Figure 1.
(a) The situation of missed detection due to too dense targets. The yellow box indicates the detected targets, and the red box indicates the missed targets. (b) The result of using the oriented bounding box.
Figure 1.
(a) The situation of missed detection due to too dense targets. The yellow box indicates the detected targets, and the red box indicates the missed targets. (b) The result of using the oriented bounding box.
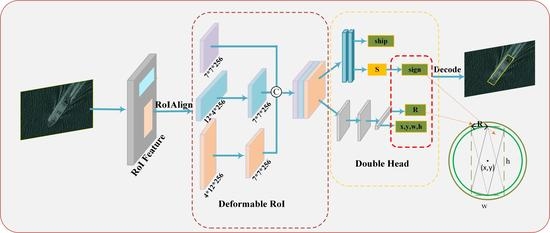
Figure 2.
Overview of the our proposed OSCD-Net. Feature extraction and RPN are located on the left. The DRoI module is an intermediate grid rectangle used for enhancement to form the final detection feature. ICR-head on the right is used to detect the horizontal rectangle and a circle, which is decoded into a rotating rectangular box.
Figure 2.
Overview of the our proposed OSCD-Net. Feature extraction and RPN are located on the left. The DRoI module is an intermediate grid rectangle used for enhancement to form the final detection feature. ICR-head on the right is used to detect the horizontal rectangle and a circle, which is decoded into a rotating rectangular box.
Figure 3.
(a) The circle marked with the radius of the circle. The circle and the horizontal rectangle will intersect into four inclined rectangles. (b) The vertex of the horizontal rectangle and the intersection with the circle, and explains that there are only two inclined rectangles using AF to draw the circle.
Figure 3.
(a) The circle marked with the radius of the circle. The circle and the horizontal rectangle will intersect into four inclined rectangles. (b) The vertex of the horizontal rectangle and the intersection with the circle, and explains that there are only two inclined rectangles using AF to draw the circle.
Figure 4.
Schematic diagram of the rectangle in the coordinate axis. are known, and vertex coordinates (A, B, C, D, E, F, G, H) are unknown.
Figure 4.
Schematic diagram of the rectangle in the coordinate axis. are known, and vertex coordinates (A, B, C, D, E, F, G, H) are unknown.
Figure 5.
Illustration of the process of the ICR-head module. Each part is marked in the red box on the right.
Figure 5.
Illustration of the process of the ICR-head module. Each part is marked in the red box on the right.
Figure 6.
Illustration of process of DRoI module. DRoI module uses three transformation operations and two deformation operations. Transformation operation and deformation operation are circled with red frames.
Figure 6.
Illustration of process of DRoI module. DRoI module uses three transformation operations and two deformation operations. Transformation operation and deformation operation are circled with red frames.
Figure 7.
(a) The step of transformation operation; (b) The process of deformation operation.
Figure 7.
(a) The step of transformation operation; (b) The process of deformation operation.
Figure 8.
(a) The case where the short side of the horizontal rectangle does not intersect the circle. (b) The parallelogram obtained by connecting the midpoint and intersection of the short side of the horizontal rectangle.
Figure 8.
(a) The case where the short side of the horizontal rectangle does not intersect the circle. (b) The parallelogram obtained by connecting the midpoint and intersection of the short side of the horizontal rectangle.
Figure 9.
(a) The tilt target represented by ; (b) the tilt target represented by ; (c) the tilt target represented by .
Figure 9.
(a) The tilt target represented by ; (b) the tilt target represented by ; (c) the tilt target represented by .
Figure 10.
Comparison of ablation study methods. In the first column, we mark the ground truth with green boxes. The second column shows the detection results of Faster-RCNN OBB. The detection result in blue boxes are the effect of our use of ICR-head. In the last column, the yellow box shows the detection results used by both the DRoI module and ICR-head.
Figure 10.
Comparison of ablation study methods. In the first column, we mark the ground truth with green boxes. The second column shows the detection results of Faster-RCNN OBB. The detection result in blue boxes are the effect of our use of ICR-head. In the last column, the yellow box shows the detection results used by both the DRoI module and ICR-head.
Figure 11.
Comparison experiment detection results on HRSC2016 dataset. The green box in the first column represents the ground truth. The yellow box indicates the detection result. The red box indicates the missed detection area, and the blue box indicates the inaccurate detection area. (a) The detection result of Faster R-CNN. (b) The detection result of RoI transformer. (c) The detection result of Gliding vertex. (d) The detection result of OSCD-Net.
Figure 11.
Comparison experiment detection results on HRSC2016 dataset. The green box in the first column represents the ground truth. The yellow box indicates the detection result. The red box indicates the missed detection area, and the blue box indicates the inaccurate detection area. (a) The detection result of Faster R-CNN. (b) The detection result of RoI transformer. (c) The detection result of Gliding vertex. (d) The detection result of OSCD-Net.
Figure 12.
Precision–recall curve of different methods on the HRSC2016 dataset.
Figure 12.
Precision–recall curve of different methods on the HRSC2016 dataset.
Figure 13.
Comparison of experiment detection results on the DOTA-Ship dataset. The green box in the first column represents the ground truth. The yellow box indicates the detection result. The red box indicates the missed detection area, and the blue box indicates the inaccurate detection area. (a) The detection result of Faster R-CNN. (b) The detection result of RoI transformer. (c) The detection result of Gliding vertex. (d) The detection result of OSCD-Net.
Figure 13.
Comparison of experiment detection results on the DOTA-Ship dataset. The green box in the first column represents the ground truth. The yellow box indicates the detection result. The red box indicates the missed detection area, and the blue box indicates the inaccurate detection area. (a) The detection result of Faster R-CNN. (b) The detection result of RoI transformer. (c) The detection result of Gliding vertex. (d) The detection result of OSCD-Net.
Figure 14.
Precision–recall curve of different methods on the DOTA-Ship dataset.
Figure 14.
Precision–recall curve of different methods on the DOTA-Ship dataset.
Figure 15.
Precision–recall curve of different methods on the SSDD+ dataset.
Figure 15.
Precision–recall curve of different methods on the SSDD+ dataset.
Figure 16.
Comparison of experiment detection results on the SSDD+ dataset. The green box in the first column represents the ground truth. The yellow box indicates the detection result. The red box indicates the missed detection area, and the blue box indicates the inaccurate detection area. (a) The detection result of Faster R-CNN. (b) The detection result of RoI transformer. (c) The detection result of Gliding vertex. (d) The detection result of OSCD-Net.
Figure 16.
Comparison of experiment detection results on the SSDD+ dataset. The green box in the first column represents the ground truth. The yellow box indicates the detection result. The red box indicates the missed detection area, and the blue box indicates the inaccurate detection area. (a) The detection result of Faster R-CNN. (b) The detection result of RoI transformer. (c) The detection result of Gliding vertex. (d) The detection result of OSCD-Net.
Figure 17.
Some detection results on the test datasets.
Figure 17.
Some detection results on the test datasets.
Table 1.
Performance comparison of Faster R-CNN under different rotated box representations. The highest value is indicated by bold numbers (%).
Table 1.
Performance comparison of Faster R-CNN under different rotated box representations. The highest value is indicated by bold numbers (%).
| Method | Num | S | AP(07) | AP(12) |
|---|
| Faster R-CNN+FP | 5 | - | 80.9 | 82.9 |
| Faster R-CNN+EP | 8 | - | 88.20 | 89.0 |
| Faster R-CNN+RHC (ours) | 5 | 98.9 | 88.6 | 89.2 |
Table 2.
Ablation study of OSCD-Net on the HRSC2016 dataset. The highest value is indicated by bold numbers (%).
Table 2.
Ablation study of OSCD-Net on the HRSC2016 dataset. The highest value is indicated by bold numbers (%).
| RHC | ICR-Head | DRoI | AP(07) | AP(12) |
|---|
| √ | | | 88.60 | 89.21 |
| √ | √ | | 89.17 | 92.10 |
| √ | | √ | 89.21 | 91.73 |
| √ | √ | √ | 89.98 | 93.52 |
Table 3.
Performance evaluation of nine different methods on HRSC2016 dataset. The highest value is indicated by bold numbers (%).
Table 3.
Performance evaluation of nine different methods on HRSC2016 dataset. The highest value is indicated by bold numbers (%).
| Method | Data Aug | Backbone | FPN | AP(07) | AP(12) |
|---|
| Faster R-CNN OBB | √ | ResNet101 | √ | 80.90 | 82.91 |
| RetinaNet OBB | √ | ResNet101 | √ | 79.17 | 82.10 |
| R2CNN | - | ResNet101 | - | 72.36 | 74.35 |
| RRPN | √ | VGG16 | - | 79.60 | - |
| RoI transformer | √ | ResNet101 | √ | 86.22 | 87.18 |
| Gliding vertex | √ | ResNet101 | √ | 88.20 | 89.02 |
| CSL | √ | ResNet101 | √ | 89.62 | - |
| RITSD | √ | ResNet101 | √ | 89.70 | 92.98 |
| OSCD-Net (ours) | √ | ResNet101 | √ | 89.90 | 93.52 |
Table 4.
Performance evaluation with Precision(P), Recall(R) and F1 on the HRSC2016 dataset. The highest value is indicated by bold numbers (%).
Table 4.
Performance evaluation with Precision(P), Recall(R) and F1 on the HRSC2016 dataset. The highest value is indicated by bold numbers (%).
| Method | P | R | F1 |
|---|
| Faster R-CNN OBB | 86.24 | 87.17 | 86.70 |
| RetinaNet OBB | 87.12 | 85.21 | 86.15 |
| RoI transformer | 88.01 | 90.15 | 89.07 |
| Gliding vertex | 89.81 | 92.67 | 91.22 |
| OSCD-Net (ours) | 90.12 | 94.54 | 92.27 |
Table 5.
Performance evaluation of nine different methods on DOTA-Ship dataset. The highest value is indicated by bold numbers (%).
Table 5.
Performance evaluation of nine different methods on DOTA-Ship dataset. The highest value is indicated by bold numbers (%).
| Method | Data Aug | FPN | AP(07) |
|---|
| Faster R-CNN OBB | √ | √ | 58.49 |
| RetinaNet OBB | √ | √ | 56.21 |
| R2CNN | - | - | 52.12 |
| RoI transformer | √ | √ | 63.75 |
| Gliding vertex | √ | √ | 66.53 |
| OSCD-Net (ours) | √ | √ | 67.62 |
| OSCD-Net (ours) | √ | √ | 67.95 |
Table 6.
Performance evaluation with Precision(P), Recall(R) and F1 on the DOTA-Ship dataset. The highest value is indicated by bold numbers (%).
Table 6.
Performance evaluation with Precision(P), Recall(R) and F1 on the DOTA-Ship dataset. The highest value is indicated by bold numbers (%).
| Method | P | R | F1 |
|---|
| Faster R-CNN OBB | 62.92 | 70.19 | 66.36 |
| RetinaNet OBB | 62.81 | 68.25 | 65.42 |
| RoI transformer | 64.89 | 75.10 | 69.62 |
| Gliding vertex | 69.01 | 77.50 | 73.01 |
| OSCD-Net (ours) | 69.04 | 78.15 | 73.31 |
Table 7.
Performance evaluation of nine different methods on the SSDD+ dataset. The highest value is indicated by bold numbers (%).
Table 7.
Performance evaluation of nine different methods on the SSDD+ dataset. The highest value is indicated by bold numbers (%).
| Method | Data Aug | FPN | AP(07) | AP(12) |
|---|
| Faster R-CNN OBB | √ | √ | 75.95 | 77.45 |
| RetinaNet OBB | √ | √ | 69.17 | 72.18 |
| R2CNN | - | - | 67.78 | 68.95 |
| RoI transformer | √ | √ | 78.32 | 79.82 |
| Gliding vertex | √ | √ | 81.22 | 83.20 |
| OSCD-Net(ours) | √ | √ | 81.01 | 83.49 |
| OSCD-Net(ours) | √ | √ | 82.90 | 84.52 |
Table 8.
Performance evaluation with Precision(P), Recall(R) and F1 on the SSDD+ dataset. The highest value is indicated by bold numbers (%).
Table 8.
Performance evaluation with Precision(P), Recall(R) and F1 on the SSDD+ dataset. The highest value is indicated by bold numbers (%).
| Method | P | R | F1 |
|---|
| Faster R-CNN OBB | 85.24 | 83.42 | 84.32 |
| RetinaNet OBB | 84.10 | 81.93 | 83.00 |
| RoI transformer | 88.23 | 87.15 | 87.69 |
| Gliding vertex | 90.04 | 88.24 | 89.13 |
| OSCD-Net (ours) | 89.25 | 90.45 | 89.85 |























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}