


Assessing the Impact of Neighborhood Size on Temporal Convolutional Networks for Modeling Land Cover Change



Abstract
1. Introduction
2. Methodology
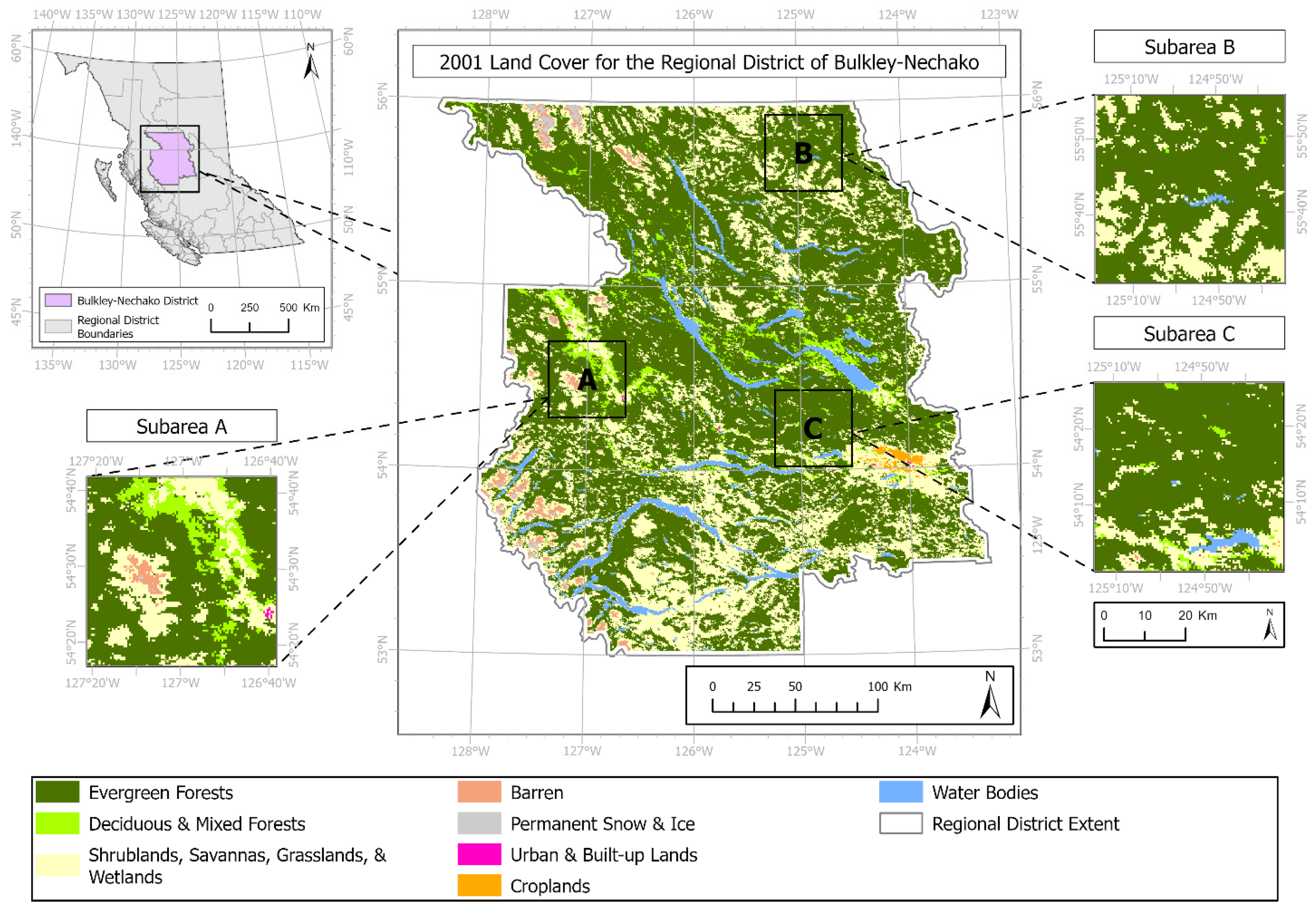
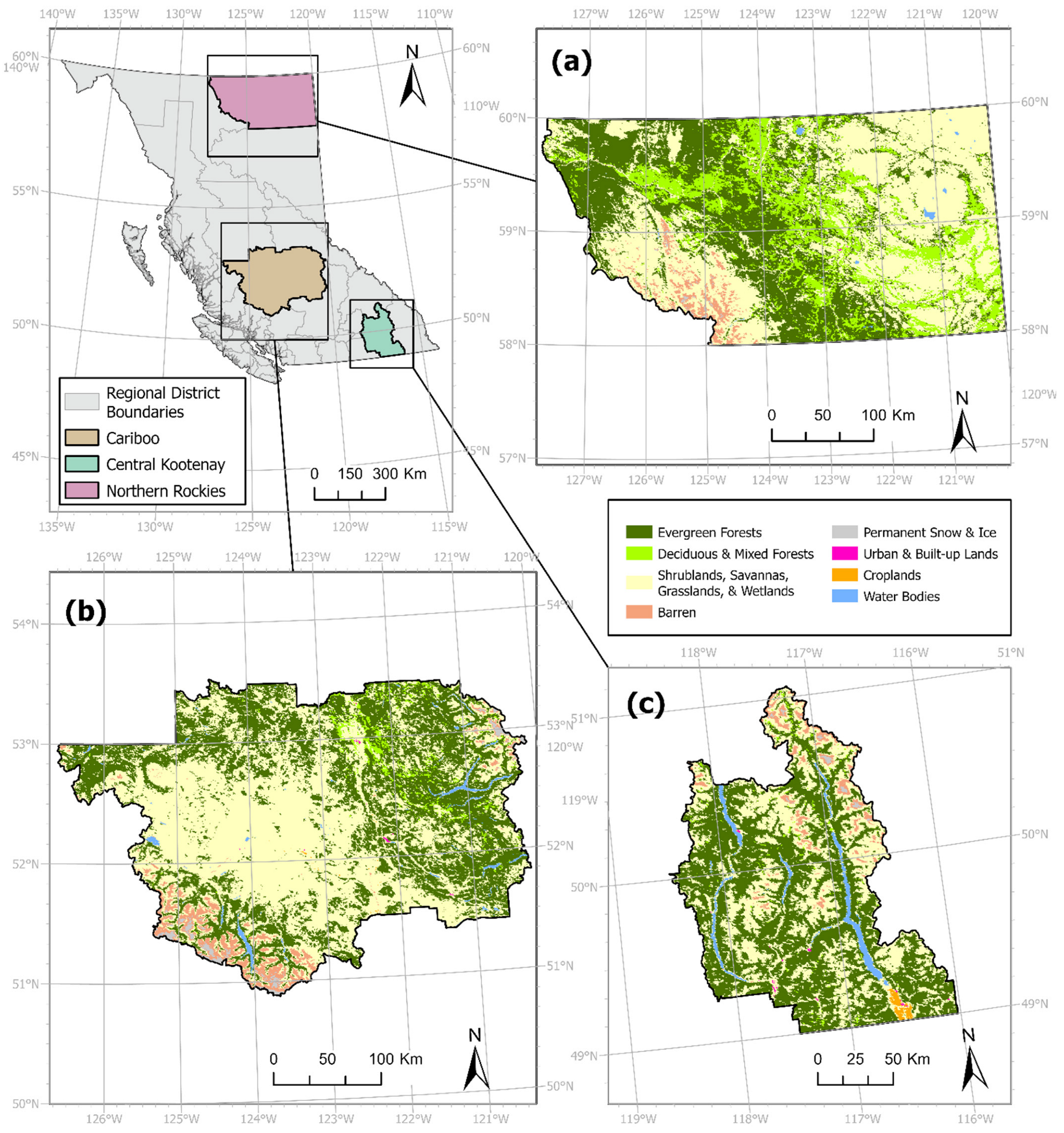
2.1. Study Area and Datasets
2.2. Overview of Deep Learning Models
2.2.1. Temporal Models (LSTM and TCN)
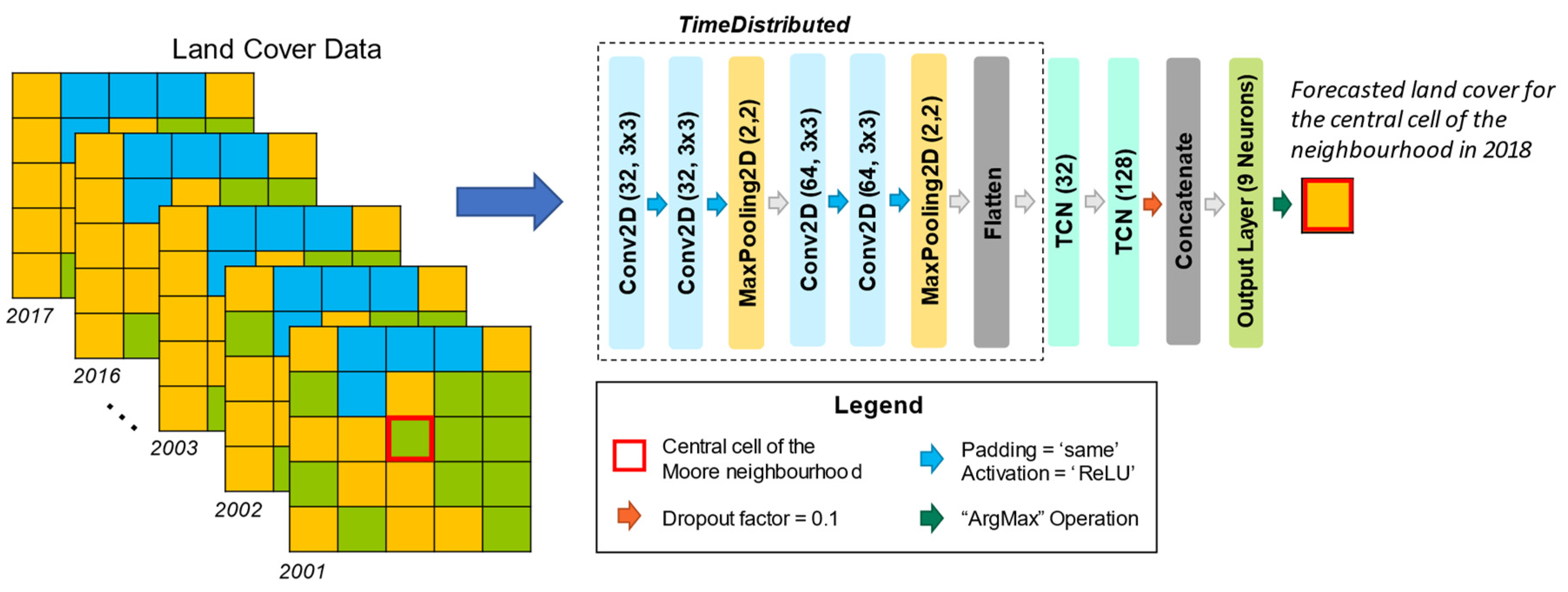
2.2.2. Spatiotemporal Models (CNN–LSTM and CNN–TCN)
2.2.3. Neighborhood Effects in Deep Learning Models
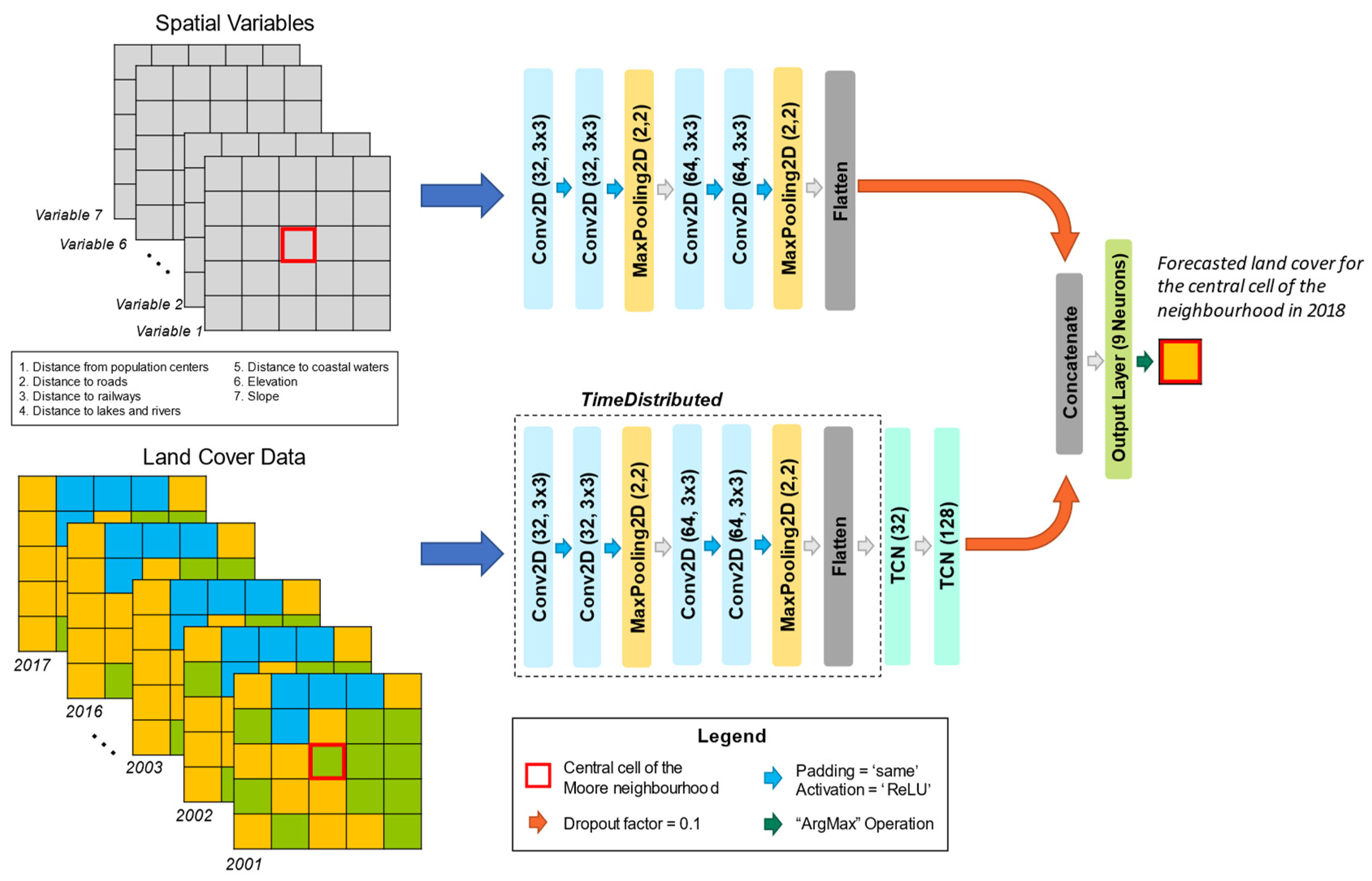
2.2.4. Adding Spatial Variables
2.3. Overview of Experiments
2.4. Model Assessment
3. Results
3.1. Case 1: Regional District of Bulkley-Nechako Experiment Results
3.1.1. Subarea Experiment Results
3.1.2. Entire Regional District of Bulkley-Nechako Experiment Results
3.2. Case 2: Comparison with Alternative Regions
3.3. Case 3: Spatial Variables Experiment Results
4. Discussion
4.1. Influence of Neighborhood Size
4.2. Influence of Model Selection
4.3. Influence of Spatial Variables
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- A = amount of area that underwent real-world change but was forecasted incorrectly as persistent.
- B = amount of area that underwent real-world change and was forecasted correctly as changed.
- C = amount of area that underwent real-world change but was forecasted incorrectly to the wrong land cover class.
- D = amount of area that was remained persistent in the real-world but was forecasted incorrectly as changed.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measure | Equation | Description and Interpretation | Reference |
|---|---|---|---|
| Figure of Merit (FOM) | Measure of overlap between real-world and forecasted changes. It provides the ratio of correctly forecasted changes (B) versus the union of projected and reference changes. FOM values assume values from 0-100%, where 0% indicates complete disagreement between real-world and forecasted changes, and 100% indicates perfect agreement between real-world and forecasted changes. | [62,64,65] | |
| Producer’s Accuracy (PA) | Measure indicating the proportion of correctly changed area (B) versus all real-world changes observed. PA values closer to 0% indicate few correctly forecasted areas versus the observed real-world changes, while values closer to 100% suggest that high amounts of observed real-world changes were forecasted correctly. | [62,63] | |
| User’s Accuracy (UA) | Measure indicating the proportion of correctly changed area (B) versus all forecasted changes produced by the model. UA values closer to 0% suggest few correctly forecasted areas versus all projected changes, while values closer to 100% suggest that high amounts of the projected changes intersected with their real-world change locations. | [62,63] | |
| Error due to Quantity (EQ) | Measure of error associated with the amount of changed area forecasted. EQ is expressed as the difference between amounts of area that have undergone changes. If low amounts of changed areas are forecasted compared to the real-world reference data, the EQ will be high. If a model forecasted similar amounts of changed areas to that observed in the real-world, the EQ will be low. | [64,65,66] | |
| Error due to Allocation (EA) | Measure of error associated with the locations of changed area forecasted. EA is expressed as the area that has been wrongly allocated. If many changes are forecasted at incorrect locations, the EA will be higher. If forecasted changes are allocated to the right locations, then EA will be lower. | [64,65,66] |
References
- Foley, J.A.; Defries, R.; Asner, G.P.; Barford, C.; Bonan, G.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Daily, G.C.; Gibbs, H.K.; et al. Global consequences of land use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef] [PubMed]
- Van Asselen, S.; Verburg, P.H. Land cover change or land-use intensification: Simulating land system change with a global-scale land change model. Glob. Chang. Biol. 2013, 19, 3648–3667. [Google Scholar] [CrossRef] [PubMed]
- Meyer, W.B.; Turner, B.L. Land-use/land-cover change: Challenges for geographers. GeoJournal 1996, 39, 237–240. [Google Scholar] [CrossRef]
- Gibbard, S.; Caldeira, K.; Bala, G.; Phillips, T.J.; Wickett, M. Climate effects of global land cover change. Geophys. Res. Lett. 2005, 32, 1–4. [Google Scholar] [CrossRef]
- Sefrin, O.; Riese, F.M.; Keller, S. Deep learning for land cover change detection. Remote Sens. 2021, 13, 78. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Sun, Z.; Di, L.; Fang, H. Using long short-term memory recurrent neural network in land cover classification on Landsat and Cropland data layer time series. Int. J. Remote Sens. 2019, 40, 593–614. [Google Scholar] [CrossRef]
- Yan, J.; Chen, X.; Chen, Y.; Liang, D. Multistep Prediction of Land Cover from Dense Time Series Remote Sensing Images with Temporal Convolutional Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5149–5161. [Google Scholar] [CrossRef]
- Wang, J.; Bretz, M.; Dewan, M.A.A.; Delavar, M.A. Machine learning in modelling land-use and land cover-change (LULCC): Current status, challenges and prospects. Sci. Total Environ. 2022, 822, 153559. [Google Scholar] [CrossRef]
- Luo, C.; Meng, S.; Hu, X.; Wang, X.; Zhong, Y. Cropnet: Deep Spatial-Temporal-Spectral Feature Learning Network for Crop Classification from Time-Series Multi-Spectral Images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Waikoloa, HI, USA, 26 September–2 October 2020; pp. 4187–4190. [Google Scholar] [CrossRef]
- Masolele, R.N.; De Sy, V.; Herold, M.; Marcos Gonzalez, D.; Verbesselt, J.; Gieseke, F.; Mullissa, A.G.; Martius, C. Spatial and temporal deep learning methods for deriving land-use following deforestation: A pan-tropical case study using Landsat time series. Remote Sens. Environ. 2021, 264, 112600. [Google Scholar] [CrossRef]
- Xiao, B.; Liu, J.; Jiao, J.; Li, Y.; Liu, X.; Zhu, W. Modeling dynamic land use changes in the eastern portion of the hexi corridor, China by cnn-gru hybrid model. GISci. Remote Sens. 2022, 59, 501–519. [Google Scholar] [CrossRef]
- Gray, P.C.; Chamorro, D.F.; Ridge, J.T.; Kerner, H.R.; Ury, E.A.; Johnston, D.W. Temporally Generalizable Land Cover Classification: A Recurrent Convolutional Neural Network Unveils Major Coastal Change through Time. Remote Sens. 2021, 13, 3953. [Google Scholar] [CrossRef]
- Verburg, P.H.; de Nijs, T.C.M.; van Eck, J.R.; Visser, H.; de Jong, K. A method to analyse neighbourhood characteristics of land use patterns. Comput. Environ. Urban Syst. 2004, 28, 667–690. [Google Scholar] [CrossRef]
- Cao, C.; Dragićević, S.; Li, S. Short-term forecasting of land use change using recurrent neural network models. Sustainability 2019, 11, 5376. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-Convolutional LSTM Based Spectral-Spatial Feature Learning for Hyperspectral Image Classification. Remote Sens. 2017, 9, 1330. [Google Scholar] [CrossRef]
- Sharma, A.; Liu, X.; Yang, X. Land cover classification from multi-temporal, multi-spectral remotely sensed imagery using patch-based recurrent neural networks. Neural Netw. 2018, 105, 346–355. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Friedl, M. The Terra and Aqua combined Moderate Resolution Imaging Spectroradiometer (MODIS) Land Cover Type (MCD12Q1) Version 6 data product. In NASA EOSDIS L. Process. DAAC. 2018. Available online: https://lpdaac.usgs.gov/dataset_discovery/modis/modis_products_table/mcd12q1_v006 (accessed on 30 January 2022).
- Ministry of Municipal Affairs. Regional Districts—Legally Defined Administrative Areas of BC. In Br. Columbia Data Cat. 2020. Available online: https://catalogue.data.gov.bc.ca/dataset/regional-districts-legally-defined-administrative-areas-of-bc (accessed on 3 October 2021).
- van Duynhoven, A.; Dragićević, S. Exploring the sensitivity of recurrent neural network models for forecasting land cover change. Land 2021, 10, 282. [Google Scholar] [CrossRef]
- Kleemann, J.; Baysal, G.; Bulley, H.N.N.; Fürst, C. Assessing driving forces of land use and land cover change by a mixed-method approach in north-eastern Ghana, West Africa. J. Environ. Manag. 2017, 196, 411–442. [Google Scholar] [CrossRef]
- Cao, M.; Zhu, Y.; Quan, J.; Zhou, S.; Lü, G.; Chen, M.; Huang, M. Spatial sequential modeling and predication of global land use and land cover changes by integrating a global change assessment model and cellular automata. Earth’s Futur. 2019, 7, 102–1116. [Google Scholar] [CrossRef]
- Phiri, D.; Morgenroth, J.; Xu, C. Long-term land cover change in Zambia: An assessment of driving factors. Sci. Total Environ. 2019, 697, 134206. [Google Scholar] [CrossRef]
- Van Berkel, D.; Shashidharan, A.; Mordecai, R.S.; Vatsavai, R.; Petrasova, A.; Petras, V.; Mitasova, H.; Vogler, J.B.; Meentemeyer, R.K. Projecting urbanization and landscape change at large scale using the FUTURES model. Land 2019, 8, 144. [Google Scholar] [CrossRef]
- Guo, A.; Zhang, Y.; Hao, Q. Monitoring and Simulation of Dynamic Spatiotemporal Land Use/Cover Changes. Complexity 2020, 2020, 3547323. [Google Scholar] [CrossRef]
- Statistics Canada. 2016 Census—Boundary Files. 2016. Available online: https://www12.statcan.gc.ca/census-recensement/2011/geo/bound-limit/bound-limit-2016-eng.cfm (accessed on 10 May 2022).
- Statistics Canada. 2016 Census Road Network File. 2016. Available online: https://open.canada.ca/data/en/dataset/57d5ffae-3048-4a19-9b4c-eab12f6322c5 (accessed on 29 July 2022).
- Hakim, A.M.Y.; Matsuoka, M.; Baja, S.; Rampisela, D.A.; Arif, S. Predicting land cover change in the mamminasata area, indonesia, to evaluate the spatial plan. ISPRS Int. J. Geo-Inf. 2020, 9, 481. [Google Scholar] [CrossRef]
- NASA/METI/AIST/Japan Spacesystems and U.S./Japan ASTER Science Team “ASTER Global Digital Elevation Model V003”. In NASA EOSDIS L. Process. DAAC. Available online: https://lpdaac.usgs.gov/products/astgtmv003/ (accessed on 10 June 2022).
- Fotheringham, A.S.; Rogerson, P.A. GIS and spatial analytical problems. Int. J. Geogr. Inf. Syst. 1993, 7, 3–19. [Google Scholar] [CrossRef]
- van Rossum, G. Python Language Reference; Python Software Foundation: Amsterdam, The Netherlands, 2009; ISBN 9780954161781. [Google Scholar]
- Chollet, F. Keras: The Python Deep Learning library. In Keras.Io. 2015. Available online: https://keras.io/ (accessed on 26 May 2022).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Remy, P. Temporal Convolutional Networks for Keras. 2020. Available online: https://github.com/philipperemy/keras-tcn (accessed on 1 May 2022).
- Oprea, S.; Martinez-Gonzalez, P.; Garcia-Garcia, A.; Castro-Vargas, J.A.; Orts-Escolano, S.; Garcia-Rodriguez, J.; Argyros, A. A Review on Deep Learning Techniques for Video Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2806–2826. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Darrell, T.; Saenko, K. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–12 June 2015; pp. 2625–2634. [Google Scholar] [CrossRef]
- Rawat, A.; Kumar, A.; Upadhyay, P.; Kumar, S. Deep learning-based models for temporal satellite data processing: Classification of paddy transplanted fields. Ecol. Inform. 2021, 61, 101214. [Google Scholar] [CrossRef]
- Pham, V.; Bluche, T.; Kermorvant, C.; Louradour, J. Dropout Improves Recurrent Neural Networks for Handwriting Recognition. In Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition, Hersonissos, Greece, 1–4 September 2014; IEEE: Crete, Greece, 2014; pp. 285–290. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006; ISBN 0387310738. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Gan, Z.; Li, C.; Zhou, J.; Tang, G. Temporal convolutional networks interval prediction model for wind speed forecasting. Electr. Power Syst. Res. 2021, 191, 106865. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Riquelme, J.C. An Experimental Review on Deep Learning Architectures for Time Series Forecasting. Int. J. Neural Syst. 2021, 31, 2130001. [Google Scholar] [CrossRef] [PubMed]
- Hewage, P.; Behera, A.; Trovati, M.; Pereira, E.; Ghahremani, M.; Palmieri, F.; Liu, Y. Temporal convolutional neural (TCN) network for an effective weather forecasting using time-series data from the local weather station. Soft Comput. 2020, 24, 16453–16482. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Hsu, H.K.; Tsai, Y.H.; Mei, X.; Lee, K.H.; Nagasaka, N.; Prokhorov, D.; Yang, M.H. Learning to tell brake and turn signals in videos using CNN-LSTM structure. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Huang, C.-J.; Kuo, P.-H. A Deep CNN-LSTM Model for Particulate Matter (PM2.5) Forecasting in Smart Cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef]
- Chen, R.; Wang, X.; Zhang, W.; Zhu, X.; Li, A.; Yang, C. A hybrid CNN-LSTM model for typhoon formation forecasting. Geoinformatica 2019, 23, 375–396. [Google Scholar] [CrossRef]
- Nikparvar, B.; Thill, J.-C. Machine Learning of Spatial Data. ISPRS Int. J. Geo-Inf. 2021, 10, 600. [Google Scholar] [CrossRef]
- Wan, L.; Zhang, H.; Lin, G.; Lin, H. A small-patched convolutional neural network for mangrove mapping at species level using high-resolution remote-sensing image. Ann. GIS 2019, 25, 45–55. [Google Scholar] [CrossRef]
- Memon, N.; Parikh, H.; Patel, S.B.; Patel, D.; Patel, V.D. Automatic land cover classification of multi-resolution dualpol data using convolutional neural network (CNN). Remote Sens. Appl. Soc. Environ. 2021, 22, 100491. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Going Deeper with Contextual CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef]
- Liu, C.; Zeng, D.; Wu, H.; Wang, Y.; Jia, S.; Xin, L. Urban land cover classification of high-resolution aerial imagery using a relation-enhanced multiscale convolutional network. Remote Sens. 2020, 12, 311. [Google Scholar] [CrossRef]
- Kastaniotis, D.; Tsourounis, D.; Fotopoulos, S. Lip Reading modeling with Temporal Convolutional Networks for medical support applications. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 17–19 October 2020; pp. 366–371. [Google Scholar] [CrossRef]
- van Vliet, J.; Naus, N.; van Lammeren, R.J.A.; Bregt, A.K.; Hurkens, J.; van Delden, H. Measuring the neighbourhood effect to calibrate land use models. Comput. Environ. Urban Syst. 2013, 41, 55–64. [Google Scholar] [CrossRef]
- Kocabas, V.; Dragicevic, S. Assessing cellular automata model behaviour using a sensitivity analysis approach. Comput. Environ. Urban Syst. 2006, 30, 921–953. [Google Scholar] [CrossRef]
- Roodposhti, M.S.; Hewitt, R.J.; Bryan, B.A. Towards automatic calibration of neighbourhood influence in cellular automata land-use models. Comput. Environ. Urban Syst. 2020, 79, 101416. [Google Scholar] [CrossRef]
- Kong, Y.L.; Huang, Q.; Wang, C.; Chen, J.; Chen, J.; He, D. Long short-term memory neural networks for online disturbance detection in satellite image time series. Remote Sens. 2018, 10, 452. [Google Scholar] [CrossRef]
- Foody, G.M. Explaining the unsuitability of the kappa coefficient in the assessment and comparison of the accuracy of thematic maps obtained by image classification. Remote Sens. Environ. 2020, 239, 111630. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Pontius, R.G.; Boersma, W.; Castella, J.C.; Clarke, K.; Nijs, T.; Dietzel, C.; Duan, Z.; Fotsing, E.; Goldstein, N.; Kok, K.; et al. Comparing the input, output, and validation maps for several models of land change. Ann. Reg. Sci. 2008, 42, 11–37. [Google Scholar] [CrossRef]
- Paegelow, M.; Camacho Olmedo, M.T.; Mas, J.; Houet, T. Benchmarking of LUCC modelling tools by various validation techniques and error analysis. CyberGeo 2015, 2014. [Google Scholar] [CrossRef]
- Yubo, Z.; Zhuoran, Y.; Jiuchun, Y.; Yuanyuan, Y.; Dongyan, W.; Yucong, Z.; Fengqin, Y.; Lingxue, Y.; Liping, C.; Shuwen, Z. A Novel Model Integrating Deep Learning for Land Use/Cover Change Reconstruction: A Case Study of Zhenlai County, Northeast China. Remote Sens. 2020, 12, 3314. [Google Scholar] [CrossRef]
- Shoyama, K. Assessment of land-use scenarios at a national scale using intensity analysis and figure of merit components. Land 2021, 10, 379. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, S.; Liu, Y.; Xing, X.; De Sherbinin, A. Analyzing historical land use changes using a Historical Land Use Reconstruction Model: A case study in Zhenlai County, northeastern China. Sci. Rep. 2017, 7, 41275. [Google Scholar] [CrossRef] [PubMed]
- Karpatne, A.; Jiang, Z.; Vatsavai, R.R.; Shekhar, S.; Kumar, V. Monitoring land-cover changes: A machine-learning perspective. IEEE Geosci. Remote Sens. Mag. 2016, 4, 8–21. [Google Scholar] [CrossRef]
- Camacho Olmedo, M.T.; Pontius, R.G.; Paegelow, M.; Mas, J.F. Comparison of simulation models in terms of quantity and allocation of land change. Environ. Model. Softw. 2015, 69, 214–221. [Google Scholar] [CrossRef]







| Study Region | Year | Evergreen Forests | Deciduous and Mixed Forests | Shrublands, Savannas, Grasslands, and Wetlands | Barren | Permanent Snow and Ice | Urban and Built-Up Lands | Croplands | Water Bodies |
|---|---|---|---|---|---|---|---|---|---|
| (R1) Bulkley-Nechako | 2001 | 46,710.59 | 2383.57 | 20,373.90 | 802.61 | 314.69 | 16.74 | 230.54 | 2949.41 |
| 2019 | 33,772.89 | 1692.15 | 33,669.00 | 665.01 | 167.86 | 16.74 | 211.87 | 3586.52 | |
| % Change | −27.70% | −29.01% | 65.26% | −17.14% | −46.66% | 0% | −8.10% | 21.60% | |
| (R2) Central Kootenay | 2001 | 11,194.45 | 227.97 | 7759.48 | 525.48 | 71.48 | 23.61 | 108.62 | 698.07 |
| 2019 | 9250.07 | 227.75 | 9586.01 | 501.23 | 116.99 | 23.61 | 69.55 | 833.95 | |
| % Change | −17.37% | −0.09% | 23.54% | −4.62% | 63.66% | 0% | −35.97% | 19.46% | |
| (R3) Northern Rockies | 2001 | 26,927.21 | 14,911.48 | 39,286.83 | 1503.04 | 119.14 | 0.86 | 0.21 | 196.20 |
| 2019 | 32,664.82 | 12,936.62 | 35,361.15 | 1403.22 | 137.60 | 0.86 | 0.21 | 440.48 | |
| % Change | 21.31% | −13.24% | −9.99% | −6.64% | 15.50% | 0% | 0% | 124.51% | |
| (R4) Cariboo | 2001 | 30,322.90 | 1603.93 | 43,009.01 | 2240.82 | 466.88 | 24.90 | 23.83 | 844.25 |
| 2019 | 21,650.69 | 1601.35 | 51,251.26 | 2116.32 | 539.65 | 24.90 | 17.60 | 1334.75 | |
| % Change | −28.60% | −0.16% | 19.16% | −5.56% | 15.59% | 0% | −26.13% | 58.10% |
| Range from Central Cell (r) | Neighborhood Size (M × M) | # of Cells or Land Cover States Contributing to Neighborhood Effects (N) | Spatial Coverage Considered for Neighborhood Effects (km2) |
|---|---|---|---|
| 0 | 1 × 1 | 1 | 0.21 |
| 1 | 3 × 3 | 9 | 1.93 |
| 2 | 5 × 5 | 25 | 5.37 |
| 3 | 7 × 7 | 49 | 10.52 |
| 4 | 9 × 9 | 81 | 17.39 |
| 5 | 11 × 11 | 121 | 25.97 |
| Case | Study Region | Changed Area between 2001 and 2019 (km2) | Changed Area between 2018 and 2019 (km2) |
|---|---|---|---|
| 1 | Subarea A 1 | 365.35 (17.02%) | 66.33 (3.09%) |
| Subarea B 1 | 661.15 (30.80%) | 138.88 (6.47%) | |
| Subarea C 1 | 1150.36 (53.59%) | 187.61 (8.74%) | |
| Full Regional District of Bulkley-Nechako | 23,452.10 (31.79%) | 4317.00 (5.85%) | |
| 2 | Regional District of Central Kootenay | 4015.83 (19.49%) | 310.40 (1.51%) |
| Northern Rockies Regional Municipality | 12,000.71 (14.47%) | 1940.51 (2.34%) | |
| Cariboo Regional District | 17,611.03 (22.42%) | 2932.67 (3.73%) |
| Figure of Merit (%) | |||||
|---|---|---|---|---|---|
| Region | M × M | LSTM | TCN | CNN–LSTM | CNN–TCN |
| R1 | 1 × 1 | 0.25 | 0.54 | 0.25 | 0.51 |
| 3 × 3 | 1.39 | 1.39 | 1.00 | 1.04 | |
| 5 × 5 | 1.83 | 1.58 | 1.25 | 2.14 | |
| 7 × 7 | 2.04 | 1.90 | 1.67 | 1.53 | |
| 9 × 9 | 2.44 | 1.46 | 1.92 | 3.01 | |
| 11 × 11 | 1.95 | 2.27 | 2.44 | 1.72 | |
| R2 | 1 × 1 | 1.82 | 1.65 | 1.14 | 1.03 |
| 3 × 3 | 3.36 | 3.00 | 2.09 | 2.89 | |
| 5 × 5 | 4.31 | 4.15 | 2.65 | 3.56 | |
| 7 × 7 | 4.33 | 4.61 | 2.53 | 3.28 | |
| 9 × 9 | 5.11 | 3.79 | 4.73 | 3.79 | |
| 11 × 11 | 4.52 | 3.86 | 4.14 | 4.24 | |
| R3 | 1 × 1 | 0.05 | 0.42 | 0.08 | 0.22 |
| 3 × 3 | 1.62 | 2.18 | 1.00 | 1.40 | |
| 5 × 5 | 2.32 | 2.23 | 1.38 | 1.37 | |
| 7 × 7 | 3.19 | 3.25 | 1.53 | 1.92 | |
| 9 × 9 | 3.09 | 2.88 | 2.10 | 2.47 | |
| 11 × 11 | 2.55 | 2.79 | 2.31 | 3.65 | |
| R4 | 1 × 1 | 0.60 | 0.65 | 0.49 | 0.59 |
| 3 × 3 | 3.73 | 3.52 | 2.98 | 3.33 | |
| 5 × 5 | 4.60 | 4.28 | 5.76 | 5.40 | |
| 7 × 7 | 5.93 | 5.89 | 6.66 | 6.11 | |
| 9 × 9 | 7.29 | 6.86 | 5.97 | 6.50 | |
| 11 × 11 | 6.87 | 7.37 | 6.43 | 7.02 | |
| Producer’s Accuracy (%) | |||||
|---|---|---|---|---|---|
| Region | M × M | LSTM | TCN | CNN–LSTM | CNN–TCN |
| R1 | 1 × 1 | 0.25 | 0.55 | 0.25 | 0.51 |
| 3 × 3 | 1.43 | 1.42 | 1.01 | 1.06 | |
| 5 × 5 | 1.89 | 1.62 | 1.28 | 2.22 | |
| 7 × 7 | 2.11 | 1.97 | 1.73 | 1.57 | |
| 9 × 9 | 2.55 | 1.50 | 2.00 | 3.20 | |
| 11 × 11 | 2.02 | 2.40 | 2.59 | 1.80 | |
| R2 | 1 × 1 | 1.91 | 1.74 | 1.19 | 1.07 |
| 3 × 3 | 3.62 | 3.17 | 2.19 | 3.07 | |
| 5 × 5 | 4.86 | 4.55 | 2.84 | 3.96 | |
| 7 × 7 | 4.93 | 5.22 | 2.79 | 3.74 | |
| 9 × 9 | 5.79 | 4.29 | 5.53 | 4.57 | |
| 11 × 11 | 5.08 | 4.43 | 5.10 | 5.55 | |
| R3 | 1 × 1 | 0.05 | 0.45 | 0.08 | 0.22 |
| 3 × 3 | 1.66 | 2.27 | 1.02 | 1.44 | |
| 5 × 5 | 2.40 | 2.30 | 1.41 | 1.40 | |
| 7 × 7 | 3.37 | 3.41 | 1.58 | 1.98 | |
| 9 × 9 | 3.25 | 3.01 | 2.19 | 2.59 | |
| 11 × 11 | 2.66 | 2.93 | 2.48 | 4.06 | |
| R4 | 1 × 1 | 0.60 | 0.66 | 0.49 | 0.59 |
| 3 × 3 | 3.91 | 3.70 | 3.11 | 3.52 | |
| 5 × 5 | 4.89 | 4.51 | 6.37 | 5.96 | |
| 7 × 7 | 6.47 | 6.48 | 7.43 | 6.80 | |
| 9 × 9 | 8.21 | 7.67 | 6.65 | 7.43 | |
| 11 × 11 | 7.56 | 8.43 | 7.30 | 8.44 | |
| User’s Accuracy (%) | |||||
|---|---|---|---|---|---|
| Region | M × M | LSTM | TCN | CNN–LSTM | CNN–TCN |
| R1 | 1 × 1 | 28.02 | 27.03 | 29.82 | 25.12 |
| 3 × 3 | 36.42 | 35.75 | 41.68 | 38.66 | |
| 5 × 5 | 36.96 | 36.10 | 34.40 | 35.82 | |
| 7 × 7 | 35.77 | 35.08 | 32.95 | 35.79 | |
| 9 × 9 | 34.69 | 31.69 | 32.03 | 31.96 | |
| 11 × 11 | 33.78 | 27.71 | 29.30 | 26.67 | |
| R2 | 1 × 1 | 28.99 | 22.81 | 20.75 | 19.23 |
| 3 × 3 | 30.58 | 35.00 | 28.40 | 31.70 | |
| 5 × 5 | 26.88 | 31.26 | 27.36 | 25.58 | |
| 7 × 7 | 25.56 | 27.86 | 20.21 | 20.15 | |
| 9 × 9 | 29.67 | 23.75 | 23.92 | 17.57 | |
| 11 × 11 | 28.10 | 22.52 | 17.20 | 14.72 | |
| R3 | 1 × 1 | 30.77 | 6.27 | 16.28 | 21.02 |
| 3 × 3 | 38.76 | 35.29 | 35.27 | 33.15 | |
| 5 × 5 | 40.26 | 40.51 | 38.78 | 40.38 | |
| 7 × 7 | 36.65 | 38.67 | 32.35 | 34.20 | |
| 9 × 9 | 37.23 | 37.64 | 32.65 | 33.88 | |
| 11 × 11 | 36.07 | 35.11 | 24.67 | 25.44 | |
| R4 | 1 × 1 | 56.25 | 40.83 | 56.41 | 38.77 |
| 3 × 3 | 43.75 | 41.80 | 42.09 | 37.48 | |
| 5 × 5 | 43.24 | 44.15 | 37.43 | 35.92 | |
| 7 × 7 | 40.77 | 39.00 | 38.74 | 36.89 | |
| 9 × 9 | 39.06 | 38.99 | 36.17 | 33.76 | |
| 11 × 11 | 42.62 | 36.38 | 34.64 | 28.93 | |
| Effect of Adding Spatial Variables on Figure of Merit (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| LSTM | TCN | CNN–LSTM | CNN–TCN | ||||||
| Region | M × M | LC+SV | Diff. | LC+SV | Diff. | LC+SV | Diff. | LC+SV | Diff. |
| R1 | 1 × 1 | 0.29 | +0.04 | 0.64 | +0.10 | 0.86 | +0.61 | 1.02 | +0.51 |
| 3 × 3 | 1.29 | −0.10 | 1.41 | +0.02 | 1.70 | +0.70 | 2.38 | +1.34 | |
| 5 × 5 | 1.86 | +0.03 | 1.33 | −0.25 | 3.51 | +2.26 | 3.28 | +1.14 | |
| 7 × 7 | 2.26 | +0.22 | 1.76 | −0.14 | 3.44 | +1.77 | 3.40 | +1.87 | |
| 9 × 9 | 2.44 | +0.00 | 2.40 | +0.94 | 3.87 | +1.95 | 4.10 * | +1.09 | |
| 11 × 11 | 1.7 | −0.25 | 1.74 | −0.53 | 3.28 | +0.84 | 3.56 | +1.84 | |
| R2 | 1 × 1 | 1.96 | +0.14 | 3.00 | +1.35 | 1.49 | +0.35 | 2.50 | +1.47 |
| 3 × 3 | 3.73 | +0.37 | 3.63 | +0.63 | 3.00 | +0.91 | 2.90 | +0.01 | |
| 5 × 5 | 4.15 | −0.16 | 2.33 | −1.82 | 3.53 | +0.88 | 3.33 | −0.23 | |
| 7 × 7 | 4.08 | −0.25 | 4.74 | +0.13 | 3.15 | +0.62 | 3.12 | −0.16 | |
| 9 × 9 | 5.03 | −0.08 | 3.90 | +0.11 | 4.23 | −0.50 | 3.92 | +0.13 | |
| 11 × 11 | 4.9 | +0.38 | 3.59 | −0.27 | 4.25 | +0.11 | 4.64 | +0.40 | |
| R3 | 1 × 1 | 0.24 | +0.19 | 0.73 | +0.31 | 0.87 | +0.79 | 1.37 | +1.15 |
| 3 × 3 | 1.71 | +0.09 | 1.90 | −0.28 | 1.56 | +0.56 | 2.33 | +0.93 | |
| 5 × 5 | 2.29 | −0.03 | 1.79 | −0.44 | 1.84 | +0.46 | 2.20 | +0.83 | |
| 7 × 7 | 2.29 | −0.90 | 2.59 | −0.66 | 2.06 | +0.53 | 2.68 | +0.76 | |
| 9 × 9 | 3.08 | −0.01 | 3.51 * | +0.63 | 2.71 | +0.61 | 3.07 | +0.60 | |
| 11 × 11 | 2.72 | +0.17 | 3.11 | +0.32 | 3.12 | +0.81 | 3.39 | −0.26 | |
| R4 | 1 × 1 | 0.6 | 0.00 | 0.95 | +0.30 | 1.14 | +0.65 | 1.79 | +1.20 |
| 3 × 3 | 3.9 | +0.17 | 3.45 | −0.07 | 4.92 | +1.94 | 4.86 | +1.53 | |
| 5 × 5 | 5.64 | +1.04 | 5.28 | +1.00 | 6.06 | +0.30 | 5.40 | +0.00 | |
| 7 × 7 | 6.81 | +0.88 | 6.69 | +0.80 | 7.03 | +0.37 | 5.24 | −0.87 | |
| 9 × 9 | 6.83 | −0.46 | 6.86 | 0.00 | 7.32 | +1.35 | 7.40 * | +0.90 | |
| 11 × 11 | 6.72 | −0.15 | 6.87 | −0.50 | 7.04 | +0.61 | 7.17 | +0.15 | |
| Effect of Adding Spatial Variables on Error due to Quantity (km2) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| LSTM | TCN | CNN–LSTM | CNN–TCN | ||||||
| M × M | LC Only | LC+SV | LC Only | LC+SV | LC Only | LC+SV | LC Only | LC+SV | |
| R1 | 1 × 1 | 4280 | 4279 (−) | 4235 | 4221 (−) | 4283 | 4214 (−) | 4236 | 4175 (−) |
| 3 × 3 | 4153 | 4160 (+) | 4150 | 4156 (+) | 4214 | 4114 (−) | 4203 | 4025 (−) | |
| 5 × 5 | 4102 | 4089 (−) | 4130 | 4166 (+) | 4162 | 3872 (−) | 4056 | 3894 (−) | |
| 7 × 7 | 4070 | 4041 (−) | 4079 | 4105 (+) | 4098 | 3865 (−) | 4135 | 3898 (−) | |
| 9 × 9 | 4006 | 4001 (−) | 4119 | 3994 (−) | 4057 | 3830 * (−) | 3896 | 3758 * (−) | |
| 11 × 11 | 4065 | 3950 * (−) | 3953 | 3891 * (−) | 3947 | 3839 (−) | 4035 | 3801 (−) | |
| R2 | 1 × 1 | 842 | 832 (−) | 837 | 785 (−) | 853 | 850 (−) | 855 | 816 (−) |
| 3 × 3 | 798 | 776 (−) | 822 | 773 (−) | 835 | 813 (−) | 815 | 804 (−) | |
| 5 × 5 | 742 | 758 (+) | 773 | 805 (+) | 812 | 776 (−) | 764 | 777 (+) | |
| 7 × 7 | 731 | 712 * (−) | 736 | 729 (−) | 783 | 763 (−) | 739 | 759 (+) | |
| 9 × 9 | 729 | 691 (−) | 743 | 726 (−) | 700 | 717 (+) | 674 | 676 (+) | |
| 11 × 11 | 744 | 639 (−) | 729 | 649 * (−) | 645 | 597 * (−) | 573 | 549 * (−) | |
| R3 | 1 × 1 | 3567 | 3549 (−) | 3318 | 3371 (+) | 3554 | 3469 (−) | 3535 | 3390 (−) |
| 3 × 3 | 3424 | 3405 (−) | 3346 | 3385 (+) | 3471 | 3420 (−) | 3421 | 3312 (−) | |
| 5 × 5 | 3364 | 3362 (−) | 3376 | 3413 (+) | 3445 | 3390 (−) | 3452 | 3343 (−) | |
| 7 × 7 | 3256 | 3349 (+) | 3265 | 3281 (+) | 3405 | 3372 (−) | 3372 | 3254 (−) | |
| 9 × 9 | 3270 | 3246 (−) | 3297 | 3227 (−) | 3343 | 3291 (−) | 3308 | 3206 (−) | |
| 11 × 11 | 3316 | 2969 * (−) | 3282 | 2997 * (−) | 3222 | 3124 * (−) | 3018 | 2974 * (−) | |
| R4 | 1 × 1 | 3822 | 3794 (−) | 3803 | 3747 (−) | 3830 | 3678 (−) | 3806 | 3590 (−) |
| 3 × 3 | 3521 | 3489 (−) | 3525 | 3504 (−) | 3579 | 3382 (−) | 3503 | 3341 (−) | |
| 5 × 5 | 3431 | 3275 (−) | 3474 | 3289 (−) | 3210 | 3235 (+) | 3229 | 3251 (+) | |
| 7 × 7 | 3257 | 3136 (−) | 3225 | 3093 (−) | 3130 | 3080 (−) | 3157 | 3291 (+) | |
| 9 × 9 | 3060 | 2989 (−) | 3109 | 3063 (−) | 3160 | 2882 * (−) | 3023 | 2868 (−) | |
| 11 × 11 | 3187 | 2934 * (−) | 2976 | 2803 * (−) | 3061 | 2905 (−) | 2752 * | 2807 (+) | |
| Effect of Adding Spatial Variables on Error due to Allocation (km2) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| LSTM | TCN | CNN–LSTM | CNN–TCN | ||||||
| M × M | LC Only | LC+SV | LC Only | LC+SV | LC Only | LC+SV | LC Only | LC+SV | |
| R1 | 1 × 1 | 52 | 50 (−) | 118 | 137 (+) | 46 | 132 (+) | 118 | 194 (+) |
| 3 × 3 | 205 | 201 (−) | 212 | 197 (−) | 119 | 255 (+) | 137 | 371 (+) | |
| 5 × 5 | 266 | 291 (+) | 234 | 184 (−) | 199 | 567 (+) | 331 | 545 (+) | |
| 7 × 7 | 311 | 350 (+) | 306 | 268 (−) | 289 | 588 (+) | 228 | 527 (+) | |
| 9 × 9 | 402 | 410 (+) | 267 | 428 (+) | 347 | 617 (+) | 565 | 735 (+) | |
| 11 × 11 | 330 | 578 (+) | 521 | 690 (+) | 517 | 651 (+) | 409 | 699 (+) | |
| R2 | 1 × 1 | 83 | 100 (+) | 97 | 173 (+) | 74 | 73 (−) | 73 | 122 (+) |
| 3 × 3 | 140 | 176 (+) | 100 | 183 (+) | 92 | 119 (+) | 117 | 137 (+) | |
| 5 × 5 | 231 | 203 (−) | 173 | 147 (−) | 126 | 179 (+) | 202 | 181 (−) | |
| 7 × 7 | 251 | 292 (+) | 236 | 247 (+) | 186 | 212 (+) | 255 | 220 (−) | |
| 9 × 9 | 240 | 313 (+) | 240 | 270 (+) | 303 | 279 (−) | 371 | 364 (−) | |
| 11 × 11 | 223 | 416 (+) | 265 | 423 (+) | 420 | 509 (+) | 556 | 592 (+) | |
| R3 | 1 × 1 | 5 | 27 (+) | 474 | 344 (−) | 27 | 140 (+) | 55 | 260 (+) |
| 3 × 3 | 176 | 206 (+) | 288 | 231 (−) | 127 | 186 (+) | 197 | 343 (+) | |
| 5 × 5 | 242 | 249 (+) | 226 | 184 (−) | 150 | 226 (+) | 137 | 292 (+) | |
| 7 × 7 | 389 | 273 (−) | 367 | 383 (+) | 219 | 245 (+) | 255 | 431 (+) | |
| 9 × 9 | 369 | 416 (+) | 332 | 422 (+) | 299 | 355 (+) | 340 | 494 (+) | |
| 11 × 11 | 319 | 983 (+) | 367 | 897 (+) | 519 | 651 (+) | 815 | 920 (+) | |
| R4 | 1 × 1 | 31 | 87 (+) | 66 | 154 (+) | 26 | 276 (+) | 65 | 397 (+) |
| 3 × 3 | 379 | 428 (+) | 387 | 434 (+) | 324 | 552 (+) | 444 | 635 (+) | |
| 5 × 5 | 483 | 698 (+) | 425 | 700 (+) | 812 | 740 (−) | 805 | 762 (−) | |
| 7 × 7 | 709 | 866 (+) | 772 | 957 (+) | 890 | 953 (+) | 882 | 698 (−) | |
| 9 × 9 | 969 | 1139 (+) | 912 | 999 (+) | 890 | 1298 (+) | 1102 | 1318 (+) | |
| 11 × 11 | 765 | 1251 (+) | 1120 | 1485 (+) | 1038 | 1279 (+) | 1567 | 1451 (−) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
van Duynhoven, A.; Dragićević, S. Assessing the Impact of Neighborhood Size on Temporal Convolutional Networks for Modeling Land Cover Change. Remote Sens. 2022, 14, 4957. https://doi.org/10.3390/rs14194957
van Duynhoven A, Dragićević S. Assessing the Impact of Neighborhood Size on Temporal Convolutional Networks for Modeling Land Cover Change. Remote Sensing. 2022; 14(19):4957. https://doi.org/10.3390/rs14194957
Chicago/Turabian Stylevan Duynhoven, Alysha, and Suzana Dragićević. 2022. "Assessing the Impact of Neighborhood Size on Temporal Convolutional Networks for Modeling Land Cover Change" Remote Sensing 14, no. 19: 4957. https://doi.org/10.3390/rs14194957
APA Stylevan Duynhoven, A., & Dragićević, S. (2022). Assessing the Impact of Neighborhood Size on Temporal Convolutional Networks for Modeling Land Cover Change. Remote Sensing, 14(19), 4957. https://doi.org/10.3390/rs14194957