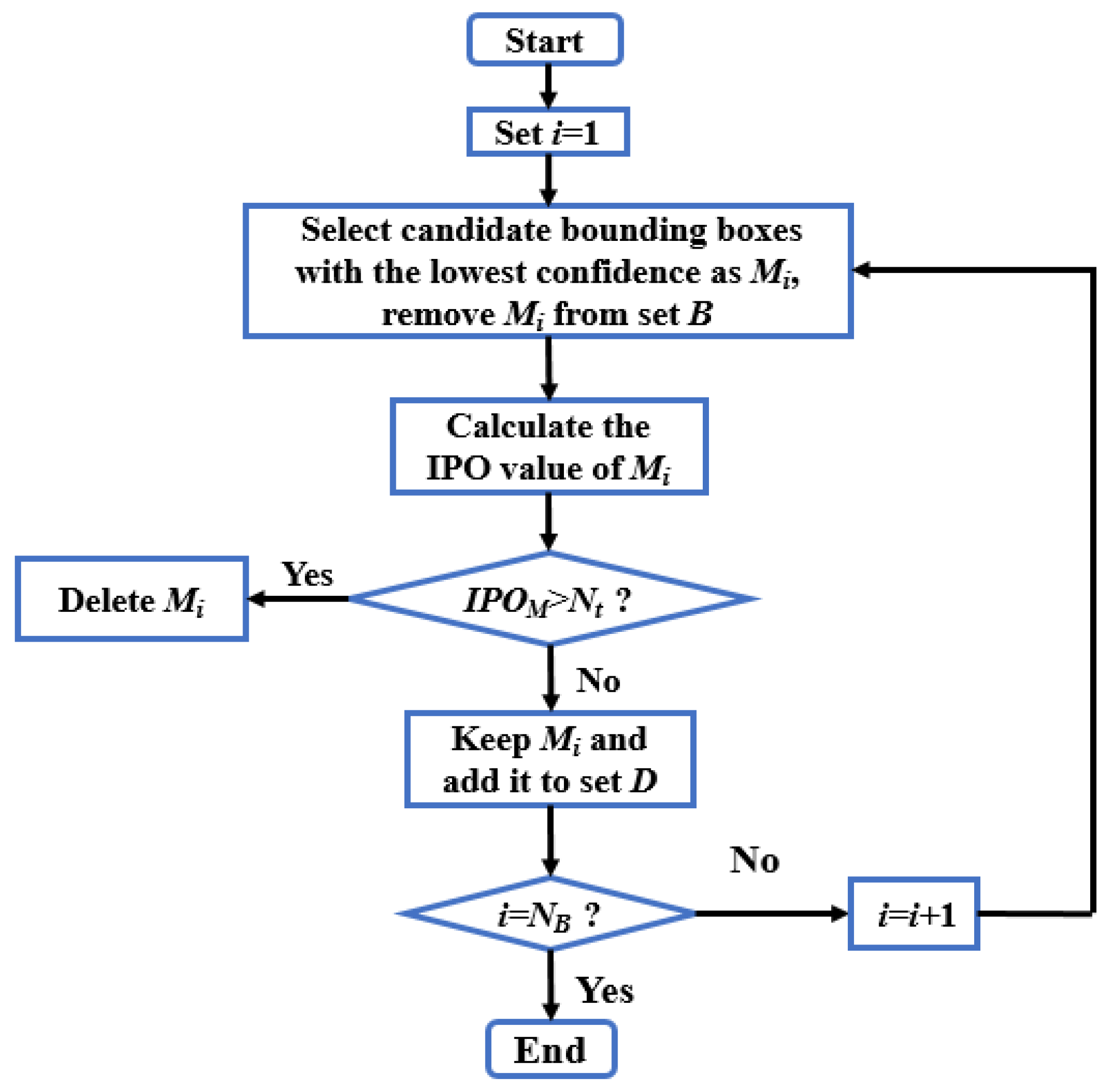
To ease the difficulty of evaluating the detection results of collapsed buildings, instead of the traditional IoU, this paper proposes a new strategy called the intersected proportion of objects (IPO), which was used to estimate the degree of intersection among boxes. The proposed IPO was also applied to determine the positive and negative bounding boxes and introduce a more reasonable approach to calculate precision and recall in the evaluation stage.
In the “many-to-many” case, to solve the problem of a few duplicate boxes still existing in the detection result after the NMS algorithm, this paper also proposes a new IPO-NMS algorithm for eliminating detected overlapping bounding boxes.
The remainder of this paper is structured as follows:
Section 2 first introduces the employed dataset of the work. Then, the corresponding proposed object detection framework and the IPO are addressed. Lastly, the relevant evaluation strategy is presented.
Section 3 reports the experimental settings and shows the comprehensive results of the proposed methods.
Section 4 discusses several detection results which are compared to ground truth pixelwise labeling, and further demonstrates the effectiveness of the proposed IPO strategy.
Section 5 summarizes and outlines the prospects for our work.
3. Results
All the reported experiments in this paper were carried out on a platform with Ubuntu 18.04 and PyTorch 1.4.0 as the training framework. In the training stage, an SGD optimizer and warmup optimization were used with 12 epochs, the learning rate was set to 0.0025 after the first 500 iterations and it started to decay from the 8th to 11th epoch, finally remaining stable at 0.00025 with a weight decay of 0.0001. This setting is applied in our network and other state-of-the-art networks (RetinaNet [
38], FSAF [
39]), whereas YOLOv3 [
40] contains 273 rounds of epochs, and the leaning rate remains at 0.001 after 2000 iterations, starts to decrease from the 218th to 246th epochs and stabilizes at 0.00001 with a weight decay of 0.0005. The programs used are from the open-source Shang Tang mmdetection v2.6.0.
The primary goal of the conducted experiments was to demonstrate the performance of our methods. Four subsections are included in this paper: in
Section 3.1, the efficacy of the proposed evaluation strategy based on the IPO is shown by the results of eliminated detected overlapping bounding boxes and the determination of positive and negative detections; in the second subsection, the performance of the introduced DCNv2 on the main framework is investigated.
Section 3.3 compares the quantitative and qualitative results of our method with those of three other different methods for detecting collapsed buildings. Lastly,
Section 3.4 discusses the settings of thresholds in the period of eliminating detected overlapping bounding boxes and the determination of positive and negative detection.
3.1. Demonstration of the Efficacy of the Proposed IPO
In order to demonstrate the efficacy of the proposed IPO, an ablation study was performed based on the framework of Faster R-CNN+DCNv2. The results with and without the IPO-NMS are discussed and the evaluation criteria of precision (P), recall (R), and F1 score (F1) computed by the IoU and IPO (see
Section 2.3.3 for more details) are shown.
Table 3 lists the corresponding quantitative results, and
Figure 10 and
Figure 11 show the qualitative results. The thresholds of IPO-NMS (N
t) and determining positive and negative detection (δ) were both set at 0.6. A detailed discussion of the investigation thresholds can be found in
Section 3.4.
In
Table 3, the values of
P,
R and
F1, which are estimated based on the IoU, are significantly lower than those based on the IPO. This can be explained by the fact that when the IoU is applied to determine the correctness of the detected bounding boxes, it is very possible that only a small portion of the detected bounding boxes can be classified as positive detections, especially in our case for dealing with collapsed buildings, and the ground truth labels are typically generated with high subjectivity (see also
Figure 2). Such detection is also inconsistent with the visualization result, as shown in
Figure 11 and
Figure 12. Therefore, to some extent, it can be concluded that the evaluation by using the IoU is not as suitable as the IPO for region-level object detection such as collapsed buildings.
To further assess the performance of the proposed IPO, taking the red box in
Figure 10a and the yellow box in
Figure 10b as examples, the conventional IoU between the red detected bounding box and the yellow ground truth bounding box is obviously less than the threshold (δ) for determining positive and negative detections; thus, the red box is fed back as a negative result. In contrast, with the strategy of the proposed IPO, the red box is predicted as a positive detection, which is consistent with the visual result of the ground truth.
The qualitative detection results from the dataset of Sichuan, Qinghai and Yunnan are presented, and for each of them, we randomly selected the detections of one representative image to be shown. Thus,
Figure 11 and
Figure 12 compare the detection results with overlapping bounding boxes with and without the proposed IPO-NMS algorithm, in which some completed overlapping bounding boxes are indicated by red arrows. Without using our IPO-NMS algorithm, in the detection result, there are few explicit repeated bounding boxes, which are nearly completely overlapping with others in the images from Sichuan and Yunnan, whereas in Qinghai, the buildings are densely distributed and, therefore, are collapsed in mutually overlapping pieces. More repeated bounding boxes were detected due to the collapsed buildings having arbitrary shapes. As mentioned, repeated bounding boxes mostly have mutually overlapping relationships, and some repeated bounding boxes were removed in the normal NMS stage but without a reliable performance. After employing the proposed IPO-NMS method, we found that all these repeated bounding boxes disappear as shown in
Figure 12. This is because instead of the IoU, which only considers a “one-to-one” case, the IPO considers cases of “one-to-many” and “many-to many” that estimate the intersection degree by using all the overlapping bounding boxes as a toy example as shown in
Figure 9. Finally, the visualization results of the experiment and evaluation indexes shown in
Table 3 prove that the IPO-NMS algorithm can effectively remove the overlapped boxes.
Revisiting
Table 3, the precision and recall are slightly lower with the introduction of the IPO-NMS algorithm. However, this result can be generated on account of these detected repeated bounding boxes as shown in the qualitative result of
Figure 11 where the IPO-NMS algorithm is not used. In other words, several detected repeated bounding boxes are likely to be classified as a positive detection in practice, as they typically perceive the same collapsed area, and the same area might be repeatedly calculated by several positive detections, resulting in an artificially high precision and recall. Therefore, the proposed IPO can act as a more objective and reasonable method for evaluating the performance of the collapsed building detection method, and the embedded IPO-NMS algorithm is superior in the case of completely mutually overlapping bounding boxes.
3.2. Evaluation of the DCNv2 Module Based on Faster R-CNN
In order to explore the performance of the DCNv2 module in collapsed building detection, another ablation study was conducted in this work by comparing the original Faster R-CNN and the improved Faster R-CNN+DCNv2.
Figure 13 shows one example of the corresponding labeled ground truth bounding boxes investigated in this study. The quantitative and qualitative results before and after integrating with the DCNv2 module are shown in
Table 4 and
Figure 14, respectively. In
Figure 14a,b, the red circles represent the false detected bounding box, and yellow circles represent the ground truth bounding boxes that are not successfully detected. After applying DCNv2, more collapsed buildings are detected as the yellow circle indicates, and fewer buildings incorrectly identified as collapsed are found, as the red circle denotes.
From the numerical results listed in
Table 4, based on the proposed IPO, and compared with the original Faster R-CNN, the values of the precision, recall and
F1 score of Faster R-CNN+DCNv2 increased by around one to two percentage points. It can be further seen that, from
Figure 14, compared with the original Faster R-CNN, the new framework has a stronger ability to perceive the information of object edges due to the addition of the DCNv2 module, which can effectively reduce the chances of false detection and missing detection. Thus, a corresponding conclusion can be drawn that the presented DCNv2 works effectively to improve the model’s ability for feature extraction and detection for variable objects with arbitrary shapes.
3.3. Comparison with Other Detection Networks
Four object detection models including the proposed one (namely, YOLOv3, RetinaNet, FSAF and Faster R-CNN+DCNv2) were individually trained and validated on the introduced dataset of collapsed buildings. The models mentioned above were mainly divided into single-stage (YOLOv3, RetinaNet, FSAF) and two-stage (Faster R-CNN+DCNv2) detection models, and the performances of different detection frameworks were compared on the same testing dataset.
Table 5 lists the numerical results of the four models with IPO-NMS. In general, the values of P, R and F1 with the IPO strategy are much higher than the corresponding values using IoU. This conclusion is analogous to
Section 3.1 where the relevant reasons are given. In addition, the P, R and F1 of Faster R-CNN+DCNv2 are not the best among the four models in the IoU, whereas R and F1 are the highest using the strategy of the IPO. The experimental results displayed above can be explained by the fact that YOLOv3 and FSAF generate fewer detected bounding boxes than Faster R-CNN+DCNv2 does, so their precision is higher with both the IoU and the IPO. However, on account of the fewer detected bounding boxes, there are fewer positive samples as well, resulting in a low value of recall. Accordingly, although there are more detected bounding boxes generated by RetinaNet, there are fewer positive samples in the detection result; hence, the value of recall is slightly lower than that of Faster R-CNN+DCNv2 using the strategy of the IPO. Consequently, compared with other models, the overall performance of Faster R-CNN+ DCNv2 is better with the proposed IPO strategy, the precision achieves fairly good values, and the recall and F1 scores are both higher.
Figure 15 shows one qualitative result detected by the presented Faster R-CNN+DCNv2 and three other models. The green boxes in the figure are the detected objects of collapsed buildings, red circles represent false detection, and yellow circles indicate missing detections. The results detected by YOLOv3 and FSAF contain many missing detections, shown by the corresponding yellow ellipses and circles which demonstrate their inferior detection capability for small objects. Meanwhile, there are more false detections for RetinaNet, in which a landslide with a similar texture is mistaken for collapsed buildings, as this model cannot easily distinguish between similar textures. The detection results above indicate that the single-stage detection model is not especially suitable for datasets of collapsed buildings, which is why the direct regression mechanism of the single-stage detector experiences difficulties in learning the parameters of the model’s localization regression, which leads to poor detection results.
Other than the single-stage detection model, Faster R-CNN+DCNv2 as a two-stage detection model obtains superior performance for object detection as it occupies two-stage features to describe the object, and the presented DCNv2 module is more flexible than the traditional convolution module, which can adaptively change the perceived feature region to obtain more effective features. Therefore, the model is more invariant to arbitrary shapes and more advanced for detecting collapsed buildings from UAV images, which decreases the occurrence of false detection and missing detection. The experimental result indicates that Faster R-CNN+DCNv2 performs better than the other detection models when detecting collapsed buildings.
3.4. Investigation of the Threshold Settings
In this work, there are two free parameters which need to be discussed: the threshold for determining positive and negative detections (δ) and the threshold used in the IPO-NMS algorithm (N
t). As for the threshold of δ, the empirical threshold value 0.6 was selected as a passing score; that is, if the IPO value of this detection is over 60%, it can be identified as a positive result. The selection of the threshold for IPO-NMS is qualitatively investigated in
Figure 16; the same image is used to show the removal of detected overlapping bounding boxes in visual results when IPO-NMS thresholds (N
t) are input as 0.5, 0.6 and 0.7.
As can be seen from these four detection results in
Figure 16, when N
t equals 0.7, there is still a small number of overlapping bounding boxes (marked by a red circle in the figure) in the detection results. When N
t = 0.5 and N
t = 0.6, in general, all the detected overlapping bounding boxes disappear. Therefore, in this study, the threshold of IPO-NMS was also selected as 0.6 which is identical to δ.
4. Discussion
There are some existing pixelwise detection and recognition methods for collapsed buildings based on deep learning [
18,
29,
30,
31]. However, the main purpose of this study was to find an approximated area where the collapsed buildings are located in the UAV images and help to implement rescue after earthquake disasters. Thus, the target object which needs to be sought simply requires rough information of the affected area instead of boundary demarcation of the damaged buildings. Nevertheless, to further verify the effectiveness of the proposed IPO strategy, we selected two representative images (named 01 and 02) and carried out pixelwise labeling, which means the boundaries of the collapsed buildings were clearly generated (shown by the dark red area in
Figure 17a and
Figure 18a), and our method was analyzed based on the pixelwise labeling results, using the number of pixels that are located in both the detected bounding boxes. The pixelwise labeling results are also discussed.
The experimental results are shown in
Table 6,
Table 7,
Figure 17 and
Figure 18, in which the light-yellow areas are generated by overlapping the detected bounding boxes with the ground truth pixelwise labeling, and the light red areas are the result of ground truth pixelwise labeling and are not successfully found by the detected bounding boxes. In this experiment, precision (P) was estimated by the ratio of the pixels in the light yellow areas and the pixels in the dark red areas in the detected bounding boxes, recall (R) was calculated by the ratio of the pixels in the light yellow areas and the pixels in the dark red areas in the ground truth pixelwise labeling, and the F1 was estimated by using the corresponding P and R.
From these two tables, a similar conclusion to that in
Section 3.1 can be drawn. First, after applying the IPO-NMS, these three criteria decreased slightly, as some pixels lying in the overlapping bounding boxes (in principle, these boxes should be eliminated) were used as correct detection multiple times. Second, the precision, recall and F1 score estimated from the traditional IoU method were obviously lower than the values based on the proposed IPO strategy. This is probably due to the fact that the IPO strategy is more suitable for determining the positive and negative detection when dealing with images with arbitrarily distributed collapsed buildings, and the relationship between the detected bounding boxes and the ground truth is more complex with “many-to-many”, “one-to-many” and “many-to-one” situations.
The numerical results provided in
Table 6 and
Table 7 can also be seen in
Figure 17 and
Figure 18. The IPO-based detection framework is able to find more positive detections (marked by green rectangles in
Figure 17d and
Figure 18d), and these positive detections contain more ground truth pixels (marked by the corresponding yellow parts) which also indicates that fewer ground truth pixels are missed, and consequently, the recall value is better. When comparing the yellow areas to the dark red areas shown in
Figure 17b and
Figure 18b, in general, more bounding boxes which have a higher percentage of collapsed buildings, are detected. Thus, it can be concluded that the IPO strategy is more sensitive to large collapsed areas, as more collapsed buildings can be detected while fewer incorrect detections remain. This also supports the findings in
Section 3.1.
One shortcoming that needs further consideration was found by comparing the ground truth pixelwise labeling and the detection result of the IPO, i.e., the contents shown by
Figure 17d and
Figure 18d; there are quite a few ambiguous background pixels which are included in some large detected bounding boxes and incorrectly identified as collapsed buildings. Extracting fewer ambiguous background pixels would be very helpful; for example, the rescue operation can be launched with a highly accurate position, and the government can provide suitable funding for rebuilding the disaster areas.
5. Conclusions
Based on high-resolution UAV images of collapsed buildings from three different post-earthquake areas in China, this study investigated one of the most popular deep-learning-based object detection models, i.e., Faster R-CNN, in relation to the target of collapsed buildings. The feature extraction network of the original Faster R-CNN was improved by introducing deformable convolution (DCNv2) to extend its adaptability to the irregular geometric characteristics of collapsed buildings. The experimental results indicate that the improved Faster R-CNN+DCNv2 model can effectively alleviate the problems of false detection and missing detection. To address the subjectivity when generating ground truth bounding boxes, which result in a more complex relationship between detections and ground truth (such as, “one-to-many”, “many-to-one”, “many-to-many”), instead of the conventional IoU, we propose the intersected proportion of objects (IPO) and improved the NMS algorithm and evaluation criteria (precision and recall) using this strategy. Finally, some corresponding experiments were conducted to assess the performance of the IPO compared with the IoU strategy in the elimination of detected overlapping bounding boxes and the evaluation of detecting collapsed buildings.
In the future, we aim to investigate the shortage of ambiguous background pixels, and three potential directions can be explored. First, instead of large bounding boxes, small yet overlapping bounding boxes are preferred. Second, the computation of the IPO could be integrated in the training loss, thus making the model more sensitive to the collapsed buildings with arbitrary shapes. Three, bounding boxes could be improved with certain degrees of rotations.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


