

Convolutional Neural Network Algorithms for Semantic Segmentation of Volcanic Ash Plumes Using Visible Camera Imagery
 , ,
, ,  , and
, and
Abstract
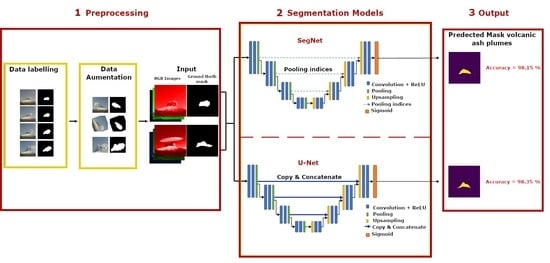
:
1. Introduction
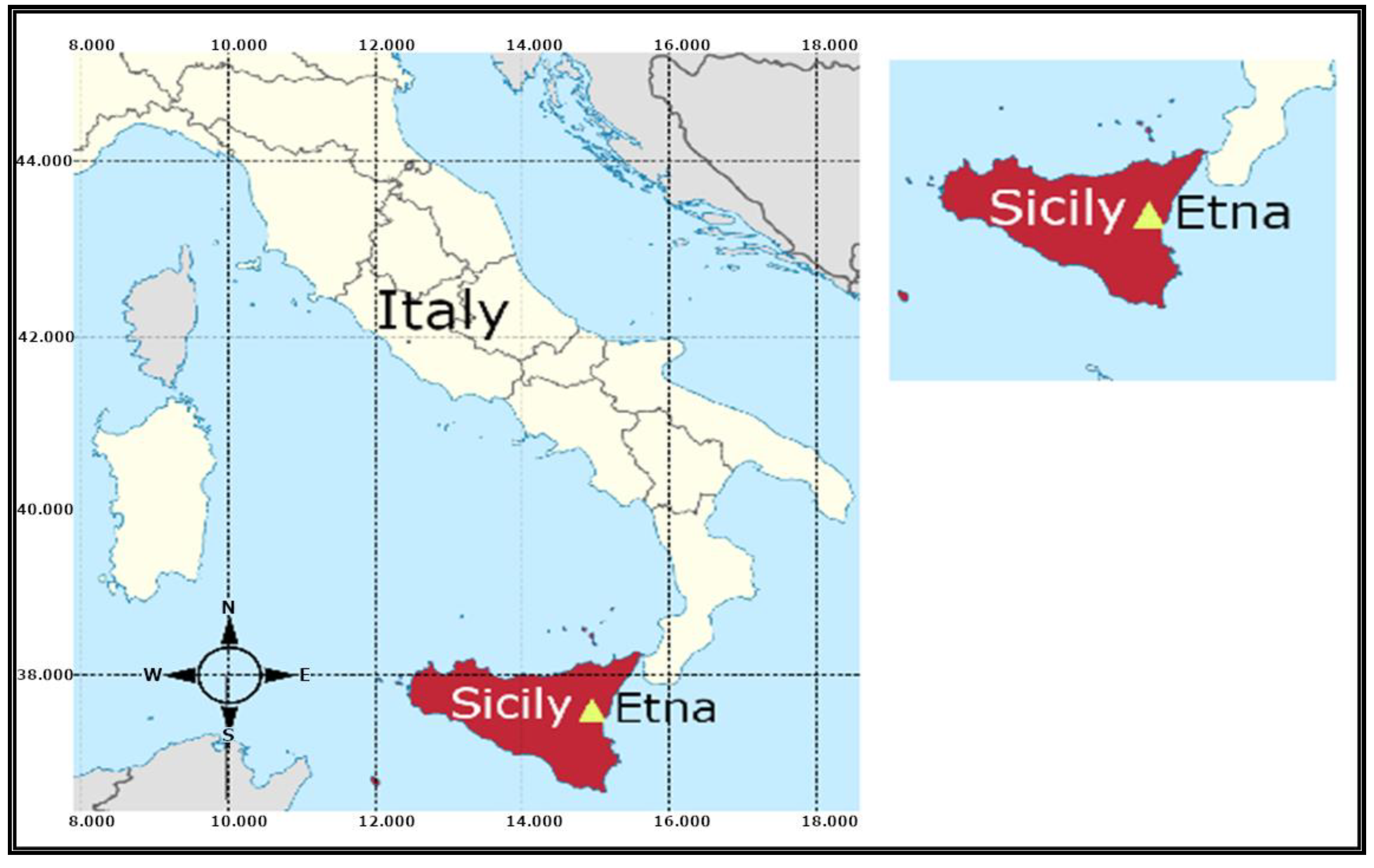
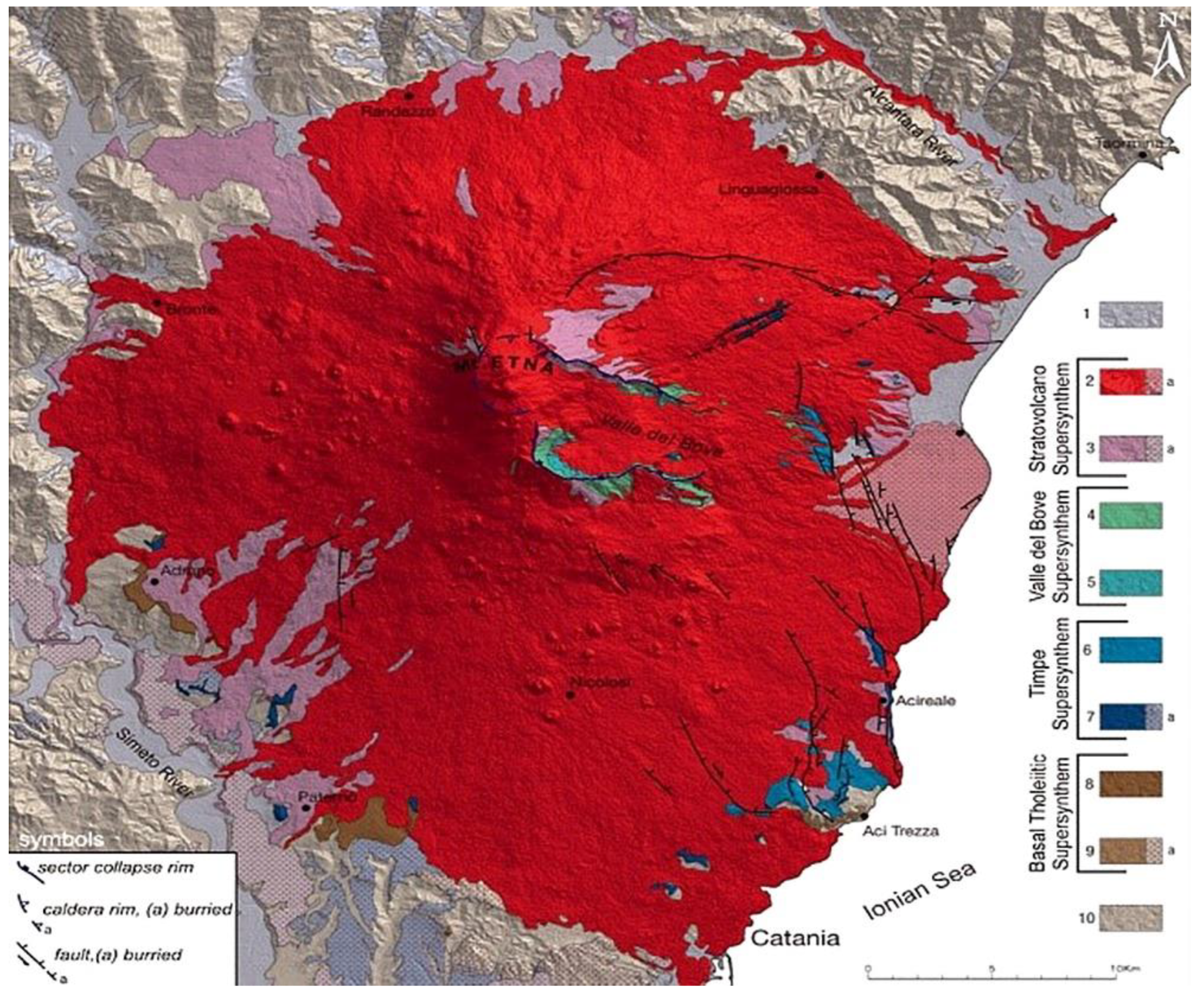
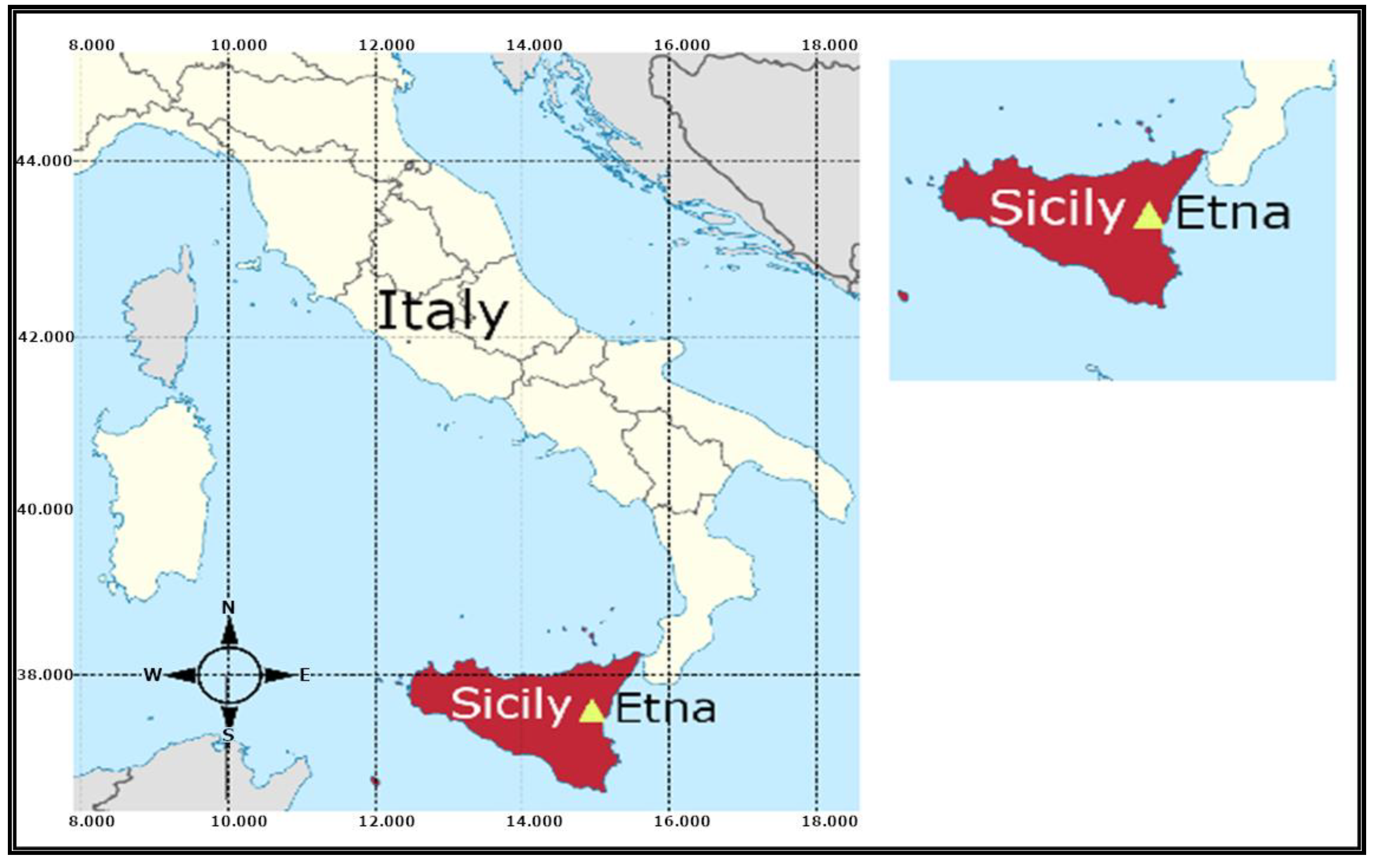
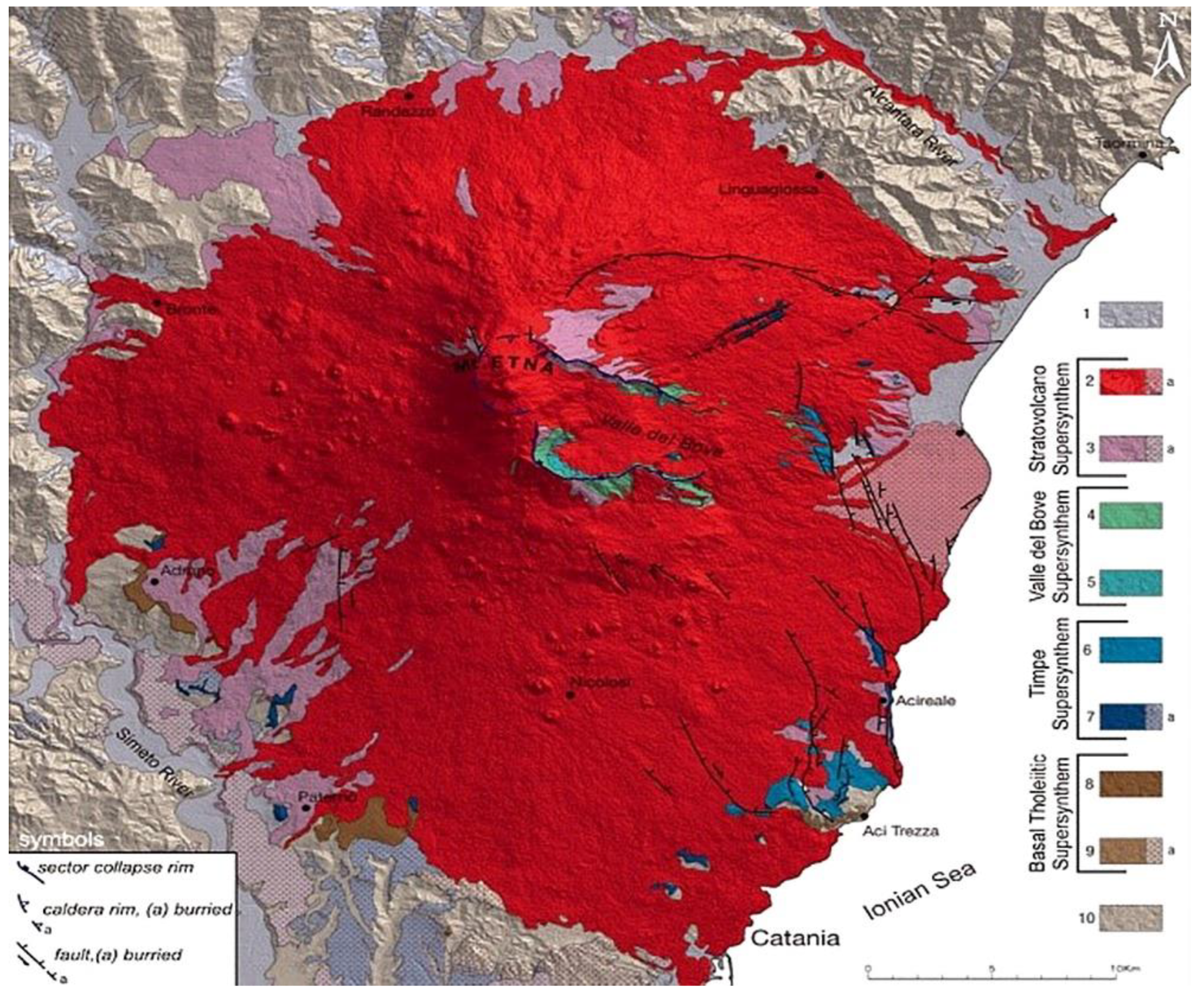
2. Geological Settings
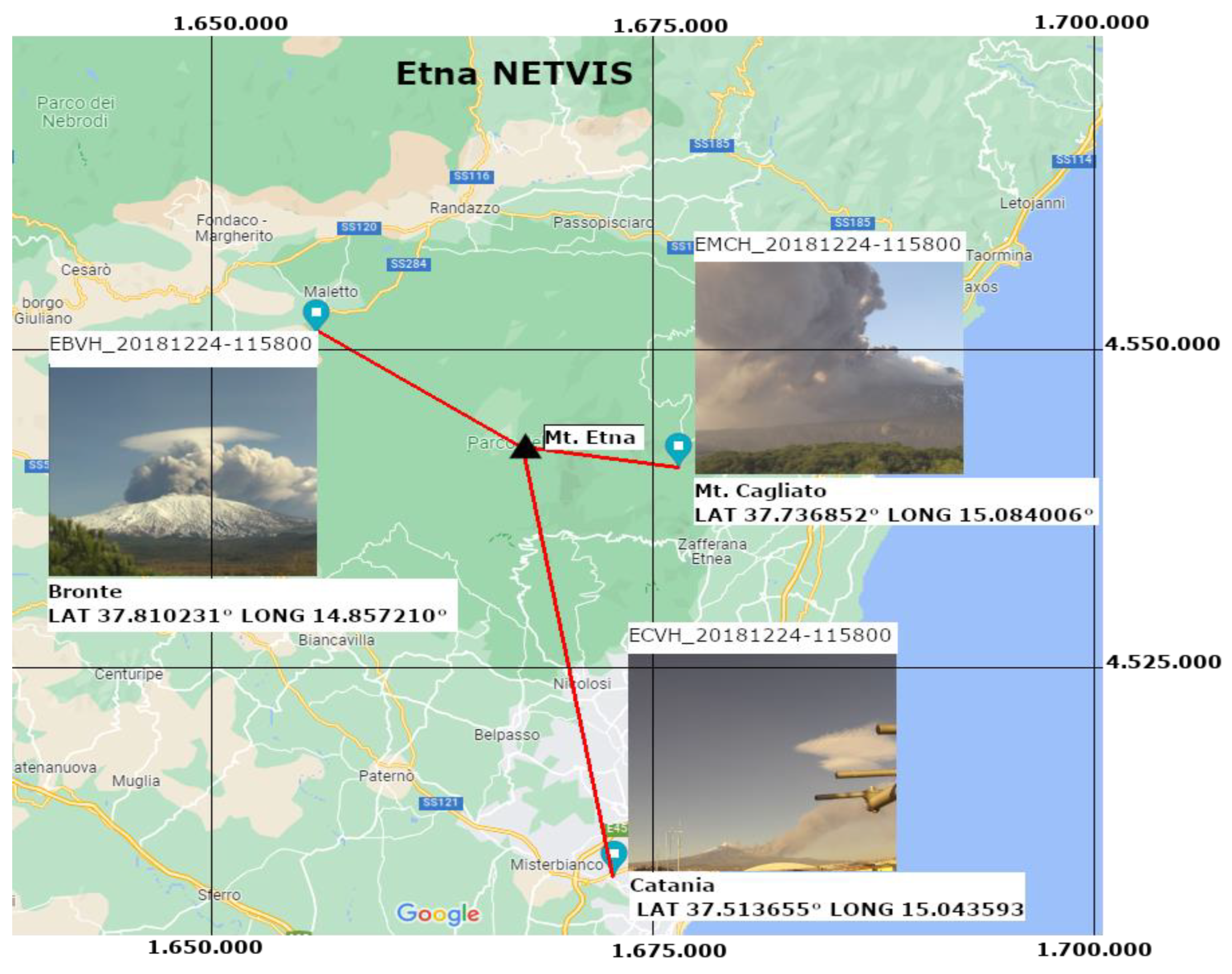
3. Etna_NETVIS Network
4. Materials and Methods
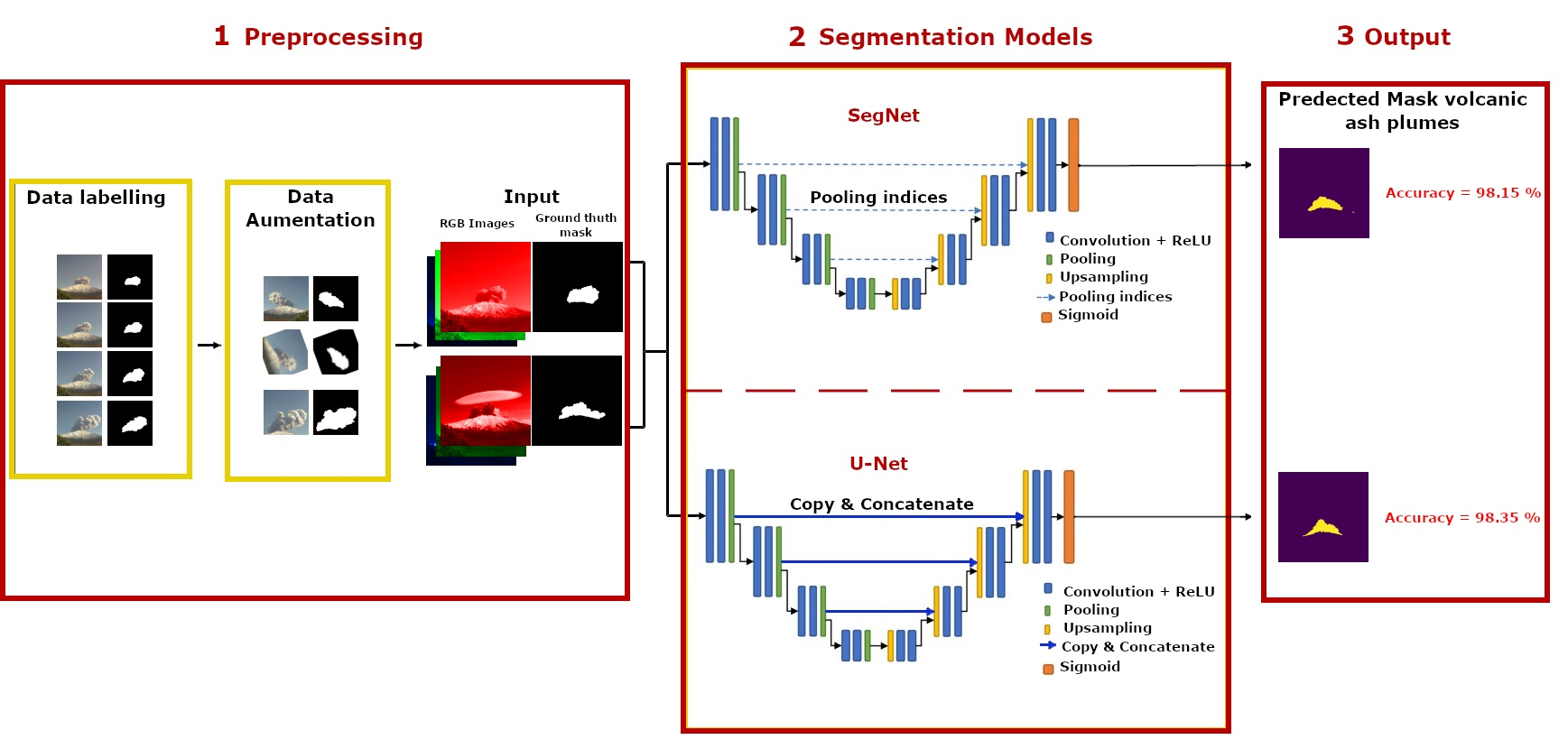
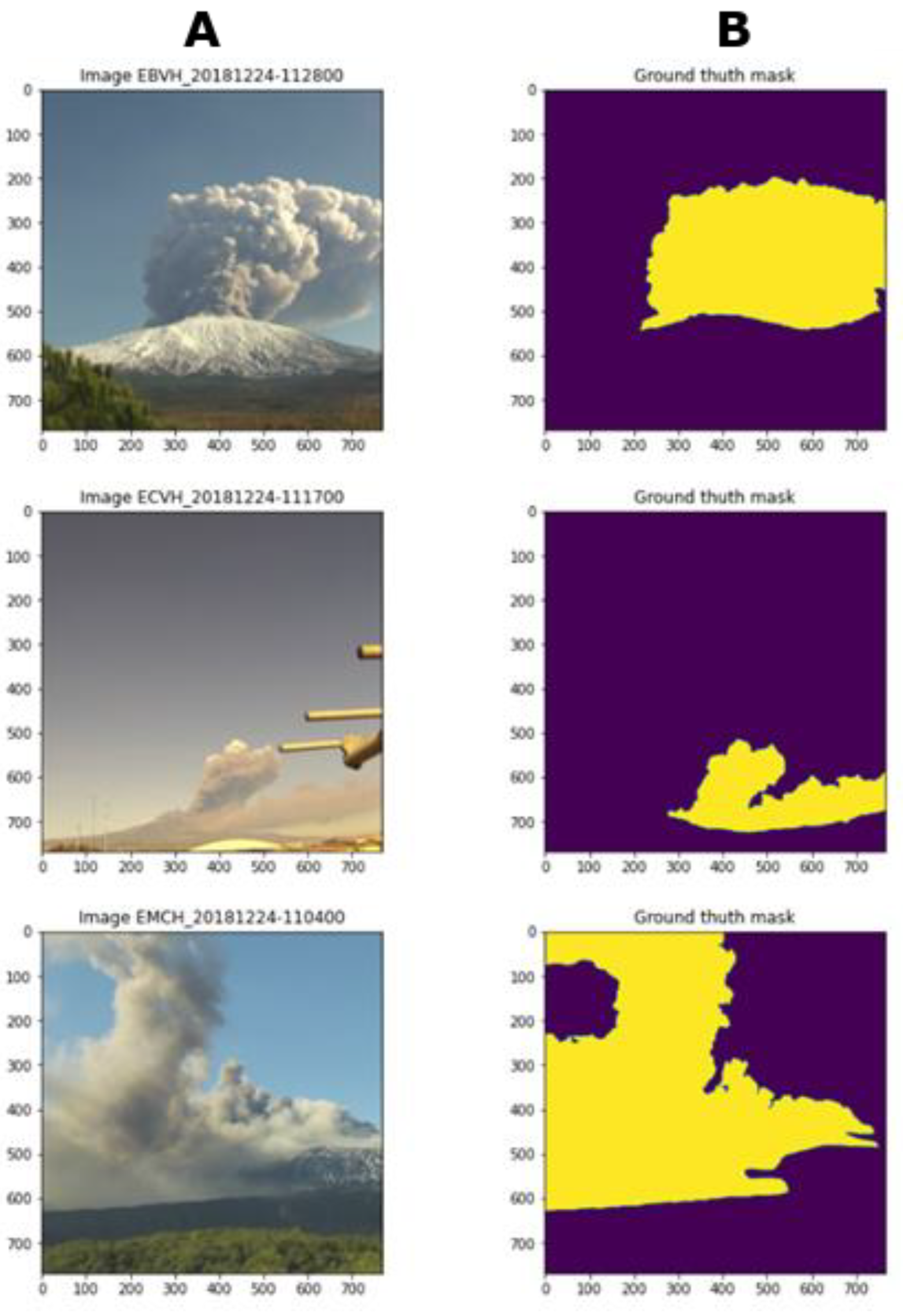
4.1. Materials: Data Preparation
4.2. Methods: ANN and UNET
Convolutional Neural Network Architectures
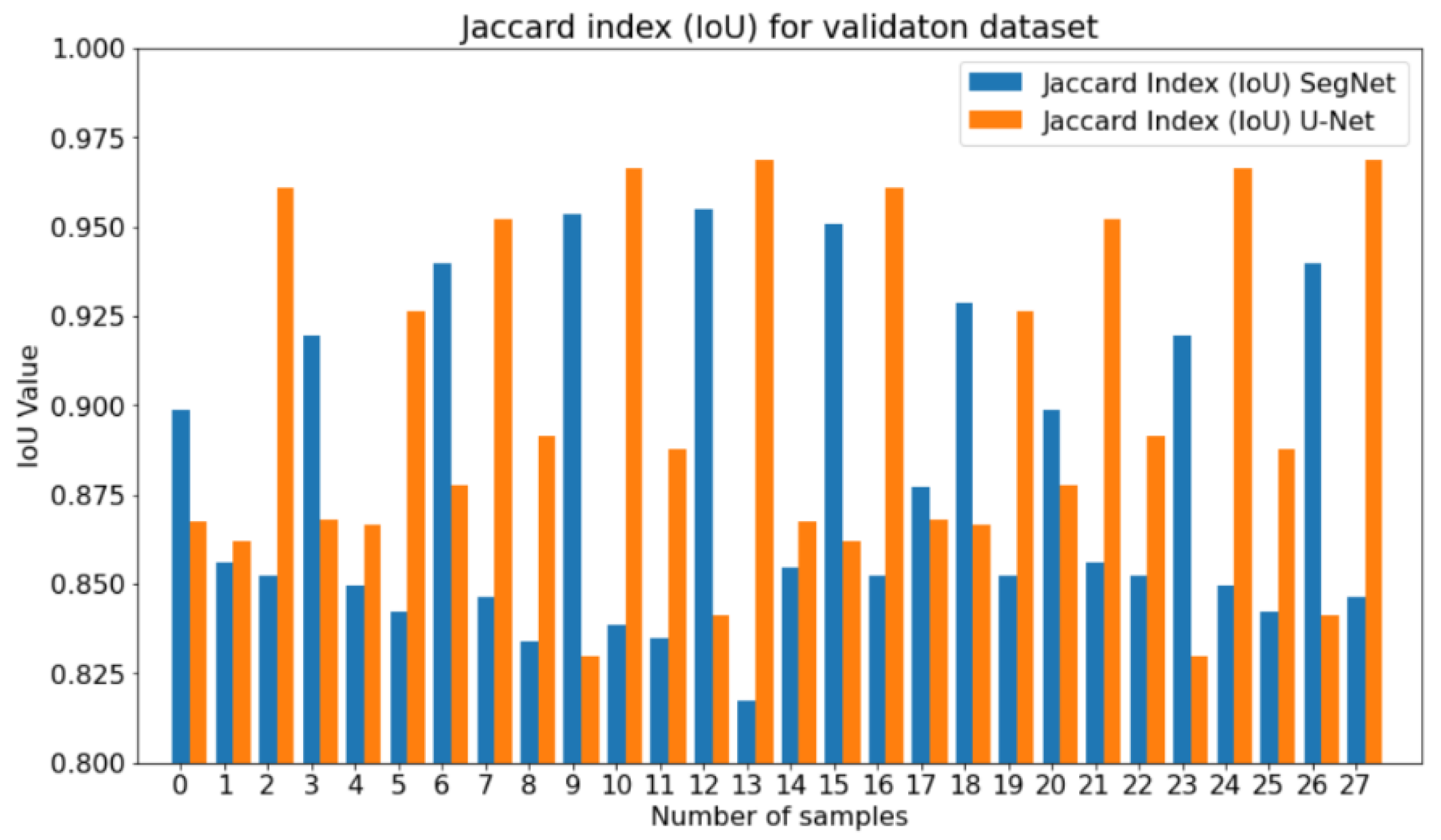
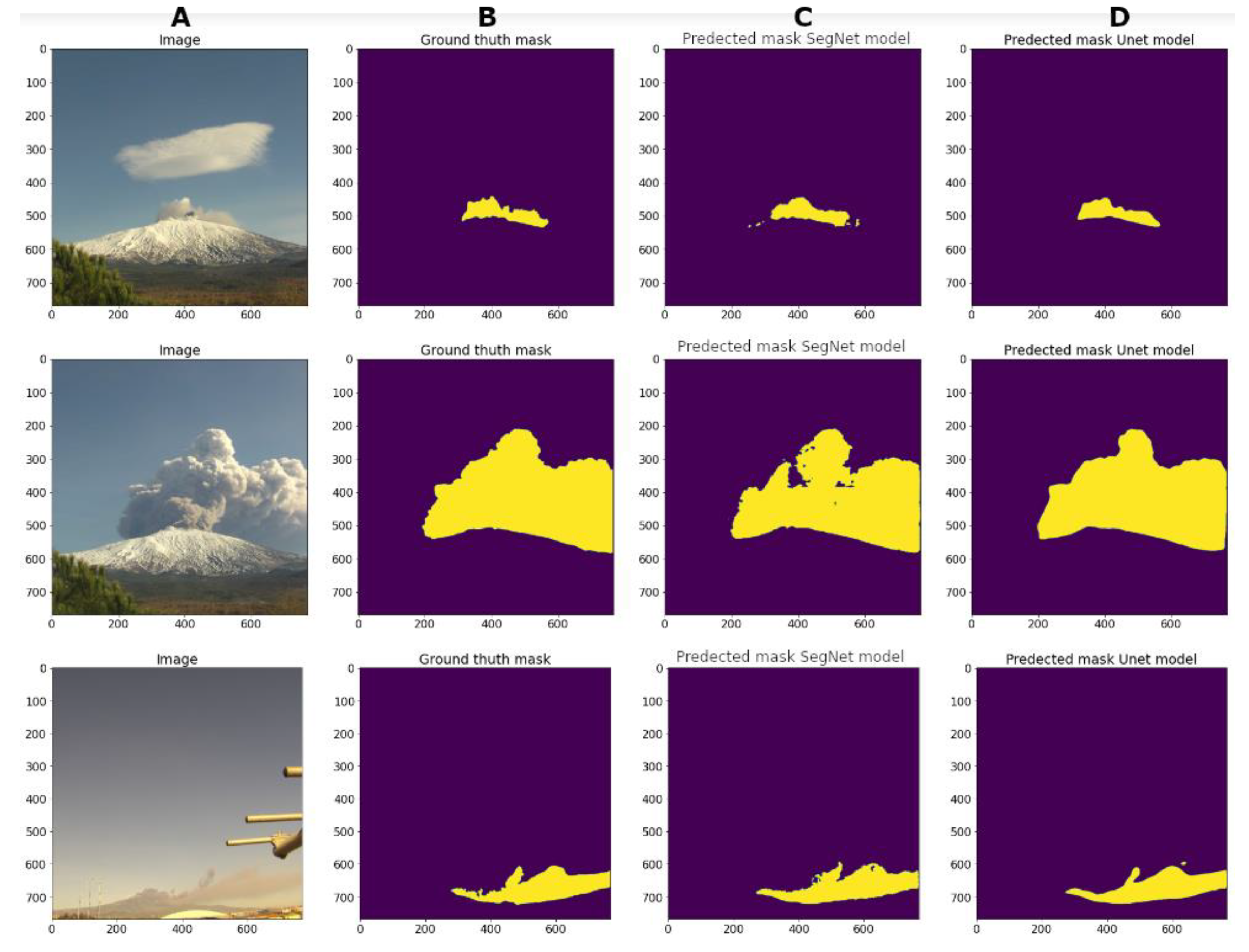
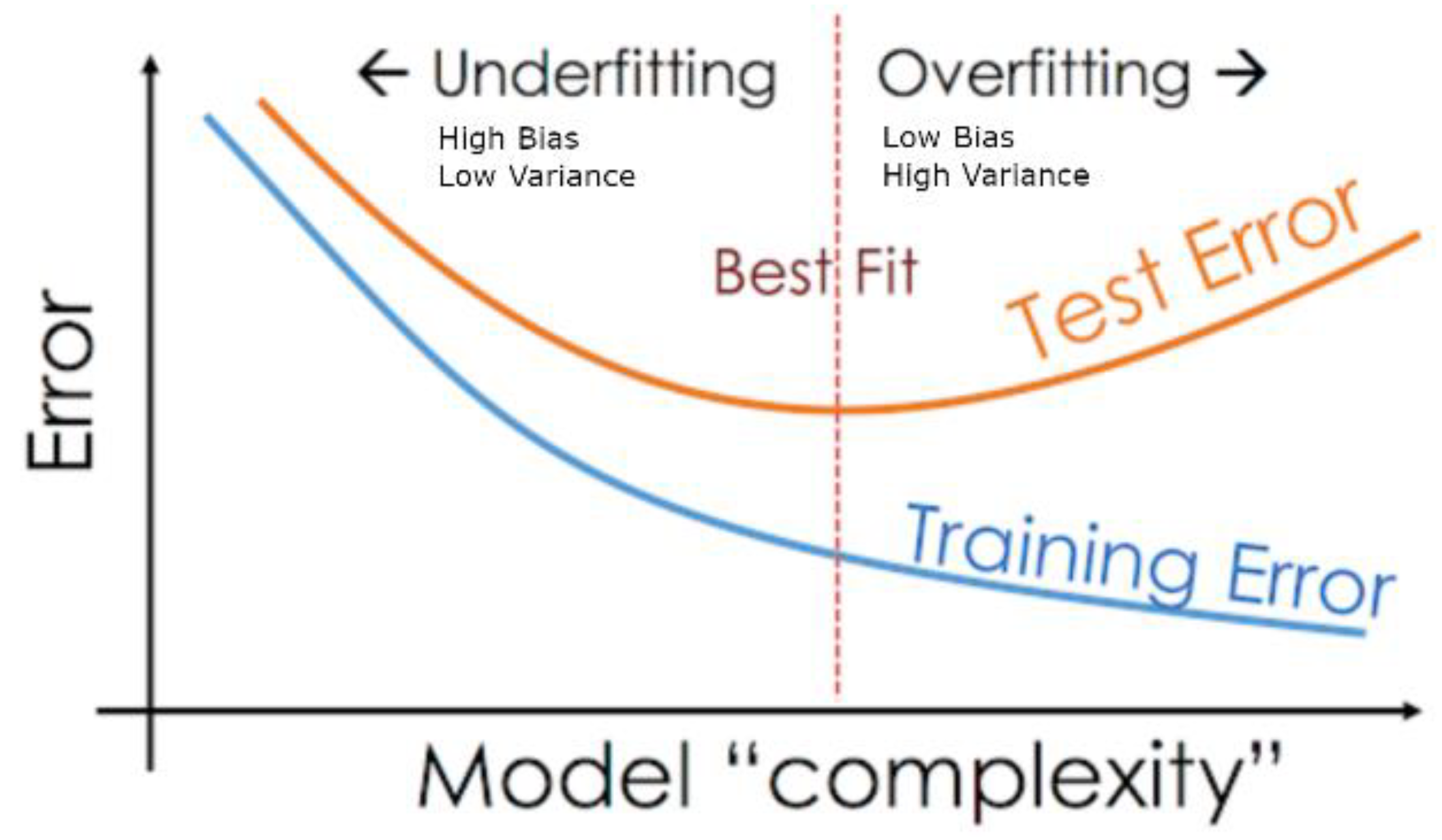
4.3. Evaluation of the Proposed Model
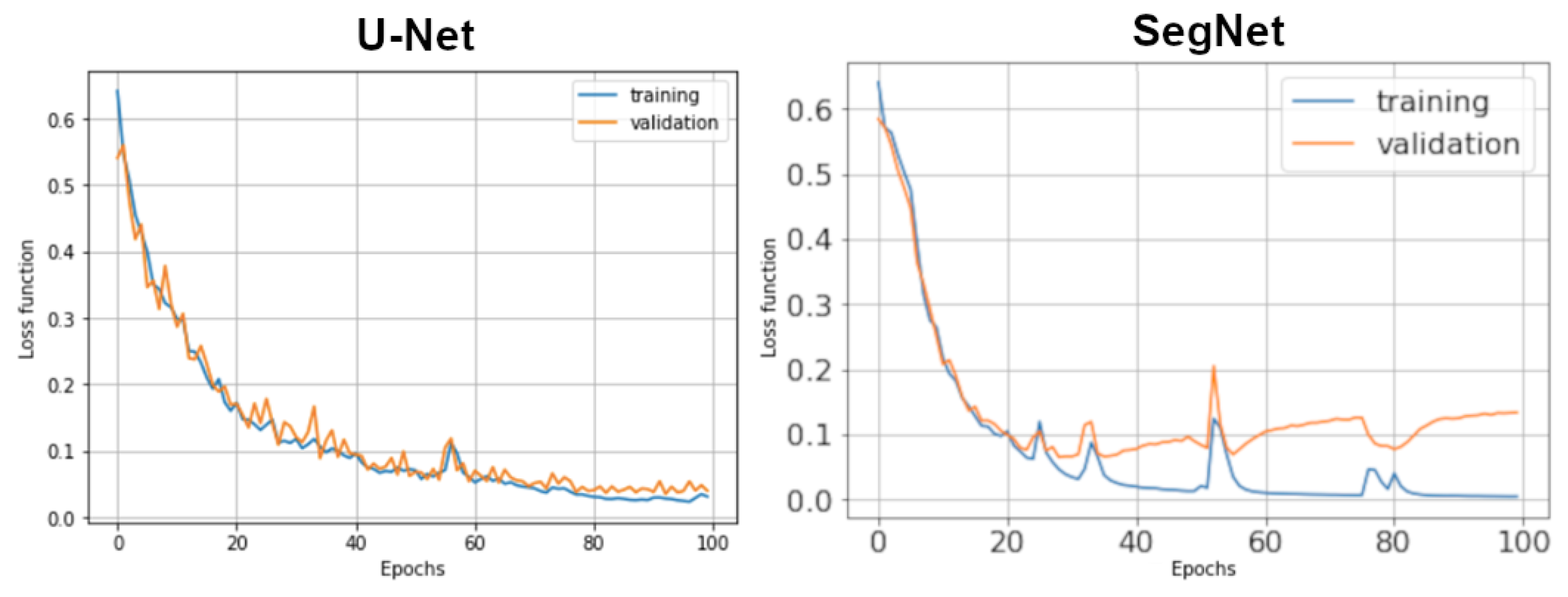
5. Discussion and Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moran, S.C.; Freymueller, J.T.; La Husen, R.G.; McGee, K.A.; Poland, M.P.; Power, J.A.; Schmidt, D.A.; Schneider, D.J.; Stephens, G.; Werner, C.A.; et al. Instrumentation Recommendations for Volcano Monitoring at U.S. Volcanoes under the National Volcano Early Warning System; U.S. G. S.: Scientific Investigations Report; U.S. Geological Survey: Liston, VA, USA, 2008; pp. 1–47. [CrossRef]
- Witsil, A.J.C.; Johnson, J.B. Volcano video data characterized and classified using computer vision and machine learning algorithms. GSF 2020, 11, 1789–1803. [Google Scholar] [CrossRef]
- Coltelli, M.; D’Aranno, P.J.V.; De Bonis, R.; Guerrero Tello, J.F.; Marsella, M.; Nardinocchi, C.; Pecora, E.; Proietti, C.; Scifoni, S.; Scutti, M.; et al. The use of surveillance cameras for the rapid mapping of lava flows: An application to Mount Etna Volcano. Remote Sens. 2017, 9, 192. [Google Scholar] [CrossRef]
- Wilson, G.; Wilson, T.; Deligne, N.I.; Cole, J. Volcanic hazard impacts to critical infrastructure: A review. J. Volcanol. Geotherm. Res. 2014, 286, 148–182. [Google Scholar] [CrossRef]
- Bursik, M.I.; Kobs, S.E.; Burns, A.; Braitseva, O.A.; Bazanova, L.I.; Melekestsev, I.V.; Kurbatov, A.; Pieri, D.C. Volcanic plumes and wind: Jetstream interaction examples and implications for air traffic. J. Volcanol. Geotherm. Res. 2009, 186, 60–67. [Google Scholar] [CrossRef]
- Barsotti, S.; Andronico, D.; Neri, A.; Del Carlo, P.; Baxter, P.J.; Aspinall, W.P.; Hincks, T. Quantitative assessment of volcanic ash hazards for health and infrastructure at Mt. Etna (Italy) by numerical simulation. J. Volcanol. Geotherm. Res. 2010, 192, 85–96. [Google Scholar] [CrossRef]
- Voight, B. The 1985 Nevado del Ruiz volcano catastrophe: Anatomy and retrospection. J. Volcanol. Geotherm. Res. 1990, 42, 151–188. [Google Scholar] [CrossRef]
- Scollo, S.; Prestifilippo, M.; Pecora, E.; Corradini, S.; Merucci, L.; Spata, G.; Coltelli, M. Eruption Column Height Estimation: The 2011–2013 Etna lava fountains. Ann. Geophys. 2014, 57, S0214. [Google Scholar]
- Li, C.; Dai, Y.; Zhao, J.; Zhou, S.; Yin, J.; Xue, D. Remote Sensing Monitoring of Volcanic Ash Clouds Based on PCA Method. Acta Geophys. 2015, 63, 432–450. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; AlDujaili, A.; Duan, Y.; AlShamma, O.; Santamaría, J.; Fadhel, M.A.; AlAmidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2001, 8, 53. [Google Scholar] [CrossRef]
- Zhang, W.; Itoh, K.; Tanida, J.; Ichioka, Y. Parallel distributed processing model with local space-invariant interconnections and its optical architecture. Appl. Opt. 1990, 29, 4790–4797. [Google Scholar] [CrossRef] [PubMed]
- Öztürk, O.; Saritürk, B.; Seker, D.Z. Comparison of Fully Convolutional Networks (FCN) and U-Net for Road Segmentation from High Resolution Imageries. Int. J. Geoinform. 2020, 7, 272–279. [Google Scholar] [CrossRef]
- Ran, S.; Ding, J.; Liu, B.; Ge, X.; Ma, G. Multi-U-Net: Residual Module under Multisensory Field and Attention Mechanism Based Optimized U-Net for VHR Image Semantic Segmentation. Sensors 2021, 21, 1794. [Google Scholar] [CrossRef] [PubMed]
- John, D.; Zhang, C. An attention-based U-Net for detecting deforestation within satellite sensor imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102685. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Jmal, M.; Souidene Mseddi, W.; Attia, R. Wildfire Segmentation Using Deep Vision Transformers. Remote Sens. 2021, 13, 3527. [Google Scholar] [CrossRef]
- Frizzi, S.; Bouchouicha, M.; Ginoux, J.M.; Moreau, E.; Sayadi, M. Convolutional neural network for smoke and fire semantic segmentation. IET Image Process 2021, 15, 634–647. [Google Scholar] [CrossRef]
- Jain, P.; Schoen-Phelan, B.; Ross, R. Automatic flood detection in Sentinel-2 imagesusing deep convolutional neural networks. In SAC ’20: Proceedings of the 35th Annual ACM Symposium on Applied Computing; Association for Computing Machinery: New York, NY, USA, 2020; pp. 617–623. [Google Scholar]
- Khaleghian, S.; Ullah, H.; Kræmer, T.; Hughes, N.; Eltoft, T.; Marinoni, A. Sea Ice Classification of SAR Imagery Based on Convolution Neural Networks. Remote Sens. 2021, 13, 1734. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, X.; Ji, S. Semantic image segmentation for sea ice parameters recognition using deep convolutional neural networks. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102885. [Google Scholar] [CrossRef]
- Perol, T.; Gharbi, M.; Denolle, M. Convolutional neural network for earthquake detection and location. Sci. Adv. 2018, 4, e1700578. [Google Scholar] [CrossRef]
- Manley, G.; Mather, T.; Pyle, D.; Clifton, D. A deep active learning approach to the automatic classification of volcano-seismic events. Front. Earth Sci. 2022, 10, 7926. [Google Scholar] [CrossRef]
- Shoji, D.; Noguchi, R.; Otsuki, S. Classification of volcanic ash particles using a convolutional neural network and probability. Sci. Rep. 2018, 8, 8111. [Google Scholar] [CrossRef] [Green Version]
- Bertucco, L.; Coltelli, M.; Nunnari, G.; Occhipinti, L. Cellular neural networks for real-time monitoring of volcanic activity. Comput. Geosci. 1999, 25, 101–117. [Google Scholar] [CrossRef]
- Gaddes, M.E.; Hooper, A.; Bagnardi, M. Using machine learning to automatically detect volcanic unrest in a time series of interferograms. J. Geophys. Res. Solid Earth 2019, 124, 12304–12322. [Google Scholar] [CrossRef]
- Del Rosso, M.P.; Sebastianelli, A.; Spiller, D.; Mathieu, P.P.; Ullo, S.L. On-board volcanic eruption detection through CNNs and Satellite Multispectral Imagery. Remote Sens. 2021, 13, 3479. [Google Scholar] [CrossRef]
- Efremenko, D.S.; Loyola R., D.G.; Hedelt, P.; Robert, J.D.; Spurr, R.J.D. Volcanic SO2 plume height retrieval from UV sensors using a full-physics inverse learning machine algorithm. Int. J. Remote Sens. 2017, 1, 1–27. [Google Scholar] [CrossRef]
- Corradino, C.; Ganci, G.; Cappello, A.; Bilotta, G.; Hérault, A.; Del Negro, C. Mapping Recent Lava Flows at Mount Etna Using Multispectral Sentinel-2 Images and Machine Learning Techniques. Remote Sens. 2019, 11, 1916. [Google Scholar] [CrossRef]
- Lentini, F.; Carbone, S. Geologia della Sicilia—Geology of Sicily III-Il dominio orogenic -The orogenic domain. Mem. Descr. Carta Geol. Ital. 2014, 95, 7–414. [Google Scholar]
- Branca, S.; Coltelli, M.; Groppelli, G.; Lentini, F. Geological map of Etna volcano, 1:50,000 scale. Italian J. Geosci. 2011, 130, 265–291. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef]
- Eli Berdesky’s Webstite. Understanding Gradient Descent. Available online: https://eli.thegreenplace.net/2016/understanding-gradient-descent/ (accessed on 1 April 2021).
- Aizawa, K.; Cimarelli, C.; Alatorre-Ibargüengoitia, M.A.; Yokoo, A.; Dingwell, D.B.; Iguchi, M. Physical properties of volcanic lightning: Constraints from magnetotelluric and video observations at Sakurajima volcano, Japan. EPSL 2016, 444, 45–55. [Google Scholar] [CrossRef]
- Hijazi, S.; Kumar, R.; Rowen, C. Using Convolutional Neural Networks for Image Recognition. Cadence Design Systems Inc. Available online: https://ip.cadence.com/uploads/901/cnn_wp-pdf (accessed on 1 April 2021).
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. Cnn-rnn: A unified framework for multi-label image classification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA; 2016; pp. 2285–2294. [Google Scholar]
- Sultana, F.; Sufian, A.; Dutta, P. Evolution of Image Segmentation using Deep Convolutional Neural Network: A Survey. Knowl.-Based Syst. 2020, 201, 106062. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 1 August 2022).
- Wikipedia–Keras. Available online: https://en.wikipedia.org/wiki/Keras (accessed on 1 August 2022).
- Pugliatti, M.; Maestrini, M.; Di Lizia, P.; Topputo, F. Onboard Small-Body semantic segmentation based on morphological features with U-Net. In Proceedings of the 31st AAS/AIAA Space Flight Mechanics Meeting, Charlotte, NC, USA, 31 January–4 February 2021; pp. 1–20. [Google Scholar]
- Gonzales, C.; Sakla, W. Semantic Segmentation of Clouds in Satellite Imagery Using Deep Pre-trained U-Nets. In Proceedings of the 2019 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 15–17 October 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Tapasvi, B.; Udaya Kumar, N.; Gnanamanoharan, E. A Survey on Semantic Segmentation using Deep Learning Techniques. Int. J. Eng. Res. Technol. 2021, 9, 50–56. [Google Scholar]
- Leichter, A.; Almeev, R.R.; Wittich, D.; Beckmann, P.; Rottensteiner, F.; Holtz, F.; Sester, M. Automated segmentation of olivine phenocrysts in a volcanic rock thin section using a fully convolutional neural network. Front. Earth Sci. 2022, 10, 740638. [Google Scholar] [CrossRef]
- Github–Semantic-Segmentation-Ash- Plumes-U-net. Available online: https://github.com/jfranciscoguerrero/semantic-segmentation-ash-plumes-U-Net/blob/main/fig10_%20Sketch%20of%20the%20U-Net%20model%20with%20deepest%204.png (accessed on 30 June 2022).
- Github-Semantic-Segmentation-Ash-Plumes-U-Net. Available online: https://github.com/jfranciscoguerrero/semantic-segmentation-ash-plumes-U-Net/blob/main/model_SegNet_volcanic.png (accessed on 2 August 2022).
- Ghojogh, B.; Crowley, M. The theory behind overfitting, cross validation, regularization, bagging, and boosting: Tutorial. arXiv 2019, arXiv:1905.12787. [Google Scholar]
- da Fontoura Costa, L. Further generalization of the Jaccard Index. arXiv 2021, arXiv:2110.09619. [Google Scholar]
- Carniel, R.; Guzmán, S.R. Machine Learning in Volcanology: A Review. In Updates in Volcanology-Transdisciplinary Nature of Volcano Science; Károly, N., Ed.; IntechOpen: London, UK, 2020. [Google Scholar] [CrossRef]
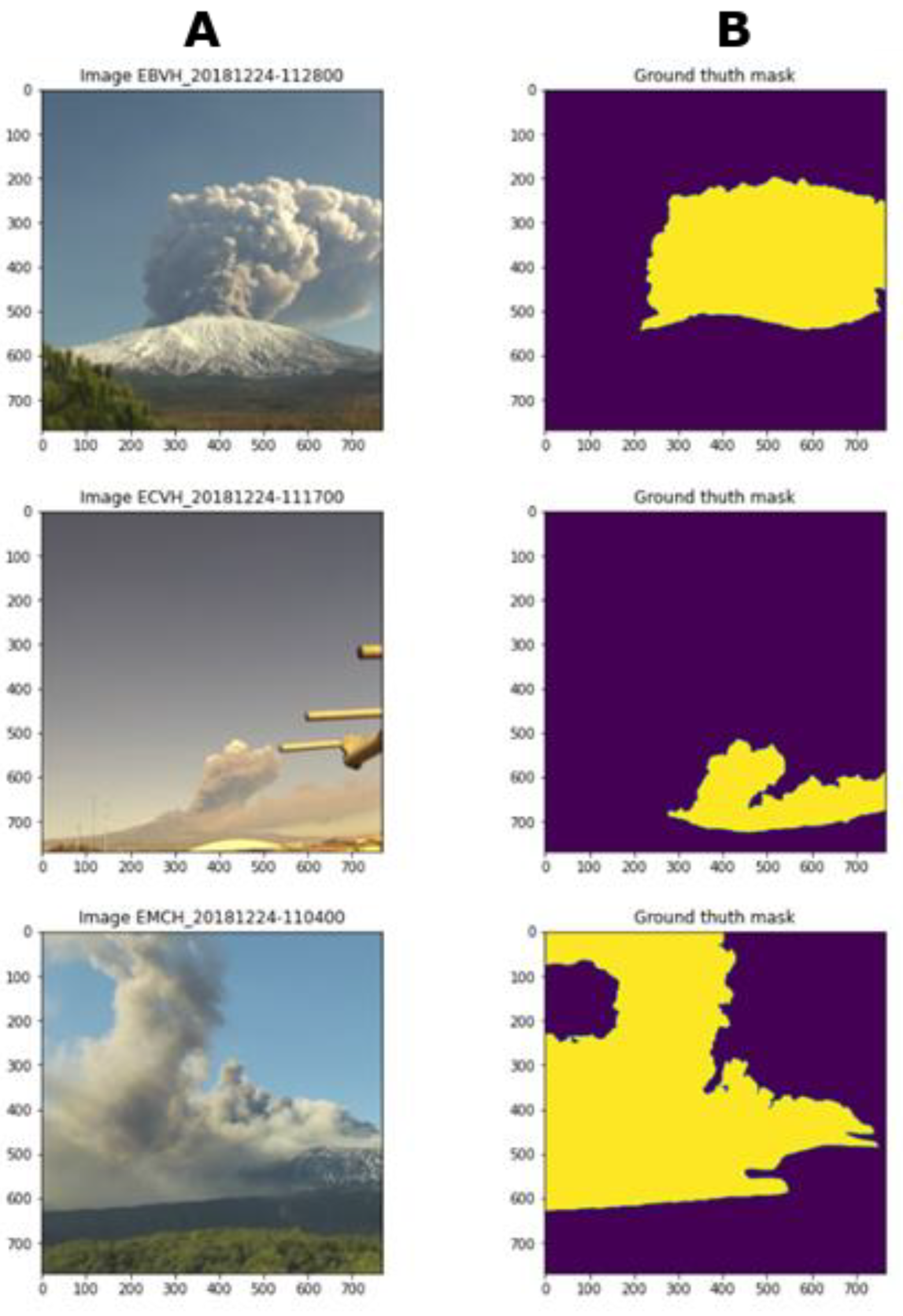

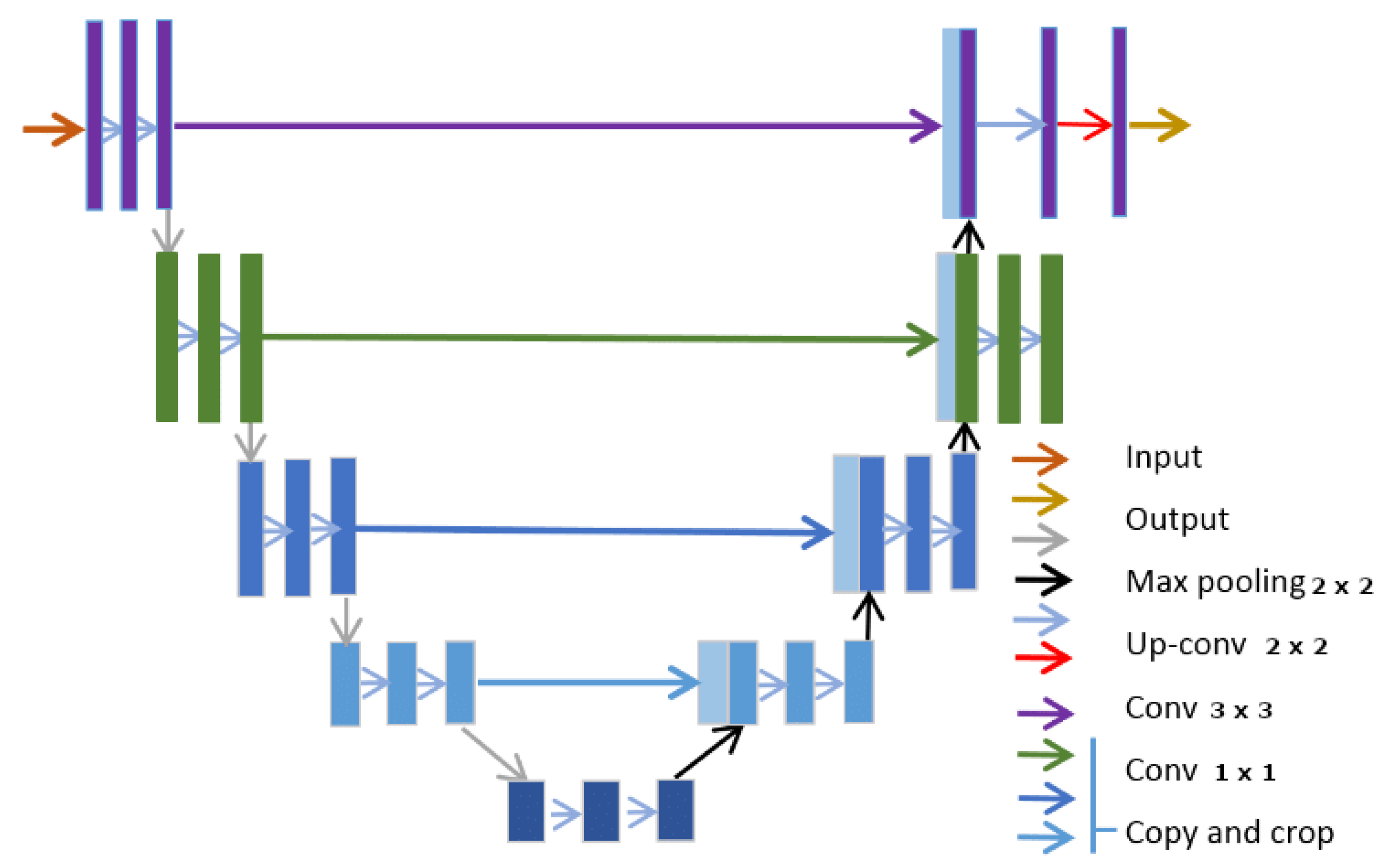


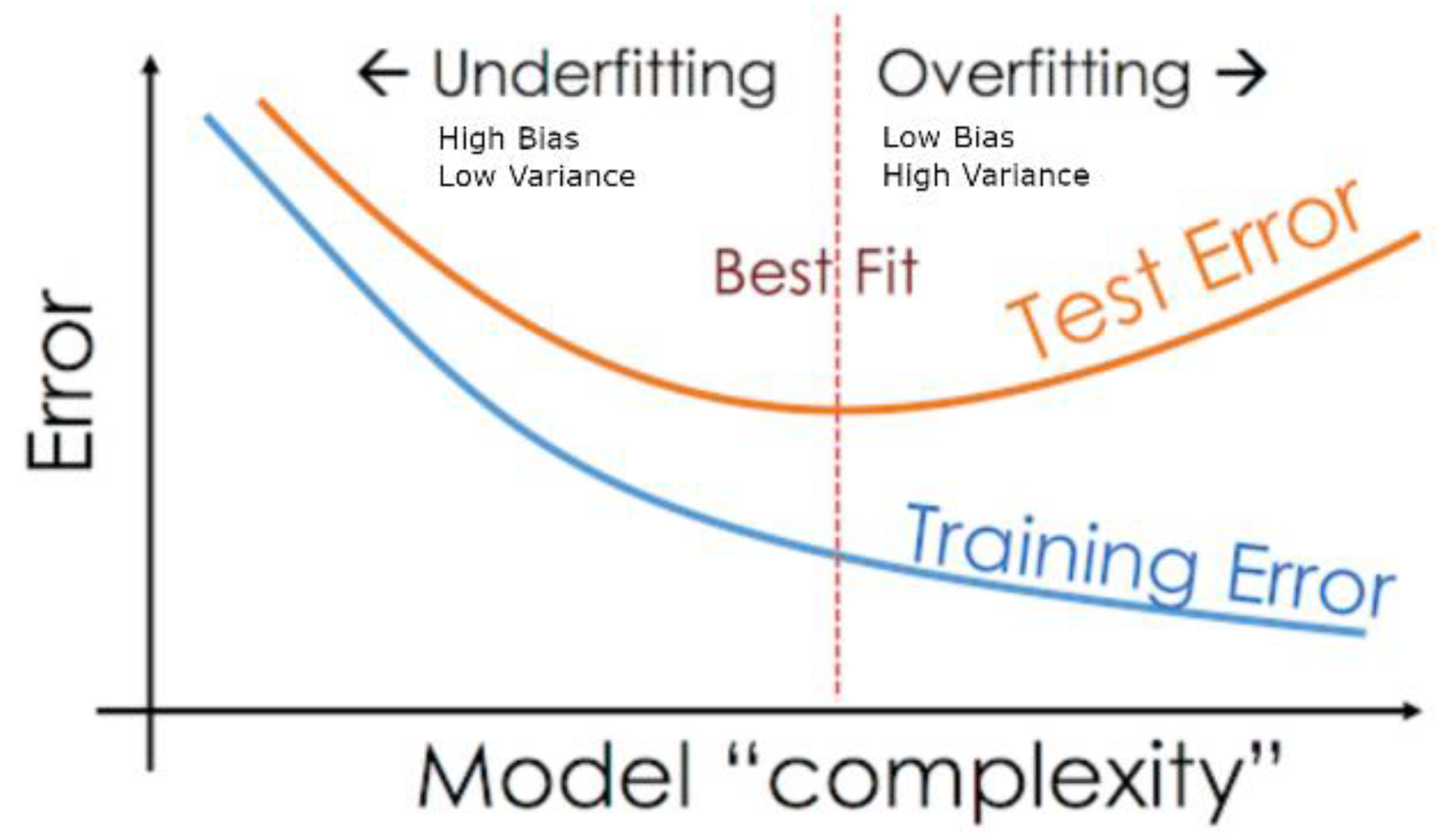
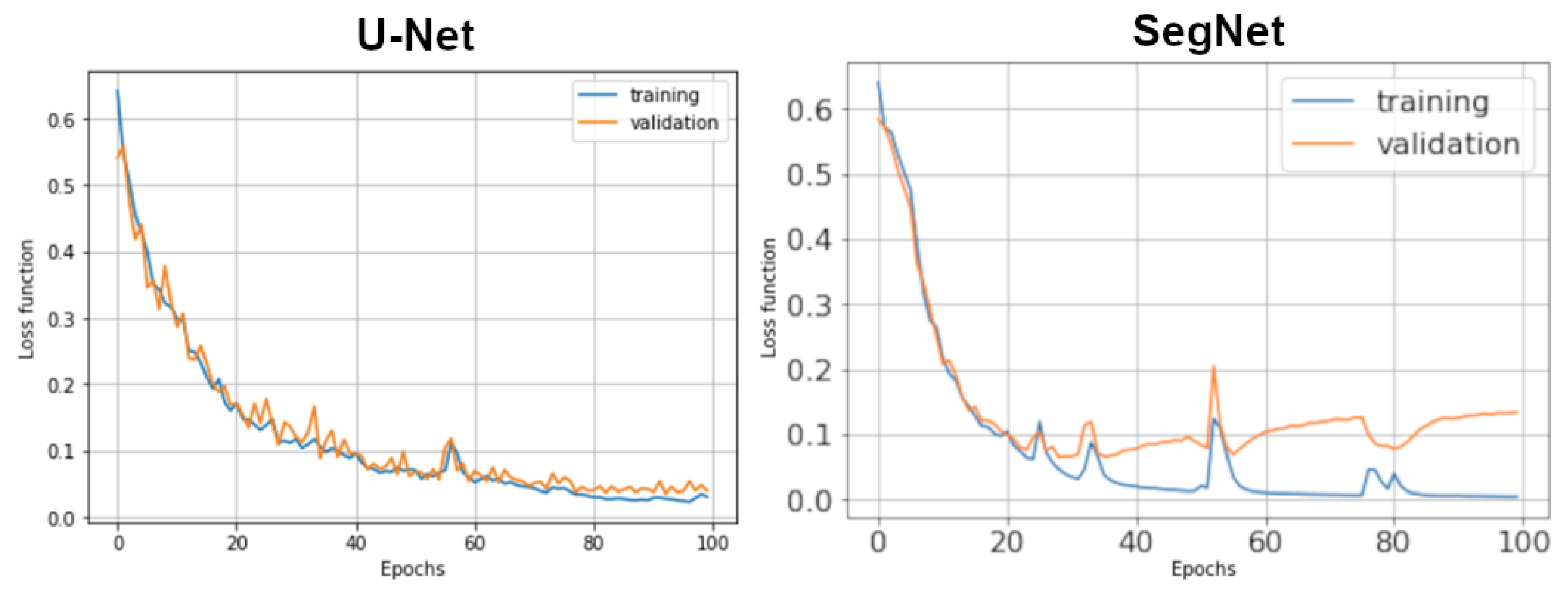



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ETNA NETVIS | |||||||
|---|---|---|---|---|---|---|---|
| Station Name | Resolution Pixel | Distance to the Vent | Image Captured per Minute | Model | Angular FOV (deg) | ||
| BRONTE | 760 × 1040 | 13.78 km | 1 | VIVOTEK | 33_~93_ (horizontal), 24_~68_ (vertical) | ||
| CATANIA | 2560 × 1920 | 27 km | 1 | ||||
| MONTE CAGLIATO | 2560 × 1920 | 8 km | 2 | VIVOTEK | 33_~93_ (horizontal), 24_~68_ (vertical) | ||
| Hyperparameters Required for Training | |
| Learning Rate | 0.0001 |
| Batch_Size | 4 |
| Compile networks | |
| Optimiser | adam |
| Loss | binary_crossentropy |
| Metrics | Accuracy; iou_score |
| Fit Generator | |
| Step_per_epoch | 112 |
| Validation_steps | 28 |
| epochs | 100 |
| Input Layer | A 2D Image with Shape (768, 768, 3) | ||||||
|---|---|---|---|---|---|---|---|
| Encoder Network | |||||||
| Convolutional Layer | Filters | Kernel Size | Pooling Layer | Activations | Kernel Initialiser | Stride | Dropout |
| Conv1 | 16 | 3 × 3 | yes | ReLU | he_normal | 1 × 1 | No |
| Conv2 | 32 | 3 × 3 | yes | ReLU | he_normal | 1 × 1 | No |
| Conv3 | 64 | 3 × 3 | yes | ReLU | he_normal | 1 × 1 | No |
| Conv4 | 128 | 3 × 3 | yes | ReLU | he_normal | 1 × 1 | No |
| Conv5 | 256 | 3 × 3 | yes | ReLU | he_normal | 1 × 1 | No |
| Bottle neck | 512 | 3 × 3 | No | ReLU | he_normal | 0.5 | |
| Decoder Network | |||||||
| Convolutional Layer | Filters | Kernel Size | Concatenate Layer | Up-Sampling | Activations | Kernel Initializer | Stride |
| Conv6 | 256 | 3 × 3 | Conv5-Conv6 | yes | ReLU | he_normal | 1 × 1 |
| Conv7 | 128 | 3 × 3 | Conv4-Conv7 | yes | ReLU | he_normal | 1 × 1 |
| Conv8 | 64 | 3 × 3 | Conv3-Conv8 | yes | ReLU | he_normal | 1 × 1 |
| Conv9 | 32 | 3 × 3 | Conv2-Conv9 | yes | ReLU | he_normal | 1 × 1 |
| Conv10 | 16 | 3 × 3 | Conv1-Conv10 | yes | ReLU | he_normal | 1 × 1 |
| Output layer | 1 | 1 × 1 | No | No | Sigmoid | he_normal | |
| Total trainable params | 7.775.877 | ||||||
| Input Layer | A 2D Image with Shape (768, 768, 3) | |||||
|---|---|---|---|---|---|---|
| Encoder Network | ||||||
| Convolutional Layer | Filters | Kernel Size | Pooling Layer | Activations | Stride | Dropout |
| Conv1 | 16 | 3 × 3 | yes | ReLU | 1 × 1 | No |
| Conv2 | 32 | 3 × 3 | yes | ReLU | 1 × 1 | No |
| Conv3 | 64 | 3 × 3 | yes | ReLU | 1 × 1 | No |
| Conv4 | 128 | 3 × 3 | yes | ReLU | 1 × 1 | 0.5 |
| Conv5 | 256 | 3 × 3 | yes | ReLU | 1 × 1 | 0.5 |
| Bottle neck | 512 | 3 × 3 | No | ReLU | 0.5 | |
| Decoder Network | ||||||
| Convolutional Layer | Filters | Kernel Size | Up-Sampling | Activations | Stride | Dropout |
| Conv6 | 256 | 3 × 3 | yes | ReLU | 1 × 1 | No |
| Conv7 | 128 | 3 × 3 | yes | ReLU | 1 × 1 | No |
| Conv8 | 64 | 3 × 3 | yes | ReLU | 1 × 1 | No |
| Conv9 | 32 | 3 × 3 | yes | ReLU | 1 × 1 | No |
| Conv10 | 16 | 3 × 3 | yes | ReLU | 1 × 1 | No |
| Output layer | 1 | 1 × 1 | No | Sigmoid | No | |
| Total trainable params | 11.005.841 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guerrero Tello, J.F.; Coltelli, M.; Marsella, M.; Celauro, A.; Palenzuela Baena, J.A. Convolutional Neural Network Algorithms for Semantic Segmentation of Volcanic Ash Plumes Using Visible Camera Imagery. Remote Sens. 2022, 14, 4477. https://doi.org/10.3390/rs14184477
Guerrero Tello JF, Coltelli M, Marsella M, Celauro A, Palenzuela Baena JA. Convolutional Neural Network Algorithms for Semantic Segmentation of Volcanic Ash Plumes Using Visible Camera Imagery. Remote Sensing. 2022; 14(18):4477. https://doi.org/10.3390/rs14184477
Chicago/Turabian StyleGuerrero Tello, José Francisco, Mauro Coltelli, Maria Marsella, Angela Celauro, and José Antonio Palenzuela Baena. 2022. "Convolutional Neural Network Algorithms for Semantic Segmentation of Volcanic Ash Plumes Using Visible Camera Imagery" Remote Sensing 14, no. 18: 4477. https://doi.org/10.3390/rs14184477
APA StyleGuerrero Tello, J. F., Coltelli, M., Marsella, M., Celauro, A., & Palenzuela Baena, J. A. (2022). Convolutional Neural Network Algorithms for Semantic Segmentation of Volcanic Ash Plumes Using Visible Camera Imagery. Remote Sensing, 14(18), 4477. https://doi.org/10.3390/rs14184477