1. Introduction
Buildings, as an integral part of human life, are among the most important elements on a map. Accordingly, building extraction is extremely important in urban planning, land use analysis, and map-making. With the rapid development of earth observation technology, the available spatial resolution of remote sensing imagery has increased year by year. By capturing rich and detailed information on ground objects, high-resolution remote sensing images enable fine extraction of ground objects (e.g., buildings and roads), providing important data support for the automatic extraction of large-scale buildings. However, because of the complexity of high-resolution remote sensing images and the lag in the development of extraction techniques [
1], the automatic and precise extraction of buildings in high-resolution remote sensing images has remained a central challenge in remote sensing applications and cartography.
Most early building extraction methods including the mathematical morphology-based methods [
2,
3,
4,
5] and methods based on shape, color, and texture features [
6,
7,
8,
9], relied on manually extracted features for judgment. However, due to their limited capabilities for image expression, manually designed features are usually applicable only to specific regions and provide minimal support for model generalization. In recent years, deep learning technology has been widely applied in various fields related to computer vision and image processing, such as image classification [
10], object detection [
11], and image segmentation [
12,
13]. Considering the similarity between building extraction from remote sensing images and computer vision tasks, some building extraction methods based on deep learning technology [
14,
15,
16] have been applied in remote sensing, enhancing the intelligence of building extraction methods to a new level. Compared with traditional building extraction methods that rely on manually designed features, deep learning methods have the advantage of powerful feature representation capabilities, enabling them to address more complex tasks.
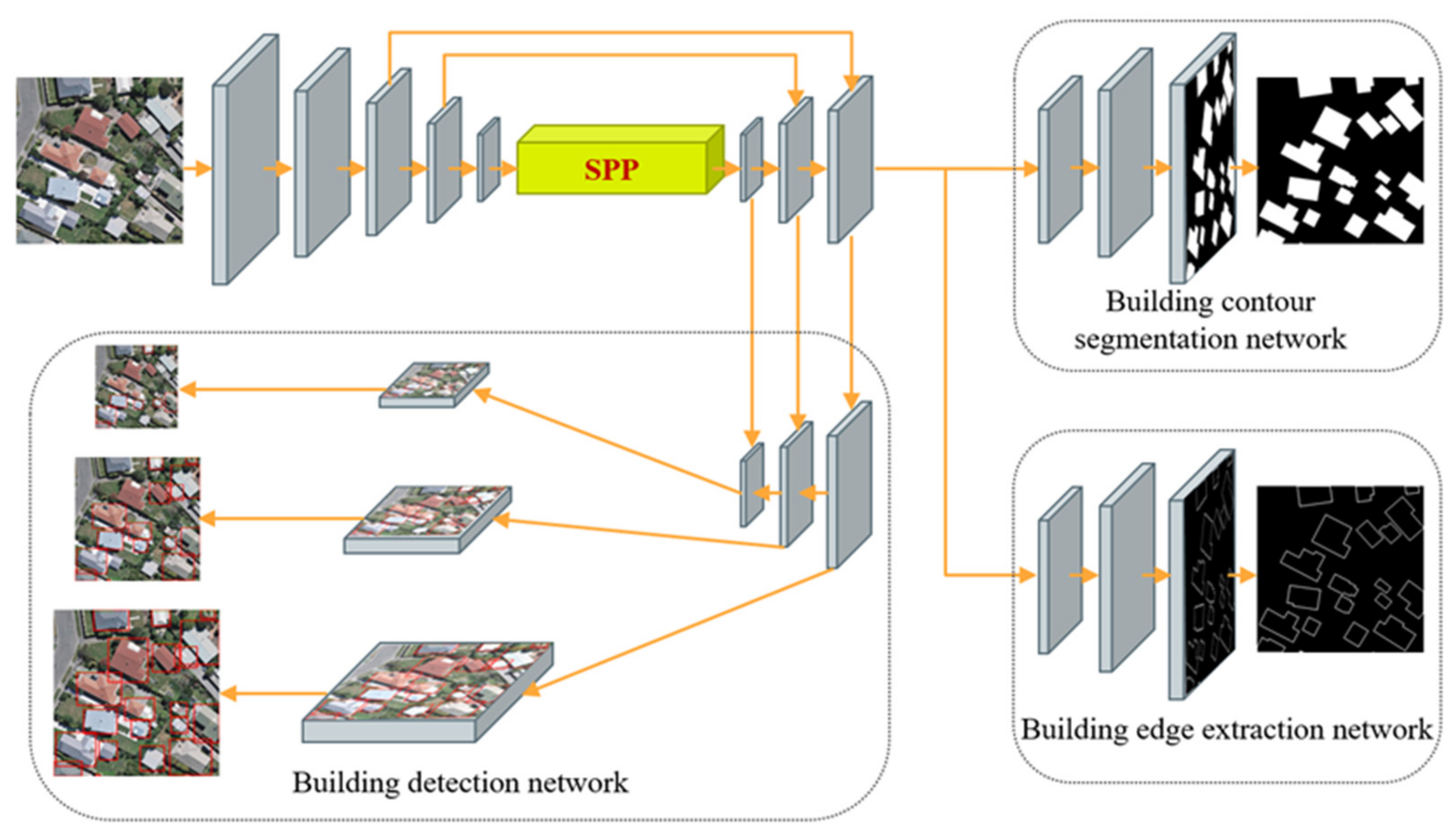
In the computer vision field, building extraction tasks are commonly divided into three categories: building detection tasks, building footprint segmentation tasks, and building edge extraction tasks.
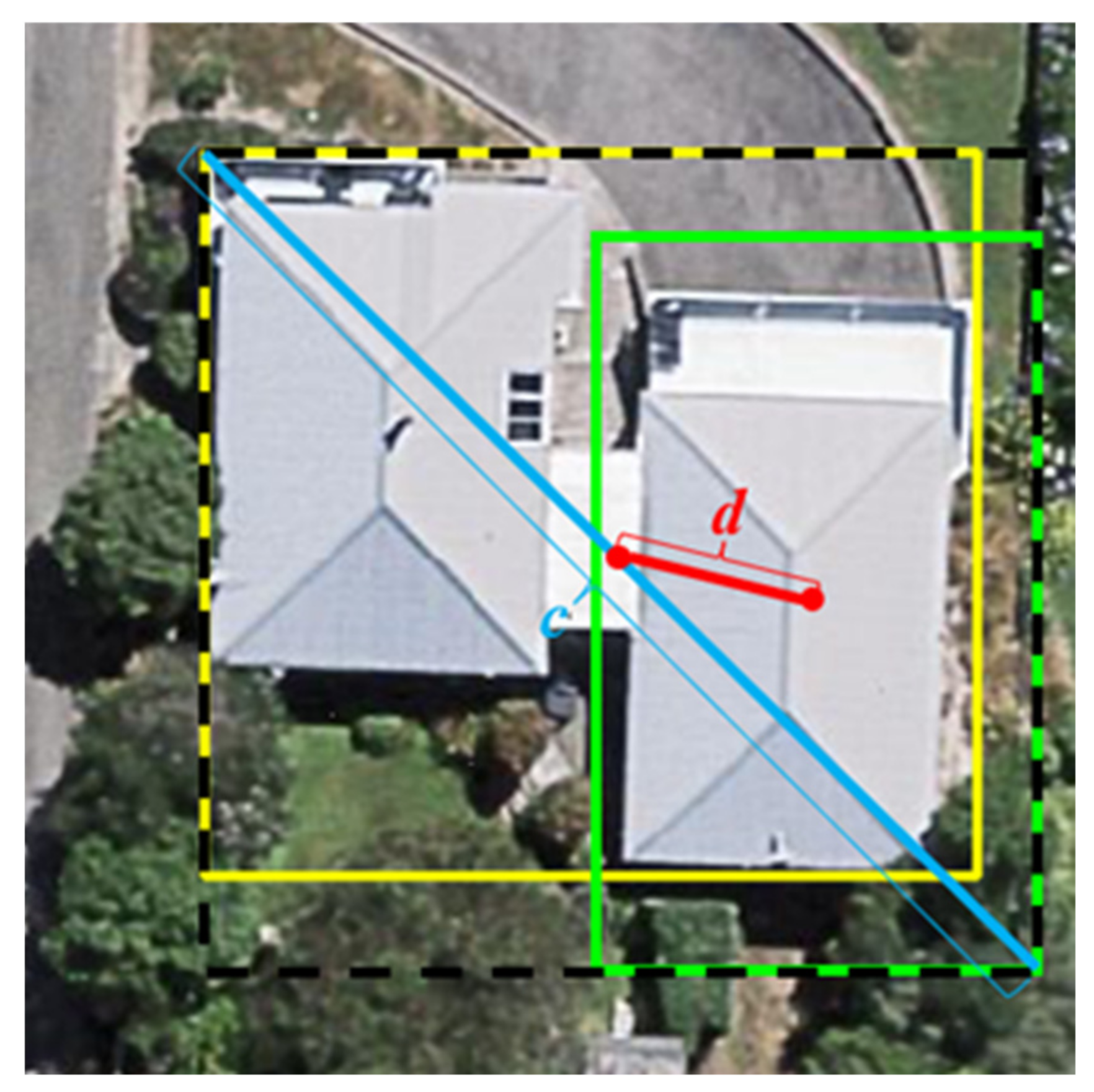
Building detection involves recognizing each building instance in a remote sensing image, applying object recognition techniques to obtain the location of each building instance as a rectangular bounding box, and determining the quantity of buildings. In recent years, as deep learning technology has rapidly advanced, a series of outstanding object detection algorithms have become available. These algorithms can be approximately divided into two categories. One category includes the two-stage object detection algorithms represented by the region-based convolutional neural network (RCNN) [
17], Fast R-CNN [
18] and Faster R-CNN [
19] methods, whose main concept is to generate regional proposal boxes first and then input them into a convolutional neural network (CNN) for further classification. The other category includes single-stage object detection algorithms represented by the single-shot multibox detector (SSD) [
20] and You Only Look Once (YOLO) [
21] series of models, which constitute an end-to-end object detection framework that can directly output the category of each detected object. The aforementioned object detection methods have been applied for building detection in remote sensing images. Based on Faster R-CNN, Ding et al. [
22] used deformable convolution to improve the adaptability to arbitrarily shaped collapsed buildings and proposed a new method of estimating the intersected proportion of objects (IPO) to describe the degrees to which bounding boxes intersect, thus offering better detection precision and recall. Bai et al. [
23] proposed a Faster R-CNN method based on DRNet and ROI Align and utilized texture information to solve region mismatch problems. Building detection method can approximately recognize building locations but cannot achieve pixel-level segmentation, which is more accurate.
Building footprint segmentation refers to the pixel-level segmentation of remote sensing images, in which each pixel in an image is assigned either a building or nonbuilding label. In most building footprint segmentation methods, the fully convolutional network (FCN) architecture [
12] or one of its variants is used as the basic architecture, and various measures are implemented to improve the multiscale learning capability of the model. Xie et al. [
24] proposed MFCNN, a symmetric CNN with ResNet [
25] as the feature extractor, which contains many complex designs, such as dilated convolution units and pyramid feature fusion. MAP-Net, proposed by Zhu et al. [
26], has an HRNet-like [
27] architecture with multiple feature encoding branches and a channel attention mechanism. Ma et al. [
28] proposed the global and multiscale encoder–decoder network (GMEDN), which consists of a U-Net-like [
29] network and a nonlocal modeling unit. These methods have greatly enhanced the accuracy of footprint segmentation for differently sized buildings in remote sensing images. However, the aforementioned methods focus only on distinguishing between building and nonbuilding pixel values and rarely closely observe building edge information, often resulting in blurred contours and failure to obtain regular boundaries in the segmentation results.
Building edge extraction refers to marking and extracting the outer boundaries of building instances in remote sensing images. Building edge extraction methods prioritize building boundary information and attempt to reach beyond pixel-level footprint segmentation to directly obtain regular and accurate building contour lines. Recently, some researchers have introduced building boundary information into deep learning networks to improve their building extraction accuracy. Lu et al. [
30] adopted a deep learning network to extract building edge probability maps from remote sensing images and applied postprocessing to the edge probability maps based on geometrical morphological analysis to achieve refined building edge extraction. Wu et al. [
31] proposed a novel deep FCN architecture, named the boundary regulated network (BRNet) architecture, which utilizes local and global information to simultaneously predict segments and contours to achieve better building segmentation and more accurate contour extraction. Jiwani et al. [
32] improved the DeepLabV3+ [
33] model by introducing a feature pyramid network (FPN) [
34] module to achieve cross-scale feature extraction and designing a special weighted boundary diagram to penalize incorrect predictions of building boundaries. Li et al. [
35] combined a graph-based conditional random field model with a segmentation network to preserve clear boundaries and fine-grained segmentation. However, due to the structural diversity of buildings and their complex environments, accurately locating and recognizing building edges remain significant challenges.
As a basis for interpreting remote sensing images, building detection provides a foundation for coping with higher-level interpretation tasks, such as building footprint segmentation and building edge extraction. Building detection determines the general locations for building footprint segmentation and edge extraction, while building footprint segmentation and edge extraction allow building shape features to be enhanced for building detection. Simultaneously, building footprint segmentation provides closed shape information for edge extraction, while building edge extraction yields exact boundary information for footprint segmentation. To an extent, building detection, building footprint segmentation, and building edge extraction have a symbiotic relationship of mutual dependence and information complementarity. Nevertheless, although many deep learning- based methods have been used to extract buildings and achieved good performance, the existing methods have been developed for certain tasks, e.g., footprint segmentation of buildings. Hence multitask learning frameworks are required to simultaneously perform multiple tasks, e.g., the detection, footprint segmentation, and edge extraction of the buildings.
Multitask learning can improve the performance on each task by learning better feature representations from the shared information for multiple related tasks. The classic instance segmentation framework Mask R-CNN [
13] is based on the object detection framework Faster R-CNN with the addition of a branch for object mask prediction. It first locates the objects in an image and then segments the target objects in the positioning boxes, effectively combining the semantic segmentation and object detection tasks to facilitate their mutual performance enhancement. Considering the symbiotic relationship between road detection and centerline extraction, Lu et al. [
36] proposed the MSMT-RE framework for performing these two tasks simultaneously, and this framework has delivered excellent road detection results. MultiNet [
37] consists of a shared encoder and three independent decoders for simultaneously completing the three scene perception tasks: scene classification, object detection, and drivable area segmentation. Wu et al. [
38] proposed the panoptic driving perception network YOLOP to simultaneously perform the tasks of traffic object detection, drivable area segmentation, and lane detection, significantly improving performance on each single task. Bischke et al. [
39] adopted a multitask learning framework to combine the learning of boundaries and semantic information to improve the semantic segmentation of building boundaries. As seen above, multitask learning methods have been widely applied in segmentation tasks, but there is a lack of multitask learning frameworks that can solve the tasks of building detection, footprint segmentation and edge extraction simultaneously.
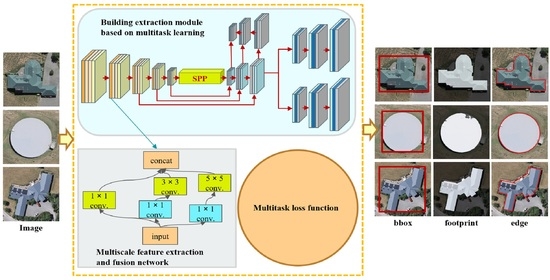
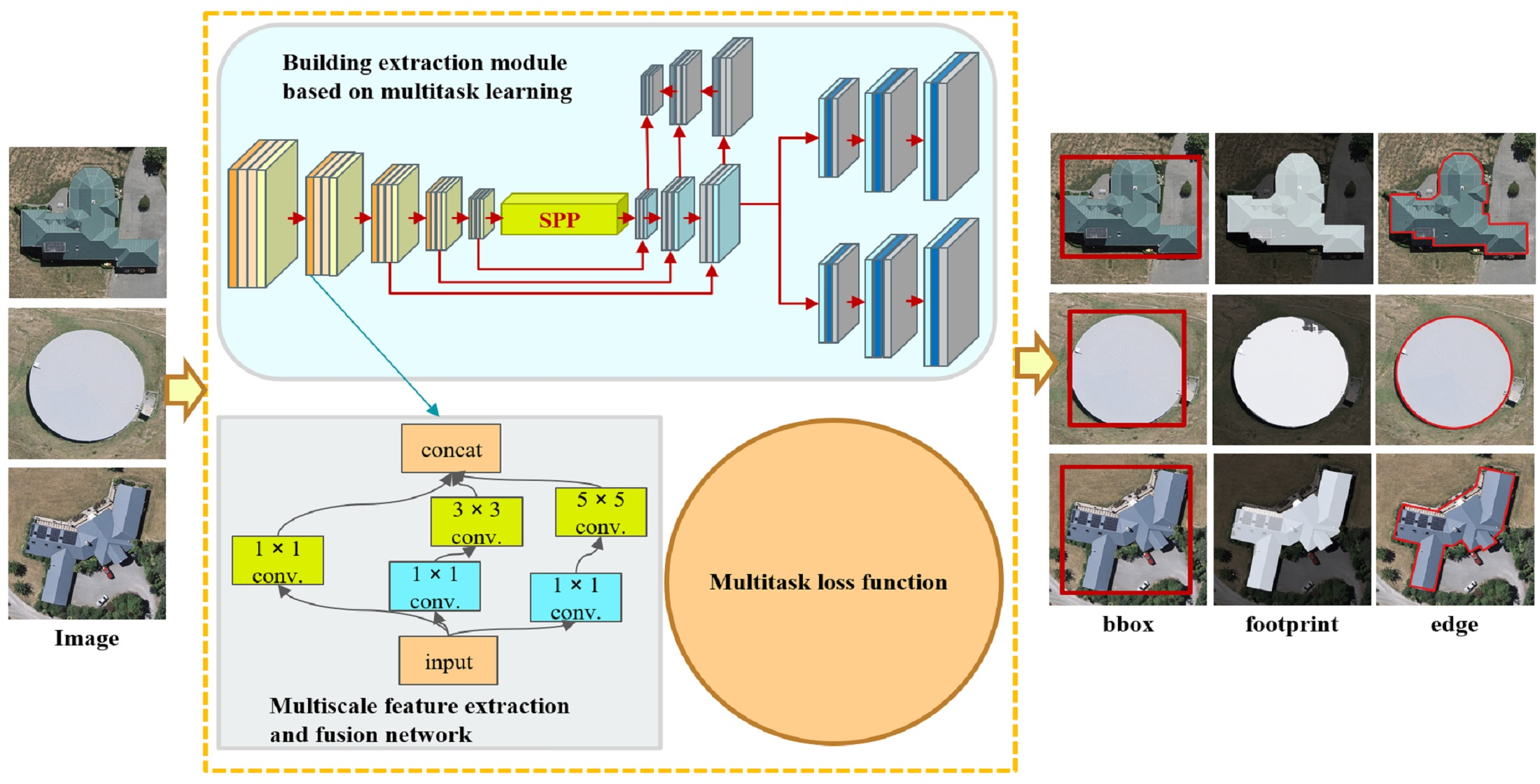
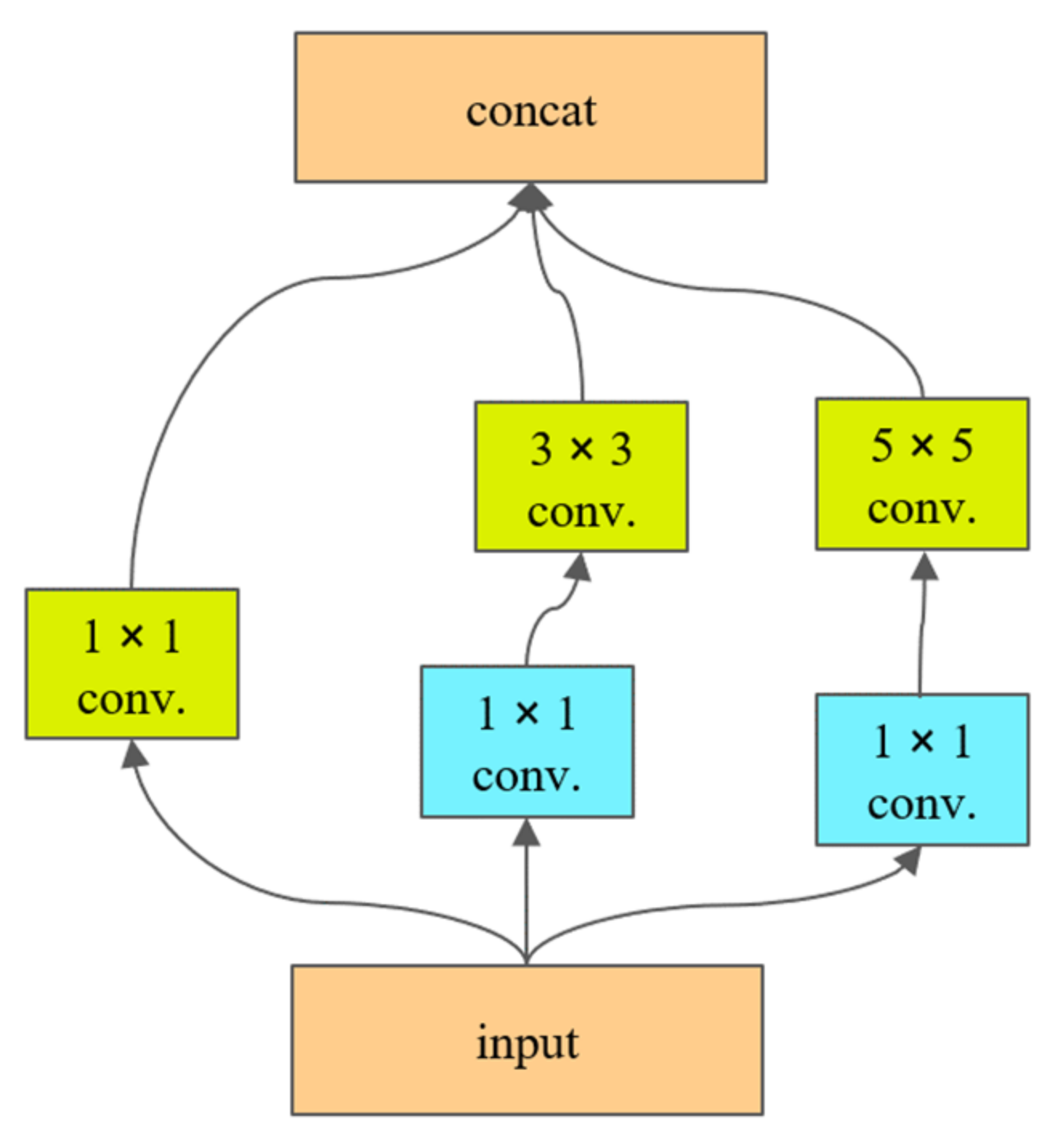
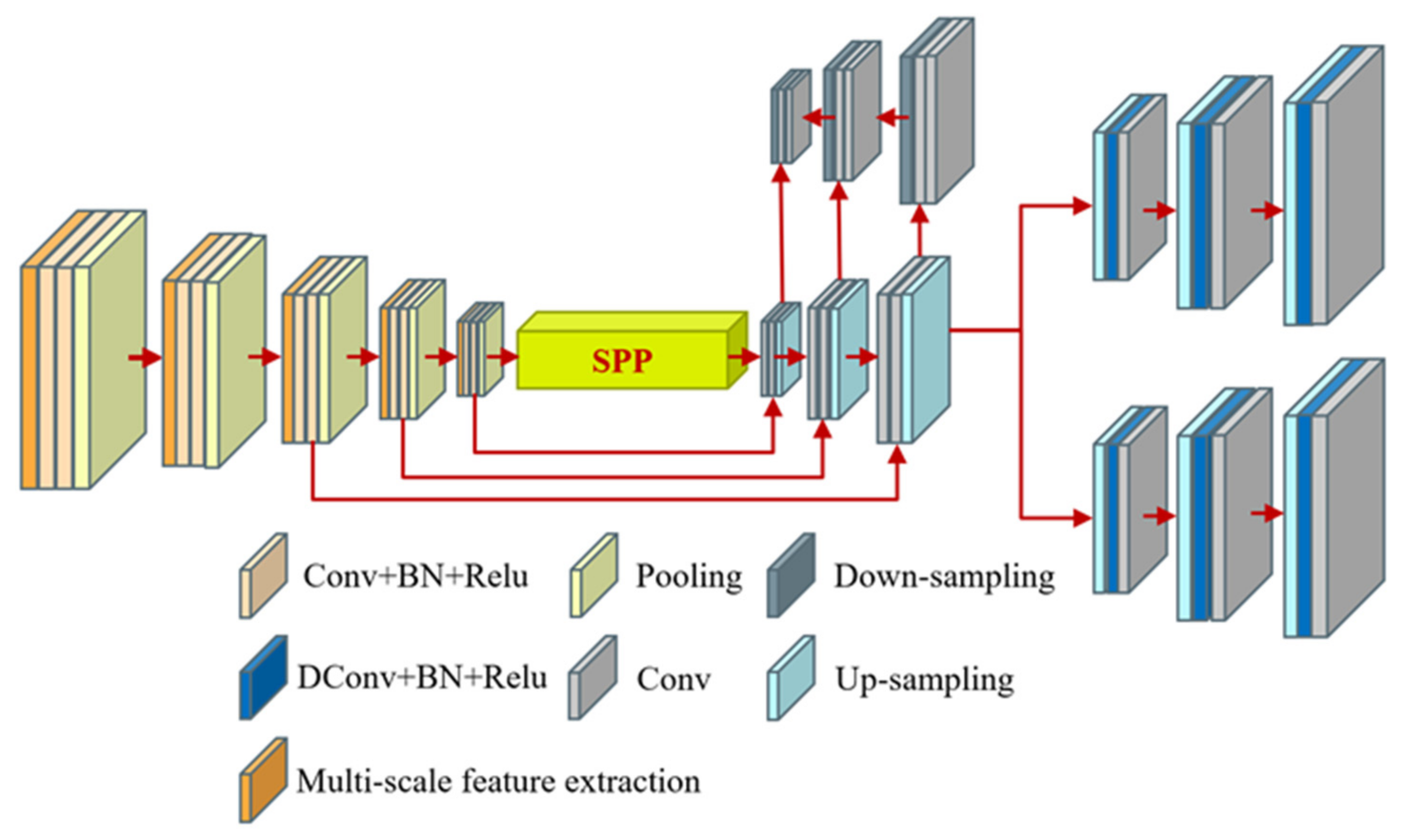
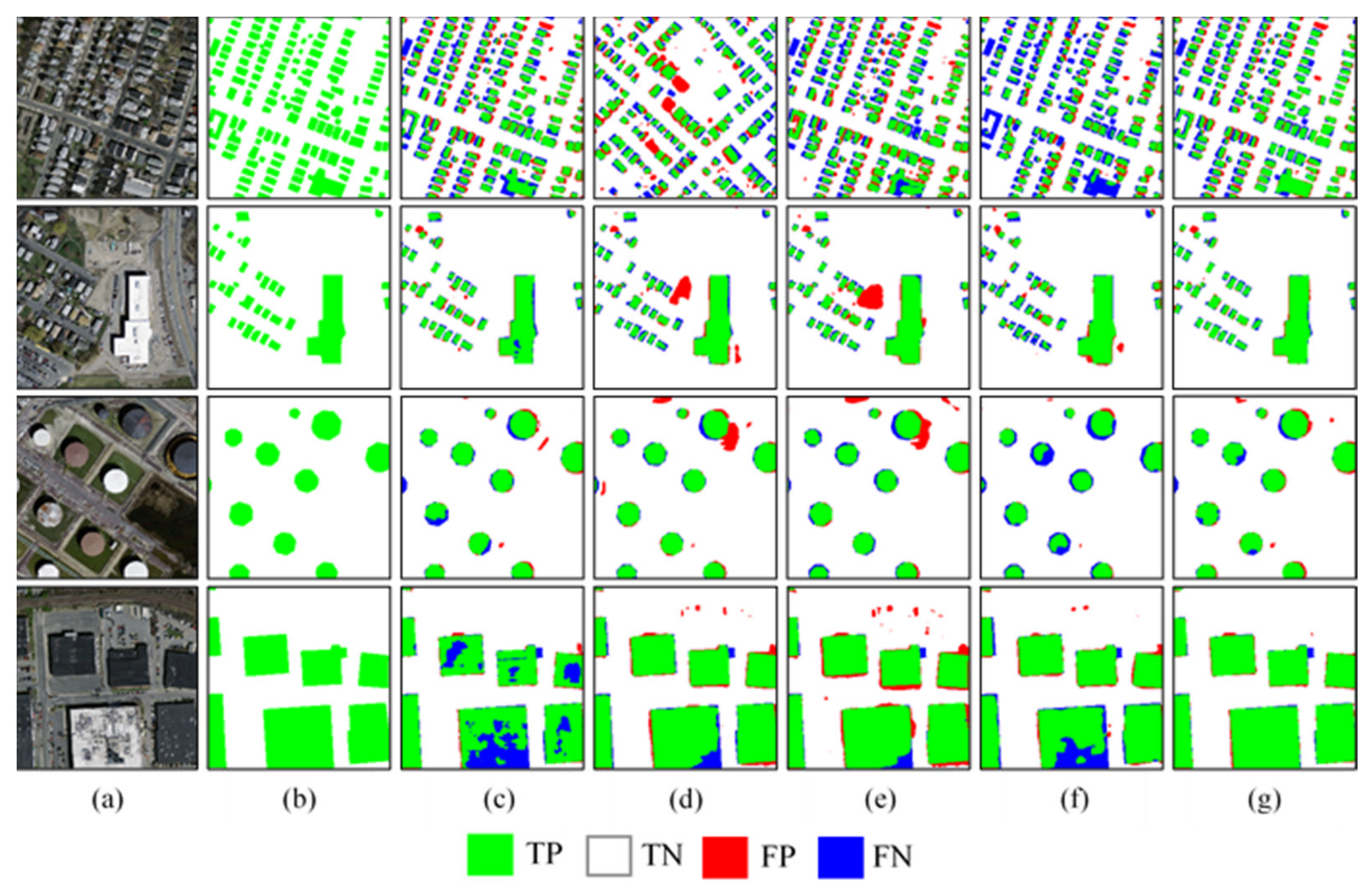
To address the abovementioned problems, this study proposes a multiscale and multitask deep learning framework called MultiBuildNet for simultaneously performing the building detection, footprint segmentation, and edge extraction tasks. This framework is also integrated with a multiscale feature fusion network to combine features from different scales, aiming to improve the robustness of feature extraction against complex backgrounds. In addition, to minimize the loss function across the three tasks, this study introduces a multitask loss function that fully considers any deviations between the predicted values and true values in all three tasks to obtain the best training effect.
The main contributions of this study are as follows:
(1) An effective multiscale and multitask deep learning framework is designed that can simultaneously handle the three key tasks in building extraction: building detection, footprint segmentation, and edge extraction.
(2) A multitask loss function is introduced that can address the imbalances between positive and negative samples and among sample categories in the three tasks.
The remainder of this study is organized as follows. The proposed MultiBuildNet framework is introduced in detail in
Section 2. Then,
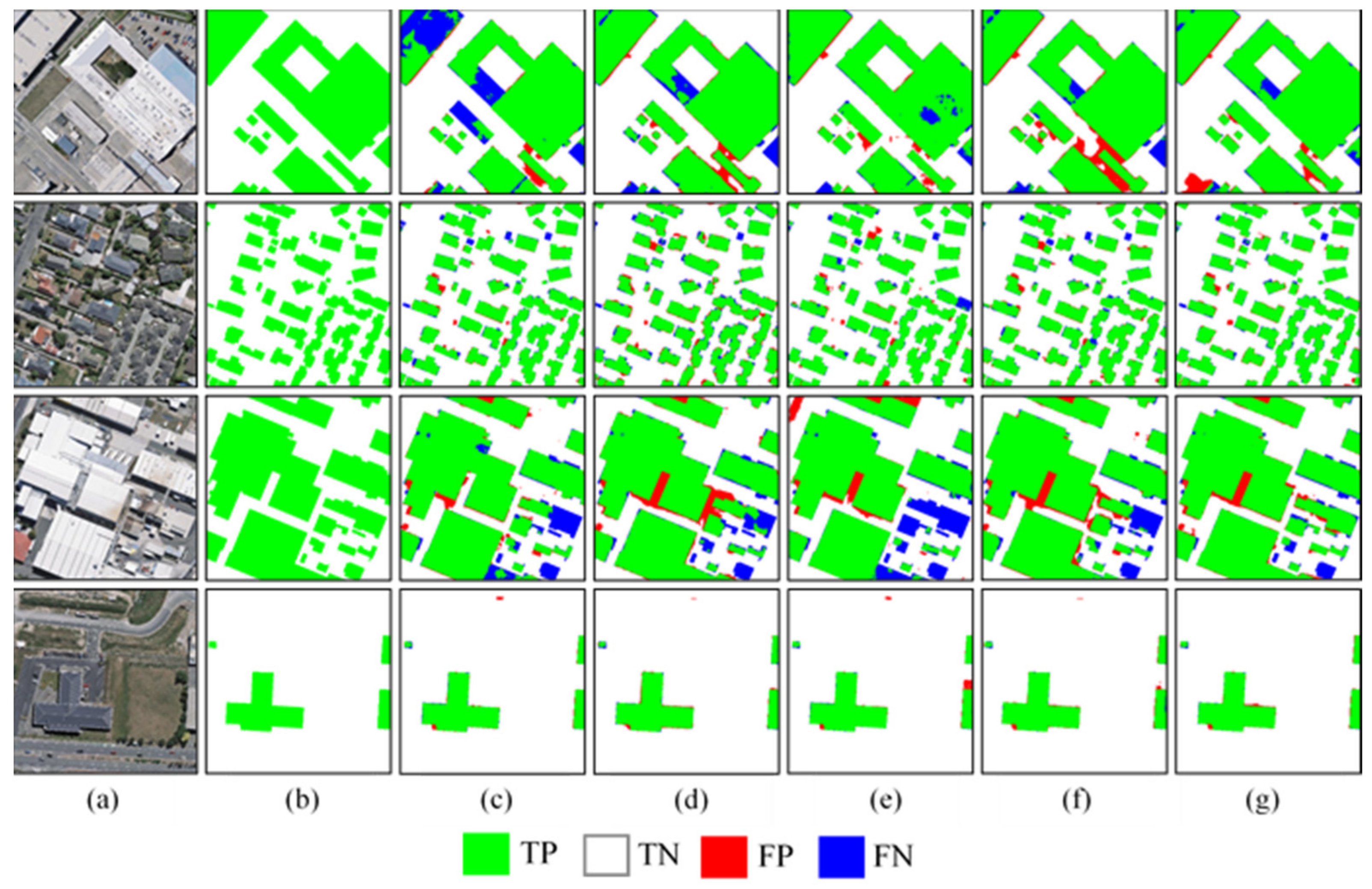
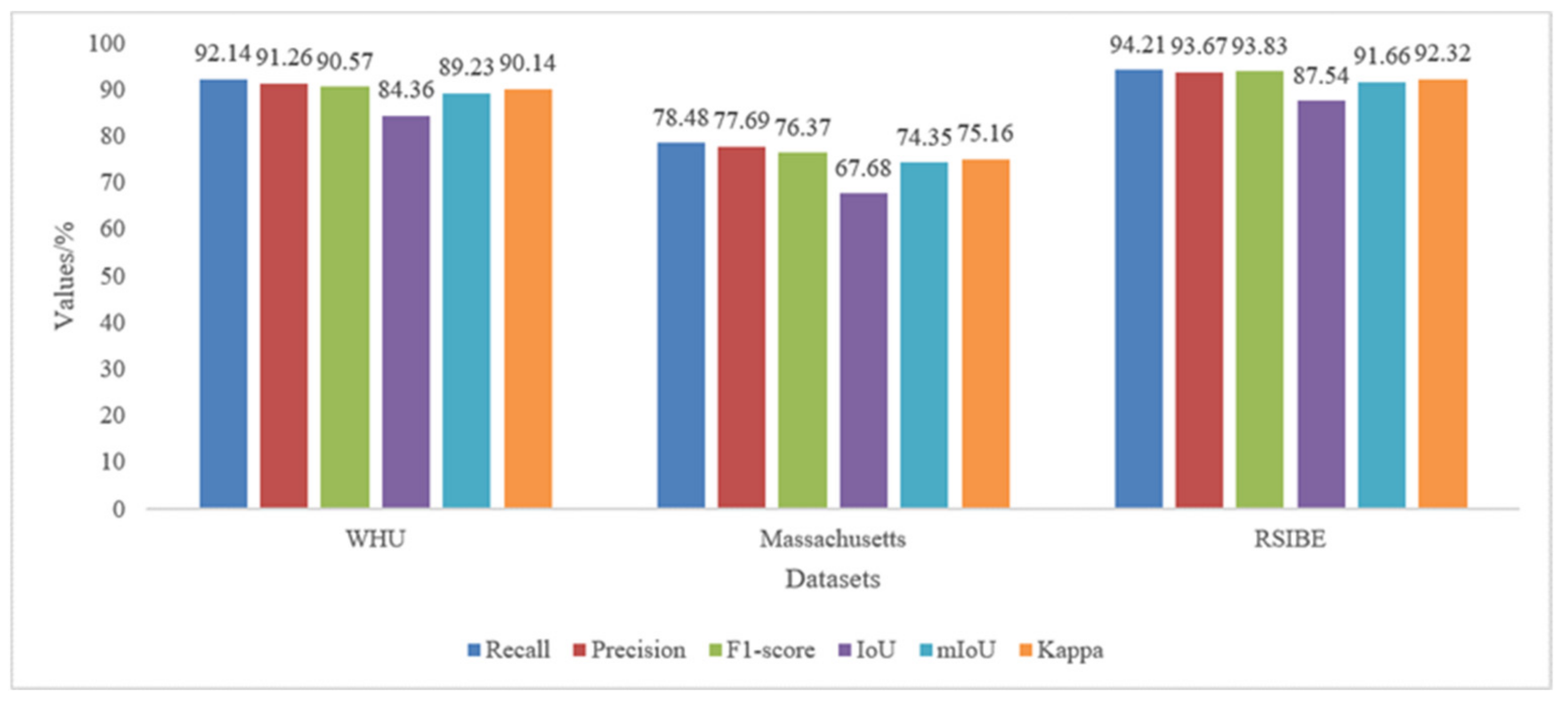
Section 3 describes experiments conducted with the proposed method on open-source building datasets and large-scale high-resolution remote sensing images and presents comparisons with other advanced building extraction methods. Ablation experiments conducted to compare the performances of multitask learning and single-task training in order to verify the effectiveness of multitask learning are also reported.
Section 4 discusses the performance improvements achieved by the MultiBuildNet framework compared with other deep learning methods as well as its limitations and prospects for future work. Finally, conclusions are presented in
Section 5.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}