1. Introduction
The Andes in Patagonia has a relief in constant evolution susceptible to environmental disturbances such as earthquakes, volcanic eruptions, and climatic events [
1,
2,
3]. The interaction of these processes at different levels of intensity has generated a response from the landscape, increasing landslide activity and, as a consequence, in danger for the communities that inhabit these mountainous localities [
1,
2,
3,
4]. In order to study the susceptibility to landslides and the evolution of landscapes through model adjustment, it is necessary to have landslide inventories that allow the relationship between climate and local geomorphological conditions [
5]. However, due to the difficulty of access, these inventories are scarce in mountainous areas, particularly with low population density.
Traditionally, the production of landslide maps was based on the visual interpretation of stereoscopic aerial photographs combined with field surveys. These production methods are limited by the high consumption of both human and technical resources, making it challenging to massify them [
5]. On the other hand, the access to remote sensing data from satellite platforms has allowed the development of semi-automatic analysis strategies for different satellite images, optical (panchromatic and multispectral), and synthetic aperture radar (SAR), thus reducing the high consumption of human resources.
The massification and free access of remotely detected data, together with the strong development of artificial intelligence techniques, particularly machine learning, have allowed the exploration of different methods for the classification or zoning of landslides. Among the methods, the most common are logistic regression algorithms, support vector machines, decision trees, random trees, among others [
6,
7]. However, environmental changes limit the transferability of these models to other areas of study post-training [
8].
Recently, a handful of investigations have used deep learning (DL) models based on convolutional neural networks (CNN) to develop landslide inventories with promising results. Compared to machine learning methods, CNNs have been a breakthrough for remote sensing data analysis. Unlike conventional classification techniques, CNNs are capable of autonomously recognizing the most noticeable features that it uses for the classification process [
9]. For example, [
7] used high-resolution images from the RapidEye satellite combined with topographic information to train a DL model for landslide detection. Network models with residual connections (ResNet) have also been implemented to map landslides using aerial images with topographic information from LIDAR data [
10]. Other efforts have been focused on introducing networks of the U-Net type combined with ResNet to perform semantic segmentation of landslides from topographic features derived from LIDAR data [
11].
Additionally, different variants of U-Net have been used in multiple studies to map landslides from optical images. These studies adopt a conventional supervised learning workflow in which a model is trained first on a region and then reused to generate a landslide map of its surroundings with comparable geoenvironmental characteristics [
12,
13]. Recently, a new landslide detection approach immediately after an extreme event has been proposed. In this approach, the authors propose a combined training strategy to build a generalized CNN-based semantic segmentation model to identify changes associated with landslide activity using a set of pre and post-slide satellite images [
14].
From the analyzed literature, it can be established that one of the main limitations detected in the current investigations is that they focus exclusively on mountain ranges in Europe and Asia, leaving aside the Andes mountain systems. This is probably because the Andes have a low density of landslide data set available, which makes it challenging to generate models based on artificial intelligence (e.g., machine learning and DL) that require large data sets for their training. This lack of information is even more critical in the Patagonian Andes [
2], where the potential of freely accessible satellite data such as that provided by the Sentinel-2 constellation has not been fully exploited.
Therefore, the objective of this work is to develop an automatic landslides detection model for the Patagonian Andes. The model is conveyed through a DL strategy trained with a datasets of 10,000 manually labeled landslides. As an operational results of this work, the Patagonian Andes landslides datasets is available trough the link
https://doi.org/10.5281/zenodo.7057656 (accessed on 8 September 2022) to train new models that allows to improve and advance the state of the art in landslide detection and prediction.
This work aims to close the existing gap in the availability of landslide inventories in the Patagonian Andes and to study the feasibility and efficiency of DL techniques to develop landslide detection models in the Andes from the Andes datasets generated. Furthermore, we seek to provide a methodology that allows to automatically create landslide datasets using freely available images and a deep-learning network for semantic segmentation algorithm. These datasets, which are not available everywhere, are crucial to recognizing what triggers or enables landslides and to moving forward in landslides’ early detection systems.
2. Materials and Methods
2.1. Datasets Generation
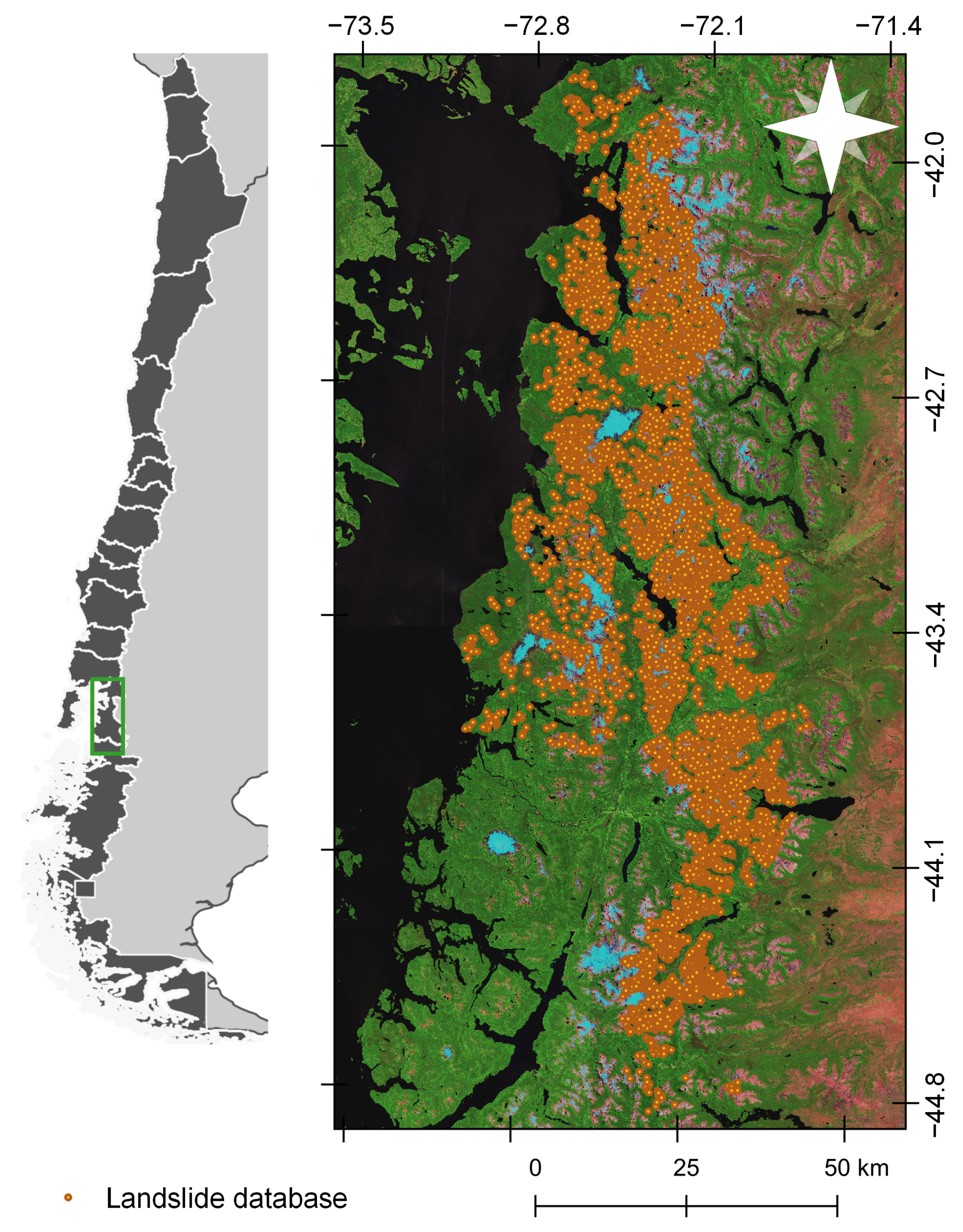
In order to have enough information for training a CNN model, we manually generated a landslide datasets for the Patagonian Andes (42–45°S) (
Figure 1). We included all the landslide types (rockfall, slides, debris flow) as landslides since we did not seek at this stage to differentiate them, which would have needed more extensive fieldwork for validation. In the first stage, we compiled 722 landslides in point-type vectorial format, inventoried by [
2] through temporary changes of Normalized Difference Vegetation Index from Landsat images and terrain campaigns. We delineated these landslides and systematically filled in the missing removals in the study area. The delineation of the removals extends from the escarpment to the deposit area; we used the open-source software QGIS 3.10. We performed this procedure on six Sentinel-2 image tiles (
Table 1) from the 2020–2021 summer season, and additionally, on high-resolution images provided by the Google Earth and Bing Maps mapping services. The morphological characteristics considered for identifying the landslides were: patches of no forest in forested areas with bare escarpments that show lobe-shaped displaced soil and/or rock. The datasets created includes the geometry, position, and area of landslides.
The primary information used for the generation of the training datasets comes from the image bands of the Sentinel-2 constellation. The images were downloaded from the Copernicus Open Access Hub (
https://scihub.copernicus.eu/) (accessed on 20 March 2021). Images with cloudiness less than 5% acquired during the summer of the years 2020–2021 were filtered. Sentinel-2 images correspond to level-2A atmospherically corrected. Their tile number and dates details are shown in
Table 1.
We excluded bands 1, 9, and 10, which provide atmospherics information (aerosol, water vapor, and cirrus, respectively), from the selected tiles; the remaining bands were resampled to 10 m resolution using the bilinear interpolation technique in QGIS 3.10. To speed up the subsequent execution of the DL algorithm, we converted the spectral information of the bands to 16-bit integer data. We then indexed all bands to a range of .
2.2. Pre-Processing Datasets for DL Training
In order to feed the CNN model, each Sentinel-2 image was cropped into patches of
pixels. In addition, data augmentation techniques [
15] were performed during training. In particular, vertical and horizontal flipping operations, and rotation with
and
angles were used. Finally, each data patch was indexed in a range
. Shapefiles with manually delineated landslides were rasterized obtaining binary masks (with the same resolution as Sentinel-2 images) where the 1s represent the landslides and the zeros represent the background. These masks underwent the same processes as the data patches, except for indexation; therefore, the data patches and masks match.
2.3. Convolutional Neural Network (CNN)
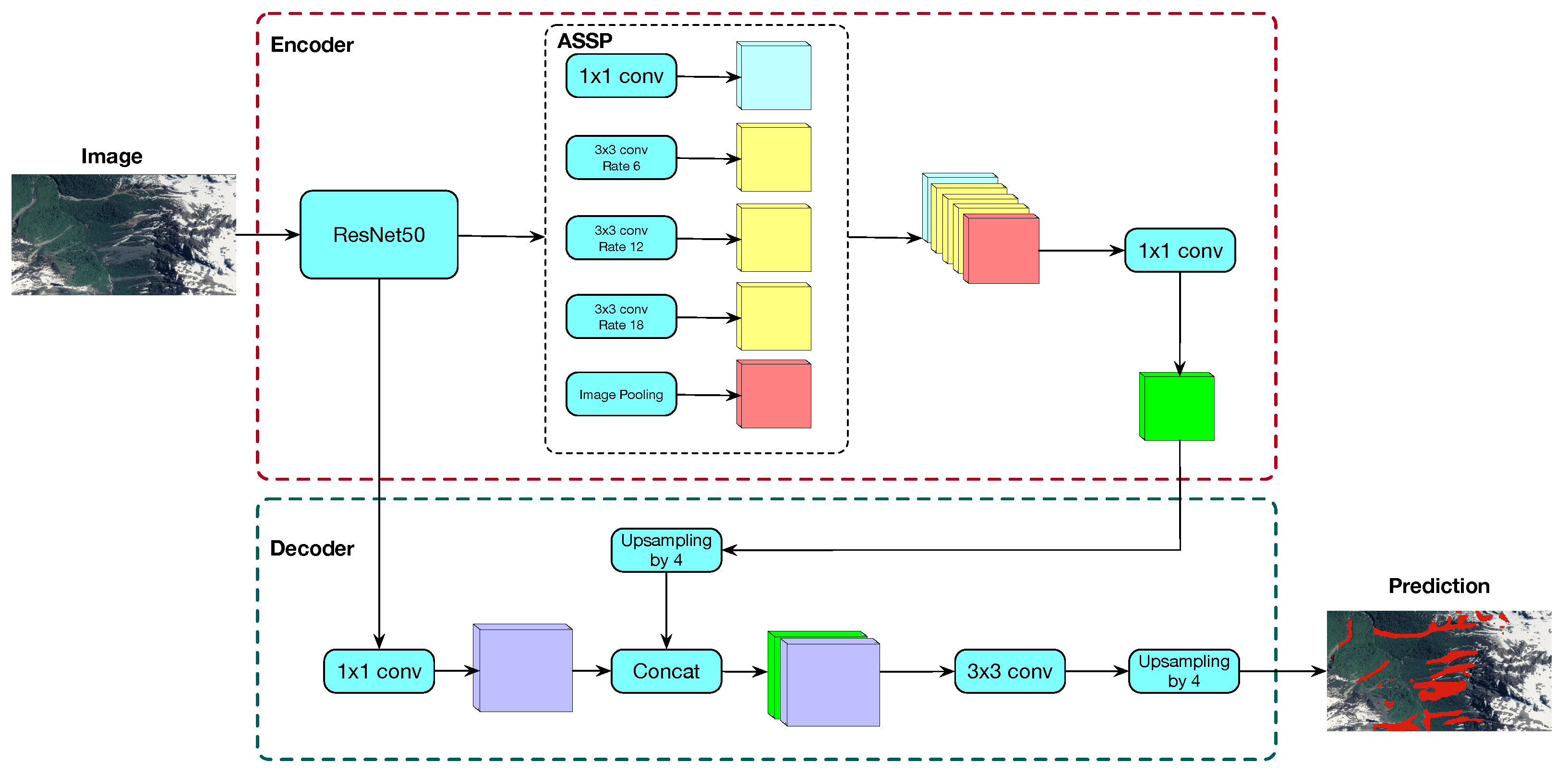
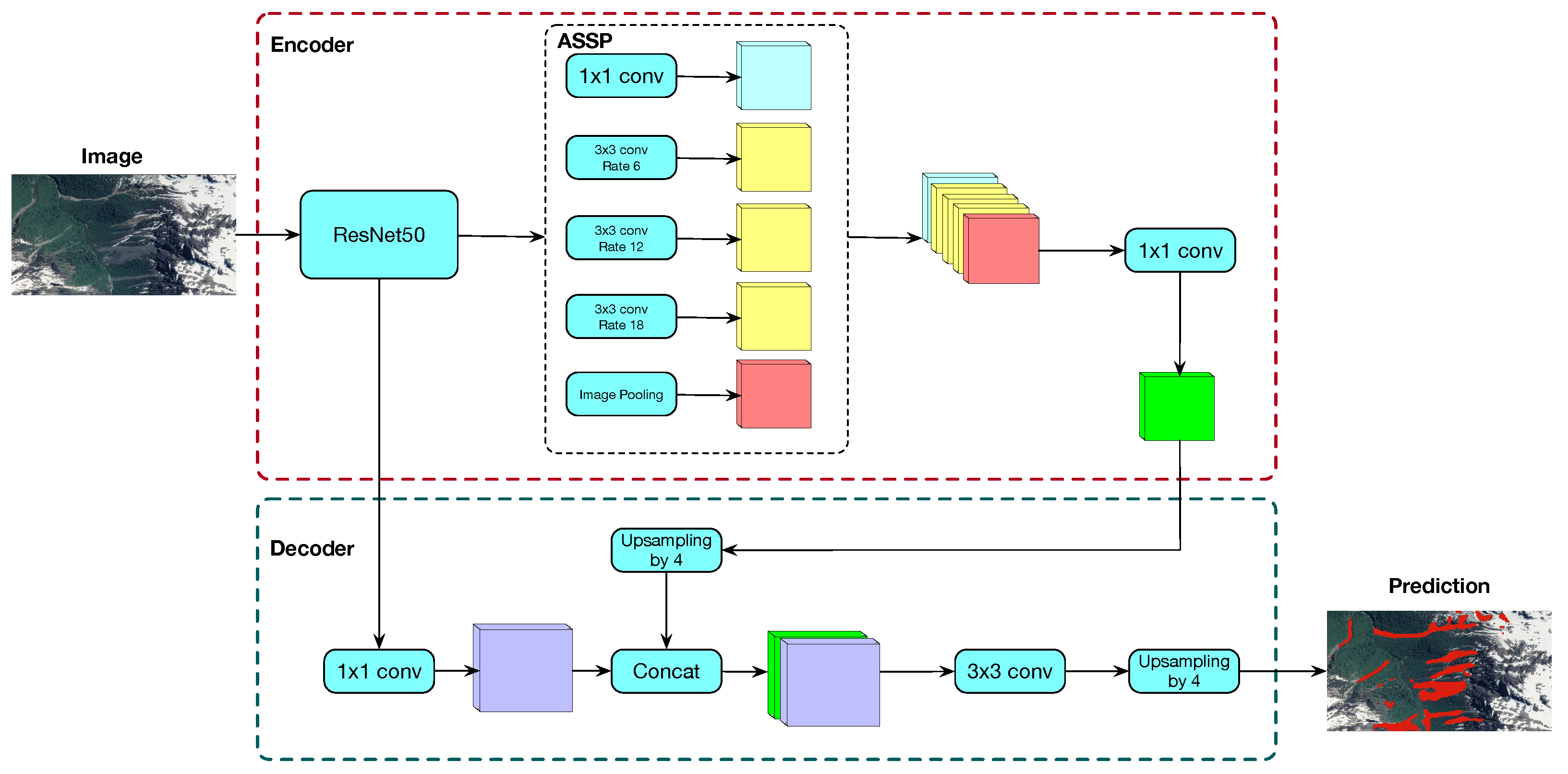
DeepLabv3+, introduced by [
16], is a state-of-the-art deep learning network for semantic segmentation, i.e., to assign semantic labels to every pixel in an image. DeepLabv3+ consists of an encoder-decoder architecture with an
à trous spatial pyramid pooling (ASPP) structure and bilinear upsampling (
Figure 2). The encoder part consists of a pre-trained ResNet50 [
17] followed by the ASpp. The ASPP consists of four parallel
à trous convolutions with different
à trous rates generating feature maps that capture high multiscale information accurately and efficiently. These feature maps are concatenated and then converted to a channel number by means
convolution layer. At the decoder part, encoder’s feature map is upsampled it by a factor of 4 and concatenated with the output of the ResNet50 followed by an
convolution. Concatenated feature maps are then processed by means of a
convolution layer and finally upsampled by a factor of 4. This final output agrees in shape with the mask. In this work, an sigmoid was used as the output activation function.
2.4. Loss Function
To train the CNNs, we used Focal Tversky Loss [
18] as the loss function, which is given as:
where
and
denote the ground-truths and the predicted probabilities of
pixel image for the class
c respectively, and
is a smoothing factor used to avoid zero division error. In this work, the following values were used:
,
,
, and
. This configuration has been used with success when dealing with unbalanced datasets, as is the case of the landslides. Training was performed using the Adam optimizer [
19] during 100 epochs using a batch size of 32.
In order to handle input images with multiple channels (more than 3 corresponding to RGB images), we modified the size of the input layer filter. In this case, instead of having an input of [B, 3, 224, 224] (for RGB images, 3 channels) in the input layer, it has a size of [B, 10, 224, 224], where 10 is the number of channels of Sentinel-2 used and B represents the number of images in the batch. In the case of the output layer, the size is [B, 1, 224, 224], corresponding to a single class (landslides). The rest of the network remains the same as the original. The changes in the filter of the input layer are needed, as we said to deal with images of more than 3 channels, as provided by Sentinel-2.
2.5. Post-Processing
During prediction stage, an overlap-tile strategy was applied in order to obtain a prediction for an entire Sentinel-2 tile. This means that the sub-images overlap to some extent, in our case, 90%. The output’s network are averaging over the overlapping pixels. Similar to [
20], a test-time-augmentation (TTA) strategy was applied to improve the changes of detecting the landslides. In particular, geometric transformations beloging to dihedral group of order 4 were used as TTA augmentations obtaining 8 different versions of a same sub-image. The final segmentation is obtained by calculating the maximum response of the 8 values corresponding to the same pixel’s location. A pixel is considered to belong to belong to a landslide if it exceeds a threshold of 0.5.
2.6. Model Evaluation
We used six tiles (
Table 1) to train the model and one tile to test the output (T18GYS). Before evaluating the model, we manually filtered the elements associated with roads and populated areas in the tile selected for validation. Then, we randomly select 10% of the landslides predicted by the algorithm in the test tile. We evaluated the predicted datasets by identifying true positives (TP) and false positives (FP) at the object level. TPs that had not been previously considered in the training datasets was incorporated as ground truth. Subsequently, using QGIS 3.10, a binary map (0-1) of the predicted landslides and the ground truth was generated to evaluate the semantic segmentation.
The model was evaluated with different performance metrics using the following approach: (1) evaluation of object-level detection by calculating accuracy. (2) evaluation of the semantic segmentation between the binary map of the predicted landslides and the ground truth using the metrics precision, recall, and F1-score. (3) evaluation of the semantic segmentation correlation using the Matthews correlation coefficient and similarity by the Jaccard score, the latter applied exclusively to TP detected landslides. Metrics were calculated based on TP, FP, false negative (FN) that are landslides that were not detected by the algorithm, and true negative (TN), corresponding to the areas without landslides correctly detected.
We also performed an exploratory analysis of the geometric characteristics of landslides correctly and incorrectly detected by the model. We considered the area–perimeter ratio and length–width ratio since they provide essential information on the geometry and complexity of the landslide shape. These four geometry descriptive elements (area, perimeter, width, length) were calculated in QGIS 3.10. To estimate length–width, we use the tool provided by QGIS called oriented minimum bounding box.
3. Results
We generated the first large-scale landslide datasets between 42–45°S spanning approximately 20,000 km
2. Ten thousand landslides were delimited and used to train and evaluate the CNN model. Our results are summarized in the
Table 2. The algorithm reaches a 0.75 accuracy to detect landslides at the object level. When we evaluated the segmentation of the predicted landslides, we obtained an accuracy of 0.86, a recall of 0.74, and an F1-score of 0.79 between the binary map of predicted landslides and the ground truth. When we evaluated the correlation of the segmentation using the Matthews correlation coefficient, the model reached a value of 0.59 and a Jaccard score of 0.70, which in this case represents the similarity of the segmentation between the TPs.
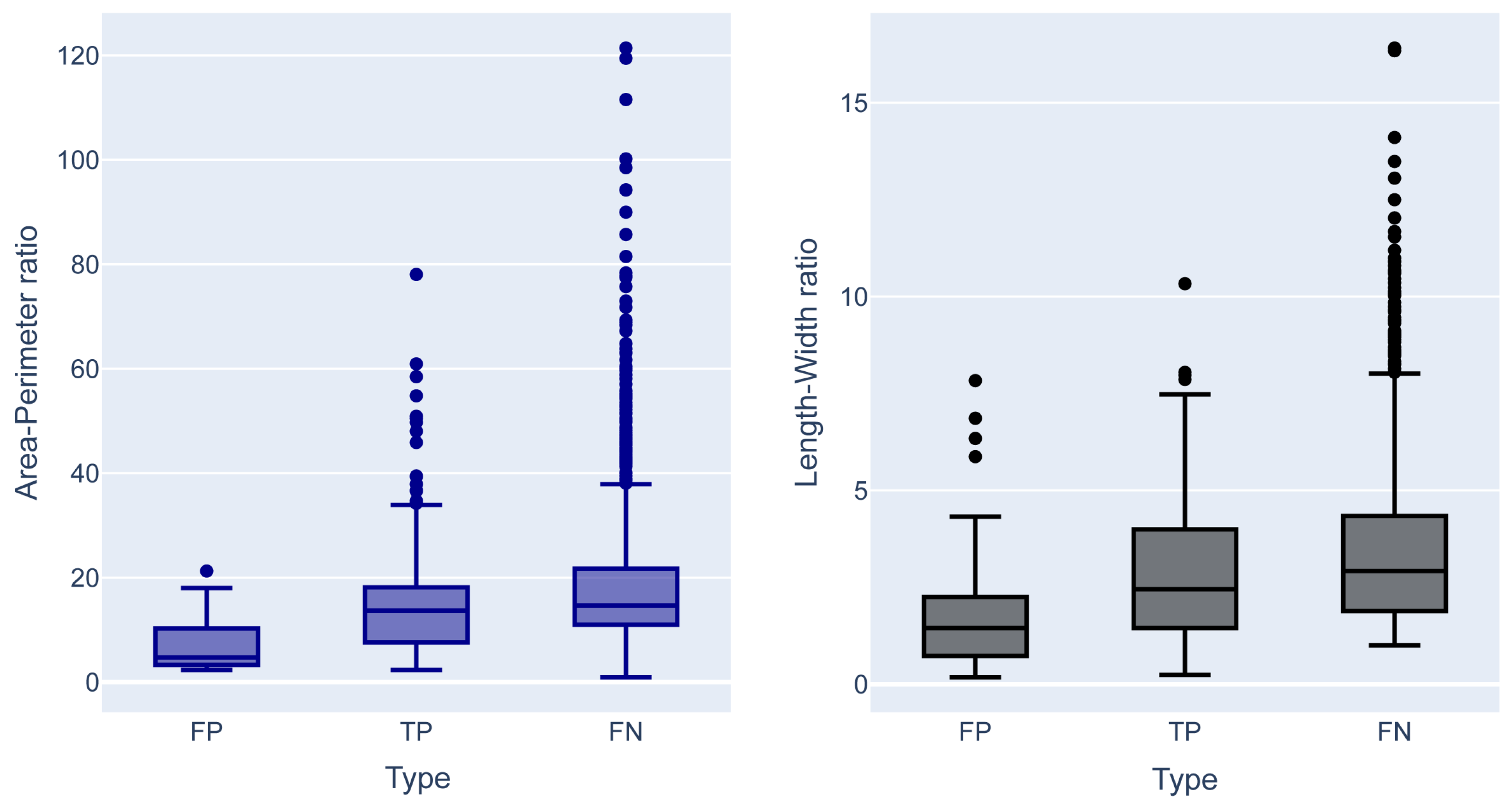
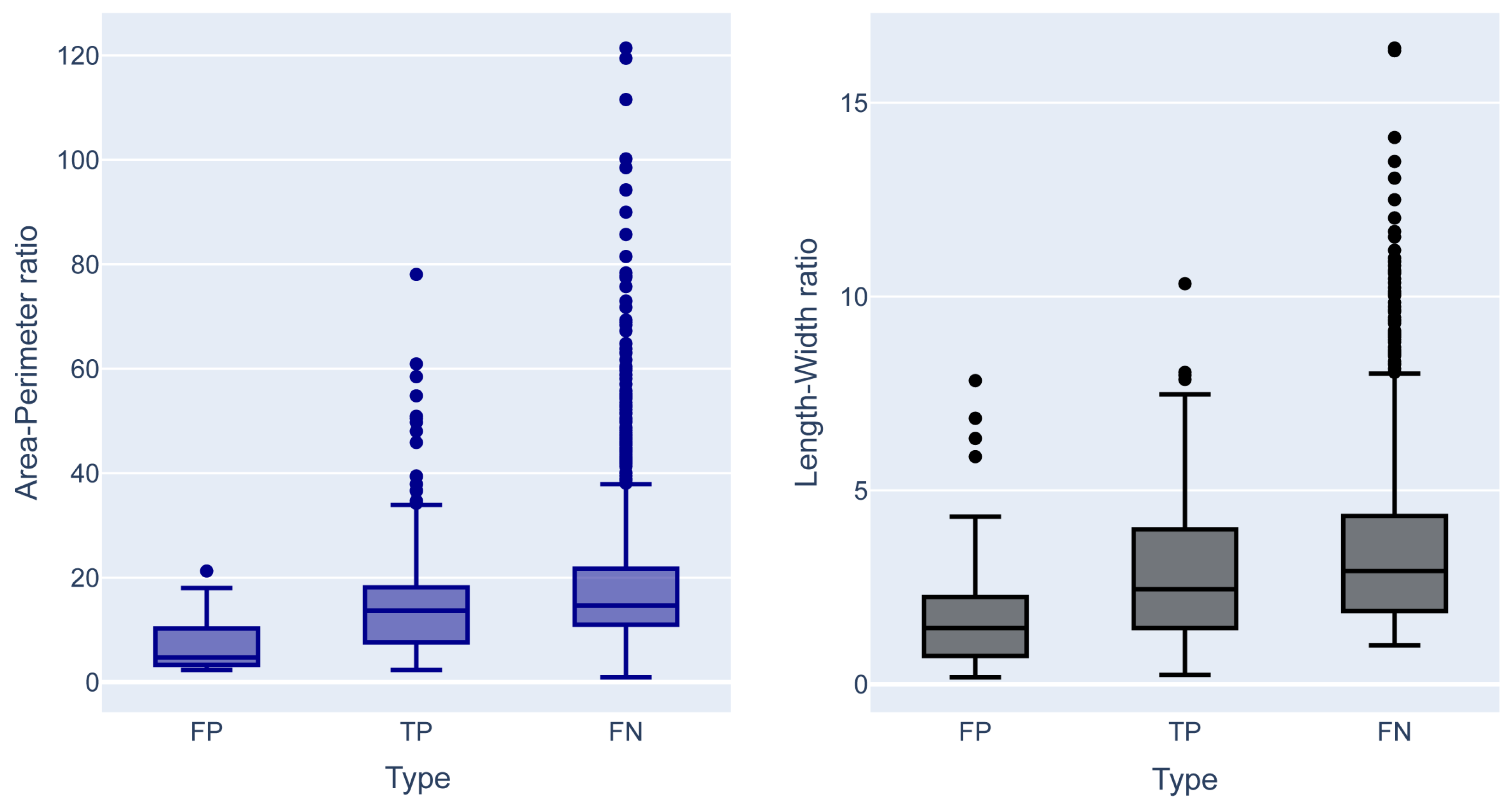
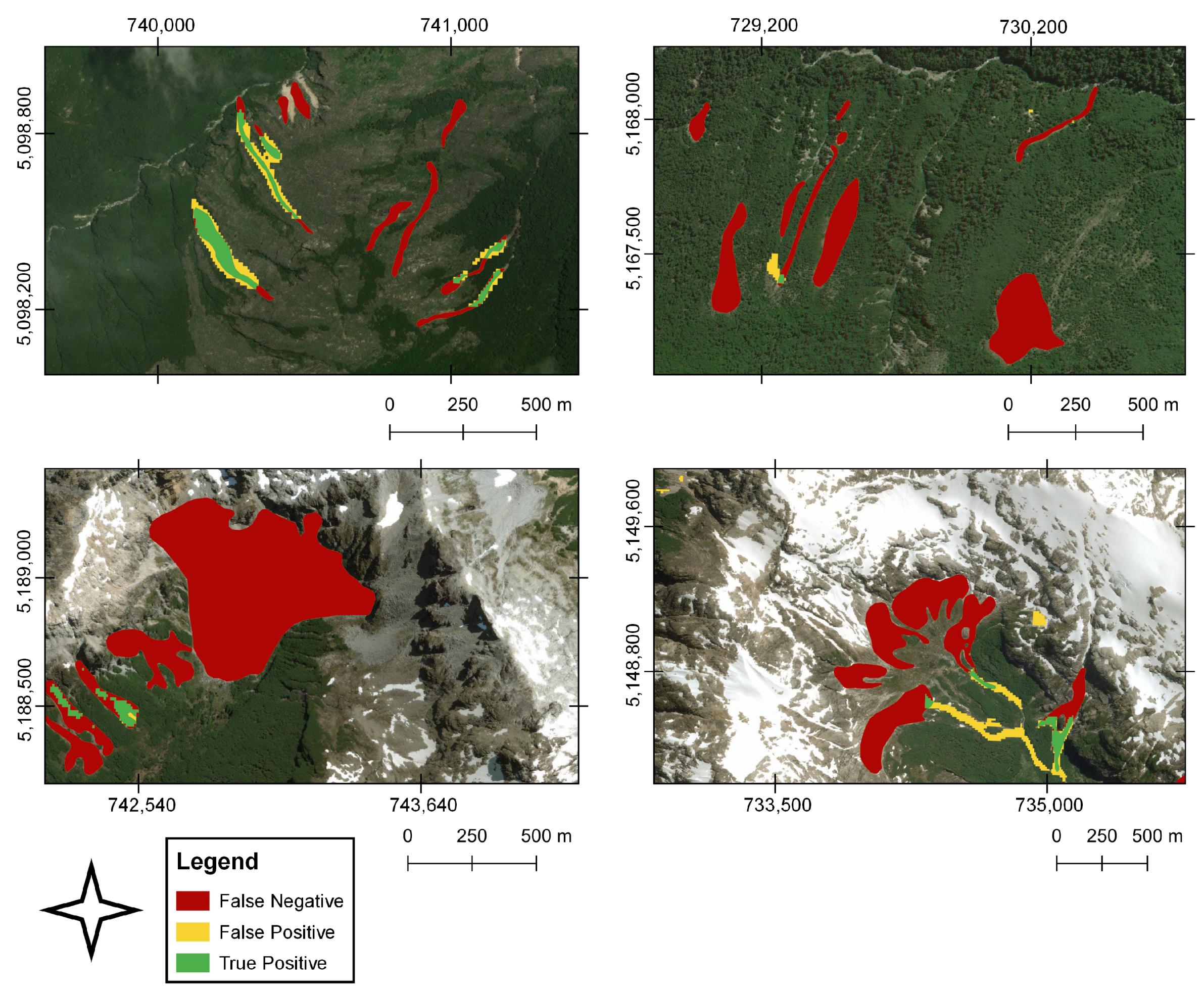
Based on the exploratory analysis, we observed apparent morphological differences between the FP, TP, and FN (
Figure 3).
For instance, the TPs present higher length–width and area–perimeter ratios than the FPs and correspond mainly to elongated morphologies but with less complexity (
Figure 4). While, FPs have low length–width and area–perimeter ratios and are mainly associated with small morphologies that can be complex in shape (
Figure 5).
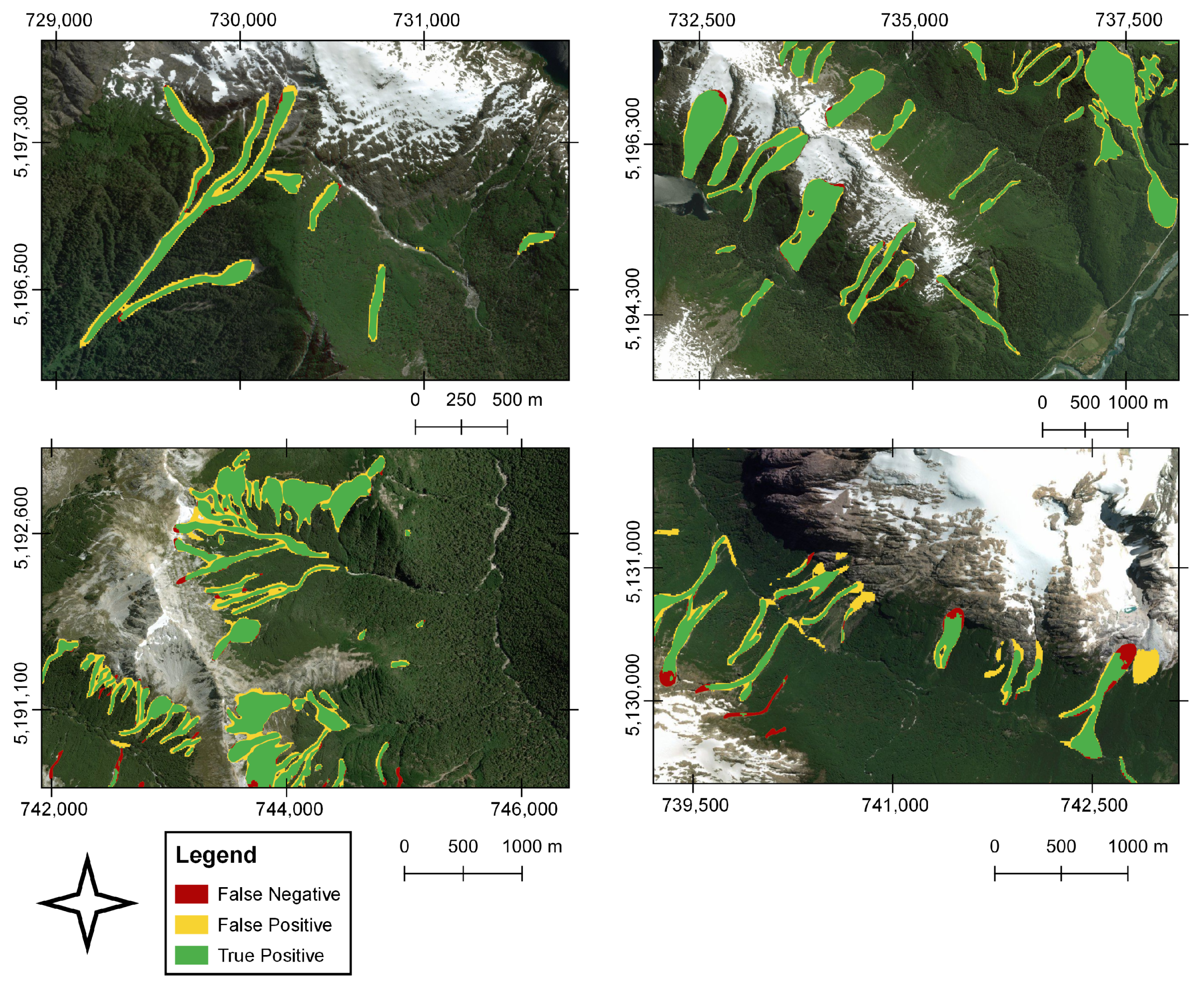
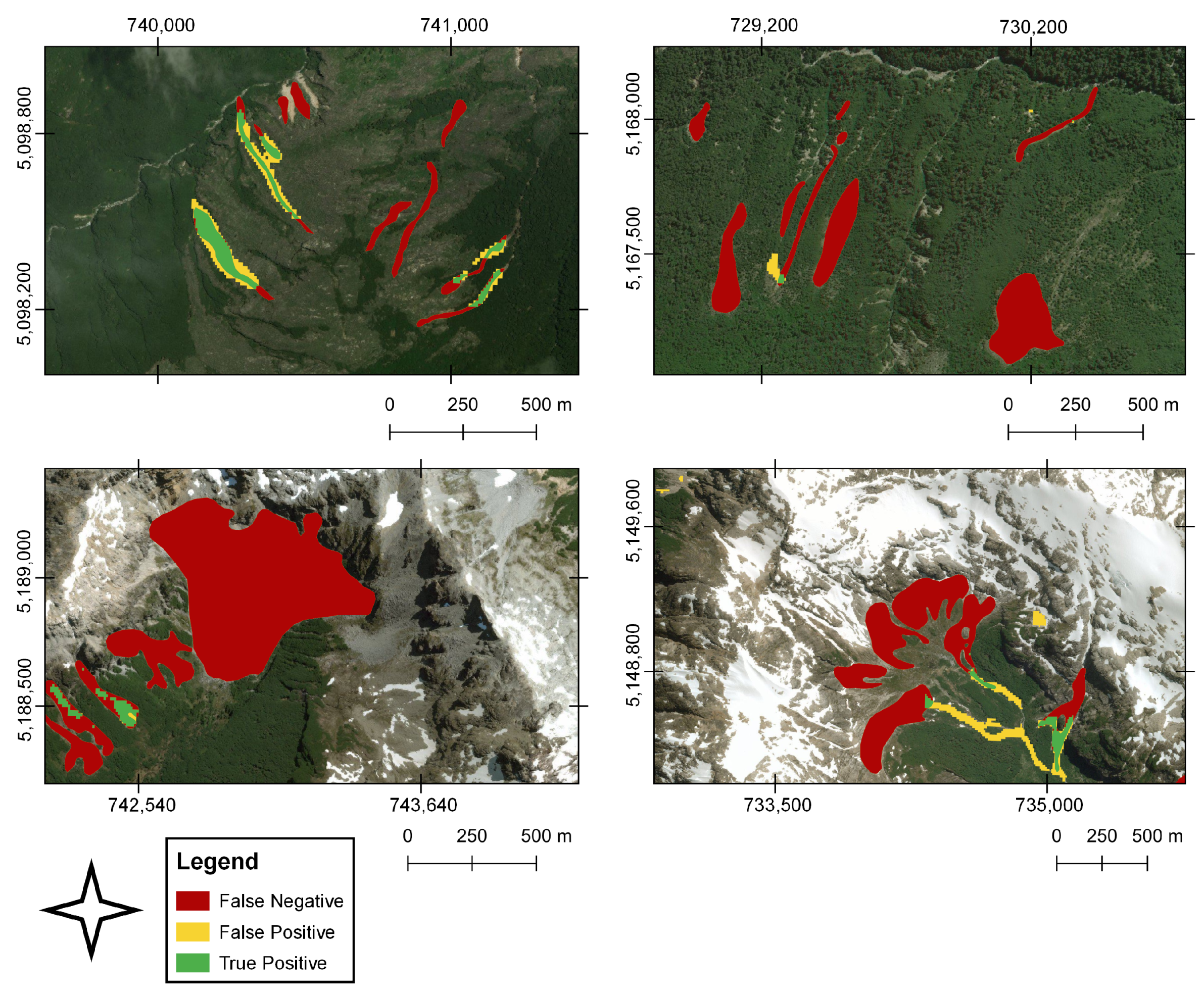
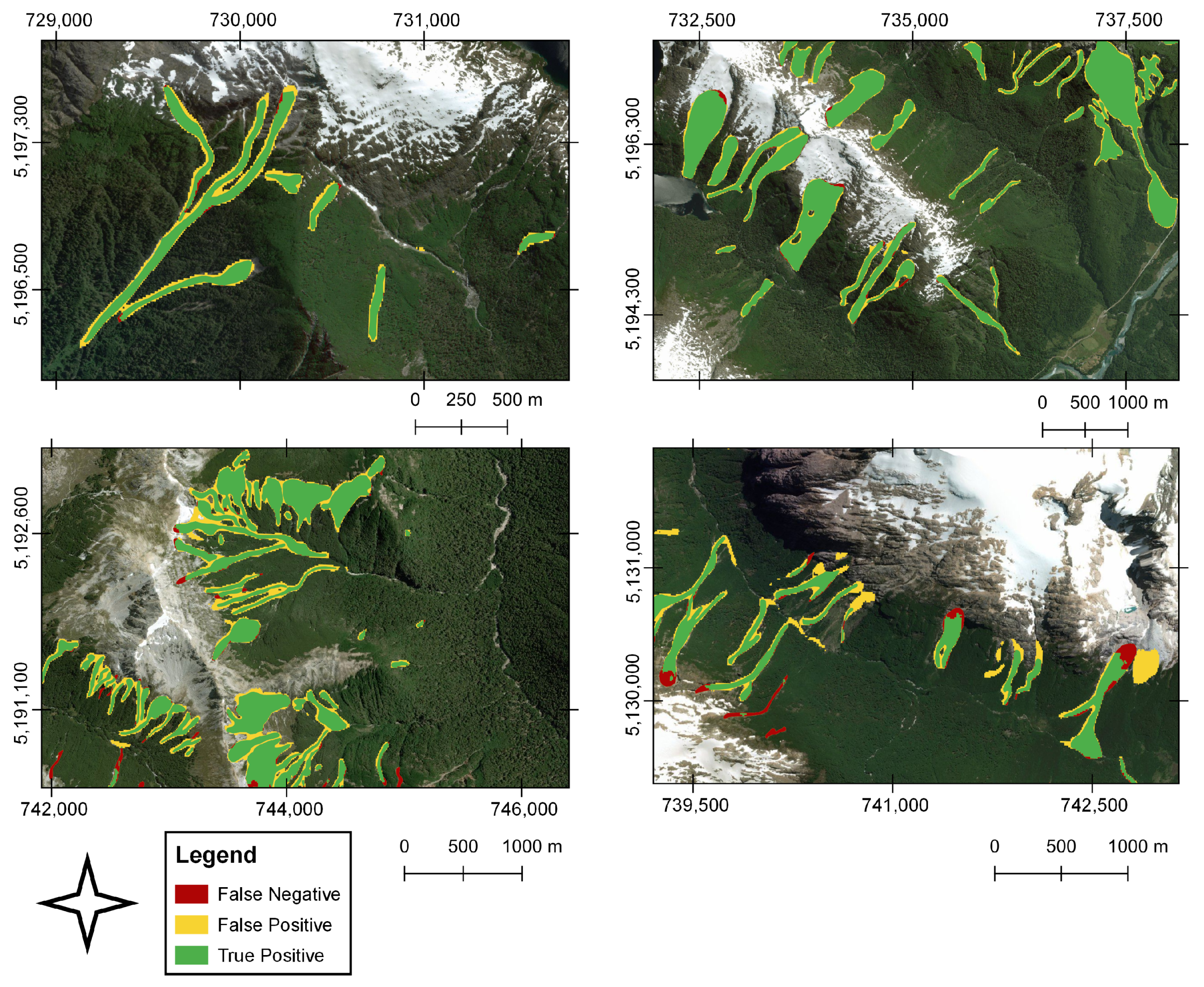
As a result of the high contrast between landslides and the land cover, there is a greater landslide segmentation (
Figure 4). On the other hand, the FN, the landslides that were not detected by the algorithm but found in the training datasets, showed high length–width and area–perimeter ratios and, in general, correspond to landslides that present a more significant run-out and elongation, substantially exceeding in some cases, the ratios of the correctly identified landslides. We identified some errors associated with the segmentation of correctly detected landslides in areas with low or no surrounding vegetation cover. This occurs mainly in the escarpment of landslides that start above 1000 m altitude, where the soil cover corresponds to bare rock (
Figure 5 bottom panels). Likewise, a limited prediction capacity was identified on snowy slopes, and to a lesser extent, on riverbanks, dirt roads-highways, constructions, and on the edge of landslides. These errors may be associated with reflectance effects that increased the number of FPs.
5. Conclusions
In this study, we manually generated the largest freely accessible landslide datasets in the Patagonian Andes (42–45°S), totaling 10,000 landslides in 20,000 km2. The landslide datasets especially delineated on Sentinel-2 images, allowed to train a model using the DeepLabv3+ DL network for semantic segmentation. We achieved a 0.75 accuracy for detecting landslides at the object level through the approach implemented in our investigation. The semantic segmentation reached a precision, recall, and F1-Score of 0.86, 0.74, and 0.79. When we evaluated the correlation of the predicted landslides and the manual datasets in terms of semantic segmentation, the model achieved a Matthews correlation coefficient of 0.59. In contrast, the geometric similarity of the correctly detected landslides measured through the Jaccard score reaches 0.70. After an in-depth analysis of the results, we observed errors associated with the geometric characteristics of the landslides and spectral properties of the landscape, whose effects can be addressed by incorporating new data sets that allow the collection of a broad spectrum of geomorphological characteristics and landslide spectra. Although we do not have a reference point for landslide detection models based on deep learning in the Andes, the results obtained reach values of quality indexes similar to those obtained in recent works developed in other mountainous regions of the world, using data sets generated from optical satellite images. The generated model and free access to data will reduce the time and resources needed for the compilation and systematic updating of landslide inventories in the Andes or other regions of the world, will allow the automated generation of landslide maps after disasters. It will be a tool that will promote the development of predictive landslide models. Finally, we believe that despite the results presented being promising, the temporal factor and cloudy conditions are critical challenges to be addressed; in this sense, everything indicates that SAR images will be a vital support for the development of more sophisticated models.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}