
Application of Random Forest Algorithm on Tornado Detection

 , ,
, ,  , ,
, ,
Abstract
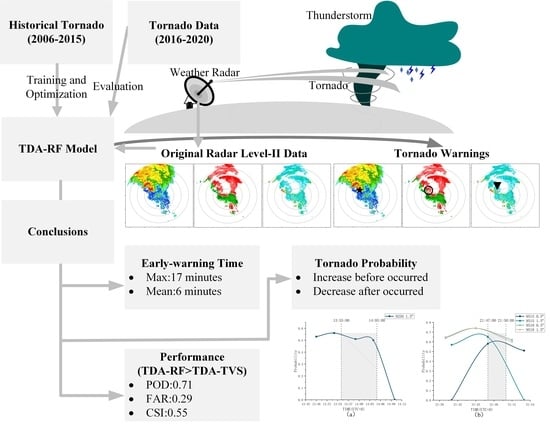
1. Introduction
2. Data
2.1. Weather Radar Data
2.2. Tornado Dataset
3. Methods
3.1. Random Forest
3.2. Features Importance
4. TDA-RF Model Training and Optimization
5. Experiments and Results
5.1. TDA-RF Evaluation
5.2. TDA-RF versus TDA-TVS
5.3. TDA-RF Tornado Detection
6. Discussion
7. Conclusions
- Features related to velocity are more critical in tornado detection; the velocity spectrum width of weather radar should be used, and features related to velocity spectrum width can improve tornado detection.
- The maximum early-warning time of the TDA-RF for tornadoes is 17 min, and the mean value is 6 min.
- Compared with the unsupervised tornado detection algorithm, such as the TDA-TVS, the TDA-RF uses the features in the block, classification using random forests, overcomes the limitation of multiple elevations, identifies more tornadoes, increases the probability of detection and critical success index, and reduces the false alarm rate.
- The probability in the TDA-RF detection results is related to the tornadogenesis. The probability increases and decreases before and after the tornado touches the ground.
- Apply TDA-RF on NEXRAD radar data, change the block size (8 × 8 or larger), add dual polarization parameters and features, test more tornado cases, and study the change in probability;
- Optimize the class imbalance of the tornado dataset to improve the tornado detection effect.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TDA | Tornado detection algorithm |
| RF | Random forest |
| TDA-RF | TDA based on RF |
| TVS | Tornado vortex signature |
| M | Mesocyclone |
| MDA | Mesocyclone detection algorithm |
| TDA-TVS | TDA based on TVS |
| CINRAD-SA | the S-band China new generation of Doppler weather radar |
| VCP | Volume coverage pattern |
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Implication | Unit |
|---|---|---|
| r_average | The average value in the 4 × 4 Z block | dBZ |
| r_max | The maximum value in the 4 × 4 Z block | dBZ |
| r_min | The minimum value in the 4 × 4 Z block | dBZ |
| v_average | The average value in the 4 × 4 V block | m/s |
| v_max | The maximum value in the 4 × 4 V block | m/s |
| v_min | The minimum value in the 4 × 4 V block | m/s |
| w_average | The average value in the 4 × 4 W block | m/s |
| w_max | The maximum value in the 4 × 4 W block | m/s |
| w_min | The minimum value in the 4 × 4 W block | m/s |
| s_average | The average value of velocity shear in the 4 × 4 V block | 1/s |
| s_max | The maximum value of velocity shear in the 4 × 4 V block | 1/s |
| s_min | The minimum value of velocity shear in the 4 × 4 V block | 1/s |
| l_average | The average value of angular momentum in the 4 × 4 V block | /s |
| l_max | The maximum value of angular momentum in the 4 × 4 V block | /s |
| l_min | The minimum value of angular momentum in the 4 × 4 V block | /s |
| vt_average | The average value of rotation speed in the 4 × 4 V block | m/s |
| vt_max | The maximum value of rotation speed in the 4 × 4 V block | m/s |
| vt_min | The minimum value of rotation speed in the 4 × 4 V block | m/s |
| c4_d_v_max | The maximum value of velocity difference in the 2 × 2 V block | m/s |
| c4_s_average | The average value of velocity shear in the 2 × 2 V block | 1/s |
| c4_s_max | The maximum value of velocity shear in the 2 × 2 V block | 1/s |
| c4_s_min | The minimum value of velocity shear in the 2 × 2 V block | 1/s |
| c4_l_average | The average value of angular momentum in the 2 × 2 V block | /s |
| c4_l_max | The maximum value of angular momentum in the 2 × 2 V block | /s |
| c4_l_min | The minimum value of angular momentum in the 2 × 2 V block | /s |
| c4_vt_average | The average value of rotation speed in the 2 × 2 V block | m/s |
| c4_vt_max | The maximum value of rotation speed in the 2 × 2 V block | m/s |
| c4_vt_min | The minimum value of rotation speed in the 2 × 2 V block | m/s |
| w_range | The range value of velocity spectral width in the 4 × 4 W block | m/s |
| w_40 | The threshould greater than 40% velocity spectral width in the 4 × 4 W block | m/s |
| w_60 | The threshould greater than 60% velocity spectral width in the 4 × 4 W block | m/s |
| w_80 | The threshould greater than 80% velocity spectral width in the 4 × 4 W block | m/s |




References
- Nouri, N.; Devineni, N.; Were, V.; Khanbilvardi, R. Explaining the trends and variability in the United States tornado records using climate teleconnections and shifts in observational practices. Sci. Rep. 2021, 11, 1–14. [Google Scholar] [CrossRef]
- Ćwik, P.; McPherson, R.A.; Brooks, H.E. What is a tornado outbreak?: Perspectives through time. Bull. Am. Meteorol. Soc. 2021, 102, E817–E835. [Google Scholar] [CrossRef]
- McCarthy, D.; Schaefer, J.; Edwards, R. What are we doing with (or to) the F-Scale. In Proceedings of the 23rd Conference of Severe Local Storms, St. Louis, MO, USA, 5 November 2006; Volume 5. [Google Scholar]
- Doswell, C.A., III; Brooks, H.E.; Dotzek, N. On the implementation of the enhanced Fujita scale in the USA. Atmos. Res. 2009, 93, 554–563. [Google Scholar] [CrossRef]
- Houser, J.B.; McGinnis, N.; Butler, K.M.; Bluestein, H.B.; Snyder, J.C.; French, M.M. Statistical and empirical relationships between tornado intensity and both topography and land cover using rapid-scan radar observations and a GIS. Mon. Weather. Rev. 2020, 148, 4313–4338. [Google Scholar] [CrossRef]
- Zhou, R.; Meng, Z.; Bai, L. Differences in tornado activities and key tornadic environments between China and the United States. Int. J. Climatol. 2022, 42, 367–384. [Google Scholar] [CrossRef]
- Yu, X.; Zhao, J.; Fan, W. Tornadoes in China: Spatiotemporal distribution and environmental characteristics. J. Trop. Meteorol. 2021, 37, 681–692. [Google Scholar]
- Yao, Y.; Yu, X.; Zhang, Y.; Zhou, Z.; Xie, W.; Lu, Y.; Yu, J.; Wei, L. Climate analysis of tornadoes in China. J. Meteorol. Res. 2015, 29, 359–369. [Google Scholar] [CrossRef]
- Chen, J.; Cai, X.; Wang, H.; Kang, L.; Zhang, H.; Song, Y.; Zhu, H.; Zheng, W.; Li, F. Tornado climatology of China. Int. J. Climatol. 2018, 38, 2478–2489. [Google Scholar] [CrossRef]
- Kumjian, M.R. Weather radars. In Remote Sensing of Clouds and Precipitation; Springer: Berlin/Heidelberg, Germany, 2018; pp. 15–63. [Google Scholar]
- Doviak, R.J.; Zrnic, D.S.; Sirmans, D.S. Doppler weather radar. Proc. IEEE 1979, 67, 1522–1553. [Google Scholar] [CrossRef]
- Snyder, J.C.; Ryzhkov, A.V. Automated detection of polarimetric tornadic debris signatures using a hydrometeor classification algorithm. J. Appl. Meteorol. Climatol. 2015, 54, 1861–1870. [Google Scholar] [CrossRef]
- Chu, Z.; Yin, Y.; Gu, S. Characteristics of velocity ambiguity for CINRAD-SA Doppler weather radars. Asia-Pac. J. Atmos. Sci. 2014, 50, 221–227. [Google Scholar] [CrossRef]
- Frank, L.R.; Galinsky, V.L.; Orf, L.; Wurman, J. Dynamic multiscale modes of severe storm structure detected in mobile Doppler radar data by entropy field decomposition. J. Atmos. Sci. 2018, 75, 709–730. [Google Scholar] [CrossRef]
- Zhang, X.; He, J.; Zeng, Q.; Shi, Z. Weather radar echo super-resolution reconstruction based on nonlocal self-similarity sparse representation. Atmosphere 2019, 10, 254. [Google Scholar] [CrossRef]
- Burgess, D.W.; Lemon, L.R.; Brown, R.A. Tornado characteristics revealed by Doppler radar. Geophys. Res. Lett. 1975, 2, 183–184. [Google Scholar] [CrossRef]
- Wakimoto, R.M.; Wilson, J.W. Non-supercell tornadoes. Mon. Weather. Rev. 1989, 117, 1113–1140. [Google Scholar] [CrossRef]
- Lemon, L.R.; Donaldson, R.J., Jr.; Burgess, D.W.; Brown, R.A. Doppler radar application to severe thunderstorm study and potential real-time warning. Bull. Am. Meteorol. Soc. 1977, 58, 1187–1193. [Google Scholar] [CrossRef]
- Brown, R.A.; Lemon, L.R.; Burgess, D.W. Tornado detection by pulsed Doppler radar. Mon. Weather. Rev. 1978, 106, 29–38. [Google Scholar] [CrossRef]
- Zrnić, D.; Burgess, D.; Hennington, L. Automatic detection of mesocyclonic shear with Doppler radar. J. Atmos. Ocean. Technol. 1985, 2, 425–438. [Google Scholar] [CrossRef]
- Stumpf, G.J.; Witt, A.; Mitchell, E.D.; Spencer, P.L.; Johnson, J.; Eilts, M.D.; Thomas, K.W.; Burgess, D.W. The National Severe Storms Laboratory mesocyclone detection algorithm for the WSR-88D. Weather. Forecast. 1998, 13, 304–326. [Google Scholar] [CrossRef]
- Mitchell, E.D.W.; Vasiloff, S.V.; Stumpf, G.J.; Witt, A.; Eilts, M.D.; Johnson, J.; Thomas, K.W. The National Severe Storms Laboratory tornado detection algorithm. Weather. Forecast. 1998, 13, 352–366. [Google Scholar] [CrossRef]
- Ryzhkov, A.V.; Schuur, T.J.; Burgess, D.W.; Zrnic, D.S. Polarimetric tornado detection. J. Appl. Meteorol. 2005, 44, 557–570. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, T.Y. Novel tornado detection using an adaptive neuro-fuzzy system with S-band polarimetric weather radar. J. Atmos. Ocean. Technol. 2015, 32, 195–208. [Google Scholar] [CrossRef]
- Hill, A.J.; Herman, G.R.; Schumacher, R.S. Forecasting severe weather with random forests. Mon. Weather. Rev. 2020, 148, 2135–2161. [Google Scholar] [CrossRef]
- Basalyga, J.N.; Barajas, C.A.; Gobbert, M.K.; Wang, J.W. Performance benchmarking of parallel hyperparameter tuning for deep learning based tornado predictions. Big Data Res. 2021, 25, 100212. [Google Scholar] [CrossRef]
- Lagerquist, R.; McGovern, A.; Homeyer, C.R.; Gagne, D.J., II; Smith, T. Deep learning on three-dimensional multiscale data for next-hour tornado prediction. Mon. Weather. Rev. 2020, 148, 2837–2861. [Google Scholar] [CrossRef]
- Min, C.; Chen, S.; Gourley, J.J.; Chen, H.; Zhang, A.; Huang, Y.; Huang, C. Coverage of China new generation weather radar network. Adv. Meteorol. 2019, 2019, 5789358. [Google Scholar] [CrossRef]
- Jianxin, H. CINRAD WSR-98D and its ground clutter filter design. In Proceedings of the 2001 CIE International Conference on Radar Proceedings (Cat No. 01TH8559), Beijing, China, 15–18 October 2001; pp. 1186–1189. [Google Scholar]
- Wang, B.; Wei, M.; Hua, W.; Zhang, Y.; Wen, X.; Zheng, J.; Li, N.; Li, H.; Wu, Y.; Zhu, J. Characteristics and possible formation mechanisms of severe storms in the outer rainbands of Typhoon Mujiga (1522). J. Meteorol. Res. 2017, 31, 612–624. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef]
- Li, Z.; Meier, M.A.; Hauksson, E.; Zhan, Z.; Andrews, J. Machine learning seismic wave discrimination: Application to earthquake early warning. Geophys. Res. Lett. 2018, 45, 4773–4779. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Wright, R.E. Logistic regression. In Reading and Understanding Multivariate Statistics; American Psychological Association: Washington, DC, USA, 1995; pp. 217–244. [Google Scholar]
- Tsangaratos, P.; Ilia, I. Comparison of a logistic regression and Naïve Bayes classifier in landslide susceptibility assessments: The influence of models complexity and training dataset size. Catena 2016, 145, 164–179. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Maalouf, M.; Homouz, D.; Trafalis, T.B. Logistic regression in large rare events and imbalanced data: A performance comparison of prior correction and weighting methods. Comput. Intell. 2018, 34, 161–174. [Google Scholar] [CrossRef]
- Peerbhay, K.Y.; Mutanga, O.; Ismail, R. Random forests unsupervised classification: The detection and mapping of solanum mauritianum infestations in plantation forestry using hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3107–3122. [Google Scholar] [CrossRef]
- Schvartzman, D.; Curtis, C.D. Signal processing and radar characteristics (SPARC) simulator: A flexible dual-polarization weather-radar signal simulation framework based on preexisting radar-variable data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 12, 135–150. [Google Scholar] [CrossRef]
- Austin, P.M. Relation between measured radar reflectivity and surface rainfall. Mon. Weather. Rev. 1987, 115, 1053–1070. [Google Scholar] [CrossRef]
- Honda, T.; Amemiya, A.; Otsuka, S.; Taylor, J.; Maejima, Y.; Nishizawa, S.; Yamaura, T.; Sueki, K.; Tomita, H.; Miyoshi, T. Advantage of 30-s-updating numerical weather prediction with a phased-array weather radar over operational nowcast for a convective precipitation system. Geophys. Res. Lett. 2022, 49, 1–9. [Google Scholar] [CrossRef]
- Hengstebeck, T.; Wapler, K.; Heizenreder, D.; Joe, P. Radar network-based detection of mesocyclones at the German weather service. J. Atmos. Ocean. Technol. 2018, 35, 299–321. [Google Scholar] [CrossRef]
- Wang, B.; Wei, M.; Fan, G.; Du, A. The evolution and mechanism of tornadic supercells in the outer rainbands of strong typhoon Mujigae (1522). Part I: Spectrum width and mesocyclone speed. J. Trop. Meteorol. 2018, 34, 472–480. [Google Scholar]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Speiser, J.L.; Miller, M.E.; Tooze, J.; Ip, E. A comparison of random forest variable selection methods for classification prediction modeling. Expert Syst. Appl. 2019, 134, 93–101. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Raileanu, L.E.; Stoffel, K. Theoretical comparison between the gini index and information gain criteria. Ann. Math. Artif. Intell. 2004, 41, 77–93. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef]
- Huang, N.; Lu, G.; Xu, D. A permutation importance-based feature selection method for short-term electricity load forecasting using random forest. Energies 2016, 9, 767. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Ramadhan, M.M.; Sitanggang, I.S.; Nasution, F.R.; Ghifari, A. Parameter tuning in random forest based on grid search method for gender classification based on voice frequency. DEStech Trans. Comput. Sci. Eng. 2017, 10. [Google Scholar] [CrossRef]
- Luque, A.; Carrasco, A.; Martín, A.; de Las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- He, H.B.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Lagerquist, R.; Gagne, D., II. Basic Machine Learning for Predicting Thunderstorm Rotation: Python Tutorial; 2019. [Google Scholar]
- Tang, J.; Tang, X.; Xu, F.; Zhang, F. Multi-scale interaction between a squall line and a supercell and its impact on the genesis of the “0612” Gaoyou tornado. Atmosphere 2022, 13, 272. [Google Scholar] [CrossRef]
- Adams, M.A.; Johnson, W.D.; Tudor-Locke, C. Steps/day translation of the moderate-to-vigorous physical activity guideline for children and adolescents. Int. J. Behav. Nutr. Phys. Act. 2013, 10, 49. [Google Scholar] [CrossRef]
- Lim, S.; Allabakash, S.; Jang, B.; Chandrasekar, V. Polarimetric radar signatures of a rare tornado event over south Korea. J. Atmos. Ocean. Technol. 2018, 35, 1977–1997. [Google Scholar] [CrossRef]
- Qing, Z.; Zeng, Q.; Wang, H.; Liu, Y.; Xiong, T.; Zhang, S. ADASYN-LOF algorithm for imbalanced tornado samples. Atmosphere 2022, 13, 544. [Google Scholar] [CrossRef]













| Radar | Information | Reflectivity | Radial Velocity | Spectrum Width |
|---|---|---|---|---|
| CINRAD-SA | Distance resolution | 1 km | 0.25 km | 0.25 km |
| Maximum detection range | 460 km | 230 km | 230 km | |
| Format for each data | 9 × 360 × 460 | 9 × 360 × 920 | 9 × 360 × 920 | |
| NEXRAD | Distance resolution | 0.25 km | 0.25 km | 0.25 km |
| Maximum detection range | 458 km | 458 km | 458 km | |
| Format for each data | 9270 × 1832 | 9270 × 1832 | 9270 × 1832 |
| Date (UTC+8) | Position | Intensity | Radar |
|---|---|---|---|
| 20060703 20:01–20:13 | 119.781,33.551 | EF1 | Z9515,Z9516 |
| 20070703 16:40–17:20 | 119.229,32.650 | EF3 | Z9250 |
| 20080817 15:05–15:15 | 120.355,33.581 | EF2 | Z9515 |
| 20090827 15:30–16:15 | 120.980,31.385 | EF0 | Z9513 |
| 20100717 19:30–19:35 | 116.563,34.677 | EF1 | Z9516 |
| 20110822 06:00–06:10 | 120.042,31.873 | EF0 | Z9519 |
| 20130707 16:40–17:15 | 119.645,32.833 | EF0 | Z9517,Z9523 |
| 20140824 15:40–15:50 | 119.656,32.629 | EF2 | Z9523 |
| 20150724 12:15–12:18 | 119.436,32.776 | EF0 | Z9523 |
| True Class | |||
|---|---|---|---|
| model predict class | positive (yes tornado) | negative (no tornado) | |
| Y (yes tornado) | (True Positives) | (False Positives) | |
| N (no tornado) | (False Negatives) | (True Negatives) | |
| column counts | |||
| ACC | PRE | F1-Score | G-Mean | POD | FAR | CSI |
|---|---|---|---|---|---|---|
| 0.9903 | 0.8667 | 0.7878 | 0.8486 | 0.7222 | 0.1333 | 0.65 |
| TDA-RF | TDA-TVS | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Radar | Date(UTC+8) | Position | Intensity | H | M | F | H | M | F |
| Z9515,Z9517 | 20160623 14:15–14:30 | 119.803,33.694 | EF4 | 4 | 1 | 1 | 3 | 2 | 2 |
| Z9517,Z9519 | 20160706 15:50–16:00 | 121.012,31.940 | EF0 | 4 | 1 | 2 | 3 | 2 | 1 |
| Z9515,Z9523 | 20170702 11:00–11:15 | 120.483,32.673 | EF1 | 4 | 2 | 1 | 4 | 2 | 4 |
| Z9527 | 20180818 18:40–19:05 | 117.052,34.339 | EF2 | 3 | 2 | 2 | 2 | 3 | 2 |
| Z9250 | 20200612 13:55–14:10 | 119.451,32.741 | EF3 | 2 | 1 | 1 | 2 | 1 | 0 |
| Total | 17 | 7 | 7 | 14 | 10 | 9 | |||
| Score | POD:0.71 FAR:0.29 CSI:0.55 | POD:0.58 FAR:0.39 CSI:0.42 | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Q.; Qing, Z.; Zhu, M.; Zhang, F.; Wang, H.; Liu, Y.; Shi, Z.; Yu, Q. Application of Random Forest Algorithm on Tornado Detection. Remote Sens. 2022, 14, 4909. https://doi.org/10.3390/rs14194909
Zeng Q, Qing Z, Zhu M, Zhang F, Wang H, Liu Y, Shi Z, Yu Q. Application of Random Forest Algorithm on Tornado Detection. Remote Sensing. 2022; 14(19):4909. https://doi.org/10.3390/rs14194909
Chicago/Turabian StyleZeng, Qiangyu, Zhipeng Qing, Ming Zhu, Fugui Zhang, Hao Wang, Yin Liu, Zhao Shi, and Qiu Yu. 2022. "Application of Random Forest Algorithm on Tornado Detection" Remote Sensing 14, no. 19: 4909. https://doi.org/10.3390/rs14194909
APA StyleZeng, Q., Qing, Z., Zhu, M., Zhang, F., Wang, H., Liu, Y., Shi, Z., & Yu, Q. (2022). Application of Random Forest Algorithm on Tornado Detection. Remote Sensing, 14(19), 4909. https://doi.org/10.3390/rs14194909